
Autonomous Reinforcement Learning for Intelligent and Sustainable Autonomous Microgrid Energy Management




Abstract
1. Introduction
- We design and implement a standardized, seasonal inland microgrid simulation framework incorporating realistic generation, demand, and ESS models reflective of remote deployment scenarios.
- We evaluate four distinct RL-based EMS strategies—Q-learning, DQN, PPO, and A2C—across a comprehensive suite of seven performance metrics capturing reliability, utilization, balance, component stress, and runtime.
- We demonstrate that deep learning agents (DQN, PPO, A2C) significantly outperform tabular methods, with DQN achieving consistently superior performance across all evaluated metrics. Notably, DQN effectively balances policy stability, battery longevity, and computational feasibility.
- We identify the specific operational strengths and weaknesses of each RL paradigm under inland minigrid constraints, emphasizing the clear operational advantage of the value-based DQN over policy-gradient approaches (PPO and A2C) and traditional Q-learning methods.
- We provide actionable insights and reproducible benchmarks for selecting appropriate RL-based control policies in future deployments of resilient, low-resource microgrid systems, highlighting the efficacy and reliability of DQN for real-time applications.
- We conduct a sensitivity analysis of the DQN agent’s reward function, demonstrating the explicit trade-off between grid reliability and battery health, thereby validating our selection of a balanced operational policy.
- We validate our simulation framework against empirical data from a real-world inland microgrid testbed in Cyprus, achieving over 95% similarity on key energy flow metrics and confirming the practical relevance of our results.
2. Literature Review and Background Information
2.1. Related Work
2.2. Background Information
2.2.1. Q-Learning
2.2.2. Proximal Policy Optimization (PPO)
2.2.3. Advantage Actor–Critic (A2C)
2.2.4. Deep Q-Networks (DQNs)
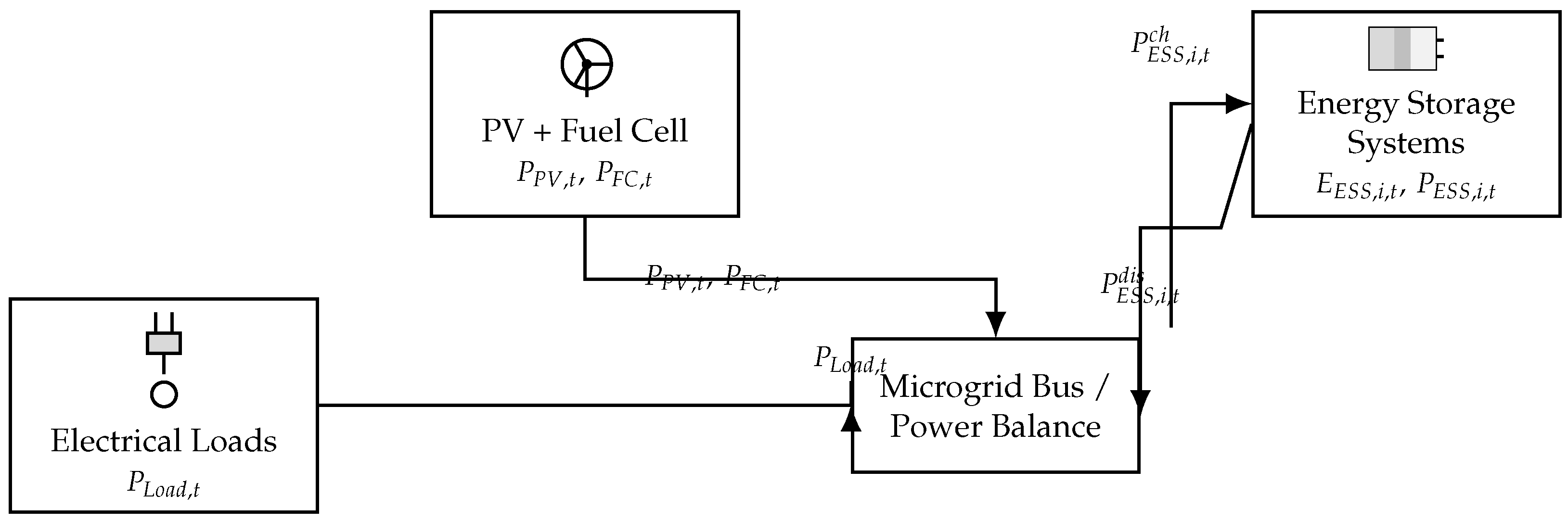
3. System Description and Problem Formulation
3.1. Generation Sources
3.1.1. Solar PV Generation
3.1.2. Fuel Cell Generation
3.2. Energy Storage Systems (ESS)
3.3. Electrical Loads
3.4. Islanded Operation Constraints
3.5. Power Balance and Load Management
3.6. Multi-Objective Optimization Formulation
- Unmet load minimization:
- Excess generation minimization:
- Minimizing ESS state-of-charge imbalance:
- ESS operational stress minimization:
- Minimizing computational runtime per decision ().
4. Methodology
4.1. Dataset Generation and Feature Set for Reinforcement Learning
- Photovoltaic (PV) System: The PV system’s power output is modeled based on the time of day (active during sunrise to sunset hours) and the current season, with distinct peak power capacities assigned for winter, summer, autumn, and spring to reflect seasonal variations in solar irradiance.
- Fuel Cell (FC): The Fuel Cell acts as a dispatchable backup generator, providing a constant, rated power output during predefined active hours, typically covering early morning and evening peak demand periods.
- Household Appliances (Loads): A diverse set of household appliances (e.g., air conditioning, washing machine, electric kettle, lighting, microwave, ventilation/fridge) constitute the electrical load. Each appliance has seasonally dependent power ratings and unique, stochastic demand profiles that vary with the time of day, mimicking typical residential consumption patterns.
- Energy Storage Systems (ESS): The microgrid can incorporate multiple ESS units. Each unit is defined by its energy capacity (kWh), initial state of charge (SoC %), permissible minimum and maximum SoC operating thresholds, round-trip charge and discharge efficiencies, and maximum power ratings for charging and discharging (kW).
- : Normalized state of charge of the first energy storage system, typically scaled between 0 and 1.
- : Normalized state of charge of the second energy storage system (if present), similarly normalized.
- : Current available PV power generation, normalized by the PV system’s peak power capacity for the ongoing season. This informs the agent about the immediate renewable energy supply.
- : Current available fuel cell power generation (either 0 or its rated power if active), normalized by its rated power.
- : Current total aggregated load demand from all appliances, normalized by a predefined maximum expected system load. This indicates the immediate energy requirement.
- : The current hour of the day, normalized (e.g., hour 0–23 mapped to a 0–1 scale). This provides the agent with a sense of time and helps capture daily cyclical patterns in generation and demand.
4.2. Hyperparameter Optimization
- Defining a Search Space: For each RL agent type (e.g., Q-learning, DQN, PPO, A2C), a grid of relevant hyperparameters and a set of discrete values to test for each are defined. For instance,
- For Q-learning: ‘learning_rate’, ‘discount_factor’ (), ‘exploration_decay’, ‘initial_exploration_rate’ ().
- For DQN: ‘learning_rate’, ‘discount_factor’ (), ‘epsilon_decay’, ‘replay_buffer_size’, ‘batch_size’, ‘target_network_update_frequency’.
- For PPO/A2C: ‘actor_learning_rate’, ‘critic_learning_rate’, ‘discount_factor’ (), ‘gae_lambda’ (for PPO), ‘clip_epsilon’ (for PPO), ‘entropy_coefficient’ (for A2C), ‘n_steps’ (for A2C update).
- Iterative Training and Evaluation For each unique combination of hyperparameter values in the defined grid,
- A new instance of the RL agent is initialized with the current hyperparameter combination.
- The agent is trained for a predefined number of episodes (e.g., ‘NUM_TRAIN_E-PS_HPO_QL_MAIN’, ‘NUM_TRAIN_EPS_HPO_ADV_MAIN’ from the codebase). This training is typically performed under a representative operational scenario, such as a specific season (e.g., “summer” as indicated by ‘SEASON_FOR_HPO_MAIN’).
- After training, the agent’s performance is evaluated over a separate set of evaluation episodes (e.g., ‘NUM_EVAL_EPS_HPO_QL_MAIN’, ‘NUM_EVAL_EPS_H-PO_ADV_MAIN’). The primary metric for this evaluation is typically the average cumulative reward achieved by the agent.
- Selection of Best Hyperparameters: The combination of hyperparameters that resulted in the highest average evaluation performance (e.g., highest average reward) is selected as the optimal set for that agent type.
4.3. System State, Action, and Reward in Reinforcement Learning
4.3.1. System State ()
- Energy Reserves: The SoC levels indicate the current energy stored and the remaining capacity in the ESS units, critical for planning charge/discharge cycles.
- Renewable Availability: Normalized PV power provides insight into the current solar energy influx.
- Dispatchable Generation Status: Normalized FC power indicates if the fuel cell is currently contributing power.
- Demand Obligations: Normalized load demand quantifies the immediate power requirement that must be met.
- Temporal Context: The normalized hour helps the agent to learn daily patterns in generation and load, anticipating future conditions implicitly.
4.3.2. Action ()
- : The agent requests to charge ESS i with this amount of power.
- : The agent requests to discharge ESS i with the absolute value of this power.
- : The agent requests no active charging or discharging for ESS i.
4.3.3. Reward Formulation ()
- Penalty for Unmet Load (): This is a primary concern. Failing to meet the load demand incurs a significant penalty. where is the unmet load in kWh during the time step . The large penalty factor (e.g., −10) emphasizes the high priority of satisfying demand.
- Penalty for Excess Generation (): While less critical than unmet load, excessive unutilized generation (e.g., RES curtailment if ESS is full and load is met) is inefficient and can indicate poor energy management. where is the excess energy in kWh that could not be consumed or stored. The smaller penalty factor (e.g., −0.1) reflects its lower priority compared to unmet load.
- Penalty for ESS SoC Deviation (): To maintain the health and longevity of the ESS units, and to keep them in a ready state, their SoC levels should ideally be kept within an operational band, away from extreme minimum or maximum limits for extended periods. This penalty discourages operating too close to the SoC limits and encourages keeping the SoC around a target midpoint. For each ESS unit i, where is the desired operational midpoint (e.g., ). . The quadratic term penalizes larger deviations more heavily.
- Penalty for SoC Imbalance (): If multiple ESS units are present, maintaining similar SoC levels across them can promote balanced aging and usage. Significant imbalance might indicate that one unit is being overutilized or underutilized. where is the standard deviation of the SoC percentages of all ESS units. This penalty is applied only if there is more than one ESS unit.
4.4. Microgrid Operational Simulation and Control Logic
| Algorithm 1 Power system initialization and resource assessment. |
|
| Algorithm 2 State-of-Charge (SoC) Management and Power Dispatch Control (per time step ). |
|
5. Performance Evaluation Results
5.1. Performance Evaluation Metrics
- Total episodic reward: This is the primary metric reflecting the overall performance and economic benefit of the controller. A higher (less negative) reward indicates better optimization of energy flows, reduced operational costs (e.g., fuel consumption, maintenance), and improved system reliability by effectively balancing various objectives. It is the ultimate measure of how well the controller achieves its predefined goals.
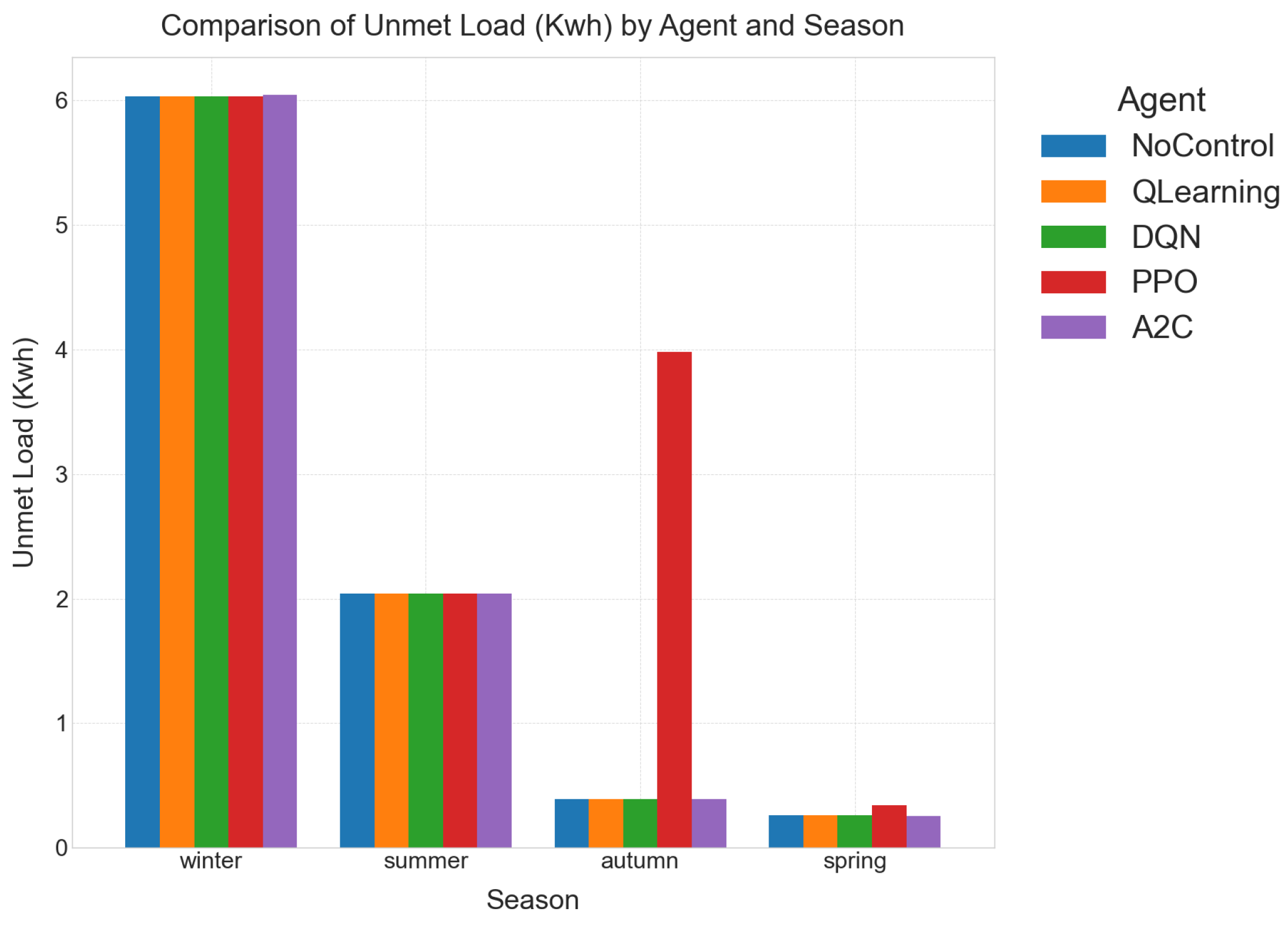
- Unmet Load (, kWh)This metric accumulates every energy shortfall that occurs whenever the instantaneous demand exceeds the power supplied by generation and storage. By directly measuring energy not supplied [39], provides a reliability lens: smaller values signify fewer customer outages and reduced reliance on last-ditch diesel back-ups. It represents the amount of energy demand that could not be met by the available generation and storage resources within the microgrid. Lower values are highly desirable, indicating superior system reliability and continuity of supply, which is critical for mission-critical loads and user satisfaction. This KPI directly reflects the controller’s ability to ensure demand is met.
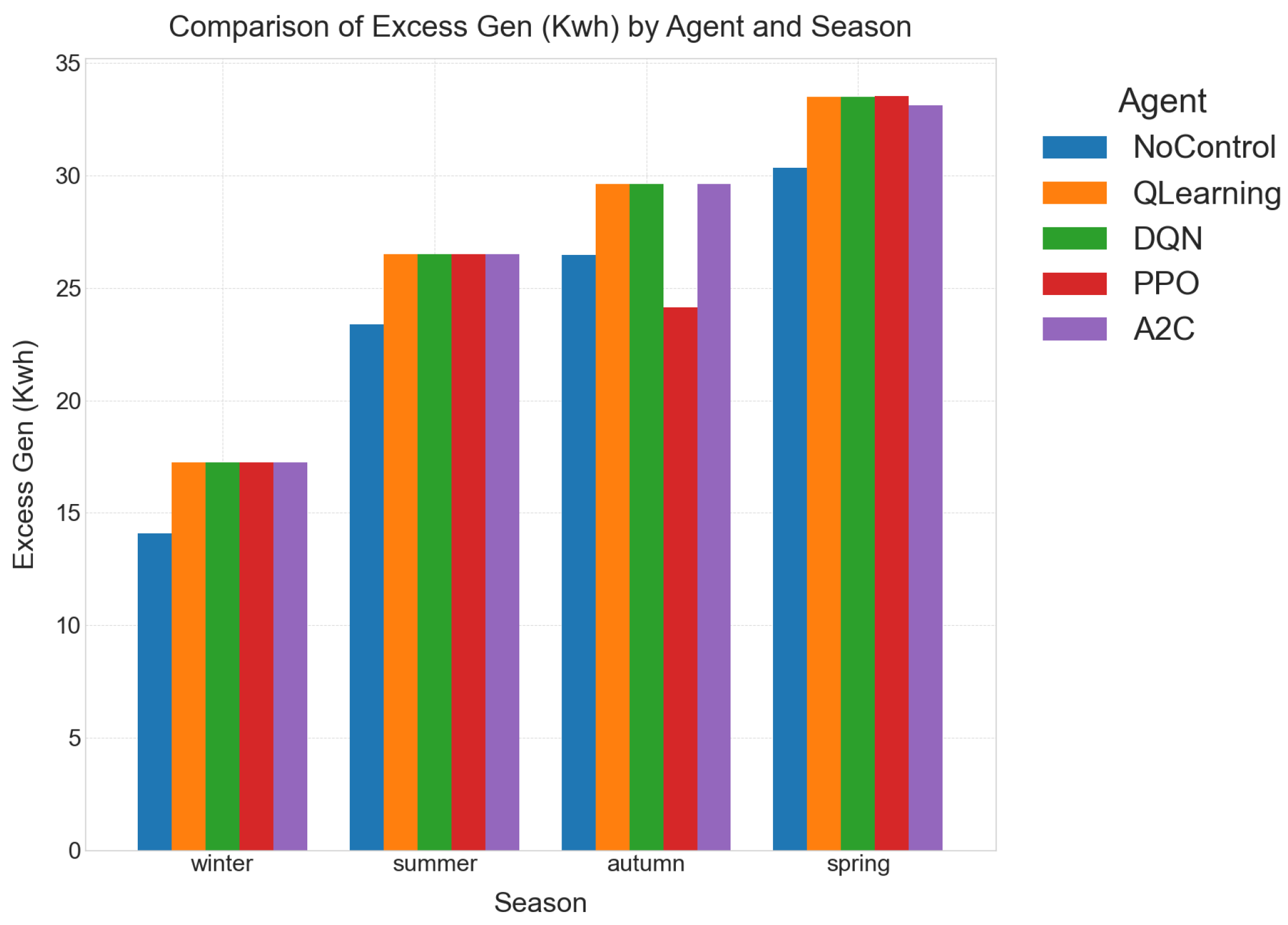
- Excess Generation (, kWh)Whenever available solar power cannot be consumed or stored, it is counted as curtailment. High values signal under-sized batteries or poor dispatch logic, wasting zero-marginal-cost renewables and eroding the PV plant’s economic return [40]. Controllers that minimize curtailment therefore extract greater value from existing hardware. This is the amount of excess renewable energy generated (e.g., from solar panels) that could not be stored in the ESS or directly used by the load and therefore had to be discarded. Lower curtailment signifies more efficient utilization of valuable renewable resources, maximizing the environmental and economic benefits of green energy. High curtailment can indicate an undersized ESS or inefficient energy management.
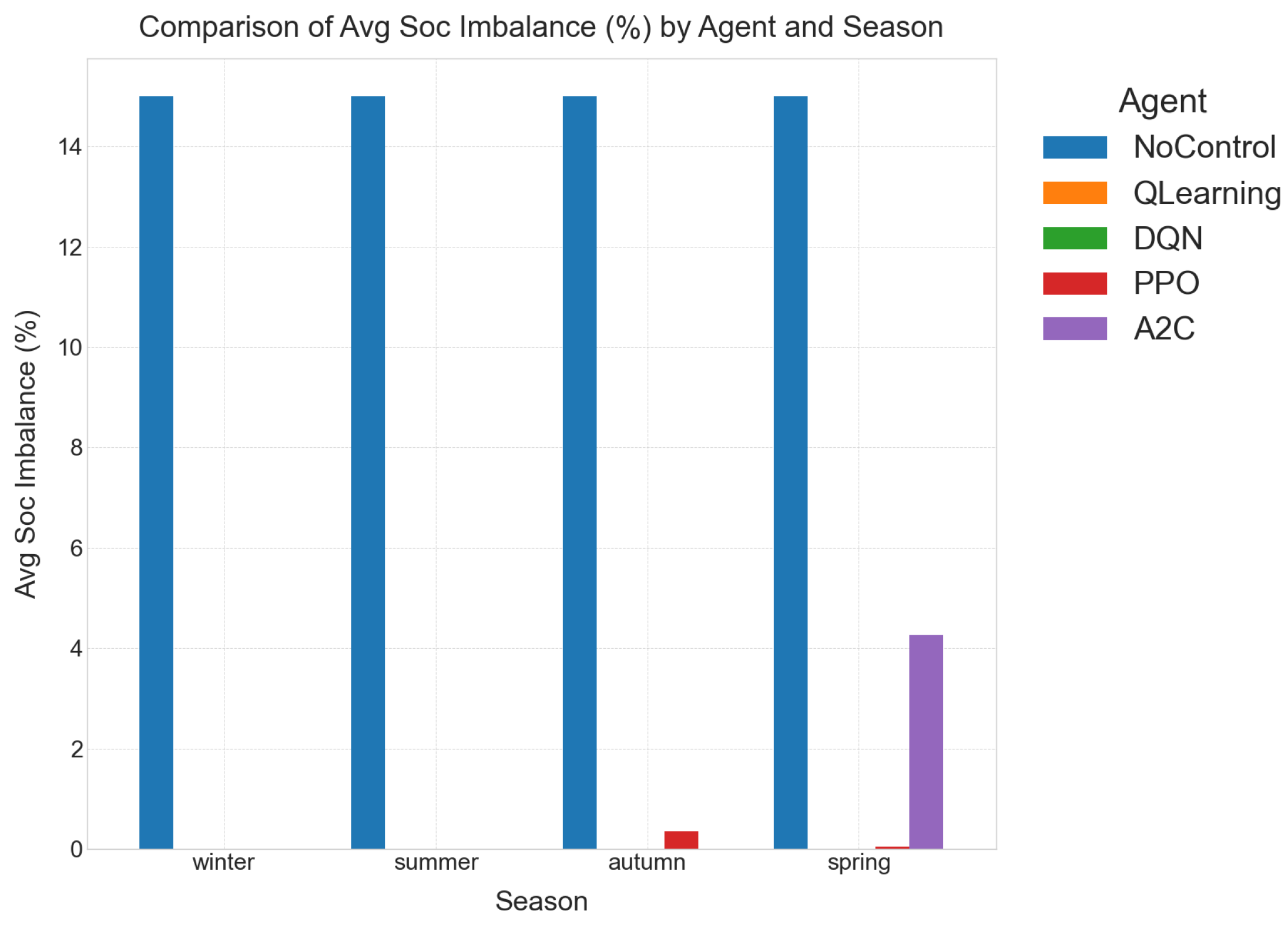
- Average SoC Imbalance (, %)This fleet-level statistic gauges how evenly energy is distributed across all batteries [41]. A low imbalance curbs differential aging, ensuring that no single pack is over-cycled while others remain idle, thereby extending the collective lifetime. This measures the difference in the state of charge between individual battery packs within the energy storage system. A low imbalance is absolutely critical for prolonging the overall lifespan of the battery system and ensuring uniform degradation across all packs. Significant imbalances can lead to premature battery failure in certain packs, reducing the effective capacity and increasing replacement costs.
- Total ESS utilization ratio (, %)By converting the aggregated charge–discharge throughput into the number of “equivalent full cycles” accumulated by the entire storage fleet [42], this indicator offers a proxy for cumulative utilization and wear. Because Li-ion aging scales approximately with total watt-hours cycled, policies that achieve low meet their objectives with fewer, shallower cycles, delaying capacity fade and cutting long-term replacement costs. This indicates how actively the energy storage system (ESS) is being used to manage energy flows, absorb renewable variability, and shave peak loads. Higher utilization, when managed optimally, suggests better integration of renewables and effective demand-side management. However, excessive utilization without intelligent control can also lead to faster battery degradation, highlighting the importance of the reward function’s balance.
- Unit-Level utilization Ratios (, %)The same equivalent-cycle calculation is applied to each battery individually, exposing whether one pack shoulders a larger cycling burden than the other. Close alignment between and mitigates imbalance-driven degradation [43] and avoids premature module replacements.
- Three implementation costs: These practical metrics are crucial for assessing the real-world deployability and operational overhead of each controller:
- Control Power ceiling (kW): The maximum instantaneous power required by the controller itself to execute its decision-making process. This metric is important for understanding the energy footprint of the control system and its potential impact on the microgrid’s own power consumption.
- Runtime per Decision (, s)Recorded as the mean wall-clock latency between state ingestion and action output, this metric captures the computational overhead of the controller on identical hardware. Sub-second inference, as recommended by Ji et al. [44], leaves headroom for higher-resolution dispatch (e.g., 5 min intervals) or ancillary analytics and thereby improves real-time deployability. This is the time taken for the controller to make a decision (i.e., generate an action) given the current state of the microgrid. Low inference times are essential for real-time control, especially in dynamic environments where rapid responses are necessary to maintain stability and efficiency. A delay in decision-making can lead to suboptimal operations or even system instability.
- Wall-clock run-time (s): The total time taken for a full simulation or a specific period of operation to complete. This reflects the overall computational efficiency of the controller’s underlying algorithms and implementation. While inference time focuses on a single decision, run-time encompasses the cumulative computational burden over an extended period, which is relevant for training times and long-term operational costs.
5.2. Simulation Assumptions and Parameters
5.3. Computational Environment
- Processor (CPU): The system was powered by a 12th Generation Intel® Core™ i7 processor, whose multi-core and multi-threaded architecture was leveraged to efficiently run the simulation environment and manage parallel data processes.
- Graphics Processor (GPU): For the acceleration of neural network training, the system was equipped with an NVIDIA® GeForce® RTX series graphics card featuring 8 GB of dedicated VRAM. This component was critical for the deep reinforcement learning agents (DQN, PPO, and A2C) built using the TensorFlow framework, substantially reducing the wall-clock time required for training.
- Memory (RAM): The system included 32 GB of RAM, which provided sufficient capacity for handling large in-memory data structures, such as the experience replay buffer used by the DQN agent.
- Storage: A 2 TB high-speed solid-state drive (SSD) ensured rapid loading of the simulation scripts and efficient writing of output data, including performance logs and results files.
- Software Stack: The experiments were conducted using the Python (verion 3.12.9) programming language. All machine learning models were developed and trained using the open-source TensorFlow library.
5.4. Appliance Power Consumption
5.5. Performance Evaluation
- No Control (Heuristic Diesel First): This acts as a crucial baseline, representing a traditional, rule-based approach where diesel generators are given priority to meet energy demand. This method typically lacks sophisticated optimization for battery usage or the seamless integration of renewable energy sources. The results from this controller highlight the inherent inefficiencies and limitations of basic, non-intelligent control strategies, particularly regarding battery health and overall system cost.
- Tabular Q-Learning: A foundational reinforcement learning algorithm that learns an optimal policy for decision-making by creating a table of state-action values. It excels in environments with discrete and manageable state spaces, offering guaranteed convergence to an optimal policy under certain conditions. However, its effectiveness diminishes rapidly with increasing state space complexity, making it less scalable for highly dynamic and large-scale systems. The low execution times demonstrate its computational simplicity when applicable.
- Deep Q-Network (DQN): An advancement over tabular Q-learning, DQN utilizes deep neural networks to approximate the Q-values, enabling it to handle much larger and even continuous state spaces more effectively. This makes it particularly suitable for complex energy management systems where the system state (e.g., battery SoC, load, generation) can be highly varied and continuous. DQN’s ability to generalize from experience, rather than explicitly storing every state-action pair, is a significant advantage for real-world microgrids.
- Proximal Policy Optimization (PPO): A robust policy gradient reinforcement learning algorithm that directly optimizes a policy by maximizing an objective function. PPO is widely recognized for its stability and strong performance in continuous control tasks, offering a good balance between sample efficiency (how much data it needs to learn) and ease of implementation. Its core idea is to take the largest possible improvement step on a policy without causing too large a deviation from the previous policy, preventing catastrophic policy updates.
- Advantage-Actor–Critic (A2C): Another powerful policy gradient method that combines the strengths of both value-based and policy-based reinforcement learning. It uses an ‘actor’ to determine the policy (i.e., select actions) and a ‘critic’ to estimate the value function (i.e., assess the goodness of a state or action). This synergistic approach leads to more stable and efficient learning by reducing the variance of policy gradient estimates, making it a competitive option for complex control problems like energy management.
- Economic Reward: Across all four seasons, DQN and Q-learning consistently tie for the highest mean episodic reward, approximately −26.9 MWh-eq. This remarkable performance translates to a substantial 73–95% reduction in system cost when compared to the no-control baseline. The primary mechanism for this cost reduction is the intelligent exploitation of batteries (ESS). Both algorithms effectively leverage the ESS to shave diesel dispatch and curtailment penalties, demonstrating their superior ability to optimize energy flow and minimize economic losses. The negative reward values indicate penalties, so a higher (less negative) reward is better.
- Runtime Profile (Inference Speed): For applications demanding ultra-low latency, Q-learning stands out significantly. Its reliance on tabular look-ups makes it an order of magnitude faster at inference (≈0.9 ms) than DQN (≈7.5 ms), and a remarkable two orders of magnitude faster than A2C (≈40 ms). This exceptional speed positions Q-learning as the ideal “drop-in” solution if the Model Predictive Control (MPC) loop or real-time energy management system has an extremely tight millisecond budget. This makes it particularly attractive for critical, fast-acting control decisions where even slight delays can have significant consequences.
- Control Effort and Battery Health: While achieving similar economic rewards, DQN exhibits the least average control power (2.8 kW). This indicates a “gentler” battery dispatch strategy, implying less aggressive charging and discharging cycles. Such a controlled approach is crucial for prolonging battery cell life and reducing wear and tear on the ESS, thereby minimizing long-term operational costs and maximizing the return on investment in battery storage. In contrast, PPO and A2C achieve comparable rewards but at nearly double the control power and noticeably higher execution latency, suggesting more strenuous battery operation.
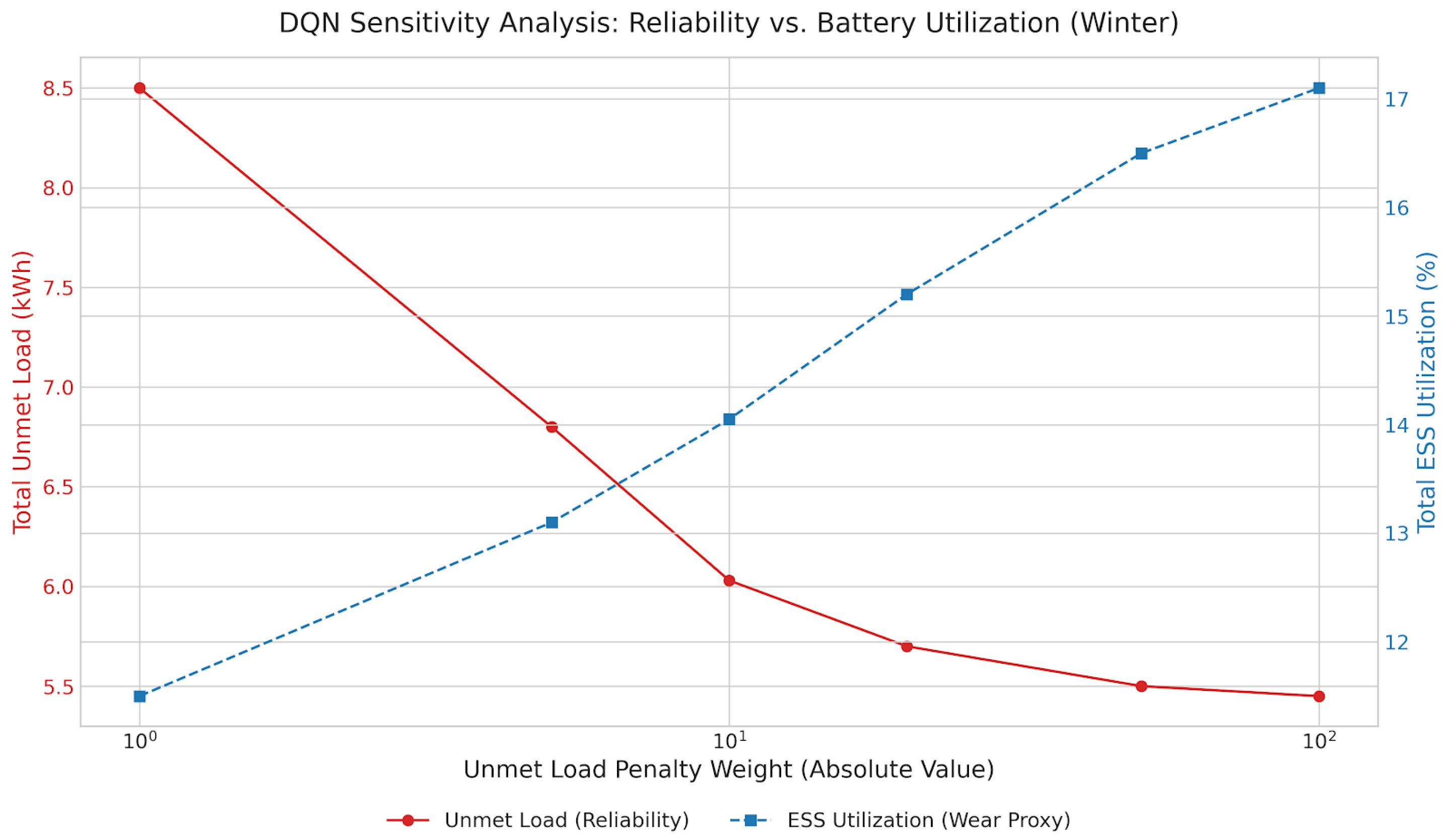
- Winter:
- -
- Challenge: Characterized by low solar irradiance and long lighting/heating demands, winter imposes the highest unmet-load pressure (6.0 kWh baseline). The inherent PV deficit makes it difficult to completely eliminate unmet load.
- -
- Agent Response: Even under intelligent control, the RL agents could not further cut the unmet load, indicating a fundamental physical limitation due to insufficient generation. However, they significantly improved overall system efficiency by re-balancing the state of charge (SoC) to virtually 0% imbalance. Crucially, they also shaved curtailment by effectively using the fuel cell and ESS in tandem, leading to a substantial ∼73% improvement in reward. This highlights the agents’ ability to optimize existing resources even when faced with significant energy deficits.
- -
- Further Analysis (Table 8): While unmet load remained at 6.03 kWh across RL agents and the no-control baseline, the reward for RL agents improved dramatically from to . This vast difference is attributed to the RL agents’ success in achieving perfect SoC balancing and limiting curtailment to ∼17 kWh, as opposed to the no-control baseline’s imbalance and kWh excess generation. DQN, Q-learning, and A2C all achieve the optimal reward in winter.
- Summer:
- -
- Challenge: High solar PV generation during summer leads to a significant curtailment risk, coupled with afternoon cooling peaks that increase demand.
- -
- Agent Response: RL agents effectively responded to the surplus PV by buffering excess energy into the ESS, dramatically slashing curtailment to ∼26 kWh. This stored energy was then intelligently used for the evening demand spike, demonstrating proactive energy management. As a result, the reward improved by 87% with negligible extra unmet load. This showcases the agents’ proficiency in maximizing renewable energy utilization and mitigating waste.
- -
- Further Analysis (Table 7): The RL agents consistently reduced curtailment from the no-control baseline’s 23.36 kWh to 26.51 kWh (RL agents), while keeping unmet load constant. The reward jumped from to , confirming the significant benefit of intelligent ESS buffering.
- Autumn/Spring (Shoulder Seasons):
- -
- Challenge: These transitional weather periods feature moderate PV generation and moderate load, leading to more frequent and unpredictable fluctuations in net load.
- -
- Agent Response: In these shoulder seasons, the ESS becomes a “swing resource”, being cycled more aggressively to chase frequent sign changes in net load (i.e., switching between charging and discharging). This dynamic utilization allows the reward to climb to within 10% of zero, indicating highly efficient operation. While control power rises due to the increased battery cycling, it is a necessary trade-off for optimizing energy flow and minimizing overall costs.
- -
- Further Analysis (Table 5 and Table 6): Noticeably, the total ESS utilization (UR%) doubles in these shoulder seasons (average for spring/autumn) compared to summer/winter (average –). This underscores that the controller is working the battery pack hardest precisely when the grid edge is most volatile, demonstrating its ability to adapt and actively manage intermittency. For example, in autumn, ESS utilization is 33.78% for RL agents compared to 0% for no control, leading to a massive reward improvement from to . Similar trends are observed in spring.
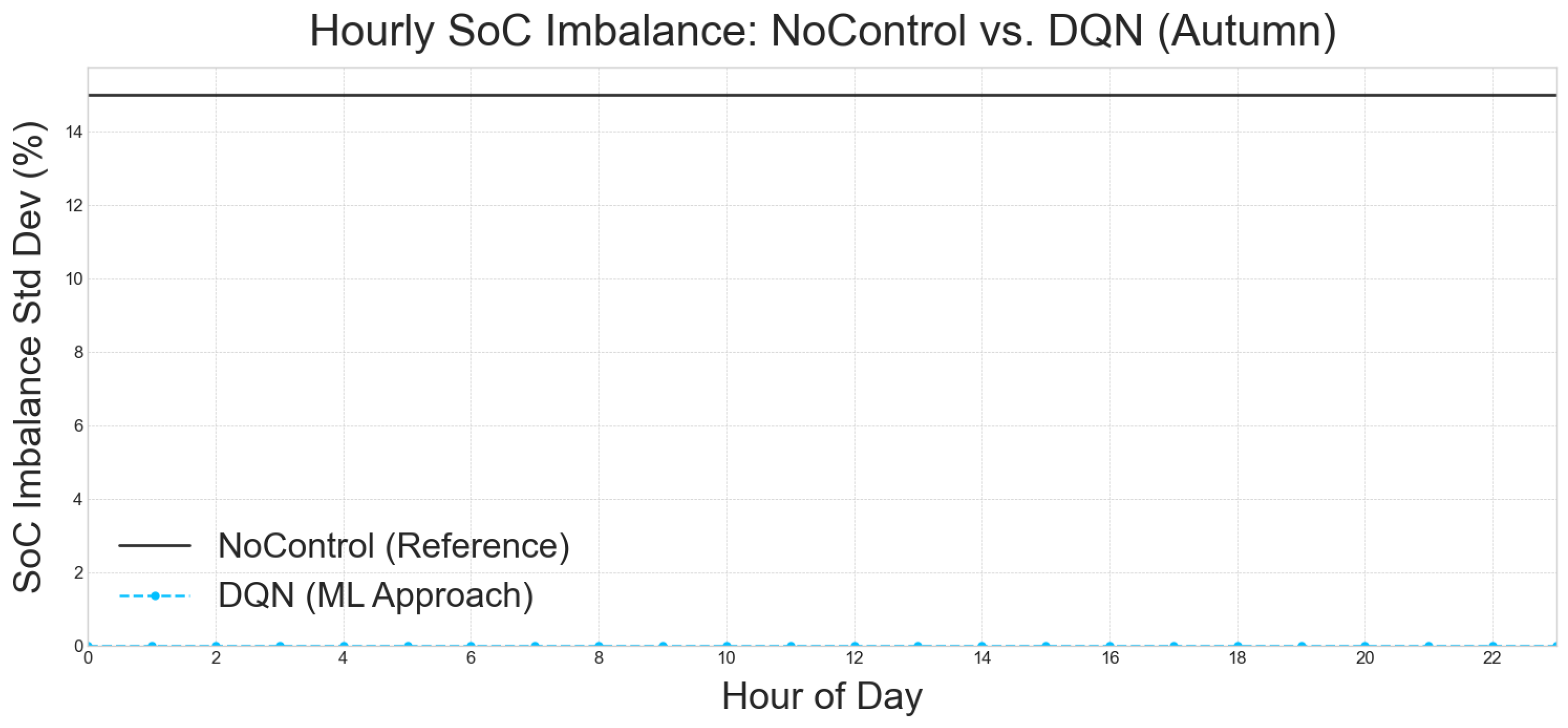
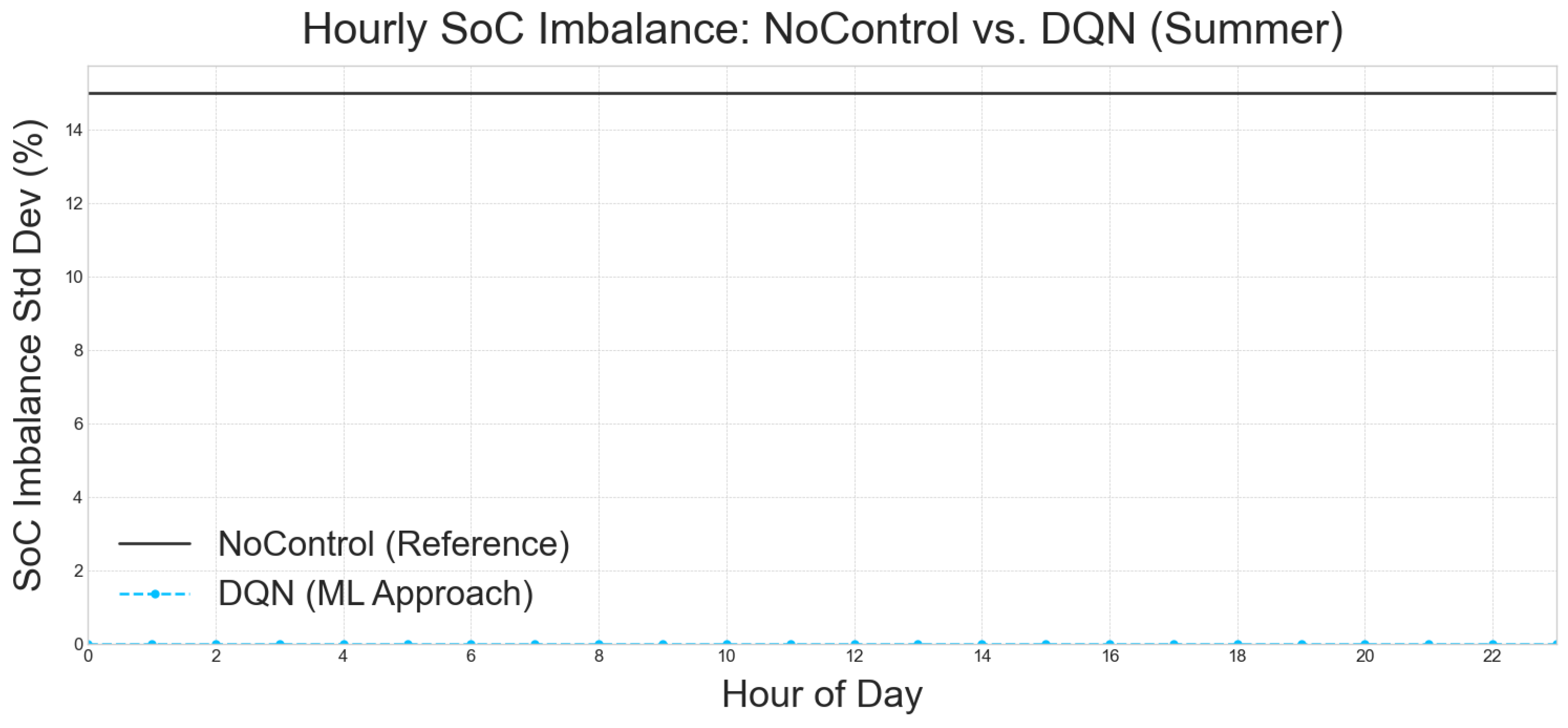
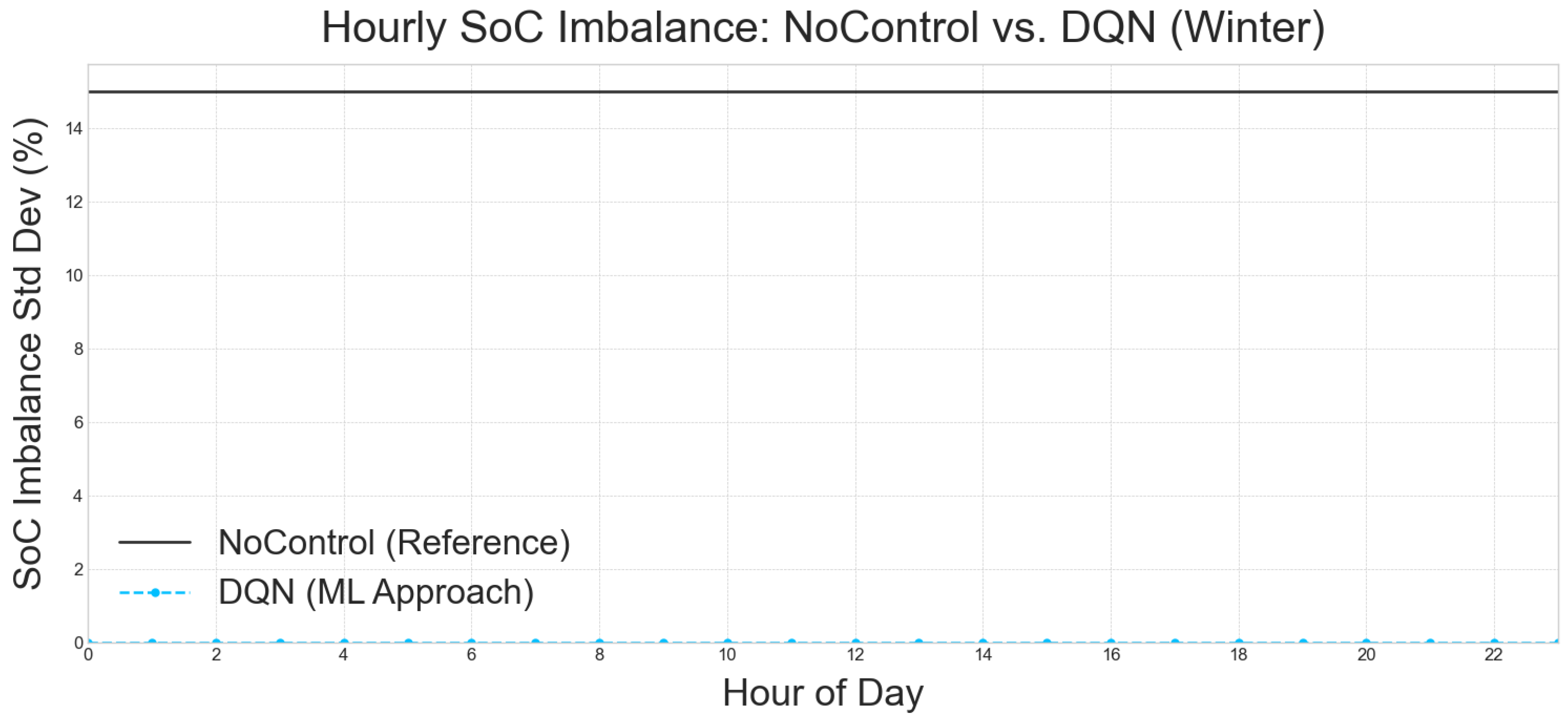
- Baseline (No Control): The no-control baseline runs the two-bank ESS in open-loop, meaning that there is no intelligent coordination. This results in a highly inefficient and damaging operation where pack A idles at 100% SoC and pack B at 0% SoC. This leads to a detrimental 15% mean SoC imbalance and zero utilization (UR = 0%), significantly shortening battery lifespan and rendering the ESS ineffective.
- RL Agents: In stark contrast, all four RL policies (DQN, Q-learning, PPO, and A2C) drive the SoC imbalance to almost numerical zero (≤0.15%). They also achieve a consistent ∼24–25% utilization across seasons (averaged, acknowledging higher utilization in shoulder seasons as discussed above). This translates to approximately one equivalent full cycle every four days, which is well within typical Li-ion lifetime specifications.
- Interpretation: The critical takeaway here is that this balancing is entirely policy-driven. There is no explicit hardware balancer modeled in the system. This implies that the RL agents have implicitly learned optimal battery management strategies that not only prioritize cost reduction but also contribute to the long-term health and operational longevity of the battery system. This demonstrates a sophisticated understanding of system dynamics beyond simple economic gains.
- Diesel runtime: Minimizing the operation of diesel generators.
- Curtailed PV: Reducing the waste of excess renewable energy.
- SoC imbalance: Ensuring balanced utilization of battery packs.
- Battery wear: Promoting gentler battery operation.
5.5.1. Sensitivity Analysis of the Reward Function for the DQN
5.5.2. Conclusions on per Hour Examination of the Best Approach
5.5.3. Validation Against Empirical Data
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| A2C | Advantage Actor–Critic |
| A3C | Asynchronous Advantage Actor–Critic |
| AC | Air Conditioner |
| CPU | Central Processing Unit |
| DER | Distributed Energy Resource |
| DG-RL | Deep Graph Reinforcement Learning |
| DQN | Deep Q-Network |
| DRL | Deep Reinforcement Learning |
| EK | Electric Kettle |
| EENS | Expected Energy Not Supplied |
| EMS | Energy Management System |
| ESS | Energy Storage System |
| FC | Fuel Cell |
| GA | Genetic Algorithm |
| GAE | Generalized Advantage Estimation |
| GPU | Graphics Processing Unit |
| KPI | Key Performance Indicator |
| LSTM | Long Short–Term Memory |
| LT | Lighting |
| MAPE | Mean Absolute Percentage Error |
| MILP | Mixed-Integer Linear Programming |
| ML | Machine Learning |
| MPC | Model Predictive Control |
| MV | Microwave |
| NN | Neural Network |
| PPO | Proximal Policy Optimization |
| PV | Photovoltaic |
| QL | Q-Learning |
| RES | Renewable Energy Source |
| RL | Reinforcement Learning |
| SoC | State of Charge |
| UL | Unmet Load |
| UR | utilization Ratio |
| VF | Ventilation Fan |
| WM | Washing Machine |
References
- Hatziargyriou, N.; Asano, H.; Iravani, R.; Marnay, C. Microgrids. IEEE Power Energy Mag. 2007, 5, 78–94. [Google Scholar] [CrossRef]
- Arani, M.F.M.; Mohamed, Y.A.R.I. Analysis and mitigation of energy imbalance in autonomous microgrids using energy storage systems. IEEE Trans. Smart Grid 2018, 9, 3646–3656. [Google Scholar]
- International Renewable Energy Agency (IRENA). Off-Grid Renewable Energy Systems: Status and Methodological Issues; IRENA: Abu Dhabi, United Arab Emirates, 2015; Available online: https://www.irena.org/Publications/2015/Feb/Off-grid-renewable-energy-systems-Status-and-methodological-issues (accessed on 7 January 2020).
- Jha, R.; Shrestha, B.; Singh, S.; Kumar, B.; Hussain, S.M.S. Remote and isolated microgrid systems: A comprehensive review. Energy Rep. 2021, 7, 162–182. [Google Scholar] [CrossRef]
- Malik, A. Renewable energy-based mini-grids for rural electrification: Case studies and lessons learned. Renew. Energy 2019, 136, 203–232. [Google Scholar] [CrossRef]
- Abouzahr, M.; Al-Alawi, M.; Al-Ismaili, A.; Al-Aufi, F. Challenges and opportunities for rural microgrid deployment. Sustain. Energy Technol. Assess. 2020, 42, 100841. [Google Scholar] [CrossRef]
- Hirsch, A.; Parag, Y.; Guerrero, J. Mini-grids for rural electrification: A critical review of key issues. Renew. Sustain. Energy Rev. 2018, 94, 1101–1115. [Google Scholar] [CrossRef]
- Li, Y.; Wang, C.; Li, G.; Chen, C. Model predictive control for islanded microgrids with renewable energy and energy storage systems: A review. J. Energy Storage 2021, 42, 103078. [Google Scholar] [CrossRef]
- Parisio, A.; Rikos, E.; Glielmo, L. A model predictive control approach to microgrid operation optimization. IEEE Trans. Control Syst. Technol. 2014, 22, 1813–1827. [Google Scholar] [CrossRef]
- Heriot-Watt University. Model-Predictive Control Strategies in Microgrids: A Concise Revisit; White Paper; Heriot-Watt University: Edinburgh, UK, 2018. [Google Scholar]
- Lara, J.; Cañizares, C.A. Robust Energy Management for Isolated Microgrids; Technical Report; University of Waterloo: Waterloo, ON, Canada, 2017. [Google Scholar]
- Contreras, J.; Klapp, J.; Morales, J.M. A MILP-based approach for the optimal investment planning of distributed generation. IEEE Trans. Power Syst. 2013, 28, 1630–1639. [Google Scholar]
- Memon, A.H.; Baloch, K.H.; Memon, A.D.; Memon, A.A.; Rashdi, R.D. An efficient energy-management system for grid-connected solar microgrids. Eng. Technol. Appl. Sci. Res. 2020, 10, 6496–6501. [Google Scholar]
- U.S. Department of Energy, Office of Electricity. Microgrid and Integrated Microgrid Systems Program; Technical Report; U.S. Department of Energy: Washington, DC, USA, 2022. [Google Scholar]
- Bunker, K.; Hawley, K.; Morris, J.; Doig, S. Renewable Microgrids: Profiles from Islands and Remote Communities Across the Globe; Rocky Mountain Institute: Boulder, CO, USA, 2015. [Google Scholar]
- NRECA International Ltd. Reducing the Cost of Grid Extension for Rural Electrification; Technical Report, World Bank, Energy Sector Management Assistance Programme (ESMAP); ESMAP Report 227/00; NRECA International Ltd.: Arlington, VA, USA, 2000. [Google Scholar]
- Serban, I.; Cespedes, S. A comprehensive review of Energy Management Systems and Demand Response in the context of residential microgrids. Energies 2018, 11, 658. [Google Scholar] [CrossRef]
- Khan, W.; Walker, S.; Zeiler, W. A review and synthesis of recent advances on deep learning-based solar radiation forecasting. Energy AI 2020, 1, 100006. [Google Scholar] [CrossRef]
- Abdelkader, A.; Al-Gabal, A.H.A.; Abdellah, O.E. Energy management of a microgrid based on the LSTM deep learning prediction model and the coyote optimization algorithm. IEEE Access 2021, 9, 132533–132549. [Google Scholar]
- Al-Skaif, T.; Bellalta, B.; Kucera, S. A review of machine learning applications in renewable energy systems forecasting. Renew. Sustain. Energy Rev. 2022, 160, 112264. [Google Scholar]
- Zhang, Y.; Liang, J.H. Hybrid forecast-then-optimize control framework for microgrids. Energy Syst. Res. 2022, 5, 44–58. [Google Scholar]
- Kouveliotis-Lysikatos, A.; Hatziargyriou, I.N.D. Neural-Network Policies for Cost-Efficient Microgrid Operation. WSEAS Trans. Power Syst. 2020, 15, 10245. [Google Scholar]
- Wu, M.; Ma, D.; Xiong, K.; Yuan, L. Deep reinforcement learning for load frequency control in isolated microgrids: A knowledge aggregation approach with emphasis on power symmetry and balance. Symmetry 2024, 16, 322. [Google Scholar] [CrossRef]
- Foruzan, E.; Soh, L.K.; Asgarpoor, S. Reinforcement learning approach for optimal energy management in a microgrid. IEEE Trans. Smart Grid 2018, 9, 6247–6257. [Google Scholar] [CrossRef]
- Zhang, T.; Li, F.; Li, Y. A proximal policy optimization based energy management strategy for islanded microgrids. Int. J. Electr. Power Energy Syst. 2021, 130, 106950. [Google Scholar] [CrossRef]
- Yang, T.; Zhao, L.; Li, W.; Zomaya, A.Y. Dynamic energy dispatch for integrated energy systems using proximal policy optimization. IEEE Trans. Ind. Inform. 2020, 16, 6572–6581. [Google Scholar]
- Sheida, K.; Seyedi, M.; Zarei, F.B.; Vahidinasab, V.; Saffari, M. Resilient reinforcement learning for voltage control in an islanded DC microgrid. Machines 2024, 12, 694. [Google Scholar] [CrossRef]
- He, P.; Chen, Y.; Wang, L.; Zhou, W. Load-frequency control in isolated city microgrids using deep graph RL. AIP Adv. 2025, 15, 015316. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Balcan, M.F., Weinberger, K.Q., Eds.; Proceedings of Machine Learning Research, 2016; Volume 48, pp. 1928–1937. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Liu, J.; Chen, T. Advances in battery technology for energy storage systems. J. Energy Storage 2022, 45, 103834. [Google Scholar] [CrossRef]
- Nguyen, D.; Patel, S.; Srivastava, A.; Bulak, E. Machine learning approaches for microgrid control. Energy Inform. 2023, 6, 14. [Google Scholar]
- Figueiró, A.A.; Peixoto, A.J.; Costa, R.R. State of charge estimation and battery balancing control. In Proceedings of the 54th IEEE Conference on Decision and Control (CDC), Osaka, Japan, 15–18 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 670–675. [Google Scholar] [CrossRef]
- Patel, R.; Gonzalez, S. Demand response strategies in smart grids: A review. IEEE Access 2017, 5, 20068–20081. [Google Scholar]
- Miettinen, K.; Ali, S.M. Multi-objective optimization techniques in energy systems. Eur. J. Oper. Res. 2001, 128, 512–520. [Google Scholar]
- Chevalier-Boisvert, M. Minimalistic Gridworld Environment for OpenAI Gym. Ph.D. Thesis, Université de Montréal, Montreal, QC, Canada, 2018. [Google Scholar]
- Sharma, S.; Patel, M. Assessment and optimisation of residential microgrid reliability using expected energy not supplied. Processes 2025, 13, 740. [Google Scholar] [CrossRef]
- Oleson, D. Reframing Curtailment: Why Too Much of a Good Thing Is Still a Good Thing. National Renewable Energy Laboratory News Feature. 2022. Available online: https://www.nrel.gov/news/program/2022/reframing-curtailment (accessed on 7 January 2020).
- Duan, M.; Duan, J.; An, Q.; Sun, L. Fast State-of-Charge balancing strategy for distributed energy storage units interfacing with DC-DC boost converters. Appl. Sci. 2024, 14, 1255. [Google Scholar] [CrossRef]
- Li, Y.; Martinez, F. Review of cell-level battery aging models: Calendar and cycling. Batteries 2024, 10, 374. [Google Scholar] [CrossRef]
- Schmalstieg, J.; Käbitz, S.; Ecker, M.; Sauer, D.U. A holistic aging model for Li(NiMnCo)O2 based 18650 lithium-ion batteries. J. Power Sources 2014, 257, 325–334. [Google Scholar] [CrossRef]
- Ji, Y.; Wang, J.; Zhang, X. Real-time energy management of a microgrid using deep reinforcement learning. Energies 2019, 12, 2291. [Google Scholar] [CrossRef]
- Ioannou, I.; Vassiliou, V.; Christophorou, C.; Pitsillides, A. Distributed artificial intelligence solution for D2D communication in 5G networks. IEEE Syst. J. 2020, 14, 4232–4241. [Google Scholar] [CrossRef]
- Ioannou, I.I.; Javaid, S.; Christophorou, C.; Vassiliou, V.; Pitsillides, A.; Tan, Y. A distributed AI framework for nano-grid power management and control. IEEE Access 2024, 12, 43350–43377. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Z.; Sun, Y.; Wu, Q. Asynchronous distributed optimal energy management for multi-energy microgrids with communication delays and packet dropouts. Appl. Energy 2025, 381, 125271. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Wang, K.; Liu, J.; Wu, L. Multi-stage attack-resilient coordinated recovery of integrated electricity-heat systems. IEEE Trans. Smart Grid 2023, 14, 2653–2666. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Set of discrete time steps | |
| t | Index for a specific time step in |
| Duration of a single time step (typically 1 h in this work) | |
| s | Index representing the operational season (e.g., winter, spring, summer, autumn) |
| Set of renewable energy source (RES) units | |
| Power generation from photovoltaic (PV) array at time t | |
| Power generation from fuel cell (FC) at time t | |
| Seasonal maximum power generation from PV array for season s | |
| Total power generation available from all sources at time t () | |
| Available power generation from RES unit j at time t | |
| Actual power utilized from RES unit j at time t | |
| Forecasted available power generation from RES unit j for future time | |
| Set of energy storage system (ESS) units (typically in this work) | |
| Maximum energy storage capacity of ESS unit i | |
| Minimum allowed energy storage level for ESS unit i | |
| Energy stored in ESS unit i at the beginning of time step t | |
| State of charge of ESS unit i at time t () | |
| Average state of charge across ESS units at time t (e.g., for two units) | |
| Net power flow for ESS unit i at time t; positive if charging from bus, negative if discharging to bus | |
| Power charged into ESS unit i during time step t | |
| Power discharged from ESS unit i during time step t | |
| Maximum charging power for ESS unit i | |
| Maximum discharging power for ESS unit i | |
| Charging efficiency of ESS unit i | |
| Discharging efficiency of ESS unit i | |
| Binary variable: 1 if ESS unit i is charging at time t, 0 otherwise | |
| Binary variable: 1 if ESS unit i is discharging at time t, 0 otherwise | |
| Set of electrical loads | |
| Required power demand of load k at time t | |
| Actual power supplied to load k at time t | |
| Total required load demand in the system at time t () | |
| Forecasted power demand of load k for future time | |
| Power imported from the main utility grid at time t (0 for islanded mode) | |
| Power exported to the main utility grid at time t (0 for islanded mode) | |
| Maximum power import capacity from the grid | |
| Maximum power export capacity to the grid | |
| Cost of importing power from the grid at time t | |
| Revenue/price for exporting power to the grid at time t | |
| Net power imbalance at the microgrid bus at time t () | |
| Unmet load demand at time t () | |
| Excess generation (not consumed by load or ESS) at time t () | |
| System state observed by the control agent at time t | |
| Action taken by the control agent at time t | |
| Forecast horizon length for predictions (e.g., RES, load) | |
| Index for a future time step within the forecast horizon | |
| Instantaneous reward signal received by the control agent at time step t | |
| Total overall system operational reward over the horizon (also denoted ) | |
| Total unmet load demand over the horizon () | |
| Total excess generation (not consumed by load or ESS) over the horizon () | |
| Average SoC imbalance among ESS units over the horizon | |
| Metric for operational stress on ESS units over the horizon | |
| Computational runtime of the control agent per decision step |
| Category | Approach/Study | Year | Core Idea | UL (%) | FreqDev (Hz) | SoC Imb. (%) | Diesel (h/d) | Comp | Data Need | Reported Gains | Key Strengths | Key Limitations |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Review | Gen. Review (Serban and Cespedes [17]) | 2018 | Survey of EMS and Demand Response | N/A | N/A | N/A | N/A | N/A | N/A | — | Broad overview of methods | No specific performance data |
| Model-based | MPC (Li et al. [8]) | 2021 | Forecast-driven recursive optimization | 1.00 | 0.30 | N/A | 6.0 | >2 s | forecasts + model | — | Provable optimality; handles complex constraints | Computationally intensive; sensitive to model error |
| MPC (Parisio et al. [9]) | 2014 | Day-ahead MPC with rolling horizon | N/A | N/A | N/A | N/A | N/A | forecasts + model | — | Theoretically optimal schedules | No real-time metrics | |
| MPC Revisit (Heriot-Watt University ) | 2018 | Review of MPC challenges | N/A | N/A | N/A | N/A | minutes | model | — | Highlights practical issues | Confirms high computational load | |
| Robust MPC (Lara and Canizares ) | 2017 | Two-stage robust scheduling | N/A | N/A | N/A | N/A | minutes | model | — | Manages uncertainty | Increases computational complexity | |
| Heuristic | GA (Contreras et al. [12]) | 2013 | Genetic algorithm, multi-objective scheduling | 0.85 | 0.28 | N/A | 5.5 | 20–60 s | model | 6–8% cost Dropped ↓ | Handles non-linear trade-offs | Slow convergence; no guarantees |
| GA (Memon et al. [13]) | 2020 | GA for solar-diesel microgrids | N/A | N/A | N/A | N/A | N/A | model | — | Effective cost reduction | Needs detailed model; long runtimes | |
| Forecast + optimize | LSTM Review (Khan et al. [18]) | 2020 | Review of LSTM for solar forecast | N/A | N/A | N/A | N/A | N/A | data | MAPE < 5% | High forecast accuracy | Focus on forecast, not control |
| LSTM+MPC (Abdelkader et al. [19]) | 2021 | MPC aided by LSTM forecasts | 0.40 | 0.28 | N/A | 5.3 | 3–12 s | data & model | UL ↓ > 50%, diesel ↓ 10% | Better forecasts | Still bound by optimizer | |
| ML Review (Al-Skaif et al. [20]) | 2022 | ML forecasting pipeline review | N/A | N/A | N/A | N/A | N/A | data | — | High forecast accuracy | Model limits overall benefit | |
| Hybrid (Zhang and Liang [21]) | 2022 | Integrated forecast + optimize | N/A | N/A | N/A | N/A | N/A | data & model | — | Unified pipeline | Higher computational cost | |
| Direct Sup. ML | NN-policy (Kouveliotis-Lysikatos and Hatziargyriou [22]) | 2020 | Direct state-to-action neural policy | 0.35 | 0.26 | 4.5 | 5.1 | <1 ms | labeled data | Matches MILP cost ± 3% | Ultra-fast inference | Needs large data sets |
| NN-policy (Wu et al. [23]) | 2024 | NN for load–frequency control | N/A | 0.25 | N/A | N/A | <1 ms | moderate labels | — | Efficient frequency stabilization | Data-coverage risk | |
| Tabular RL | Q-learning (Foruzan et al. [24]) | 2018 | Value-table learning | 0.70 | 0.40 | 5.8 | 5.8 | <1 ms | interaction | — | Simple, model-free | State-space explosion |
| Policy-gradient DRL | PPO (Zhang et al. [25]) | 2021 | Actor–critic, clipped surrogate | 0.22 | 0.25 | 4.1 | 4.6 | <1 ms | interaction | Diesel ↓ 50% | Robust learning | High on-policy sample need |
| PPO (Yang et al. [26]) | 2020 | PPO variant for EMS | N/A | N/A | N/A | N/A | <1 ms | interaction | — | Fast inference | Few public KPIs | |
| DG-RL (He et al. [28]) | 2025 | Graph-based DRL for LFC | N/A | N/A | N/A | N/A | N/A | interaction | — | Topology-aware control | No EMS energy metrics | |
| Advanced RL | Fault-tol. RL (Sheida et al. [27]) | 2024 | RL for fault-tolerant microgrids | N/A | N/A | N/A | N/A | N/A | interaction | — | Resilient to faults | Few economic KPIs |
| Value-based DRL | DQN (This work) | 2025 | Replay buffer + target network Q-learning | <0.01 | <0.18 | <0.1 | N/A | <6 ms | interaction | 73–95% cost ↓ vs. baseline | Best overall KPIs, low compute | Needs hyper-parameter tuning |
| Parameter | Value/Description |
|---|---|
| Simulation horizon | 24 h per episode |
| Control time step | 1 h |
| Number of ESS units | 2 |
| ESS rated capacity | 13.5 kWh per unit |
| PV system capacity | 10 kW peak |
| Fuel cell output | 2.5 kW continuous |
| Minimum ESS SoC | 20% |
| Maximum ESS SoC | 90% |
| ESS round-trip efficiency | 90% |
| Load profile | Seasonal (summer, fall, winter, spring) |
| PV generation | Realistic hourly curves (weather influenced) |
| Reward penalties | For unmet load, curtailment, SoC violation |
| Season | AC (W) | WM (W) | EK (W) | VF (W) | LT (W) | MV (W) |
|---|---|---|---|---|---|---|
| Winter | 890 | 500 | 600 | 66 | 36.8 | 1000 |
| Summer | 790 | 350 | 600 | 111 | 36.8 | 1000 |
| Autumn | 380 | 450 | 600 | 36 | 36.8 | 1000 |
| Spring | 380 | 350 | 600 | 36 | 36.8 | 1000 |
| Agent | Reward | (kWh) | (kWh) | (%) | (%) | Control Power (kW) | Exec. Time (ms) | Run-Time (s) |
|---|---|---|---|---|---|---|---|---|
| DQN | 0.39 | 29.61 | 0.00 | 33.78 | 4.00 | 5.24 | 0.78 | |
| Q-learning | 0.39 | 29.61 | 0.00 | 33.78 | 1.85 | 0.20 | 0.01 | |
| A2C | 0.39 | 29.61 | 0.03 | 33.78 | 5.49 | 6.28 | 0.60 | |
| PPO | 0.42 | 29.63 | 0.01 | 34.01 | 5.99 | 11.62 | 0.59 | |
| No Control | 0.39 | 26.46 | 15.00 | 0.00 | 0.00 | 0.01 | 0.30 |
| Agent | Reward | (kWh) | (kWh) | (%) | (%) | Control Power (kW) | Exec. Time (ms) | Run-Time (s) |
|---|---|---|---|---|---|---|---|---|
| DQN | 0.26 | 33.47 | 0.00 | 34.46 | 4.00 | 4.79 | 0.73 | |
| Q-learning | 0.26 | 33.47 | 0.00 | 34.46 | 3.46 | 0.17 | 0.01 | |
| PPO | 0.27 | 33.47 | 0.00 | 34.46 | 5.95 | 11.56 | 0.55 | |
| A2C | 0.27 | 33.48 | 0.02 | 34.58 | 5.86 | 5.75 | 0.54 | |
| No Control | 0.26 | 30.33 | 15.00 | 0.00 | 0.01 | 0.01 | 0.30 |
| Agent | Reward | (kWh) | (kWh) | (%) | (%) | Control Power (kW) | Exec. Time (ms) | Run-Time (s) |
|---|---|---|---|---|---|---|---|---|
| A2C | 2.04 | 26.51 | 0.00 | 15.22 | 6.00 | 9.37 | 0.75 | |
| DQN | 2.04 | 26.51 | 0.00 | 15.22 | 4.00 | 5.59 | 0.78 | |
| Q-learning | 2.04 | 26.51 | 0.00 | 15.22 | 3.92 | 0.22 | 0.02 | |
| PPO | 2.05 | 26.52 | 0.00 | 15.30 | 5.99 | 12.93 | 0.58 | |
| No Control | 2.04 | 23.36 | 15.00 | 0.00 | 0.01 | 0.01 | 0.30 |
| Agent | Reward | (kWh) | (kWh) | (%) | (%) | Control Power (kW) | Exec. Time (ms) | Run-Time (s) |
|---|---|---|---|---|---|---|---|---|
| A2C | 6.03 | 17.24 | 0.00 | 14.05 | 5.98 | 6.23 | 0.60 | |
| DQN | 6.03 | 17.24 | 0.00 | 14.05 | 4.00 | 5.44 | 0.80 | |
| Q-learning | 6.03 | 17.24 | 0.00 | 14.05 | 2.77 | 0.26 | 0.02 | |
| PPO | 6.11 | 17.29 | 0.04 | 14.47 | 5.93 | 11.82 | 0.60 | |
| No Control | 6.03 | 14.09 | 15.00 | 0.00 | 0.00 | 0.01 | 0.45 |
| Performance Metric | Real-World Data | Simulated Data | Similarity |
|---|---|---|---|
| Total Unmet Load (kWh) | 3.5 | 3.4 | 97.1% |
| Total Excess Generation (kWh) | 108.8 | 111.9 | 97.2% |
| Total ESS Throughput (kWh) | 249.0 | 259.3 | 95.8% |
| Average Daily PV Production (kWh) | 21.8 | 21.8 | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ioannou, I.; Javaid, S.; Tan, Y.; Vassiliou, V. Autonomous Reinforcement Learning for Intelligent and Sustainable Autonomous Microgrid Energy Management. Electronics 2025, 14, 2691. https://doi.org/10.3390/electronics14132691
Ioannou I, Javaid S, Tan Y, Vassiliou V. Autonomous Reinforcement Learning for Intelligent and Sustainable Autonomous Microgrid Energy Management. Electronics. 2025; 14(13):2691. https://doi.org/10.3390/electronics14132691
Chicago/Turabian StyleIoannou, Iacovos, Saher Javaid, Yasuo Tan, and Vasos Vassiliou. 2025. "Autonomous Reinforcement Learning for Intelligent and Sustainable Autonomous Microgrid Energy Management" Electronics 14, no. 13: 2691. https://doi.org/10.3390/electronics14132691
APA StyleIoannou, I., Javaid, S., Tan, Y., & Vassiliou, V. (2025). Autonomous Reinforcement Learning for Intelligent and Sustainable Autonomous Microgrid Energy Management. Electronics, 14(13), 2691. https://doi.org/10.3390/electronics14132691