
Architectural Ambiance: ChatGPT Versus Human Perception



Abstract

1. Introduction
1.1. Assessing a Built Environment with AI
1.2. Contributions of the Work
Research Questions
- How do AI-generated assessments compare to human perceptions in characterizing urban spaces based on spatial, architectural, and emotional attributes?
- To what extent can AI models replicate human subjective interpretations of urban ambiance, and what factors influence discrepancies between AI and human responses?
- We will provide elements of response using three urban scenes of a diverse character: a business district, a strip mall, and a green residential area. Four aspects of architectural ambiance are investigated—space and scale, enclosure, architectural style, and overall feelings—with each one characterized by a set of subjective attributes covering the feelings evoked via an urban environment.
2. Literature Review
2.1. Assessment of Architectural Ambiance
2.2. AI in Urban Scene Analysis
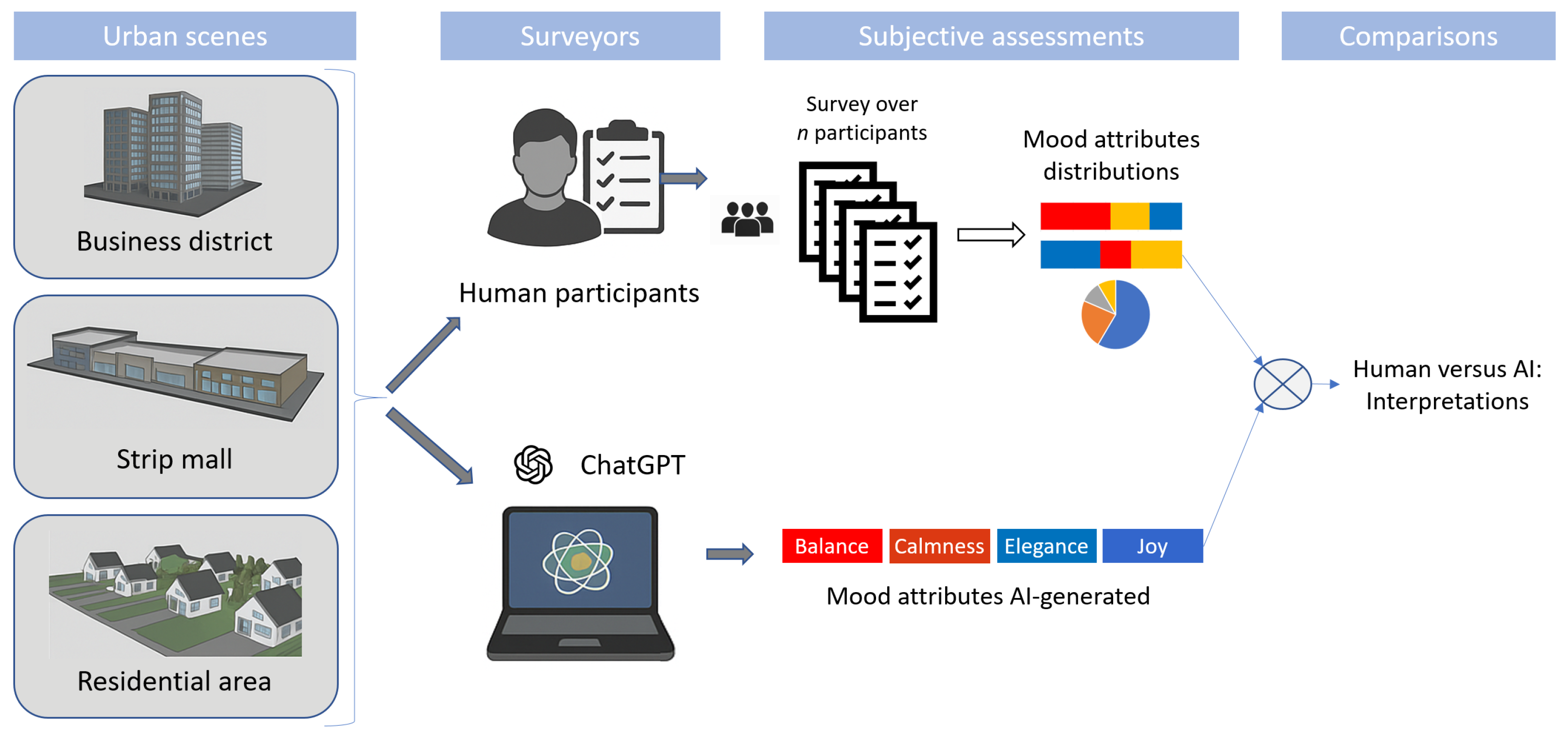
3. Materials and Methods
3.1. Materials
3.2. Methodology
3.2.1. Evaluation by GPT-4
“These three images illustrate a small part of an urban district. Imagine visiting the urban environment shown in these three images. We ask you to characterize this space according to four factors: (1) Space and scale, (2) Enclosure, (3) Architectural style and (4) General Feelings.
Space and scale: what feeling would you feel there? Choose between the three answers: Restlessness, Balance or Grandeur.
Enclosure: What degree of enclosure would you feel inside the scene? Choose between one of these four: Protection, Calmness, Freedom, Animation.
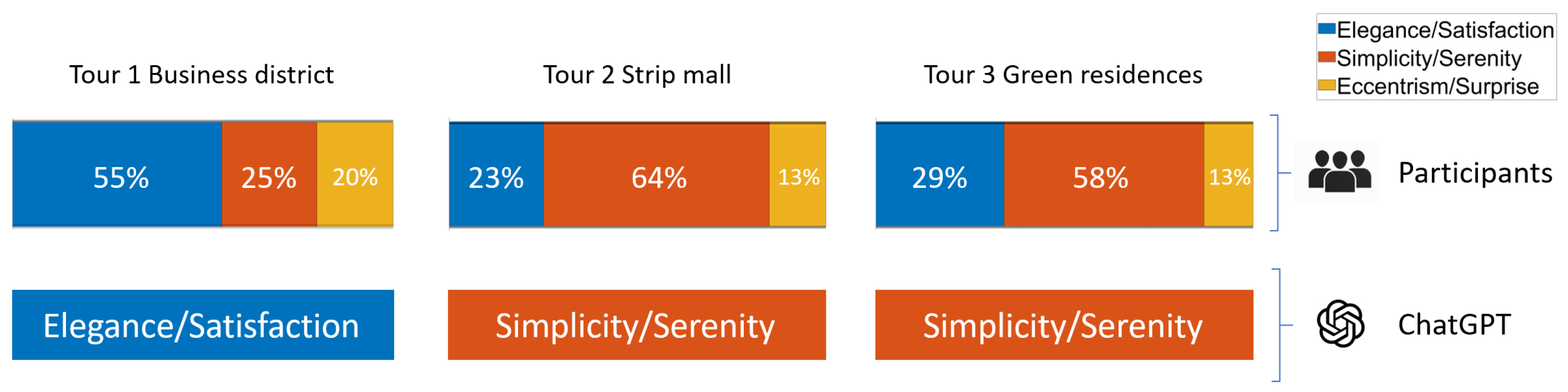
Architectural style: What do the buildings inspire you? Choose between one the three couples: Elegance/Satisfaction or Simplicity/Serenity or Eccentricism/Surprise.
General feelings: What kind of feeling describe the most your sensation inside the scene? Choose between one of the four couples: Joy/Theatricality or Sadness/Nostalgia or Emotion/Spirituality or Indifference/Unnoticed.”
“Space and Scale: The environment feels Balanced. The scale of the buildings and their repetition create a sense of proportion and uniformity, without overwhelming grandeur or creating restlessness.”
3.2.2. Architectural Aspects and Mood Attributes
- Space and scale are fundamental in shaping perceptions and experience of a built environment. The proportions of spaces influence whether an area feels grand and imposing, intimate and human-scaled, or claustrophobic. Mood attributes that can characterize these aspects are balance, grandeur, and restlessness.
- Enclosure determines openness versus containment in a space. An environment with high enclosure can feel protected, private, or even restrictive, while highly open spaces convey freedom, exposure, and accessibility. This aspect is key to defining how people interact with the space emotionally. Attributes related to this aspect can include the following: protection, calmness, freedom, and animation.
- Style embodies historical, cultural, and aesthetic values. Whether a space is modern and minimalist, ornate, or industrial and raw, it immediately affects ambiance and perception. The materials, geometry, and detailing play a role in reinforcing a mood—whether eccentric, elegant, or simplistic.
- Overall feelings encapsulate subjective experience, integrating physical attributes with emotional response. Architecture is not just about form; it influences psychological comfort. Whether a space feels nostalgic, spiritual, theatrical, or indifferent, these impressions result from the interplay of the previous three aspects, making this the final necessary piece to complete ambiance characterization.
4. Experiment and Results
4.1. Experimental Protocol
4.2. Analysis of Results by Architectural Aspects
4.2.1. Space and Scale Criteria
4.2.2. Enclosure Feelings
The visual analysis of the scene is indeed correct, even though the model did not explain why the other characterizations fit less with the ambiance.The combination of continuous facades and the open street with tree planting offers a blend of spatial definition and visual breathing room.
4.2.3. Architecture Style
4.2.4. Overall Feelings
This is convincing argumentation, and it fit well with the visual scene. But this choice qualifies as a form of hallucination since it significantly deviates from the dominant human perception. ChatGPT categorized it as joy/theatricality, which contradicts the prevailing sentiment and suggests a disconnect in its contextual understanding. ChatGPT may associate business districts with vibrancy, energy, and modernity, leading it to overemphasize positive emotions. In the two other tours, GPT-4 correctly chose indifference because the tours lacked standout features that might evoke a stronger emotional or memorable response, an opinion that seemed to be shared by the majority of the public audience.The sleek design, interplay of glass and sunlight, and the vibrant urban environment contribute to a lively and dynamic atmosphere.
4.2.5. Overall Feelings: Cross-AI Comparison
Figure 8 shows the resulting generated environments. Some elements on which Imagen based its generated can be inferred. For instance, in Figure 8a, the use of light pink tones and the orderly, open courtyard space evokes a feeling of calm positivity and visual harmony that suggest joy. The warm tones on the buildings, combined with the rich blue sky, evoke a feeling of lightness and positivity. In Figure 8b, the color palette is very muted and de-saturated, giving it a washed-out, almost melancholic appearance favorable to a nostalgic experience. Somewhere between atmospheric minimalism and brutalism, the scenes of Figure 8c display a soft haze, muted tones, and pale lighting that give the scenes contemplative feelings. This creates a serene, contemplative mood that leans toward the introspective. In the four scenes depicted in Figure 8d, the buildings are stark, geometric, and nearly identical, creating a sterile and depersonalized environment. There is no architectural detail or color variation to provoke emotional engagement, suggesting an impersonal, utilitarian design.Let us suppose that the general feeling of an urban scene can be described by one of the following four pairs of attributes: Joy/Theatricality, Sadness/Nostalgia, Emotion/Spirituality, or Indifference/Unnoticed. Please generate four urban scene images illustrating these types of built environments, all under the same conditions: clear weather, during daytime (at noon), with the sun and lighting not influencing these feelings. Could you ensure that the setup features modern buildings in an urban area, with no people, no cars, and no fountains?
4.3. Overview Evaluation of AI-Generated Outputs
4.3.1. Analysis by Urban Identity
4.3.2. Analysis by Gender and Age
5. Discussion
5.1. General Findings of the Work
5.2. Limitations of the Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ogawa, Y.; Oki, T.; Zhao, C.; Sekimoto, Y.; Shimizu, C. Evaluating the subjective perceptions of streetscapes using street-view images. Landsc. Urban Plan. 2024, 247, 105073. [Google Scholar] [CrossRef]
- Gomez-Tone, H.C.; Alpaca Chávez, M.; Vásquez Samalvides, L.; Martin-Gutierrez, J. Introducing Immersive Virtual Reality in the Initial Phases of the Design Process–Case Study: Freshmen Designing Ephemeral Architecture. Buildings 2022, 12, 518. [Google Scholar] [CrossRef]
- Belaroussi, R.; González, E.D.; Dupin, F.; Martin-Gutierrez, J. Appraisal of Architectural Ambiances in a Future District. Sustainability 2023, 15, 13295. [Google Scholar] [CrossRef]
- Luo, J.; Liu, P.; Xu, W.; Zhao, T.; Biljecki, F. A perception-powered urban digital twin to support human-centered urban planning and sustainable city development. Cities 2025, 156, 105473. [Google Scholar] [CrossRef]
- Luo, J.; Zhao, T.; Cao, L.; Biljecki, F. Water View Imagery: Perception and evaluation of urban waterscapes worldwide. Ecol. Indic. 2022, 145, 109615. [Google Scholar] [CrossRef]
- OpenAI. GPT-4: OpenAI’s Multimodal Large Language Model. 2013. Available online: https://openai.com/gpt-4 (accessed on 15 January 2025).
- Gómez-Tone, H.C.; Bustamante Escapa, J.; Bustamante Escapa, P.; Martin-Gutierrez, J. The drawing and perception of architectural spaces through immersive virtual reality. Sustainability 2021, 13, 6223. [Google Scholar] [CrossRef]
- Bornioli, A. The walking meeting: Opportunities for better health and sustainability in post-COVID-19 cities. Cities Health 2023, 7, 556–562. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, Y.; Biljecki, F. Understanding the user perspective on urban public spaces: A systematic review and opportunities for machine learning. Cities 2025, 156, 105535. [Google Scholar] [CrossRef]
- Biljecki, F.; Ito, K. Street view imagery in urban analytics and GIS: A review. Landsc. Urban Plan. 2021, 215, 104217. [Google Scholar] [CrossRef]
- Corticelli, R.; Pazzini, M.; Mazzoli, C.; Lantieri, C.; Ferrante, A.; Vignali, V. Urban Regeneration and Soft Mobility: The Case Study of the Rimini Canal Port in Italy. Sustainability 2022, 14, 14529. [Google Scholar] [CrossRef]
- Brown, G.; Gifford, R. Architects predict lay evaluations of large contemporary buildings: Whose conceptual properties? J. Environ. Psychol. 2001, 21, 93–99. [Google Scholar] [CrossRef]
- Li, F.; Zhang, Z.; Xu, L.; Yin, J. The effects of professional design training on urban public space perception: A virtual reality study with physiological and psychological measurements. Cities 2025, 158, 105654. [Google Scholar] [CrossRef]
- Hashemi Kashani, S.; Pazhouhanfar, M.; van Oel, C. Role of physical attributes of preferred building facades on perceived visual complexity: A discrete choice experiment. Environ. Dev. Sustain. 2023, 26, 13515–13534. [Google Scholar] [CrossRef]
- Gómez-Tone, H.C.; Martin-Gutierrez, J.; Bustamante-Escapa, J.; Bustamante-Escapa, P. Spatial Skills and Perceptions of Space: Representing 2D Drawings as 3D Drawings inside Immersive Virtual Reality. Appl. Sci. 2021, 11, 1475. [Google Scholar] [CrossRef]
- Sioui, G.B. Ambiantal Architecture—Defining the role of water in the aesthetic experience of sensitive architectural ambiances. In SHS Web of Conferences; EDP Sciences: Les Ulis, France, 2019. [Google Scholar]
- Gascon, M.; Zijlema, W.; Vert, C.; White, M.P.; Nieuwenhuijsen, M.J. Outdoor blue spaces, human health and well-being: A systematic review of quantitative studies. Int. J. Hyg. Environ. Health 2017, 220, 1207–1221. [Google Scholar] [CrossRef]
- Cai, M. Natural language processing for urban research: A systematic review. Heliyon 2021, 7, e06322. [Google Scholar] [CrossRef]
- Wagiri, F.; Wijaya, D.C.; Sitindjak, R.H.I. Embodied spaces in digital times: Exploring the role of Instagram in shaping temporal dimensions and perceptions of architecture. Architecture 2024, 4, 948–973. [Google Scholar] [CrossRef]
- Olson, A.W.; Calderón-Figueroa, F.; Bidian, O.; Silver, D.; Sanner, S. Reading the city through its neighbourhoods: Deep text embeddings of Yelp reviews as a basis for determining similarity and change. Cities 2021, 110, 103045. [Google Scholar] [CrossRef]
- Lee, M.; Kim, H.; Hwang, S. Virtual audit of microscale environmental components and materials using streetscape images with panoptic segmentation and image classification. Autom. Constr. 2025, 170, 105885. [Google Scholar] [CrossRef]
- Tang, J.; Long, Y. Measuring visual quality of street space and its temporal variation: Methodology and its application in the Hutong area in Beijing. Landsc. Urban Plan. 2019, 191, 103436. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (long and short papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, A.; Feng, B.; Xue, B.; Wang, B.; Wu, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; Ruan, C.; et al. Deepseek-v3 technical report. arXiv 2024, arXiv:2412.19437. [Google Scholar]
- Fu, C.; Zhang, R.; Wang, Z.; Huang, Y.; Zhang, Z.; Qiu, L.; Ye, G.; Shen, Y.; Zhang, M.; Chen, P.; et al. A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise. arXiv 2023, arXiv:2312.12436. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Liang, H.; Zhang, J.; Li, Y.; Wang, B.; Huang, J. Automatic Estimation for Visual Quality Changes of Street Space Via Street-View Images and Multimodal Large Language Models. IEEE Access 2024, 12, 87713–87727. [Google Scholar] [CrossRef]
- Malekzadeh, M.; Willberg, E.; Torkko, J.; Toivonen, T. Urban attractiveness according to ChatGPT: Contrasting AI and human insights. Comput. Environ. Urban Syst. 2025, 117, 102243. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. Available online: https://dl.acm.org/doi/10.5555/3295222.3295349 (accessed on 13 April 2025).
- Xiao, Y.; Song, M. How are urban design qualities associated with perceived walkability? An AI approach using street view images and deep learning. Int. J. Urban Sci. 2024, 1–26. [Google Scholar] [CrossRef]
- Ewing, R.; Clemente, O.; Neckerman, K.M.; Purciel-Hill, M.; Quinn, J.W.; Rundle, A. Measuring Urban Design: Metrics for Livable Places; Springer: Berlin/Heidelberg, Germany, 2013; Volume 200. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted | |||||
|---|---|---|---|---|---|
| Joy | Sad. | Emot. | Indiff. | ||
| Actual | Joy | 1 | 2 | 1 | 0 |
| Sadness | 0 | 0 | 2 | 2 | |
| Emotion | 1 | 1 | 1 | 1 | |
| Indifference | 0 | 0 | 0 | 4 | |
| Ambiance Aspect | Business District | Strip Mall | Green Residencies |
|---|---|---|---|
| Space and scale | 38% | 58% | 67% |
| Enclosure | 42% | 27% | 45% |
| Architecture style | 55% | 64% | 58% |
| Overall feelings | 15% | 58% | 40% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belaroussi, R.; Martín-Gutierrez, J. Architectural Ambiance: ChatGPT Versus Human Perception. Electronics 2025, 14, 2184. https://doi.org/10.3390/electronics14112184
Belaroussi R, Martín-Gutierrez J. Architectural Ambiance: ChatGPT Versus Human Perception. Electronics. 2025; 14(11):2184. https://doi.org/10.3390/electronics14112184
Chicago/Turabian StyleBelaroussi, Rachid, and Jorge Martín-Gutierrez. 2025. "Architectural Ambiance: ChatGPT Versus Human Perception" Electronics 14, no. 11: 2184. https://doi.org/10.3390/electronics14112184
APA StyleBelaroussi, R., & Martín-Gutierrez, J. (2025). Architectural Ambiance: ChatGPT Versus Human Perception. Electronics, 14(11), 2184. https://doi.org/10.3390/electronics14112184