
Multimodal Feature-Guided Audio-Driven Emotional Talking Face Generation

 , , and
, , and
Abstract
1. Introduction
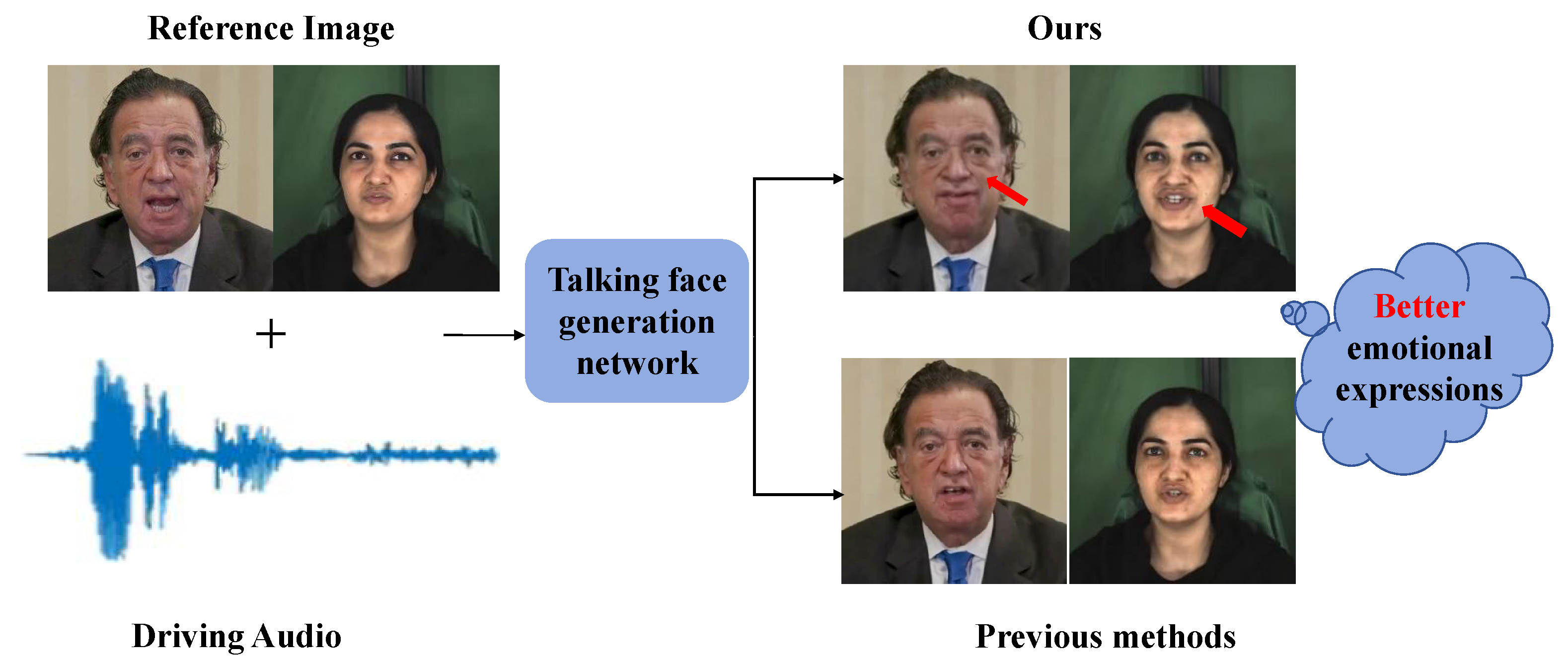
- We propose a Multimodal Feature-Guided Emotional talking face generation method, which effectively solves the problem of emotional expression and provides an effective method for complex emotional video generation.
- We design an emotion-aware multimodal feature disentanglement and fusion framework. It achieves multi-level emotion modeling and optimization from granular details to overall dynamics by employing AU-guided local expression disentanglement with residual encoding, alongside multimodal feature hierarchical fusion, significantly enhancing the naturalness of generated facial expressions.
- We introduce an emotion consistency loss function to make the expression on the generated face more vivid and expressive. This function utilizes the HSEmotionRecognizer algorithm to recognize emotions in the generated face.
2. Related Work
2.1. Emotional Talking Face Generation
2.2. Diffusion Models
2.3. Multimodal Fusion Strategies
3. Methods
3.1. Overview
3.2. Generative Model Network Architecture
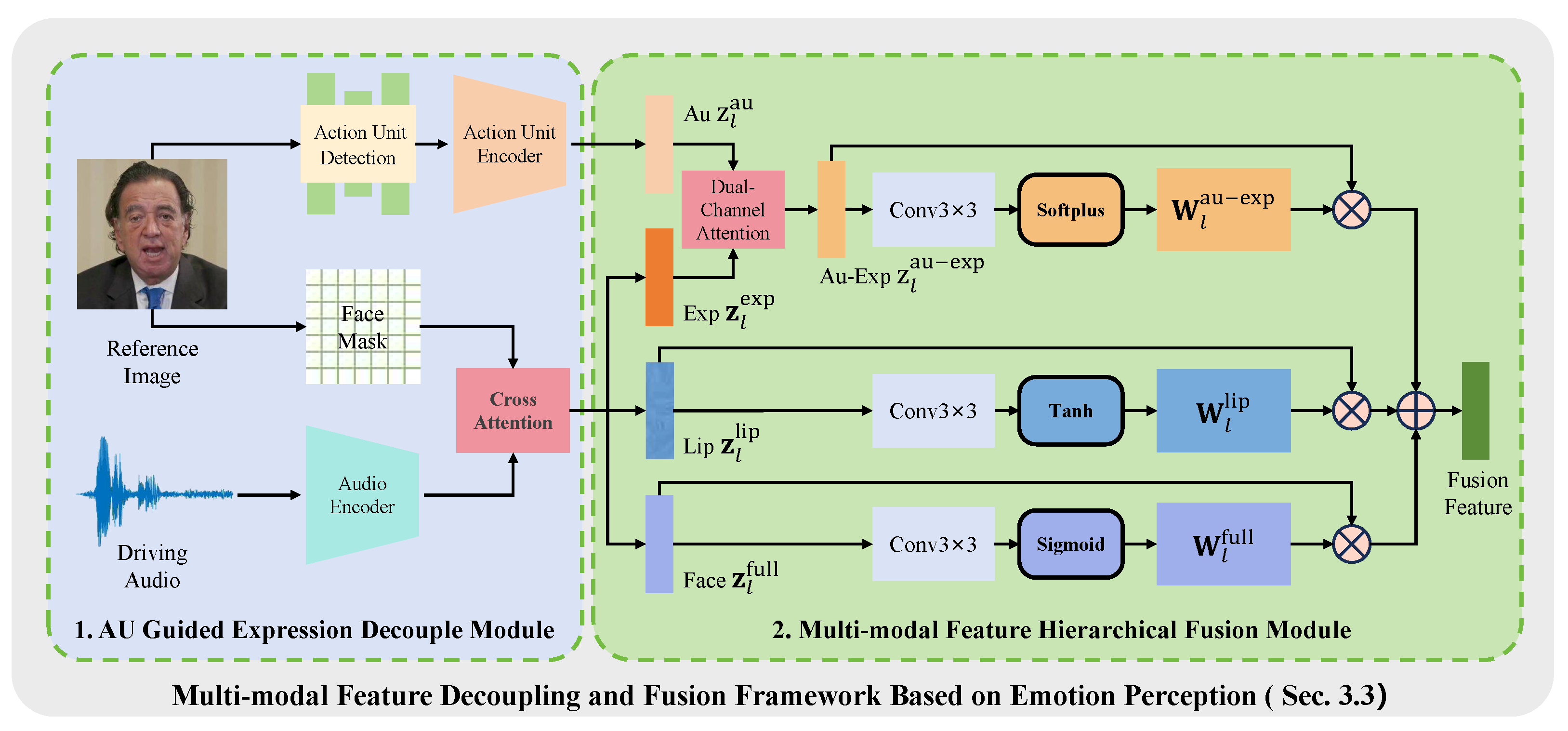
3.3. Emotion-Aware Multimodal Feature Disentanglement
3.3.1. AU-Guided Expression Decoupling Module
3.3.2. Multimodal Feature Hierarchical Fusion Module
3.4. Emotion Consistency Loss
4. Results
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Comparisons with Other Methods
4.4. Qualitative Results
4.5. Quantitative Results
4.6. Ablation Study
4.7. User Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AUs | Action Units |
| GANs | Generative Adversarial Networks |
| DMs | Diffusion Models |
| MF-ETalk | Emotional talking face generation method |
| SDv1.5 | Stable Diffusion v1.5 |
| FACS | Facial Action Coding System |
| MLP | multi-layer perceptron |
| AU | Action Unit |
| FID | Fréchet Inception Distance |
| LSE-C | Lip Sync Error-Confidence |
| LSE-D | Lip Sync Error-Distance |
| E-FID | Expression-FID |
| MFDF | effectiveness of the emotion-perception |
References
- Mitsea, E.; Drigas, A.; Skianis, C. A Systematic Review of Serious Games in the Era of Artificial Intelligence, Immersive Technologies, the Metaverse, and Neurotechnologies: Transformation Through Meta-Skills Training. Electronics 2025, 14, 649. [Google Scholar] [CrossRef]
- Toshpulatov, M.; Lee, W.; Lee, S. Talking human face generation: A survey. Expert Syst. Appl. 2023, 219, 119678. [Google Scholar] [CrossRef]
- Prajwal, K.; Mukhopadhyay, R.; Namboodiri, V.P.; Jawahar, C. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 484–492. [Google Scholar]
- Zhou, Y.; Han, X.; Shechtman, E.; Echevarria, J.; Kalogerakis, E.; Li, D. MakeItTalk: Speaker-aware talking-head animation. ACM Trans. Graph. 2020, 39, 1–15. [Google Scholar]
- Wang, S.; Li, L.; Ding, Y.; Yu, T.; Xia, Z.; Ma, L. Audio-driven One-shot Talking-head Generation with Natural Head Motion. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 1098–1105. [Google Scholar]
- Zhou, H.; Sun, Y.; Wu, W.; Loy, C.C.; Wang, X.; Liu, Z. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4176–4186. [Google Scholar]
- Wang, J.; Qian, X.; Zhang, M.; Tan, R.T.; Li, H. Seeing what you said: Talking face generation guided by a lip reading expert. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14653–14662. [Google Scholar]
- Zhong, W.; Fang, C.; Cai, Y.; Wei, P.; Zhao, G.; Lin, L.; Li, G. Identity-Preserving Talking Face Generation with Landmark and Appearance Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 9729–9738. [Google Scholar]
- Eskimez, S.E.; Zhang, Y.; Duan, Z. Speech driven talking face generation from a single image and an emotion condition. IEEE Trans. Multimed. 2022, 24, 3480–3490. [Google Scholar] [CrossRef]
- Sinha, S.; Biswas, S.; Yadav, R.; Namboodiri, V.P.; Jawahar, C.; Kumar, R. Emotion-controllable generalized talking face generation. In Proceedings of the International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 1320–1327. [Google Scholar]
- Ji, X.; Zhou, H.; Wang, K.; Liu, W.W.; Hong, F.; Qian, C.; Loy, C.C. Audio-driven emotional video portraits. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14080–14089. [Google Scholar]
- Ji, X.; Zhou, H.; Wang, K.; Hong, F.; Wu, W.; Qian, C.; Loy, C.C. EAMM: One-Shot Emotional Talking Face via Audio-Based Emotion-Aware Motion Model. In Proceedings of the ACM SIGGRAPH 2022 Conference, Vancouver, BC, Canada, 7–11 August 2022; p. 61. [Google Scholar]
- Tian, L.; Wang, Q.; Zhang, B.; Bo, L. EMO: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 244–260. [Google Scholar]
- Cui, J.; Li, H.; Yao, Y.; Zhu, H.; Shang, H.; Cheng, K.; Zhou, H.; Zhu, S.; Wang, J. Hallo2: Long-duration and high-resolution audio-driven portrait image animation. arXiv 2024, arXiv:2410.07718. [Google Scholar]
- Chen, Z.; Cao, J.; Chen, Z.; Li, Y.; Ma, C. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; pp. 2403–2410. [Google Scholar]
- Zhang, J.; Mai, W.; Zhang, Z. EMOdiffhead: Continuously Emotional Control in Talking Head Generation via Diffusion. arXiv 2024, arXiv:2409.07255. [Google Scholar]
- Dong, Z.; Hu, C.; Zhu, L.; Ji, X.; Lai, C.S. A Dual-Pathway Driver Emotion Classification Network Using Multi-Task Learning Strategy: A Joint Verification. IEEE Internet Things J. 2025, 12, 14897–14908. [Google Scholar] [CrossRef]
- Xu, M.; Li, H.; Su, Q.; Shang, H.; Zhang, L.; Liu, C.; Wang, J.; Yao, Y.; Zhu, S. Hallo: Hierarchical audio-driven visual synthesis for portrait image animation. arXiv 2024, arXiv:2406.08801. [Google Scholar]
- Wang, K.; Wu, Q.; Song, L.; Liu, W.; Qian, C.; Loy, C.C. MEAD: A large-scale audio-visual dataset for emotional talking-face generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 700–717. [Google Scholar]
- Liang, B.; Pan, Y.; Guo, Z.; Zou, Y.; Yan, J.; Xie, W.; Yang, Y. Expressive talking head generation with granular audio-visual control. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3387–3396. [Google Scholar]
- Zhang, Z.; Li, L.; Ding, Y.; Fan, C. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3661–3670. [Google Scholar]
- Zhang, W.; Cun, X.; Wang, X.; Zhang, Y.; Shen, X.; Guo, Y.; Shan, Y.; Wang, F. Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 8652–8661. [Google Scholar]
- Wang, H.; Weng, Y.; Li, Y.; Zhou, H.; Qian, C.; Lin, D. EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion. arXiv 2024, arXiv:2411.16726. [Google Scholar]
- Zheng, L.; Zhang, Y.; Guo, H.; Pan, J.; Tan, Z.; Lu, J.; Tang, C.; An, B.; Yan, S. MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation. arXiv 2024, arXiv:2412.04448. [Google Scholar]
- Sauer, A.; Boesel, F.; Dockhorn, T.; Blattmann, A.; Esser, P.; Rombach, R. Fast high-resolution image synthesis with latent adversarial diffusion distillation. In Proceedings of the SIGGRAPH Asia 2024 Conference Papers, Tokyo, Japan, 3–6 December 2024; pp. 1–11. [Google Scholar]
- Teng, Y.; Wu, Y.; Shi, H.; Ning, X.; Dai, G.; Wang, Y.; Li, Z.; Liu, X. Dim: Diffusion mamba for efficient high-resolution image synthesis. arXiv 2024, arXiv:2405.14224. [Google Scholar]
- Liu, Y.; Cun, X.; Liu, X.; Wang, X.; Zhang, Y.; Chen, H.; Liu, Y.; Zeng, T.; Chan, R.; Shan, Y. Evalcrafter: Benchmarking and evaluating large video generation models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 22139–22149. [Google Scholar]
- Bar-Tal, O.; Chefer, H.; Tov, O.; Herrmann, C.; Paiss, R.; Zada, S.; Ephrat, A.; Hur, J.; Liu, G.; Raj, A.; et al. Lumiere: A space-time diffusion model for video generation. In Proceedings of the SIGGRAPH Asia 2024 Conference Papers, Tokyo, Japan, 3–6 December 2024; pp. 1–11. [Google Scholar]
- Huang, Z.; Luo, D.; Wang, J.; Liao, H.; Li, Z.; Wu, Z. Rhythmic foley: A framework for seamless audio-visual alignment in video-to-audio synthesis. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing, Hyderabad, India, 6–11 April 2025; pp. 1–5. [Google Scholar]
- Truong, V.T.; Dang, L.B.; Le, L.B. Attacks and defenses for generative diffusion models: A comprehensive survey. ACM Comput. Surv. 2025, 57, 1–44. [Google Scholar] [CrossRef]
- Stypułkowski, M.; Vougioukas, K.; He, S.; Zięba, M.; Petridis, S.; Pantic, M. Diffused heads: Diffusion models beat gans on talking-face generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–6 January 2024; pp. 5091–5100. [Google Scholar]
- Tang, H.; Li, Z.; Zhang, D.; He, S.; Tang, J. Divide-and-Conquer: Confluent Triple-Flow Network for RGB-T Salient Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 1958–1974. [Google Scholar] [CrossRef]
- Hossain, M.R.; Hoque, M.M.; Dewan, M.A.A.; Hoque, E.; Siddique, N. AuthorNet: Leveraging attention-based early fusion of transformers for low-resource authorship attribution. Expert Syst. Appl. 2025, 262, 125643. [Google Scholar] [CrossRef]
- Shen, M.; Zhang, S.; Wu, J.; Xiu, Z.; AlBadawy, E.; Lu, Y.; Seltzer, M.; He, Q. Get Large Language Models Ready to Speak: A Late-fusion Approach for Speech Generation. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing, Hyderabad, India, 6–11 April 2025; pp. 1–5. [Google Scholar]
- Fontanini, T.; Ferrari, C.; Lisanti, G.; Bertozzi, M.; Prati, A. Semantic image synthesis via class-adaptive cross-attention. IEEE Access 2025, 13, 10326–10339. [Google Scholar] [CrossRef]
- Shen, J.; Chen, Y.; Liu, Y.; Zuo, X.; Fan, H.; Yang, W. ICAFusion: Iterative cross-attention guided feature fusion for multispectral object detection. Pattern Recognit. 2024, 145, 109913. [Google Scholar] [CrossRef]
- Diao, X.; Cheng, M.; Barrios, W.; Jin, S. Ft2tf: First-person statement text-to-talking face generation. In Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision, Tucson, AZ, USA, 28 February–4 March 2025; pp. 4821–4830. [Google Scholar]
- Jang, Y.; Kim, J.H.; Ahn, J.; Kwak, D.; Yang, H.S.; Ju, Y.C.; Kim, I.H.; Kim, B.Y.; Chung, J.S. Faces that speak: Jointly synthesising talking face and speech from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 8818–8828. [Google Scholar]
- Luo, S.; Tan, Y.; Patil, S.; Gu, D.; von Platen, P.; Passos, A.; Huang, L.; Li, J.; Zhao, H. Lcm-lora: A universal stable-diffusion acceleration module. arXiv 2023, arXiv:2311.05556. [Google Scholar]
- Wang, C.; Tian, K.; Zhang, J.; Guan, Y.; Luo, F.; Shen, F.; Jiang, Z.; Gu, Q.; Han, X.; Yang, W. V-express: Conditional dropout for progressive training of portrait video generation. arXiv 2024, arXiv:2406.02511. [Google Scholar]
- Jacob, G.M.; Stenger, B. Facial action unit detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7680–7689. [Google Scholar]
- Pumarola, A.; Agudo, A.; Martinez, A.M.; Sanfeliu, A.; Moreno-Noguer, F. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 818–833. [Google Scholar]
- Liu, Z.; Liu, X.; Chen, S.; Liu, J.; Wang, L.; Bi, C. Multimodal Fusion for Talking Face Generation Utilizing Speech-Related Facial Action Units. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–24. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Robinson, P.; Morency, L.P. Openface: An open source facial behavior analysis toolkit. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Shen, S.; Zhao, W.; Meng, Z.; Li, W.; Zhu, Z.; Zhou, J.; Lu, J. Difftalk: Crafting diffusion models for generalized audio-driven portraits animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1982–1991. [Google Scholar]
- Liang, M.; Cao, X.; Du, J. Dual-pathway attention based supervised adversarial hashing for cross-modal retrieval. In Proceedings of the 2021 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Republic of Korea, 17–20 January 2021; pp. 168–171. [Google Scholar]
- Fonteles, J.; Davalos, E.; Ashwin, T.; Zhang, Y.; Zhou, M.; Ayalon, E.; Lane, A.; Steinberg, S.; Anton, G.; Danish, J.; et al. A first step in using machine learning methods to enhance interaction analysis for embodied learning environments. In Proceedings of the International Conference on Artificial Intelligence in Education, Recife, Brazil, 8–12 July 2024; pp. 3–16. [Google Scholar]
- Ma, Y.; Zhang, S.; Wang, J.; Wang, X.; Zhang, Y.; Deng, Z. DreamTalk: When Emotional Talking Head Generation Meets Diffusion Probabilistic Models. arXiv 2023, arXiv:2312.09767. [Google Scholar]
- Wei, H.; Yang, Z.; Wang, Z. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv 2024, arXiv:2403.17694. [Google Scholar]
- Zhang, C.; Wang, C.; Zhang, J.; Xu, H.; Song, G.; Xie, Y.; Luo, L.; Tian, Y.; Guo, X.; Feng, J. DREAM-Talk: Diffusion-based realistic emotional audio-Driven method for single image talking face generation. arXiv 2023, arXiv:2312.13578. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Years | FID ↓ | LSE-C ↑ | LSE-D ↓ | E-FID ↓ |
|---|---|---|---|---|---|
| Wav2Lip | 2020 | 69.296 | 6.535 | 7.925 | 3.335 |
| PC-AVS | 2021 | 128.191 | 5.628 | 8.836 | 8.823 |
| EAMM | 2022 | 138.802 | 4.351 | 9.890 | 8.598 |
| SadTalker | 2023 | 120.127 | 6.709 | 8.103 | 5.118 |
| DreamTalk | 2023 | 148.664 | 5.910 | 8.278 | 8.616 |
| AniPortrait | 2024 | 85.708 | 3.233 | 10.917 | 3.753 |
| Hallo | 2024 | 46.691 | 6.561 | 8.201 | 2.814 |
| EchoMimic | 2024 | 100.182 | 5.419 | 9.447 | 4.571 |
| Ours | 43.052 | 6.781 | 7.962 | 2.403 |
| Method | Years | FID ↓ | LSE-C ↑ | LSE-D ↓ | E-FID↓ |
|---|---|---|---|---|---|
| Wav2Lip | 2020 | 42.681 | 6.752 | 8.979 | 3.837 |
| PC-AVS | 2021 | 100.763 | 7.413 | 8.184 | 6.711 |
| EAMM | 2022 | 126.153 | 4.448 | 10.686 | 5.419 |
| SadTalker | 2023 | 106.031 | 7.517 | 7.778 | 4.095 |
| DreamTalk | 2024 | 133.078 | 6.503 | 8.156 | 5.354 |
| AniPortrait | 2024 | 54.309 | 4.026 | 10.537 | 4.128 |
| Hallo | 2024 | 36.980 | 7.535 | 7.728 | 3.907 |
| EchoMimic | 2024 | 81.230 | 5.371 | 9.594 | 3.679 |
| Ours | 35.348 | 7.501 | 7.628 | 3.521 |
| Setting | MFDF | Loss | FID ↓ | LSE-C ↑ | LSE-D ↓ | E-FID ↓ |
|---|---|---|---|---|---|---|
| a | × | × | 46.691 | 6.561 | 8.201 | 2.814 |
| b | ✓ | × | 45.179 | 6.702 | 8.389 | 2.637 |
| c (Ours) | ✓ | ✓ | 43.052 | 6.781 | 7.962 | 2.403 |
| Method Name | Naturalness (%) | Expressiveness (%) | Composite Score (%) |
|---|---|---|---|
| Wav2Lip | 16.7 | 0 | 16.7 |
| PC-AVS | 0 | 0 | 0 |
| EAMM | 8.3 | 0 | 8.3 |
| SadTalker | 16.7 | 16.7 | 16.7 |
| DreamTalk | 0 | 8.3 | 8.3 |
| AmiPortrait | 8.3 | 0 | 8.3 |
| Hallo | 8.3 | 33.3 | 20.8 |
| EchoMimic | 16.7 | 25 | 20.85 |
| Ours | 33.3 | 16.7 | 25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Huo, Y.; Liu, Y.; Guo, X.; Yan, F.; Zhao, G. Multimodal Feature-Guided Audio-Driven Emotional Talking Face Generation. Electronics 2025, 14, 2684. https://doi.org/10.3390/electronics14132684
Wang X, Huo Y, Liu Y, Guo X, Yan F, Zhao G. Multimodal Feature-Guided Audio-Driven Emotional Talking Face Generation. Electronics. 2025; 14(13):2684. https://doi.org/10.3390/electronics14132684
Chicago/Turabian StyleWang, Xueping, Yuemeng Huo, Yanan Liu, Xueni Guo, Feihu Yan, and Guangzhe Zhao. 2025. "Multimodal Feature-Guided Audio-Driven Emotional Talking Face Generation" Electronics 14, no. 13: 2684. https://doi.org/10.3390/electronics14132684
APA StyleWang, X., Huo, Y., Liu, Y., Guo, X., Yan, F., & Zhao, G. (2025). Multimodal Feature-Guided Audio-Driven Emotional Talking Face Generation. Electronics, 14(13), 2684. https://doi.org/10.3390/electronics14132684