1. Introduction
Coronary artery disease (CAD), also referred to coronary heart disease or ischemic heart disease, is a chronic condition characterized by the accumulation of atherosclerotic plaques in the coronary arteries. This accumulation reduces blood flow to the heart muscle and can lead to serious complications such as angina pectoris, acute myocardial infarction, heart failure, or sudden cardiac death. Major risk factors include hypertension, dyslipidemia, smoking, diabetes, obesity, physical inactivity, advanced age, and a family history of cardiovascular disease. Despite advances in diagnosis and treatment, CAD remains one of the leading causes of mortality worldwide [
1].
To improve early detection and treatment planning, image processing has become a critical tool in the clinical management of CAD. Advanced imaging modalities such as coronary computed tomography angiography (CCTA), magnetic resonance imaging (MRI), intravascular ultrasound (IVUS), and optical coherence tomography (OCT) provide high-resolution visualizations of coronary anatomy and pathology. However, extracting clinically meaningful insights from these modalities requires robust image processing techniques capable of handling large volumes of complex data.
For example, CCTA is a non-invasive method widely used to visualize coronary arteries and assess atherosclerotic plaque burden and luminal stenosis. Image processing techniques such as segmentation, 3D reconstruction, and coronary tree extraction are essential for delineating vessel boundaries and identifying regions of interest. Automated or semi-automated segmentation algorithms, including region-growing, active contours, and machine learning-based models, have been developed to improve efficiency and reproducibility in clinical workflows [
2,
3].
Similarly, in IVUS and OCT, which offer microscopic-level resolution, image processing techniques play a key role in characterizing plaque composition and vessel wall morphology. Methods such as speckle noise reduction, edge detection, and texture analysis are employed to distinguish between fibrous, lipid-rich, and calcified plaques. In addition, elastography and deep learning-based techniques are increasingly being integrated to enhance tissue characterization and risk assessment [
4].
A central component of many of these imaging applications is segmentation, which is a foundational step in medical image analysis that is particularly crucial for delineating anatomical structures such as the coronary artery lumen, vessel wall, and atherosclerotic plaques. Accurate segmentation enables the quantitative assessment of vascular morphology, plaque burden, and luminal narrowing—metrics that are critical for guiding therapeutic decisions such as stent placement or coronary artery bypass grafting [
5]. Traditional segmentation techniques, including thresholding, region growing, edge detection, and active contour models, rely on predefined features and intensity gradients. Although useful in ideal conditions, they often lack robustness in noisy or complex coronary imaging data [
6], and their reliance on manual input introduces interoperator variability [
7].
To overcome these limitations, deep learning (DL) has emerged as a transformative approach in image segmentation. Architectures like U-Net, introduced by Ronneberger et al. [
8], use encoder–decoder structures with skip connections to preserve spatial context while enabling detailed segmentation. Variants such as ResUNet, Attention U-Net, and 3D U-Net have further improved performance in cardiovascular imaging applications, showing high accuracy in segmenting coronary arteries, lumen borders, and plaques [
9,
10,
11]. In modalities such as CCTA and IVUS, these networks have also supported the characterization of plaque tissue types [
12,
13], while in IVUS and OCT, they have enabled detailed analysis of vessel wall microstructure [
14].
Building on these architectural innovations, new DL training strategies (such as multi-task learning and weakly supervised learning) have improved model generalization across imaging modalities and patient cohorts [
15]. These advances reduce the dependence on large annotated datasets and enhance the applicability of DL segmentation in real-world settings. Additionally, DL-based radiomics workflows can extract high-dimensional image features from segmented regions, transforming anatomical structures into predictive biomarkers for personalized risk assessment, including the prediction of major adverse cardiac events (MACEs) [
16,
17].
While segmentation remains a critical tool in CAD imaging, the need for faster, real-time analysis has catalyzed interest in object detection frameworks, particularly in dynamic or intraoperative contexts. Emerging models based on the YOLOv8 (You Only Look Once, version 8) architecture are helping redefine CAD analysis by detecting pathological structures directly in imaging data with high speed and accuracy. Unlike pixel-wise segmentation, YOLOv8 uses region-based detection, allowing it to identify features such as stenotic lesions, calcified plaques, and vessel bifurcations in a single pass. Its anchor-free detection head, adaptive loss functions, and robust backbone architecture enable simultaneous multi-feature detection with scalability and computational efficiency.
A notable application of this model is the DCA-YOLOv8, which integrates histogram equalization, Canny edge detection, a double coordinate attention mechanism, and a custom AICI loss function. This framework achieved 96.62% precision and 95.06% recall in detecting coronary artery stenosis from X-ray angiography, showing strong clinical potential [
18]. Another implementation, YOLO-Angio, employs a three-phase pipeline (including preprocessing, YOLOv8-based vessel candidate detection, and logic-based tree reconstruction) and achieved an F1-score of 0.4289 in the ARCADE challenge, demonstrating effectiveness in vascular segmentation from angiography [
19].
Furthermore, studies have shown that preprocessing techniques significantly affect the performance of YOLOv8 in CAD imaging. For example, contrast enhancement, image sharpening, and U-Net-generated binary masks have been found to markedly improve YOLOv8’s detection accuracy in coronary angiograms [
20]. These results highlight the synergistic potential of combining classical segmentation outputs with object detection models to create hybrid frameworks that balance interpretability, accuracy, and speed. As such, YOLOv8 represents a promising advance in AI-driven cardiovascular imaging, bridging the gap between high-throughput analysis and real-time clinical decision making.
In line with the importance of preprocessing, recent work by Lin et al. [
21] introduced StenUNet, which is a novel deep learning framework for automatic stenosis detection from X-ray coronary angiography. Their approach incorporates a directional subband enhancement module based on decimation-free directional filter banks (DFDFBs) to improve vascular feature visibility prior to segmentation. This frequency-domain preprocessing strategy enhances directional consistency and vessel continuity while suppressing background noise, allowing the network to better detect stenotic regions. While the results are promising, such a specialized preprocessing pipeline represents a fundamentally different methodology from contrast-based approaches like CLAHE.
In this work, we present an experimental comparison of the performance of the YOLO (You Only Look Once) architecture across the most recent versions (YOLOv8, YOLOv9, and YOLOv11) for the task of coronary vessel segmentation and stenosis detection. The evaluation is conducted using the ARCADE dataset, which provides a standardized benchmark for coronary artery analysis in X-ray angiography. Furthermore, we conducted a comparative analysis between the most effective YOLO-based model and models built on the UNet++ and DeepLab v3+ segmentation architectures. To further investigate factors influencing model performance, we incorporate image preprocessing techniques in order to assess their impact on the learning process and detection accuracy. The performance of each model will be quantitatively assessed using standard segmentation metrics precision, recall, and F1-score with the aim of identifying the most robust and generalizable configuration for clinical application in coronary artery disease segmentation.
2. Materials and Methods
In this section, we describe the characteristics of the dataset used in our experiments, including its structure, annotation format, and the clinical relevance of its contents. Additionally, we provide a detailed explanation of the image preprocessing technique applied prior to training. Finally, we discuss the different versions of the YOLO architecture (v8, v9, and v11) employed in this study, outlining their structural differences, advancements in detection accuracy and speed, and the rationale behind their selection for the task of coronary vessel classification and stenosis detection. It is important to note that YOLOv10 was excluded from this evaluation due to the lack of official pretrained weights for segmentation at the time of experimentation; only object detection weights were available. As this study focuses on pixel-level coronary vessel and stenosis segmentation, pretrained segmentation weights were essential for a fair comparison. In contrast, YOLOv9 and YOLOv11 include official segmentation support and pretrained weights, making them more suitable for the purposes of this study.
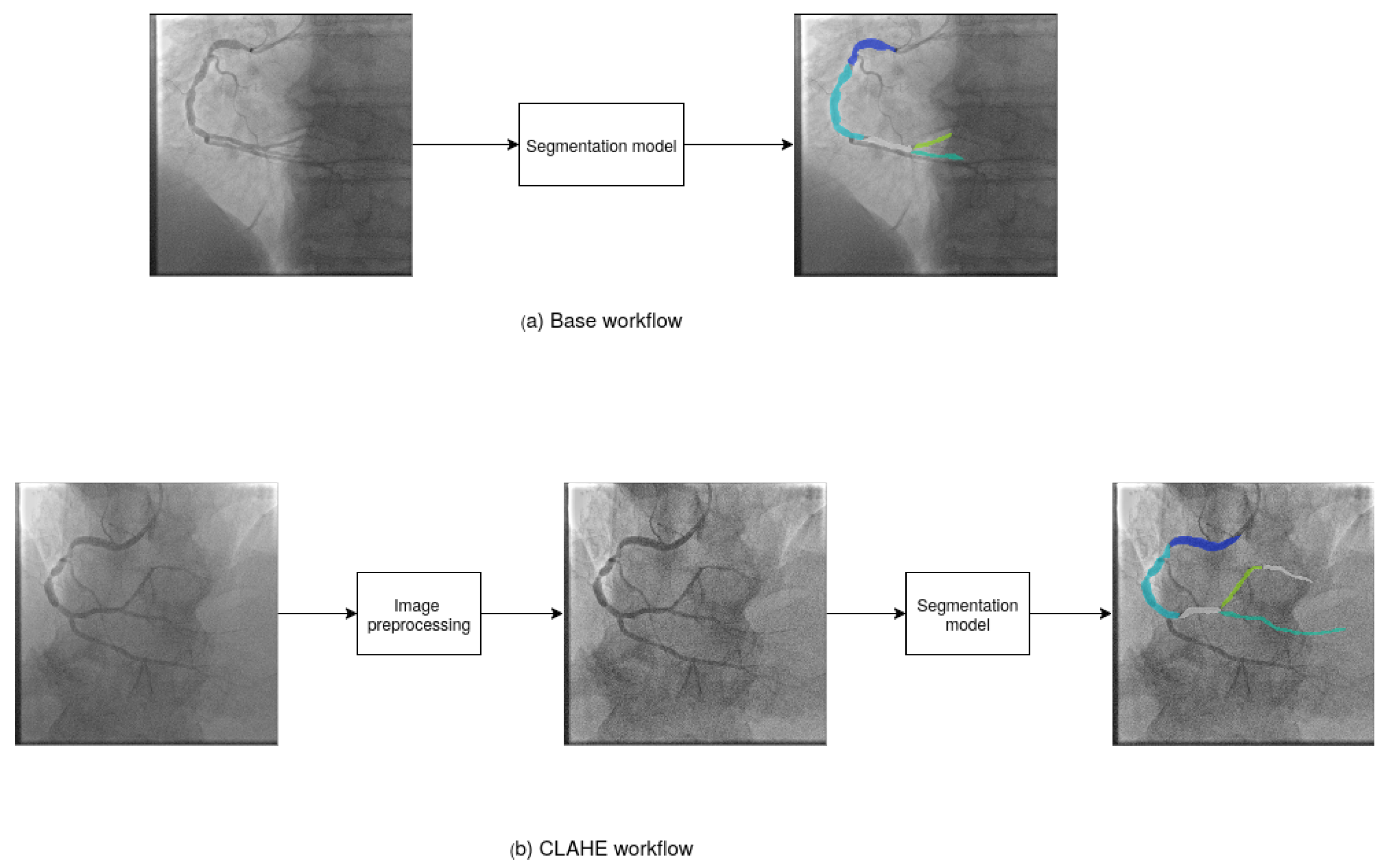
Figure 1 shows the workflow of the experiments. We proposed two experimental configurations. In
Figure 1a, we show the base workflow. We used the base images as input data to segmentation models and obtain the final segmented image. In
Figure 1b, we show the CLAHE workflow. We applied image preprocessing to enhance the images and assist the segmentation models in identifying objects. Then, we used the preprocessed images as input data to segmentation models to obtain the final segmented images.
2.1. ARCADE Dataset
The Automatic Region-based Coronary Artery Disease Diagnostics using X-ray Angiography Images (ARCADE) [
20] dataset is a publicly available collection designed to support the development, training, and evaluation of AI-based diagnostic tools for coronary artery disease (CAD) using X-ray coronary angiography (XCA) images. It was introduced as part of the ARCADE challenge at the 26th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) with the objective of promoting research in automated detection and the interpretation of coronary anatomy and pathology in clinical imaging. The dataset is organized into two primary tasks, each focusing on a critical component of CAD diagnosis:
Coronary artery segmentation: This subset includes 1200 XCA images with 1000 designated for training and 200 for validation. Each image has been annotated according to the SYNTAX Score methodology, which is a clinically validated system for evaluating coronary complexity. The annotations divide the coronary tree into 26 anatomically defined segments, enabling the fine-grained segmentation of major vessels such as the left anterior descending (LAD), right coronary artery (RCA), and left circumflex artery (LCX), as well as their branches.
Stenosis detection: This subset also contains 1200 XCA images, which are similarly split into 1000 training and 200 validation images. Annotations in this task are designed to localize and label regions affected by atherosclerotic plaques, allowing for the classification of stenosis presence. Each instance highlights pathologically significant lesions that impact coronary blood flow, providing ground truth for evaluating automated diagnostic models.
In addition to the training and validation sets, the ARCADE dataset includes test sets containing 300 annotated images for each task, which were made available for benchmarking model performance in blinded evaluations. All images are standardized to a resolution of
pixels and formatted in a consistent structure suitable for deep learning pipelines. The dataset has been carefully curated and annotated by expert radiologists and cardiologists to ensure clinical validity and labeling consistency. Furthermore, its design aligns with real-world diagnostic workflows, thereby enabling robust testing of machine learning models in scenarios representative of clinical practice. As such, the ARCADE dataset serves as a valuable benchmark for advancing the state-of-the-art in computer-aided diagnosis with the potential to improve the accuracy, efficiency, and scalability of CAD screening and risk assessment in interventional cardiology. In
Figure 2, we show an example of ground truth annotations for vessel and stenosis segmentation from the dataset.
2.2. Image Preprocessing
In order to enhance the vessel and highlight the object to our segmentation model, we used CLAHE. CLAHE (Contrast Limited Adaptive Histogram Equalization) is an advanced image enhancement technique widely used in medical image processing to improve local contrast and reveal fine structural details in low-contrast or non-uniformly illuminated images. Unlike global histogram equalization, which enhances contrast uniformly across the entire image, CLAHE operates locally by dividing the image into small, non-overlapping regions called tiles and applying histogram equalization to each tile independently. This localized processing preserves edge details and avoids the over-amplification of noise.
To further mitigate the risk of noise amplification, CLAHE introduces a contrast-limiting mechanism by clipping the histogram at a predefined threshold, which is known as the clip limit. The clipped pixels are then redistributed across the histogram, ensuring that areas with uniform intensity do not become oversaturated. After histogram equalization is applied within each tile, bilinear interpolation is used to smoothly combine adjacent tiles, eliminating artificial boundaries and ensuring a seamless transition across the image.
Due to its ability to enhance visibility in regions of low contrast without introducing significant artifacts, CLAHE is particularly beneficial in medical imaging modalities such as X-ray, ultrasound, CT, and coronary angiography, where subtle intensity differences are critical for detecting pathological structures. Its application has been shown to improve both human interpretation and the performance of automated systems for segmentation, classification, and feature extraction [
22,
23].
2.3. YOLOv8
YOLOv8 [
24] is a single-stage, end-to-end deep learning architecture for object detection, instance segmentation, and other visual tasks, which was developed by Ultralytics as the latest evolution in the “You Only Look Once” (YOLO) family of models. In the context of segmentation, YOLOv8 integrates a lightweight convolutional backbone with a decoupled head architecture, supporting instance-level segmentation masks using a mask prediction branch alongside bounding box regression and classification. It builds upon advancements in previous YOLO versions (e.g., YOLOv5 and YOLOv7) while introducing architectural optimizations such as an anchor-free detection head, dynamic input shapes, and an improved loss function tailored for segmentation accuracy and efficiency.
Unlike classical semantic segmentation networks (e.g., U-Net or DeepLab), YOLOv8 approaches segmentation from an object-centric perspective, predicting polygonal masks for each detected instance using a prototype-based mask representation. This allows YOLOv8 to combine the real-time inference speed of object detectors with the fine-grained mask outputs needed for instance segmentation tasks.
YOLOv8’s segmentation capabilities have been evaluated on benchmarks such as COCO and used in domain-specific tasks, including medical imaging and biomedical instance segmentation, demonstrating competitive performance with significantly lower inference times compared to traditional multi-stage pipelines.
2.4. YOLOv9
Although originally developed as an object detection framework, YOLOv9 [
25] has been extended to support image segmentation tasks through architectural adaptations and the integration of task-specific prediction heads. In the context of semantic and instance segmentation, YOLOv9 incorporates an additional segmentation head parallel to the detection head, enabling pixel-wise classification while maintaining its hallmark real-time processing capabilities. The backbone architecture, enhanced by the Generalized Efficient Layer Aggregation Network (GELAN), enables rich multi-scale feature extraction, which is essential for capturing fine spatial details in segmentation outputs.
Moreover, YOLOv9 introduces the Programmable Gradient Information (PGI) mechanism, which is a novel training strategy that adaptively emphasizes informative spatial regions during backpropagation. This innovation improves convergence stability and enhances the model’s ability to distinguish subtle object boundaries, making it particularly effective in domains such as medical imaging, where anatomical structures may be small or poorly contrasted. The efficient feature aggregation enabled by GELAN further allows YOLOv9 to perform accurate segmentation in challenging environments, including those involving densely packed or overlapping objects.
When configured for segmentation tasks, YOLOv9 is capable of producing both binary and multi-class masks alongside bounding box predictions, offering a unified approach to detection and segmentation. This dual capability is highly advantageous in real-time applications that demand both object localization and detailed region delineation—such as surgical guidance, autonomous navigation, and pathology identification.
2.5. YOLOv11
YOLOv11 [
26] represents the most recent advancement in the YOLO object detection series, introducing significant improvements not only in detection but also in segmentation capabilities. While primarily developed for real-time object detection, YOLOv11 has been adapted to perform semantic and instance segmentation through the integration of a dedicated segmentation head alongside the standard detection pipeline. This configuration enables the model to generate high-resolution, pixel-level masks in addition to bounding boxes, making it suitable for tasks that require both spatial localization and detailed object delineation.
One of the key innovations in YOLOv11 is the incorporation of a lightweight Vision Transformer (ViT) module into its backbone, which enhances the model’s ability to capture global contextual information across the image. This transformer-based attention mechanism, combined with traditional convolutional layers, improves segmentation accuracy by enabling the network to model long-range dependencies—which is especially valuable in complex segmentation tasks such as those in medical imaging or remote sensing.
Furthermore, YOLOv11 continues to refine training efficiency through multi-resolution feature fusion and enhanced data augmentation strategies, allowing for better generalization across varying image scales and qualities. The segmentation head in YOLOv11 benefits from precise multi-scale feature aggregation, enabling the robust detection of fine structures such as blood vessels, lesions, or boundaries of overlapping objects.
When applied to segmentation, YOLOv11 outputs class-specific segmentation masks at high speed, making it ideal for real-time applications like intraoperative imaging, smart surveillance, and automated visual inspection. Its unified architecture allows the simultaneous training of detection and segmentation tasks, leading to improved performance without sacrificing inference speed.
3. Results
We conducted experiments using the ARCADE dataset to train models to segment vessels and stenosis objects in images. The experiments were conducted using a computer with an Intel Xeon W-2133 processor, 32 GB of RAM, and an NVIDIA GeForce GTX 1080 graphics card (Dell Inc., Round Rock, TX, USA; Intel Corporation, Santa Clara, CA, USA; NVIDIA Corporation, Santa Clara, CA, USA). The system ran on a Ubuntu 18.04 operating system, and the CUDA toolkit 10.0 library was used.
3.1. Performance Measurements
The models were evaluated using three statistical metrics:
Precision (
1),
Recall (
2) and
F1-score (
3).
TP corresponds to true positive (there was an object and it was correctly segmented),
FP false positive (there was no object but the model segmented it as object), and
FN false negative (the model failed to segment an object in the image). Precision is a measure to know how many objects the model segmented correctly out of all the objects that it segmented. Recall is a measure to know how many objects the model segmented compared to the total number of objects. F1-score is a measure that combines precision and recall to know the average performance of the model in both measures.
3.2. Metric-Based Analysis of YOLO Architectures for Segmentation
We trained the YOLOv8, YOLOv9, and YOLOv11 models for 100 epochs using a batch size of 4. The training was performed using the AdamW optimizer with a learning rate of 0.0003 and a momentum value of 0.9. To leverage prior knowledge, we initialized the models with pretrained weights from the COCO dataset.
For model validation, we used the TorchMetrics library to compute pixel-wise evaluation metrics for multi-class segmentation tasks. Specifically, we used the MulticlassPrecision, MulticlassRecall, and MulticlassF1Score functions, which compare the predicted and ground truth masks on a per-pixel basis. These metrics allow for a rigorous and standardized assessment of segmentation performance in terms of true positives, false positives, and false negatives across all classes.
Table 1 presents the results of the different segmentation models trained with base workflow and CLAHE workflow. The “Images” column indicates the total number of test images used for each task (300 for stenosis and 300 for vessel segmentation), while the “Instances” column corresponds to the number of annotated objects within those images. For stenosis, an instance represents a localized lesion annotated as atherosclerotic narrowing, whereas for vessels, instances represent segmented subregions of the coronary artery tree as defined by the 26 anatomical classes in the ARCADE dataset. The experimental results using the ARCADE dataset provide valuable insights into the performance of YOLOv8, YOLOv9, and YOLOv11 in multi-class segmentation tasks both with and without CLAHE as an image preprocessing technique. Overall, performance across all models and configurations indicates that segmentation quality is highly dependent on the specific class, the number of instances, and the anatomical relevance of each coronary segment. For example, vessel segments with a high number of annotated instances and clear anatomical boundaries (such as the main coronary arteries) tend to yield consistently higher F1-scores across models, often exceeding 0.70. In contrast, segments with fewer instances or more complex morphologies present lower performance. For example, vessel segments that are composed of 25 segments showed average F1-scores below 0.46. This pattern suggests that both data availability and anatomical distinctiveness play a critical role in the model’s ability to learn and generalize segmentation features effectively.
For the stenosis class, which represents a critical target in CAD diagnosis, YOLOv11 achieved the highest F1-score under both workflows: 0.7826 in the base condition and 0.7677 with CLAHE. This performance surpassed that of YOLOv9 (0.7737 base, 0.7753 CLAHE) and YOLOv8 (0.7628 base, 0.7568 CLAHE), indicating that YOLOv11 maintains strong segmentation capabilities regardless of preprocessing. Also, CLAHE did not consistently improve F1-scores for stenosis across models. In YOLOv8 and YOLOv11, CLAHE slightly reduced performance, while YOLOv9 showed a marginal gain. These results suggest that although CLAHE can enhance local contrast, it may also introduce artifacts that affect the segmentation of complex pathological regions like stenoses.
In contrast, vessel segmentation results were generally lower and more variable across models and workflows with F1-scores ranging from 0.4176 to 0.4524. Under the base condition, YOLOv8 (0.4439), YOLOv9 (0.4361), and YOLOv11 (0.4345) showed similar outcomes, while CLAHE caused a small drop in YOLOv11 (to 0.4176) but a minor improvement in YOLOv9 (to 0.4524). This suggests that vessel detection is less sensitive to preprocessing, which is possibly due to the more continuous and larger-scale structure of vessels compared to focal stenotic regions.
CLAHE showed mixed effects depending on the model and anatomical structure. While some YOLOv9 results improved in CLAHE due to enhanced contrast, other models (especially YOLOv11) showed minimal variation or slight decreases. This may reflect a trade-off between the improved visibility of vessel boundaries and the introduction of noise or non-informative patterns. YOLOv11 demonstrated the most consistent performance across both classes and preprocessing conditions, indicating a more robust architecture less dependent on image enhancement techniques.
3.3. Statistical Significance of CLAHE Preprocessing Effects Using Wilcoxon Test
The Wilcoxon signed-rank test was applied to determine whether the use of CLAHE preprocessing introduces statistically significant differences in segmentation performance, measured by F1-score, for each YOLO version and target class (stenosis and vessel).
Table 2 summarizes the F1-scores for both the base and CLAHE workflows along with the corresponding Wilcoxon
p-values.
For stenosis segmentation, the p-values for YOLOv8-X (0.5794) and YOLOv9-E (0.9950) indicate no statistically significant difference between workflows, suggesting that CLAHE preprocessing does not meaningfully alter segmentation performance in these models. However, for YOLOv11-X, the p-value is 0.0148, which is below the conventional significance threshold of 0.05. This result implies that CLAHE introduces a statistically significant effect on stenosis segmentation performance for YOLOv11-X, although the actual F1-score change is relatively small (from 0.7826 to 0.7677), indicating a slight but consistent reduction in performance.
For vessel segmentation, the YOLOv8-X model shows a highly significant difference (p = 0.0000), confirming that the drop in F1-score when using CLAHE (from 0.4439 to 0.4316) is statistically robust. YOLOv9-E also exhibits a statistically significant improvement (p = 0.0189) with its F1-score increasing from 0.4361 to 0.4524 under CLAHE. Conversely, YOLOv11-X presents a non-significant p-value (0.1205), suggesting that its performance is stable across both preprocessing conditions.
These findings indicate that the impact of CLAHE preprocessing is model- and task-dependent. While some configurations benefit slightly or remain unaffected, others experience small but statistically significant changes in performance. YOLOv11-X demonstrates the highest overall stability and accuracy, although its sensitivity to preprocessing for stenosis highlights the importance of careful tuning in clinical deployment.
3.4. Visual Analysis of YOLO Model Predictions
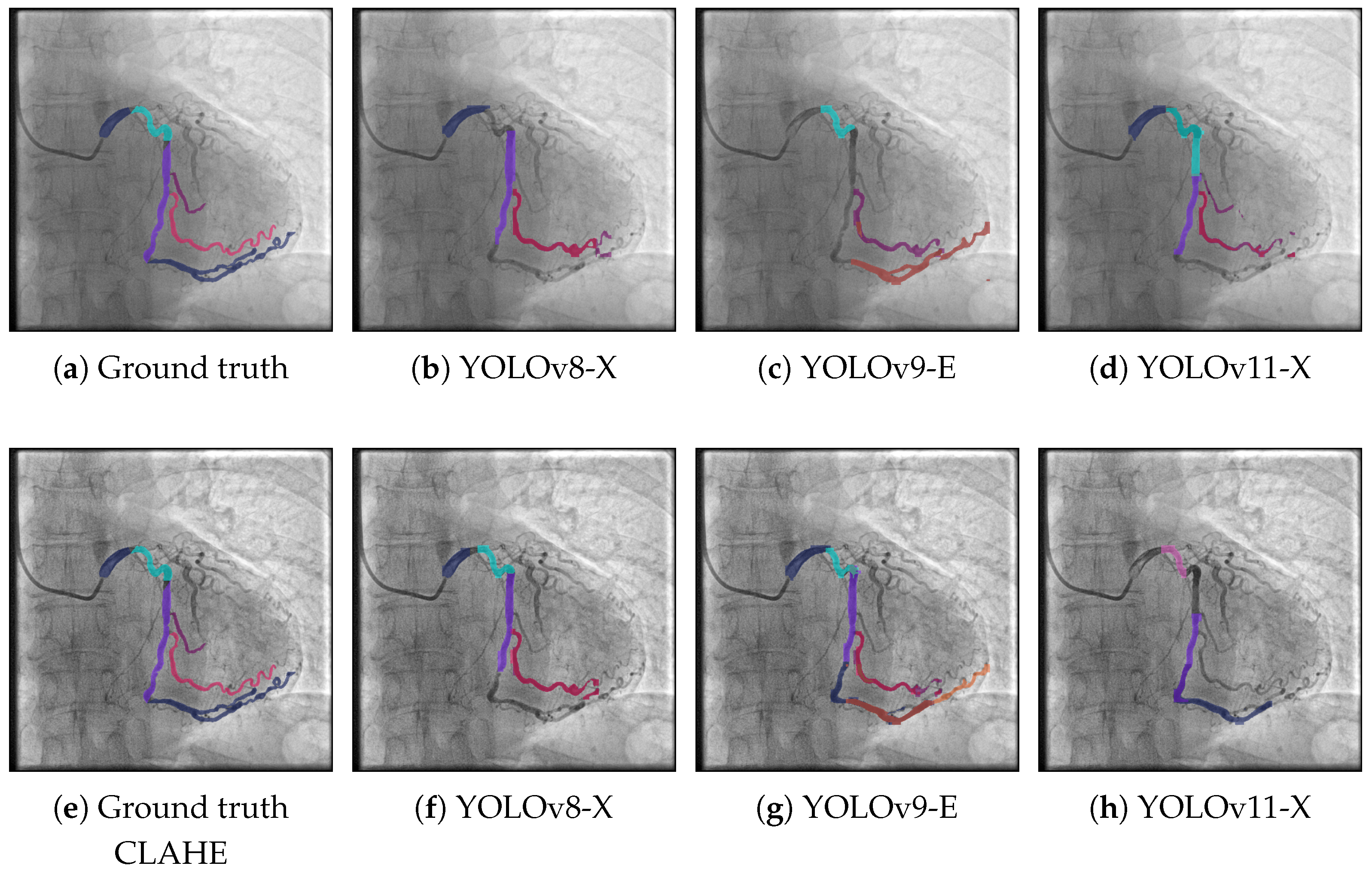
To complement the quantitative evaluation of model performance, this section presents a visual analysis of the segmentation results produced by the different YOLO-based architectures. The visual inspection of model predictions provides valuable insight into the spatial accuracy and morphological coherence of the segmented structures particularly in clinical tasks such as coronary vessel delineation and stenosis detection. By comparing the outputs of each model with the annotated ground truth under different preprocessing conditions, it is possible to assess the models’ ability to generalize across image variations and to identify specific strengths or limitations that may not be fully captured by numerical metrics alone.
Figure 3 presents segmentation results on the ARCADE dataset using three different YOLO-based models under two distinct workflows: the base pipeline (top row) and a pipeline enhanced with CLAHE preprocessing (bottom row). In the base workflow, YOLOv8-X (
Figure 3b) captures the main vascular structures but misses several finer branches, particularly in distal regions. YOLOv9-E (
Figure 3c) exhibits enhanced sensitivity in detecting vessel structures, particularly in challenging or low-contrast regions. Notably, it is the only model among the three that successfully identifies the vessel segment located in the bottom-center region of the image. However, despite this correct localization, the segment is misclassified, indicating limitations in the model’s class discrimination capabilities. Moreover, YOLOv9-E tends to produce a higher number of false positives compared to the other models, which negatively impacts the overall segmentation precision. This suggests that while the model is effective in capturing subtle vascular structures, further refinement is needed to improve its specificity and reduce erroneous detections. YOLOv11-X (
Figure 3d) shows the most faithful reproduction of the ground truth among the base models, offering better continuity and coverage of vessel bifurcations. When applying CLAHE preprocessing, a noticeable improvement is observed across all models. YOLOv8-X (
Figure 3f) exhibits enhanced vessel continuity and more complete segment detection compared to its base counterpart. But it continues to misclassify some zones that were correctly segmented. If the classification component of YOLOv9-E was improved, this could improve the metrics. Notably, YOLOv11-X (
Figure 3h) delivers the most accurate segmentation overall, closely aligning with the annotated ground truth and effectively capturing complex vascular morphologies. These findings suggest that CLAHE significantly enhances model performance by improving vessel visibility in angiographic images particularly in cases where vessel contrast is low or spatial resolution is limited.
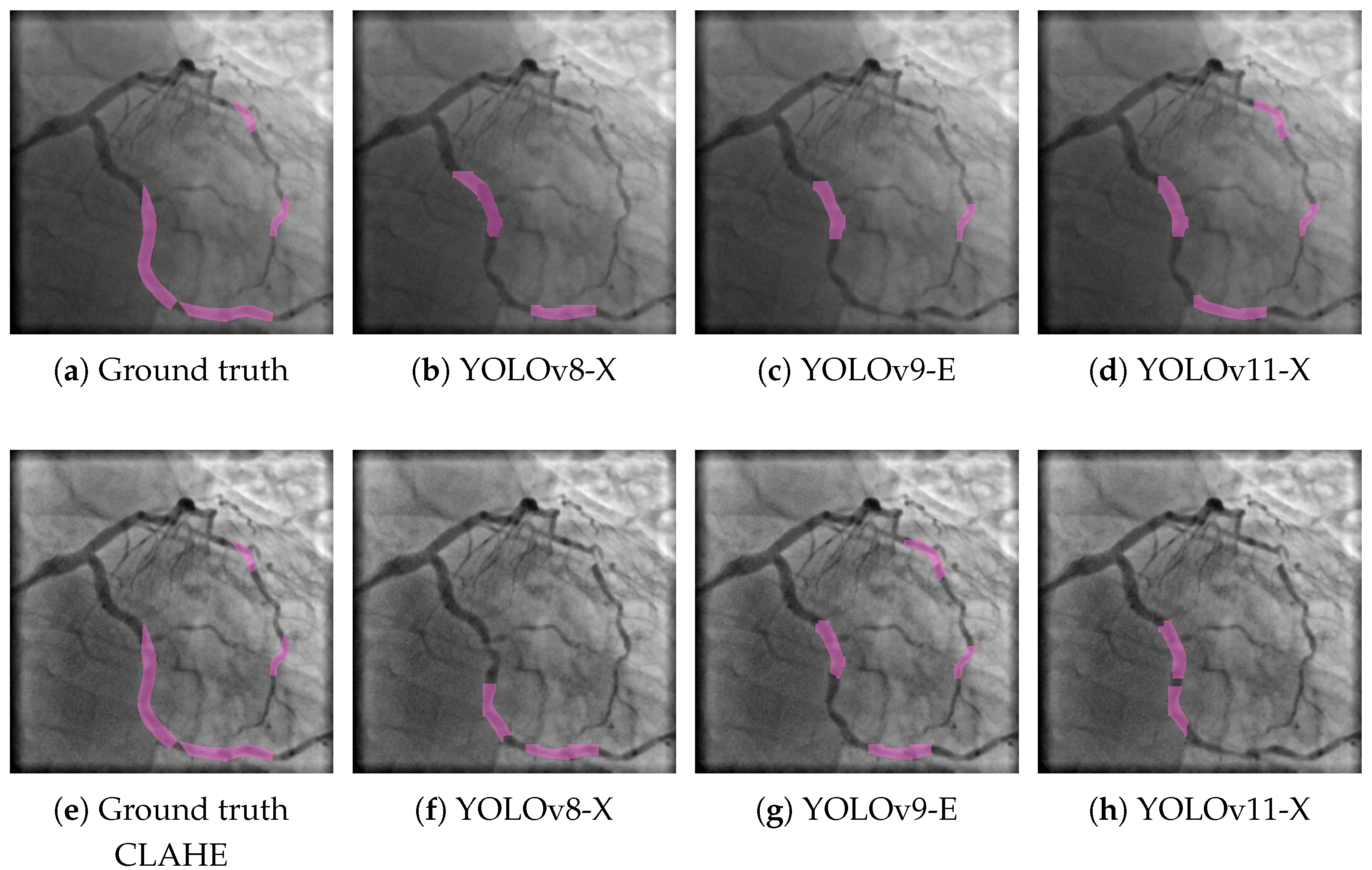
A similar trend is observed in the results for the stenosis class, as shown in
Figure 4. Here, the three YOLO-based models were also evaluated under both the base and CLAHE-enhanced workflows. In the top row, YOLOv8-X (
Figure 4b) detects stenotic regions with moderate accuracy but misses portions of the ground truth, resulting in partial segmentation. YOLOv9-E (
Figure 4c) exhibits lower sensitivity, capturing only a small fraction of the stenotic segments. YOLOv11-X (
Figure 4d) improves upon previous models by identifying a greater extent of the target regions, yet it still fails to fully match the reference annotations shown in
Figure 4a. When CLAHE preprocessing is applied, a marked improvement is observed across all models. YOLOv8-X (
Figure 4f) shows increased alignment with the ground truth (
Figure 4e), suggesting enhanced contrast allows for better localization of stenotic lesions. YOLOv9-E (
Figure 4g) achieves more complete and accurate segmentations compared to its base counterpart, while YOLOv11-X (
Figure 4h) delivers the most precise and continuous detection, closely resembling the ground truth. These results confirm the positive impact of CLAHE preprocessing in improving segmentation performance not only for vascular structures but also for more localized pathological features such as stenosis. The consistent benefit across both classes and all model variants reinforces the robustness of CLAHE as a preprocessing strategy in angiographic image analysis.
3.5. Comparison with Other State-of-the-Art Detection Models
Table 3 presents a comparative evaluation of YOLOv11-X against two widely adopted segmentation architectures, UNet++ and DeepLab v3+, in the context of stenosis and vessel detection under two preprocessing conditions: the base workflow and a CLAHE-enhanced workflow. The evaluation includes metrics of precision, recall, and F1-score for both anatomical targets across 300 test images.
To enable this comparison under consistent conditions, both U-Net++ and DeepLab v3+ were implemented using the EfficientNet-B4 backbone, which provides a strong balance between performance and computational cost. This backbone was selected to align with the high-capacity backbones used in the YOLO variants (such as YOLOv11-X), ensuring that the differences observed in segmentation performance are attributable to architectural components rather than differences in feature extraction.
For stenosis detection, all three models demonstrated strong performance with YOLOv11-X achieving competitive results. Under the base condition, YOLOv11-X attained a precision of 0.7971, a recall of 0.7694, and an F1-score of 0.7826, outperforming both UNet++ (F1 = 0.7453) and DeepLab v3+ (F1 = 0.7129). When applying CLAHE preprocessing, YOLOv11-X maintained robust performance with a slightly reduced F1-score of 0.7677, while UNet++ and DeepLab v3+ recorded F1-scores of 0.7423 and 0.7266, respectively. These results indicate that YOLOv11-X exhibits superior generalization for detecting stenotic lesions regardless of preprocessing conditions.
In vessel segmentation, the results were more modest across all models, reflecting the complexity of accurately delineating elongated and branching vessel structures. YOLOv11-X achieved the highest F1-score under the base workflow (0.4345), surpassing UNet++ (0.3924) and DeepLab v3+ (0.3945). A similar trend was observed under CLAHE preprocessing, where YOLOv11-X again led with an F1-score of 0.4176 compared to 0.3856 for UNet++ and 0.3908 for DeepLab v3+. These findings suggest that YOLOv11-X is not only effective in localizing compact pathological regions like stenoses but also performs competitively in segmenting more complex vascular geometries.
Overall, the results highlight YOLOv11-X as a versatile and high-performing model for CAD image segmentation tasks. It demonstrates strong performance across both lesion-focused and vessel-focused segmentation objectives and maintains robustness across preprocessing workflows.
4. Discussion
The experimental results demonstrate the practical strengths of YOLO-based architectures for coronary artery disease (CAD) segmentation. Among the evaluated models, YOLOv11 consistently achieved the highest F1-scores for both stenosis and vessel segmentation regardless of the preprocessing strategy. This suggests that architectural enhancements in YOLOv11—such as improved attention mechanisms and feature fusion—contribute to greater robustness and generalization, making it the most reliable of the evaluated variants for this clinical task.
CLAHE preprocessing did not consistently improve segmentation performance across models or tasks. For stenosis detection, CLAHE slightly reduced F1-scores in YOLOv8 and YOLOv11, while YOLOv9 showed a marginal improvement. For vessel segmentation, CLAHE had mixed effects, yielding a modest gain in YOLOv9 but slight declines in YOLOv8 and YOLOv11. These findings underscore that the utility of contrast enhancement is neither universal nor consistent—it varies by both model and anatomical target. In some cases, CLAHE may help reveal vessel boundaries, but it may also introduce visual artifacts or noise that hinder the segmentation of fine vascular structures or small stenotic regions.
Precision and recall trade-offs were also observed across models. While the YOLO variants generally achieved moderate to high precision, recall values—particularly for the vessel class—remained lower, indicating a tendency to undersegment complex or ambiguous structures. This limitation reflects a common challenge in object detection-based segmentation frameworks, where models prioritize confident predictions over comprehensive coverage.
Moreover, the inclusion of multiple YOLO versions and comparative preprocessing workflows allowed us to assess the stability of each architecture under varying input conditions. YOLOv11 exhibited the most stable performance, with minimal variation in F1-score across workflows, supporting its suitability for real-world applications where input quality may vary. In contrast, YOLOv9’s greater sensitivity to CLAHE suggests that while its training mechanisms (e.g., PGI) offer benefits, they may also introduce vulnerability to preprocessing variations.
The statistical analysis using the Wilcoxon signed-rank test provided further insights into the effects of CLAHE preprocessing. While some F1-score variations between base and CLAHE workflows appeared minor, the p-values revealed that several of these changes were statistically significant. Notably, YOLOv11-X exhibited a significant difference in stenosis segmentation performance (p = 0.0148), despite only a slight decrease in F1-score, suggesting a consistent sensitivity to contrast enhancement in pathological regions. Conversely, YOLOv11-X showed no significant variation in vessel segmentation (p = 0.1205), reinforcing its robustness across tasks. YOLOv8-X and YOLOv9-E presented opposing patterns: CLAHE significantly reduced performance in YOLOv8-X (p = 0.0000) for vessel segmentation, while it significantly improved YOLOv9-E (p = 0.0189). These findings confirm that the impact of preprocessing is both model-specific and task-dependent, and they highlight the need to validate enhancement techniques not only empirically but also statistically when deploying segmentation systems in clinical workflows.
In addition to intra-YOLO comparisons, our evaluation against classical segmentation frameworks further reinforces the strengths of YOLOv11-X. When compared with UNet++ and DeepLab v3+, YOLOv11-X consistently achieved higher F1-scores for both stenosis and vessel segmentation across both base and CLAHE workflows. Its superior performance in detecting stenotic regions, coupled with competitive results in the more challenging task of vessel delineation, underscores its versatility across different anatomical targets. Notably, YOLOv11-X also demonstrated greater resilience to contrast enhancement variations than the classical models, suggesting that its architectural innovations contribute not only to improved accuracy but also to better generalization under varying input conditions. These findings position YOLOv11-X as a robust and high-performing alternative to traditional segmentation approaches in the context of coronary artery disease imaging.
In summary, while YOLO-based models remain promising for efficient CAD segmentation, particularly in real-time scenarios, further improvements in vessel recall and robustness to preprocessing may require integrating architectural innovations—such as multi-scale decoding, adaptive contrast learning, or task-specific loss functions—to further enhance performance and address remaining challenges in complex vessel delineation tasks.
5. Conclusions
This study presented a comparative evaluation of recent YOLO architectures (YOLOv8, YOLOv9, and YOLOv11) for the tasks of coronary vessel segmentation and stenosis detection using the ARCADE dataset. The results confirm that YOLO-based models are viable for medical segmentation in real-time clinical environments, offering competitive accuracy alongside efficient inference capabilities.
Among the evaluated models, YOLOv11-X consistently achieved the highest F1-scores for both stenosis and vessel segmentation across preprocessing workflows. Its robustness and stable performance suggest that architectural enhancements in YOLOv11 contribute to generalization across diverse anatomical targets and input conditions.
The effect of CLAHE preprocessing was found to be model and task dependent. While it offered improvements in specific cases, it also introduced negative performance in others, particularly in vessel segmentation with YOLOv8-X. Statistical analysis using the Wilcoxon signed-rank test confirmed that some of these changes were significant, underscoring the importance of validating preprocessing techniques beyond empirical observations.
In addition, YOLOv11-X outperformed classical segmentation models such as UNet++ and DeepLab v3+, especially in stenosis detection, highlighting its versatility and strength compared to traditional architectures.
Overall, these findings position YOLOv11-X as a robust and high-performing alternative for automatic CAD segmentation. Future work may focus on enhancing vessel recall and refining sensitivity to contrast variations through the integration of multi-scale decoding strategies, attention mechanisms, or task-specific loss functions.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}