1. Introduction
In recent years, virtual agents and digital systems designed for human collaboration have advanced rapidly, with many major manufacturers developing them [
1]. As collaboration between humans and these systems becomes more common, there is increasing interest in equipping them with social communication capabilities, including providing human-like faces to virtual agents for richer interaction [
2,
3]. In the foreseeable future, people will frequently interact with these types of collaborative and interactive AI agents in immersive environments, such as virtual reality (VR) or augmented reality (AR), for education, training, and services [
4].
For these interactions to be effective, users need to understand what the agent is thinking or learning in real time. In other words, the agent’s internal state and intentions should be transparent to the user, as this can improve the user’s trust and engagement [
5,
6]. In the field of artificial intelligence, this motivation aligns with the objectives of explainable AI (XAI), namely making an AI’s decision process understandable to humans [
7]. Modern deep learning systems often operate as “black boxes” whose internal workings are opaque, leading to a lack of interpretability. This opacity is a well-known problem: users may not trust or effectively cooperate with it if they cannot interpret its behavior [
8]. The strategic importance of this field is growing, with recent analyses highlighting the need for transparent and trustworthy AI systems to drive user adoption in 2025 and beyond [
9,
10]. While existing research has explored various XAI techniques [
8] and the importance of agent expressiveness in human–computer interaction [
11], the specific question of whether users can intuitively identify an agent’s internal learning state—a complex cognitive process distinct from basic emotions—using only facial cues in virtual reality has not been systematically investigated. Therefore, the contribution of this work lies not in the avatar technology itself, but in its novel application for transparent communication and the empirical validation of its effectiveness for this specific purpose.
One intuitive approach to increase the transparency in VR is to leverage the social and emotional cues that humans naturally understand. Research in human–AI interaction suggests that endowing AI agents with socio-emotional attributes can foster trust, empathy, and better collaboration [
12]. In particular, giving a virtual agent the ability to express emotions or internal states through facial expressions or other nonverbal cues may help human users read the agent’s mind in a natural way [
11,
13]. Emotions are a universal language: psychological studies have shown that humans instinctively respond to facial expressions, and can even attribute mental states to inanimate agents that exhibit facial cues [
14]. Facial expressions are one of the most effective nonverbal communication channels for conveying affect and intention. Paul Ekman’s seminal work identified six basic emotions (happiness, sadness, fear, anger, surprise, and disgust) with associated facial expressions that are recognized across cultures [
15]. These basic expressions, and combinations can be used to communicate a wide range of feelings and states. Importantly, recent studies in educational technology and human–computer interaction have demonstrated that a virtual agent’s emotional expressiveness can influence users’ perceptions, motivation, and even learning outcomes. For example, the presence of appropriate facial expressions in a pedagogical agent can positively affect learners’ emotional state and engagement [
16]. Conversely, an agent with mismatched or fake-looking expressions can induce negative reactions or reduce credibility. This view highlights the value of emotional transparency and appropriate expressiveness in virtual agents.
Building on these insights, it is posited that a virtual agent can provide real-time, transparent feedback about its own learning process by displaying intuitive facial expressions. In other words, as the virtual agent learns (for instance, as an AI algorithm trains or a virtual student avatar attempts a task), it can outwardly show signs of its internal cognitive state of learning–a more nuanced process than expressing basic emotions–such as confidence, confusion, or progress, through a human-like face. If users can correctly interpret these facial cues, they gain an immediate understanding of the agent’s status without needing technical metrics or explanations. This approach could make interactions with AI in immersive environments more natural and foster a sense of empathy: the user can feel when the agent is struggling or succeeding, much as a human teacher gauges a student’s understanding from their expressions. Such emotional feedback could be especially useful in educational or collaborative scenarios, allowing a human to intervene or adjust their assistance based on the agent’s apparent state. It effectively embeds a form of explainability into the agent’s behavior, by leveraging affective signals.
The primary contribution of this paper is the empirical investigation into the intuitive recognition of a virtual agent’s learning state via its facial expressions within a virtual reality setting. The key question is “Can the user correctly discern how well the agent is learning by watching the its face?” To explore this, a 3D virtual agent (facial avatar) is designed with a stylized human face that can display various facial expressions. A set of facial expressions is identified to represent different possible learning states of the agent (for example, “I’m confidently understanding,” “I’m confused,” or “I’m struggling but trying”). These expressions were informed by Ekman’s basic emotions and by prior studies on student facial expressions during learning (e.g., a nod and smile might imply the agent has grasped the material, whereas a furrowed brow or yawn might imply difficulty or boredom) [
17]. Then expression sequences are created to simulate the agent’s facial progression over the course of a learning session under different conditions. In a user study, participants wearing a VR headset observed these facial-expression sequences and attempted to infer the agent’s learning state. The following primary hypothesis is tested.
Hypothesis 1 ((H1) Main Hypothesis). Participants will be able to intuitively and accurately recognize the virtual agent’s learning state from its facial expressions.
In addition, we formulated three exploratory sub-hypotheses to examine the potential influence of user background factors: potential differences based on gender (H2), prior virtual reality experience (H3), and academic major (H4). Our results provide strong empirical evidence for our main hypothesis, supporting the concept of facial expressions as a means of real-time, affective explainable AI (affective XAI). Our results provide novel empirical evidence that this approach is viable, offering a new channel for affective XAI that relies on innate human social perception rather than technical readouts. The novelty lies not in the avatar technology itself, but in its specific application to convey cognitive states and the validation of its effectiveness in enhancing human-centric transparency. Our findings show a high overall accuracy of approximately 91% in recognizing the agent’s learning state, supporting the effectiveness of this approach for affective XAI in virtual reality.
The remainder of this paper is organized as follows.
Section 2 reviews the background and preliminary work that informs our avatar’s expression design purpose, including the role of facial expressions in communication and learning.
Section 3 describes the agent’s facial expression design and a preliminary validation of their intended meanings.
Section 4 details the implementation of the avatar in VR and VR experiment settings, and
Section 5 presents the experimental results. In
Section 6, the findings, implications for explainable AI (virtual agent) and user trust, and limitations of the study are discussed. Finally,
Section 7 concludes the paper.
3. Avatar Expression Design and Preliminary Validation
After defining the target expressions for the three learning-state cases, we implemented them on our facial virtual agent using the NaturalFront 3D Face Animation Plugin within the Unity3D (Unity 2020.3.21 LTS) engine. The avatar’s face is represented by a 3D mesh, a structure composed of interconnected vertices (small triangles). To create expressions, this mesh is deformed in real-time. The deformation process is driven by a set of adjustable control points on the face. When a control point is moved, it pulls the surrounding vertices with it. The influence on these linked vertices is calculated using a bell-shaped weighting function, where vertices closer to the control point are moved more significantly, ensuring a smooth and organic deformation.
To create a systematic and reproducible set of expressions, the locations and control logic for these points were configured to align with the facial action parameters defined by the Affectiva SDK. This provided a framework of 16 controllable parameters, including brow raise, brow furrow, eye closure, smile, lip pucker, and jaw drop, in addition to head orientation. The final emotional expressions for Case A, Case B, and Case C were not single static poses, but rather short animated sequences scripted by setting and interpolating the values (typically from 0 to 100) of these parameters over time.
For example, the happy expression for Case A, reflecting its successful learning outcome, was constructed using high values for the ‘Smile‘ and ‘Cheek raise‘ parameters. The puzzled look for Case B, designed to reflect the cognitive dissonance of its mixed learning outcome, combined a ‘Brow furrow‘ with a slight head tilt. Similarly, the sad expression for Case C, in line with its mediocre performance, was constructed primarily by activating the ‘Lip Corner Depressor‘ and raising the inner brows via the ‘Brow Raise‘ parameter. The transitions between different emotional states within a sequence were smoothed using sigmoid interpolation over 1.5 s to appear natural rather than abrupt.
Figure 1,
Figure 2, and
Figure 3 show example expression sequences for Case A, Case B, and Case C respectively.
To verify that our designed expressions were being interpreted as intended, we first conducted an online survey using pre-recorded, 2D videos of the avatar’s three expression sequences (this survey was distinct from the main experiment conducted in a VR setting). In this survey, 93 respondents of various ages viewed these sequences (presented in random order) and were asked to match each sequence to the learning scenario it represented. Participants for this online survey were recruited through university online forums and social media, and constituted a convenience sample intended to provide an initial check on the clarity of the designed expressions before the main, resource-intensive virtual reality experiment. While demographic details beyond age range were not the focus of this preliminary validation, the sample size of was deemed adequate for a robust initial assessment of three distinct animated sequences. We informed participants of the meaning of each case beforehand (e.g., “Case A: the agent mastered both memorization and application; Case B: the agent did well in memorization but not in application; Case C: the agent achieved moderate results in both”) and told them to assume the agent’s facial expressions correctly reflect its internal state. The respondents thus had a clear mapping of scenario to expected agent feeling, and they simply had to match the shown facial sequence to one of the cases.
The validation results from the 93 respondents were very encouraging: the expression sequences for Case A, Case B, and Case C were correctly identified with rates of 90%, 78%, and 87%, respectively. In other words, a large majority matched the avatar’s expressions to the correct learning scenario. Case B’s sequence had the lowest recognition rate (78%), which we anticipated because it involved a more complex blend of emotions not corresponding to a single basic emotion (the agent in Case B might look slightly confused yet somewhat content). In contrast, Case A (primarily joyful expressions) and Case C (which included an obvious sad expression at the end) were based on more clear-cut basic emotions, yielding higher recognition. These results gave us confidence that the virtual agent’s facial expressions were indeed conveying the desired information about its learning state.
Figure 4 summarizes the validation survey outcomes, showing the percentage of respondents who identified the sequence as belonging to Case A, Case B, or Case C scenarios, respectively.
4. Experimental Design for Virtual Agent Expression Test in VR
Having validated the expression designs, we proceeded to the main VR experiment to test our hypotheses with users in an immersive scenario.
4.1. Virtual Agent and Apparatus
For the main experiment, an interactive procedure was prepared for participants to observe and interpret the agent’s learning-state expressions within a VR environment, using the following setup. We used a head-mounted display (HMD) to present a simple virtual scene containing the 3D agent’s face. The agent’s face was animated in Unity3D with the preset expression sequences for Case A, Case B, Case C as described in
Section 3. Participants could view the agent from a frontal perspective in VR, similar to facing a person. No audio or textual cues were provided—the agent did not speak or display any explicit indicators of its performance, relying solely on facial expressions. The VR scenario was framed as “observe this learning AI avatar and tell us how well it is learning.”
4.2. Participants
We recruited 30 participants (university students, 17 male and 13 female, ages 20–26) for the VR experiment. University students were selected for this study as this demographic is relatively more likely to have prior exposure to VR technology, and their academic enrollment allows for a clear distinction between engineering and non-engineering majors for analyzing background influences. To examine these background effects and to investigate potential differences based on gender, we recorded each participant’s self-reported VR experience (whether they had used VR before), experience interacting with virtual agents, and academic major. Participants were roughly balanced across these background categories (17 had prior VR experience, 13 did not; 10 were engineering majors, 20 were non-engineering).
4.3. Procedure
To help standardize interpretation and minimize subjective variance, participants were briefed at the start on the meanings of the three learning-state cases (A, B, C) exactly as in the preliminary survey. We explicitly told them that “the virtual agent’s facial expressions will honestly reflect its learning progress.” This was to ensure participants approached the task with the expectation that the expressions are informative (no deception). We then explained that the agent would go through a learning session and that they would see a sequence of the agent’s facial expressions. Their task was to identify which of the three cases the agent’s experience best matched. To avoid order biases, each participant was shown the expression sequences in a random order. That is, the agent would perform three separate learning sessions, and the order of these sessions was randomized per participant. After viewing each sequence, the participant indicated their guess (Case A, Case B or Case C). We included a short break between sequences and ensured that participants understood that each sequence was independent (the agent restarts its learning each time, so there is one of each case per person, in random sequence order). This randomization and independence were important to prevent participants from simply deducing the last case by elimination; each sequence had to be recognized on its own merits.
In our mapping, the agent’s memorization ability corresponded to the training accuracy of a deep learning model, and its application ability corresponded to the test accuracy. While participants did not see any numeric accuracies, this conceptual mapping underpinned how we envisioned the agent’s internal state: e.g., Case B could be thought of as “high training accuracy (applied knowledge) but medium test accuracy,” which might make the agent feel proud of memorizing well but slightly uncertain due to not applying test examples. This internal mapping was not directly disclosed to participants (to avoid confusion with technical terms), but it guided how we animated the subtle cues in expressions. After the VR viewing and responses, we collected basic feedback from participants on whether they found the expressions realistic and any difficulties they faced in interpretation.
6. Discussion
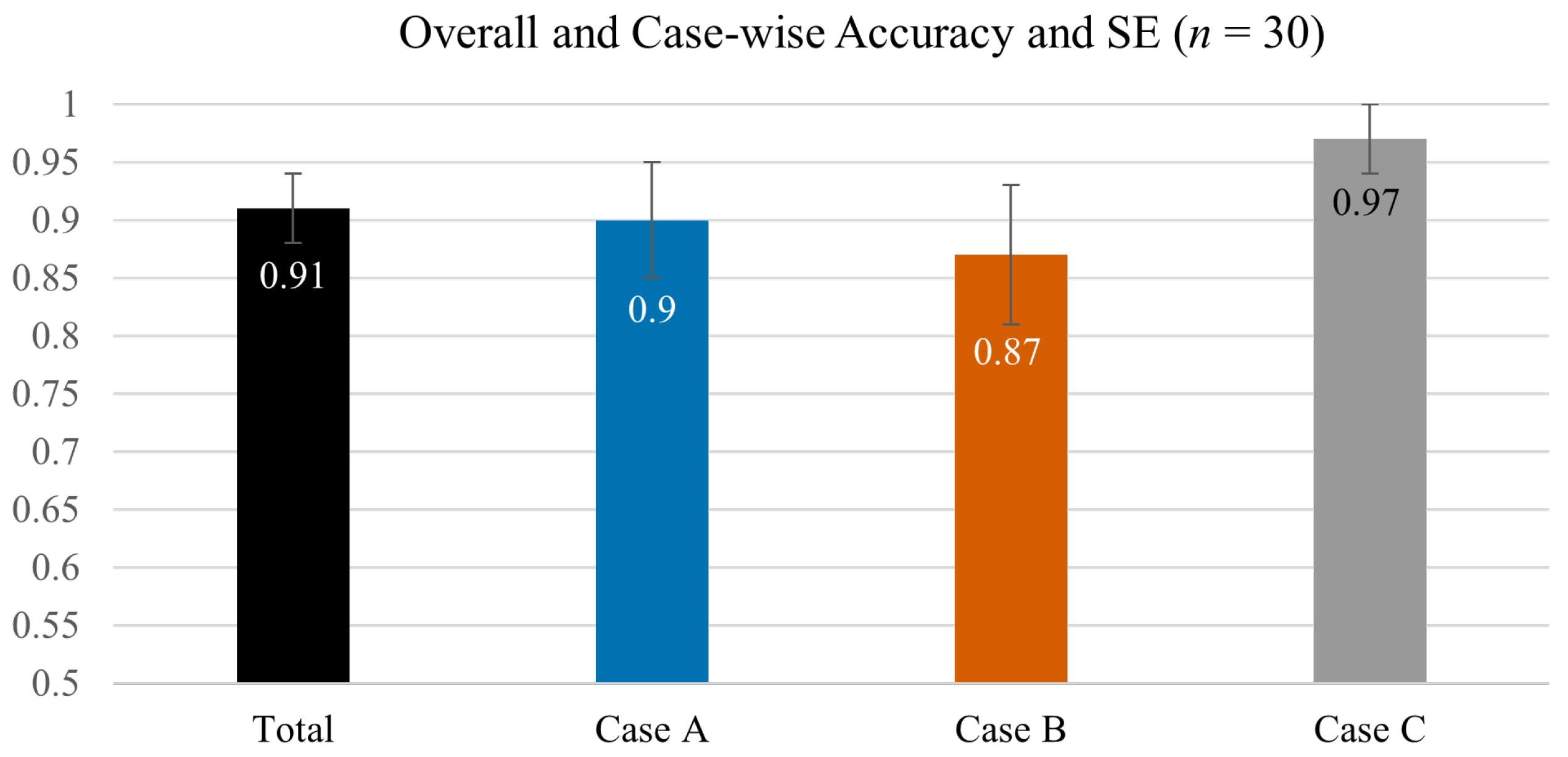
Our findings provide a proof-of-concept that a virtual agent’s facial expressions can serve as an intuitive, real-time window onto its internal learning state. Participants—without any analytic briefing—correctly inferred how well the agent was learning simply by “reading the face,” achieving an overall accuracy of roughly 91%.
Figure 5 and
Table 2 show that all three learning-state sequences were recognised well above chance (
). As in the preliminary on-line survey, the mixed-performance sequence (Case B) remained the most challenging, yet even there accuracy exceeded 90 % in VR—substantially higher than the 78% observed on-line—suggesting that the immersive, animated avatar provided additional perceptual nuance that aided interpretation.
6.1. Emotional Transparency as Explainability
Our findings make a specific contribution to the field of explainable AI by providing novel empirical evidence for the viability of affective XAI in virtual reality. The contribution lies not in the avatar technology itself, but in demonstrating that its application can successfully convey a nuanced, internal cognitive state (learning progress), which is distinct from expressing basic, general emotions. The ease with which users decoded the avatar’s facial feedback supports our central thesis: an AI agent can explain its status by showing how it feels about its performance. This leverages the user’s innate social-cognitive skills and complements existing XAI techniques by offering a continuous, human-readable cue rather than a static technical explanation. Our results thus extend prior claims about socio-emotional transparency to immersive virtual contexts by validating a new communication channel for human–agent interaction.
6.2. Influence of User Factors (H2–H4)
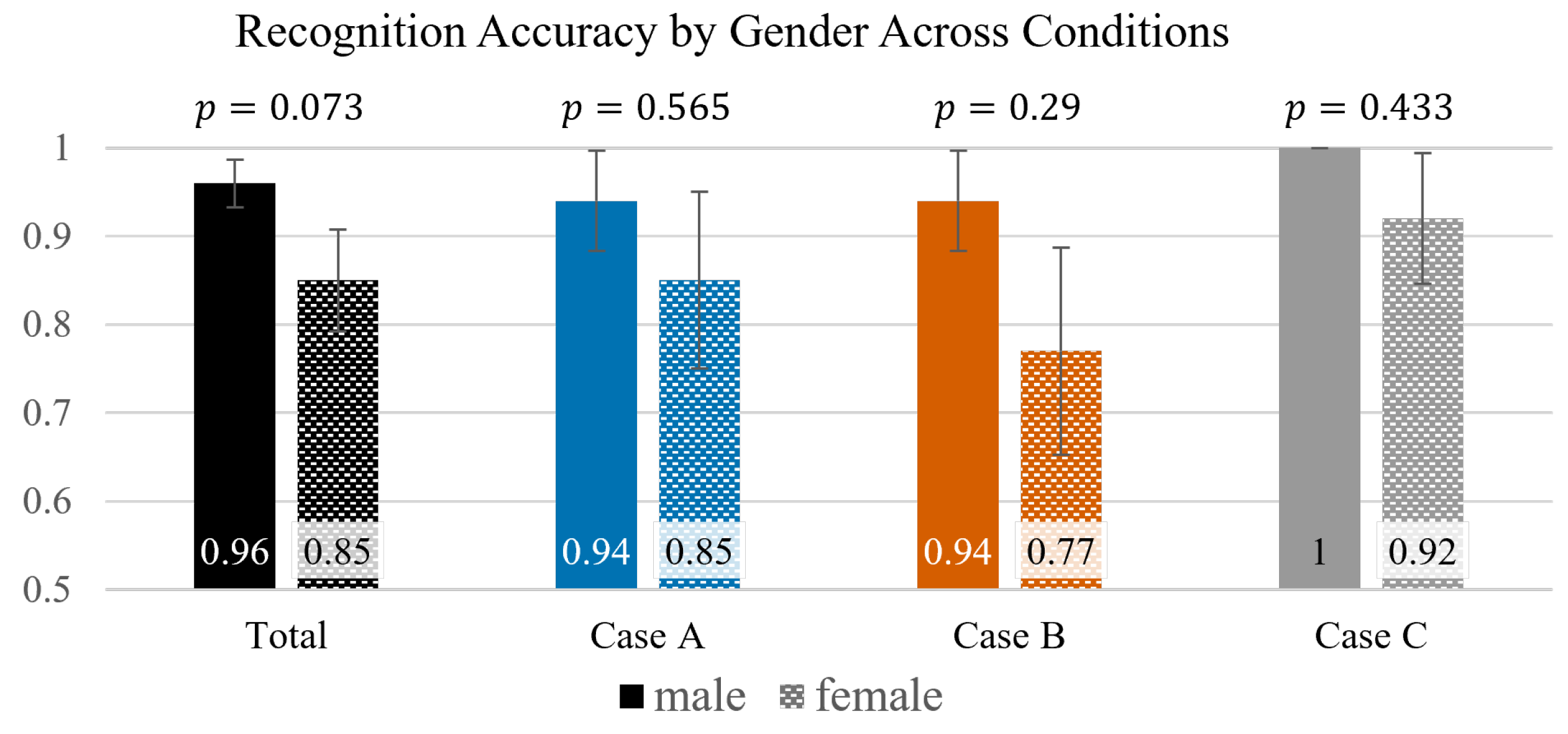
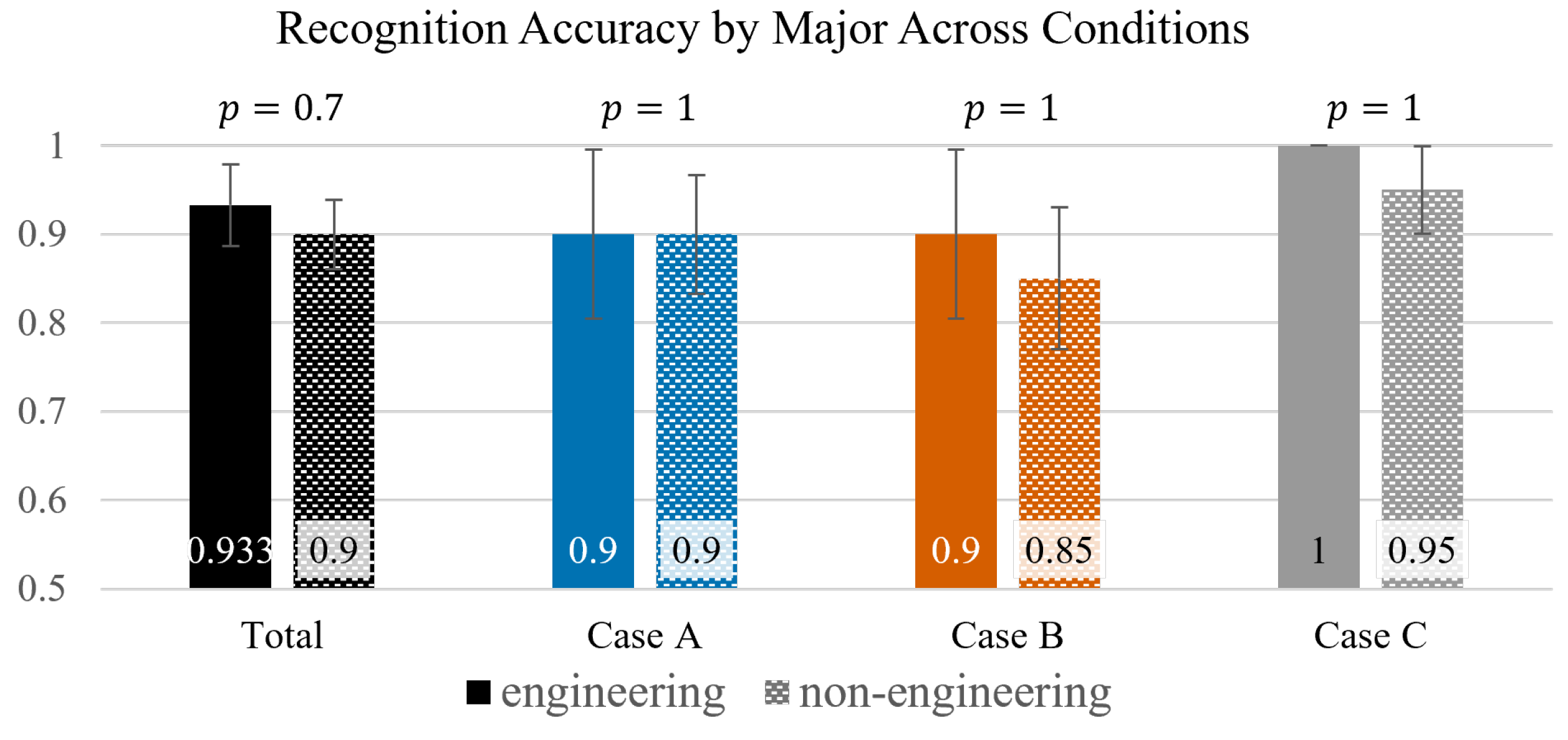
Three exploratory background variables were investigated (
Table 3,
Table 4 and
Table 5). (i) Gender. Males outperformed females numerically in every condition (
), but none of the Fisher
p-values reached
; the strongest trend was
. A possible reason is that males often adapt more quickly to fully-immersive 3-D environments and outperform females on spatial-orientation tasks in VR [
32]. Such spatial ease could free cognitive resources for reading subtle facial cues, which may explain why the biggest male–female gap appeared in the mixed-state sequence (Case B), the most ambiguous of the three. (ii) VR experience. VR-experienced users showed higher accuracy in three of four comparisons, with
and
, yet again fell short of significance. Prior exposure likely reduces sensory and interface load, allowing users to concentrate on the avatar’s expression rather than on basic locomotion or headset discomfort. (iii) Academic major. Engineering majors were marginally ahead (
,
), a direction consistent with evidence that engineering curricula frequently integrate VR tools and thus cultivate interface familiarity [
33,
34]. However, the very small gap (and
) suggests that recognising facial emotion is primarily a social–cognitive skill: domain knowledge adds little once the interface itself is mastered.
Across all factors, the directions were consistent but the sample—small and unbalanced, with several zero-error cells—was under-powered to confirm statistical reliability. Practically, these trends imply that minimal acclimation (e.g., a short VR familiarisation or an introductory demonstration) might further flatten the small performance gaps observed.
6.3. Design Lessons from the Mixed-State Sequence
Errors clustered on Case B, whose facial script blended satisfaction with mild puzzlement. This is not surprising: laboratory work on “compound” emotions shows that recognition accuracy drops markedly when two affects are expressed simultaneously, compared with the six basic emotions [
35]. Post-session interviews echoed this difficulty—several participants “felt the clip sat between the other two,” often mislabelling it as the moderate-performance case. A well-established remedy is to layer additional channels: human observers integrate facial and bodily cues when disambiguating affect [
36]; even a quick self-shrug or head-tilt can boost recognition rates. Likewise, giving a robot or avatar a short “inner-speech” utterance (e.g., “Hmm…I’m not sure I got that all correct”) has been shown to increase users’ understanding and trust, essentially making the agent’s thought process explicit. Future iterations could therefore augment Case B with a brief puzzled shrug or a one-line inner-speech cue, or end the sequence with a distinctive relief smile once the agent resolves its uncertainty, to sharpen users’ interpretation of this mixed state. This direction is consistent with current trends in multi-modal emotion analysis and empathetic computing, which seek to build more sophisticated and context-aware agents by integrating various communication channels [
37].
6.4. Trust and Engagement Potential
Although we did not measure trust directly, participants frequently described the avatar as “alive” or “easy to empathise with.” Anecdotally, one user remarked: “When it smiled, I felt proud of it.” Such comments echo the “machine-as-teammate” literature, suggesting that facial transparency may foster rapport and sustained engagement.
6.5. Difficulties, Limitations, and Future Work
In conducting this research, we faced several challenges and disappointments that are important to acknowledge. A key design challenge was crafting the “mixed-performance” (Case B) expression. Because it inherently combines conflicting emotional cues (satisfaction and puzzlement), designing a sequence that was both distinct and interpretable was difficult. The lower (though still high) recognition rate for Case B reflects this difficulty. Furthermore, recruitment for in-person virtual reality studies often faces logistical constraints, which in our case led to a relatively small and homogeneous student sample. Achieving broader demographic representation was a practical disappointment that defines a crucial area for improvement.
These challenges inform the study’s primary limitations. The most significant constraint, is the small () and culturally homogeneous student sample. This limits the statistical power of our subgroup analyses (H2–H4) and restricts the generalizability of our findings. Other limitations include the use of a single, stylized avatar, which means our findings may not generalize to other avatar designs; the subjective nature of interpretation, which can vary by individual and cultural background; and the discretization of learning into only three static states, which is a simplification of real-world dynamic learning.
These limitations, in turn, define a clear path for future research. Future work must aim to replicate and extend our findings with larger, more diverse, and cross-cultural samples. Furthermore, the set of three learning outcomes, while distinct, is limited. Subsequent studies should aim to expand this repertoire to capture a broader spectrum of learner performance and affective states, such as varying degrees of partial understanding, frustration, boredom, or moments of insight. A key avenue for future research is to explore the representation of dynamic learning outcomes that change over time. The current study focused on the recognition of discrete, static learning endpoints. Investigating how an agent’s facial expressions can convey an evolving learning trajectory—including transitions between states of understanding, confusion, and insight within a single continuous session—would significantly enhance the ecological validity and utility of this affective XAI approach. Finally, to move beyond subjective user reports, future iterations could integrate objective physiological measures, such as electroencephalography (EEG) or eye-tracking, to provide a valuable complementary channel for understanding the user’s cognitive and affective response. A particularly promising avenue for future work is the application of this affective agent framework to industrial-scale technical training. For example, our industrial partner, MyMeta, has been developing a VR-based training suite for semiconductor back-end processing, incorporating emotionally expressive agents into simulations of die bonding and wire bonding procedures. Initial results from this collaboration suggest that learners can interpret facial feedback to assess their procedural understanding, indicating the viability of such systems in specialized engineering education.
Furthermore, we acknowledge that the interpretation of facial expressions inherently involves a degree of subjectivity, influenced by individual differences in perception, cultural background—a factor our homogeneous sample did not allow us to explore—and familiarity with virtual agents. While the high overall accuracy in both our preliminary validation and the main VR study suggests our designed expressions were generally well-understood within our sample, we recognize this as a potential margin of error. Future research should therefore systematically explore these individual and cultural differences to enhance the generalizability of the findings.
7. Conclusions
Our study demonstrates that a virtual agent can make its learning state intuitively transparent by expressing context-appropriate facial emotions in VR. Participants, after only a brief primer, recognised the agent’s three learning scenarios with an overall accuracy of 91%, thereby confirming H1. The subgroup analyses (H2–H4) revealed no statistically reliable effects of gender, VR familiarity, or academic major, yet all three factors showed numerically positive—and therefore encouraging—trends. These trends motivate larger, balanced samples and mixed-effects logistic modelling to test whether modest background advantages become significant at scale.
Beyond hypothesis testing, the results endorse facial affect as a lightweight, real-time channel for affective XAI: users could “read” the AI’s internal confidence or confusion without needing textual or numeric explanations. Such emotional transparency fits calls in the human–AI interaction literature for socio-emotional cues that foster trust and smooth collaboration.
In sum, giving an VR AI avatar a human-readable “face” offers a practical route to human-centric transparency: users can gauge at a glance whether the system is thriving or struggling and decide when to intervene. As VR and AI grows in ubiquity and complexity, such intuitive feedback may prove vital for keeping humans in the loop and cultivating empathy-based trust. We regard the present work as a step toward VR and AI systems that not only perform but also communicate their learning journeys in ways people naturally understand.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}