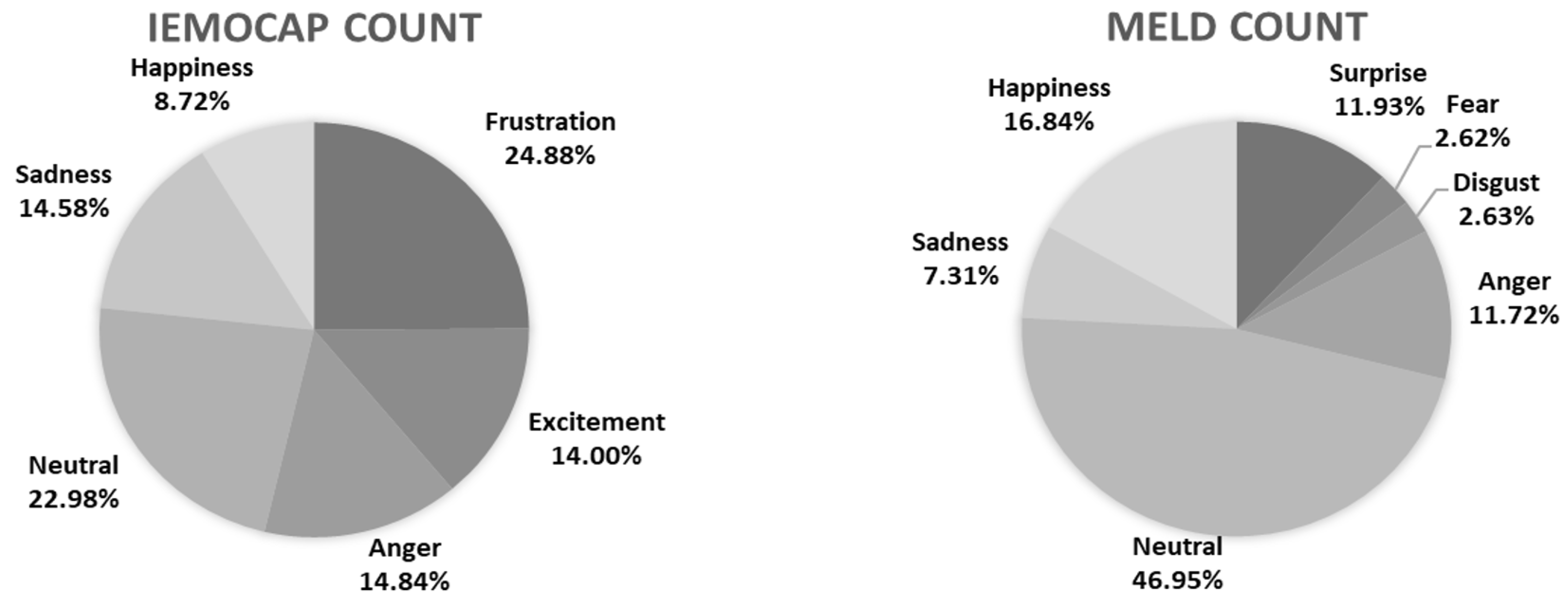
3.1. Problem Definition
Formally, given a conversation C consists of a series of utterances , where N is the number of utterances in the conversation, and denotes the utterance in the conversation, which contains the representations of two modalities (text), (audio) and (visual). For the conversation C, speakers participate in the conversation, where M is the number of participants, and a function is defined for obtaining the speaker is defined for obtaining the speaker of the utterance . The objective of emotion recognition in conversation is to accurately predict the emotion label for each utterance in the given conversation C from a predefined set of emotion labels , where k is the number of labels.
3.3. Dynamic Screening of Commonsense Knowledge
For a given utterance, we take it as input and use COMET [
24] trained on ATOMIC, a knowledge generation model, as the only source to acquire the corresponding commonsense knowledge related to the speaker’s emotion state. ATOMIC is an event-centered knowledge graph that allows for the execution of the corresponding inference task based on the 9 if-then relation types identified as (i) xIntent, (ii) xNeed, (iii) xAttr, (iv) xEffect, (v) xWanted, (vi) xReact, (vii) oEffect, (viii) oWant, and (ix) oReact [
23].
Referring to existing work that enhances ERC with commonsense knowledge [
20,
21], this paper excludes the relation types xNeed, xWant and oWant because they are predictions of character actions before and after the event. Whereas in the dialogue dataset, considering that each dialogue lasts for a shorter period, we do not assume that more actions take place during the conversation. Yet, there is still a controversy about the role of the remaining part of the relationship types for sentiment recognition, existing work [
20,
21] have experimentally sifted the relation types used in the model species. It has been observed that incorporating additional relation types into the model results in a decline in model performance. However, even within the same dialogue, the applicability of relation types to utterances can vary. For some utterances, all relation categories can provide valid commonsense knowledge, while for other utterances, only some of the relation categories may be able to provide valid commonsense knowledge. Thus, the manual selection method can not make the best use of commonsense knowledge. In this paper, we use the remaining six relational categories for our experiments. The usage of relationship types in related work is shown in
Table 1.
In addition, as COMET [
37] is built upon a pre-trained GPT-2 model, the knowledge it generates tends to be diverse and includes multiple plausible alternatives. Additionally, the generated commonsense knowledge is inevitably speculative, based on current circumstances, and its reliability requires validation by subsequent factual developments. Directly using raw dialogue utterances as input for COMET further exacerbates these challenges, introducing additional issues that compromise the quality and relevance of the generated knowledge. These speculative, low-quality pieces of commonsense knowledge should not be directly adopted by the model, as they could potentially mislead it.
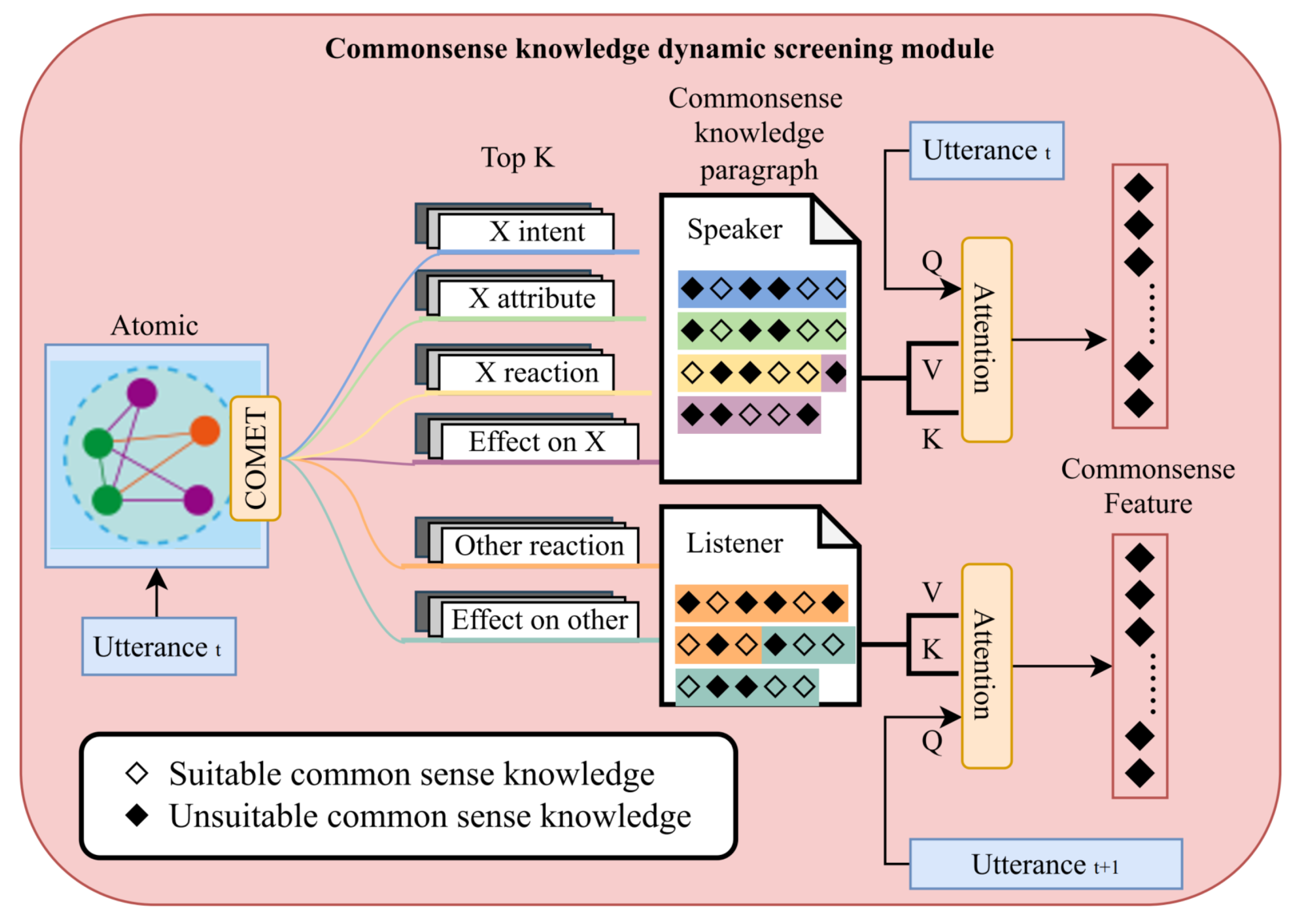
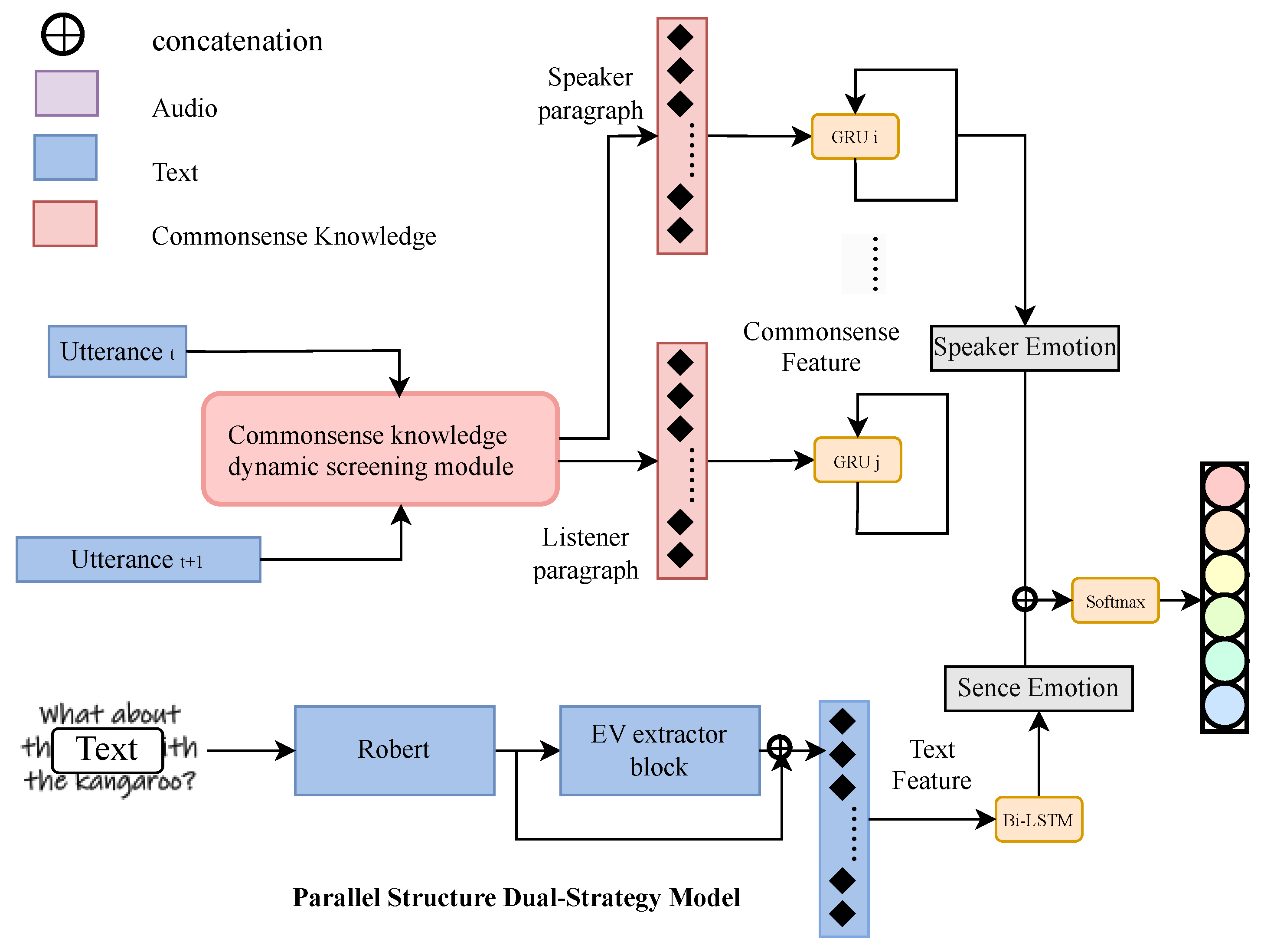
Therefore, to ensure that the model acquires sufficient and reliable commonsense knowledge, we propose a three-tier dynamic filtering module to refine and enhance the quality of commonsense knowledge. The main structure is shown in
Figure 3.
First, most previous studies directly use dialogue utterances as input, which presents two key problems. The first issue is that COMET’s training data consists of descriptive statements with subject–verb–object structures, whereas in dialogues, the speaker and listener are often omitted from the utterances. The second issue arises from the segmentation criterion of dialogue datasets, which is typically based on punctuation marks such as periods. As a result, some utterances contain limited information, and directly inputting them into COMET may generate meaningless or even ambiguous knowledge.
To address these issues at the input level, we adopt a strategy that combines sentence completion with both single- and dual-sentence inputs. Specifically, for each utterance, we complete the missing subjects and verbs following the format of COMET’s training data. Additionally, when a change in speaker occurs, we use the listener of the next utterance as the object and incorporate the subsequent utterance as a response to further enhance the input, thereby forming a dual-sentence input structure. As shown in Algorithm 1.
For each of the 6 relation types containing potentially valid information, the top k most plausible pieces of knowledge are generated in text form as candidates.
At the output level, we implement an initial filtering step. Our experiments reveal that the generated outputs often contain meaningless words or symbols, such as “none”, “.”, “ ”, “y”, “x”, and “n/a”. We first eliminate such outputs and, for utterances that fail to produce meaningful commonsense knowledge, we apply padding using [pad] as a fallback mechanism. After that, by adding descriptive sentence components or subjects, we integrate all candidate knowledge into two general knowledge paragraphs according to subject differences. The detailed methodology is provided in Algorithm 2. The final filtered knowledge output from these steps is treated as input features for our end-to-end trainable model. Therefore, the inclusion of these algorithms does not break the end-to-end trainability of the SSEAN architecture.
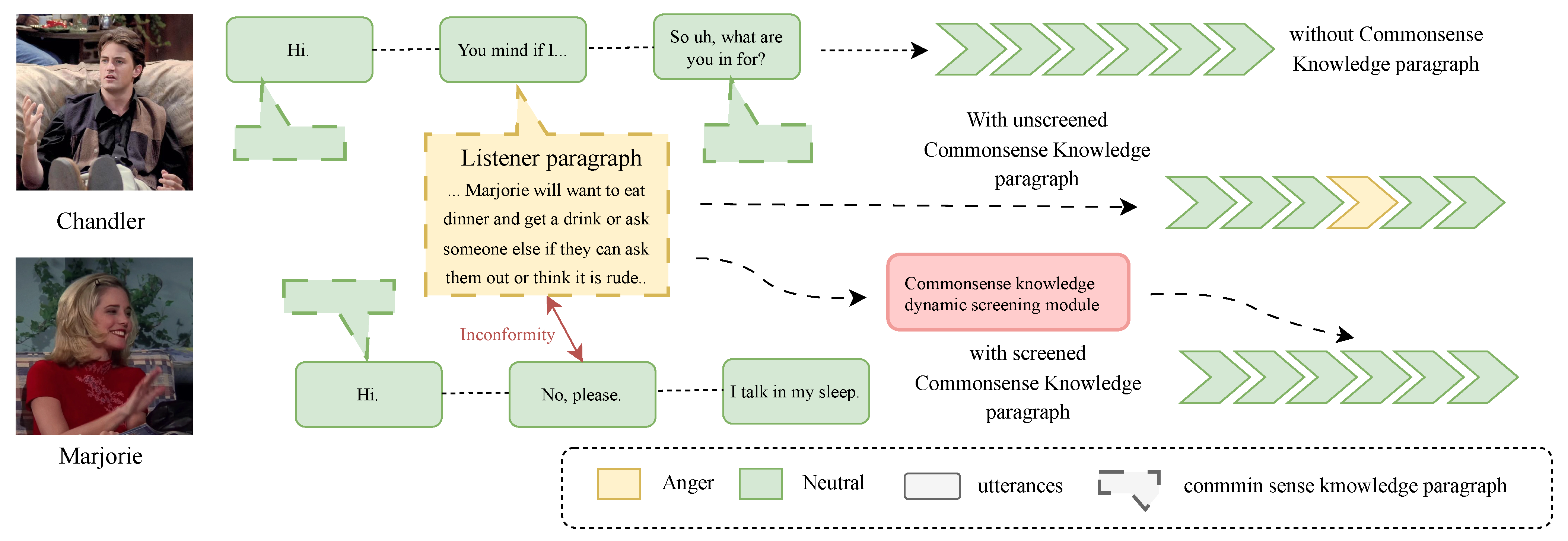
To further ensure the reliability of commonsense knowledge across different subjects, we apply an additional filtering and guidance process to the generated commonsense knowledge paragraphs. Specifically, for the commonsense knowledge extracted from the current discourse, we identify the current discourse (for the speaker’s knowledge paragraph) and the subsequent discourse (for the listener’s knowledge paragraph) as valid facts. Commonsense knowledge that exhibits greater similarity to these valid facts is considered more reliable.
| Algorithm 1: Speaker-listener-aware input structuring. |
![Electronics 14 02660 i001]() |
| Algorithm 2: Generate speaker and listener paragraphs. |
![Electronics 14 02660 i002]() |
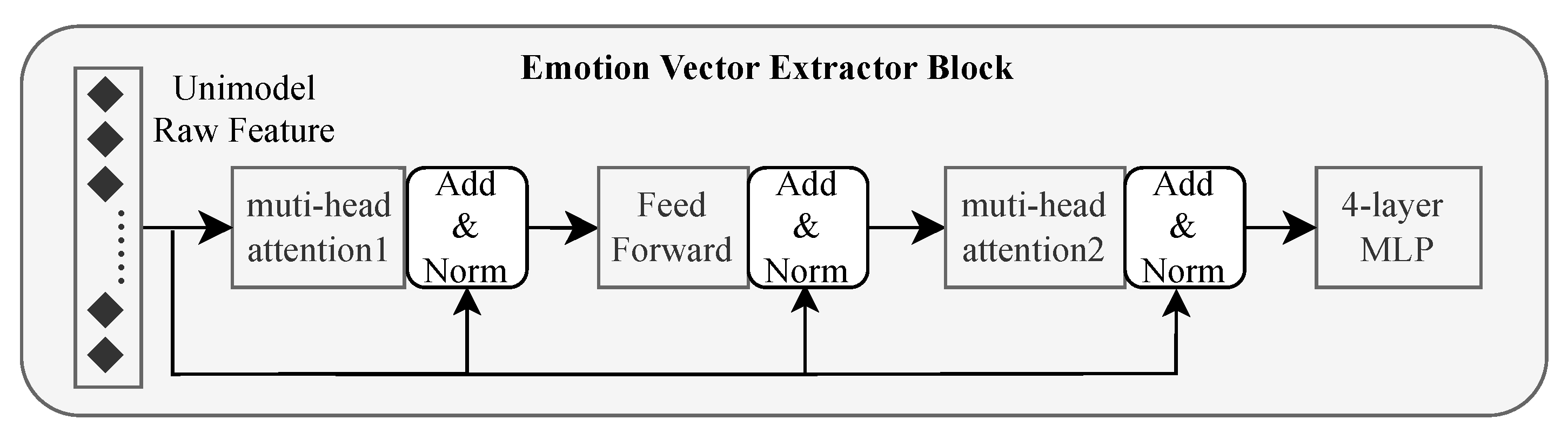
Using the same encoder as for the raw textual modality, we obtain utterance features
(current speaker and next-utterance listener) and the corresponding candidate knowledge features
from COMET. For each role
, queries, keys and values are computed as
where
are learnable parameter matrices. The most informative and reliable knowledge representation is obtained through a single cross-attention layer followed by a position-wise feed-forward network:
where the FNN is a two-layer feedforward network containing a ReLU activation layer. Since the attention mechanism is used as a filter here, no residual structure is added. The obtained output
is the speaker commonsense feature vector and listener commonsense feature vector for the given discourse
.
3.4. Dual-Strategy Framework
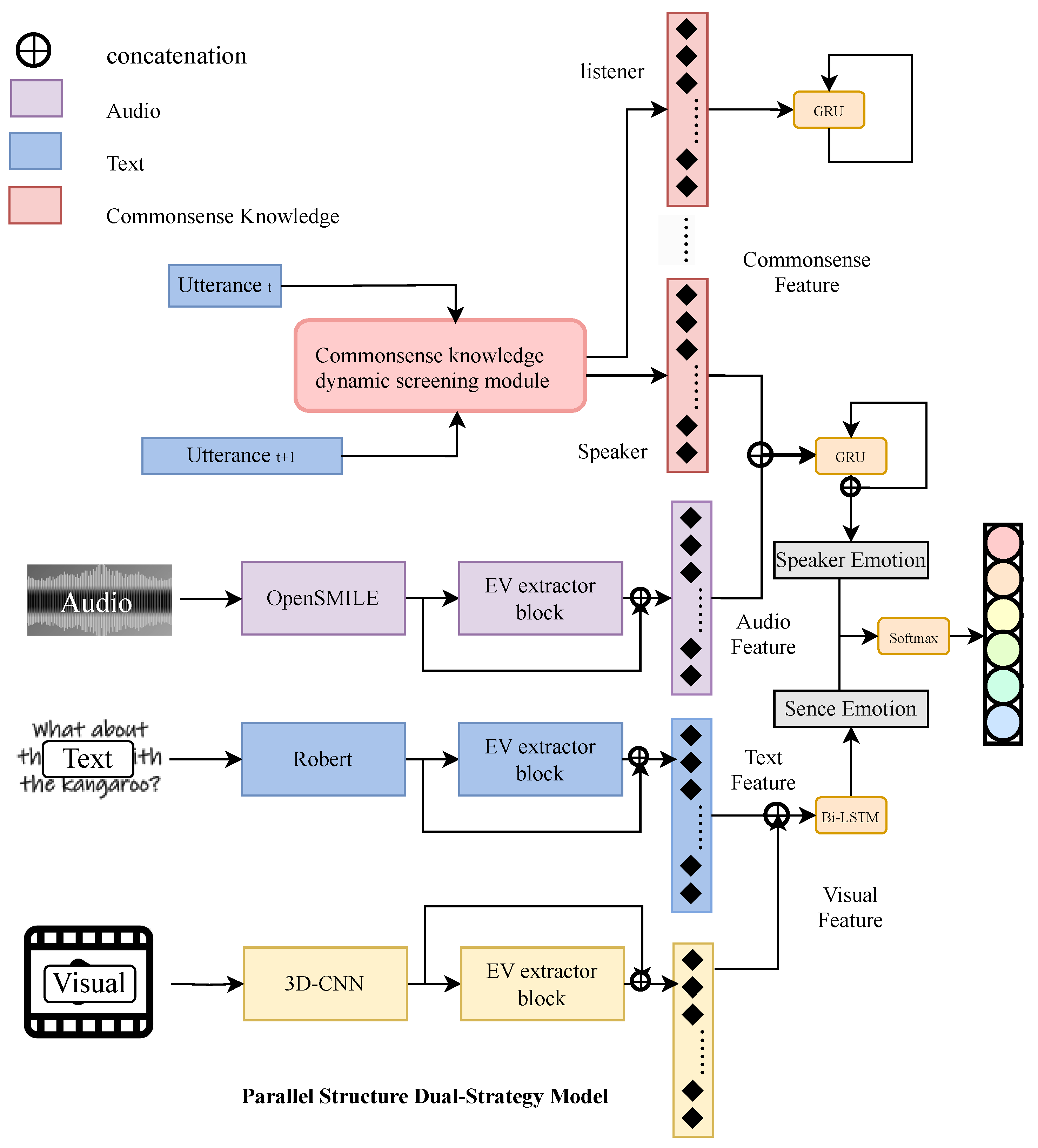
In this paper, we propose the Scene-Speaker Emotion Aware Network (SSEAN), a dialogue emotion recognition framework that employs dual-strategy parallel modeling to distinguish between the global conversational context and speaker-specific context, enabling the simultaneous utilization of multimodal and multi-source information.
Conversational Emotion recognition differs from general emotion recognition tasks in that it is difficult to make correct judgments about emotion by focusing only on utterance-level features. A significant amount of information is contained within the dialogue-level context and the multi-turn interactions among speakers. The components that can reflect the emotions of the utterances require selection and extraction through effective modeling methods.
Fundamentally, based on contextual relevance, we categorize emotional information within dialogues into two mutually exclusive types. The first type exhibits contextual relevance at the global dialogue level but loses this relevance within the same speaker, which involves the textual modality of utterances. Conversely, the second type includes commonsense knowledge about speaker states and the audio modality of utterances, showing contextual relevance within the same speaker while containing a lot of redundant speaker information at the global dialogue level. In this paper, this type involves textual modality of utterances and commonsense knowledge related to the speaker’s state. To minimize the introduction of redundant information for these two types, we adopt different modeling strategies. We propose a parallel structure designed to capture the dialogue-level context, the emotional states of speakers, and multi-turn interactions between speakers independently. This architecture ensures that information about each dialogue participant remains distinct, minimizing redundant speaker-related data. The specific structure is shown in
Figure 1.
A significant portion of information in dialogue is often embedded within long-term dependencies. Therefore, global-level contextual relationships can help the model better comprehend the overall progression and state of events throughout the conversation. By maintaining and updating dialogue history across multiple turns, the model gains a deeper understanding of the emotional tone underlying the conversation. Consequently, we refer to the features extracted based on global contextual information as global vectors. The Scene Emotion Vector is utilized to aid the model in understanding the continuity of emotions between adjacent utterances, such as being consistently neutral or negative throughout a particular paragraph. In this paper, we use a Bi-directional Long Short-Term Memory (Bi-LSTM) network [
38] to model the global conversational context and extract the Scene Emotion Vector for each utterance from both video and textual modality features.
Throughout the process, emotional information can naturally be categorized according to the participants of the conversation. For the same event, the identity of the conversation participants might have a significant impact on the emotion of the utterances, which is particularly evident in multi-participant dialogues. Thus, we refer to the features extracted based on the state of conversation participants as Speaker Emotion Vectors. The update mechanism of the Speaker Scene Vector is utilized to help the model understand the inertia of emotions within the same speaker and the emotional interactions triggered between different speakers by the utterances. Due to the model’s structure, information centered on different conversation participants remains independent, preventing cross-interaction. This design minimizes the introduction of speaker-related redundant information and mitigates its negative impact on model performance. To ensure this, we automatically assign independent GRU networks [
39] to each speaker based on speaker labels, allowing the model to update the emotional states of individual speakers and obtain a Speaker Emotion Vector for each utterance.
In addition with the help of commonsense knowledge, we have also modeled the interaction between different speakers. Carrying on from the work in the previous section, we extracted the commonsense knowledge features by obtaining two commonsense knowledge feature vectors whose subjects are the speaker and the listener of utterance , respectively, where contains the current speaker’s influence on the listener’s emotion state, which is used to update the listener’s emotion state.
This maintenance of the listener’s state effectively captures the interaction dynamics between speakers in each turn.This mechanism also increases the window in which the model understands changes in emotion, i.e., the emotion of each utterance is judged jointly by information from at least two utterances, and can increase the probability of correct classification when the sentiment state changes.
For the current utterance, we select the GRU network corresponding to the next speaker to update the listener’s emotion state.
The listener here is the chivalrous listener, precisely defined as the speaker of the next time step, expressed as the hearer for ease of understanding. Since the listener knowledge paragraph uses the next utterance as a fact, to ensure the validity of the commonsense knowledge paragraph, when a dialogue consists of more than two participants, the listener’s commonsense knowledge feature is only used for updating the status of the speaker of the next utterance, and the status of the other non-current speakers remains unchanged.
Ultimately, we add the Scene Emotion Vector and the Speaker Emotion Vector of the same utterance together and input the result into the softmax layer after going through a linear layer to obtain the final emotion classification of each utterance.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}