1. Introduction
The advancement of LLMs has intensified the need for more meaningful and adaptive evaluation mechanisms. While standard benchmarks serve as valuable tools for gauging general model performance, they fall short of capturing the nuanced, context-dependent expectations of individual users. As LLMs become embedded in an ever-expanding range of applications—from healthcare to creative writing—the inadequacy of one-size-fits-all evaluation methods becomes increasingly apparent. It is no longer sufficient to rely solely on static metrics; instead, there is a pressing need for dynamic, user-centric frameworks that align model assessment with the diverse and evolving goals of real-world users. The LPS framework emerges from this motivation, aiming to bridge the gap between generic evaluation protocols and the specific quality demands that arise in practical, domain-sensitive deployments. Moreover, in many specialized domains, suitable benchmarks are absent, leaving practitioners without systematic tools for model evaluation. The LPS framework aims to address both the shortcomings of existing benchmarks and the complete lack of benchmarks in domain-specific scenarios.
Various benchmarks are utilized across multiple domains, including the safety of LLMs. HarmBench [
1], SimpleQA [
2], AgentHarm [
3], StrongReject [
4], AIR-Bench [
5], and ForbiddenQuestions [
6] collectively assess the safety and reliability of LLMs. Also, they evaluate LLMs’ coding abilities across various aspects of code generation and reasoning. CRUXEval [
7] tests Python functions through input and output prediction, while BigCodeBench [
8] focuses on complex function-level generation. CrossCodeEval [
9] assesses multilingual code completion across real-world GitHub repositories. EvalPlus [
10] significantly expands HumanEval [
11] and MBPP [
12] for rigorous testing, and ClassEval [
13] challenges models with class-level Python generation. Repobench [
14] integrates retrieval, next-line prediction, and complex task handling for Python and Java. Together, these benchmarks offer a comprehensive assessment of LLMs’ coding capabilities.
The most researched domain in which benchmarks are utilized is the assessment of language understanding and reasoning abilities of LLMs. HellaSwag [
15] evaluates models by requiring them to predict the most likely ending of a sentence using a multiple-choice format that tests contextual understanding and reasoning. The Chain-of-Thought Hub [
16] provides curated complex reasoning tasks that encompass math, science, coding, and long-context reasoning, challenging models to perform multi-step problem-solving and achieve profound understanding. ANLI [
17] is a large-scale Natural Language Inference (NLI) benchmark dataset collected through an iterative, adversarial human-and-model-in-the-loop procedure, emphasizing the ability of models to understand nuanced language relationships. SuperGLUE [
18] is an improved and more challenging version of the GLUE [
19] benchmark, designed to evaluate a wide range of language understanding tasks with higher difficulty. GPQA [
20] contains a set of multiple-choice questions written by domain experts in biology, physics, and chemistry, testing models’ ability to reason in specialized scientific contexts. Finally, HotpotQA [
21] focuses on multi-hop questions based on Wikipedia, assessing models’ ability to combine information from different parts of a document to answer complex queries. These benchmarks collectively provide a broad evaluation of models’ capabilities in both general language understanding and more specific, complex reasoning tasks.
The growing complexity of real-world applications necessitates a shift toward qualitative evaluation, taking into account factors such as code readability, maintainability, efficiency, and adaptability.
Despite the ability of Chain of Thought, ANLI, SuperGLUE, GPQA, and HotpotQA to assess complex reasoning and coherence, they remain inherently limited in their adaptability to user-specific needs. These benchmarks primarily provide statistical evaluations based on predefined datasets and tasks, offering general performance assessments rather than personalized evaluations that cater to domain-specific requirements.
One of the fundamental distinctions between these benchmarks and our proposed framework lies in the degree of customization allowed in the evaluation process. Traditional benchmarks employ standardized metrics, ensuring that models are assessed on a broad and uniform scale. While this enables objective comparisons, it does not account for individual users who require models to perform well in highly specialized contexts, such as legal text generation, scientific research, or industry-specific applications. While they assess performance in various categories, they do not provide an interactive framework for users to determine which model best suits their unique needs.
Additionally, benchmarks like ANLI and SuperGLUE integrate qualitative assessment criteria, but they still operate within a fixed framework of linguistic tasks. This means that while they can evaluate aspects such as reasoning and factual consistency, they also do not allow users to directly influence or redefine evaluation parameters based on personal or professional criteria.
LPS addresses this shortcoming by offering an interactive and versatile framework, allowing both technical and non-technical users to explore and test language models that align with their domain-specific requirements rather than choosing a model solely based on its leaderboard ranking without considering domain alignment.
This paper follows a logical progression, beginning with an exploration of standard benchmarks and their inherent limitations in capturing user-defined preferences. This analysis sets the stage for the introduction of the LPS framework, which addresses these shortcomings by enabling users to define evaluation criteria dynamically. Samples from three of the most commonly used datasets for LLM evaluation are selected randomly and used for this purpose. Building on this conceptual foundation, we examine a real-world case study within LPS, illustrating how iterative preference specification can lead to high-quality datasets optimized for fine-tuning LLMs. The subsequent discussion on LLM-as-a-Judge naturally follows from the need for a structured mechanism to assess generated responses. By incorporating this technique, users can systematically enforce evaluation criteria, ensuring consistency and alignment with their intended outcomes. Ultimately, our experimental evaluation bridges the gap between theoretical discussion and empirical validation, demonstrating the effectiveness of LPS in enhancing model selection by incorporating qualitative assessment.
2. Related Work
Several existing applications aim to bridge this gap by offering tools for model comparison, evaluation, and selection in real-world contexts. In the following section, we examine related software solutions that share similarities with our approach, highlighting their functionalities, advantages, and differences.
One notable related work is Auto-Arena [
22], which automates LLM evaluations by using peer battles between LLMs. This framework aims to address the limitations of human evaluations by leveraging automated LLM-powered agents, thereby enhancing reliability and efficiency in the evaluation process. Compared to static benchmarks, Auto-Arena demonstrates a significant correlation with human preferences while reducing manual labor.
Platforms such as Chatbot Arena [
23] focus on dynamic evaluation methods through crowdsourced human preferences, showcasing a shift towards user-centered evaluation approaches while confronting the limitations of static benchmarks. The comparative analysis of LLMs and their outputs aligns with the core purpose of LPS, which enables a broad evaluation spectrum by leveraging the capabilities of multiple LLMs.
Another substantial contribution comes from ChainForge [
24], which presents a visual toolkit for prompt engineering and hypothesis testing specific to LLMs. This platform focuses on model selection and prompt template design, offering an interface for comparing responses across various prompts. Similar to LPS, ChainForge aims to improve the usability of LLMs, focusing specifically on enhancing the interaction between users and models without requiring advanced programming skills.
PromptTools [
25], an open-source framework, underscores the importance of prompt experimentation by integrating vector databases, enabling multi-model evaluations and comparisons as judges. The combination of these tools signifies a broader movement towards enhancing the capabilities of LLMs through robust, prompt engineering and responsive evaluation frameworks.
Prompt engineering and evaluation have seen the emergence of several innovative tools that complement the objectives of LPS. For instance, PromptIDE [
26] provides an integrated development environment designed to enable users to design, test, and refine prompts effectively, particularly for models like GROK. Its user-friendly interface fosters engagement with LLM functionalities without necessitating extensive programming expertise. Similarly, PromptChainer [
27] enhances the prompt engineering process through a visual programming paradigm that enables users to create multi-step workflows by chaining prompts together. This feature supports a nuanced approach to prompt structuring, significantly optimizing interactions with LLMs.
Additionally, platforms such as Everyprompt [
28] and PromptSource [
29] introduce analytical capabilities to prompt experimentation. Every prompt provides built-in Application Programming Interface (API) call statistics, allowing for quantitative analysis of prompt performance and facilitating the refinement of prompts for optimal effectiveness. PromptSource focuses on executing prompts while gathering performance metrics, enabling users to identify the most effective prompts for specific tasks. These analytical approaches resonate with LPS’s emphasis on evaluating multiple outputs alongside structured feedback.
It is a versatile platform capable of meeting diverse user needs and enhancing the efficacy of LLM applications more comprehensively than existing tools, as shown in
Table 1.
While these benchmarks provide a comparative foundation, they often fall short in addressing domain-specific requirements or adapting to emerging real-world application challenges. We explored related work on synthetic data generation, examining techniques used to create high-quality, diverse, and contextually relevant training data for optimizing model performance.
Self-Instruct is a notable framework that bootstraps a language model’s generations to create diverse instruction data. It follows a pipeline of generating, filtering, and fine-tuning, resulting in substantial performance improvements [
30]. By applying this method to GPT-3, Self-Instruct achieves a 33% absolute improvement on Super-NI [
31], approaching the performance of InstructGPT, which was trained with private user data and human annotations. This work demonstrates that synthetic instruction generation can significantly enhance instruction-following abilities, reducing dependency on manually curated datasets. Despite its effectiveness, Self-Instruct inherits the limitations of the underlying LLMs, particularly their bias toward frequent language patterns observed during pre-training.
Instruction augmentation plays a vital role in enhancing the performance of LLMs in downstream tasks. Existing methods, such as Self-Instruct, primarily rely on in-context learning to simulate new instructions from a small set of initial examples. To address these shortcomings, recent research has explored fine-tuning open-source LLMs for instruction generation. Fine-tuning has been demonstrated to require significantly fewer examples while producing high-quality, task-aligned instructions. Unlike Self-Instruct approaches that depend on closed-source models, fine-tuning methods ensure better control over instruction generation and improve distributional consistency [
32].
SymGen contributes to this emerging field by leveraging LLMs for generating annotation-intensive symbolic language data. It introduces an informative prompting strategy and an agreement-based verifier to enhance data correctness. Prior work has shown that data generated with minimal human supervision can significantly reduce annotation costs while maintaining or even surpassing the performance of models trained on human-annotated data [
33].
Reducing the cost of high-quality data annotation has been a long-standing challenge in Natural Language Processing (NLP). Traditional solutions, such as active learning for Small Language Models (SLMs) and in-context learning with LLMs, have alleviated some of the labeling burden but still require human intervention. FreeAL builds upon these advancements by introducing a collaborative learning framework that fully utilizes LLMs for task-specific knowledge distillation and filtering [
34]. Unlike conventional active learning, which typically relies on human annotations, FreeAL employs an LLM as an active annotator and an SLM as a filtering mechanism to refine generated labels iteratively. This autonomous framework enhances zero-shot performance for both LLMs and Small Language Models (SLMs) without human supervision, offering a promising direction for annotation-free learning.
Preceding research has emphasized the necessity of validating LLM-generated annotations against human-labeled data to ensure reliability. Recent studies have explored LLM-assisted annotation workflows to address these challenges. One such approach systematically evaluates LLM performance across 27 annotation tasks from 11 high-impact social science studies. The findings suggest that while LLMs can provide high-quality labels for many tasks, their effectiveness remains highly contingent on task-specific attributes, particularly on whether classification tasks require factual assessment or subjective judgment. These insights reinforce the importance of a hybrid approach that integrates LLMs with human validation [
35].
While these methods have demonstrated effectiveness in augmenting datasets and addressing data scarcity, they often lack mechanisms to incorporate domain-specific preferences or ensure qualitative alignment with expert-defined standards.
3. Architecture and Development
The system was developed using a combination of Hypertext Markup Language (HTML), Cascading Style Sheets (CSS), Hypertext Preprocessor (PHP), Asynchronous JavaScript and XML (AJAX), and JavaScript, forming a robust and responsive architecture that supports real-time interactions with multiple LLMs. Each of these technologies contributes distinct functionalities that collectively enable efficient request handling, dynamic data exchange, and interactive user experiences.
In more detail, this system’s architecture leverages AJAX and PHP to handle asynchronous requests to the various LLM endpoints, enabling efficient server-side processing and seamless data retrieval without requiring full-page reloads. This design choice significantly enhances the user experience by ensuring that model interactions and evaluations occur smoothly and without interruption. On the client side, JavaScript is used to manage the user interface dynamically, executing context-aware actions that display the generated responses and evaluation scores in real time. This separation of concerns between backend logic and frontend responsiveness facilitates a more intuitive and interactive system, enhancing usability while maintaining high performance in multi-model evaluation workflows.
First, the parallelized interaction with multiple LLMs enhances the comparative analysis process by significantly reducing latency and enabling the real-time benchmarking of model outputs. This concurrency enables more efficient utilization of computational resources. It facilitates the rapid acquisition of diverse model responses under identical prompt conditions, thereby enhancing the validity and reproducibility of comparative studies.
Second, the self-assessment mechanism, in which the LLMs themselves perform scoring and evaluation, introduces a dimension of meta-evaluation. By leveraging the inherent linguistic and reasoning capabilities of LLMs to assess their own or peer outputs, the system reduces human bias and labor requirements in the evaluation loop. This approach is particularly advantageous in scenarios involving subjective or context-dependent tasks, where human annotation may be inconsistent or resource-intensive.
Third, the modular architecture based on PHP, AJAX, and JavaScript ensures a high degree of flexibility, extensibility, and integration capability. It enables seamless deployment in web-based environments, supports dynamic client-server communication, and facilitates the integration of additional LLM endpoints or evaluation strategies without requiring substantial architectural reconfiguration.
Performance implications—such as increased network and processing load—are mitigated through a division of responsibilities between server-side PHP processing and client-side JavaScript rendering.
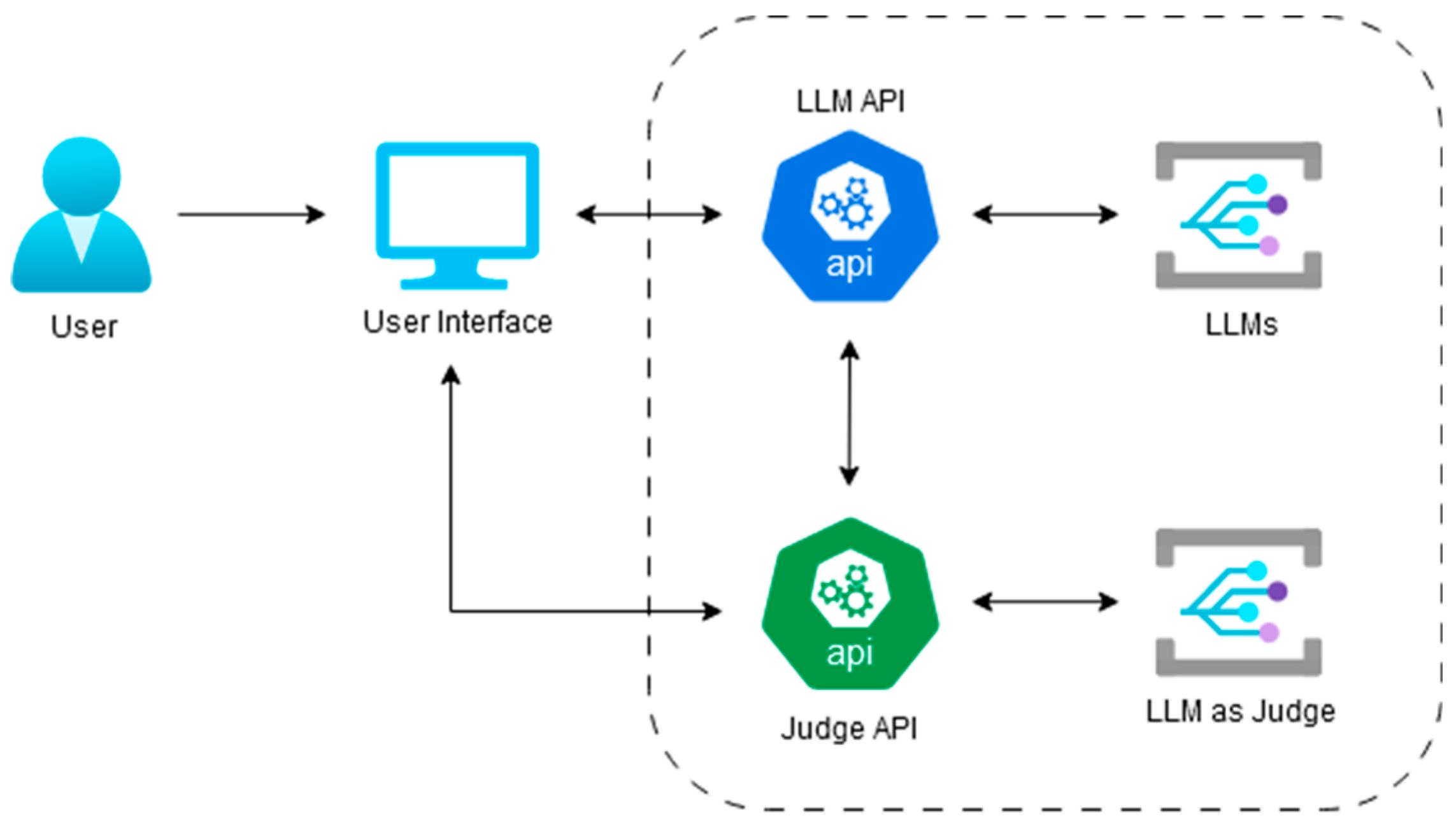
In short, with LPS, upon authentication, the user accesses a main interface featuring a multiple-selection panel of available LLMs, input fields for Application Programming Interface (API) credentials, and prompt configuration options. Users can specify diverse domain-specific prompts, configure model answer generation general parameters such as the number of tokens and temperature, and designate an LLM as a judge. The evaluation process conducted by the evaluator is asynchronous, with results displayed directly beneath the corresponding model responses. LPS architecture is shown in
Figure 1. Our framework’s use is explained in more detail in
Section 5.
Several advanced LLMs have been integrated to enhance their evaluative and prompting capabilities. The models utilized in our work include GPT-4o-mini [
36], recognized for its efficiency in reasoning with LLMs. Additionally, the Gemini family of models, particularly the Gemini 1.5 Pro, is included for its advanced contextual understanding and performance across a variety of tasks [
37]. The LLaMA family, including the latest variant, LLaMA 3.2, provides a robust foundation with its strong performance in diverse applications [
38]. We also incorporated Claude 3.5 Sonnet, which focuses on alignment and user safety, making it particularly valuable for sensitive tasks requiring nuanced evaluation [
39]. Moreover, Mixtral-8x7B Instruct [
40] and the Qwen family, including Qwen 2.5 [
41], contribute unique strengths, especially in instruction-following scenarios and creative tasks. By strategically selecting these models, LPS enhances its ability to leverage various strengths in NLP, facilitating a comprehensive evaluative process that benefits users across a wide range of applications. The DeepSeek LLM Chat model is another pivotal inclusion. Originating from the DeepSeek LLM project, it represents a significant step forward in advancing open-source Large Language Models with a focus on long-term scalability and performance [
42].
We selected the aforementioned models for inclusion in our study based on three key factors. First, at the time the research was conducted, these models represented flagship LLMs from leading Artificial Intelligence (AI) developers, embodying state-of-the-art capabilities. Second, we had access to their APIs. Third, these models ranked at the top of the leaderboards according to MMLU-Pro evaluations [
43] and LLM-stats [
44], ensuring that our software incorporated the highest-performing LLMs available.
Our framework offers several advantages, including an automated evaluator that reduces reliance on human feedback and enhances objectivity. It enables dynamic evaluation alongside prompt crafting, allowing real-time, multi-model assessments based on user-defined criteria. This comprehensive approach makes it a versatile and accessible platform that enhances usability and effectiveness in the LLM selection process, addressing the absence of integrated solutions as far as this research was conducted.
4. Beyond Standardized LLM Evaluation
Having established the architectural foundation and usage of the framework, it is now essential to explore its practical applications. Understanding how the system components interact provides valuable insight into its capabilities, but real-world use cases demonstrate its effectiveness in diverse scenarios.
The process begins by selecting a sample from three widely recognized benchmark datasets: MMLU [
45], MATH [
46], and HumanEval, known for targeting different capabilities of language models—general knowledge and reasoning (MMLU), mathematical problem-solving (MATH), and code generation or functional correctness (HumanEval). From each dataset, a single prompt was chosen, presumably to keep the experiment manageable while still covering a range of skill areas.
To introduce an additional dimension of complexity and realism, hypothetical user preferences were layered onto the prompts. These preferences may involve factors such as tone, style, format, or problem-solving approach. This customization helps test the adaptability of LLMs to user-centric requirements, extending beyond just solving the core task.
That said, our experiment prompts are as follows:
MMLU Dataset
Math Dataset
Prompt: Let \\[f(x) = \\left\\{\n\\begin{array}{cl} ax+3, &\\text{ if }x>2, \\\\\nx-5 &\\text{ if } -2 \\le x \\le 2, \\\\\n2x-b &\\text{ if } x <-2.\n\\end{array}\n\\right.\\] Find $a+b$ if the piecewise function is continuous (which means that its graph can be drawn without lifting your pencil from the paper).
User Preferences: Formality, rigor, and mathematical notation
HumanEval Dataset
Next, four different LLMs were selected for testing: GPT-4o-mini, Anthropic Claude Sonnet, LLaMA 3.2-90B, and Gemini 1.5 Pro. Each model was given the same prompt and user preferences, ensuring a uniform basis for comparison.
Each LLM’s response was evaluated by a designated LLM judge three times, assigning a score on a 0–100 scale to account for variability in judgment, and the average of these three evaluations was initially calculated. However, to enhance the robustness and neutrality of the assessment, all four aforementioned LLMs were also rotated into the role of evaluator. In other words, each model’s response was judged not just by one model but by all four acting in turn as the evaluating judge, each performing three evaluation runs per prompt.
As a result, for each LLM’s response to a prompt, a total of twelve evaluations were conducted: four judges times three evaluations each. The average of these twelve individual evaluation scores constituted the final performance score of the LLM on the task, referred to as the LPSs’ score.
We designed a series of targeted experiments (
Table 2) with explicit variation in prompt and evaluation awareness. This phase of analysis introduces a three-case experimental framework to isolate how the presence—or absence—of user-defined preferences impacts both model generation and judgment. By systematically controlling who has access to preference information (the model, the evaluator, or both), we were able to observe the mechanisms driving the shifts in rankings and performance metrics.
Our findings reveal significant discrepancies between traditional benchmark rankings and evaluations based on user-defined quality criteria. The results are presented in
Table 3 below.
According to the results, we noticed that when only the judge is aware of preferences (Case 1), HumanEval performance drops significantly across most models. This indicates that a preference-aware judge penalizes generic or misaligned outputs, even when the base model performs well under benchmark conditions. The LLM is not optimizing for subjective criteria, so the evaluation highlights perceived misalignment. On objective tasks (e.g., Math, MMLU), scores remain relatively stable or slightly lower than the LPS-aware settings, showing that preference mismatch matters most in an open-ended generation.
In the standard benchmark-style setting (Case 2), HumanEval scores are very high, even higher than Case 3 in some cases:
This reflects a misleading inflation in subjective quality scores. Because the judge is unaware of user preferences, it evaluates using generic criteria, allowing outputs that may be style-inconsistent to score well, nonetheless. This highlights a major limitation of traditional benchmark-style evaluations for generative LLMs: they fail to penalize misalignment with user intent.
Under LPS alignment (Case 3), the scores are as follows:
Lower than Case 2 in HumanEval (due to stricter judgment);
Higher than Case 1 across all datasets (due to improved generation);
Balanced and realistic, especially in subjective tasks.
Example (Claude 3.5, HumanEval):
To assess the reliability of these differences, we conducted Welch’s t-tests and Spearman rank correlation analyses across three datasets (MMLU, Math, and HumanEval).
We use Welch’s
t-test because it is specifically designed to handle cases with unequal variances and different sample sizes between groups, making it more robust and reliable than the standard Student’s
t-test in real-world, non-ideal data conditions. Spearman correlation is chosen because it captures the strength and direction of a monotonic relationship between ranked variables without assuming a linear relationship or normally distributed data, which is ideal when comparing model rankings or subjective evaluation scores. Together, they offer complementary insights: Welch tests whether there is a statistically significant difference in means. At the same time, Spearman assesses consistency in ordinal patterns, providing a fuller picture of both absolute and relative performance. The results are shown in
Table 4.
In Case 1 vs. HumanEval Benchmark, the tested LLMs received a generic prompt—one that does not include any user preferences—while the LLM-as-a-Judge was instructed to evaluate responses based on explicit user preferences. The Welch’s t-test yielded a statistically significant result (t = −3.08, p = 0.046), indicating that the scores assigned by the preference-aware judge were substantially lower than those reported by the standardized HumanEval benchmark. Furthermore, the Spearman correlation coefficient was a perfect negative correlation (ρ = −1.0, p = 0.0), suggesting that the models that performed best on the HumanEval benchmark were ranked lowest when assessed through the lens of user preferences. This result reveals a discrepancy between generic benchmarks and preference-driven quality judgments, underscoring a significant blind spot in current evaluation practices. It validates one of the core premises of the LPS framework: user preferences significantly influence perceived response quality, and ignoring them can lead to misleading conclusions about model performance.
In Case 2 vs. HumanEval Benchmark, both the LLM prompt and the LLM-as-a-Judge were entirely preference-agnostic. The system operated under conventional benchmark conditions, making it a direct parallel to standardized evaluations. Here, Welch’s t-test result (t = 2.02, p = 0.131) indicated no statistically significant difference in absolute scores between the LPS assessment and the HumanEval benchmark. However, the Spearman correlation showed a perfect positive alignment (ρ = 1.0, p = 0.0), confirming that the relative model rankings were identical under both evaluation regimes. This suggests that when preference is not a factor, the LPS system yields results that are functionally equivalent to traditional benchmarks. However, this alignment also reveals a limitation of benchmarks: they only measure performance in the absence of user context, underscoring the importance of frameworks like LPS when real-world applicability and user satisfaction are considered.
The comparison of HumanEval results between Case 1 and Case 2 reveals a critical insight into the limitations of standardized benchmarks and the essential value of incorporating user preferences into evaluation. Together, these results highlight that while standardized benchmarks like HumanEval may offer consistency in generic evaluation scenarios, they fail to capture what matters most in real-world applications: user-aligned utility.
For mathematical reasoning tasks, the same preference-agnostic setup from Case 2 vs. MATH was applied. Interestingly, Welch’s t-test showed a substantial and statistically significant improvement in LPS scores compared to benchmark values (t = 5.40, p = 0.012), suggesting that LLMs performed much better in practice than the benchmark might indicate. However, this gain in absolute performance did not correlate strongly with benchmark rankings, as evidenced by a weak and non-significant Spearman correlation (ρ = 0.25, p = 0.74). This discrepancy suggests that benchmarks may undervalue models’ capabilities in structured domains, such as mathematics, mainly when evaluated by generalist criteria. The LPS framework, even when not preference-aware, provides a more fine-grained evaluation that may better reflect the task-specific strengths of LLMs—suggesting again that benchmarks are not always optimal proxies for real-world success, especially in domains that require precision or formality.
Additionally, Case 2 vs. MMLU Benchmark shows perfect ranking agreement and a highly significant t-value, suggesting that generic prompts evaluated by a general judge yield results strongly aligned with standardized MMLU benchmarks. This outcome highlights that benchmarks can be valid and consistent only in neutral, de-personalized use cases.
Overall, these results collectively demonstrate that traditional benchmarks fail to capture the nuances introduced by user preferences. In Case 1, we consistently observe penalties and ranking reversals when preference-aware judges evaluate generic outputs. Case 2 aligns closely with benchmarks, offering minimal new insight. Case 3 reveals that when both prompt and evaluation are tailored to user preferences (the LPS framework), models produce content that deviates from but often exceeds standardized expectations in ways more relevant to the user.
It is essential to clarify that these findings do not imply that the LPS framework provides a superior evaluation to traditional benchmarks. Instead, LPS provides a complementary lens—one that captures domain-specific or task-specific priorities that standardized metrics often overlook. Benchmarks remain essential for general-purpose assessments, offering reproducibility and comparability across models. However, in real-world deployments, users frequently operate under criteria that are not reflected in standard scores; for instance, a legal professional may value precision and formality. At the same time, an educator might prioritize pedagogical clarity and step-by-step reasoning.
The practical implication is that users and institutions who rely solely on benchmark scores risk selecting models that underperform in their actual use cases. LPS addresses this gap by allowing customizable, preference-aligned evaluation, enabling users to identify models that better satisfy their specific needs. For example, in the HumanEval case, a model that consistently ranked lower in benchmark scores (Gemini 1.5 Pro) outperformed others when judged on clarity and directness—attributes critical for technical communication or instructional use.
In this sense, LPS does not compete with benchmarks but complements them. It enables a layered evaluation strategy, where benchmark results provide a general overview, and LPS allows for fine-grained, context-aware assessments. This dual perspective is especially valuable as LLMs are increasingly deployed in sensitive, high-stakes, or domain-specific environments, where the alignment between model behavior and user expectations is as vital as overall performance scores.
5. Use Case: Walkthrough of the LPS
To demonstrate the practical utility of our framework, this section provides a detailed walkthrough of its core components as experienced through its interactive interface. LPS is structured into five logically distinct tabs, each designed to streamline the process of interacting with and analyzing Large Language Models (LLMs) in a controlled, testable environment. The framework is intended for researchers, developers, and practitioners engaged in prompt engineering, model evaluation, and interface-based LLM experimentation.
5.1. Model Selection Landing Page
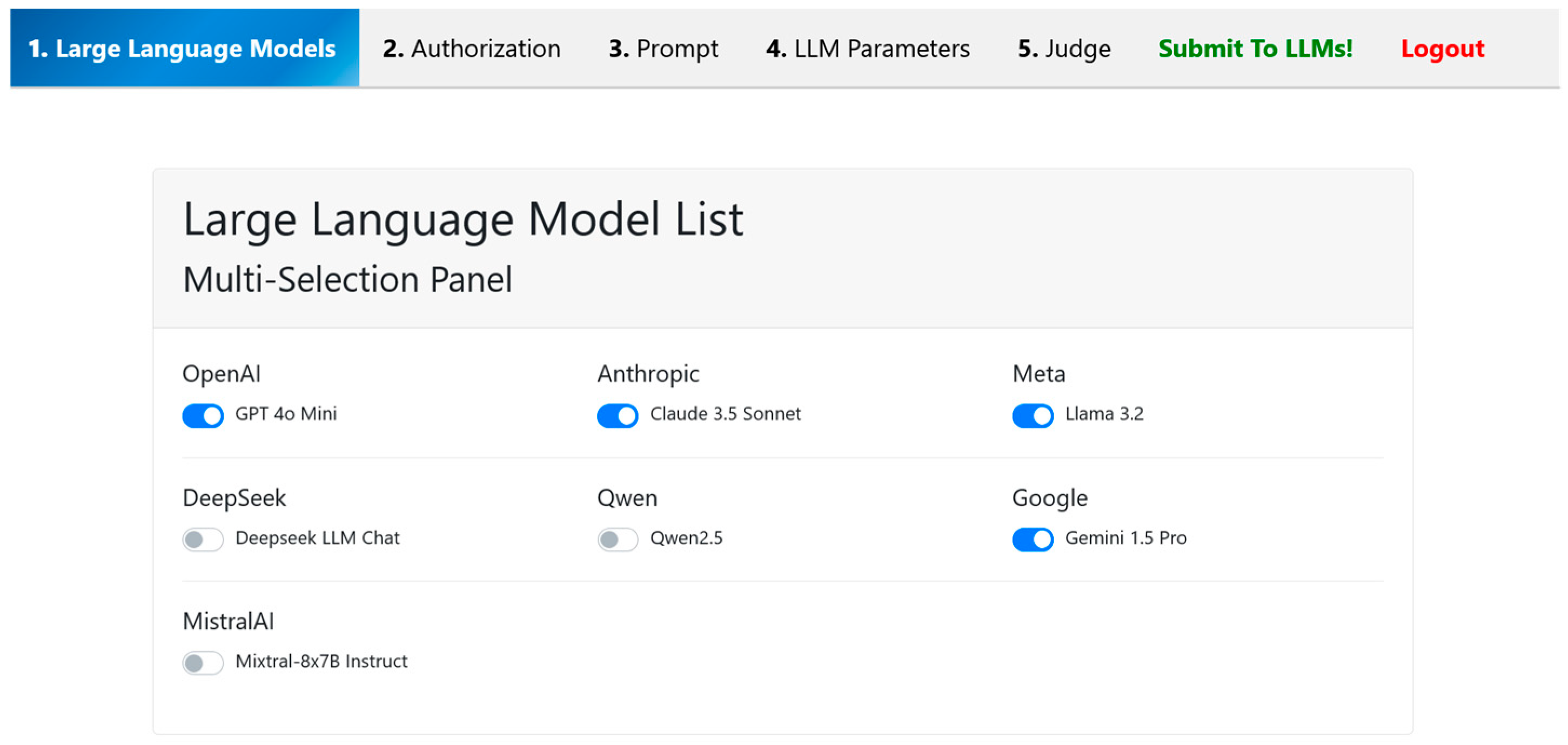
The first tab serves as the main landing interface and acts as the entry point for user engagement. Upon accessing the framework, users are presented with a curated list of available LLMs currently integrated into the system. This list may include both open-source models and commercial APIs, depending on the system’s configuration and the available access credentials.
Each listed model is accompanied by identifying metadata such as model name, version, and source (e.g., OpenAI, Anthropic, etc.), as shown in
Figure 2. The design facilitates comparative experimentation by allowing users to switch seamlessly between models without reloading or losing session context. This modular approach to model selection supports the framework’s broader aim of enabling reproducible and side-by-side prompt testing.
By centralizing model selection at the beginning of the workflow, LPS promotes clarity and structured experimentation from the outset.
5.2. API Credential Configuration
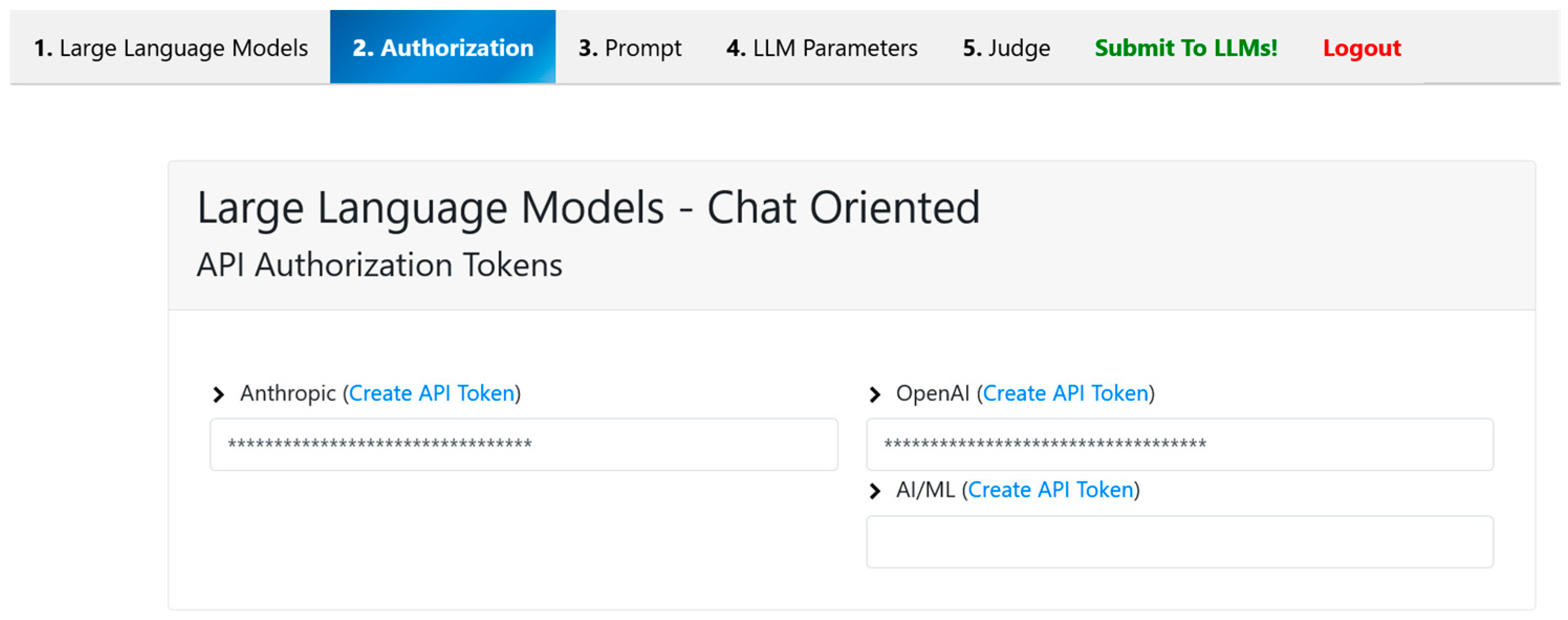
Following model selection, the second tab facilitates the secure configuration of API credentials required to interface with the selected LLM. Given the diversity of LLM providers and their respective authentication mechanisms, this tab ensures that users can establish authorized access in a streamlined and guided manner.
Upon entering this tab, users are prompted to input their API keys corresponding to the selected language model provider, as shown in
Figure 3.
To enhance usability, the interface also includes direct navigational links to the official API management or registration portals of the respective LLM providers. For example, if a user selects a model provided by OpenAI, the framework displays a contextual button redirecting the user to OpenAI’s API dashboard, where they can log in, create an account if needed, and generate an API key. This feature significantly lowers the barrier to entry for users unfamiliar with the procedural aspects of accessing commercial LLM APIs.
Credential data entered in this tab is securely managed within the client session and is not stored persistently, maintaining user privacy and compliance with best practices in API key handling. Once valid credentials are entered, the framework verifies access and enables downstream functionality in the subsequent tabs, ensuring that all operations are securely authorized before interaction with external APIs begins.
5.3. Prompt Input and Contextualization
The third tab provides the core interaction interface for users to compose and submit prompts to the previously selected and authenticated LLMs. This component serves as the primary experimentation zone within the framework, offering a flexible and intuitive environment for testing prompt behavior under various contextual conditions.
At its simplest, the interface allows users to input a raw prompt directly into a designated text area, as shown in
Figure 4. This prompt is then dispatched to the selected model(s) via their respective APIs, returning a real-time response for user inspection. However, LPS extends beyond basic prompt submission by offering optional fields for additional context. This design supports more complex and realistic testing scenarios where prompt output is influenced by an auxiliary system or user-defined information—such as prior dialogue history, instructions, or scenario-specific metadata.
5.4. Parameter Configuration for Response Generation
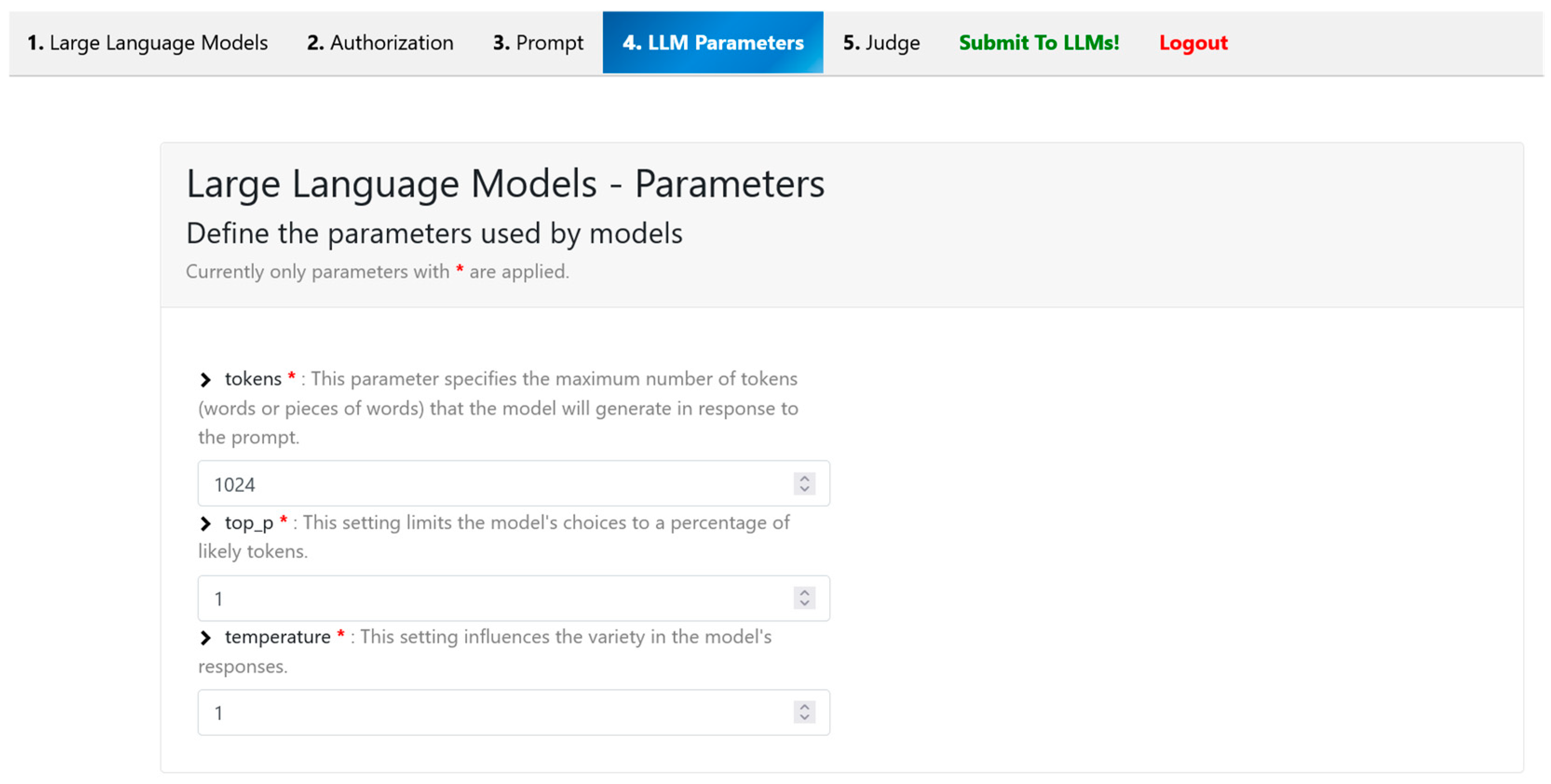
The fourth tab provides users with a dedicated interface for configuring generation parameters that directly influence the behavior of the selected LLMs during response synthesis, as shown in
Figure 5. These parameters are applied uniformly across all API calls made to the chosen models, ensuring consistency and comparability when conducting controlled prompt evaluations.
The current implementation exposes a focused set of the most commonly utilized parameters in LLM-based text generation:
Token Limit: Specifies the maximum number of tokens to be generated in the output. This control allows users to constrain response length, which is particularly important when testing model verbosity, focus, or summarization capabilities.
Temperature: Regulates the randomness or creativity of the generated output. Lower values result in more deterministic and conservative responses, while higher values introduce greater variability, which is useful in creative or open-ended tasks.
Top-p: Determines the cumulative probability threshold for token sampling. This parameter fine-tunes the diversity of output by limiting the token selection pool to those that fall within a specified probability mass.
By isolating parameter control into a distinct tab, LPS encourages a modular workflow where users can independently define the generation conditions before executing prompts. This not only supports reproducible experimentation but also facilitates comparative studies across different parameter settings and model behaviors.
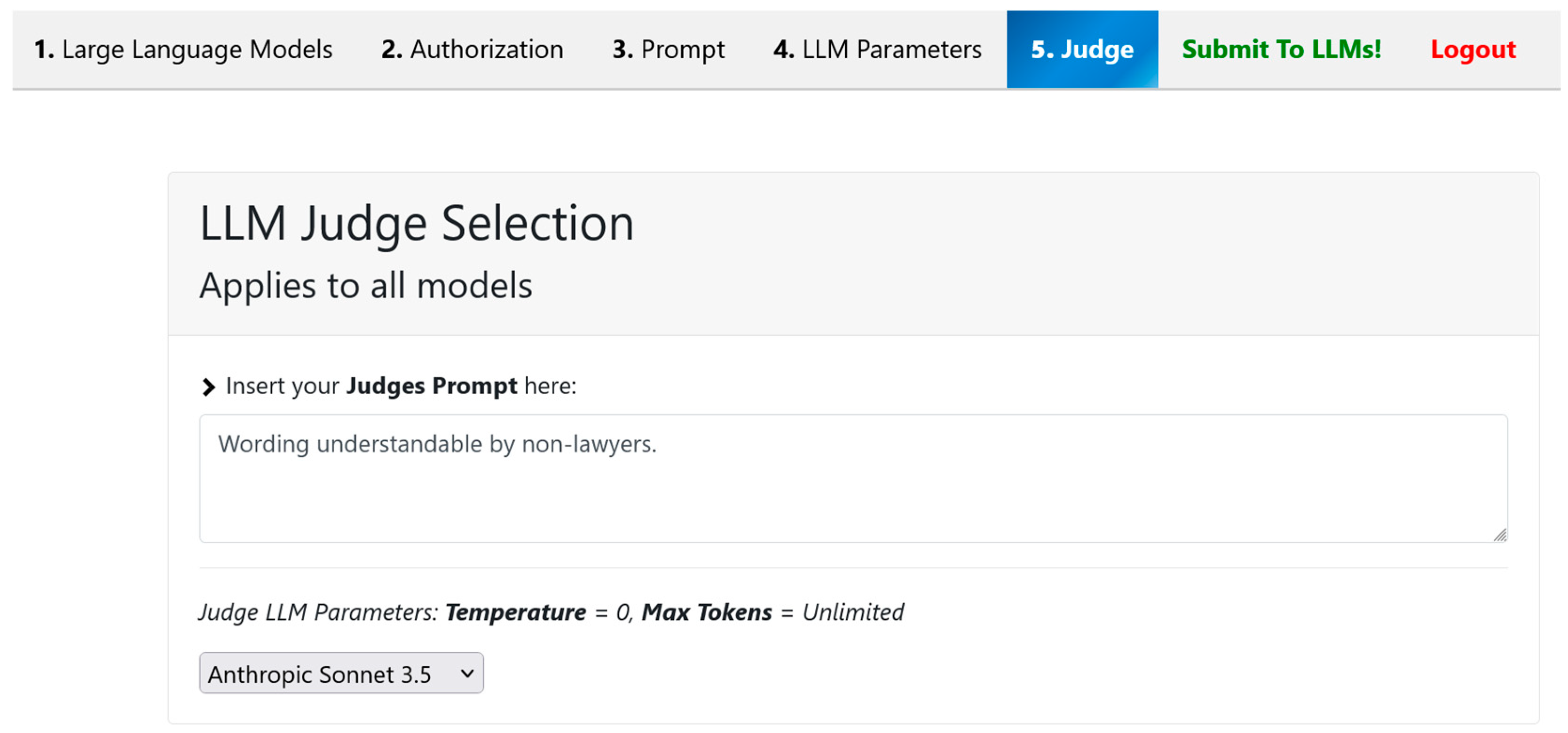
5.5. LLM-as-a-Judge Evaluation Interface
The fifth and final tab introduces an evaluative layer to the LPS by implementing an LLM-as-a-Judge paradigm. This component enables users to perform qualitative or criteria-based assessments of the outputs generated by the selected LLMs using another language model as a meta-evaluator.
Within this interface, users are prompted to define evaluation preferences or criteria through a structured prompt field. These preferences may reflect specific goals—such as accuracy, coherence, creativity, relevance, or factual consistency—and serve as the guiding rubric by which the judging model will assess the responses previously defined in Tab 3.
A key feature of this tab is the ability to select from a dropdown menu of available judge models. This allows the user to assign a different LLM as the evaluator, independent of the models initially used to generate the responses, as shown in
Figure 6. For example, a user might compare outputs from OpenAI’s GPT-4o-mini and Gemini 1.5 Pro but use Anthropic’s Claude model to adjudicate based on predefined criteria.
Once configured, the judge model is prompted with the evaluation instruction and the candidate responses. It then returns a structured assessment or ranking, depending on the format specified by the user.
5.6. Dynamic Response Display and Evaluation
Once the user completes the configuration across the five primary tabs—including model selection, credential entry, prompt input, parameter tuning, and evaluation criteria—the interaction culminates with the submission action. Upon submission, the LPS dynamically generates a set of new result tabs, each named after one of the initially selected LLMs. These tabs are populated with the results of the prompt execution and the corresponding evaluation, enabling a focused yet comparative exploration of model behavior. Within each model-specific tab, the interface displays two structured outputs, as shown in
Figure 7 and described as follows:
- 4.
Model Response Section: This area presents the raw output generated by the selected LLM in response to the user’s prompt. Accompanying the response are key metadata elements, including:
Prompt Tokens: Number of tokens used in the input.
Completion Tokens: Number of tokens generated by the model.
Total Tokens: Combined count of prompt and response tokens, often relevant for API cost estimation or performance tuning.
- 5.
LLM-as-a-Judge Evaluation Section: Directly beneath the response, the framework displays the evaluation result generated by the selected judge model. This evaluation is based on the user-defined criteria specified in Tab 5. The judging model processes both the original user prompt and the LLM’s response to produce a contextualized assessment—which may take the form of a qualitative explanation, score, ranking, or critique. This section is also accompanied by the same token-level metadata, offering insight into the cost and complexity of the evaluative pass.
The separation of generation and judgment within each tab facilitates a layered analysis of performance. Users can compare how different models respond to the same prompt and how those responses are interpreted under a consistent evaluative rubric. This architecture encourages both model benchmarking and prompt optimization, making PromptScope a practical framework for systematic experimentation in prompt engineering workflows.
6. Limitations
Despite its innovative contributions, the proposed framework is subject to several limitations. First, the use of LLMs as evaluators—while efficient and scalable—introduces the risk of bias and circularity. Since these models are trained on large-scale, often opaque corpora, their judgments may reflect embedded biases and fail to capture domain-specific nuances, primarily when the evaluator and evaluated share similar architectures. Additionally, the reliance on user-defined evaluation criteria, although empowering, introduces subjectivity and inconsistency, which can potentially complicate reproducibility across different users or studies.
Another constraint lies in the generalizability of the results; the evaluation is limited to a specific subset of prompts from three datasets, and further validation across broader and more specialized domains is needed. The system’s dependence on third-party APIs also raises concerns about long-term accessibility, scalability, and cost, especially in settings with limited resources.
Furthermore, LPS currently lacks integration with interpretability tools, which could help users understand model behavior beyond performance scores.
Finally, considerations around data privacy and security must be addressed, particularly when user-provided prompts or generated outputs contain sensitive or proprietary information. These limitations highlight important directions for future research.
7. Conclusions and Future Research
Our research highlights a fundamental tension between standardized datasets of LLMs and user domain-specific evaluations. Through the development and implementation of the LPS framework, we have identified several key insights regarding LLM evaluation and deployment in practical applications.
To address these challenges, the LPS framework introduces several features that enhance the precision and relevance of evaluations. It enables multi-model comparison, allowing users to evaluate multiple LLMs simultaneously, saving time on prompting and evaluation, and identifying the strengths and weaknesses of each model. Additionally, it supports customizable evaluation through user-defined criteria, flexible model selection for judges, and domain-specific assessment capabilities. The framework also enhances contextualization by allowing users to provide additional context for prompt generation, leading to improved response relevance and better alignment with specific use cases.
Despite the growing proliferation of general-purpose LLM benchmarks, a notable scarcity of domain-specific evaluation benchmarks remains. In such cases, LPS may serve as the only available systematic evaluation tool, enabling practitioners to define customized criteria that reflect the unique demands of their applications. Moreover, standard benchmarks (e.g., LegalBench, MMLU) typically do not account for user-centered criteria such as clarity, accessibility, or stylistic preferences, which are critical in real-world applications involving non-expert end-users. Our proposed framework directly addresses this gap by enabling dynamic, preference-aligned evaluation of model outputs on a per-prompt basis, regardless of the domain.
Addressing the limitations mentioned above highlights essential directions for future research, including human-in-the-loop validation, ethical prompt engineering, and support for explainable evaluations.
To further enhance LPS’s robustness, future work will focus on minimizing reliance on third-party APIs. A key priority is the integration of automatic updates for proprietary model endpoints, along with the incorporation of open-source or locally deployable alternatives as fallback options. This strategy will enhance the platform’s resilience, reduce costs, and ensure long-term continuity, eliminating dependency on external providers. Additionally, adopting a model-agnostic architecture will enable LPS to seamlessly adapt to emerging LLMs with minimal modifications.
Addressing data privacy and security is equally critical. Future developments will emphasize support for on-premise model deployment and the use of models offering explicit data governance guarantees. We will also explore embedding encryption and anonymization techniques within LPS to protect sensitive user inputs and generated outputs. Clear, transparent user agreements and built-in safeguards will be essential components of these enhancements, ensuring that privacy is maintained without compromising system usability or performance.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}