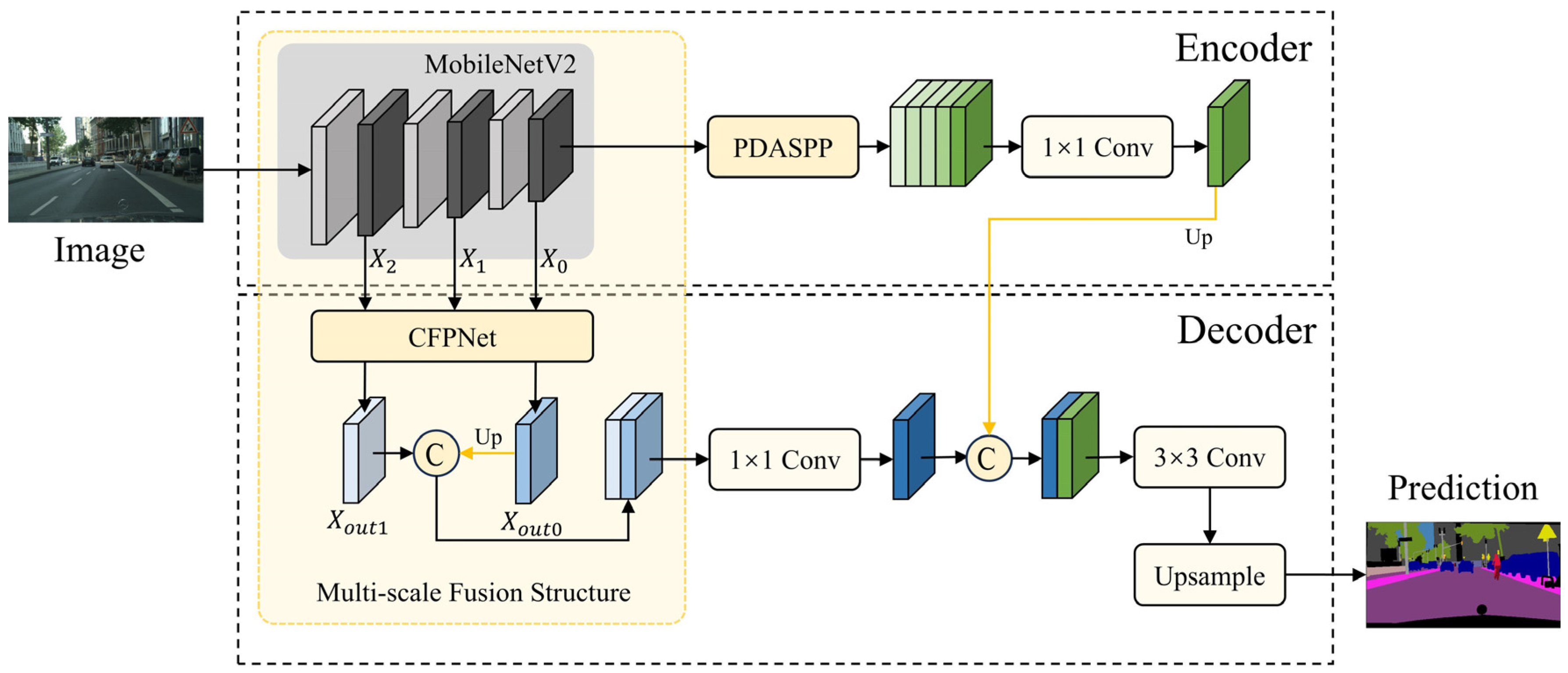
To overcome the limitation of insufficient multi-scale information utilization in DeepLabV3+, MPNet incorporates a novel multi-scale feature fusion structure by integrating the backbone network with the CFPNet. This structure simultaneously receives low-level, mid-level, and high-level features, and outputs fused low-level and fused high-level features. The fused high-level feature map is concatenated with the fused low-level feature map along the channel dimension after upsampling. Through this multi-scale fusion design, MPNet effectively solves the problem of the insufficient utilization of multi-scale information in DeepLabV3+.
In the decoder, the feature map processed by the PDASPP module is compressed through a 1 × 1 convolution channel and upsampled four times, and then concatenated with the feature map processed by the multi-scale fusion structure. The concatenated feature map is compressed through a 3 × 3 convolution and then upsampled to the size of the original image, and finally the semantic segmentation prediction result is output.
2.1. Backbone Network
In the DeepLabV3+ network, although Xception [
22] serves as the backbone and provides excellent performance, its complex structure and large number of parameters limit its efficiency. Therefore, this paper adopts MobileNetV2 [
23] as the backbone network. MobileNetV2 introduces depthwise separable convolutions and inverted residual structures, significantly reducing model complexity while maintaining high accuracy.
Depthwise separable convolution splits the convolution into two steps: channel-by-channel convolution and point-by-point convolution. Channel-by-channel convolution uses a separate K × K convolution kernel on each input channel, reducing cross-channel calculations and thus reducing the number of parameters, while point-by-point convolution uses a 1 × 1 convolution kernel to fuse channel information.
In conventional convolutional neural networks, the number of channels is usually reduced to lower computational costs, and later restored during the decoding phase. In contrast, at the beginning, the inverted residual structure of MobileNetV2 increases the number of channels, extracts features through depthwise separable convolutions, and then projects the features back to a lower-dimensional space using a 1 × 1 convolution. The intermediate expansion of channel dimensions facilitates the extraction of critical information, while skip connections preserve information flow.
The inverted residual structure of MobileNetV2 is illustrated in
Figure 2. ReLU6 was adopted as the activation function to enhance nonlinear feature extraction and extract richer spatial features after depthwise separable convolutions while maintaining computational efficiency. Unlike ResNet [
24], there is a skip connection only when Stride = 1, and the input and output feature maps have the same dimensions.
The layer parameters of MobileNetV2 are shown in
Table 1. Initially, a convolutional layer was used for preliminary feature extraction and resolution reduction. Then, a series of inverted residual structures were used to progressively extract deep features. These inverted residual structures adjust the number of channels and resolution at different stages. Then, a 1 × 1 convolution was used to further expand the feature dimension, and subsequently, the feature map was compressed to a 1×1 size through global average pooling. Finally, a fully connected layer was used to output the classification result.
Here, t represents the expansion factor, controlling the degree of channel expansion within the inverted residual block; c represents the number of output channels; n represents the number of times the inverted residual structure is repeated; s represents the stride used for downsampling during convolution operations; and k represents the number of classification categories.
2.2. Progressive Dilated ASPP
In the DeepLabV3+ network, the dilated convolutions in the ASPP module expand the receptive field, enhancing feature extraction capabilities without significantly increasing computational costs. However, the original ASPP extracts information from only nine effective sampling points, with the remaining positions zero-padded to reduce computational load. This characteristic limits the ability to capture local features, resulting in incomplete fine-grained structure representation and a relatively restricted receptive field.
To mitigate the disruption to local structures caused by zero padding in dilated convolutions, increase the number of effective sampling points, and further expand the receptive field, we designed progressive dilated atrous spatial pyramid pooling (PDASPP). As shown in
Figure 3, PDASPP stacks multiple dilated convolution with different dilation rates following the first layer of dilated convolution, enabling higher layers to utilize features from lower layers and achieve denser pixel sampling.
In the first layer, dilated convolutions with dilation rates of 6, 9, and 12 are used to establish an initial multi-scale feature representation. This layer ensures that the receptive field captures both local and medium-scale information while avoiding the sparsity issues caused by directly using large dilation rates. It maintains feature continuity and preserves edge details, optimizes gradient propagation, and provides stable feature inputs for subsequent layers with larger dilation rates.
In the second layer, hierarchical and diverse dilation rates were applied. This approach prevents excessive overlap of receptive fields, enhancing the network’s perception of objects of different scales in complex scenes, while also avoiding redundant sampling and improving information utilization. Through this strategy, features were sequentially extracted from near to far, enabling a comprehensive description of target objects at multiple scales. Moreover, stacking two dilated convolutions resulted in an expanded receptive field. As illustrated in
Figure 4, assuming that the receptive fields of two dilated convolutions are
and
, the new receptive field size
can be expressed as
Additionally, PDASPP retains the 1 × 1 convolution from the original ASPP module for feature compression and channel fusion, and preserves the global average pooling branch to supplement global contextual information, further enhancing the feature representation capability.
The PDASPP module takes the high-level features from the backbone as input, facilitating more comprehensive sampling across the receptive field. This design fills the zero-valued gaps caused by sparse sampling distributions in convolutions with different dilation rates, although the receptive field expansion after a single stage remains limited. To further enlarge the receptive field, PDASPP compresses and fuses the features through a 1 × 1 convolution after the first stage, and then reprocesses them through a second round of dilated convolution. This second loop increases sampling diversity beyond the original receptive field, resulting in a more enriched receptive field distribution. In our progressive dilated structure, the receptive field radius (dilation rates) after loops through a sequence of branches is given by
where
denotes the dilation rate of the
-th convolution in the
-th branch during the
-th loop.
As illustrated in
Figure 5, the six branches of the PDASPP module undergo further expansion and diversification of their receptive fields after passing through the (6,4) dilated convolutional branch. Through this loop process, the receptive field variation becomes more comprehensive, effectively enhancing feature sampling and making full use of the global characteristics and valuable surrounding contextual information of the target objects. The PDASPP process can be expressed as
where
denotes a 3 × 3 dilated convolution with a dilation rate of
,
denotes the output of a single PDASPP loop, and
denotes number of loops.
2.3. Multi-Scale Feature Fusion
In the DeepLabV3+ architecture, the decoder performs multi-scale fusion by combining a low-level feature with the high-level features output by the ASPP module. However, this approach does not fully exploit the multi-scale information available within the backbone. Such a limitation often results in blurred boundaries or missing details, negatively impacting the segmentation accuracy.
To address this issue, we integrated MobileNetV2 with CFPNet [
25] to construct a new network architecture, as shown in
Figure 6. CFPNet incorporates four CSPlayers [
26] and the explicit visual center (EVC) module to enhance feature representation. The CSPlayers optimize computational efficiency while improving multi-scale feature extraction by partially separating and fusing features across stages. Meanwhile, the EVC module, which utilizes a lightweight MLP module, effectively captures long-range dependencies in the image. By combining the EVC with a learnable visual center (LVC) module, the network can accurately aggregate detailed regional information within the image, thereby improving overall segmentation performance.
Initially, the MobileNetV2 backbone processes the input image to obtain feature maps at low, mid, and high levels. The spatial resolutions of each layer, denoted as
(where
= 0, 1, 2),
are 1/4, 1/8, and 1/16 of the input image size, respectively. The high-level feature
is refine through a Stem block to produce the enhanced high-level feature map
, which can be formulated as
where
represents a 7 × 7 convolution operation with 256 output channels and stride of 1,
represents batch normalization, and
is ReLU.
The obtained
is fed into the EVC module, which employs a lightweight MLP to model global dependencies across long spatial ranges, as shown in
Figure 7. This MLP is composed of two residual branches: one utilizing depthwise convolutions and the other based on channel-wise transformations.
Specifically, the feature
produced by the stem block first passes through the depthwise convolution-based MLP to produce an intermediate feature
Subsequently,
is further processed by the channel-based MLP to generate the final output of the lightweight MLP. The process can be express as
where
refers to channel scaling and dropPath operations,
represents depthwise convolution with kernel size 1 × 1, and
indicates the channel-based MLP module,
denotes a group normalization operation.
Meanwhile,
is also fed into the learnable visual center (LVC) module, which operates in parallel with the lightweight MLP, as shown in
Figure 8. The LVC module is an encoder equipped with a built-in dictionary and comprises two main components:
An inherent codebook . is the score of feature map height and width.
A set of scaling factors for the LVC.
The feature
generated by the stem block is initially processed through sequential convolutional operations to extract local features representations. Subsequently, the feature is passed through a CBR block—consisting of a 3 × 3 convolution, batch normalization, and ReLU—to generate the encoded feature
. For each pixel feature
, mapping is established relative to each codeword
in the codebook using the corresponding scaling factors
. The encoded information
for the k-th codeword over the information of the global image context can be formulated as
where
denotes the feature vector of the i-th pixel, and
is the k-th codeword. The term
denotes the positional relevance of each pixel to a codeword.
All
are subsequently fused using an aggregation operation
, which is constructed with batch normalization, ReLU activation, and average pooling. With this configuration, the overall image context related to the k-th codewords can be formulated as
After extracting the output
from the codebook, it is passed through a fully connected layer and a subsequent 1 × 1 convolution to refine predictions for detailed image regions. The scaling coefficients
are then applied to the input feature
via channel-wise multiplication, producing a refined detail feature map
. Finally, a channel-wise addition is conducted between
and
, and the entire procedure is defined as follows:
where
represents a 1 × 1 convolution operation,
refers to the sigmoid activation function,
represents channel-wise addition, and
represents channel-wise multiplication.
The feature maps from both branches are finally concatenated along the channel dimension, and the output of the EVC module
can be formulated as
The output is then upsampled and concatenated with the CSP layers, enabling each CSP layer to fully leverage the information from the EVC module. This design effectively enhances the global and discriminative feature representation, ultimately producing the fused feature maps and .

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}