Abstract
The increasing demands for high-precision semantic segmentation in applications such as autonomous driving, unmanned aerial vehicles, and robotics has made improving segmentation accuracy a major research focus. In this paper, we propose MPNet, (multi-scale progressive network) a novel semantic segmentation model based on the DeepLabV3+ architecture. First, a lightweight MobileNetV2 was employed as the backbone network, and a new multi-scale feature fusion structure was constructed by integrating the backbone with the centralized feature pyramid network (CFPNet). Then, based on the ASPP module, a progressive dilated atrous spatial pyramid pooling (PDASPP) module was designed to further enhance feature extraction. Extensive experiments were conducted on the Cityscapes and PASCAL VOC 2012 Augmented. The experimental results show that MPNet achieved 75.23% mIoU and 83.54% mPA on the Cityscapes dataset, outperforming DeepLabV3+ by 3.01% and 3.31%, respectively. On the PASCAL VOC 2012 Augmented dataset, MPNet achieved 72.70% mIoU and 83.57% mPA, with improvements of 1.59% and 1.30% over DeepLabV3+, respectively. These results demonstrate that MPNet significantly improves segmentation accuracy while maintaining model complexity under control, providing an effective solution for semantic segmentation in road scene understanding.
1. Introduction
With the rapid development of deep learning and computer vision technologies, applications such as autonomous driving have attracted increasing attention [1]. Visual perception is crucial in autonomous driving systems, as it not only requires the efficient processing of massive image data, but also demands extremely high accuracy to ensure that the system can make correct decisions under complex road conditions [2]. In this context, road semantic segmentation serves as a key technology for environmental perception, directly impacting the system’s ability to understand roads, pedestrians, and obstacles [3]. Especially with the continuous improvement of onboard sensors and camera resolution, higher demands are placed on the balance between accuracy and computational efficiency of segmentation algorithms. High-quality road scene segmentation not only provides more reliable inputs for autonomous driving systems, but also lays a foundation for their safety and stability [4,5].
The semantic segmentation of road scenes is an important research area in computer vision and plays a vital role in enabling autonomous systems to understand road environments [6,7,8]. Early semantic segmentation methods, such as the fully convolutional network (FCN) [9], replaced fully connected layers with convolutional layers, transforming segmentation tasks into pixel-wise classification and laying the groundwork for subsequent research. With the evolution of segmentation architectures, encoder–decoder structures have become mainstream. This architectural pattern leverages an encoder to extract hierarchical semantic features, and a decoder to progressively recover spatial resolution, enabling a balance between global context understanding and precise object localization. SegNet [10] employs a symmetric structure using max pooling indices to guide the decoding process, thereby more effectively restoring the image spatial information. U-Net [11] introduces skip connections to directly pass the low-level features of the encoder to the decoder, effectively enhancing the ability to retain boundary information.
To address complex scenes and long-range dependencies, multi-scale feature fusion and attention mechanisms have emerged as research hotspots. PSPNet [12] employs pyramid-based feature aggregation to obtain contextual cues across different scales, enhancing the network’s understanding of global structures. BiSeNetV2 [13] balances accuracy and speed by combining semantic and detail branches, making it suitable for real-time applications. DANet [14] incorporates both spatial and channel attention mechanisms, showing significant advantages in enhancing the response to key areas and improving feature representation. Additionally, OCRNet [15] proposes the object-contextual module (OCM), which models object relationships to improve segmentation accuracy by effectively fusing local and global contextual information. SeaFormer [16] further advances lightweight design by incorporating transformer-style attention into a compact framework, achieving global context modeling with minimal overhead. P2AT [17] proposes a real-time semantic segmentation architecture based on a pyramid pooling axial transformer, which captures spatial and channel dependencies at multiple scales. It introduces a bidirectional fusion module and a global context enhancer to aggregate and refine semantic features.
The DeepLab series has significantly advanced semantic segmentation. DeepLabV1 [18] introduces dilated convolutions to enlarge the receptive field without reducing resolution. DeepLabV2 [19] adds CRFs for better boundary refinement. DeepLabV3 [20] and V3+ [21] integrate atrous spatial pyramid pooling (ASPP) to enhance multi-scale feature extraction, achieving accurate segmentation in complex scenarios. DeepLabV3+ also balances efficiency and accuracy, making it suitable for tasks like autonomous driving.
However, DeepLabV3+ has some limitations. The Xception backbone is computationally heavy. The ASPP module samples sparsely and relies on zero padding, which weakens local feature capture. Moreover, the decoder only fuses shallow and deep features, underutilizing multi-scale information from the backbone, which limits performance in complex scenarios.
To overcome the above limitations, we propose MPNet, a DeepLabV3+-based segmentation model designed for complex urban road scenes. MPNet improves the recognition of road elements of various sizes through effective multi-scale feature fusion, and enhances segmentation accuracy in complex environments. In this paper, Section 2 introduces the overall architecture of MPNet, with a focus on the PDASPP module and multi-scale fusion. Section 3 presents comparative and generalization experiments to validate the effectiveness of our method. Section 4 concludes the paper and outlines potential directions for future research on MPNet.
The main contributions of this paper are summarized as follows:
- (1)
- The lightweight MobileNetV2 was used to replace Xception as the backbone network, which significantly reduced the model complexity while maintaining high segmentation accuracy.
- (2)
- A progressive dilated ASPP (PDASPP) module was constructed, which uses stacked dilated convolutions to increase the effective sampling points in the receptive field and the loop structure to expand the range of the receptive field, effectively integrating contextual information and improving accuracy.
- (3)
- A multi-scale feature fusion structure based on CFPNet was designed, which integrates low-, mid-, and high-level features in the backbone network to enhance both global semantic representation and local detail expression.
- (4)
- Comparative experiments were conducted on the Cityscapes and PASCAL VOC 2012 Augmented datasets. The experimental results show that MPNet had better semantic segmentation accuracy while maintaining a smaller model size.
2. Materials and Methods
The MPNet model is shown in Figure 1. The MPNet model adopts MobileNetV2 as the backbone network. In the encoder part of MPNet, the input data consist of a three-channel road scene image, which is preprocessed and then fed into MobileNetV2 to extract three different levels of feature maps: low, mid, and high levels. High-level features are directly passed into the PDASPP, where richer contextual information is obtained through stacked dilated convolutions and a progressive recurrent structure.

Figure 1.
Overall architecture of the MPNet network. The yellow dotted-line area represents the multi-scale fusion structure.
To overcome the limitation of insufficient multi-scale information utilization in DeepLabV3+, MPNet incorporates a novel multi-scale feature fusion structure by integrating the backbone network with the CFPNet. This structure simultaneously receives low-level, mid-level, and high-level features, and outputs fused low-level and fused high-level features. The fused high-level feature map is concatenated with the fused low-level feature map along the channel dimension after upsampling. Through this multi-scale fusion design, MPNet effectively solves the problem of the insufficient utilization of multi-scale information in DeepLabV3+.
In the decoder, the feature map processed by the PDASPP module is compressed through a 1 × 1 convolution channel and upsampled four times, and then concatenated with the feature map processed by the multi-scale fusion structure. The concatenated feature map is compressed through a 3 × 3 convolution and then upsampled to the size of the original image, and finally the semantic segmentation prediction result is output.
2.1. Backbone Network
In the DeepLabV3+ network, although Xception [22] serves as the backbone and provides excellent performance, its complex structure and large number of parameters limit its efficiency. Therefore, this paper adopts MobileNetV2 [23] as the backbone network. MobileNetV2 introduces depthwise separable convolutions and inverted residual structures, significantly reducing model complexity while maintaining high accuracy.
Depthwise separable convolution splits the convolution into two steps: channel-by-channel convolution and point-by-point convolution. Channel-by-channel convolution uses a separate K × K convolution kernel on each input channel, reducing cross-channel calculations and thus reducing the number of parameters, while point-by-point convolution uses a 1 × 1 convolution kernel to fuse channel information.
In conventional convolutional neural networks, the number of channels is usually reduced to lower computational costs, and later restored during the decoding phase. In contrast, at the beginning, the inverted residual structure of MobileNetV2 increases the number of channels, extracts features through depthwise separable convolutions, and then projects the features back to a lower-dimensional space using a 1 × 1 convolution. The intermediate expansion of channel dimensions facilitates the extraction of critical information, while skip connections preserve information flow.
The inverted residual structure of MobileNetV2 is illustrated in Figure 2. ReLU6 was adopted as the activation function to enhance nonlinear feature extraction and extract richer spatial features after depthwise separable convolutions while maintaining computational efficiency. Unlike ResNet [24], there is a skip connection only when Stride = 1, and the input and output feature maps have the same dimensions.
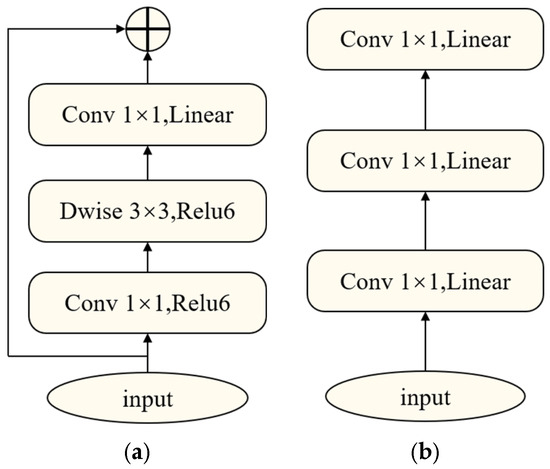
Figure 2.
Inverted residual structure: (a) stride = 1; (b) stride = 2.
The layer parameters of MobileNetV2 are shown in Table 1. Initially, a convolutional layer was used for preliminary feature extraction and resolution reduction. Then, a series of inverted residual structures were used to progressively extract deep features. These inverted residual structures adjust the number of channels and resolution at different stages. Then, a 1 × 1 convolution was used to further expand the feature dimension, and subsequently, the feature map was compressed to a 1×1 size through global average pooling. Finally, a fully connected layer was used to output the classification result.

Table 1.
Network structure parameter table.
Here, t represents the expansion factor, controlling the degree of channel expansion within the inverted residual block; c represents the number of output channels; n represents the number of times the inverted residual structure is repeated; s represents the stride used for downsampling during convolution operations; and k represents the number of classification categories.
2.2. Progressive Dilated ASPP
In the DeepLabV3+ network, the dilated convolutions in the ASPP module expand the receptive field, enhancing feature extraction capabilities without significantly increasing computational costs. However, the original ASPP extracts information from only nine effective sampling points, with the remaining positions zero-padded to reduce computational load. This characteristic limits the ability to capture local features, resulting in incomplete fine-grained structure representation and a relatively restricted receptive field.
To mitigate the disruption to local structures caused by zero padding in dilated convolutions, increase the number of effective sampling points, and further expand the receptive field, we designed progressive dilated atrous spatial pyramid pooling (PDASPP). As shown in Figure 3, PDASPP stacks multiple dilated convolution with different dilation rates following the first layer of dilated convolution, enabling higher layers to utilize features from lower layers and achieve denser pixel sampling.

Figure 3.
PDASPP model diagram. The blue dotted line represents an additional loop.
In the first layer, dilated convolutions with dilation rates of 6, 9, and 12 are used to establish an initial multi-scale feature representation. This layer ensures that the receptive field captures both local and medium-scale information while avoiding the sparsity issues caused by directly using large dilation rates. It maintains feature continuity and preserves edge details, optimizes gradient propagation, and provides stable feature inputs for subsequent layers with larger dilation rates.
In the second layer, hierarchical and diverse dilation rates were applied. This approach prevents excessive overlap of receptive fields, enhancing the network’s perception of objects of different scales in complex scenes, while also avoiding redundant sampling and improving information utilization. Through this strategy, features were sequentially extracted from near to far, enabling a comprehensive description of target objects at multiple scales. Moreover, stacking two dilated convolutions resulted in an expanded receptive field. As illustrated in Figure 4, assuming that the receptive fields of two dilated convolutions are and , the new receptive field size can be expressed as
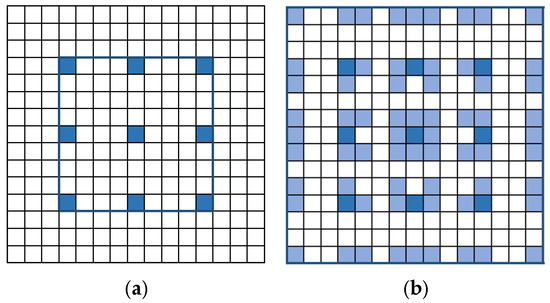
Figure 4.
Comparisons between the densities of effective sampling points and the receptive field sizes in ASPP and PDASPP: (a) ASPP; (b) PDASPP.
Additionally, PDASPP retains the 1 × 1 convolution from the original ASPP module for feature compression and channel fusion, and preserves the global average pooling branch to supplement global contextual information, further enhancing the feature representation capability.
The PDASPP module takes the high-level features from the backbone as input, facilitating more comprehensive sampling across the receptive field. This design fills the zero-valued gaps caused by sparse sampling distributions in convolutions with different dilation rates, although the receptive field expansion after a single stage remains limited. To further enlarge the receptive field, PDASPP compresses and fuses the features through a 1 × 1 convolution after the first stage, and then reprocesses them through a second round of dilated convolution. This second loop increases sampling diversity beyond the original receptive field, resulting in a more enriched receptive field distribution. In our progressive dilated structure, the receptive field radius (dilation rates) after loops through a sequence of branches is given by
where denotes the dilation rate of the -th convolution in the -th branch during the -th loop.
As illustrated in Figure 5, the six branches of the PDASPP module undergo further expansion and diversification of their receptive fields after passing through the (6,4) dilated convolutional branch. Through this loop process, the receptive field variation becomes more comprehensive, effectively enhancing feature sampling and making full use of the global characteristics and valuable surrounding contextual information of the target objects. The PDASPP process can be expressed as
where denotes a 3 × 3 dilated convolution with a dilation rate of , denotes the output of a single PDASPP loop, and denotes number of loops.

Figure 5.
Example of new receptive field radius. The green band represents the newly generated receptive field of all branches in the second loop of PDASPP after the expansion rate is (6,4).
2.3. Multi-Scale Feature Fusion
In the DeepLabV3+ architecture, the decoder performs multi-scale fusion by combining a low-level feature with the high-level features output by the ASPP module. However, this approach does not fully exploit the multi-scale information available within the backbone. Such a limitation often results in blurred boundaries or missing details, negatively impacting the segmentation accuracy.
To address this issue, we integrated MobileNetV2 with CFPNet [25] to construct a new network architecture, as shown in Figure 6. CFPNet incorporates four CSPlayers [26] and the explicit visual center (EVC) module to enhance feature representation. The CSPlayers optimize computational efficiency while improving multi-scale feature extraction by partially separating and fusing features across stages. Meanwhile, the EVC module, which utilizes a lightweight MLP module, effectively captures long-range dependencies in the image. By combining the EVC with a learnable visual center (LVC) module, the network can accurately aggregate detailed regional information within the image, thereby improving overall segmentation performance.
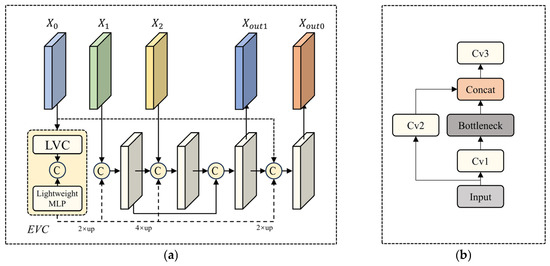
Figure 6.
Multi-scale feature fusion structure. (a) Multi-scale feature fusion structure based on MobileNetV2. (b) CSPlayer module.
Initially, the MobileNetV2 backbone processes the input image to obtain feature maps at low, mid, and high levels. The spatial resolutions of each layer, denoted as (where = 0, 1, 2), are 1/4, 1/8, and 1/16 of the input image size, respectively. The high-level feature is refine through a Stem block to produce the enhanced high-level feature map , which can be formulated as
where represents a 7 × 7 convolution operation with 256 output channels and stride of 1, represents batch normalization, and is ReLU.
The obtained is fed into the EVC module, which employs a lightweight MLP to model global dependencies across long spatial ranges, as shown in Figure 7. This MLP is composed of two residual branches: one utilizing depthwise convolutions and the other based on channel-wise transformations.

Figure 7.
Lightweight MLP module.
Specifically, the feature produced by the stem block first passes through the depthwise convolution-based MLP to produce an intermediate feature Subsequently, is further processed by the channel-based MLP to generate the final output of the lightweight MLP. The process can be express as
where refers to channel scaling and dropPath operations, represents depthwise convolution with kernel size 1 × 1, and indicates the channel-based MLP module, denotes a group normalization operation.
Meanwhile, is also fed into the learnable visual center (LVC) module, which operates in parallel with the lightweight MLP, as shown in Figure 8. The LVC module is an encoder equipped with a built-in dictionary and comprises two main components:
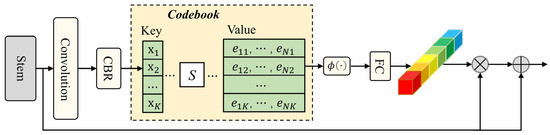
Figure 8.
Learnable visual center.
- An inherent codebook . is the score of feature map height and width.
- A set of scaling factors for the LVC.
The feature generated by the stem block is initially processed through sequential convolutional operations to extract local features representations. Subsequently, the feature is passed through a CBR block—consisting of a 3 × 3 convolution, batch normalization, and ReLU—to generate the encoded feature . For each pixel feature , mapping is established relative to each codeword in the codebook using the corresponding scaling factors . The encoded information for the k-th codeword over the information of the global image context can be formulated as
where denotes the feature vector of the i-th pixel, and is the k-th codeword. The term denotes the positional relevance of each pixel to a codeword.
All are subsequently fused using an aggregation operation , which is constructed with batch normalization, ReLU activation, and average pooling. With this configuration, the overall image context related to the k-th codewords can be formulated as
After extracting the output from the codebook, it is passed through a fully connected layer and a subsequent 1 × 1 convolution to refine predictions for detailed image regions. The scaling coefficients are then applied to the input feature via channel-wise multiplication, producing a refined detail feature map . Finally, a channel-wise addition is conducted between and , and the entire procedure is defined as follows:
where represents a 1 × 1 convolution operation, refers to the sigmoid activation function, represents channel-wise addition, and represents channel-wise multiplication.
The feature maps from both branches are finally concatenated along the channel dimension, and the output of the EVC module can be formulated as
The output is then upsampled and concatenated with the CSP layers, enabling each CSP layer to fully leverage the information from the EVC module. This design effectively enhances the global and discriminative feature representation, ultimately producing the fused feature maps and .
3. Results
3.1. Dataset
We evaluated MPNet on both Cityscapes and Pascal VOC 2012 Augmented datasets to demonstrate its generalization across different scenarios. Cityscapes provides high-resolution urban street scenes with fine-grained annotations for driving-related classes. In contrast, Pascal VOC includes more diverse object categories and natural scenes, posing greater challenges in scale variation and object diversity. This comparison highlights the adaptability of our model across different segmentation contexts.
3.1.1. Cityscapes
The Cityscapes dataset [27] serves as a popular benchmark for semantic segmentation tasks. It consists of high-resolution images with semantic labels collected from 50 German cities, encompassing 19 classes such as roads, pedestrians, vehicles, and buildings. Widely utilized in autonomous driving research, this dataset provides 5000 finely annotated images alongside 19,998 with coarse annotations. Of the finely labeled images, 2975 are designated for training, 500 for validation, and 1525 for testing. In this study, the model’s performance was assessed solely on the validation subset.
3.1.2. Pascal VOC 2012 Augmented
The Pascal VOC 2012 Augmented dataset is a well-established benchmark in image semantic segmentation within computer vision. It integrates the original Pascal VOC 2012 dataset [28] with the SBD dataset [29], covering 21 detailed categories such as people, animals, and household items. The dataset includes 10,582 images for training, 1449 for validation, and 1456 for testing. This augmented dataset offers a rich variety of training examples, making it ideal for assessing the generalization performance of segmentation models.
3.2. Experimental Environment
The experiments were carried out on a Windows Server 2012 R2 system featuring NVIDIA Tesla V100 GPUs and memory configurations of 96 GB and 32 GB. PyTorch version 1.9.1 was used as the deep learning framework. Training employed the Stochastic Gradient Descent (SGD) optimizer with a momentum factor of 0.9.
For the Cityscapes dataset, images were cropped to a resolution of 768 × 768 pixels. Training ran for up to 300 epochs with a batch size of 8 for both training and validation. The starting learning rate was set to 0.1.
Regarding the Pascal VOC 2012 Augmented dataset, images were cropped to 513 × 513 pixels. The model was trained for 300 epochs using a batch size of 16 for both training and validation. The initial learning rate was 0.01.
3.3. Evaluating Indicator
To comprehensively assess model performance, both qualitative and quantitative analyses were carried out. The qualitative assessment involved visual inspection of segmentation outputs, emphasizing the model’s ability to capture fine details such as small-scale objects and precise object contours.
For the quantitative evaluation, we conducted a series of experiments including ablation studies and model comparisons on the Cityscapes dataset, as well as cross-dataset generalization tests using the Pascal VOC 2012 Augmented dataset. Evaluation was based on four key metrics: mean intersection over union (mIoU), mean pixel accuracy (mPA), computational complexity (GFLOPs), and the number of parameters (Param).
Mean intersection over union (mIoU) is a standard metric for semantic segmentation, evaluating the overlap between predicted results and ground truth. It averages the IoU across all classes, providing a measure of overall segmentation accuracy. The computation of mIoU is defined as
where is the count of correctly predicted pixels for a class, refers to pixels wrongly assigned to that class, and represents pixels of the class that were misclassified.
Mean pixel accuracy (mPA) quantifies the average percentage of correctly predicted pixels for each class. It is computed by averaging the pixel accuracy over all categories. The formula for mPA is given as
Floating point operations (FLOPs) measure the computational cost of a model during a single forward pass. They depend on network depth, layer size, and operation types. Higher FLOPs imply greater computational load and longer inference time.
The number of parameters (Param) indicates the total trainable weights in a model. It reflects the model size and affects memory usage and overfitting risk.
3.4. Ablation Experiments
3.4.1. Ablation Study on Cityscapes Dataset
Ablation studies were performed using the Cityscapes dataset, with the outcomes presented in Table 2. The backbone network used was MobileNetV2.
Table 2.
Cityscapes dataset ablation study.
When the PDASPP module was added, the mIoU increased by 2.07% and the mPA increased by 2.32% compared to the baseline model. When the CFP module was introduced, the mIoU improved by 1.79% and the mPA increased by 1.91%. When both modules were incorporated simultaneously, the mIoU increased by 3.01%, reaching a final value of 75.23%, and the mPA increased by 3.31%, achieving a final value of 83.54%.
These results demonstrate that both the PDASPP module and the multi-scale feature fusion method enhance the effectiveness of scene segmentation. The modules effectively select and output more informative features, and their combination further enhances the segmentation capability of the model. These results strongly validate the effectiveness of the proposed enhancements.
3.4.2. Ablation Study on Backbone Network
To evaluate the impact of the backbone network on model performance, this paper conducted ablation experiments on the Cityscapes dataset, and the results are shown in Table 3. In DeepLabV3+, after replacing the backbone from Xception to MobileNetV2, although the mIoU decreased slightly, the model parameters and FLOPs are significantly reduced. Under the MPNet framework, the use of MobileNetV2 not only maintained the lightweight advantage, but also achieved the highest mIoU reaching 75.23% and mPA reaching 83.54%. Although MPNet with the Xception backbone was also better than the original DeepLabV3+, the parameters and computational complexity were further increased. In summary, MobileNetV2 achieved a better balance between accuracy and efficiency, and was more suitable for actual deployment needs.
Table 3.
Backbone network ablation study.
3.4.3. Ablation Study on the Number of Loops in the PDASPP Module
To investigate the effectiveness and practicality of the PDASPP module, we conducted experiments to study the impact of the number of loops on the module’s performance. The experimental results are summarized in Table 4, with MobileNetV2 used as the backbone network.
Table 4.
Number of progressive iteration ablation study.
As shown in Table 4, the mIoU improved significantly with the increase in the number of iterations, indicating that additional loops help enhance the model’s feature representation capability. The highest mIoU is achieved when the Nums is set to 2. However, when the Nums was further increased to 3 and 4, the mIoU began to decline. This phenomenon is attributed to the fact that excessive loops cause redundant sampling points and result in a receptive field that exceeds the effective range of the feature map, ultimately leading to a decrease in segmentation accuracy.
3.5. Comparison Experiments on Different Models
3.5.1. Results on the Cityscapses Dataset
To further validate the rationality and effectiveness of MPNet, we conducted multiple groups of comparative experiments on the Cityscapes dataset. In these experiments, several representative models from the widely used DeepLab series were selected for evaluation. By comparing MPNet against these established baselines, we aimed to demonstrate its competitive performance and advantages in semantic segmentation tasks. The detailed quantitative results of these comparisons are presented in Table 5.
Table 5.
Performance comparison on the Cityscapes datasets with the DeepLab series.
As shown in the table, MPNet demonstrated higher performance compared to the DeepLabV3 model. Compared with DeepLabV3+ using the Xception backbone, MPNet achieved improvements of 2.76% in mIoU and 1.65% in mPA. Compared with DeepLabV3+ using the ResNet-50 backbone, MPNet showed only a minor decrease of 0.63% in mIoU and 0.47% in mPA, while reducing Params to approximately 36% and FLOPs to about 23% of the original model. These results indicate that MPNet significantly reduces computational resource consumption while maintaining high segmentation accuracy. Overall, MPNet effectively improved segmentation performance while controlling model complexity.
To further verify the advantages of MPNet compared to other mainstream semantic segmentation models, additional experiments comparing models were carried out using the Cityscapes dataset. The models selected for comparison include SegNet [10], PSPNet [12], DANet [14], BiSeNetV2 [13], SeaFormer [16], and P2AT-M [17]. The experimental results are summarized in Table 6.
Table 6.
Performance comparison on the Cityscapes datasets with other state-of-the-art models.
The experimental results demonstrate that MPNet achieved a significant improvement over SegNet and PSPNet in both mIoU and mPA, while also greatly reducing Params and FLOPs. Although DANet achieved mIoU and mPA slightly higher than MPNet by 0.25% and 0.19%, respectively, MPNet required 116.18 G fewer FLOPs than DANet, indicating a significant reduction in computational cost. Compared to the lightweight model BiSeNetV2, MPNet achieved improvements of 2.30% in mIoU and 1.56% in mPA while maintaining a similarly compact model size, demonstrating its superior accuracy. In addition, MPNet outperformed SeaFormer by 2.89% in mIoU and 1.87% in mPA, with only a moderate increase in complexity. Compared to the more accurate P2AT-M, MPNet delivered competitive results while reducing parameters by 8.48 M and FLOPs by 29.0 G, showing a better balance between accuracy and efficiency. However, MPNet’s mIoU and mPA were 3.72% and 4.35% lower, respectively, indicating room for improvement in segmentation accuracy, particularly in capturing fine details and small objects. Future work will focus on enhancing the model’s precision without compromising its lightweight design.
The visualization results are shown in Figure 9, where (a–g) corresponds to segmentation outputs under different road conditions. It can be observed that MPNet provides better completeness in road object segmentation compared to DeepLabV3+. For instance, as shown in (a–c), MPNet can accurately segment the complete contours of vehicles. Regarding object boundaries, MPNet achieved more precise segmentation results; for example, as shown in (d,e), the contours of traffic signs and vehicles were segmented more accurately. For smaller or distant objects, MPNet also delivered better segmentation results, as demonstrated in (f,g), where the segmentation of distant vehicles was significantly improved.

Figure 9.
Comparison of the segmentation results on the Cityscapes dataset. The DeepLabV3+ uses MobileNetV2 as the backbone.
3.5.2. Generalization Experiment
To evaluate the generalization ability of the model, we tested MPNet on the BDD100K validation set using weights pretrained on Cityscapes. Both Cityscapes and BDD100K [30] focus on urban scene segmentation and share 19 common semantic categories, which facilitates effective model transfer. We conducted comparative experiments with various models, and the visual segmentation results are shown in Figure 10.

Figure 10.
Generalization experiment with different models on BDD100K datasets.
It can be observed that the segmentation accuracy of all models decreased after switching to a different dataset. This is mainly due to the differences in data collection: Cityscapes was captured in German cities, whereas BDD100K was collected in U.S. cities with more complex and diverse scenes. Despite this, MPNet still demonstrated strong generalization ability and maintained high accuracy in segmenting detailed objects such as utility poles, traffic signs, and curbs, highlighting its robustness in challenging environments.
3.5.3. Results on Pascal VOC 2012 Augmented Dataset
To further assess the effectiveness and cross-dataset generalization of the proposed model, MPNet was evaluated on the PASCAL VOC 2012 Augmented dataset, which features diverse scenes beyond urban street environments. This experiment also demonstrated its general applicability and robustness in practical applications. Comparative experiments were conducted with models from the DeepLab series, and the experimental results are summarized in Table 7.
Table 7.
Performance comparison on the Pascal VOC 2012 Augmented with the DeepLab series.
As shown in Table 7, MPNet exhibited competitive performance in terms of mIoU and mPA on the PASCAL VOC 2012 Augmented dataset. Although DeepLabV3+ with a ResNet-50 backbone achieved slightly higher scores, with 1.67% higher in mIoU and 1.11% higher in mPA, MPNet demonstrated significant advantages in the Params and FLOPs. Overall, MPNet maintained high segmentation accuracy while substantially reducing model complexity, highlighting its strong practicality and efficiency.
To evaluate the effectiveness of MPNet, we compared it with several mainstream semantic segmentation models on the Pascal VOC 2012 Augmented validation set. As shown in Table 8, MPNet achieved strong segmentation performance with only 14.28 million parameters and 32.83 GFLOPs, significantly smaller than models like PSPNet and DANet, yet still reaching 72.70% mIoU and 83.51% mPA, outperforming many lightweight models.
Table 8.
Performance comparison on the Pascal VOC 2012 Augmented with other state-of-the-art models.
Compared to BiSeNetV2, MPNet improved mIoU by 2.8% with a modest increase in model size. It also slightly outperformed SeaFormer in accuracy while maintaining similar efficiency. Though P2AT-M achieved the best mIoU at 79.16%, it required much larger resources. MPNet, by contrast, provided a more practical balance between accuracy and efficiency.
The visualization results on the PASCAL VOC 2012 Augmented dataset are illustrated in Figure 11, where (a–e) represents segmentation outputs under different scenes, and the DeepLabV3+ uses MobileNetV2 as the backbone. In (a), MPNet successfully segmented the entire sofa; in (b), MPNet accurately segmented the outline of a dog; and in (c) and (e), MPNet successfully segmented the legs of a person. In (d), MPNet correctly segmented the cow, while DeepLabV3+ misclassified it into other categories. Although MPNet shows improvements over other methods, it still faces significant challenges in accurately segmenting objects with complex details. However, some segmentation results still require improvement, particularly for objects such as potted plant, bicycle, and dining table.

Figure 11.
Comparison of Pascal VOC 2012 Augmented dataset segmentation results. The DeepLabV3+ uses MobileNetV2 as the backbone.
4. Conclusions
To better address the demand for high-accuracy semantic segmentation in road driving scenarios and similar applications, this study presents MPNet, a novel segmentation framework built upon an enhanced DeepLabV3+ architecture. The standard Xception backbone is substituted with a lightweight MobileNetV2 network, which greatly lowers the computational burden and model size. To overcome the limitations of sparse sampling and insufficient receptive fields in the original ASPP structure, a progressive dilated atrous spatial pyramid pooling (PDASPP) module is introduced, allowing for the network to effectively capture contextual information at multiple scales. In addition, a multi-scale feature fusion design inspired by CFPNet was adopted to aggregate features from low, mid, and high levels of the encoder, thereby improving detail representation and robustness in challenging scenes.
Extensive experiments on the Cityscapes and Pascal VOC 2012 datasets validated that MPNet achieved notable gains in segmentation accuracy, inference speed, and model compactness compared to DeepLabV3+ and other state-of-the-art approaches. In summary, MPNet offers a practical and efficient solution for urban road scene parsing and related applications. Although generalization experiments were conducted, the segmentation accuracy on unseen domains remains suboptimal. Future work will focus on cross-dataset collaborative learning to improve performance in diverse and complex scenarios. In addition, reducing model complexity while further enhancing segmentation accuracy will also be a key direction for future optimization.
Author Contributions
Conceptualization, C.S. and Y.M.; methodology, Y.M.; software, Y.M.; investigation, Y.Z., Z.W. and Q.Q.; resources, C.S.; writing—original draft preparation, Y.M.; writing—review and editing, Y.M.; visualization, Y.M.; supervision, K.H. and X.G.; funding acquisition, C.S. All authors have read and agreed to the published version of the manuscript.
Funding
The National Natural Science Foundation of China (grant no. 61902205) provided financial support for this research, under the direction of project leader Keyong Hu.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
We gratefully acknowledge the insightful suggestions of the anonymous reviewers, which have helped improve the quality of this manuscript.
Conflicts of Interest
The authors affirm that there are no known conflicts of interest related to this work.
References
- Tan, K.; Zhang, Y.; Li, M.; Chen, J. Integrating Advanced Computer Vision and AI Algorithms for Autonomous Driving Systems. J. Theory Pract. Eng. Sci. 2024, 4, 41–48. [Google Scholar]
- Zablocki, É.; Ben-Younes, H.; Pérez, P.; Cord, M. Explainability of deep vision-based autonomous driving systems: Review and challenges. Int. J. Comput. Vis. 2022, 130, 2425–2452. [Google Scholar] [CrossRef]
- Rajasekaran, U.; Malini, A.; Murugan, M. Artificial Intelligence in Autonomous Vehicles—A Survey of Trends and Challenges. Artif. Intell. Auton. Veh. 2024, 1, 1–24. [Google Scholar]
- Gupta, A.; Anpalagan, A.; Guan, L.; Khwaja, A.S. Deep learning for object detection and scene perception in self-driving cars: Survey, challenges, and open issues. Array 2021, 10, 100057. [Google Scholar] [CrossRef]
- Zhao, J.; Zhao, W.; Deng, B.; Wang, Z.; Zhang, F.; Zheng, W.; Cao, W.; Nan, J.; Lian, Y.; Burke, A.F. Autonomous driving system: A comprehensive survey. Expert Syst. Appl. 2024, 242, 122836. [Google Scholar] [CrossRef]
- Chao, Q.; Bi, H.; Li, W.; Mao, T.; Wang, Z.; Lin, M.C.; Deng, Z. A survey on visual traffic simulation: Models, evaluations, and applications in autonomous driving. Comput. Graph. Forum 2020, 39, 287–308. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Jung, J.; Kim, S.; Lee, D.; Park, H. An Energy-Efficient, Unified CNN Accelerator for Real-Time Multi-Object Semantic Segmentation for Autonomous Vehicle. IEEE Trans. Circuits Syst. I Regul. Pap. 2024, 71, 2093–2104. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; MICCAI 2015. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiseNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 173–190. [Google Scholar]
- Wan, Q.; Li, X.; Zhang, Y.; Chen, W. Seaformer: Squeeze-Enhanced Axial Transformer for Mobile Semantic Segmentation. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Elhassan, M.A.; Ahmed, S.; Mohamed, T.; Ali, H. P2AT: Pyramid Pooling Axial Transformer for Real-Time Semantic Segmentation. Expert Syst. Appl. 2024, 255, 124610. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized feature pyramid for object detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [CrossRef] [PubMed]
- Howard, A.G. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Schiele, B. The Cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) 2011, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2636–2645. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).