
GazeHand2: A Gaze-Driven Virtual Hand Interface with Improved Gaze Depth Control for Distant Object Interaction






Abstract
1. Introduction
1.1. Interfaces Using Gaze or Hand
1.1.1. Hand-Only Interface
1.1.2. Gaze-Only Interface
1.2. Interfaces Using Both Gaze and Hand
1.2.1. Gaze+Screen Touch Interface
1.2.2. Gaze+Hand Gesture Interface for Object Selection
1.2.3. Gaze+Hand Gesture Interface for Object Selection and Manipulation
1.3. Distance Control for Object Interaction in VR
1.4. Contribution
- We proposed the extension of the GazeHand interface, named GazeHand2, that supports hand-based free selection, rotation, and quick translation in all directions.
- We compared and evaluated the interface with two popular interaction methods that combine both gaze and hand inputs.
- We suggested implications and future directions for GazeHand2.
2. Materials and Methods
2.1. System Design
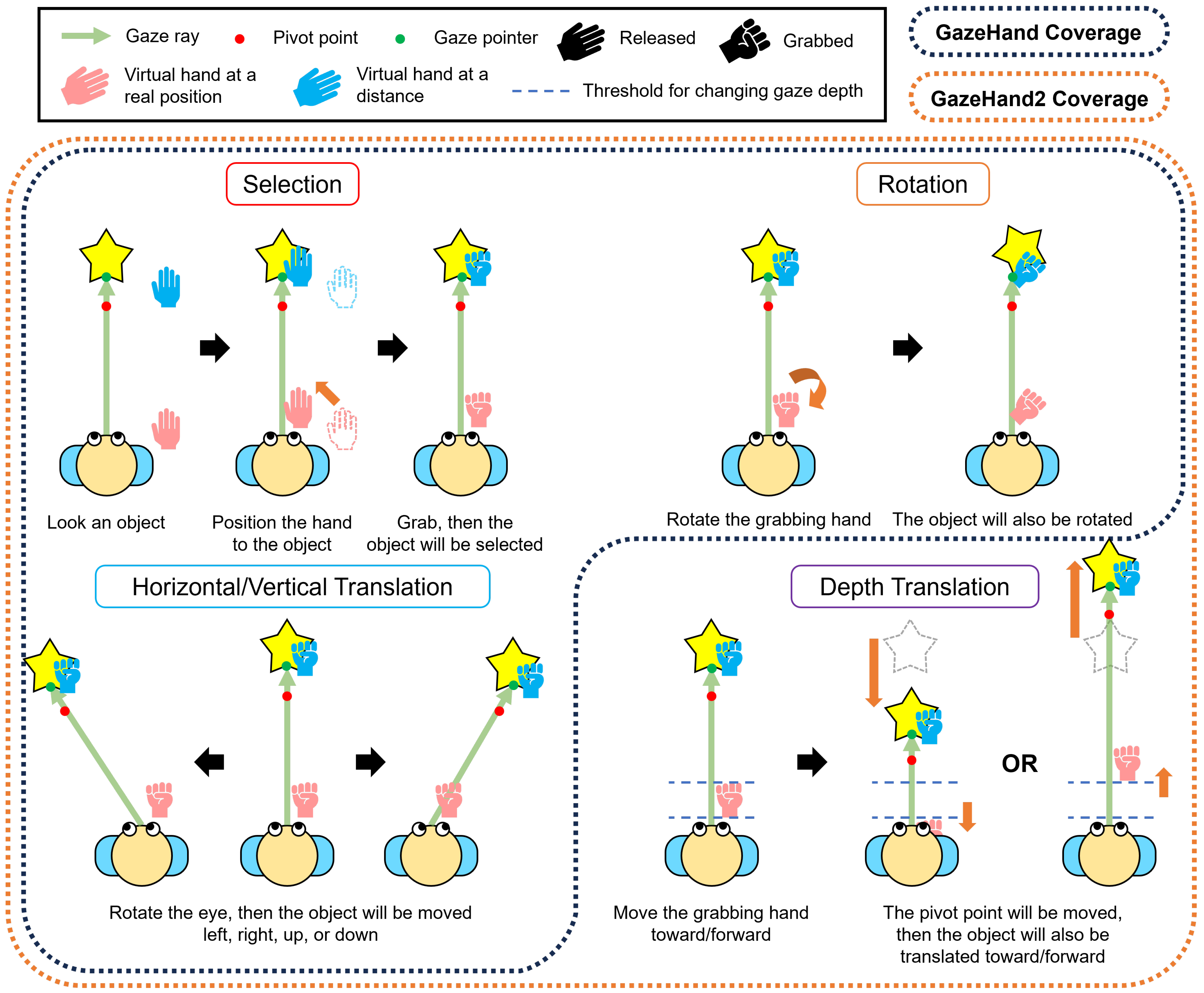
2.1.1. GazeHand
2.1.2. GazeHand2
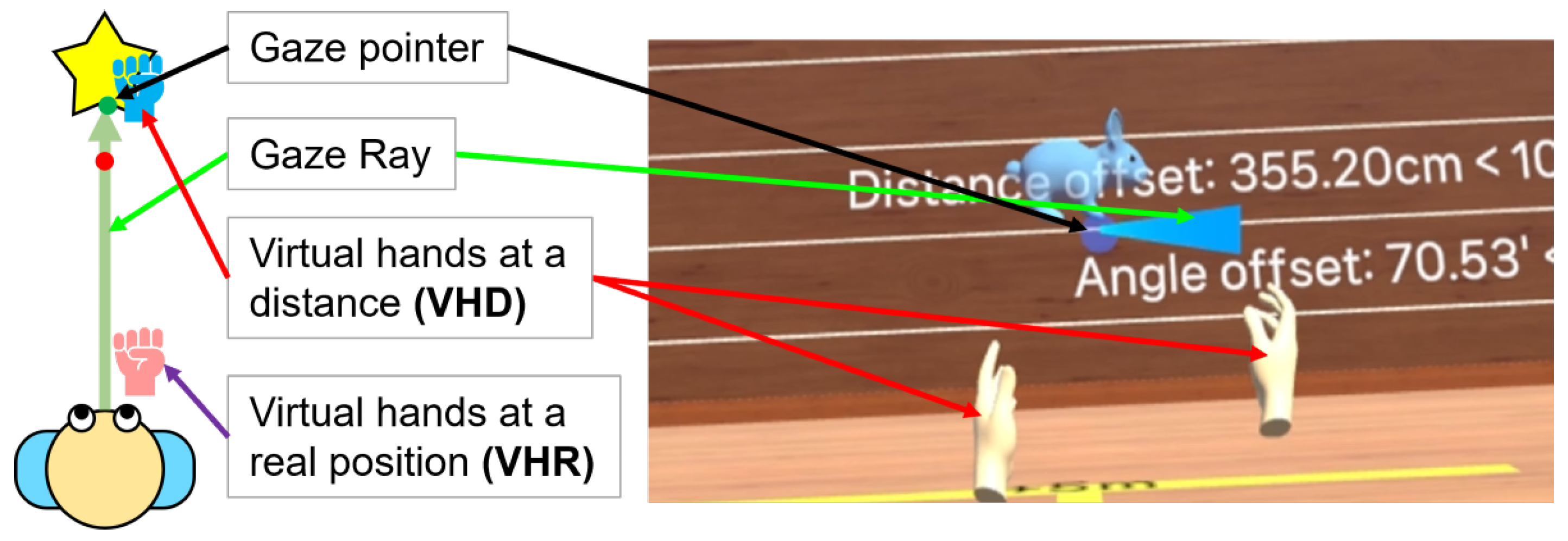
2.2. Implementation
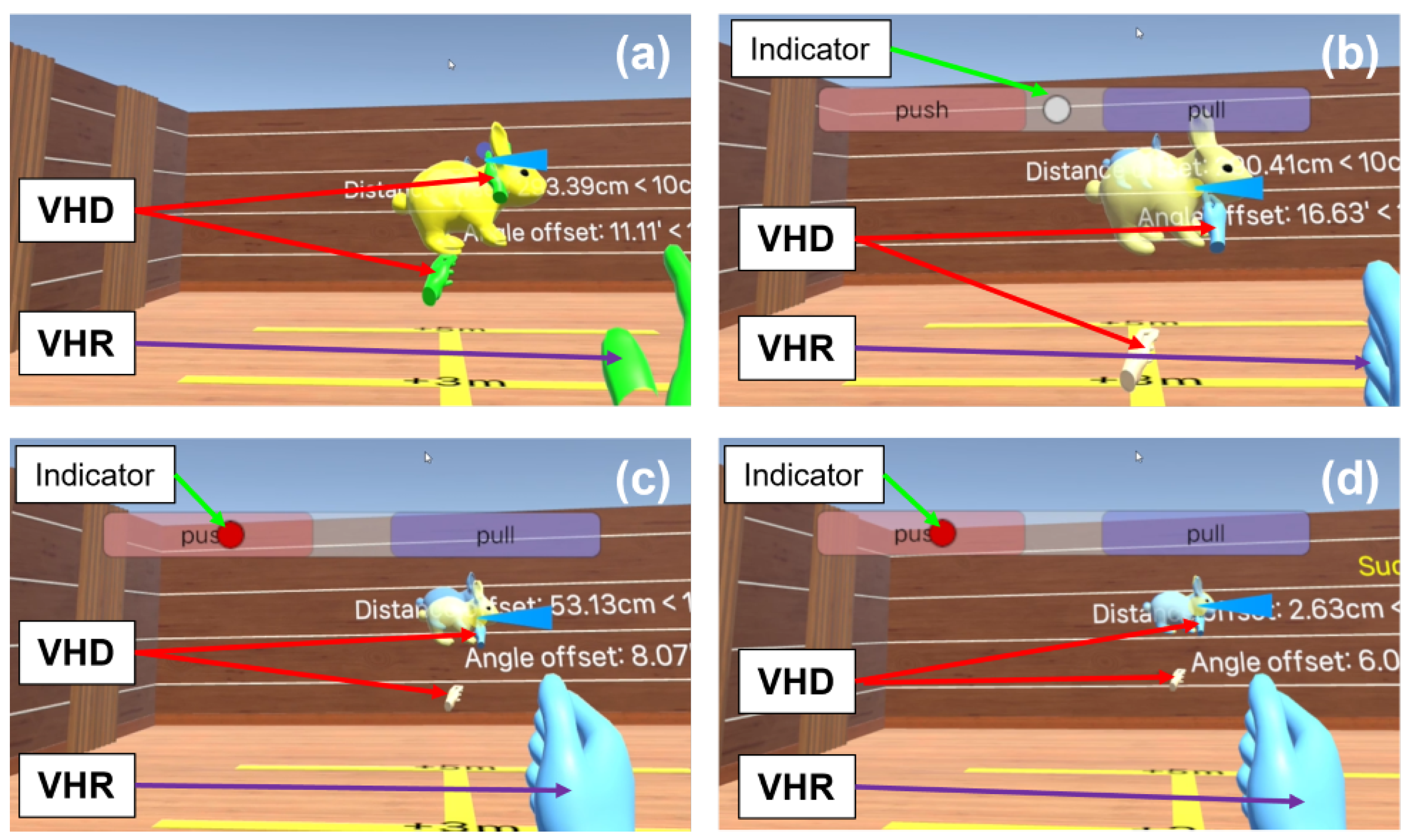
2.3. User Study Design
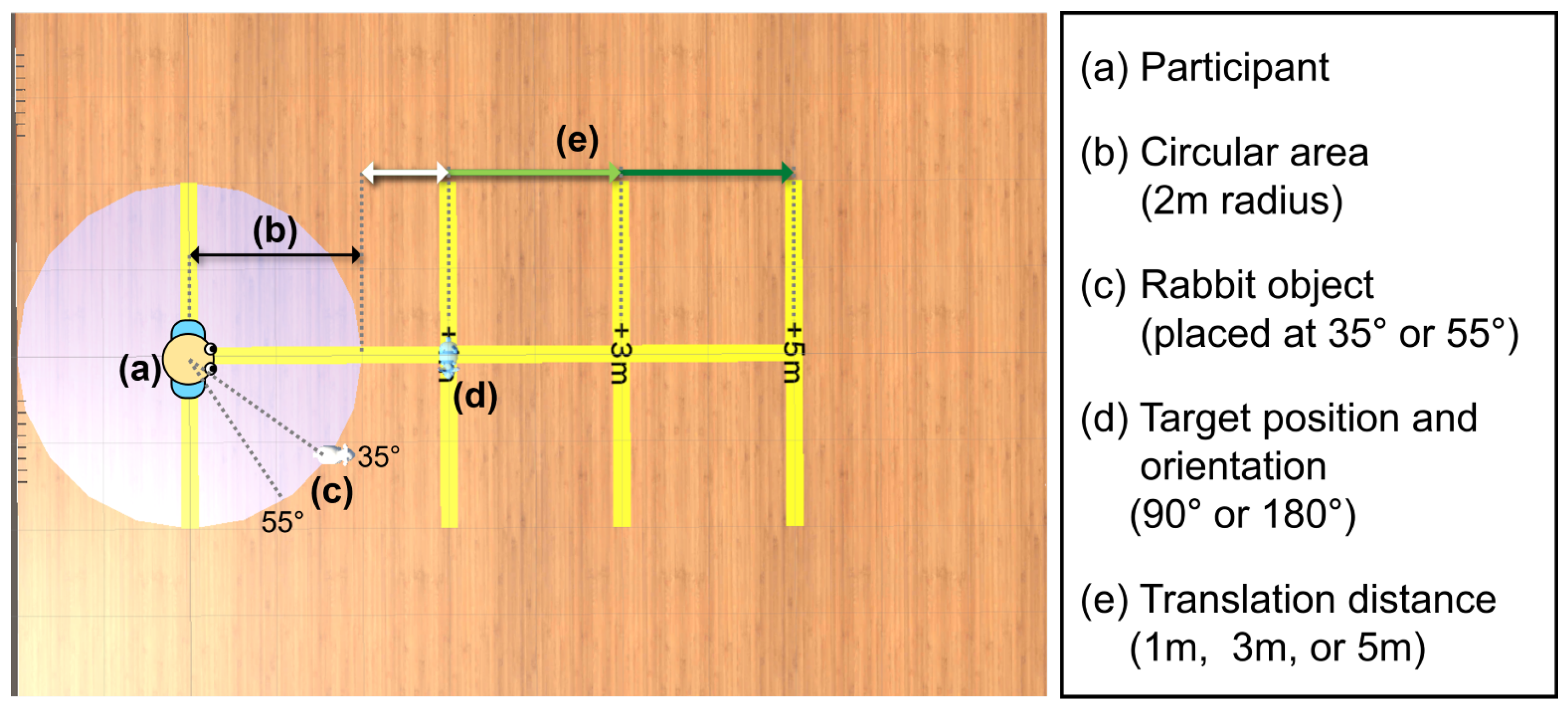
2.4. Environment and Task
2.5. Participants
2.6. Interfaces
2.6.1. Gaze+Pinch (GP)
2.6.2. ImplicitGaze (IG)
2.7. Procedure and Data Collection
- Task Completion Time (in s) for overall task performance. For further analysis, we split the Task Completion Time into two subscales: Coarse Translation Time and Reposition Time.
- Coarse Translation Time (in s) [7], which is related to the ease of manipulating an object to the approximate pose, as this time was counted until the object is approximately matched to the semi-transparent target. The coarse threshold was set to a 20 cm distance with an angle of 20°, which is twice the primary threshold.
- Reposition Time (in s), which indicates the ease of precise object manipulation (=Task Completion Time − Coarse Translation Time).
- Hand Movement (in m) and Head Movement (in °) represent the physical activity related to participants’ physical fatigue to complete the task. These values were accumulated from every frame of the system.
- Object Selection Count represents the number of attempts to select the rabbit object that the user needs to finish manipulation. It is related to the efficiency of object manipulation.
2.8. Data Analysis
2.8.1. Analysis on Quantitative and Subjective Data
2.8.2. Analysis on Participants’ Feedback
3. Results
3.1. Quantitative Data
- GH2 required less Coarse Translation Time than other interfaces under 1 m and 3 m tasks.
- GH2 required fewer Object Selection Count than other interfaces under 3 m and 5 m tasks.
- GH2 produced less Hand and Head Movement than other interfaces under 3 m and 5 m tasks.
3.1.1. Task Completion Time
3.1.2. Coarse Translation Time and Reposition Time
3.1.3. Physical Movement
3.1.4. Object Selection Count
3.2. Subjective Data
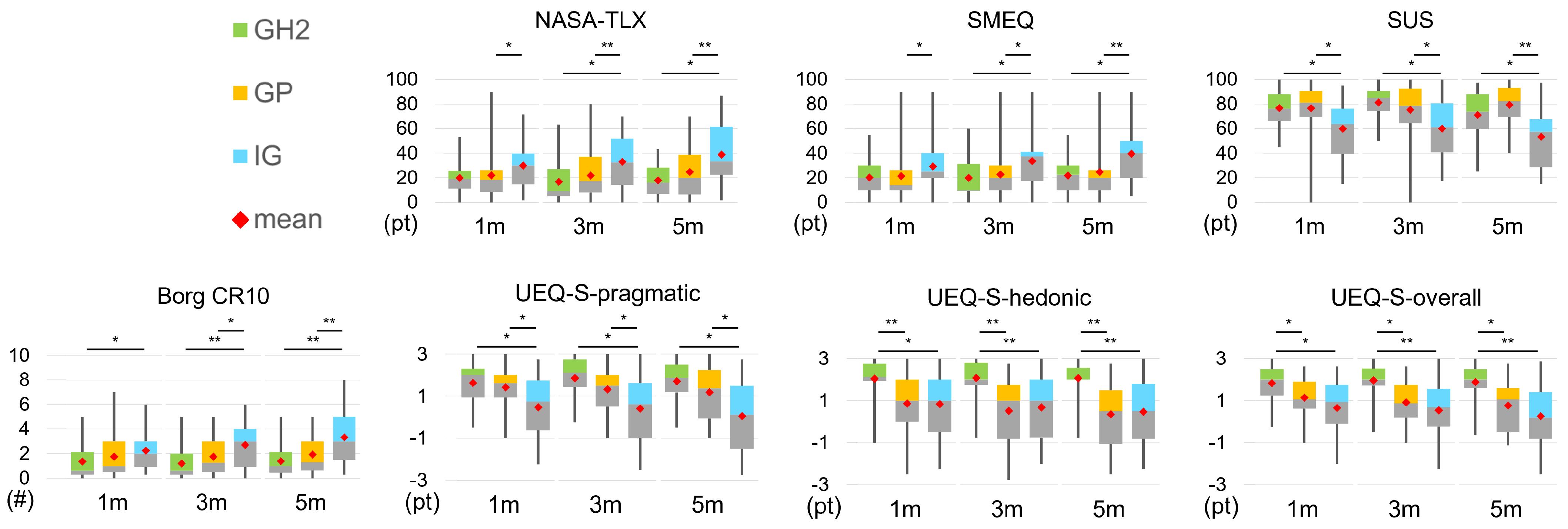
- GH2 supported higher hedonic experiences and overall experiences compared to other interfaces.
- GH2 showed a higher usability score and lower arm fatigue compared to IG.
- GH2 required lower task and mental load compared to IG under 3 m and 5 m tasks.
3.2.1. NASA-TLX (Overall Task Load)
3.2.2. SMEQ (Mental Load)
3.2.3. SUS (Usability)
3.2.4. Borg CR10 (Arm Fatigue)
3.2.5. UEQ-S (User Experience)
3.2.6. Preferences
3.3. Observation
3.4. Participants’ Feedback
4. Discussion
4.1. Overall Performance of GH2
4.2. User Experience on GH2
4.3. Comparing GH2 with GP: Direct Object Rotation with Virtual Hand
4.4. Comparing GH2 with IG: The Effect of Safe Region on Precise Manipulation
4.5. Comparing GH2 with the Original GazeHand
4.6. Design Improvement
4.7. Findings and Limitations
- Task Completion Time from IG depends on the distance.
- Both GH2 and GP achieved above-average SUS scores for distant object interaction.
- GH2 produced less physical movement than both GP and IG in most cases.
- GH2 produced a higher hedonic experience than both GP and IG.
- IG’s safe region may reduce the reposition time compared to GH2.
- Using a gaze pointer is recommended for better distant object selection.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- LaViola, J.J., Jr.; Kruijff, E.; McMahan, R.P.; Bowman, D.; Poupyrev, I.P. 3D User Interfaces: Theory and Practice; Addison-Wesley Professional: Boston, MA, USA, 2017. [Google Scholar]
- Mendes, D.; Caputo, F.M.; Giachetti, A.; Ferreira, A.; Jorge, J. A survey on 3D virtual object manipulation: From the desktop to immersive virtual environments. Comput. Graph. Forum 2019, 38, 21–45. [Google Scholar] [CrossRef]
- Hertel, J.; Karaosmanoglu, S.; Schmidt, S.; Bräker, J.; Semmann, M.; Steinicke, F. A Taxonomy of Interaction Techniques for Immersive Augmented Reality based on an Iterative Literature Review. In Proceedings of the 2021 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Bari, Italy, 4–8 October 2021; pp. 431–440. [Google Scholar] [CrossRef]
- Yu, D.; Dingler, T.; Velloso, E.; Goncalves, J. Object Selection and Manipulation in VR Headsets: Research Challenges, Solutions, and Success Measurements. ACM Comput. Surv. 2024, 57, 1–34. [Google Scholar] [CrossRef]
- Bowman, D.A.; Hodges, L.F. An evaluation of techniques for grabbing and manipulating remote objects in immersive virtual environments. In Proceedings of the 1997 Symposium on Interactive 3D Graphics, Providence, RI, USA, 27–30 April 1997; I3D ’97. pp. 35–38. [Google Scholar] [CrossRef]
- Pfeuffer, K.; Mayer, B.; Mardanbegi, D.; Gellersen, H. Gaze + pinch interaction in virtual reality. In Proceedings of the 5th Symposium on Spatial User Interaction, Brighton, UK, 16–17 October 2017; SUI ’17. pp. 99–108. [Google Scholar] [CrossRef]
- Yu, D.; Lu, X.; Shi, R.; Liang, H.N.; Dingler, T.; Velloso, E.; Goncalves, J. Gaze-supported 3D object manipulation in virtual reality. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. CHI ’21. [Google Scholar] [CrossRef]
- Poupyrev, I.; Billinghurst, M.; Weghorst, S.; Ichikawa, T. The go-go interaction technique: Non-linear mapping for direct manipulation in VR. In Proceedings of the 9th Annual ACM Symposium on User Interface Software and Technology, Seattle, WA, USA, 6–8 November 1996; UIST ’96. pp. 79–80. [Google Scholar] [CrossRef]
- Khamis, M.; Oechsner, C.; Alt, F.; Bulling, A. VRpursuits: Interaction in virtual reality using smooth pursuit eye movements. In Proceedings of the 2018 International Conference on Advanced Visual Interfaces, Castiglione della Pescaia, Grosseto, Italy, 29 May–1 June 2018. AVI ’18. [Google Scholar] [CrossRef]
- Liu, C.; Plopski, A.; Orlosky, J. OrthoGaze: Gaze-based three-dimensional object manipulation using orthogonal planes. Comput. Graph. 2020, 89, 1–10. [Google Scholar] [CrossRef]
- Bao, Y.; Wang, J.; Wang, Z.; Lu, F. Exploring 3D interaction with gaze guidance in augmented reality. In Proceedings of the 2023 IEEE Conference Virtual Reality and 3D User Interfaces (VR), Shanghai, China, 25–29 March 2023; pp. 22–32. [Google Scholar] [CrossRef]
- Ryu, K.; Lee, J.J.; Park, J.M. GG Interaction: A gaze–grasp pose interaction for 3D virtual object selection. J. Multimodal User Interfaces 2019, 13, 383–393. [Google Scholar] [CrossRef]
- Rothe, S.; Pothmann, P.; Drewe, H.; Hussmann, H. Interaction Techniques for Cinematic Virtual Reality. In Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, 23–27 March 2019; pp. 1733–1737. [Google Scholar] [CrossRef]
- Wither, J.; Hollerer, T. Evaluating techniques for interaction at a distance. In Proceedings of the Eighth International Symposium on Wearable Computers, Arlington, VA, USA, 31 October–3 November 2004; Volume 1, pp. 124–127. [Google Scholar] [CrossRef]
- Poupyrev, I.; Ichikawa, T.; Weghorst, S.; Billinghurst, M. Egocentric object manipulation in virtual environments: Empirical evaluation of interaction techniques. Comput. Graph. Forum 1998, 17, 41–52. [Google Scholar] [CrossRef]
- Bowman, D.A.; McMahan, R.P.; Ragan, E.D. Questioning naturalism in 3D user interfaces. Commun. ACM 2012, 55, 78–88. [Google Scholar] [CrossRef]
- Boletsis, C. The new era of virtual reality locomotion: A systematic literature review of techniques and a proposed typology. Multimodal Technol. Interact. 2017, 1, 24. [Google Scholar] [CrossRef]
- Stoakley, R.; Conway, M.J.; Pausch, R. Virtual reality on a WIM: Interactive worlds in miniature. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 7–11 May 1995; CHI ’95. pp. 265–272. [Google Scholar] [CrossRef]
- Wentzel, J.; d’Eon, G.; Vogel, D. Improving virtual reality ergonomics through reach-bounded non-linear input amplification. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; CHI ’20. pp. 1–12. [Google Scholar] [CrossRef]
- Mine, M.R. Virtual Environment Interaction Techniques; Technical Report; University of North Carolina: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Wilkes, C.; Bowman, D.A. Advantages of velocity-based scaling for distant 3D manipulation. In Proceedings of the 2008 ACM Symposium on Virtual Reality Software and Technology, Bordeaux, France, 27–29 October 2008; VRST ’08. pp. 23–29. [Google Scholar] [CrossRef]
- Schjerlund, J.; Hornbæk, K.; Bergström, J. Ninja hands: Using many hands to improve target selection in VR. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. CHI ’21. [Google Scholar] [CrossRef]
- Jang, S.; Stuerzlinger, W.; Ambike, S.; Ramani, K. Modeling cumulative arm fatigue in mid-air interaction based on perceived exertion and kinetics of arm motion. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; CHI ’17. pp. 3328–3339. [Google Scholar] [CrossRef]
- Ware, C.; Mikaelian, H.H. An evaluation of an eye tracker as a device for computer input. In Proceedings of the SIGCHI/GI Conference on Human Factors in Computing Systems and Graphics Interface, Toronto, ON, Canada, 5–9 April 1987; CHI ’87. pp. 183–188. [Google Scholar] [CrossRef]
- Sibert, L.E.; Jacob, R.J.K. Evaluation of eye gaze interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, The Hague, The Netherlands, 1–6 April 2000; CHI ’00. pp. 281–288. [Google Scholar] [CrossRef]
- Tanriverdi, V.; Jacob, R.J.K. Interacting with eye movements in virtual environments. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, The Hague, The Netherlands, 1–6 April 2000; CHI ’00. pp. 265–272. [Google Scholar] [CrossRef]
- Pfeuffer, K.; Alexander, J.; Chong, M.K.; Gellersen, H. Gaze-touch: Combining gaze with multi-touch for interaction on the same surface. In Proceedings of the 27th Annual ACM Symposium on User Interface Software and Technology, Honolulu, HI, USA, 1–6 April 2014; UIST ’14. pp. 509–518. [Google Scholar] [CrossRef]
- Jacob, R.J.K. What you look at is what you get: Eye movement-based interaction techniques. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Seattle, WA, USA, 1–5 April 1990; CHI ’90. pp. 11–18. [Google Scholar] [CrossRef]
- Mohan, P.; Goh, W.B.; Fu, C.W.; Yeung, S.K. DualGaze: Addressing the midas touch problem in gaze mediated VR interaction. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Munich, Germany, 16–20 October 2018; pp. 79–84. [Google Scholar] [CrossRef]
- Bowman, D.A.; Johnson, D.B.; Hodges, L.F. Testbed evaluation of virtual environment interaction techniques. In Proceedings of the ACM Symposium on Virtual Reality Software and Technology, London, UK, 20–22 December 1999; VRST ’99. pp. 26–33. [Google Scholar] [CrossRef]
- Hansen, J.; Johansen, A.; Hansen, D.; Itoh, K.; Mashino, S. Command without a click: Dwell time typing by mouse and gaze selections. In Proceedings of the 10th International Conference on Human–Computer Interaction, HCI International 2003, Crete, Greece, 22–27 June 2003; pp. 121–128. [Google Scholar]
- Lystbæk, M.N.; Rosenberg, P.; Pfeuffer, K.; Grønbæk, J.E.; Gellersen, H. Gaze-hand alignment: Combining eye gaze and mid-air pointing for interacting with menus in augmented reality. Proc. ACM Hum.-Comput. Interact. 2022, 6, 1–18. [Google Scholar] [CrossRef]
- Steed, A. Towards a general model for selection in virtual environments. In Proceedings of the 3D User Interfaces (3DUI’06), Alexandria, VA, USA, 25–26 March 2006; pp. 103–110. [Google Scholar] [CrossRef]
- Vidal, M.; Bulling, A.; Gellersen, H. Pursuits: Spontaneous interaction with displays based on smooth pursuit eye movement and moving targets. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; UbiComp ’13. pp. 439–448. [Google Scholar] [CrossRef]
- Chatterjee, I.; Xiao, R.; Harrison, C. Gaze+Gesture: Expressive, precise and targeted free-space interactions. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; ICMI ’15. pp. 131–138. [Google Scholar] [CrossRef]
- Grauman, K.; Betke, M.; Lombardi, J.; Gips, J.; Bradski, G.R. Communication via eye blinks and eyebrow raises: Video-based human–computer interfaces. Univers. Access Inf. Soc. 2003, 2, 359–373. [Google Scholar] [CrossRef]
- Lu, X.; Yu, D.; Liang, H.N.; Xu, W.; Chen, Y.; Li, X.; Hasan, K. Exploration of hands-free text entry techniques For virtual reality. In Proceedings of the 2020 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Porto de Galinhas, Brazil, 9–13 November 2020; pp. 344–349. [Google Scholar] [CrossRef]
- Lu, F.; Davari, S.; Bowman, D. Exploration of techniques for rapid activation of glanceable information in head-worn augmented reality. In Proceedings of the 2021 ACM Symposium on Spatial User Interaction, Virtual Event, USA, 9–10 November 2021. SUI ’21. [Google Scholar] [CrossRef]
- Shi, R.; Wei, Y.; Qin, X.; Hui, P.; Liang, H.N. Exploring gaze-assisted and hand-based region selection in augmented reality. Proc. ACM Hum.-Comput. Interact. 2023, 7, 160. [Google Scholar] [CrossRef]
- Zhai, S.; Morimoto, C.; Ihde, S. Manual and gaze input cascaded (MAGIC) pointing. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Pittsburgh, PA, USA, 15–20 May 1999; CHI ’99. pp. 246–253. [Google Scholar] [CrossRef]
- Kytö, M.; Ens, B.; Piumsomboon, T.; Lee, G.A.; Billinghurst, M. Pinpointing: Precise head- and eye-based target selection for augmented reality. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; CHI ’18. pp. 1–14. [Google Scholar] [CrossRef]
- Pfeuffer, K.; Mecke, L.; Delgado Rodriguez, S.; Hassib, M.; Maier, H.; Alt, F. Empirical evaluation of gaze-enhanced menus in virtual reality. In Proceedings of the 26th ACM Symposium on Virtual Reality Software and Technology, Virtual Event, Canada, 1–4 November 2020. VRST ’20. [Google Scholar] [CrossRef]
- Pfeuffer, K.; Alexander, J.; Chong, M.K.; Zhang, Y.; Gellersen, H. Gaze-shifting: Direct-indirect input with pen and touch modulated by gaze. In Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology, Charlotte, NC, USA, 11–15 November 2015; UIST ’15. pp. 373–383. [Google Scholar] [CrossRef]
- Stellmach, S.; Dachselt, R. Still looking: Investigating seamless gaze-supported selection, positioning, and manipulation of distant targets. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; CHI ’13. pp. 285–294. [Google Scholar] [CrossRef]
- Turner, J.; Bulling, A.; Alexander, J.; Gellersen, H. Cross-device gaze-supported point-to-point content transfer. In Proceedings of the Symposium on Eye Tracking Research and Applications, Safety Harbor, FL, USA, 26–28 March 2014; ETRA ’14. pp. 19–26. [Google Scholar] [CrossRef]
- Turner, J.; Alexander, J.; Bulling, A.; Gellersen, H. Gaze+RST: Integrating gaze and multitouch for remote rotate-scale-translate tasks. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; CHI ’15. pp. 4179–4188. [Google Scholar] [CrossRef]
- Simeone, A.L.; Bulling, A.; Alexander, J.; Gellersen, H. Three-point interaction: Combining bi-manual direct touch with gaze. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Bari, Italy, 7–10 June 2016; AVI ’16. pp. 168–175. [Google Scholar] [CrossRef]
- Lystbæk, M.N.; Pfeuffer, K.; Grønbæk, J.E.S.; Gellersen, H. Exploring gaze for assisting freehand selection-based text entry in AR. Proc. ACM Hum.-Comput. Interact. 2022, 6, 1–16. [Google Scholar] [CrossRef]
- Reiter, K.; Pfeuffer, K.; Esteves, A.; Mittermeier, T.; Alt, F. Look & turn: One-handed and expressive menu interaction by gaze and arm turns in VR. In Proceedings of the 2022 Symposium on Eye Tracking Research and Applications, Seattle, WA, USA, 8–11 June 2022. ETRA ’22. [Google Scholar] [CrossRef]
- Sidenmark, L.; Gellersen, H. Eye&Head: Synergetic eye and head movement for gaze pointing and selection. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology, New Orleans, LA, USA, 20–23 October 2019; UIST ’19. pp. 1161–1174. [Google Scholar] [CrossRef]
- Wagner, U.; Lystbæk, M.N.; Manakhov, P.; Grønbæk, J.E.S.; Pfeuffer, K.; Gellersen, H. A fitts’ law study of gaze-hand alignment for selection in 3D user interfaces. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023. CHI ’23. [Google Scholar] [CrossRef]
- Jeong, J.; Kim, S.H.; Yang, H.J.; Lee, G.A.; Kim, S. GazeHand: A gaze-driven virtual hand interface. IEEE Access 2023, 11, 133703–133716. [Google Scholar] [CrossRef]
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (task load index): Results of empirical and theoretical research. Adv. Psychol. 1988, 52, 139–183. [Google Scholar] [CrossRef]
- Hart, S.G. Nasa-task load index (NASA-TLX); 20 years later. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2006, 50, 904–908. [Google Scholar] [CrossRef]
- Brooke, J. SUS-A quick and dirty usability scale. Usability Eval. Ind. 1996, 189, 4–7. [Google Scholar] [CrossRef]
- Gao, M.; Kortum, P.; Oswald, F.L. Multi-language toolkit for the system usability scale. Int. J. -Hum.-Comput. Interact. 2020, 36, 1883–1901. [Google Scholar] [CrossRef]
- Zijlstra, F.R.H. Efficiency in Work Behaviour: A Design Approach for Modern Tools. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 1995. [Google Scholar]
- Zijlstra, F.R.H.; Van Doorn, L. The Construction of a Scale to Measure Subjective Effort; Technical Report; Department of Philosophy and Social Sciences, Delft University of Technology: Delft, The Netherlands, 1985; Volume 43, pp. 124–139. [Google Scholar]
- Borg, G. Borg’s Perceived Exertion and Pain Scales; Human Kinetics: Champaign, IL, USA, 1998. [Google Scholar]
- Laugwitz, B.; Held, T.; Schrepp, M. Construction and evaluation of a user experience questionnaire. In Proceedings of the HCI and Usability for Education and Work; Holzinger, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 63–76. [Google Scholar]
- Schrepp, M.; Thomaschewski, J.; Hinderks, A. Design and evaluation of a short version of the user experience questionnaire (UEQ-S). Int. J. Interact. Multimed. Artif. Intell. 2017, 4, 103–108. [Google Scholar] [CrossRef]
- Wobbrock, J.O.; Findlater, L.; Gergle, D.; Higgins, J.J. The aligned rank transform for nonparametric factorial analyses using only anova procedures. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; CHI ’11. pp. 143–146. [Google Scholar] [CrossRef]
- Kim, S.; Lee, G.; Sakata, N.; Billinghurst, M. Improving co-presence with augmented visual communication cues for sharing experience through video conference. In Proceedings of the 2014 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 10–12 September 2014; pp. 83–92. [Google Scholar] [CrossRef]
- Braun, V.; Clarke, V. Using thematic analysis in psychology. Qual. Res. Psychol. 2006, 3, 77–101. [Google Scholar] [CrossRef]
- Steenstra, I.; Nouraei, F.; Bickmore, T. Scaffolding Empathy: Training Counselors with Simulated Patients and Utterance-level Performance Visualizations. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 26 April–1 May 2025. CHI ’25. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, S.; Wang, Y.; Han, H.Z.; Liu, X.; Yi, X.; Tong, X.; Li, H. Raise Your Eyebrows Higher: Facilitating Emotional Communication in Social Virtual Reality Through Region-Specific Facial Expression Exaggeration. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 26 April–1 May 2025. CHI ’25. [Google Scholar] [CrossRef]
- Mueller, A. Amueller/Wordcloud. Available online: https://github.com/amueller/word_cloud (accessed on 12 June 2025).
- Python. Python Programming Language. Available online: https://www.python.org/ (accessed on 12 June 2025).
- Kang, S.; Jeong, J.; Lee, G.A.; Kim, S.H.; Yang, H.J.; Kim, S. The rayhand navigation: A virtual navigation method with relative position between hand and gaze-ray. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024. CHI ’24. [Google Scholar] [CrossRef]
- Lewis, J.R.; Sauro, J. Item benchmarks for the system usability scale. J. Usability Stud. 2018, 13, 158–167. [Google Scholar]
- Feit, A.M.; Williams, S.; Toledo, A.; Paradiso, A.; Kulkarni, H.; Kane, S.; Morris, M.R. Toward everyday gaze input: Accuracy and precision of eye tracking and implications for design. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; CHI ’17. pp. 1118–1130. [Google Scholar] [CrossRef]
- Chaffangeon Caillet, A.; Goguey, A.; Nigay, L. 3D selection in mixed reality: Designing a two-phase technique to reduce fatigue. In Proceedings of the 2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Sydney, Australia, 16–20 October 2023; pp. 800–809. [Google Scholar] [CrossRef]
- Pierce, J.S.; Forsberg, A.S.; Conway, M.J.; Hong, S.; Zeleznik, R.C.; Mine, M.R. Image plane interaction techniques in 3D immersive environments. In Proceedings of the 1997 Symposium on Interactive 3D Graphics, Providence, RI, USA, 27–30 April 1997; I3D ’97. pp. 39–43. [Google Scholar] [CrossRef]
- Kim, H.; Kim, Y.; Lee, J.; Kim, J. Stereoscopic objects affect reaching performance in virtual reality environments: Influence of age on motor control. Front. Virtual Real. 2024, 5, 1475482. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GazeHand2 | Gaze+Pinch [6] | ImplicitGaze [7] | |
|---|---|---|---|
| Approaching | Eye + hand | Eye | Eye |
| Pointing | Virtual hands following eye gaze | Eye–gaze ray | Hidden eye gaze pointer |
| Selection trigger | Hand grab or pinch gesture | Hand pinch gesture | Trigger button on a controller |
| Modalities | Gaze and hand | Gaze and Hand | Gaze and Controller |
| Interaction metaphor | Virtual hand | Virtual Hand | Controller |
| Gesture type | Motion (hand movement) + Symbolic (grab or pinch) | Symbolic (pinch) | Symbolic (button) |
| Selection space | 3D | 3D | 3D |
| Object rotation | Free rotation | One main axis | Free rotation |
| Gaze depth control | Moving a hand forward or backward | Hand amplification [5,8,19] | None (In this study, hand amplification is applied) |
| Measurements | Pairwise Results |
|---|---|
| Task completion time ↓ | GH2 < IG under 3 m |
| Coarse translation time ↓ | GH2 < GP under 3 m and 5 m; GH2 < IG under all distances |
| Reposition time ↓ | No better results |
| Object selection count ↓ | GH2 < GP under all distances; GH2 < IG under 3 m and 5 m |
| Hand movement ↓ | GH2 < GP under all distances; GH2 < IG under 3 m and 5 m |
| Head movement ↓ | GH2 < GP under all distances; GH2 < IG under 3 m and 5 m |
| Measurements | Pairwise Results |
|---|---|
| Task load ↓ | GH2 < IG under 3 m and 5 m |
| Mental load ↓ | GH2 < IG under 3 m and 5 m |
| Arm fatigue ↓ | GH2 < IG under all distances |
| Usability ↑ | GH2 > IG under all distances |
| Pragmatic experience ↑ | GH2 > IG under all distances |
| Hedonic experience ↑ | GH2 > (GP and IG) under all distances |
| Overall user experience ↑ | GH2 > (GP and IG) under all distances |
| Distance | Ranking | GH2 | GP | IG |
|---|---|---|---|---|
| 1st | 15 | 6 | 3 | |
| 1 m | 2nd | 5 | 14 | 5 |
| 3rd | 4 | 4 | 16 | |
| 1st | 13 | 10 | 1 | |
| 3 m | 2nd | 7 | 11 | 6 |
| 3rd | 4 | 3 | 17 | |
| 1st | 14 | 9 | 1 | |
| 5 m | 2nd | 7 | 11 | 6 |
| 3rd | 3 | 4 | 17 |
| Category | GH2 | GP | IG |
|---|---|---|---|
| Positive | Convenient and Efficient Translation (9); Hand-based Immersive & Realistic Interaction (6) | Precise Control based on Object Fixation (5); Simple Interaction Method (4) | Precise Control based on Hand Rotation (3); Effective Left–Right Translation with Gaze (2) |
| Neutral | Simultaneous Rotation and Translation (3) 1; Quality of Eye Tracking (2) 2 | Quality of Eye Tracking (4) 2 | Quality of Eye Tracking (2) 2 |
| Negative | Requiring Practice to Rotate Objects Fluently (4); Less Precise Translation with Distant Objects (4) | Arm Fatigue with Distant Objects (6); Unnatural Rotation Method (4); No Realism on Object Manipulation (4) | A Lack of Gaze Pointer with No Feedback (7); Overall Complexity and Learning Difficulty (4); Unnatural Interaction Method (4); Physical Fatigue over Longer Distances(4) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, J.; Kim, S.-H.; Yang, H.-J.; Lee, G.; Kim, S. GazeHand2: A Gaze-Driven Virtual Hand Interface with Improved Gaze Depth Control for Distant Object Interaction. Electronics 2025, 14, 2530. https://doi.org/10.3390/electronics14132530
Jeong J, Kim S-H, Yang H-J, Lee G, Kim S. GazeHand2: A Gaze-Driven Virtual Hand Interface with Improved Gaze Depth Control for Distant Object Interaction. Electronics. 2025; 14(13):2530. https://doi.org/10.3390/electronics14132530
Chicago/Turabian StyleJeong, Jaejoon, Soo-Hyung Kim, Hyung-Jeong Yang, Gun Lee, and Seungwon Kim. 2025. "GazeHand2: A Gaze-Driven Virtual Hand Interface with Improved Gaze Depth Control for Distant Object Interaction" Electronics 14, no. 13: 2530. https://doi.org/10.3390/electronics14132530
APA StyleJeong, J., Kim, S.-H., Yang, H.-J., Lee, G., & Kim, S. (2025). GazeHand2: A Gaze-Driven Virtual Hand Interface with Improved Gaze Depth Control for Distant Object Interaction. Electronics, 14(13), 2530. https://doi.org/10.3390/electronics14132530