
GSTD-DETR: A Detection Algorithm for Small Space Targets Based on RT-DETR

Abstract
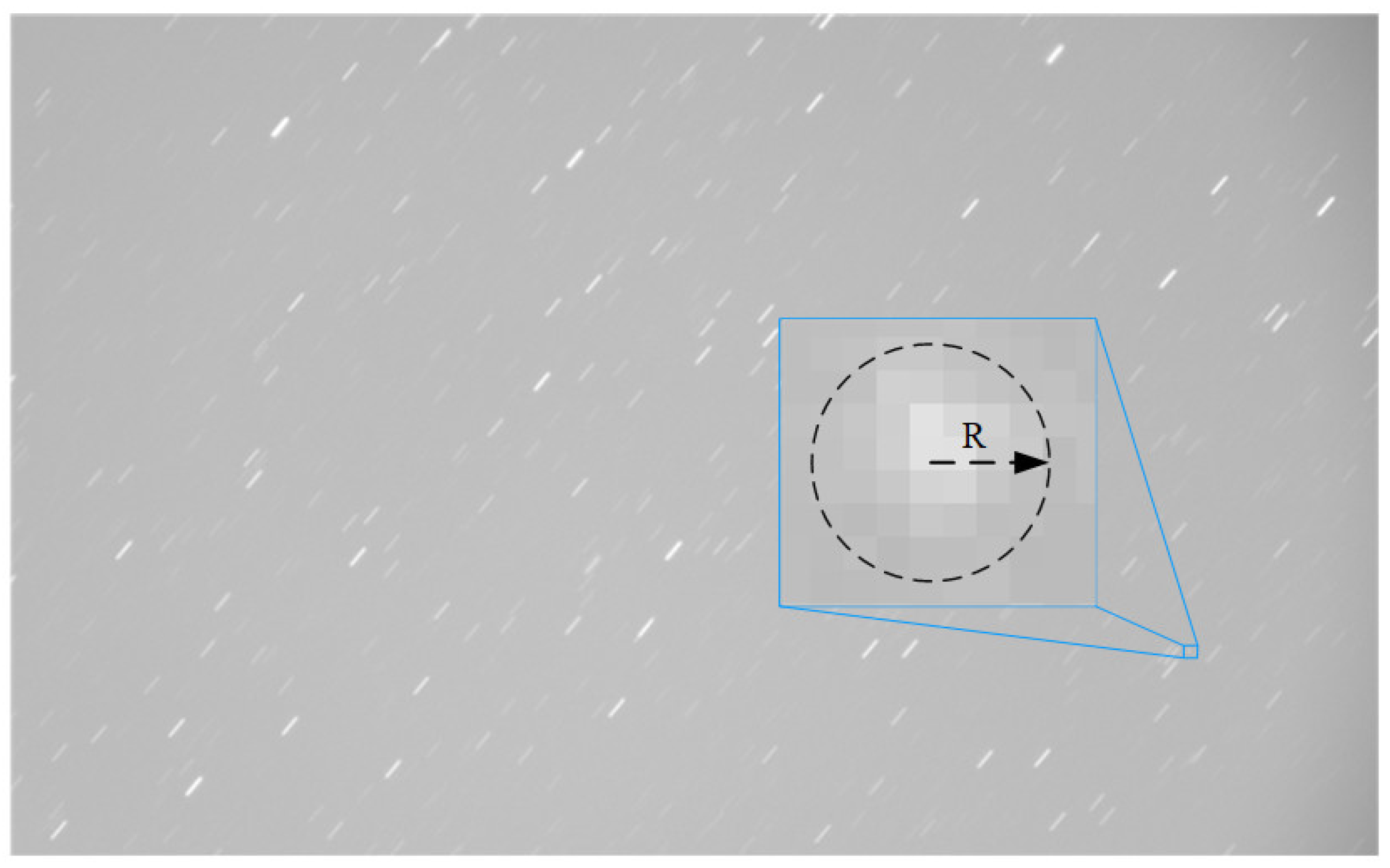
1. Introduction
- (1)
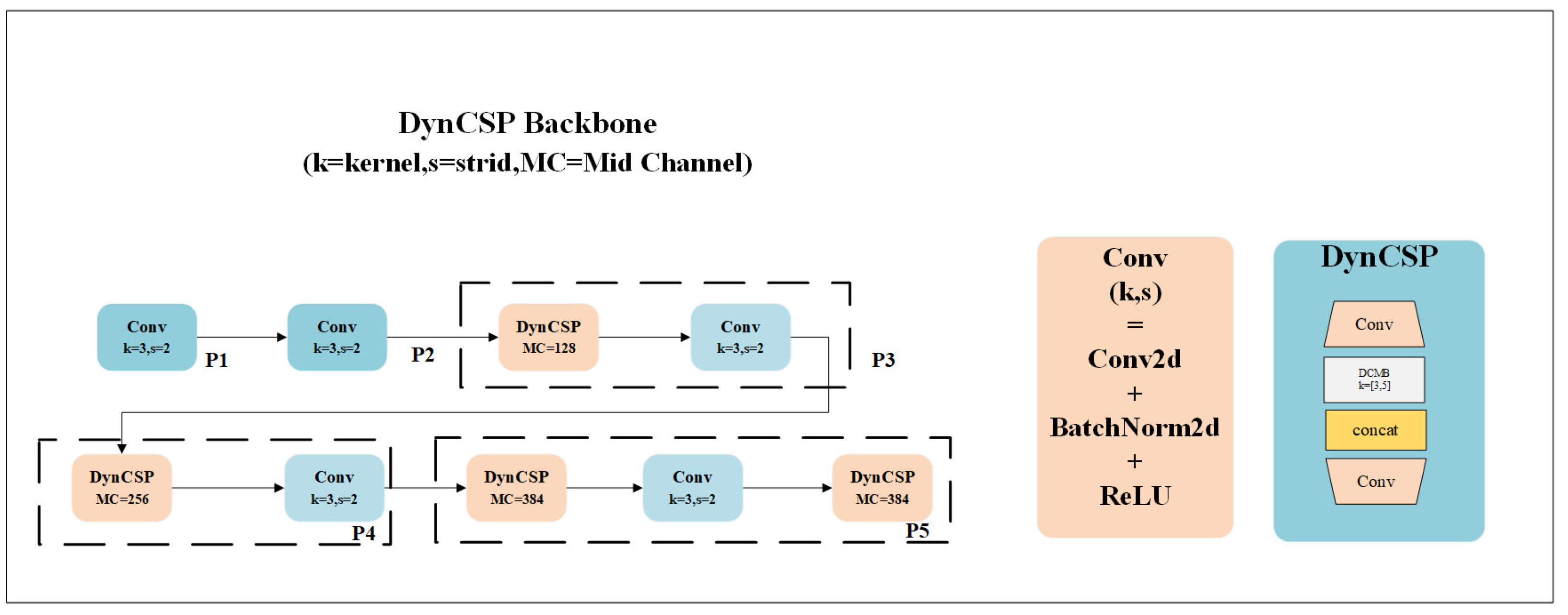
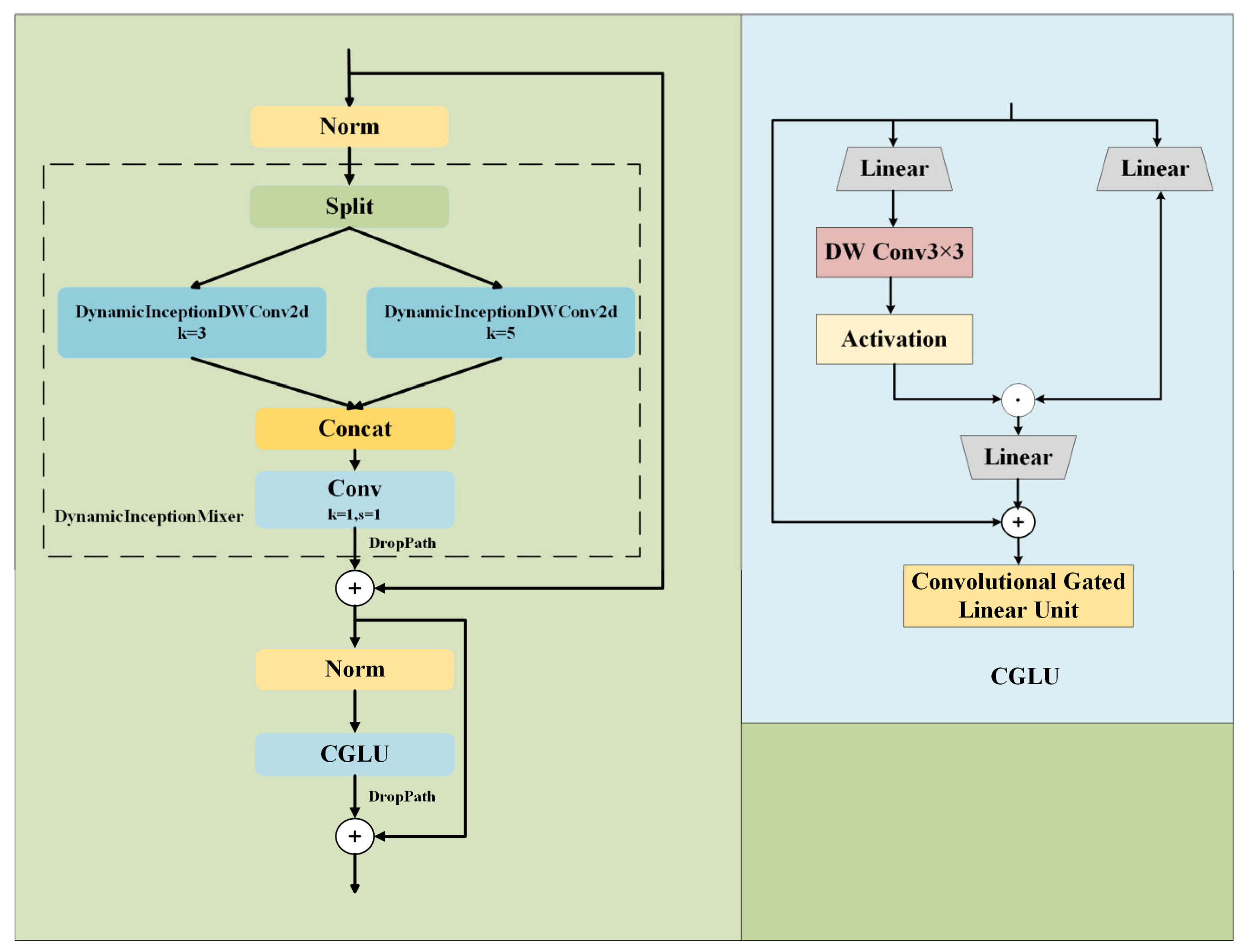
- We propose a DynCSP architecture as the backbone network. This backbone not only extracts high-quality feature representations but also significantly reduces the number of parameters and computational costs. By splitting the feature map and processing each part separately, the DynCSP architecture improves information exchange between channels and enhances the network’s feature extraction capability, which is particularly useful for small target detection.
- (2)
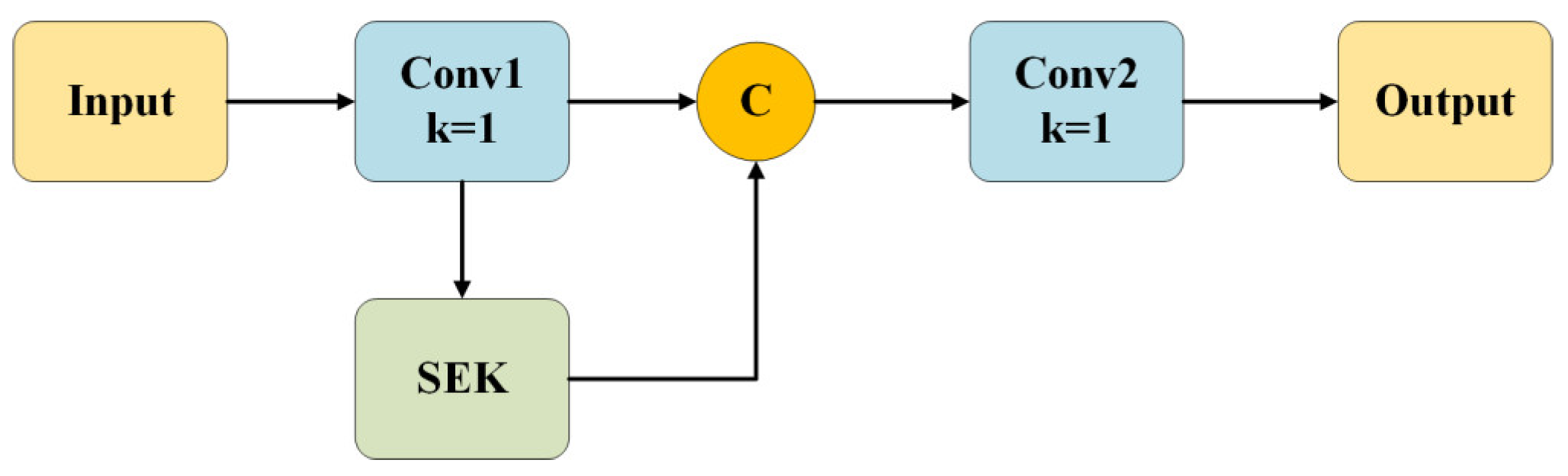
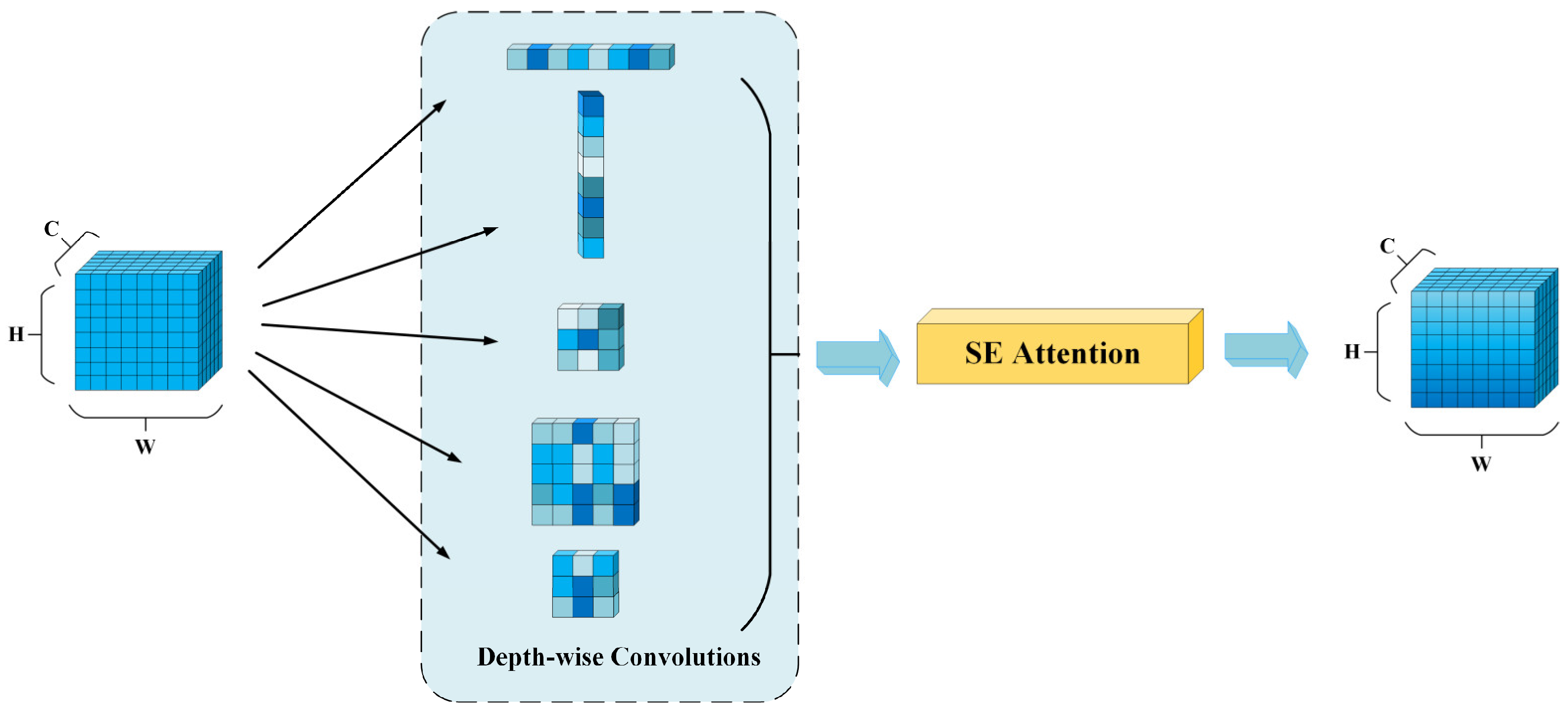
- We propose a ResFine model to enhance the network’s ability to perceive small targets, especially in feature extraction and information fusion. The model incorporates a feature pyramid structure, which improves the ability to capture small-scale details. Additionally, we design an SEK module for feature integration, allowing for a more efficient fusion of multi-scale features and enhancing detection accuracy.
- (3)
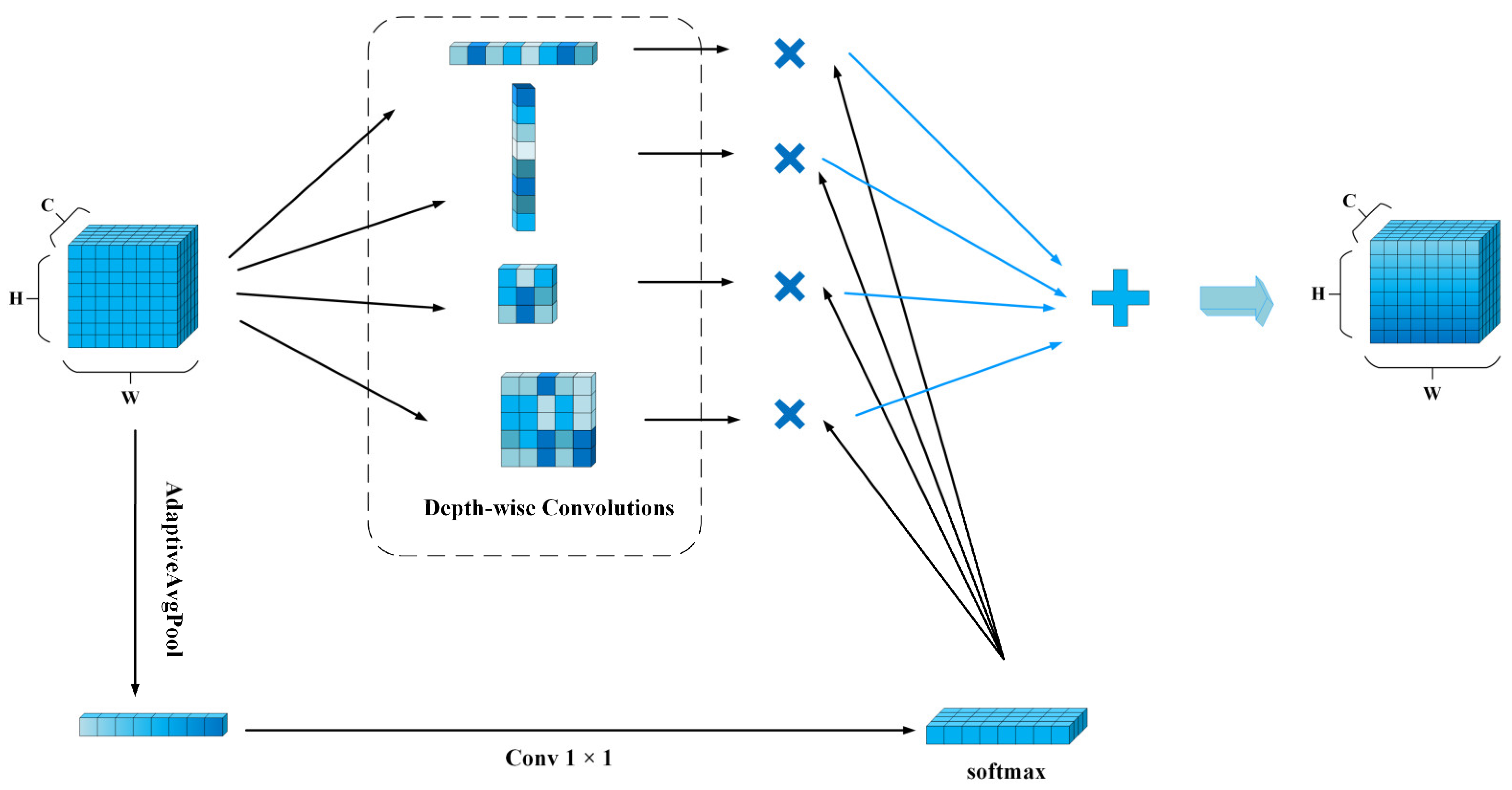
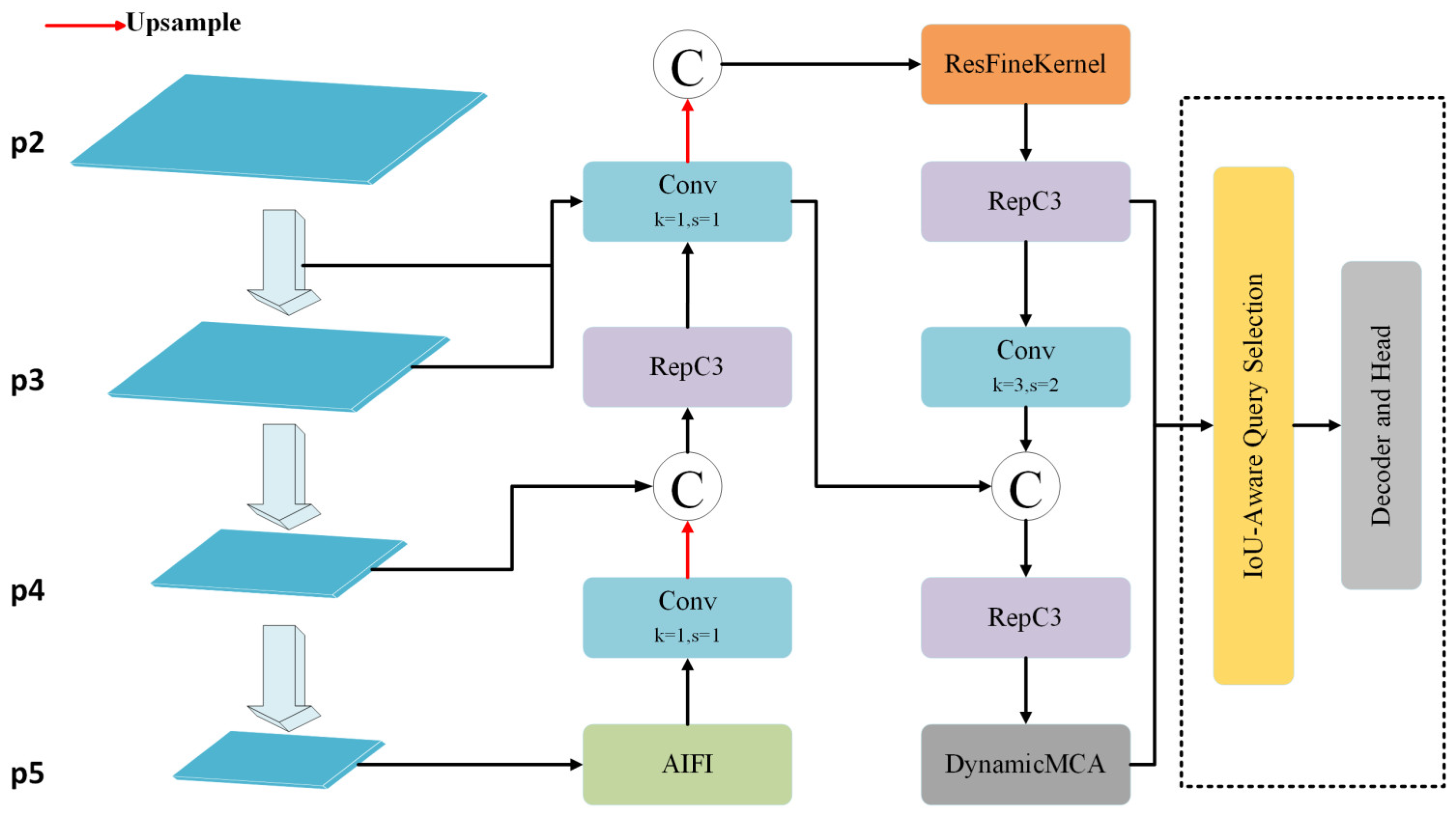
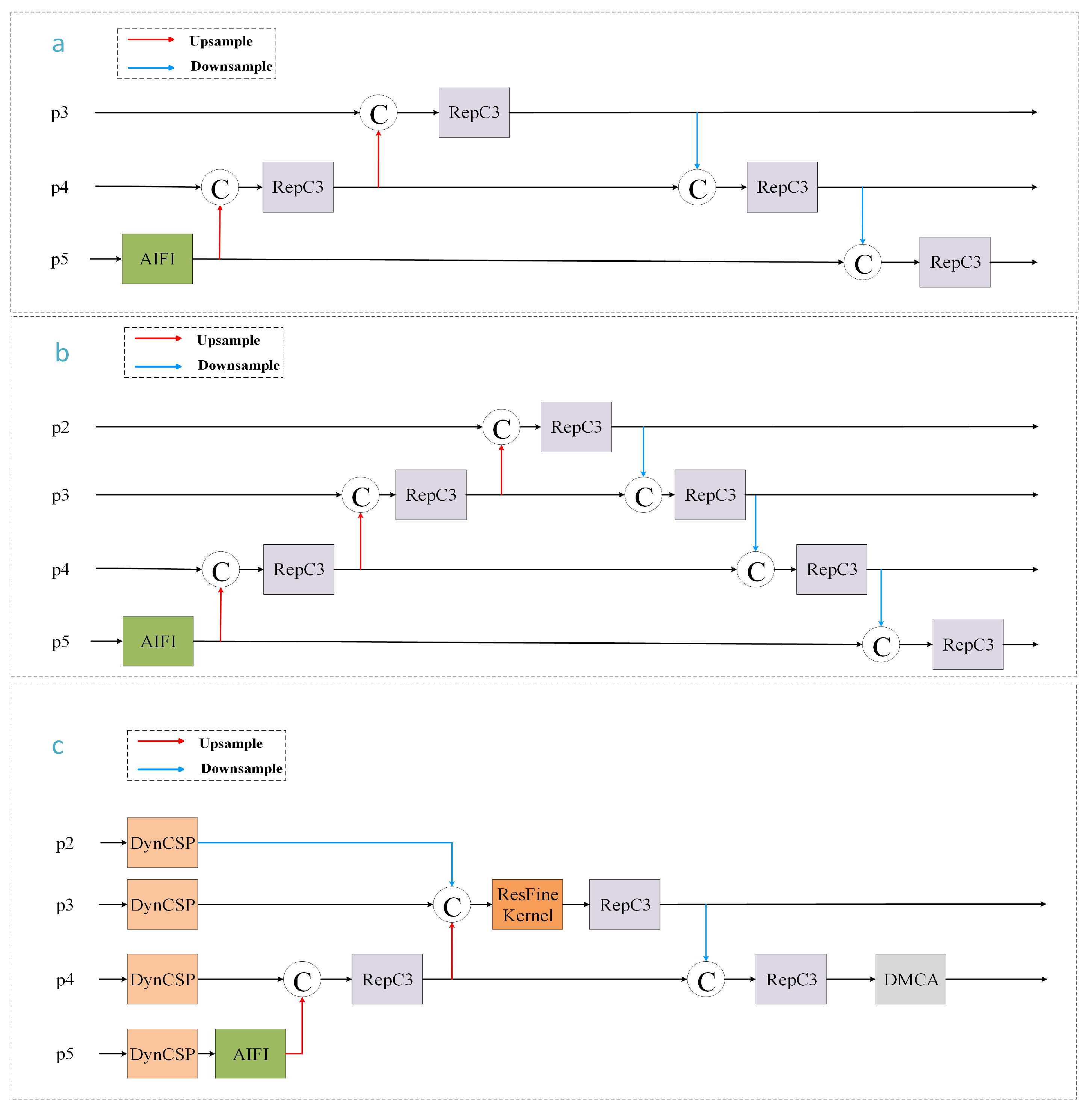
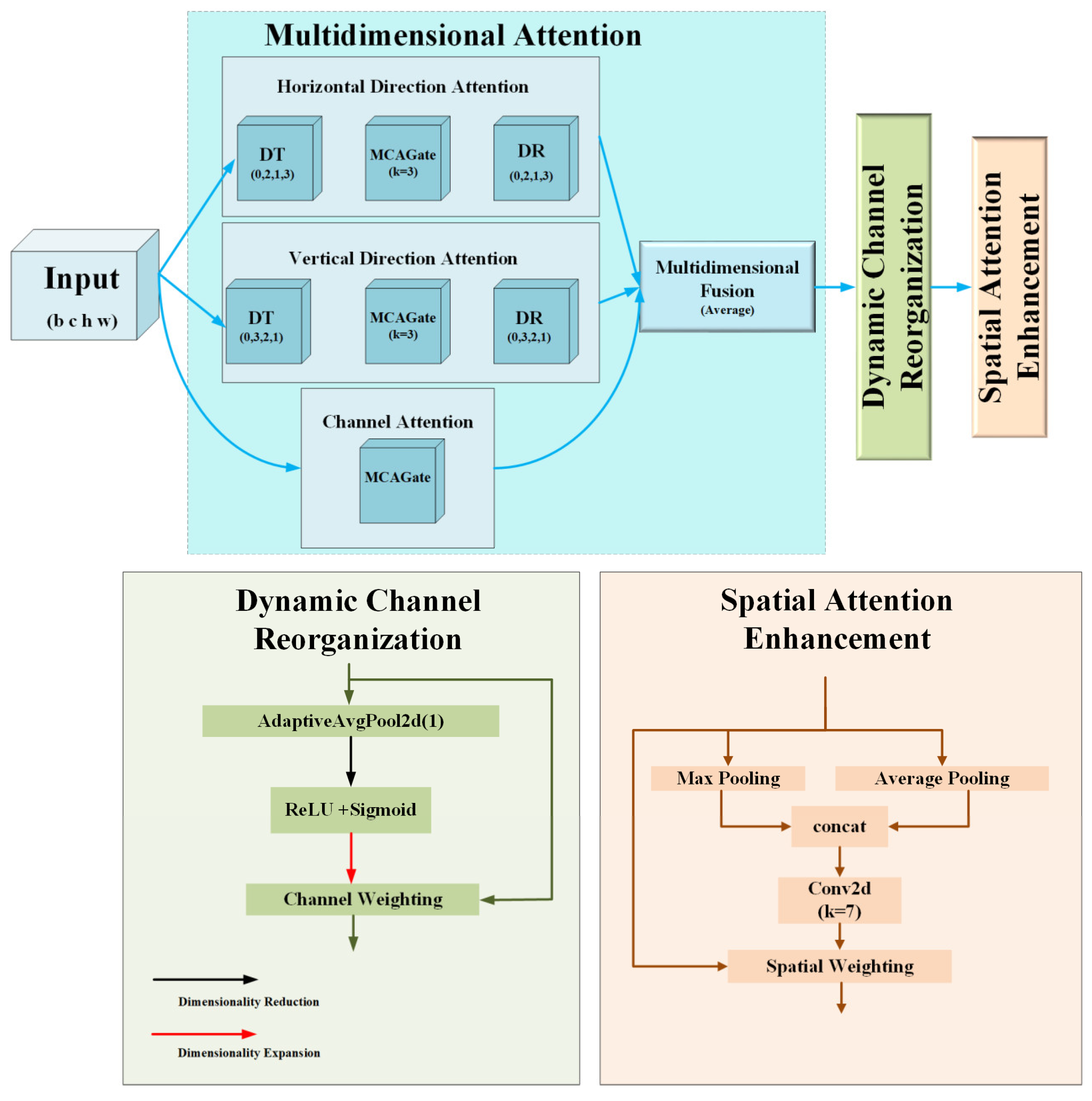
- We introduce a Dynamic Multi-Channel Attention (DMCA) mechanism, which is an improvement over the original Moment Channel Attention (MCA) mechanism. The DMCA mechanism dynamically adjusts the importance of feature channels, helping the model focus on critical regions while maintaining computational efficiency. Additionally, we modify the network’s neck by removing the P5 layer and retaining only the P3 and P4 layers, enabling the model to focus on high-resolution features that are better at preserving small target details, thus improving small target detection accuracy.
- (4)
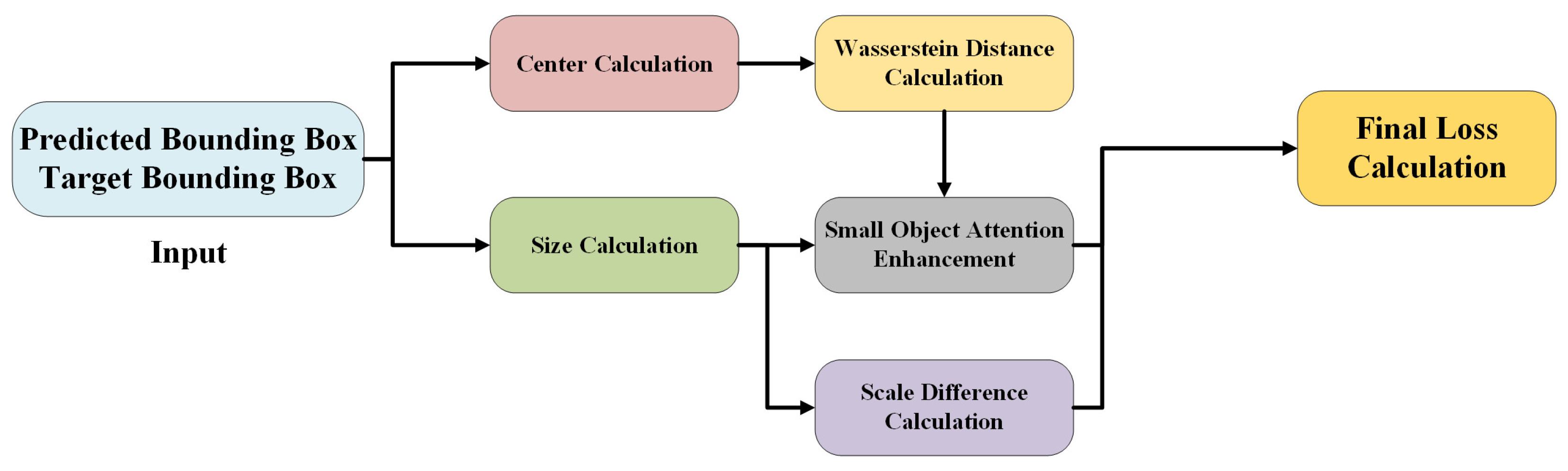
- We propose an Area-Weighted NWD (AWNWD) loss function, which builds on the Normalized Wasserstein Distance (NWD) loss function. This loss function introduces small target-aware enhancements and scale difference terms, improving the model’s focus on small targets. By incorporating both the area and scale differences, this loss function improves the robustness and precision of small object detection, particularly in complex environments.
2. Related Works
3. Methodology
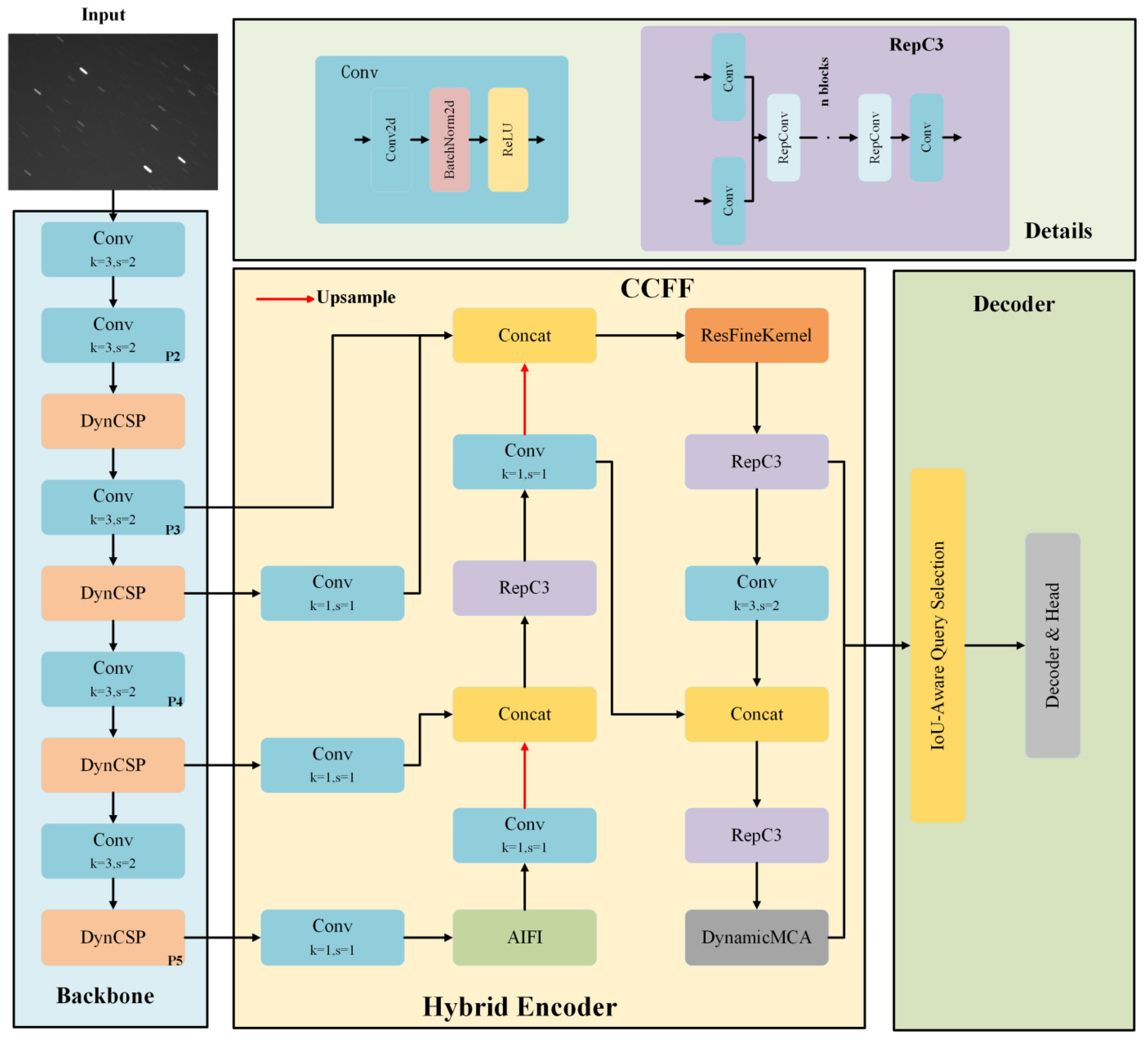
3.1. GSTD-DETR Model
3.2. DynCSP Backbone Network
3.3. ResFine Model
3.4. Dynamic Multi-Channel Attention
3.5. Area-Weighted NWD Loss Function
4. Results
4.1. Dataset and Experimental Setup
4.2. Evaluation Metrics
4.3. Ablation Experiments
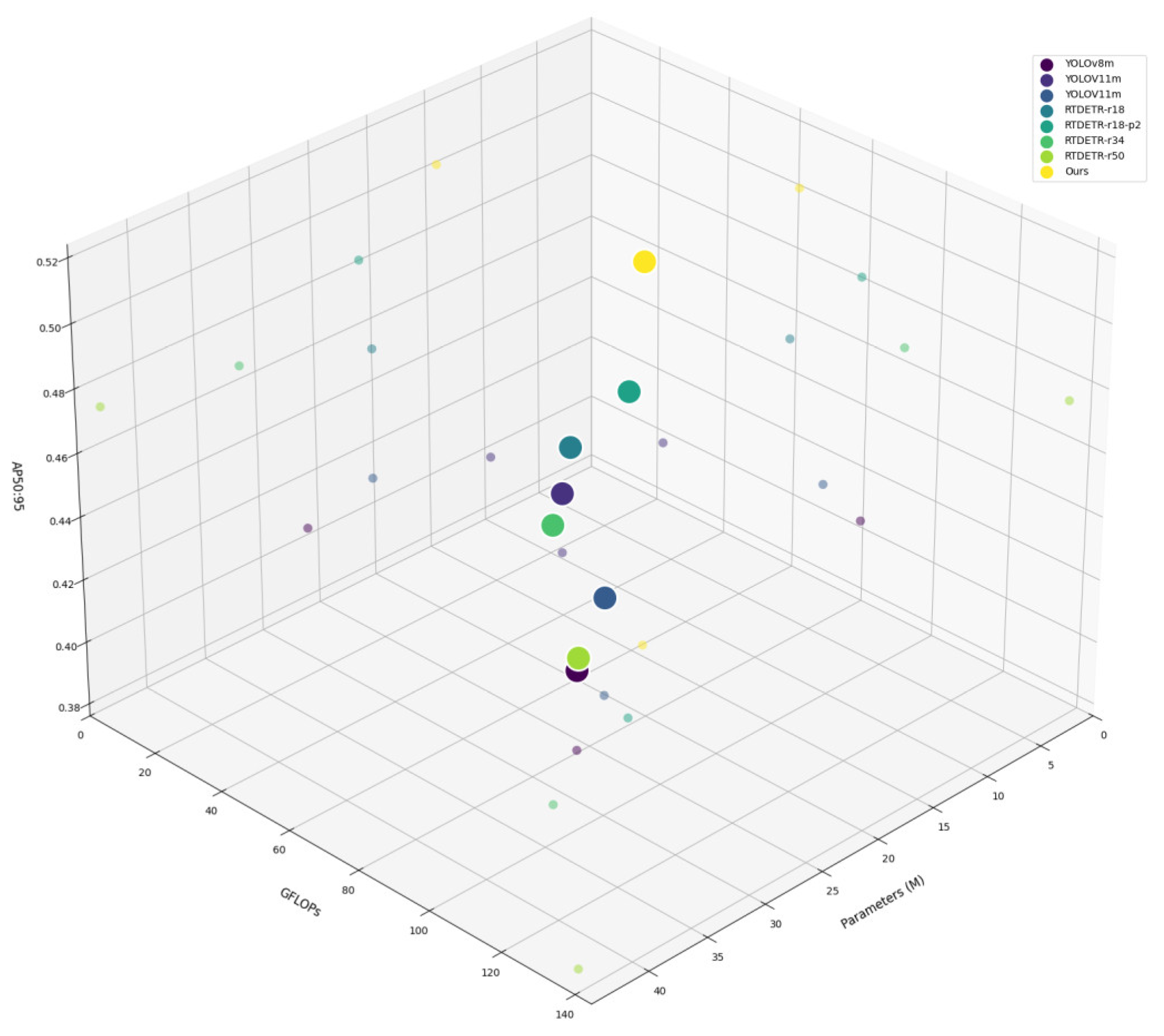
4.4. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hussain, K.F.; Safwat, N.E.-D.; Thangavel, K.; Sabatini, R. Space-based debris trajectory estimation using vision sensors and track-based data fusion techniques. Acta Astronaut. 2025, 229, 814–830. [Google Scholar] [CrossRef]
- Koldasbayeva, D.; Tregubova, P.; Gasanov, M.; Zaytsev, A.; Petrovskaia, A.; Burnaev, E. Challenges in data-driven geospatial modeling for environmental research and practice. Nat. Commun. 2024, 15, 10700. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Yin, X.; Xiao, Y.; Zhao, Z.; Yang, X.; Dai, C. Enhanced YOLOv8-based method for space debris detection using cross-scale feature fusion. Discov. Appl. Sci. 2025, 7, 95. [Google Scholar] [CrossRef]
- Su, S.; Niu, W.; Li, Y.; Ren, C.; Peng, X.; Zheng, W.; Yang, Z. Dim and small space-target detection and centroid positioning based on motion feature learning. Remote Sens. 2023, 15, 2455. [Google Scholar] [CrossRef]
- Gao, W.; Niu, W.; Lu, W.; Wang, P.; Qi, Z.; Peng, X.; Yang, Z. Dim small target detection and tracking: A novel method based on temporal energy selective scaling and trajectory association. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 17239–17262. [Google Scholar] [CrossRef]
- Kong, S. Research on Extraction Technology of Faint Targets Against a Dense Stellar Background. Ph.D. Thesis, University of Chinese Academy of Sciences (Institute of Optics and Electronics, Chinese Academy of Sciences), Chengdu, China, 2019. [Google Scholar]
- Han, L.; Tan, C.; Liu, Y.; Song, R. Research on the on-orbit real-time space target detection algorithm II. Spacecr. Recovery Remote Sens. 2021, 42, 122–131. [Google Scholar]
- Yang, Y.; Yu, L.; Mao, X.; Yan, X.; Zheng, X. Algorithm of space target quick acquisition in the complex background of the sky. Acta Photonica Sin. 2020, 49, 62–71. [Google Scholar]
- Yao, Y.; Zhu, J.; Liu, Q.; Lu, Y.; Xu, X. An adaptive space target detection algorithm. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6517605. [Google Scholar] [CrossRef]
- Wang, M.; Zhao, J.; Chen, T.; Cui, B. Moving point target detection from faint space based on temporal-space domain. J. Electron Inf. Technol. 2017, 39, 1578–1584. [Google Scholar]
- Miao, S.; Fan, C.; Wen, G.; Gao, J.; Zhao, G. Space target recognition method based on adaptive spatial filtering multistage hypothesis testing. Acta Photonica Sin. 2021, 50, 1110003. [Google Scholar]
- Pan, H.; Song, G.; Xie, L.; Zhao, Y. Detection method for small and dim targets from a time series of images observed by a space-based optical detection system. Opt. Rev. 2014, 21, 292–297. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Proceedings, Part I 14, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Abay, R.G.K. GEO-FPN: A convolutional neural network for detecting GEO and near-GEO space objects from optical images. In Proceedings of the 8th European Conference on Space Debris, Darmstadt, Germany, 20–23 April 2021. [Google Scholar]
- De Vittori, A.; Cipollone, R.; Di Lizia, P.; Massari, M. Real-time space object tracklet extraction from telescope survey images with machine learning. Astrodynamics 2022, 6, 205–218. [Google Scholar] [CrossRef]
- Jia, P.; Liu, Q.; Sun, Y. Detection and classification of astronomical targets with deep neural networks in wide-field small aperture telescopes. Astron. J. 2020, 159, 212. [Google Scholar] [CrossRef]
- Guo, X.; Chen, T.; Liu, J.; Liu, Y.; An, Q. Dim space target detection via convolutional neural network in single optical image. IEEE Access 2022, 10, 52306–52318. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Shen, Z.; Wang, K.; Zhang, X. Convolutional long-short term memory network for space debris detection and tracking. Knowl.-Based Syst. 2024, 304, 112535. [Google Scholar] [CrossRef]
- Liu, S.; Guo, Y.; Wang, G. Space target detection algorithm based on attention mechanism and dynamic activation. Laser Optoelectron. Prog. 2022, 59, 236–242. [Google Scholar]
- Yuan, Y.; Bai, H.; Wu, P.; Guo, H.; Deng, T.; Qin, W. An intelligent detection method for small and weak objects in space. Remote Sens. 2023, 15, 3169. [Google Scholar] [CrossRef]
- Wang, X.; Xi, B.; Xu, H.; Zheng, T.; Xue, C. AgeDETR: Attention-guided efficient DETR for space target detection. Remote Sens. 2024, 16, 3452. [Google Scholar] [CrossRef]
- Carion, N.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Lv, W.; Zhao, Y.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Shafiq, M.; Gu, Z. Deep residual learning for image recognition: A survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chen, B.; Zou, X.; Zhang, Y.; Li, J.; Li, K.; Xing, J.; Tao, P. LEFormer: A hybrid CNN-Transformer architecture for accurate lake extraction from remote sensing imagery. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes, Greece, 14–19 May 2023. [Google Scholar]
- Xiao, Y.; Xu, T.; Yu, X.; Fang, Y.; Li, J. A lightweight fusion strategy with enhanced inter-layer feature correlation for small object detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4708011. [Google Scholar] [CrossRef]
- Zheng, C.; Li, Y.; Li, J.; Li, N.; Fan, P.; Sun, J.; Liu, P. Dynamic convolution neural networks with both global and local attention for image classification. Mathematics 2024, 12, 1856. [Google Scholar] [CrossRef]
- Chen, D.; Zhang, L. SL-YOLO: A stronger and lighter drone target detection model. arXiv 2024, arXiv:2411.11477. [Google Scholar]
- Gong, C.X.Y.; Yao, X.; Yan, K.; Zeng, Q.; Xie, X.; Han, J. Towards large-scale small object detection: Survey and benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13467–13488. [Google Scholar]
- Yu, Y.; Zhang, Y.; Cheng, Z.; Song, Z.; Tang, C. MCA: Multidimensional collaborative attention in deep convolutional neural networks for image recognition. Eng. Appl. Artif. Intell. 2023, 126 Pt C, 107079. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Zhang, H.; Zhang, S. Shape-IoU: More accurate metric considering bounding box shape and scale. arXiv 2023, arXiv:2312.17663. [Google Scholar]
- Zhang, H.; Zhang, S. Focaler-IoU: More focused intersection over union loss. arXiv 2024, arXiv:2401.10525. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2022, arXiv:2110.13389. [Google Scholar]
- Chen, B.; Liu, D.; Chin, T.J.; Rutten, M.; Derksen, D.; Martens, M.; Looz, M.; Lecuyer, G.; Lzzo, D. Spot the GEO satellites: From dataset to Kelvins SpotGEO challenge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Kelvins Spotgeo Challenge. Available online: https://kelvins.esa.int/spot-the-geo-satellites/home/ (accessed on 25 December 2024).
- Ultralytics. Available online: https://github.com/ultralytics/ultralytics (accessed on 7 December 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Parameter Setting of DETR | ||
|---|---|---|---|
| GPU | RTX4090 | Batch size | 16 |
| CPU | AMD EPYC 7352 | Momentum | 0.9 |
| Development environment | Python 3.10.0 Pytorch 2.3.0 CUDA 12.1 | Optimizer | AdamW |
| Learning rate | 0.0001 | ||
| Weight decay coefficient | 0.0001 | ||
| Input size | 640 × 480 | ||
| 0.01 | 0.05 | 0.1 | 0.15 | 0.2 | |
| AP50:95 | 0.365 | 0.412 | 0.499 | 0.451 | 0.401 |
| DynCSP | ResFineKernel | DMCA | AWNWD | Layers | Parameters (M) | GFLOPs | AP50:95 |
|---|---|---|---|---|---|---|---|
| - | - | - | - | 295 | 19.97 | 58.3 | 0.45 |
| √ | - | - | - | 439 | 13.31 | 43.9 | 0.478 |
| √ | - | - | 317 | 20.48 | 64.3 | 0.458 | |
| - | - | √ | - | 297 | 18.65 | 56.0 | 0.452 |
| √ | √ | - | - | 483 | 15.21 | 61.2 | 0.49 |
| √ | √ | √ | - | 488 | 14.03 | 60.2 | 0.497 |
| √ | √ | √ | √ | 488 | 14.03 | 60.2 | 0.499 |
| Model | Backbone | File Weights (MB) | Parameters (M) | GFLOPs | AP | AR | AP50 | AP50:95 |
|---|---|---|---|---|---|---|---|---|
| YOLOv8m | CSPDarknet | 49.6 | 25.90 | 79.3 | 0.820 | 0.651 | 0.765 | 0.402 |
| YOLOv11m | CSPDarknet | 38.6 | 20.11 | 68.5 | 0.811 | 0.671 | 0.775 | 0.408 |
| RT-DETR-r18 | ResNet18 | 38.6 | 19.97 | 58.3 | 0.904 | 0.787 | 0.873 | 0.45 |
| RT-DETR-r18-p2 | ResNet18 | 40.8 | 20.94 | 78 | 0.907 | 0.775 | 0.858 | 0.480 |
| RT-DETR-r34 | ResNet34 | 60.09 | 31.32 | 90.2 | 0.914 | 0.8 | 0.875 | 0.464 |
| RT-DETR-r50 | ResNet50 | 654 | 42.78 | 134.4 | 0.911 | 0.801 | 0.878 | 0.471 |
| ours | DynCSP | 27.2 | 14.03 | 60.2 | 0.925 | 0.805 | 0.886 | 0.499 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Guo, H.; Zhao, Y.; Zhang, L.; Luan, C.; Li, Y.; Zhang, X. GSTD-DETR: A Detection Algorithm for Small Space Targets Based on RT-DETR. Electronics 2025, 14, 2488. https://doi.org/10.3390/electronics14122488
Zhang Y, Guo H, Zhao Y, Zhang L, Luan C, Li Y, Zhang X. GSTD-DETR: A Detection Algorithm for Small Space Targets Based on RT-DETR. Electronics. 2025; 14(12):2488. https://doi.org/10.3390/electronics14122488
Chicago/Turabian StyleZhang, Yijian, Huichao Guo, Yang Zhao, Laixian Zhang, Chenglong Luan, Yingchun Li, and Xiaoyu Zhang. 2025. "GSTD-DETR: A Detection Algorithm for Small Space Targets Based on RT-DETR" Electronics 14, no. 12: 2488. https://doi.org/10.3390/electronics14122488
APA StyleZhang, Y., Guo, H., Zhao, Y., Zhang, L., Luan, C., Li, Y., & Zhang, X. (2025). GSTD-DETR: A Detection Algorithm for Small Space Targets Based on RT-DETR. Electronics, 14(12), 2488. https://doi.org/10.3390/electronics14122488