

AgriTransformer: A Transformer-Based Model with Attention Mechanisms for Enhanced Multimodal Crop Yield Prediction

 , , , and
, , , and
Abstract
1. Introduction
- Integration of heterogeneous data sources.
- Modeling nonlinear relationships and latent interactions.
- Enhancing robustness across diverse field conditions.
1.1. Related Work
1.2. The Attention Mechanism in AgriTransformer
1.2.1. Types of Attention in Deep Learning
1.2.2. Comparison with Traditional Methods
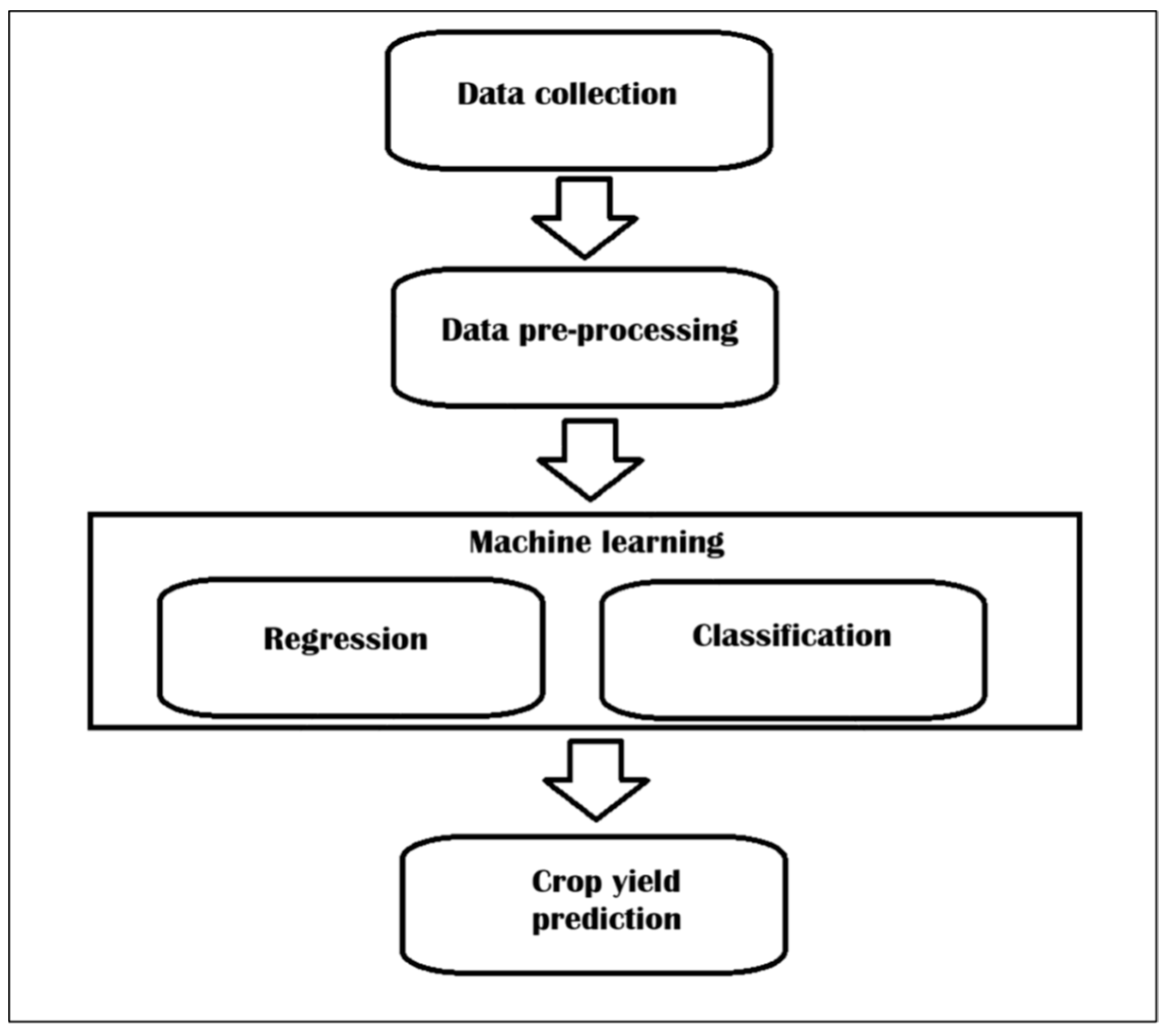
2. Materials and Methods
2.1. Methodology
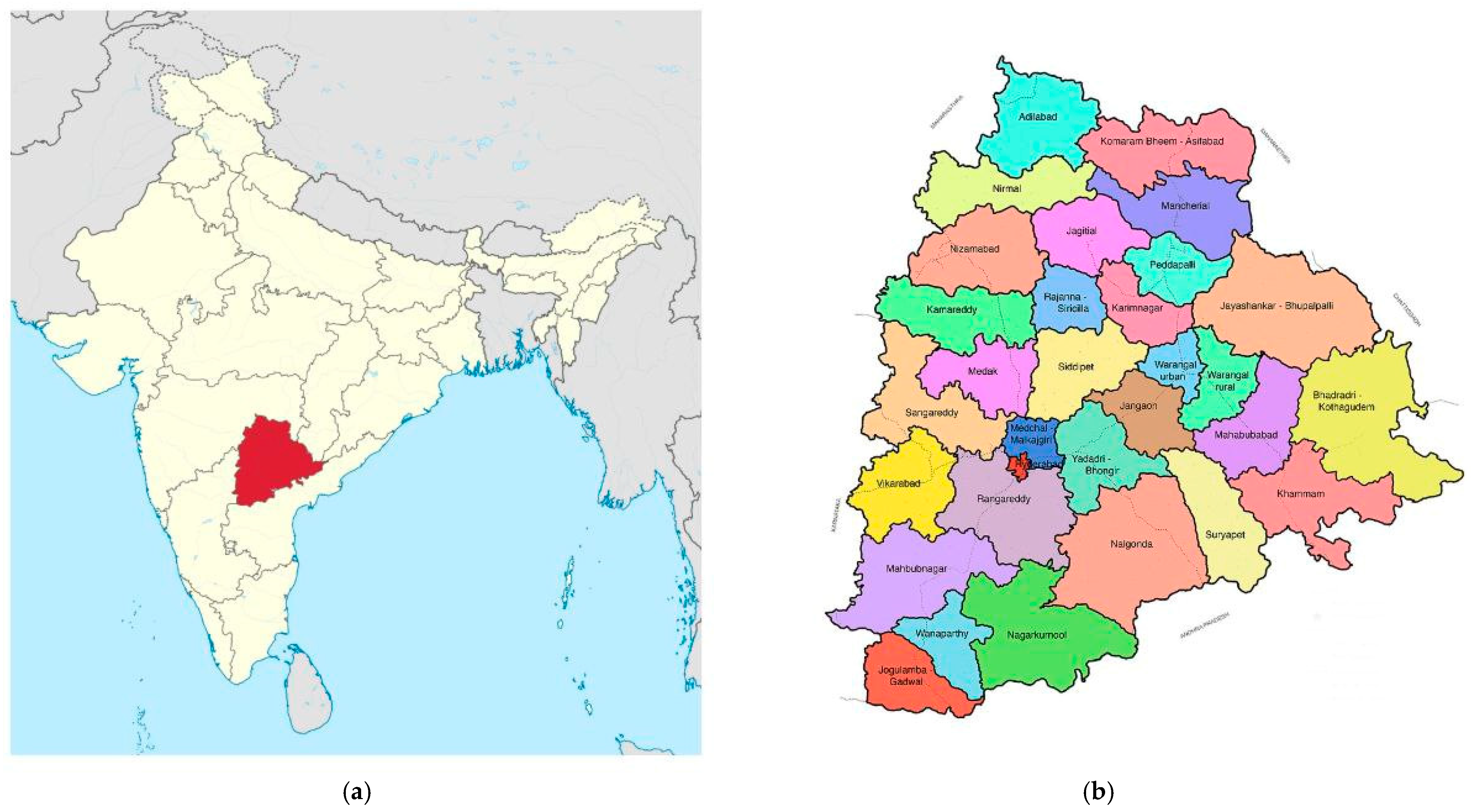
2.2. Description of the Utilised Dataset
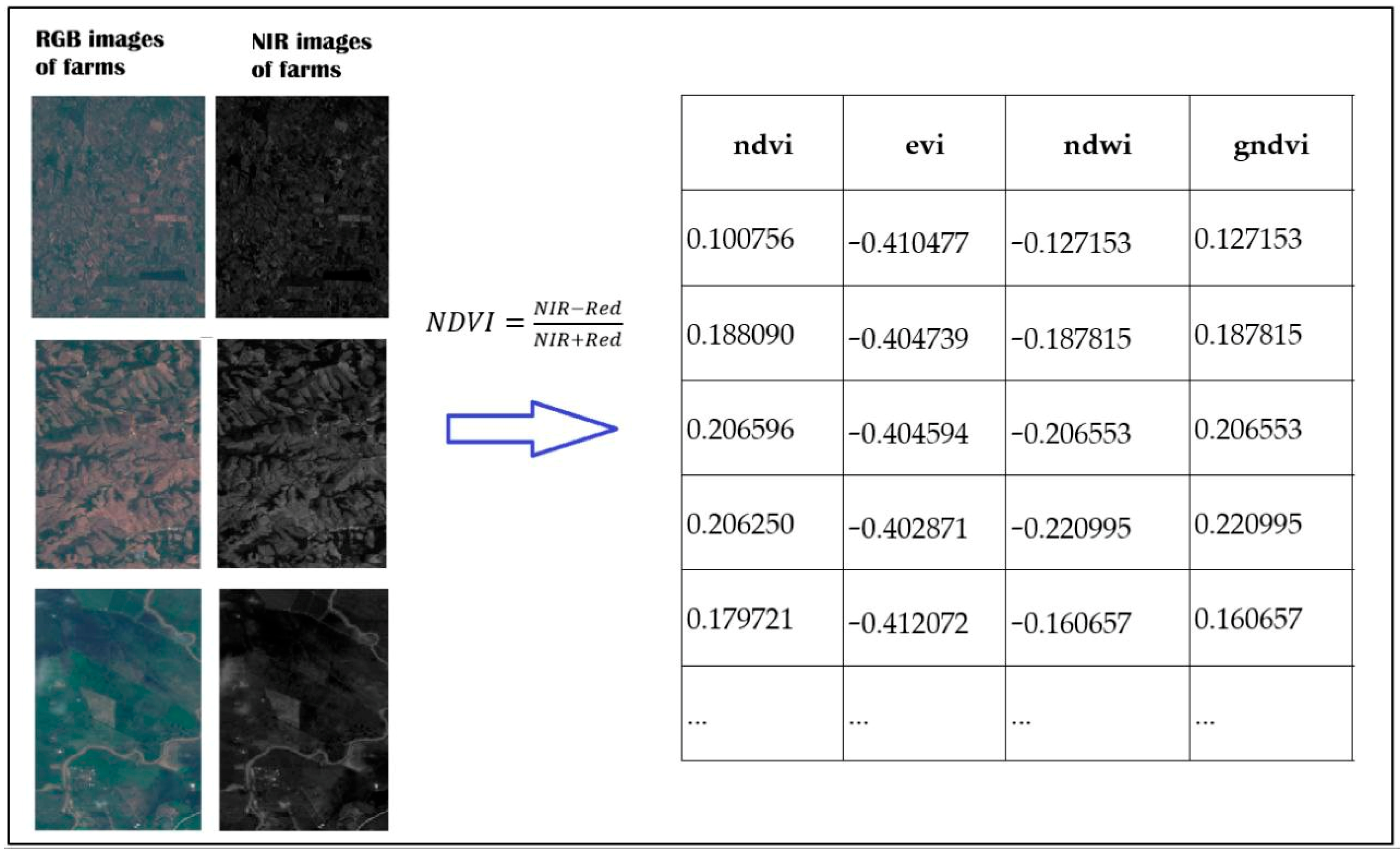
2.3. Data Pre-Processing
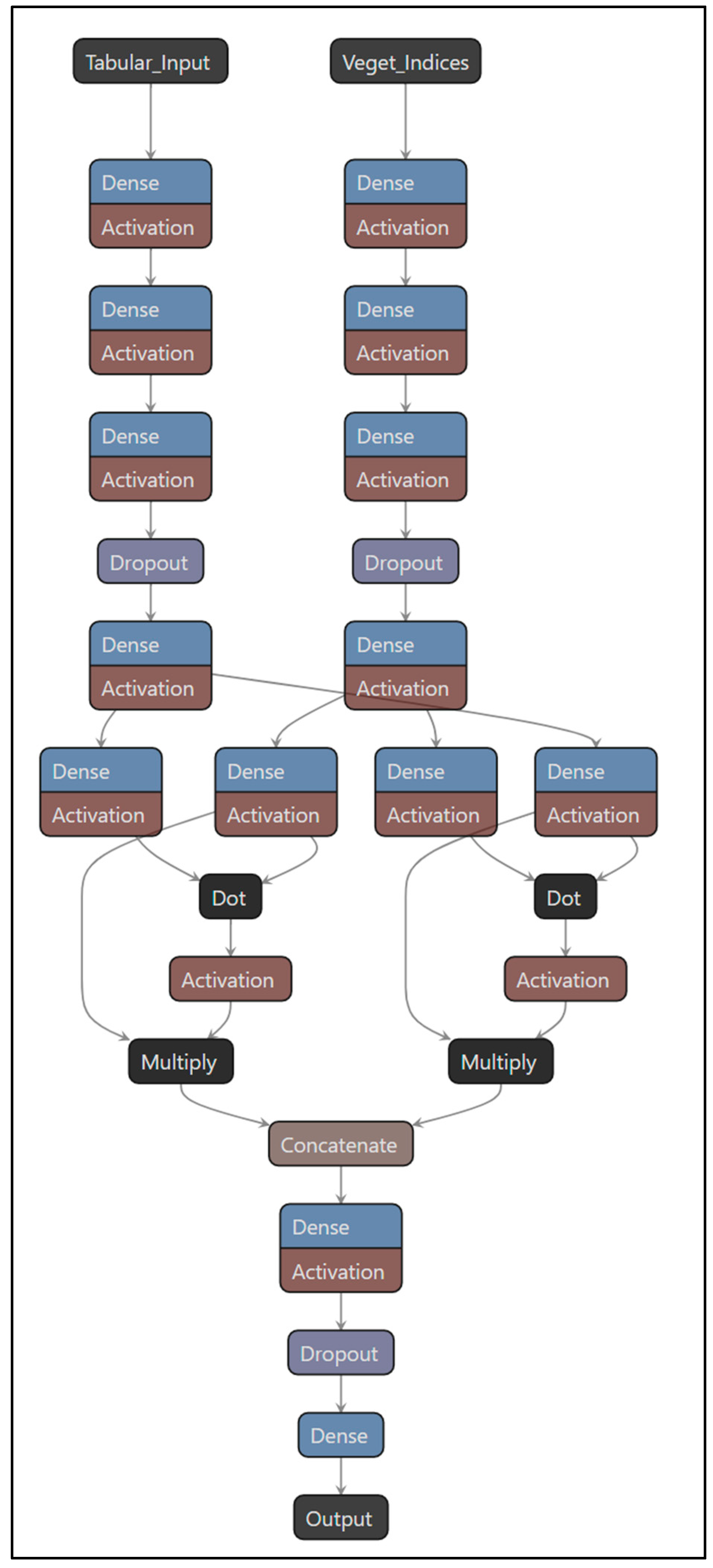
2.4. AgriTransformer: Model Description
2.4.1. Input Modalities
- Tabular data: Structured features such as crop type, irrigation, and management practices.
- Vegetation indices (VIs): Remotely sensed indices of vegetation (e.g., NDVI and EVI) derived from multispectral satellite imagery during the growing season.
2.4.2. Architecture
- (a)
- Embedding layers
- The tabular features are passed through a dense layer to obtain a fixed-dimensional embedding.
- The vegetation indices were obtained in a pre-processing stage by the VI formulas described in Table 1.
- (b)
- Cross-modal co-attention
- The embeddings from both modalities are input into a co-attention module, adapted from the concept of cross-attention in vision-language models.
- The dot product calculates the similarities between the projections of each modality [31].
- Normalization with the softmax function is used, and then the model applies weights with the multiplication operation. This multiplication operation is crucial to determine the relevance of one modality with respect to the other.
- This mechanism allows the model to attend to relevant VI patterns conditioned on the tabular context, and vice versa.
- It enables learning interactions such as “how irrigation affects the relationship between NDVI values and final yield.”
- (c)
- Fusion and prediction
- The attended representations are concatenated and passed through a feed-forward network (FFN).
- The model outputs a scalar value representing the predicted crop yield.
2.4.3. Training Setup
2.4.4. Advantages
2.5. Evaluation Metrics of the Model
- Mean Squared Error (MSE): Penalizes larger errors.
- Coefficient of Determination (R2): Indicates the proportion of variance explained by the model.
3. Results
3.1. Quantitative Results
3.2. Statistical Significance
- MSE (Mean Squared Error)
- Paired t-test: p = 0.0023 < 0.01
- Wilcoxon signed-rank test: p = 0.0059 < 0.01
- R2 (Coefficient of Determination)
- Paired t-test: p = 0.0032 < 0.01
- Wilcoxon signed-rank test: p = 0.0032 < 0.01
3.3. Interpretation
3.4. Data Interpretability
3.5. Deployment Validation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahn, D.; Kim, S.; Hong, H.; Ko, B. Star-transformer: A spatio-temporal cross attention transformer for human action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision 2023, Waikoloa, HI, USA, 2–7 January 2023; pp. 3330–3339. [Google Scholar]
- Ajith, S.; Vijayakumar, S.; Elakkiya, N. Yield prediction, pest and disease diagnosis, soil fertility mapping, precision irrigation scheduling, and food quality assessment using machine learning and deep learning algorithms. Discov. Food 2025, 5, 63. [Google Scholar]
- Hobbs, P. Conservation agriculture: What is it and why is it important for future sustainable food production? J. Agric. Sci. 2007, 145, 127. [Google Scholar] [CrossRef]
- Marshall, M.; Belgiu, M.; Boschetti, M.; Pepe, M.; Stein, A.; Nelson, A. Field-level crop yield estimation with PRISMA and Sentinel-2. ISPRS J. Photogramm. Remote Sens. 2022, 187, 191–210. [Google Scholar] [CrossRef]
- Roznik, M.; Boyd, M.; Porth, L. Improving crop yield estimation by applying higher resolution satellite NDVI imagery and high-resolution cropland masks. Remote Sens. Appl. Soc. Environ. 2022, 25, 100693. [Google Scholar] [CrossRef]
- Nikhil, U.; Pandiyan, A.; Raja, S.; Stamenkovic, Z. Machine learning-based crop yield prediction in south india: Performance analysis of various models. Computers 2024, 13, 137. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Oikonomidis, A.; Catal, C.; Kassahun, A. Deep learning for crop yield prediction: A systematic literature review. N. Z. J. Crop Hortic. Sci. 2023, 51, 1–26. [Google Scholar] [CrossRef]
- Mingyong, L.; Yewen, L.; Mingyuan, G.; Longfei, M. CLIP-based fusion-modal reconstructing hashing for large-scale unsupervised cross-modal retrieval. Int. J. Multimed. Inf. Retr. 2023, 12, 2. [Google Scholar] [CrossRef]
- Bhattacharyya, B.; Biswas, R.; Sujatha, K.; Chiphang, D. Linear regression model to study the effects of weather variables on crop yield in Manipur state. Int. J. Agric. Stat. Sci. 2021, 17, 317–320. [Google Scholar]
- Dhillon, M.; Dahms, T.; Kuebert-Flock, C.; Rummler, T.; Arnault, J.; Steffan-Dewenter, I.; Ullmann, T. Integrating random forest and crop modeling improves the crop yield prediction of winter wheat and oil seed rape. Front. Remote Sens. 2023, 3, 1010978. [Google Scholar] [CrossRef]
- Kok, Z.; Shariff, A.; Alfatni, M.; Khairunniza-Bejo, S. Support vector machine in precision agriculture: A review. Comput. Electron. Agric. 2021, 191, 106546. [Google Scholar] [CrossRef]
- Mahesh, P.; Soundrapandiyan, R. Yield prediction for crops by gradient-based algorithms. PLoS ONE 2024, 19, e0291928. [Google Scholar] [CrossRef] [PubMed]
- Anderson, K. Detecting Environmental Stress in Agriculture Using Satellite Imagery and Spectral Indices. Ph.D. Thesis, Obafemi Awolowo University, Ile-Ife, Nigeria, 2024. [Google Scholar]
- Peng, M.; Liu, Y.; Khan, A.; Ahmed, B.; Sarker, S.; Ghadi, Y.; Ali, Y. Crop monitoring using remote sensing land use and land change data: Comparative analysis of deep learning methods using pre-trained CNN models. Big Data Res. 2024, 36, 100448. [Google Scholar] [CrossRef]
- Petit, O.; Thome, N.; Rambour, C.; Themyr, L.; Collins, T.; Soler, L. U-net transformer: Self and cross attention for medical image segmentation. In Machine Learning in Medical Imaging, Proceedings of the 12th International Workshop, MLMI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, 27 September 2021, Proceedings 12; Springer International Publishing: Cham, Switzerland, 2021; pp. 267–276. [Google Scholar]
- Rahimi, E.; Jung, C. The efficiency of long short-term memory (LSTM) in phenology-based crop classification. Korean J. Remote Sens. 2024, 40, 57–69. [Google Scholar]
- Dieten, J. Attention Mechanisms in Natural Language Processing. Bachelor’s Thesis, University of Twente, Enschede, The Netherlands, 2024. [Google Scholar]
- Guo, M.; Xu, T.; Liu, J.; Liu, Z.; Jiang, P.; Mu, T.; Hu, S. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Lin, H.; Cheng, X.; Wu, X.; Shen, D. Cat: Cross attention in vision transformer. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Rashid, M.; Bari, B.; Yusup, Y.; Kamaruddin, M.; Khan, N. A comprehensive review of crop yield prediction using machine learning approaches with special emphasis on palm oil yield prediction. IEEE Access 2021, 9, 63406–63439. [Google Scholar] [CrossRef]
- Kaggle. Telangana Crop Health Challenge. Kaggle. 2024. Available online: https://www.kaggle.com/datasets/adhittio/z-1-telangana-crop-health-challenge (accessed on 1 December 2024).
- Pettorelli, N.; Vik, J.; Mysterud, A.; Gaillard, J.; Tucker, C.; Stenseth, N. Using the satellite-derived NDVI to assess ecological responses to environmental change. Trends Ecol. Evol. 2005, 20, 503–510. [Google Scholar] [CrossRef]
- Gurung, R.; Breidt, F.; Dutin, A.; Ogle, S. Predicting Enhanced Vegetation Index (EVI) curves for ecosystem modeling applications. Remote Sens. Environ. 2009, 113, 2186–2193. [Google Scholar] [CrossRef]
- Ashok, A.; Rani, H.; Jayakumar, K. Monitoring of dynamic wetland changes using NDVI and NDWI based landsat imagery. Remote Sens. Appl. Soc. Environ. 2021, 23, 100547. [Google Scholar] [CrossRef]
- Basso, M.; Stocchero, D.; Ventura, R.; Vian, A.; Bredemeier, C.; Konzen, A.; Pignaton de Freitas, E. Proposal for an embedded system architecture using a GNDVI algorithm to support UAV-based agrochemical spraying. Sensors 2019, 19, 5397. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, H.; Zhang, L.; Liao, X. Multi-dimensional attention with similarity constraint for weakly-supervised temporal action localization. IEEE Trans. Multimed. 2022, 25, 4349–4360. [Google Scholar] [CrossRef]
- Ren, H.; Zhou, G.; Zhang, F. Using negative soil adjustment factor in soil-adjusted vegetation index (SAVI) for aboveground living biomass estimation in arid grasslands. Remote Sens. Environ. 2018, 209, 439–445. [Google Scholar] [CrossRef]
- Novando, G.; Arif, D. Comparison of soil adjusted vegetation index (SAVI) and modified soil adjusted vegetation index (MSAVI) methods to view vegetation density in padang city using landsat 8 image. Int. Remote Sens. Appl. J. 2021, 2, 31–36. [Google Scholar] [CrossRef]
- Wen, Z.; Lin, W.; Wang, T.; Xu, G. Distract your attention: Multi-head cross attention network for facial expression recognition. Biomimetics 2023, 8, 199. [Google Scholar] [CrossRef]
- Soydaner, D. Attention mechanism in neural networks: Where it comes and where it goes. Neural Comput. Appl. 2022, 34, 13371–13385. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Geometry |
|---|---|
| 0 | POLYGON ((78.18143 17.97888, 78.18149 17.97899, 78.18175 17.97887, 78.18166 17.97873, 78.18143 17.97888)) |
| 1 | POLYGON ((78.17545 17.98107, 78.17578 17.98104, 78.17574 17.98086, 78.17545 17.98088, 78.17545 17.98107)) |
| 2 | POLYGON ((78.16914 17.97621, 78.1693 17.97619, 78.16928 17.97597, 78.16911 17.97597, 78.16914 17.97621)) |
| 3 | POLYGON ((78.16889 17.97461, 78.16916 17.97471, 78.16923 17.97456, 78.16895 17.97446, 78.16889 17.97461)) |
| 4 | POLYGON ((78.17264 17.96925, 78.17276 17.96926, 78.17276 17.96913, 78.17273 17.96905, 78.17264 17.96925)) |
| … | … |
| 8770 | POLYGON ((78.79225 19.7354, 78.79276 19.73531, 78.7927 19.73418, 78.79213 19.73423, 78.79225 19.7354)) |
| 8771 | POLYGON ((78.79762 19.75388, 78.79859 19.75375, 78.79853 19.75335, 78.79751 19.75337, 78.79762 19.75388)) |
| 8772 | POLYGON ((78.80798 19.75445, 78.80899 19.75448, 78.80895 19.75415, 78.80795 19.75412, 78.80798 19.75445)) |
| 8773 | POLYGON ((78.80939 19.75338, 78.81022 19.75344, 78.81018 19.75305, 78.80942 19.75302, 78.80939 19.75338)) |
| 8774 | POLYGON ((80.11489 17.37211, 80.11505 17.37208, 80.11508 17.37193, 80.11511 17.37158, 80.11489 17.37211)) |
| Vegetation Index | Use | Formula | |
| NDVI (Normalized Difference Vegetation Index) | It is used for assessing the health and density of vegetation [23] | (2) | |
|
EVI (Enhanced Vegetation Index) | It is used for adjusting the relation between vegetation and soil or when the NDVI index is not good [24] | (3) | |
|
NDWI (Normalized Difference Water Index) | It is used to monitor the amount of water on the surface or moisture on the ground [25] | (4) | |
|
GNDVI (Green Normalized Difference Vegetation Index) | It is used to assess the health of vegetation, especially when the NDVI index is not sensitive enough [10,26,27] | (5) | |
|
SAVI (Soil Adjusted Vegetation Index) | It is used when the soil is visible in satellite images in order to reduce the effect of soil in areas with a low amount of vegetation [28] | (6) | |
|
MSAVI (Modified Soil Vegetation Index) | It is used in areas with low vegetation amount and to obtain a more accurate assessment of the vegetation [29] | (7) | |
| Crop | State | District | Sub-District | CropCoveredArea | CHeight | IrriType | IrriSource | IrriCount | WaterCov |
|---|---|---|---|---|---|---|---|---|---|
| 5 | 0 | 5 | 61 | 97 | 54 | 1 | 1 | 4 | 87 |
| 5 | 0 | 5 | 61 | 82 | 58 | 1 | 0 | 5 | 94 |
| 5 | 0 | 5 | 61 | 92 | 91 | 1 | 0 | 3 | 99 |
| 5 | 0 | 5 | 61 | 91 | 52 | 1 | 0 | 5 | 92 |
| 5 | 0 | 5 | 61 | 94 | 55 | 1 | 0 | 5 | 97 |
| … | … | … | … | … | … | … | … | … | … |
| 2 | 0 | 0 | 11 | 78 | 81 | 0 | 3 | 2 | 60 |
| 2 | 0 | 0 | 11 | 81 | 110 | 0 | 2 | 3 | 45 |
| 2 | 0 | 0 | 11 | 68 | 66 | 2 | 0 | 3 | 58 |
| 2 | 0 | 0 | 11 | 84 | 101 | 0 | 2 | 3 | 52 |
| 1 | 0 | 2 | 51 | 60 | 100 | 0 | 1 | 2 | 46 |
| ndvi | evi | ndwi | gndvi | savi | msavi | ExpYield |
|---|---|---|---|---|---|---|
| 0.100756 | −0.410477 | −0.127153 | 0.127153 | 0.150938 | 0.182590 | 17 |
| 0.188090 | −0.404739 | −0.187815 | 0.187815 | 0.281782 | 0.316035 | 15 |
| 0.206596 | −0.404594 | −0.206553 | 0.206553 | 0.309491 | 0.341444 | 20 |
| 0.206250 | −0.402871 | −0.220995 | 0.220995 | 0.308917 | 0.340748 | 16 |
| 0.179721 | −0.412072 | −0.160657 | 0.160657 | 0.269242 | 0.304072 | 20 |
| … | … | … | … | … | … | … |
| −0.004249 | −0.417536 | −0.014609 | 0.014609 | −0.006368 | −0.008525 | 18 |
| −0.006838 | −0.417692 | −0.013866 | 0.013866 | −0.010247 | −0.013755 | 11 |
| 0.059614 | −0.410222 | −0.099442 | 0.099442 | 0.089317 | 0.112032 | 14 |
| −0.013908 | −0.417783 | −0.005324 | 0.005324 | −0.020841 | −0.028154 | 20 |
| 0.191313 | −0.402399 | −0.205605 | 0.205605 | 0.286604 | 0.320355 | 9 |
| Aspect | Value |
|---|---|
| Optimizer | Adam |
| Initial learning rate | 0.001 |
| Search technique | Random search |
| Batch sizes tested | 32, 16, 12 |
| Epoch numbers tested | 20, 50, 70 |
| Dropout rate | 0.10, 0.20, 0.25 |
| Hidden layers | 3, 4 |
| Random seed configuration | 42 |
| Dataset split ratio | 90% train, 10% test |
| Cross-validation | 10-fold cross-validation to ensure robustness |
| Deep Learning Model | Hidden Layers | Hidden Nodes | Activation Function | Loss Function |
|---|---|---|---|---|
| Dense neural networks | 3 | 128, 64, 32 | Relu | MSE |
| Convolutional neural networks (1D) | 3 | 64, 128, 64, kernel_size = 3, pool_size = 2 | Relu | MSE |
| AgriTransformer | 4 for each branch + 1 after fusion | 128, 64, 32, 16, 128 | Relu | MSE |
| Model | MSE (Media) | MSE (Std) | R2 (Media) | R2 (Std) |
|---|---|---|---|---|
| Linear reg. (Tabular only) | 9.399 | 0.406 | 0.703 | 0.024 |
| Linear reg. (VI only) | 31.516 | 2.008 | 0.007 | 0.009 |
| Linear reg. (Tabular + VI) | 9.364 | 0.402 | 0.704 | 0.024 |
| Dense neural networks (Tabular + VI) | 3.666 | 0.219 | 0.884 | 0.012 |
| Convolutional neural networks (Tabular + VI) | 4.726 | 1.289 | 0.849 | 0.054 |
| AgriTransformer with Tabular-attention (Tabular + VI) | 5.037 | 0.481 | 0.841 | 0.021 |
| AgriTransformer with VI-attention (Tabular + VI) | 31.832 | 1.833 | −0.002 | 0.003 |
| AgriTransformer with co-attention (Tabular + VI) | 2.598 | 0.816 | 0.919 | 0.022 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jácome Galarza, L.; Realpe, M.; Viñán-Ludeña, M.S.; Calderón, M.F.; Jaramillo, S. AgriTransformer: A Transformer-Based Model with Attention Mechanisms for Enhanced Multimodal Crop Yield Prediction. Electronics 2025, 14, 2466. https://doi.org/10.3390/electronics14122466
Jácome Galarza L, Realpe M, Viñán-Ludeña MS, Calderón MF, Jaramillo S. AgriTransformer: A Transformer-Based Model with Attention Mechanisms for Enhanced Multimodal Crop Yield Prediction. Electronics. 2025; 14(12):2466. https://doi.org/10.3390/electronics14122466
Chicago/Turabian StyleJácome Galarza, Luis, Miguel Realpe, Marlon Santiago Viñán-Ludeña, María Fernanda Calderón, and Silvia Jaramillo. 2025. "AgriTransformer: A Transformer-Based Model with Attention Mechanisms for Enhanced Multimodal Crop Yield Prediction" Electronics 14, no. 12: 2466. https://doi.org/10.3390/electronics14122466
APA StyleJácome Galarza, L., Realpe, M., Viñán-Ludeña, M. S., Calderón, M. F., & Jaramillo, S. (2025). AgriTransformer: A Transformer-Based Model with Attention Mechanisms for Enhanced Multimodal Crop Yield Prediction. Electronics, 14(12), 2466. https://doi.org/10.3390/electronics14122466