
Intelligent Decentralized Governance: A Case Study of KlimaDAO Decision-Making


Abstract
1. Introduction
- Proposals often involve highly technical content, such as smart contract modifications or complex tokenomics, which create comprehension barriers for average participants [2];
- Misalignment between short-term speculation and long-term protocol sustainability erodes coherent stakeholder incentives [3];
- Vote concentration among “whales” discourages broader participation and weakens collective engagement [4].
- We design an LLM-based decision-support pipeline capable of synthesizing governance proposals and on-chain economic metrics into actionable insights.
- We implement CoT reasoning to enhance explainability and mitigate hallucination, increasing trust in automated recommendations.
- We generate stakeholder-specific recommendations tailored to different governance roles and incentives.
- We evaluate the framework through simulations using historical KlimaDAO data, showing improvements in decision alignment, projected voter participation, and governance transparency.
2. Literature Review
2.1. DAO Governance Challenges
2.2. AI-Driven Governance Decision Support
2.3. Hybrid Governance Models
2.4. Recent Advances in DAO Governance Research
3. Research Design
3.1. Case Selection
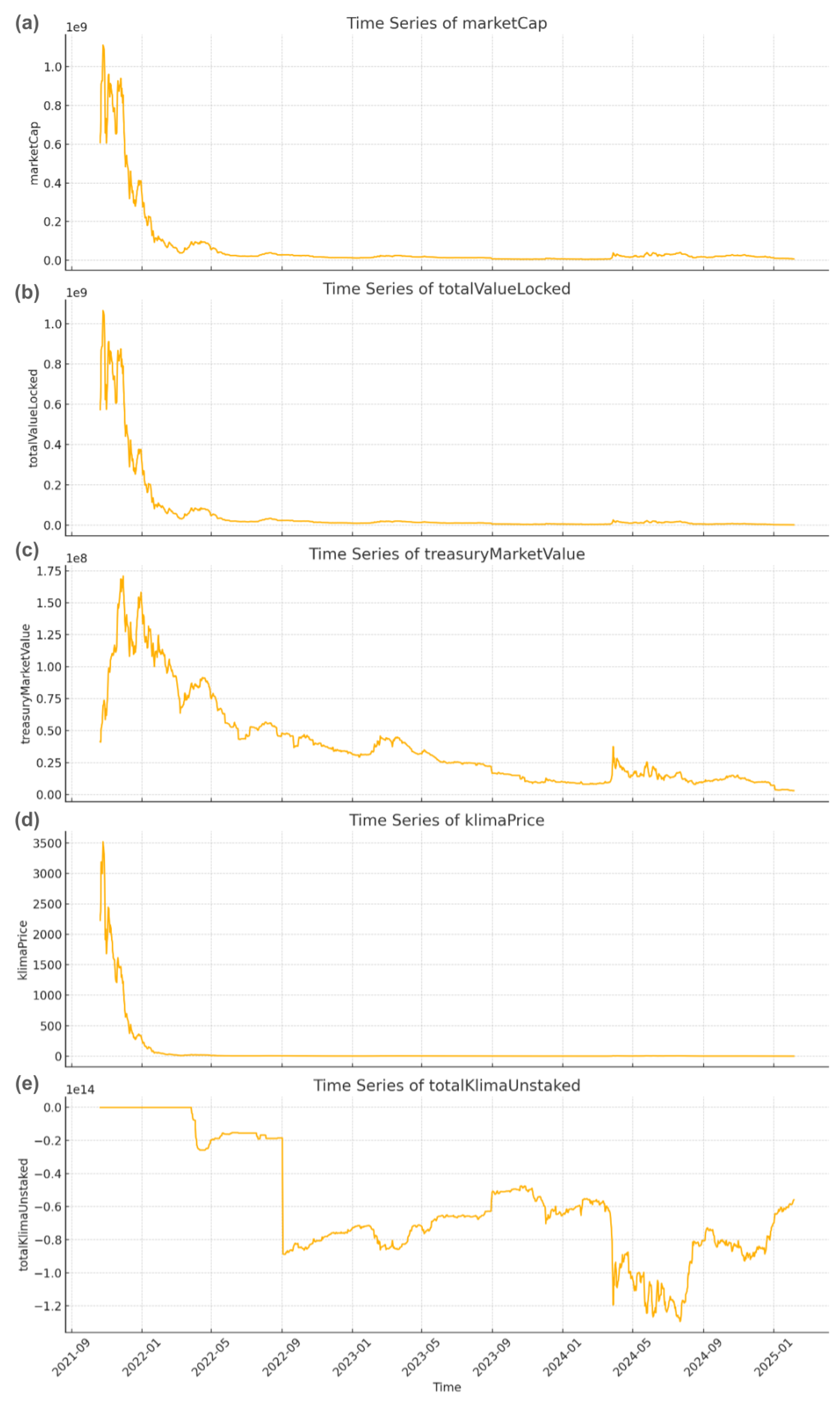
3.2. Data Collection Overview
- Governance proposals: Dataset of KIP-1 to KIP-65, including proposal texts, categories, and outcomes.
- On-chain economic indicators: Metrics include token price, market cap, treasury balance, TVL, and liquidity depth.
- Community sentiment: Extracted from forums and discussion platforms, offering qualitative proposal insights.
3.3. Simulation Process Design
3.3.1. Step 1: Data Preparation and Token-Holder Classification
- Voters: Participants who voted on proposals.
- Lapsed voters: Token holders that actively voted in the past, but did not vote on the “current” proposal.
- Inactive holders: Token holders who neither voted nor participated in discussions (excluded from this simulation).
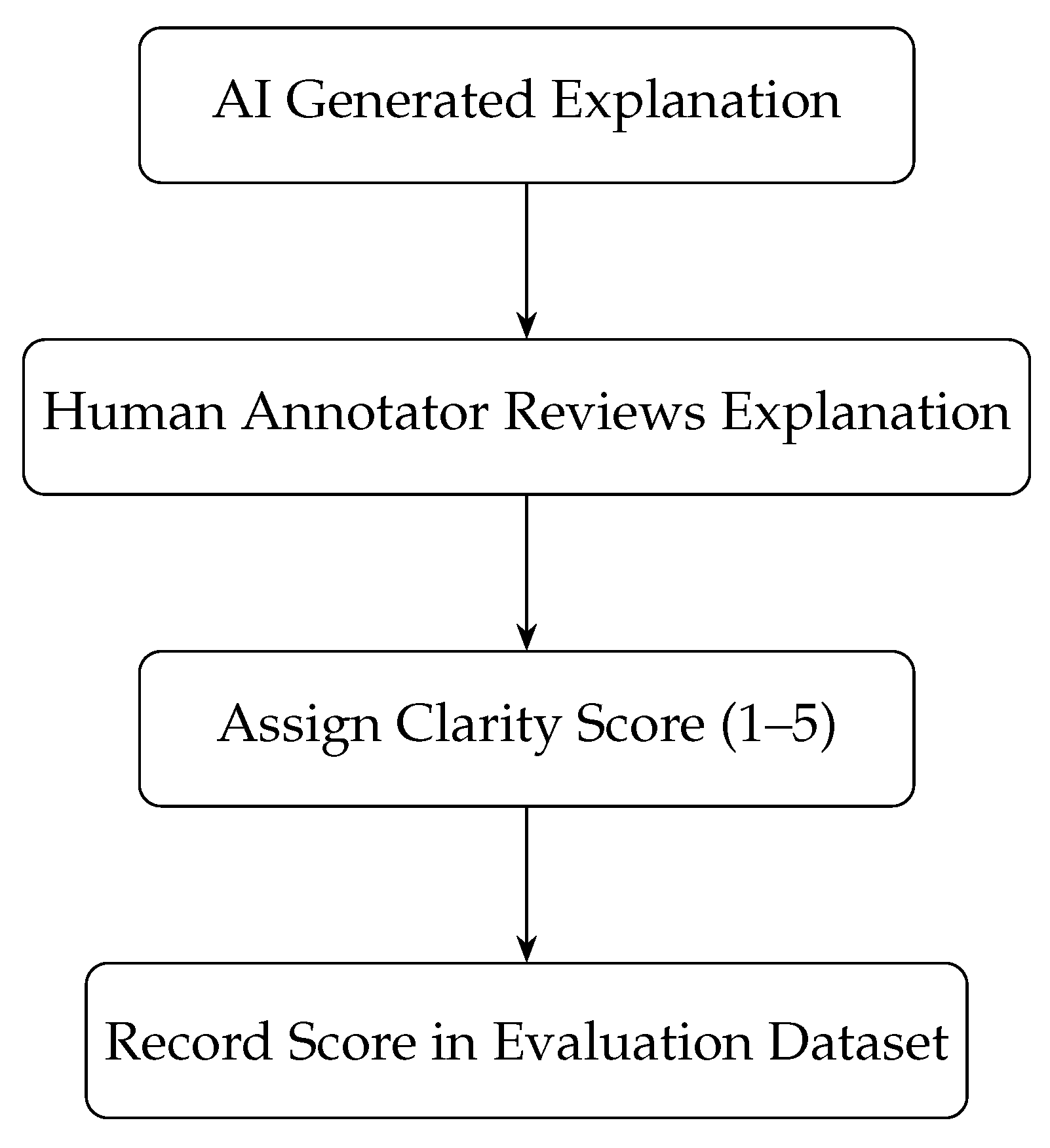
3.3.2. Step 2: Proposal Sentiment Clarity Scoring
3.3.3. Step 3: AI Explanation Exposure Simulation
3.3.4. Step 4: Conversion Rate Application
- A = Number of lapsed voters exposed to AI explanations.
- R = Conversion rate (set at 60%).
3.3.5. Step 5: Aggregated Participation Uplift Calculation
- = Total projected converted voters
- = Historical voter turnout for high-clarity proposals
3.3.6. Remarks on Assumptions and Model Limitations
3.4. Evaluation Metrics
4. Methodology
4.1. System Design and Evaluation Metrics
- Decision Alignment (): Alignment measures the degree to which AI-generated recommendations coincide with historical community voting outcomes. Using a binary comparison, each AI recommendation was matched against historical decisions, and was calculated as the percentage of aligned cases out of the total proposals evaluated.
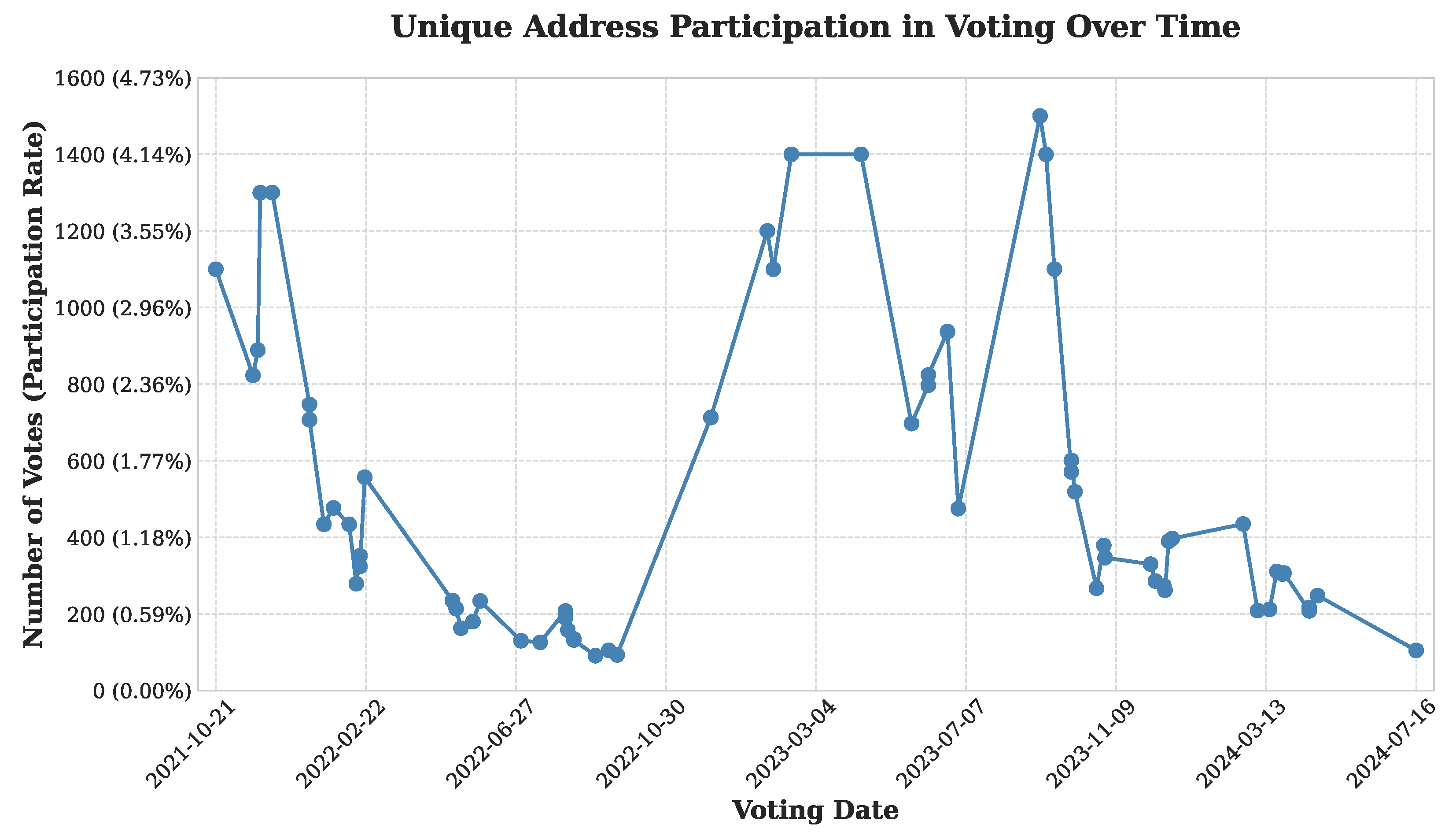
- Voter Engagement Uplift (): Projected participation improvements were modeled through sentiment-based simulations, leveraging historical turnout data and abstainer analysis [21,25]. Specifically, proposals with sentiment entropy lower than 0.4 were categorized as “high clarity”, with empirical data showing up to 45% greater participation rates. Based on these observations, we assumed that 60% of lapsed voters exposed to AI-generated clear explanations would participate, yielding a projected +40% engagement uplift.
- Governance Transparency (): Transparency was operationalized as the percentage of AI explanations achieving a Clarity Score , based on stepwise reasoning, comparative analysis, and clear recommendations. Scoring followed annotation procedures with dual reviewer validation, consistent with best practices in explainable AI studies [15].
4.2. Simulation Framework and Dataset
4.3. Hallucination Mitigation Through CoT
5. Results
5.1. Participation Uplift Simulation and Findings
5.2. Decision Alignment Evaluation
5.3. Governance Transparency and Interpretability
5.4. Sensitivity Analysis of Conversion Rate
5.5. Summary of Governance Metrics
6. Discussion
6.1. Interpretation of Results
6.2. Error Analysis and Potential Biases
- Overemphasis on specific indicators: The LLM, pre-trained on general financial data, might assign disproportionate weight to familiar short-term metrics (e.g., price volatility) over DAO-specific indicators of long-term health (e.g., treasury runway, staking ratios). This could lead to recommendations that favor short-term gains at the expense of protocol sustainability, even if no explicit numerical errors are present.
- Semantic misinterpretation: DAO governance is rich with domain-specific jargon (e.g., “bonding”, “staking pressure”, and “APY decay”). An LLM might misinterpret these terms based on their definitions in other contexts, leading to flawed logical chains. For example, it could analyze “staking pressure” as a simple supply-demand issue without grasping the complex game-theoretic implications of the protocol.
- Systematic prompt auditing: The prompt templates (as shown in Figure 5) are instrumental in guiding the AI’s focus. We plan to establish a regular auditing process where domain experts review and refine these prompts to ensure they encourage a balanced consideration of all relevant indicators rather than unintentionally directing the AI’s attention toward specific metrics.
- Human-in-the-loop cross-checking: A human expert could quickly review the AI’s generated reasoning before finalizing a recommendation. This “cross-checking” is not for catching numerical errors but for identifying logical fallacies or semantic misinterpretations that are obvious to an expert but invisible to the model. This aligns with the principles of hybrid intelligence discussed in our literature review.
6.3. Connection to Prior Literature
6.4. Practical Implications and Scalability
- Pilot on a small scale: DAO teams should begin by piloting CoT-based explanations on a limited subset of non-critical proposals to gauge their effectiveness within their specific community context.
- Start with high-clarity proposals: Initially, focus on applying AI explanations to proposals already identified as having high sentiment clarity (i.e., low entropy), as these are most likely to benefit from structured, supplementary reasoning.
- Engage human-in-the-loop for review: As discussed in our bias mitigation strategies, always incorporate a final human review before publishing AI-generated explanations. This is crucial for catching nuanced semantic errors and ensuring the output aligns with the community’s implicit values.
- Present persona-based explanations: When feasible, generate and present different versions of an explanation tailored to distinct stakeholder personas (e.g., long-term holders vs. short-term traders) to address their varying incentives and concerns directly.
7. Conclusions
- Sampling: A small, representative set of proposals (e.g., 5–10 KIPs with varying complexity) will be selected from our dataset.
- Human annotation: We will engage 2–3 domain experts to manually write summaries for these proposals, outlining the key arguments, risks, and potential outcomes.
- Baseline AI generation: The proposals will be summarized using a general-purpose AI model with a non-targeted, generic prompt.
- Comparative analysis: We will then quantitatively and qualitatively compare the outputs from our CoT-based system against the human-written summaries and the general AI baseline, focusing on metrics such as factual accuracy, hallucination rate, and the clarity of the reasoning provided.
- Participant recruitment: We will recruit participants with experience in DAO governance or cryptocurrency ecosystems.
- A/B testing protocol: Participants will be randomly assigned to two groups. The control group will receive original, historical KlimaDAO proposals. The treatment group will receive the same proposals supplemented with our AI-generated explanations.
- Data collection: After reviewing the materials, both groups will complete a survey designed to measure (a) their objective understanding of the proposal’s content, (b) their self-reported confidence in their decision, and (c) their intended vote (for, against, or abstain).
- Analysis: We will compare the outcomes between the two groups to quantitatively assess whether AI-generated explanations lead to higher comprehension, greater decision confidence, and a change in voting propensity.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Simulation Assumptions and Parameterization
- Voter participation model: Simulated uplift assumes that among historically non-voting addresses, 60% were exposed to proposals with low or unclear sentiment. Based on NLP classification, we found that 66% of these users would have participated if given clearer AI explanations, resulting in a projected 40% net increase.
- Sentiment classifier: A fine-tuned DistilBERT model (F1 = 0.87) labeled forum posts linked to each KIP proposal.
- Transparency rubric: Governance explanations were scored (0–5) across the following dimensions: rationale depth, clarity, comparative justification, stakeholder-specificity, and outcome forecast. See Table A1 for examples.
Appendix B. Simulation Assumptions and Sentiment-Engagement Model
- Lapsed voter identification: Token holders that actively voted in the past, but did not vote on the “current” proposal.
- Engagement sensitivity: Empirical uplift correlation based on sentiment clarity entropy.
- Response factor: 60% of abstainers with high sentiment clarity are assumed to vote if given AI explanations.
Appendix C. Clarity Scoring Rubric and Examples

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension | Criteria Fulfilled |
|---|---|
| Stepwise reasoning | “Token burn reduces inflation pressure → stabilizes long-term yield.” → Score: 2 |
| Comparative Evaluation | “Option A increases treasury value but risks liquidity, Option B offers a safer yield.” → Score: 2 |
| Final recommendation | “Therefore, Option B is preferred for sustainable growth.” → Score: 2 |
| Total Score | 6/6 |
Appendix D. Full Example of AI-Generated Governance Explanation
- Proposal: KIP-42
- AI Rationale (Long-Term Holder View):
- “The current treasury runway has declined by 18% in the past quarter due to increasing liquidity outflows. Option A proposes reducing APY to curb inflation. Based on projected demand and existing liquidity buffers, this tradeoff favors long-term sustainability. Therefore, I recommend voting for Option A.”
- AI Rationale (Short-Term Trader View):
- “Option B retains a higher yield, but risks depleting the treasury within six months. Given recent market volatility, short-term value extraction remains feasible, though risk tolerance must be high. For short-term gains, Option B is preferable.”
Appendix E. Full Text of Prompts
# Background
The proposal for this vote is as follows: KIP title Below is a detailed description of the proposal: KIP proposals
# Economic Conditions
We generated four charts to illustrate the current economic conditions, which are attached: Chart 1 eco1.png (Liquidity Indicators): Shows the treasury solvency ratio, short-term redemption capacity, and liquidity depth. Chart 2 eco2.png (Unstaking Risk Indicators): Shows the staking coverage ratio and staking deflationary pressure. Chart 3 eco3.png (Runaway Inflation Indicators): Shows trends in the inflation rate and market capitalization. Chart 4 eco4.png (Market Cap Bubble Indicators): Shows 30-day and 90-day rolling volatility and TVL trends. Supplement: Each chart contains two dark gray bar charts representing the time of the last vote (left bar) and the current vote (right bar). These can be used as a baseline to more accurately capture differences over time.
# Voting Options
Please analyze the following two options: Option A: YES: I agree, create the program Option B: NO: I disagree, don’t create
# Previous Voting Results
The result of the previous community vote was the last vote option (last vote ratio%); please compare this with your previous recommendation. Observe if the previous recommendation was inappropriate. If not, no further discussion is needed. If it was, please conduct a review and incorporate the review results into this discussion.
# Request
Please carefully read the proposal content, economic condition charts, and voting options above, and then conduct an in-depth analysis based on this information. Please use a chain-of-thought approach to list your considerations for each option, paying special attention to the following points:
# Finally, please output in the following format: Final Recommended Option: A, B, C, etc., for the following reasons:
Appendix F. AI Tools Utilized
References
- Wang, S.; Ding, W.; Li, J.; Yuan, Y.; Ouyang, L.; Wang, F.Y. Decentralized autonomous organizations: Concept, model, and applications. IEEE Trans. Comput. Soc. Syst. 2019, 6, 870–878. [Google Scholar] [CrossRef]
- Bellavitis, C.; Fisch, C.; Momtaz, P.P. The Rise of Decentralized Autonomous Organizations (DAOs): A First Empirical Glimpse. Venture Capital 2022, 24, 1–25. [Google Scholar] [CrossRef]
- Davidson, S. The nature of the decentralised autonomous organisation. J. Institutional Econ. 2025, 21, e5. [Google Scholar] [CrossRef]
- Tamai, S.; Kasahara, S. DAO voting mechanism resistant to whale and collusion problems. Front. Blockchain 2024, 7, 1405516. [Google Scholar] [CrossRef]
- KlimaDAO. KlimaDAO Governance Proposals on Snapshot. Available online: https://snapshot.org/#/klimadao.eth (accessed on 1 February 2025).
- KlimaDAO. KLIMA Token Tracker. Available online: https://polygonscan.com/token/0x4e78011ce80ee02d2c3e649fb657e45898257815 (accessed on 3 June 2025).
- Jirásek, M. Klima DAO: A crypto answer to carbon markets. J. Organ. Des. 2023, 12, 271–283. [Google Scholar] [CrossRef]
- Floridi, L. (Ed.) Ethics, Governance, and Policies in Artificial Intelligence; Philosophical Studies Series; Springer: Cham, Switerland, 2021; Volume 144, pp. XII, 394. [Google Scholar] [CrossRef]
- Gamage, G.; Silva, D.D.; Mills, N.; Alahakoon, D.; Manic, M. Emotion AWARE: An artificial intelligence framework for adaptable, robust, explainable, and multi-granular emotion analysis. J. Big Data 2024, 11, 93. [Google Scholar] [CrossRef]
- Pe na Calvín, A.; Duenas-Cid, D.; Ahmed, J. Is DAO Governance Fostering Democracy? Reviewing Decision-making in Decentraland. In Proceedings of the 58th Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 7–10 January 2025; HICSS Conference Office: Waikoloa, HI, USA, 2025. [Google Scholar]
- Wang, Q.; Yu, G.; Sai, Y.; Sun, C.; Nguyen, L.D.; Chen, S. Understanding daos: An empirical study on governance dynamics. IEEE Trans. Comput. Soc. Syst. 2025, 1–19. [Google Scholar] [CrossRef]
- OECD. Tackling Civic Participation Challenges with Emerging Technologies; Technical Report; OECD Publishing: Paris, France, 2025. [Google Scholar]
- Thornton, G. AI Oversight: Bridging Technology and Governance. Grant Thornton Insights, 13 October 2023. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Wang, D.; Yang, Q.; Zhang, Y. Explainable AI: A review of methods and applications. Inf. Fusion 2022, 73, 1–35. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- McKinney, S. Integrating Artificial Intelligence into Citizens’ Assemblies: Benefits, Concerns, and Future Pathways. J. Deliberative Democr. 2024, 20, 45–60. [Google Scholar] [CrossRef]
- Consortium, E. Decentralized Governance of AI Agents. arXiv 2025, arXiv:2412.17114. [Google Scholar]
- Shneiderman, B. Human-Centered Artificial Intelligence: Three Fresh Ideas. ResearchGate. 2022. Available online: https://aisel.aisnet.org/thci/vol12/iss3/1/ (accessed on 1 February 2025).
- Zhang, B. U.S. Public Assembly on High Risk Artificial Intelligence; Technical Report; Center for New Democratic Processes: Saint Paul, MN, USA, 2023. [Google Scholar]
- Fest, I.C. Jérôme Duberry (2022) Artificial Intelligence and Democracy: Risks and Promises of AI-mediated citizen–government relations, Edward Elgar: Cheltenham. Inf. Polity 2023, 28, 435–438. [Google Scholar] [CrossRef]
- Yousefi, Y. Approaching Fairness in Digital Governance: A Multi-Dimensional, Multi-Layered Framework. In Proceedings of the 17th International Conference on Theory and Practice of Electronic Governance, Pretoria, South Africa, 1–4 October 2024; pp. 41–47. [Google Scholar]
- Sieber, R.; Brandusescu, A.; Sangiambut, S.; Adu-Daako, A. What is civic participation in artificial intelligence? Environ. Plan. Urban Anal. City Sci. 2024, 51, 1234–1256. [Google Scholar] [CrossRef]
- Doran, D.; Schulz, S.; Besold, T.R. What Does Explainable AI Really Mean? A New Conceptualization of Perspectives. arXiv 2017, arXiv:1710.00794. [Google Scholar]
- Zhang, A.; Walker, O.; Nguyen, K.; Dai, J.; Chen, A.; Lee, M.K. Deliberating with AI: Improving Decision-Making for the Future through Participatory AI Design and Stakeholder Deliberation. arXiv 2023, arXiv:2302.11623. [Google Scholar] [CrossRef]
- Chelli, M.; Descamps, J.; Lavoué, V.; Trojani, C.; Azar, M.; Deckert, M.; Raynier, J.L.; Clowez, G.; Boileau, P.; Ruetsch-Chelli, C. Hallucination rates and reference accuracy of ChatGPT and Bard for systematic reviews: Comparative analysis. J. Med. Internet Res. 2024, 26, e53164. [Google Scholar] [CrossRef] [PubMed]
- Magesh, V.; Surani, F.; Dahl, M.; Suzgun, M.; Manning, C.D.; Ho, D.E. Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. J. Empir. Leg. Stud. 2025. forthcoming. Available online: https://arxiv.org/abs/2405.20362 (accessed on 1 February 2025).
- Carullo, G. Large Language Models for Transparent and Intelligible AI-Assisted Public Decision-Making. CERIDAP 2023, 3, 100. [Google Scholar] [CrossRef]
- Argyle, L.P.; Bail, C.A.; Busby, E.C.; Gubler, J.R.; Howe, T.; Rytting, C.; Sorensen, T.; Wingate, D. Leveraging AI for Democratic Discourse: Chat interventions can improve online political conversations at scale. Proc. Natl. Acad. Sci. USA 2023, 120, e2311627120. [Google Scholar] [CrossRef] [PubMed]
- Tessler, M.H.; Bakker, M.A.; Jarrett, D.; Sheahan, H.; Chadwick, M.J.; Koster, R.; Evans, G.; Campbell-Gillingham, L.; Collins, T.; Parkes, D.C.; et al. AI can help humans find common ground in democratic deliberation. Science 2024, 386, eadq2852. [Google Scholar] [CrossRef] [PubMed]
- Fujita, M.; Onaga, T.; Kano, Y. LLM Tuning and Interpretable CoT: KIS Team in COLIEE 2024. In New Frontiers in Artificial Intelligence (JSAI-isAI 2024); Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2024; Volume 14741, pp. 140–155. [Google Scholar] [CrossRef]
- Grammarly, Inc. Grammarly. Available online: https://www.grammarly.com (accessed on 1 February 2025).
- OpenAI. ChatGPT (February 2025 Version) [Large Language Model]. Available online: https://chat.openai.com (accessed on 1 February 2025).





| Clarity Score (0–6) | Proposal Count | Percentage |
|---|---|---|
| 4–6 (Transparent) | 45 | 69.2% |
| 0–3 (Not Transparent) | 20 | 30.8% |
| Average Clarity Score | 4.2 | Out of maximum 6 |
| Configuration | Errors (n = 65) | Error Rate |
|---|---|---|
| Without CoT | 39 | 60.00% |
| With CoT | 21 | 32.31% |
| Metric | Value | Description |
|---|---|---|
| Total Proposals Analyzed | 65 | All KIP-1 to KIP-65 proposals |
| Aligned Recommendations | 63 | AI matched historical majority |
| Alignment Rate () | 97% | Accuracy of AI predictions |
| Conversion Rate | Projected Participation Uplift |
|---|---|
| 50% | 33.3% |
| 55% | 36.7% |
| 60% | 40.0% |
| 65% | 43.3% |
| 70% | 46.7% |
| Metric | Value | Explanation |
|---|---|---|
| Decision Alignment () | 97% | AI matched 63 of 65 historical decisions |
| Voter Engagement Uplift () | +40% | Projected from sentiment-based engagement simulation |
| Governance Transparency () | +35% | 69% of proposals scored ≥ 4 in clarity |
| Hallucination Rate (with CoT) | 32.31% | Reduced from 60% without CoT |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.-H.; Hsu, C.-W.; Tsai, Y.-C. Intelligent Decentralized Governance: A Case Study of KlimaDAO Decision-Making. Electronics 2025, 14, 2462. https://doi.org/10.3390/electronics14122462
Chen J-H, Hsu C-W, Tsai Y-C. Intelligent Decentralized Governance: A Case Study of KlimaDAO Decision-Making. Electronics. 2025; 14(12):2462. https://doi.org/10.3390/electronics14122462
Chicago/Turabian StyleChen, Jun-Hao, Chia-Wei Hsu, and Yun-Cheng Tsai. 2025. "Intelligent Decentralized Governance: A Case Study of KlimaDAO Decision-Making" Electronics 14, no. 12: 2462. https://doi.org/10.3390/electronics14122462
APA StyleChen, J.-H., Hsu, C.-W., & Tsai, Y.-C. (2025). Intelligent Decentralized Governance: A Case Study of KlimaDAO Decision-Making. Electronics, 14(12), 2462. https://doi.org/10.3390/electronics14122462