1. Introduction
Improving and recognizing underwater images is vital for diverse underwater exploration and research activities, including underwater robotics, marine studies, resource discovery, and archeological investigations [
1,
2]. The underwater environment degrades image quality due to water absorption and scattering, reducing contrast, color, and sharpness [
3]. This poses a challenge to traditional processing methods. Underwater image enhancement (UIE) [
4,
5] aims to restore color, sharpness, and detail, thereby enhancing the precision of tasks like object recognition [
6] and trajectory planning.
Key challenges in UIE are light refraction and color distortion, leading to blue/green hues and changed contrast. Enhancement improves color realism and object recognition, crucial for underwater tasks. Integrating enhancement with recognition boosts system robustness and automation, allowing underwater robots [
7] to navigate and work autonomously in complex scenarios, thus enhancing efficiency and application scope.
Underwater images often suffer from poor quality, manifested as color distortion, low contrast, and structural degradation such as blurred details. This degradation primarily stems from the absorption and scattering of light caused by impurities in water. Crucially, the attenuation of light underwater is uneven across different color channels and spatial regions. For instance, red light typically attenuates faster than green and blue light. This uneven attenuation is the fundamental cause of the observed color distortion and loss of image detail.
Several studies have explored the challenges of UIE [
8,
9,
10,
11,
12,
13,
14,
15]. UDnet [
13] is an unsupervised UIE framework that combines U-Net and PAdaIN [
16], employing a convolutional neural network as well as Probabilistic Adaptive Instance Normalization (PAdaIN). The framework is able to transform global enhancement statistics, encode uncertainty, and introduce a multi-color spatial stretching method based on the guidance of multiscale statistical information as a way to enhance contrast and optimize color performance. Nonetheless, there are still areas for enhancement regarding color and visualization of UDnet-enhanced images compared to the reference image. DewaterNet [
17] is an advanced underwater image enhancement network that improves image quality by integrating Generative Adversarial Networks (GANs) [
18] and multi-term objective functions. This approach achieves good results in color correction and contrast enhancement, effectively addressing common color distortion issues in underwater images and enhancing their visual contrast. Nonetheless, U-Net-based models do not adequately enhance parts of underwater images that suffer from severe attenuation across color channels and spatial regions. Compared to reference images, there is still room for improvement in terms of the color and visualization of the enhanced images by UDnet. It may not fully achieve the desired level of naturalness and clarity when processing images with rich colors and complex structures. The U-Shape Transformer [
19] integrates ViT and specially designed multiscale feature fusion transformers and global feature modeling transformers for the UIE task. This approach demonstrates richer color representation and higher accuracy when dealing with underwater images that suffer from inconsistent attenuation across different color channels and spatial regions. Moreover, it provides more ideal detail recovery and rendering effects in the processing of complex structures. Despite this, the model still has limitations in terms of color and semantic structure for underwater images under specific scenarios.
To address the structural issues of color distortion, low contrast, and blurred details, we introduce a bootstrap evaluation framework that evaluates underwater image quality through multi-branch cooperative learning mechanisms. We incorporate the pre-trained MCOLE [
20] model to process the original images for bootstrapping training, ensuring that the generated enhanced images exhibit greater similarity to reference images in terms of color accuracy and visual clarity.
To further tackle the issue of inconsistent attenuation across different color channels and spatial regions in underwater images, we integrate a visual transformer (ViT) [
21] in the feature extraction module. The ViT segments the image into fixed-size blocks and treats these blocks as continuous inputs to model the global information through the self-attentive mechanism. Unlike U-Net networks and GANs, it can effectively capture long-range dependencies and global features in images and better address the issue of inconsistent attenuation in different regions of underwater images. We derive hierarchical features through parallel analysis of distinct quality attributes such as chromatic properties and structural visibility to improve assessment accuracy and interpretability. The method enables an objective assessment of enhancement techniques and helps to accomplish tasks such as underwater image defogging, color correction, and contrast enhancement. Our main contributions are as follows:
Color-guided evaluation construction: An innovative loss function framework is proposed to enhance image quality by synergistically combining three distinct components: MCOLE-driven perceptual loss, color space constraints, and structural feature MSE. This method addresses the limitations of traditional VGG-16 [
22] perceptual loss and MSE by optimizing color and structural similarity in a unified manner. Experimental evaluations show that this multi-faceted approach achieves advanced results in PSNR and SSIM, outperforming baseline methods by a significant margin.
Optimizing the design of feature extraction structure: ViT is innovatively integrated into the feature extraction module, replacing the conventional method and accurately capturing global features. This approach effectively addresses the challenge of inconsistent attenuation in different areas of underwater images. Additionally, the multiscale feature fusion strategy is employed, allowing the model to thoroughly extract image features from various levels and scales. As a result, the model can acquire image information more comprehensively, significantly improving its adaptability to complex scenes. In non-referenced evaluation, this feature extraction structure enables the model to deliver outstanding performance, effectively enhancing the image’s clarity, color richness, and contrast.
2. Related Work
Although difficult, UIE is a rewarding endeavor that addresses issues such as color imbalance, diminished contrast, reduced brightness, and increased noise levels [
3]. There are three main approaches to tackling these problems: model-free methods, deep learning-based methods, and probability-based methods.
2.1. Model-Free Methods
Model-free methods optimize underwater imagery through pixel-level manipulation paradigms, bypassing dependency on preformulated computational frameworks while maintaining photometric integrity through direct signal transformation operations. The SPDF framework [
23] generates two complementary versions of an image—one with corrected contrast and the other with sharpened details—through preprocessing. These are divided into three separate elements: mean intensity, contrast, and structure, which are then fused in a perceptually aware image space and integrated through the inverse decomposition process to rebuild the enhanced image. The MLLE method [
24] dynamically enhances contrast by locally modifying color and fine details through the computation of local block statistics (mean and variance). It introduces a strategy for color equilibrium in the CIELAB color space, significantly improving color vividness, contrast, and detail. TOPAL [
25] enhances visual contrast and performs color correction using multiscale dense boosting and advanced aesthetic rendering modules, and integrates details with a dual-channel attention module. This approach utilizes a multiscale adversarial framework to reduce discrepancies between synthetic and authentic visual data, integrating perceptual cues to enhance scene understanding.
Model-free UIE methods are efficient in computation and easy to integrate, thereby enabling live processing and environments with limited hardware resources. They do not rely on prior knowledge, offering better generalizability and lightweight characteristics, which allow for rapid deployment and effective image enhancement. However, these methods have limited adaptability and struggle to handle complex underwater environments and dynamic scenes. They are prone to over-enhancement and lack global consistency, and they cannot effectively model the uncertainties in the underwater imaging process, leading to instability in complex scenes. Thus, those methods are only applied for image enhancement after generating three reference images in our approach, and it introduces uncertainty to help the resulting virtual reference images more closely approximate the real reference images.
2.2. Deep Learning-Based Methods
Deep learning-based methods improve UIE by learning from training datasets. FloodNet [
26] employs a multiscale feature fusion and enhancement method to achieve feature extraction and hierarchical fusion. It utilizes adaptive local–global residual learning to generate high-quality restored images. ADMNNet [
27], with its attention-guided dynamic multi-branch structure, overcomes the limitations of traditional convolutional neural networks by incorporating attention mechanisms and dynamic fusion of multiscale features. It employs a dynamic feature optimization method to enhance feature representation by adjusting receptive field sizes and channel attention. WaveNet [
28] dynamically adjusts receptive field sizes based on color channel propagation and introduces an attention-based skip mechanism for better performance. LiteEnhanceNet [
14], a lightweight network, reduces computational complexity with depthwise separable convolution and one-shot aggregation connections while maintaining high image enhancement performance through activation functions and a squeeze-and-excitation module. SNR-Net [
29] presents a dual-branch approach for UIE by merging transformer models, which are based on the Signal-to-Noise Ratio (SNR), with convolutional networks. By dynamically enhancing pixel quality and strengthening multiscale feature perception, it effectively improves color imbalance, underexposure, and blurriness in underwater images. CE-CGAN [
30] enhances image quality by using a generator to map input image features to high-contrast images and employing a discriminator to classify both generated and real images. UDAformer [
31] is a method for UIE that utilizes a dual-attention Transformer. It efficiently encodes and decodes underwater image features through a dual-attention feature encoding and decoding method. The method uses residual connections to restore underwater images, significantly improving the enhancement results. Phaseformer [
32] proposes a lightweight phase-based Transformer framework for underwater image reconstruction. The method extracts clean features through a phase self-attention mechanism and restores structural information by propagating salient features using an optimized phase attention module.
These methods leverage the powerful capabilities of convolutional neural networks (CNNs) [
33], GANs, and Transformers [
34] to adapt to various underwater environments. Substantial advancements have been achieved in enhancing underwater images through deep learning-based approaches. However, they face challenges such as high data dependency, limited generalization ability, high computational complexity, and insufficient modeling of the underwater imaging process. Although Transformers demonstrate notable strengths in capturing long-range dependencies and enabling parallel computation, enabling them to better capture global features in underwater images, they also have drawbacks such as elevated computational resource utilization, long training times, and a high demand for large-scale data. These issues limit their practical application in complex and dynamic underwater environments. Therefore, in subsequent methods, we skillfully introduce uncertainty into the U-Net-based network and employ ViT to capture global features, thereby simulating diverse underwater environments and enhancing the model’s generalization ability.
2.3. Probabilistic-Based Methods
Probability-based deep learning methods, especially Conditional Variational Autoencoders (cVAEs) [
35], incorporate uncertainty modeling to manage perturbations, modeling errors and inherent uncertainties in underwater environments. These methods utilize Variational Autoencoders (VAEs) [
36], which map input data to a compact feature space and restore it through a decoding process. Unlike traditional encoders, VAEs model the probability distributions of latent variables, enabling better handling of diverse data characteristics. During training, regularization and reconstruction losses ensure effective data representation by minimizing discrepancies between posterior and prior distributions.
Recent research, such as PUIE-Net [
16], combines cVAEs with adaptive instance normalization to formulate an improvement distribution for degraded underwater images. By utilizing a consensus approach to anticipate predictable conclusions, it addresses the ambiguity of reference maps and reduces bias. This method improves adaptability to labeling biases while maintaining result stability. Experimental results demonstrate its competitive performance on multiple real-world datasets. Building on this, UDNet [
13] establishes an end-to-end framework that synergistically combines an adaptive uncertainty quantification module with a stochastic reference sample selection strategy during training, systematically enhancing cross-domain generalization performance in visual computing systems.
Probabilistic methods, such as cVAEs and VAEs, effectively handle disturbances and uncertainties in underwater environments by integrating uncertainty modeling. These methods capture diverse data characteristics through probability distributions, generate varied enhanced results, and improve model generalization via techniques like PAdaIN. However, their training process is complex, requiring optimization of reconstruction loss and regularization terms, which may lead to unstable training. In the subsequent methods, we optimized the loss functions and regularization terms of the probabilistic methods, making them more stable and efficient.
3. Methods
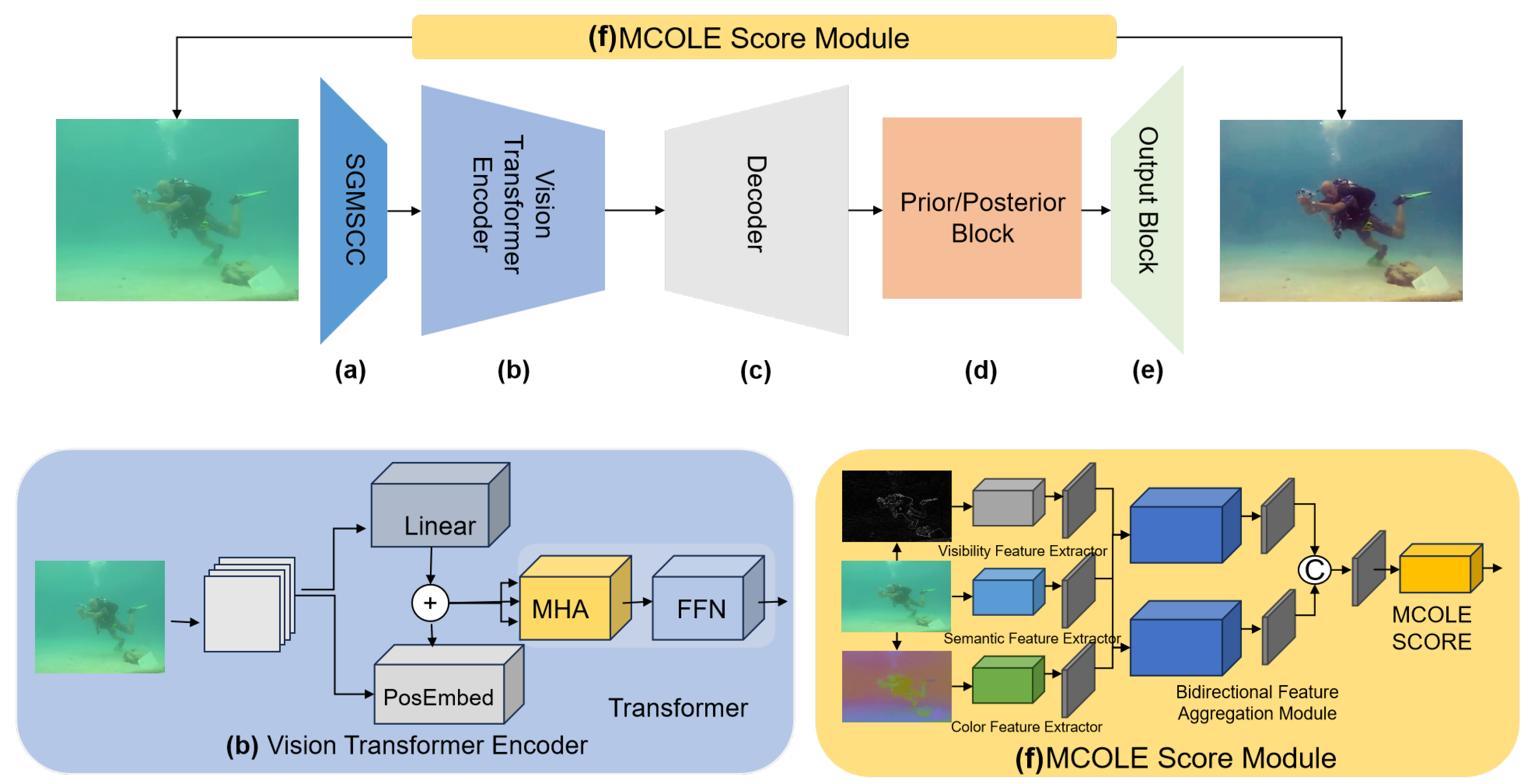
To alleviate the inconsistency of the model in color attenuation regions, we have integrated ViT as the feature extractor into the UDnet framework. ViT is capable of effectively capturing the characteristics of spatial regions in images, thereby enabling the entire network to better handle complex underwater scenes and providing a more robust foundation for multi-color space stretching and uncertainty modeling. Meanwhile, to enhance the capacity of the model to perceive images, we have incorporated the MCOLE score module into the loss function. The MCOLE score module can comprehensively evaluate the enhanced images in terms of color and visual features, thereby further optimizing the model’s performance. We present the overall architecture in
Figure 1.
3.1. Network Structure
The original image first goes through the Statistically Guided Multi-Color Space Stretch (SGMCSS) (a) to generate a reference image. Then the ViT (b) is used to replace the initial feature descriptors of UDnet, allowing the network to more effectively capture global information and increase its focus on areas with low visibility or significant degradation. The input feature map has dimensions of
H ×
W ×
C. For the sequence compatible with transformer architectures, the feature map of the input data is decomposed into a sequence of flattened 2D patches
. Here,
L refers to the patch resolution, while
N stands for the number of patches obtained. To retain the valuable positional details of each area, learnable position embeddings are directly incorporated, which can be formulated as follows:
where Linear denotes a linear projection process, and PosEmbed signifies a position embedding process.
The feature sequence
is introduced into the transformer encoder block, which is composed of
transformer encoder layers. The transformer encoder layer processes the sequence through multi-head self-attention (MSA) and multi-layer perceptron (MLP) blocks,
This formulation employs LN to represent layer normalization operations, with corresponding to the feature sequence generated from the l-th transformer layer’s computational process.
The final transformer block outputs a feature sequence , which contains spatial and color information. This sequence is passed into the prior and posterior processing module. After passing through the decoder (c), the sequence is then transferred to the Prior/Posterior Block (d). This module aims to calculate the mean and standard deviation distributions, which helps determine the potential enhancements for the image. Finally, the enhanced image is output through the Output Block (e).
3.2. MCOLE Score Module
The MCOLE (f) method enhances underwater image quality through multi-level feature fusion. It first extracts three key features—color (YCbCr), structural visibility (Gradient), and semantic (RGB) features—from the image using different layers of the VGG-11 [
22] network. These features are then fused via the Bidirectional Feature Aggregation Module (BFAM), which includes the Global Context Interaction Module (GCIM) and the Bidirectional Visual Fusion Module (BVFM) for feature compression, fusion, and aggregation.
MCOLE relies on VGG-11 to extract color, structural, and semantic features. The YCbCr color space isolates luminance (Y) from chrominance (Cb, Cr), which enhances color accuracy. The gradient map highlights structural details, especially background elements that are often overlooked. Therefore, we first preprocess the image by converting RGB to YCbCr and generating a gradient map for feature extraction. In our implementation, we use the Scharr operator [
37] to generate the gradient map, which effectively obtains the structural details of the image.
The YCbCr color space and gradient map are processed using VGG-11 as the backbone network to extract color features and structural visibility features. After optimization with a dataset, the color features
, structural visibility features
, and semantic features
can be obtained as follows:
Then the GCIM method adopts the following workflow after feature extraction: First, a 1 × 1 convolutional layer is applied to reduce the dimensionality of feature channels. Subsequently, the processed features undergo non-linear transformation through the Sigmoid activation function. This pipeline ultimately generates spatial attention-guided weight distribution maps that capture position-wise importance across feature representations. Specifically, the GCIM operation is articulated as follows:
Next, the BVFM progressively aggregates these fused features along both bottom–up and top–down paths, reducing computational burden and extracting key information:
where FB denotes the BVFM, indicating the feature aggregation process using convolution, max-pooling, the position attention module (PAM) [
38], and the channel attention module (CAM) [
38] to enhance the features.
Finally, MCOLE concatenates the bottom–up and top–down features and passes them through three fully connected layers to yield the final quality score:
where
represents the quality prediction function. Through this multi-level, bidirectional feature aggregation and quality prediction process, MCOLE effectively enhances underwater image quality and provides accurate quality assessment.
3.3. Loss Function
The DeepSeaNet model is constructed based on the cVAEs, and its training process optimizes the variational lower bound to achieve feature learning. Compared with traditional deterministic enhancement models, the innovation of this system lies in the probabilistic modeling of enhancement statistics in the latent space. Specifically, a dual-channel posterior inference module is designed in the network architecture. Through deep feature analysis, the input image is mapped to a parameterized Gaussian distribution, and latent variables are sampled from the mean
and standard deviation
of this distribution for image reconstruction. Thus, to improve the enhancement performance of the model, the total loss function we designed consists of the enhancement loss and the Kullback–Leibler (KL) [
39] divergence loss. The enhancement loss is composed of the MSE loss and the perceptual loss, while the KL divergence loss is made up of the KL divergence losses based on variance and mean.
In terms of loss function design, the system adopts a multi-dimensional error joint optimization strategy:
The first two terms measure the structural similarity in the visible light band and the MSE in the color space. The innovative use of the MCOLE scoring mechanism to construct the perceptual loss involves calculating the score
of the enhanced image through a pre-trained quality evaluation network and establishing the negative log-likelihood loss
This design guides the model to generate images with superior quality that conform to human visual perception through backpropagation. The hyperparameter employs a dynamic adjustment strategy to adaptively balance the relationship between pixel precision and perceptual quality in the training process.
In terms of probabilistic modeling, the system uses KL divergence to constrain the matching of latent variable distributions. The KL divergence loss based on variance and mean is as follows:
Here, represents the mean and represents the variance of the prior distribution, while and are the posterior estimates. This normalization strategy guarantees that the hidden space retains the critical features of the data while avoiding overfitting.
The final objective function integrates the enhancement loss and the distribution alignment term:
The balance coefficient is determined through grid search. This hybrid optimization mechanism enables the model to maintain its capability to restore details while effectively enhancing its adaptability to underwater optical distortions.
6. Discussion
The DeepSeaNet model innovatively introduces the MCOLE scoring module in the UDnet framework and the global attention mechanism in the encoder, which exhibits significant performance improvement in UIE. Performing effective capture of global features and long-range dependencies in underwater images is essential to solving the problem of inconsistent region attenuation. Especially when dealing with underwater images with blue, green, and yellow tones, our model can effectively filter these tones and restore the real colors more accurately, whereas other models such as Funie-GAN may perform well on some tones but may suffer from color distortion on other tones.
In addition, DeepSeaNet performs well in handling noise introduced by scattered light. DeepSeaNet demonstrates superior capabilities in systematic noise suppression and structural refinement compared to conventional approaches like U-Shape Transformer, which tend to introduce high-frequency artifacts and amplify structural artifacts during enhancement procedures. Through multistage feature purification, our architecture achieves a balanced preservation of critical edge information while enhancing textural fidelity in processed visual outputs. Compared with brightness enhancement models such as LiteEnhanceNet, our model not only heightens the image brightness but also sharpens the contrast, making the image brighter and more vivid.
Our analysis highlights the significant impact of different encoders on model performance. Unlike the U-Net encoder, the ViT encoder shows a significant enhancement in PSNR, SSIM, and MSE metrics, highlighting its superior performance in image restoration tasks. This advantage arises from the ViT encoder’s use of the Transformer framework, which allows it to efficiently grasp long-range dependencies within images—a key factor in restoring overall structure and fine details. In contrast, while the U-Net encoder performs reasonably well in extracting local features, its ability to handle complex image scenarios is relatively constrained.
By conducting ablation studies, we were able to identify the critical contributions of the loss function’s various components to how the model performs. Findings indicate that eliminating the enhancement loss results in the most significant reduction in PSNR and SSIM values, which highlights its crucial role in improving image quality and structural similarity. Removing the KL scattering loss, on the other hand, mainly affects PSNR values, highlighting its importance in optimizing image brightness and contrast. These findings demonstrate the important role of these loss function components in driving model performance. Despite DeepSeaNet’s excellent performance in image enhancement, there are still some limitations. For example, although and contribute significantly to performance, the model may not be able to completely remove all distortions in complex scenarios such as high-noise or extreme-lighting conditions. In addition, the current loss function design may not be robust enough for certain types of images such as low-contrast or high-dynamic-range images. These limitations suggest that although the current design is effective in most cases, further optimization is needed to cope with more challenging scenarios and enhance the model’s ability.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}