
Empirical Analysis of Learning Improvements in Personal Voice Activity Detection Frameworks


Abstract
1. Introduction
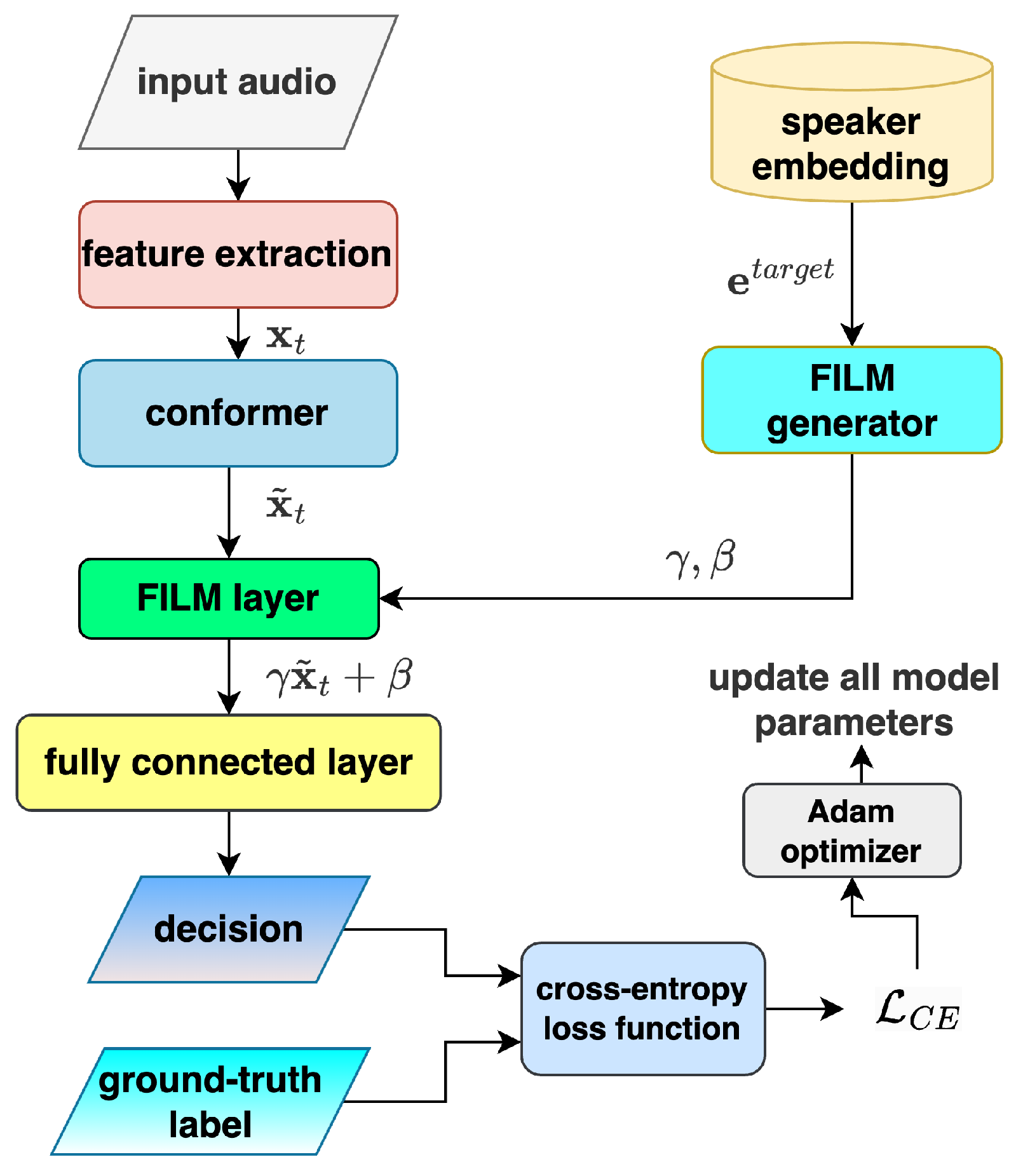
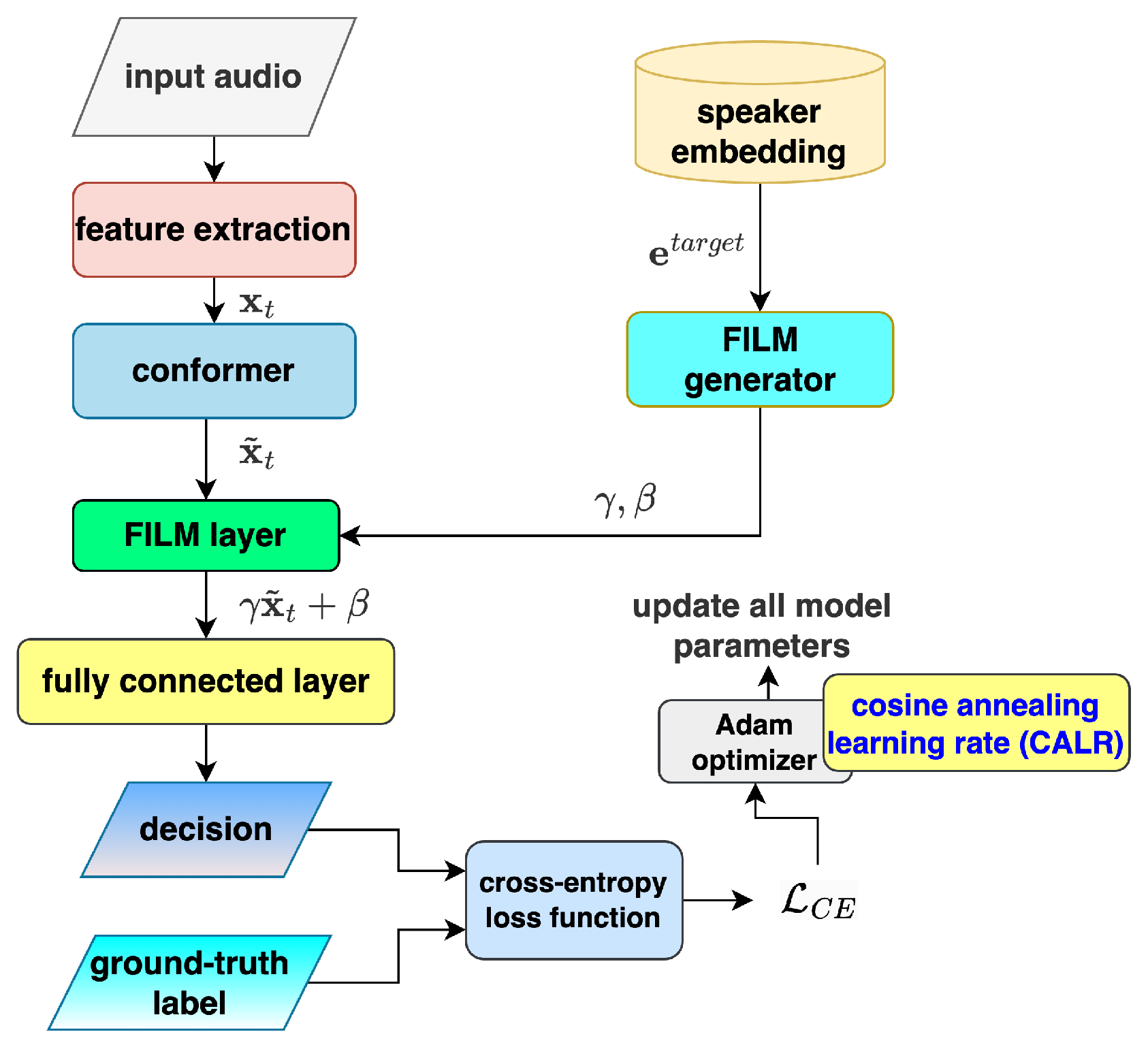
2. Backbone Model: Personal VAD 2.0
- Architectural Evolution: PVAD 1.0 relied on LSTM/BLSTM networks and simple concatenation of speaker embeddings with acoustic features, resulting in limited efficiency for real-time applications. In contrast, PVAD 2.0 adopts a streaming-friendly Conformer architecture, which enables efficient frame-level analysis with limited left-context and no right-context, significantly reducing latency [19].
- Advanced Speaker Conditioning: Instead of basic concatenation, PVAD 2.0 integrates speaker embeddings using Feature-wise Linear Modulation (FiLM) [20]. This approach allows dynamic scaling and shifting of acoustic features conditioned on the speaker embedding, thereby enhancing the model’s ability to discriminate target speaker activity.
- Feature Extraction:The system first extracts acoustic features (log-Mel-filterbank energies) from the incoming audio stream, where t is the frame index.
- Streaming Conformer Processing:The raw acoustic features are processed by a streaming-friendly Conformer neural network, which operates with limited left-context and no right-context. This enables low-latency, frame-by-frame analysis suitable for real-time applications. The Conformer block outputs the enhanced acoustic features .
- Speaker Embedding Integration:When a target speaker is enrolled, their speaker embedding is extracted from a short reference utterance. PVAD 2.0 enhances speaker discrimination by integrating with acoustic features via Feature-wise Linear Modulation (FiLM), replacing the simple concatenation method used in earlier versions. The FiLM parameters and are dynamically conditioned on , enabling the model to adaptively refine the acoustic features. This modulation transforms into speaker-conditional features through the operation , allowing more precise differentiation of the target speaker’s voice activity compared to previous approaches.
- Frame-Level Classification:For each audio frame t with feature , a fully connected layer classifies it as either target speaker speech (tss), non-target speaker speech (ntss), or non-speech (ns).
- Model Optimization:During training, the model’s predictions are evaluated against ground-truth labels using cross-entropy (CE) loss . The optimizer minimizes this loss through gradient descent: gradients of with respect to model parameters are computed via backpropagation (), and parameters are iteratively updated to reduce prediction errors.
3. Presented Strategies to Enhance PVAD 2.0
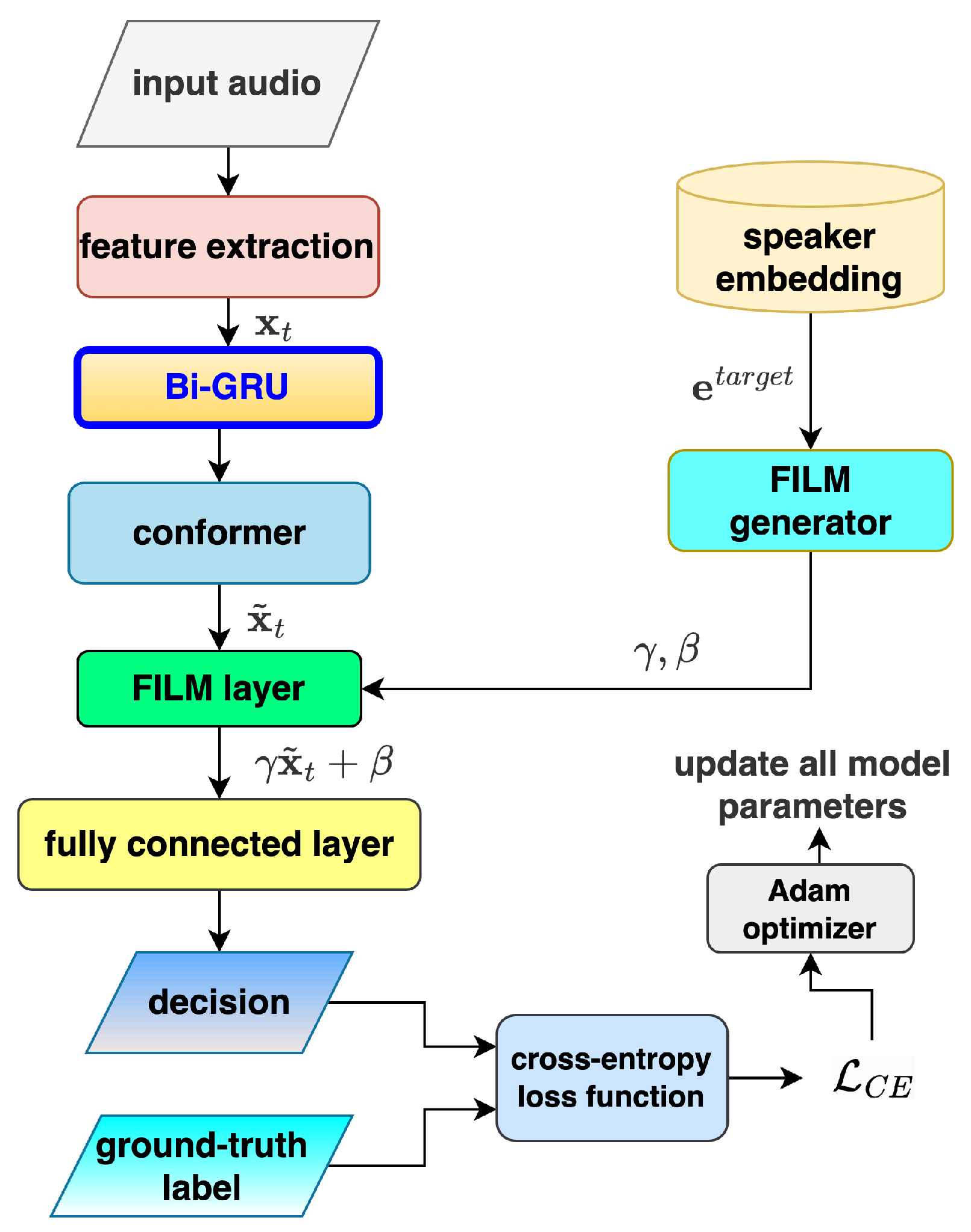
3.1. BI-GRU Equipped Speech Representation
- Reset Gate:The reset gate manages the retention of historical information. Here, and are the weight matrices for input and hidden states, respectively, while is the bias vector. The function represents the sigmoid activation.
- Update Gate:The update gate determines the blend ratio between the old hidden state and the new candidate state . It utilizes separate parameters , , and the bias .
- Candidate Hidden State:The candidate hidden state integrates history filtered by the reset gate. In this equation, ⊙ denotes element-wise multiplication, with and as the weights and as the bias.
- Final Hidden State:The new hidden state is a combination of preserved history (the portion) and new candidate information (the portion).
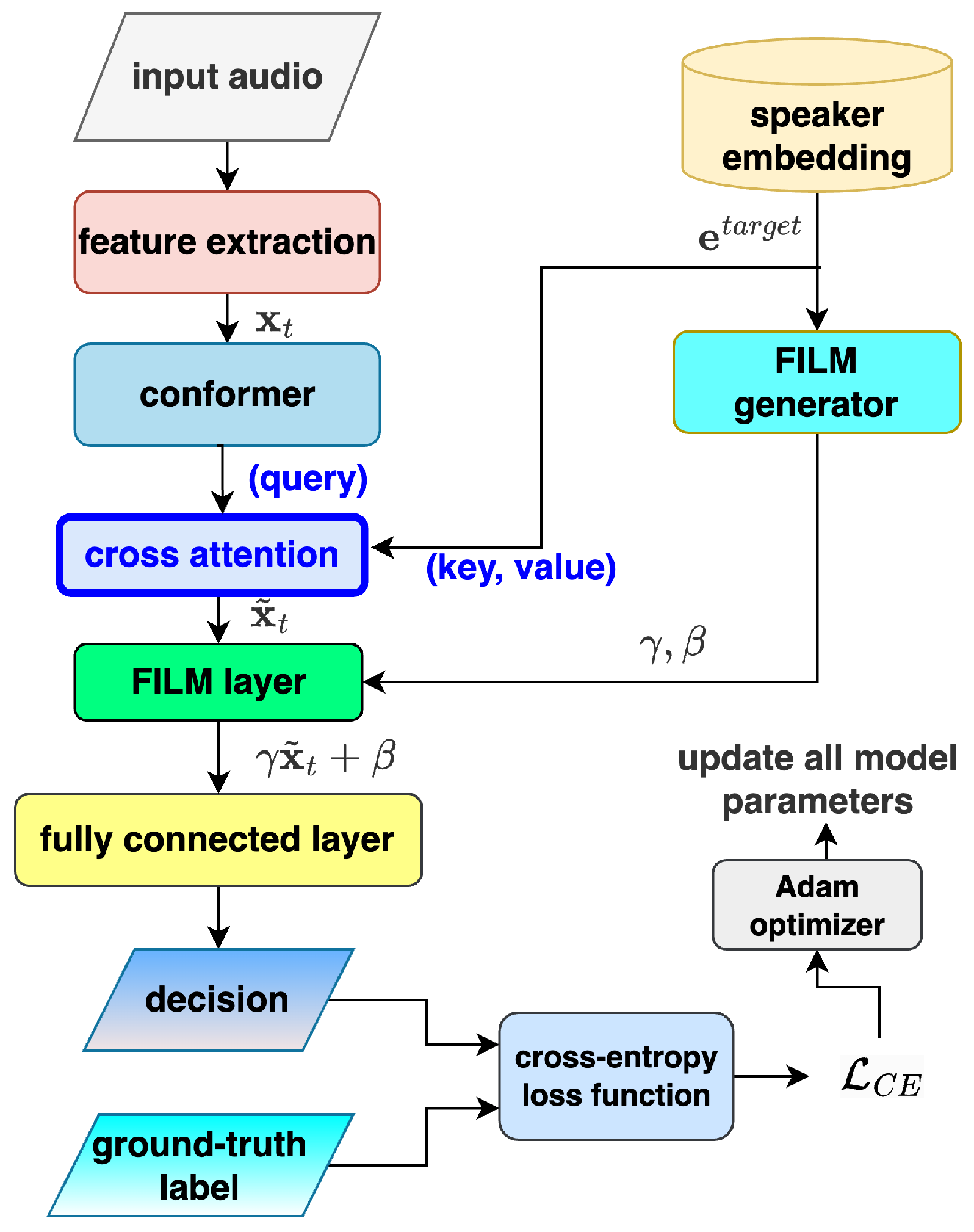
3.2. Cross-Attention for Personalized Embedding Integration
- The acoustic features are utilized as the query (Q).
- The speaker embeddings are linearly mapped to form both the key (K) and value (V).
- Q denotes the query matrix (from acoustic features),
- K is the key matrix (from speaker embeddings),
- V is the value matrix (from speaker embeddings),
- represents the dimensionality of the key and value vectors.
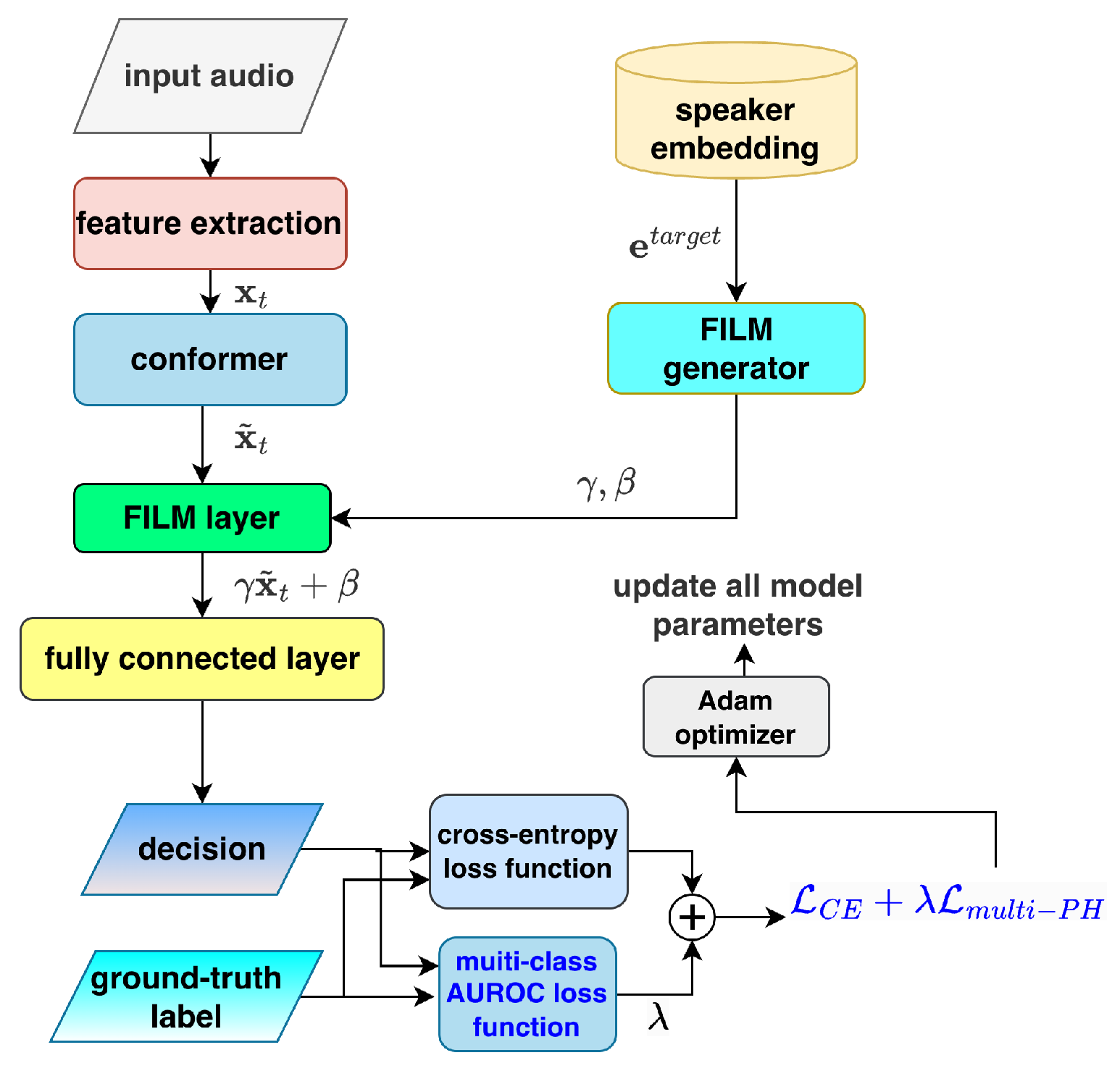
3.3. Integrating PH Loss with CE Loss
- and are the sets of positive and negative samples, respectively,
- and are the predicted scores for samples i and j,
- is a margin parameter (often set to ).
- (number of classes: tss, ntss, ns);
- denotes the binary PH loss computed for class i (treated as positive) versus class j (treated as negative);
- The denominator normalizes the loss by the total number of unique ordered class pairs (six pairs for ).
3.4. Cosine Annealing Learning Rate (CALR) in PVAD Training
- Smooth Convergence: Gradual decay prevents instability in optimization and leads to better convergence behavior.
- Balanced Learning: Higher learning rates early in training help in exploring parameter space, while lower rates later refine and stabilize the model, especially in frame-level detection.
4. Experimental Setup
4.1. Dataset
- Clean speech subsets:
- –
- train-clean-100: 100 h of high-quality recordings
- –
- train-clean-360: 360 h of clean speech
- Noisy speech subset:
- –
- train-other-500: 500 h of challenging audio with background noise and varied accents
- Randomly selected 1–3 speakers using a uniform distribution.
- Concatenated their speech segments.
- Designated one randomly chosen speaker as the target speaker.
- Introduced multi-speaker segments without the target speaker in 20% of the cases to prevent the model from overfitting to the target speaker’s characteristics.
4.2. Speaker Embedding Preparation
4.3. Other Implementation Details
- Acoustic Feature Extraction and Baseline Training Protocol:We utilize 40-dimensional Mel-filterbank energy coefficients as input features, computed using 25 ms analysis windows with 10 ms frame shifts. The baseline implementation leverages PyTorch [23] with the Adam optimizer [24], employing a two-phase learning rate schedule to balance training stability and fine-tuning. During initial epochs (1–2), the learning rate is set to to facilitate stable convergence, then reduced to at epoch 7 for precise parameter adjustment. This two-phase scheduling strategy operates independently of the CALR-enhanced training discussed in Section 3.4, serving as our reference optimization baseline.
- Conformer Configuration: The Conformer encoder is designed with multi-head self-attention comprising eight heads, feed-forward modules that expand the dimensionality by a factor of 4, and convolutional layers with a kernel size of 7 and twice the channel expansion. To enhance training stability, half-step residual connections are incorporated throughout the architecture. Regularization is achieved by applying a default dropout rate of 0.1 to the attention, feed-forward, and convolutional modules, which helps to mitigate overfitting.
- Bi-GRU and Cross-Attention Modules: The Bi-GRU implements single-layer GRUs in both forward and backward directions, each with a hidden state dimension of 128. For speaker-aware feature integration, the cross-attention module utilizes an eight-head attention mechanism where acoustic encoding features (with dimension 40) serve as keys and values, and speaker embeddings (with dimension 256) act as queries.
- CALR Scheduler Setting: The CALR schedule is applied over 10 epochs (), matching the training length used in the original PVAD setup. The learning rate decreases smoothly from a maximum value of to a minimum of following a cosine decay curve. At the halfway point (epoch 5), the learning rate is about 0.000525, providing a good compromise between fast initial learning and stable convergence. In this implementation, we omit warm restarts from the CALR scheduler to ensure the learning rate steadily decreases throughout all epochs. This approach is consistent with our 10-epoch training setup, as warm restarts are typically more advantageous in longer training scenarios with more epochs.
4.4. Evaluation Metrics
- Average Precision (AP): Measures the area under the precision–recall curve for each individual class: target speaker speech (tss), non-target speaker speech (ntss), and non-speech (ns). Calculated separately for each category.
- mean Average Precision (mAP): Computes the unweighted average of AP scores across all three classes (tss, ntss, ns). Reflects overall detection performance rather than target-specific accuracy.
- Accuracy: Calculated asEvaluates frame-level classification across all three categories, not just target vs non-target distinction.
- Parameter Count (#Para.): Assesses model complexity and deployment feasibility, particularly for resource-constrained devices where PVAD systems are typically deployed.
- Floating-Point Operations (#FLOPs): Measures the total floating-point operations needed for a single forward pass of the model, providing a hardware-independent indicator of computational complexity and real-time suitability.
5. Experimental Results and Discussion
5.1. Results Brought by the Addition of Bi-GRU
- Overall Performance: The Bi-GRU-enhanced model achieves the highest scores across all metrics, with an accuracy of 87.12% and an mAP of 0.9449, outperforming all other recurrent structures evaluated.
- Target Speaker Speech Detection (tss): The Bi-GRU model demonstrates a notable improvement in target speaker speech detection () compared to the baseline (). This suggests that bidirectional processing with GRU units effectively captures temporal dependencies crucial for distinguishing target speaker segments.
- Non-Target Classification (ntss, ns): All models maintain high performance on non-speech (ns) and non-target speaker speech (ntss) classification, with the Bi-GRU model again achieving the best results (, ). The differences among models for these metrics are relatively minor, indicating that the main performance gains are concentrated in target speaker detection.
- Accuracy vs. Model Complexity: The Bi-GRU model requires 111.2 k parameters, representing an increase over the baseline (62.2 k). However, this additional complexity is justified by the significant performance gains, especially in mAP and and . Notably, the Bi-GRU also increases computational cost, with 93.06 M floating-point operations (FLOPs) compared to the baseline’s 42.98 M. In contrast, the Bi-LSTM model, despite having the highest parameter count (127.5 k) and even more FLOPs (109.54 M), underperforms in both accuracy and , highlighting that increased complexity does not always translate to better results.
- GRU and LSTM Variants: Both GRU and LSTM models offer modest improvements over the baseline, but their gains are less pronounced than those achieved with the Bi-GRU architecture. Notably, the Bi-LSTM model does not leverage the benefits of bidirectionality as effectively as Bi-GRU in this context.
5.2. Results Brought by the Cross-Attention Configuration
5.3. Results Brought by Integrating PH Loss with CE Loss
5.4. Results Brought by Cosine Annealing Learning Rate (CALR) Strategy
- The implementation of CALR learning rate scheduling delivers significant performance enhancements across all evaluation metrics for PVAD 2.0. Specifically, accuracy improves from 86.18% to 87.59%, while mAP increases from 0.9378 to 0.9481, demonstrating enhanced detection capabilities and precision.
- Notably, these substantial improvements are obtained while maintaining the same parameter budget (62.2 k parameters) and FLOPs (42.98 M), highlighting how CALR optimizes the training process without introducing additional model complexity.
5.5. Overall Discussions
- First, many of these techniques might fix the same problems in different ways. For example, both Bi-GRU and cross-attention seem to improve how the model processes time-based information, so using both does not double the benefit.
- Second, when these different enhancement methods are combined, they can actually work against each other. Each method has its own approach to optimization that can clash with others, potentially canceling out their individual advantages.
- Lastly, we face practical limitations. Our computing resources cannot handle overly complex models, and adding too many enhancements at once risks overfitting the training data. There is also a natural ceiling where additional complexity brings fewer and fewer benefits, as we reach the inherent limitations of the dataset itself.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Q.; Muckenhirn, H.; Wilson, K.; Sridhar, P.; Wu, Z.; Hershey, J.; Saurous, R.A.; Weiss, R.J.; Jia, Y.; Moreno, I.L. Personal VAD: Speaker-conditioned voice activity detection. arXiv 2019, arXiv:1908.04284. [Google Scholar]
- Ding, S.; He, T.; Xue, W.; Wang, Z. Personal VAD 2.0: Optimizing personal voice activity detection for on-device speech recognition. In Proceedings of the Interspeech, Incheon, Republic of Korea, 18–22 September 2022; pp. 2293–2297. [Google Scholar]
- Zeng, B.; Cheng, M.; Tian, Y.; Liu, H.; Li, M. Efficient personal voice activity detection with wake word reference speech. In Proceedings of the ICASSP, Seoul, Republic of Korea, 14–19 April 2024; pp. 12241–12245. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, M.; Zhang, W.; Wang, T.; Yin, J.; Gao, Y. Personal voice activity detection with ultra-short reference speech. In Proceedings of the APSIPA, Macao, China, 3–6 December 2024. [Google Scholar]
- Yu, E.L.; Ho, K.H.; Hung, J.W.; Huang, S.C.; Chen, B. Speaker conditional sinc-extractor for personal VAD. In Proceedings of the Interspeech 2024, Kos, Greece, 1–5 September 2024; pp. 2115–2119. [Google Scholar] [CrossRef]
- Yu, E.L.; Chang, R.X.; Hung, J.W.; Huang, S.C.; Chen, B. COIN-AT-PVAD: A conditional intermediate attention PVAD. In Proceedings of the APSIPA, Macao, China, 3–6 December 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Kumar, S.; Buddi, S.S.; Sarawgi, U.O.; Garg, V.; Ranjan, S.; Rudovic, O.; Abdelaziz, A.H.; Adya, S. Comparative analysis of personalized voice activity detection systems: Assessing real-world effectiveness. arXiv 2024, arXiv:2406.09443. [Google Scholar]
- Bovbjerg, H.S.; Jensen, J.; Østergaard, J.; Tan, Z.H. Self-supervised pretraining for robust personalized voice activity detection in adverse conditions. In Proceedings of the ICASSP, Seoul, Republic of Korea, 14–19 April 2024; pp. 10126–10130. [Google Scholar] [CrossRef]
- Kang, J.; Shi, W.; Liu, H.; Li, Z. SVVAD: Personal voice activity detection for speaker verification. In Proceedings of the Interspeech, Dublin, Ireland, 20–24 August 2023; pp. 5067–5071. [Google Scholar]
- Hsu, Y.; Bai, M.R. Array configuration-agnostic personal voice activity detection based on spatial coherence. arXiv 2023, arXiv:2304.08887. [Google Scholar] [CrossRef]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning; Cambridge University Press: Cambridge, UK, 2023; Available online: https://d2l.ai (accessed on 30 April 2025).
- Chollet, F. Deep Learning with Python, 2nd ed.; Manning Publications: Greenwich, CT, USA, 2021. [Google Scholar]
- Zhu, Z.; Dai, W.; Hu, Y.; Li, J. Speech emotion recognition model based on Bi-GRU and focal loss. Pattern Recognit. Lett. 2020, 140, 358–365. [Google Scholar] [CrossRef]
- Gheini, M.; Ren, X.; May, J. Cross-Attention is all you need: Adapting pretrained transformers for machine translation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 1754–1765. [Google Scholar] [CrossRef]
- Gajic, B.; Baldrich, R.; Dimiccoli, M. Area under the ROC curve maximization for metric learning. In Proceedings of the CVPRW, New Orleans, LA, USA, 19–20 June 2022; pp. 2807–2816. [Google Scholar]
- Namdar, K.; Wagner, M.W.; Hawkins, C.; Tabori, U.; Ertl-Wagner, B.B.; Khalvati, F. Improving pediatric low-grade neuroepithelial tumors molecular subtype identification using a novel AUROC loss function for convolutional neural networks. arXiv 2024, arXiv:2402.03547. [Google Scholar]
- Gao, W.; Zhou, Z.H. On the consistency of AUC pairwise optimization. arXiv 2014, arXiv:1208.0645. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Perez, E.; Strub, F.; de Vries, H.; Dumoulin, V.; Courville, A. FiLM: Visual reasoning with a general conditioning layer. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. LibriSpeech: An ASR corpus based on public domain audio books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5206–5210. [Google Scholar]
- Wan, L.; Wang, Q.; Papir, A.; Moreno, I.L. Generalized end-to-end loss for speaker verification. In Proceedings of the ICASSP, Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4879–4883. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-Performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Eyben, F.; Weninger, F.; Squartini, S.; Schuller, B. Real-life voice activity detection with LSTM recurrent neural networks and an application to Hollywood movies. In Proceedings of the ICASSP, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 766–770. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy (%) | mAP | #Para. (k) | #FLOPs (M) | |||
|---|---|---|---|---|---|---|---|
| PVAD 2.0 Baseline | 86.18 | 0.9465 | 0.9533 | 0.8946 | 0.9378 | 62.2 | 42.98 |
| +GRU | 86.17 | 0.9463 | 0.9539 | 0.8995 | 0.9391 | 91.7 | 73.34 |
| +LSTM | 86.41 | 0.9451 | 0.9550 | 0.9028 | 0.9397 | 101.6 | 77.65 |
| +Bi-LSTM | 85.44 | 0.9449 | 0.9487 | 0.8806 | 0.9323 | 127.5 | 109.54 |
| +Bi-GRU | 87.12 | 0.9482 | 0.9585 | 0.9147 | 0.9449 | 111.2 | 93.06 |
| Model | Accuracy (%) | mAP | #Para. (k) | #FLOPs (M) | |||
|---|---|---|---|---|---|---|---|
| PVAD 2.0 Baseline | 86.18 | 0.9465 | 0.9533 | 0.8946 | 0.9378 | 62.2 | 42.98 |
| +Cross-Attention | 86.42 | 0.9466 | 0.9550 | 0.9011 | 0.9398 | 73.7 | 51.06 |
| Model | Accuracy (%) | mAP | #
Para. (k) | #FLOPs (M) | |||
|---|---|---|---|---|---|---|---|
| PVAD 2.0 Baseline | 86.18 | 0.9465 | 0.9533 | 0.8946 | 0.9378 | 62.2 | 42.98 |
| 86.34 | 0.9462 | 0.9535 | 0.8958 | 0.9382 | 62.2 | 42.98 | |
| 86.63 | 0.9456 | 0.9559 | 0.9062 | 0.9413 | 62.2 | 42.98 |
| Model | Accuracy (%) | mAP | #Para. (k) | #FLOPs (M) | |||
|---|---|---|---|---|---|---|---|
| PVAD 2.0 Baseline | 86.18 | 0.9465 | 0.9533 | 0.8946 | 0.9378 | 62.2 | 42.98 |
| +CALR | 87.59 | 0.9487 | 0.9614 | 0.9181 | 0.9481 | 62.2 | 42.98 |
| Model | Accuracy (%) | mAP | #Para. (k) | #FLOPs (M) | |||
|---|---|---|---|---|---|---|---|
| PVAD 2.0 baseline | 86.18 | 0.9465 | 0.9533 | 0.8946 | 0.9378 | 62.2 | 42.98 |
| +Bi-GRU | 87.12 | 0.9482 | 0.9585 | 0.9147 | 0.9449 | 111.2 | 93.06 |
| +Cross-Attention | 86.42 | 0.9466 | 0.9550 | 0.9011 | 0.9398 | 73.7 | 51.06 |
| +0.01 × multi-PH loss | 86.63 | 0.9456 | 0.9559 | 0.9062 | 0.9413 | 62.2 | 42.98 |
| +CALR | 87.59 | 0.9487 | 0.9614 | 0.9181 | 0.9481 | 62.2 | 42.98 |
| Model | Accuracy (%) | mAP | |||
|---|---|---|---|---|---|
| CALR | 87.59 | 0.9487 | 0.9614 | 0.9182 | 0.9481 |
| CALR +0.01 × multi-PH loss | 87.52 | 0.9494 | 0.9609 | 0.9152 | 0.9474 |
| BiGRU | 87.12 | 0.9482 | 0.9585 | 0.9147 | 0.9449 |
| BiGRU +Cross-Attention | 86.99 | 0.9446 | 0.9579 | 0.9108 | 0.9433 |
| BiGRU +0.03 × multi-PH loss | 86.68 | 0.9460 | 0.9562 | 0.9093 | 0.9419 |
| Cross-Attention | 86.42 | 0.9466 | 0.9550 | 0.9011 | 0.9398 |
| Cross-Attention +0.01 × multi-PH loss | 86.49 | 0.9470 | 0.9540 | 0.8993 | 0.9392 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeh, Y.-T.; Chang, C.-C.; Hung, J.-W. Empirical Analysis of Learning Improvements in Personal Voice Activity Detection Frameworks. Electronics 2025, 14, 2372. https://doi.org/10.3390/electronics14122372
Yeh Y-T, Chang C-C, Hung J-W. Empirical Analysis of Learning Improvements in Personal Voice Activity Detection Frameworks. Electronics. 2025; 14(12):2372. https://doi.org/10.3390/electronics14122372
Chicago/Turabian StyleYeh, Yu-Tseng, Chia-Chi Chang, and Jeih-Weih Hung. 2025. "Empirical Analysis of Learning Improvements in Personal Voice Activity Detection Frameworks" Electronics 14, no. 12: 2372. https://doi.org/10.3390/electronics14122372
APA StyleYeh, Y.-T., Chang, C.-C., & Hung, J.-W. (2025). Empirical Analysis of Learning Improvements in Personal Voice Activity Detection Frameworks. Electronics, 14(12), 2372. https://doi.org/10.3390/electronics14122372