
CBAM-ResNet: A Lightweight ResNet Network Focusing on Time Domain Features for End-to-End Deepfake Speech Detection


Abstract
1. Introduction
1.1. Research Status
1.2. Proposed Method
- The CBAM-ResNet model is proposed, which uses 1D convolution and residual blocks, greatly reducing the amount of model calculation and making it more lightweight.
- We introduce a 1D-CBAM attention mechanism, which combines channel attention and spatial attention to dynamically focus on the key features of the 1D signal and accurately capture the different features from forged speech, thereby improving the model’s sensitivity to real and forged speech.
- During the training process, random noise, time-shift perturbation, and volume scaling are added to the speech to enhance the robustness of the model. Adding a Dropout module to the ResNet model improves the generalization of the model. We conducted a cross-dataset evaluation between ASVspoof2019 and ASVspoof2015, and the experimental results proved that the model has good generalization.
2. Methods
2.1. ResNet Network
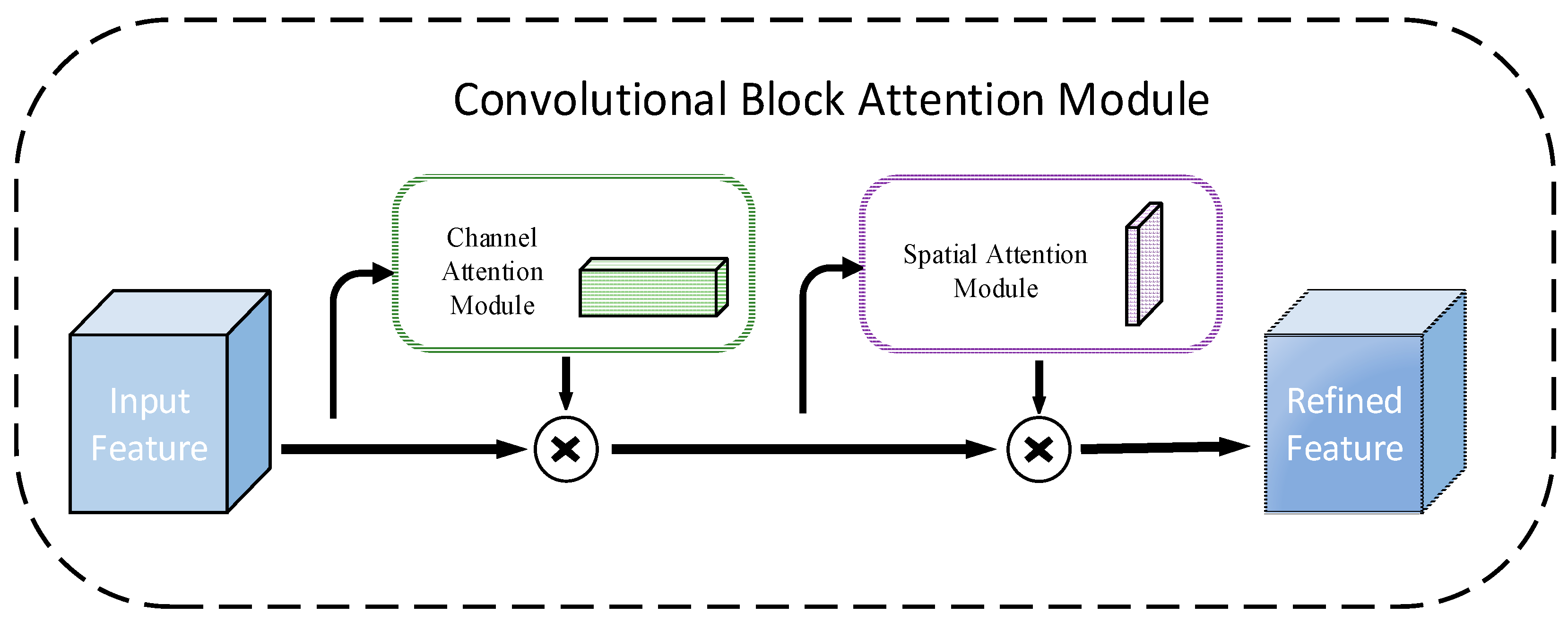
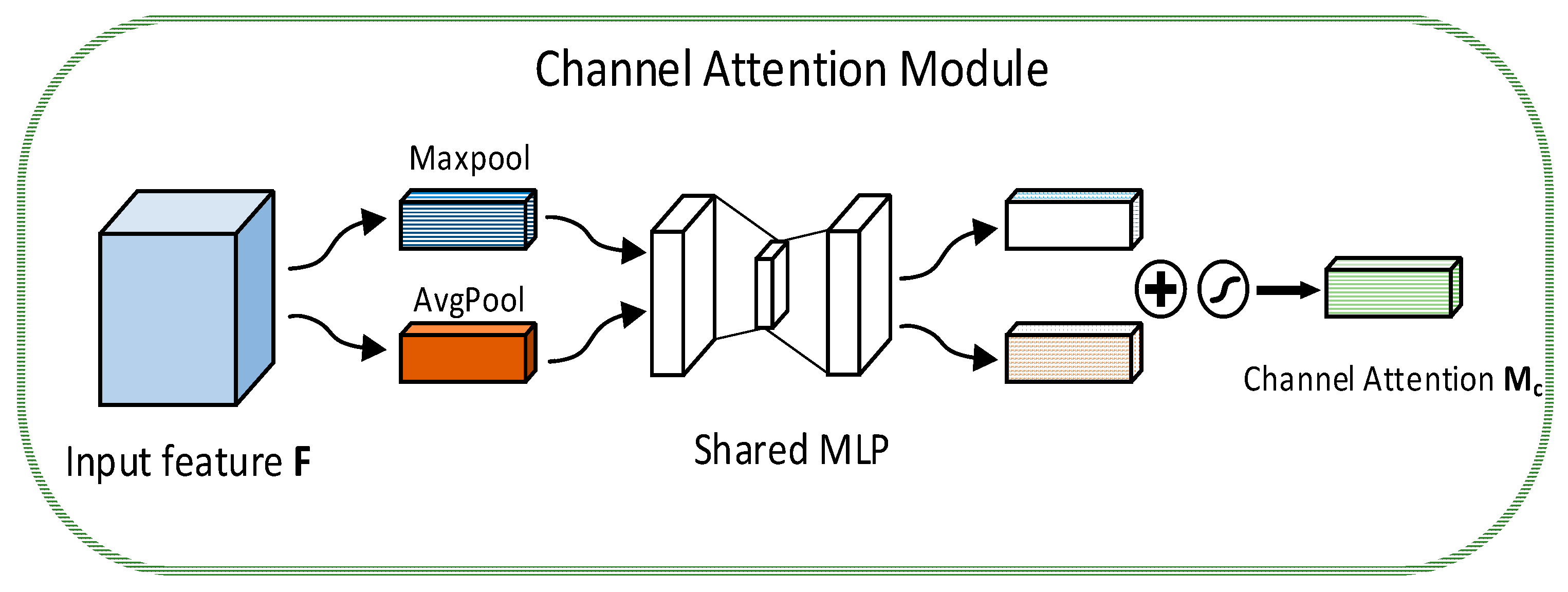
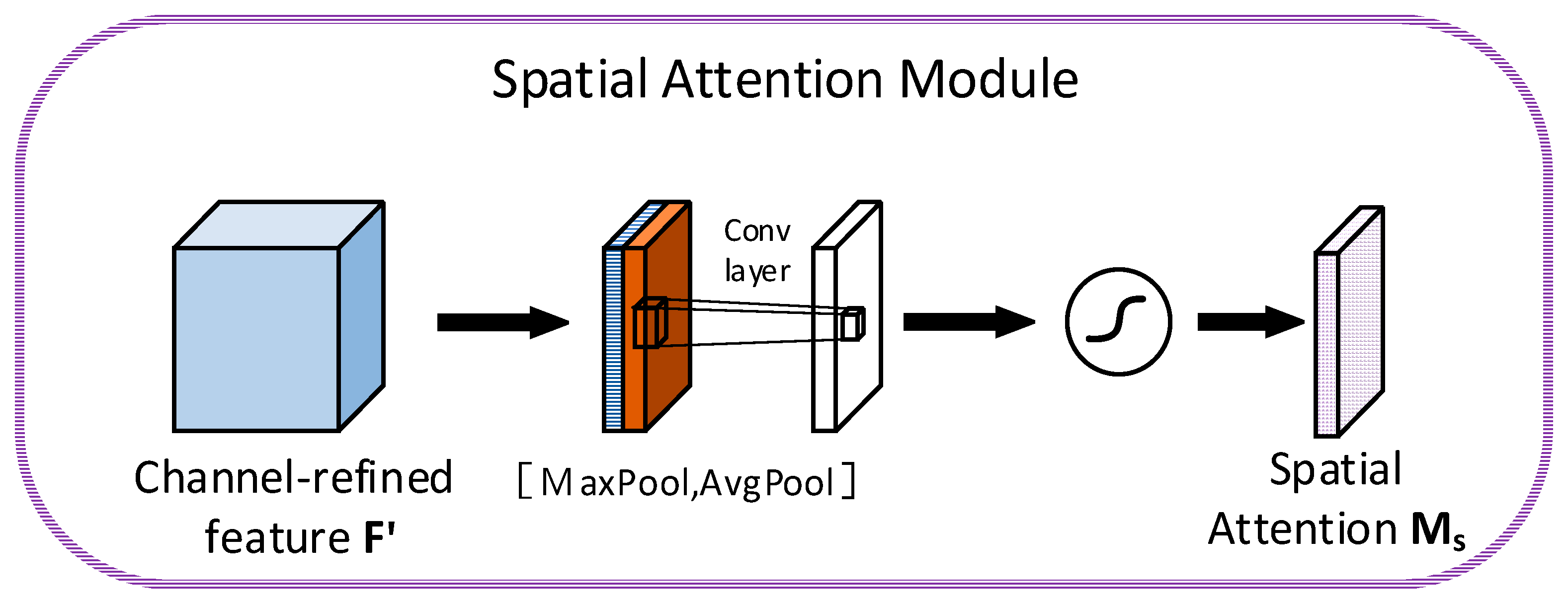
2.2. CBAM Attention Mechanism
2.3. Focal Loss
3. Network Model Structure
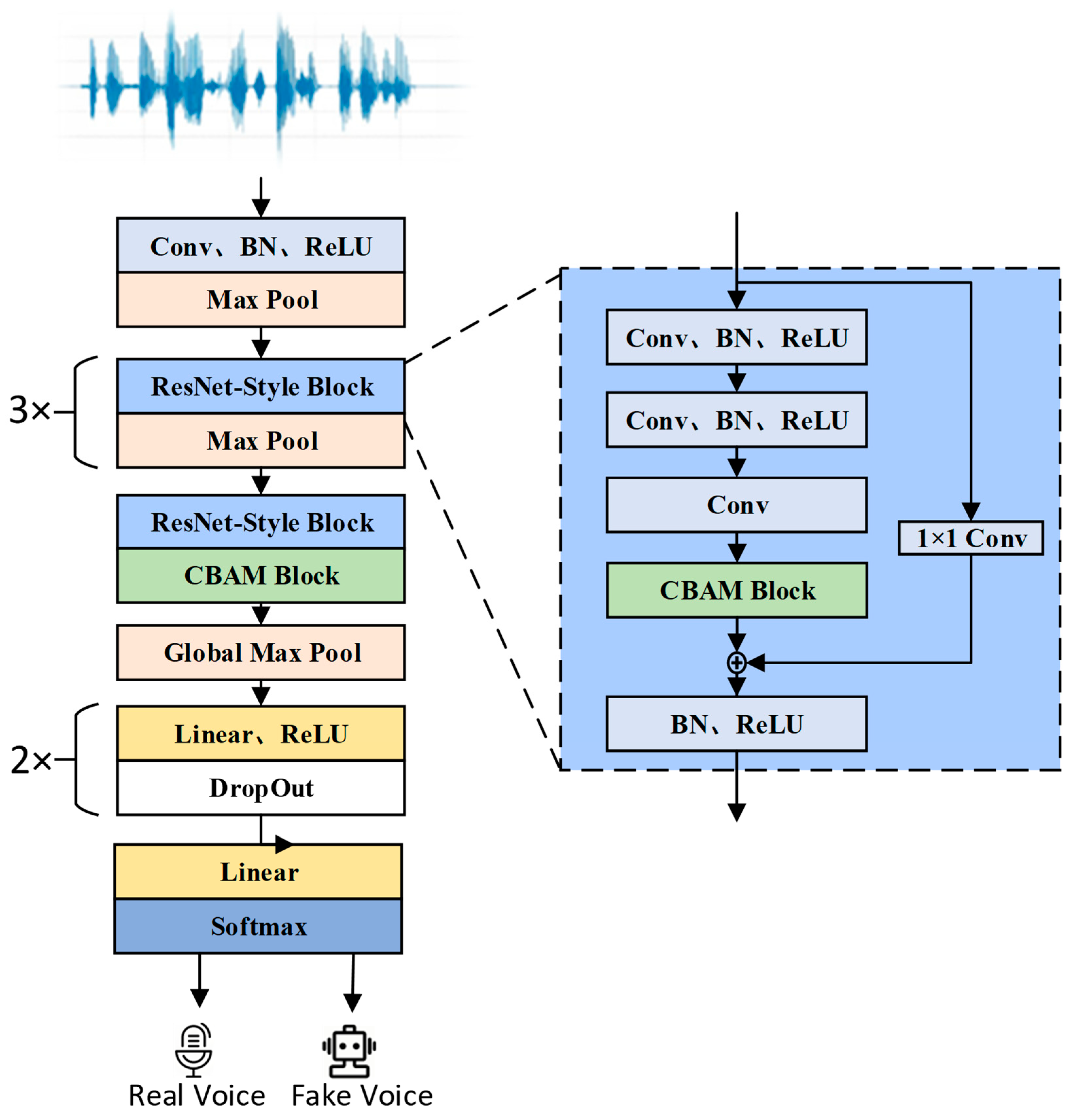
3.1. Model Structure
3.2. 1D Attention Module
3.3. Data Processing
3.4. Data Augmentation
4. Experimental Configuration
4.1. Training Strategy
4.2. Experimental Dataset
4.3. Evaluation Metrics
4.4. Lightweight Analysis
5. Results Analysis
5.1. Comparisons with Other Methods
5.2. Cross-Dataset Experiments
5.3. Ablation Experiment
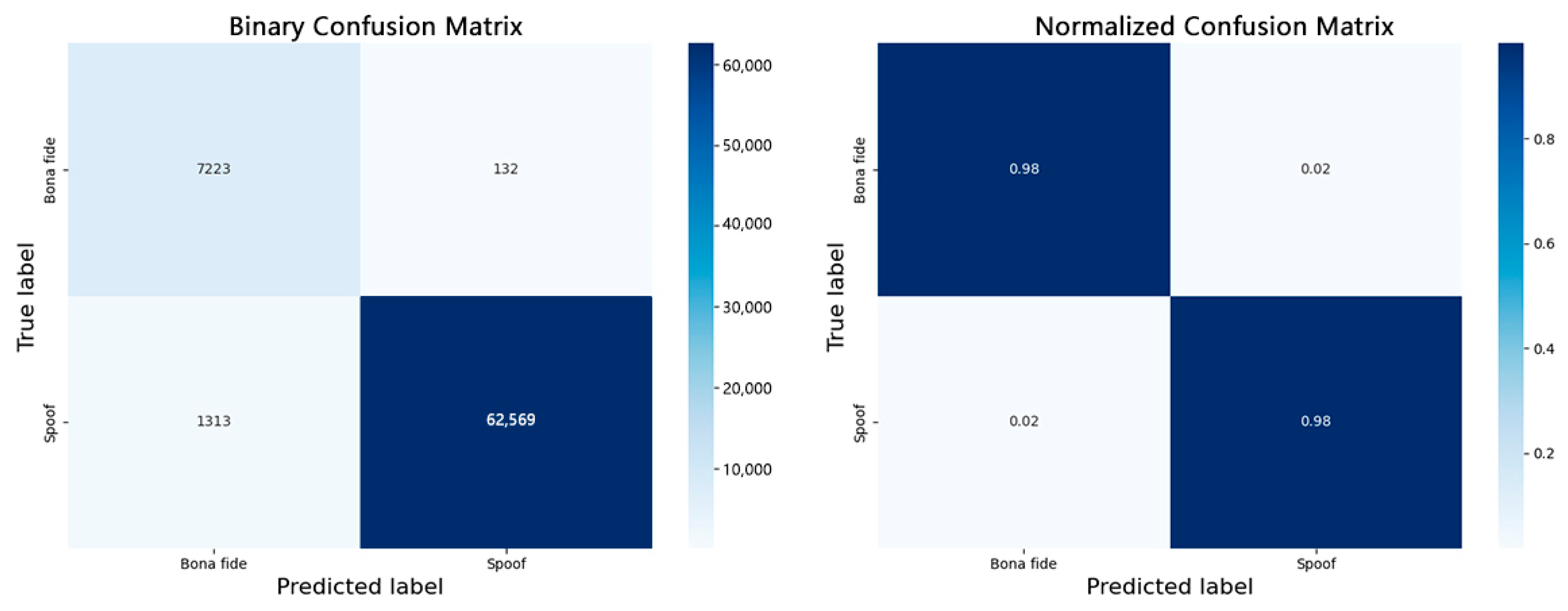
5.4. Discussion of Classification Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CBAM | Convolutional Block Attention Module |
| ResNet | Residual Network |
| ASV | Automatic Speaker Verification |
| EER | Equal Error Rate |
| TTS | Text-to-Speech Synthesis |
| VC | Voice Conversion |
| DNN | Deep Neural Network |
| HMM | Hidden Markov Model |
| GMM | Gaussian Mixture Model |
| LFCC | Linear Frequency Cepstrum Coefficient |
| MFCC | Mel-frequency Cepstral Coefficient |
| CMVN | Cepstral Mean and Variance Normalization |
| MGD | Corrected Group Delay |
| RPS | Relative Phase Shift |
| CQCC | Constant-Q Cepstral Coefficient |
| CQT | Constant-Q Transform |
| SVM | Support Vector Machine |
| MLP | Multilayer Perceptron |
| STFT | Short-Time Fourier Transform |
| 1D | One-Dimensional |
| BN | Batch Normalization |
| LA | Logical Access |
| PA | Physical Access |
| ECA-NET | Efficient Channel Attention Network |
| FAR | False Acceptance Rate |
| FRR | False Rejection Rate |
| ROC | Receiver Operating Characteristic |
| DET | Detection Error Tradeoff |
| AUC | Area Under the ROC Curve |
| FN | False Negative |
| FP | False Positive |
| GAN | Generative Adversarial Network |
References
- Wu, Z.; Evans, N.; Kinnunen, T.; Yamagishi, J.; Alegre, F.; Li, H. Spoofing and countermeasures for speaker verification: A survey. Speech Commun. 2015, 66, 130–153. [Google Scholar] [CrossRef]
- Shchemelinin, V.; Simonchik, K. Examining vulnerability of voice verification systems to spoofing attacks by means of a TTS system. In Proceedings of the International Conference on Speech and Computer, Pilsen, Czech Republic, 1–5 September 2013; Springer International Publishing: Cham, Switzerland, 2013; pp. 132–137. [Google Scholar]
- Kinnunen, T.; Wu, Z.Z.; Lee, K.A.; Sedlak, F.; Chng, E.S.; Li, H. Vulnerability of speaker verification systems against voice conversion spoofing attacks: The case of telephone speech. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; IEEE: New York, NY, USA, 2012; pp. 4401–4404. [Google Scholar]
- Das, R.K.; Tian, X.; Kinnunen, T.; Li, H. The attacker’s perspective on automatic speaker verification: An overview. arXiv 2020, arXiv:2004.08849. [Google Scholar]
- Chen, Z.; Xie, Z.; Zhang, W.; Xu, X. ResNet and Model Fusion for Automatic Spoofing Detection. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 102–106. [Google Scholar]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. Fastspeech 2: Fast and high-quality end-to-end text to speech. arXiv 2020, arXiv:2006.04558. [Google Scholar]
- Bevinamarad, P.R.; Shirldonkar, M.S. Audio forgery detection techniques: Present and past review. In Proceedings of the 2020 4th International Conference on Trends in Electronics and Informatics (ICOEI)(48184), Tirunelveli, India, 15–17 June 2020; IEEE: New York, NY, USA, 2020; pp. 613–618. [Google Scholar]
- Tokuda, K.; Nankaku, Y.; Toda, T.; Zen, H.; Yamagishi, J.; Oura, K. Speech synthesis based on hidden Markov models. Proc. IEEE 2013, 101, 1234–1252. [Google Scholar] [CrossRef]
- Yang, J.; Das, R.K.; Zhou, N. Extraction of octave spectra information for spoofing attack detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 2373–2384. [Google Scholar] [CrossRef]
- Tian, X.; Xiao, X.; Chng, E.S.; Li, H. Spoofing voice detection using temporary convolutional neurons. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Republic of Korea, 13–16 December 2016; IEEE: New York, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Muckenhirn, H.; Korshunov, P.; Magimai-Doss, M.; Marcel, S. Long-term spectral statistics for voice presentation attack detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2098–2111. [Google Scholar] [CrossRef]
- Yu, H.; Tan, Z.H.; Ma, Z.; Martin, R.; Guo, J. Spoofing detection in automatic speaker verification systems using DNN classifiers and dynamic acoustic features. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 4633–4644. [Google Scholar] [CrossRef]
- Zhang, C.; Yu, C.; Hansen, J.H.L. An investigation of deep-learning frameworks for speaker verification antispoofing. IEEE J. Sel. Top. Signal Process. 2017, 11, 684–694. [Google Scholar] [CrossRef]
- Chettri, B.; Stoller, D.; Morfi, V.; Ramírez, M.A.M.; Benetos, E.; Sturm, B.L. Ensemble models for spoofing detection in automatic speaker verification. arXiv 2019, arXiv:1904.04589. [Google Scholar]
- Lai, C.I.; Chen, N.; Villalba, J.; Dehak, N. ASSERT: Anti-spoofing with squeeze-excitation and residual networks. arXiv 2019, arXiv:1904.01120. [Google Scholar]
- Zeinali, H.; Stafylakis, T.; Athanasopoulou, G.; Rohdin, J.; Gkinis, I.; Burget, L.; Černocký, J. Detecting spoofing attacks using vgg and sincnet: But-omilia submission to asvspoof 2019 challenge. arXiv 2019, arXiv:1907.12908. [Google Scholar]
- Sanchez, J.; Saratxaga, I.; Hernaez, I.; Navas, E.; Erro, D.; Raitio, T. Toward a universal synthetic speech spoofing detection using phase information. IEEE Trans. Inf. Forensics Secur. 2015, 10, 810–820. [Google Scholar] [CrossRef]
- Saratxaga, I.; Sanchez, J.; Wu, Z.; Hernaez, I.; Navas, E. Synthetic speech detection using phase information. Speech Commun. 2016, 81, 30–41. [Google Scholar] [CrossRef]
- Patel, T.B.; Patil, H.A. Significance of source–filter interaction for classification of natural vs. spoofed speech. IEEE J. Sel. Top. Signal Process. 2017, 11, 644–659. [Google Scholar] [CrossRef]
- Todisco, M.; Delgado, H.; Evans, N. Constant Q cepstral coefficients: A spoofing countermeasure for automatic speaker verification. Comput. Speech Lang. 2017, 45, 516–535. [Google Scholar] [CrossRef]
- Pal, M.; Paul, D.; Saha, G. Synthetic speech detection using fundamental frequency variation and spectral features. Comput. Speech Lang. 2018, 48, 31–50. [Google Scholar] [CrossRef]
- Wang, X.; Yamagishi, J.; Todisco, M.; Delgado, H.; Nautsch, A.; Evans, N.; Sahidullah; Vestman, V.; Kinnunen, T.; Lee, K.A.; et al. ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech. Comput. Speech Lang. 2020, 64, 101114. [Google Scholar] [CrossRef]
- Yang, J.; Das, R.K.; Li, H. Significance of subband features for synthetic speech detection. IEEE Trans. Inf. Forensics Secur. 2019, 15, 2160–2170. [Google Scholar] [CrossRef]
- Das, R.K.; Yang, J.; Li, H. Long Range Acoustic Features for Spoofed Speech Detection. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 1058–1062. [Google Scholar]
- Sahidullah, M.; Kinnunen, T.; Hanilçi, C. A comparison of features for synthetic speech detection. In Proceedings of the 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Lavrentyeva, G.; Novoselov, S.; Tseren, A.; Volkova, M.; Gorlanov, A.; Kozlov, A. STC antispoofing systems for the ASVspoof2019 challenge. arXiv 2019, arXiv:1904.05576. [Google Scholar]
- Li, X.; Li, N.; Weng, C.; Liu, X.; Su, D.; Yu, D. Replay and synthetic speech detection with res2net architecture. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: New York, NY, USA, 2021; pp. 6354–6358. [Google Scholar]
- Alzantot, M.; Wang, Z.; Srivastava, M.B. Deep residual neural networks for audio spoofing detection. arXiv 2019, arXiv:1907.00501. [Google Scholar]
- Monteiro, J.; Alam, J.; Falk, T.H. Generalized end-to-end detection of spoofing attacks to automatic speaker recognizers. Comput. Speech Lang. 2020, 63, 101096. [Google Scholar] [CrossRef]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-end anti-spoofing with rawnet2. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: New York, NY, USA, 2021; pp. 6369–6373. [Google Scholar]
- Wang, X.; Yamagishi, J. Investigating self-supervised front ends for speech spoofing countermeasures. arXiv 2021, arXiv:2111.07725. [Google Scholar]
- Wang, C.; Yi, J.; Zhang, X.; Tao, J.; Xu, L.; Fu, R. Low-rank adaptation method for wav2vec2-based fake audio detection. arXiv 2023, arXiv:2306.05617. [Google Scholar]
- Liu, X.; Wang, X.; Sahidullah, M.; Patino, J.; Delgado, H.; Kinnunen, T.; Todisco, M.; Yamagishi, J.; Evans, N.; Nautsch, A.; et al. Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 2507–2522. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lei, Z.; Yan, H.; Liu, C.; Zhou, Y.; Ma, M. GMM-ResNet2: Ensemble of group ResNet networks for synthetic speech detection. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 12101–12105. [Google Scholar]
- Ma, Y.; Ren, Z.; Xu, S. RW-Resnet: A novel speech anti-spoofing model using raw waveform. arXiv 2021, arXiv:2108.05684. [Google Scholar]
- Zhang, Y.; Jiang, F.; Duan, Z. One-class learning towards synthetic voice spoofing detection. IEEE Signal Process. Lett. 2021, 28, 937–941. [Google Scholar] [CrossRef]
- Chen, L.; Yao, H.; Fu, J.; Ng, C.T. The classification and localization of crack using lightweight convolutional neural network with CBAM. Eng. Struct. 2023, 275, 115291. [Google Scholar] [CrossRef]
- Fu, H.; Song, G.; Wang, Y. Improved YOLOv4 marine target detection combined with CBAM. Symmetry 2021, 13, 623. [Google Scholar] [CrossRef]
- Zhao, Y.; Ding, Q.; Wu, L.; Lv, R.; Du, J.; He, S. Synthetic Speech Detection Using Extended Constant-Q Symmetric-Subband Cepstrum Coefficients and CBAM-ResNet. In Proceedings of the 2023 7th International Conference on Imaging, Signal Processing and Communications (ICISPC), Kumamoto, Japan, 21–23 July 2023; IEEE: New York, NY, USA, 2023; pp. 70–74. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Dou, Y.; Yang, H.; Yang, M.; Xu, Y.; Ke, D. Dynamically mitigating data discrepancy with balanced focal loss for replay attack detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: New York, NY, USA, 2021; pp. 4115–4122. [Google Scholar]
- Hua, G.; Teoh, A.B.J.; Zhang, H. Towards end-to-end synthetic speech detection. IEEE Signal Process. Lett. 2021, 28, 1265–1269. [Google Scholar] [CrossRef]
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah, M.; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.; Kinnunen, T.; Lee, K.A. ASVspoof 2019: Future horizons in spoofed and fake audio detection. arXiv 2019, arXiv:1904.05441. [Google Scholar]
- Zhu, Y.; Powar, S.; Falk, T.H. Characterizing the temporal dynamics of universal speech representations for generalizable deepfake detection. In Proceedings of the 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), Seoul, Republic of Korea, 14–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 139–143. [Google Scholar]
- Sun, C.; Jia, S.; Hou, S.; Lyu, S. Ai-synthesized voice detection using neural vocoder artifacts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 904–912. [Google Scholar]
- Ko, K.; Kim, S.; Kwon, H. Selective Audio Perturbations for Targeting Specific Phrases in Speech Recognition Systems. Int. J. Comput. Intell. Syst. 2025, 18, 103. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Layer | Kernel Size/Filters/Step Size |
|---|---|
| Convolutional layer 1 | 9 × 3, 16, 3 × 1 |
| Downsampling residual block 1 | 3 × 3, 64, 2 × 2 |
| Residual block 1 | 3 × 3, 64, 1 × 1 |
| Downsampling residual block 2 | 3 × 3, 128, 2 × 2 |
| Residual block 2 | 3 × 3, 128, 1 × 1 |
| Downsampling residual block 3 | 3 × 3, 256, 2 × 2 |
| Residual block 3 | 3 × 3, 256, 1 × 1 |
| Downsampling residual block 4 | 3 × 3, 512, 2 × 2 |
| Residual block 4 | 3 × 3, 512, 1 × 1 |
| Convolutional layer 1 | 3 × 3, 256, 1 × 1 |
| Adaptive pooling layer | Adaptive pooling |
| Fully connected layer | Fully connected layer, Softmax |
| Name | Specific Configuration |
|---|---|
| Operating System | Windows 11 |
| Processor | NVIDIA vGPU-32GB |
| Memory | 32 GB |
| OS Bit | 64-bit |
| CPU | Intel(R) Xeon(R) Platinum 8352V CPU |
| Programming Language | Python 3.8 |
| IDE | PyCharm 2024.2.1 |
| Dataset | ASVspoof2019 |
| Deep Learning Framework | PyTorch 1.7 |
| Dataset | Number of Speakers | Number of Attacks | Number of Voices | ||
|---|---|---|---|---|---|
| Male | Female | Real Voice | Fake Voice | ||
| Train set | 8 | 12 | 6 | 2580 | 22,800 |
| Development set | 4 | 6 | 6 | 2548 | 22,296 |
| Evaluation set | 21 | 26 | 13 | 7355 | 63,822 |
| Attack Type Number | Attack Type | Technical Implementation Method |
|---|---|---|
| A01 | Speech Synthesis | Neural waveform node |
| A02 | Speech Synthesis | Vocoder |
| A03 | Speech Synthesis | Vocoder |
| A04 | Speech Synthesis | Waveform concatenation |
| A05 | Voice Conversion | Waveform filtering |
| A06 | Voice Conversion | Spectral filtering |
| Attack Type Number | Attack Type | Technical Implementation Method |
|---|---|---|
| A07 | Speech Synthesis | Vocoder + GAN |
| A08 | Speech Synthesis | Neural waveform |
| A09 | Speech Synthesis | Vocoder |
| A10 | Speech Synthesis | Neural waveform |
| A11 | Speech Synthesis | Griffin lim |
| A12 | Speech Synthesis | Neural waveform |
| A13 | Speech Synthesis+ Voice Conversion | Waveform concatenation + waveform filtering |
| A14 | Speech Synthesis+ Voice Conversion | Vocoder |
| A15 | Speech Synthesis+ Voice Conversion | Neural waveform |
| A16 | Speech Synthesis+ Voice Conversion | Waveform concatenation |
| A17 | Voice Conversion | Waveform filtering |
| A18 | Voice Conversion | Vocoder |
| A19 | Voice Conversion | Spectral filtering |
| Project | Numeric | Illustrate |
|---|---|---|
| Number of parameters | 362,168 | Total trainable parameters |
| Model size | 1.38 MB | Memory size after parameter conversion |
| Disk file size | 1.42 MB | .pt model file size |
| CPU inference latency | 158.50 ms | Average CPU time for one sample |
| GPU inference latency | 4.86 ms | Average GPU time for one sample |
| CPU memory usage | 0.71 MB | RAM usage on CPU during inference |
| GPU memory usage | 23.08 MB | Inference time on GPU memory usage |
| FLOPs (per inference) | 686,793,420 | Number of floating point operations |
| GFLOPS | 0.69 | Represents model complexity |
| Method | #Param | Dev | Eval |
|---|---|---|---|
| Baseline LFCC + GMM [45] | - | 0.43 | 9.57 |
| Baseline CQCC + GMM [45] | - | 2.71 | 8.09 |
| Baseline RawNet [33] | 6.52 M | - | 7.46 |
| Sub-band CQCC + MLP [23] | - | - | 8.04 |
| 8 Features + MLP [24] | - | 0.00 | 4.13 |
| Spec + VGG + SincNet [16] | >4.32 M | 0.00 | 8.01 |
| Spec + CQCC + ResNet + SE [15] | 5.80 M | 0.00 | 6.70 |
| Sinc + RawNet2 [46] | 11.79 M | 0.00 | 4.54 |
| FFT + CNN [26] | 10.2 M | 0.04 | 4.53 |
| CQT + Res2Net + SE [27] | 0.92 M | 0.43 | 2.50 |
| WavLM + MLB [47] | 5.0 M | 0.00 | 2.47 |
| 3 Features + Res2Net + SE [27] | 2.76 M | 0.00 | 1.89 |
| 3 Features + CNN [26] | 30.6 M | 0.00 | 1.86 |
| 1DResNet + CBAM [ours] | 0.36 M | 0.55 | 1.94 |
| Method | 2019 | 2015 | |
|---|---|---|---|
| Eval | Dev | Eval | |
| Baseline LFCC + GMM [32] | 9.57 | 19.82 | 15.91 |
| Baseline CQCC + GMM [32] | 8.09 | 47.72 | 49.90 |
| 1DResNet + CBAM [ours] | 1.94 | 7.06 | 4.94 |
| Experiment Number | Data Augmentation | Channel Attention | Spatial Attention | ECA-NET | EER (%) |
|---|---|---|---|---|---|
| 1 | × | × | × | × | 5.98 |
| 2 | √ | × | × | × | 3.74 |
| 3 | × | √ | × | × | 2.72 |
| 4 | × | × | √ | × | 2.77 |
| 5 | × | √ | √ | × | 2.33 |
| 6 | × | × | × | √ | 5.17 |
| 7 | √ | √ | √ | × | 1.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Huang, H.; Li, Z.; Zhang, S. CBAM-ResNet: A Lightweight ResNet Network Focusing on Time Domain Features for End-to-End Deepfake Speech Detection. Electronics 2025, 14, 2456. https://doi.org/10.3390/electronics14122456
Wu Y, Huang H, Li Z, Zhang S. CBAM-ResNet: A Lightweight ResNet Network Focusing on Time Domain Features for End-to-End Deepfake Speech Detection. Electronics. 2025; 14(12):2456. https://doi.org/10.3390/electronics14122456
Chicago/Turabian StyleWu, Yuezhou, Hua Huang, Zhiri Li, and Siling Zhang. 2025. "CBAM-ResNet: A Lightweight ResNet Network Focusing on Time Domain Features for End-to-End Deepfake Speech Detection" Electronics 14, no. 12: 2456. https://doi.org/10.3390/electronics14122456
APA StyleWu, Y., Huang, H., Li, Z., & Zhang, S. (2025). CBAM-ResNet: A Lightweight ResNet Network Focusing on Time Domain Features for End-to-End Deepfake Speech Detection. Electronics, 14(12), 2456. https://doi.org/10.3390/electronics14122456