


Sign Language Anonymization: Face Swapping Versus Avatars

 , and
, and 
Abstract
1. Introduction
- We compare two formats of video anonymization: one using realistic avatars, and another using face swapping techniques.
- We propose a new measure to evaluate the anonymization of the facial expression preservation of the generated Sign Language videos.
- An extensive survey for a group of deaf individuals was carried out to evaluate the anonymization and comprehension of the synthetic videos.
2. Related Work
- Avatar-based techniques
- Photorealistic retargeting
2.1. Using Avatars for Anonymization
2.2. Photorealistic Retargeting
2.3. Conclusions
3. Methodology
3.1. Collection of Original Video
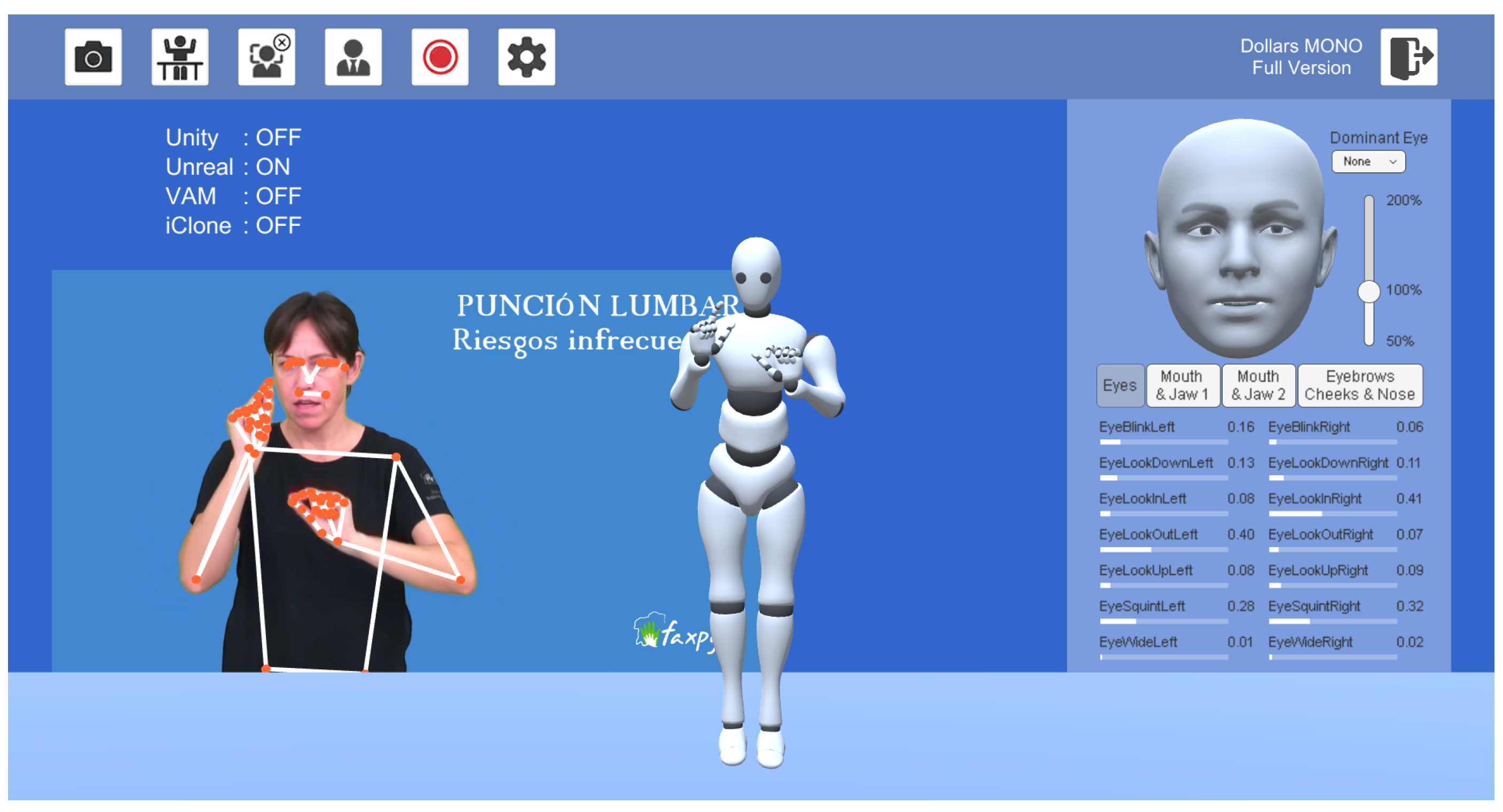
3.2. Video Synthesis with Avatars
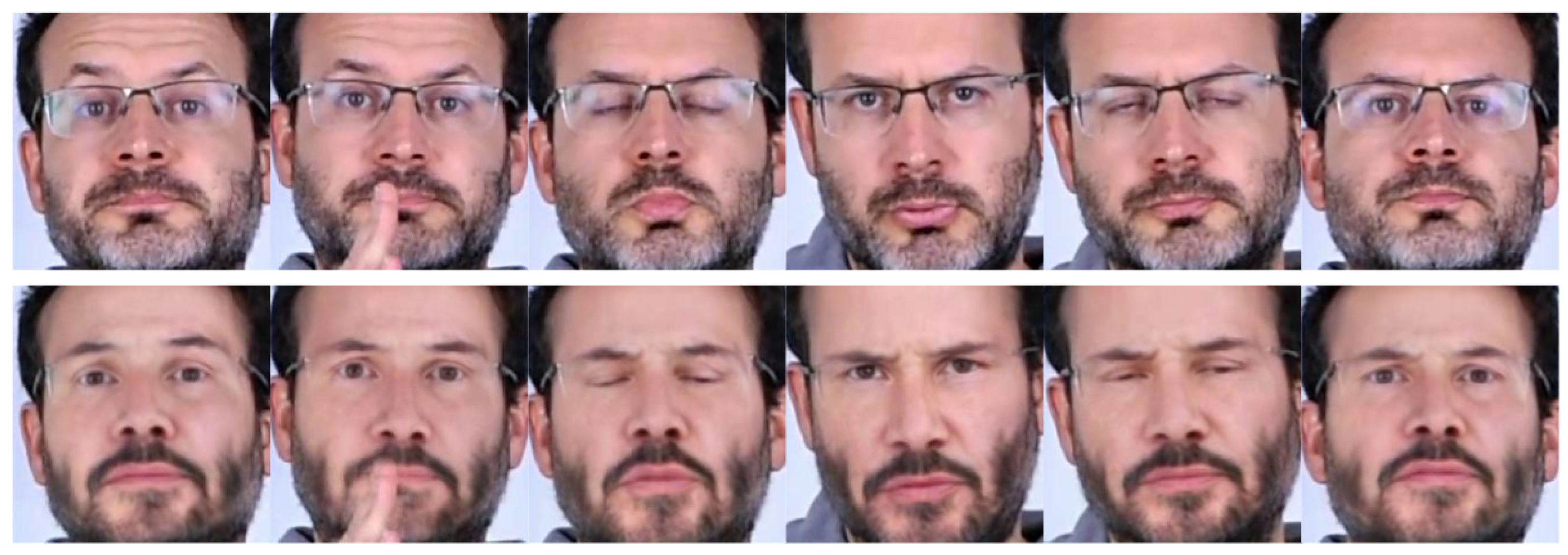
3.3. Video Synthesis with Face Swapping
4. Experiments on Video Synthesis
4.1. Evaluation Metrics
4.1.1. Quality Metrics
- : the set of frames selected in the original video (the swapped frames in , are the same),
- : a distance function between the embedding vectors coming out from the Face Verification model () corresponding to aligned frames, f, , and
- , the same for the AU intensity embedding vectors.
| Algorithm 1: Recursively select frames from original video |
 |
| Algorithm 2: Select frames based on Action Unit (AU) changes |
 |
- Robustness of ID-Embedding: The largest intra-ID scores provide insights into the robustness of the ID-embedding against changes in expression and pose. Smaller intra-ID values indicate a more robust ID model.
- Anonymization Quality: For a robust ID-embedding, the difference between inter-ID and intra-ID scores quantifies the separability of identities, offering an objective assessment of anonymization effectiveness.
- Robustness of AU-Embedding: inter-AU and intra-AU scores provide insights into the robustness of the AU-embedding to variations in identity and pose. In general, inter-AU scores are expected to be smaller than intra-AU scores.
- Expressivity Transfer: For a robust AU-embedding and effective transfer of expressivity, the distribution of intra-AU scores in the original video should closely match that of the swapped video, and the inter-AU scores should remain minimal.
4.1.2. Subjective Evaluation
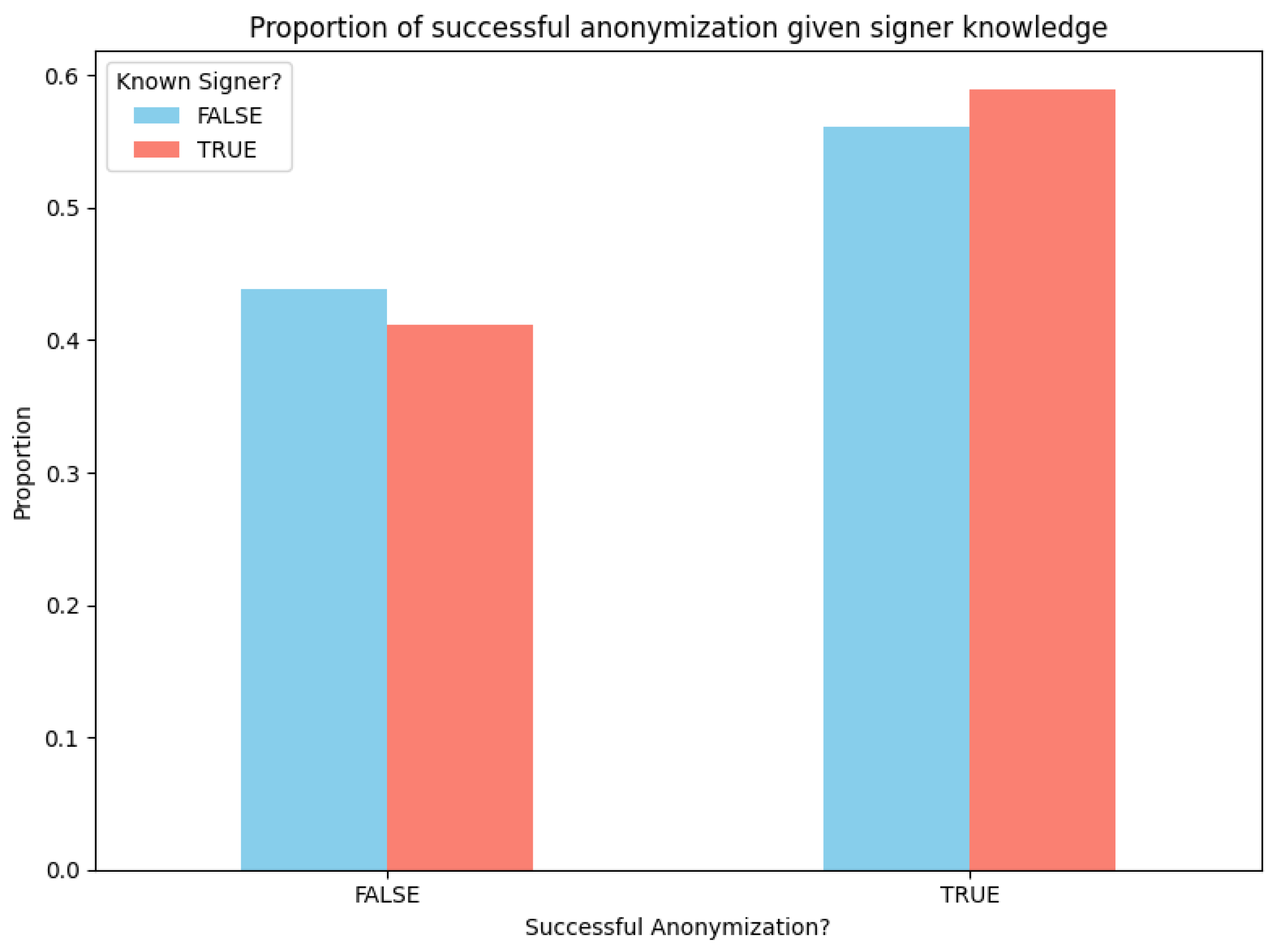
- Part 1: Anonymization through Face Swapping: The first part aimed to assess whether a face swapping technique successfully anonymized the identity of the signer. Familiarity of the participant with the signing person might bias their response, so we designed two questions. The participants are first asked if they recognize the signer, which helps gauge how familiar they are with the person signing. The second question directly asks whether they believe the face swapping has successfully anonymized the person’s identity.
- Part 2: Preservation of Meaning with Facial Expression: The second part focuses on whether face swapping has preserved the meaning of signs where facial expressions are crucial. Participants watch videos of words that vary in meaning depending on facial expression and are then asked a single question: they must choose the correct meaning from several options.
- Part 3: Comprehensibility of Avatars: In the third part, instead of using face swapping for anonymization, avatars are used. Here, the goal is to assess whether the avatar can generate an understandable signed sentence. Participants were asked three questions: Whether they understood the phrase signed by the avatar. After watching the original video with the phrase, participants were asked if the recognized phrase matched the original one. Finally, participants were asked what they believe could be improved, specifically whether the manual components of the sign or the facial expressiveness could be enhanced for better clarity.
5. Results
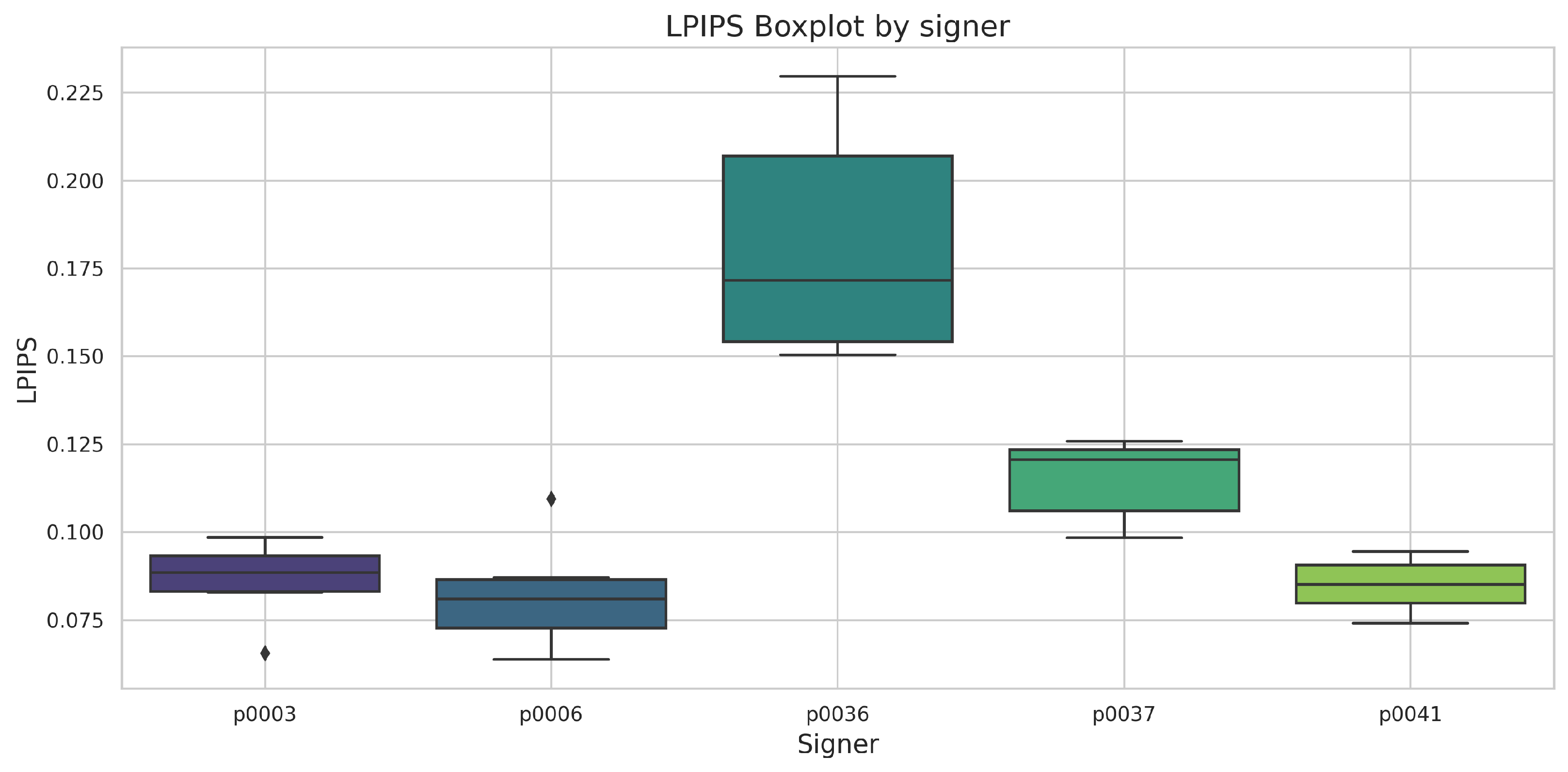
5.1. Quality Metrics Results
5.2. Survey Results
5.3. Discussion
- Effectiveness of Face Swapping: Face swapping proved to be a viable anonymization technique, achieving decent rates of perceived anonymization among participants and large rates of measured face discriminability. However, certain discrepancies, such as variations in hairstyle, subtle visual inconsistencies, or even questionable understanding of the query about signer–celebrity anonymization, impacted participants’ perceptions, underscoring the need for a greater understanding of anonymity perception.
- Challenges with Avatar-Based Anonymization: The results demonstrate that avatar-based anonymization struggles with comprehensibility, particularly for complex sentences. The survey responses indicate that both hand movements and facial expressions need refinement to meet the high expectations of Sign Language users. The low comprehension rates observed highlight the need for further improvements in avatar synthesis technologies.
- The current work highlights the need for larger and more diverse datasets for sign language anonymization research. In future work, we aim to expand our dataset by defining clear collection targets—e.g., several hundred signers across different age groups, signing styles, and regions. This will require building long-term collaborations with deaf communities and institutions, possibly through partnerships with national federations or sign language interpretation networks. Such collaborations would not only increase the scale and demographic variety, but also promote inclusiveness and ethical engagement.
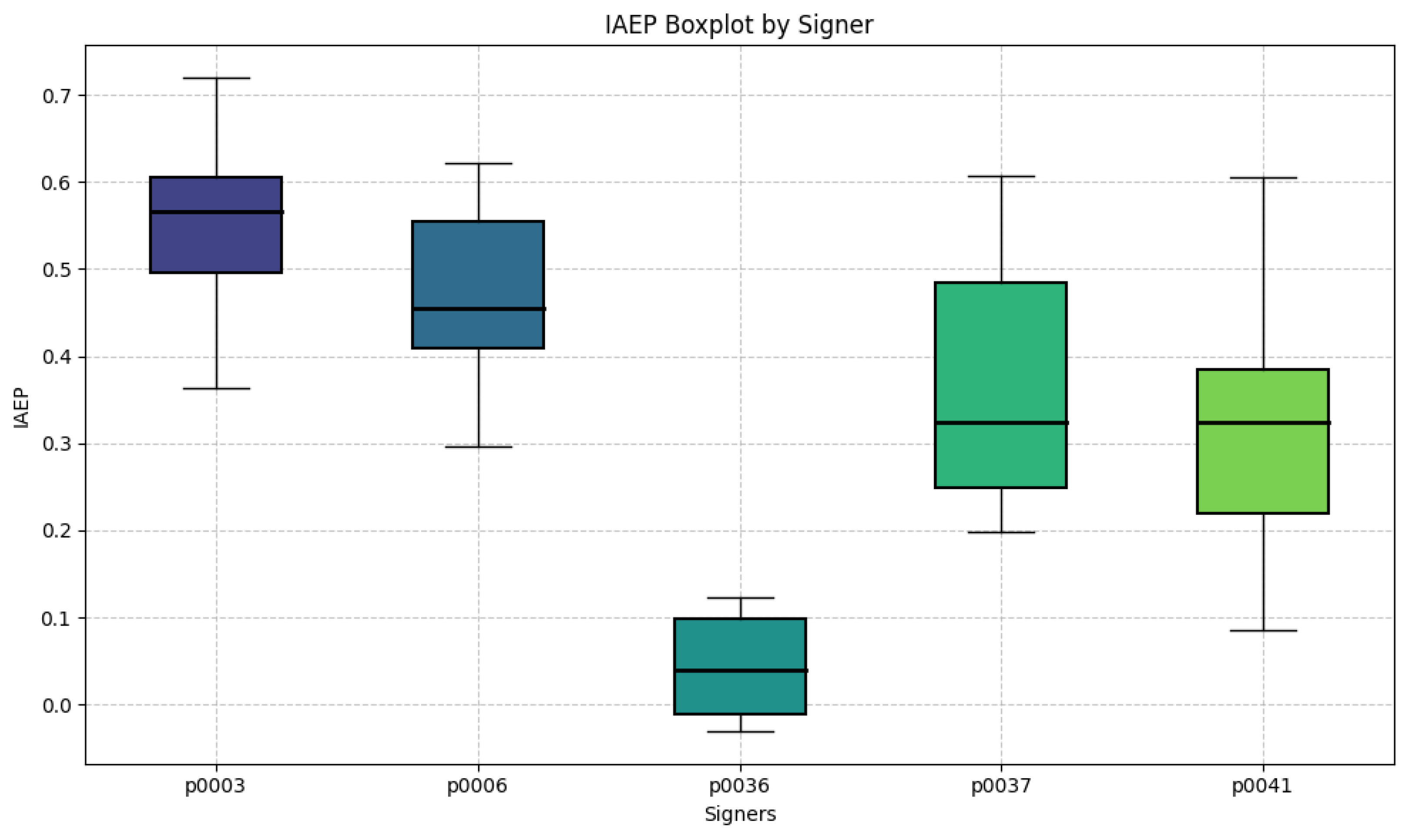
- Metrics for Evaluation: The introduction of the IAEP metric provided an innovative way to assess the balance between anonymization and expressivity preservation. While the metric showed promise, its performance in certain scenarios suggested that more robust or complementary subjective metrics may be needed to capture all relevant aspects of anonymization quality, particularly when dealing with varied signer swapped attributes.
- User Perception and Practical Usability: This small scale survey provided valuable insights into how deaf participants perceived the anonymization techniques. The alignment of their perceptions with FID and IAEP metrics for some signers indicates the potential of these tools to reflect user experience. However, variations in the comprehension and anonymization success across different signers suggest that additional contextual or subjective factors influence user perception.
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bragg, D.; Koller, O.; Caselli, N.; Thies, W. Exploring collection of sign language datasets: Privacy, participation, and model performance. In Proceedings of the 22nd International ACM SIGACCESS Conference on Computers and Accessibility, Virtual, 26–28 October 2020; pp. 1–14. [Google Scholar]
- Rudge, L.A. Analysing British Sign Language Through the Lens of Systemic Functional Linguistics. Ph.D. Thesis, University of the West of England, Bristol, UK, 2018. [Google Scholar]
- Bleicken, J.; Hanke, T.; Salden, U.; Wagner, S. Using a language technology infrastructure for German in order to anonymize German Sign Language corpus data. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 3303–3306. [Google Scholar]
- Das, S.; Biswas, S.K.; Purkayastha, B. Occlusion robust sign language recognition system for indian sign language using CNN and pose features. Multimed. Tools Appl. 2024, 83, 84141–84160. [Google Scholar] [CrossRef]
- Najib, F.M. A multi-lingual sign language recognition system using machine learning. Multimed. Tools Appl. 2024. [Google Scholar] [CrossRef]
- Liu, Y.; Lu, F.; Cheng, X.; Yuan, Y. Asymmetric multi-branch GCN for skeleton-based sign language recognition. Multimed. Tools Appl. 2024, 83, 75293–75319. [Google Scholar] [CrossRef]
- Perea-Trigo, M.; López-Ortiz, E.J.; Soria-Morillo, L.M.; Álvarez-García, J.A.; Vegas-Olmos, J. Impact of Face Swapping and Data Augmentation on Sign Language Recognition; Springer Nature: Berlin, Germany, 2024. [Google Scholar] [CrossRef]
- Dhanjal, A.S.; Singh, W. An optimized machine translation technique for multi-lingual speech to sign language notation. Multimed. Tools Appl. 2022, 81, 24099–24117. [Google Scholar] [CrossRef]
- Xu, W.; Ying, J.; Yang, H.; Liu, J.; Hu, X. Residual spatial graph convolution and temporal sequence attention network for sign language translation. Multimed. Tools Appl. 2023, 82, 23483–23507. [Google Scholar] [CrossRef]
- Lee, S.; Glasser, A.; Dingman, B.; Xia, Z.; Metaxas, D.; Neidle, C.; Huenerfauth, M. American sign language video anonymization to support online participation of deaf and hard of hearing users. In Proceedings of the 23rd International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS ’21), Association for Computing Machinery, New York, NY, USA, 22–25 October 2023; pp. 1–13. [Google Scholar]
- Mack, K.; Bragg, D.; Morris, M.R.; Bos, M.W.; Albi, I.; Monroy-Hernández, A. Social App Accessibility for Deaf Signers. Proc. ACM Hum.-Comput. Interact. 2020, 4, 125. [Google Scholar] [CrossRef]
- Yeratziotis, A.; Achilleos, A.; Koumou, S.; Zampas, G.; Thibodeau, R.A.; Geratziotis, G.; Papadopoulos, G.A.; Kronis, C. Making social media applications inclusive for deaf end-users with access to sign language. Multimed. Tools Appl. 2023, 82, 46185–46215. [Google Scholar] [CrossRef]
- Isard, A. Approaches to the anonymisation of sign language corpora. In Proceedings of the LREC2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges And Application Perspectives; European Language Resources Association (ELRA): Marseille, France, 2020; pp. 95–100. [Google Scholar]
- Xia, Z.; Chen, Y.; Zhangli, Q.; Huenerfauth, M.; Neidle, C.; Metaxas, D. Sign language video anonymization. In Proceedings of the LREC2022 10th Workshop on the Representation and Processing of Sign Languages: Multilingual Sign Language Resources, Marseille, France, 25 June 2022; pp. 202–211. [Google Scholar]
- Battisti, A.; van den Bold, E.; Göhring, A.; Holzknecht, F.; Ebling, S. Person Identification from Pose Estimates in Sign Language. In Proceedings of the LREC-COLING 2024 11th Workshop on the Representation and Processing of Sign Languages: Evaluation of Sign Language Resources, Torino, Italy, 25 May 2024; pp. 13–25. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.L.; Yong, M.G.; Lee, J.; et al. Mediapipe: A framework for building perception pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S.; Sabokrou, M. Sign Language Production: A Review. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 3446–3456. [Google Scholar]
- Tze, C.O.; Filntisis, P.P.; Roussos, A.; Maragos, P. Cartoonized Anonymization of Sign Language Videos. In Proceedings of the 2022 IEEE 14th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Nafplio, Greece, 26–29 June 2022; pp. 1–5. [Google Scholar]
- Heloir, A.; Nunnari, F. Toward an intuitive sign language animation authoring system for the deaf. Univers. Access Inf. Soc. 2016, 15, 513–523. [Google Scholar] [CrossRef]
- McDonald, J. Considerations on generating facial nonmanual signals on signing avatars. Univers. Access Inf. Soc. 2024, 24, 19–36. [Google Scholar] [CrossRef]
- Krishna, S.; P, V.V.; J, D.B. SignPose: Sign language animation through 3D pose lifting. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2640–2649. [Google Scholar]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.; Tzionas, D.; Black, M.J. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10967–10977. [Google Scholar]
- Rong, Y.; Shiratori, T.; Joo, H. Frankmocap: Fast monocular 3d hand and body motion capture by regression and integration. arXiv 2020, arXiv:2008.08324. [Google Scholar]
- Choutas, V.; Pavlakos, G.; Bolkart, T.; Tzionas, D.; Black, M.J. Monocular expressive body regression through body-driven attention. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part X 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 20–40. [Google Scholar]
- Forte, M.P.; Kulits, P.; Huang, C.H.P.; Choutas, V.; Tzionas, D.; Kuchenbecker, K.J.; Black, M.J. Reconstructing Signing Avatars from Video Using Linguistic Priors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 12791–12801. [Google Scholar]
- Baltatzis, V.; Potamias, R.A.; Ververas, E.; Sun, G.; Deng, J.; Zafeiriou, S. Neural Sign Actors: A diffusion model for 3D sign language production from text. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 1985–1995. [Google Scholar]
- Stoll, S.; Camgoz, N.C.; Hadfield, S.; Bowden, R. Text2Sign: Towards sign language production using neural machine translation and generative adversarial networks. Int. J. Comput. Vis. 2020, 128, 891–908. [Google Scholar] [CrossRef]
- Saunders, B.; Camgoz, N.C.; Bowden, R. Progressive transformers for end-to-end sign language production. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 687–705. [Google Scholar]
- Zelinka, J.; Kanis, J. Neural sign language synthesis: Words are our glosses. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 3384–3392. [Google Scholar]
- Saunders, B.; Camgoz, N.C.; Bowden, R. Anonysign: Novel human appearance synthesis for sign language video anonymisation. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; pp. 1–8. [Google Scholar]
- Kingma, D.P. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Saunders, B. Photo-Realistic Sign Language Production. Ph.D. Thesis, University of Surrey, Guildford, UK, 2024. [Google Scholar] [CrossRef]
- Saunders, B.; Camgoz, N.C.; Bowden, R. Everybody sign now: Translating spoken language to photo realistic sign language video. arXiv 2020, arXiv:2011.09846. [Google Scholar]
- Bishop, C.M. Mixture Density Networks; Aston University: Birmingham, UK, 1994. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10674–10685. [Google Scholar]
- Xia, Z.; Neidle, C.; Metaxas, D.N. DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization. arXiv 2023, arXiv:2311.16060. [Google Scholar]
- Xia, Z.; Zhou, Y.; Han, L.; Neidle, C.; Metaxas, D.N. Diffusion models for Sign Language video anonymization. In Proceedings of the LREC-COLING 2024 11th Workshop on the Representation and Processing of Sign Languages: Evaluation of Sign Language Resources, Torino, Italia, 25 May 2024; pp. 395–407. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 4–6 October 2023; pp. 3813–3824. [Google Scholar]
- Tze, C.O.; Filntisis, P.P.; Dimou, A.L.; Roussos, A.; Maragos, P. Neural sign reenactor: Deep photorealistic sign language retargeting. arXiv 2022, arXiv:2209.01470. [Google Scholar]
- Docío-Fernández, L.; Alba-Castro, J.L.; Torres-Guijarro, S.; Rodríguez-Banga, E.; Rey-Area, M.; Pérez-Pérez, A.; Rico-Alonso, S.; García-Mateo, C. LSE_UVIGO: A Multi-source Database for Spanish Sign Language Recognition. In Proceedings of the LREC2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives; European Language Resources Association (ELRA): Marseille, France, 2020; pp. 45–52. [Google Scholar]
- DollarsMocap. 2024. Available online: https://www.dollarsmocap.com/ (accessed on 20 May 2024).
- Bitouk, D.; Kumar, N.; Dhillon, S.; Belhumeur, P.; Nayar, S.K. Face swapping: Automatically replacing faces in photographs. ACM Trans. Graph. 2008, 27, 1–8. [Google Scholar] [CrossRef]
- DeepFaceLive. 2023. Available online: https://github.com/iperov/DeepFaceLive (accessed on 15 May 2024).
- Perov, I.; Gao, D.; Chervoniy, N.; Liu, K.; Marangonda, S.; Umé, C.; Dpfks, M.; Facenheim, C.S.; RP, L.; Jiang, J.; et al. DeepFaceLab: Integrated, flexible and extensible face-swapping framework. arXiv 2020, arXiv:2005.05535. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. How far are we from solving the 2d & 3d face alignment problem? (And a dataset of 230,000 3d facial landmarks). In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1021–1030. [Google Scholar]
- Feng, Y.; Wu, F.; Shao, X.; Wang, Y.; Zhou, X. Joint 3d face reconstruction and dense alignment with position map regression network. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part XIV. Springer: Berlin/Heidelberg, Germany, 2018; pp. 557–574. [Google Scholar]
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Nunn, E.J.; Khadivi, P.; Samavi, S. Compound frechet inception distance for quality assessment of gan created images. arXiv 2021, arXiv:2106.08575. [Google Scholar]
- Dong, L.; Chaudhary, L.; Xu, F.; Wang, X.; Lary, M.; Nwogu, I. SignAvatar: Sign Language 3D Motion Reconstruction and Generation. arXiv 2024, arXiv:2405.07974. [Google Scholar]
- Lakhal, M.I.; Bowden, R. Diversity-Aware Sign Language Production through a Pose Encoding Variational Autoencoder. arXiv 2024, arXiv:2405.10423. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2022, 13, 1195–1215. [Google Scholar] [CrossRef]
- Porta-Lorenzo, M.; Vázquez-Enríquez, M.; Pérez-Pérez, A.; Alba-Castro, J.L.; Docío-Fernández, L. Facial Motion Analysis beyond Emotional Expressions. Sensors 2022, 22, 3839. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W. Manual for the Facial Action Code; Consulting Psychologist Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Serengil, S.; Ozpinar, A. A Benchmark of Facial Recognition Pipelines and Co-Usability Performances of Modules. J. Inf. Technol. 2024, 17, 95–107. [Google Scholar] [CrossRef]
- Chang, D.; Yin, Y.; Li, Z.; Tran, M.; Soleymani, M. LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 1–6 January 2024; pp. 8190–8200. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Value |
|---|---|
| Total number of responses | 1403 |
| Number of different respondents | 76 |
| Number of responses for part 1 | 580 |
| Number of responses for part 2 | 523 |
| Number of responses for part 3 | 300 |
| Number of completed surveys | 100 |
| Average number of completed surveys per different user | 1.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perea-Trigo, M.; Vázquez-Enríquez, M.; Benjumea-Bellot, J.C.; Alba-Castro, J.L.; Álvarez-García, J.A. Sign Language Anonymization: Face Swapping Versus Avatars. Electronics 2025, 14, 2360. https://doi.org/10.3390/electronics14122360
Perea-Trigo M, Vázquez-Enríquez M, Benjumea-Bellot JC, Alba-Castro JL, Álvarez-García JA. Sign Language Anonymization: Face Swapping Versus Avatars. Electronics. 2025; 14(12):2360. https://doi.org/10.3390/electronics14122360
Chicago/Turabian StylePerea-Trigo, Marina, Manuel Vázquez-Enríquez, Jose C. Benjumea-Bellot, Jose L. Alba-Castro, and Juan A. Álvarez-García. 2025. "Sign Language Anonymization: Face Swapping Versus Avatars" Electronics 14, no. 12: 2360. https://doi.org/10.3390/electronics14122360
APA StylePerea-Trigo, M., Vázquez-Enríquez, M., Benjumea-Bellot, J. C., Alba-Castro, J. L., & Álvarez-García, J. A. (2025). Sign Language Anonymization: Face Swapping Versus Avatars. Electronics, 14(12), 2360. https://doi.org/10.3390/electronics14122360