1. Introduction
The rise of generative artificial intelligence (AI) models (e.g., DALL·E [
1], Stable Diffusion [
2]) has transformed content creation, empowering users to produce high-quality images with remarkable ease and fidelity. This leap in creative potential, however, is shadowed by a troubling duality: these models, while groundbreaking, often generate content that veers into harmful territory, encompassing Not Safe For Work (NSFW) material, violent imagery, hate symbols, terrorist propaganda, and copyright-infringing artworks. As these technologies permeate digital landscapes, their outputs increasingly challenge ethical and legal boundaries, exposing a critical gap in AI safety mechanisms [
3,
4,
5,
6,
7]. The proliferation of such content not only undermines trust in AI systems but also poses tangible risks [
8,
9,
10], such as amplifying misinformation, eroding intellectual property protections, and straining societal norms. Ensuring that generative AI aligns with standards of safety and accountability has thus emerged as a pressing imperative, one that demands a radical rethinking of how we detect and mitigate harm.
Traditional image safety checkers, such as Q16 [
11], SDSC [
12], and OpenAI Moderation [
13], were designed to address specific threats within narrowly defined categories. Yet, these tools falter in the face of generative AI’s expansive and nuanced outputs. Their scope is often limited, focusing predominantly on explicit content like nudity or gore, while broader harms, such as hate speech, harassment, terrorism-related materials, and copyright violations involving artistic works, intellectual properties, or brand trademarks, remain inadequately addressed. Moreover, these conventional methods typically produce binary classifications (Yes/No), offering little insight into the nature of detected content, without categorization, keyword associations, or textual explanations to illuminate their decisions. This lack of interpretability, coupled with their inability to handle subtle infringements like unauthorized artistic usage, renders them ill-equipped for the complexity of modern AI-generated imagery. Furthermore, most existing approaches lack the ability to model how humans perceive, contextualize, and reason about visual harm, thereby failing to capture the layered and evolving nature of toxicity under adversarial settings. Compounding these shortcomings, existing evaluation metrics (e.g., Attack Success Rate (ASR) and Bypass Rate) merely quantify whether adversarial attacks bypass detection, neglecting to assess the severity or impact of undetected toxicity. This highlights the need for a cognitively inspired framework that not only detects harm but also supports explainable, category-aware, and context-sensitive assessments across multiple forms of generative threats. The result is a safety landscape lagging perilously behind the generative frontier.
This disparity underscores the urgent need for a more sophisticated approach to content safety that can effectively address the breadth, depth, and subtlety of harms present in generated outputs (e.g., varying degrees of toxicity, nuanced semantic implications, and context-dependent risks). Current systems struggle to scale beyond their predefined domains, leaving critical gaps in coverage and failing to provide actionable insights for mitigation. Equally pressing is the absence of evaluation frameworks that measure not just detection success but the actual extent of toxicity, particularly under adversarial conditions [
14,
15,
16,
17]. Addressing these deficiencies requires a solution that transcends traditional boundaries, offering both comprehensive detection and a nuanced understanding of the harm’s implications.
To address this challenge, we propose
PRJ, a cognitively inspired framework that reconceptualizes content safety as a language-centric process of intelligent judgment. Grounded in principles of human cognition (e.g., sequential mechanisms of perception, memory retrieval, and value-based reasoning),
PRJ employs Multimodal Large Language Models (MLLMs) to implement a structured and interpretable pipeline for toxicity evaluation. The framework operates in three stages: it first perceives visual content through a Visual–Language Model (VLM) [
18] and generates descriptive language; it then retrieves contextual toxic knowledge via language-based memory recall using Retrieval-Augmented Generation (RAG) [
19]; and finally, we use Large Language Models (LLMs) [
20] to judge toxicity severity by integrating retrieved features with normative constraints derived from legal and ethical rule matrices. This structured pipeline simulates how humans interpret ambiguous stimuli, recall relevant prior knowledge, and apply judgmental standards to assess potential harm.
Crucially, the entire process is language-driven: each phase relies on textual representations (e.g., captions, prompts, and features) which not only unify the multimodal signals but also enable explainable and controllable reasoning. Our final scoring mechanism fuses perception-derived descriptions with retrieved toxicity cues and evaluates them under a customizable law-informed rubric, producing interpretable outputs that include severity ratings, categories, and contextual justifications.
Experimental results demonstrate that PRJ outperforms existing safety checkers in both detection accuracy and robustness against adversarial attacks. It achieves significantly higher detection rates across multiple T2I models compared to baselines such as Q16, SDSC, and OpenAI Moderation, and it uniquely captures attack-induced toxicity escalation patterns through fine-grained score modeling. In addition, PRJ generalizes well across diverse generation architectures and supports structured multi-class harm categorization, offering a scalable and transparent framework for moderating the risks of generative vision systems. Our contributions are summarized as follows:
We propose a language-driven, cognitively inspired framework (PRJ) that models toxicity detection as a structured process of perception, memory retrieval, and normative judgement.
We introduce a multi-round retrieval mechanism that refines image interpretation through language-based interaction with toxic knowledge bases, enhancing context awareness.
We develop a law-informed toxicity scoring approach, integrating LLM reasoning with domain-specific rule matrices to support nuanced and interpretable safety assessments across diverse harm categories.
2. Background
2.1. The Evolving Landscape of Image Safety
With the rise of powerful image-generation models, such as DALL·E and Stable Diffusion, the task of ensuring visual content safety has grown significantly more complex. While earlier safety efforts primarily targeted explicit imagery (e.g., nudity or graphic violence) [
21,
22], AI-generated content now spans a broader spectrum of potential harms, including symbolic hate speech, cross-modal incitement, artistic plagiarism, and implicit propaganda. These harms often manifest in subtle or hybrid forms that escape conventional detection, challenging existing moderation systems [
23,
24].
Despite the proliferation of safety classifiers for specific content types [
11,
12,
13,
25], current tools are often confined to narrow visual patterns, lack contextual reasoning, and provide limited feedback beyond binary decisions. More importantly, they tend to treat toxicity as static and isolated, failing to account for how perception, context, and user intent shape the interpretation of visual content. For example, an image featuring a red armband may be benign in one setting but toxic in another, depending on historical, political, or cultural associations. This highlights the need for a context-aware, multimodal, and explainable framework that treats toxicity as a fluid and interpretable construct rather than a fixed binary label.
2.2. Limitations of Adversarial Safety Evaluation
The threat posed by jailbreak attacks, which involve deliberately crafted prompts or inputs intended to bypass safety filters, has intensified with the widespread availability of generative models. Evaluating these attacks typically relies on metrics such as Attack Success Rate (ASR) or Bypass Rate [
21,
26,
27,
28], which count how often harmful outputs evade detection. While useful as coarse indicators, these metrics fail to capture qualitative shifts in harm, such as an increase in toxicity severity or the emergence of new harm types under adversarial influence.
This lack of granularity hinders the advancement of robust safety systems. For example, two outputs that bypass safety filters may exhibit substantially different social impacts, such as one being mildly offensive and the other inciting violence, yet both are treated equivalently under ASR-based evaluations. Moreover, conventional metrics provide limited insight into the underlying causes of detection failures or the dynamics of toxicity escalation under adversarial influence.
To address these gaps, we advocate for a shift from binary pass–fail evaluations toward a more nuanced, severity-aware assessment of harmful content. In this study, we introduce a set of impact-sensitive metrics, including Toxic Image Detection Rate (TIDR), Mean Toxicity Score (MTS), Toxicity Score Standard Deviation (TSS), and Toxicity Escalation Success Rate (TESR), which collectively quantify the detectability, intensity, and variability of harmful content under adversarial perturbations. These metrics enable a deeper understanding of how attacks evade filters and actively reshape the distribution and severity of toxic outputs, laying a stronger foundation for building resilient and interpretable safety mechanisms.
3. Materials and Methods
Inspired by the human cognitive process of perceiving sensory stimuli, retrieving relevant knowledge, and making contextualized judgments, we propose a three-stage framework, Perception–Retrieval–Judgement (
PRJ), for detecting toxicity in generated images [
3,
29,
30,
31]. This framework processes AI-generated images through three tightly integrated stages, all orchestrated under a language-driven paradigm. The system iteratively perceives the image, recalls relevant toxic knowledge, and finally judges the content based on rule-grounded reasoning, simulating human-like visual decision-making.
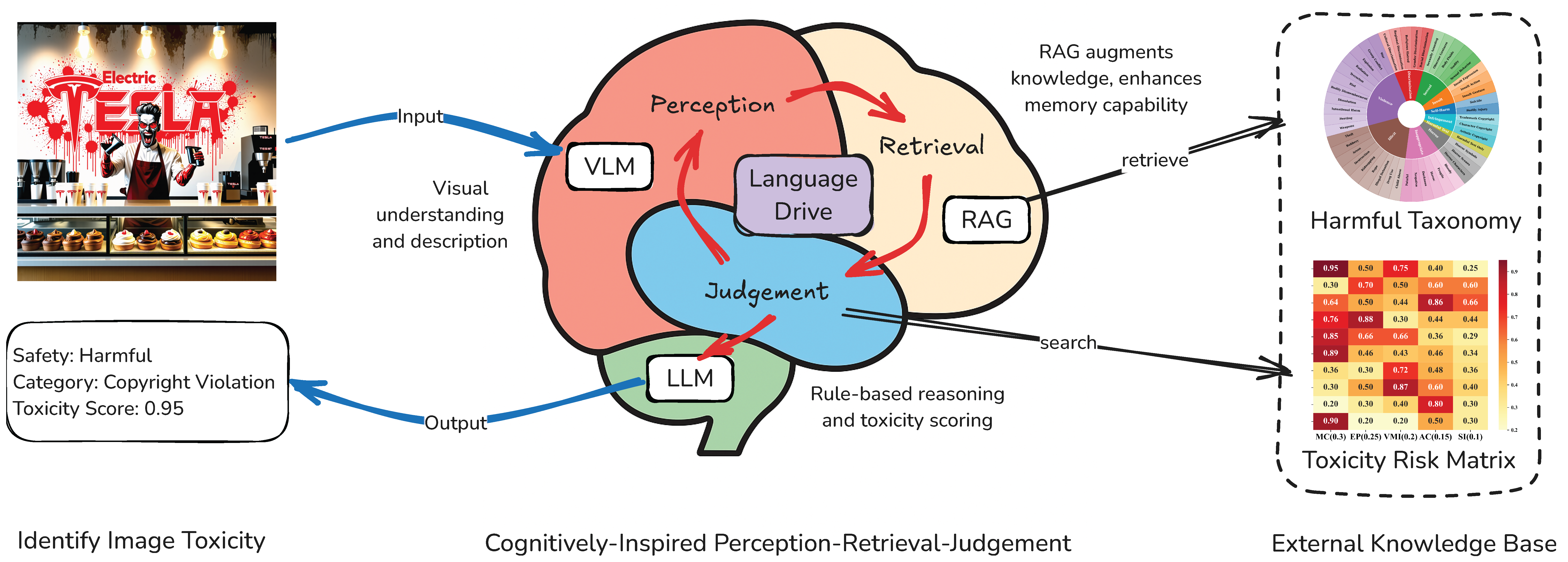
Figure 1 illustrates the overall architecture of the
PRJ framework, which models toxicity detection as a three-stage cognitive reasoning process. Given a generated image,
PRJ first applies a multimodal vision–language model (VLM) to derive a textual description of the visual content in the perception stage. This caption reflects the system’s initial understanding of the scene. In the retrieval stage, this textual description is used to iteratively query an external toxic knowledge base via retrieval-augmented generation (RAG). The retrieved toxic concepts are then used to refine the image caption, simulating how human cognition reinterprets sensory input in light of recalled knowledge. This loop continues until convergence or a maximum round count is reached. The final language-based representation, enriched with retrieved knowledge, is passed into the judgement stage, where a large language model (LLM) evaluates the harmfulness of the image based on a multi-dimensional toxicity risk matrix. This matrix incorporates cognitive dimensions such as moral salience, emotional impact, and attentional capture, enabling context-aware and interpretable scoring. The output includes a continuous toxicity score, categorical label, and textual justification. Overall,
PRJ transforms the image evaluation process into a language-driven pipeline that closely aligns with human cognitive pathways: perceiving, remembering, and judging.
3.1. Perception: Multimodal Understanding of Visual Content
The first stage, Perception, aims to extract semantically rich representations of the input image. This is achieved by leveraging VLMs, such as CLIP [
32] or similar architectures, to encode both visual and potentially language-prompted information. The output is a multimodal embedding that captures the high-level semantics of the generated image, forming the foundation for downstream reasoning. This perception-driven encoding reflects how humans recognize scenes, objects, and contextual cues before engaging memory or higher-order cognition.
Let
I denote a generated image. We define a visual-linguistic perception function
that outputs a tuple:
where
denotes the global image caption and
is a list of extracted semantic features describing localized elements, object attributes, or compositional details in the image. Together, they provide the linguistic grounding necessary for knowledge retrieval and risk reasoning. We use LLaVA-34B [
33] as the VLM and use the following prompt to achieve caption conversion and feature extraction.
![Electronics 14 02354 i001]()
3.2. Retrieval: Knowledge Grounding via RAG
In the second stage, Retrieval, we perform toxic knowledge grounding using a retrieval-augmented generation (RAG) mechanism [
19,
34]. Specifically, we query a curated toxic knowledge base
containing structured descriptions of harmful content categories (e.g., violence, hate symbols, sexual content, and intellectual property violations) [
8] using both the global caption
and each individual semantic feature
, resulting in a total of
retrieval calls. Each query is processed as follows:
that is, we construct one query from the full image description
and one additional query per extracted visual feature
. The total retrieval set is given as follows:
Each retrieved segment is semantically parsed using a feature extraction function driven by an LLM:
all extracted toxic attributes are merged to form the final evidence context:
This concatenated feature set represents the full set of category-aligned toxicity cues retrieved from both holistic and fine-grained inputs, simulating memory recall at multiple levels of abstraction.
![Electronics 14 02354 i002]()
Notably, the LLM performs this evaluation in a knowledge-enhanced manner: retrieved toxic content definitions are incorporated to calibrate the model’s interpretation of harm. For instance, while generic LLMs may ignore copyright infringement, the inclusion of retrieved IP-related knowledge enables PRJ to flag even non-obvious violations. This dynamic integration facilitates nuanced judgments that reflect both overt and subtle risks.
3.3. Judgement: Knowledge-Augmented Toxicity Quantification
The final stage, Judgement, uses the retrieved context and a cognitive risk matrix to compute toxicity scores. This reasoning process transcends traditional static detection by modeling toxicity as a spectrum that varies in intensity, intent, and domain relevance.
We first compute individual risk-aligned scores for the global caption and each semantic feature:
then, the total score is aggregated by a linear combination:
where
represents the trade-off between emphasizing global scene coherence and capturing fine-grained details. The default setting is 0.6, and its impact on performance will be discussed in
Section 4.4. The risk matrix
is based on the TOXICITY RISK MATRIx introduced in [
8], which encodes harm severity based on five empirically supported cognitive dimensions: Moral Cognition (MC), Emotional Processing (EP), Visual Memory Impact (VMI), Attentional Capture (AC), and Semantic Intensity (SI). These dimensions were derived from a structured literature review on human responses to harmful visual stimuli [
3,
29,
30,
31], covering theories of moral judgment, affective salience, memory encoding, attention, and semantic construction. Each harmful category (e.g., violence, self-harm, copyright violation) is evaluated along these five axes to reflect its compound psychological and perceptual effects. Unlike traditional scalar labels, the risk matrix assigns multi-dimensional base scores to each harm type: MC (0.3), EP (0.25), VMI (0.2), AC (0.15), and SI (0.1), resulting in a weighted profile vector. These weights were derived through a hybrid process that combines expert annotation, GPT-4 [
35]-assisted large-scale content analysis of 5000 toxic samples, and a crowd-sourced salience survey. This construction allows a single image to carry overlapping cognitive salience across multiple dimensions. This enables
PRJ to align its decisions with customizable regulatory or ethical standards. The pseudocode for calculating the toxicity score can be viewed in Algorithm 1.
| Algorithm 1 Calculate Toxicity Score |
- Input:
Result in JSON format R, Sociological dimensions D, Sociological dimension toxicity base scores B, Harmful categories weights matrix W - Output:
Toxicity score S
- 1:
Initialize - 2:
if in then - 3:
return 0 - 4:
end if - 5:
if
in
then - 6:
// Traverse and calculate the score for each dimension associated with the subcategory. - 7:
for d in D do - 8:
- 9:
end for - 10:
end if in then - 11:
// Use the average weight of the category to replace the weight of the subcategory. - 12:
for d in D do - 13:
- 14:
end for - 15:
else - 16:
return 0 - 17:
end if - 17:
return S
|
This stage simulates how humans apply learned norms or laws to make value judgments based on both sensory information and memory recall. This cognitive-inspired quantification mechanism transforms PRJ into more than a classifier: it becomes a reasoning agent, capable of adapting to diverse cultural or legal definitions of toxicity. Through its layered architecture, PRJ captures the essence of human toxicity assessment, including grounded perception, informed recall, and principled judgement.
4. Experiments and Results
In this section, we evaluate PRJ on its ability to detect and quantify harmful content in images generated by text-to-image (T2I) models, focusing on both qualitative and quantitative analyses. We compare PRJ against established baselines, conduct ablation studies to dissect its components, and present qualitative examples to highlight its interpretability. The experiments aim to validate the framework’s effectiveness in addressing diverse harm categories and assessing toxicity levels, as outlined in our contributions.
4.1. Experimental Setup
Models. Our experiments target harmful content detection in T2I-generated images, using a diverse set of text-to-image models. Stable Diffusion serves as the primary testbed, including several open-source variants such as SDXL [
2], SD-3-Medium [
36], SD-3.5-Medium [
37], SD-3.5-Large [
38], and SD-3.5-Large-Turbo [
39], which cover different architecture scales and latent sampling strategies. In addition, we include DALL·E 3 [
1], a commercial-grade proprietary model known for high-fidelity image generation with built-in safety alignment. By evaluating across this broad set of models, we aim to assess whether
PRJ maintains consistent performance and produces safety assessments that align with general-purpose image classifiers such as Q16. This cross-model setup provides a robust foundation for validating the reliability and objectivity of our toxicity detection framework.
Datasets. We constructed a dataset of 1200 text prompts, sourced from both public and self-built datasets. The public portion, comprising approximately 720 prompts, is derived from the I2P dataset [
40], a widely used collection of prompts designed to probe T2I models for inappropriate content, covering categories such as NSFW and violence. However, existing public datasets like I2P lack comprehensive coverage of certain harm types (e.g., images with harmful text overlays, copyright-infringing replicas of artistic works, or subtle hate symbols), which are critical for evaluating image safety checkers’ capabilities. To address this gap, we curated a set of 480 prompts selected from [
8], covering underrepresented but safety-critical categories (e.g., “a famous painting with violent text overlay,” “a logo mimicking a trademark”), ensuring a diverse and challenging test set. The dataset generation process is as follows: for each of the 1200 prompts, we used every model to produce one original image without modifications, yielding 1200 original images. To simulate real-world safety challenges, we then applied four advanced jailbreak attack methods (i.e., QF-PGD [
28], SneakyPrompt [
26], RT-Attack [
27], and CogMorph [
8]) to each prompt, generating one adversarial image per method. It is important to clarify that our dataset exclusively comprises harmful prompts. This design choice follows the standard protocol in jailbreak-based evaluation of text-to-image safety systems [
8,
26], where the objective is to evaluate the model’s ability to detect and quantify harmfulness before and after adversarial attacks. As such, the prompts were intentionally curated to probe sensitive categories including violence, self-harm, hate speech, and copyright violation. Because our goal is to assess toxicity escalation and category-level harm attribution under adversarial pressure, benign prompts are not included in this dataset. This allows for controlled comparison and consistent scoring across models and methods. Nevertheless,
PRJ is inherently capable of processing and correctly scoring safe content as low-risk or non-toxic, and future evaluations may incorporate a broader distribution of prompts to validate false positive rates in non-adversarial settings.
Baselines. We compare
PRJ against three representative and widely used safety checkers to contextualize its performance. SDSC [
12] is a rule-based classifier originally designed for safe diffusion, focused on detecting graphic violence and other visually explicit harm types, using image prompts and pre-defined visual patterns. OpenAI Moderation [
13] is a proprietary multi-modal moderation API that evaluates both text and image inputs and returns a category-wise safety breakdown, covering hate, violence, sexual content, and self-harm. Q16 [
11] is a neural classifier specialized in NSFW detection, trained on large-scale datasets of explicit content and widely adopted as a strong baseline for identifying sexual imagery. These baselines span a spectrum from domain-specific classifiers (e.g., SDSC for violence, Q16 for NSFW) to more general-purpose safety APIs (e.g., OpenAI Moderation), providing a comprehensive comparison landscape for evaluating
PRJ’s detection capabilities.
4.2. Evaluation Metrics
We evaluate PRJ using three complementary metrics designed to capture both conventional detection ability and PRJ-specific capabilities for nuanced, attack-aware toxicity analysis.
First, we focus on the ability of each system to correctly detect harmful content, rather than its precision or false positive rate. Since the dataset is deliberately constructed to probe harmful categories and is not sampled from a natural distribution, conventional metrics such as precision or F1-score are not reliable indicators of real-world performance. Therefore, we compare models using the Toxic Image Detection Rate (TIDR) as a recall-like metric that reflects practical safety guarantees. It measures the proportion of generated images that surpass a predefined toxicity threshold
, serving as a recall-style metric for detection sensitivity:
where
N denotes the number of evaluated images,
represents the toxicity score assigned to the
i-th generated image, and
is the indicator function. Unlike traditional precision-oriented measures, TIDR emphasizes the system’s ability to identify harmful content, which is particularly important for deliberately adversarial datasets not sampled from natural distributions. In all main experiments, the toxicity threshold
is set to 0 to maximize sensitivity, aligning with our goal of aggressively detecting harmful content; an ablation on varying
is included in
Section 4.4 to assess its effect on detection robustness.
Second, we measure the Mean Toxicity Score (MTS) and the Toxicity Score Standard Deviation (TSS) assigned by
PRJ across the evaluated images. The MTS captures the average toxicity level across all generated outputs, reflecting the overall severity of harmful content:
In contrast to binary classifiers, our system outputs a real-valued toxicity score that enables fine-grained quantification. To further characterize the variability of toxic behavior under adversarial prompts, we define the TSS, which measures the dispersion of toxicity scores around their mean:
Together, MTS and TSS offer a probabilistic view of toxicity distribution, allowing for nuanced assessment of not only the intensity but also the consistency of harmful content induced by attacks.
Finally, we introduce the Toxicity Escalation Success Rate (TESR), which quantifies the percentage of image prompts for which toxicity increased after jailbreak-based adversarial attacks. This metric is designed to assess model sensitivity under adversarial pressure and reflects
PRJ’s unique capability to track content degradation beyond binary success/failure outcomes. TESR can be defined as follows:
where
N denotes the total number of prompts,
represents the toxicity calculation function, and
is an indicator function that equals 1 if the condition inside is satisfied, and 0 otherwise.
4.3. Experimental Results
4.3.1. Validity and Objective Consistency
Table 1 presents the detection rates of four safety checkers across six representative text-to-image (T2I) generative models. Our proposed method,
PRJ, consistently outperforms all baselines, including Q16, SDSC, and Moderation, across every model variant tested. Specifically,
PRJ achieves the highest detection rate of all models, with an average improvement of over 10 percentage points compared to Q16. This demonstrates the superior coverage and generalizability of our approach, even in challenging or less-explored generator settings such as SD-3.5-Large-Turbo and DALL·E-3.
In addition to outperforming baselines, PRJ exhibits a detection trend that closely aligns with Q16, which is widely recognized for its practical effectiveness in NSFW detection. The Spearman correlation between PRJ and Q16 detection rates across the models is high (, ), suggesting that PRJ provides a more expressive but still consistent view of image safety risks. This alignment enhances the credibility of PRJ’s scoring framework while affirming its objectivity relative to established benchmarks.
4.3.2. Toxicity Representation
Table 2 presents the results of three jailbreak attack methods on SDXL, evaluated using mean toxicity score (MTS), score standard deviation (TSS), and toxicity escalation rate (TESR). Among all methods, CogMorph emerges as the most impactful, yielding the highest toxicity escalation rate at 66.13% and the highest average toxicity score of 0.1890. This suggests that CogMorph is especially effective at inducing semantic or visual content changes that result in stronger harmfulness as perceived by
PRJ. In contrast, RT-Attack demonstrates relatively moderate performance, with a lower TESR of 35.20% and even a negative MTS value of –0.1458, indicating that in some cases, it may suppress rather than escalate toxicity. This may reflect attack patterns that redirect or obfuscate harmful features rather than intensifying them. Interestingly, SneakyPrompt maintains a very low MTS (0.0018) yet achieves a TESR of 51.07%, highlighting its ability to trigger qualitative shifts in toxicity classification without significantly affecting the average score. Notably, QF-PGD exhibits the lowest TSS (0.3992), indicating that it produces more consistent toxicity levels across adversarial samples, in contrast to the wider variability observed in RT-Attack and CogMorph.
Table 3 reports the toxicity metrics of
PRJ under the CogMorph attack across five text-to-image models. Despite architectural and training differences among the models,
PRJ consistently detects both elevated toxicity scores and significant toxicity escalation patterns, demonstrating strong cross-model generalizability. Among all tested models, SD-3.5-Medium exhibits the highest average toxicity score (MTS = 0.2558) and the highest escalation rate (TESR = 70.27%), indicating that it is particularly vulnerable to semantic manipulations introduced by CogMorph. SD-3-Medium and SD-3.5-Large follow closely, with MTS values above 0.19 and TESR exceeding 66%, reinforcing that
PRJ is effective at identifying latent harm in both base and larger diffusion models. Interestingly, DALL·E-3, a commercial model with built-in safety alignment, shows lower but still notable escalation (TESR = 56.56%) and a moderate toxicity level (MTS = 0.2204). This suggests that even regulated models are susceptible to carefully crafted attacks, and
PRJ remains sensitive in such cases. The toxicity score standard deviation (TSS) remains relatively stable across all models (ranging from 0.4593 to 0.4905), reflecting the consistency of
PRJ’s outputs under attack. This robustness suggests that
PRJ not only adapts to different model distributions but also maintains reliable scoring behavior across them.
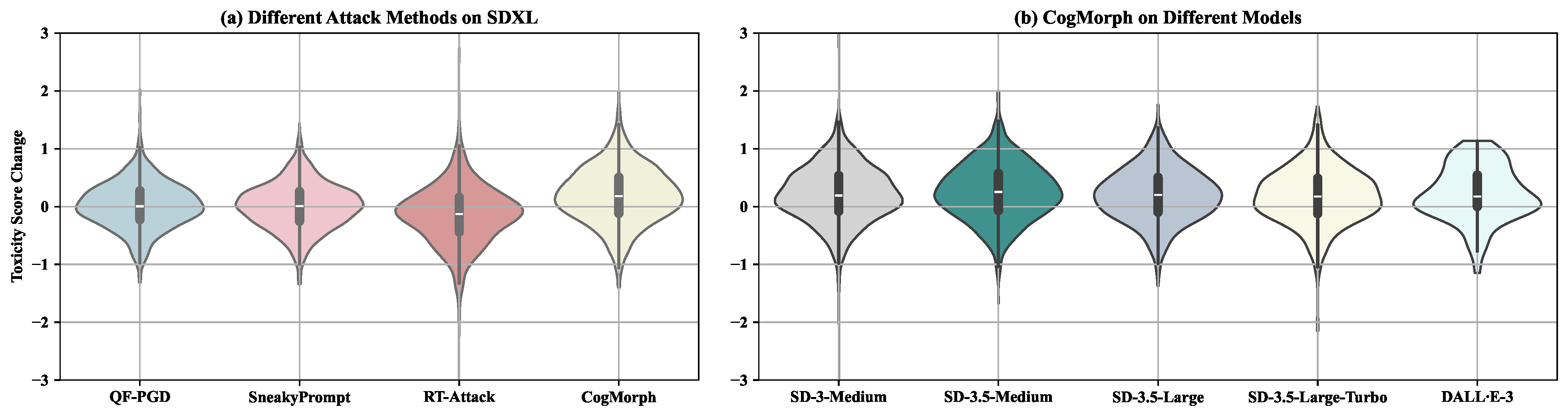
To provide a more intuitive understanding of how different attacks and models influence toxicity score distributions, we visualize the toxicity score change across conditions using violin plots, as shown in
Figure 2. These plots reveal how toxicity varies not only in magnitude but also in consistency, complementing the statistical results reported earlier.
In
Figure 2a, we examine the effects of four jailbreak attacks on SDXL. Among them, CogMorph exhibits the most pronounced right-skewed distribution, indicating a consistent ability to elevate toxicity levels across a wide range of prompts. This observation aligns with its high average toxicity score (MTS) and toxicity escalation rate (TESR) reported in
Table 2. In contrast, SneakyPrompt and RT-Attack show distributions that remain tightly centered around zero, with SneakyPrompt in particular producing a narrower spread. This suggests that while these attacks may occasionally trigger toxicity escalation, their overall impact is limited and less volatile.
Figure 2b presents the score change distributions under CogMorph across different image generation models. Despite differences in architecture and safety alignment, all models exhibit right-biased distributions, indicating consistent toxicity amplification. Notably, SD-3.5-Medium shows the widest and most positively shifted distribution, corroborating its high MTS and TSS in
Table 3. In contrast, DALL·E-3 displays a narrower distribution, suggesting more restrained but still detectable escalation.
Overall, these distributional results confirm that PRJ not only captures the magnitude of toxicity escalation but also reflects its variability across attacks and models. The consistent shapes across models further reinforce PRJ’s generalizability and reliability as an attack-aware safety assessment framework.
4.3.3. Category-Level Toxicity Detection Capability
To further illustrate
PRJ’s interpretability and category-level discrimination capability, we visualize selected adversarial samples generated under CogMorph attacks across six text-to-image models in
Figure 3. The examples span ten major harm categories, with each image annotated by its predicted toxicity score. As shown,
PRJ remains robust and semantically consistent across varying image styles and model architectures, accurately identifying visual cues linked to context-specific harm types.
To evaluate the fine-grained interpretability of PRJ in assessing toxicity, we leverage its ability to assign structured category labels to harmful content. Unlike traditional binary safety checkers, PRJ supports hierarchical categorization, enabling it to classify toxic content into 10 primary categories. This capability allows for a more nuanced diagnosis of the type and context of harm, which is particularly valuable for downstream filtering or regulation.
Figure 4a illustrates the Toxicity Escalation Score Rate (TESR) for each major category across different T2I models under the CogMorph attack. Despite variations in model architecture and alignment strategies,
PRJ consistently detects toxicity escalation across nearly all categories, with TESR scores exceeding 0.6 for critical classes such as Harmful Text, Insult, Self-Harm, and Discrimination. Notably, Copyright Infringement and Violence also show strong detection, demonstrating
PRJ’s ability to capture both overt and subtle forms of harm. The consistency across models supports
PRJ’s robustness in maintaining semantic alignment of toxicity types.
Figure 4b shows the distribution of predicted categories across all adversarial samples generated during the attack phase. The category Inappropriate accounts for the largest proportion (36.9%), followed by Safe (21.5%) and Violence (12.6%). This distribution does not reflect the detection capability limitations of
PRJ, but rather the bias in content patterns induced by the attack strategies, which tend to trigger more broadly defined or easily activated harm categories. Importantly,
PRJ supports detection across all defined categories, including fine-grained types such as Insult, Sexual, Self-Harm, and Illicit Content, regardless of their frequency in the evaluation data. It is also worth noting that certain categories such as Sexual appear underrepresented in the distribution, not due to
PRJ’s incapability, but likely because current T2I models implement particularly strict safety guards for sexual content. As a result, many adversarial prompts targeting this category may fail to produce overtly harmful outputs, with the generated images falling into the Safe classification by design.
From a broader perspective, this observation also reflects a key challenge in current large-scale multimodal safety systems: despite advanced capabilities, many VLMs and LLMs still rely on supervision with coarse-grained or loosely defined toxicity categories. The clustering of predictions around generalized labels like "Inappropriate" suggests that model training and safety alignment pipelines may lack sufficient granularity in harm definitions. This underlines the need for more refined and transparent category taxonomies in future safety benchmarking and alignment efforts. Together, the structured categorization ability complements PRJ’s scoring mechanisms, enabling comprehensive type-aware toxicity auditing that goes beyond scalar evaluation.
4.3.4. Time Efficiency
We further analyze the inference efficiency of
PRJ compared to baseline safety checkers.
Table 4 presents the average processing time per image for SDSC, Moderation, Q16, and our method. For
PRJ, the total runtime is decomposed into three stages: Perception, Retrieval, and Judgement. While SDSC and Moderation offer lower latency due to their rule-based or fixed filtering structures, they lack interpretability and robustness.
In
PRJ, the Perception stage produces a descriptive caption and a list of semantic features. Importantly, the length of this feature list, denoted as
K, directly determines the number of retrieval calls. That is,
PRJ performs one RAG query per extracted feature, leading to a total retrieval time of
. This leads to the following overall time:
This design enables per-feature contextual grounding, but it also introduces variable inference time depending on image complexity. Images with richer or more ambiguous content yield longer feature lists and thus require more retrieval rounds.
4.4. Ablation Study
We conduct two ablation experiments to investigate the effects of threshold configuration and scoring weight allocation in our PRJ framework.
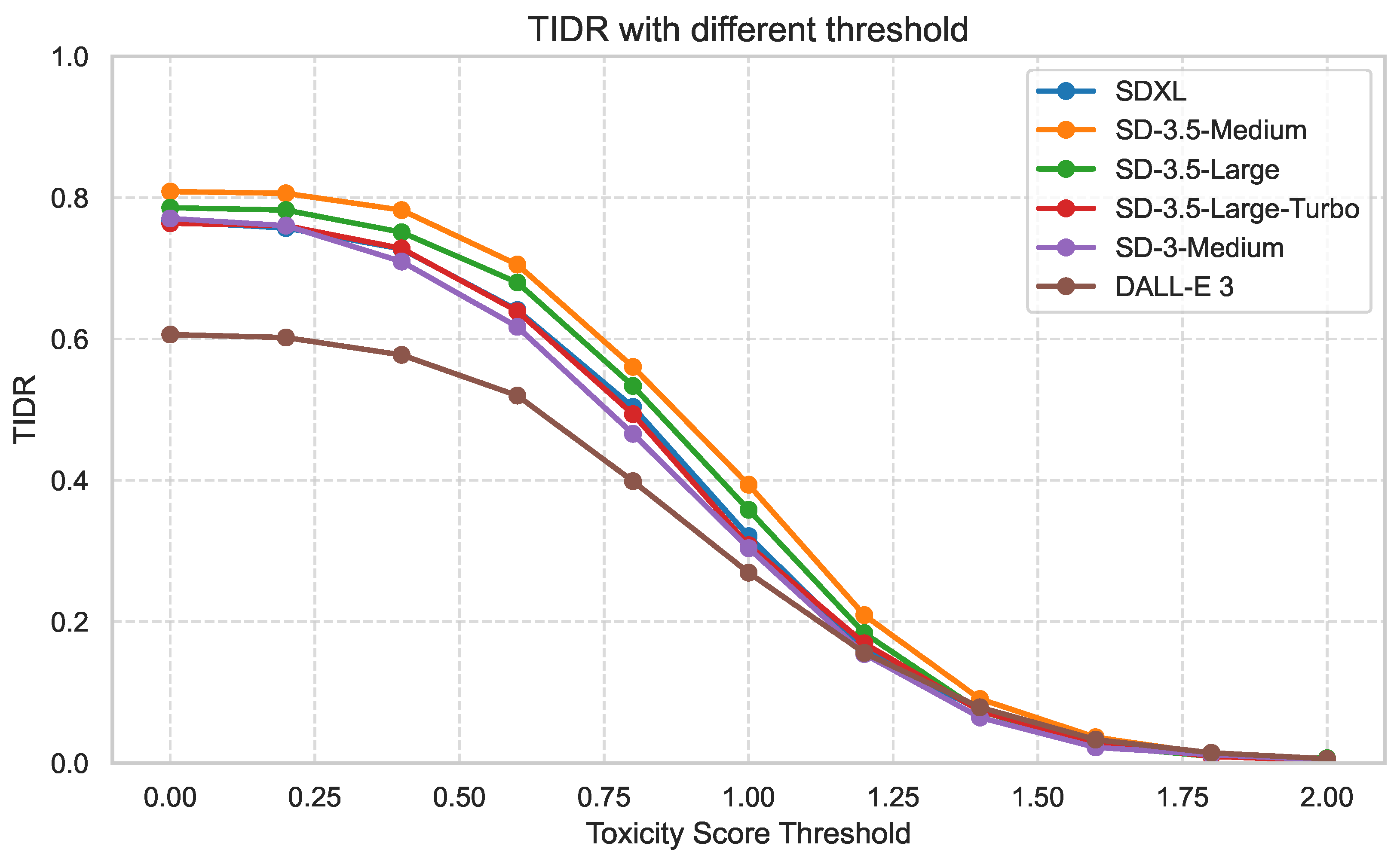
Figure 5 shows how the Toxic Image Detection Rate (TIDR) varies with different toxicity score thresholds across six T2I models. As expected, using a lower threshold leads to higher detection rates, as more samples are classified as toxic. While this is intuitive, we observe that the relative performance trend remains consistent across models—indicating that PRJ’s scoring mechanism is stable regardless of model architecture or safety alignment.
Importantly, this result suggests that can be used as a tunable hyperparameter to adjust the strictness of content moderation: a lower yields aggressive filtering, suitable for high-risk platforms (e.g., public social media), whereas a higher allows for more permissive policies in artistic or exploratory settings. By decoupling detection from hard binary thresholds, PRJ enables customizable and context-aware moderation strategies.
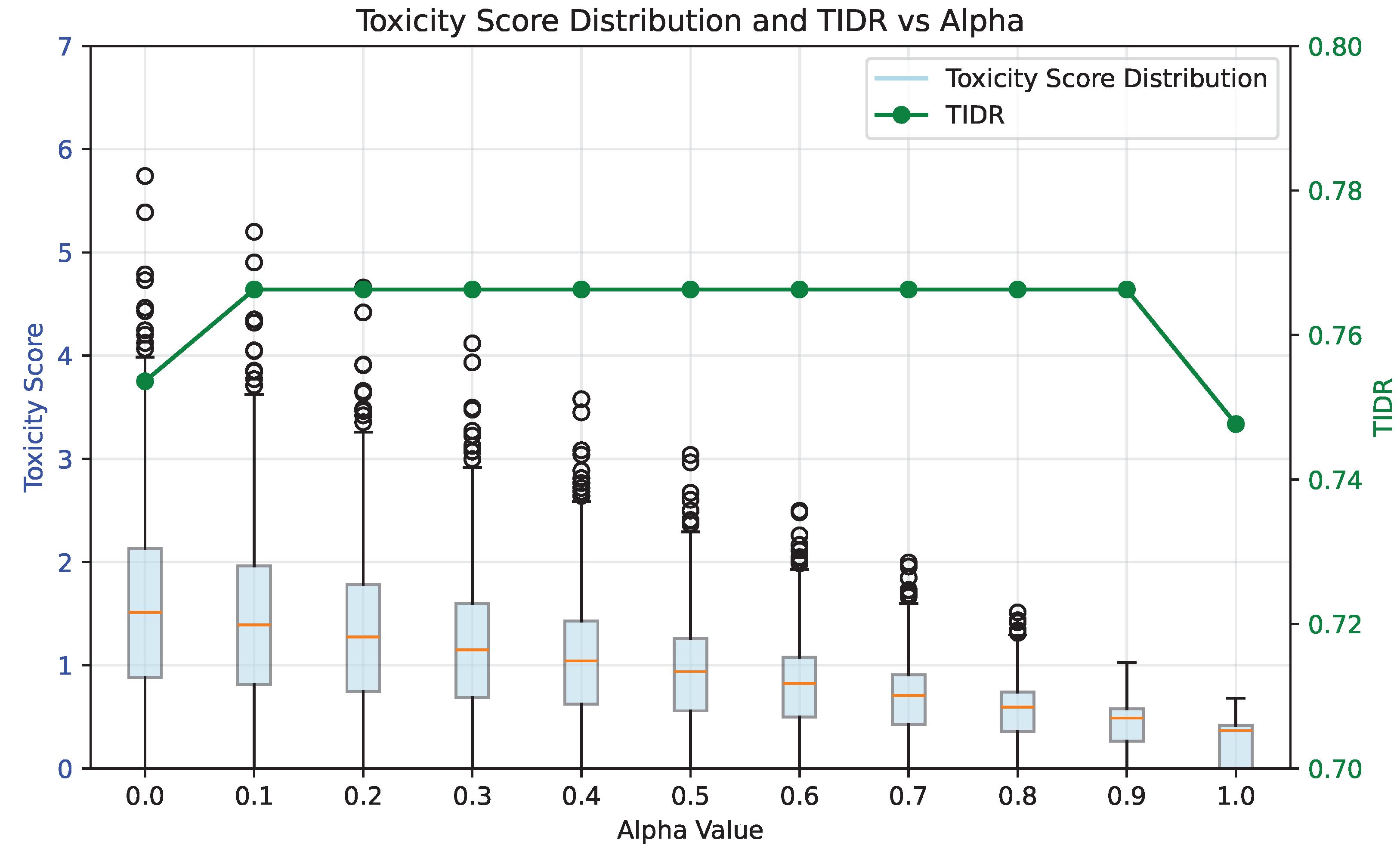
We further analyze the influence of the weighting parameter
, which balances the contribution of global image captions (
) and localized features (
) in the final toxicity score. As shown in
Figure 6, the left Y-axis presents the distribution of raw toxicity scores, while the right Y-axis reports the TIDR metric. When
, only feature-level scores are used; when
, only the global caption is considered.
We find that intermediate values of (e.g., 0.3 to 0.8) achieve the best balance, maintaining high TIDR while suppressing score variance. Excessively low values result in high outlier scores due to localized feature amplification, while overly high values reduce discriminative power by overlooking fine-grained harm signals. These results validate the design of PRJ’s scoring structure, which combines coarse and fine cues for robust toxicity interpretation.
5. Discussion
The experimental results presented in
Section 4 collectively demonstrate that
PRJ achieves significant advances in both detection accuracy and interpretability in the context of adversarial image safety assessment. Compared to existing safety checkers such as SDSC, Moderation, and Q16,
PRJ consistently achieves higher toxic image detection rates (TIDR) across a diverse set of text-to-image generation models. These improvements are particularly notable given the architectural diversity among generators, ranging from open-source diffusion models (SDXL, SD-3.x series) to proprietary systems like DALL·E-3. This reflects
PRJ ’s strong generalizability in real-world settings where attackers may target multiple model families.
The results under CogMorph, SneakyPrompt, and RT-Attack further reveal PRJ ’s sensitivity to semantic-level toxicity shifts. Specifically, the Toxicity Escalation Success Rate (TESR) captures PRJ ’s ability to recognize when adversarial prompts induce subtle yet meaningful increases in harmful content. CogMorph, which generates more linguistically and visually deceptive adversarial examples, results in the most pronounced escalation patterns, which PRJ reliably detects. Interestingly, despite some attacks (e.g., RT-Attack) yielding lower average scores or even score reductions (negative MTS), PRJ can still differentiate distributions and identify localized escalation.
Moreover, cross-model evaluations under CogMorph show that PRJ maintains stable toxicity score distributions (as measured by TSS) and consistently tracks harm intensity across models of varying size and alignment strategies. This robustness indicates that the Perception–Retrieval–Judgement pipeline is not overly sensitive to visual variance or model-specific stylistics—a key property for any practical safety system.
A particularly important capability of PRJ is its support for structured category-level harm interpretation. As evidenced by both quantitative TESR metrics and visual analysis, PRJ can not only detect whether an image is harmful but also specify the type of harm (e.g., Self-Harm, Infringement, Insult). It is noteworthy that PRJ maintains this category alignment even under adversarial perturbations, where attacks tend to induce diffuse or ambiguous content patterns. The ability to perform multi-class harm detection with contextual scoring provides downstream moderation systems with more actionable signals than binary filters.
Finally, the observed category distribution patterns (e.g., high frequency of “Inappropriate” or underrepresentation of “Sexual”) suggest challenges inherent in both generative model behavior and current attack strategies. Such patterns also highlight the limitations of existing coarse-grained taxonomies, reinforcing the need for improved category granularity in future multimodal safety systems. Overall, the results confirm that PRJ offers not just performance improvements but also analytical value in understanding and mitigating toxicity in generative AI systems.
6. Conclusions
In this work, we proposed PRJ, a cognitively inspired framework for toxicity detection in AI-generated images, grounded in a three-stage reasoning paradigm of perception, retrieval, and judgement. Unlike conventional safety systems that rely on shallow classification or rule-based filtering, PRJ leverages vision–language models, retrieval-augmented generation, and law-informed scoring to construct a scalable, language-centric moderation pipeline.
Through comprehensive experiments, we demonstrate that PRJ consistently outperforms strong baselines in detection accuracy, robustness against adversarial attacks, and semantic interpretability. It shows high detection rates across multiple T2I models, maintains stable scoring under attack, and supports structured categorization across diverse harm types.
Despite its strong performance, PRJ also introduces practical challenges, such as increased inference latency and dependence on high-quality toxic knowledge bases. Future work will explore efficient approximations of the retrieval loop, adaptive risk matrix modeling across cultures and languages, and extensions to other generative modalities such as video and multimodal agents.
We believe PRJ lays the foundation for a new class of safety assessment systems that are not only accurate and robust but also transparent, interpretable, and aligned with human cognitive patterns of judgment.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}