1. Introduction
Cattle face recognition paves a feasible way for identification of cattle in all aspects of information management for large-scale pasture, such as individual record establishment, epidemic prevention registration, and pedigree information maintenance. It also provides an effective method for identity verification in procedures in commercial insurance that needs cattle ID. Thus, it is becoming a topic of great interest with regard to computer vision in agriculture. With the extraordinary progress of deep learning, cattle face recognition based on Deep Convolutional Neural Networks (DCNNs) has developed rapidly due to its remarkable feature extraction capability.
For cattle face recognition based on DCNNs, approaches on Deep Metric Learning (DML) are the common methods. This mainly includes two tasks: the construction of convolutional network structure and the design of effective loss function. ResNet or Inception-based networks [
1,
2], trained with distance restraint as triplet loss [
3], are typical frameworks in current cattle face recognition tasks. The network structure used will directly affect the quality of the extracted cattle face features, which in turn affects the accuracy and robustness of the recognition. In accordance with the well-designed architecture, an effective loss function is equally important for model training. The researchers primarily adopted ArcFace [
4,
5], which has demonstrated strong performance in face recognition, and refined the conventional cross-entropy loss [
6]. A well-designed loss function can enhance the learning capability of convolutional neural networks and boost feature discriminability, thereby facilitating individual identification.
However, current cattle face recognition algorithms using DML are mainly based on supervised learning and heavily rely on a large amount of labeled data for model training. The annotation of cattle images is both time-consuming and labor-intensive. Moreover, in practical livestock farming scenarios, there are a very large number of unlabeled individuals being born or in newly established farmlands.
Unsupervised learning provides an effective approach to training models using unlabeled data, addressing the reliance on annotations. Pseudo-label-based unsupervised learning methods primarily consist of two stages: (1) generating pseudo-labels for unlabeled data based on unsupervised clustering [
7,
8,
9], and (2) utilizing the generated pseudo-labels to guide model training. Unsupervised learning with the above stages has achieved great success in human recognition tasks. However, pseudo-labels obtained with the clustering method inevitably include noise, and the inferior quality of these pseudo-labels directly impacts the learning ability of the module.
To mitigate the impact of noise in pseudo-labels, extensive efforts have been made to increase the label reliability, including the use of auxiliary networks [
10,
11] and the enhancement of clustering algorithms [
12,
13]. However, these approaches neglect the importance of localized fine-grained cues. Research [
14] has shown that fine-grained information in local features contribute to identity recognition. The pseudo-label refinement approach proposed in [
15] also explicitly demonstrates the effectiveness of enforcing the reliability of the labels with refined local information, while it still omits strengthening the model’s extraction capability of local informative characteristics.
Thus, we propose an unsupervised learning framework with part-attention-based pseudo-label refinement reciprocal compact loss (USL-PARC) for cattle face recognition. Our USL-PARC framework refines pseudo-labels by incorporating discriminative local information to mitigate the impact of pseudo-label noise, while the SimAM attention mechanism [
16] is integrated into our ResNet-Sim network to enhance fine-grained feature extraction. Additionally, compact loss, including smoothed cross-entropy loss, triplet loss, and density loss, is introduced to enlarge the inter-class separability and enhance intra-class compactness.
The contributions of this work are as follows:
- (1)
Since local features remain relatively stable despite variations in viewpoint and cattle posture, ResNet-Sim network based on SimAM is constructed to capture fine-grained details, while a cross agreement score is employed to assess the reliability of local information, with which the local context uncovered above is adaptively supplemented to refine pseudo-labels.
- (2)
Compact loss is adopted to strengthen the discriminability of both global and local features by increasing the distances between features of different individuals and compressing the feature cluster of the same class.
- (3)
The CattleFace2025 dataset is created to support unsupervised learning tasks for cattle face recognition. It is encouraging to find that our proposed USL-PARC framework outperforms the state-of-the-art unsupervised learning models on CattleFace2025. CattleFace2025 will be available publicly after the paper is accepted.
The rest of the paper is organized as follows: the CattleFace2025 dataset is introduced in
Section 3. The USL-PARC framework is proposed in
Section 4. The experimental details and results are provided in
Section 5. Finally, conclusions and future work are presented in
Section 6.
4. Methods: Our Proposed USL-PARC Framework
We propose a part-attention-based pseudo-label refinement reciprocal compact loss (USL-PARC) framework, which mitigates the noise of the pseudo-label by enhancing its reliability using attention-guided fine-grained local context. Furthermore, compact loss is utilized to improve the feature distribution by minimizing intra-class distance while maintaining inter-class separability.
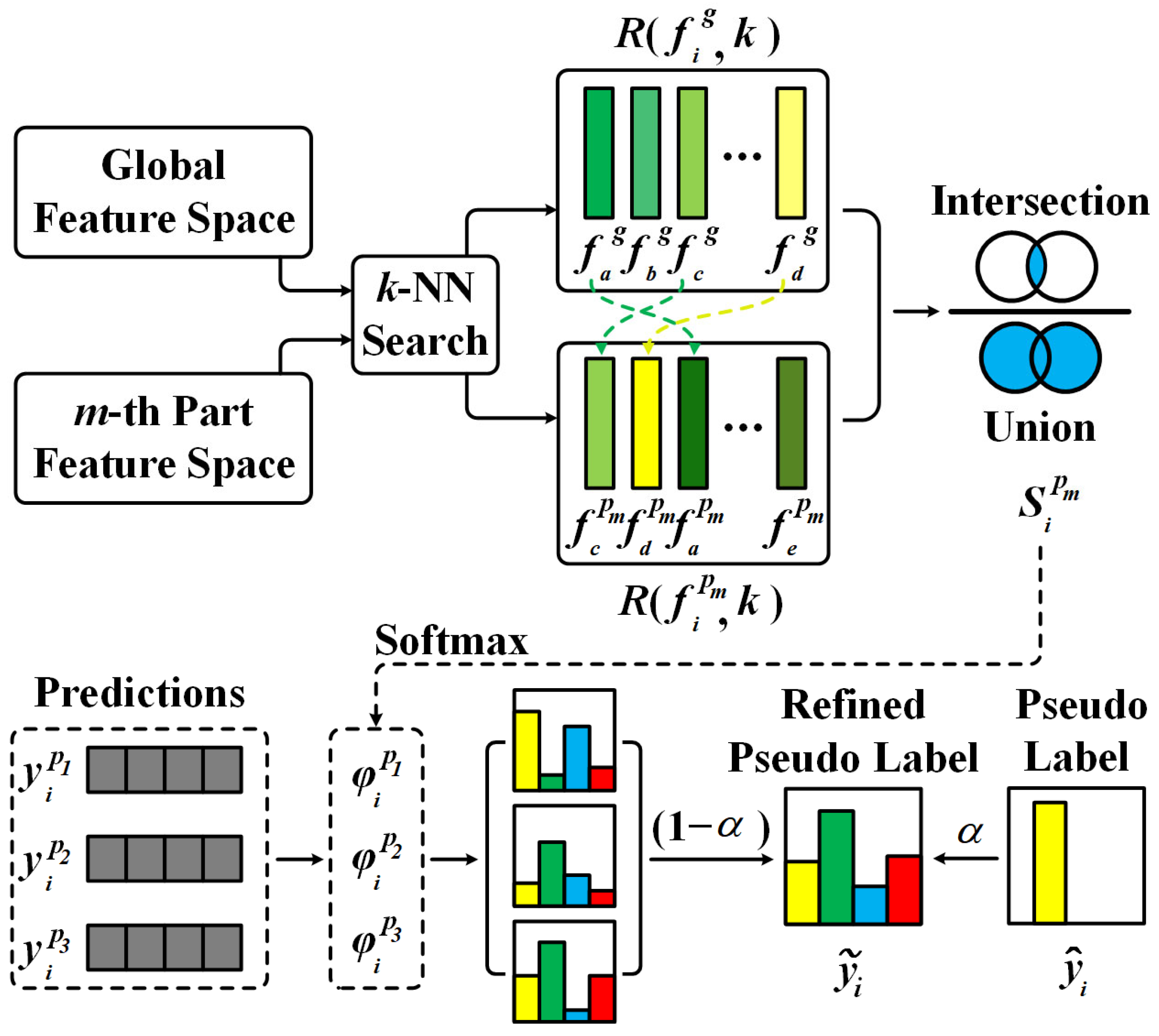
Following existing pseudo-label-based unsupervised learning methods, USL-PARC comprises two alternating phases: clustering and training. In the clustering phase, global and local features are extracted using the ResNet-Sim network. Then, pseudo-labels are generated by clustering global features, while the cross agreement score [
15] is calculated to evaluate similarity between part and global features. In the training phase, pseudo-labels are refined by aggregating local fine-grained information based on the cross agreement score. The model is trained using compact loss guided by the refined pseudo-labels. The framework of USL-PARC is illustrated in
Figure 2.
4.1. ResNet-Sim Network
ResNet-Sim network focuses on fine-grained local details to extract global and part features. Given an unlabeled cattle face dataset denoted by , where is the number of samples, global features and corresponding local features , where represents the number of local features, are extracted using the ResNet-Sim network.
Specifically, we use ResNet50 as the backbone, embedding SimAM to capture more discriminative representations. The SimAM is a parameter-free attention mechanism that enhances the model’s representational learning ability without increasing computational overhead. It evaluates the feature discriminability using active parameters. The detailed structure of SimAM is shown in
Figure 3.
Given the
i-th element
within the
c-th channel of the feature map, the active parameter
is represented as follows:
where
denotes the mean value of elements within the
c-th channel,
represents the variance of elements,
refers to the total number of elements in the channel, and
is the regularization coefficient. The activity level of element
is expressed by
, based on which the adjusted element
on the feature map is represented as follows:
In our ResNet-Sim, the SimAM attention mechanism is embedded after the outputs of Layer3 and Layer4 in the ResNet50 backbone. The global feature map is evenly divided into three horizontal regions to generate local feature maps. Global and corresponding local features are obtained via average pooling and max pooling, respectively. ResNet-Sim effectively enhances the ability to extract local features, which in turn provides reliable complementary information for the refinement of pseudo-labels.
4.2. Part-Attention-Based Pseudo-Label Refinement
4.2.1. Cross Agreement Score
Local information of a specific part of the face maintains relative invariance to variations in viewpoint and posture, making it a reliable basis for identification. Inspired by this, we aggregate local predictions to refine the global pseudo-labels. However, local features from the same image may capture identity-related information that differs from the global features and may also be susceptible to the effects of noise. Accordingly, the cross agreement score [
15] is introduced to evaluate the reliability of local features, with the aim of reducing interference from irrelevant regions.
The cross agreement score
is defined as the similarity between the global feature of
and the local feature of its
m-th part. Firstly, a
k-nearest neighbor search is conducted separately on the global and each local feature spaces to generate ranked lists of indices containing the
k most similar samples for
and
. The cross agreement score is then calculated using the Jaccard similarity coefficient between the sets, and is represented as follows:
where
and
represent the sets of indices from the ranked lists computed by
and
, respectively, and
denotes the cardinality of a set.
According to Equation (3), a strong complementary relationship between of image and leads to an increase in , indicating that the local features provide reliable supplementary information. Conversely, a decrease in suggests that the local features may introduce misleading information into pseudo-label refinement, where . The cross agreement score is utilized in both pseudo-label refinement and smoothed cross-entropy loss.
4.2.2. Part-Based Pseudo-Label Refinement
The pseudo-label for sample
, generated by DBSCAN clustering, is defined as
, which represents the one-hot encoding of the hard assignment with
C clusters. Since the cross agreement score quantifies the reliability of local features, a weighted sum of local predictions based on the corresponding score is conducted for refinement. The refined pseudo-label
, leveraging reliable fine-grained local context, is represented as follows:
where
represents the prediction vector of
,
is the number of local features set to three,
denotes the value obtained by applying the softmax function to the three cross agreement score of image
, and
is the strength coefficient for label refinement.
The pseudo-labels obtained by clustering global features lack the learning of local information, and the one-hot labels generated via label scattering disregard inter-class relationships. In contrast, the refined pseudo-labels derived by dynamically incorporating local predictions effectively address these problems and enhance the applicability of pseudo-labels in model training. The specific structure of the part-based pseudo-label refinement is shown in
Figure 4.
4.3. Compact Loss
During model training, compact loss is employed to improve feature distribution by enlarging inter-class distances and minimizing intra-class variation, including smoothed cross-entropy loss, triplet loss, and density loss.
4.3.1. Smoothed Cross-Entropy Loss
Smoothed cross-entropy loss consists of dynamic label smoothing loss for calibrating local predictions and adaptive label refinement loss for enhancing global feature similarity, calculated as follows:
Dynamic label smoothing loss aims to discard fine-grained information with low reliability in local predictions. Based on the cross agreement score, it is computed by flexibly adjusting the weights of the cross-entropy loss and Kullback–Leibler (KL) divergence loss, which is represented as follows:
where
is the number of local features set to three,
is the pseudo-label,
is the prediction vector of
,
is the cross agreement score,
is a uniform vector with equal probability for each class,
denotes the cross-entropy, and
represents the KL divergence.
As approaches one, the cross-entropy loss calibrates the local prediction for higher confidence aligned with pseudo-labels. Conversely, as converges to zero, the KL divergence loss is employed to guide the prediction towards the uniform vector, thereby weakening this component. Compared with label smoothing by a constant value, our approach adjusts the smoothing strength based on feature reliability, preserving valid information while suppressing noisy interference.
Adaptive label refinement loss is defined as the cross-entropy between the refined pseudo-labels and the prediction vector of the global feature, as given by the following:
where
denotes the refined pseudo-label, and
represents the prediction vector of
. The refined pseudo-labels effectively reduce the impact of label noise while promoting the global features to learn rich fine-grained information.
4.3.2. Triplet Loss
The traditional triplet loss employs a predefined margin to ensure that the distance between hard positive and hard negative samples is at least
m. To alleviate the sensitivity to margin selection, a softmax smoothing technique is introduced, which is defined as follows:
where
and
denote the hard positive and hard negative samples corresponding to
, respectively, and
is the Euclidean norm. The triplet loss contributes to increasing inter-class separability, thereby reinforcing the reliability of class boundaries.
4.3.3. Density Loss
Density loss promotes clustering compactness by minimizing the distance between anchors and hard positive samples, aligning them with the average intra-class distance. The optimization schematic of density loss is shown in
Figure 5. It consists of global and local density losses, formulated as follows:
where
and
represent the weight coefficients for global and local density losses, respectively, and their values are experimentally validated in
Section 5.
Specifically, global density loss
is formulated as follows:
where
represents the distance between
and its hard positive sample
,
is the total number of samples in the same class as
, and
denotes the average intra-class distance. The triplet loss improves inter-class separability of global features, while the application of density loss further strengthens intra-class compactness, thereby ensuring reliable class boundaries.
Local density loss
is given by the following:
where
denotes the average intra-class distance of the
m-th part, and
represents the number of local features set to three. Enhancing the compactness of local features provides more reliable supplementary information for pseudo-label refinement.
Specifically, the density loss in our work uses the hard positive sampling strategy, while, in [
29], it operates on all the positive samples. Additionally, it is applied to both global and local features here, which is different from the strategy in [
29] applied to only global features.
4.3.4. Compact Loss
The overall loss function of USL-PARC is as follows:
Compact loss ensures inter-class separability while effectively enhancing the compactness of the feature space. Therefore, the pseudo-labels obtained by clustering global features can have higher confidence, and the local information aggregated for pseudo-label refinement is more reliable.
5. Results
5.1. Implementation Details
We used a GeForce GTX 1070 GPU as the main hardware for training and testing, and the algorithm platform was built on UBUNTU 18.04 and Pytorch 1.12.0. The backbone of the model is the ResNet-Sim network loaded with ImageNet pre-training weights. The input cattle face images were resized to 224 × 224. Random horizontal flipping (p = 0.5), 10-pixel padding followed by random cropping, and random erasing (p = 0.5) were applied for data augmentation. The mini-batch size was 32 consisting of 8 pseudo-classes and 4 images for each class, ensuring a balanced number of samples per class in each batch. Adam with weight decay of 5 × 10−4 was employed for training. The initial learning rate was set to 3.5 × 10−4 and decreased by a factor of 10 after every 20 epochs. The model was trained for a total of 50 epochs, with each epoch consisting of 200 iterations. In the pseudo-label generation phase, DBSCAN based on Jaccard distance with k-reciprocal encoding was employed for clustering. The DBSCAN parameters were set with a maximum distance of 0.5 and a minimum cluster size of 4. During testing, only global features were utilized for retrieval, and their dimensionality was 2048.
The proposed method was evaluated on the CattleFace2025 dataset. The CattleFace2025 dataset was split into training and testing sets in a 1:1 ratio based on identity categories, with no overlap of image data. The training set consisted of 5898 cattle face images from 287 individuals. For the query set, 5 images were randomly selected from each identity in the test set, resulting in a total of 1435 images from 287 individuals. The remaining images in the test set formed the gallery set, comprising 4547 images from the same 287 individuals. We evaluated the performance using mean average precision (mAP), cumulative matching characteristic (CMC) at Rank-1, Rank-5, and Rank-10, as well as the accuracy of k-NN (k = 5) classifier.
5.2. Ablation Study
In this subsection, a comprehensive ablation study was conducted to validate the effectiveness of ResNet-Sim in capturing key information and to examine the contribution of each component of the compact loss in supervising the learning of separable feature distributions. The experimental results are reported in
Table 2.
As shown in
Table 2, the accuracy under “ResNet-Sim +
+
” increases by 6.6% with the adaptive label refinement loss adding to dynamic label smoothing in “ResNet-Sim +
”. And this shows the effectiveness of the pseudo-label refinement with supplementary local fine-grained information. Triplet loss and density loss progressively improve the accuracy by 1.2% and 0.7%, demonstrating its effectiveness in maintaining inter-class separability and minimizing intra-class distance. In addition, the accuracy in “ResNet-Sim +
” with SimAM attention mechanism increases by 1.3% over that in “ResNet +
” without SimAM, demonstrating the learning ability of fine-grained information with SimAM attention mechanism. Meanwhile, the average inference time increases only marginally from 3.65 ms to 3.83 ms per image, indicating that the integration of SimAM introduces negligible computational overhead.
5.3. Parameter Analysis of k and α
In the pseudo-label refinement strategy, k-NN is used to obtain the top-k ranked lists of global and corresponding local features. Then, the cross agreement score is calculated with the top-k lists to quantify the reliability of local features.
The value of parameter
k controls the number of retrieved nearest neighbors, which determines the effectiveness of the reliability assessment for local features. To identify the optimal value of
k, we conduct experiments by incrementally increasing
k with a step size of 5, while keeping other parameters fixed. The results are shown in
Table 3.
According to the results in
Table 3, as
k increases, the
k-nearest neighbor search retrieves more diverse samples, which leads to an overall decrease in the calculated cross agreement scores. Conversely, a small
k limits the search range and reduces the generality and robustness of the retrieved samples, making the computed scores more susceptible to randomness. Thus, a proper value of
k can provide reliable weighting for pseudo-label refinement and smoothed cross-entropy loss. Based on the experimental results, we set
k to 20.
The parameter
determines the strength of the complementary local information in pseudo-label refinement. To analyze the effect of
on performance, we conducted experiments with
varying from 0 to 1, in steps of 0.1, and results are presented in
Table 4.
When
is set to 0, pseudo-label refinement relies exclusively on local predictions, while with
set to 1, it excludes local fine-grained information and depends entirely on labels derived from global feature clustering. As presented in
Table 4, optimal model performance is achieved when the one-hot labels are refined by an appropriate proportion of local predictions. Consequently, we set
to 0.5.
5.4. Experiment on β and γ
In the loss computation, density loss is utilized to enhance the compactness of both global and local features, with
and
controlling the strength of intra-class distance constraints for the global and local levels, respectively. To determine the optimal combination of the two parameters, we conducted the following experiment. We first fixed
at 0.1 and varied
from 0.05 to 0.4. As shown in
Table 5, the results indicate that the model achieves the best performance when
= 0.1.
Then, we fixed
at 0.1, and conducted experiments with different
from 0.05 to 0.4. The results presented in
Table 6 demonstrate that the model achieves the best performance when
is set to 0.1, and maintains relatively stable accuracy across various values of
and
.
5.5. Effect of Local Feature Quantity
Pseudo-labels are refined by supplementing local fine-grained context. Different strategies for partitioning local regions directly impact the effectiveness of the supplementary information, thereby influencing the quality of the refined pseudo-labels. To verify the optimal composition of local regions, we conducted experiments to compare the effects of different scales of the local features by dividing the image into
r rows and
c columns. The experimental results for various partitioning strategies are shown in
Table 7.
It can be seen from
Table 7 that different divisions of the image significantly impact the refinement of pseudo-labels with the different scales of local information. Due to the lack of fine-grained information for refining pseudo-labels, the performance with (1*1) division is limited. After incorporating local features, the performance is improved. Specifically, dividing the image into (3*1) parts, the accuracy improves over 0.5%, and this confirms the effectiveness of local fine-grained information. However, more division with smaller local regions, such as those cut into (5*1) parts, may result in incomplete local information, which is insufficient for unique identity representation. The experimental results show proper division is effective to learn more informative and fine-grained local features, which is helpful to enhance the reliability of the pseudo-labels.
5.6. Comparison with State-of-the-Art Models
In this subsection, we conduct comparative experiments to validate the effectiveness of the proposed framework. Since supervised methods rely on labeled datasets and this study focuses on training with unlabeled data, USL-PARC is compared only with recent state-of-the-art fully unsupervised person re-identification methods on the CattleFace2025 dataset, including MMCL [
30], ICE [
9], RLCC [
26], PPLR [
15], ISE [
24], STDA [
31], and DCSG [
32]. MMCL utilizes a memory-based non-parametric classifier, integrating multi-label and single-label classification into a unified framework. ICE employs pairwise similarity scoring between instances to enhance contrastive learning performance. RLCC and PPLR mitigate label noise via pseudo-label refinement. ISE improves clustering reliability by generating supportive samples around real instances. STDA refines pseudo-labels by mining spatial-level connections among positive instances. DCSG complements source image data using information from multiple augmented views, based on which the pseudo-labels are optimized. The results of the comparison are shown in
Table 8.
Compared to the above methods, our approach focuses on the complementary relationship between global and local features after attention processing, along with feature space compactness. The experimental results demonstrate that our USL-PARC achieves the best performance on all evaluation metrics. Specifically, in terms of k-NN accuracy, it outperforms MMCL, ICE, RLCC by 8.1%, 6.0%, 4.8%, respectively, and surpasses PPLR and ISE by 2.3%. Specifically, in terms of k-NN accuracy, the proposed method outperforms MMCL, ICE, RLCC, PPLR, ISE, STDA, and DCSG by 8.1%, 6.0%, 4.8%, 2.3%, 2.3%, 1.8%, and 2.4%, respectively.
6. Conclusions and Future Work
In this paper, a part-attention-based pseudo-label refinement reciprocal compact loss is proposed for fully unsupervised cattle face recognition. The USL-PARC provides more discriminative global and local features through the ResNet-Sim network. Meanwhile, fine-grained local contexts with high similarity to global features are utilized for pseudo-label refinement, effectively mitigating label noise. Finally, compact loss is employed to guide the model in learning a separable and discriminative feature space. The proposed method eliminates reliance on annotations during training and effectively mitigates the impact of pseudo-label noise. The effectiveness of USL-PARC has been validated through extensive experiments on the CattleFace2025 dataset.
Although pseudo-label refinement based on local fine-grained context demonstrates significant competitiveness, it still has limitations to overcome. In existing local feature extraction methods, local regions are obtained by uniformly dividing the feature map. To ensure that each local feature corresponds to the same facial region, the images used for training are aligned with the cattle face. However, in practical scenarios, the captured images are not always well aligned, and misalignment can negatively affect the reliability of local information. In our future work, we will explore semantic matching techniques to construct feature spaces that better represent semantically corresponding regions of the cattle face, thereby alleviating the need for manual face alignment.
In addition, the cross agreement score provides an intuitive method for evaluating the reliability of local information by calculating the Jaccard similarity coefficient between the
k-nearest neighbors of global and local features. However, Jaccard similarity focuses on the intersection and union of two sets, neglecting the order of elements. When the
k-nearest neighbors of two local features contain the same elements but in reversed order, the computed reliability remains the same, which may result in local information with significant semantic differences being unrecognized. We will further consider the order of elements to study a more precise method for reliability assessment in subsequent research. Moreover, we will explore replacing DBSCAN with other clustering algorithms for pseudo-label generation, such as fuzzy clustering [
33], to enhance the reliability of pseudo-labels.
At present, the CattleFace2025 dataset satisfies the requirements for cattle identification in small- to medium-sized ranches, but the environmental diversity of the images remains insufficient. Generative Adversarial Networks (GANs) [
34] and diffusion models [
35] are widely used for image synthesis. In subsequent work, we will explore synthesizing images with blur, fog, or noise conditions using GANs or diffusion models. Moreover, we will try to leverage GAN-based human face image generation techniques to enlarge the dataset with artificial cattle faces for the evaluation of the generation ability of the module.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}