1. Introduction
Colorectal cancer (CRC) is one of the most prevalent and deadly cancers worldwide. Studies indicate that nearly 70% to 80% of colorectal cancers originate from colorectal polyps [
1]. The gold standard for early CRC screening is colonoscopy [
2], which enables the timely identification and removal of colorectal polyps, effectively preventing lesion progression [
3] and reducing morbidity and mortality. However, approximately 25% of polyps are missed in clinical practice due to variable size, location, and physician subjectivity [
4,
5]. Therefore, research on polyp segmentation algorithms is essential for enhancing detection accuracy and reducing patient disease risk in clinical cancer prevention.
However, the automatic segmentation of polyps from colonoscopy images remains a challenging task. The presence of specular highlights, fecal occlusions, and luminal folds in polyp images often results in under-segmentation and over-segmentation during the segmentation process. Additionally, the irregular shapes, varying sizes, diverse textures, and different locations of polyps contribute to inaccurate segmentation. Furthermore, polyp lesions exhibit high similarity to the surrounding complex background tissues, leading to blurred segmentation edges. These challenges are illustrated in
Figure 1.
For the challenge of automatic polyp segmentation, polyp segmentation algorithms have evolved from image processing techniques to deep learning algorithms. Early image processing approaches primarily relied on thresholding, edge detection, region-based segmentation, and morphological operations [
6]. However, these methods are highly sensitive to noise and exhibit low segmentation accuracy. Convolutional Neural Network (CNN) [
7] extracts local features, and Full Convolutional Neural Network [
8] adds an inverse convolutional layer to achieve pixel-level segmentation results. The encoding and decoding structure of U-Net is used for feature extraction and spatial restoration [
9], and U-Net++ introduces jumping connections [
10] to enhance feature representation. Nevertheless, convolutional layers are constrained by their limited receptive fields, and the segmentation accuracy needs to be improved. Transformer [
11] was proposed to compute the interaction features between image blocks for capturing global contextual features to improve the limitation of the receptive field. Automatic polyp segmentation algorithms combining Transformer and CNN significantly improve the accuracy of polyp segmentation [
12,
13]. However, the automatic polyp segmentation algorithm still has limitations. The insufficiency of feature extraction and the redundancy of fusion information make it difficult to cope with the diversity of polyp shapes. In addition, the imbalance between global and local information and the problems of polyp boundary blurring and mis-segmentation need to be solved.
To deal with the above deficiencies, this paper proposes a Dual Attention and Fusion Mechanism Network (DAFM-Net). To cope with the diversity of polyp shapes, the Multi-scale Convolutional Patch Aware module (MCPA) captures the features of polyps at different scales through a multi-branch convolutional patch structure. For the information redundancy problem of multilevel feature fusion, the Cross-layer Aware Selective Fusion module (CASF) performs semantic complementation and enhancement of multilevel feature information. To solve the imbalance between global and local information, the Dual Context-Enhanced Attention module (DCEA) combines the channel and spatial attention mechanism to extract global features, uses the spatial local attention mechanism to focus on local features, fuses cross-level information using cosine similarity, and enhances the boundary details through edge operators to achieve the complementarity between global and local features. The contributions of this study are summarized as follows:
To address the issues of insufficient feature extraction, redundant information fusion, and the imbalance between global and local information fusion in polyp segmentation, this paper proposes a Dual Attention and Fusion Mechanisms Network (DAFM-Net).
This paper designs three modules to enhance the performance of the polyp segmentation network, including MCPA, CASF, and DCEA.
Through multiple experiments on five public polyp datasets, it is demonstrated that DAFM-Net possesses strong learning and generalization capabilities, enabling accurate segmentation of various types of polyps.
2. Related Work
2.1. Traditional Polyp Segmentation Methods
Traditional polyp segmentation methods integrate morphological features, texture, and boundary information to achieve segmentation. For instance, Wang et al. [
14] constructed an ellipsoidal polyp model based on the characteristic that malignant polyps often exhibit an elliptical shape. This method uses local geometric information to identify the morphology of the suspicious region, employs edge detection methods to identify polyp boundaries, and creates a 3D ellipsoidal polyp model based on the boundary information. Among edge detection methods, Vincent & Folorunso [
15] highlighted that the Sobel algorithm, which measures the two-dimensional spatial gradient of an image through a convolutional mask, effectively detects edges and reduces data redundancy. Cheng et al. [
16] investigated texture features to distinguish between polyps and normal tissues, employing the
t-test to select significant features and utilizing a support vector machine (SVM) to identify polyp locations. To accurately identify abnormal regions, Peng et al. [
17] proposed the use of multi-size patches to construct image blocks while classifying them using a discriminative binary SVM. Tjoa & Krishnan [
18] introduced a method for efficient polyp segmentation based on color features, extracting novel texture features from texture spectra in both color and achromatic domains and applying principal component analysis (PCA) to identify polyp regions. However, polyp images are diverse in terms of color, texture features, and morphological size, so traditional polyp segmentation methods have limitations in practical applications.
2.2. Convolution-Based Polyp Segmentation Method
Convolution-based polyp segmentation methods employ convolutional neural networks for feature extraction, effectively addressing complex texture and morphological variations in polyp images, thereby advancing the field of medical image segmentation [
19]. The U-Net architecture utilizes an encoder for feature extraction and a decoder to restore spatial resolution. High-resolution features from the encoder are fused with the up-sampled output of the decoder, enabling cross-level feature fusion and significantly enhancing segmentation performance. Although improvements to U-Net have enhanced its ability to extract contextual information [
20], repetitive feature sampling can lead to the degradation of small polyps [
21], and accurate segmentation becomes challenging in complex backgrounds.
To improve the representation of complex features, attention mechanisms have been integrated into polyp segmentation algorithms. Fan et al. [
22] proposed the Parallel Reverse Attention Network (PraNet), which employs a parallel decoder to fuse multi-level features and incorporates a reverse attention module to mine boundary cues and establish relationships between target regions and boundaries, thereby improving segmentation accuracy in scenarios with high background similarity. Zhang et al. [
23] introduced a lesion-aware dynamic kernel network for polyp segmentation, which utilizes a gating mechanism for kernel updating, dynamically fuses multi-scale lesion information, captures global relationships through an efficient multi-head self-attention mechanism, and integrates mask-based lesion region perception. To enhance lesion region perception, Zhao et al. [
24] proposed a multi-scale subtraction network that employs a pyramid structure for multi-scale subtraction, achieving inter-layer multi-scale aggregation and feature complementarity. Qiu et al. proposed [
25] the Boundary Distribution-Guided Network (BDG-Net), which generates boundary distribution maps by supervising multi-level features at target boundaries and fuses these maps to enhance spatial information capture at different scales. CR-Net [
26] combines channel attention and spatial attention mechanisms, progressively integrating features captured by boundary distribution maps into global information. DCR-Net [
27] leverages two parallel attention modules to focus on intra-image similarity and inter-image correlations, capturing contextual information and addressing intra-class inconsistency in polyps. CFA-Net [
28] integrates boundary information with cross-level semantic features at different scales, thereby improving segmentation accuracy.
U-Net [
9] and its variants [
20,
21] achieve multi-level feature fusion via an encoder-decoder architecture, while methods incorporating attention mechanisms differ by emphasizing the polyp region and boundary features in the decoder. For instance, PraNet [
22] initially predicts the polyp region using the decoder and integrates parallel reverse attention to capture polyp contour information. DCR-Net [
27] and CFA-Net [
28] improve the capture of global contextual information through parallel attention modules and cross-level semantic fusion, respectively. Although these methods demonstrate superior performance in polyp segmentation, they exhibit limitations in capturing long-range dependencies, a challenge effectively addressed by Transformer-based methods [
29].
2.3. Transformer-Based Method for Polyp Segmentation
The Vision Transformer [
30] excels in classifying sequences of image patches. To adapt to tasks such as object detection, instance segmentation, and semantic segmentation, several studies [
31,
32,
33] have incorporated a pyramid structure into the Transformer backbone network design, inspired by the CNN pyramid structure. Wang et al. [
34] proposed the PVT v2 backbone model, which improves local information representation through overlapping patch embeddings and introduces a convolutional feed-forward network capable of adaptively processing input images of varying resolutions. PVT-v2 outperforms other models [
35,
36] in handling high-resolution images and is widely used in polyp image segmentation.
Based on the PVT v2 backbone model, researchers have proposed many new research methods for polyp image segmentation. Dong et al. [
37] proposed the Polyp-PVT network, which captures high-level semantic information via the Cascade Fusion Module and extracts low-level semantic features using the Camouflage Identification Module. The network employs the Similarity Aggregation Module for cross-level feature fusion and utilizes spatial graph convolution to capture inter-level relationships, effectively enhancing segmentation performance for polyps of various sizes and shapes. To accurately identify tiny polyps, CAFE-Net [
38] leverages parallel multi-scale convolution and a polarized attention mechanism to capture detailed features, and the decoding phase incorporates cross-attention to recover fine features and aggregates multi-scale features. Addressing the limitations of multi-scale feature aggregation, the PVT-CASCADE model [
31] progressively fuses features at different levels through up-sampling paths and skip connections, optimizing losses in a cascading manner. Additionally, recent studies have proposed various approaches to tackle the challenges of polyp segmentation. Liu et al. [
32] proposed a multi-view orientational attention network combining point-based affinity for polyp segmentation, focusing on geometric orientation information with the Point Affinity Module, and extracting global contextual features using the Cross-Attention Feature Fusion Module, effectively addressing intra-class inconsistency in polyp datasets. CTNET [
33] integrates SMIM and CIM to extract multi-resolution and multi-scale features, achieving accurate segmentation results for polyps of different sizes. Liu et al. [
39] proposed the Multi-Level Feature Fusion Network (MLFF-Net), which incorporates an attention mechanism to mitigate semantic conflicts and information redundancy caused by feature fusion.
Transformer-based polyp segmentation methods improve the ability to model long-range dependencies of multi-scale polyps through the global self-attention mechanism and pyramid structure design [
34]. In addition, Polyp-PVT [
37] improves cross-layer feature interaction via cascade fusion and spatial graph convolution, CAFE-Net [
38] enhances the detection of tiny polyps by employing polarized attention and multi-scale convolution, and PVT-CASCADE [
31] achieves fine-grained feature fusion through cascade loss optimization. Although these methods have achieved good results in polyp segmentation, there are limitations in striking a balance between global semantic consistency and local detail preservation. To improve this problem, we propose a polyp segmentation network with dual attention and fusion mechanisms based on the Transformer architecture.
3. Methodology
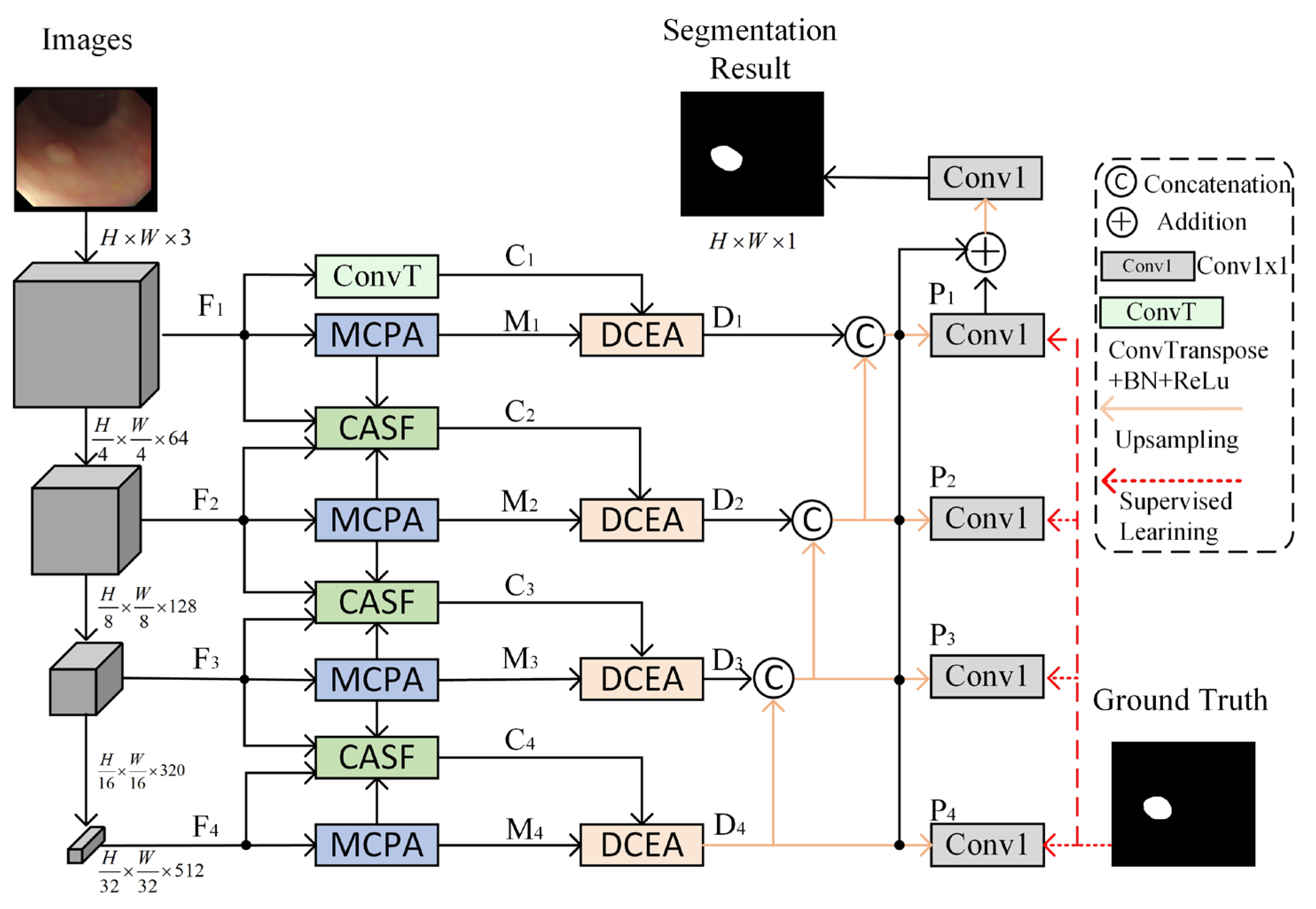
In this paper, a Dual Attention and Fusion Mechanism Network (DAFM-Net) for polyp segmentation is proposed, which consists of three main modules: the Multi-scale Convolutional Patch Aware module (MCPA), the Cross-layer Aware Selective Fusion module (CASF), and the Dual Context-Enhanced Attention module (DCEA). The MCPA module enhances the extraction of fine-grained polyp features by introducing multi-scale convolutional kernels and a patch-blocks mechanism. The CASF module adaptively fuses local features between adjacent layers to promote feature complementarity and mitigate semantic conflicts. The DCEA module integrates global and local attention mechanisms to comprehensively capture the overall structure and boundary details of polyps and further improves segmentation accuracy through step-by-step feature fusion.
3.1. Overall Architecture
The network architecture of DAFM-Net for polyp segmentation is illustrated in
Figure 2, which comprises three core modules: MCPA, CASF, and DCEA. The input is an original polyp image in RGB format with a resolution set to
. DAFM-Net initially processes the polyp image through the network architecture PVT-v2 [
34] to extract features from four distinct layers, denoted as
. The corresponding feature map resolutions are as follows:
the number of channels
. Subsequently, the MCPA module is employed to enhance the features at each layer level, yielding multi-scale features
. To address the limitations of single-level features, up-sampling is performed on shallow features using transposed convolution to enhance detailed information. The CASF module is then utilized to fuse features between adjacent layers, combining the detailed information of lower levels with the semantic information of higher levels to generate complementary features
. Finally, the extracted two-branch features are co-optimized using the DCEA module for global and local information to comprehensively capture the overall structure and boundary details of the polyp, and obtain multi-level features
, which are fused and supervised level by level to improve the accuracy of polyp segmentation.
3.2. Multi-Scale Convolutional Patch Aware Module (MCPA)
In the polyp segmentation task, significant variations in the size and shape of polyps often lead to the model overlooking detailed information of small polyps while compromising the structural integrity of large polyps. To address this issue, a Multi-scale Convolutional Patch-Aware module (MCPA) is proposed, which employs a multi-branch strategy and a patch local attention mechanism to capture multi-scale features of polyps. The specific structure of MCPA is illustrated in
Figure 3.
First, the MCPA module utilizes multi-scale convolutional layers to extract features, enhancing feature representation and adaptive capability. Specifically, Branch 1 employs a 3 × 3 standard convolution kernel to extract small-scale features. Branch 2 constructs a 3 × 3 convolutional cascade structure to contextualize medium-scale features, progressively extending the receptive field to 5 × 5. Branch 3 introduces dilated convolution (dilation rate = 2) to replace traditional large-kernel convolution, achieving an equivalent 7 × 7 receptive field for extracting morphological features of large-scale targets while avoiding a surge in parameters.
Second, the MCPA module introduces a two-branch local patch
, focusing on the extraction of fine-grained features and the construction of contextual relationships, respectively. Given the input features
, channel features are transformed into local patches
through convolutional operations. These features
are then unfolded into local patch features
, where N denotes the total number of patches
. Subsequently, different channel features are linearly combined using lightweight convolution
to enhance the correlation between channels within a patch. These features are unfolded and fed into a feedforward neural network
, where local attention weights are generated using the softmax function. To enhance the nonlinear expressive ability, the activation function is Gelu. This process is described by Equation (1):
where
denotes the saliency weight of the patch and
represents the local features of the patch.
To enhance the nonlinear expression of patch features, the nonlinear features extracted by the feedforward neural network are multiplied pointwise with the local attention weights. The enhanced patch features are then restored to spatial resolution using bicubic interpolation, and spatial details are preserved through residual connections. The channel dimensions are adjusted using
convolution to obtain the features of the patch branches. Finally, the MCPA module fuses the features extracted from the multi-scale convolutional layers and the two-branch patch blocks. Multi-scale features
are obtained through
convolution, where
in
, as described by Equation (2):
where
denotes the features extracted from each branch.
3.3. Cross-Layer Aware Selective Fusion Module (CASF)
The core design of the Cross-layer Aware Selective Fusion module (CASF) is to achieve efficient fusion of deep semantic information from the encoder and shallow detailed features from the decoder through cross-layer feature interactions and an attention-guided weighting mechanism. The structure of CASF is illustrated in
Figure 4. The CASF module acquires layer features through the PVT-v2 [
34] backbone network and simultaneously fuses multi-layer features from the neighboring layers of the MCPA. Specifically, it integrates low-resolution deep-layer features
, multi-scale deep semantic features
, high-resolution shallow detail features
, and multi-scale shallow context features
. First, the channel dimensionality is adjusted using lightweight convolution, while the spatial resolution of the deep-layer features is aligned to the dimensions of the shallow features using transposed convolution. The aligned features are then processed
. Subsequently, the module is cascaded with
convolution through feature interaction operations to obtain the nonlinear correlation and linear superposition relationships between features, thereby enhancing the discriminative nature of feature representation. The expression for the neighboring layer aggregation features
is given by Equation (3):
where ⊙ denotes element-wise multiplication and ⊕ denotes element-wise addition.
Then, the aggregated features are gated by a sigmoid function to generate spatial attention weights. These attention weights are used to autonomously regulate the contribution of features at different layers, enhancing the response of the target region in complex backgrounds. Finally, cross-layer features
are generated. The specific expression is given by Equation (4):
where
represents the weight parameters generated by the sigmoid function for the aggregated features.
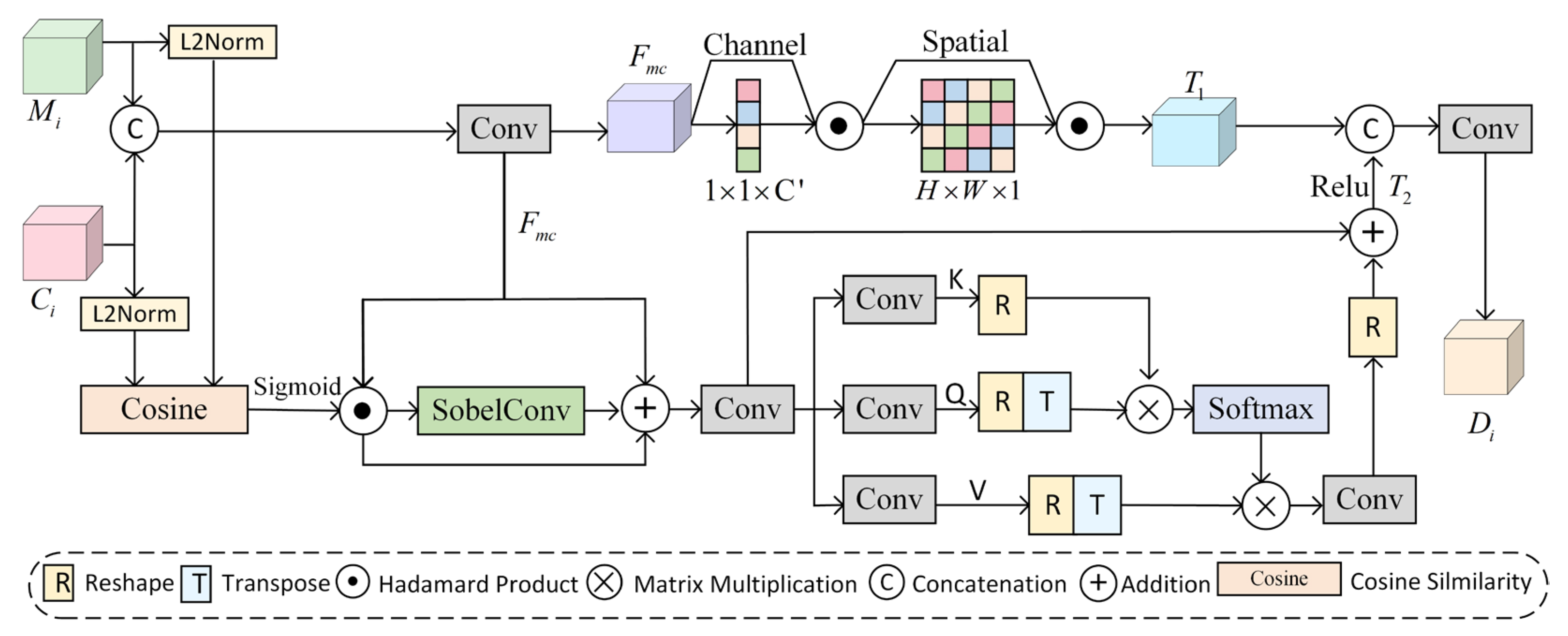
3.4. Dual-Context Enhanced Attention Module (DCEA)
In the polyp segmentation task, where edges are blurred and there is high similarity between lesion areas and surrounding tissues, the Dual Context Enhancement Attention (DCEA) module is proposed in this paper. The core design of DCEA integrates global semantic guidance, local structural enhancement, and edge feature sensing. The module achieves refined extraction and fusion of multi-scale contextual information through a dual-path synergistic mechanism. The structure of DCEA is illustrated in
Figure 5.
The module receives multi-scale features
and cross-level fusion features
, which are concatenated and processed using
convolution to adjust the channel dimensions, generating initial fusion features
. These features are then combined with a dual-attention mechanism to capture contextual information. Global attention enhances the saliency of the target region through the cascade of channel attention
and spatial attention
, resulting in global features. This process is described by Equation (5):
Channel attention combines global average pooling
and global maximum pooling
to extract global channel features and generate channel attention weights, as expressed in Equation (6):
where
denotes the input feature map,
represents the Sigmoid function, and
denotes the fully connected layer. Spatial attention enhances the spatial response of the target region by aggregating the mean
and maximum
values of the spatial dimensions, generating spatial weights, as described in Equation (7):
where
denotes a convolutional layer with a kernel size of 7 and padding of 3.
Local attention incorporates cosine similarity
, the Sobel operator
, and spatial graph convolution
. The core objective is to establish contextual relationships to obtain spatial detail features
, as described in Equation (8):
First, spatial cosine similarity
is calculated, as expressed in Equation (9):
where
denotes the Sigmoid function and denotes the inner product operation.
To enhance boundary perception, the DCEA module introduces the Sobel operator in the local attention mechanism to extract multi-channel edge features. The structure of the Sobel operator is shown in
Figure 6. The Sobel operator is used to extract horizontal
and vertical
gradients, and the gradient magnitude is calculated via convolution along these directions to obtain edge features.
These edge features are then fused with channel features as the input for spatial graph convolution. Through the attention mechanism, the inter-pixel correlation weights are dynamically adjusted, breaking the limitations of the local receptive field of traditional convolution and enhancing the recognition capability for irregular polyps. The spatial graph convolution
process is described by Equation (10):
where
,
, and
denote the key, query, and value matrices, which are mapped from the input features via convolution. Finally, the global features containing channel-space information are fused with edge-enhanced local features to obtain dual-context features
, achieving complementary optimization of contextual information.
3.5. Loss Function
To enhance the ability of the polyp segmentation model to perceive the fine structures of polyps, this paper adopts the Weighted Intersection-Over-Union Loss
and the Weighted Binary Cross-Entropy Loss
to construct the base loss function
. These two improved loss functions enable the polyp segmentation model to focus more on sample regions that are difficult to recognize in segmentation results through a pixel-level dynamic weighting mechanism. Specifically, the
emphasizes global structural consistency, while the
focuses on the precise optimization of local boundary details. The base loss function
is expressed as Equation (11):
where
denotes the prediction result and
represents the segmentation mask. The polyp segmentation model generates four levels of prediction maps
through a deep supervision mechanism, and the corresponding loss function is expressed as Equation (12):
where
represents the sum of the loss functions.
The is primary supervision signal, which incorporates overall structural features and detailed features, serves as the main guide for network learning. The is an auxiliary supervision layer, combined with deep features, that further refines the learning process.
4. Experiments
4.1. Datasets
The experiments conducted in this study utilize five publicly available polyp datasets, including Kvasir-SEG [
40], CVC-ClinicDB [
41], CVC-ColonDB [
42], EndoScene [
43], and ETIS [
44]. Kvasir-SEG comprises 1000 gastrointestinal polyp images along with their corresponding segmentation masks, covering a wide range of polyp morphologies, sizes, and mucosal backgrounds. CVC-ClinicDB is a clinical endoscopic sequence of images provided by the Central Vision Centre (CVC) in Barcelona, Spain, which is applied to polyp segmentation and multi-scale detection algorithms. CVC-ColonDB contains 380 endoscopic polyp images, predominantly featuring medium-sized polyps. EndoScene includes images of polyps, inflammatory regions, and healthy tissues, highlighting the challenges of detection in the presence of complex background interference. ETIS contains high-resolution and low-contrast images of 196 polyps with polyp size dimensions ranging from 0.1% to 29.1%. These datasets form a diverse combination of key parameters such as image resolution, polyp size, and contrast, as detailed in the comparative analysis presented in
Table 1.
4.2. Implementation Details
The proposed model in this study is based on the PVT-v2 [
34] backbone network and is implemented using the DAFM-Net architecture on the PyTorch2.2.1 framework. The experiments are conducted on an AMD EPYC 7302 512 G CPU (manufactured by Advanced Micro Devices, Santa Clara, CA, USA) and an NVIDIA GeForce RTX 3090 24 G GPU (manufactured by NVIDIA Corporation, Santa Clara, CA, USA). The dataset is partitioned according to the PraNet [
22] methodology, and the resolution of all input images is uniformly resized to 352 × 352. During training, data augmentation strategies such as horizontal flipping, vertical flipping, random rotation, and random scaling are applied, with the batch size set to 16. The AdamW optimizer is employed to optimize the model parameters, with an initial learning rate of 1 × 10
−4, which is reduced to 1 × 10
−5 after 50 epochs. The model is trained for a total of 100 epochs. In the testing phase, the test images are resized to 352 × 352 and fed into the optimal model to generate the polyp prediction maps.
4.3. Evaluation Criteria
To comprehensively evaluate the segmentation results of colorectal polyps, seven commonly used evaluation metrics are employed in this study. These metrics include the mean Dice similarity coefficient (mDice), mean Intersection over Union (mIoU), weighted F-measure (
), similarity metric (
), mean E-measure (
), maximum E-measure (
), and Mean Absolute Error (MAE) [
45]. Among these metrics, a lower MAE value indicates better segmentation performance, while higher values for the other metrics signify superior segmentation quality.
5. Results
5.1. Quantitative Results
To validate the effectiveness of the proposed DAFM-Net model, it is compared with 10 state-of-the-art polyp segmentation algorithms, including UNet [
9], UNet++ [
10], PraNet [
22], Polyp-PVT [
37], SSFormer [
46], HSNet [
36], M2SNet [
24], PVT-CASCADE [
31], CTNet [
33], and MLFF-Net [
39]. Quantitative comparison experiments are conducted on five datasets. Specifically, 80% of the Kvasir-SEG and CVC-ClinicDB datasets are used for training, while the remaining 20% are reserved for testing. The CVC-ColonDB, EndoScene, and ETIS datasets are entirely used for testing. The known test dataset is employed to evaluate the model’s learning ability, whereas the unknown test dataset is utilized to assess its generalization ability. The state-of-the-art comparative models chosen for this paper include classic network architectures such as UNet, Res2Net50, and PVTv2.
The quantitative comparison results of the DAFM-Net model on the Kvasir-SEG and CVC-ClinicDB datasets are presented in
Table 2 and
Table 3. Compared to the current state-of-the-art model, MLFF-Net, the proposed method improves the mDice and mIoU metrics on the Kvasir-SEG dataset by 1.3% and 2%, respectively, while the MAE metric is reduced to 0.018. On the CVC-ClinicDB dataset, the mDice metric achieves a value of 94.5%, indicating that the model achieves simultaneous optimization of global segmentation accuracy and local detail retention. The quantitative comparison results of the two polyp segmentation datasets demonstrate that the segmentation accuracy of the DAFM-Net model is improved, along with a better learning ability.
To further validate the generalization ability of the DAFM-Net model, quantitative comparison experiments were conducted on the EndoScene, CVC-ColonDB, and ETIS datasets against state-of-the-art models, with the results presented in
Table 4,
Table 5 and
Table 6. Compared to the State Of The Art (SOTA) model MLFF-Net, all evaluation metrics of the EndoScene dataset are superior to those of MLFF-Net, although the
is sub-optimal, while the
is optimal, indicating that the segmentation model performs better in overall effectiveness. According to the data in
Table 4 and
Table 5, the proposed method achieves the best performance on both the CVC-ColonDB and ETIS datasets. Specifically, compared to MLFF-Net, the mDice metrics are improved by 1.3% for the CVC-ColonDB dataset and by 4.6% for the ETIS dataset. When analyzed in conjunction with the size distribution of the CVC-ColonDB and ETIS datasets, the segmentation accuracy of the medium model and smaller polyps is enhanced. Based on the above experimental results, the DAFM-Net model demonstrates superior generalization ability across multiple datasets.
To validate the statistical significance of the model’s quantitative analysis, the Wilcoxon rank-sum test
p-values are presented in
Table 7. This table compares the proposed DAFM-Net with the SOTA model CTNet [
33] across five datasets and evaluation metrics. The results demonstrate statistically significant differences (
p < 0.05) between DAFM-Net and CTNet in all evaluation metrics on the Kvasir-SEG, CVC_ClinicDB, EndoScene, CVC_ColonDB, and ETIS datasets.
5.2. Qualitative Results
The segmentation visualization comparison results between the DAFM-Net model and other State Of The Art (SOTA) models are illustrated in
Figure 7, demonstrating significant advantages in handling complex scenarios. For instance, the polyp morphology in rows 1 to 3 exhibits diversity. While CTNet, M2S, and PraNet partially identify regions with irregular polyp morphology, EU-Net, UNet++, and UNet exhibit missed detection and mis-segmentation, and SANet struggles to segment large-scale polyps completely. The polyps in rows 4 to 6 are highly similar to the background, with DCRNet misidentifying folds as polyps and PolypPVT and PraNet incorrectly labeling raised tissues as polyps. Row 7 shows incomplete segmentation due to interference from bloodstains. Row 8 contains multiple polyps, but most methods identify only a few polyps, with frequent omissions and misclassifications, particularly in recognizing small-sized features in multi-target scenarios. In contrast, the DAFM-Net model demonstrates more accurate and stable segmentation when dealing with complex situations such as irregular shapes, high similarity between polyps and background tissues, interference from intraluminal folds and bloodstains, and the simultaneous appearance of multiple polyps.
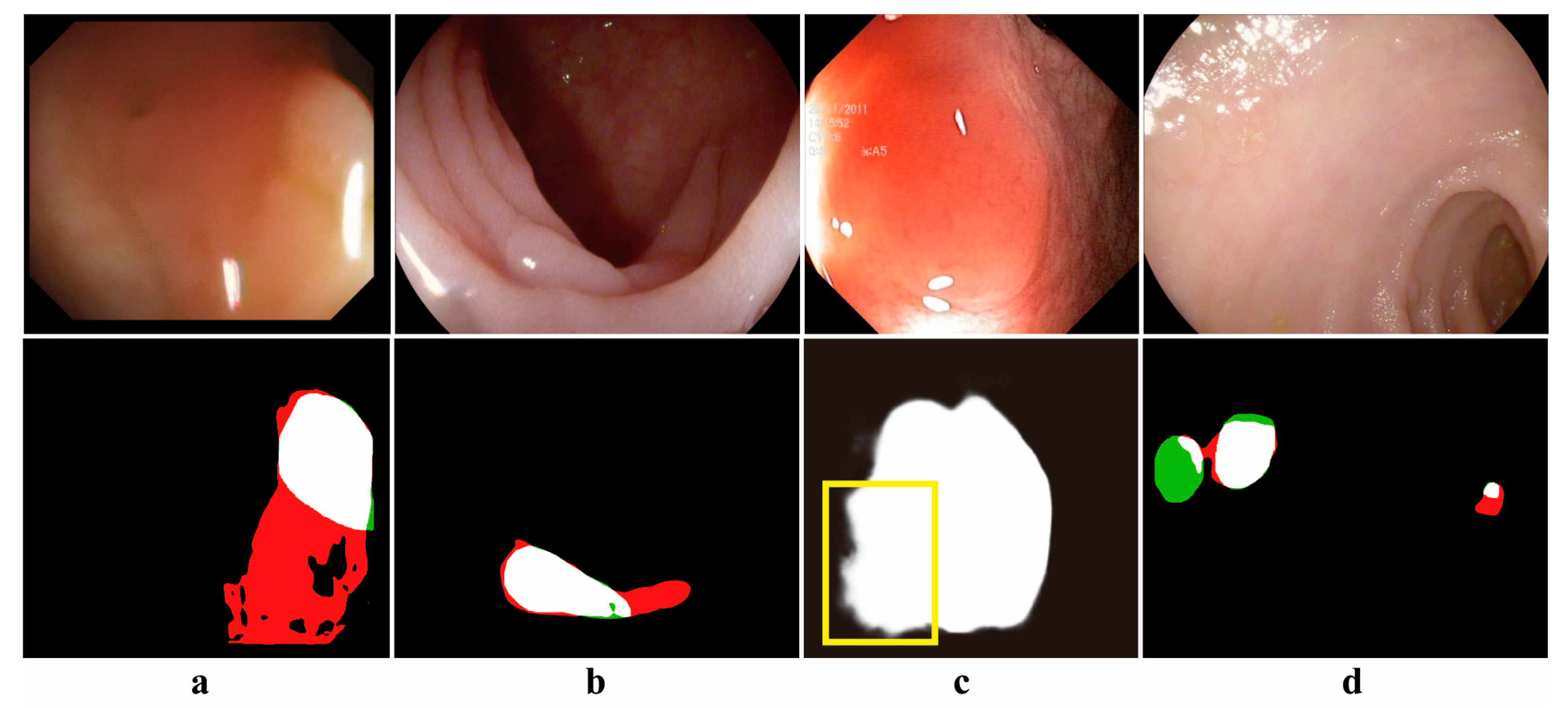
To more clearly elucidate the working mechanism of the model, the depth feature maps generated within the network are visualized and analyzed in this paper, with the specific results shown in
Figure 8. Taking the small polyp segmentation in the last row as an example, M1 employs a multi-scale mechanism to capture the detailed information of the polyp, including uterine folds that are highly similar in color to the polyp. C2 adaptively preserves background tissues related to the polyp through cross-layer fusion. C3 initially locates the two polyp regions after fusing positional information. D4, combined with a dual-attention mechanism, further identifies and accurately locates the polyp regions while preserving local details and removing interference from highly similar parts. Finally, P1 identifies the polyp region and its edge details. Through multi-scale feature extraction, cross-layer information fusion, and a dual-attention mechanism, DAFM-Net effectively reduces interference from complex backgrounds, significantly improving the accuracy and robustness of polyp detection.
5.3. Ablation Study
In this paper, three new modules are introduced to enhance model performance, including MCPA, CASF, and DCEA. To validate the effectiveness of each module, ablation experiments are conducted on the DAFM-Net model. The experiments utilize the PVT-v2 [
34] backbone UNet structure as the baseline (Baseline), and the MCPA, CASF, and DCEA modules are incrementally integrated into the baseline network to evaluate the mDice and mIoU metrics across multiple datasets. The results of the ablation experiments are presented in
Table 8.
Compared to the baseline, the inclusion of the MCPA module improves the mDice of the CVC-ClinicDB, Kvasir-SEG, CVC-ColonDB, and ETIS datasets by 1.8%, 0.5%, 1.5%, and 1.4%, respectively, and the mIoU by 2.4%, 0.9%, 4.1%, and 2.1%, respectively. However, the performance on the Endoscene dataset is degraded, indicating insufficient adaptability to complex contexts in Endoscene. With the addition of the DCEA module, which enhances the capture of global and local information through a dual-attention mechanism, the CVC-ClinicDB dataset achieves mDice and mIoU scores of 94.9% and 90.2%, respectively. However, the performance on the Kvasir-SEG dataset is slightly reduced, suggesting potential feature redundancy issues with the DCEA module on specific datasets. To address these issues, the CASF module is incorporated. CASF mitigates conflicts during feature aggregation and improves the adaptability of the model to complex backgrounds by enhancing the adaptive fusion of features at all levels. Consequently, the performance across all five datasets is significantly improved, with the mDice of CVC-ColonDB and ETIS increasing by 6% and 6.4% and the mIoU by 8% and 7.1%, respectively. These results demonstrate that the CASF module effectively balances the fusion of multi-scale features. By sequentially integrating the MCPA, DCEA, and CASF modules, DAFM-Net exhibits substantial performance improvements across multiple datasets, validating the effectiveness of each module and the robustness of the model.
The segmentation results for each module ablation experiment are presented in
Figure 9. Compared to the baseline model, the addition of the MCPA module enhances the model’s ability to identify lesion regions and captures detailed polyp information through a multi-scale mechanism. However, some mis-segmentation issues persist. Subsequently, the DCEA module is introduced, which effectively reduces redundant interference from background tissues by enhancing the capture of contextual information, thereby improving the segmentation accuracy of lesion regions in terms of both global and local information. Nevertheless, discontinuities within the lesion regions remain. Finally, the CASF module is incorporated, which optimizes the aggregation process of multi-level information through a cross-layer adaptive feature fusion mechanism. This significantly improves the discontinuities within lesion regions, resulting in more complete and precise segmentation outcomes.
5.4. Computational Efficiency
To verify the computational efficiency of the model, we employ three metrics: Parameters, Flops, and the Frame rate Per Second (FPS) for analysis. The results are shown in
Table 9. The experiments were conducted on a computer equipped with an Intel Core i7-14650HX processor, 16 GB RAM, and an NVIDIA RTX-4060 GPU, using an input size of
. U-Net [
9] and UNet++ [
10] exhibit higher FLOPs due to successive convolutional layers and dense nested skip connections. PraNet [
22], M2SNet [
24], and CR-Net [
26], all based on the ResNet-50 architecture, demonstrate different optimization strategies: PraNet incorporates reverse attention to reduce FLOPs, while M2SNet employs a subtractive design to decrease parameter count. Although multi-level feature fusion in these models improves accuracy, it increases computational latency, thereby reducing FPS.
Polyp-PVT [
37] adopts a chunking process to divide images into local patches, effectively reducing the complexity of self-attention mechanisms and improving parameter efficiency. HSNet [
36], PVT-CASCADE [
31], CAFE-Net [
38], DAFM-Net, and Polyp-PVT all utilize the PVT-v2 [
34] backbone network. The CAFE-Net model increases parameter count through its multi-branch structure and stacked attention mechanisms. CTNet [
33], based on the MiT-b3 [
47] backbone, achieves higher accuracy on the EndoScenes dataset but suffers from slower inference speed. In DAFM-Net, the MCPA module employs a multi-branch structure and cascaded convolutional layers to capture multi-scale features, which inevitably increases the parameter count. Furthermore, the inclusion of extensive matrix multiplication operations in the DCEA module for enhanced local-global context perception significantly reduces computational speed. In the field of polyp segmentation, while segmentation accuracy remains paramount, balancing computational efficiency presents an important direction for future research.
6. Conclusions
In this paper, a Dual Attention and Fusion Mechanism polyp segmentation network (DAFM-Net) is proposed. By integrating a Multi-scale Convolutional Patch Aware module (MCPA), a Cross-layer Awareness Selective Fusion module (CASF), and a Dual Context-Enhanced Attention module (DCEA), significant advancements are achieved in multi-scale feature extraction, cross-layer feature fusion, and the synergistic optimization of global and local information. The MCPA module addresses the limitations of insufficient feature extraction through a multi-branch convolutional patch structure and a local attention mechanism, particularly excelling in handling irregularly shaped and multi-sized polyps. The CASF module enhances the complementarity of features at different levels by adaptively fusing cross-layer features, effectively eliminating redundant information in cases where polyps are highly similar to background tissue. The DCEA module improves the ability to capture global and local information through a dual attention mechanism and an edge operator, not only enhancing attention to the overall structure of polyps but also optimizing the extraction of edge details, demonstrating higher robustness when dealing with polyp-background tissue similarity and intraluminal fold interference. Experimental results demonstrate that DAFM-Net exhibits superior performance on multiple publicly available polyp datasets, outperforming existing state-of-the-art models in terms of learning capability and generalization and achieving higher segmentation accuracy and robustness when handling complex backgrounds, irregular shapes, and multi-sized polyps.
Although the DAFM-Net model has improved segmentation accuracy and generalization ability, it has some limitations. Firstly, the DAFM-Net model consumes a large amount of computational resources while maintaining high segmentation accuracy. We will explore methods to improve the computational efficiency of the model, such as light-weight model design, knowledge distillation techniques, and the introduction of variants of the Transformer. Secondly, the polyp segmentation model suffers from leakage detection in multi-target segmentation tasks, and we will construct a dedicated multi-target segmentation dataset to optimize the model performance in a targeted manner. In addition, due to the large scene differences between different datasets of polyps and the high number of reflections, artefacts, and interferences, it is particularly important to enhance the anti-interference ability of the data. We will explore new training strategies and preprocessing methods in future work to further improve the adaptability of models.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}