Abstract
Rapid urbanization in China has led to an increase in the volume of daily road garbage, posing challenges to municipal sanitation. Automatic garbage collection is thus essential for sustainable management. This paper proposes an improved RT-DETR-based (Real-Time Detection Transformer) detection model, RGD-DETR, to improve road garbage detection performance. Firstly, an improved feature pyramid module that leverages multi-scale feature fusion techniques to enhance feature extraction effectiveness is designed. Secondly, a state space model is introduced to accurately capture long-range dependencies between image pixels with its spatial modeling capability, thus obtaining high-quality feature representation. Thirdly, a Dynamic Sorting-aware Decoder is adopted to embed a dynamic scoring module and a query-sorting module in adjacent decoder layers, enabling the model to focus on high-confidence predictions. Finally, the classification- and localization-oriented loss and matching cost are introduced to improve target localization accuracy. The experimental results on the road garbage dataset show that the RGD-DETR model improves detection accuracy (mAP) by 1.8% compared with the original RT-DETR, performing well for small targets and in occlusion scenarios.
1. Introduction
Urban garbage management constitutes a critical component of municipal environmental governance and public health maintenance [1,2]. With the acceleration of urbanization, the generation of daily garbage from residential, commercial, and industrial sources has exhibited sustained growth patterns [3]. This surge poses formidable challenges to conventional manual cleaning methods, particularly in areas such as urban public roads, internal roads within industrial zones, and institutional campuses such as schools, government buildings, and corporate buildings. The persistent accumulation of garbage in these sites not only degrades urban aesthetics but also increases the risks of environmental contamination and disease transmission vectors [4]. Current municipal sanitation operations are mainly based on scheduled manual inspections [5], a methodology increasingly constrained by dual limitations: increasing labor costs and inherent human inefficiencies. Field observations confirm that substantial proportions of sudden garbage overflow incidents escape timely detection, while manual recording methods exhibit inherent limitations in the accuracy of the identification of the pollution source [6]. These systemic deficiencies impede the realization of smart city management. The emergence of artificial intelligence and robotic technologies presents transformative potential for urban sanitation systems. Autonomous garbage collection vehicles equipped with multimodal sensors and machine vision systems have demonstrated measurable improvements in operational efficiency and emergency response capabilities compared with traditional methods [7]. These advancements are primarily driven by the deployment of object detection and autonomous navigation technologies in self-driving waste collection vehicles, which allow for real-time identification of road litter and adaptive route planning in complex urban environments, thereby enhancing waste management efficiency. This technological evolution positions automatic garbage detection as the foundational capability for modern urban environmental management [8]. Accurate real-time detection of garbage distribution patterns across diverse urban roads has consequently emerged as the primary research frontier in intelligent municipal governance.
Early research on deep learning-based garbage detection primarily focused on single-objective detection tasks in individual images, where scenarios typically contained either a solitary target or sparse instances, with research priorities emphasizing feature representation optimization through convolutional neural networks. Liu et al. [9] enhanced cross-channel feature interaction by embedding a lightweight attention mechanism into YOLOv3, proposing the ECA-YOLO framework. Jiang et al. [10] improved rural garbage detection in YOLOv5 by integrating an attention fusion mechanism, adding a dedicated small object detection layer and adopting the CIoU loss function with Adam optimization. While these methods achieved notable progress in controlled environments, they revealed three critical challenges in real-world applications: (1) drastic scale variations in garbage targets caused by varying sensing distances, leading to severe accuracy degradation for small nearby objects; (2) category distribution shifts due to geographic and container-type dependencies in complex scenes; and (3) insufficient labeled samples in specialized scenarios such as remote areas.
Researchers have explored attention mechanisms, hybrid architectures, and data-efficient strategies to address the aforementioned challenges. Guo et al. [11] incorporated CBAM attention modules and focal loss into YOLOv4 to enhance feature discriminability and alleviate class imbalance. Zhao et al. [12] designed Skip-YOLO, with large convolutional kernels and dense blocks, to expand receptive fields and strengthen shallow–deep feature sharing, improving sensitivity to subtle intra-class variations. Tang et al. [13] proposed the RGB–Thermal Salient Object Detection (RGB-T SOD) task for accurately identifying salient objects from aligned RGB and thermal image pairs. They introduced ConTriNet, a robust, confluent, triple-flow architecture that employed a “Divide-and-Conquer” strategy to extract both modality-specific and complementary features through a unified encoder and specialized decoders, thereby enhancing saliency prediction robustness and accuracy. Quan et al. [14] proposed the Centralized Feature Pyramid (CFP) network, which enhanced intra-layer feature representation through a globally explicit visual center mechanism. This approach effectively captured local information in crucial corner regions, addressing the limitation of existing visual feature pyramids that overly focus on inter-layer interactions while neglecting intra-layer regulation. Li et al. [15] proposed DN-DETR, which accelerated DETR convergence and improved accuracy by injecting noisy ground-truth boxes into the Transformer decoder during training to alleviate the instability of bipartite graph matching in the early training stages. Meng et al. [16] proposed Conditional DETR, introducing a conditional spatial query to the cross-attention mechanism to reduce dependence on content embeddings. This design accelerated DETR training convergence. Wang et al. [17] proposed YOLOv9, a next-generation real-time object detection algorithm, in 2024. It introduced a learnable re-parameterization module (RepDet) and improved feature extraction structures, achieving a better balance between accuracy and efficiency. However, its training architecture was more complex than that of traditional YOLO models, and further optimization was needed for deployment on resource-constrained devices. In 2021, Sun et al. [18] proposed Sparse R-CNN, a two-stage object detection algorithm based on the concept of sparse learning. It replaced traditional dense candidate box generation with a fixed number of learnable proposals, simplifying the detection pipeline. However, its inference speed was relatively slow, and the use of a fixed number of proposals may be insufficient for complex scenes with many objects, leading to potential missed detections. Zhang et al. [19] proposed DINO, an advanced end-to-end object detector that improves detection accuracy and convergence speed through denoising training, hybrid query initialization, and a dual prediction strategy, demonstrating excellent performance on the COCO dataset. However, its relatively slow inference speed limited its widespread use in applications with high real-time requirements. Regarding data scarcity, Qin et al. [20] proposed AL-DETR, integrating active learning into DETR for efficient training with limited annotations. Inspired by Transformer’s success in NLP, Zhao et al. [21] developed a dual-branch network combining the CNN’s local feature extraction with Transformer’s global modeling, while Sun et al. [22] enhanced YOLOv5-OCDS using omnidimensional dynamic convolutions and decoupled heads for task-specific adaptability. Notably, balancing accuracy and efficiency remains an open issue. Tan et al. [23] improved multi-scale detection through spatial pyramid attention at the cost of increased computational complexity. Sun et al. [24] achieved a lightweight–accuracy trade-off in YOLOv8n via GhostNet modules and an asymptotic feature pyramid design.
The introduction of DETR (Detection Transformer) by Carion et al. [25] marked a paradigm shift in object detection by reformulating the task as a sequence-to-sequence problem using Transformer architectures [6]. This end-to-end framework employed a Transformer encoder–decoder architecture, treating object detection as a set prediction task. It used a CNN to extract image features, leveraged self-attention mechanisms to establish global dependencies, and directly outputted bounding boxes and categories in parallel. Its core innovation lay in the bipartite, matching-based, Hungarian loss, which enforced unique alignment between predictions and ground truth, eliminating traditional anchor designs and non-maximum suppression (NMS) post-processing for end-to-end detection. DETR computed pixel-wise correlations across the entire feature map through self-attention, whereas CNNs relied on localized receptive fields. This demonstrated that Transformers inherently captured broader contextual relationships than CNNs as self-attention mechanisms enabled global interaction between all spatial positions in a single layer.
However, the application of the DETR framework to object detection has also revealed its limitations and shortcomings, mainly reflected in the following aspects: (1) slow training convergence due to global dependency learning in self-attention and the unstable optimization of bipartite matching loss during early training stages; (2) suboptimal performance in small object detection, attributed to the lack of explicit multi-scale feature fusion mechanisms (e.g., FPN) and fixed query slots that limit adaptability to dense small objects; (3) quadratic computational complexity with respect to feature map resolution, leading to high memory consumption for high-resolution images; (4) a mismatch between the classification scores and localization accuracy of queries leading to suboptimal localization performance and degraded Average Precision at high IoU thresholds (mAP75); and (5) fixed prediction slots, where the preset number of object queries (e.g., 100) causes missed detections for crowded scenes or redundant “no object” predictions for sparse scenes. Subsequent studies enhanced DETR’s capabilities while addressing its inherent limitations.
Zhu et al. [7] proposed Deformable DETR, which replaced global attention with deformable attention mechanisms to reduce computational complexity by focusing on sparse key feature points, improving both efficiency and small-object detection accuracy. Building upon this, Liu et al. [26] introduced DAB-DETR, where dynamic anchor boxes were implemented as learnable parameters iteratively refined in the Transformer decoder, enhancing spatial localization precision. To mitigate query misalignment during training, Li et al. developed DN-DETR by injecting noise into positive queries and integrating a denoising task, forcing the model to recover accurate prediction patterns. In 2023, Pu et al. [27] proposed Rank-DETR to address the mismatch between classification scores and localization accuracy in DETR. They introduced a rank-oriented architectural design that promoted positive predictions and suppressed negative ones to ensure a lower false positive rate. Additionally, they developed rank-oriented loss functions and matching cost that prioritized predictions with higher localization accuracy during ranking, thereby improving the Average Precision (AP) at high IoU thresholds. In 2023, Lv et al. [28] further advanced the framework by designing RT-DETR with an Attention-based Intra-scale Feature Interaction (AIFI) module for intra-scale feature refinement and a Cross-scale Feature-fusion Module (CCFM) for multi-scale representation complemented by dynamic query–target matching to accelerate convergence and boost small-object detection.
Despite advancements in the end-to-end detection frameworks of DETR and its variants, it still exhibits notable limitations. Small-scale object detection remains a persistent challenge as the fixed-size feature maps generated by multi-head self-attention mechanisms struggle to effectively capture discriminative features for low-resolution targets. Furthermore, this background interference frequently results in localization drift or false positive detection, particularly for objects lacking clear contrast boundaries. These limitations collectively highlight the need for enhanced feature representation learning in complex visual environments. In this paper, we present the RGD-DETR, a real-time detection framework that achieves promising performance on challenging road debris datasets. Our work overcomes the limitations of DETR-based detectors in road garbage detection through four contributions as follows:
- An enhanced feature pyramid module utilizing channel attention mechanisms is designed to improve the effectiveness of feature learning.
- A state space model is incorporated to capture the long-range dependencies among image pixels, thereby obtaining high-quality feature representations.
- A Dynamic Sorting-aware Decoder is adopted to integrate a dynamic scoring module and a query-sorting module between decoder layers, which enables the model to prioritize the high-confidence predictions.
- The classification- and localization-oriented loss and matching cost are introduced to improve localization precision and achieve superior performance at high IoU thresholds.
2. Materials and Methods
2.1. RT-DETR Model
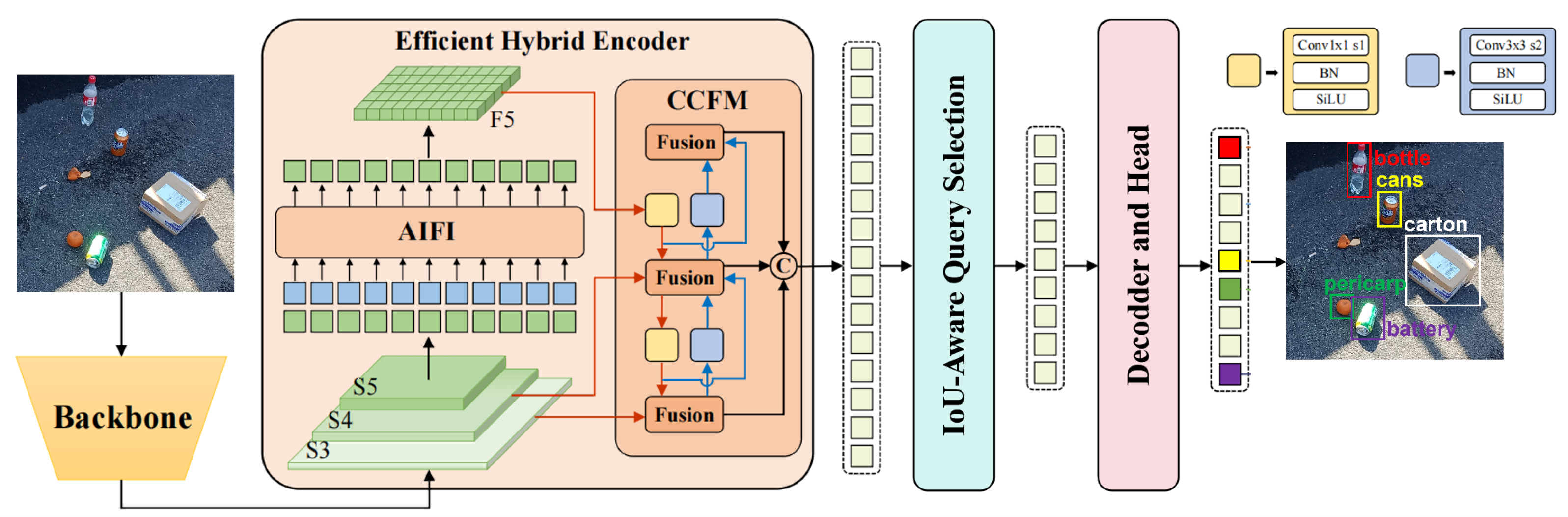
RT-DETR has emerged as a state-of-the-art framework within the DETR-based architecture family for real-time object detection. The pipeline of RT-DETR commences with the backbone network generating three hierarchical multi-scale feature maps. Then the generated feature maps are fed into a hybrid encoder to effectively fuse multi-scale information and enhance the feature representations. The hybrid encoder comprises two complementary components: (1) the Attention-based Intra-scale Feature Interaction (AIFI) module, which implements self-attention mechanisms to facilitate region-wise feature correlation within identical scales, thereby refining granularity representation for local features, and (2) the Cross-scale Feature-fusion Module (CCFM) that leverages CNN architecture to synergistically integrate cross-scale contextual information, enabling adaptive detection for multi-size objects. Through coordinated operation of these modules, the framework achieves optimal balance between feature granularity preservation and scale-invariant representation learning.
The IoU-aware mechanism initializes object queries by adaptively extracting spatially discriminative features. To ensure query efficiency, the model probabilistically selects top-k high-confidence features from the encoder output based on the classification scores. RT-DETR associates high IoU predictions with high classification scores while assigning lower scores to predictions with low IoU values. This design addresses the mismatch between classification confidence scores and enhances the localization qualities of bounding boxes, thereby effectively boosting the model’s detection performance. The overall pipeline of the RT-DETR model is illustrated in Figure 1.
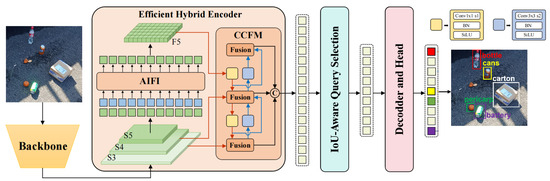
Figure 1.
Structure of the RT-DETR model.
Building upon RT-DETR, RT-DETRv2 introduces several improvements aimed at enhancing both flexibility and practicality. Specifically, it adopts scale-specific sampling configurations in deformable attention to enable selective multi-scale feature extraction, and introduces a discrete sampling operator to replace the grid-sample operator, thereby reducing deployment constraints. Furthermore, dynamic data augmentation and scale-adaptive hyperparameter tuning are employed during training to improve accuracy without compromising inference speed. These bag-of-freebies optimizations further strengthen the real-time performance and deployment versatility of the RT-DETR architecture.
2.2. Road Garbage Detection DETR (RGD-DETR) Model
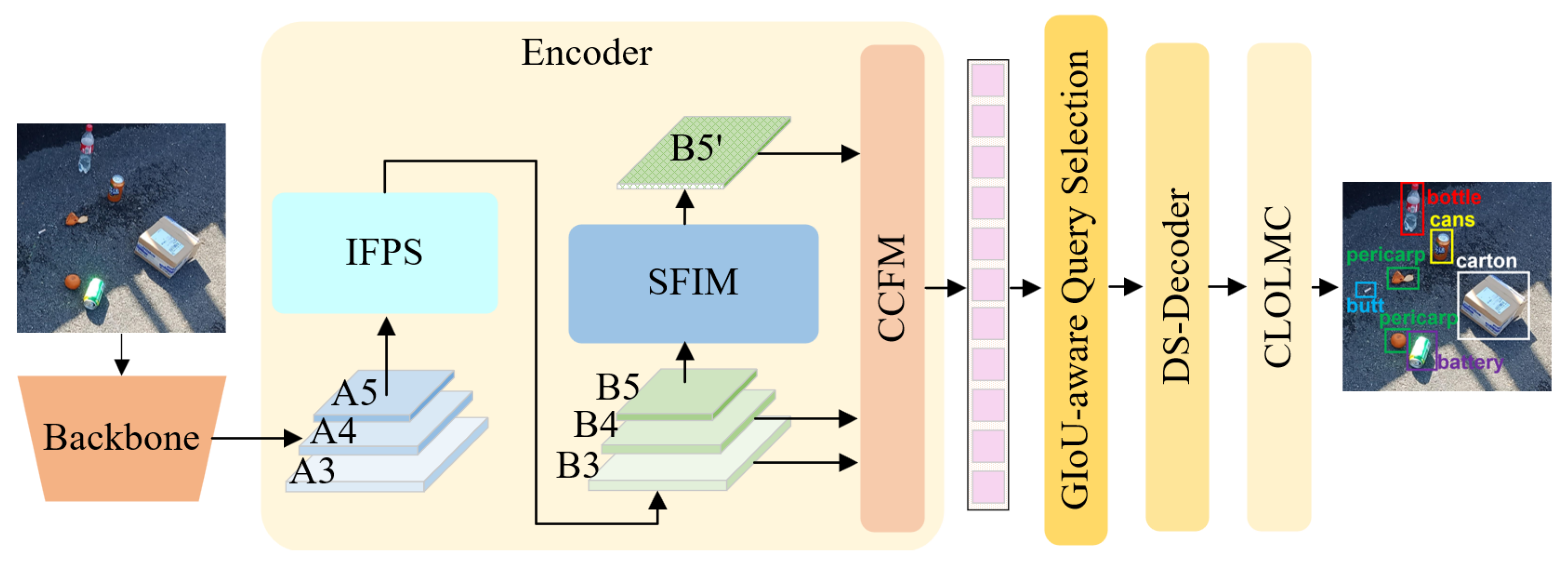
Our proposed architecture reveals the RT-DETR framework. As shown in Figure 2, the backbone network generates hierarchical feature maps (A3, A4, and A5) at three different receptive fields, corresponding to progressively upsampling-like visual representation of the input image. The Improved Feature Pyramid Structure (IFPS) performs the initial fusion and enhancement of these multi-scale features in preparation for the rich feature extraction in the subsequent processing. Then the model introduces the State-space Feature Interaction Module (SFIM) to enable deep interaction between feature maps, along with the CCFM. This design strengthens the feature expression capability of the model.
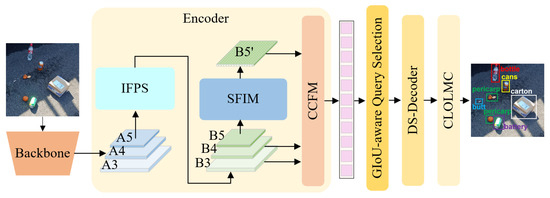
Figure 2.
The structure of the improved RGD-DETR model. The model incorporates the Improved Feature Pyramid Structure (IFPS) into the RT-DETR encoder, replacing the original Attention-based Intra-scale Feature Interaction (AIFI) module with the State-space Feature Interaction Module (SFIM). Additionally, a Dynamic Sorting-aware Decoder (DS-Decoder) is introduced, along with the classification- and localization-oriented loss and matching cost (CLOLMC).
The model includes a generalized intersection over union (GIoU)-aware query selection mechanism to rank the feature sequence and identify the top-k most representative features. These filtered features serve as initial query input for the Dynamic Sorting-aware Decoder (DS-Decoder). Within the decoder module, a dynamic scoring strategy, which utilizes classification confidence scores, is integrated between adjacent layers, positioned prior to the penultimate decoder layer. Through this module, the model is able to dynamically refine the classification confidence scores based on the features at the current layer. Additionally, after each dynamic scoring module, a dynamic query-sorting module is sequentially embedded to further optimize the sorting of object queries, ensuring that the model pays more attention to high-confidence predictions. Finally, by integrating localization information into the classification- and localization-oriented loss and matching cost (CLOLMC), the decoder gradually optimizes both the localization accuracy and classification confidence of the object queries. This progressive optimization strategy enhances the model’s detection performance in complex scenarios, especially for small objects and instances of occlusion.
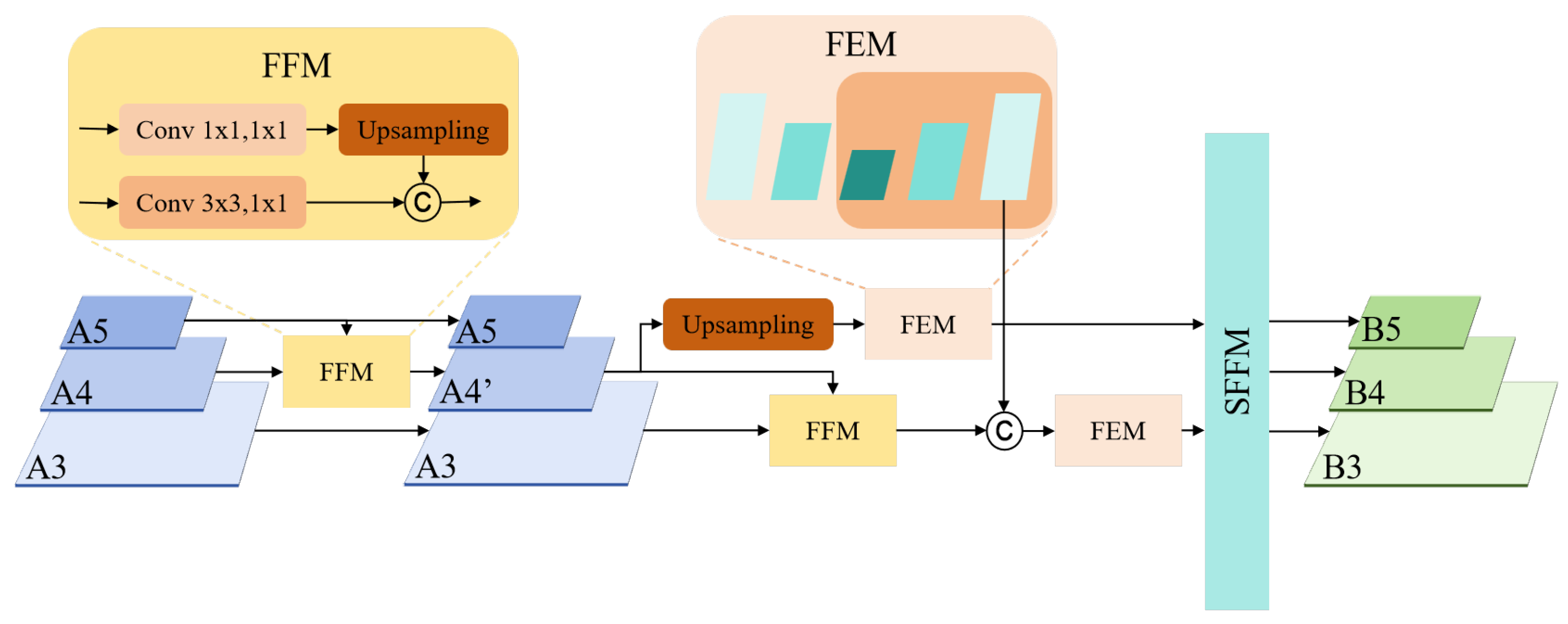
2.2.1. Improved Feature Pyramid Structure
The Improved Feature Pyramid Structure (IFPS) is primarily designed to enhance and fuse multi-scale features extracted by the backbone network, establishing a foundation for subsequent processing. The structure is illustrated in Figure 3. Initially, the model processes the multi-scale features using a Feature Fusion Module (FFM) in conjunction with two Feature Enhancement Modules (FEM). This approach ensures that the features not only accurately capture key information across varying spatial scales but also enhance the inter-scale correlation among features. Subsequently, a Scale-aware Feature Fusion Module (SFFM) is employed for comprehensive fusion across all feature levels. This module innovatively integrates a channel attention mechanism and employs an adaptive weight allocation strategy to enable the fusion of same-scale features, thus obtaining a unified multi-scale feature representation with rich semantic information.
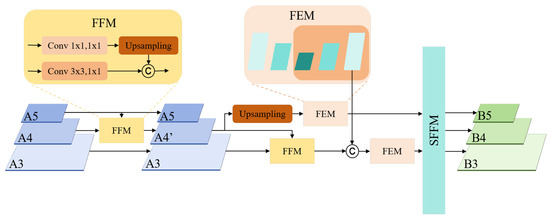
Figure 3.
Improved Feature Pyramid Structure. FFM stands for Feature Fusion Module, FEM stands for Feature Enhancement Module, and SFFM stands for Scale-aware Feature Fusion Module.
The Feature Fusion Module (FFM) commences by compressing the channel dimensions of each feature map using 1 × 1 convolution layers. Then, all input feature maps are resized to the same spatial resolution through upsampling. Finally, a concatenation operation is performed to merge them into a new unified feature layer.
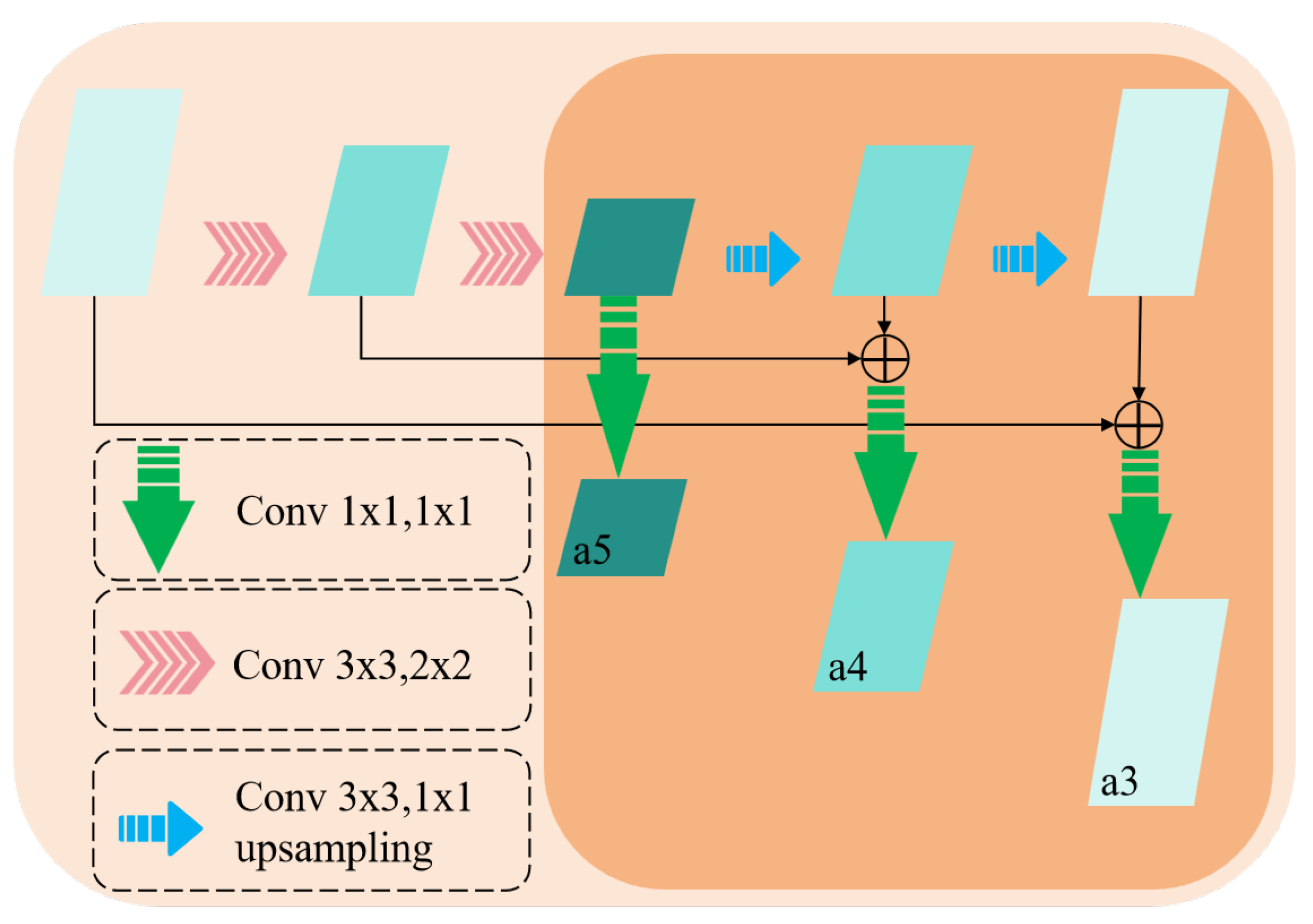
The Feature Enhancement Module (FEM) adopts a lightweight U-Net [29] architecture specifically designed to enhance the correlation between features across different scales, thereby improving the model’s feature representation capability. The structure is illustrated in Figure 4. The FEM processes multi-scale feature maps using both upsampling and downsampling operations, fusing feature maps of the same resolution via element-wise addition to effectively capture contextual information across scales. The FEM incorporates a 1 × 1 convolution layer to augment the expressive capability of channel features.
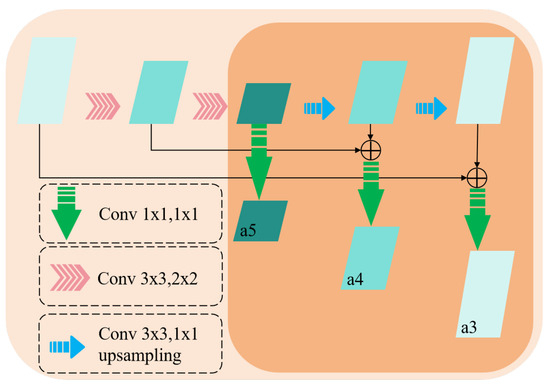
Figure 4.
Feature Enhancement Module. The FEM follows the design principles of U-Net, utilizing multiple upsampling, downsampling, and residual connection mechanisms while incorporating a 1 × 1 convolution layer at the output feature map to enhance feature representation capability.
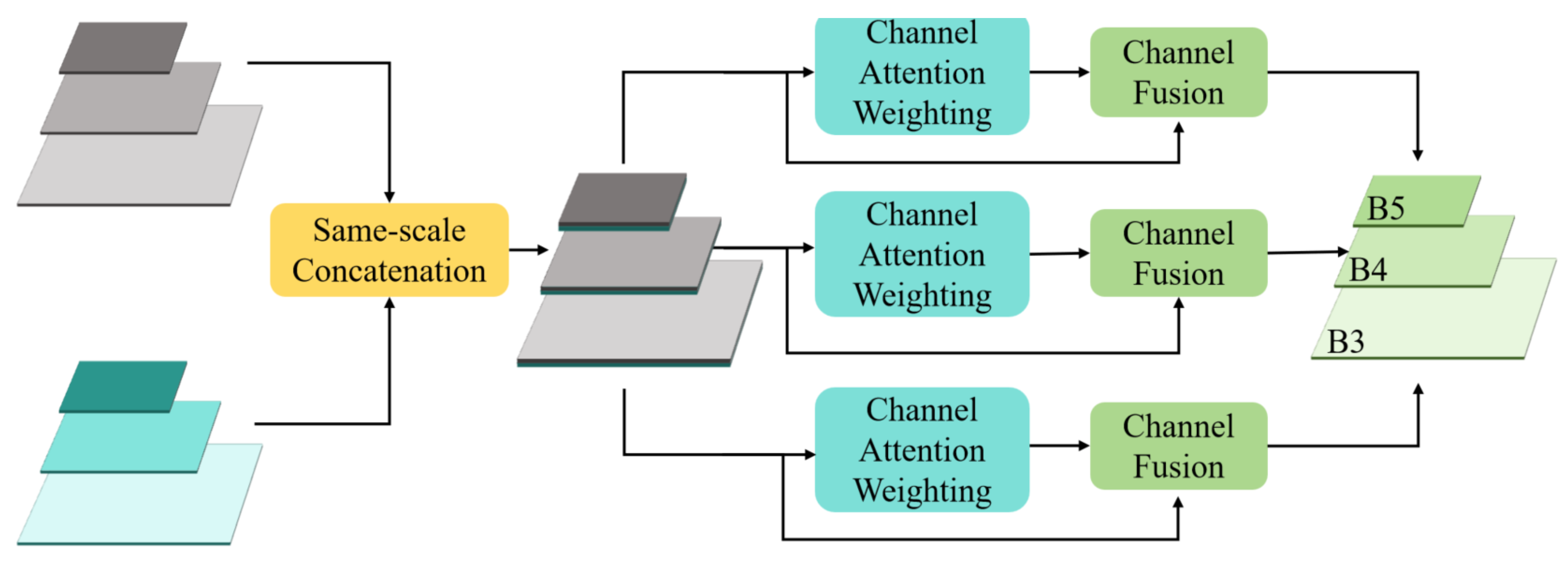
The Scale-aware Feature Fusion Module (SFFM) is designed to efficiently aggregate multi-level and multi-scale features generated from the FEM, thereby constructing a more representative feature pyramid. Its structure is illustrated in Figure 5. Initially, the SFFM concatenates the feature maps along the channel dimension at the same scale. Then, a channel attention mechanism inspired by the design of Squeeze-and-Excitation Networks (SENet [30]) is introduced. This mechanism computes inter-channel relationships within the feature maps and assigns a weight to each channel to automatically focus on the more important features for the task. After channel weighting, the SFFM fuses the channels based on the computed weights to achieve the final multi-scale fused feature maps (B3, B4, and B5).
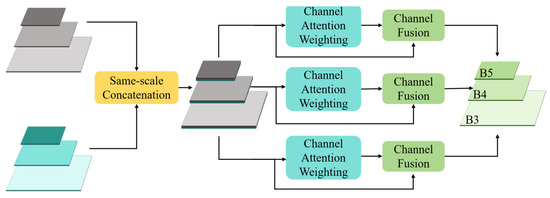
Figure 5.
Scale-aware Feature Fusion Module. The SFFM concatenates the feature maps along the channel dimension at the same scale and introduces a channel attention mechanism to capture the inter-channel weight relationships, thereby adaptively fusing channel features based on the computed attention weights.
2.2.2. State-Space Feature Interaction Module
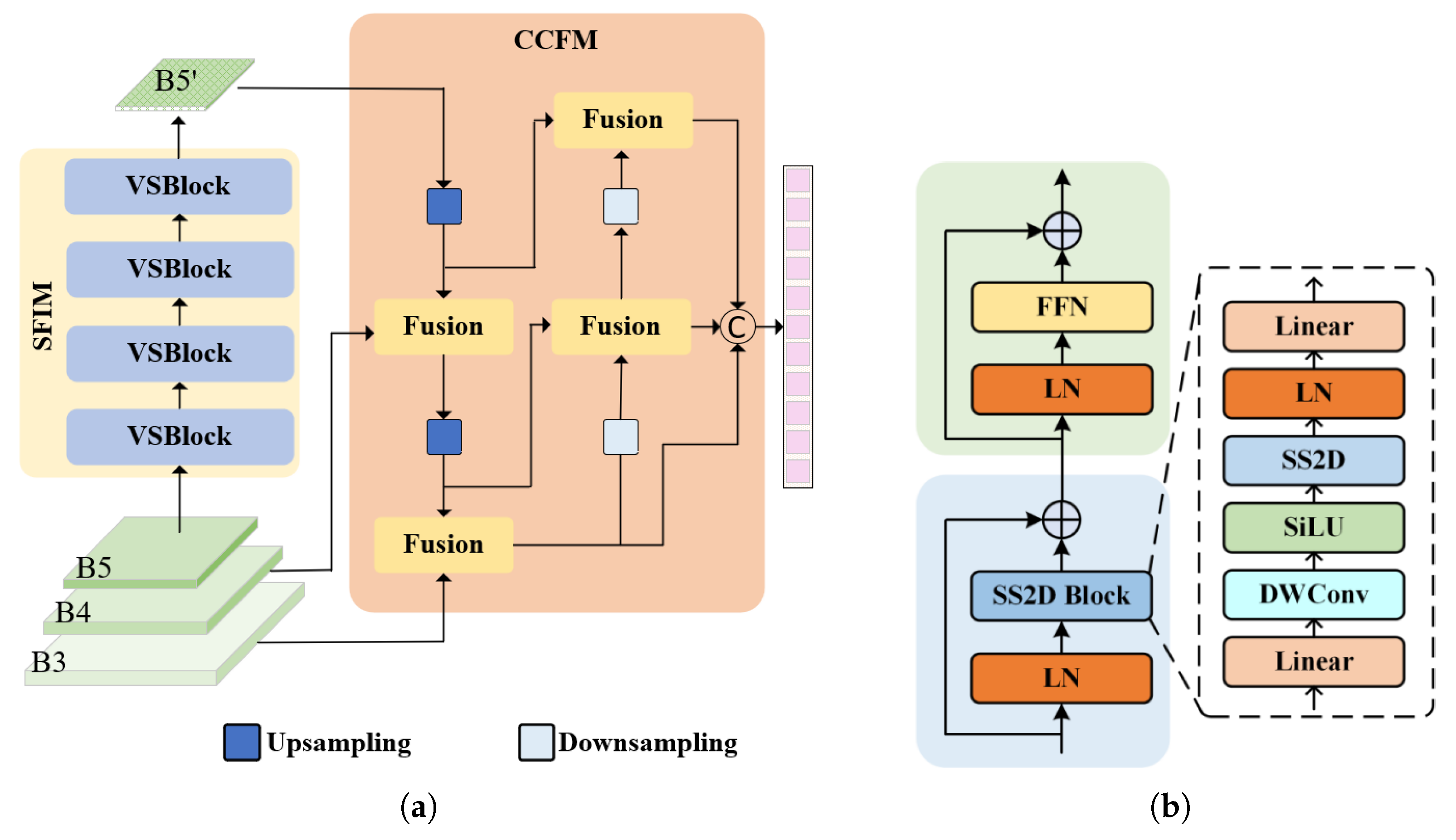
The State-space Feature Interaction Module (SFIM) employs the high-level feature map B5 from the multi-scale fused feature maps as input to enhance features and then generate a new high-level feature layer, B5’. Then, the feature maps B3, B4, and B5’ are subsequently fed into the Cross-scale Feature-fusion Module (CCFM) for cross-scale feature integration. Finally, the encoded feature sequence is transmitted to the decoder to facilitate the subsequent object detection tasks. The structures of the SFIM and CCFM are illustrated in Figure 6a.
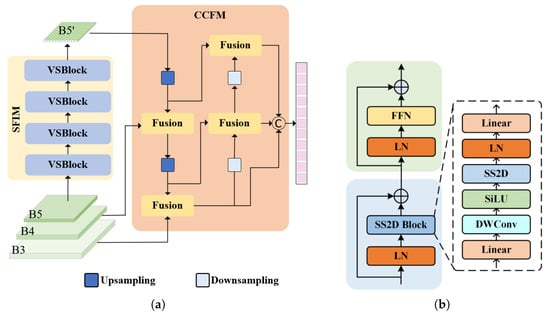
Figure 6.
(a) State-space Feature Interaction Module (SFIM) and CNN-Based Feature-fusion Module (CCFM). (b) Visual State-Space Block (VSBlock).
The SFIM consists of four identical Visual State-Space Blocks (VSBlocks) designed to achieve high-quality feature representations, as shown in Figure 6b. When processing the input feature layer B5, the SFIM first applies layer normalization (LN) to the input feature. The normalized input feature is then processed by the Spatially Aware 2D Convolution Block (SS2D Block [31]). The SS2D Block not only extracts spatial features but also enhances the model’s ability to perceive spatial information. The output of the SS2D Block is added to the initial input feature via residual connections and further processed through a normalization layer to mitigate potential gradient vanishing or explosion issues. Next, the feature undergoes processing through the Feed-Forward Network (FFN) to perform deeper feature transformation and enhancement and further explore the potential information within the features. Ultimately, the residual connection allows the output feature layer to fully integrate spatial features and contextual information, providing a richer feature representation for subsequent multi-scale fusion.
In the SFIM, the design of the SS2D Block is crucial. Firstly, the input features undergo an initial linear transformation via a linear layer to adjust the feature dimensions and value range. Secondly, the features are processed through Depthwise Separable Convolutions (DWConv [32]) and the SiLU activation function, further extracting richer spatial features and uncovering local details within the image. Then, inspired by the VMamba [33] method, the SS2D Block introduces a dedicated SS2D layer to enhance the model’s understanding of spatial structure. Finally, the features undergo layer normalization (LN) and are passed through a second linear layer to perform a dimensional transformation, ensuring that the features are suitable for the input requirements of subsequent modules and further optimizing the feature representation.
Note that the Cross-scale Feature-fusion Module (CCFM) leverages CNN architecture to effectively fuse contextual information across scales, enabling adaptive detection for multi-size objects [28].
2.2.3. Dynamic Sorting-Aware Decoder
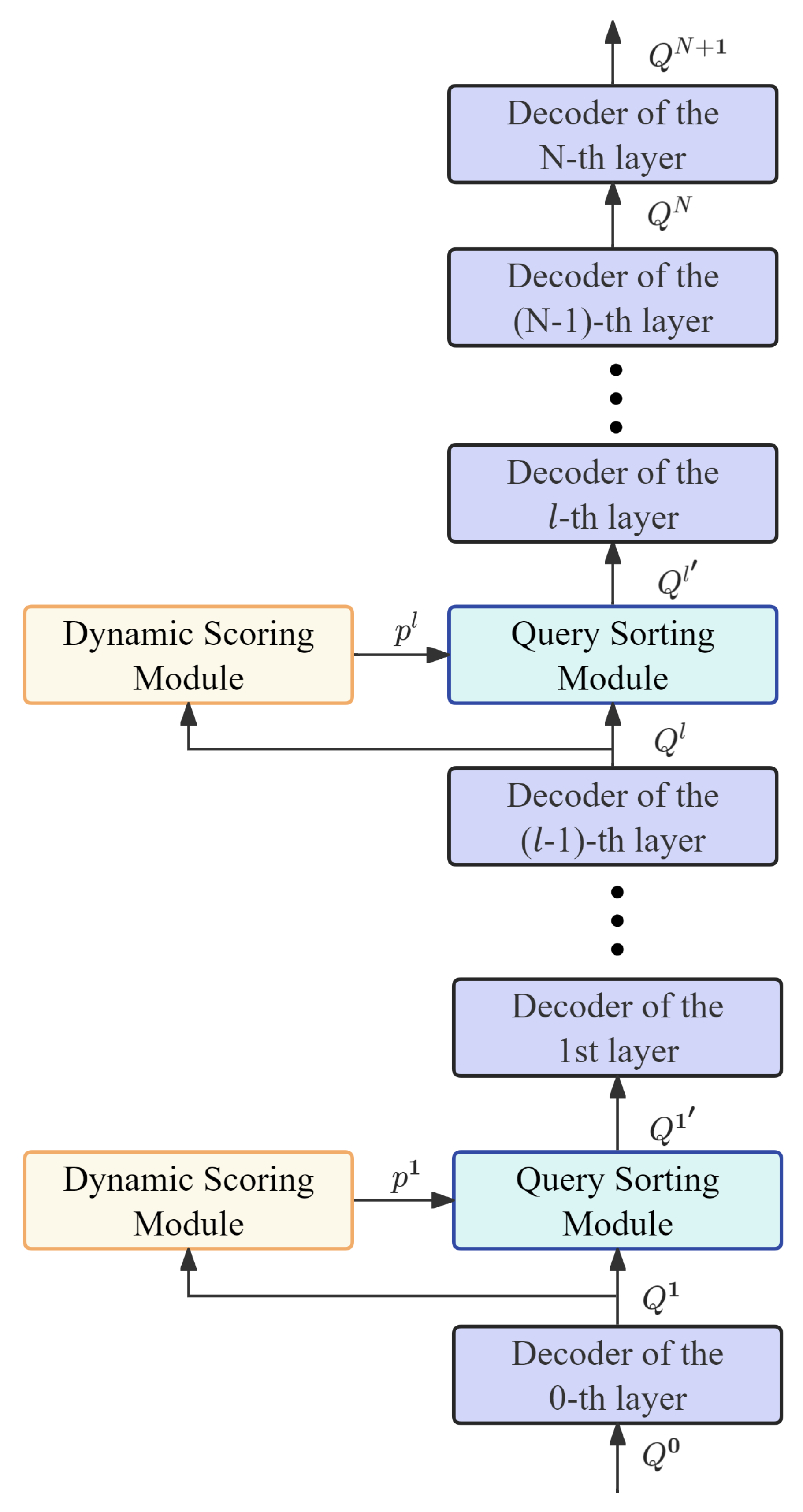
The Dynamic Sorting-aware Decoder (DS-Decoder) proposed in this paper leverages the advantages of sorting information throughout the entire Transformer decoding process. Specifically, a dynamic scoring module based on classification confidence scores is embedded between adjacent layers, before the second-to-last decoder layer. Through this module, the model dynamically adjusts the classification confidence score based on the features at the current layer to accurately differentiate the true positives and noisy predictions. Additionally, after each dynamic scoring module based on classification confidence scores, a dynamic scoring-based query-sorting module is sequentially embedded. This module further optimizes the sorting of object queries, ensuring that subsequent processing focuses more on high-confidence predictions. Figure 7 below illustrates the structure of this Dynamic Sorting-aware Decoder.
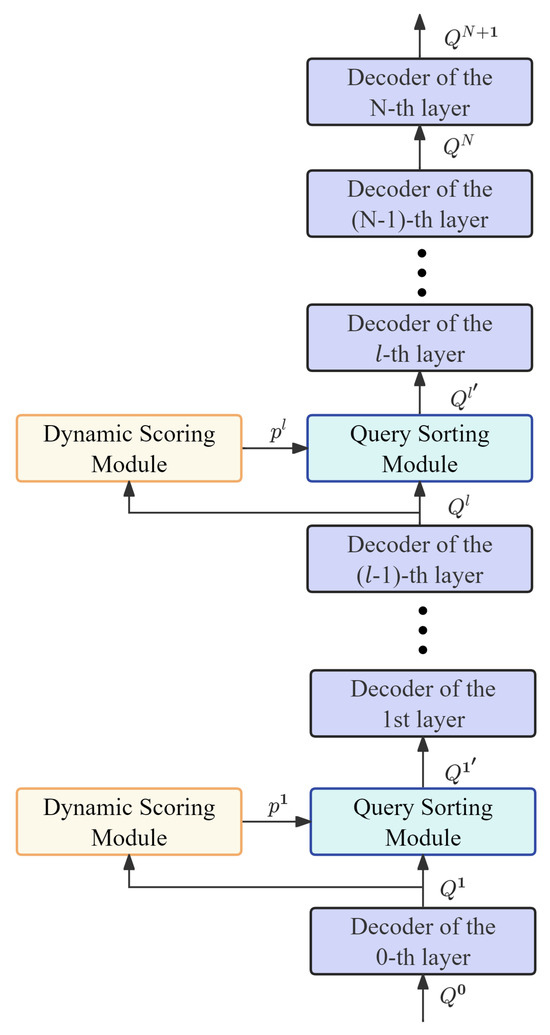
Figure 7.
Dynamic Sorting-aware Decoder (DS-Decoder).
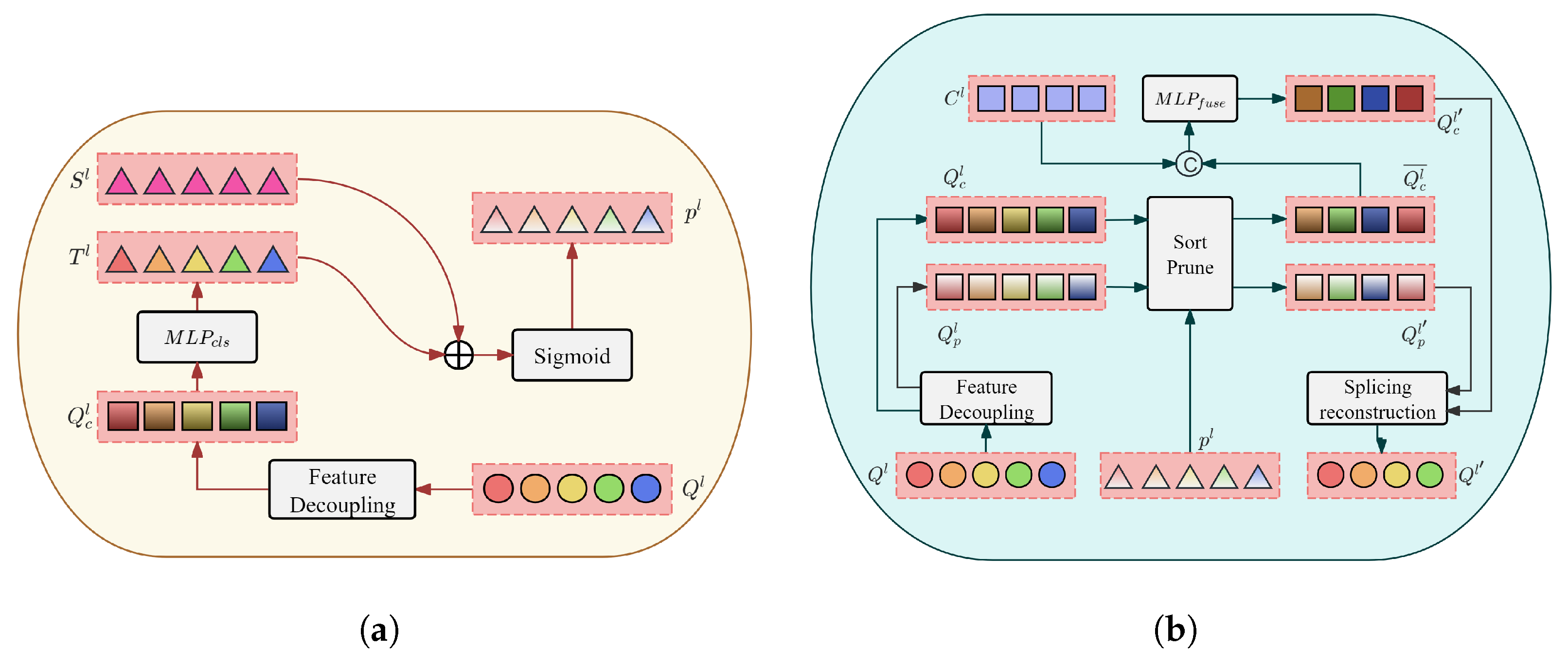
The dynamic scoring module, based on the classification confidence scores, innovatively introduces a set of learnable logit bias vectors , which are added to the classification confidence scores corresponding independently to each object query. After passing through the Sigmoid function, the classification confidence scores for the l-th layer decoder are obtained as follows:
where represents the output of the query vector by the l-th layer of the Transformer decoder, while the hidden dimensions of and are both the total number of categories K. The flowcharts of the dynamic scoring module based on classification confidence scores and the dynamic scoring-based query-sorting module are shown in Figure 8 below.
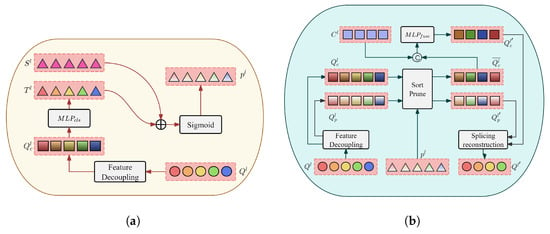
Figure 8.
(a) Flowchart of the dynamic scoring module based on classification confidence scores. (b) Flowchart of the query-sorting module based on dynamic scores.
Each layer of the Transformer decoder generates a query vector . The model first employs a dedicated projection network to decouple the query features into classification-specific queries . These queries are then passed through a multi-layer perceptron (MLP) to generate individual classification scores , which correspond one-to-one to the object query , providing initial classification information for each object query . A set of learnable logit bias vectors is subsequently added to the classification scores to introduce sorting-aware score calibration and dynamically adjust the scores. This step refines the original scores by introducing sorting sensitivity. After logit calibration, the results are passed through a Sigmoid function to convert them into probability values. The Sigmoid function maps the calibrated scores to the range of [0, 1], completing the normalization process and yielding the final classification confidence scores . These scores are then forwarded to the subsequent query-sorting module based on dynamic scoring. The query-sorting module leverages the classification confidence scores obtained from the preceding dynamic scoring module to re-sort and optimize the object queries. This process ensures that the final queries not only achieve higher positional accuracy but also exhibit enhanced semantic representations. First, this paper details the construction of content queries endowed with dynamic sorting awareness—an essential step for ensuring the effectiveness of query sorting throughout the detection pipeline.
Specifically, in the l-th () layer of the Transformer decoder, the object queries are first passed through a dedicated projection network to decouple their features into classification queries and positional queries . Simultaneously, the classification confidence score vector is obtained from the preceding dynamic scoring module. Since each element in is a K-dimensional vector, the maximum value among the classification confidence scores is adopted as the sorting criterion. Based on these confidence scores, both and are sorted in descending order. A progressive pruning strategy is then applied using a descending keep ratio , whereby only the top-K queries are retained while the remaining ones are discarded to optimize computational efficiency (e.g., five query blocks are reduced to four in the figure). Thus, we obtain the sorted classification queries and positional queries . In this context, the operator is defined to sort elements in Q based on the descending order of corresponding elements in p, while the operator prunes S according to the ratio k, retaining the top k proportion of elements in S and discarding the remaining proportion. The keep ratio is precisely controlled by the hyperparameter , and the configuration of keep ratios for different decoder layers is detailed in Table 1.

Table 1.
Query retention settings across decoder layers.
In the shallow layers (early stages) of the model, a higher query retention rate is maintained to ensure that potential targets (especially small or occluded ones) are not prematurely filtered out. The filtering criteria are gradually tightened as the network depth increases. In the deeper layers (later stages), only the most discriminative and high-quality queries are retained. All queries are preserved at the final output layer to ensure the completeness of the prediction results. Next, the pruned and sorted classification queries are concatenated (denoted by the symbol ) with a set of content queries that are randomly initialized in the feature dimension. These content queries are optimized in an end-to-end manner throughout the training process, enabling them to capture common semantic patterns that align better with the detection task’s requirements. A lightweight MLP (), composed of a single linear layer, a ReLU activation function, and a Dropout layer is subsequently applied to fuse the concatenated features and project them back to the original dimension, producing a new set of classification queries . In other words, a set of static content embeddings , shared across different samples and carrying sorting-aware information, is maintained. These embeddings effectively simulate and capture the most common semantic information [34], thereby enhancing the model’s detection performance in complex scenarios.
It is worth noting that, compared with the query rank layer of Rank-DETR, our query-sorting module adds a prune operator after the sort operator to reduce the number of queries at each decoder layer. In this way, our proposed method focuses on the high-quality queries and decreases the number of model parameters to boost the detection efficiency.
2.2.4. Classification- and Localization-Oriented Loss and Matching Cost
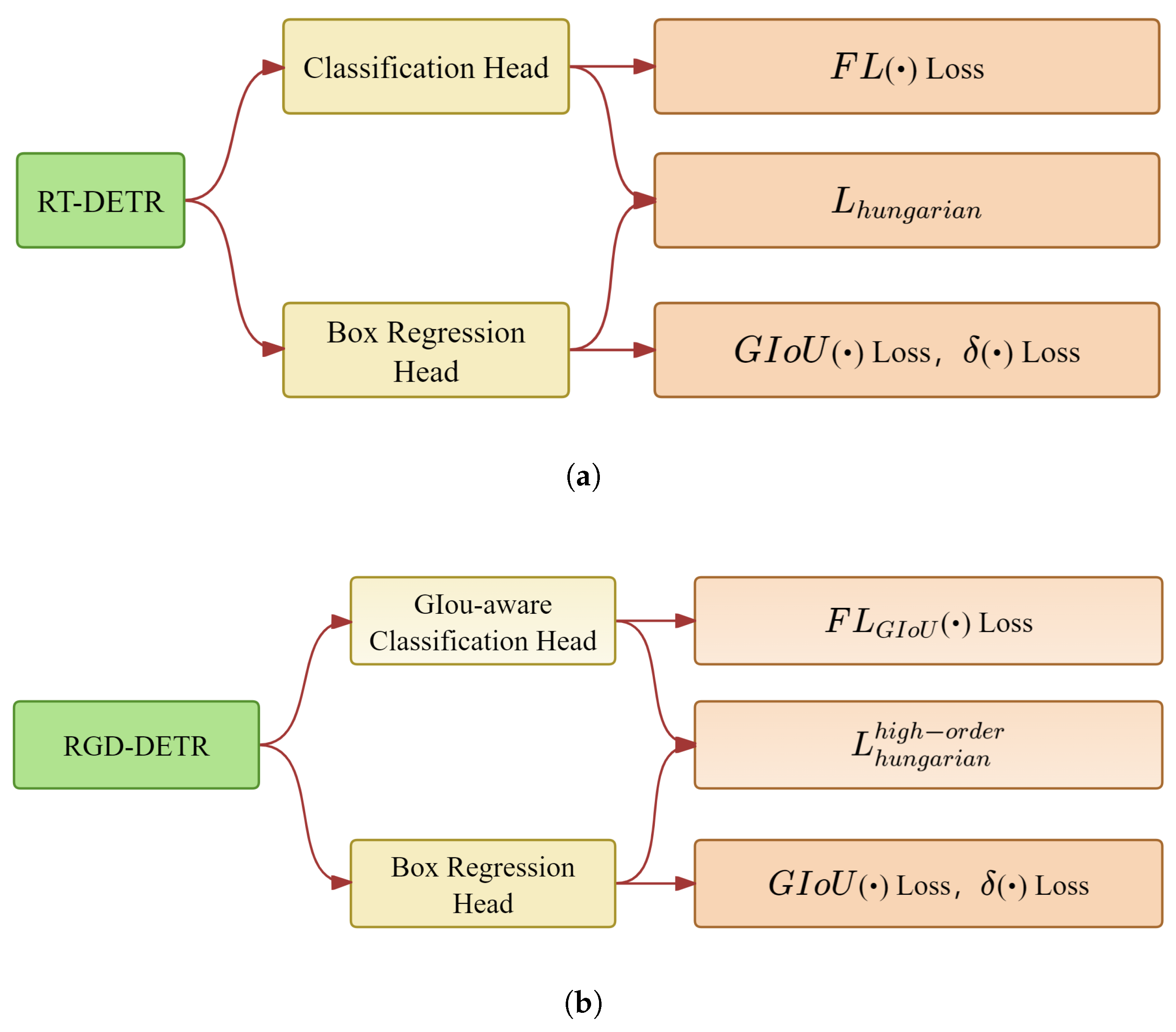
The original RT-DETR ignores the localization information in the loss function and matching cost function. Inspired by Rank-DETR, this paper introduces the localization information, and the classification- and localization-oriented loss and matching cost (CLOLMC) were designed to improve the garbage detection performance of our RGD-DETR. Specifically, the classification- and localization-oriented loss and matching cost consist of two components: (1) the classification- and localization-oriented loss function and (2) the classification- and localization-oriented matching cost function. The classification- and localization-oriented loss function integrates the generalized intersection over union (GIoU) into the semantic classification focal loss [35]. Meanwhile, the classification- and localization-oriented matching cost function combines the high-order IOU and the conventional matching cost function. The classification- and localization-oriented loss and matching cost are shown in Figure 9.
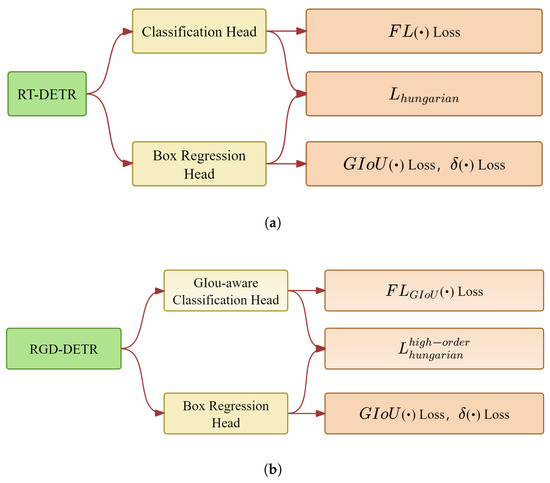
Figure 9.
(a) Original RT-DETR matching loss and matching cost. (b) Our classification- and localization-oriented loss and matching cost (CLOLMC).
We incorporate the GIoU score into the classification loss function. This methodology ensures that during the training procedure, the model not only learns to accurately classify the target category but also optimizes the localization of the corresponding bounding boxes. Unlike conventional classification heads that are based on binary targets, this approach employs the GIoU as a supervisory signal, thereby enabling the model to simultaneously refine both classification and localization tasks. Throughout the training phase, the model learns the category information of each target while adjusting the bounding box predictions to improve localization accuracy. This dual-focus strategy leads to enhanced classification performance and superior localization accuracy.
A newly designed loss function is presented in this paper based on GIoU-aware classification loss which enhances both classification and localization accuracy by normalizing the GIoU score. Specifically, let , where and b represent the predicted bounding box and ground-truth bounding boxes, respectively, and denotes the generalized intersection over union between them. Based on this formula, this paper defines the classification loss function as , which simultaneously considers both the classification information of the object and the localization accuracy of the bounding box.
where is the predicted probability of the target category, and is the magnification factor. It is worth noting that when , the GIoU value reaches its maximum, indicating perfect overlap between the predicted box and the ground truth. In this case, the proposed focal loss function degenerates into the original focal loss function , i.e., the standard classification loss. Therefore, the proposed method offers greater flexibility and adaptability compared with the traditional focal loss by effectively integrating semantic information and spatial localization cues. To further emphasize the advantage of localization accuracy, this paper introduces a magnification factor to enhance the influence of accurately localized scores. Specifically, is defined as the ratio between the accurately localized score and the inaccurately localized score. During the optimization process, this factor amplifies the impact of accurate localization predictions, thereby encouraging the model to favor more accurate bounding box predictions.
To validate the effectiveness of the proposed method, a comparison was conducted with the focal loss variant known as Zoom Loss [36]. Zoom Loss is used to address class imbalance by dynamically adjusting the loss weights for different classes, allowing the model to focus more on hard-to-classify samples during training. The mathematical formulation of Zoom Loss is expressed as follows:
where denotes the predicted probability of the target category, is the class-balancing coefficient, and is the hyperparameter that adjusts the contribution of hard and easy samples. In contrast, the classification- and localization-oriented loss function proposed in this paper enhances the model’s performance at high IoU thresholds by incorporating bounding box localization information into the classification process.
The classification- and localization-oriented matching cost function considers both the classification confidence scores and IoU scores of the queries to match the prediction and ground truth of each target.
where is the predicted probability of the target category, and the measures the overlap between a predicted box and its corresponding ground truth as a key indicator of localization accuracy. In addition, a relatively large hyperparameter is introduced into the classification- and localization-oriented matching cost function to emphasize the importance of localization precision, thereby encouraging the model to generate more accurate bounding box predictions while reducing the influence of inaccurate predictions. Such a mechanism is particularly beneficial for enhancing overall detection performance, especially in scenarios where high precision is required.
It is important to note that the proposed classification- and localization-oriented matching cost function primarily takes effect during the middle and late stages of training. This is due to the fact that in the early stages, the model’s predictions are typically rough, and the localization accuracy is relatively poor, rendering it unsuitable for incorporating localization information for matching purposes. Introducing the classification- and localization-oriented matching cost function in the middle and late stages can guide the model toward improving localization quality, thereby accelerating convergence toward more accurate predictions.
3. Experiments
3.1. Dataset
Considering the imbalance in object sizes (large, medium, and small) and the insufficient number of categories in public datasets for road garbage detection, a novel road garbage detection dataset was constructed in this study. The dataset is composed of images from multiple public datasets, AI-generated images, and self-collected images, totaling over 60,000 images. The proposed dataset covers a wide range of urban road scenes, including sandy, grassy, and concrete surfaces. It includes various common types of roadside garbage and images captured under different weather conditions, providing a solid foundation for deploying detection models in real-world environments. A large number of images containing small objects and occluded targets were deliberately included in the dataset to address the challenging detection in these circumstances. Each image is accompanied by accurate bounding boxes and corresponding category labels. Furthermore, the dataset follows the standard COCO format, ensuring compatibility with mainstream object detection frameworks. The object sizes within the dataset are shown in Table 2. The sample images of the dataset are illustrated in Figure 10.
Table 2.
Target size statistics of the dataset.

Figure 10.
Image samples of our dataset. The proposed RGD-DETR was evaluated on a self-built road garbage dataset, which is publicly available at https://aistudio.baidu.com/datasetdetail/340081 (accessed on 1 June 2025).
3.2. Parameter Settings
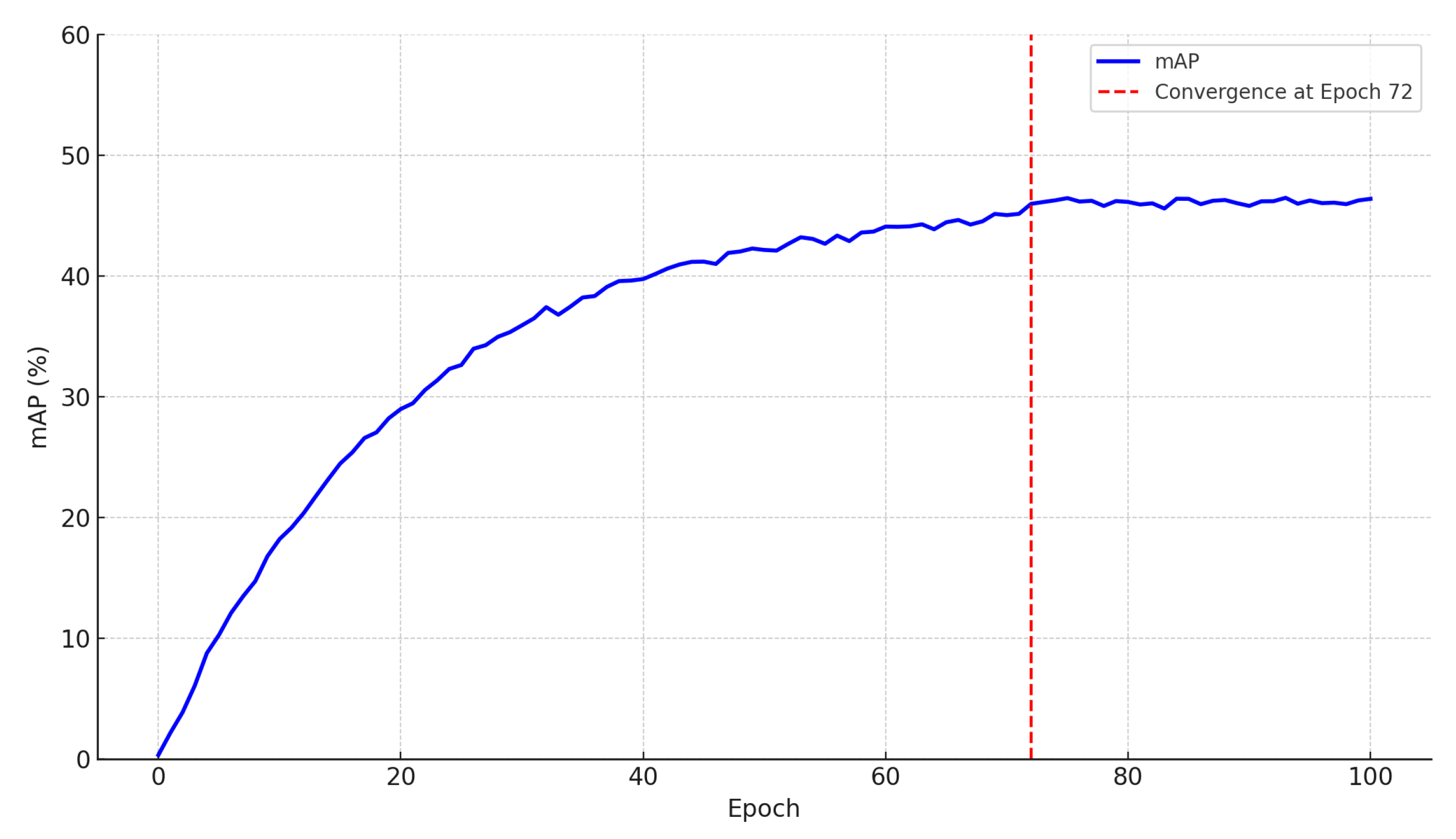
The experiments in this study were conducted on an Ubuntu 18.04 system equipped with four NVIDIA GeForce RTX 4090 Graphics Cards (manufactured by Taiwan Semiconductor Manufacturing Company Limited, Hsinchu, Taiwan). The deep learning framework used is PyTorch (v2.1.0), running on Python v3.8 and accelerated by CUDA v11.2 and cuDNN v8.1.1 libraries to improve computational efficiency. The optimal configuration of our model parameters was initialized before training. Based on empirical principles and prior experience from the related literature [28], we set the key training hyperparameters. Specifically, the learning rate and weight decay were set to 0.0001 to ensure stable convergence while preventing overfitting, which aligns with common practice in Transformer-based detection models. The AdamW optimizer was configured with the parameters [0.9, 0.999], as widely adopted in existing object detection frameworks for maintaining gradient stability. Considering the experimental environment and hardware configuration, the batch size was set to 16 images. Furthermore, the learning curves observed during training (as shown in Figure 11) exhibit smooth convergence around the 72nd epoch with mild oscillations, suggesting that the model is not overly sensitive to moderate changes in these parameters. These findings imply that our model maintains reliable performance across a reasonable hyperparameter range and is robust in the current training scheme and computational setting.
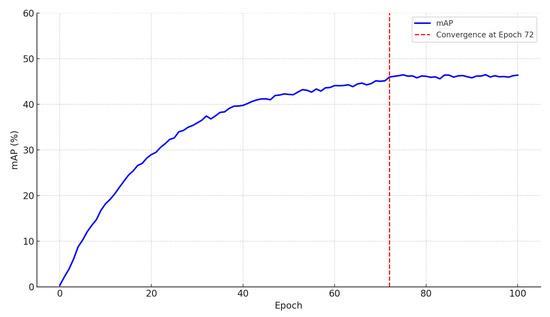
Figure 11.
Training mAP curve across 100 epochs. The model exhibits stable convergence around epoch 72, with only minor fluctuations, indicating the robustness of the chosen hyperparameter settings.
A set of evaluation metrics were employed to assess the model’s performance: mean Average Precision (mAP), mean Average Precision at different target scales (mAPs, mAPm, and mAPl), and mean Average Precision at various IoU thresholds (mAP50 and mAP75). Additionally, the evaluation metrics included Giga-FLOPs (GFLOPs), which corresponds to the computational resource requirements of the model. The total number of model parameters (Params), reflecting the number of parameters that need to be learned in the deep network model, was also considered. To further reflect practical applicability, Frames Per Second (FPS) was included as a measure of inference speed and real-time processing capability.
3.3. Ablation Experiments
To validate the effectiveness of each component of the proposed method, an ablation study was conducted based on the self-built road garbage dataset. The components are as follows: (1) the Improved Feature Pyramid Module (IFPS), (2) the State-space Feature interaction Module (SFIM), (3) the Dynamic Sorting-aware Decoder (DS-Decoder), and (4) the classification- and localization-oriented loss and matching cost (CLOLMC). The experimental results are shown in Table 3.
Table 3.
Ablation study of each component in our method.
Experiment 1 in Table 3 was used as a baseline with a mAP of 44.3% and a small target detection capability (mAPs) of 26.4%. After the introduction of the Improved Feature Pyramid Structure (IFPS) (Experiment 2), the overall mAP of our proposed method increased to 44.7%, and the detection accuracy of targets at all scales (mAPs, mAPm, and mAPl) was improved, especially the ability to detect small targets (mAPs), which proves the effectiveness of the model in representing multi-scale features. With the addition of the State-Spatial Feature Interaction Module (SFIM) (Experiment 3), our proposed method achieved a mAP of 45.5%, mAPs of 28.5%, and mAP75 (average detection accuracy of a high IoU threshold) of 40.0%. These improvements in detection accuracy show the SFIM’s ability to capture relationships between distant pixels in an image. In Experiment 4, the introduction of the Dynamic Sorting-aware Decoder (DS-Decoder) increased the mAP of our proposed method to 45.9%, while also improving the mAP50, mAP75, mAPl, mAPm, and mAPl. Finally, by adding the classification- and localization-oriented loss matching cost (CLOLMC) (Experiment 5), the mAP of our proposed method reached 46.1%, and the mAP75 reached 50.3%. This indicates that the localization performance of our method was improved. In conclusion, the experiment proves the role of the above components in enhancing the detection performance.
The modules are not simply combined. Instead, they mutually promote and synergistically enhance each other. First, the IFPS and the SFIM help each other, enabling the network to accurately capture local details while effectively integrating global information. Next, the DS-Decoder further optimizes the query structure based on this foundation, allowing the model to focus on high-quality queries. Finally, the CLOLMC ensures coordinated improvements in classification and localization performance. It is precisely the close cooperation of these modules at different levels—from feature extraction and prediction decoding to matching and loss design—that empowers the model to achieve stronger detection capabilities in complex scenarios.
3.4. Comparison with the State-of-the-Art Methods
To validate the performance of our proposed RGD-DETR model, we conducted comparative experiments on the self-built road garbage dataset against state-of-the-art methods, including YOLOv5 [37], YOLOv8 [38], DETR [25], Deformable-DETR [7], DAB-DETR [26], Rank-DETR [27], and RT-DETR [28]. During the experiments, the number of training epochs for each model was not predetermined but was dynamically determined based on its actual convergence behavior. Training was terminated once the model’s performance became stable, ensuring that each model achieved its optimal performance. The experimental results are shown in Table 4.
Table 4.
Comparison with the state-of-the-art methods.
Table 4 shows a performance comparison between the proposed RGD-DETR method and current state-of-the-art object detection methods. Compared with the YOLO series, our proposed RGD-DETR shows an advantage in terms of overall detection accuracy. YOLOv5 has a mAP of 42.1%, YOLOv8 improves this value to 45.5%, and RGD-DETR reaches 46.1%, representing improvements of 4.0% and 0.6%, respectively. Regarding the high IoU threshold (mAP75), RGD-DETR reaches 50.3% compared with 49.9% of YOLOv8. In addition, in the case of small object detection (mAPs), RGD-DETR achieves 28.7% compared with 25.3% of YOLOv5 and 28.1% of YOLOv8, with improvements of 3.4% and 0.6%, respectively. Moreover, RGD-DETR has fewer parameters, lower GFLOPs, and faster inference speed. This efficient use of computational resources enables RGD-DETR to maintain high detection performance while offering stronger real-time processing capabilities and reduced hardware demands, demonstrating an excellent balance between performance and efficiency.
Our RGD-DETR also outperforms the original DETR-based methods. The mAP of the original DETR model was only 35.7%, while Deformable-DETR, DAB-DETR, Rank-DETR, and RT-DETR reached 37.9%, 38.7%, 43.5%, and 44.3%, respectively. Compared with RT-DETR, our RGD-DETR increased mAP from 44.3% to 46.1%, mAP75 from 47.8% to 50.3%, and mAPs from 26.4% to 28.7%, increases of 1.8%, 2.5%, and 2.3%, respectively. It can be seen that our RGD-DETR is superior to existing DETR variants, especially for small target detection. Although RGD-DETR has a moderately larger number of parameters (65 M vs. 42 M) compared to RT-DETR, it reduces GFLOPs to 121 G (from RT-DETR’s 136 G) and increases inference speed to 116 FPS, surpassing RT-DETR’s 108 FPS. In practical deployment scenarios, inference speed and detection accuracy are often more critical than a slight increase in model size. Through effective structural optimization and pruning, RGD-DETR achieves a superior balance by delivering faster inference and higher accuracy while maintaining manageable computational complexity, making it well-suited for resource-constrained environments. Overall, our RGD-DETR demonstrates promising experimental results in road garbage detection, showing potential advantages over the compared state-of-the-art methods.
3.5. Visualization
We also qualitatively compared the detection results generated by our proposed RGD-DETR model with those of several state-of-the-art methods, including YOLOv5, YOLOv8, and various DETR variants. As shown in Figure 12, our RGD-DETR consistently shows more accurate localization, fewer missed small targets, and accurate occlusion object detection in road, sand, and grass scenes, respectively.

Figure 12.
Visualization comparison of the detection results with state-of-the-art methods. The figure shows the detection results of garbage targets, where “bag1” represents a plastic bag, and “bag2” represents a garbage bag.
In the case of the YOLO series, as can be seen from Figure 12, YOLOv5 exhibits a number of missed detections in all four columns, especially small and occluded targets. Even though YOLOv8 captured more junk items, it failed to detect small cigarette butts in the first column and incorrectly classified partially clogged cups as cans in the second column. Also, YOLOv8 incurred obvious positioning errors in the third column and ignored clogged plastic bags in the fourth column.
Similarly, the DETR series also exhibits detection errors. The DETR model and the Deformable-DETR model produced missed detections. The DAB-DETR also incorrectly detected the can at the bottom of the first column as a battery and the occluded bottle in the fourth column as a can. Although Rank-DETR exhibits strong localizability for garbage objects, it still exhibits missed detections in each column of images. The RT-DETR model, which had the best detection performance, also erroneously detected small targets, i.e., cigarette butts and the pericarp in the first column. The cans and clothes in the second and third columns were also missed. In the occlusion scene, the plastic bag in the fourth column was missed by the RT-DETR model.
In contrast, our proposed RGD-DETR model achieves better detection performance. It can accurately detect small-scale targets and occluded targets, showing accurate localization capacity. This is due to the incorporation of the channel attention mechanism, the state-space model, the Dynamic Sorting-aware Decoder, and the classification and positioning-oriented losses and matching costs. The experimental results prove that our proposed model has better detection performance for small targets and occluded targets compared with state-of-the-art methods.
4. Conclusions
This paper proposes the RGD-DETR model to address the challenges in road garbage detection, such as small object detection and occlusion. An Improved Feature Pyramid Structure is designed for efficient multi-scale feature fusion, and a state-space feature interaction module is introduced to enhance global representation. To address the mismatch between classification confidence and localization quality in RT-DETR, a Dynamic Sorting-aware Decoder incorporating dynamic scoring and query sorting for better query selection is proposed. Additionally, the classification- and localization-oriented loss and matching cost are adopted to improve bounding box accuracy. The experimental results show that our RGD-DETR achieves a mAP of 46.1%, mAP75 of 50.3%, and mAPs of 28.7% on the road garbage dataset. Moreover, our RGD-DETR reduces GFLOPs while delivering faster inference speed.
Although the performance of the presented model is optimized, there is still room to improve computational efficiency, especially for mobile and real-time detection. RT-DETR uses deformable attention, which introduces extra overhead due to offset computation, limiting deployment on resource-constrained devices. In contrast, RT-DETRv2 adopts fixed sampling points, reducing complexity and improving inference speed. Future work should focus on further streamlining computation based on RT-DETRv2 to enhance real-time deployment on edge devices. In future work, we will conduct comprehensive comparisons between the proposed RGD-DETR model and state-of-the-art object detection models, such as YOLOv10, RT-DETRv2, Sparse R-CNN, and DINO. By performing systematic experiments across multiple benchmark datasets and evaluation metrics, we aim to thoroughly analyze the performance of each model in terms of detection accuracy, computational efficiency, and robustness, thereby further validating the adaptability and effectiveness of RGD-DETR in complex real-world scenarios.
Author Contributions
Conceptualization, Y.S.; Methodology, Y.S., Z.L. and M.C.; Software, Z.L.; Validation, Z.L., Q.S., G.Y. and C.X.; Formal Analysis, G.Y., C.X. and Y.S.; Investigation, C.X., M.C. and Y.S.; Resources, G.Y., C.X., Y.S. and M.C.; Data Curation, Z.L. and Q.S.; Writing—Original Draft Preparation, Z.L.; Writing—Review and Editing, Z.L., M.C., G.Y., Q.S. and Y.S.; Visualization, Z.L. and Y.S.; Supervision, M.C., Q.S., G.Y., C.X. and Y.S.; Project Administration, G.Y., C.X., M.C. and Y.S.; Funding Acquisition, M.C. and Y.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the National Natural Science Foundation of China (Grant No. 61671255 and No. 62201295), Nantong Social Livelihood Science and Technology Plan (Grant No. MS2024025), Jiangsu Province’s “Qinglan Project” for Middle-Aged and Young Academic Leaders (2023), and the Postgraduate Research & Practice Innovation Program of Jiangsu Province (Grant No. SJCX24_2015).
Data Availability Statement
Data are contained within the article.
Acknowledgments
This paper and research would not have been possible without the support of the Transportation Safety and Intelligence Analysis Team from Nan Tong University.
Conflicts of Interest
Author Changyong Xu was employed by the company Nantong Zhixingweilai Vehicle to Everything Innovation Center Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Zhao, X.; Zhu, J. Industrial Restructuring, Energy Consumption and Economic Growth: Evidence from China. J. Clean. Prod. 2022, 335, 130242. [Google Scholar]
- Kruse, H.; Mensah, E.; Sen, K.; De Vries, G. A Manufacturing (Re)naissance? Industrialization in the Developing World. IMF Econ. Rev. 2022, 71, 439–473. [Google Scholar] [CrossRef]
- Wang, H.; Lei, Y.; Wang, H.; Liu, M.; Yang, J.; Bi, J. Carbon reduction potentials of China’s industrial parks: A case study of Suzhou Industry Park. Energy 2013, 55, 668–675. [Google Scholar] [CrossRef]
- Abdu-Raheem, Y.A.; Oyebamiji, A.O.; Afolagboye, L.O.; Talabi, A.O. Assessment of ecological and health risk impact of heavy metals contamination in stream sediments in Itapaji-Ekiti, SW Nigeria. J. Trace Elem. Miner. 2024, 8, 100121. [Google Scholar] [CrossRef]
- Ramalingam, B.; Hayat, A.A.; Elara, M.R.; Félix Gómez, B.; Yi, L.; Pathmakumar, T.; Rayguru, M.M.; Subramanian, S. Deep learning based pavement inspection using self-reconfigurable robot. Sensors 2021, 21, 2595. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Wu, Y.Z.; Shen, X.H.; Liu, Q.; Xiao, F.; Li, C. A garbage detection and classification method based on visual scene understanding in the home environment. Complexity 2021, 2021, 1055604. [Google Scholar] [CrossRef]
- Liu, B.; Wang, X. Garbage detection algorithm based on YOLO v3. In Proceedings of the 2022 IEEE International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 25–27 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 784–788. [Google Scholar]
- Jiang, X.; Hu, H.; Qin, Y.; Hu, Y.; Ding, R. A real-time rural domestic garbage detection algorithm with an improved YOLOv5s network model. Sci. Rep. 2022, 12, 16802. [Google Scholar] [CrossRef]
- Guo, D.; Cheng, L.; Zhang, M.; Sun, Y. Garbage detection and classification based on improved YOLOv4. J. Phys. Conf. Ser. 2021, 2024, 012–023. [Google Scholar] [CrossRef]
- Zhao, L.; Pan, Y.L.; Wang, S.; Abbas, Z.; Islam, M.S.; Yin, S. Skip-YOLO: Domestic garbage detection using deep learning method in complex multi-scenes. Int. J. Comput. Intell. Syst. 2023, 16, 139–155. [Google Scholar]
- Tang, H.; Li, Z.; Zhang, D.; He, S.; Tang, J. Divide-and-Conquer: Confluent Triple-Flow Network for RGB-T Salient Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 1958–1974. [Google Scholar] [CrossRef] [PubMed]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized Feature Pyramid for Object Detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. DN-DETR: Accelerate DETR training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 13619–13627. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional DETR for Fast Training Convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3651–3660. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning What You Want to Learn Using Programmable Gradient Information. Eur. Conf. Comput. Vis. 2024, 1, 1–21. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. 2021, 1, 14454–14463. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Qin, H.; Shu, L.; Zhou, L.; Deng, S.; Xiao, H.; Sun, W.; Liang, Q.; Zhang, D.; Wang, Y. Active Learning-DETR: Cost-effective object detection for kitchen waste. IEEE Trans. Instrum. Meas. 2024, 73, 99–114. [Google Scholar] [CrossRef]
- Zhao, W.; Zhang, L.; Kan, X.; Zheng, H. Outdoor garbage detection and recognition based on dual-branch network. Electron. Sci. Technol. 2025, 5, 1–11. [Google Scholar]
- Sun, Q.H.; Zhang, X.T.; Li, Y.J.; Wang, J. YOLOv5-OCDS: An improved garbage detection model based on YOLOv5. Electronics 2023, 12, 3403. [Google Scholar] [CrossRef]
- Tan, L.; Wu, H.; Xu, Z.; Xia, J. Multi-object garbage image detection algorithm based on SP-SSD. Expert Syst. Appl. 2025, 263, 125773–125785. [Google Scholar] [CrossRef]
- Sun, S.; He, L.; Zheng, S.; Xu, X.; Chen, R. YOLOv8n lightweight improvement for garbage detection in complex background environments. J. Electron. Meas. Instrum. 2025, 4, 1–12. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Springer International Publishing: New York, NY, USA, 2020; pp. 213–229. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. DAB-DETR: Dynamic anchor boxes are better queries for DETR. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- Pu, Y.; Liang, W.; Hao, Y.; Yuan, Y.; Yang, Y.; Zhang, C.; Hu, H.; Huang, G. Rank-DETR for high quality object detection. Adv. Neural Inf. Process. Syst. 2023, 36, 16100–16113. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 7132–7141. [Google Scholar]
- Liu, X.; Zhang, C.; Zhang, L. Vision Mamba: A Comprehensive Survey and Taxonomy. arXiv 2024, arXiv:2405.04404. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. VMamba: Visual State Space Model. Adv. Neural Inf. Process. Syst. 2024, 37, 103031–103063. [Google Scholar]
- He, H.; Yuan, Y.; Yue, X.; Hu, H. RankSeg: Adaptive Pixel Classification with Image Category Ranking for Segmentation. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 682–700. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. VarifocalNet: An IoU-ware Dense Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8510–8519. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Ingham, F.; Poznanski, J.; Fang, J.; Yu, L.; et al. Ultralytics/YOLOv5: v3.1-Bug Fixes and Performance Improvements; Zenodo: Geneva, Switzerland, 2020. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Rami Reddy, C.V. A Review on YOLOv8 and Its Advancements. In Proceedings of the 5th International Conference on Data Intelligence and Cognitive Informatics (ICDICI), Singapore, 18–20 November 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 529–545. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).