
Resilient Predefined-Time Flocking of Networked Agent Systems Against False Data Injection Attacks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
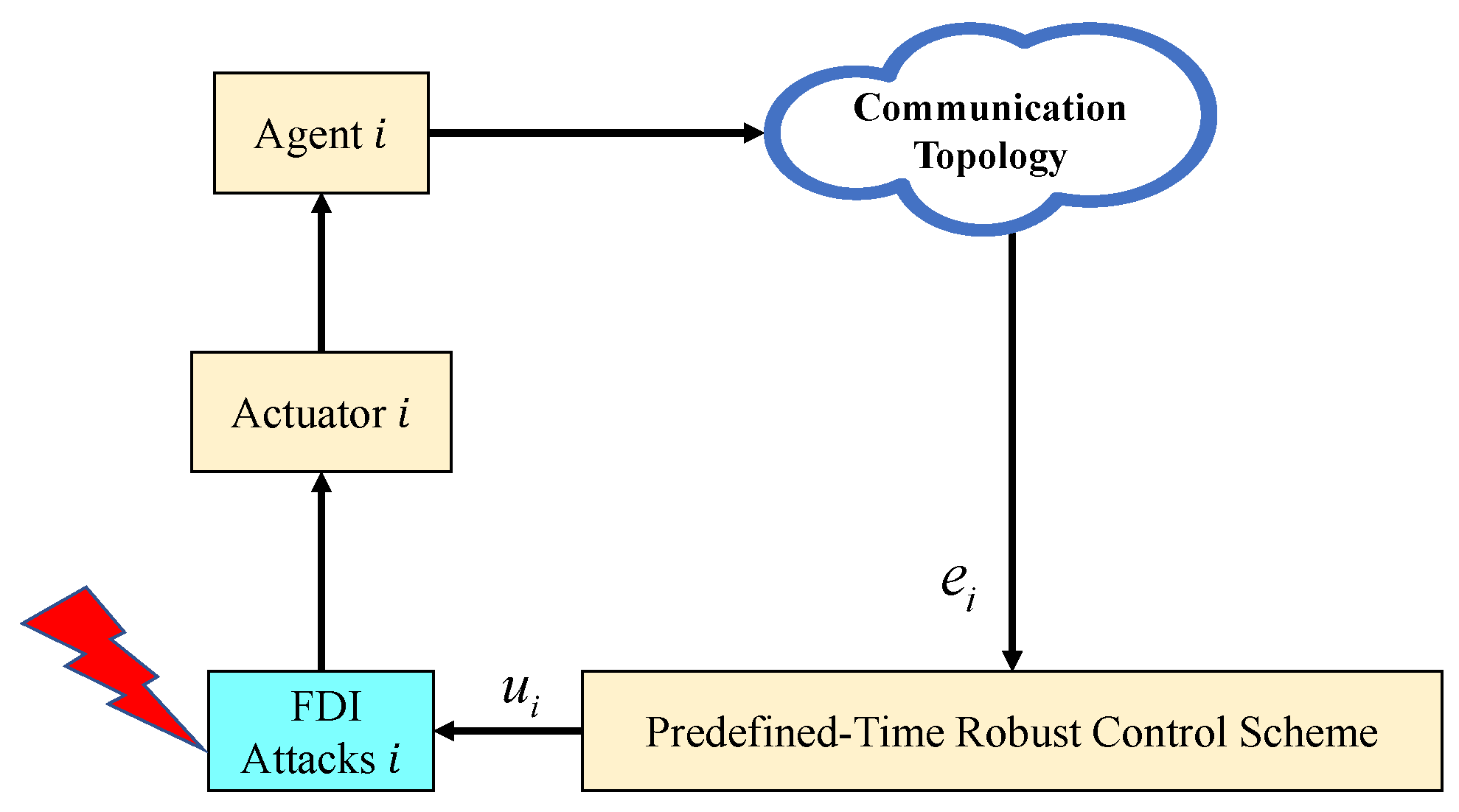
1. Introduction
1.1. Background
1.2. Related Works
1.3. Motivations
1.4. Contributions
- (1)
- A predefined-time control scheme is constructed to ensure that the flocking behavior is achieved within an arbitrarily prescribed time interval, regardless of the initial conditions and control parameter selections. This property distinguishes the proposed approach from conventional finite-time and fixed-time flocking strategies [41,43,52], whose convergence time is typically influenced by system-dependent factors. The ability to explicitly specify the settling time makes the proposed method particularly suitable for time-critical coordination tasks.
- (2)
- A robust quasi-flocking control strategy is developed for networked agent systems subject to FDI attacks, where RBF neural networks are introduced to approximate and compensate for unknown nonlinear disturbances induced by the attacks. An adaptive weight update law is designed in conjunction with the predefined-time stability framework to enable real-time suppression of adversarial influences. In contrast to existing methods such as [53], which do not consider the impact of FDI attacks, the proposed scheme explicitly accounts for adversarial disturbances and thereby substantially enhances the robustness of the controller.
1.5. Organization
2. Preliminaries
2.1. Notations
2.2. Graph Theory
2.3. Predefined-Time Stability
- (1)
- , where ;
- (2)
- .
2.4. RBF Neural Network
3. Problem Formulation
- (1)
- Velocity Alignment: The velocity of each agent converges to a common value within a predefined time T, i.e., for all ,where denotes the initial time.
- (2)
- Cohesion: There exists a constant such that the group’s spatial spread remains uniformly bounded:
- (3)
- Collision Avoidance: A constant exists such that the minimum inter-agent distance remains strictly positive:
4. Flocking Controller Design and Stability Analysis
4.1. Predefined-Time Flocking Controller Design
4.2. Stability Analysis: Velocity Alignment
4.3. Stability Analysis: Cohesion
4.4. Stability Analysis: Collision Avoidance
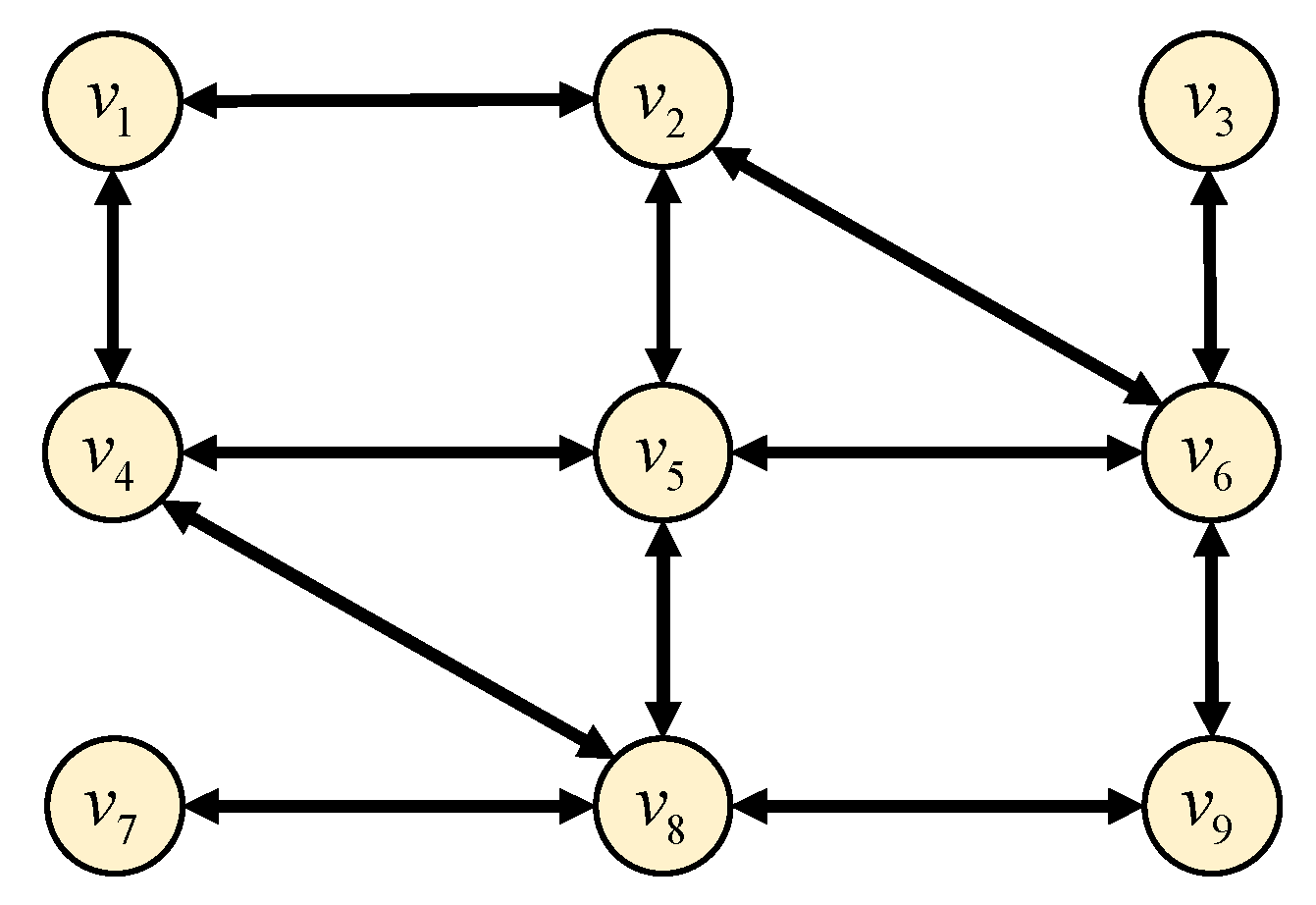
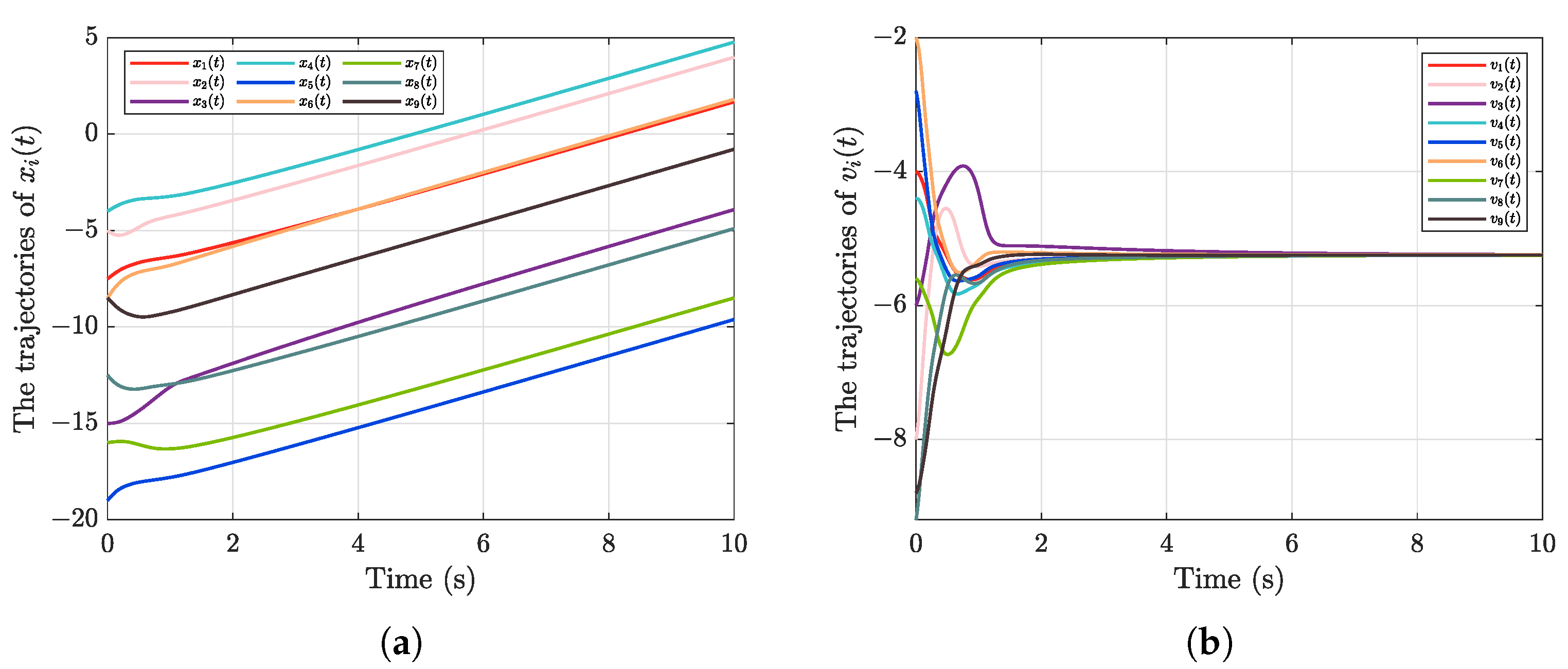
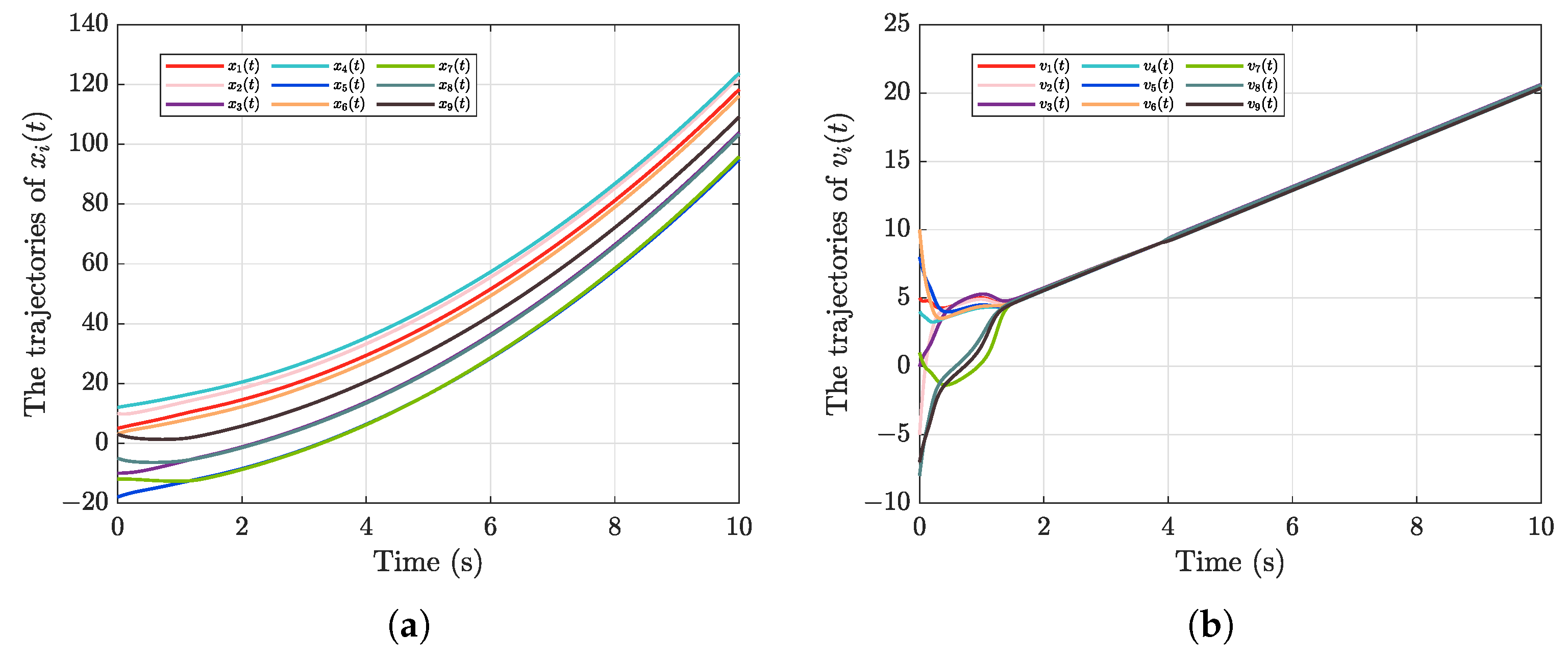
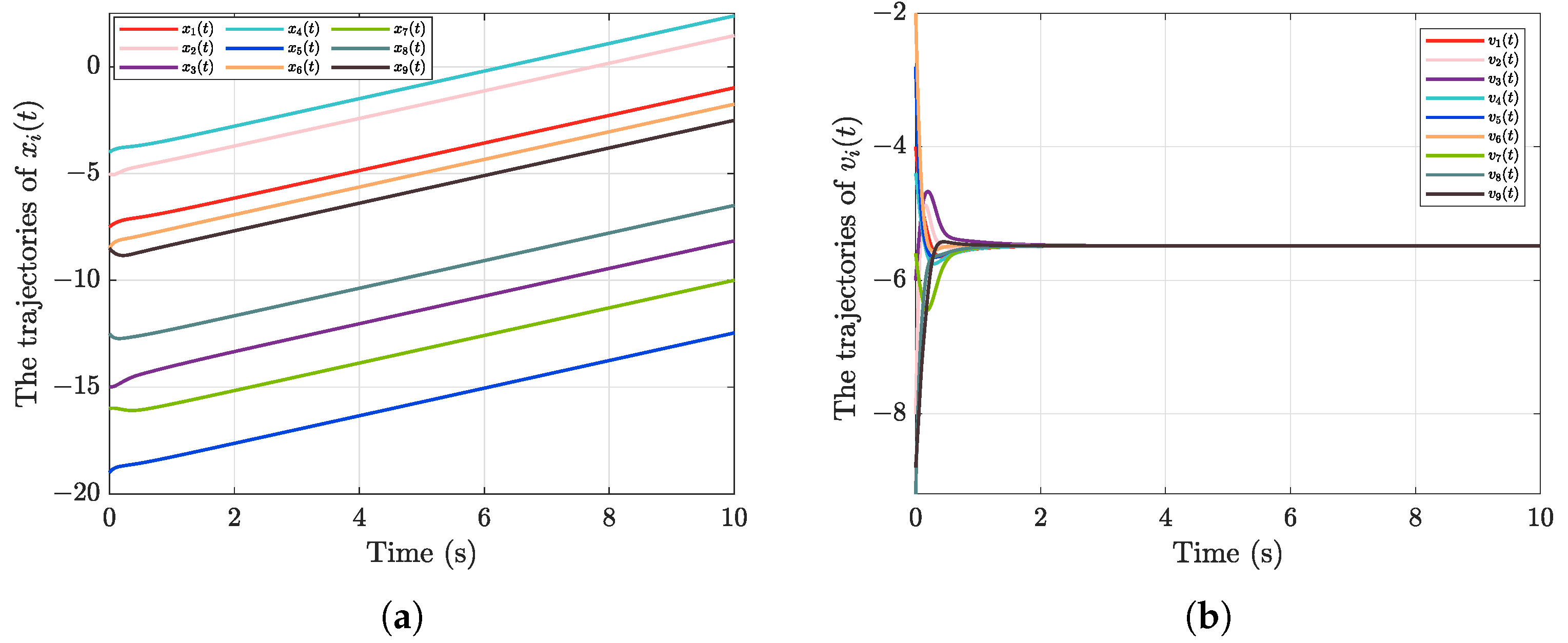
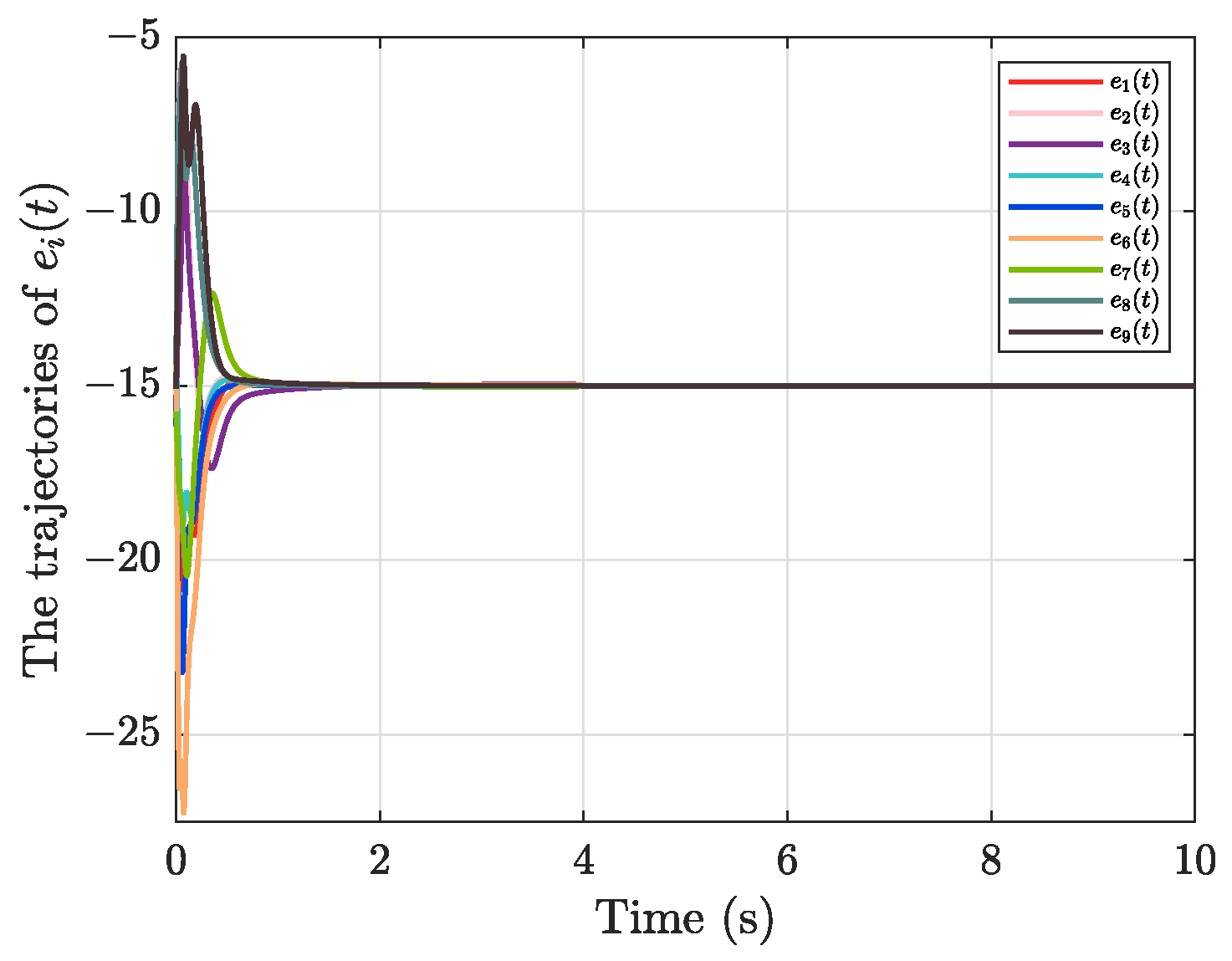
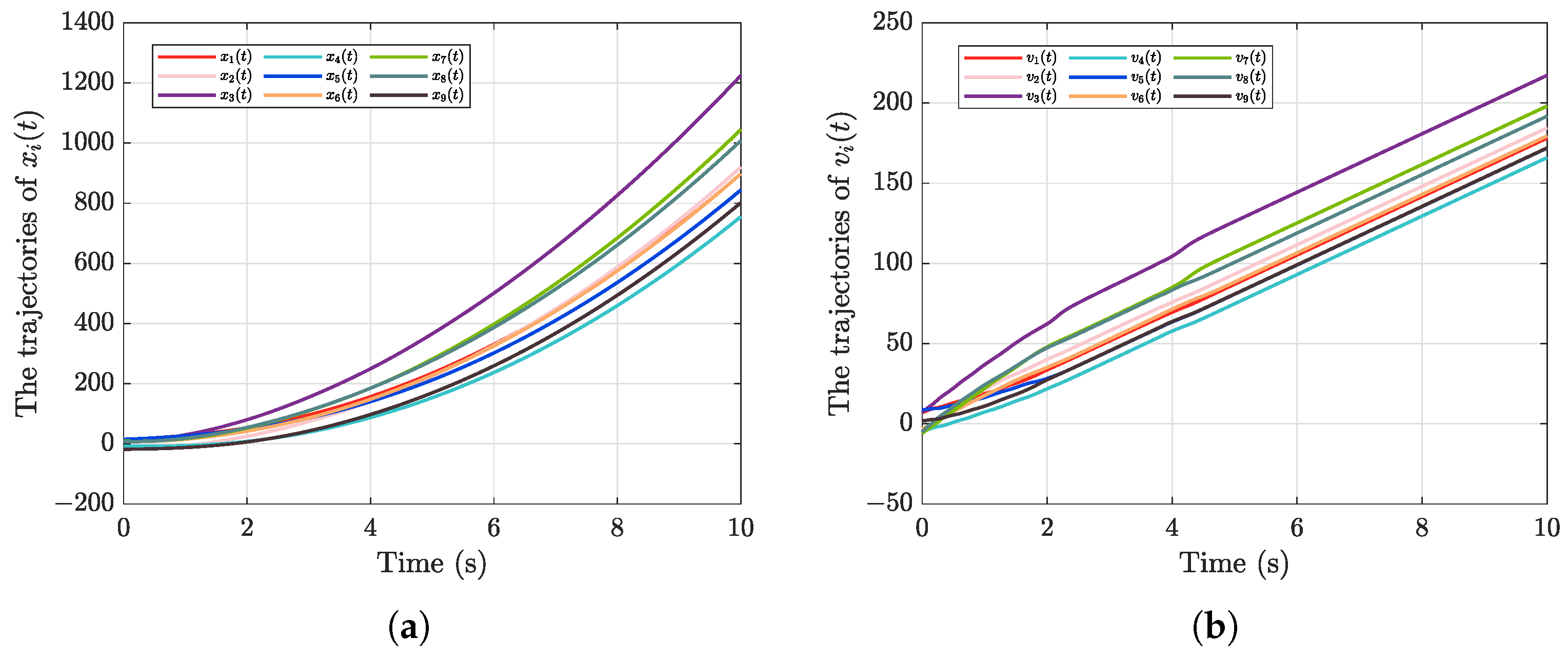
5. Numerical Simulation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, Z.; Li, B.; Shi, L.; Cheng, Y.; Shao, J. Broadcasting-based Cucker–Smale flocking control for multi-agent systems. Neurocomputing 2024, 573, 127266. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y.; Wu, Y.; Liu, Z.; Chen, K.; Chen, C.P. Fixed-time formation control for uncertain nonlinear multi-agent systems with time-varying actuator failures. IEEE Trans. Fuzzy Syst. 2024, 32, 1965–1977. [Google Scholar] [CrossRef]
- Wang, Y.; Han, L.; Li, X.; Ren, Z. Time-varying formation tracking for multi-agent systems with maneuvering leader under DDoS attacks and actuator faults. ISA Trans. 2024, 144, 38–50. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Peng, L.; Xie, L.; Yu, H. Dynamic event-triggered sliding-mode bipartite consensus for multi-agent systems with unknown dynamics. IEEE Trans. Autom. Sci. Eng. 2024, 22, 7170–7180. [Google Scholar] [CrossRef]
- Yang, S.; Liang, H.; Pan, Y.; Li, T. Security control for air-sea heterogeneous multiagent systems with cooperative-antagonistic interactions: An intermittent privacy preservation mechanism. Sci. China Technol. Sci. 2025, 68, 1420402. [Google Scholar] [CrossRef]
- Guo, S.; Pan, Y.; Li, H.; Cao, L. Dynamic event-driven ADP for N-player nonzero-sum games of constrained nonlinear systems. IEEE Trans. Autom. Sci. Eng. 2025, 22, 7657–7669. [Google Scholar] [CrossRef]
- Wang, X.; Pang, N.; Xu, Y.; Huang, T.; Kurths, J. On state-constrained containment control for nonlinear multiagent systems using event-triggered input. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 2530–2538. [Google Scholar] [CrossRef]
- Wang, Z.; Mu, C.; Hu, S.; Chu, C.; Li, X. Modelling the Dynamics of Regret Minimization in Large Agent Populations: A Master Equation Approach. In Proceedings of the IJCAI, Vienna, Austria, 23–29 July 2022; pp. 534–540. [Google Scholar]
- Li, C.; Yang, Y.; Huang, T.Y.; Chen, X.B. An improved flocking control algorithm to solve the effect of individual communication barriers on flocking cohesion in multi-agent systems. Eng. Appl. Artif. Intell. 2024, 137, 109110. [Google Scholar] [CrossRef]
- Liang, Z.; Liu, X. Hybrid event-triggered impulsive flocking control for multi-agent systems via pinning mechanism. Appl. Math. Model. 2023, 114, 23–43. [Google Scholar] [CrossRef]
- Pei, H.; Hu, X.; Luo, Z. Multi-agent flocking control with complex obstacles and adaptive distributed convex optimization. J. Frankl. Inst. 2024, 361, 107181. [Google Scholar] [CrossRef]
- Dey, S.; Xu, H. Distributed Adaptive Flocking Control for Large-Scale Multiagent Systems. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 3126–3135. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Sun, J.; Wang, G.; Allgöwer, F.; Chen, J. Data-driven control of distributed event-triggered network systems. IEEE/CAA J. Autom. Sin. 2023, 10, 351–364. [Google Scholar] [CrossRef]
- Hung, S.M.; Givigi, S.N. A Q-learning approach to flocking with UAVs in a stochastic environment. IEEE Trans. Cybern. 2016, 47, 186–197. [Google Scholar] [CrossRef] [PubMed]
- Reynolds, C.W. Flocks, herds and schools: A distributed behavioral model. In Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques, Anaheim, CA, USA, 27–31 July 1987; pp. 25–34. [Google Scholar]
- Olfati-Saber, R. Flocking for multi-agent dynamic systems: Algorithms and theory. IEEE Trans. Autom. Control 2006, 51, 401–420. [Google Scholar] [CrossRef]
- Chen, J.; Yang, Y.; Qin, S. A distributed optimization algorithm for fixed-time flocking of second-order multiagent systems. IEEE Trans. Netw. Sci. Eng. 2024, 11, 152–162. [Google Scholar] [CrossRef]
- Semnani, S.H.; Basir, O.A. Semi-flocking algorithm for motion control of mobile sensors in large-scale surveillance systems. IEEE Trans. Cybern. 2014, 45, 129–137. [Google Scholar] [CrossRef]
- Wang, G.G.; Wei, C.L.; Wang, Y.; Pedrycz, W. Improving distributed anti-flocking algorithm for dynamic coverage of mobile wireless networks with obstacle avoidance. Knowl.-Based Syst. 2021, 225, 107133. [Google Scholar] [CrossRef]
- Beaver, L.E.; Malikopoulos, A.A. An overview on optimal flocking. Annu. Rev. Control 2021, 51, 88–99. [Google Scholar] [CrossRef]
- Wang, H.; Xu, K.; Qiu, J. Event-triggered adaptive fuzzy fixed-time tracking control for a class of nonstrict-feedback nonlinear systems. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 3058–3068. [Google Scholar] [CrossRef]
- Chen, H.; Zong, G.; Shen, M.; Gao, F. Finite-Time Resilient Control of Networked Markov Switched Nonlinear Systems: A Relaxed Design. IEEE Trans. Syst. Man Cybern. Syst. 2025, 55, 2569–2579. [Google Scholar] [CrossRef]
- Lu, J.; Qin, K.; Li, M.; Lin, B.; Shi, M. Robust finite/fixed-time bipartite flocking control for networked agents under actuator attacks and perturbations. Chaos Solitons Fractals 2024, 180, 114556. [Google Scholar] [CrossRef]
- Shi, L.; Cheng, Y.; Shao, J.; Sheng, H.; Liu, Q. Cucker-Smale flocking over cooperation-competition networks. Automatica 2022, 135, 109988. [Google Scholar] [CrossRef]
- Shi, X.; Shi, L.; Zhou, Q.; Chen, K.; Cheng, Y. Bipartite flocking for Cucker-Smale model on cooperation-competition networks subject to denial-of-service attacks. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 69, 3379–3390. [Google Scholar] [CrossRef]
- Chen, K.; Ma, Z.; Bai, L.; Sheng, H.; Cheng, Y. Emergence of bipartite flocking behavior for Cucker-Smale model on cooperation-competition networks with time-varying delays. Neurocomputing 2022, 507, 325–331. [Google Scholar] [CrossRef]
- Fan, M.C.; Zhang, H.T.; Wang, M. Bipartite flocking for multi-agent systems. Commun. Nonlinear Sci. Numer. Simul. 2014, 19, 3313–3322. [Google Scholar] [CrossRef]
- Ahn, H. Finite-time flocking of uncountable agents. Chaos, Solitons Fractals 2024, 185, 115107. [Google Scholar] [CrossRef]
- Guo, W.; Shi, L.; Sun, W.; Jahanshahi, H. Predefined-time average consensus control for heterogeneous nonlinear multi-agent systems. IEEE Trans. Circuits Syst. II: Express Briefs 2023, 70, 2989–2993. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, Z.; Liang, H.; Ahn, C.K. Neural-network-based predefined-time adaptive consensus in nonlinear multi-agent systems with switching topologies. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 9995–10005. [Google Scholar] [CrossRef]
- Chen, X.; Sun, Q.; Yu, H.; Hao, F. Predefined-time practical consensus for multi-agent systems via event-triggered control. J. Frankl. Inst. 2023, 360, 2116–2132. [Google Scholar] [CrossRef]
- Yang, T.; Dong, J. Practically predefined-time leader-following funnel control for nonlinear multi-agent systems with fuzzy dead-zone. IEEE Trans. Autom. Sci. Eng. 2024, 21, 3886–3895. [Google Scholar] [CrossRef]
- Liu, Y.; Xia, Z.; Gui, W. Multiobjective Distributed Optimization via a Predefined-Time Multiagent Approach. IEEE Trans. Autom. Control 2023, 68, 6998–7005. [Google Scholar] [CrossRef]
- Pan, Y.; Chen, Y.; Liang, H. Event-triggered predefined-time control for full-state constrained nonlinear systems: A novel command filtering error compensation method. Sci. China Technol. Sci. 2024, 67, 2867–2880. [Google Scholar] [CrossRef]
- Li, K.; Hu, Q.; Liu, Q.; Zeng, Z.; Cheng, F. A predefined-time consensus algorithm of multi-agent system for distributed constrained optimization. IEEE Trans. Netw. Sci. Eng. 2024, 11, 957–968. [Google Scholar] [CrossRef]
- Ni, J.; Liu, L.; Tang, Y.; Liu, C. Predefined-time consensus tracking of second-order multiagent systems. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 2550–2560. [Google Scholar] [CrossRef]
- Jiang, J.; Chi, J.; Wu, X.; Wang, H.; Jin, X. Adaptive predefined-time consensus control for disturbed multi-agent systems. J. Frankl. Inst. 2024, 361, 110–124. [Google Scholar] [CrossRef]
- Zhang, J.; Fu, Y.; Fu, J. Optimal Formation Control of Second-Order Heterogeneous Multi-Agent Systems Using Adaptive Predefined-Time Strategy. IEEE Trans. Fuzzy Syst. 2024, 32, 2390–2402. [Google Scholar] [CrossRef]
- Ren, D.; Liu, Y.J.; Lan, J. Event-Based Predefined-Time Fuzzy Formation Control for Nonlinear Multi-Agent Systems with Unknown Disturbances. IEEE Trans. Fuzzy Syst. 2024, 32, 3497–3507. [Google Scholar] [CrossRef]
- Pan, Y.; Ji, W.; Lam, H.K.; Cao, L. An improved predefined-time adaptive neural control approach for nonlinear multiagent systems. IEEE Trans. Autom. Sci. Eng. 2024, 21, 6311–6320. [Google Scholar] [CrossRef]
- Xiao, Q.; Liu, H.; Wang, X.; Huang, Y. A note on the fixed-time bipartite flocking for nonlinear multi-agent systems. Appl. Math. Lett. 2020, 99, 105973. [Google Scholar] [CrossRef]
- Yu, J.; Yu, S. An improved fixed-time bipartite flocking protocol for nonlinear multi-agent systems. Int. J. Control 2022, 95, 900–905. [Google Scholar] [CrossRef]
- Liu, H.; Wang, X.; Huang, Y.; Liu, Y. A new class of fixed-time bipartite flocking protocols for multi-agent systems. Appl. Math. Model. 2020, 84, 501–521. [Google Scholar] [CrossRef]
- Yang, Y.; Qian, Y.; Yue, W. A secure dynamic event-triggered mechanism for resilient control of multi-agent systems under sensor and actuator attacks. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 69, 1360–1371. [Google Scholar] [CrossRef]
- Chen, H.; Zong, G.; Liu, X.; Zhao, X.; Niu, B.; Gao, F. A sub-domain-awareness adaptive probabilistic event-triggered policy for attack-compensated output control of Markov jump CPSs with dynamically matching modes. IEEE Trans. Autom. Sci. Eng. 2024, 21, 4419–4431. [Google Scholar] [CrossRef]
- Xia, W.; Xiao, Q.; Luo, Z. Fixed-time consensus and finite-time flocking of second-order nonlinear multi-agent systems under false data injection attacks. Int. J. Control 2024, 1–10. [Google Scholar] [CrossRef]
- Zhang, H.; Gu, M.; Jiang, X.; Thompson, J.; Cai, H.; Paesani, S.; Santagati, R.; Laing, A.; Zhang, Y.; Yung, M.H.; et al. An optical neural chip for implementing complex-valued neural network. Nat. Commun. 2021, 12, 457. [Google Scholar] [CrossRef]
- Lin, H.; Wang, C.; Deng, Q.; Xu, C.; Deng, Z.; Zhou, C. Review on chaotic dynamics of memristive neuron and neural network. Nonlinear Dyn. 2021, 106, 959–973. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A survey of uncertainty in deep neural networks. Artif. Intell. Rev. 2023, 56, 1513–1589. [Google Scholar] [CrossRef]
- Wang, Y.; Song, Q.; Liu, Y. Synchronisation of quaternion-valued neural networks with neutral delay and discrete delay via aperiodic intermittent control. Int. J. Syst. Sci. 2025, 56, 1395–1412. [Google Scholar] [CrossRef]
- Zhang, Q.; Hao, Y.; Yang, Z.; Chen, Z. Adaptive flocking of heterogeneous multi-agents systems with nonlinear dynamics. Neurocomputing 2016, 216, 72–77. [Google Scholar] [CrossRef]
- Li, P.; Xu, S.; Chen, W.; Wei, Y.; Zhang, Z. Adaptive finite-time flocking for uncertain nonlinear multi-agent systems with connectivity preservation. Neurocomputing 2018, 275, 1903–1910. [Google Scholar] [CrossRef]
- Cheng, X.; Yu, J.; Chen, X.; Yu, J.; Cheng, B. Preassigned-Time Bipartite Flocking Consensus Problem in Multi-Agent Systems. Symmetry 2023, 15, 1105. [Google Scholar] [CrossRef]
- Song, Y.; Wang, Y.; Holloway, J.; Krstic, M. Time-varying feedback for regulation of normal-form nonlinear systems in prescribed finite time. Automatica 2017, 83, 243–251. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, C.; Shang, Y. Prescribed-time adaptive neural feedback control for a class of nonlinear systems. Neurocomputing 2022, 511, 155–162. [Google Scholar] [CrossRef]
- Wu, C.W. Synchronization in Complex Networks of Nonlinear Dynamical Systems; World Scientific: Singapore, 2007. [Google Scholar]
- Qian, C.; Lin, W. A continuous feedback approach to global strong stabilization of nonlinear systems. IEEE Trans. Autom. Control 2001, 46, 1061–1079. [Google Scholar] [CrossRef]
- Zhang, X.; Zheng, S.; Ahn, C.K.; Xie, Y. Adaptive neural consensus for fractional-order multi-agent systems with faults and delays. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7873–7886. [Google Scholar] [CrossRef]
- Meng, M.; Xiao, G.; Li, B. Adaptive consensus for heterogeneous multi-agent systems under sensor and actuator attacks. Automatica 2020, 122, 109242. [Google Scholar] [CrossRef]
- Ma, L.; Zhu, F.; Zhang, J.; Zhao, X. Leader–follower asymptotic consensus control of multiagent systems: An observer-based disturbance reconstruction approach. IEEE Trans. Cybern. 2021, 53, 1311–1323. [Google Scholar] [CrossRef]
- Wei, H.; Chen, X.B. Flocking for multiple subgroups of multi-agents with different social distancing. IEEE Access 2020, 8, 164705–164716. [Google Scholar] [CrossRef]
- Liu, H.; Wang, X.; Li, X.; Liu, Y. Finite-time flocking and collision avoidance for second-order multi-agent systems. Int. J. Syst. Sci. 2020, 51, 102–115. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, B.; Li, M.; Liu, Y.; Li, Z.; Qin, K.; Shi, M. Resilient Predefined-Time Flocking of Networked Agent Systems Against False Data Injection Attacks. Electronics 2025, 14, 2282. https://doi.org/10.3390/electronics14112282
Lin B, Li M, Liu Y, Li Z, Qin K, Shi M. Resilient Predefined-Time Flocking of Networked Agent Systems Against False Data Injection Attacks. Electronics. 2025; 14(11):2282. https://doi.org/10.3390/electronics14112282
Chicago/Turabian StyleLin, Boxian, Meng Li, Yiru Liu, Zhiqiang Li, Kaiyu Qin, and Mengji Shi. 2025. "Resilient Predefined-Time Flocking of Networked Agent Systems Against False Data Injection Attacks" Electronics 14, no. 11: 2282. https://doi.org/10.3390/electronics14112282
APA StyleLin, B., Li, M., Liu, Y., Li, Z., Qin, K., & Shi, M. (2025). Resilient Predefined-Time Flocking of Networked Agent Systems Against False Data Injection Attacks. Electronics, 14(11), 2282. https://doi.org/10.3390/electronics14112282