
Adaptive Control Strategy for the PI Parameters of Modular Multilevel Converters Based on Dual-Agent Deep Reinforcement Learning



Abstract
1. Introduction
2. Topology and Control Principles of MMCs
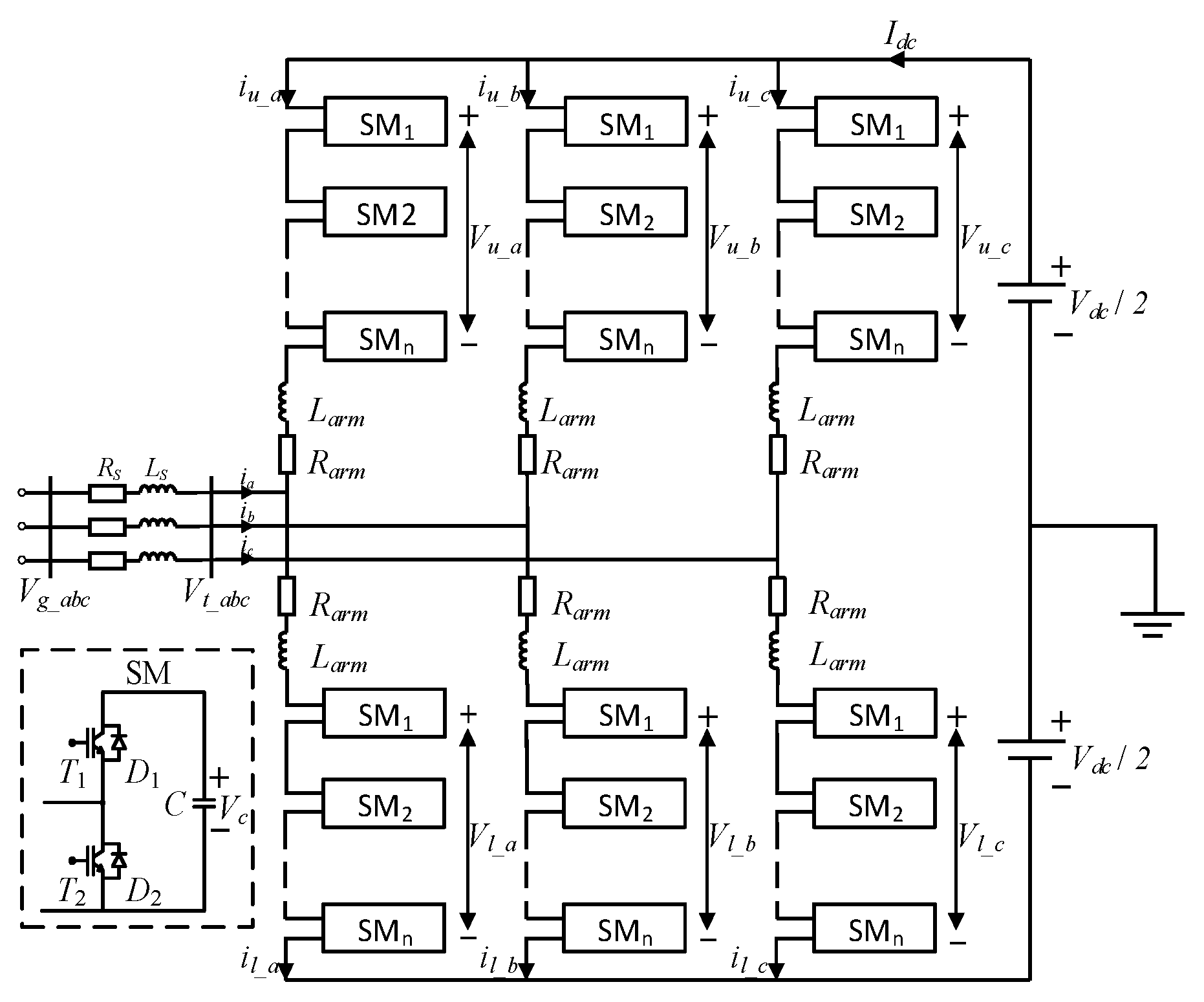
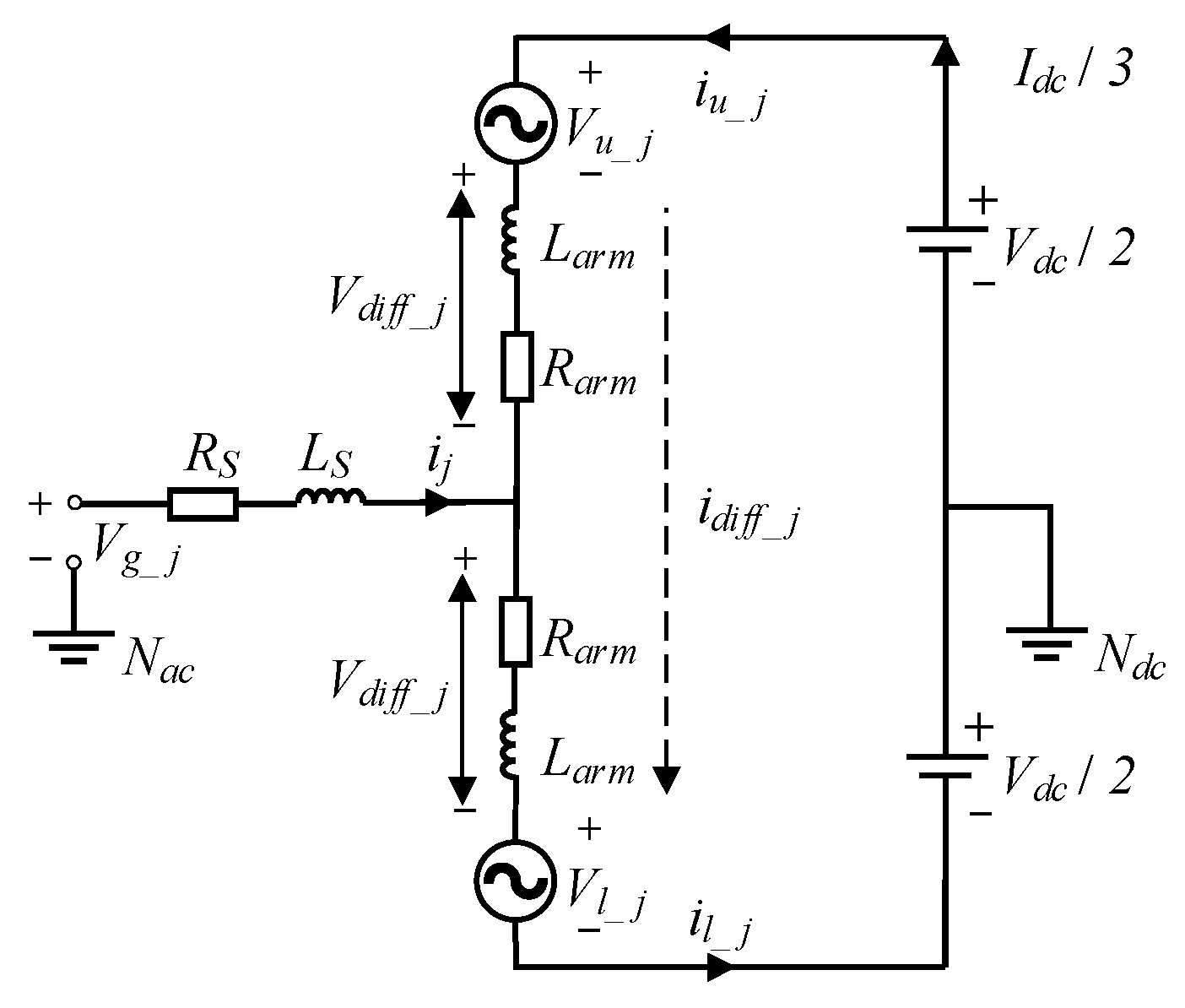
2.1. Topological Structure and Mathematical Modeling of MMCs
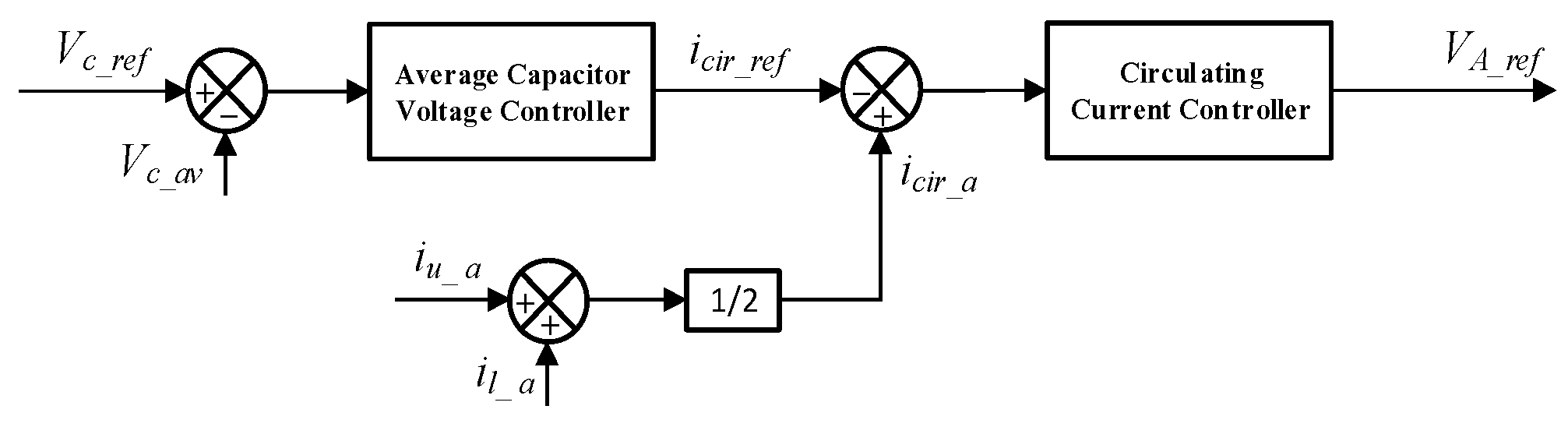
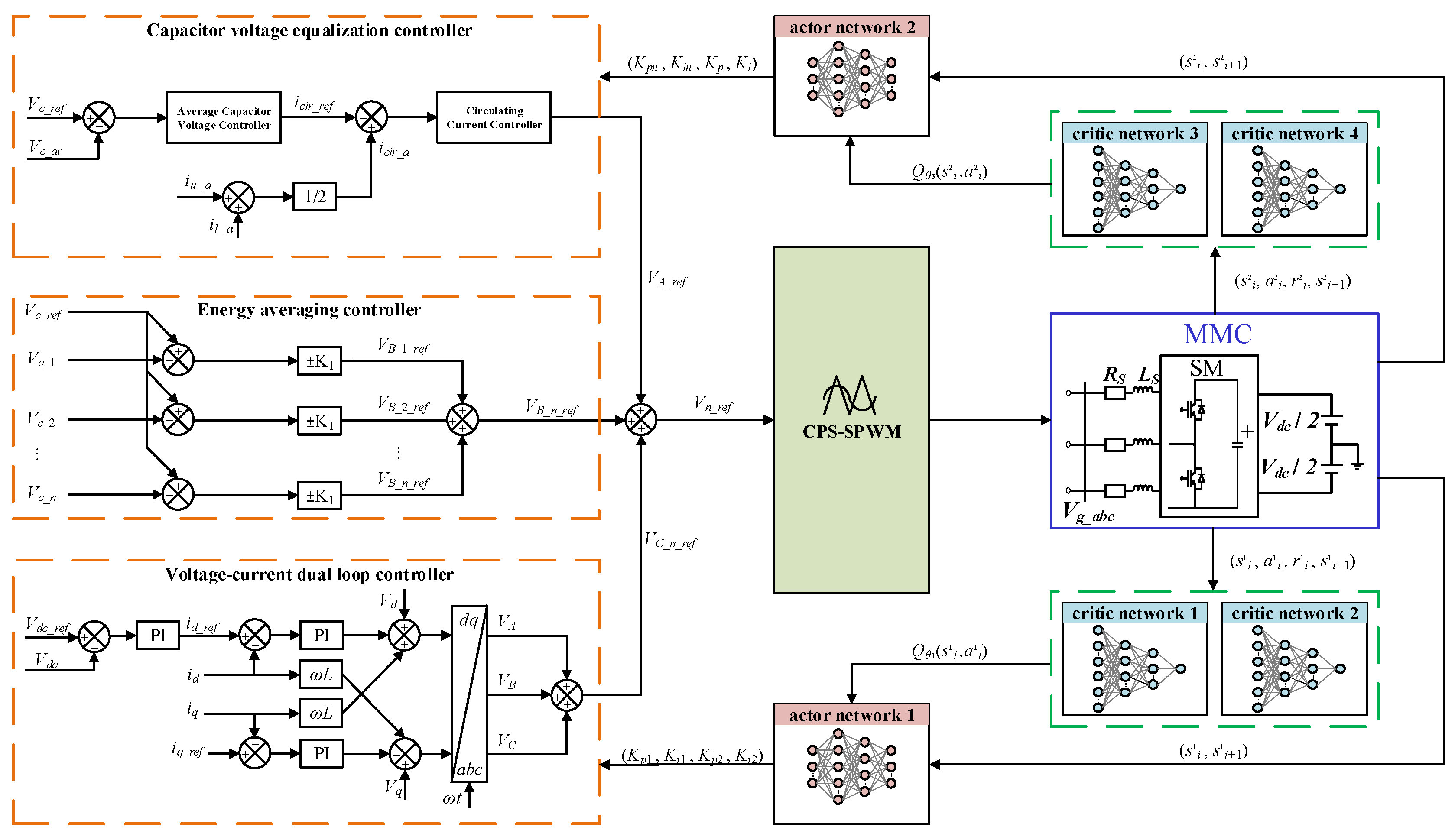
2.2. The Control Strategy of MMCs
3. DA-TD3 Algorithm for Optimized Control of MMCs
3.1. The Core Principles Underlying the TD3 Algorithm
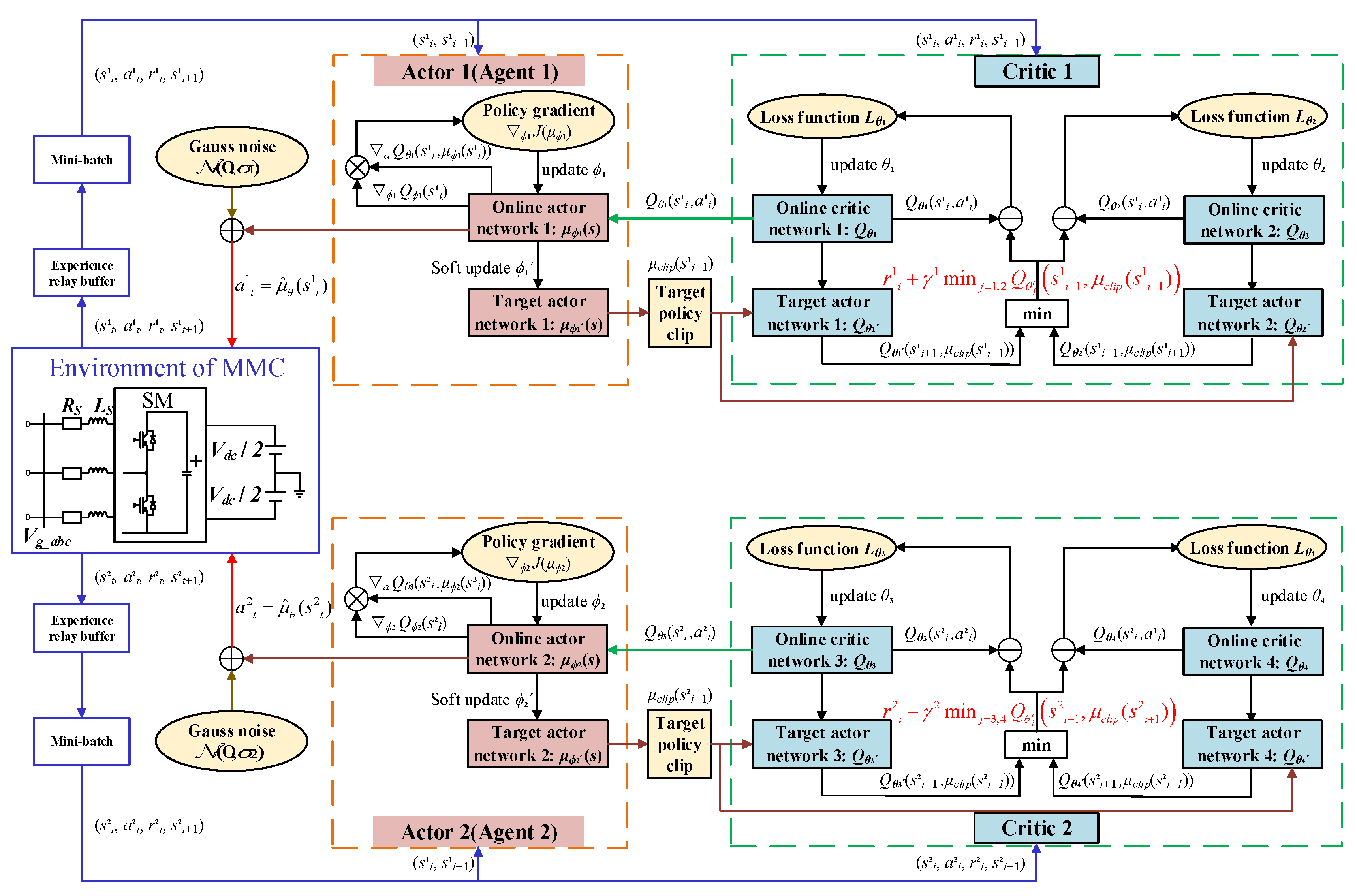
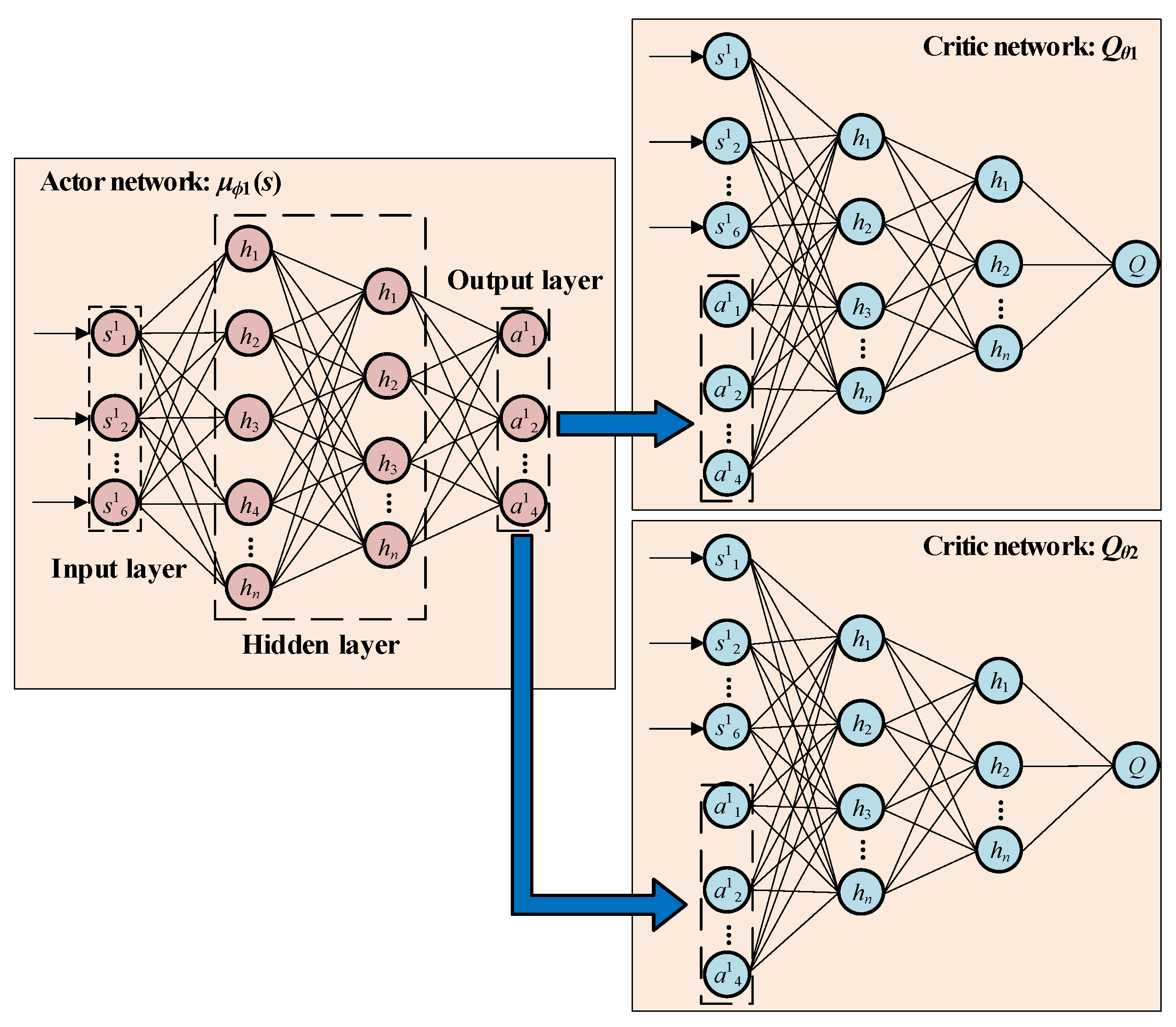
3.2. Dual-Agent Training Mechanism in DA-TD3
| Algorithm 1. DA-TD3 algorithm [32] |
| Input: Operating environment of the MMC |
| 1: Initialize the actor network μϕ1 and critic networks Qθ1, Qθ2 for Agent 1. Initialize the actor network μϕ2 and critic networks Qθ3, Qθ4 for Agent 2. |
| 2: Initialize target network parameters: |
| 3: Initialize independent replay buffers M1 and M2. |
| 4: for episode = 1, 2, … N do |
| 5: Agents 1 and 2 select actions with exploration noise: |
| 6: Perform joint action (a1, a2), observe rewards r1, r2, and new states s1′, s2′. |
| 7: Store interaction data in the reply buffers: |
| 8: Sample mini-batch of m1, m2 transition from reply buffers M1, M2. |
| 9: Compute greedy actions for the next states through |
| 10: Compete target Q-values according to (14) |
| 11: Update critic networks through: |
| 12: if Episode mod 2 = 0 then |
| 13: Update actor networks ϕ1, ϕ2 by deterministic policy gradient according to (15) |
| 14: Update target networks according to (16) |
| 15: end if |
| 16: end for |
4. Algorithm Training and Simulation Analysis
4.1. Deep Reinforcement Learning Algorithm Training
4.2. Simulation Analysis
4.2.1. Steady-State Operating Condition
4.2.2. Grid Voltage Sag Operating Condition
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khodayar, M.; Liu, G.; Wang, J.; Khodayar, M.E. Deep Learning in Power Systems Research: A Review. CSEE J. Power Energy Syst. 2021, 7, 209–220. [Google Scholar] [CrossRef]
- Dang, R.; Jin, G. High-Frequency Oscillation Suppression Strategy for Renewable Energy Integration via Modular Multilevel Converter—High-Voltage Direct Current Transmission System Under Weak Grid Conditions. Electronics 2025, 14, 1622. [Google Scholar] [CrossRef]
- Liu, Y.; Li, K.-J.; Liu, J.; Fan, H.; Sun, K. Start-up Control and Frequency Oscillation Control of the 100% Renewable Energy Islanded Grid Fed by MMC-HVDC System. In Proceedings of the 2023 5th Asia Energy and Electrical Engineering Symposium (AEEES), Chengdu, China, 23–26 March 2023; pp. 1644–1648. [Google Scholar]
- Chao, C.; Zheng, X.; Weng, Y.; Ye, H.; Liu, Z.; Liu, H.; Liu, Y.; Tai, N. High-Sensitivity Differential Protection for Offshore Wind Farms Collection Line with MMC-HVDC Transmission. IEEE Trans. Power Deliv. 2024, 39, 1428–1439. [Google Scholar] [CrossRef]
- Joshi, S.D.; Ghat, M.B.; Shukla, A.; Chandorkar, M.C. Improved Balancing and Sensing of Submodule Capacitor Voltages in Modular Multilevel Converter. IEEE Trans. Ind. Appl. 2021, 57, 537–548. [Google Scholar] [CrossRef]
- Li, J.; Sun, N.; Dong, H. Distributed Collaborative Optimization of Active Power Allocation for MMC-MTDC with Renewable Energy Integration. In Proceedings of the 2021 IEEE 4th International Electrical and Energy Conference (CIEEC), Wuhan, China, 28–30 May 2021; pp. 1–6. [Google Scholar]
- Huang, T.; Wang, B.; Xie, H.; Wu, T.; Li, C.; Li, S.; Hao, J.; Luo, J. Research on Reactive Power Control Strategy of MMC HVDC Converter. In Proceedings of the 2020 IEEE 4th Conference on Energy Internet and Energy System Integration (EI2), Wuhan, China, 30 October–1 November 2020; pp. 880–884. [Google Scholar]
- Niu, X.; Qiu, R.; Liu, S.; Chow, X. DC-Link Voltage Fluctuation Suppression Method for Modular Multilevel Converter Based on Common-Mode Voltage and Circulating Current Coupling Injection under Unbalanced Grid Voltage. Electronics 2024, 13, 3379. [Google Scholar] [CrossRef]
- Tavakoli, S.D.; Sánchez-Sánchez, E.; Prieto-Araujo, E.; Gomis-Bellmunt, O. DC Voltage Droop Control Design for MMC-Based Multiterminal HVDC Grids. IEEE Trans. Power Deliv. 2020, 35, 2414–2424. [Google Scholar] [CrossRef]
- Avdiaj, E.; D’Arco, S.; Piegari, L.; Suul, J.A. Frequency-Adaptive Energy Control for Grid-Forming MMCs Under Unbalanced Conditions. IEEE J. Emerg. Sel. Top. Ind. Electron. 2023, 4, 1124–1137. [Google Scholar] [CrossRef]
- Xi, Q.; Tian, Y.; Fan, Y. Capacitor Voltage Balancing Control of MMC Sub-Module Based on Neural Network Prediction. Electronics 2024, 13, 795. [Google Scholar] [CrossRef]
- Huang, C.; Tian, Y.; Chen, J. Circulating Current Suppression Combined with APF Current Control for the Suppression of MMC Voltage Fluctuations. Electronics 2025, 14, 64. [Google Scholar] [CrossRef]
- Wang, Z.; Yin, X.; Chen, Y. Model Predictive Arm Current Control for Modular Multilevel Converter. IEEE Access 2021, 9, 54700–54709. [Google Scholar] [CrossRef]
- Li, J.; Konstantinou, G.; Wickramasinghe, H.R.; Pou, J. Operation and Control Methods of Modular Multilevel Converters in Unbalanced AC Grids: A Review. IEEE J. Emerg. Sel. Top. Power Electron. 2019, 7, 1258–1271. [Google Scholar] [CrossRef]
- Wen, C.; Li, S.; Wang, P.; Li, J. An Input-Series Output-Parallel DC–DC Converter Based on Fuzzy PID Three-Loop Control Strategy. Electronics 2024, 13, 2342. [Google Scholar] [CrossRef]
- Chen, G.; Li, Z.; Zhang, Z.; Li, S. An Improved ACO Algorithm Optimized Fuzzy PID Controller for Load Frequency Control in Multi Area Interconnected Power Systems. IEEE Access 2020, 8, 6429–6447. [Google Scholar] [CrossRef]
- Yadav, S.K.; Patel, A.; Mathur, H.D. PSO-Based Online PI Tuning of UPQC-DG in Real-Time. IEEE Open J. Power Electron. 2024, 5, 1419–1431. [Google Scholar] [CrossRef]
- Kakkar, S.; Maity, T.; Ahuja, R.K.; Walde, P.; Saket, R.K.; Khan, B.; Padmanaban, S. Design and Control of Grid-Connected PWM Rectifiers by Optimizing Fractional Order PI Controller Using Water Cycle Algorithm. IEEE Access 2021, 9, 125941–125954. [Google Scholar] [CrossRef]
- Li, J.; Li, W. On-Line PID Parameters Optimization Control for Wind Power Generation System Based on Genetic Algorithm. IEEE Access 2020, 8, 137094–137100. [Google Scholar] [CrossRef]
- Antonio Acosta-Rodríguez, R.; Hernán Martinez-Sarmiento, F.; Ardul Múñoz-Hernandez, G. Design Methodology for Optimized Control of High-Power Quadratic Buck Converters Using Sliding Mode and Hybrid Controllers. IEEE Access 2025, 13, 49416–49432. [Google Scholar] [CrossRef]
- Liu, Y.; Lin, Z.; Xu, C.; Wang, L. Fault Ride-through Hybrid Controller for MMC-HVDC Transmission System via Switching Control Units Based on Bang-Bang Funnel Controller. J. Mod. Power Syst. Clean Energy 2023, 11, 599–610. [Google Scholar] [CrossRef]
- Isik, S.; Alharbi, M.; Bhattacharya, S. An Optimized Circulating Current Control Method Based on PR and PI Controller for MMC Applications. IEEE Trans. Ind. Appl. 2021, 57, 5074–5085. [Google Scholar] [CrossRef]
- Zhou, S.; Qin, L.; Ruan, J.; Wang, J.; Liu, H.; Tang, X.; Wang, X.; Liu, K. An AI-Based Power Reserve Control Strategy for Photovoltaic Power Generation Systems Participating in Frequency Regulation of Microgrids. Electronics 2023, 12, 2075. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhou, L.; Yi, Z.; Shi, D.; Guo, M. Leveraging AI for Enhanced Power Systems Control: An Introductory Study of Model-Free DRL Approaches. IEEE Access 2024, 12, 98189–98206. [Google Scholar] [CrossRef]
- Duan, J.; Shi, D.; Diao, R.; Li, H.; Wang, Z.; Zhang, B.; Bian, D.; Yi, Z. Deep-Reinforcement-Learning-Based Autonomous Voltage Control for Power Grid Operations. IEEE Trans. Power Syst. 2020, 35, 814–817. [Google Scholar] [CrossRef]
- Khalid, J.; Ramli, M.A.M.; Khan, M.S.; Hidayat, T. Efficient Load Frequency Control of Renewable Integrated Power System: A Twin Delayed DDPG-Based Deep Reinforcement Learning Approach. IEEE Access 2022, 10, 51561–51574. [Google Scholar] [CrossRef]
- Yan, Z.; Xu, Y. A Multi-Agent Deep Reinforcement Learning Method for Cooperative Load Frequency Control of a Multi-Area Power System. IEEE Trans. Power Syst. 2020, 35, 4599–4608. [Google Scholar] [CrossRef]
- Zhang, H.; Sun, X.; Lee, M.H.; Moon, J. Deep Reinforcement Learning-Based Active Network Management and Emergency Load-Shedding Control for Power Systems. IEEE Trans. Smart Grid 2024, 15, 1423–1437. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, J.; Liu, Y.; Zhang, L.; Zhou, J. Distributed Hierarchical Deep Reinforcement Learning for Large-Scale Grid Emergency Control. IEEE Trans. Power Syst. 2024, 39, 4446–4458. [Google Scholar] [CrossRef]
- Cui, Q.; Hashmy, S.M.Y.; Weng, Y.; Dyer, M. Reinforcement Learning Based Recloser Control for Distribution Cables With Degraded Insulation Level. IEEE Trans. Power Deliv. 2021, 36, 1118–1127. [Google Scholar] [CrossRef]
- Wei, Z.; Quan, Z.; Wu, J.; Li, Y.; Pou, J.; Zhong, H. Deep Deterministic Policy Gradient-DRL Enabled Multiphysics-Constrained Fast Charging of Lithium-Ion Battery. IEEE Trans. Ind. Electron. 2022, 69, 2588–2598. [Google Scholar] [CrossRef]
- Tang, Y.; Hu, W.; Cao, D.; Hou, N.; Li, Z.; Li, Y.W.; Chen, Z.; Blaabjerg, F. Deep Reinforcement Learning Aided Variable-Frequency Triple-Phase-Shift Control for Dual-Active-Bridge Converter. IEEE Trans. Ind. Electron. 2023, 70, 10506–10515. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, P.; Xie, H.; Lu, X.; Wu, X.; Liu, Z. Graph Attention Network Based Deep Reinforcement Learning for Voltage/Var Control of Topologically Variable Power System. J. Mod. Power Syst. Clean Energy 2025, 13, 215–227. [Google Scholar] [CrossRef]
- Wang, S.; Duan, J.; Shi, D.; Xu, C.; Li, H.; Diao, R.; Wang, Z. A Data-Driven Multi-Agent Autonomous Voltage Control Framework Using Deep Reinforcement Learning. IEEE Trans. Power Syst. 2020, 35, 4644–4654. [Google Scholar] [CrossRef]
- Hu, X.; Xiong, L.; You, L.; Han, G.; Xu, C. Comparative Analysis of Instantaneous Voltage Support Capability Under Voltage and Current Dual-Loop Control and Single-Loop Voltage Magnitude Control. In Proceedings of the 2024 IEEE 7th International Electrical and Energy Conference (CIEEC), Harbin, China, 10–12 May 2024; pp. 3797–3802. [Google Scholar]
- Jang, Y.-N.; Park, J.-W. New Circulating Current Suppression Control for MMC Without Arm Current Sensors. IEEE Trans. Power Electron. 2024, 39, 11232–11243. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed]
- Fan, Z.; Zhang, W.; Liu, W. Multi-Agent Deep Reinforcement Learning-Based Distributed Optimal Generation Control of DC Microgrids. IEEE Trans. Smart Grid 2023, 14, 3337–3351. [Google Scholar] [CrossRef]
- Zeng, Y.; Pou, J.; Sun, C.; Mukherjee, S.; Xu, X.; Gupta, A.K.; Dong, J. Autonomous Input Voltage Sharing Control and Triple Phase Shift Modulation Method for ISOP-DAB Converter in DC Microgrid: A Multiagent Deep Reinforcement Learning-Based Method. IEEE Trans. Power Electron. 2023, 38, 2985–3000. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | ||
|---|---|---|---|
| Episode number (N) | 3000 | ||
| Sample time (T1, T2) | [1 × 10−3, 1 × 10−3] | ||
| Learning rate for the actor [λa1, λa2] | [1 × 10−4, 1 × 10−4] | ||
| Learning rate for the critic [λc1, λc2] | [2 × 10−3, 5 × 10−4] | ||
| Discount factor [γ1, γ2] | [0.995, 0.999] | ||
| Replay buffer size [M1, M2] | [1 × 104, 1 × 104] | ||
| Mini batch size [m1, m2] | [128, 128] | ||
| Target update frequency [FT1, FT2] | [2, 2] | ||
| Soft target update factor [τ1, τ2] | [1 × 10−3, 5 × 10−3] | ||
| Policy updates frequency [d1, d2] | [2, 2] | ||
| Exploration model | Gaussian action noise | ||
| Initial value of noise standard deviation | [0.3, 0.1] | ||
| Decay rate of the standard deviation | [1 × 10−4, 1 × 10−5] | ||
| Agent 1PI parameter range [Kp1, Ki1, Kp2, Ki2] | |||
| 0.05 ≤ Kp1 ≤ 1 | 2 ≤ Ki1 ≤ 20 | 10 ≤ Kp2 ≤ 50 | 100 ≤ Ki2 ≤ 500 |
| Agent 2 PI parameter range [Kpu, Kiu, Kp, Ki] | |||
| 0.5 ≤ Kpu ≤ 12 | 10 ≤ Kiu ≤ 500 | 1 ≤ Kp ≤ 20 | 10 ≤ Ki ≤ 600 |
| Parameter | Value |
|---|---|
| Grid voltage Vg_abc (kV) | 3.3 |
| DC output voltage Vdc (kV) | 6 |
| Submodule capacitor C (mF) | 7 |
| Arm resistance Rarm (Ω) | 0.04 |
| Arm inductance Larm (mH) | 13.5 |
| Grid equivalent resistance Rs (Ω) | 0.04 |
| Grid equivalent inductance Ls (mH) | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Guan, W.; Lu, Y.; Zhou, Y. Adaptive Control Strategy for the PI Parameters of Modular Multilevel Converters Based on Dual-Agent Deep Reinforcement Learning. Electronics 2025, 14, 2270. https://doi.org/10.3390/electronics14112270
Liu J, Guan W, Lu Y, Zhou Y. Adaptive Control Strategy for the PI Parameters of Modular Multilevel Converters Based on Dual-Agent Deep Reinforcement Learning. Electronics. 2025; 14(11):2270. https://doi.org/10.3390/electronics14112270
Chicago/Turabian StyleLiu, Jiale, Weide Guan, Yongshuai Lu, and Yang Zhou. 2025. "Adaptive Control Strategy for the PI Parameters of Modular Multilevel Converters Based on Dual-Agent Deep Reinforcement Learning" Electronics 14, no. 11: 2270. https://doi.org/10.3390/electronics14112270
APA StyleLiu, J., Guan, W., Lu, Y., & Zhou, Y. (2025). Adaptive Control Strategy for the PI Parameters of Modular Multilevel Converters Based on Dual-Agent Deep Reinforcement Learning. Electronics, 14(11), 2270. https://doi.org/10.3390/electronics14112270