
EvoContext: Evolving Contextual Examples by Genetic Algorithm for Enhanced Hyperparameter Optimization Capability in Large Language Models


 , ,
, ,
Abstract
1. Introduction
- We propose updating contextual examples in prompts using genetic algorithms to address the limited search space exploration caused by repetition issues in LLMs during HPO, thus enhancing optimization performance.
- We design an iterative optimization method that alternates between genetic algorithms and LLMs, balancing solution space exploration and local refinement.
- The superiority of EvoContext is verified on different datasets, and the experiments show that EvoContext outperforms traditional and LLM-based HPO methods.
- Revealing through ablation studies the indispensable synergistic effects between genetic evolutionary and LLMs reasoning modules, providing new insights for integrating traditional optimization algorithms with LLMs.
2. Related Work
2.1. Hyperparameter Optimization
2.2. LLMs and Optimization Algorithms
3. Background
4. Methodology
- Collaborative Optimization: The genetic algorithm is responsible for global exploration. The LLM performs local optimization using high-quality examples. Their alternating updates help balance exploration and exploitation, leading toward the global optimum.
- Dynamic Example: Adding examples generated by the genetic algorithm into prompts helps break the repetition in LLM outputs. This improves both the diversity and quality of hyperparameter configurations.
4.1. Problem Formulation
4.2. EvoContext
4.2.1. Framework Overview
| Algorithm 1 EvoContext |
Input: Evaluation budget N, initialization mode Starting (cold/warm) Output: Optimal configuration index Phase 1: Examples Initialization 1: if Starting is cold then 2: LLM_Generate(Promptzero-shot) 3: Evaluate , update 4: 5: else 6: History_Data 7: end if Phase 2: Iterative Optimization 8: while
do 9: Evolutionary operations 10: RouletteWheelSelection () 11: UniformCrossover() 12: GaussianMutate() 13: RandomCategoryReplace() 14: Evaluate , update 15: 16: LLM operations 17: GreedySelect() 18: LLM_Generate(Textualize()) 19: Evaluate , update 20: 21: end while 22: return |
4.2.2. Genetic Algorithm
4.2.3. LLM Operation
5. Experiments
5.1. Experimental Setup
- Role: the role the LLM is expected to play.
- Task: the task to be completed by the LLM.
- Model: the algorithm to be tuned.
- Dataset: the information about the dataset used.
- Examples: the reference examples for the LLM (included only in few-shot prompts).
- Output Format: the required output format.
5.2. Comparative Study
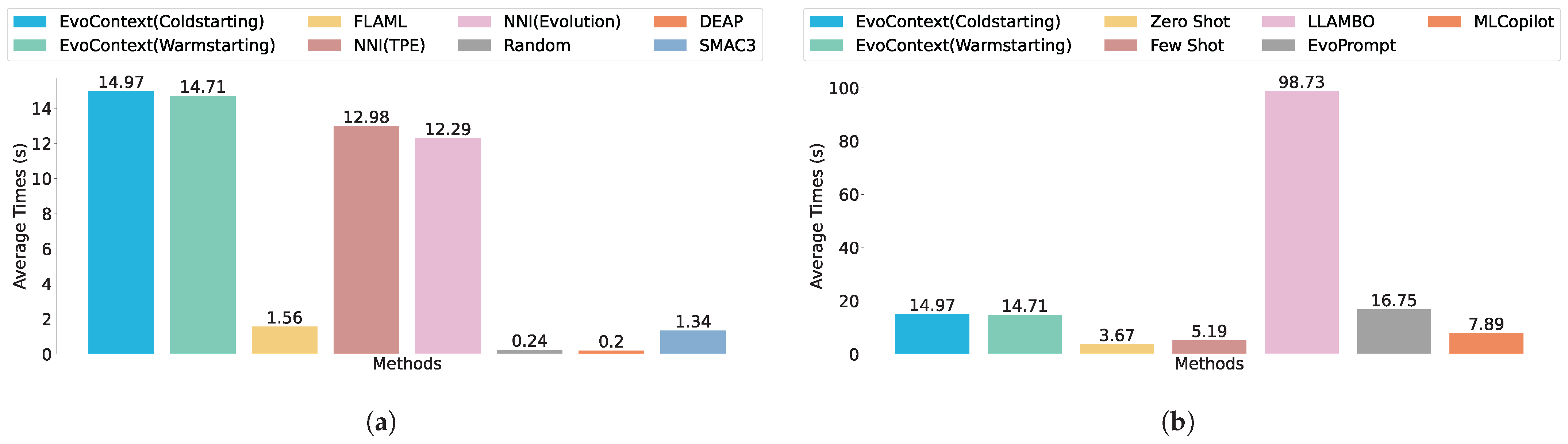
5.2.1. Baselines
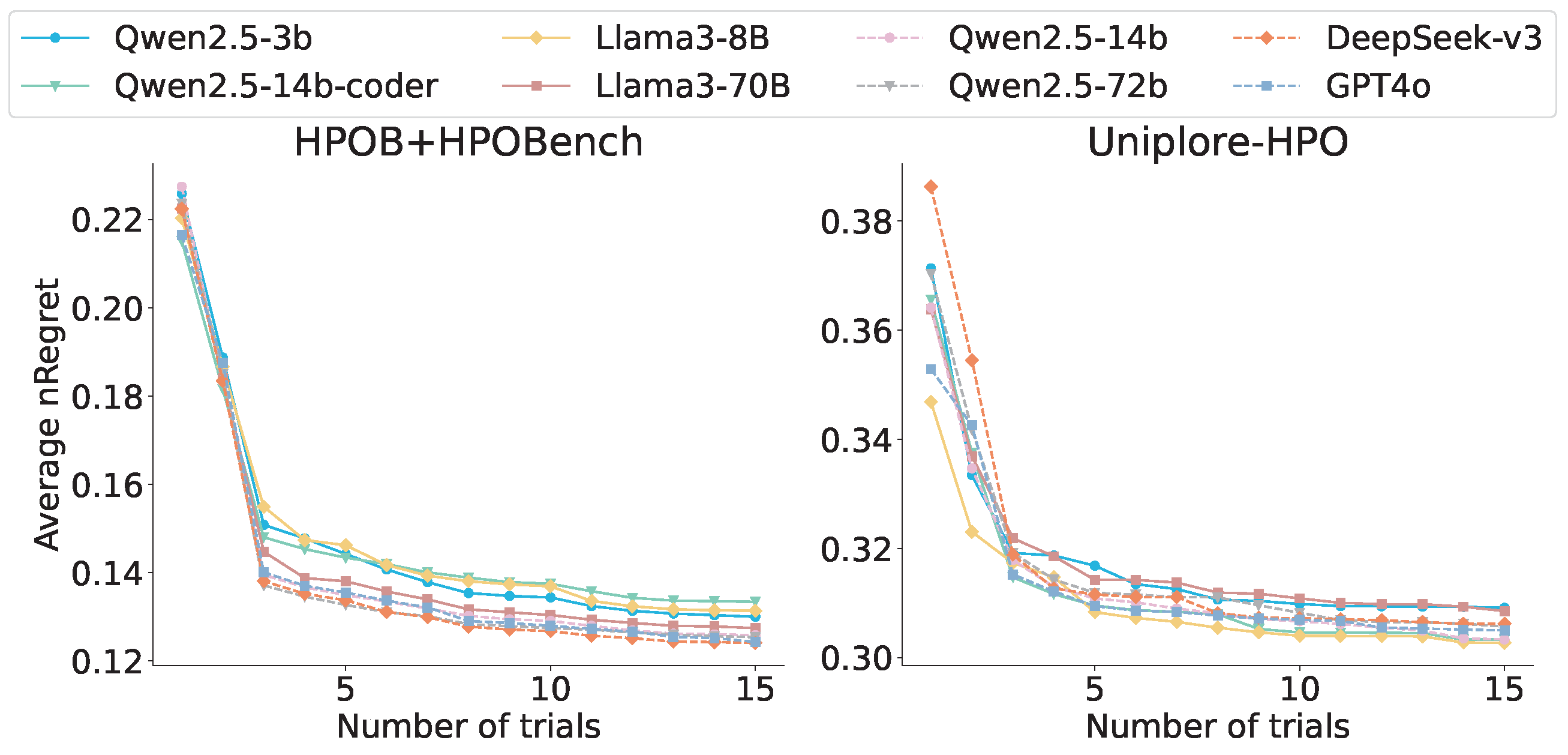
5.2.2. Results
5.2.3. Significance Test
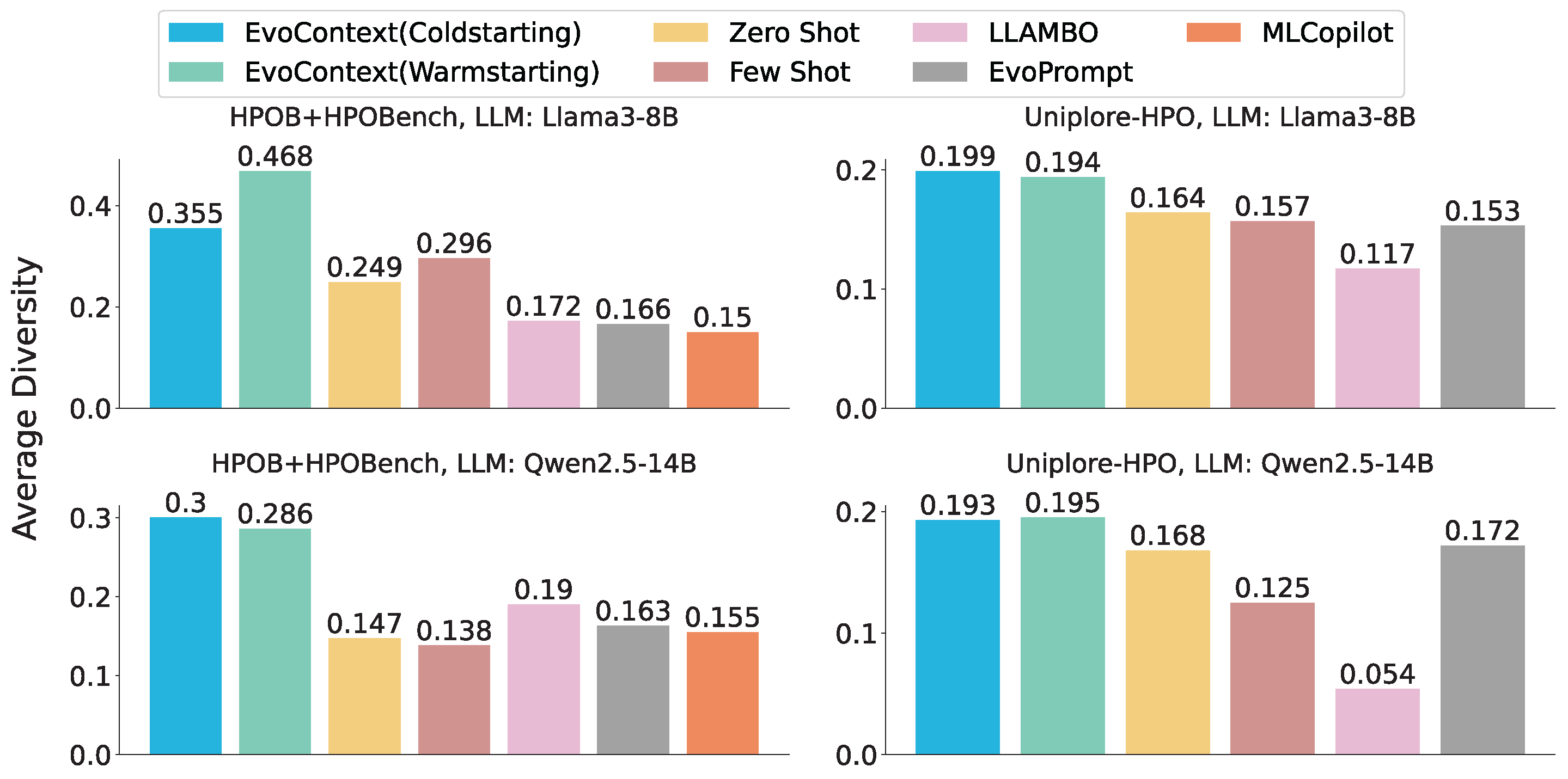
5.3. Ablation Study
5.3.1. Module Ablation
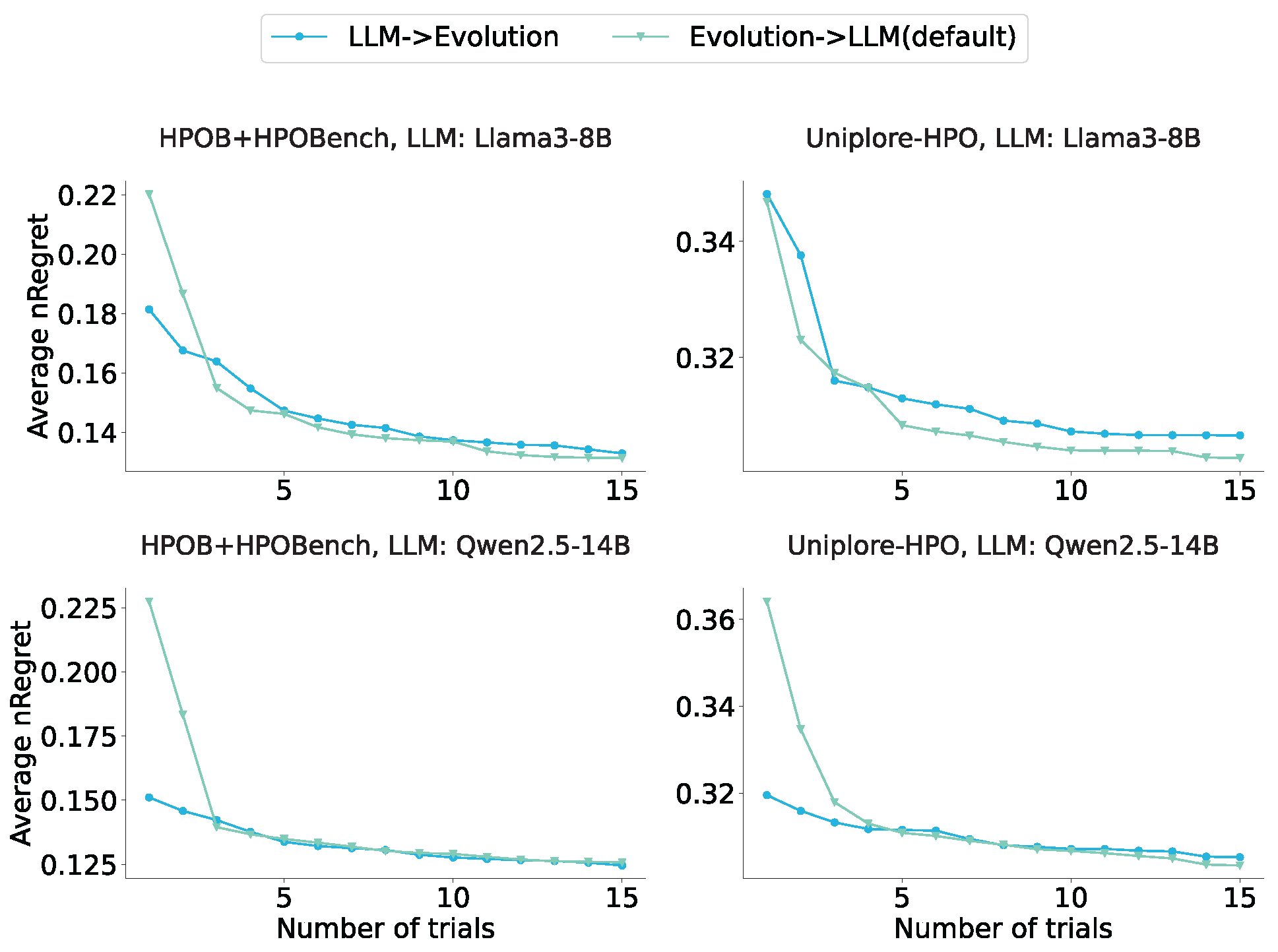
5.3.2. Iteration Order
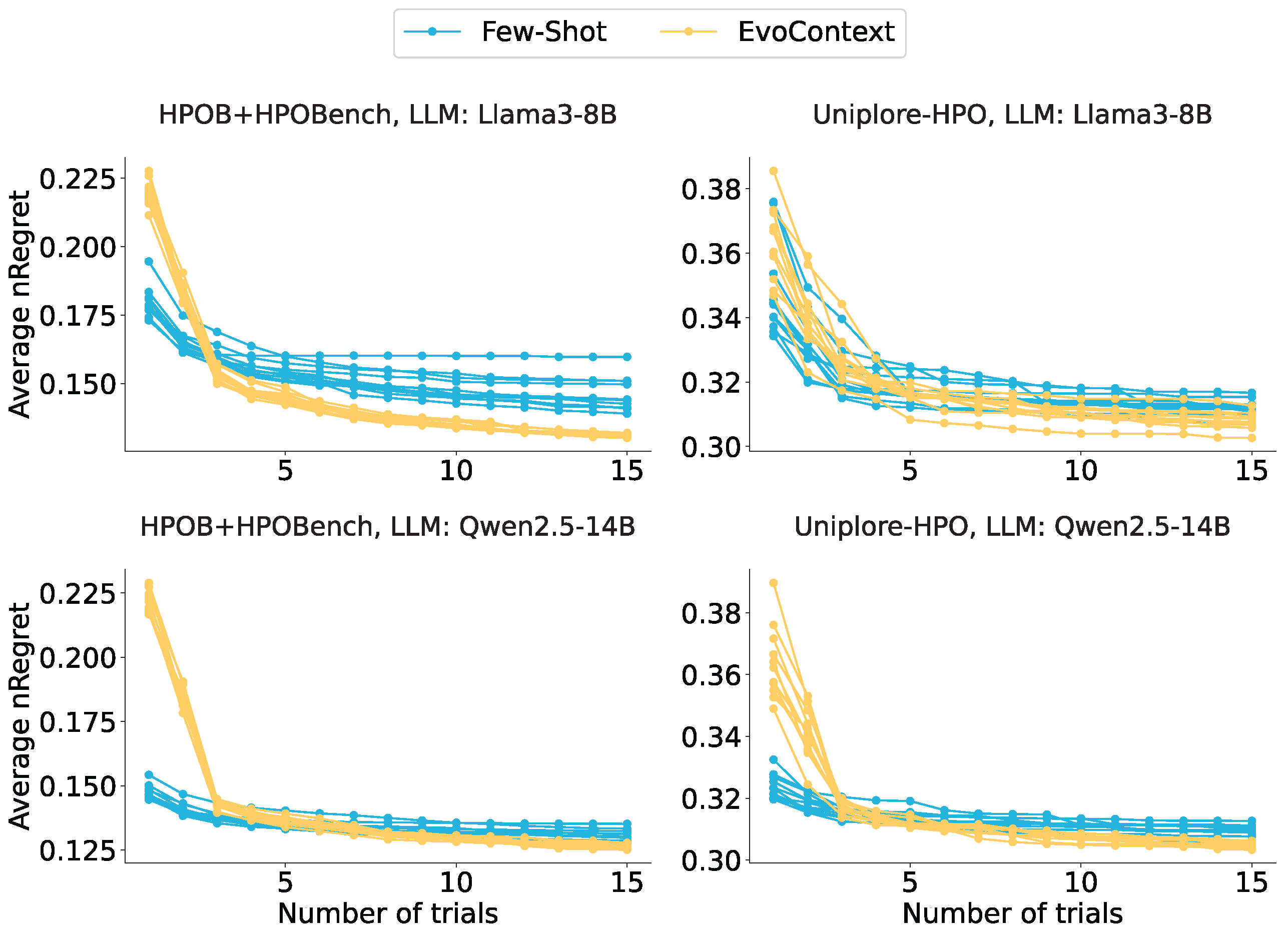
5.3.3. Prompt Engineering
5.4. Effect of Algorithm Parameters
5.4.1. Effect of LLM Temperature Parameter
5.4.2. Crossover and Mutation Rates
5.4.3. LLM-Driven Algorithms
6. Discussions
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2951–2959. [Google Scholar]
- Weerts, H.J.P.; Müller, A.C.; Vanschoren, J. Importance of Tuning Hyperparameters of Machine Learning Algorithms. arXiv 2020, arXiv:2007.07588. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Mirjalili, S.; Song Dong, J.; Sadiq, A.S.; Faris, H. Genetic Algorithm: Theory, Literature Review, and Application in Image Reconstruction. In Nature-Inspired Optimizers: Theories, Literature Reviews and Applications; Springer: Cham, Switzerland, 2020; pp. 69–85. [Google Scholar] [CrossRef]
- Microsoft. NNI. Available online: https://github.com/microsoft/nni (accessed on 29 March 2025).
- Wang, C.; Wu, Q.; Weimer, M.; Zhu, E. FLAML: A Fast and Lightweight AutoML Library. In Proceedings of the Fourth Conference on Machine Learning and Systems, Virtual, 5–9 April 2021; pp. 434–447. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models are Zero-Shot Reasoners. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; pp. 22199–22213. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Virtual, 6–12 December 2020; pp. 1877–1901. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; pp. 27730–27744. [Google Scholar]
- Xu, J.; Liu, X.; Yan, J.; Cai, D.; Li, H.; Li, J. Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; pp. 3082–3095. [Google Scholar]
- Wang, W.; Li, Z.; Lian, D.; Ma, C.; Song, L.; Wei, Y. Mitigating the Language Mismatch and Repetition Issues in LLM-based Machine Translation via Model Editing. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 15681–15700. [Google Scholar] [CrossRef]
- Fu, Z.; Lam, W.; So, A.M.; Shi, B. A Theoretical Analysis of the Repetition Problem in Text Generation. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; pp. 12848–12856. [Google Scholar] [CrossRef]
- Freitag, M.; Al-Onaizan, Y. Beam Search Strategies for Neural Machine Translation. In Proceedings of the First Workshop on Neural Machine Translation, Vancouver, BC, Canada, 4 August 2017; pp. 56–60. [Google Scholar] [CrossRef]
- Peeperkorn, M.; Kouwenhoven, T.; Brown, D.; Jordanous, A. Is Temperature the Creativity Parameter of Large Language Models? In Proceedings of the 15th International Conference on Computational Creativity, Jönköping, Sweden, 17–21 June 2024; pp. 226–235. [Google Scholar] [CrossRef]
- Wang, C.; Liu, X.; Awadallah, A.H. Cost-effective hyperparameter optimization for large language model generation inference. In Proceedings of the Second International Conference on Automated Machine Learning, Hasso Plattner Institute, Potsdam, Germany, 12–15 November 2023; pp. 1–17. [Google Scholar]
- Renze, M. The effect of sampling temperature on problem solving in large language models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; pp. 7346–7356. [Google Scholar] [CrossRef]
- Welleck, S.; Kulikov, I.; Roller, S.; Dinan, E.; Cho, K.; Weston, J. Neural Text Generation with Unlikelihood Training. In Proceedings of the Eighth International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar]
- Lin, X.; Han, S.; Joty, S.R. Straight to the Gradient: Learning to Use Novel Tokens for Neural Text Generation. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 6642–6653. [Google Scholar]
- Liu, T.; Astorga, N.; Seedat, N.; van der Schaar, M. Large Language Models to Enhance Bayesian Optimization. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Guo, Q.; Wang, R.; Guo, J.; Li, B.; Song, K.; Tan, X.; Liu, G.; Bian, J.; Yang, Y. Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Zhang, L.; Zhang, Y.; Ren, K.; Li, D.; Yang, Y. MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, St. Julian’s, Malta, 17–22 March 2024; pp. 2931–2959. [Google Scholar]
- Pineda-Arango, S.; Jomaa, H.S.; Wistuba, M.; Grabocka, J. HPO-B: A Large-Scale Reproducible Benchmark for Black-Box HPO based on OpenML. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Virtual, 6–14 December 2021; pp. 1–12. [Google Scholar]
- Eggensperger, K.; Müller, P.; Mallik, N.; Feurer, M.; Sass, R.; Klein, A.; Awad, N.H.; Lindauer, M.; Hutter, F. HPOBench: A Collection of Reproducible Multi-Fidelity Benchmark Problems for HPO. In Proceedings of the Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Virtual, 6–14 December 2021; pp. 1–17. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef]
- Hayes-Roth, F. Review of “Adaptation in Natural and Artificial Systems by John H. Holland”, The U. of Michigan Press, 1975. SIGART Newsl. 1975, 53, 15. [Google Scholar] [CrossRef]
- Zhang, M.R.; Desai, N.; Bae, J.; Lorraine, J.; Ba, J. Using Large Language Models for Hyperparameter Optimization. In Proceedings of the NeurIPS 2023 Foundation Models for Decision Making Workshop, New Orleans, LA, USA, 4–9 December 2023; pp. 1–29. [Google Scholar]
- Zhang, S.; Gong, C.; Wu, L.; Liu, X.; Zhou, M. AutoML-GPT: Automatic Machine Learning with GPT. arXiv 2023, arXiv:2305.02499. [Google Scholar] [CrossRef]
- Huang, S.; Yang, K.; Qi, S.; Wang, R. When large language model meets optimization. Swarm Evol. Comput. 2024, 90, 101663. [Google Scholar] [CrossRef]
- Yang, C.; Wang, X.; Lu, Y.; Liu, H.; Le, Q.V.; Zhou, D.; Chen, X. Large Language Models as Optimizers. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Romera-Paredes, B.; Barekatain, M.; Novikov, A.; Balog, M.; Kumar, M.P.; Dupont, E.; Ruiz, F.J.R.; Ellenberg, J.S.; Wang, P.; Fawzi, O.; et al. Mathematical discoveries from program search with large language models. Nat. Commun. 2024, 625, 468–475. [Google Scholar] [CrossRef] [PubMed]
- Chen, A.; Dohan, D.; So, D.R. EvoPrompting: Language Models for Code-Level Neural Architecture Search. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; pp. 7787–7817. [Google Scholar]
- Meta AI. Llama 3. Available online: https://github.com/meta-llama/llama3 (accessed on 29 March 2025).
- Qwen Team. Qwen2 Technical Report. arXiv 2024, arXiv:2407.10671. [Google Scholar] [CrossRef]
- Lindauer, M.; Eggensperger, K.; Feurer, M.; Biedenkapp, A.; Deng, D.; Benjamins, C.; Ruhkopf, T.; Sass, R.; Hutter, F. SMAC3: A versatile Bayesian optimization package for hyperparameter optimization. J. Mach. Learn. Res 2022, 23, 1–9. [Google Scholar]
- Fortin, F.A.; De Rainville, F.M.; Gardner, M.A.G.; Parizeau, M.; Gagné, C. DEAP: Evolutionary algorithms made easy. J. Mach. Learn. Res 2012, 13, 2171–2175. [Google Scholar]
- Caccia, M.; Caccia, L.; Fedus, W.; Larochelle, H.; Pineau, J.; Charlin, L. Language GANs Falling Short. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- OpenAI. GPT-4o. Available online: https://openai.com/index/hello-gpt-4o (accessed on 29 March 2025).
- Liu, A.; Feng, B.; Xue, B.; Wang, B.; Wu, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; Ruan, C.; et al. Deepseek-v3 technical report. arXiv 2024, arXiv:2412.19437. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Warm | Cold | Warm | Cold |
|---|---|---|---|---|
| (Llama3-8B) | (Llama3-8B) | (Qwen2.5-14B) | (Qwen2.5-14B) | |
| LLAMB0 | 0.0007 | 0.0281 | 0.0084 | 0.0504 |
| EvoPrompt | 0.0 | 0.0001 | 0.002 | 0.0163 |
| MLCopilot | 0.1926 | 0.761 | 0.0558 | 0.234 |
| Zero Shot | 0.0 | 0.0002 | 0.0 | 0.0001 |
| Few Shot | 0.0051 | 0.1137 | 0.0841 | 0.2722 |
| NNI(TPE) | 0.0 | 0.001 | 0.0 | 0.0 |
| NNI(Evolution) | 0.0 | 0.0016 | 0.0 | 0.0 |
| FLAML | 0.0009 | 0.0372 | 0.0001 | 0.001 |
| Random | 0.0 | 0.0032 | 0.0 | 0.0 |
| DEAP | 0.0394 | 0.357 | 0.0064 | 0.0429 |
| SMAC3 | 0.0357 | 0.3388 | 0.0057 | 0.039 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Qin, G.; Wang, Y.; Chen, P.; Wang, X.; Zhou, W.; Chen, M.; Li, H. EvoContext: Evolving Contextual Examples by Genetic Algorithm for Enhanced Hyperparameter Optimization Capability in Large Language Models. Electronics 2025, 14, 2253. https://doi.org/10.3390/electronics14112253
Xu Y, Qin G, Wang Y, Chen P, Wang X, Zhou W, Chen M, Li H. EvoContext: Evolving Contextual Examples by Genetic Algorithm for Enhanced Hyperparameter Optimization Capability in Large Language Models. Electronics. 2025; 14(11):2253. https://doi.org/10.3390/electronics14112253
Chicago/Turabian StyleXu, Yutian, Guozhong Qin, Yanhao Wang, Panfeng Chen, Xibin Wang, Wei Zhou, Mei Chen, and Hui Li. 2025. "EvoContext: Evolving Contextual Examples by Genetic Algorithm for Enhanced Hyperparameter Optimization Capability in Large Language Models" Electronics 14, no. 11: 2253. https://doi.org/10.3390/electronics14112253
APA StyleXu, Y., Qin, G., Wang, Y., Chen, P., Wang, X., Zhou, W., Chen, M., & Li, H. (2025). EvoContext: Evolving Contextual Examples by Genetic Algorithm for Enhanced Hyperparameter Optimization Capability in Large Language Models. Electronics, 14(11), 2253. https://doi.org/10.3390/electronics14112253