
Visual Information Decoding Based on State-Space Model with Neural Pathways Incorporation


Abstract
1. Introduction
2. Related Work
2.1. Deep Learning and Modeling of Biological Vision Systems
2.2. Visual Information Decoding Based on Neural Networks
3. Method
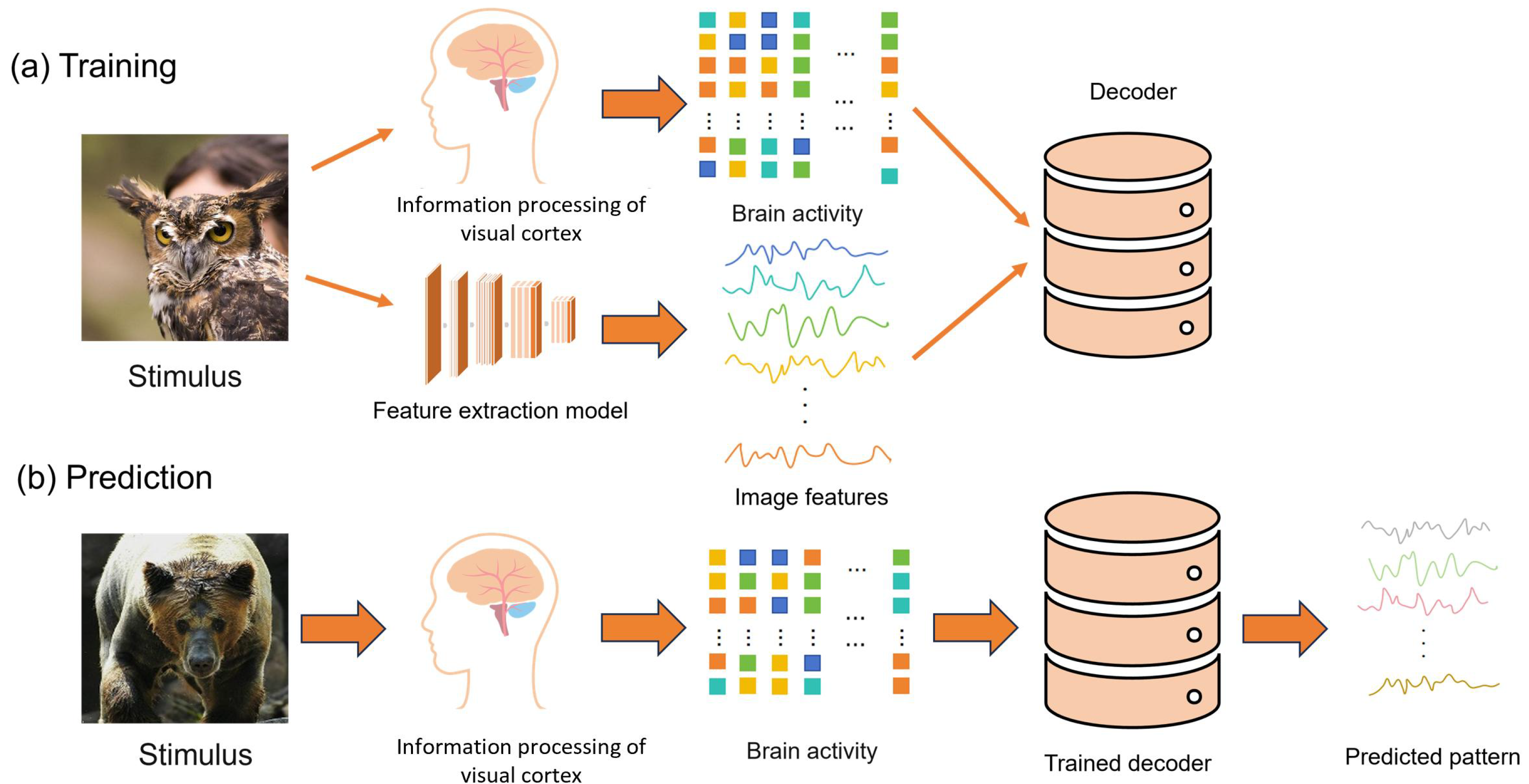
3.1. Visual Information Decoding Process
3.2. Feature Extraction Model
3.2.1. Visual Information Decoding Model Based on State Space Model
3.2.2. Visual Information Decoding Model Based on Convolutional Neural Network
3.3. Visual Feature Decoder
3.4. Model Effectiveness Evaluation
3.4.1. Decoding Effectiveness Evaluation
3.4.2. Identification Accuracy Evaluation
4. Results
4.1. fMRI Data
4.2. Comparison of Decoding Performance Between SSM-VIDM and CNN-VIDM
4.3. Comparison of Image Recognition Accuracy Between SSM-VIDM and CNN-VIDM
4.4. Accuracy Comparison of SSM-VIDM and CNN-VIDM with Different Features
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Naselaris, T.; Kay, K.N.; Nishimoto, S.; Gallant, J.L. Encoding and Decoding in FMRI. NeuroImage 2011, 56, 400–410. [Google Scholar] [CrossRef] [PubMed]
- Cox, D.D.; Savoy, R.L. Functional magnetic resonance imaging (fMRI) “brain reading”: Detecting and classifying distributed patterns of fMRI activity in human visual cortex. NeuroImage 2003, 19, 261–270. [Google Scholar] [CrossRef] [PubMed]
- Norman, K.A.; Polyn, S.M.; Detre, G.J.; Haxby, J.V. Beyond mind-reading: Multi-voxel pattern analysis of fMRI data. Trends Cogn. Sci. 2006, 10, 424–430. [Google Scholar] [CrossRef] [PubMed]
- Haxby, J.V.; Ungerleider, L.G.; Clark, V.L.; Schouten, J.L.; Vuilleumier, P.; DiCarlo, J.J. Distributed and Overlapping Representations of Faces and Objects in Ventral Temporal Cortex. Science 2001, 293, 2425–2430. [Google Scholar] [CrossRef] [PubMed]
- Kamitani, Y.; Tong, F.; Nishida, S.; Haxby, J.V. Decoding the visual and subjective contents of the human brain. Nat. Neurosci. 2005, 8, 679–685. [Google Scholar] [CrossRef] [PubMed]
- Marr, D.; Vaina, L. Representation and recognition of the movements of shapes. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1982, 214, 501–524. [Google Scholar] [CrossRef] [PubMed]
- Zeki, S. A Vision of the Brain; Blackwell Scientific Publications: Hoboken, NJ, USA, 1993. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Ferrier Lecture. Functional Architecture of Macaque Monkey Visual Cortex. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1977, 198, 1–59. [Google Scholar] [CrossRef] [PubMed]
- Himberger, K.D.; Chien, H.-Y.; Honey, C.J. Principles of Temporal Processing Across the Cortical Hierarchy. Neuroscience 2018, 389, 161–174. [Google Scholar] [CrossRef] [PubMed]
- Grill-Spector, K.; Malach, R. The human visual cortex. Annu. Rev. Neurosci. 2004, 27, 649–677. [Google Scholar] [CrossRef] [PubMed]
- Van Essen, D.C.; Maunsell, J.H. Hierarchical organization and functional streams in the visual cortex. Trends Neurosci. 1983, 6, 370–375. [Google Scholar] [CrossRef]
- Chen, D.; Wang, Z.; Guo, D.; Orekhov, V.; Qu, X. Review and Prospect: Deep Learning in Nuclear Magnetic Resonance Spectroscopy. Chemistry 2020, 26, 10391–10401. [Google Scholar] [CrossRef] [PubMed]
- Agostinho, D.; Borra, D.; Castelo-Branco, M.; Simões, M. Explainability of fMRI Decoding Models Can Unveil Insights into Neural Mechanisms Related to Emotions. In Progress in Artificial Intelligence. EPIA 2024; Santos, M.F., Machado, J., Novais, P., Cortez, P., Moreira, P.M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Swizterland, 2025; Volume 14968, pp. 1–14. [Google Scholar] [CrossRef]
- Lelièvre, P.; Chen, C.C. Integrated Gradient Correlation: A Method for the Interpretability of fMRI Decoding Deep Models. J. Vis. 2024, 24, 2. [Google Scholar] [CrossRef]
- Phillips, E.M.; Gillette, K.D.; Dilks, D.D.; Berns, G.S. Through a Dog’s Eyes: FMRI Decoding of Naturalistic Videos from Dog Cortex. J. Vis. Exp. 2022, 187, e64442. [Google Scholar] [CrossRef] [PubMed]
- Alotaibi, S.; Alotaibi, M.M.; Alghamdi, F.S.; Alshehri, M.A.; Bamusa, K.M.; Almalki, Z.F.; Alamri, S.; Alghamdi, A.J.; Alhazmi, M.; Osman, H.; et al. The role of fMRI in the mind decoding process in adults: A systematic review. PeerJ 2025, 13, e18795. [Google Scholar] [CrossRef]
- Ferrante, M.; Boccato, T.; Passamonti, L.; Toschi, N. Retrieving and reconstructing conceptually similar images from fMRI with latent diffusion models and a neuro-inspired brain decoding model. J. Neural Eng. 2024, 21, 046001. [Google Scholar] [CrossRef] [PubMed]
- Haxby, J.V.; Connolly, A.C.; Guntupalli, J.S. Decoding neural representational spaces using multivariate pattern analysis. Annu. Rev. Neurosci. 2014, 37, 435–456. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurones in the cat’s striate cortex. J. Physiol. 1959, 148, 574. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Wu, J.; Liang, W.; Wang, K.I.; Yan, Z.; Yang, L.T.; Jin, Q. Reconstructed Graph Neural Network With Knowledge Distillation for Lightweight Anomaly Detection. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 11817–11828. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Xu, G.; Xu, X.; Jiang, H.; Tian, Z.; Ma, T. Multicenter Hierarchical Federated Learning with Fault-Tolerance Mechanisms for Resilient Edge Computing Networks. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 47–61. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zhang, W.; Xu, X.; Cao, W. A public and large-scale expert information fusion method and its application: Mining public opinion via sentiment analysis and measuring public dynamic reliability. Inf. Fusion 2022, 78, 78. [Google Scholar] [CrossRef]
- Zhang, J.; Bhuiyan, M.Z.; Yang, X.; Wang, T.; Xu, X.; Hayajneh, T.; Khan, F. AntiConcealer: Reliable Detection of Adversary Concealed Behaviors in EdgeAI-Assisted IoT. IEEE Internet Things J. 2022, 9, 22184–22193. [Google Scholar] [CrossRef]
- Li, X.; Cai, J.; Yang, J.; Guo, L.; Huang, S.; Yi, Y. Performance Analysis of Delay Distribution and Packet Loss Ratio for Body-to-Body Networks. IEEE Internet Things J. 2021, 8, 16598–16612. [Google Scholar] [CrossRef]
- Chen, Z.S.; Yang, Y.; Wang, X.J.; Chin, K.S.; Tsui, K.L. Fostering linguistic decision-making under uncertainty: A proportional interval type-2 hesitant fuzzy TOPSIS approach based on Hamacher aggregation operators and andness optimization models. Inf. Sci. Int. J. 2019, 500, 229–258. [Google Scholar] [CrossRef]
- Jiang, F.; Wang, K.; Dong, L.; Pan, C.; Xu, W.; Yang, K. AI Driven Heterogeneous MEC System with UAV Assistance for Dynamic Environment: Challenges and Solutions. IEEE Netw. Mag. Glob. Internetwork. (M-NET) 2021, 35, 9. [Google Scholar] [CrossRef]
- Allen, E.J.; St-Yves, G.; Wu, Y.; Breedlove, J.L.; Prince, J.S.; Dowdle, L.T.; Nau, M.; Caron, B.; Pestilli, F.; Charest, I.; et al. A massive 7T fMRI dataset to bridge cognitive neuroscience and artificial intelligence. Nat. Neurosci. 2022, 25, 116–126. [Google Scholar] [CrossRef] [PubMed]
- Wen, H.; Shi, J.; Zhang, Y.; Lu, K.H.; Cao, J.; Liu, Z. Neural encoding and decoding with deep learning for dynamic natural vision. Cereb. Cortex 2018, 28, 4136–4160. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. VMamba: Visual State Space Model. arXiv 2024, arXiv:2401.10166v4. [Google Scholar] [CrossRef]
- Schoenmakers, S.; Barth, M.; Heskes, T.; van Gerven, M. Linear reconstruction of perceived images from human brain activity. NeuroImage 2013, 83, 951–961. [Google Scholar] [CrossRef] [PubMed]
- Cowen, A.S.; Chun, M.M.; Kuhl, B.A. Neural portraits of perception: Reconstructing face images from evoked brain activity. NeuroImage 2014, 94, 12–22. [Google Scholar] [CrossRef] [PubMed]
- Güçlütürk, Y.; Güçlü, U.; Seeliger, K.; Bosch, S.; van Lier, R.; van Gerven, M.A.J. Reconstructing perceived faces from brain activations with deep adversarial neural decoding. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Long Beach, CA, USA, 2017; pp. 4249–4260. [Google Scholar]
- Shen, G.H.; Horikawa, T.; Majima, K.; Kamitani, Y. Deep image reconstruction from human brain activity. PLoS Comput. Biol. 2019, 15. [Google Scholar] [CrossRef] [PubMed]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef] [PubMed]
- Song, S.; Zhan, Z.; Long, Z.; Zhang, J.; Yao, L. Comparative Study of SVM Methods Combined with Voxel Selection for Object Category Classification on fMRI Data. PLoS ONE 2011, 6, e17191. [Google Scholar] [CrossRef] [PubMed]
- Fujiwara, Y.; Miyawaki, Y.; Kamitani, Y. Modular encoding and decoding models derived from Bayesian canonical correlation analysis. Neural Comput. 2013, 25, 979–1005. [Google Scholar] [CrossRef] [PubMed]
- Horikawa, T.; Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 2017, 8, 15037. [Google Scholar] [CrossRef] [PubMed]
- Du, C.D.; Du, C.Y.; Huang, L.J.; Wang, H.B.; He, H.G. Structured neural decoding with multi-task transfer learning of deep neural network representations. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 600–614. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. arXiv 2013, arXiv:1311.2901. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Sereno, M.I.; Dale, A.M.; Reppas, J.B.; Kwong, K.K.; Belliveau, J.W.; Brady, T.J.; Rosen, B.R.; Tootell, R.B. Borders of multiple visual areas in humans revealed by functional magnetic resonance imaging. Science 1995, 268, 889–893. [Google Scholar] [CrossRef] [PubMed]
- Kourtzi, Z.; Kanwisher, N. Cortical regions involved in perceiving object shape. J. Neurosci. 2000, 20, 3310–3318. [Google Scholar] [CrossRef] [PubMed]
- Kanwisher, N.; McDermott, J.; Chun, M.M. The fusiform face area: A module in human extrastriate cortex specialized for face perception. J. Neurosci. 1997, 17, 4302–4311. [Google Scholar] [CrossRef] [PubMed]
- Epstein, R.; Kanwisher, N. A cortical representation of the local visual environment. Nature 1998, 392, 598–601. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Operation | Output Size |
|---|---|---|
| Input | ||
| LGN | csm | |
| V1 | conv , stride = 2, padding = 3 | |
| conv , stride = 1, padding = 1 | ||
| csm | ||
| V2 | conv | |
| conv , stride = 2, padding = 1 | ||
| conv | ||
| csm | ||
| V4 | conv | |
| conv , stride = 2, padding = 1 | ||
| conv | ||
| csm | ||
| IT | conv | |
| conv , stride = 2, padding = 1 | ||
| conv | ||
| csm | ||
| avgpool | ||
| flatten | 1536 | |
| Linear | 1000 |
| V1 | V2 | V3 | V4 | Loc | FFA | PPA | |
|---|---|---|---|---|---|---|---|
| IT Block | 0.312 | 0.352 | 0.413 | 0.468 | 0.545 | 0.587 | 0.567 |
| CNN4 | 0.191 | 0.234 | 0.376 | 0.497 | 0.458 | 0.468 | 0.472 |
| GoogLeNet | 0.244 | 0.271 | 0.343 | 0.449 | 0.517 | 0.531 | 0.506 |
| ResNet-18 | 0.286 | 0.325 | 0.403 | 0.448 | 0.551 | 0.547 | 0.539 |
| IT Block | CNN4 | GoogLeNet | ResNet-18 | |
|---|---|---|---|---|
| Seen object identification | 0.920 | 0.838 | 0.874 | 0.895 |
| Imagined object identify | 0.712 | 0.601 | 0.647 | 0.682 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Zhang, J.; Shan, Q.; Xiao, P.; Liu, A. Visual Information Decoding Based on State-Space Model with Neural Pathways Incorporation. Electronics 2025, 14, 2245. https://doi.org/10.3390/electronics14112245
Wang H, Zhang J, Shan Q, Xiao P, Liu A. Visual Information Decoding Based on State-Space Model with Neural Pathways Incorporation. Electronics. 2025; 14(11):2245. https://doi.org/10.3390/electronics14112245
Chicago/Turabian StyleWang, Haidong, Jianhua Zhang, Qia Shan, Pengfei Xiao, and Ao Liu. 2025. "Visual Information Decoding Based on State-Space Model with Neural Pathways Incorporation" Electronics 14, no. 11: 2245. https://doi.org/10.3390/electronics14112245
APA StyleWang, H., Zhang, J., Shan, Q., Xiao, P., & Liu, A. (2025). Visual Information Decoding Based on State-Space Model with Neural Pathways Incorporation. Electronics, 14(11), 2245. https://doi.org/10.3390/electronics14112245