
Lightweight Semantic Segmentation Network with Multi-Level Feature Fusion and Dual Attention Collaboration

Abstract
1. Introduction
- A lightweight backbone network with multi-level feature fusion capability using a branch-fusion-enhancement structure is proposed. This greatly reduces the number of parameters and computational cost of the overall network while overcoming the defect that the traditional backbone network lacks a multi-level feature fusion design, resulting in high-level semantic information dominating the encoding process, while the local boundaries and fine-grained structural information in the low-level features are not effectively preserved.
- A multi-level collaborative attention mechanism with position awareness was introduced, and attention modules were introduced before and after the fusion of features of different scales. The model’s adaptive feature selection capability in the process of feature extraction and reconstruction was enhanced with extremely low parameter overhead, and the problem of partial information loss in the process of obtaining multi-scale information was alleviated, ultimately achieving an improvement in segmentation performance.
- Our method achieves 74.24% mIOU on the PASCAL VOC 2012 dataset with only 5.869 M parameters and an average pixel accuracy of 83.08%. On the Cityscapes dataset, it achieves 75.29% mIoU with only 5.82 M parameters, achieving a good balance between segmentation accuracy and model lightweightness.
2. Related Work
2.1. High-Accuracy Semantic Segmentation
2.2. Lightweight Semantic Segmentation
2.3. Emerging Research Paradigms in Semantic Segmentation
3. Methods
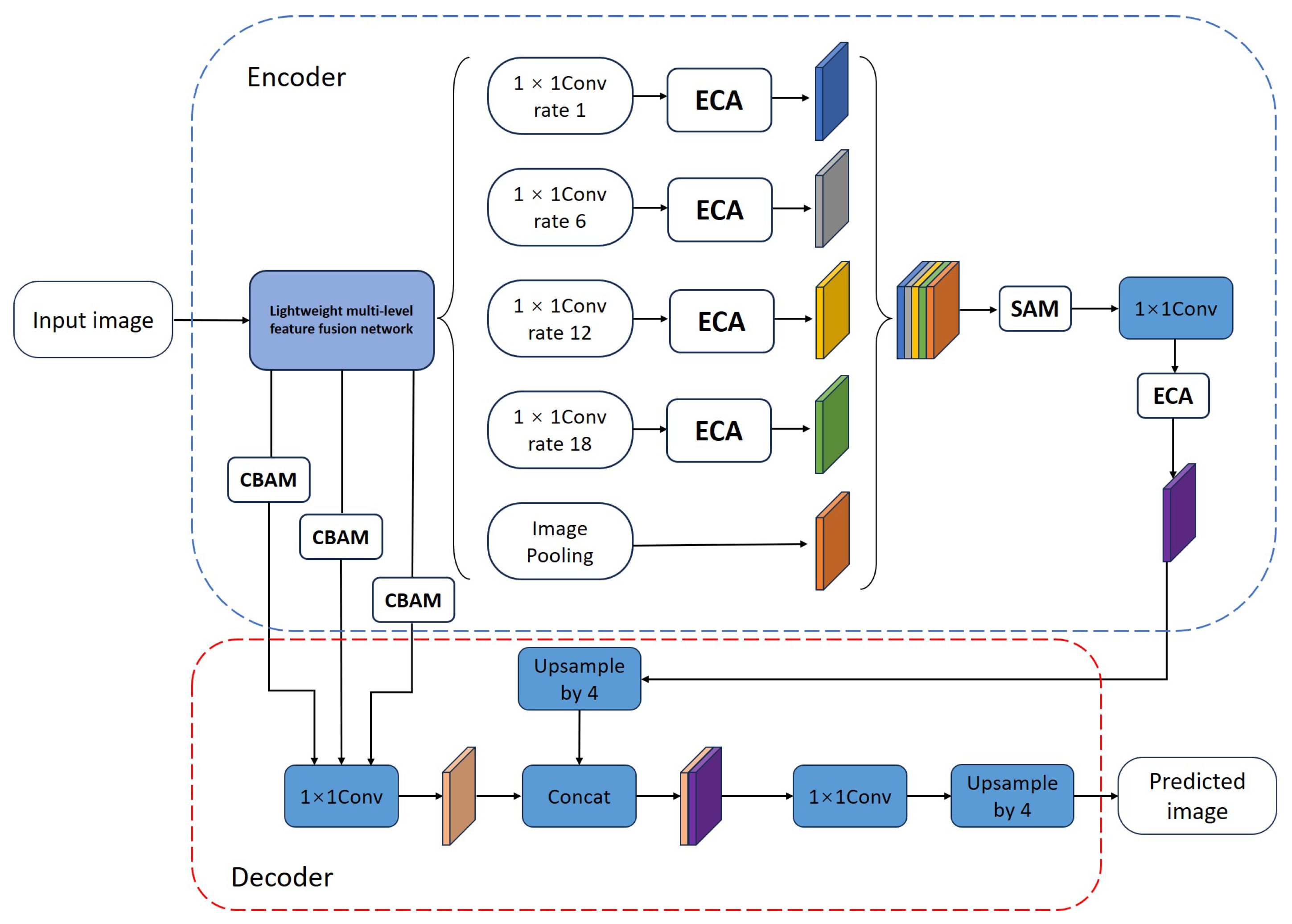
3.1. Lightweight Semantic Segmentation Network with Multi-Level Feature Fusion and Dual Attention Collaboration
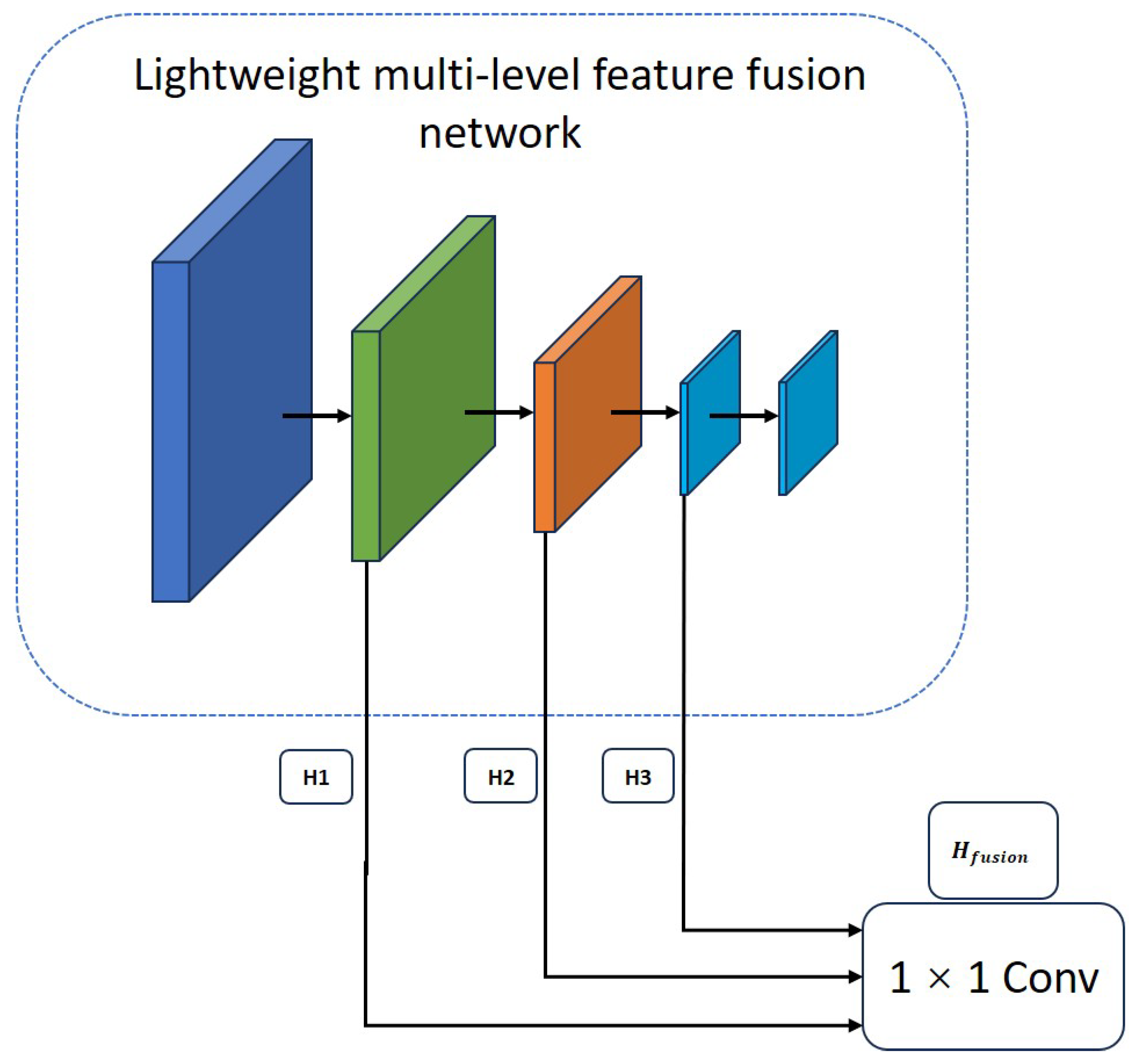
3.2. Lightweight Multi-Level Feature Fusion Backbone Network
3.3. Multi-Channel Feature Aggregation with CBAM
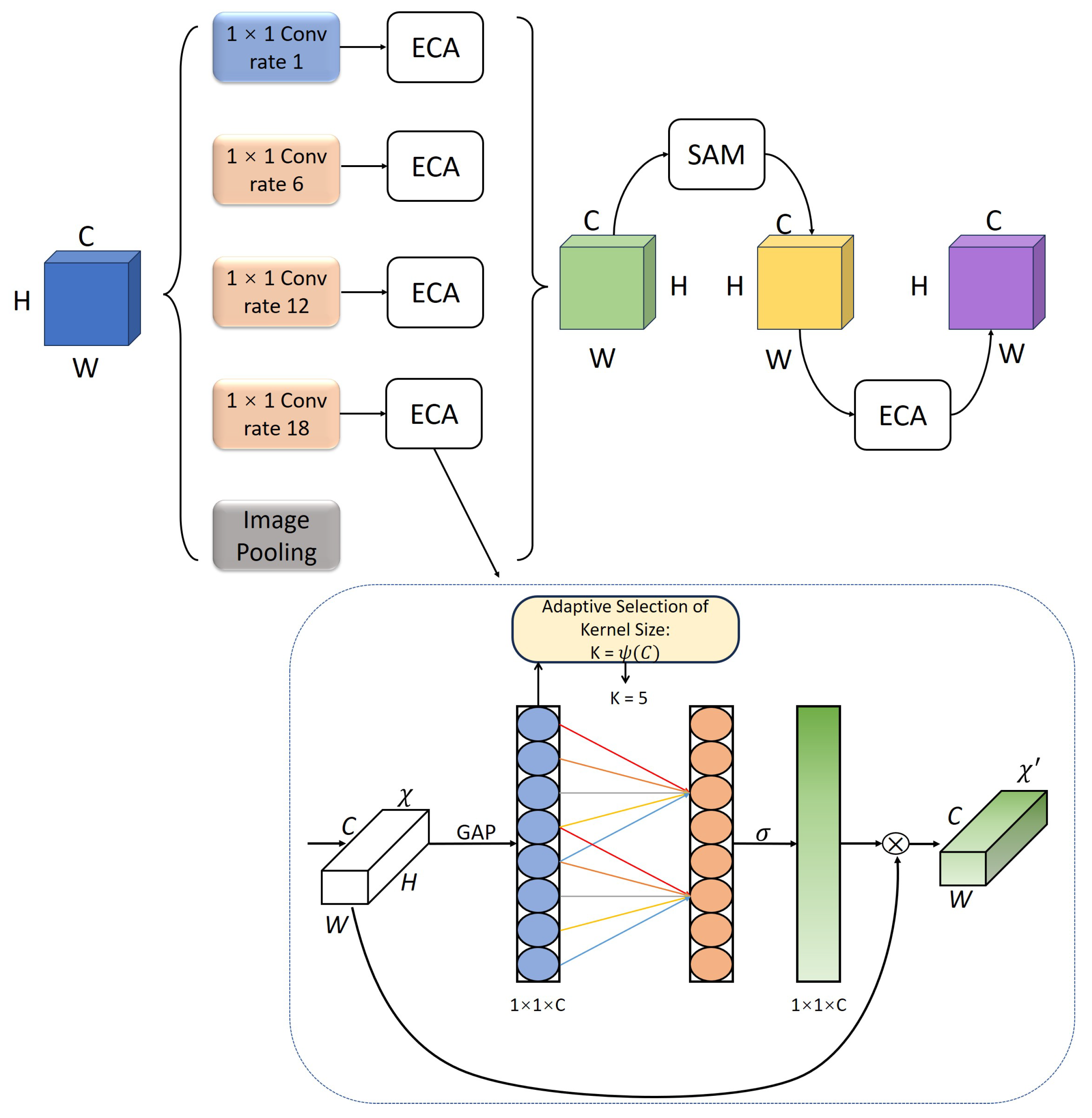
3.4. DCA Module
3.5. Loss Function
4. Results
4.1. Dataset
4.1.1. Pascal VOC 2012
4.1.2. Cityscapes
4.2. Implementation Details
4.3. Experimental Evaluation Indicators
4.4. Performance on Pascal VOC 2012 Dataset
4.4.1. Ablation Study on Pascal VOC 2012
4.4.2. Visualization Results on the Pascal VOC 2012 Dataset
4.5. Performance on the Cityscapes Dataset
Visualization Results on Cityscapes
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, Y.; Wang, C.; Fu, Q.; Kou, R.; Huang, F.; Yang, B.; Yang, T.; Gao, M. Techniques and challenges of image segmentation: A review. Electronics 2023, 12, 1199. [Google Scholar] [CrossRef]
- Qin, F.; Shen, X.; Peng, Y.; Shao, Y.; Yuan, W.; Ji, Z.; Bai, J. A real-time semantic segmentation approach for autonomous driving scenes. J. Comput. Aided Des. Comput. Graph. 2021, 33, 1026–1037. [Google Scholar] [CrossRef]
- Tsai, J.; Chang, C.C.; Li, T. Autonomous driving control based on the technique of semantic segmentation. Sensors 2023, 23, 895. [Google Scholar] [CrossRef]
- Fu, Y.; Lei, Y.; Wang, T.; Curran, W.J.; Liu, T.; Yang, X. A review of deep learning based methods for medical image multi-organ segmentation. Phys. Medica 2021, 85, 107–122. [Google Scholar] [CrossRef] [PubMed]
- Zheng, B.; Zhang, R.; Diao, S.; Zhu, J.; Yuan, Y.; Cai, J.; Shao, L.; Li, S.; Qin, W. Dual domain distribution disruption with semantics preservation: Unsupervised domain adaptation for medical image segmentation. Med. Image Anal. 2024, 97, 103275. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, Z.; Zheng, G.; Yao, X. Semantic segmentation of high-resolution remote sensing images with improved U-Net based on transfer learning. Int. J. Comput. Intell. Syst. 2023, 16, 181. [Google Scholar] [CrossRef]
- Huang, L.; Jiang, B.; Lv, S.; Liu, Y.; Fu, Y. Deep-learning-based semantic segmentation of remote sensing images: A survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 8370–8396. [Google Scholar] [CrossRef]
- Tong, L.; Song, K.; Tian, H.; Man, Y.; Yan, Y.; Meng, Q. SG-grasp: Semantic segmentation guided robotic grasp oriented to weakly textured objects based on visual perception sensors. IEEE Sens. J. 2023, 23, 28430–28441. [Google Scholar] [CrossRef]
- Ainetter, S.; Fraundorfer, F. End-to-end trainable deep neural network for robotic grasp detection and semantic segmentation from rgb. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13452–13458. [Google Scholar]
- Liang, Y.; Xu, Z.; Rasti, S.; Dev, S.; Campbell, A.G. On the use of a semantic segmentation micro-service in ar devices for ui placement. In Proceedings of the IEEE Games, Entertainment, Media Conference (GEM), Bridgetown, Barbados, 27–30 November 2022; pp. 1–6. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. Automatica 1975, 11, 23–27. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder–decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Liu, J. Ce-net: Context encoder network for 2D medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 July 2019; pp. 6105–6114. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–2 July 2016; pp. 770–778. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.; et al. Segment Anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 3992–4003. [Google Scholar]
- Zhou, T.; Wang, W. Prototype-Based Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 6858–6872. [Google Scholar] [CrossRef]
- Zhou, T.; Wang, W. Cross-Image Pixel Contrasting for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5398–5412. [Google Scholar] [CrossRef]
- Zhou, T.; Zhang, F.; Chang, B.; Wang, W.; Yuan, Y.; Konukoglu, E.; Cremers, D. Image Segmentation in Foundation Model Era: A Survey. arXiv 2024, arXiv:2408.12957. [Google Scholar]
- Chern, W.C.; Nguyen, T.V.; Asari, V.K.; Kim, H. Impact of loss functions on semantic segmentation in far-field monitoring. Comput. Civ. Infrastruct. Eng. 2023, 38, 372–390. [Google Scholar] [CrossRef]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Peng, H.; Xiang, S.; Chen, M.; Li, H.; Su, Q. DCN-Deeplabv3+: A novel road segmentation algorithm based on improved Deeplabv3+. IEEE Access 2024, 12, 87397–87406. [Google Scholar] [CrossRef]
- Xu, L.; Ouyang, W.; Bennamoun, M.; Boussaid, F.; Xu, D. Multi-class Token Transformer for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4300–4309. [Google Scholar]
- Lee, M.; Kim, D.; Shim, H. Threshold Matters in WSSS: Manipulating the Activation for the Robust and Accurate Segmentation Model Against Thresholds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4320–4329. [Google Scholar]
- Zhang, H.; Dana, K.J.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context Encoding for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2022; pp. 7151–7160. [Google Scholar]
- Pan, H.; Hong, Y.; Sun, W.; Jia, Y. Deep Dual-Resolution Networks for Real-Time and Accurate Semantic Segmentation of Traffic Scenes. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3448–3460. [Google Scholar] [CrossRef]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking BiSeNet For Real-time Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 9711–9720. [Google Scholar]
- Yang, G.; Wang, Y.; Shi, D. Reparameterizable Dual-Resolution Network for Real-time Semantic Segmentation. arXiv 2024, arXiv:2406.12496. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Floating Point Calculation/Gflops | Parameters/M | Speed/FPS | mIoU/% |
|---|---|---|---|---|
| PSPNet | 118.447 | 46.716 | 64.7 | 83.16 |
| UNet | 184.737 | 43.934 | 39.5 | 70.34 |
| Deeplabv3+ | 167.00 | 54.714 | 42.9 | 78.03 |
| BiseNet | 13.65 | 49 | 64.8 | 65.28 |
| DCN-Deeplabv3+ | 62.36 | 12.28 | - | 72.38 |
| MCTformer | 22.58 | 21.66 | 41.6 | 71.9 |
| AMN | 55.58 | 73.55 | 49.1 | 70.7 |
| Ours | 56.596 | 5.869 | 89.6 | 74.24 |
| Model | DCA Module | Multi-Level Feature Fusion | Dice Loss Function | Speed/FPS | Parameters | mIoU/% |
|---|---|---|---|---|---|---|
| Model0 | - | - | - | 95.7 | 5.81 M | 72.64 |
| Model1 | ✓ | - | - | 95.3 | 5.82 M | 73.69 |
| Model2 | ✓ | ✓ | - | 89.4 | 5.87 M | 73.94 |
| Model3 | ✓ | ✓ | ✓ | 89.6 | 5.87 M | 74.24 |
| Methods | Floating Point Calculation/Gflops | Parameters/M | Speed/FPS | mIoU/% |
|---|---|---|---|---|
| PSPNet | 116.9 | 58.1 | 66.3 | 78.5 |
| EncNet | 1748.0 | 55.1 | 56.6 | 76.9 |
| BiseNet | 118.0 | 13.3 | 65.9 | 74.4 |
| DCN-Deeplabv3+ | 62.34 | 12.28 | - | 75.22 |
| DDRNet | 143.0 | 20.3 | 54.6 | 77.82 |
| STDC | 66.1 | 14.2 | 74.7 | 74.5 |
| RDRNet | 238.0 | 36.9 | 39.3 | 78.6 |
| Ours | 56.38 | 5.82 | 90.1 | 75.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Wang, X.; Deng, B.; Yu, Y. Lightweight Semantic Segmentation Network with Multi-Level Feature Fusion and Dual Attention Collaboration. Electronics 2025, 14, 2244. https://doi.org/10.3390/electronics14112244
Ma Y, Wang X, Deng B, Yu Y. Lightweight Semantic Segmentation Network with Multi-Level Feature Fusion and Dual Attention Collaboration. Electronics. 2025; 14(11):2244. https://doi.org/10.3390/electronics14112244
Chicago/Turabian StyleMa, Yulong, Xiaoyu Wang, Bo Deng, and Yue Yu. 2025. "Lightweight Semantic Segmentation Network with Multi-Level Feature Fusion and Dual Attention Collaboration" Electronics 14, no. 11: 2244. https://doi.org/10.3390/electronics14112244
APA StyleMa, Y., Wang, X., Deng, B., & Yu, Y. (2025). Lightweight Semantic Segmentation Network with Multi-Level Feature Fusion and Dual Attention Collaboration. Electronics, 14(11), 2244. https://doi.org/10.3390/electronics14112244