

Enhancing Interprofessional Communication in Healthcare Using Large Language Models: Study on Similarity Measurement Methods with Weighted Noun Embeddings

Abstract
1. Introduction
2. Materials and Methods
2.1. Similarity Analysis Methods
2.1.1. Cosine Similarity
2.1.2. Word2Vec
2.1.3. FastText
2.1.4. Sentence-BERT
2.2. Corpus Utilization
2.3. Weighted Noun Embeddings
- : High-scoring nouns, ,
- : Positive domain terms, ,
- : Mid-scoring nouns, ,
- : Low-scoring nouns, ,
2.3.1. Word2Vec and FastText Fine-Tuning
2.3.2. Sentence-BERT Fine-Tuning
2.4. Experimental Setup
2.5. Experiment Setup
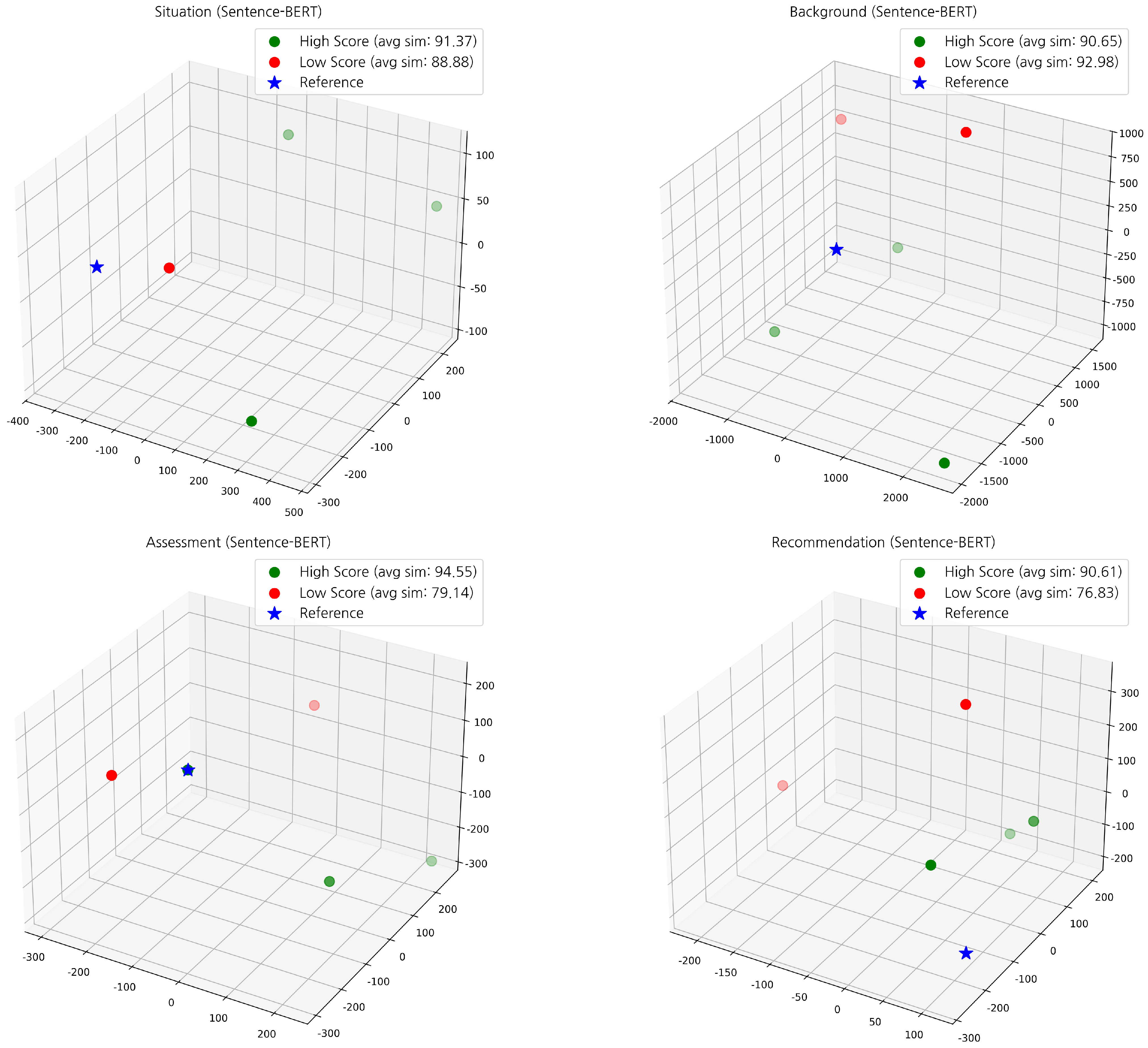
3. Results
3.1. SBAR Scenario and Data Collection
3.2. Corpus Statistics
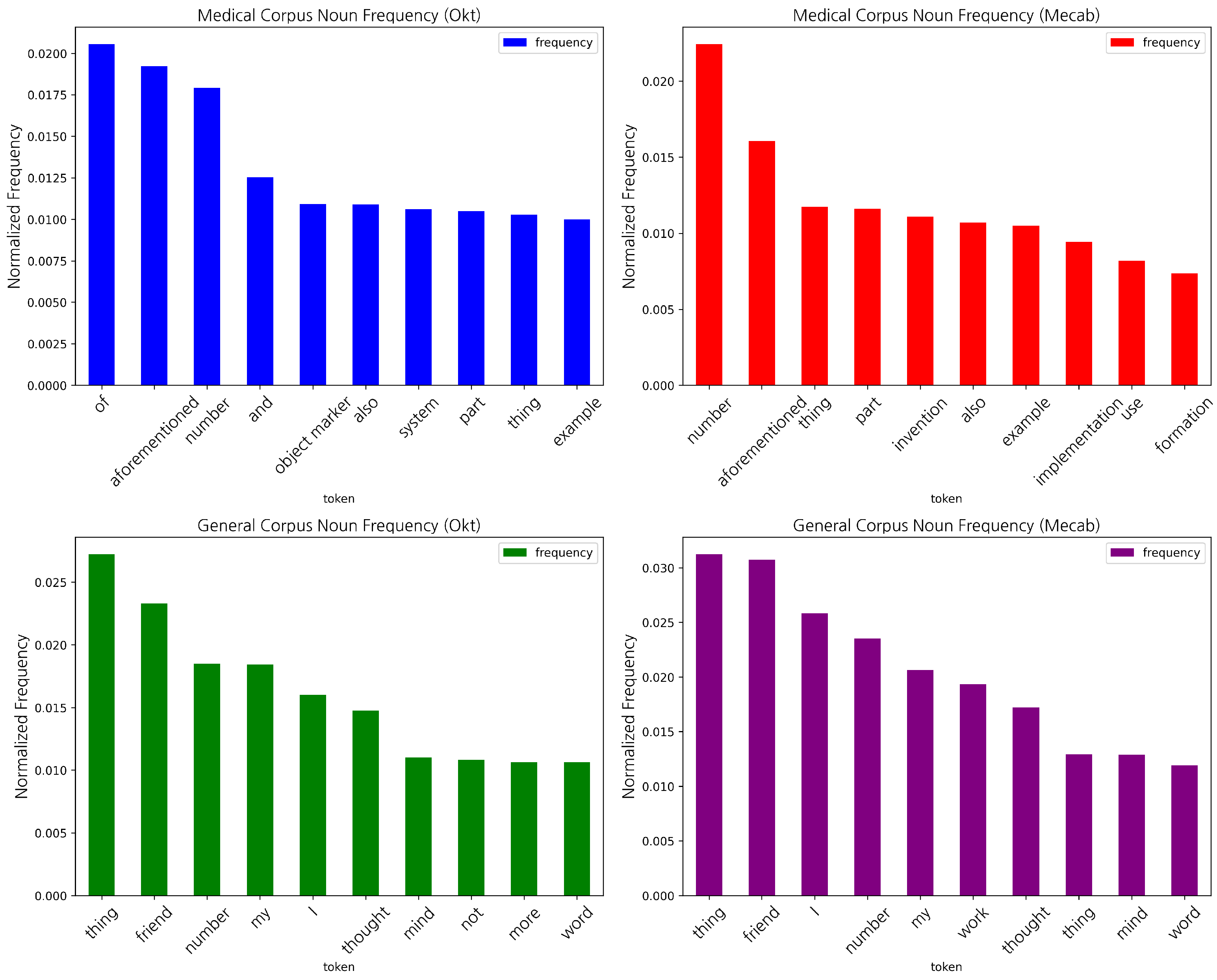
3.3. Token Frequency and Embedding Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Burisch, C.; Bellary, A.; Breuckmann, F.; Ehlers, J.; Thal, S.; Sellmann, T.; Gödde, D. ChatGPT-4 Performance on German Continuing Medical Education—Friend or Foe (Trick or Treat)? Protocol for a Randomized Controlled Trial. JMIR Res. Protoc. 2025, 14, e63887. [Google Scholar] [CrossRef] [PubMed]
- Müller, M.; Jürgens, J.; Redaèlli, M.; Klingberg, K.; Hautz, W.E.; Stock, S. Impact of the communication and patient hand-off tool SBAR on patient safety: A systematic review. BMJ Open 2018, 8, e022202. [Google Scholar] [CrossRef]
- Hang, C.N.; Tan, C.W.; Yu, P.-D. MCQGen: A Large Language Model-Driven MCQ Generator for Personalized Learning. IEEE Access 2024, 12, 102261–102273. [Google Scholar] [CrossRef]
- Reference Answer Corpus. Available online: https://github.com/skyoum00/SBAR_Assessment_Tool/blob/main/referenceAnswerCorpus (accessed on 7 March 2025).
- Wang, J.; Dong, Y. Measurement of Text Similarity: A Survey. Information 2020, 11, 421. [Google Scholar] [CrossRef]
- Medical Corpus. Available online: https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=71487 (accessed on 7 March 2025).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. NeurIPS 2020, 33, 1877–1901. [Google Scholar]
- Yenduri, G.; Garg, D.; Oak, R.; Hooda, D.; Aggarwal, B.; Kumar, V.; Singh, A.; Lal, S. Generative Pre-trained Transformer: A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions. arXiv 2023, arXiv:2305.10435. [Google Scholar] [CrossRef]
- Song, G.; Ye, Y.; Du, X.; Huang, X.; Bie, S. Short Text Classification: A Survey. J. Med. Microbiol. 2014, 9, 635–643. [Google Scholar] [CrossRef]
- Yi, E.; Koenig, J.-P.; Roland, D. Semantic similarity to high-frequency verbs affects syntactic frame selection. Cogn. Linguist. 2019, 30, 601–628. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, C.; Huang, G.; Guo, Q.; Li, H.; Wei, X. A Short-Text Similarity Model Combining Semantic and Syntactic Information. Electronics 2023, 12, 3126. [Google Scholar] [CrossRef]
- Lahitani, A.R.; Permanasari, A.E.; Setiawan, N.A. Cosine similarity to determine similarity measure: Study case in online essay assessment. In Proceedings of the 2016 4th International Conference on Cyber and IT Service Management, Bandung, Indonesia, 26–27 April 2016; pp. 1–6. [Google Scholar]
- Nurfadila, P.D.; Wibawa, A.P.; Zaeni, I.A.E.; Nafalski, A. Journal Classification Using Cosine Similarity Method on Title and Abstract with Frequency-Based Stopword Removal. Int. J. Artif. Intell. Res. 2019, 3, 41–47. [Google Scholar] [CrossRef]
- Ristanti, P.Y.; Wibawa, A.P.; Pujianto, U. Cosine Similarity for Title and Abstract of Economic Journal Classification. In Proceedings of the 2019 5th International Conference on Science in Information Technology (ICSITech), Yogyakarta, Indonesia, 23–24 October 2019; pp. 123–127. [Google Scholar]
- Conversational Corpus. Available online: https://raw.githubusercontent.com/byungjooyoo/Dataset/main/corpus.txt (accessed on 7 March 2025).
- Steinberger, J.; Ježek, K. Text Summarization and Singular Value Decomposition. In Proceedings of the 7th International Conference on Advances in Information Systems (ADVIS), Istanbul, Turkey, 20–22 October 2004; pp. 245–254. [Google Scholar]
- Li, X.; Yao, C.; Fan, F.; Yu, X. A Text Similarity Measurement Method Based on Singular Value Decomposition and Semantic Relevance. J. Inf. Process. Syst. 2017, 13, 863–875. [Google Scholar] [CrossRef]
- Cheng, C.-H.; Chen, H.-H. Sentimental text mining based on an additional features method for text classification. PLoS ONE 2019, 14, e0217591. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Bandar, Z.; McLean, D.; O’Shea, J. A Method for Measuring Sentence Similarity and its Application to Conversational Agents. In Proceedings of the 17th International Florida Artificial Intelligence Research Society Conference, Miami Beach, FL, USA, 17–19 May 2004. [Google Scholar]
- Borgeaud, S.; Mensch, A.; Hoffmann, J.; Cai, T.; Rutherford, E.; Casas, D.d.L.; Hendricks, L.A.; Welbl, J.; Clark, A.; Hattingh, J.; et al. Improving language models by retrieving from trillions of tokens. arXiv 2022, arXiv:2112.04426. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wahyudi; Akbar, R.; Suharsono, T.N.; Indrapriyatna, A.S. Essay Test Based E-Testing Using Cosine Similarity Vector Space Model. In Proceedings of the 2022 International Symposium on Information Technology and Digital Innovation (ISITDI), Padang, Indonesia, 27–28 July 2022; pp. 80–85. [Google Scholar]
- Davis, B.P.; Mitchell, S.A.; Weston, J.; Dragon, C.; Luthra, M.; Kim, J.; Stoddard, H.; Ander, D. Situation, Background, Assessment, Recommendation (SBAR) Education for Health Care Students: Assessment of a Training Program. MedEdPORTAL 2023, 19, 11293. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Kudo, T.; Yamamoto, K.; Matsumoto, Y. Applying Conditional Random Fields to Japanese Morphological Analysis. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP), Barcelona, Spain, 25–26 July 2004; pp. 230–237. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Park, J.; Shin, J.; Woo, S.; Lee, J.; Jang, M.; Lee, H.; Ham, D. KLUE: Korean Language Understanding Evaluation. arXiv 2021, arXiv:2105.09680. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. arXiv 2018, arXiv:1803.08808. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SBAR | Contents |
|---|---|
| Situation | Hello, I am Kim Jiwoo, a nurse in the emergency room. Are you Dr. Choi Junsu? I am contacting you regarding a 6-year-old boy, Kim Rian, who has a history of asthma and has been admitted to the emergency room with difficulty breathing, coughing, and fever symptoms. |
| Background | The symptoms started a week ago, and he was treated with medication at a local clinic, but there has been no improvement. He was brought in today due to a fever and difficulty breathing. |
| Assessment | Vital signs measurements show a pulse rate of 92 beats per minute and a respiratory rate of 28. He took an antipyretic two hours ago, but he is still showing symptoms of fever and difficulty breathing. His SpO2 is checked at 94%. |
| Recommendation | The child is in a lot of distress, and the guardian wishes to see the primary physician. Please come quickly to assess the patient’s condition and prescribe medication and oxygen as necessary. |
| Characteristic | Conversation Corpus | Medical Corpus | Reference Answers |
|---|---|---|---|
| Total Tokens | 2,922,486 | 42,093,425 | 732 |
| Vocabulary Diversity | 0.0184 | 0.0057 | 0.4249 |
| Number of Sentences | 65,117 | 1,106,104 | 49 |
| Average Sentence Length | 44.88 | 38.06 | 14.94 |
| File Size | 18 MB | 433 MB | 8 KB |
| SBAR Section | FastText—Before | FastText—After | ||||
|---|---|---|---|---|---|---|
| High | Low | Diff. | High | Low | Diff. | |
| Situation | 86.71 | 72.97 | 13.74 | 88.21 | 60.65 | 27.56 |
| Background | 77.99 | 89.27 | −11.28 | 76.80 | 74.29 | 2.51 |
| Assessment | 89.60 | 51.39 | 38.21 | 90.55 | 51.80 | 38.75 |
| Recommendation | 79.66 | 53.80 | 25.86 | 82.10 | 41.40 | 40.70 |
| Avg. Difference | 16.63 | 27.38 | ||||
| SBAR Section | Word2Vec—Before | Word2Vec—After | ||||
|---|---|---|---|---|---|---|
| High | Low | Diff. | High | Low | Diff. | |
| Situation | 87.05 | 72.39 | 14.66 | 88.26 | 58.11 | 30.15 |
| Background | 76.79 | 89.16 | −12.37 | 75.58 | 74.63 | 0.95 |
| Assessment | 88.99 | 50.02 | 38.97 | 90.55 | 50.26 | 40.28 |
| Recommendation | 79.92 | 52.59 | 27.33 | 81.69 | 40.27 | 41.42 |
| Avg. Difference | 17.15 | 28.20 | ||||
| SBAR Section | Sentence-BERT—Before | Sentence-BERT—After | ||||
|---|---|---|---|---|---|---|
| High | Low | Diff. | High | Low | Diff. | |
| Situation | 92.56 | 91.54 | 1.02 | 90.56 | 80.78 | 9.79 |
| Background | 93.08 | 93.74 | −0.66 | 89.85 | 84.84 | 5.01 |
| Assessment | 95.53 | 85.24 | 10.29 | 93.93 | 77.71 | 16.22 |
| Recommendation | 92.94 | 83.55 | 9.38 | 89.11 | 69.68 | 19.43 |
| Avg. Difference | 5.01 | 12.61 | ||||
| id | Eval.1 | Eval.2 | Word2Vec | FastText | Sentence-BERT |
|---|---|---|---|---|---|
| 01 | Average | Average | 368.05 | 367.85 | 388.38 |
| 02 | Average | Average | 248.66 | 247.68 | 281.31 |
| 03 | Low | Average | 0.00 | 0.00 | 0.00 |
| 04 | Average | Low | 312.16 | 313.59 | 377.90 |
| 05 | High | High | 373.85 | 375.45 | 394.40 |
| 06 | High | High | 345.61 | 349.74 | 388.83 |
| 07 | Average | Average | 336.66 | 337.53 | 386.65 |
| 08 | High | High | 357.51 | 356.88 | 384.59 |
| 09 | Low | Low | 348.02 | 348.08 | 362.24 |
| 10 | Average | Average | 306.23 | 309.22 | 364.65 |
| 11 | Average | Average | 236.58 | 236.55 | 281.09 |
| 12 | Average | Average | 266.01 | 266.09 | 288.47 |
| 13 | Average | Average | 355.65 | 359.26 | 375.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeo, J.-Y.; Youm, S.; Shin, K.-S. Enhancing Interprofessional Communication in Healthcare Using Large Language Models: Study on Similarity Measurement Methods with Weighted Noun Embeddings. Electronics 2025, 14, 2240. https://doi.org/10.3390/electronics14112240
Yeo J-Y, Youm S, Shin K-S. Enhancing Interprofessional Communication in Healthcare Using Large Language Models: Study on Similarity Measurement Methods with Weighted Noun Embeddings. Electronics. 2025; 14(11):2240. https://doi.org/10.3390/electronics14112240
Chicago/Turabian StyleYeo, Ji-Young, Sungkwan Youm, and Kwang-Seong Shin. 2025. "Enhancing Interprofessional Communication in Healthcare Using Large Language Models: Study on Similarity Measurement Methods with Weighted Noun Embeddings" Electronics 14, no. 11: 2240. https://doi.org/10.3390/electronics14112240
APA StyleYeo, J.-Y., Youm, S., & Shin, K.-S. (2025). Enhancing Interprofessional Communication in Healthcare Using Large Language Models: Study on Similarity Measurement Methods with Weighted Noun Embeddings. Electronics, 14(11), 2240. https://doi.org/10.3390/electronics14112240