
A Three-Channel Improved SE Attention Mechanism Network Based on SVD for High-Order Signal Modulation Recognition


Abstract
1. Introduction
- We first employ entropy-based SVD to denoise the signals in the dataset. By selecting the minimum number k of singular values whose cumulative entropy reaches 90%, we preserve the key features of the signals and effectively enhance their quality.
- We propose a novel and efficient deep-learning model. The model processes signals through three channels: I, Q, and A/P signal. By combining 1D and 2D convolutional layers, time domain and frequency domain features are extracted respectively. Multi-dimensional features are fused by serial splicing and parallel interaction, further enhancing the feature expression ability. In addition, we introduce an improved SE attention mechanism to dynamically enhance the weights of critical features, improving the model’s ability to focus on important information.
- To verify the effectiveness of the method, we conduct comparative experiments with six other mainstream network models. The experimental results demonstrate that the model exhibits superior recognition performance in complex environments, particularly showing strong discriminative capability for high-order signal (such as 16QAM and 64QAM). Specifically, the average confusion probability for 16QAM and 64QAM is significantly reduced from 46.50% to 7.10%, which proves the effectiveness and robustness of the model.
2. Modulation Signal Model
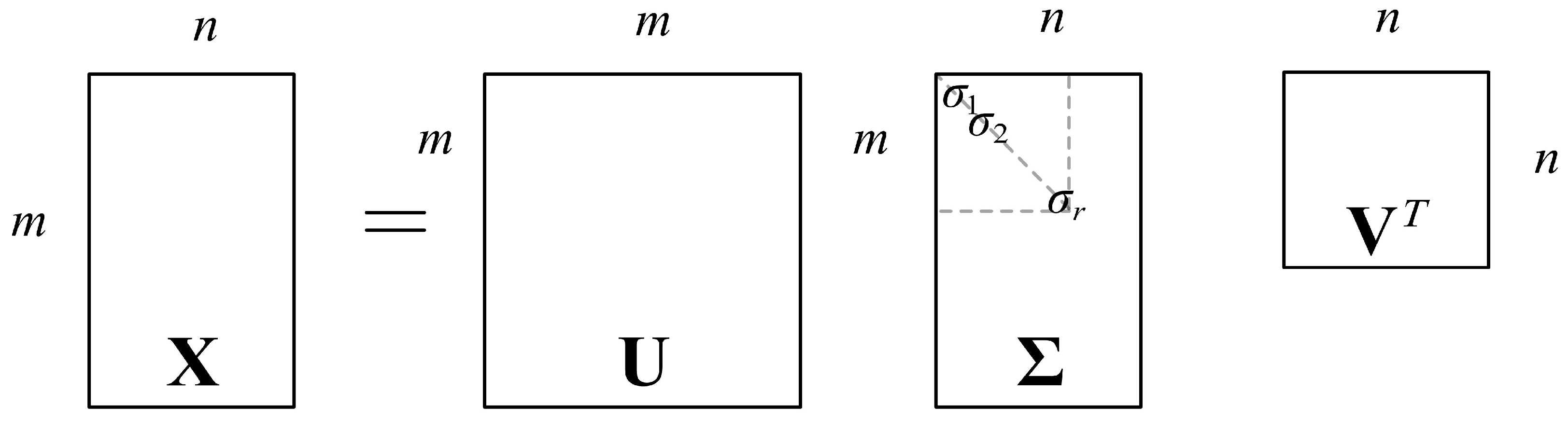
3. Entropy-Based SVD Denoising
- Normalization: normalize each row of to obtain the matrix , as shown in the following formula:where represents the i-th row of matrix , which corresponds to the raw data of the i-th pulse signal. represents the normalized data of the i-th row.
- SVD: perform SVD decomposition on the matrix to obtain the matrix and the singular value matrix .
- Metric calculation: compute the normalized energy and total information entropy .
- Iterative k-value search: determine the minimal k satisfying by cumulative entropy proportion analysis. Construct a diagonal matrix .
- Signal reconstruction: select the first k columns in the matrix to construct a matrix , the first k rows in the matrix to construct a matrix , and obtain the final denoised signal matrix .
4. Proposed Framework
4.1. Three-Channel Spatial Feature Extraction Module
- Propose a bimodal feature extraction strategy that combines global maximum pooling (GMP) and GAP to more comprehensively extract channel features.
- Introduce a batch normalization (BN) layer in the Excitation module to effectively alleviate parameter coupling issues in the FC layers, further improving training stability and efficiency.
- Reconstruct the network topology of the Excitation module to build a composite excitation structure containing multi-level nonlinear transformations, enabling refined modeling of high-order correlations between channels.
4.2. Temporal Feature Extraction Module

4.3. Fully Connected Classification and Recognition Module
5. Simulation Experiment and Performance Analysis
5.1. Dataset
5.2. Experimental Environment
5.3. Comparative Experiment
5.4. Ablation Experiment
6. Discussion
6.1. Technical Features and Contributions
6.2. Limitations and Prospects
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Li, C.J.; Jin, C.T.; Leong, P.H.W. Wireless Signal Representation Techniques for Automatic Modulation Classification. IEEE Access 2022, 10, 84166–84187. [Google Scholar] [CrossRef]
- Jassim, S.A.; Khider, I. Comparison of Automatic Modulation Classification Techniques. J. Commun. 2022, 17, 574–580. [Google Scholar] [CrossRef]
- Ding, R.; Zhang, H.; Zhou, F.; Wu, Q.; Han, Z. Data-and-knowledge dual-driven automatic modulation recognition for wireless communication networks. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1962–1967. [Google Scholar]
- O’Shea, T.; West, N. Radio Machine Learning Dataset Generation with GNU Radio. In Proceedings of the GNU Radio Conference, Boulder, CO, USA, 12–16 September 2016; Volume 1. [Google Scholar]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-air deep learning based radio signal classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zeng, Y.; Zhang, M.; Han, F.; Gong, Y.; Zhang, J. Spectrum analysis and convolutional neural network for automatic modulation recognition. IEEE Wirel. Commun. Lett. 2019, 8, 929–932. [Google Scholar] [CrossRef]
- Qi, P.; Zhou, X.; Zheng, S.; Li, Z. Automatic modulation classification based on deep residual networks with multimodal information. IEEE Trans. Cogn. Commun. Netw. 2020, 7, 21–33. [Google Scholar] [CrossRef]
- Zhang, Z.; Luo, H.; Wang, C.; Gan, C.; Xiang, Y. Automatic modulation classification using CNN-LSTM based dual-stream structure. IEEE Trans. Veh. Technol. 2020, 69, 13521–13531. [Google Scholar] [CrossRef]
- Kohler, M.; Ahlemann, P.; Bantle, A.; Rapp, M.; Weiß, M.; O’Hagan, D. Transfer learning based intra-modulation of pulse classification using the continuous Paul-wavelet transform. In Proceedings of the 2022 23rd International Radar Symposium (IRS), Gdansk, Poland, 12–14 September 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 496–500. [Google Scholar]
- Zheng, Y.; Ma, Y.; Tian, C. Tmrn-glu: A transformer-based automatic classification recognition network improved by gate linear unit. Electronics 2022, 11, 1554. [Google Scholar] [CrossRef]
- Deng, W.; Wang, X.; Huang, Z.; Xu, Q. Modulation classifier: A few-shot learning semi-supervised method based on multimodal information and domain adversarial network. IEEE Commun. Lett. 2022, 27, 576–580. [Google Scholar] [CrossRef]
- Parmar, A.; Divya, K.; Chouhan, A.; Captain, K. Dual-stream CNN-BiLSTM model with attention layer for automatic modulation classification. In Proceedings of the 2023 15th International Conference on COMmunication Systems & NETworkS (COMSNETS), Bangalore, India, 3–8 January 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 603–608. [Google Scholar]
- Xu, T.; Ma, Y. Signal automatic modulation classification and recognition in view of deep learning. IEEE Access 2023, 11, 114623–114637. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Yu, Z.; Wang, H.; Elhanashi, A.; Saponara, S. DL-PR: Generalized automatic modulation classification method based on deep learning with priori regularization. Eng. Appl. Artif. Intell. 2023, 122, 106082. [Google Scholar] [CrossRef]
- Jang, J.; Pyo, J.; Yoon, Y.I.; Choi, J. Meta-transformer: A meta-learning framework for scalable automatic modulation classification. IEEE Access 2024, 12, 9267–9276. [Google Scholar] [CrossRef]
- An, Z.; Xu, Y.; Tahir, A.; Wang, J.; Ma, B.; Pedersen, G.F.; Shen, M. Physics-Informed Scattering Transform Network for Modulation Recognition in 5G Industrial Cognitive Communications Considering Nonlinear Impairments in Active Phased Arrays. IEEE Trans. Ind. Inform. 2024, 21, 425–434. [Google Scholar] [CrossRef]
- Beard, J.K. Singular value decomposition of a matrix representation of the Costas condition for Costas array selection. IEEE Trans. Aerosp. Electron. Syst. 2020, 57, 1139–1161. [Google Scholar] [CrossRef]
- Zhang, F.; Luo, C.; Xu, J.; Luo, Y.; Zheng, F.C. Deep learning based automatic modulation recognition: Models, datasets, and challenges. Digit. Signal Process. 2022, 129, 103650. [Google Scholar] [CrossRef]
- Ba, Y.; Ping, Y.; Tianyao, Z. Radar emitter signal identification based on weighted normalized singular-value decomposition. J. Radars 2019, 8, 44–53. [Google Scholar]
- Zhang, T.; Weng, H.; Yi, K.; Chen, C. OneDConv: Generalized convolution for transform-invariant representation. arXiv 2022, arXiv:2201.05781. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Ballakur, A.A.; Arya, A. Empirical evaluation of gated recurrent neural network architectures in aviation delay prediction. In Proceedings of the 2020 5th International Conference on Computing, Communication and Security (ICCCS), Patna, India, 14–16 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Tekbıyık, K.; Ekti, A.R.; Görçin, A.; Kurt, G.K.; Keçeci, C. Robust and fast automatic modulation classification with CNN under multipath fading channels. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Hong, D.; Zhang, Z.; Xu, X. Automatic modulation classification using recurrent neural networks. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 695–700. [Google Scholar]
- Ke, Z.; Vikalo, H. Real-time radio technology and modulation classification via an LSTM auto-encoder. IEEE Trans. Wirel. Commun. 2021, 21, 370–382. [Google Scholar] [CrossRef]
- Rajendran, S.; Meert, W.; Giustiniano, D.; Lenders, V.; Pollin, S. Distributed deep learning models for wireless signal classification with low-cost spectrum sensors. arXiv 2017, arXiv:1707.08908. [Google Scholar] [CrossRef]
- Liu, X.; Yang, D.; El Gamal, A. Deep neural network architectures for modulation classification. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 915–919. [Google Scholar]
- Jin, X.; Ma, J.; Ye, F. Radar signal recognition based on deep residual network with attention mechanism. In Proceedings of the 2021 IEEE 4th International Conference on Electronic Information and Communication Technology (ICEICT), Xi’an, China, 18–20 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 428–432. [Google Scholar]
- Abdel-Galil, T.; El-Hag, A.H.; Gaouda, A.; Salama, M.; Bartnikas, R. De-noising of partial discharge signal using eigen-decomposition technique. IEEE Trans. Dielectr. Electr. Insul. 2008, 15, 1657–1662. [Google Scholar] [CrossRef]
- Baglama, J.; Chávez-Casillas, J.A.; Perović, V. A hybrid algorithm for computing a partial singular value decomposition satisfying a given threshold. Numer. Algorithms 2024, 1–17. [Google Scholar] [CrossRef]
- Hermawan, A.P.; Ginanjar, R.R.; Kim, D.S.; Lee, J.M. CNN-based automatic modulation classification for beyond 5G communications. IEEE Commun. Lett. 2020, 24, 1038–1041. [Google Scholar] [CrossRef]
- West, N.E.; O’shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; pp. 1–6. [Google Scholar]
- Perenda, E.; Rajendran, S.; Pollin, S. Automatic modulation classification using parallel fusion of convolutional neural networks. In Proceedings of the BalkanCom’19, Skopje, North Macedonia, 10–12 June 2019. [Google Scholar]
- Zhang, F.; Luo, C.; Xu, J.; Luo, Y. An efficient deep learning model for automatic modulation recognition based on parameter estimation and transformation. IEEE Commun. Lett. 2021, 25, 3287–3290. [Google Scholar] [CrossRef]
- Wu, X.; Wei, S.; Zhou, Y. Deep multi-scale representation learning with attention for automatic modulation classification. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Parameters | Parameter Settings |
|---|---|
| Data format | IQ data format; 2 × 128 |
| Number of samples | 220,000 |
| Sampling frequency | 1 MHz |
| Modulation schemes | 11 classes: 8PSK, BPSK, CPFSK, GFSK, PAM4, 16QAM, 64QAM, QPSK, AM-DSB, AM-SSB, WBFM |
| SNR (dB) | |
| Channel environment | Additive Gaussian white noise, selective fading (Rice + Rayleigh) |
|
Network Model | Parameters |
Training Epochs |
Single Signal Test Time/ms | 0–18 dB | |||
|---|---|---|---|---|---|---|---|
|
Average Classifica- tion Accuracy |
Average Probability of 16QAM Being Confused with 64QAM |
Average Probability of 64QAM Being Confused with 16QAM |
Average Confusion Probability | ||||
| TCGDNN | 489,341 | 95 | 40.808 | 91.16% | 3.80% | 10.40% | 7.10% |
| CLDNN | 517,643 | 188 | 38.280 | 82.23% | 55.60% | 14.00% | 34.80% |
| CNN | 1,592,383 | 154 | 29.988 | 82.66% | 56.90% | 36.10% | 46.50% |
| ResNet | 3,098,283 | 125 | 44.333 | 82.55% | 71.30% | 16.60% | 43.95% |
| GRU2 | 151,179 | 106 | 33.267 | 84.05% | 48.10% | 38.10% | 43.10% |
| DAE | 1,063,659 | 242 | 46.358 | 85.75% | 35.50% | 38.10% | 36.80% |
| LSTM2 | 201,099 | 114 | 30.400 | 83.82% | 62.90% | 28.20% | 45.55% |
| 0–18 dB | ||||
|---|---|---|---|---|
| Network Model | Average Classification Accuracy | Average Probability of 16QAM Being Confused with 64QAM | Average Probability of 64QAM Being Confused with 16QAM | Average Confusion Probability |
| TCGDNN | 91.25% | 3.80% | 10.40% | 7.10% |
| TCGDNN-A | 89.35% | 13.90% | 24.10% | 19.00% |
| TCGDNN-B | 89.95% | 7.30% | 27.60% | 17.45% |
| TCGDNN-C | 85.96% | 11.90% | 43.20% | 27.55% |
| TCGDNN-D | 89.88% | 7.00% | 24.90% | 15.95% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Tu, G.; Zhu, X.; Zhao, D.; Zhang, L. A Three-Channel Improved SE Attention Mechanism Network Based on SVD for High-Order Signal Modulation Recognition. Electronics 2025, 14, 2233. https://doi.org/10.3390/electronics14112233
Zhou X, Tu G, Zhu X, Zhao D, Zhang L. A Three-Channel Improved SE Attention Mechanism Network Based on SVD for High-Order Signal Modulation Recognition. Electronics. 2025; 14(11):2233. https://doi.org/10.3390/electronics14112233
Chicago/Turabian StyleZhou, Xujia, Gangyi Tu, Xicheng Zhu, Di Zhao, and Luyan Zhang. 2025. "A Three-Channel Improved SE Attention Mechanism Network Based on SVD for High-Order Signal Modulation Recognition" Electronics 14, no. 11: 2233. https://doi.org/10.3390/electronics14112233
APA StyleZhou, X., Tu, G., Zhu, X., Zhao, D., & Zhang, L. (2025). A Three-Channel Improved SE Attention Mechanism Network Based on SVD for High-Order Signal Modulation Recognition. Electronics, 14(11), 2233. https://doi.org/10.3390/electronics14112233