1. Introduction
Industrial robots have been widely adopted in manufacturing processes, offering substantial gains in productivity, precision, and operational safety [
1]. Among these applications, robotic multi-pin-hole assembly tasks—particularly involving Circular Aviation Electrical Connectors (CAECs)—are essential for establishing reliable electrical links within industrial control boxes due to their compact form and high connection stability. However, during the buckling servo process, posture disturbance errors often lead to insertion failure. Achieving precise and robust connector alignment under multi-error tolerance conditions in both position and orientation remains a major challenge.
CAEC assembly generally comprises two stages: (i) an initial alignment stage where connectors are coarsely positioned without contact, and (ii) a contact engagement stage requiring high-precision alignment for successful pin insertion.
Figure 1 illustrates this process using YP21-3 pin model CAEC connectors, showing posture disturbances during alignment, as well as successful insertion. In this figure,
and
denote the hole positions on the female connector and probe tips on the male connector, respectively. The main challenges of CAEC assembly include:
- 1.
Visual Occlusion: Regardless of sensor configuration, visual occlusions are inevitable during the pin-hole engagement stage. The robotic end-effector and connector body often obstruct visual detection of internal pin-hole alignment, limiting the effectiveness of vision-based methods that rely on clear observation.
- 2.
Higher Precision and Error Tolerance: As shown in
Figure 1a, the pin-hole diameter is 2 mm, with a 5 mm spacing between adjacent holes, while the probe diameter is only 1.8 mm. Posture errors, such as those shown in
Figure 1b during the CAEC servo alignment process, can significantly reduce assembly success rates. This requires both high precision and the ability to tolerate small deviations for successful insertion.
Recent research has focused on unimodal approaches for multi-pin-hole assembly. Chen et al. [
2] proposed a vision-based method using multiple visual sensors to correct alignment deviations. However, this method cannot compensate for end-effector orientation errors and struggles with posture disturbances during assembly. It also requires precise localization and angular computation to prevent pin misalignment, which can lead to component damage or assembly failure. In contrast, Yang et al. [
3] introduced a tactile-based positioning strategy that effectively corrects angular deviations. Building on these studies, we propose a task-specific Haptic–Vision Dual-Stream Siamese Network (HV-DSSN) that integrates visual and tactile features via gated attention for dynamic fusion across assembly phases. The framework combines ConvNeXt and SE-ResNet-50 encoders with a Bi-LSTM-based regression head to jointly estimate six-DoF deviations under posture disturbances. A closed-loop servo control strategy is further designed to apply online corrections in real time. Extensive experiments on a newly collected CAEC dataset demonstrate that our method significantly outperforms state-of-the-art approaches in both regression accuracy and assembly success rates.
The remainder of this paper is organized as follows.
Section 2 reviews related studies on peg-in-hole assembly methods.
Section 3 details the proposed HV-DSSN framework.
Section 4 presents experimental validations and comparisons with state-of-the-art methods.
Section 5 discusses the observed results and design implications. Finally,
Section 6 concludes the work and outlines directions for future research.
2. Related Work
2.1. Robotic Peg-in-Hole Assembly Methods
Traditional robotic peg-in-hole assembly methods include position-based and compliant control strategies. While position-based approaches offer high repeatability, they are sensitive to positional errors in tasks involving posture disturbances and high error tolerance. Compliant methods, such as hybrid force–position and impedance control, improve contact adaptability through real-time force feedback but often require manual parameter tuning and accurate contact modeling, limiting their applicability in precision tasks like CAEC assemblies [
4].
Recent learning-based methods, including imitation and deep reinforcement learning, enhance flexibility by learning from data; however, they typically demand large-scale training and struggle with generalization in high-precision settings. For instance, Zhang et al. [
5] proposed a residual policy learning framework that refines classical controllers using data-driven residuals, demonstrating improved success rates in tight-tolerance insertion tasks. To address these challenges, this work proposes an integrated framework that combines the strengths of both conventional and learning-based approaches to improve the robustness of robotic assembly.
2.2. Tactile–Visual Fusion Strategies in Robotic Assembly
Vision sensing offers global localization capabilities, enabling pre-contact alignment in robotic assembly tasks [
6,
7], but its performance degrades under occlusions or poor lighting during insertion. In contrast, tactile sensing provides precise real-time feedback for in-contact adjustments [
8], though it lacks spatial awareness in early phases. To overcome these limitations, recent studies have explored vision–tactile fusion to enhance adaptability. Li et al. [
9] proposed a multi-sensory control framework that combines visual and tactile data for tight-clearance insertions, while Yu et al. [
10] integrated visual–tactile fusion into a reinforcement learning pipeline for contact-rich manipulation, achieving higher robustness under uncertainty.
However, most existing fusion strategies rely on static or heuristic weighting, limiting their ability to adjust across different assembly phases. To address this, attention mechanisms have gained traction for dynamic modality selection. Fan et al. [
11] introduced a multi-branch gated fusion network to enhance perception in maritime environments, while Cui et al. [
12] applied self-attention for visual–tactile fusion learning to predict grasp outcomes. Zhang et al. [
13] demonstrated that attention-guided cross-modality fusion improves grasp stability assessment, and Lee et al. [
14] proposed a cross-modal attention mechanism for visuo-tactile inputs in deformable object grasping. Based on these insights, this study adopts a gated attention mechanism to dynamically fuse visual and tactile features for robust robotic assembly.
2.3. Deep Learning Models for Robotic Assembly
Dual-stream Siamese neural networks (DSSNs) have recently been employed for robotic alignment and positioning due to their ability to learn deep spatial correlations from paired inputs [
15]. These networks have shown strong performance in detecting fine misalignments in both visual and tactile domains. However, most existing DSSN applications are single-modality, limiting their robustness tasks involving posture disturbances and high error tolerance. Few studies have explored fusing visual and tactile streams within the DSSN architecture to enhance feature richness and decision reliability in complex tasks such as connector insertion.
In parallel, recurrent neural networks—particularly Long Short-Term Memory (LSTM) and its variants—have proven effective in capturing temporal dependencies in sequential robotic control tasks [
16]. LSTM-based models enable the extraction of dynamic patterns in force signals, trajectories, or time-sequenced sensor data. Yet, their integration with multimodal spatial representations for high-precision robotic assembly tasks remains limited. To address these gaps, this study proposes a Haptic–Vision DSSN framework that combines multimodal spatial encoding with Bi-LSTM to jointly capture spatiotemporal features for robust CAEC assembly.
2.4. Robotic Motion Control in Assembly Tasks
In robotic peg-in-hole assembly, effective state representation and adaptive control strategies are essential to ensuring precise alignment and insertion. Prior work has explored compact latent state encoding using autoencoders and variational autoencoders [
17], as well as CNN-based perception modules such as ConvNeXt [
18] and SE-ResNet-50 [
19] to process visual and tactile data. Meanwhile, control-oriented research has employed reward-driven reinforcement learning methods [
20] to guide insertion behavior based on fuzzy reward definitions.
However, existing approaches suffer from two key limitations: (1) the decoupling of perception and control logic, which hinders real-time adaptive behavior, and (2) reliance on manually tuned reward functions that struggle to capture fine-grained pose deviations necessary for tight-clearance insertions. To address these issues, this study introduces a unified perception–regression–servo control strategy, where visual and tactile inputs are encoded into compact features and fused to estimate 6-DoF deviations between the robot’s current and target TCP poses. These estimates directly drive an iterative servo mechanism for real-time correction, eliminating the need for handcrafted reward design or explicit stage supervision.
3. Methodology
Figure 2 illustrates the architecture of the proposed HV-DSSN framework for accurate pose alignment in CAEC assembly. Although the diagram is arranged spatially, the system proceeds sequentially through four functional modules: (B) haptic–vision perception and representation, which preprocesses visual and tactile inputs; (C) feature extraction and fusion using dedicated encoders and a gated attention mechanism; (D) position identification regression via a BiLSTM network; and (A) robotic servo control for real-time pose adjustment module. The mathematical symbols shown after Module D summarize the iterative update mechanism, which is detailed in
Section 3.4. This modular design enables phase-aware sensing, temporal error modeling, and closed-loop correction throughout the connector insertion process.
3.1. Haptic–Vision Perception and Representation
3.1.1. Visual Perception
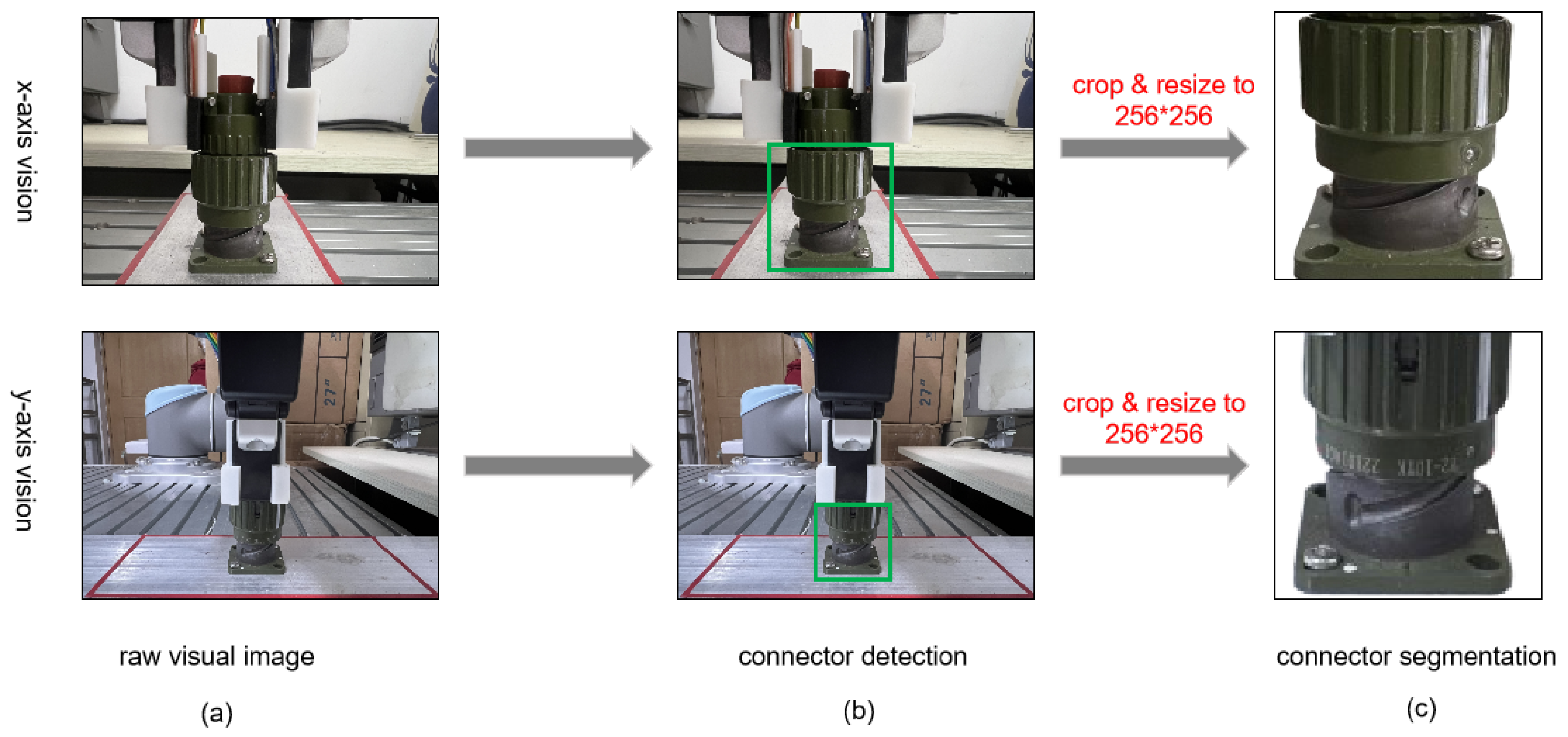
In robotic CAEC insertion tasks, significant positional uncertainty and complex visual occlusions can pose challenges during assembly. To address these issues, two RGB cameras are configured in an eye-in-hand setup, mounted at the robotic end-effector along the robot’s x-axis and y-axis directions. This configuration effectively captures detailed images of the connector near the aligned positions, enabling accurate initial detection of the CAEC connector during the preliminary alignment phase. To enhance detection efficiency, the Transformer-based real-time detection model RT-DETR [
21] is employed for initial CAEC localization in the visual perception module. Subsequently, high-resolution images are cropped to regions of interest (ROIs), focusing exclusively on the connector assembly components and reducing computational redundancy.
However, during assembly, images of aligned and misaligned connectors at various positions may contain diverse background clutter, which complicates generalized feature representation. In contrast to previous studies [
22], which directly utilized cropped ROIs, our work employs the FastSAM model [
23] to further segment and isolate the physical connector from complex backgrounds. The integration of FastSAM ensures real-time segmentation performance while significantly reducing environmental interference and background noise, thereby enhancing the robustness of subsequent spatial feature encoding.
Figure 3 illustrates the overall image processing procedure, with
Figure 3c presenting the segmented visual images obtained by FastSAM. The resulting connector images are then resized to an optimized resolution (256 × 256 pixels) suitable for deep learning-based encoders. While traditional CNN architectures such as VGG-16 [
24] or ResNet-50 [
25] have been commonly adopted in previous research, our study further explores and compares several advanced encoders, including ConvNeXt [
26] and SE-ResNet50 [
27], aiming to identify the encoder providing optimal spatial feature representations for CAEC alignment tasks. A detailed ablation study evaluating the performance impact of these encoders is presented in
Section 4.
3.1.2. Tactile Perception
In CAEC assembly tasks, posture disturbances during the servo alignment process often lead to challenges such as visual occlusion and positioning inaccuracies, which can significantly degrade alignment precision. Prior studies have demonstrated that tactile sensing enhances fine manipulation by providing real-time contact feedback, particularly in scenarios with uncertain physical interactions [
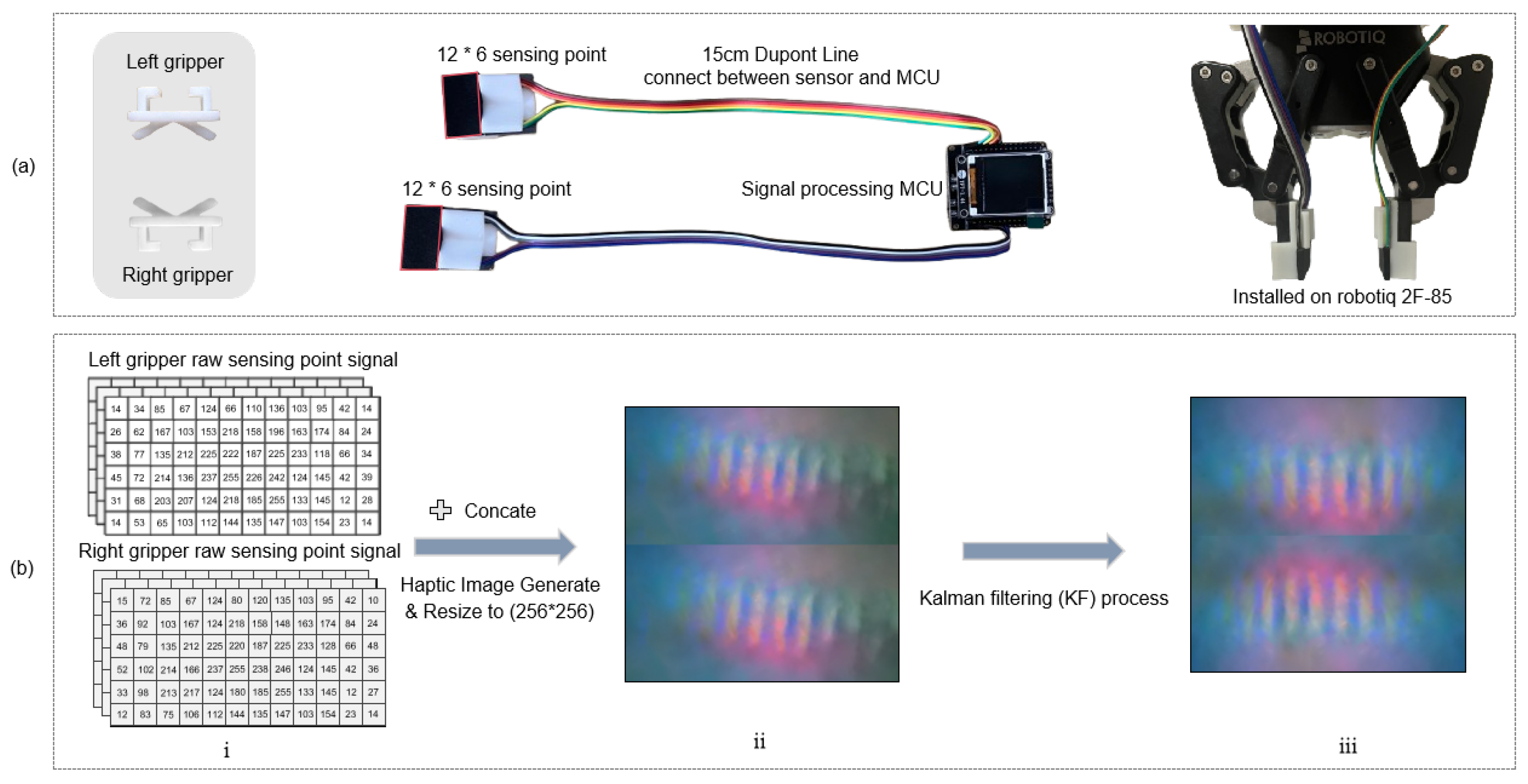
28]. Leveraging this capability, tactile perception enables the robot to detect local rotational deviations and yaw misalignments between the connector and gripper. To improve tactile signal quality and minimize the effects of minor collisions on pose estimation, a customized 3D-printed gripper kit was developed based on the Robotiq 2F-85 parallel gripper. As shown in
Figure 4, two XELA 3D tactile sensors, each comprising a
taxel array, are symmetrically embedded on the inner surfaces of the kit to ensure high-resolution contact detection.
Each taxel independently measures three-dimensional force components . The Z-axis reflects the normal force perpendicular to the contact surface, while the X and Y axes capture tangential forces along the sensor plane. These forces are sampled via an STM32F107 microcontroller (Waveshare Electronics, Shenzhen, China). and transmitted to the host computer over USB for real-time processing. The analog outputs are proportional to the contact force at each sensing point, enabling the robot to accurately detect micro-scale displacement or rotation of the connector during contact phases of assembly.
To convert tactile signals into a format suitable for deep learning, the
taxel maps from both gripper fingers are vertically concatenated and interpolated into a unified
RGB image, where the red, green, and blue channels encode forces along the
X,
Y, and
Z axes, respectively. Before interpolation, each channel is normalized based on predefined sensor limits to ensure consistent intensity distribution across samples. This transformation facilitates structured spatial learning using standard CNN architectures. As shown in
Figure 4(i)–(ii), stronger contact forces are visually represented in warmer tones, highlighting pressure concentrations during alignment.
To avoid damaging the internal structure of CAEC connectors, the gripping force is carefully controlled within the range of 5–10 N, with a nominal 5 N applied during grasping. This ensures both firm holding and reduced slippage throughout the insertion process. Tactile signals are sampled at 125 Hz to meet the responsiveness requirements of real-time servo control. Additionally, Kalman filtering [
29] is applied to mitigate sensor noise, including Gaussian and impulsive disturbances. As shown in
Figure 4(iii), the denoised tactile map effectively preserves the spatial distribution of contact forces, ensuring high-quality tactile input for subsequent multimodal learning and position deviation estimation. This tactile sensing strategy strengthens the robot’s adaptability to posture variations, contributing to robust and precise connector alignment under dynamic assembly conditions.
3.2. Feature Extraction and Fusion in DSSN
Efficient feature extraction and fusion are crucial to the DSSN framework for achieving precise spatial alignment in CAEC assembly. Following the acquisition of multimodal sensor data, this module encodes spatial information from each modality and integrates them to support robust pose estimation. Given the significant differences between visual and tactile inputs in terms of signal characteristics, scale distribution, and noise patterns, this study designs dedicated encoders for each modality and introduces a gated attention mechanism at the fusion stage to adaptively balance the contribution of each modality during different contact states of the assembly process.
3.2.1. Visual and Tactile Feature Extraction
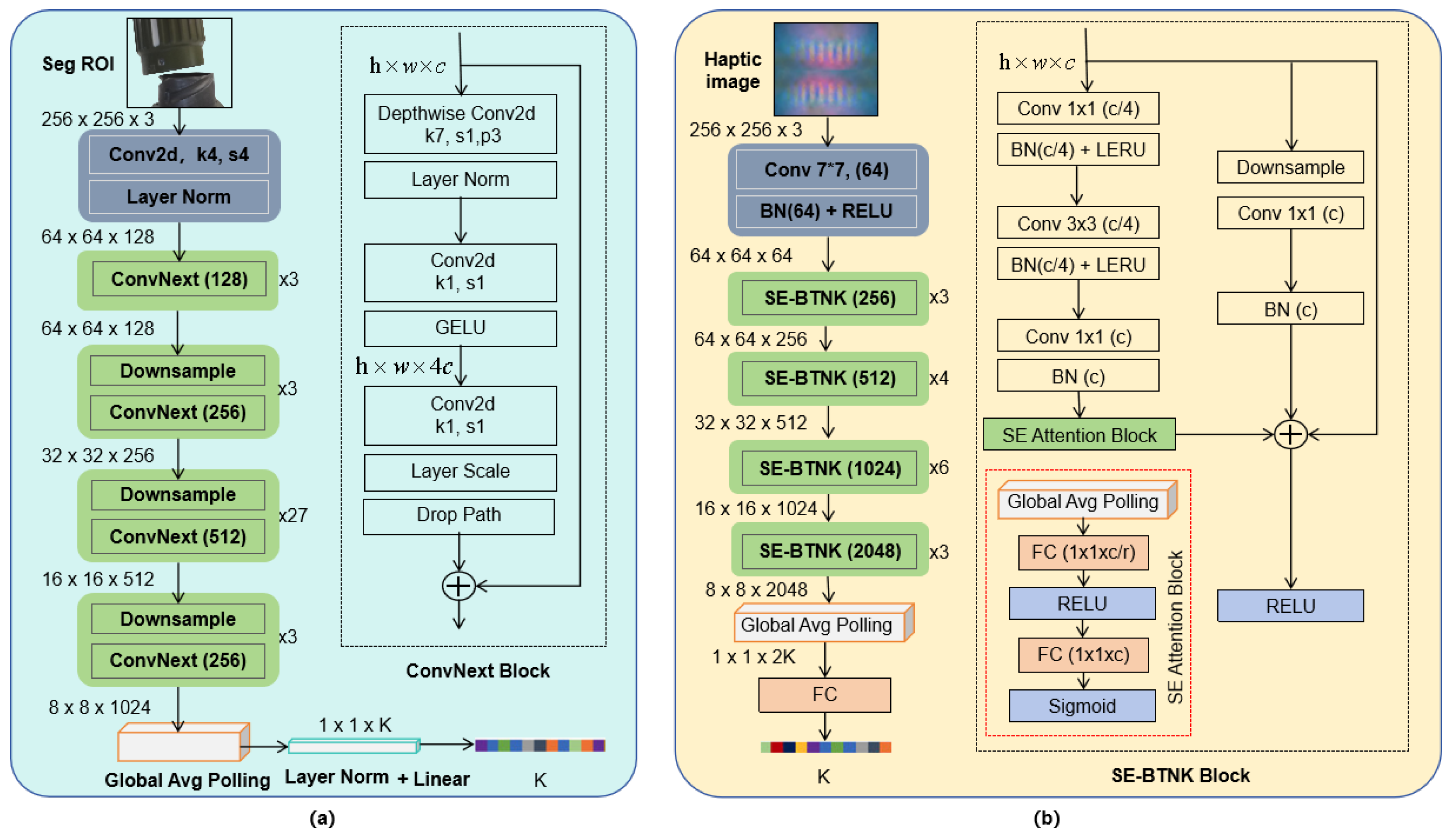
For visual feature extraction, a ConvNeXt-B encoder is employed, with input consisting of segmented and background-removed binocular RGB images (256 × 256 × 3). The images first pass through a convolutional layer with stride 4 and a Layer Normalization (LayerNorm) operation for downsampling, followed by four stages of feature extraction where the spatial resolution is progressively halved and the channel dimensions increase from 128 to
K by a factor of two at each stage. Within each stage, hierarchical spatial features are extracted using depthwise separable convolutions, GELU activations, and DropPath modules. Ultimately, a feature map of 8 × 8 × 1024 is obtained, upon which global average pooling (GAP) is applied, followed by a LayerNorm and a linear projection, yielding a compact visual feature vector
of length
K, as shown in
Figure 5a.
For tactile feature extraction, an enhanced SE-ResNet-50 encoder is utilized, with input consisting of tactile RGB images of 256 × 256 × 3. The images are first processed by a 7 × 7 convolutional layer, Batch Normalization (BatchNorm), and a ReLU activation, reducing the spatial size to 64 × 64. This is followed by four stages of SE-Bottleneck (SE-BTNK) modules, where the spatial dimensions are progressively halved and the channel dimensions increase from 256 to
by a factor of two. Each SE-BTNK module extracts local features through stacked convolutions and residual connections, while the integrated Squeeze-and-Excitation (SE) modules dynamically model channel-wise attention by leveraging global average pooling and two fully connected layers (FC-ReLU-FC-Sigmoid) to emphasize critical tactile patterns. After the four stages, a global average pooling operation reduces the tactile feature map to a 2048-dimensional vector, which is then flattened and projected through a fully connected layer to obtain a tactile feature vector
of length
K, as illustrated in
Figure 5b.
The resulting compact feature vectors and , each of length K, serve as the inputs to the fusion module described next.
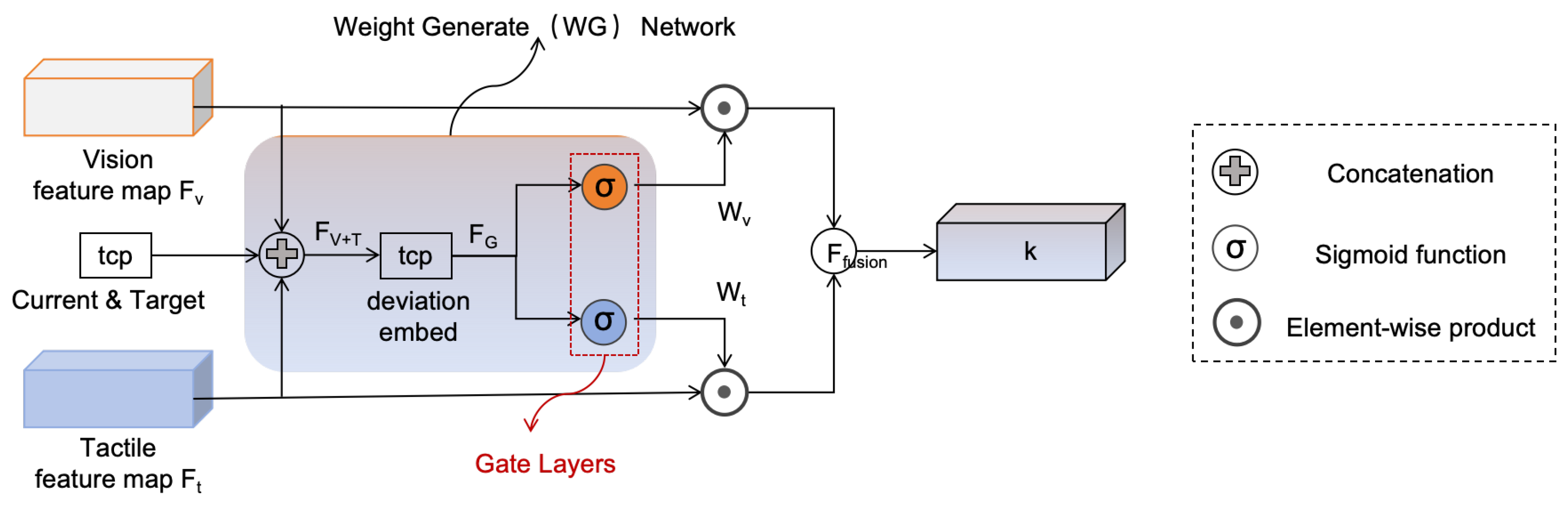
3.2.2. Phase-Adaptive Feature Fusion via Gated Attention
Figure 6 illustrates the proposed gated attention fusion module. Visual and tactile feature vectors
and
are concatenated with the 6-DoF tool center point (TCP) deviation to form a contextual representation
. This fused input captures alignment phase cues and is used to compute two modality-specific gating factors via sigmoid-activated fully connected branches.
The two gating factors
and
are learned jointly from the shared context
, but produced by independent branches. These weights modulate the input features through element-wise multiplication, and the final fused representation is computed by
This phase-adaptive design enables the network to dynamically modulate visual and tactile contributions based on current sensory deviations—without requiring explicit stage labels. Its quantitative impact is validated through ablation experiments in
Section 4.4.2, where we compare it against static fusion strategies such as concatenation and equal weighting.
3.3. Regression for Position Identification
As shown in
Figure 2 “Position Recognition Regression”, after fusing the extracted visual–tactile spatial features, a bidirectional long short-term memory (BiLSTM) network is used to regress the 6-DoF deviations required for CAEC alignment. Specifically, given a sequence of fused features
obtained from the AutoEncoder modules, the BiLSTM models both forward and backward temporal dependencies to enhance positional inference during training. This temporal modeling process is performed exclusively offline; during online control, only the current observation and most recent prediction are used to generate servo commands, ensuring causal inference and real-time responsiveness.
To capture temporal dependencies in the fused feature sequence, a two-layer bidirectional LSTM (BiLSTM) network is employed, with hidden dimensions set to
,
K, and
from bottom to top. At each timestep
t, the input vector
is constructed by concatenating the current fused perception features and the target reference features. The LSTM cell updates follow the standard gating mechanism: the forget gate
, input gate
, and output gate
are first computed using the previous hidden state
and current input
; the candidate cell state
is generated via a tanh transformation; the memory cell
is updated by combining retained past memory with new information; and the final hidden state
is derived by applying the output gate to the activated memory. These steps are formally described in Equations (2)–(7).
where
and
denote the sigmoid and hyperbolic tangent activation functions, respectively, ⊙ denotes element-wise multiplication, and
W,
b are the learnable weights and biases. The forward and backward hidden states
and
are then concatenated to form a temporally enriched feature vector
. This vector is subsequently passed through a lightweight fully connected neural network with a structure of
K-
-32-6 to produce a compact intermediate output vector
at each time step
t, where each component corresponds to a coarse-scaled estimate of positional or orientational deviation.
To ensure a smooth and bounded transformation from intermediate estimates to continuous deviation predictions, this study applies a softmax normalization over
, followed by a linear projection to obtain the final 6-DoF deviation vector
. This normalization constrains the relative magnitude of each component and encourages stable learning behavior across different motion dimensions. The entire transformation and loss computation process is defined as follows:
Here, includes position deviations (, , ) and orientation deviations (, , ). During training, the network parameters are optimized by minimizing the Euclidean distance-based loss function until the assembly deviation requirements of the CAEC system are satisfied.
3.4. Robot Assembly Online Control
The deviation parameters predicted by the Bi-LSTM regression module,
and
, are directly applied to the real-time robotic assembly control as represented by the blue arrow in
Figure 2. To achieve high-precision connector alignment under dynamic posture variations, an incremental servo adjustment strategy is employed. The robot’s end-effector continuously updates its pose based on the estimated deviations, enabling progressive alignment refinement.
In each control cycle, the system collects and processes multimodal sensory data (visual and tactile) in real time through the DSSN to predict the six-dimensional deviations, including position errors (
) and rotational errors (
). These predicted deviations are applied as incremental updates to the end-effector’s current pose, gradually reducing the misalignment relative to the reference pose.
As shown in the CAEC Online Alignment Control Algorithm 1 the system continuously monitors the deviation norm between the current and reference poses during the iterative control process. According to Equation (11), once the deviation norm falls below the predefined threshold
or the maximum iteration count
is reached, the control loop terminates, indicating successful alignment. This closed-loop adjustment mechanism enables the robot to dynamically compensate for posture disturbance errors that may occur during servo-based alignment, ensuring stable convergence toward the target pose while enhancing the robustness and precision of CAEC multi-pin connector assembly tasks.
| Algorithm 1: CAEC Online Alignment Control |
| Input: | , , , |
| Output: | |
| 1: | |
| 2: | while and do |
| 3: | Acquire multimodal sensory data (visual, tactile); |
| 4: | ; |
| 5: | ; |
| 6: | ; |
| 7: | if |
| 8: | return ; |
| 9: | else |
| 10: | continue; |
4. Experiments and Results
4.1. Experimental Setup
Similar to the setup presented in [
2,
30], we established an experimental CAEC assembly platform based on a UR5e robotic manipulator (Universal Robots, Odense, Denmark) integrated with a Robotiq 2F-85 parallel gripper (Robotiq, Lévis, Canada). Unlike previous studies, two RGB cameras were mounted at the robotic end-effector, and two XELA 3D tactile sensors (XELA Robotics, Tokyo, Japan) were installed on the inner surfaces of the parallel gripper fingers. Tactile signals were acquired via an STM32F107 micro controller and transmitted in real-time to a host computer through USB communication.
Figure 7 illustrates the developed CAEC assembly platform, where the blue rectangle labeled “M” indicates the placement area of the CAEC female connector. The red rectangle outlines two possible target positions (“T1” and “T2”) for the male connector, along with two RGB cameras (“C1” and “C2”) arranged along orthogonal axes to capture alignment states from different viewpoints. Due to inherent visual occlusions and the inability of vision alone to precisely detect internal pin alignment states, tactile sensor modules (“H”) were integrated into the gripper fingers (as detailed in
Figure 4), providing real-time three-dimensional force feedback during the insertion stage.
4.2. Calibration-Guided Dataset Construction
To support the generation of high-quality training datasets for the Siamese neural network, comprehensive data collection, annotation, and detection model training were conducted to characterize calibration error distributions. A total of 1000 high-resolution CAEC images (1920 × 1080 pixels) were captured under varying poses and lighting conditions. Each image was manually annotated with bounding boxes and connector types, comprising 500 male and 500 female connector samples. The dataset was then divided into training, testing, and validation sets in a 7:2:1 ratio. Model training was performed on a workstation equipped with an Intel(R) Core(TM) i9-13900K CPU (5.8 GHz, Intel Corporation, Santa Clara, CA, USA), 32 GB RAM, and an NVIDIA GeForce RTX 3090 GPU (24 GB memory, NVIDIA Corporation, Santa Clara, CA, USA), with the batch size set to “auto” to utilize approximately 60% of the GPU memory across 300 epochs.
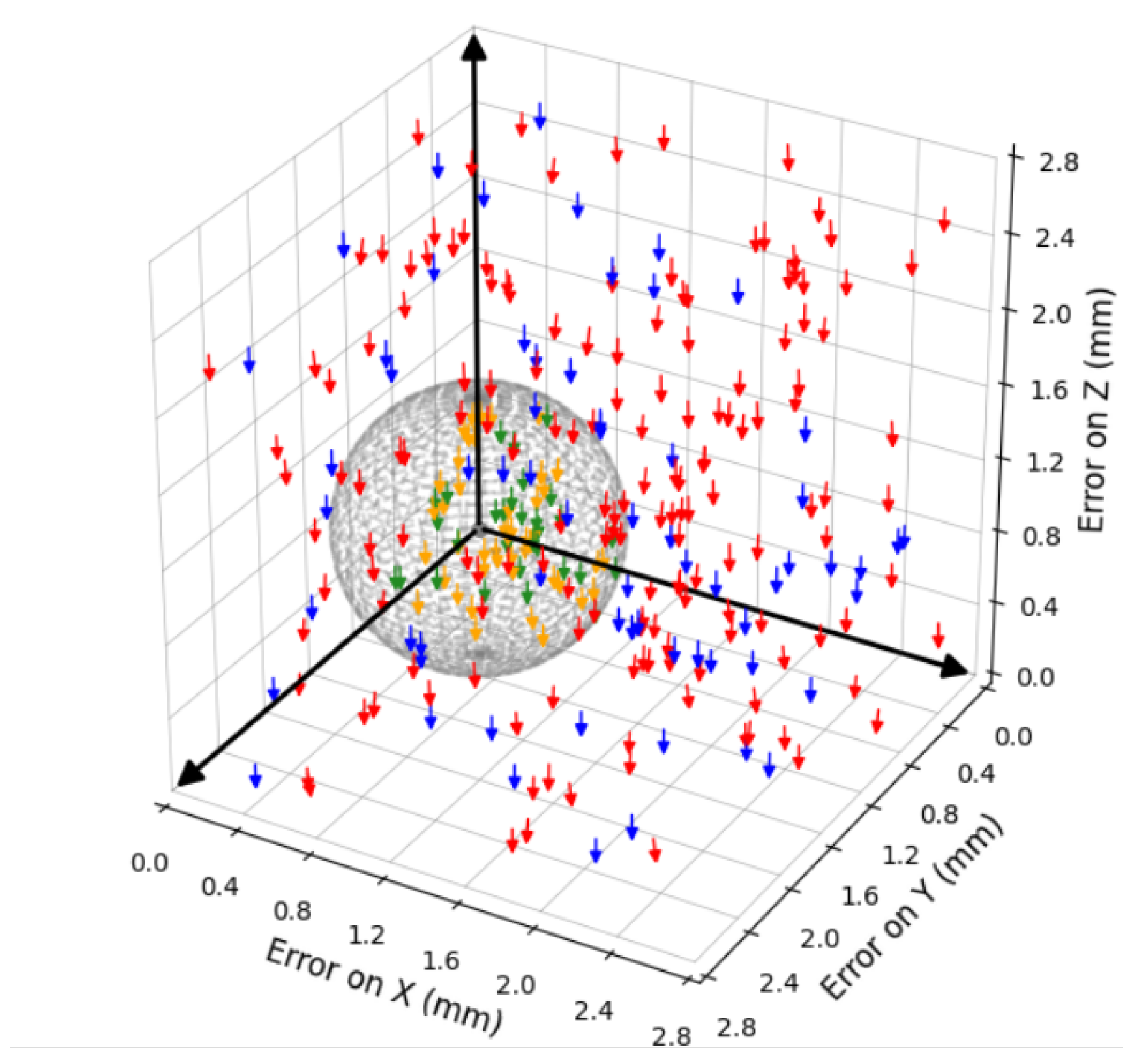
After training, 300 random placement experiments of female CAEC connectors were conducted to quantitatively assess calibration errors. To minimize perspective-induced errors, an eye-in-hand camera configuration was employed, with the robotic arm using tracking control to center the target within the camera’s field of view. Camera coordinates were subsequently transformed into the robot’s world coordinate frame. The Euclidean distances between the transformed tool center point (TCP) and the actual target positions were computed, resulting in the calibration error distribution shown in
Figure 8.
In
Figure 8, each arrow represents a calibration error vector in the three-dimensional workspace. Arrow colors categorize the errors as follows: green indicates samples with Euclidean distance
mm and rotation error
; orange corresponds to
mm but
; blue denotes
mm with
; and red represents
mm and
. The rotation error rot is calculated as follows:
where
,
, and
represent the rotation errors along the Roll, Pitch, and Yaw axes, respectively.
Building on the initial calibration error analysis, we further collected a structured dataset for regression training and structure performance evaluation. Specifically, based on the typical deviation ranges quantified in the calibration experiments—with positional errors ranging from 0 to 2.5 mm and rotational errors up to 3°—we employed a combination of manual teaching and programmatic control to place the connector in near-ideal but deliberately offset positions.
At each placement, paired visual and tactile observations were recorded, resulting in 20,000 multimodal samples covering diverse non-aligned contact states. Each sample is associated with both the current and target TCP poses, enabling the network to learn the 6-DoF deviation for corrective alignment. The dataset covers the same error bounds as the calibration analysis and forms the training foundation for subsequent feature regression and DSSN structure evaluation in
Section 4.3 and
Section 4.4.
4.3. AutoEncoder Feature Representation Evaluation
To evaluate the feature representation capabilities of different encoders prior to their integration into the DSSN framework, we conducted regression-based experiments for position and orientation estimation using both visual and tactile modalities.
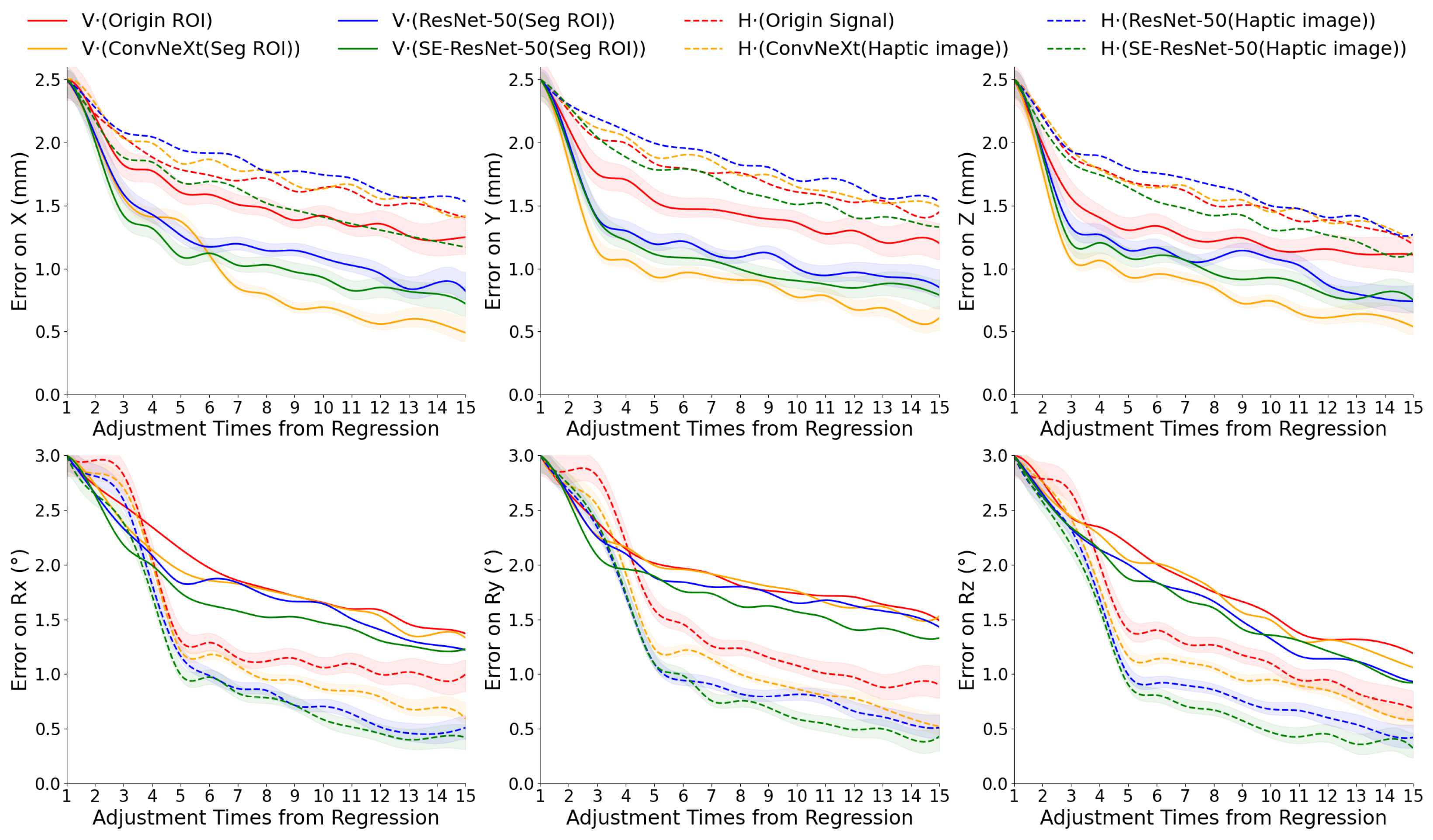
The dataset was divided into training, validation, and test sets in an 8:1:1 ratio. As shown in
Figure 9, we compared three autoencoder architectures—ConvNeXt, ResNet-50, and SE-ResNet-50—applied to both visual and tactile inputs. For each modality, we evaluated four input types: raw images or signals, and encoded features of dimension
generated by the three encoders. These features were then input into a Siamese regression network to predict 6-DoF deviations.
The first row of
Figure 9 shows error convergence curves for displacement along the
X,
Y, and
Z axes; the second row presents rotation errors for Roll (
), Pitch (
), and Yaw (
). In each subfigure, we highlight the top four encoder–modality combinations with the lowest average error. Shaded areas around the curves represent standard deviation across test samples, emphasizing differences in convergence stability and regression accuracy. Results demonstrate the complementary nature of visual and tactile data. Visual features achieved lower errors in position estimation, while tactile features were more effective for orientation prediction.
Among the visual encoders, ConvNeXt achieved the highest accuracy on displacement regression, benefiting from hierarchical feature extraction and robust spatial encoding. For tactile inputs, SE-ResNet-50 achieved superior performance and faster convergence, likely due to its built-in attention mechanisms that emphasize relevant contact patterns.
After 15 iterations of vision-based regression, initial position deviations (up to 2.5 mm) were reduced to within 1 mm on average. Likewise, rotational errors starting from approximately 3° were reduced to within using tactile feedback. These thresholds— for position and for rotation—define the success condition for CAEC alignment and are used throughout the subsequent DSSN training and evaluation. Accordingly, we set the maximum adjustment iteration count in the online control loop for all later experiments.
4.4. DSSN Structure Performance Evaluation
4.4.1. Model Architecture Comparison
A total of 20,000 random position and rotation samples were divided into training, evaluation, and test sets with a ratio of 7:2:1, and approximately 14,000 tactile–visual data pairs were used as inputs to train the DSSN for shift error regression.
Table 1 presents the performance comparison between the proposed DSSN structure and several state-of-the-art (SOTA) methods reported in [
31,
32].
In the Model Structure column of
Table 1, the proposed method is denoted as
DSSN+V(ConvNeXt)+H(SE-ResNet-50)+BiLSTM, where
and
denote the visual and tactile encoders, respectively. To ensure consistency and comparability across different modules, the feature vector length was uniformly set to 1024 dimensions, regardless of the modality. Following the design proposed in [
31], a fully connected (FC) neural network module was employed to map the 2K-dimensional features to robot action outputs. The Bi-LSTM network was trained with a learning rate of 0.0001, consistent with prior settings in precision force-guided assembly tasks [
33,
34].
In
Table 1,
represents the mean error, calculated according to Equation (
13), where
and
are the predicted and ground-truth values,
C denotes the number of channels corresponding to
position coordinates and
rotational angles, and
N is the number of samples in the evaluation or test set.
From the results in
Table 1, it can be observed that the proposed DSSN structure consistently outperforms the VGG-16+FC model [
31] and the DT model [
32]. LSTM-based structures achieved better performance than FC layers, and the Bi-LSTM network, by simultaneously modeling past and future temporal dependencies, provided more accurate corrections, avoided local optima, and demonstrated improved convergence compared to traditional LSTM architectures, leading to further reductions in assembly errors. Moreover, compared to approaches using a single encoder, the proposed DSSN configuration, which employs ConvNeXt for visual feature extraction and SE-ResNet-50 for tactile feature extraction, achieved the best experimental performance. Specifically, the proposed method reduced the position and orientation errors by 22% and 34%, respectively, relative to the required assembly precision thresholds.
4.4.2. Ablation Study on Fusion Mechanisms
To evaluate the effectiveness of the proposed gated attention mechanism, we compared it against four representative fusion strategies: unimodal baselines (vision only and tactile only), element-wise averaging, and feature concatenation followed by a fully connected layer. All models were trained and tested under identical settings using the same regression and servo control protocols.
The results in
Table 2 demonstrate that the proposed gated attention mechanism consistently outperforms other fusion strategies across all translational and rotational components. Compared to the unimodal baseline, it reduces the mean rotation error by up to 40.8%, and even against the strongest baseline (concatenation + FC), it achieves a relative improvement of 10.6%. Furthermore, it increases the assembly success rate from 86.5% to 94.3%, representing a 9.0% enhancement in practical robustness. These results validate the benefit of adaptive, context-aware fusion in multimodal learning for robotic assembly.
4.4.3. Performance in Practical Assembly
In practical assembly experiments, to balance safety, stability, and convergence speed, the servo control parameters were set as follows:
The control frequency was set to 125 Hz (8 ms per control cycle) to ensure timely updates while maintaining controller stability.
The maximum translational velocity was limited to 10 mm/s, and the maximum rotational velocity was limited to 1.5 rad/s, preventing large abrupt motions that could damage connector pins.
Incremental adjustments per cycle were constrained to 0.5 mm in translation and 0.1 rad in rotation, enabling smooth and fine-grained pose correction.
An adaptive damping mechanism was introduced: as the deviation norm decreased, the adjustment magnitude was linearly reduced to avoid overshooting near the target.
The servo adjustment process was terminated once the position error norm fell below 0.5 mm and the rotational error fell below 0.3 rad, or when the maximum number of adjustment iterations was reached.
These parameter settings enabled the robot to perform safe and precise servo adjustments throughout the buckling phase, ensuring compliant operations even under initial posture disturbances. Subsequently, using the proposed vision–tactile fusion method under the DSSN framework, 1000 practical CAEC assembly trials were conducted. The assembly performance was compared against several state-of-the-art (SOTA) methods in terms of assembly success rate and buckling iterations. To assess statistical significance, we conducted two-sample t-tests between our method and each baseline across 10 experimental runs. The observed improvements in assembly success rate were statistically significant () in all evaluated conditions (1, 5, and 10 iterations).
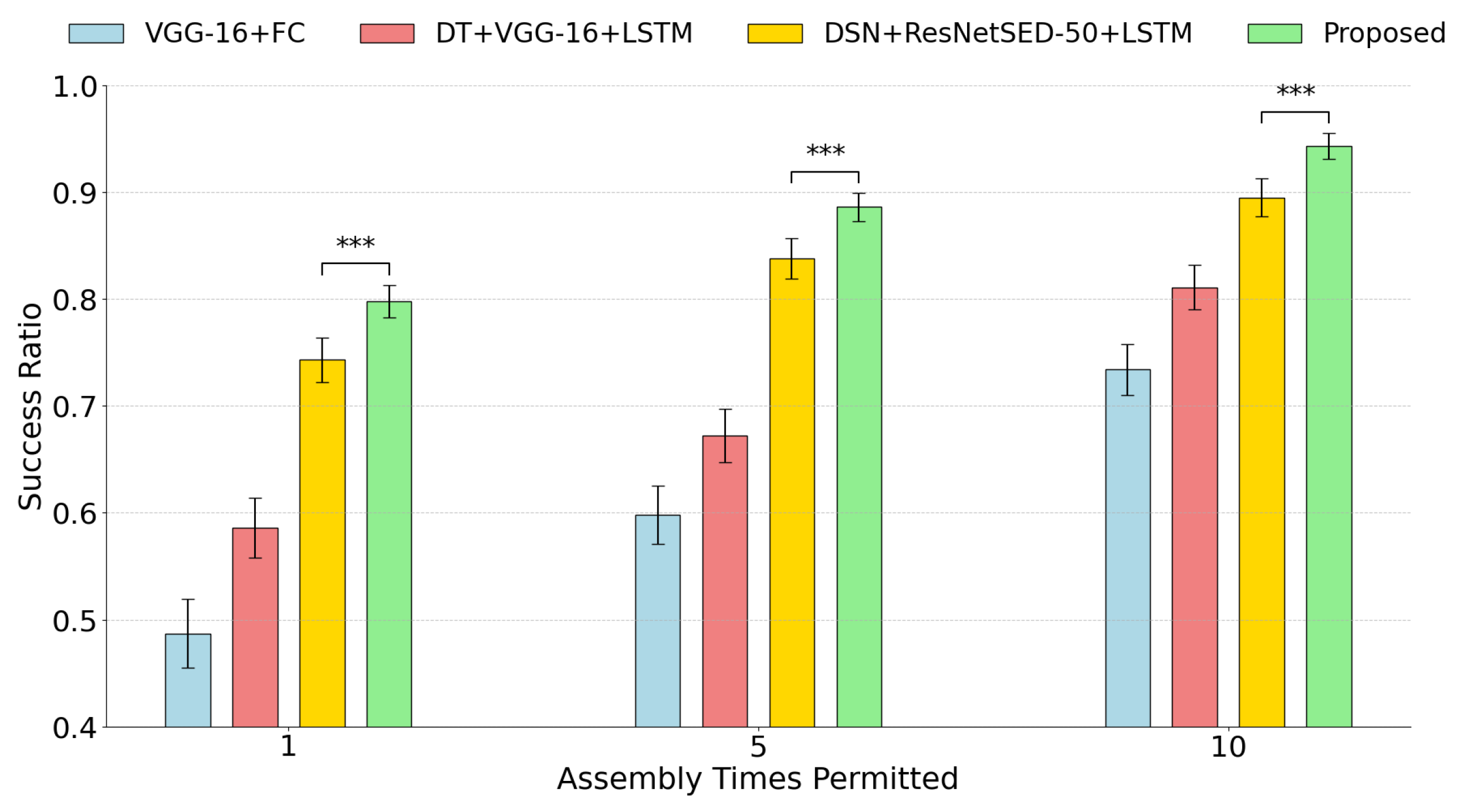
As shown in
Figure 10, the proposed method achieved assembly success rates of 79.8%, 88.6%, and 94.3% after 1, 5, and 10 buckling iterations, respectively, outperforming VGG-16+FC (48.7%, 59.8%, 73.4%), DT+VGG-16+LSTM (58.6%, 67.2%, 81.1%), and DSN+ResNetSE-50+LSTM (74.3%, 83.8%, 89.5%). Overall, compared to the best baseline method (indicated in yellow in
Figure 10), the proposed DSSN+V(ConvNeXt)H(SE-ResNet-50)+BiLSTM network improved the assembly success rates by approximately 7.4%, 5.7%, and 5.4% after 1, 5, and 10 buckling iterations, respectively.
5. Discussion
Experimental results highlight a strong complementarity between visual and tactile sensing in multi-peg-hole robotic assembly. Visual features contributed effectively to translational accuracy, especially during initial alignment phases, while tactile signals played a dominant role in refining rotational deviations during contact. This modality-specific behavior was particularly evident under occlusions or complex backgrounds, where tactile feedback remained stable despite degraded visual cues. Notably, previous studies often reported high assembly success rates under idealized conditions without accounting for such disturbances—especially rotational deviations caused by incidental collisions—which remain difficult to resolve using vision alone. The gated attention mechanism successfully leveraged this complementarity, outperforming static fusion strategies such as equal weighting or concatenation. Moreover, the BiLSTM-based temporal regression consistently converged across repeated buckling attempts, suggesting that temporal modeling captures cumulative pose deviations more effectively than single-frame estimation.
Beyond empirical performance, these findings offer broader insights into multimodal learning for robotics. The phase-adaptive fusion strategy reflects sensorimotor selectivity, dynamically adjusting attention according to contact state and alignment phase. However, limitations remain. The tactile encoding depends on fixed sensor resolution and positioning, which may underperform on deformable components or irregular surfaces. In addition, the BiLSTM model, while stable, lacks online adaptability for rapid or unexpected contact dynamics. These observations motivate future work on integrating transformer-based temporal models, self-calibrating tactile systems, and reinforcement-driven policy updates to further enhance real-time visuo-haptic manipulation capabilities.
6. Conclusions
We proposed a gated attention-based visuo-haptic fusion framework with BiLSTM regression to enhance six-DoF alignment accuracy in CAEC robotic assembly. The system achieved assembly success rates of 79.8%, 88.6%, and 94.3% after 1, 5, and 10 buckling iterations, respectively—demonstrating notable improvements in robustness, particularly in compensating for rotational deviations. Compared to the best-performing baseline, the proposed method achieved relative gains of 7.4%, 5.7%, and 5.4% at the corresponding stages, underscoring the effectiveness of dynamic, temporally-aware sensor fusion in managing pose disturbances under high-precision requirements.
The proposed strategy is particularly valuable for real-world CAEC scenarios, where visual occlusion, calibration drift, and unmodeled contact forces challenge conventional vision-guided alignment. By combining multimodal representation with sequential modeling and phase-adaptive fusion, the system enhances assembly reliability in complex and uncertain environments. Although the current method is effective within its tested scope, it relies on static tactile sensor configurations and offline temporal learning, which may limit flexibility in dynamic or deformable assembly contexts.
Future work will explore the use of transformer-based temporal modeling, sensor-specific feature adaptation, and hybrid policy learning to further generalize the system toward scalable, high-precision, and adaptive robotic assembly. This study contributes toward bridging static perception with dynamic closed-loop control and establishes a foundation for robust, multimodal manipulation systems in modern industrial automation.
Author Contributions
Conceptualization, D.L.; methodology, D.L.; validation, D.L. and Z.X.; formal analysis, D.L., M.Y. and J.C.; investigation, D.L.; resources, D.L. and M.Y.; data curation, D.L.; writing—original draft preparation, D.L.; writing—review and editing, D.L. and M.Y.; visualization, D.L. and Z.X.; supervision, J.C. and M.Y.; project administration, M.Y. and Y.Z.; Funding Acquisition: X.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Guangxi Key Research and Development Program (AB25069476, AB24010164, AB23026048), the Beijing Natural Science Foundation (F2024205028), the Hebei Natural Science Foundation (F2024205028), and the Guilin Science and Technology Project (20230112-1, 20230104-6).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| CAEC | Circular Aviation Electrical Connector |
| DSSN | Dual-Stream Siamese Network |
| ROI | Region of Interest |
| SE-ResNet-50 | Squeeze-and-Excitation ResNet-50 |
| TCP | Tool Center Point |
References
- Baizid, K.; Ćuković, S.; Iqbal, J.; Yousnadj, A.; Chellali, R.; Meddahi, A.; Devedžić, G.; Ghionea, I. IRoSim: Industrial Robotics Simulation Design Planning and Optimization platform based on CAD and knowledgeware technologies. Robot. Comput.-Integr. Manuf. 2016, 42, 121–134. [Google Scholar] [CrossRef]
- Chen, J.; Tang, W.; Yang, M. Deep Siamese Neural Network-Driven Model for Robotic Multiple Peg-in-Hole Assembly System. Electronics 2024, 13, 3453. [Google Scholar] [CrossRef]
- Yang, M.; Zhao, Y.; Li, J.; Tang, W.; Pan, H.; Chen, J.; Sun, F. Accurate Flexible Printed Circuit (FPC) Position Identification Using Haptic Information in Industrial Robotic Mobile Phone Assembly. IEEE Trans. Ind. Electron. 2024, 71, 16143–16152. [Google Scholar] [CrossRef]
- Xu, J.; Hou, Z.; Liu, Z.; Qiao, H. Compare contact model-based control and contact model-free learning: A survey of robotic peg-in-hole assembly strategies. arXiv 2019, arXiv:1904.05240. [Google Scholar]
- Zhang, Z.; Wang, Y.; Zhang, Z.; Wang, L.; Huang, H.; Cao, Q. A residual reinforcement learning method for robotic assembly using visual and force information. J. Manuf. Syst. 2024, 72, 245–262. [Google Scholar] [CrossRef]
- Kim, L.; Li, Y.; Posa, M.; Jayaraman, D. Im2contact: Vision-based contact localization without touch or force sensing. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023; pp. 1533–1546. [Google Scholar]
- Shahria, M.T.; Sunny, M.S.H.; Zarif, M.I.I.; Ghommam, J.; Ahamed, S.I.; Rahman, M.H. A comprehensive review of vision-based robotic applications: Current state, components, approaches, barriers, and potential solutions. Robotics 2022, 11, 139. [Google Scholar] [CrossRef]
- Jin, P.; Huang, B.; Lee, W.W.; Li, T.; Yang, W. Visual-Force-Tactile Fusion for Gentle Intricate Insertion Tasks. IEEE Robot. Autom. Lett. 2024, 9, 4830–4837. [Google Scholar] [CrossRef]
- Li, H.; Zhang, Y.; Zhu, J.; Wang, S.; Lee, M.A.; Xu, H.; Adelson, E.; Fei-Fei, L.; Gao, R.; Wu, J. See, hear, and feel: Smart sensory fusion for robotic manipulation. arXiv 2022, arXiv:2212.03858. [Google Scholar]
- Yu, K.; Han, Y.; Wang, Q.; Saxena, V.; Xu, D.; Zhao, Y. MimicTouch: Leveraging Multi-modal Human Tactile Demonstrations for Contact-rich Manipulation. arXiv 2023, arXiv:2310.16917. [Google Scholar]
- Fan, Y.; Niu, L.; Liu, T. Multi-Branch Gated Fusion Network: A Method That Provides Higher-Quality Images for the USV Perception System in Maritime Hazy Condition. J. Mar. Sci. Eng. 2022, 10, 1839. [Google Scholar] [CrossRef]
- Cui, S.; Wang, R.; Wei, J.; Hu, J.; Wang, S. Self-attention based visual-tactile fusion learning for predicting grasp outcomes. IEEE Robot. Autom. Lett. 2020, 5, 5827–5834. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, Z.; Wang, H.; Zhang, Z.; Huang, H.; Cao, Q. Grasp stability assessment through attention-guided cross-modality fusion and transfer learning. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 9472–9479. [Google Scholar]
- Lee, Y.; Hong, S.; Kim, M.g.; Kim, G.; Nam, C. Grasping Deformable Objects via Reinforcement Learning with Cross-Modal Attention to Visuo-Tactile Inputs. arXiv 2025, arXiv:2504.15595. [Google Scholar]
- Yu, C.; Cai, Z.; Pham, H.; Pham, Q.C. Siamese Convolutional Neural Network for Sub-millimeter-accurate Camera Pose Estimation and Visual Servoing. arXiv 2023, arXiv:2407.10536. [Google Scholar]
- Lee, T.Y.; van Baar, J.; Wittenburg, K.; Sullivan, A. Analysis of the contribution and temporal dependency of LSTM layers for reinforcement learning tasks. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 99–102. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. 2013. Available online: http://web2.cs.columbia.edu/~blei/fogm/2018F/materials/KingmaWelling2013.pdf (accessed on 1 April 2025).
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Jin, X.; Xie, Y.; Wei, X.S.; Zhao, B.R.; Chen, Z.M.; Tan, X. Delving deep into spatial pooling for squeeze-and-excitation networks. Pattern Recognit. 2022, 121, 108159. [Google Scholar] [CrossRef]
- Xu, J.; Hou, Z.; Wang, W.; Xu, B.; Zhang, K.; Chen, K. Feedback deep deterministic policy gradient with fuzzy reward for robotic multiple peg-in-hole assembly tasks. IEEE Trans. Ind. Inform. 2018, 15, 1658–1667. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Haugaard, R.; Langaa, J.; Sloth, C.; Buch, A. Fast robust peg-in-hole insertion with continuous visual servoing. In Proceedings of the Conference on Robot Learning. PMLR, London, UK, 8–11 November 2021; pp. 1696–1705. [Google Scholar]
- Zhao, X.; Ding, W.; An, Y.; Du, Y.; Yu, T.; Li, M.; Tang, M.; Wang, J. Fast segment anything. arXiv 2023, arXiv:2306.12156. [Google Scholar]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Y.; Wang, H.; Yang, G.; Zhang, J.; Gong, C.; Wang, Y. CSNet: A ConvNeXt-based Siamese network for RGB-D salient object detection. Vis. Comput. 2024, 40, 1805–1823. [Google Scholar] [CrossRef]
- Theckedath, D.; Sedamkar, R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks. SN Comput. Sci. 2020, 1, 79. [Google Scholar] [CrossRef]
- Iqbal, J.; Tsagarakis, N.G.; Caldwell, D.G. Design of a wearable direct-driven optimized hand exoskeleton device. In Proceedings of the 4th International Conference on Advances in Computer-Human Interactions (ACHI), Gosier, France, 23–28 February 2011; pp. 142–146. [Google Scholar]
- Piga, N.A.; Pattacini, U.; Natale, L. A differentiable extended Kalman filter for object tracking under sliding regime. Front. Robot. AI 2021, 8, 686447. [Google Scholar] [CrossRef]
- Murali, P.K.; Dutta, A.; Gentner, M.; Burdet, E.; Dahiya, R.; Kaboli, M. Active visuo-tactile interactive robotic perception for accurate object pose estimation in dense clutter. IEEE Robot. Autom. Lett. 2022, 7, 4686–4693. [Google Scholar] [CrossRef]
- Perez-Dattari, R.; Celemin, C.; Franzese, G.; Ruiz-del Solar, J.; Kober, J. Interactive learning of temporal features for control: Shaping policies and state representations from human feedback. IEEE Robot. Autom. Mag. 2020, 27, 46–54. [Google Scholar] [CrossRef]
- Yang, M.; Huang, Z.; Sun, Y.; Zhao, Y.; Sun, R.; Sun, Q.; Chen, J.; Qiang, B.; Wang, J.; Sun, F. Digital twin driven measurement in robotic flexible printed circuit assembly. IEEE Trans. Instrum. Meas. 2023, 72, 5007812. [Google Scholar] [CrossRef]
- Luo, J.; Li, H. A learning approach to robot-agnostic force-guided high precision assembly. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 2151–2157. [Google Scholar]
- Papenberg, B.; Rückert, P.; Tracht, K. Classification of Assembly Operations Using Recurrent Neural Networks. In Annals of Scientific Society for Assembly, Handling and Industrial Robotics 2021; Springer: Berlin/Heidelberg, Germany, 2022; p. 301. [Google Scholar]
Figure 1.
CAEC assembly example. (a) CAEC receiver and connector; (b) CAEC misalignment status; (c) CAEC alignment status; (d) successful assembly case.
Figure 1.
CAEC assembly example. (a) CAEC receiver and connector; (b) CAEC misalignment status; (c) CAEC alignment status; (d) successful assembly case.
Figure 2.
Workflow of the proposed framework.
Figure 2.
Workflow of the proposed framework.
Figure 3.
Overall image processing procedure for CAEC alignment. (a) Original image. (b) ROI detection using RT-DETR. (c) Segmented image after FastSAM, cropped and resized to 256 × 256.
Figure 3.
Overall image processing procedure for CAEC alignment. (a) Original image. (b) ROI detection using RT-DETR. (c) Segmented image after FastSAM, cropped and resized to 256 × 256.
Figure 4.
(a) The 3D-printed gripper kit integrated with XELA 3D tactile sensors. (b) Visualization of raw tactile signals from the taxel array during connector grasping. Subfigures (i,ii) show the concatenation process and the final tactile image generation. subfigure (iii) Denoised tactile map after applying Kalman filtering. The intensity of the image indicates the pressure applied at each sensing point, with higher intensities appearing redder.
Figure 4.
(a) The 3D-printed gripper kit integrated with XELA 3D tactile sensors. (b) Visualization of raw tactile signals from the taxel array during connector grasping. Subfigures (i,ii) show the concatenation process and the final tactile image generation. subfigure (iii) Denoised tactile map after applying Kalman filtering. The intensity of the image indicates the pressure applied at each sensing point, with higher intensities appearing redder.
Figure 5.
(a) Visual feature extraction network architecture based on ConvNeXt-B. (b) Tactile feature extraction network architecture based on SE-ResNet-50.
Figure 5.
(a) Visual feature extraction network architecture based on ConvNeXt-B. (b) Tactile feature extraction network architecture based on SE-ResNet-50.
Figure 6.
Gated attention fusion module.A shared context vector , formed by combining visual/tactile features and TCP deviation, generates modality-specific gating weights used to compute the fused output via weighted summation.
Figure 6.
Gated attention fusion module.A shared context vector , formed by combining visual/tactile features and TCP deviation, generates modality-specific gating weights used to compute the fused output via weighted summation.
Figure 7.
(a) CAEC assembly scene configuration. (b) Assembly viewpoint during the peg-hole alignment phase.
Figure 7.
(a) CAEC assembly scene configuration. (b) Assembly viewpoint during the peg-hole alignment phase.
Figure 8.
Distribution of target center position calibration errors from 300 calibration experiments.
Figure 8.
Distribution of target center position calibration errors from 300 calibration experiments.
Figure 9.
Statistical error curves of displacement and rotation along X, Y, and Z axes, evaluated over 15 adjustment iterations using autoencoder-based methods on visual and haptic sensor data.
Figure 9.
Statistical error curves of displacement and rotation along X, Y, and Z axes, evaluated over 15 adjustment iterations using autoencoder-based methods on visual and haptic sensor data.
Figure 10.
Comparison of assembly success rates under different buckling iterations for various methods. Error bars indicate standard deviations over 10 experimental runs. *** indicates statistical significance at (two-sample t-test).
Figure 10.
Comparison of assembly success rates under different buckling iterations for various methods. Error bars indicate standard deviations over 10 experimental runs. *** indicates statistical significance at (two-sample t-test).
Table 1.
Performance comparison of different model structures based on mean error . red indicates the best result in each direction, blue indicates the second best, and orange denotes tied second-best values.
Table 1.
Performance comparison of different model structures based on mean error . red indicates the best result in each direction, blue indicates the second best, and orange denotes tied second-best values.
| Model Structure | Evaluation Set | Test Set |
|---|
| x | y | z | rx | ry | rz | x | y | z | rx | ry | rz |
|---|
| VGG-16+FC [31] | 1.41 | 1.44 | 1.32 | 0.65 | 0.68 | 0.65 | 1.39 | 1.42 | 1.30 | 0.63 | 0.69 | 0.66 |
| DT+VGG-16+LSTM [32] | 1.21 | 1.27 | 1.15 | 0.60 | 0.57 | 0.53 | 1.24 | 1.33 | 1.21 | 0.62 | 0.71 | 0.64 |
| DSSN+ConvNeXt+LSTM | 0.82 | 0.85 | 0.91 | 0.52 | 0.53 | 0.51 | 0.80 | 0.87 | 0.90 | 0.58 | 0.56 | 0.59 |
| DSSN+ConvNeXt+BiLSTM | 0.77 | 0.78 | 0.68 | 0.48 | 0.54 | 0.55 | 0.78 | 0.79 | 0.71 | 0.52 | 0.51 | 0.49 |
| DSSN+ResNet-50+BiLSTM | 0.85 | 0.81 | 0.84 | 0.42 | 0.41 | 0.37 | 0.88 | 0.87 | 0.85 | 0.41 | 0.43 | 0.40 |
| DSSN+SE-ResNet-50+BiLSTM | 0.83 | 0.78 | 0.78 | 0.36 | 0.37 | 0.27 | 0.86 | 0.82 | 0.85 | 0.37 | 0.39 | 0.35 |
| Proposed | 0.76 | 0.77 | 0.72 | 0.33 | 0.35 | 0.26 | 0.80 | 0.78 | 0.75 | 0.36 | 0.34 | 0.29 |
Table 2.
Ablation study on fusion mechanisms: detailed regression error and success rate.
Table 2.
Ablation study on fusion mechanisms: detailed regression error and success rate.
| Fusion Strategy | | | | | | | (Pos/Rot) | Success Rate |
|---|
| Vision only | 1.12 | 1.10 | 1.17 | 0.71 | 0.72 | 0.70 | 1.13/0.71 | 74.1% |
| Tactile only | 1.27 | 1.22 | 1.20 | 0.52 | 0.47 | 0.45 | 1.23/0.48 | 69.7% |
| Equal weighting | 0.93 | 0.91 | 0.95 | 0.53 | 0.51 | 0.52 | 0.93/0.52 | 82.0% |
| Concatenation + FC | 0.91 | 0.89 | 0.87 | 0.45 | 0.49 | 0.47 | 0.89/0.47 | 86.5% |
| Gated attention (Ours) | 0.76 | 0.77 | 0.75 | 0.41 | 0.43 | 0.42 | 0.76/0.42 | 94.3% |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 and
and 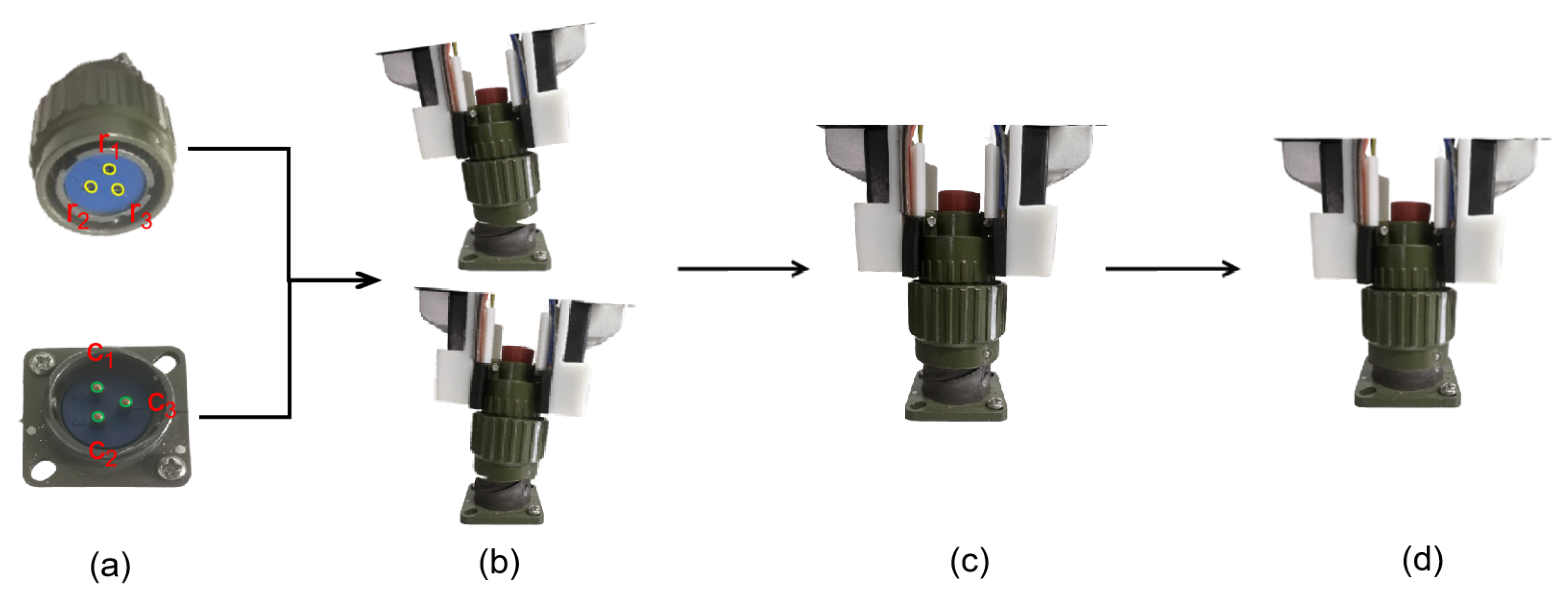



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}