
Venous Thrombosis Risk Assessment Based on Retrieval-Augmented Large Language Models and Self-Validation


Abstract
1. Introduction
- The heterogeneous nature of EMRs, such as being unstructured and involving a large amount of specialized terminology, leads to large errors in feature extraction of the trained model even after extensive manual annotation [21].
- The lack of model interpretability makes physicians have insufficient trust in the results of automated assessment [22].
- The existing systems are mostly limited to single-scale optimization and lack cross-scale risk prediction capability.
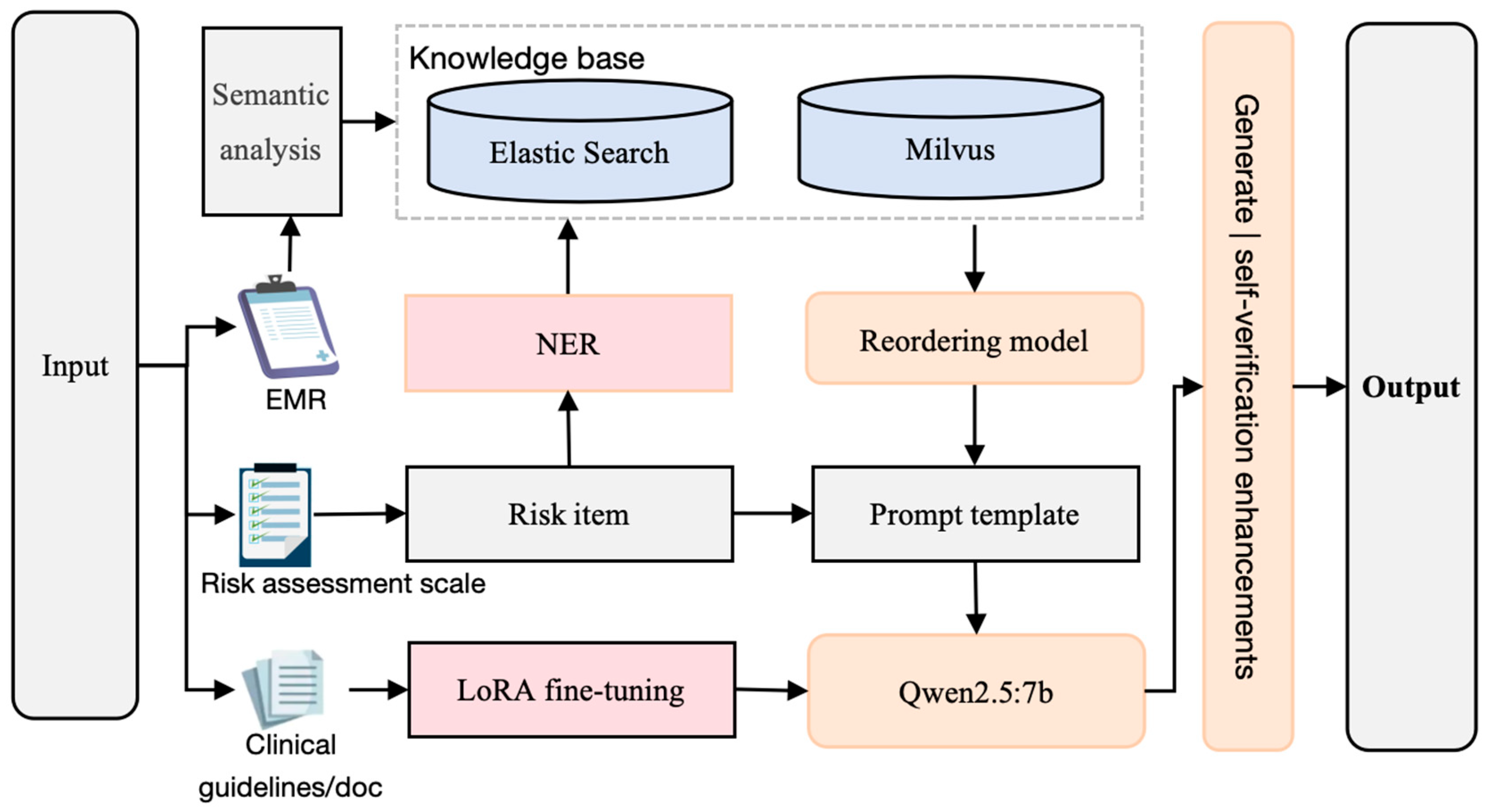
2. Methods
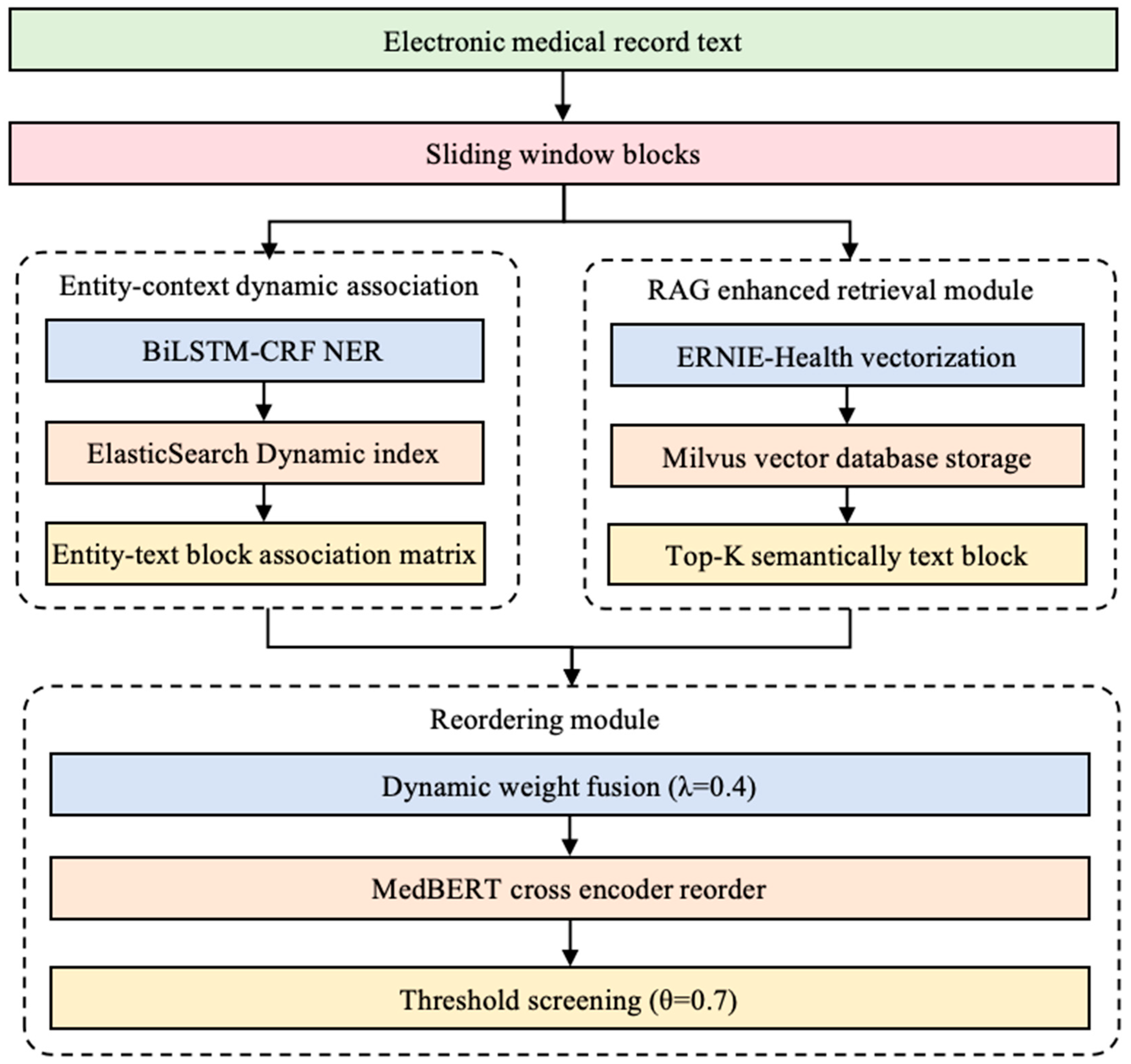
2.1. Knowledge Base Optimized for Multiple Searches
2.1.1. Entity–Context Dynamic Associations
2.1.2. Milvus Vector Retrieval
2.1.3. Reordering
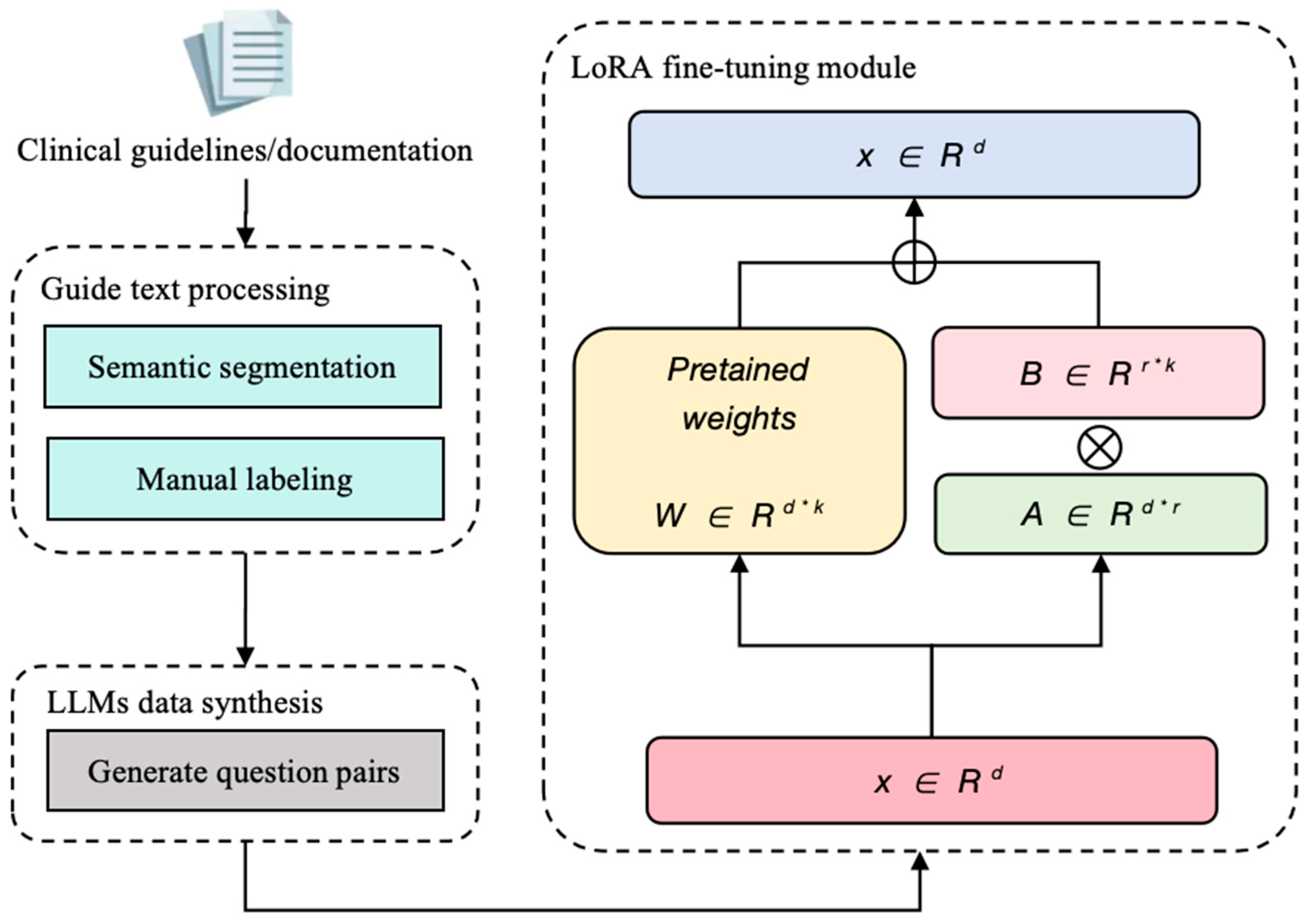
2.2. Domain-Adaptive Fine-Tuning Strategies
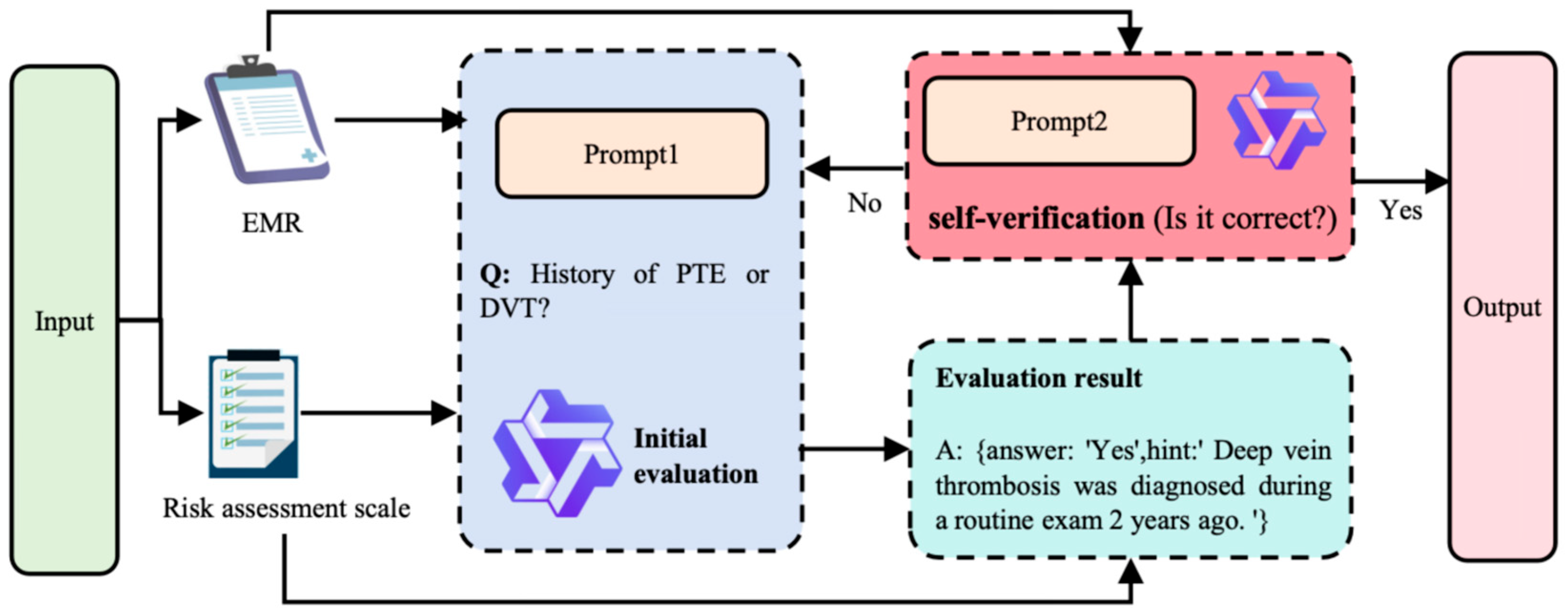
2.3. Generation–Verification Closed-Loop Mechanism
2.3.1. Dynamic Hints Project
2.3.2. SVA
3. Experimentation and Analysis
3.1. Data
3.1.1. Data Pre-Processing
3.1.2. Scale Introduction
3.1.3. Fine-Tuning Dataset Generation
3.2. Experimental Setup
3.2.1. Experimental Environment
3.2.2. LLM Selection
3.3. Evaluation Indicators
3.4. Experimental Results and Analysis
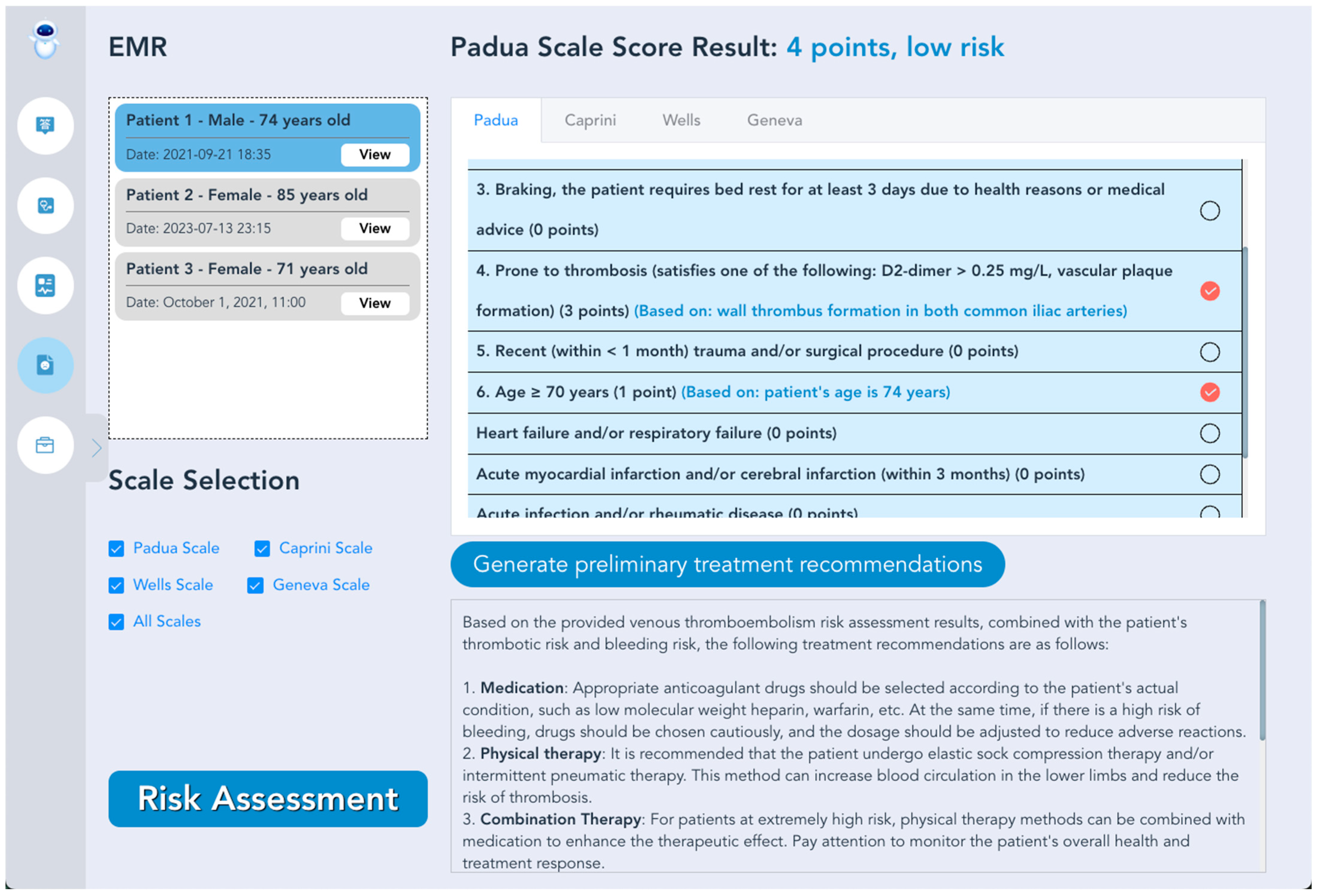
3.5. VTE Intelligent Prevention and Treatment LLMs System Prototype
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simplified Wells Scoring Program | Mark | Revised Geneva Scoring Program | Mark |
|---|---|---|---|
| History of PTE or DVT | 1 | History of PTE or DVT | 1 |
| Fracture or surgery within 4 weeks | 1 | Surgery or fracture within one month | 1 |
| Active tumor | 1 | Active tumor | 1 |
| Heart rate (beats/min) ≥ 100 | 1 | Heart rate (beats/min) 75–94 | 1 |
| Hemoptysis | 1 | Heart rate (beats/min) ≥ 95 | 2 |
| DVT signs or symptoms | 1 | Hemoptysis | 1 |
| Other differential diagnoses less likely than PTE | 1 | Unilateral lower extremity pain | 1 |
| Deep vein tenderness and unilateral lower extremity edema in the lower extremities | 1 | ||
| Age > 65 | 1 |
| Padua Scoring Program | Mark |
|---|---|
| Active cancer | 3 |
| Previous history of VTE (excluding superficial venous thrombosis) | 3 |
| Reduced activity | 3 |
| Known embolism vulnerability | 3 |
| Recent (1 month) trauma and/or surgery | 2 |
| Age ≥ 70 years | 1 |
| Heart and/or respiratory failure | 1 |
| Acute myocardial infarction or ischemic stroke | 1 |
| Acute infectious and/or rheumatic diseases | 1 |
| Obesity (BMI ≥ 30 kg/m²) | 1 |
| Currently on hormone therapy | 1 |
| 1 Point | 2 Points | 3 Points | 5 Points |
|---|---|---|---|
| Age 41–60 | Age 61–74 | Age ≥ 75 years | Stroke (<1 month) |
| Minor operation | Arthroscopic surgery | VTE History | Elective arthroplasty |
| Body mass index > 25 kg/m² | Major open surgery (>45 min) | Family history of VTE | Fractures of the hip, pelvis or lower extremities |
| Swelling of the lower limbs | Limb laparoscopy (>45 min) | Coagulation Factor V Leiden Mutation | Acute spinal cord injury (<1 month) |
| Varicose veins | Malignant tumor | Thrombospondin G20210A mutation | |
| Pregnancy or postpartum | Bedridden > 72 h | Lupus anticoagulant positive | |
| History of unexplained or habitual miscarriages | Plaster cast (for a broken bone) | Positive anticardiolipin antibodies | |
| Oral contraceptives or hormone replacement therapy | Central venous route | Elevated serum homocysteine | |
| Infectious toxicosis (<1 month) | Heparin-induced thrombocytopenia | ||
| Severe lung disease (<1 month) | Other congenital or acquired thrombotic tendencies | ||
| Lung function abnormality | |||
| Acute myocardial infarction | |||
| Congestive heart failure (<1 month) | |||
| History of inflammatory bowel disease | |||
| Need bed rest. |
References
- Wendelboe, A.; Weitz, J.I. Global health burden of venous thromboembolism. Arterioscler. Thromb. Vasc. Biol. 2024, 44, 1007–1011. [Google Scholar] [CrossRef] [PubMed]
- Khan, F.; Tritschler, T.; Kahn, S.R.; Rodger, M.A. Venous thromboembolism. Lancet 2021, 398, 64–77. [Google Scholar] [CrossRef]
- Lutsey, P.L.; Zakai, N.A. Epidemiology and prevention of venous thromboembolism. Nat. Rev. Cardiol. 2023, 20, 248–262. [Google Scholar] [CrossRef]
- Pandor, A.; Tonkins, M.; Goodacre, S.; Sworn, K.; Clowes, M.; Griffin, X.L.; Holland, M.; Hunt, B.J.; de Wit, K.; Horner, D. Risk assessment models for venous thromboembolism in hospitalised adult patients: A systematic review. BMJ Open 2021, 11, e045672. [Google Scholar] [CrossRef]
- Zhou, C.; Yi, Q.; Ge, H.; Wei, H.; Liu, H.; Zhang, J.; Luo, Y.; Pan, P.; Zhang, J.; Peng, L. Validation of risk assessment models predicting venous thromboembolism in inpatients with acute exacerbation of chronic obstructive pulmonary disease: A multicenter cohort study in China. Thromb. Haemost. 2022, 122, 1177–1185. [Google Scholar] [CrossRef] [PubMed]
- Hayssen, H.; Sahoo, S.; Nguyen, P.; Mayorga-Carlin, M.; Siddiqui, T.; Englum, B.; Slejko, J.F.; Mullins, C.D.; Yesha, Y.; Sorkin, J.D. Ability of Caprini and Padua risk-assessment models to predict venous thromboembolism in a nationwide Veterans Affairs study. J. Vasc. Surg. Venous Lymphat. Disord. 2024, 12, 101693. [Google Scholar] [CrossRef]
- Liu, J.; Dai, L.; Li, Z. Establishment of a prediction model for venous thromboembolism in patients with acute exacerbation of chronic obstructive pulmonary disease based on serum homocysteine levels and Wells scores: A retrospective cohort study. BMC Cardiovasc. Disord. 2024, 24, 586. [Google Scholar] [CrossRef] [PubMed]
- Häfliger, E.; Kopp, B.; Farhoumand, P.D.; Choffat, D.; Rossel, J.-B.; Reny, J.-L.; Aujesky, D.; Méan, M.; Baumgartner, C. Risk assessment models for venous thromboembolism in medical inpatients. JAMA Netw. Open 2024, 7, e249980. [Google Scholar] [CrossRef]
- Qiao, L.; Yao, Y.; Wu, D.; Xu, R.; Cai, H.; Shen, Y.; Xu, Z.; Jiang, Q. The validation and modification of the Caprini risk assessment model for evaluating venous thromboembolism after joint arthroplasty. Thromb. Haemost. 2024, 124, 223–235. [Google Scholar] [CrossRef]
- Nguyen, T.T.T.; Tong, H.T.; Nguyen, H.T.L.; Nguyen, T.D. A Call to Action for Anticoagulation Stewardship to Address Suboptimal Thromboprophylaxis Practices for at-Risk Non-Orthopedic Surgical Patients in Vietnam: An Explanatory Sequential Mixed-Methods Study. Vasc. Health Risk Manag. 2025, 21, 305–326. [Google Scholar] [CrossRef]
- Cook, N.; Biel, F.M.; Cartwright, N.; Hoopes, M.; Al Bataineh, A.; Rivera, P. Assessing the use of unstructured electronic health record data to identify exposure to firearm violence. JAMIA Open 2024, 7, ooae120. [Google Scholar] [CrossRef]
- Mubashar, A.; Asghar, K.; Javed, A.R.; Rizwan, M.; Srivastava, G.; Gadekallu, T.R.; Wang, D.; Shabbir, M. Storage and proximity management for centralized personal health records using an ipfs-based optimization algorithm. J. Circuits Syst. Comput. 2022, 31, 2250010. [Google Scholar] [CrossRef]
- Contreras-Luján, E.E.; García-Guerrero, E.E.; López-Bonilla, O.R.; Tlelo-Cuautle, E.; López-Mancilla, D.; Inzunza-González, E. Evaluation of machine learning algorithms for early diagnosis of deep venous thrombosis. Math. Comput. Appl. 2022, 27, 24. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Y.-Q.; Hong, X.-Y.; Liu, S.-H.; Li, J.-C.; Chen, T.; Shi, J.-H. A new risk assessment model of venous thromboembolism by considering fuzzy population. BMC Med. Inform. Decis. Mak. 2024, 24, 413. [Google Scholar] [CrossRef]
- He, L.; Luo, L.; Hou, X.; Liao, D.; Liu, R.; Ouyang, C.; Wang, G. Predicting venous thromboembolism in hospitalized trauma patients: A combination of the Caprini score and data-driven machine learning model. BMC Emerg. Med. 2021, 21, 60. [Google Scholar] [CrossRef]
- Chen, J.; Yang, J.; He, J. Prediction of venous thrombosis Chinese electronic medical records based on deep learning and rule reasoning. Appl. Sci. 2022, 12, 10824. [Google Scholar] [CrossRef]
- Yang, J.; He, J.; Zhang, H. Automating venous thromboembolism risk assessment: A dual-branch deep learning method using electronic medical records. Front. Med. 2023, 10, 1237616. [Google Scholar] [CrossRef] [PubMed]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.-t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; p. 793. [Google Scholar]
- Mansurova, A.; Mansurova, A.; Nugumanova, A. QA-RAG: Exploring LLM Reliance on External Knowledge. Big Data Cogn. Comput. 2024, 8, 115. [Google Scholar] [CrossRef]
- Hang, C.N.; Tan, C.W.; Yu, P.-D. MCQGen: A large language model-driven MCQ generator for personalized learning. IEEE Access 2024, 12, 102261–102273. [Google Scholar] [CrossRef]
- Hossain, E.; Rana, R.; Higgins, N.; Soar, J.; Barua, P.D.; Pisani, A.R.; Turner, K. Natural language processing in electronic health records in relation to healthcare decision-making: A systematic review. Comput. Biol. Med. 2023, 155, 106649. [Google Scholar] [CrossRef]
- Lam, B.D.; Zerbey, S.; Pinson, A.; Robertson, W.; Rosovsky, R.P.; Lake, L.; Dodge, L.E.; Adamski, A.; Reyes, N.; Abe, K. Artificial intelligence for venous thromboembolism prophylaxis: Clinician perspectives. Res. Pract. Thromb. Haemost. 2023, 7, 102272. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Bao, R.; Zheng, H.; Qi, Z.; Wei, J.; Hu, J. Optimizing Retrieval-Augmented Generation with Elasticsearch for Enhanced Question-Answering Systems. arXiv 2024, arXiv:2410.14167. [Google Scholar]
- Topsakal, O.; Akinci, T.C. Creating large language model applications utilizing langchain: A primer on developing llm apps fast. Int. Conf. Appl. Eng. Nat. Sci. 2023, 1, 1050–1056. [Google Scholar] [CrossRef]
- Sun, Y.; Zeng, J.; Shan, S.; Chen, X. Cross-encoder for unsupervised gaze representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3702–3711. [Google Scholar]
- Ma, X.; Zhang, X.; Pradeep, R.; Lin, J. Zero-shot listwise document reranking with a large language model. arXiv 2023, arXiv:2305.02156. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. Int. Conf. Learn. Represent. 2022, 1, 3. [Google Scholar]
- Hao, P.; Zhang, L. Chinese Electronic Medical Records Named Entity Recognition Based on RoBERTa-wwm and MultiHead Attention. In Proceedings of the 2024 IEEE 3rd International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 27–29 February 2024; pp. 1022–1026. [Google Scholar]
- Wang, Q.; Dai, S.; Xu, B.; Lyu, Y.; Zhu, Y.; Wu, H.; Wang, H. Building chinese biomedical language models via multi-level text discrimination. arXiv 2021, arXiv:2110.07244. [Google Scholar]
- Vithana, S.; Cardone, M.; Calman, F.P. Private approximate nearest neighbor search for vector database querying. In Proceedings of the 2024 IEEE International Symposium on Information Theory (ISIT), San Francisco, CA, USA, 22–26 May 2024; pp. 3666–3671. [Google Scholar]
- Rognoni, C.; Lugli, M.; Maleti, O.; Tarricone, R. Clinical guidelines versus current clinical practice for the management of deep vein thrombosis. J. Vasc. Surg. Venous Lymphat. Disord. 2021, 9, 1334–1344.e1331. [Google Scholar] [CrossRef]
- Li, J.; Yuan, Y.; Zhang, Z. Enhancing llm factual accuracy with rag to counter hallucinations: A case study on domain-specific queries in private knowledge-bases. arXiv 2024, arXiv:2403.10446. [Google Scholar]
- Weng, Y.; Zhu, M.; Xia, F.; Li, B.; He, S.; Liu, S.; Sun, B.; Liu, K.; Zhao, J. Large language models are better reasoners with self-verification. arXiv 2022, arXiv:2212.09561. [Google Scholar]
- Kumar, S.; Alam, M.S.; Khursheed, Z.; Bashar, S.; Kalam, N. Enhancing Relational Database Interaction through Open AI and Stanford Core NLP-Based on Natural Language Interface. In Proceedings of the 2024 5th International Conference on Recent Trends in Computer Science and Technology (ICRTCST), Jamshedpur, India, 9–10 April 2024; pp. 589–602. [Google Scholar]
- Xu, L.; Li, A.; Zhu, L.; Xue, H.; Zhu, C.; Zhao, K.; He, H.; Zhang, X.; Kang, Q.; Lan, Z. Superclue: A comprehensive chinese large language model benchmark. arXiv 2023, arXiv:2307.15020. [Google Scholar]
| Step | Design Description |
|---|---|
| Character | Suppose you are an experienced clinician in the field of VTE. |
| Task | Determine whether a patient has a particular risk factor for VTE in response to the patient’s relevant medical presentation. |
| Order | Returned in standard JSON format for direct code parsing; “Format”: “{ “answer”: “(yes/no, one word)”, “basis”: “(give basis if answer is yes, leave no blank)”}” |
| Input | “Reference case”: “{Top-5 text block}”, “Risk Factors”: “{Current assessment items, e.g., history of PTE or DVT?}”, |
| Ouput | {answer: “Yes”, hint: “DVT diagnosed during routine exam 2 years ago”.} |
| Step | Design Description |
|---|---|
| Character | Suppose you are an experienced clinician in the field of VTE. |
| Task | In response to the relevant case presentation, determine whether the patient’s risk assessment conclusions are consistent with the presentation. |
| Order | Returned in standard JSON format for direct code parsing; “Format”: “{“answer”: “(yes/no, one word)”}” |
| Input | “Risk Factor”:”{History of PTE or DVT?}”, “Related Cases”: “{Top-5 Text Block}”, “Assessment Conclusion”: “{answer: ‘Yes’, hint: ‘DVT was diagnosed during a routine examination 2 years ago’.}” |
| Ouput | {answer: “Yes”} |
| Index | Q&A Session | Results |
|---|---|---|
| 1 | Q: Are cardiac biomarkers elevated? A: Significantly associated with poor short-term prognosis in PTE. | Rule 1 out |
| 2 | Q: What are the diagnostic criteria for low-risk PTE? A: Patients with intermediate-risk PTE. | Rule 2 out |
| 3 | Q: What is the definition of intermediate to high risk PTE? A: Presence of right ventricular dysfunction. | Rule 3 out |
| 4 | Q: What are the imaging criteria for CTPA to diagnose RVD? A: A four-chambered cardiac plane showing a ventricular end-diastolic internal diameter >1.0 or 0.9. | Carry |
| 5 | Q: What is the main purpose of the clinical application of the PESI/sPESI score? A: To assess the prognosis of patients with PTE and to guide whether early discharge is possible. | Carry |
| Environments | Configuration Parameters |
|---|---|
| hardware environment | GPU: NVIDIA RTX 4090 (24 GB VRAM) |
| CPU: AMD EPYC 7742 (64 cores) | |
| Memory: 512 GB DDR4 | |
| Storage: 8 TB NVMe SSDs | |
| software environment | Operating System: Ubuntu Server 22.04 LTS |
| CUDA: 11.8 | |
| Python: 3.10.12 | |
| Core Framework: Ollama 0.5.4/PyTorch 2.1.0/Transformers 4.32.0 |
| LLMs | Organization | Performance Advantages |
|---|---|---|
| DeepSeek-R1-7B | DeepSeek | Chinese General + Code Generation |
| Qwen2.5-7B | Alibaba | Medical Dialogue + Physical Understanding |
| Llama2-7B | Meta | Generic English + Open Source Community Optimization |
| Llama 3.1-8B | Meta | Long Text Comprehension + Enhanced Logical Reasoning |
| Rank | LLMs | Organization | Totals | Science | Literature | Hard | Parameter |
|---|---|---|---|---|---|---|---|
| 1 | DeepSeek-V3 | DeepSeek | 68.3 | 72 | 78.2 | 54.8 | 671 B |
| 2 | Qwen2.5-72B-Instruct | Alibaba | 65.4 | 66.2 | 80.3 | 49.7 | 72 B |
| 3 | Qwen2.5-32B-Instruct | Alibaba | 63.7 | 66.9 | 79.1 | 44.9 | 32 B |
| 4 | DeepSeek-V2.5 | DeepSeek | 63 | 67.6 | 76.1 | 45.3 | 236 B |
| 5 | TeleChat2-35B | TeleAI | 57.1 | 55.6 | 78.2 | 37.6 | 35 B |
| 6 | Qwen2.5-7B-Instruct | Alibaba | 55.5 | 54.4 | 76.4 | 35.7 | 7 B |
| 7 | QwQ-32B-Preview | Alibaba | 54.3 | 59.8 | 76.5 | 26.6 | 32 B |
| 8 | GLM-4-9B-Chat | ZHIPU AI | 52.4 | 50.6 | 75.1 | 31.6 | 9 B |
| 9 | Yi-1.5-34B-Chat | LingYiWanWu | 48.2 | 48.2 | 75.9 | 20.6 | 34 B |
| 10 | 360Zhinao2-7B | 360 | 47.8 | 50.7 | 75.2 | 17.5 | 7 B |
| Scales | P | R | F1 | Clinical Specialist Accuracy Rate (%) |
|---|---|---|---|---|
| Caprini | 79.56 | 76.82 | 78.16 | 82.52 |
| Padua | 88.32 | 85.71 | 87 | 86.41 |
| Wells | 90.51 | 88.46 | 89.47 | 89.32 |
| Geneva | 84.67 | 82.14 | 83.38 | 85.44 |
| Methods | Scales | P | R | F1 |
|---|---|---|---|---|
| He et al. [15] | Caprini | 79.9 | - | - |
| Chen et al. [16] | Wells | 84.7 | - | - |
| Chen et al. [16] | Geneva | 86.1 | - | - |
| Yang et al. [17] | Padua | - | - | 88.3 |
| Our | Caprini | 79.56 | 76.82 | 78.16 |
| Wells | 90.51 | 88.46 | 89.47 | |
| Geneva | 84.67 | 82.14 | 83.38 | |
| Padua | 88.32 | 85.71 | 87 |
| Mould | Scales | P | R | F1 | Time (s) | H (%) |
|---|---|---|---|---|---|---|
| DeepSeek-R1-7B | Caprini | 73.79 | 70.59 | 72.15 | 9.1 | 18.4 |
| Padua | 82.61 | 79.41 | 80.98 | 2.1 | 15.7 | |
| Wells | 85.44 | 83.02 | 84.21 | 2.1 | 17.2 | |
| Geneva | 79.61 | 76.47 | 78.01 | 6.1 | 19.3 | |
| Qwen2.5-7B (Our) | Caprini | 79.56 | 76.82 | 78.16 | 9.3 | 3.1 |
| Padua | 88.32 | 85.71 | 87 | 2.3 | 2.8 | |
| Wells | 90.51 | 88.46 | 89.47 | 2.3 | 2.5 | |
| Geneva | 84.67 | 82.14 | 83.38 | 4.3 | 3.4 | |
| Llama2-7B | Caprini | 65.05 | 62.75 | 63.88 | 8.9 | 12.2 |
| Padua | 74.76 | 71.43 | 73.06 | 1.9 | 10.8 | |
| Wells | 78.64 | 76.19 | 77.39 | 1.9 | 11.5 | |
| Geneva | 69.9 | 67.65 | 68.75 | 6 | 13.6 | |
| Llama 3.1-8B | Caprini | 68.93 | 66.67 | 67.78 | 9.4 | 14.5 |
| Padua | 77.39 | 74.12 | 75.71 | 2.4 | 13.2 | |
| Wells | 81.55 | 79.25 | 80.38 | 2.4 | 14 | |
| Geneva | 73.79 | 71.57 | 72.66 | 6.4 | 15.8 |
| Ablation Module | Scales | P | R | F1 | Time (s) | H (%) |
|---|---|---|---|---|---|---|
| Full model | Caprini | 79.56 | 76.82 | 78.16 | 9.3 | 3.1 |
| Padua | 88.32 | 85.71 | 87 | 2.3 | 2.8 | |
| Wells | 90.51 | 88.46 | 89.47 | 2.3 | 2.5 | |
| Geneva | 84.67 | 82.14 | 83.38 | 4.3 | 3.4 | |
| Remove Entity–Context Dynamic Association | Caprini | 72.82 | 69.61 | 71.18 | 9 | 8.7 |
| Padua | 81.55 | 78.43 | 79.96 | 2 | 7.4 | |
| Wells | 84.47 | 82.08 | 83.26 | 2 | 8.1 | |
| Geneva | 77.67 | 74.51 | 76.05 | 4.1 | 9.2 | |
| Remove RAG | Caprini | 75.73 | 72.55 | 74.11 | 8.9 | 12.4 |
| Padua | 84.47 | 81.37 | 82.89 | 1.9 | 11.2 | |
| Wells | 87.38 | 85 | 86.17 | 2 | 10.9 | |
| Geneva | 80.58 | 77.45 | 78.99 | 3.9 | 13.1 | |
| Remove reordering | Caprini | 77.67 | 74.51 | 76.05 | 9.2 | 6.8 |
| Padua | 85.44 | 82.35 | 83.87 | 2.2 | 6.1 | |
| Wells | 88.35 | 86.04 | 87.18 | 2.2 | 5.7 | |
| Geneva | 82.52 | 79.41 | 80.93 | 4.2 | 7.3 | |
| Remove fine-tuning | Caprini | 74.76 | 71.57 | 73.13 | 9.3 | 15.6 |
| Padua | 83.4 | 80.39 | 81.87 | 2.3 | 14.3 | |
| Wells | 86.41 | 84.09 | 85.24 | 2.3 | 14 | |
| Geneva | 80.58 | 77.45 | 78.99 | 4.3 | 16.1 | |
| Remove SVA | Caprini | 76.7 | 73.53 | 75.07 | 9.1 | 14.8 |
| Padua | 86.41 | 83.33 | 84.84 | 2.1 | 13.5 | |
| Wells | 88.35 | 86.04 | 87.18 | 2.1 | 12.9 | |
| Geneva | 82.52 | 79.41 | 80.93 | 4.1 | 15.4 |
| Evaluation Metric | Unit | Before (Mean ± SD) | After (Mean ± SD) |
|---|---|---|---|
| Average time per single risk assessment | minutes | 12.4 ± 2.1 | 2.1 ± 0.6 |
| Average number of assessments per clinician per week | times | 18.6 | 21.4 |
| Average job satisfaction score (5-point Likert scale) | score | 1.8 | 4.3 |
| Average time to submit and review assessment results | hours | 14.8 ± 4.5 | 6.2 ± 2.1 |
| Training time per clinician | hours | – | 0.5 ± 0.1 |
| Total number of system crashes/errors | times | – | 11 |
| System uptime per clinician (cumulative over 2 weeks) | hours | – | 2.1 |
| Continuous usage rate (more than five days) | % | – | 68% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, D.; Pu, H.; He, J. Venous Thrombosis Risk Assessment Based on Retrieval-Augmented Large Language Models and Self-Validation. Electronics 2025, 14, 2164. https://doi.org/10.3390/electronics14112164
He D, Pu H, He J. Venous Thrombosis Risk Assessment Based on Retrieval-Augmented Large Language Models and Self-Validation. Electronics. 2025; 14(11):2164. https://doi.org/10.3390/electronics14112164
Chicago/Turabian StyleHe, Dong, Hongrui Pu, and Jianfeng He. 2025. "Venous Thrombosis Risk Assessment Based on Retrieval-Augmented Large Language Models and Self-Validation" Electronics 14, no. 11: 2164. https://doi.org/10.3390/electronics14112164
APA StyleHe, D., Pu, H., & He, J. (2025). Venous Thrombosis Risk Assessment Based on Retrieval-Augmented Large Language Models and Self-Validation. Electronics, 14(11), 2164. https://doi.org/10.3390/electronics14112164