1. Introduction
As the demand for advanced robotics and autonomous driving technologies increases, precise 3D object detection becomes essential for enabling these systems to function safely and effectively in various environments [
1,
2,
3]. LiDAR, in comparison to RGB images, is particularly suited for 3D object detection under challenging environmental and lighting conditions. It provides high-accuracy point cloud data, offering detailed 3D information about objects, making LiDAR a primary sensor in autonomous driving and robotics applications. Deep learning-based 3D object detection methods can be broadly divided into voxel-based [
4,
5,
6,
7] and point-based [
8] approaches. Voxel-based methods transform point clouds into 3D voxels or 2D grids, enabling the application of sparse convolutions for feature extraction, which improves computational efficiency. However, the process of voxelization and the use of sparse convolutions can result in a loss of important 3D spatial details, which may reduce detection accuracy [
5,
9,
10]. On the other hand, point-based approaches, such as PointNet [
11] and its variants [
12,
13], directly operate on the original point clouds, preserving fine-grained 3D information and enabling more flexible receptive field selection, leading to improved detection. Despite their advantage in maintaining spatial accuracy, these methods typically use furthest-point sampling (FPS) to select keypoints, which can miss foreground points and produce less effective proposals due to imbalanced point distributions. Since foreground points are essential for accurate detection, their presence in the sampled keypoints directly influences performance. To address this issue, methods like [
14,
15] have been proposed to capture a larger number of keypoints, improving the distinction between foreground and background.
This paper introduces the semantic-guided multi-feature attention aggregation (SMA2) network, a novel approach that combines the foreground point extraction capability of semantic sampling and the feature representation strength of a sparse convolution backbone. By fusing semantically enhanced keypoints, voxels, and BEV, SMA2 captures both local structures and global information in point cloud data, enhancing object detection accuracy. The network adopts a series of progressive steps for feature fusion, detailed as follows.
To extract more valuable foreground points, Yang et al. [
16] utilized point cloud feature information for downsampling and employed Distance-FPS (D-FPS) to retain foreground points, thereby improving classification accuracy. Wu et al. [
17] proposed a semantic-based strategy for foreground point extraction, which focuses on acquiring important spatial and positional information while minimizing computational cost. Extracting foreground points from a large pool of background points relies heavily on semantic information. Drawing inspiration from Part
[
7], the method uses point cloud semantic segmentation results as prior knowledge to guide the detector in extracting more foreground points. Specifically, each point is assigned a semantic segmentation class label based on its position relative to the 3D ground-truth annotation box.
To achieve this, a novel Keypoint Attention Enhancement (KAE) module is introduced. The semantic segmentation scores are used as weights for semantic-guided sampling, extracting foreground points from raw point clouds. Simultaneously, segmented semantic features are aggregated with the sampled foreground points via cross-attention, forming keypoint semantic enhancement features. Unlike FPS [
12], S-FPS [
18], and Sectorized-Centric Keypoint Sampling [
15], this approach maximizes the retention of keypoint features from foreground points, enhancing attention mechanisms for better detection performance.
After obtaining semantic-enhanced keypoint features, the challenge arises as to how to aggregate keypoint and multi-scale features. We aim to model the relationship between keypoints and multi-scale sparse voxels. Previous works [
12,
19] in 3D object detection have constructed these relationships by using point–voxel fusion, maximum pooling layers [
14,
20,
21], and graph relationships [
19,
22]. The advantage is that the context information and dependencies can be captured, which can greatly enhance the ability to identify fine-grained patterns. However, the key challenge is to mine the correlation between key point features and multi-scale voxel features while effectively fusing the two features together. Inspired by the transformer architecture [
23,
24], a multi-feature attention aggregation (MFAA) module is proposed, which consists of three components: keypoints, BEV, and multi-scale sparse voxel features. By leveraging self-attention mechanisms, the MFAA module adaptively attends to relevant features from each representation, enabling the precise fusion of local and global information. The keypoint query guides attention, focusing on pertinent regions while ensuring efficient communication between features extracted from keypoints, BEV, and voxel grids.
The MFAA module facilitates cross-feature interactions, allowing keypoint features to be enhanced by semantic information and effectively fused with multi-scale voxel representations. This process captures both local and global spatial relationships, improving object detection accuracy, particularly in complex scenes. Additionally, hierarchical feature interactions at different scales help the model to focus on both fine details and broader contextual patterns, resulting in more robust detection performance.
In summary, the main contributions in this work are summarized as follows:
A Keypoint Attention Enhancement (KAE) module is introduced to capture more valuable foreground points from the raw point cloud, enabling the model to focus accurately on areas containing small objects;
We propose a multi-feature attention aggregation (MFAA) module, designed to aggregate keypoints and their corresponding voxel features to generate a comprehensive feature representation. This method effectively leverages the complementarity between point cloud and voxelized representations;
The proposed keypoint query allows for the direct extraction of voxel features near the keypoints, eliminating the need to traverse all voxels and thereby improving computational efficiency.
Extensive experiments demonstrate that SMA2 achieves competitive performance on the widely used KITTI 3D object detection benchmark. Furthermore, the method has been validated for robustness on the Waymo and DAIR-V2X-V validation sets.
The structure of this paper is as follows.
Section 2 surveys related work on LiDAR-based 3D object detection, covering point-based, voxel-based, and hybrid methods. In
Section 3, we introduce the SMA
2 network, which integrates semantic-aware modules with multi-feature attention mechanisms.
Section 4 details the experimental setup, datasets, and implementation specifics.
Section 5 reports quantitative results on the KITTI, Waymo, and DAIR-V2X-V benchmarks.
Section 6 presents a comprehensive analysis, including ablation studies and module evaluations.
Section 7 compares the inference performance of SMA
2 against existing approaches.
3. Methodology
3.1. The Overview of Our Method
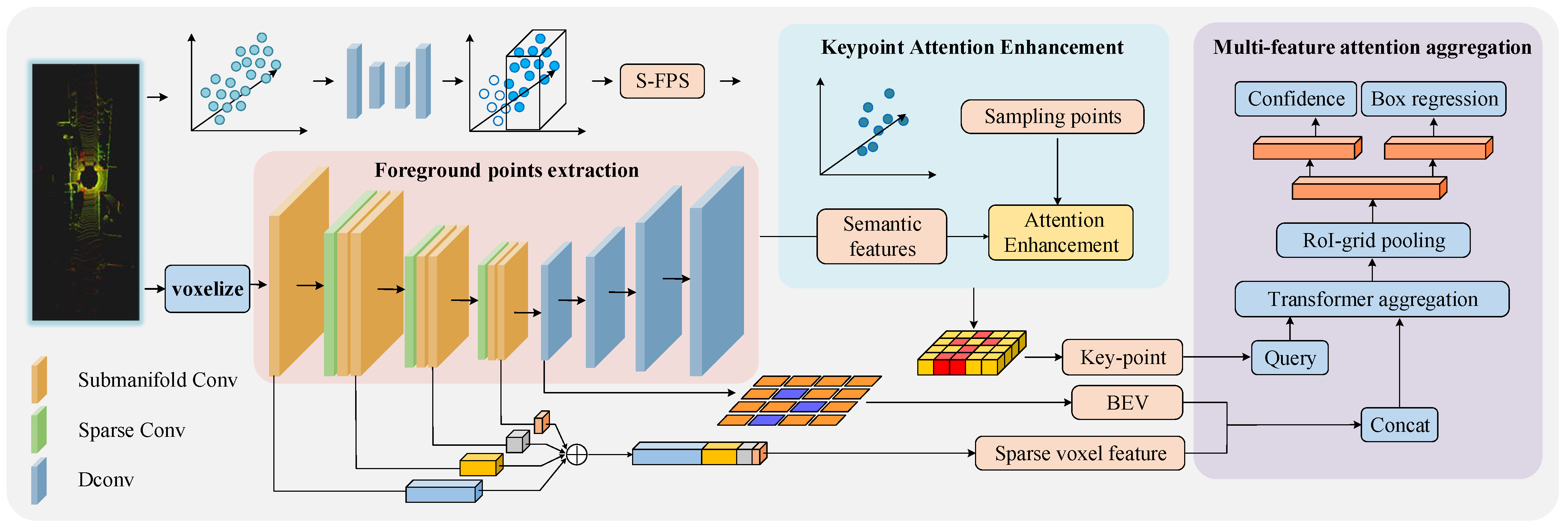
The pipeline of SMA
2 is shown in
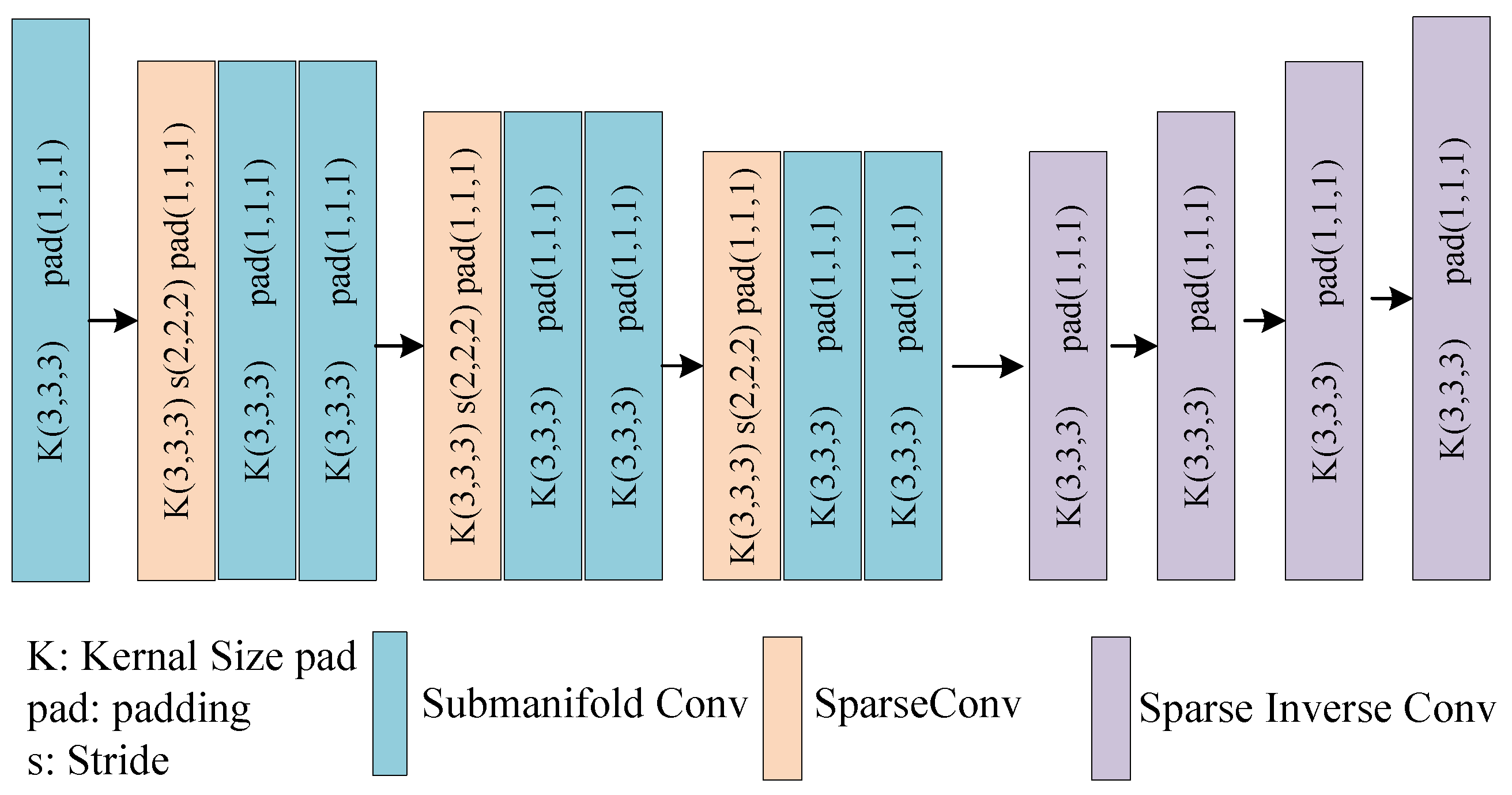
Figure 1. The network is composed of three main components. First, the foreground point extraction module utilizes the Spconv–Unet encoder–decoder architecture, as depicted in
Figure 2. This network combines sparse convolution blocks with submanifold convolution blocks to learn discriminative voxel features. The encoder employs three sparse convolution blocks to downsample the input voxel space by a factor of eight, effectively capturing essential feature information. The second component, the Keypoint Attention Enhancement module, samples the raw point clouds based on the detected point categories from the first stage. A self-attention mechanism is then applied between the voxelized sampling points and semantic space features, computing the offsets between location features and input features to refine keypoint selection. Finally, the multi-feature attention aggregation module leverages a 3D sparse CNN to extract voxel features, which are subsequently compressed into 2D BEV features. The keypoints, BEV features, and sparse voxel features are then passed through the transformer aggregation module, where they are integrated to optimize detection performance.
3.2. Foreground Points Extraction
To segment foreground points, an Spconv–Unet encoder–decoder network is used to learn discriminative voxel features through sparse and submanifold convolution blocks. The encoder downsamples the voxel space using three sparse convolution layers followed by two submanifold convolution layers to capture high-level features efficiently. The decoder then restores the original spatial resolution using four upsampling blocks, aiming to recover non-empty voxel features while maintaining computational efficiency. This architecture enables effective segmentation of foreground points by handling sparse point cloud data efficiently.
And then we choose a voxel-based data representation as input and divide the raw point clouds into regular small voxels with spatial resolution . Each voxel represents the characteristics of points contained in its grid. The mean of coordinates among points within a non-empty voxel is firstly calculated as the initial value of the voxel feature.
Given the size
, orientation
in the bird’s-eye view, and the center position
from the 3D ground-truth boxes, represented as
, we compute the relative position of each foreground point using Equation (
1). The relative position of the foreground points, denoted as
, is expressed as
.
where
and the center of relative position is
. It is worth noting that all coordinates follow the LiDAR coordinate system in the KITTI dataset, which is a right-handed coordinate system with the z-axis up, the x-axis forward, and the y-axis left.
For each foreground point within a 3D bounding box, the process begins by shifting the point coordinates relative to the box center , so that the position is described in the object’s local coordinate system. A 2D rotation matrix, with angle , is then applied to the point in the x–y plane to align the local coordinate frame with the object’s orientation in the bird’s-eye view. This rotation ensures that all objects are standardized to a common heading direction. The resulting offsets , along with the vertical difference , are normalized by the bounding box dimensions to map the point’s relative position into a canonical coordinate space within the range of . This normalization centers the object at , ensuring a consistent geometric representation regardless of object scale or orientation. It should be noted that this transformation is based on the LiDAR coordinate system defined in the KITTI dataset, a right-handed system where the x-axis points forward, the y-axis points left, and the z-axis points upward.
The 3D ground-truth boxes inherently encode semantic categories for associated foreground points, while a significant imbalance exists between foreground and background point distributions [
7]. To alleviate this class imbalance problem, we use focal loss [
44], defined by
where
where
represents the probability of classifying a point as foreground or background, with hyperparameters set to
and
.
3.3. Semantic FPS
Farthest-point sampling (FPS) [
45] is commonly employed for point cloud sampling, aiming to maintain the spatial structure and balance of the original data. It excels at selecting a subset of informative points that reflect the overall geometry of the scene. Nevertheless, in outdoor LiDAR scenarios, where point clouds can be dense and unevenly distributed, FPS may struggle to consistently capture representative points. This limitation can lead to missing critical features, such as small or distant objects, ultimately affecting the accuracy of 3D object detection.
To address this challenge, we propose a foreground-aware distance-weighted sampling strategy, inspired by [
17]. The key idea is to incorporate foreground information into the FPS process to prioritize important points that contribute to object detection. Specifically, we leverage a foreground point segmentation module, which classifies each point as either foreground or background. This classification helps in assigning different importance to points, with foreground points receiving higher weights during the sampling process. A two-layer Multi-Layer Perceptron (MLP) is employed to classify points. Given
N input points with feature vectors
, each of dimension
L, the MLP predicts a foreground score
for each point, representing the probability of being part of the foreground. The foreground score
for the
i-th point is computed as follows:
where
represents the segmentation module, which maps the input point-wise features
to foreground scores
, and
is the sigmoid activation function. A score near 1 implies a strong association with the foreground, whereas a value closer to 0 indicates a higher likelihood of being part of the background. Once the foreground scores are obtained, we incorporate these scores into the FPS process to refine the selection of keypoints. Let
represent the distances from each unselected point to the existing keypoints in the keypoint set. In each iteration, the point with the largest semantically weighted distance is selected as a keypoint. The weight is computed by multiplying the foreground score
with the distance
, as follows:
where
represents the weighted score for the
i-th point. By incorporating the foreground score, we prioritize points that are both far from the existing keypoints and likely to be part of the foreground, ensuring that informative points are selected. The point with the largest weighted score
is added to the keypoint set
K, which is iteratively updated as
This process allows us to adaptively select keypoints based on both their spatial distribution and their importance in representing the foreground, resulting in more efficient and effective point cloud sampling.
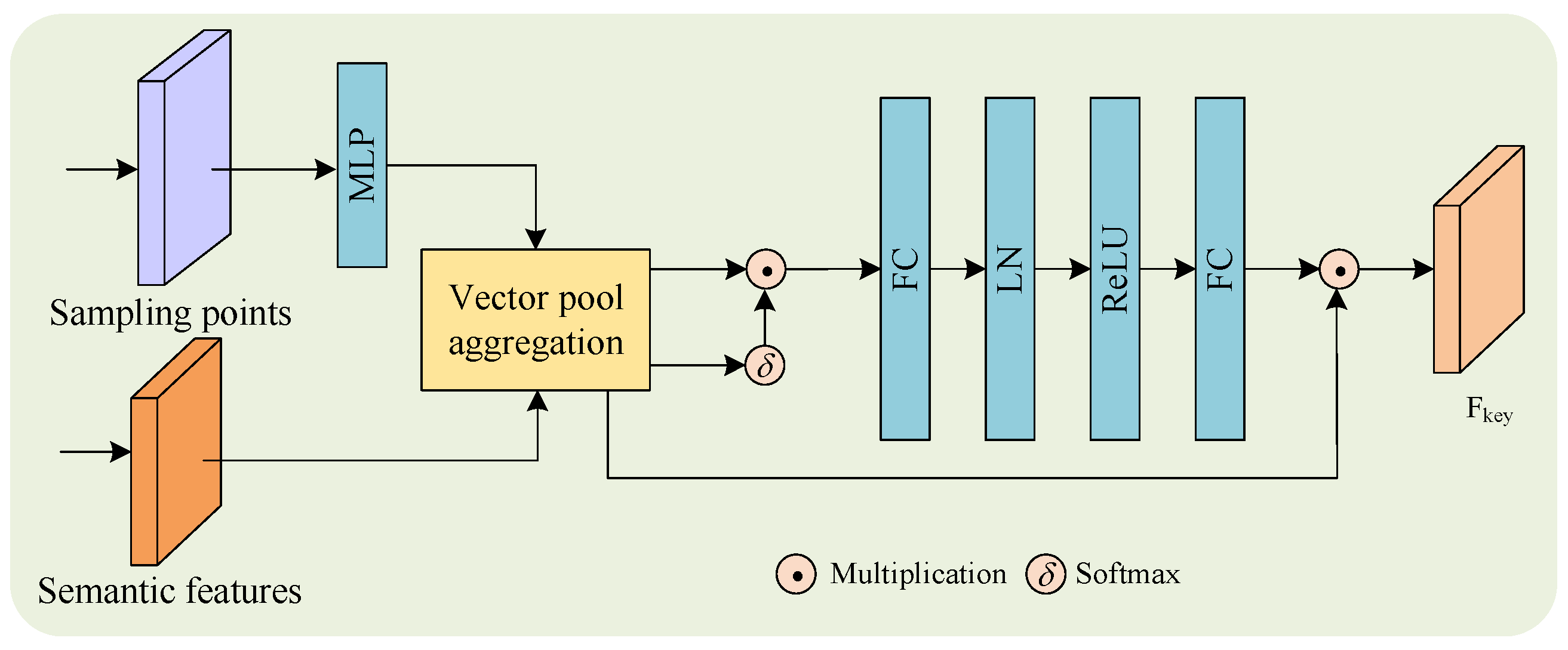
3.4. Keypoint Attention Enhancement
Our proposed Keypoint Attention Enhancement module dynamically enhances 3D keypoint features through the hierarchical fusion of geometric and semantic cues, enabling robust representation learning in complex scenes. As shown in
Figure 3, given an input set of 3D keypoints
, where
N denotes the number of points and each point
is represented by its
coordinates, the module operates as follows.
The raw keypoints
K are encoded into high-dimensional semantic–geometric features using a feature extractor (e.g., MLP or PointNet-based backbone). This yields a feature map:
where
C is the feature dimension. Each
encapsulates local geometric structures and global semantic contexts.
To prioritize discriminative regions, we compute a global attention map
by fusing voxel foreground point features and semantic keypoint features using vector pool aggregation [
15]. The attention weights are normalized via softmax:
where
reflects the global significance of the
i-th keypoint. The feature map
is refined through a fully connected (FC) layer with layer normalization (LN):
The attention map
b dynamically weights
via element-wise multiplication:
For each keypoint
i, we enhance its representation using a two-layer network with ReLU and LayerNorm:
where ⊙ denotes element-wise multiplication and
are learnable weights.
The final output consolidates discriminative geometric and semantic features.
3.5. Multi-Feature Attention Aggregation
3.5.1. Multi-Scale Voxel Feature Group
Sparse voxels enable higher spatial resolution by leveraging a smaller number of occupied voxels, thereby preserving fine-grained geometric structures. This characteristic is particularly advantageous for capturing subtle object boundaries and small-scale scene details in 3D perception tasks. However, voxelization inherently introduces quantization artifacts and information loss due to the discretization of irregular point clouds. To mitigate this issue, we adopt a multi-scale voxel feature aggregation strategy that captures point cloud information across multiple spatial resolutions and enriches context representation.
Instead of enhancing the sparse voxel backbone via isolated stages as in [
46,
47], we construct a hierarchical feature aggregation framework that aligns sparse voxel features with BEV (bird’s-eye view) features at multiple scales. Specifically, we extract downsampled sparse voxel features
from four stages with strides
. These features are progressively aligned to a common BEV resolution and concatenated with coarse-resolution voxel features. This results in a multi-scale hierarchical feature representation that captures both fine and coarse spatial information, which is then used to guide feature propagation to higher scales. The resulting non-empty voxel features
, centered around keypoints, are aggregated to enhance semantic richness. To handle discrepancies in feature dimensions across different scales, we apply a channel reduction step using sparse 3D convolution (SparseConv), ensuring consistent feature dimensionality before fusion.
This process not only bridges the resolution gap among features at different levels but also facilitates efficient information flow across scales. Moreover, our design allows for contextual feature enhancement in both dense and sparse regions by adaptively integrating voxel features with varying levels of granularity. This proves particularly beneficial for detecting small or distant objects, where fine-scale features provide critical cues. By fusing multi-scale voxel features into a unified representation, our method achieves a more comprehensive understanding of the scene while maintaining computational efficiency inherent to sparse convolutional networks.
3.5.2. BEV Feature Map Representation
In the 3D voxel CNN branch, we first extract the 8-times downsampled voxel feature map , with dimensions , where L, W, and H represent the length, width, and height of the input voxel grid, respectively. To effectively transform the voxel features into a bird’s-eye view (BEV) representation, we stack the features along the z-axis, aggregating the three-dimensional voxel features into two-dimensional BEV feature maps with a size of . This representation not only preserves the spatial geometry of the scene but also ensures higher computational efficiency. Subsequently, to obtain the semantic embeddings of the downsampled points in the BEV space, we employ bilinear interpolation to extract the corresponding feature vectors from the BEV feature map, denoted as , where N is the number of points and C represents the number of channels. This process enhances the contextual information of the point cloud representation, providing more robust features for subsequent fusion and detection tasks.
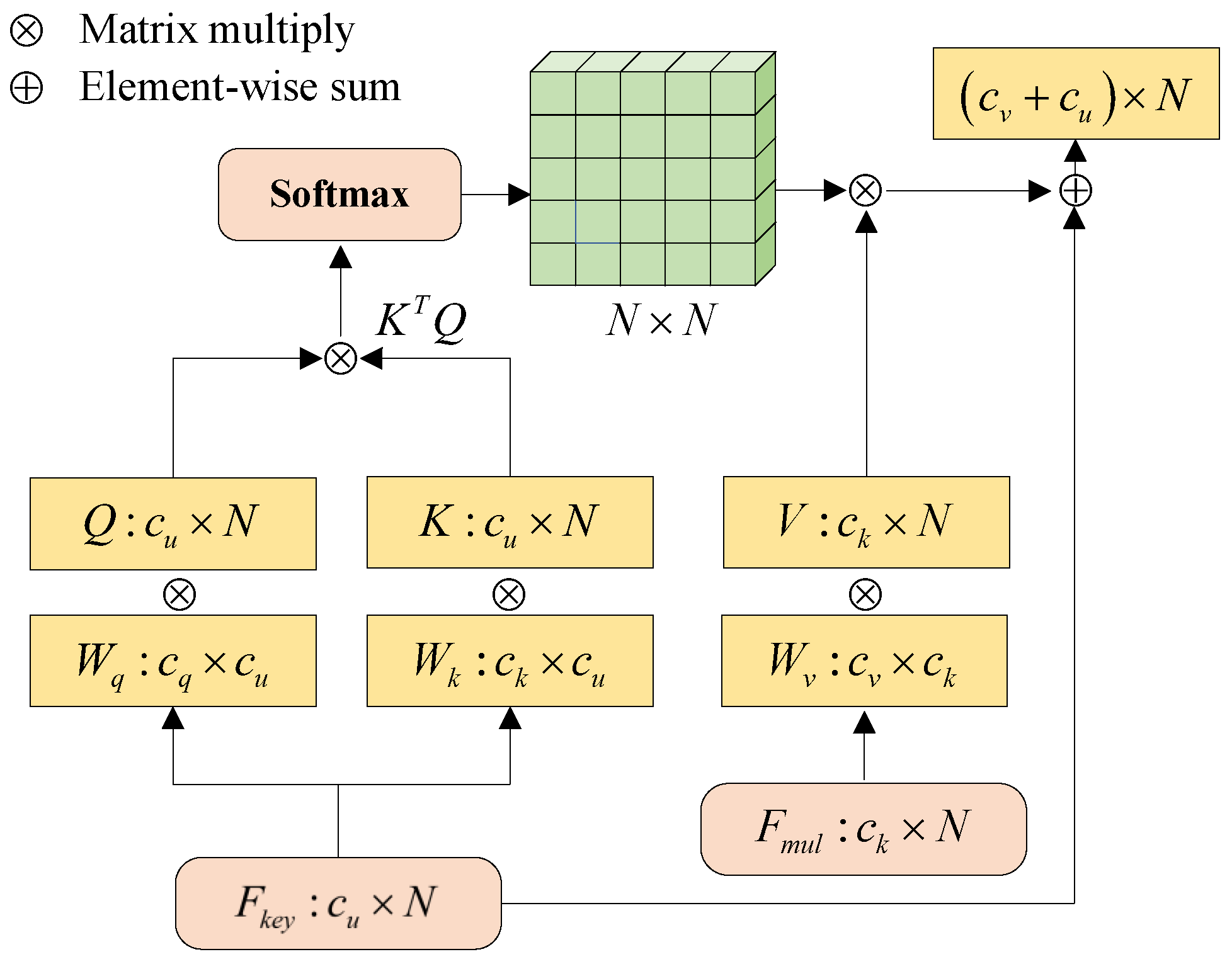
3.5.3. Transformer-Based Multi-Feature Aggregation
We aim to obtain a more accurate and comprehensive data representation by aggregating multi-feature information. The voxel features and BEV features are connected to obtain multi-scale aggregation features
, where the dimension of each class of feature is equal to C. Inspired by the linear combination of inputs using relevant weights in the attention mechanism [
48,
49], two input matrices
and
are interacted and weighted by correlation scores in the self-attention mechanism. The attention output layer is defined as
where the matrices
Q,
K, and
V correspond to the query, key, and value, respectively, while
,
, and
represent their respective linear projections. As illustrated in
Figure 4, the multi-feature aggregation method incorporates fused feature maps that combine multi-scale voxel groups and semantic keypoint information, which are then processed through self-attention. The key distinction is that we compute the weight between the semantic keypoint feature
using the query and key feature vector matrices. By applying a weighted sum, we efficiently fuse the resulting outputs, denoted as
.
3.6. Loss Functions
Our approach can be trained in an end-to-end manner through the RPN and R-CNN stages, optimized using a multi-task loss function
, defined as follows:
The segmentation loss
is calculated using binary cross-entropy to extract the semantic features of foreground points. Following the approach in [
7], the RPN loss
is composed of three components: object classification loss, box localization regression loss, and corner loss.
where
represent the weight coefficients of the above three sub-tasks. Smooth-L1 loss [
15] is adopted for calculating
, the regression objective function is calculated by the relative offset between the anchor and the ground truth:
,
,
,
,
,
, where
. And the regression loss
can be defined as
and the classification loss
can be expressed by the focal loss as follows:
the hyperparameters
and
require manual tuning, and
represents the classification predictions. In this study,
is set to 0.25, while
is set to 2. The corner loss
is calculated using sine-error loss [
5] for angle regression. In the refinement stage,
is used as the loss for classification and localization. Its objective is to filter proposals using ground truth during the Region of Interest (ROI) process. This loss consists of three parts: the classification confidence loss
, location regression loss
, and box corner loss
, and is defined as follows:
4. Experiment
In this section, we assess the performance of SMA2 on the KITTI dataset for LiDAR-based 3D object detection through efficiency analysis and ablation studies.
4.1. Datasets and Evaluation Metric
KITTI Dataset: A widely recognized benchmark for 3D object detection. The LiDAR coordinate system range is restricted to
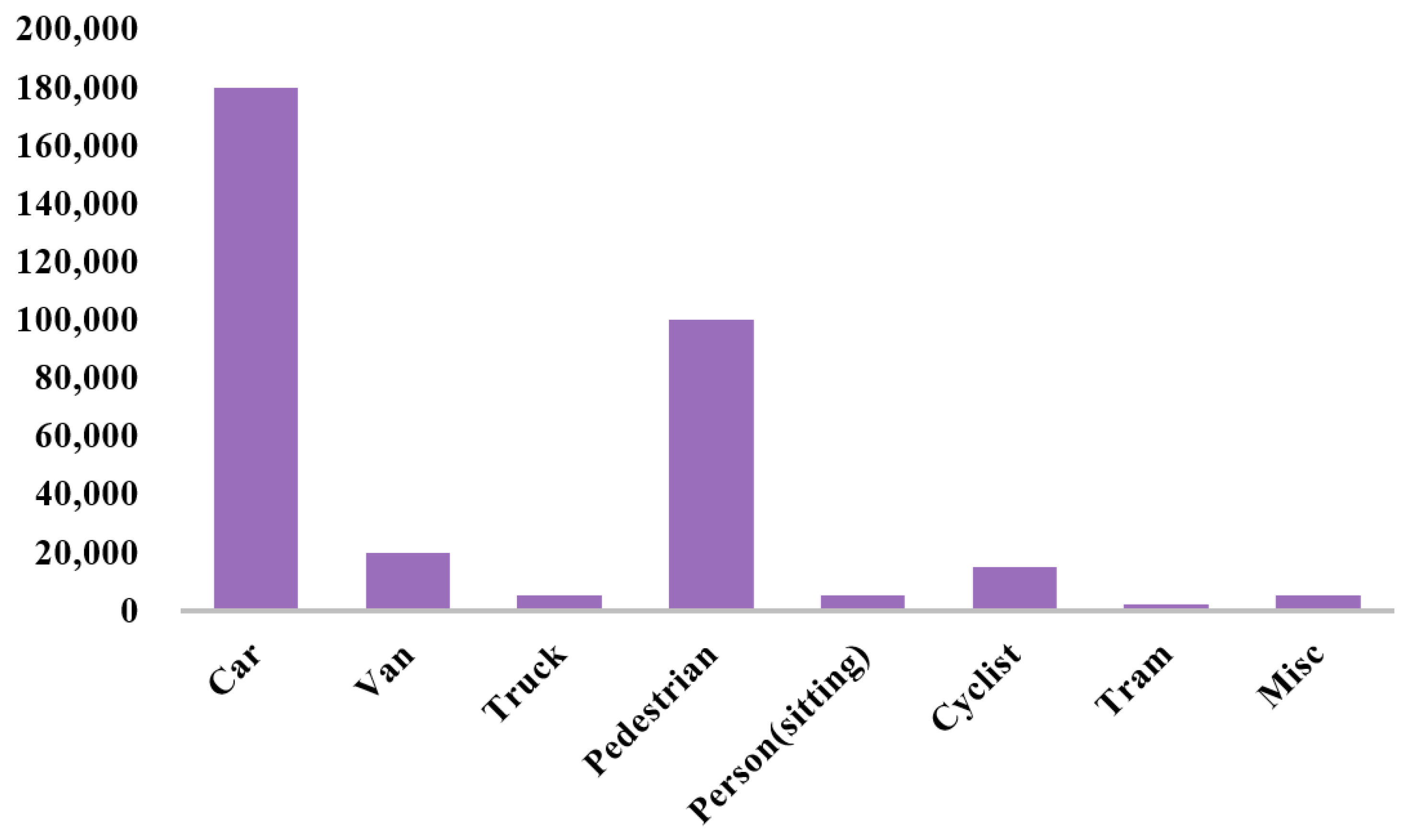
, according to common practice. The dataset contains 7481 training and 7518 testing LiDAR scans. The standard split is used, with 3712 samples for training and 3769 samples for validation. The purpose of such segmentation is to ensure that images of the same sequence are distributed as independently as possible in the training and validation sets. For each object category, the detection results are evaluated based on three standard regimes: easy, moderate, hard, defined according to the object size, occlusion state, and truncation level. As shown in
Figure 5, these statistics show the distribution of different object categories in the dataset. The Car and Pedestrian categories contain a large number of samples, while Truck, Person (sitting), Tram, and Misc have relatively fewer instances. However, for comparison with mainstream methods, we only report results for the Car, Pedestrian, and Cyclist categories.
Waymo Dataset: The Waymo Open dataset is one of the most extensive and high-resolution datasets available for autonomous driving research, featuring a diverse set of sensor data and complex traffic scenarios. It consists of 798 training sequences (about 158k point cloud samples) and 202 validation sequences (approximately 40k point cloud samples), each with 360-degree field-of-view annotations. Performance evaluation is carried out using metrics like mean average precision (mAP) and mean average precision with heading angle (mAPH). Predictions are classified into two levels: LEVEL_1, which includes 3D labels with more than five LiDAR points, and LEVEL_2, which includes labels with at least one LiDAR point. The detection range spans [−75.2 m, 75.2 m] along the X and Y axes, and [−2 m, 4 m] along the Z axis. Raw point clouds are voxelized with a resolution of (0.1 m, 0.1 m, 0.15 m).
DAIR-V2X-V Dataset: The DAIR-V2X-V dataset is a pioneering large-scale, multi-modal resource designed for cooperative vehicle–road autonomous driving research. It features data gathered from real-world scenarios and includes both 2D and 3D annotations. The dataset contains 22,325 image frames and an equal number of point cloud frames, with 3D annotations for 15 common road obstacles. The dataset is split into training, validation, and testing sets in a 5:2:3 ratio, with evaluation performed on the validation set. Consistent with KITTI, the evaluation uses average bounding box perception. Vehicle classification is evaluated using intersection-over-union (IoU) thresholds set at [0.7, 0.5, 0.5] to account for varying difficulty levels in the evaluation process.
4.2. Implementation Details
In line with the standard practices adopted by recent works [
5,
6,
14,
26], evaluation on the validation set is conducted using 11 recall positions to compute average precision (AP), while the KITTI test benchmark utilizes 40 recall positions. As a result, 11-point AP is used for validation and 40-point AP for testing. For the final test benchmark submission, the complete KITTI training set is employed to train the SMA
2 model. The performance is assessed using two key metrics: 3D average precision (3D AP) and bird’s-eye view average precision (BEV AP). The model is trained using the Adam optimizer [
50] with a weight decay of 0.01 and a momentum of 0.9. The training process spans 70 epochs, starting with an initial learning rate of 0.003. Specifically, the learning rate is initialized at 0.01 and a step decay strategy is employed, reducing the learning rate by a factor of 0.1 at the 40th and 60th epochs. The batch size is set to eight for all experiments. To generate the final predictions during inference, the process begins by filtering the initial 3D proposals through a non-maximum suppression (NMS) step with an IoU threshold of 0.7, retaining the top-100 candidates. These selected proposals are subsequently refined via RoI Grid Pooling, which integrates detailed keypoint features to enhance spatial representation. After refinement, a second NMS with a stricter threshold of 0.1 is performed to remove duplicate detections and produce the final outputs. In the keypoint semantic enhancement module, the S-FPS module precedes the self-attention (SA) layers, where 16,384 points are sampled from the raw point cloud as input. The initialization stage includes a voxel-based submodule consisting of two 3 × 3 × 3 3D convolutional layers, both with a stride of 1 and a padding of 1.
In our training framework, we adopt Smooth-L1 loss for bounding box regression and focal loss for classification. These losses are applied to both the region proposal network (RPN) and the region-based CNN (RCNN) stages. Empirically, we observe that the RPN loss stabilizes rapidly during early training, effectively generating high-quality object proposals. This allows the RCNN loss to focus on refining detection results with improved precision. The two losses interact in a complementary manner, and no conflicting gradients or training instability were observed. This stable convergence behavior confirms the compatibility and mutual reinforcement between the RPN and RCNN stages in our framework.
6. Inference Analysis
Table 11 summarizes the inference efficiency and detection performance of SMA
2 across three benchmark datasets. The model is trained for 70 epochs on KITTI, 60 epochs on 10% of the Waymo training split, and 60 epochs on DAIR-V2X-V. All experiments are conducted using an Intel i7-7820X CPU and a single GTX 1080Ti GPU with a batch size of 1. For consistency, the number of proposals generated by the region proposal network (RPN) is fixed: K = 90 for KITTI and DAIR-V2X-V, and K = 275 for Waymo.
Compared to PV-RCNN, SMA2 achieves faster inference, reducing runtime by 18.1%, 15.5%, and 12.7% on KITTI, Waymo, and DAIR-V2X-V, respectively. In addition, it delivers improved detection accuracy, achieving gains of +2.43% AP on KITTI, +3.55% mAPH on Waymo, and +0.76% Car 3D AP on DAIR-V2X-V.
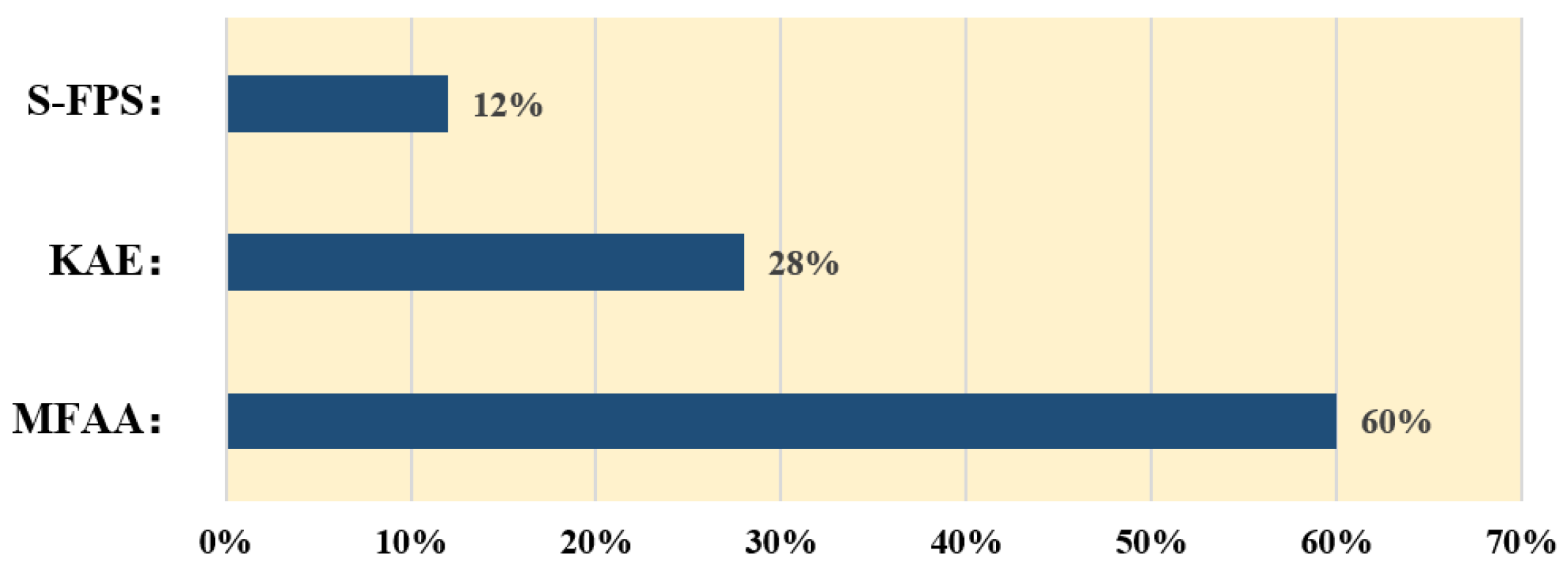
We analyze the runtime overhead of the proposed keypoint-based querying pipeline. As illustrated in
Figure 7, MFAA accounts for approximately 60% of the runtime, followed by KAE (28%) and S-FPS (12%). Despite the additional computation introduced by MFAA, the overall increase in runtime is marginal (∼6.7%), which we consider a favorable trade-off for the observed ∼5% AP gain.
8. Conclusions and Discussion
In this paper, we present SMA2, a unified framework that fuses keypoint, bird’s-eye view (BEV), and sparse voxel features for enhanced 3D object detection. To begin with, we design a Keypoint Attention Enhancement module that extracts discriminative local keypoints from foreground points by applying semantic-guided sampling and self-attention to segmented foreground features. Then, to capture the interactions between keypoints and non-empty voxels, we propose a multi-feature attention aggregation module that performs keypoint-guided feature fusion across multiple representations. Experimental results on the KITTI dataset show that SMA2 achieves superior performance over existing two-stage detectors. Moreover, it exhibits strong robustness and generalization on the Waymo and DAIR-V2X-V validation sets.
While our method demonstrates strong performance overall, it still struggles with highly occluded pedestrian instances. In future work, we plan to incorporate morphological features, such as human shape priors and skeleton-based keypoints, to enhance the model awareness of structural cues and reduce false positives in complex scenes. Meanwhile, we will explore different representations and fusion methods of point clouds in multi-modal scenes.
Beyond current benchmarks, the proposed SMA2 model can be extended to a wide range of 3D perception tasks. In autonomous driving, it enables the accurate and real-time detection of vehicles, pedestrians, and cyclists. In robotics, it supports fine-grained scene understanding to facilitate safe navigation. In augmented reality (AR) or digital twin systems, SMA2 can contribute to precise environment reconstruction and interactive understanding.
To comprehensively assess the robustness of the method, it is important to consider the impact of varying LiDAR sensors and scanning conditions. Differences in LiDAR sensor configurations, scanning density, and point cloud acquisition conditions can significantly affect detection performance in real-world scenarios. Therefore, incorporating data from different LiDAR setups and evaluating how these variations influence model performance, particularly in spatial information integration during classification decisions, will be essential for improving the method’s applicability in diverse environments.
Furthermore, integrating contextual information, such as semantic context or point cloud density, using Graph Convolution Networks (GCNs) or attention-based mechanisms, could enhance the model’s ability to capture local features and improve classification stability. This is especially important for small object detection. Leveraging these additional features aims to improve detection accuracy, particularly in complex scenarios involving small targets, such as pedestrians or cyclists. These future directions will be further explored in ongoing research.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}