1. Introduction
With the rapid development of modern Internet technology, the public is no longer passively receiving information through traditional television and print media. As of early 2024, China had approximately 1.09 billion Internet users, with an Internet penetration rate of about 76.4% of the population. By the end of 2023, Weibo had about 598 million monthly active users. Therefore, Weibo has become a center for information dissemination not only nationwide but also globally. There are many hot topics on Weibo and Twitter every day, usually involving significant social events, controversial public figures, or eye-catching public policies. Behind each topic, there may be complex economic, social, and political factors, covering people and issues in multiple fields. As a result, users’ opinions on the same hot issue vary greatly, with diverse stances and viewpoints. Understanding the different stances of Weibo users on these hot topics helps us to assess the overall public opinion trend.
Therefore, in order to deepen the understanding of public reactions and enhance the accuracy of stance detection, this paper is committed to proposing a multi-task model assisted by sentiment analysis and toxic language detection to improve the accuracy of stance detection. It should be able to handle highly heterogeneous and dynamic data streams while identifying and adapting to the subtle changes in sentiment and toxicity in social discourse. Toxic language refers to words with hatred, offense, discrimination, or insult, and the task of toxic language detection helps to model the stance-related information associated with sentiment more finely. In addition, for the analysis of specific hot issues, cultural and contextual factors need to be particularly considered, as well as how to extract valuable information from the noisy background of social media.
This paper proposes a multi-task stance detection model for hot issues combined with sentiment analysis and toxic language detection to automatically identify and analyze public comments on hot issues on social media. By selecting Chinese and English hot cases, we ensure that the comments on hot issues are extensive and have clear stances, with complex and emotionally rich comment data, which improves the accuracy and granularity of stance detection. The research results not only have practical significance for understanding the public’s reactions to hot issues but also provide a certain reference value for public opinion tendency analysis and public opinion guidance.
The main contributions of this paper comprise three aspects:
This paper constructs a new stance detection dataset, and for each record in the dataset, manual annotation is performed based on the text stance, sentiment tendency, and toxic language features of users on specific topics. This newly constructed dataset covers a total of 2000 Weibo texts and 1500 Twitter texts.
The embedding network is implemented, using SBERT sentence embedding and employing an attention mechanism to enable the model to focus on the most informative embeddings, enhancing the ability to process diverse text data; the Bi-LSTM network is used to capture long-term dependencies in text data, improving the accuracy of the model; the fusion module is designed and implemented to combine the results of sentiment analysis and toxic language detection, optimizing the performance of stance detection.
A multi-task learning model combining sentiment analysis and toxic language detection is designed. In this model, stance detection is a multi-classification task, while sentiment analysis and toxic language detection are multi-label tasks. The model uses the embedding network and Bi-LSTM network to process text data and enhances the ability to capture key information through a multi-task attention mechanism.
2. Related Work
To date, numerous scholars have conducted relevant research on the topics covered in this paper. First, sentiment analysis focuses on identifying emotional nuances in text, such as positive, negative, or neutral sentiments, or even more nuanced emotions. This technology has been widely applied in fields such as social media analysis and brand monitoring. The seminal paper by Pang et al. [
1] provides a comprehensive overview of sentiment analysis. They introduced various machine learning-based methods for identifying and classifying sentiment tendencies in text. Specifically, they explored the use of supervised learning techniques, such as Support Vector Machines (SVMs), Naive Bayes models, and Maximum Entropy models, to classify text into positive, negative, or neutral sentiments. These techniques have been widely used in the sentiment analysis of product reviews and social media posts.
Regarding discussions on hot issues, toxic language detection is particularly important because intense emotional discussions may contain insulting or exclusionary remarks. The research by Ellery et al. developed a machine learning system called “Conversation AI” that is specifically designed to identify and flag offensive or harmful speech online [
2]. This system utilized a large-scale dataset manually annotated for training a deep neural network to recognize toxic speech in online conversations.
The multi-task learning applied in this paper refers to the simultaneous execution of multiple learning tasks, improving the learning efficiency and predictive accuracy of each individual task by sharing representations or model parameters. Caruana et al. pioneered multi-task learning in 1997 [
3], detailing the neural network architecture where different tasks share hidden layers and experimentally verifying the effectiveness of multi-task learning in various applications, such as medical diagnosis and vehicle recognition. Since then, multi-task learning models have rapidly expanded in numerous fields, significantly enhancing model performance and universality. This has led to substantial improvements in both efficiency and accuracy when handling multiple related tasks.
Regarding stance detection, research on stance detection models began earlier in foreign countries. In 2010, Thomas et al. first introduced the concept of stance detection [
4], applying it to political argumentative texts, marking the beginning of stance detection research. Subsequently, Task 6 in the 2016 SemEval competition was specifically dedicated to stance detection, further fueling the research boom in this field. With the advent of the deep learning era, deep learning-based models, due to their powerful feature extraction and context understanding capabilities, have significantly improved the accuracy of stance detection.
In recent years, with the rise of deep learning technologies, the field of natural language processing has undergone significant changes, giving rise to word embeddings and pre-trained language models (such as BERT and GPT) that automatically learn complex feature representations from text. This has greatly enhanced the model’s ability to understand text semantics. Deep neural networks, especially Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), as well as their variants (such as LSTM and GRU), have been widely used in stance detection tasks, significantly improving detection accuracy and efficiency. Augenstein proposed Bi-LSTM [
5], which encodes topics and text together and has been widely used for the joint modeling of text [
6].
Subsequently, the Transformer model, introduced by Vaswani et al. in 2017 [
7], has become a revolutionary architecture in the field of natural language processing. It can process sequence data in parallel and effectively capture relationships between different parts of a sequence through its self-attention mechanism. This has enabled it to achieve remarkable performance in various NLP tasks. Initially, it achieved significant success in machine translation tasks and quickly expanded to other fields, such as text summarization, sentiment analysis, and question-answering systems. Subsequently, models based on the Transformer architecture, such as BERT, GPT, and RoBERTa, have further advanced the model’s capabilities in language understanding and generation, greatly improving the performance of downstream tasks.
In 2021, Karande et al. proposed a model [
8] for detecting the credibility of information on social media. The study utilized pre-trained contextualized word embeddings and BERT to achieve state-of-the-art results in fake news detection. The experimental results showed that the model performed excellently on real-world datasets, achieving an accuracy rate of 95.32% in detecting fake news. In the same year, AlDayel et al. reviewed the work on stance detection on social media [
9], including task definitions, different types of targets for stance detection, feature sets used, and various machine learning methods applied. In 2022, Kumar et al. proposed a new method [
10] to improve the accuracy of sentiment analysis using the BERT algorithm and compared it with Support Vector Machines. The results showed that the BERT algorithm achieved an average accuracy of 83.5% on the IMDB movie review dataset, outperforming the SVM algorithm’s 75.3%. In recent years, researchers have extended the study of natural language processing and stance detection models to many other fields. For example, Radiology et al. explored the use of Transformer-based natural language processing (NLP) techniques for the non-invasive prediction of tumor biomarkers [
11]. This study demonstrated the potential of NLP technology in the medical field, where processing and analyzing large amounts of medical text data can help doctors make more accurate diagnoses and treatment decisions. Additionally, Maeda et al. conducted experiments using the RoBERTa model for English reading comprehension tests [
12], calculating the psychometric properties of the items through data analysis to verify the application effectiveness of RoBERTa in educational assessment. These studies not only expanded the application scope of stance detection but also showcased the potential of natural language processing technologies in various fields.
With the rise of social media and online forums, natural language processing and stance detection have attracted increasing interest from domestic researchers in China. In 2017, Bai Jing [
13] combined multiple word segmentation models to reduce noise interference and utilized sentence sentiment tendencies as features. This approach achieved a multi-feature sentence representation based on multiple word segmentation sequences and adopted an attention-based pooling strategy, effectively improving the deficiencies of traditional CNN models in information extraction.
With the development of machine learning technologies, sophisticated feature engineering [
14] has been developed on the basis of simple machine learning models (such as Support Vector Machines and Naive Bayes models) to improve the accuracy of stance detection. This includes the use of text features (such as word frequency and n-grams), semantic features (such as sentiment words and thematic consistency), and author features (such as historical stance tendencies and social network structures). Meanwhile, more complex machine learning models have been applied to the task of stance detection, such as Random Forests and Gradient-Boosting Trees.
In 2020, Zhang Cui Xiao et al. [
15] combined word embedding technology with CNN-BiLSTM. They used Convolutional Neural Networks (CNNs) to extract detailed features from text and employed Bidirectional Long Short-Term Memory Networks (BiLSTMs) to capture the overall semantic information of the text. This effectively addressed the limitations of relying solely on CNNs for understanding the global context and the gradient vanishing problem associated with traditional Recurrent Neural Networks. In 2021, Li Yang et al. reviewed the research work on text stance detection from three perspectives: target type, text granularity, and research methods [
16]. They introduced the foundational research on text stance detection and analyzed the stance tendencies expressed in text towards specific targets. In 2023, Cao Wei et al. [
17] improved the semantic and sentiment uncertainty of short social media texts through visual context enhancement and multi-granularity semantic expression. They adopted a narrative understanding-based method for sentiment cause detection, with the causal association module and sentiment attention module working together to enhance the performance of text sentiment cause identification. They also proposed a global context enhancement and local multi-attribution fusion method for dialog sentiment recognition, effectively identifying sentiment changes in conversations.
4. Stance Detection Model Based on Multi-Task Learning
4.1. Overall Design of the Multi-Task Model
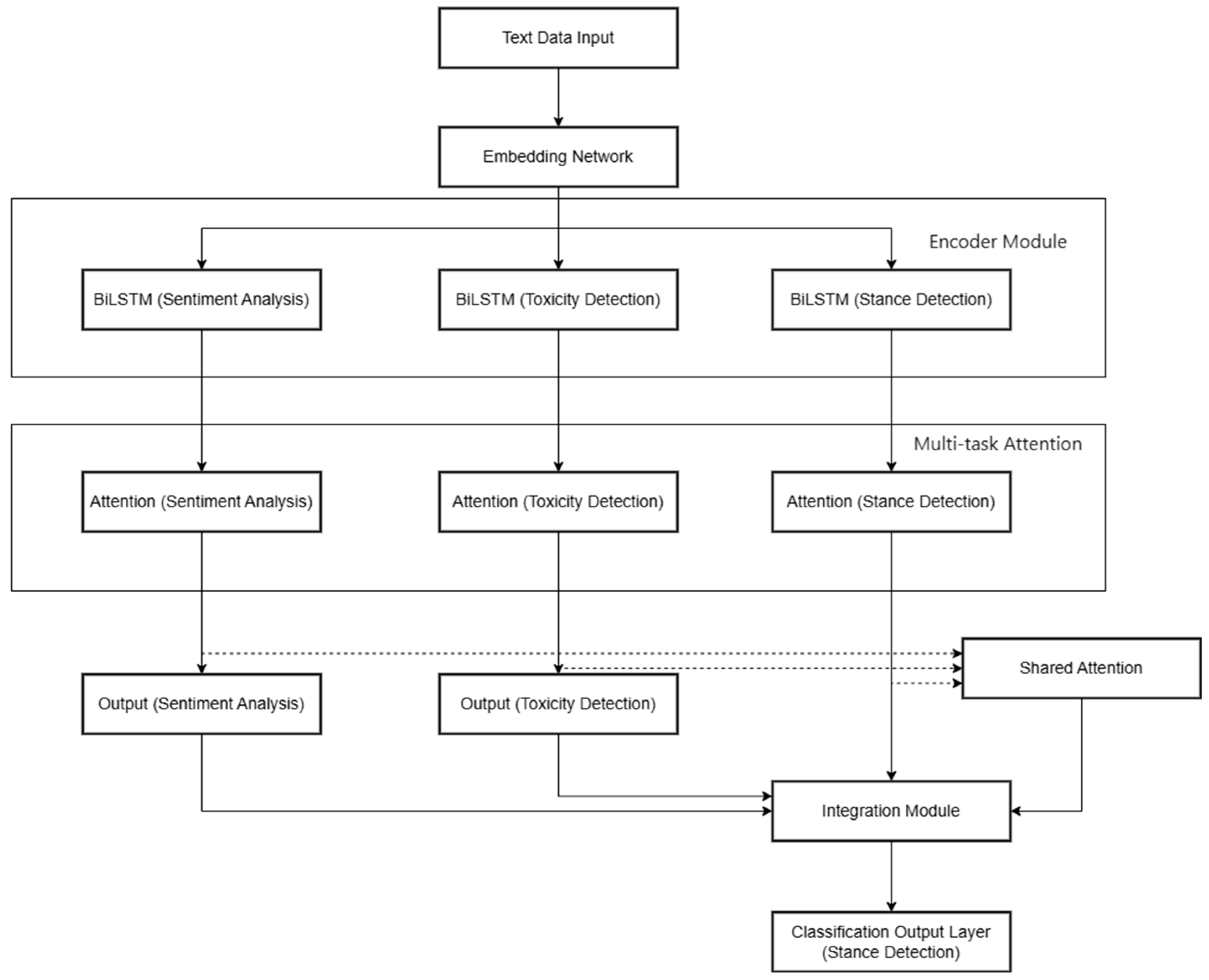
This paper aims to implement a multi-task stance detection model [
18]. A standalone stance detection model may fail to capture the implicit emotional cues and extreme language in comments, resulting in lower accuracy in identifying complex emotional expressions and a weaker generalization ability. Therefore, this paper enriches the semantic features of the comments and the input information of the model by combining sentiment analysis and toxic language detection with text features. By sharing parameters, the risk of overfitting is reduced, allowing for a more comprehensive capture of stance expressions in comments. This enables the analysis of the commenter’s attitude and categorizes it into one of the polarized categories (faver, against, or ambiguous). The multi-task model mainly consists of the following components: an embedding network, encoder module, multi-task attention module, ensemble module, and a classification layer [
18]. First, the input comment data are initialized through the embedding network, then encoded using respective Bi-LSTM layers. A multi-task attention module is introduced to compute attention weights to weigh important input parts, provide task-specific attention, and obtain an averaged shared attention vector. The shared attention vector and task-specific attention vectors are combined and fed into the softmax layer to produce outputs for the sentiment analysis and toxic language detection tasks. These outputs, along with the task-specific attention and shared attention vectors for the stance detection task, are passed through the ensemble module and subsequently through the softmax layer to obtain the final stance of the Weibo comment, as shown in the
Figure 2.
While multi-task architectures for stance detection with sentiment and offensiveness have been explored, our model offers several novel aspects beyond just auxiliary task set replacement or minor architectural changes. Our embedding network uniquely combines SBERT sentence embeddings and attention mechanisms in a multi-task learning framework, enabling more effective processing of diverse text data across different languages. The Stance-Specific Shared Attention Module (SAM) in the fusion module is a distinct addition that addresses the issue of irrelevant feature interference in multi-task learning, enhancing the model’s focus on stance-relevant features.
4.2. Embedding Network
The embedding network of this model initializes the input comments by feeding pre-trained sentence embeddings into a shared fully connected layer and expanding them through a Lambda layer. These shared embeddings are then used as inputs for multiple tasks (stance, emotion, toxic). By processing these inputs with BiLSTM layers and attention mechanisms, the multi-task model is trained to generate the final classification results.
The sentence embeddings are loaded from the file sentence_embed.npy, representing high-dimensional vectors for each sentence with an input shape of (768,), indicating that each embedding vector has a dimension of 768. The input embeddings are processed through a shared fully connected layer, changing the shape to (None, 100) and expanded using a Lambda layer to fit the input of the subsequent LSTM layers. In multi-task learning, the model uses a shared embedding layer as the input, and the LSTM layers and attention mechanisms handle the three tasks separately.
Specifically, sentence_embed.npy is a pre-trained embedding file, with different pre-trained models used for the Chinese and English datasets. For the Chinese dataset, bert-base-chinese is used as the pre-trained model, while for the English dataset, bert-base-uncased is employed. SBERT (Sentence-BERT) is a sentence-level embedding technique based on BERT that can more effectively generate embedding vectors from sentences. By using pre-trained BERT models and tokenizers, SBERT can process longer text sequences and create sentence-level embedding vectors by aggregating the hidden states output by the model. This embedding method provides strong support for various natural language processing tasks, particularly in stance detection, sentiment analysis, and toxic language detection within a multi-task learning framework. The sentence-level embedding vectors generated by SBERT enhance the model’s ability to understand and analyze text semantics, thereby improving the overall performance and effectiveness of the model.
First, the text data are processed by the tokenizer and converted into a format acceptable to the model. Then, these encoded texts are input into the BERT model, which outputs the hidden states for each input token. By averaging these hidden states, a sentence-level embedding vector for the entire input text is obtained. These generated vectors are subsequently stored as a NumPy array and saved to a specified file. This makes the SBERT method not only applicable for single-word analysis but also for the semantic analyses of entire sentences or paragraphs, providing a powerful way to transform text data into numerical representations for various machine learning and data analysis tasks. Therefore, SBERT sentence embeddings provide strong support for the stance detection task, sentiment analysis task, and toxic language detection task within the multi-task learning framework.
4.3. Multi-Task Attention
First, the text data are processed through a Bidirectional Long Short-Term Memory (Bi-LSTM) layer to capture the long-term dependencies in sequential data and extract the basic feature representations of the text. The output of the Bi-LSTM is then transformed through three fully connected layers. After further feature extraction from the output of the Bi-LSTM layer, it is converted into queries Q, keys K, and values V, generating three tuples, namely ,, and .
Subsequently, the Multi-Head Self-Attention (MSA) scores are calculated using specific formulas. The similarity between
Q and
K is assessed using the softmax function to determine the importance of different parts in the input sequence. The calculation formula is as follows:
where
i represents different tasks. Based on the calculated
MSA scores, the values (
V) are weighted and summed to generate a weighted feature representation that focuses on the most relevant parts of the input, providing information-rich features for subsequent tasks.
Figure 3 illustrates the attention mechanism for the stance detection task; the sentiment analysis and toxic language detection tasks follow the same principle. This module is implemented based on the attention function, which calculates the attention mechanism through the interaction of three matrices: query (
Q), key (
K), and value (
V) to generate an output vector. The function first calculates the similarity scores between queries and keys, then transforms them into a probability distribution using the softmax function, and finally applies these scores to the value matrix to generate a weighted output. This enhances the model’s ability to focus and improves its performance.
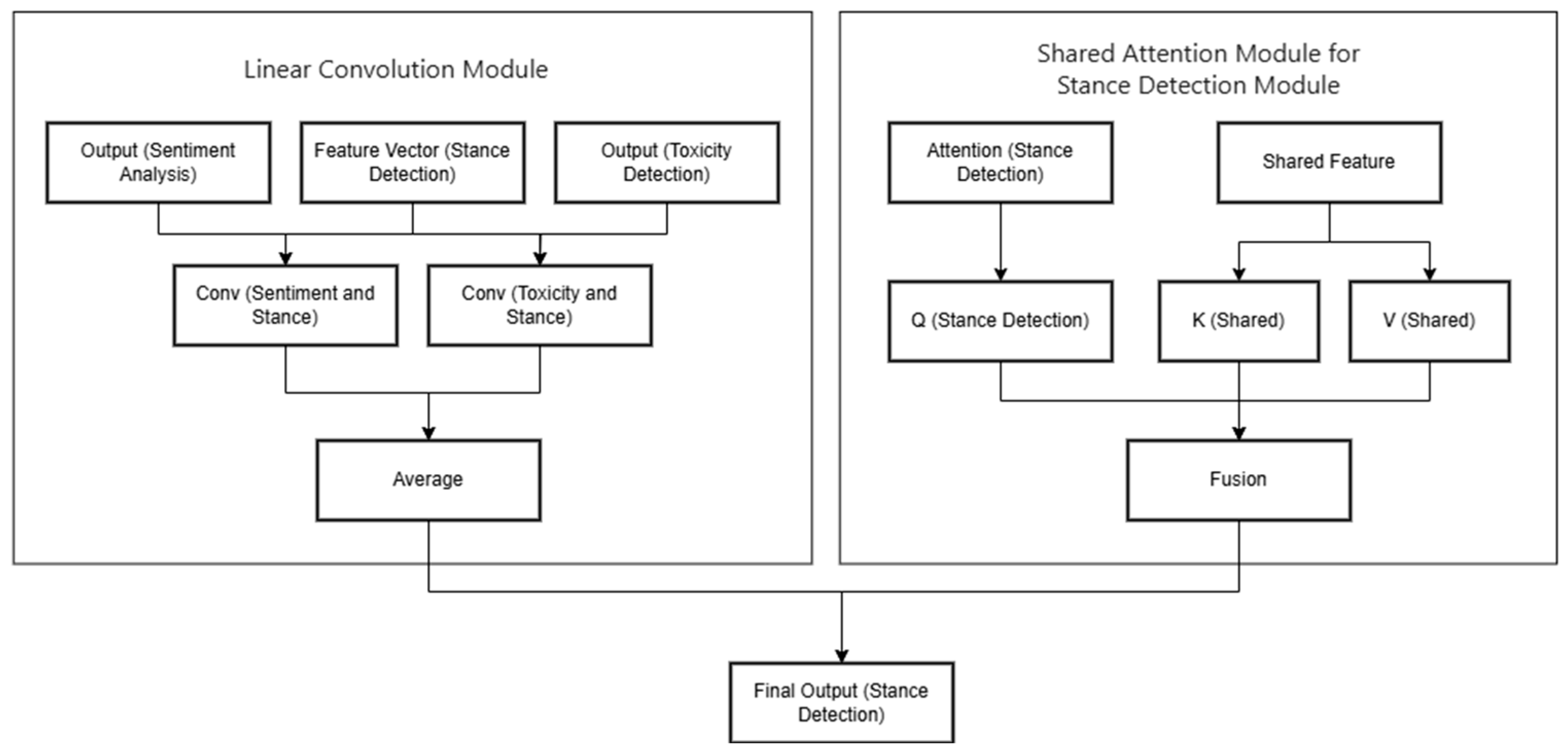
4.4. Fusion Module
The fusion module consists of two parts: the Linear Convolution Module (LCM) and the Stance-Specific Shared Attention Module (SAM), aiming to optimize the performance of stance detection. The main structure is shown in the
Figure 4.
The Linear Convolution Module (
LCM) utilizes the learned features from the sentiment analysis and toxic language detection tasks to capture the overall attitudinal representation of the input text. This module receives the outputs from the sentiment analysis and toxic language detection tasks, as well as the final feature vector specific to the stance task, as its inputs. Through convolutional operations, the following formulas simulate the impact of sentiment and toxic language features on stance features, and the average of the two convolutional outputs is taken as the final output of the Linear Convolution Module:
This module is primarily based on a linear convolution function that performs a one-dimensional convolution operation, mainly for feature fusion. It first expands the dimensions of sentiment and toxic language outputs as well as stance features, enabling them to interact in the convolution operation. Then, using specific convolution kernels, it performs a one-dimensional convolution operation to extract and fuse local features or patterns from different feature vectors. The newly generated feature vectors from the convolution directly map the influence of sentiment and toxicity onto the stance representation, further refining and strengthening the stance features.
The Stance-Specific Shared Attention Module (SAM) aims to address the issue that the shared space in multi-task learning may introduce features irrelevant to the task. The SAM uses the query (Q), key (K), and value (V) mechanism to focus on the shared features most relevant to the stance detection task. The stance-specific attention vector generates a query, which is combined with the keys and values of the shared features to focus on the shared features relevant to the stance task.
After obtaining the outputs from the LCM and SAM modules, a specific fusion technique is adopted to optimize the performance of stance detection, forming the final fused output. The specific fusion operations include the absolute difference and the element-wise product. The absolute difference is used to measure the difference between two vectors or signals by calculating the absolute value of the difference between corresponding elements of two vectors of the same dimension, resulting in a new vector whose elements are the absolute differences of the corresponding elements of the original two vectors. The element-wise product (also known as the Hadamard product or element-wise multiplication) is a multiplication operation performed element-wise on two vectors of the same dimension, enhancing the weights of relatively important features in both feature sets. It is suitable for strengthening the model’s ability in aspects commonly emphasized by the two vectors. By combining the absolute difference and element-wise products, the complementary and opposing information from different features is effectively integrated, enhancing the model’s depth of understanding of the data, helping the model find a balance between different feature representations, optimizing the mutual influence between tasks, and thereby improving the overall performance.
In the fusion module, the Linear Convolution Module (LCM) combines sentiment and toxic language features with stance-specific ones through convolution, refining the stance features. For example, it can better classify a comment’s stance considering sentiment and toxicity. The Stance-Specific Shared Attention Module (SAM) then uses the query–key–value mechanism to focus on relevant shared features for stance detection. Together, they improve the stance detection task by enhancing semantic understanding and filtering out noise. For other tasks like sentiment analysis and toxic language detection, they offer more context and focus on relevant features, respectively.
4.5. Resampling Module
4.5.1. Resampling for Multi-Class Tasks
Resampling techniques in multi-class tasks aim to address the issue of class imbalance. When certain classes in a dataset have significantly more data points than others, the model may become biased towards the majority class, leading to a poor prediction performance on the minority classes. In this paper, an upsampling method is employed, which involves duplicating samples from the minority class to increase their quantity to match or approximate that of the majority class. This approach balances the number of samples across classes without losing any original data, effectively increasing the proportion of minority class samples and thereby enhancing the model’s performance on minority classes.
4.5.2. Resampling for Multi-Label Tasks
The principle of resampling for multi-label data is to adjust the number of positive instances (label value of 1) and negative instances (label value of 0) for each label, making the distribution of each label more balanced. This enhances the performance and generalization ability of machine learning models. In multi-label classification tasks, such as sentiment analysis and toxic language detection, the distribution of labels is often imbalanced. By resampling, the number of positive and negative instances for each sentiment and toxicity label can be balanced, reducing the negative impact of data skewness on model training and improving the classification performance of the model on different labels.
In this paper, resampling for multi-label data is primarily implemented through the resample_multilabel_data function, which takes a dataset and a list of columns to be resampled as inputs. First, the original data are copied to avoid direct modification. Then, each label is iterated over. For each label, the data are divided into positive instances (a label value of one) and negative instances (a label value of zero). The number of positive and negative instances is calculated. If the numbers are not equal, the function resamples the smaller class to match the number of the larger class. If there are fewer positive instances than negative instances, the function increases the number of positive instances through resampling; otherwise, it increases the number of negative instances. The resampled data are merged with the original data and replace the original positive and negative instance subsets. To avoid a bias in the data order, the function shuffles the resampled data and returns the final resampled dataset.
5. Experiments and Analysis
5.1. Experimental Setup
This paper employs K-fold cross-validation, training the model on the training set, tuning parameters on the validation set, and verifying the best model results on the test set. In this multi-task learning model, the parameter settings for each task share some commonalities, with the common parameter configurations as follows:
The common parameter settings in
Table 1 were determined through a combination of prior knowledge and experimental tuning. The Adam optimization method is a popular choice known for its effectiveness in handling various problems. The LSTM hidden dimension of 100, learning rate of 0.0001, dropout of 0.2, batch size of 32, and regularization L2 coefficient of 0.07 were found through multiple experiments using K-fold cross-validation. By adjusting these parameters and evaluating the model’s performance on validation and test sets, we aimed to balance factors like the model’s complexity, training speed, and generalization ability. While these parameters perform well for our model, they might not be the absolute best in all scenarios since they are optimized for our specific multi-task stance detection model setup.
In addition, the multi-task learning model also has specific configurations for the stance detection, sentiment analysis, and toxicity detection tasks, as shown in
Table 2. Since stance detection is a multi-class, single-label task, it is suitable to use softmax as the activation function and categorical_crossentropy as the loss function. Sentiment analysis and toxicity detection are multi-label tasks, making sigmoid a suitable activation function and binary_crossentropy a suitable loss function.
Other parameters are set as follows. The embedding dimension after the FC layer is 128, chosen for its balance between complexity and performance. Our model uses 2 Bi-LSTM layers, determined through testing for optimal pattern capture. We used the Adam optimizer with a learning rate decay starting from 0.0001, halving every 5 epochs to ensure stable convergence. The training was run for 20 epochs, which was found to be sufficient for the model to converge without overfitting.
Regarding the dataset size, although 3500 instances might seem small for a deep model, we have carefully designed the model architecture with shared parameters and employed techniques like L2 regularization. The resampling techniques are used not only to address class imbalance but also to enrich the data representation in a controlled manner. Through rigorous five-fold cross-validation, we have effectively mitigated the risk of overfitting. Our experimental results demonstrate that the model can achieve a competitive performance compared to larger models like BERT, indicating its ability to generalize well despite the relatively small dataset size.
5.2. Results and Analysis
To thoroughly analyze the effectiveness of each component of the proposed method, this paper compares multiple baseline methods and designs a series of ablation experiments. By removing each component one by one, the results are analyzed in detail. The specific experimental methods are as follows:
CNN-GloVe: A stance detection model using a Convolutional Neural Network (CNN) with GloVe for word embeddings, suitable for English datasets [
19].
CNN-Word2vec: Combines word embedding technology with a Convolutional Neural Network, suitable for both Chinese and English datasets, and can be applied to stance detection tasks in various fields [
19].
DNN: Based on Recurrent Neural Networks, it simulates the working mechanism of the human brain’s neural network to automatically identify and judge the stance or sentiment tendency in text [
20].
BiLSTM: A deep learning-based text analysis model that handles text data with temporal dependencies and introduces bidirectionality to capture contextual information in the text [
21].
SP-MT: A multi-task framework that can perform stance detection and sentiment analysis simultaneously on the Twitter comment dataset [
22].
BERT: Using pre-trained BERT models, including BERT-base-uncased and BERT-base-Chinese, for stance detection on comment data.
RoBERTa: RoBERTa [
23] is a pre-trained model optimized based on BERT. It improves performance by adjusting training data, hyperparameters, and training objectives, and shows excellent results in multiple NLP tasks. Chinese-RoBERTa-wwm [
24] is a model designed for Chinese natural language processing, which uses the whole-word masking pre-training method to accelerate the processing of Chinese tasks.
TR-ZSSD: This is a recent method for stance identification that relies on a new Tree-of-Counterfactual prompting framework, which allows for multiple stance object types and requires no examples of stance attribution [
25].
Multi-Task Stance Detection Model: The multi-task learning model proposed in this paper, which incorporates sentiment analysis and toxic language detection as auxiliary tasks, based on a multi-embedding text attention mechanism.
Stance-Emotion Model: The multi-task stance detection model without the toxic language detection task, using only sentiment analysis as an auxiliary task.
Stance-Toxic Model: The multi-task stance detection model without the sentiment analysis task, using only toxic language detection as an auxiliary task.
Single-Task Stance Detection Model: A single-task model for stance detection without using sentiment analysis or toxic language detection as auxiliary tasks.
5.3. Experimental Results
5.3.1. Multi-Task Model Experimental Results
In the comparative experiments, the multi-task stance detection model was compared with other baseline models. The evaluation metrics used were the macro-average indicators of accuracy (Accuracy), precision (Precision), recall (Recall), and F1-score. The results are shown in the
Table 3 and
Table 4. We conducted two-tailed, paired Student’s
t-tests (
p < 0.05) to examine whether the improvements are significant relative to the baseline models, where an asterisk (*) indicates significant improvements over RoBERTa-based method and a dagger (†) indicates significant improvements over the TR-ZSSD model.
The experimental results show that the multi-task learning model performs well in multiple evaluation metrics. For both the Chinese and English datasets, it achieves the highest accuracy. Due to the different pre-trained models used in the embedding network, the performance of the models trained on different datasets varies. Moreover, with a smaller dataset, fewer parameters, and a shorter training time, the model achieves a performance comparable to the large language model BERT, meeting the expected experimental outcomes. In summary, the model demonstrates high precision and a good generalization ability in stance detection, effectively distinguishing between supportive, opposing, and ambiguous stances. This highlights the advantages of the multi-task learning-based stance detection model in handling complex text data.
5.3.2. Ablation Experiment and Result Analysis
In the evaluation of ablation experiment results, this study also uses the macro-average indicators of accuracy (Accuracy), precision (Precision), recall (Recall), and F1-score as evaluation metrics for multi-class classification. The datasets used are the Chinese comment dataset collected from Weibo and the English comment dataset collected from Twitter. Different models were trained, including the multi-task model with sentiment analysis and toxic language detection assisting stance detection, the multi-task model with sentiment analysis assisting stance detection, the multi-task model with toxic language detection assisting stance detection, and the single-task stance detection model. The results are shown in the
Table 5 and
Table 6.
The results of the ablation experiments show that the multi-task model performs superiorly in terms of accuracy and overall performance on both the Chinese and English datasets. On the Chinese dataset, the improvement in performance of the multi-task model is more significant, with an accuracy increase of about 20% compared to the single-task model. In summary, the addition of sentiment analysis and toxic language detection tasks provides additional contextual information for stance detection, enhancing the model’s ability to capture subtle semantic changes. Toxic language detection helps the model avoid deviating from normal semantic judgment due to extreme statements, while sentiment analysis provides a variety of emotional contexts, making the determination of stance more precise.
5.4. Misclassification Cases and Model Limitations
Despite the effectiveness of the proposed multi-task stance detection model, several common misclassification cases have been identified.
5.4.1. Misclassification Cases
One prevalent issue is the misclassification of comments with ambiguous or implicit language. Some users express their stances in a roundabout way, using sarcasm, irony, or veiled references. For example, in a comment about the stray cat compensation event, a user said, “Oh, sure, let’s just blame the feeder for everything. That’s totally fair”. Without proper context or a more sophisticated understanding of language nuances, the model may misinterpret this sarcastic comment as supportive instead of opposing. Similarly, when a comment contains cultural references or idiomatic expressions that are not well-represented in the training data, the model may struggle to correctly classify the stance.
Comments with a complex interplay of sentiment and toxicity can also lead to misclassification. In some cases, a comment may have a positive sentiment overall but contain a minor toxic element. For instance, “I support this policy, but those who oppose it are so stupid”. The model is confused by the co-existence of positive-stance-related language and the toxic insult, potentially misclassifying the comment’s stance or the degree of toxicity. Additionally, if the sentiment and toxicity are expressed in a very subtle manner, the model may not accurately capture these features, affecting the stance detection.
Comments that lack sufficient context are often misclassified. Social media posts are typically short, and without additional information about the conversation thread or the user’s background, it can be difficult for the model to determine the correct stance. For example, a simple comment like “It’s not right” could refer to a wide range of issues related to the event. Without context, the model randomly assigned a stance, leading to misclassification.
5.4.2. Model Limitations
When applying the model to languages other than Chinese and English, significant challenges arise. Different languages have unique syntactic, semantic, and morphological structures. For example, languages with highly inflected forms require different approaches for word segmentation and feature extraction. The pre-trained models used in the embedding network, like the BERT-based models for Chinese and English, may not be directly applicable to other languages. Moreover, cultural and linguistic norms vary widely across languages, and the sentiment and toxicity annotation guidelines developed for Chinese and English may not be suitable for languages with different cultural connotations. For instance, certain words or expressions that are considered offensive in one language may have a completely different meaning or no negative connotation in another.
Each social media platform has its own unique features and user behavior patterns. The model was trained on data from Weibo and Twitter, and these platforms have distinct posting styles, character limits, and user interactions. Platforms like Reddit or Instagram may have different types of content, such as longer text-based discussions on Reddit or more visual-centric content on Instagram with text captions. The model may struggle to adapt to these differences. For example, Reddit posts often have a more in-depth and multi-faceted discussion structure, and the model may find it difficult to handle the complex argumentation and stance-taking within these longer posts. Instagram captions, on the other hand, may be more image-related, and the model may not be able to fully utilize the visual context to detect stances accurately.
The model’s performance may degrade when applied to domains outside of social media hot-issue discussions. For example, in a legal or medical domain, the language used is highly specialized, and the concepts of stance, sentiment, and toxicity may have different definitions. In a legal document, a neutral stance may be expressed in a very different way compared to a social media comment. The model lacks the domain-specific knowledge to handle such specialized language. Additionally, the data distribution and class imbalance issues may be different in other domains, requiring different resampling and model-tuning strategies.
In summary, while our multi-task stance detection model shows promising results for Chinese and English social media comment analyses, these misclassification cases and limitations highlight the need for further research and adaptation when applying the model to broader contexts. Future work could focus on developing more language-independent and domain-adaptable models, as well as incorporating additional context-awareness mechanisms to improve the model’s performance.
6. Conclusions
This paper proposes a multi-task stance detection model that integrates sentiment analysis and toxic language detection for detecting public attitudes towards hot issues in social media texts. The research results show that the model performs exceptionally well in handling complex and diverse text data, significantly improving the accuracy and reliability of stance detection. By incorporating sentiment analysis and toxic language detection tasks, the model is able to understand text content from multiple perspectives, capturing not only the emotional attitudes of commenters but also identifying potential harmful speech, thereby providing more comprehensive semantic information for stance detection. This multi-task learning framework leverages shared parameters and attention mechanisms to reduce the risk of overfitting while effectively enhancing the model’s generalization ability.
The Chinese and English comment datasets constructed in this paper, which include stance, sentiment, and toxicity labels, provide valuable resources for future research. Through the detailed analysis of comments on hot issues from Weibo and Twitter, this paper reveals the diverse attitudes and emotional reactions of the public towards different social events, offering an important perspective for understanding public opinion dynamics. Experimental results demonstrate that the multi-task stance detection model outperforms traditional single-task models on both datasets, especially in handling texts with extreme emotional expressions and complex semantic structures. This validates the effectiveness of the proposed method in improving the precision of stance detection.
Future research can be expanded in the following areas: first, exploring more advanced attention mechanisms and deep learning models to further improve the accuracy of stance detection; second, expanding the scale and diversity of datasets to enhance the model’s adaptability and robustness; third, applying stance detection to more practical scenarios, such as policy-making, public opinion monitoring, and public relations management, to provide more scientific decision-making support for social governance. Through continuous technological innovation and interdisciplinary cooperation, stance detection will play an increasingly important role in understanding and guiding public opinion.






{kind=link}
{kind=link}
{kind=link}
{kind=link}