1. Introduction
In the highly competitive apparel market, brand image is a pivotal factor in influencing consumer purchasing decisions. As the primary visual identifier of a brand, clothing trademarks significantly affect consumer choices. Even minor defects, such as blurring, damage, or printing deviations, can diminish product competitiveness and harm brand reputation. For companies, allowing defective trademarks to enter the market not only increases logistics and after-sales costs but also risks damaging brand equity and losing market share. Therefore, enhancing the efficiency and accuracy of trademark quality inspection is essential for the garment manufacturing industry.
Traditional manual inspection methods, which depend on worker experience, are plagued by low efficiency and susceptibility to subjective biases, rendering them inadequate for large-scale production demands. Template-matching-based detection approaches achieve high accuracy in specific scenarios but exhibit limited generalization, struggling to adapt to emerging defect types and incurring high maintenance costs. With the advancement of deep learning, CNNs have increasingly been employed in trademark defect detection, enabling automated feature extraction and improved detection accuracy. However, classical CNN architectures (e.g., ResNet [
1], VGG [
2]) still encounter instability issues in complex scenarios, failing to meet the real-time requirements of industrial production.
In recent years, the YOLO series of algorithms has gained significant attention in the object detection field due to their fast detection capabilities and high accuracy. YOLOv11 [
3] further optimizes the backbone network and feature fusion methods, enhancing multi-scale feature extraction and detection robustness, and has demonstrated exceptional performance in general object detection tasks. However, research on applying existing YOLO models to trademark defect detection remains scant, and this task confronts numerous challenges, such as diverse defects with imbalanced sample categories, varying clothing materials and colors, and changing lighting conditions, all of which contribute to the unsatisfactory detection performance of current methods.
Additionally, challenges persist in acquiring clothing trademark defect samples. On the one hand, the demand for sample quantity in trademark defect detection is often unmet, with a relative scarcity of samples. On the other hand, defect types are highly diverse, including damage, printing deviations, color abnormalities, etc., and the sample distribution among defect categories is severely imbalanced. For instance, common minor blurring defects have abundant samples, whereas defects caused by rare special printing processes are extremely scarce. This makes it difficult for models to comprehensively and accurately capture features of all defect types during training, negatively impacting detection accuracy and generalization. The limitations of sample data further exacerbate the difficulties faced by algorithms in practical applications.
Upon in-depth analysis of the current state of trademark defect detection, the algorithmic challenges emerge as particularly formidable. Trademarks on garments exhibit varying orientations, while fabric wrinkles introduce significant interference. Combined with defects of diverse sizes and complex types, these factors impose stringent requirements on algorithmic recognition accuracy, maintainability, and reliability. Existing algorithms struggle to stably extract accurate defect features under complex and dynamic conditions, resulting in unstable detection outcomes that fail to meet the high-precision and high-reliability demands of real-world production. These algorithmic limitations not only compromise detection accuracy and stability but also pose substantial challenges to detection efficiency in practical industrial settings. Similar to the multi-scale and multi-modal challenges addressed by CONTRINET’s triple-flow framework [
4], our work draws inspiration from its design philosophy. In that study, separate branches specific to each modality dynamically combined features to reduce interference. We apply a similar concept to handle variations in fabric texture and defect scales in trademark inspection.
Moreover, on actual clothing production lines, detection efficiency is a critical factor determining production scale and cost. Commercialization requirements impose higher demands for lightweight and real-time algorithms, necessitating the deployment of detection systems under online, high-speed conditions to match large-scale production rhythms. However, existing deep learning algorithms often suffer from high computational complexity and model intricacy, making it difficult to achieve fast inference while maintaining detection accuracy, thus failing to meet the stringent speed requirements of production lines. This renders efficient real-time detection infeasible in practical applications, limiting the large-scale adoption of deep learning algorithms in garment manufacturing.
To address the challenges, we conduct in-depth optimizations based on YOLOv11 and propose DLF-YOLO through a three-tier architectural innovation: “intelligent feature fusion-dynamic attention enhancement-lightweight backbone”.
The main contributions of this paper are as follows:
Improving model generalization via data augmentation strategies: CycleGAN was introduced to generate adversarial networks to expand sample diversity through unsupervised learning. At the same time, by rotating, introducing noise, and changing brightness and contrast to simulate trademarks under different angles and lighting conditions, the data complexity is enhanced, and the model’s ability to adapt to varying image quality is improved.
Proposing the multi-scale dynamic synergy attention (MDSA): The MDSA attention mechanism can focus on the key areas of trademark image adaptively and strengthen the capability of flaw feature extraction. In the face of interference such as clothing material reflection and light change, the mechanism uses dual attention dynamic calculation of space and channel to accurately capture defect features and optimize model detection capability.
Optimizing network structure to reduce model complexity: The neck structure is optimized using the HS-FPNs module, which fuses multi-scale image information while significantly reducing computational complexity without compromising accuracy. DWConv replaces traditional convolutions in select layers to maintain feature extraction capability while lowering computational load. Furthermore, HetConv is introduced to enhance the C3k2 module, improving model expressiveness while reducing computational cost and parameters.
2. Related Works
2.1. YOLO Algorithms
The YOLO series is a leading real-time object detection framework, widely recognized for its end-to-end, one-stage detection approach. Unlike traditional two-stage methods, YOLO directly performs regression-based prediction of bounding boxes and class information, achieving high computational efficiency and inference speed, making it ideal for industrial inspection scenarios with strict real-time requirements.
YOLOv1 [
5] pioneered the one-stage detection framework by modeling object detection as a regression problem. YOLOv3 [
6] introduced the feature pyramid network and multi-scale prediction strategy, significantly improving small object detection capabilities. YOLOv5 [
7], with its simplified network architecture and automated data augmentation, has become a popular choice for industrial deployment.
In recent years, the robustness of the YOLO series in complex scenarios has been continuously optimized. YOLOv7 [
8] proposed a dynamic label assignment strategy to enhance detection performance for occluded objects. YOLOv8 [
9] strengthened multi-scale feature representation through a decoupled head and adaptive feature fusion. YOLOv9 [
10] incorporated the generalized efficient layer aggregation network, optimizing inference speed while maintaining high detection accuracy.
The latest YOLOv11 further refines the network architecture by adopting the C3k2 module and C2PSA mechanism, improving detection accuracy while reducing computational complexity and, thus, is well-suited for high-real-time industrial inspection tasks.
2.2. Data Augmentation and GAN
GANs are essential approaches to addressing sample scarcity and class imbalance in industrial inspection. Traditional data augmentation methods expand datasets through geometric transformations (e.g., rotation, flipping) and image processing operations (e.g., noise injection, blurring). While these techniques improve model robustness, they are limited in generating physically plausible complex defects. For instance, trademark deformations caused by fabric wrinkles cannot be accurately simulated using traditional methods, which limits model generalization.
The development of GANs has provided a breakthrough solution for data augmentation. DCGAN [
11] employs deep convolutional networks as generators and discriminators, incorporating batch normalization to enhance training stability and produce relatively clear samples. However, its limited controllability makes it insufficient for complex industrial scenarios. ACGAN [
12] enhances control over generated image categories through its auxiliary classifier, enabling the generation of category-specific trademark images. However, it still exhibits limitations in handling defect features and cross-domain image generation.
CycleGAN [
13] addresses these limitations by enabling unsupervised image-to-image translation using only unpaired data. This capability is particularly valuable for trademark detection, where acquiring large-scale paired normal and defective images is challenging. CycleGAN converts normal trademarks into various defect forms, diversifying defective samples. Experiments demonstrate that using CycleGAN-generated defects improves mAP@0.5 on rare defects, effectively enhancing generalization in few-shot scenarios. Furthermore, CycleGAN mitigates mode collapse in traditional GAN training through cycle-consistency loss and multi-scale discriminators, improving sample generation quality.
2.3. Attention Mechanisms
Attention mechanisms in deep learning significantly enhance the model’s expressive ability by dynamically focusing on key features. Channel attention and spatial attention are the most representative paradigms in this area.
Hu et al. [
14] first introduced channel attention in the SE module. By capturing the interdependencies between channels and adaptively adjusting the weights, it enhances the feature representation ability. Woo et al. [
15] further integrated spatial attention on the basis of SE and proposed the CBAM, enabling the model to focus on both channel and spatial information simultaneously and improving the feature selection ability.
In recent years, many more efficient attention mechanisms have emerged in the field of object detection, evolving from single-dimensional attention to multi-dimensional collaborative optimization. The MLCA proposed by Wu et al. [
16] integrates both channel and spatial information, combining local and global features. It enhances feature representation while reducing computational overhead and improving detection accuracy. The EMA proposed by Ouyang et al. [
17] reshapes some channels into the batch dimension and groups the channel dimension for cross-scale information fusion, allowing it to possess both channel and spatial information. In addition to traditional channel and spatial attention, Yang et al. [
18] innovatively proposed SimAM without additional parameters. Based on neuroscience theory, this module calculates attention using an optimized energy function, simplifying the structural design without the need for additional parameter adjustment and demonstrating good detection performance. Zhu et al. [
19] proposed the omnidimensional dynamic convolution head (OD-Head) in SDD-Net, which integrates spatial, channel, kernel, and dimension-wise attention to capture multi-scale dependencies in PCB defect detection.
Although existing attention mechanisms have made significant progress in object detection tasks, their effectiveness in trademark defect detection tasks remains limited, and they do not fully adapt to the complexity and diversity of trademark defects. Therefore, based on previous research, this paper proposes a new attention mechanism, multi-scale dynamic synergy attention (MDSA), to further enhance the model’s ability to extract features of trademark defects and improve detection accuracy and robustness.
2.4. Feature Pyramid Network
In the field of object detection, the feature pyramid network (FPN) [
20] first addressed the challenge of multi-scale object detection via a top-down feature fusion framework. However, its unidirectional feature propagation and fixed-weight mechanism limited feature utilization efficiency. To overcome these limitations, researchers have proposed successive improvements: Tan et al. [
21] introduced BiFPN, which significantly enhanced feature fusion while maintaining computational efficiency through a bidirectional architecture and dynamic weight mechanisms. Building on this, Pan et al. [
22] developed PaFPN, strengthening small object localization by adding a bottom-up supplementary path. Fang et al. [
23] addressed feature misalignment issues by designing a feature alignment module, effectively optimizing spatial consistency across layers.
When transferring these methods to industrial inspection, researchers have proposed tailored solutions for challenges such as complex background interference, multi-scale object characteristics, and dynamic deformations in industrial quality control. Chen et al. [
24] proposed CE-FPN, which enhances target feature selection during fusion using channel attention. Sun et al. [
25] further designed SSP-FPN, improving multi-scale object perception through spatial pyramid pooling. These approaches optimize feature representation from the channel and spatial dimensions, respectively, collectively enhancing the model’s adaptability to complex industrial scenarios.
Notably, similar multi-scale detection challenges in medical imaging have been tackled by HS-FPN [
26]. Originally proposed by Wang et al. for leukocyte detection, this module constructs a high-level screening branch to suppress background noise while preserving feature resolution, significantly improving detection accuracy for leukocytes with size variations (10–200 μm). Given the substantial scene similarity between clothing trademark defect detection and leukocyte analysis, this study pioneers the adaptation of HS-FPN to industrial inspection. Experiments demonstrate that this module effectively mitigates fabric texture interference in trademark detection.
2.5. Convolutional Optimization
Convolutional optimization remains a critical factor in improving the efficiency of object detection models. Traditional CNNs rely on standard convolutions for feature extraction, but their high computational complexity restricts real-time performance. To address this, researchers have proposed various lightweight convolution strategies to reduce computational overhead while maintaining detection performance.
The most common lightweight strategy involves reducing the number and size of convolutional kernels through channel splitting. Chollet et al. [
27] introduced DSConv, which splits standard convolutions into depth-wise and point-wise convolutions, significantly reducing parameters. This technique is widely adopted in lightweight networks such as MobileNet [
28] and Xception [
27]. Building on depthwise convolutions, Han et al. [
29] proposed ghost convolution, which preserves information integrity while reducing computational redundancy. Group convolution, introduced by Xie et al. [
30], reduces redundancy through channel grouping and has achieved success in networks like ResNeXt [
30] and ShuffleNet [
31]. Additionally, HetConv proposed by Singh et al. [
32] uses alternating kernel sizes to maintain multi-scale receptive fields while lowering computational cost, further optimizing efficiency compared to traditional lightweight convolutions.
Other studies expand receptive fields through simple operations to achieve the effects of large kernels. For example, dilated convolution proposed by Yu et al. [
33] expands receptive fields without increasing computation by introducing dilation factors, performing well in semantic segmentation tasks like DeepLab [
34]. Similarly, deformable convolution [
35] adaptively adjusts receptive fields via learnable offsets, aligning sampling with object shapes and sizes.
Wang et al. [
36] proposed the GhostBottleneck (GB) module, which utilizes a dual-channel architecture of “conventional convolution + lightweight depthwise separable convolution” to generate comparable features while significantly reducing computational load. This design inspires the principle that lightweight convolution design must balance feature integrity with computational efficiency. In this study, we integrate the lightweight advantages of DWConv with the multi-scale feature extraction capabilities of HetConv to develop a “DWConv + HetConv” hybrid architecture. Within the YOLOv11 model, convolutional layers are rationally configured based on their functional roles and spatial positions.
3. Method
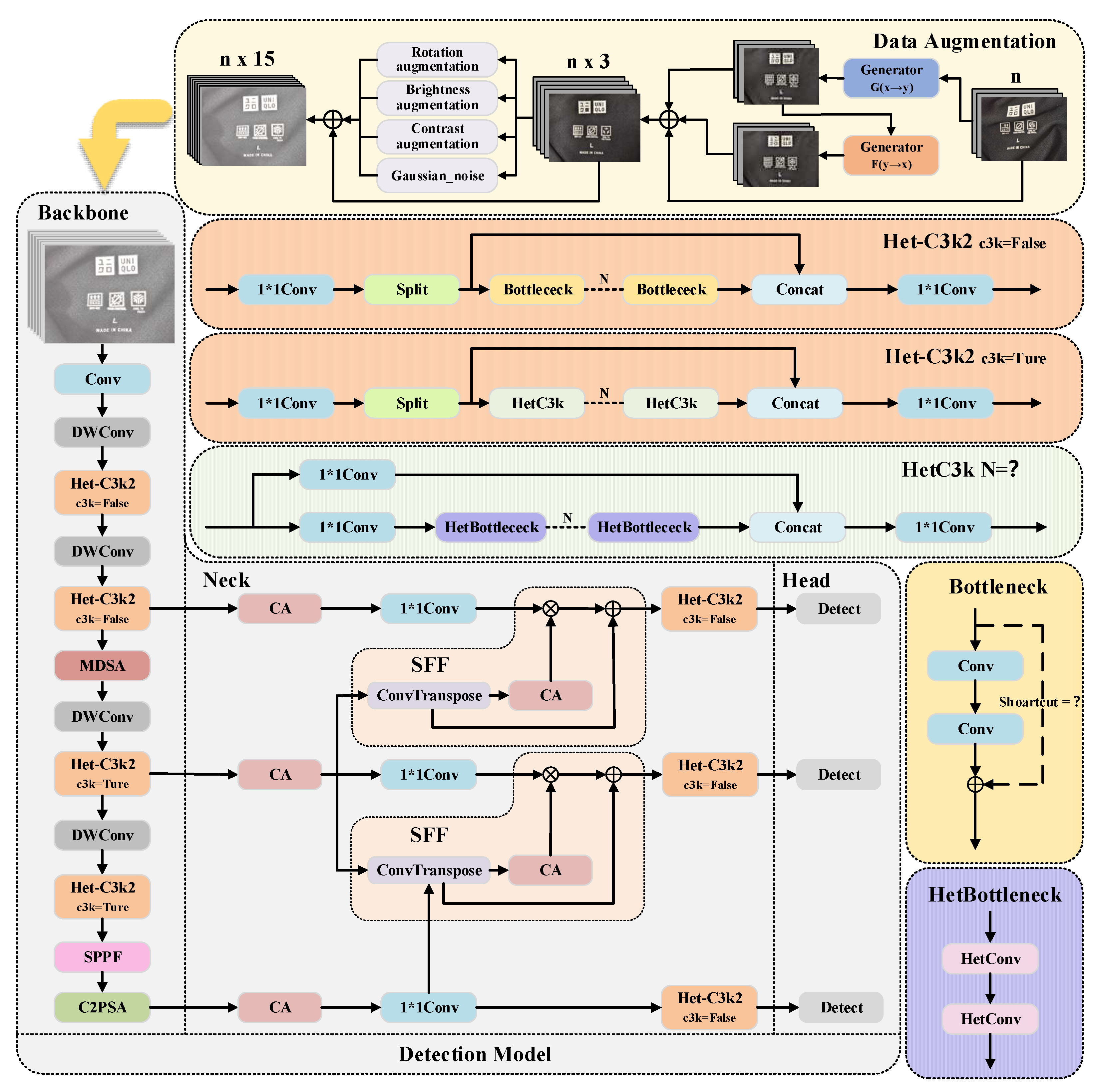
To address the challenges of insufficient defect samples, unstable performance in complex industrial environments, and low detection efficiency, this paper proposes a novel trademark defect detection algorithm, DLF-YOLO, based on YOLOv11. The overall structure of the algorithm is illustrated in
Figure 1. To expand the dataset, CycleGAN is first introduced, followed by traditional data augmentation methods, ultimately increasing the dataset size to more.
The main structure of the detection part is composed of three key components:
Embedding MDSA in the backbone. MDSA can dynamically adjust the proportion of channel attention and spatial attention, guiding the model to focus on key areas. Adding this attention mechanism here can capture the local defect details of clothing labels while retaining sufficient context information to distinguish complex background interference, and it will not significantly increase the computational load.
The neck of the model adopts an improved high-level selective feature pyramid network (HS-FPNs), a lightweight multi-scale feature fusion module inspired by medical imaging techniques [
26], which enhances multi-scale defect detection capabilities through feature selection and dynamic fusion. By using a dual-channel attention mechanism, it dynamically adjusts the weight distribution of features at different scales, reducing FLOPs while ensuring detection stability in scenarios with significant differences in trademark sizes.
In the backbone section, two lightweight convolution modules, DWConv and HetConv, are adopted to reduce the model parameters. Specifically, all Conv layers in the backbone except the first one are replaced with DWConv modules, and the original C3k2 module is substituted by the Het-C3k2 module constructed using HetConv. The Het-C3k2 module is designed as follows: First, the standard convolution (Conv) in the bottleneck of the original C3k2 module is replaced with HetConv, and the residual connection is removed to form the HetBottleneck. Then, the bottleneck in the original C3k is replaced with HetBottleneck to obtain the HetC3k module. The structure of the Het-C3k2 module remains unchanged from the original C3k2 module when C3k = false. When C3k = true, the C3k component in the original C3k2 module is replaced with HetC3k to form the structure of the Het-C3k2 module.
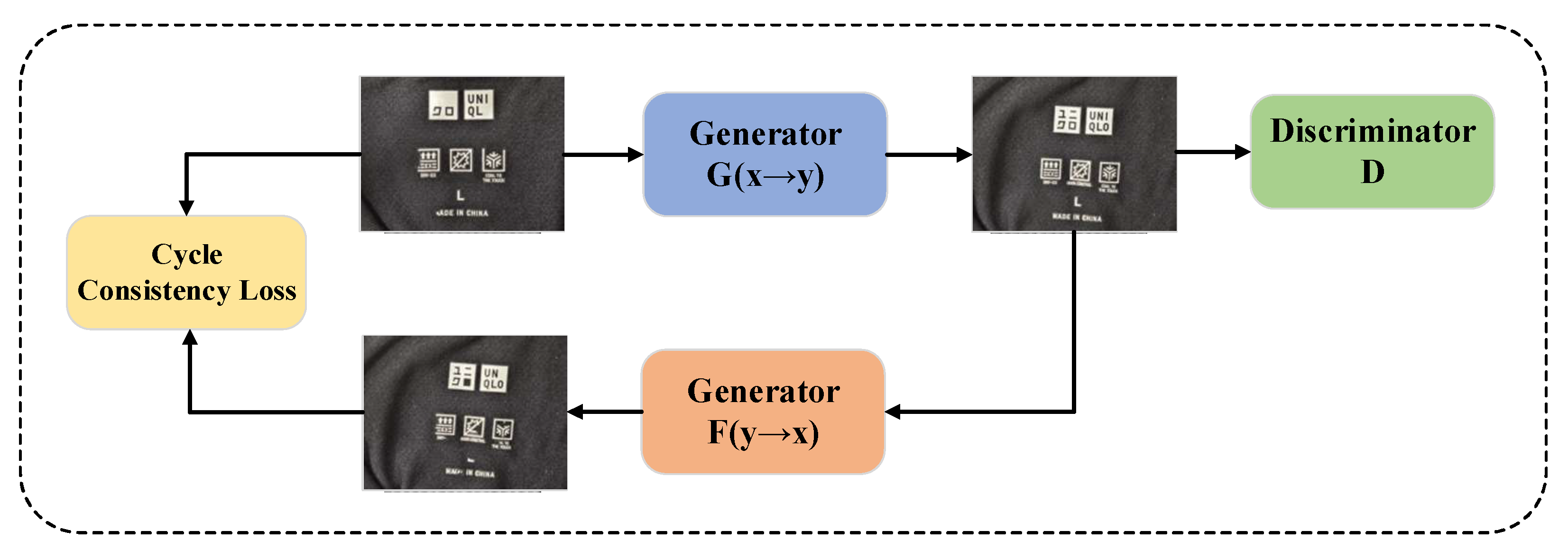
3.1. CycleGAN-Based Data Augmentation
To address the issues of dataset sample imbalance and the scarcity of rare defect samples, the CycleGAN generative adversarial network is introduced. Through unsupervised learning, normal trademark images are transformed into rare defect forms (such as simulated printing offset and printing defects), which increases the number of rare defect samples by three times and alleviates the problem of class imbalance. CycleGAN, a groundbreaking generative adversarial network in the field of image style transfer, is distinguished by its core innovation, i.e., achieving cross-domain style conversion through training with unpaired data. Unlike traditional GAN models (such as pix2pix [
37]) that rely on strictly paired training samples, CycleGAN constructs a dual-generator–discriminator architecture by introducing cycle-consistency loss. It enables bidirectional domain mapping under unsupervised conditions. The overall structure is shown in
Figure 2.
The CycleGAN model employs the first generator to transform input images from domain X into domain Y. Subsequently, the second generator converts the generated Y-domain images back into X-domain images. For Y-domain images, the model follows a similar process; it first transforms the input Y-domain images into X-domain images via the generator , and then converts the generated X-domain images back into the Y-domain.
After two transformations, the input image is compared with the original input to compute the cycle-consistency loss. The calculation method of the CycleGAN cycle-consistency loss function is as shown in Equation (1):
Adversarial loss consists of two components, corresponding to two independent GAN models, as shown in Equations (2) and (3):
The total loss calculation formula for the entire CycleGAN network is as follows:
where X and Y represent data domains X and Y, respectively; x and y denote sample data in the two domains. G is the mapping function from domain X to Y. F is the mapping function from domain Y to X. D
x and D
y are discriminator networks.
is the weight value controlling the cycle-consistency network.
The objective of the cycle-consistency loss function is to ensure that the input image and the twice-generated images are as similar as possible. This guarantees consistency between the original and transformed images, allowing the algorithm to operate without reliance on strictly paired datasets.
3.2. Multi-Scale Dynamic Synergy Attention
In DLF-YOLO, we introduce a new attention mechanism based on the CBAM design concept—multi-scale dynamic synergy attention (MDSA), which can effectively extract and enhance features in garment trademark defect detection to improve the detection performance. MDSA comprises three key components: multi-scale channel attention (MSCA), a dual-branch module that emphasizes defect-relevant feature channels by fusing global semantic pooling (GAP/GMP) with local detail extraction (LAP/LMP); multi-scale spatial attention (MSSA), which adopts the spatial attention from CBAM and captures positional information at multiple scales through multi-level pooling; and the dynamic synergistic layer (DSL), a learnable fusion unit that adaptively balances channel and spatial attention weights via two dynamic parameters. It inherits the idea of CBAM’s spatial attention module and the cascaded calculation of channel attention combined with spatial attention. Its most significant feature is the ability to capture key information at different scales and adaptively adjust the weight ratio of channel and spatial attention, achieving more accurate object detection.
MDSA enhances the extraction of defect features through a three-stage process, as follows: Firstly, MSCA captures global semantic and local detail features to generate a channel-refined feature (CRF). Then, the CRF generated by MSCA is processed through pooling and convolution in MSSA to generate spatial attention weights, focusing on the shape and position changes of defect regions. Finally, DSL adaptively adjusts the proportion of feature weights extracted by DSConv from CRF and the spatial attention weights generated by MSSA through two dynamic weights, improving the model’s ability to extract trademark features.
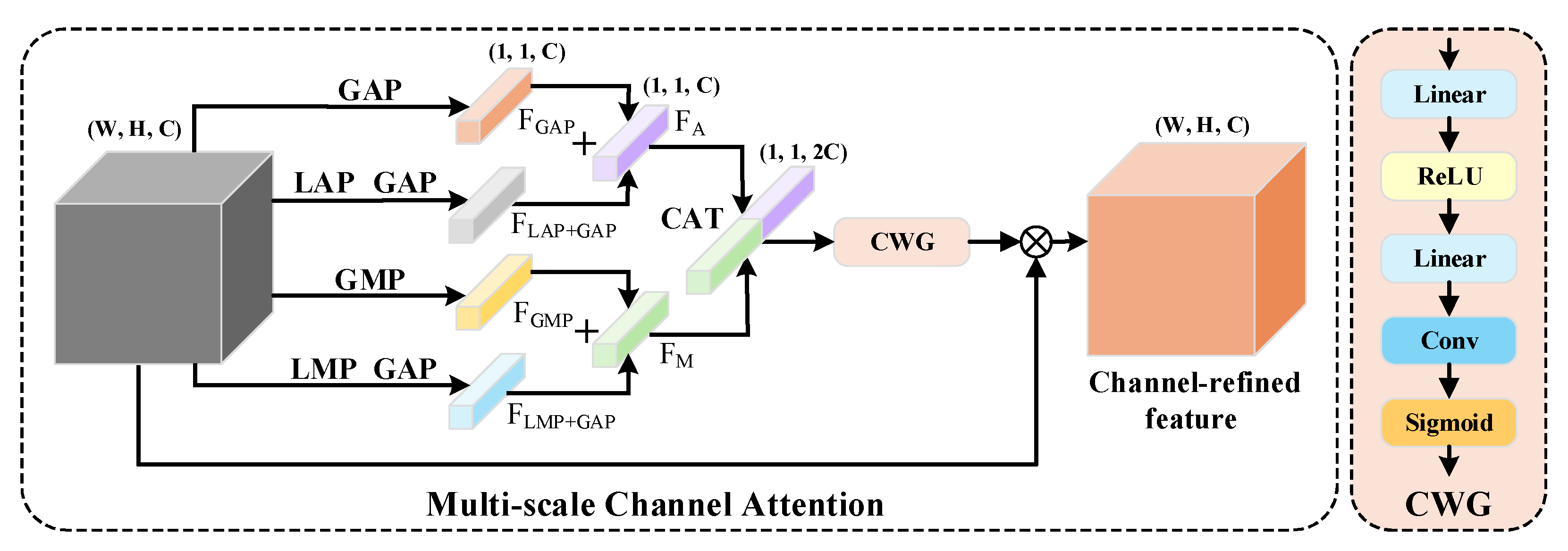
3.2.1. Multi-Scale Channel Attention
The MSCA consists of two stages, namely, feature extraction and channel feature fusion. In the feature extraction stage, first, global average pooling (GAP) and global max pooling (GMP) are used to extract global channel information, obtaining global features and . Then, local average pooling (LAP) + GAP and local max pooling (LMP) + GMP are utilized to obtain local features and . Using global pooling can enhance the model’s channel sensitivity to large-area defects, but it may also cause the model to overlook small flaws in certain regions, thereby losing some effective channel information. In contrast, combining local pooling with global pooling can strengthen the focus on small areas, effectively improving the model’s channel sensitivity to minor defects.
In the channel feature fusion stage, the two global features and two local features obtained in the feature extraction stage are subjected to addition operations:
Then, the features
and
after addition are concatenated (CAT) along the channel dimension and passed through the channel weight gate (CWG) for inter-channel information interaction to generate channel attention weights. The generated channel attention weights are applied to the input feature to obtain the CRF after the action of the MSCA. The CWG is composed of a fully connected layer, a ReLU activation function, a fully connected layer, a convolutional layer, and a sigmoid activation function in series. The network structure of MSCA is shown in
Figure 3. This mechanism can effectively increase the model’s attention to trademark defect areas and strengthen the representation ability of defect areas at different scales.
3.2.2. Multi-Scale Spatial Attention
The spatial attention mechanism is used to enhance the model’s focus on target regions, particularly in handling shape and positional variations of trademark defect areas, thereby effectively strengthening the extraction of critical features. In this section, MSSA adopts the spatial attention module from CBAM.
In MSSA, first, the CRF output by MSCA is subjected to GAP and GMP along the channels, respectively, and then concatenated in the channel dimension to construct a multi-scale spatial feature representation. Subsequently, Conv is used to extract information from the multi-scale spatial features to generate spatial attention weights. MSSA is illustrated in
Figure 4.
3.2.3. Dynamic Synergy Layer
To further enhance the representation capability of attention mechanisms, MDSA designs a DSL to adaptively adjust the weight ratio between channel attention and spatial attention. For different datasets, the sensitivity of channel attention and spatial attention varies, and the use of dynamic weights can effectively address this issue.
Specifically, the module first performs feature re-extraction on the CRF using DSConv, followed by GAP along the channel dimension to generate channel attention weights Wc. Subsequently, combined with spatial attention weights Ws, two learnable dynamic weights are applied to perform multiplicative weighted fusion on the channels, resulting in the integrated attention weights W.
These weights are then activated via a Sigmoid function and applied to the input CRF to achieve precise focus on target regions. The architecture of the MSSA + DSL network is illustrated in
Figure 4.
The adoption of DSConv for computing channel attention weights is motivated by its ability to effectively decouple spatial and channel information. Its independent channel-wise convolution process enhances spatial feature extraction while maintaining lightweight characteristics, thereby reducing computational complexity and enabling efficient attention modeling.
The MDSA mechanism can effectively enhance the performance of YOLOv11 in the trademark defect detection task, enabling the model to have stronger real-time performance and detection accuracy in the industrial production environment, and improving the model’s robustness and detection accuracy. It significantly improves the efficiency of trademark defect detection through the following three core advantages: Firstly, by extracting global and local features, it achieves precise perception of targets at different scales. Secondly, it dynamically adjusts the weight ratio between channel attention and spatial attention to enhance the model’s generalization ability. Thirdly, it performs well with a relatively small number of parameters and low computational complexity.
3.3. High-Level Screening Feature Pyramid Network
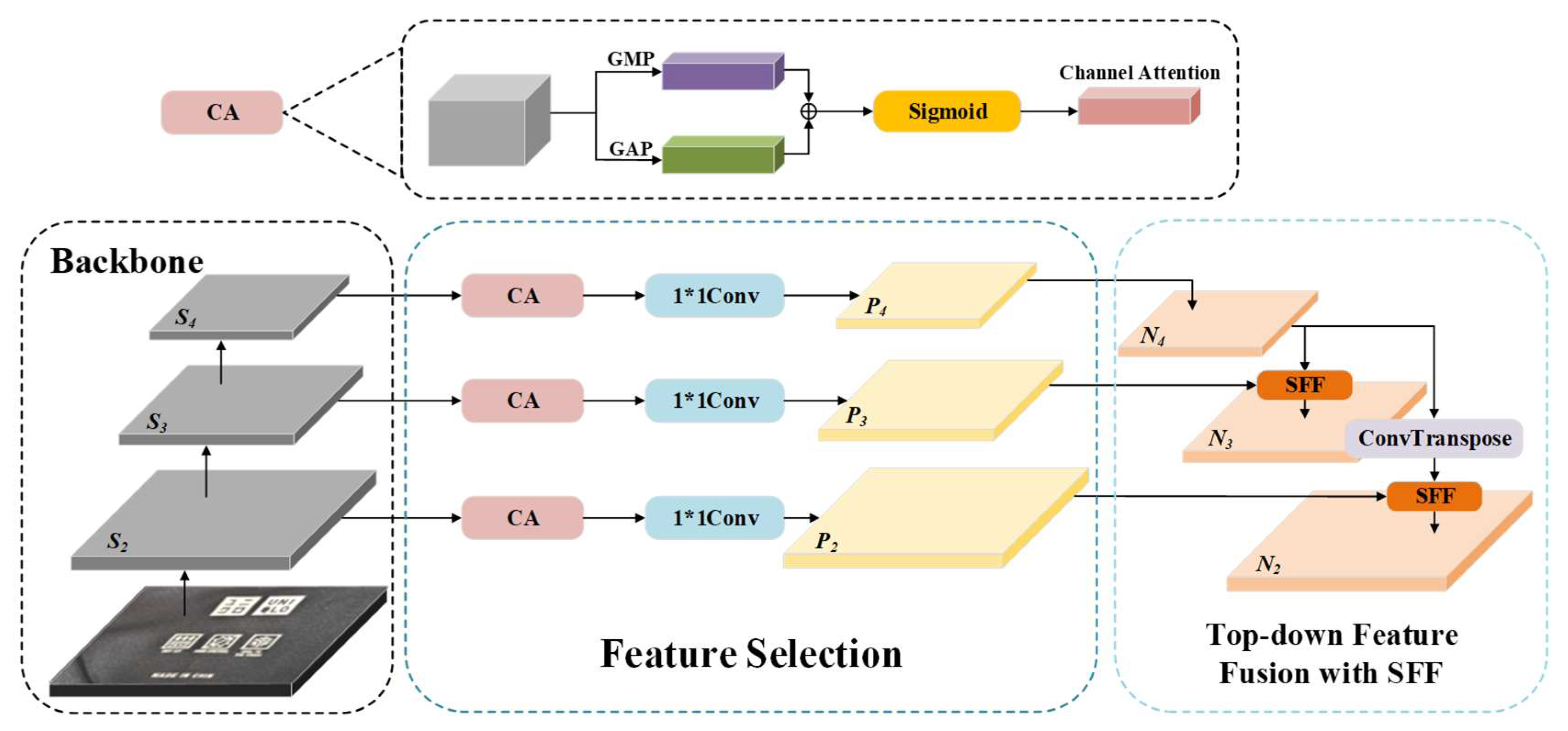
In DLF-YOLO, we address the challenge of multi-scale feature processing in finished garment trademark defect detection by proposing HS-FPNs, which are developed by modifying the network structure and SFF module structure based on the HS-FPN. Leveraging its innovative feature screening and cross-scale fusion mechanism, HS-FPNs significantly enhance the multi-scale feature representation capabilities for trademark defects of varying sizes. As shown in
Figure 5, the network introduces a channel attention (CA) [
38] module in the feature selection module, generating channel-weighted feature masks through a joint operation of global average pooling and max pooling. These masks adaptively screen valid information from low-level features and suppress redundant noise. In the dimension-matching module, 1 × 1 convolutions are used to unify multi-scale features to 256 channels, laying a foundation for subsequent fusion.
During the feature fusion stage, HS-FPNs employ a top-down selective feature fusion (SFF) strategy. Specifically, the spatial dimension of the high-level feature is up-sampled by transposing the convolution to make it reach the same spatial dimension as the low-level feature. The CA module then converts high-level features into attention weights to perform channel-wise weighted screening on low-level features. Finally, the screened low-level features and high-level features are element-wise summed to form the fused feature (). This fusion strategy effectively preserves detailed information from low-level features while injecting high-level semantics, enabling the model to capture structural features of small defects and contextual information of large defects. The detailed principal analysis will be provided in the following sections.
3.3.1. Feature Selection Module
The feature selection module is based on the channel attention mechanism, which screens the multi-scale feature (, , ) output by the backbone network. The feature selection module can suppress fabric texture noise in low-level features and enhance defect edge responses. The specific process is as follows:
For each layer of features (e.g.,
,
i ∈ {2,3,4}) output by the backbone network, they are first input into the CA module. The CA module extracts the statistical information of the channel dimension through global average pooling (GAP) and global max pooling (GMP), as shown in Equations (7) and (8).
Here, feature map from the i-th layer of the backbone network, with dimensions H (height), W (width), and one channel dimension. “:” is used to indicate operations along this dimension. is the output from GAP, and is the output from GMP.
After concatenating the results of the two pooling operations, the channel attention weights
are generated through a fully connected layer and a Sigmoid activation function
σ. The formula is as follows, where MLP (fully connected neural network) transforms the concatenated
and
:
The input features are weighted by the attention weights to obtain the filtered features
:
Finally, the number of channels is adjusted using 1 × 1 convolutions, and the feature selection results (
P2,
P3,
P4) are output, as shown in Equation (11):
3.3.2. Top-Down Selective Feature Fusion Module
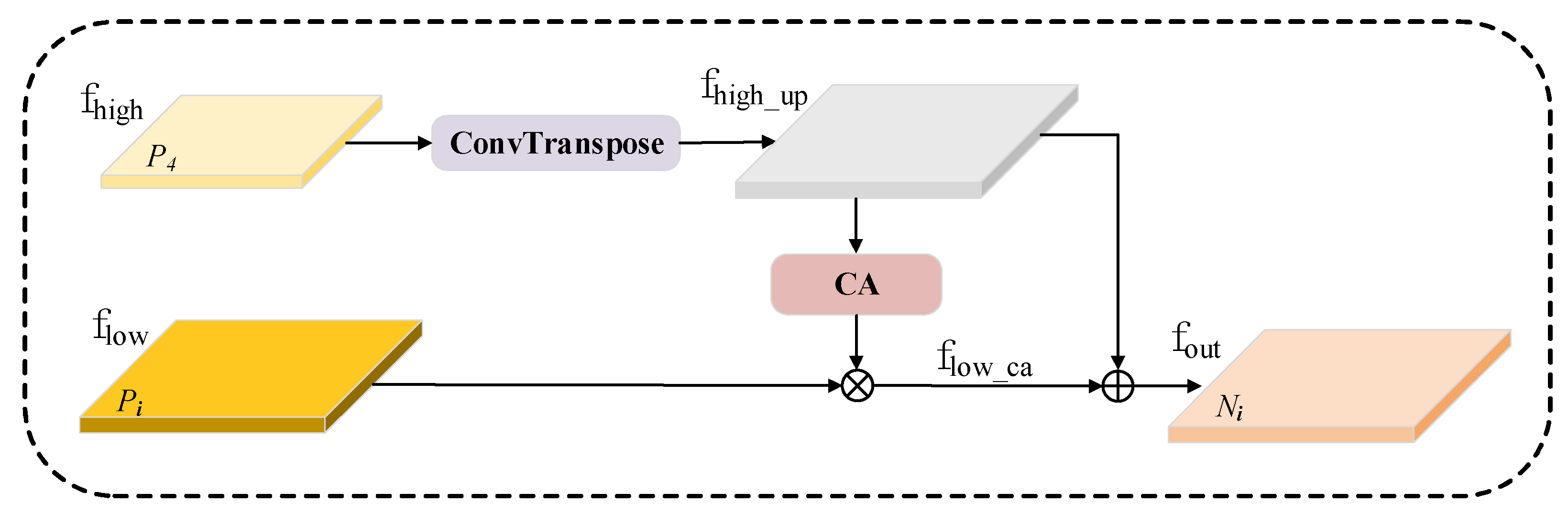
The SFF module focuses on the effective fusion of high-level and low-level features to enhance the representation capability of trademark defect features under fabric texture interference. As shown in
Figure 6, the specific process is as follows:
High-level feature upsampling: First, perform ConvTranspose operations on high-level features
to adjust their spatial dimensions and match them with low-level features
, as shown in Equation (12):
High-level feature attention screening: The high-level features
are input into the CA module. The CA module extracts channel statistics through global average pooling and global max pooling, generates channel weights,
, via a fully connected layer and Sigmoid activation, and completes channel-wise weighted screening of low-level features:
Feature fusion output: The upsampled high-level features
and attention-screened low-level features
are fused, and the final fused feature
is computed as follows:
HS-FPN demonstrates multiple technical advantages in trademark defect detection: Through a dual-channel attention mechanism and selective feature fusion strategy, it dynamically adjusts the weight distribution of multi-scale features to effectively handle trademark size variations and enhance responses to tiny defect features. Its channel attention module suppresses background interference such as fabric textures and wrinkles, improving feature representation capabilities in complex scenarios. Furthermore, its lightweight design achieves a balance between high detection accuracy and efficiency by reducing computational redundancy through channel dimension matching and dynamic feature routing, while maintaining detection precision.
3.4. Network Lightweighting
In DLF-YOLO, considering the actual clothing production line scenario where real-time performance is a critical metric, we introduce two lightweight convolutional modules—DWConv and HetConv—to reduce model parameters. In the field of finished garment defect detection, DWConv and HetConv complement each other’s advantages. DWConv focuses computational resources on the spatial dimension by preserving channel independence, enabling in-depth exploration of local spatial patterns in input feature maps. HetConv excels in multi-scale feature fusion. Its 3 × 3 kernel has strong local perception capabilities to precisely capture local texture details on trademark edges, which may arise from poor printing processes or improper fabric handling and are easily overlooked. Meanwhile, the 1 × 1 kernel integrates global semantic information such as overall trademark offsets and misalignment, allowing HetConv to effectively identify complex defects through this multi-scale feature fusion mechanism, further enhancing recognition of intricate flaws.
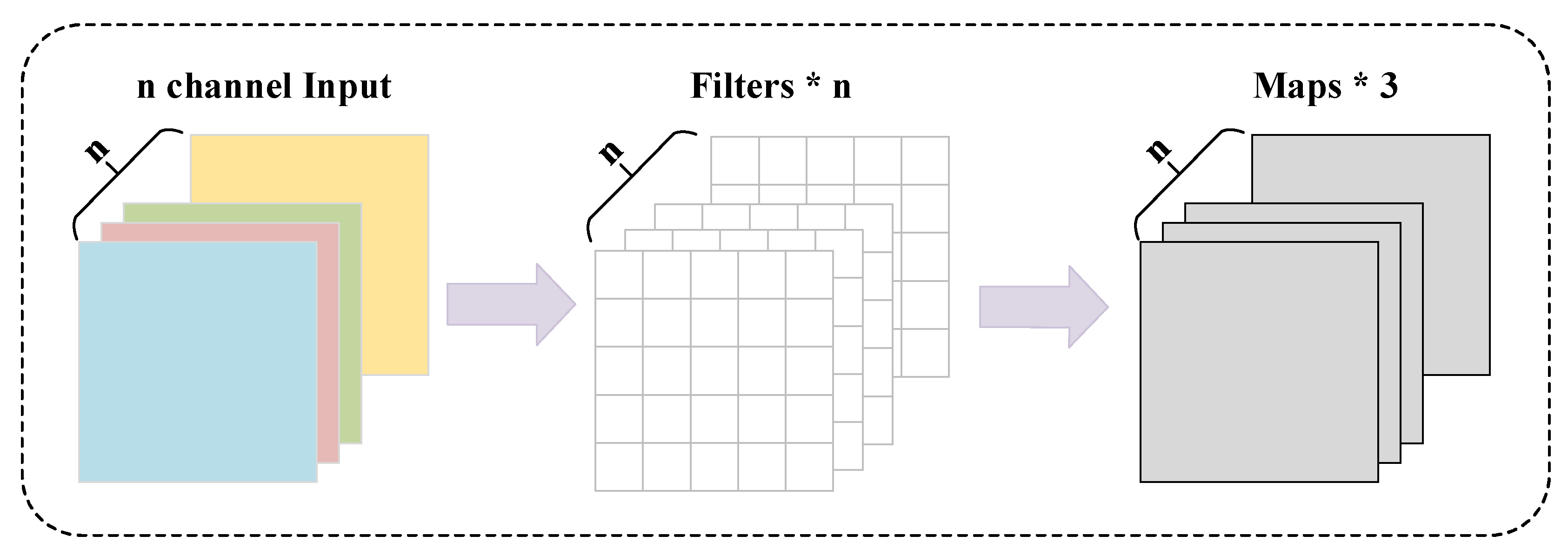
3.4.1. DWConv
DWConv achieves efficient feature extraction through a clever channel separation strategy. Its specific structure is shown in
Figure 7. It independently applies a 3 × 3 convolution kernel to each input channel for convolution operations, and the number of output channels remains the same as that of the input channels. This design decomposes the originally complex cross-channel convolution into multiple independent single-channel convolutions, greatly reducing unnecessary computations.
From the perspective of computational complexity, the computational complexity of DWConv can be computed by Equation (15):
where
Do denotes the size of the output feature map,
M is the number of input channels, and
K is the size of the convolution kernel (
K = 3 here).
Meanwhile, the computational complexity formula for conventional convolution is shown in Equation (16):
A clear comparison reveals that the computational complexity of DWConv is only 1/N (where N is the number of output channels) of conventional convolution. For example, when the input channels M = 64, output channels N = 128, output feature map size Do = 32, and convolution kernel size K = 3, the computational complexity of conventional convolution amounts to 32 × 32 × 64 × 128 × 3 × 3 FLOPs, whereas DWConv only requires 32 × 32 × 64 × 128 × 3 FLOPs—a significant disparity.
The design of DWConv, which preserves channel independence, offers several notable advantages. By focusing computational resources on the spatial dimension, it enables convolution kernels to deeply explore local spatial patterns in input feature maps. In the field of image processing, these local spatial patterns encapsulate rich information such as textures and edges. Texture information reflects the microstructural characteristics of image surfaces, which is crucial for recognizing objects of different materials. Edge information, on the other hand, outlines object contours, assisting the model in accurately locating and distinguishing different objects. In the specific application scenario of the finished garment defect detection, the advantages of DWConv are fully realized. Conventional convolution operations may fail to precisely capture these subtle defect details due to their computational limitations, whereas DWConv, with its efficient local spatial pattern capture capabilities, can sensitively identify these minute flaws, thereby improving the accuracy and reliability of finished garment defect detection.
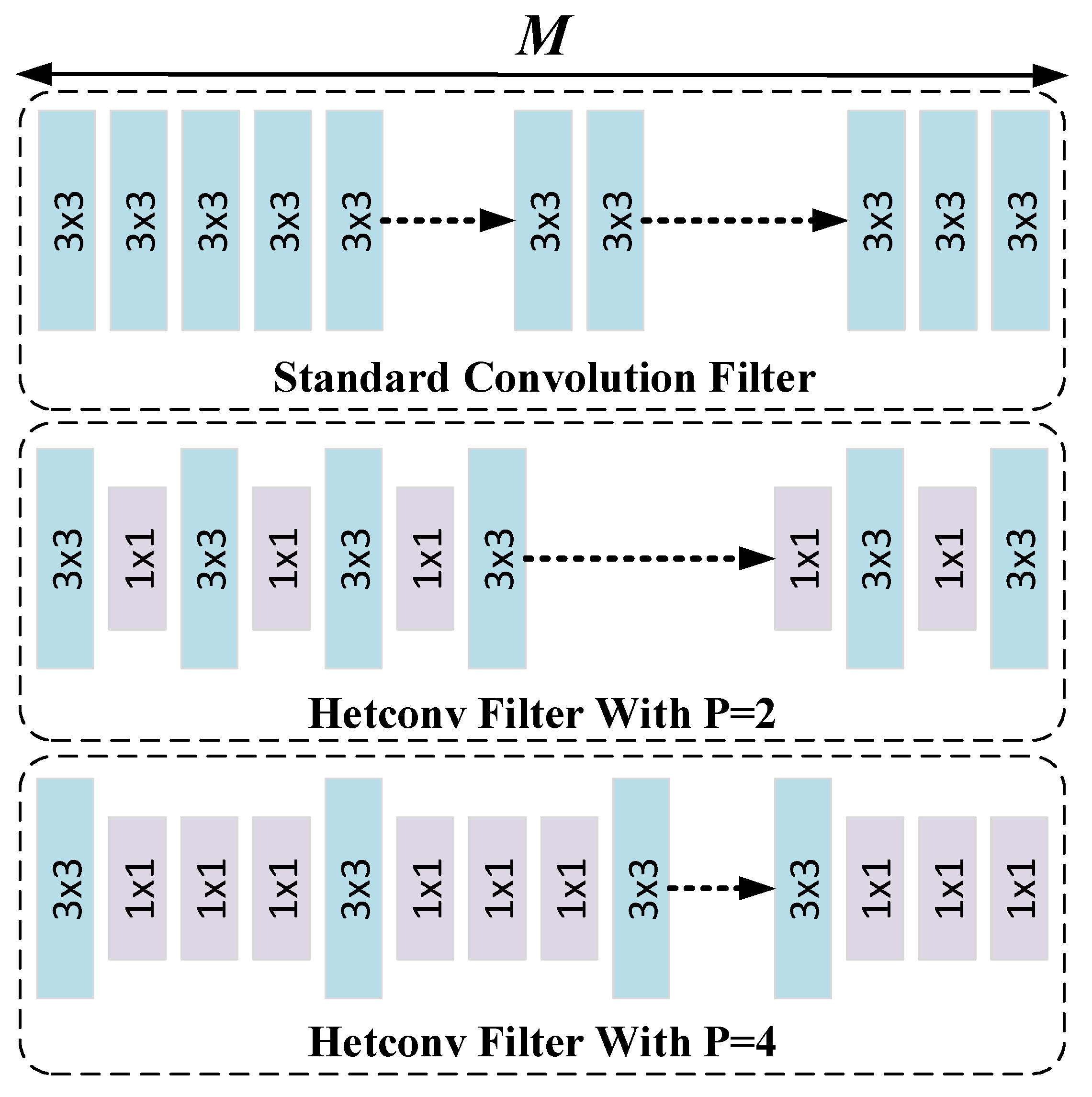
3.4.2. HetConv
To enhance both computational efficiency and feature diversity, we introduce HetConv.
Figure 8 illustrates the comparison between HetConv and standard convolution. HetConv employs a unique dynamic kernel combination strategy, where each convolution kernel integrates sub-kernels of varying sizes (typically a combination of 3 × 3 and 1 × 1 kernels). The parameter P flexibly controls the proportion of different kernel sizes. For example, when P = 4, it means 25% of the kernels are 3 × 3 and 75% are 1 × 1. This dynamic kernel combination breaks the limitation of conventional convolutions’ fixed kernel size, allowing the convolution operation to adaptively adjust kernel usage ratios according to task requirements and data characteristics, thus achieving a better balance between computational efficiency and feature extraction capabilities.
Regarding computational complexity, conventional convolution incurs relatively high costs due to its fixed computational pattern. The computational complexity formula for HetConv is shown in Equation (17):
Here, Do denotes the size of the output feature map, M is the number of input channels, N is the number of output channels, and K is the size of the convolution kernel. When K = 3 and P = 4, the computational complexity of HetConv is only 31% of conventional convolution, indicating a 3× to 8× reduction in FLOPs. This significant reduction in computational complexity is crucial for practical model training and inference, as it substantially reduces computational resource consumption and improves the model’s operating speed.
Figure 9 clearly demonstrates the latency comparison between HetConv filters and other efficient convolutional filters. DWC + PWC and GWC + PWC adopt a two-stage cascaded structure, where this serial processing introduces a latency of 1. In contrast, HetConv ingeniously avoids the latency caused by serial processing by integrating heterogeneous kernels into a single layer. This zero-latency characteristic is critical in practical applications, especially in scenarios with high real-time requirements, ensuring that the model can quickly provide detection results.
Clearly, the introduction of DWConv significantly reduces model complexity, parameter count, and computational complexity, thereby shortening inference time. HetConv also provides excellent real-time performance, and its zero-latency characteristic ensures a stable detection frame rate during the high-speed operation of the clothing trademark production line.
4. Experiments
4.1. Environment Configuration and Dataset
All deep learning models in this study were implemented using PyTorch 2.1.2 and executed on an Ubuntu 22.04 system with Python 3.10. During training, the models were accelerated by an NVIDIA GeForce RTX 3080 Ti GPU, utilizing CUDA 11.8. Under this configuration, the average training time per epoch for the DLF-YOLO model was approximately 3 s for 300 samples, 9 s for 750 samples, and 15 s for 1200 samples, with mixed precision training (AMP) enabled to improve computational efficiency.
The dataset used in this study consists of real clothing trademarks captured in a garment manufacturing enterprise. Defective samples were manually selected from the acquired images and annotated using LabelImg. Images with trademark defects were labeled as “NG”, while those featuring non-defective L-shaped trademarks were labeled as “L”. For industrial deployment, only defect detection (NG) is required; thus, the “L” class and other non-defective cases were treated as a unified background class during training, eliminating the need for further classification of normal types. This process established the original dataset, with all images sized at 1440 × 1080 pixels to retain high-resolution details of trademark textures and defects. To evaluate the performance of the algorithm, the original size of the training set was set to three scenarios: 20, 50, and 80, while the validation set was fixed at 150, with a ratio of 1:4 for defective to non-defective samples. We first applied the CycleGAN generative network to the original data, creating a training set that is twice as large and combining it with the original dataset. Subsequently, we applied traditional data augmentation methods to the CycleGAN-augmented training samples, including random rotation, Gaussian noise injection, and adjustments to brightness and contrast, for a five-fold increase. As shown in
Figure 10. Ultimately, we obtained three datasets of different sizes: 20-60-300, 50-150-750, and 80-240-1200, resulting in a total of nine training sets to validate the performance of the detection model.
4.2. Experiments for Validating Data Augmentation
To verify the generalizability of the data augmentation strategy, this study conducted controlled experiments based on the improved model (DLF-YOLO). The results demonstrate that the strategy significantly enhances detection performance.
The controlled experiments are divided into three scenarios, using the original dataset size as a reference. Specifically, 20, 50, and 80 samples are selected as Scenario 1, Scenario 2, and Scenario 3, respectively. Each scenario includes the following three datasets:
① Original dataset.
② CycleGAN-generated data, doubling the original dataset, combined with the original dataset.
③ Traditional data augmentation applied to Experiment ②, including rotation augmentation, brightness augmentation, contrast augmentation, and Gaussian noise augmentation.
The standard object detection metrics, mAP@0.5 and mAP@0.5:0.95, were used for evaluation.
The experimental results presented in
Figure 11 provide valuable insights into the effectiveness of the proposed data augmentation strategy. Several key observations emerged when analyzing the performance across varying dataset sizes and augmentation techniques.
Initially, the baseline performance of our improved model (DLF-YOLO) on the original datasets highlighted the limitations imposed by small sample sizes. With only 20 samples, the model exhibited a relatively low mAP@0.5 score, indicating that the scarcity of training data severely hindered the model’s generalization capability. As the dataset size increases to 50 and 80 samples, the performance improves but with diminishing returns, highlighting the inherent challenges of relying solely on expanded sample quantities to address small-data problems.
The introduction of CycleGAN-generated data significantly altered this landscape. By doubling the original dataset through CycleGAN, the model’s performance improved substantially, particularly under the smallest dataset condition. For instance, after data augmentation using CycleGAN, DLF-YOLO’s mAP@0.5 increased from 61.4% to 82.8%, a gain of 21.4%. This remarkable improvement validates the effectiveness of CycleGAN in mitigating the negative effects of limited training samples. The generated data not only expanded the dataset but also introduced stylistic and contextual diversity, enabling the model to learn from a broader feature distribution. Such diversity is crucial for enhancing generalization, as it reduces the risk of overfitting to the characteristics of small datasets. This improvement benefits from the synergistic effect of CycleGAN’s cyclic consistency loss and multi-scale discriminators: The former constrains the structural consistency between generated defects and real trademarks (e.g., preserving recognizable contour features) to avoid creating pseudo-defects with distorted features. The latter ensures that generated samples maintain semantic rationality at different resolutions through multi-scale feature discrimination, while introducing diverse style perturbations (e.g., blur levels, color deviations, and texture anomalies). Although the cyclic consistency mechanism significantly reduces generation bias and the multi-scale discriminator broadens the diversity boundary of defect styles, the high proportion of generated data may still lead to potential style shift issues. For example, generated blurry defects may concentrate in a specific blur range, whereas defect severity in real scenarios follows a continuous distribution. Future research could introduce conditional generation mechanisms based on defect type labels (e.g., “blur”, “damage”, “offset”) or filter style-shifted samples through dynamic screening strategies to further improve the controllability and physical rationality of generated data.
Building on this foundation, the application of traditional data augmentation techniques further enhanced the model’s capabilities. Techniques such as rotation, Gaussian noise addition, and adjustments to brightness and contrast introduced additional layers of variability. These augmentations simulate real-world imaging conditions, such as changes in lighting and orientation, thereby enabling the model to more reliably detect subtle defect features. When combined with CycleGAN-generated data, even greater improvements were observed, particularly under minimal data conditions, demonstrating the complementary nature of these two approaches. The hybrid strategy achieves a synergistic effect: CycleGAN expands the semantic space of defect patterns, while traditional methods refine the model’s sensitivity to low-level visual cues. While the performance gains diminished as dataset size increased, this trend was expected, as the model benefited from a richer pool of real samples, reducing the marginal utility of synthetic augmentation.
However, a decline in mAP@0.5:0.95 when transitioning from 50 to 80 samples warrants careful consideration. This observation suggests a potential overfitting issue arising from extensive data expansion. The augmented dataset may have introduced noise or artificial patterns that the model inadvertently learned, thereby weakening its ability to generalize across the full range of intersection over union (IoU) thresholds. This highlights the importance of balancing data augmentation with appropriate regularization techniques and validation protocols to ensure robustness.
In conclusion, the hybrid augmentation strategy emerges as a powerful solution for defect detection tasks under limited data conditions. CycleGAN effectively broadens the representation of defect categories, while traditional augmentation enhances the model’s sensitivity to fine-grained defect features. Together, they offer a robust framework for industrial applications where training data is inherently constrained. Future work may explore advanced regularization methods to mitigate overfitting risks and further optimize the synergy between generative and traditional augmentation techniques.
4.3. Comparative Experiments on Attention Mechanisms
To validate the effectiveness of the MDSA attention mechanism, this study designed comparison experiments with mainstream attention modules such as CBAM, MLCA, and EMA. The experiments were conducted on a 50-sample augmented dataset using the DLF-YOLO architecture, where only the MDAS was replaced with other attention mechanism modules. The experiments focused on examining the impact of different attention mechanisms on detection accuracy, inference speed, and model complexity, with results shown in
Table 1:
From the experimental results in
Table 1, it can be seen that traditional attention mechanisms such as CBAM, MLCA, and EMA all improve model accuracy to a certain extent, indicating that attention mechanisms have a positive effect on this task.
CBAM’s sequential channel-spatial attention structure (mAP@0.5: 97.5%) enhances feature selectivity but struggles with multi-scale dependencies, as it processes each scale independently. Notably, CBAM achieves a recall rate of 95.1%, higher than the baseline (93.4%), indicating improved overall defect detection capability. MLCA’s pyramid pooling (mAP@0.5: 97.7%) improves global context modeling but introduces redundant computations for small defects, leading to a 0.2% drop in mAP@0.5:0.95 compared to the baseline. Its recall rate is 94.3%, slightly lower than CBAM, potentially due to missed tiny defects from redundant computations. EMA’s efficient attention (mAP@0.5: 97.5%) reduces parameter overhead but fails to model fine-grained spatial details, resulting in a 12% lower recall for micro-defects than MDSA. Its recall rate is 94.8%, hindered by its inability to model fine-grained spatial details, leading to suboptimal performance on subtle defects.
The proposed MDSA achieves 98.0% and 80.2% on mAP@0.5 and mAP@0.5:0.95, respectively, significantly outperforming other attention mechanisms. MDSA achieves the highest recall rate of 95.6%, demonstrating superior ability to identify defect regions, especially for small and irregular defects, by fusing multi-scale channels and spatial attention. With only a slight increase in FLOPs and parameters, it achieves the optimal balance between accuracy and efficiency.
MDSA enhances the model’s ability to express trademark defect features by integrating multi-scale channel attention (MSCA) and multi-scale spatial attention (MSSA). MSCA can adaptively identify and enhance key channel features, effectively capturing hard-to-distinguish details such as printing defects and blurred edges, while MSSA focuses on spatial-level information perception, improving the model’s localization accuracy under complex backgrounds (such as fabric wrinkles and light reflections). Notably, the synergistic design of MSCA and MSSA also reduces performance variance: MDSA achieves lower standard deviations in recall (±0.44) and mAP@0.5:0.95 (±0.46) compared to other attention mechanisms, demonstrating stable feature extraction across diverse defect scales and backgrounds. The fusion of the two enables the model to be more robust and generalizable when dealing with small and irregular defects in trademarks.
In addition, MDSA’s dynamic synergistic layer (DSL) can adaptively adjust the fusion ratio of channel attention and spatial attention during training according to task characteristics and sample differences, overcoming the problem that fixed attention structures lack adaptability in different detection scenarios.
The experimental results indicate that MDSA achieves the best balance between detection accuracy and computational efficiency through its multi-scale dynamic synergy mechanism. Its innovative three-stage feature enhancement strategy (MSCA → MSSA → dynamic synergy) significantly improves the model’s recognition capability for trademark defects, providing an efficient solution for industrial real-time detection.
4.4. Ablation Experiments
In this study, ablation experiments were conducted to validate the effectiveness of each improved module. Based on the data comparison in the data augmentation validation experiments, it was found that the augmented dataset with 50 samples was the most balanced and representative. Therefore, the augmented dataset with 50 samples was used for the comparison experiment data (the same as in the comparison experiment). The results are shown in
Table 2:
The experimental results in
Table 2 indicate that the synergistic effect of HS-FPNs, MDSA, and hybrid convolution is critical for improving model performance and lightweighting, with specific analysis as follows:
The joint optimization of the HS-FPNs module and hybrid convolution architecture achieves significant lightweighting while maintaining detection performance. By means of a selective feature fusion strategy and channel dimension matching, HS-FPNs eliminate redundant cross-layer connections and repetitive feature calculations. Compared with the original neck structure of YOLOv11n, the parameters of HS-FPNs are reduced by 28.5% (from 2.583 M to 1.846 M), and the FLOPs are decreased by 11.1% (from 6.3 to 5.6 GFLOPs). This is because its dynamic weight mechanism only retains high-value features (e.g., defect edges and texture differences) and suppresses background noise (e.g., fabric wrinkles and uneven light), thus maintaining the detection accuracy while achieving lightweight. This suggests that HS-FPNs reduce redundant computations through selective feature fusion, and the lightweight design only causes a negligible loss of detailed features. Replacing conventional convolution with the “DWConv + HetConv” hybrid convolution architecture sharply reduces model parameters by 51.7% (1.247 × 106), decreases FLOPs by 33.3% (4.2 GFLOPs), and boosts inference speed to 302.6 FPS. However, mAP@0.5 and mAP@0.5:0.95 decrease by 0.2% and 1%, recall decreases slightly from 95.8% (YOLOv11n) to 95.1%. This suggests that while lightweight convolutions efficiently reduce computational complexity, they may sacrifice some high-level semantic features to distinguish subtle defect patterns (e.g., complex texture variations or multi-scale printing deviations). Nevertheless, the combined effect of hybrid convolution and HS-FPNs maintains mAP@0.5 at 97.4%, demonstrating that lightweighting does not undermine the effectiveness of feature fusion.
The MDSA attention mechanism plays a crucial compensatory role in model improvements, addressing both feature loss caused by the lightweight design of HS-FPNs and feature weakening from hybrid convolution. Adding the HS-FPNs module alone results in partial loss of detailed features, but introducing MDSA restores mAP@0.5:0.95 to 79.8%, confirming that MDSA effectively compensates for feature loss through dynamic feature focusing. Moreover, the final model (ours), by integrating the MDSA attention mechanism, achieves a 0.6% improvement in mAP@0.5 on top of the HS-FPNs and hybrid convolution structure, reaching 98.0%, outperforming all ablation variants, while maintaining a recall rate of 95.6%—closely matching the baseline YOLOv11n (95.8%) and reducing recall standard deviation to ±0.30 and ±0.44, respectively, stabilizing feature focusing and mitigating instability. The final model (ours) achieves the lowest mAP@0.5 standard deviation (±0.12), highlighting robust performance across diverse defects and imaging conditions. Additionally, the parameter count is controlled at 1.302M, and the FPS reaches 303.4, achieving an optimal balance between detection accuracy, inference speed, and model size. This effectively compensates for the weakened feature representation caused by lightweight convolution.
4.5. Comparison Experiments with Mainstream Algorithms
This section compares the detection performance of the proposed DLF-YOLO algorithm with six other mainstream detection models, and their specific results are shown in
Table 3.
The results in
Table 3 demonstrate that the DLF-YOLO model proposed in this study achieves an excellent balance between accuracy, speed, and complexity. In terms of recall, DLF-YOLO achieves 95.6%, closely matching the baseline YOLOv11n (95.8%) and outperforming lightweight models like Tiny-YOLOv7 (90.2%) and EfficientDet (82.8%). Notably, DLF-YOLO’s 95.6% is nearly on par with RT-DETR’s 95.8%, but with significantly lower standard deviation (±0.44 vs. ±1.03), indicating more stable defect detection across diverse samples. DLF-YOLO’s recall stability (standard deviation ±0.44) also surpasses YOLOv11n (±0.90) and YOLOv12n (±1.16), reflecting the stabilizing effect of the MDSA attention mechanism on feature extraction. This balance of high recall, stability, and efficiency highlights its suitability for industrial scenarios requiring both precision and real-time performance.
In terms of key object detection metrics, DLF-YOLO attains an mAP@0.5 of 98.0%, trailing only slightly behind the current state-of-the-art RT-DETR algorithm by 0.4 percentage points, while significantly outperforming YOLOv11 (97.6%) and matching YOLOv8 (98.0%). DLF-YOLO achieves this with an mAP@0.5 standard deviation of ±0.12, demonstrating tighter consistency than YOLOv11n (±0.20) and YOLOv12n (±0.05), and comparable stability to RT-DETR (±0.06). On the more stringent mAP@0.5:0.95 metric, the model maintains a robust performance of 80.2%, just 0.1 percentage points lower than RT-DETR and YOLOv11, with a standard deviation of ±0.46 that highlights its reliability across diverse defect scales and imaging conditions. This underscores the enhanced robustness in complex backgrounds brought about by the integrated MDSA attention mechanism.
Furthermore, the model achieves remarkable breakthroughs in lightweight design. With a parameter count of only 1.302 × 106, it represents a 49.5% reduction compared to YOLOv11 (2.583 × 106) and a staggering 96.0% reduction compared to RT-DETR (32.810 × 106). The computational cost is also significantly lowered from YOLOv11’s 6.3 GFLOPs to 4.5 GFLOPs, which is merely 16.6% of that of EfficientDet.
Additionally, the inference speed of the model reaches 303.4 FPS, tripling that of YOLOv11 (100.0 FPS) and more than doubling that of YOLOv8 (117.6 FPS). This lightweight design lays a solid foundation for real-time deployment on edge devices, significantly reducing hardware dependencies while maintaining detection capabilities. It offers an innovative solution to meet the industrial inspection field’s demands for high accuracy, low power consumption, and rapid response.
4.6. Results Visualization
In this section, we further provide the visualization results of the algorithm, as shown in
Figure 12. In the baseline model (without attention mechanism), the model’s attention is evenly distributed across different regions of the image, failing to effectively focus on the defect areas. After introducing CBAM, the model’s attention to the defect regions is slightly enhanced, but the improvement is limited. For the MLCA and EMA mechanisms, experiments show that although they significantly enhance the model’s attention to trademark edges and textual features, they do not effectively focus on the defect areas. In contrast, the proposed MDSA module adopts a dual-focus mechanism that combines both local and global attention, along with dynamic adjustment of channel and spatial attention weights. This design effectively achieves the goal of focusing on defect regions and guides the model to attend to key features of trademark defects.
Figure 13 further demonstrates the performance comparison between the improved model and the original YOLOv11 in trademark defect detection tasks. As shown in the third column of the figure, both YOLOv8 and YOLOv12 exhibit false detections under the interference of clothing distortions. In contrast, the optimized model demonstrates enhanced feature extraction capability and achieves a lower false positive rate. The improved model can more accurately distinguish between normal and defective trademarks, thereby improving detection reliability. Moreover, the improved model exhibits a certain degree of generalization ability. In the fourth column of the figure, which presents a previously unseen defect type, both YOLOv11 and YOLOv12 fail to detect the defect, while the optimized model successfully makes a correct prediction. However, there is a slight decline in detection performance for text trademarks, which may be due to the relatively complex structure of text and subtle defect features, weakening the model’s recognition capability in specific scenarios. Overall, while our model’s performance is slightly inferior to RT-DETR, it achieves this result with significantly fewer parameters and lower computational complexity compared to RT-DETR.
5. Conclusions
This study is committed to surmounting the long-standing challenges in the domain of clothing trademark quality inspection, including the scarcity of defect samples, suboptimal performance in intricate industrial settings, and low detection efficiency. To address these issues, we elaborately developed the DLF-YOLO model, which was optimized and enhanced based on YOLOv11. Specifically, the CycleGAN generative adversarial network was harnessed for data augmentation. The MDSA mechanism was devised. The HS-FPNs module was utilized to optimize the Neck network architecture, and DWConv and HetConv were adopted to realize the lightweight construction of the network. This suite of innovative measures functioned in harmony to comprehensively boost the overall performance of the model in the task of clothing trademark defect detection.
The experimental data compellingly validate the outstanding performance of DLF-YOLO. On the self-constructed dataset, DLF-YOLO attained an accuracy of 80.2% in terms of mAP@0.5:0.95. Compared to the original YOLOv11, its parameter count decreased substantially by 49.6%, and the computational burden was markedly reduced by 25.6%. In the data augmentation experiment, the seamless integration of CycleGAN and traditional data augmentation techniques significantly enhanced the model’s generalization capacity. The attention mechanism comparison experiment clearly demonstrates that MDSA outperforms mainstream attention modules in balancing detection accuracy and efficiency. The ablation experiment further elucidates the synergistic effect among HS-FPNs, MDSA, and hybrid convolutions, which is pivotal for improving the model’s performance and achieving a lightweight design. The comparison experiment with mainstream algorithms further accentuates the remarkable equilibrium achieved by DLF-YOLO among accuracy, speed, and complexity.
DLF-YOLO has created a highly scalable and efficient new trail for the lightweight and industrial-grade defect detection of clothing trademarks. This model not only enriches the application accomplishments of object detection algorithms in a specific field at the theoretical level but also furnishes a practical solution for quality control in actual production. It is anticipated to considerably enhance the production efficiency and product quality in the clothing manufacturing industry.
Future research can center on exploring more advanced data augmentation strategies to adapt to more complex and diverse real-world production environments. Notably, the current model’s dataset is sourced exclusively from a single clothing manufacturer, which is a limitation that necessitates retraining when applied to new datasets. Additionally, the model’s detection performance on fabrics with intricate weaves or multi-colored trademarks remains unvalidated, underscoring the urgency of further testing across diverse industrial scenarios to ensure robust applicability. Simultaneously, continuous endeavors should be made to optimize the model architecture and fully augment the model’s performance in detecting small targets and subtle defects. For example, techniques like color space fusion and super-resolution reconstruction have proven effective in enhancing detection accuracy for fine details in similar fields [
42]. Such advancements would expedite the widespread implementation and in-depth application of this technology in the clothing manufacturing industry.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}