1. Introduction
Generative AI, a category within the realm of artificial intelligence, is characterized by its ability to produce new data by learning from existing datasets. These models can generate content spanning a wide spectrum of domains, including text, imagery, music, and education [
1,
2,
3,
4,
5]. The foundation of generative AI lies in the utilization of deep learning techniques and neural networks, which enable comprehensive analysis, comprehension, and generation of content that closely mimics the outputs created by humans. A noteworthy example in this realm is the introduction of OpenAI’s ChatGPT (
https://openai.com/blog/chatgpt (accessed on 1 January 2025)), a state-of-the-art generative AI model that has significantly impacted diverse domains, including the academic landscape. Notably, ChatGPT’s proficiency in processing text-based open-ended queries and producing responses that closely resemble human-generated inputs has elicited admiration and apprehension among researchers and scholars.
The rapid advancement of natural language processing (NLP) has been largely driven by the development of transformer-based architectures, particularly the Generative Pre-trained Transformer (GPT) models, such as ChatGPT. These models are designed to generate coherent, human-like text across a wide range of formats, including sentences, paragraphs, and documents.
Given that GPT models are trained on human-generated content, comparing ChatGPT’s output with that of humans presents both a critical and inevitable challenge. Recent studies have rigorously evaluated ChatGPT across various domains—including education [
1,
6,
7], healthcare [
8,
9,
10], research [
11,
12,
13,
14], programming [
15,
16,
17], translation [
18], and text generation [
19,
20,
21,
22,
23]. These evaluations suggest that while ChatGPT achieves near-human performance in some areas, its capabilities remain limited in others, as discussed in
Section 2.
Our study narrows this focus to the task of summarization—an essential and widely applicable NLP function. Summarization enhances communication efficiency, facilitates information management, and plays a vital role across fields such as education, research, and decision-making.
The crucial task of summarization is also a core function that ChatGPT can perform. Accordingly, several studies have evaluated the performance of ChatGPTs in this specific aspect of functionality. For instance, Goyal et al. [
24] investigated the impact of GPT-3 on text summarization, with a specific focus on the well-established news summarization domain. The primary objective was to compare GPT-3 with fine-tuned models trained on extensive summarization datasets. Their results demonstrated that GPT-3 summaries, generated solely based on task descriptions, not only garnered strong preference from human evaluators, but also exhibited a notable absence of common dataset-specific issues, such as factual inaccuracies. Gao et al. [
25] explored ChatGPT’s ability to perform summarization evaluations resembling human judgments. They employed four distinct human evaluation methods on five datasets. Their findings indicated that ChatGPT could proficiently complete annotations through Likert-scale scoring, pairwise comparisons, pyramid evaluations, and binary factuality assessments. Soni and Wade [
26] conducted an evaluation of ChatGPT’s performance in the realm of abstractive summarization. They employed both automated metrics and blinded human reviewers to assess summarization capabilities. Notably, their research revealed that, while text classification algorithms were effective in distinguishing between genuine and ChatGPT-generated summaries, human evaluators struggled to differentiate between the two. Additionally, Yang et al. [
27] evaluated ChatGPT performance using four widely recognized benchmark datasets that encompassed diverse types of summaries from sources such as Reddit posts, news articles, dialogue transcripts, and stories. Their experiments demonstrated that ChatGPT’s performance, as measured by Rouge scores, was comparable to that of traditional fine-tuning methods. The collective findings of these studies underscore the considerable potential of ChatGPT as a robust and effective instrument for text summarization.
Our study presents a novel approach that compares not only the quantitative differences but also the qualitative distinctions between summaries generated by human authors and those generated by a ChatGPT-based language model. In particular, the qualitative aspect of this comparison focuses on the degree of bias present in each summary.
The motivation for considering bias as a qualitative indicator lies in its potential to adversely influence public perception through skewed media coverage. Exposure to distorted or misleading information can lead to inaccurate understandings of events or individuals, thereby hindering fair and objective judgment. Moreover, biased reporting contributes to ideological polarization and intensifies social conflict, potentially fostering political division and antagonism among different groups.
Given these consequences, various studies have explored the nature and classification of media bias. For instance, Hamborg et al. [
28] highlighted that news reports often lack objectivity, with bias emerging from the selection of events, labeling, word choices, and accompanying images. They also advocated for automated approaches to identify such biases. Similarly, Meyer et al. [
29] argued that the rise of AI/ML technologies has amplified bias within language models, largely due to the nature of the training data. As such, they emphasized the importance of using large language models (LLMs) with caution and awareness of their embedded biases.
Recent research has examined the potential of LLMs in mitigating such biases. For example, Schneider et al. [
30] investigated the application of language models to promote diverse perspectives while avoiding the explicit transmission of biased information. While the final outputs are still dependent on the underlying training data, their findings indicate that few-shot learning can serve to partially mitigate such biases. Additionally, Törnberg [
31] evaluated the accuracy, reliability, and bias of language models by analyzing their classification of Twitter users’ political affiliations and comparing them to human experts. Their findings showed that the language model achieved higher accuracy and exhibited less bias than the human evaluators, thereby demonstrating its potential to perform large-scale interpretative tasks.
Consequently, this study proposes a novel approach that simultaneously compares the summaries generated by ChatGPT and those written by humans in both quantitative and qualitative dimensions. A key distinction of this research lies in its focus on examining differences in bias between human-authored and AI-generated summaries. While previous studies have primarily relied on human evaluations or text-based metrics to assess summary quality, our study uniquely emphasizes the dual analysis of both semantic similarity and bias by comparing each summary with the original text.
To conduct our investigation, we utilized a sample dataset from The New York Times, a reputable source of news content. Each article typically includes a title, body text, and an editorial summary. We compare the body of each article with the editorial summary provided by The New York Times as well as the corresponding summary generated by ChatGPT.
In terms of methodology, we applied BERTScore as a quantitative metric to assess the semantic similarity between the human-generated summary (reference sentence) and the ChatGPT-generated summary (candidate sentence). BERTScore enabled us to evaluate the extent of textual alignment between the two summaries. Additionally, to assess differences in bias from a qualitative standpoint, we conducted a moderation violation test to examine potential disparities in the expression and content of each summary. A detailed explanation of our research design is presented in
Section 3.1.
The primary contribution of this study lies in its empirical comparison of summarization performance between ChatGPT and human writers. While analyzing the full text of news articles in sentiment analysis can result in inaccuracies due to the overwhelming volume of data, using summaries introduces variation depending on their quality. Our findings demonstrate that summaries produced by ChatGPT are of comparable quality to those written by professional journalists, indicating their applicability in subsequent tasks such as sentiment analysis.
Moreover, the presence of immoderate or emotionally charged language can skew sentiment analysis results. By using ChatGPT-generated summaries, which tend to reduce linguistic excess, more neutral and unbiased sentiment assessments can be achieved.
Finally, from a data management perspective, maintaining and analyzing large-scale news archives entails significant costs. In cases where journalists do not provide summaries, automatically generated summaries can offer a cost-effective alternative by reducing storage requirements while preserving essential information.
The remainder of this paper is organized as follows. In the following section, several recent studies on ChatGPT are briefly reviewed.
Section 3 describes the data and methodologies (ChatGPT, BERTScore, moderation) used in this study. In
Section 4, we present comparison results and a case study. Finally,
Section 5 provides concluding remarks.
2. Literature Review
Recent academic studies have focused on conducting comprehensive assessments of ChatGPT’s performance, potentialities, and limitations.
2.1. ChatGPT Performance Across Diverse Fields
Research on the performance of ChatGPT is being conducted across diverse fields of study, including but not limited to education and medicine.
Several scholars have investigated multifaceted applications of ChatGPT in education. For instance, Rudolph et al. [
1] investigated its potential to foster creativity within educational environments, whereas Mhlanga [
6] investigated its role in facilitating personalized learning experiences. Furthermore, Wang et al. [
32] investigated the effectiveness of providing real-time feedback to students during online learning activities. Together, these studies enrich our understanding of the impact of ChatGPT on education and highlight various aspects of its utility and effectiveness in educational settings.
In a medical field study, ChatGPT’s performance and concerns were analyzed. De Angelis et al. [
8] highlight ChatGPT’s significant impact on the general public and research community but raise concerns about ethical challenges, especially in medicine due to potential misinformation risks. Rao et al. [
9] demonstrate ChatGPT’s potential for radiologic decision making, suggesting it could enhance clinical workflow and the responsible use of radiology services. Hulman et al. [
10] assess ChatGPT’s ability to answer diabetes-related questions, revealing the need for careful integration into clinical practice, as participants only marginally outperformed random guessing, contrary to expectations.
Several studies have examined the performance of ChatGPT in computer programming tasks, highlighting its strengths and limitations. Koubaa et al. [
15] highlight human superiority in programming tasks, particularly evident in the IEEExtreme Challenge. Surameery and Shakor [
17] advocate for ChatGPT’s integration into a comprehensive debugging toolkit to augment bug identification and resolution. Similarly, Yilmaz and Yilmaz [
16] stressed the importance of cautious integration, and offered recommendations for effectively incorporating ChatGPT into programming education.
Finally, according to Minaee et al. [
33], who conducted a comprehensive review of major large language models—including GPT, LLaMA, and PaLM—covering their architectures, training methodologies, applications, and performance comparisons, as well as discussing the contributions and limitations of each model, GPT-4 is regarded as a leading LLM that demonstrates state-of-the-art (SOTA) performance across most tasks, including commonsense reasoning and world knowledge.
2.2. ChatGPT Performance in Summarization
Generating human-like summaries is an important part of natural language processing (NLP). Summarizing a text into succinct sentences containing important information differs from the traditional method of extracting key sentences from the original text. The quality of the generated summaries has also improved rapidly with the development of LLMs. Recently, various studies have been conducted to generate summaries using GPT-3.
Zhang et al. [
34] conducted a systematic human evaluation of news summarization using ten different large language models, including GPT, to assess how effectively LLMs perform in this task. The results showed that zero-shot instruction-tuned GPT-3 achieved the best performance, and the summaries it generated were rated as comparable to those written by freelance writers. Furthermore, the study suggests that instruction tuning, rather than model size, is the key factor contributing to improved summarization performance in LLMs.
According to Gao et al. [
25], ChatGPT was used to evaluate summaries, and the results showed that ChatGPT has human-like evaluation abilities, and its performance is highly dependent on prompt design.There has also been research interest in controllable text summarization [
19]. This methodology generates summaries by adding specific requirements or constraints to a prompt. This allows the user to control the length, style, or tone of the summarized sentences. The study showed that ChatGPT outperformed the previous language model (text-style transfer).
Furthermore, Alomari et al. [
35] provide a comprehensive review of recent approaches aimed at improving the performance of abstractive text summarization (ATS), focusing on deep reinforcement learning (RL) and transfer learning (TL) as key techniques to overcome the limitations of traditional sequence-to-sequence (seq2seq) models. According to the study, Transformer-based transfer learning models have significantly addressed the shortcomings of earlier seq2seq approaches, which often produced low-quality, low-novelty summaries. These models have optimized summary quality, novelty, and fluency, thereby substantially advancing SOTA performance in the field.
2.3. Evaluation Methodologies
According to Yang et al. [
27], ChatGPT’s summarization performance can be measured using aspect- or query-based summarization methods. Aspect-based summarization is a method that promptly presents certain aspects and asks for a summary of them, whereas query-based summarization is a method that performs summarization based on questions. The results showed that ChatGPT performed well in news summarization.
Moreover, several studies have assessed ChatGPT’s text-generation capabilities compared with human-authored content. Pu and Demberg [
19] find instances where humans excel in various styles, while Herbold et al. [
20] observe ChatGPT’s superiority in generating argumentative essays. Additionally, studies such as those by [
21,
23] examined the disparities between humans and ChatGPT-generated text. However, Pegoraro et al. [
22] note the difficulty of effectively distinguishing between the two. These findings highlight the nuances of ChatGPT’s performance and underscore the ongoing challenges in discerning between human- and AI-generated texts.
2.4. Bias and Moderation in AI-Generated Text
Research has been conducted on whether ChatGPT biases summaries. According to Barker and Kazakov [
36], an experiment was conducted to determine whether ChatGPT-generated summaries reduced some textual indicators compared to the original. The results show that some textual indicators were removed during the transformation from the original to the summary, which could reduce discrimination based on the region of origin. However, there are studies that show a bias in sentences generated by ChatGPT [
37]. The study found that when politicians were used as prompts to generate sentences, the frequency of positive and negative words differed between liberal and conservative politicians, indicating a bias. Lucy and Bamman [
38] also showed that the sentences generated using GPT-3 have a gender preference depending on the specific context. When generating sentences about storytelling, the study showed that women were more likely to be described in terms of their physical appearance and men were more likely to be described in terms of their ability to be powerful. This suggests that GPT-3 has a gender bias.
While ChatGPT’s efficacy is acknowledged in the field of research, it also triggers discussions about its ethical implications and inaccuracy [
11,
12,
13,
14], signaling a multifaceted evaluation of its role in the field.
In addition, although our study addresses a similar topic to the aforementioned works, it introduces several important advancements that distinguish it from prior research. Compared to previous studies that primarily relied on human preference evaluations [
25], we quantitatively assessed semantic similarity by employing BERTScore. Furthermore, unlike previous research that focused solely on summarization performance [
24,
26,
27], our study uniquely incorporates an ethical evaluation, analyzing to what extent the generated summaries reduced violent, biased, or harmful expressions through the use of the Moderation API. This approach offers a novel perspective by simultaneously evaluating both the factual consistency and the social acceptability of the generated summaries.
3. Research Design and Models
3.1. Research Design
The research workflow in this study is outlined as follows. Initially, we gathered human-generated text summaries and created text summaries using ChatGPT. For this purpose, we used New York Times articles that provide both the original text and a summary for each article. We utilized ChatGPT to generate individual article summaries and subsequently conducted a comparative analysis with the corresponding New York Times summaries. In our analysis, we computed the BERTscore to assess the disparity between the two summaries. Furthermore, a moderation validation test was conducted on the summaries to identify instances in which they deviated from moderation principles. The research process is illustrated in
Figure 1. The specific prompt design used for ChatGPT during this phase is as follows:
Figure 2 illustrates the process of generating a summary using ChatGPT. We used a GPT3.5 turbo-16K model to account for the number of tokens in the news body. We selected GPT-3.5-turbo-16k rather than GPT-4 primarily due to the significant cost differences associated with text generation tasks. Specifically, GPT-4 costs approximately USD 30 per 1 million input tokens and USD 60 per 1 million output tokens, whereas GPT-3.5-turbo-16k costs only around USD 0.5 per 1 million input tokens and USD 1.5 per 1 million output tokens. This price difference—GPT-4 being approximately 60 times more expensive—makes GPT-3.5-turbo-16k substantially more practical and economically viable, especially given the large-scale summarization tasks involving thousands of news articles analyzed in this study. In total, we analyzed 1737 news bodies from The New York Times, each paired with its corresponding editorial summary; ChatGPT was given the role of generating summaries of The New York Times articles when given their bodies. The prompt used is “We’ll take a News text as input and produce a news summary as output”. This standardized prompt was applied consistently across all 1737 pairs with the same parameters. In this study, we used the parameters used in the ChatGPT API example of a text summary. Here, each parameter indicates that the temperature was set to 0, producing deterministic outputs by removing randomness. Higher value of temperature indicated a higher probability of generating unpredictable words. A frequency penalty and presence penalty were set to 0, imposing no restrictions or penalties on token repetition or presence. Top_P was used to determine whether to use the top few percentages of words among the candidates to generate words. The maximum length determines the length of the generated sentence. We then matched the maximum length of the tokens to the number of tokens in the New York Times summary. These parameters are shown in
Table 1. After setting the parameters, we provided ChatGPT to news bodies. Consequently, ChatGPT generated a summary of the news based on internal probability calculations.
3.2. Data
We harvested articles from
The New York Times “Today’s Paper” section, which provides a daily list of the newspaper’s print articles. For each date from 26 January 2018 to 31 December 2022, we retrieved only the first textual news article listed on the “Today’s Paper” page. If the first entry was an advertisement or a multimedia-only item (photo essay, video, etc.), that date was excluded, maintaining a uniform one article per day sampling rule. Each selected item follows the standard New York Times article format—headline, editor-written abstract (summary), and full body text. Using Selenium for navigation and BeautifulSoup for parsing, we extracted these three components separately and stored them in distinct fields—title, summary, and body—so that the body–summary pair is explicitly available for downstream analysis. The resulting corpus comprises 1737 article–summary pairs. On average, the editor-written abstracts contain 30.13 tokens, whereas the corresponding full-text bodies contain 1420.24 tokens. New York Times articles have also been used as training data for machine-learning models in several studies [
39,
40,
41,
42].
3.3. Methods for Summary
3.3.1. GPT
The field of language processing has seen rapid development since the release of the transformer architecture, with the generative pretrained transformer (GPT) model receiving particular attention. One example is OpenAI’s ChatGPT. GPT is a large language model trained on massive amounts of language data. The early GPT was designed differently from current learning methods. GPT-1 uses a semi-supervised approach. It was pretrained on a large corpus, and then transfer learning was performed by fine-tuning each downstream task using labeled data [
43]. GPT-2, on the other hand, used an approach that did not include fine-tuning in the traditional semi-supervised approach because changes in the data distribution or minor modifications would reduce the accuracy of discriminative downstream operations. The ultimate goal of the GPT model is to avoid manual generation and use of labeled data for cost-effective learning. Although it still uses a transformer architecture, layer normalization has been moved to be an input to each sub-block and has been added after the self-attention blocks. It increased the vocabulary size, context size, and batch size and used 1.5 billion parameters. However, GPT-2 does not perform well in summarization and question-answering tasks [
44]. Subsequently, while there were no algorithmic changes with GPT-3, it increased the number of parameters by up to 175 billion without fine-tuning the training. Performance improvements were observed across classification, extraction, generation rewriting, and chatting close QA open QA summarization compared to previous models, such as GPT-2; however, limitations exist, such as hallucinations and misaligned sentence creation [
45,
46,
47]. To address these issues, fine-tuning was conducted by following broad instructions without violating conventions via human feedback, which resulted in the creation of an instruct-GPT model that generated results aligned with human preferences, even for tasks that were not pretrained, unlike traditional GPT-3 models. However, expanding parameters inevitably increases costs, including those associated with fine-tuning, making discriminative downstream tuning difficult; however, providing examples of questions within prompts confirmed human-level performance even for non-pre-trained tasks through few-shot learning [
48,
49,
50].
3.3.2. BERTScore
In this study, we used the BERTScore [
51] similarity measure to evaluate the similarity between the reference and candidate sentences. BERTScore is a metric that measures how similar the meanings of two sentences are. Unlike traditional similarity evaluation methods that rely on exact match of words and perform only surface-level comparisons, BERTScore analyzes the meanings of words even when the sentence structures differ. By leveraging the BERT language model to understand the meanings of individual words, BERTScore evaluates the semantic similarity between sentences based on their conveyed meanings.
Specifically, BLEU [
52] uses n-grams to compare similarities. However, this does not account for the similarity of sentences that have the same meaning but use different words. For example, BLEU and METEOR [
53], which use n-grams, assign higher scores to sentences that use the same words as the reference but do not have meanings that are similar to those that use different words, and penalize sentences based on the order of word arrangement. BERTScore uses BERT’s [
54] contextual embedding method to tokenize and measure their similarities to calculate the BERTScore. Contextual embedding is a method that changes the embedding of a word depending on the context. For example, in these sentences, “I need a new mouse for my computer” and “There’s a mouse in the kitchen”, mouse is the same word, but it is counted as a different embed in the contextual embedding method. To compute the BERTScore, we used BERT to embed the reference and candidate sentences. The reference sentence is represented by
and the candidate sentence is represented by
We perform pairwise cosine similarity between the embedded vectors of each sentence to calculate the cosine similarity between multiple vectors. Because we normalize them beforehand, we simplify the calculation to
. The Recall, Precision, and F1-score formulas for each sentence were calculated as follows:
The cosine similarity has the same range as
as shown in the formula. However, it has a more restricted interval owing to the geometry of contextual embeddings. In general, it is recommended to rescale BERTScore by setting an empirical lower bound,
b for the capability of the calculated score.
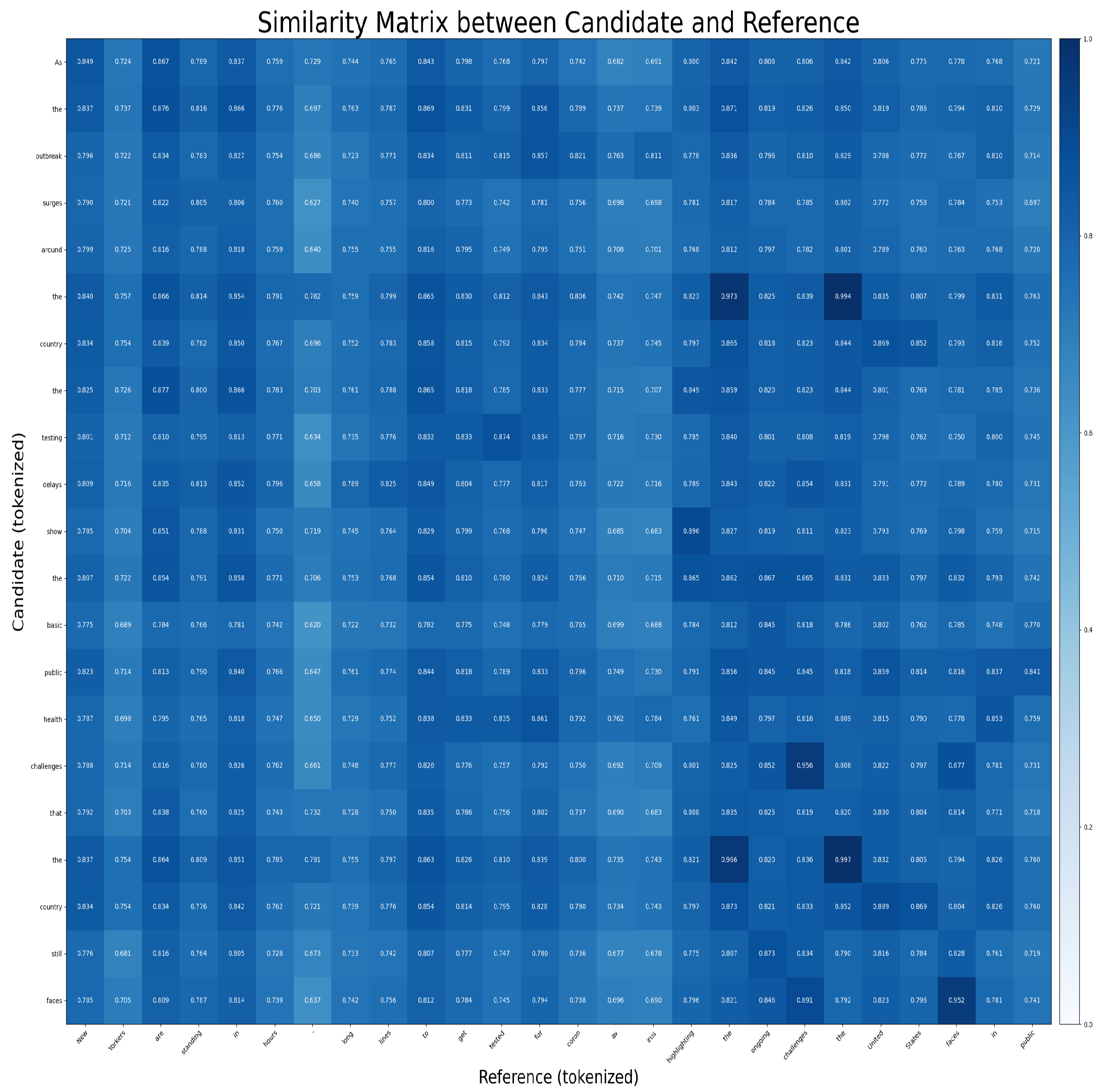
Figure 3 employed two illustrative summary sentences, one provided by a human editor from The New York Times (“New Yorkers are standing in hours-long lines to get tested for coronavirus, highlighting the ongoing challenges the United States faces in public”) and the other generated by ChatGPT (“As the outbreak surges around the country, the testing delays show the basic public health challenges that the country still faces”). Each sentence was first tokenized into WordPiece tokens. Subsequently, embeddings for each token were extracted using BERT contextual embedding methods, resulting in embedding vectors of dimension 768 per token. Using these token-level embeddings, we computed pairwise cosine similarities to produce a token-to-token similarity matrix in
Figure 4. Finally, following the BERTScore methodology, we calculated Recall, Precision, and F-score metrics from this similarity matrix, quantifying the semantic similarity between the two sentences.
3.3.3. Moderation
When performing sentiment analysis on sentences, violent, stigmatized, and biased sentences often have a negative impact on sentiment analysis. In other words, what words are a sentence made up of, or what nuances are important to both humans and machines? News, in particular, conveys the author’s intentions, which can be biased. Therefore, if a sentence is extremely violent, simplistic, or sexual in content, it can lead to misunderstandings or preconceived notions [
55,
56].
Therefore, this study conducted a moderation validation test using the Moderation API to verify whether our summaries contained any bias.
Moderation API is a tool that automatically checks whether text is safe and appropriate. Specifically, it is an endpoint API developed by OpenAI to detect policy violations in the outputs generated by large language models. It allows for the categorization of violent, emotionally charged, and sexual elements in sentences produced by either LLMs or humans. The system calculates a confidence score for each category, ranging from 0 to 1. Technically, OpenAI’s moderation API (
https://platform.openai.com/docs/guides/moderation (accessed on 1 May 2025)) is a tool used to identify and prevent inappropriate or dangerous content in the generated sentences. It includes the following categories: hate, hate/threatening, harassment, harassment/threatening, self-harm, self-harm/intent, self-harm/instruction, sexual, sexual/minor, violence, and violence/graphic. OpenAI’s moderation calculates whether the input sentence violates a category and calculates the extent to which the sentence falls into a category. In this study, we compared the number of moderation violations in summaries provided by the New York Times and summaries provided by ChatGPT, as well as the word composition of each summary, to show that summarizing using ChatGPT is less biased than human summarization.
4. Results and Discussion
Our approach involves two primary steps. Initially, we calculated and compared the BERTScore between the summary derived from the original New York Times article and that generated by ChatGPT. This analysis was supplemented by case studies that underscored the comparison results obtained. Subsequently, we turned our attention to the assessment and comparison of bias within the summaries of the original New York Times articles and those produced by ChatGPT. Case studies were presented to highlight and elucidate the outcomes of this comparative analysis.
The quantitative results demonstrate that ChatGPT outperforms T5 in semantic similarity to human-written summaries, as confirmed by statistically significant differences across all BERTScore metrics (Precision, Recall, and F1-score). This performance advantage may be attributed to ChatGPT’s underlying moderation-driven generation process, which inherently filters out violent or emotionally charged language. As a result, ChatGPT produces summaries that are more objective, fact-centered, and aligned with content moderation standards.
Furthermore, ChatGPT-generated summaries tend to avoid subjective or biased expressions often present in human-written summaries, particularly in politically or emotionally sensitive contexts. This contributes to higher moderation compliance and a more neutral tone overall.
However, several limitations must be acknowledged. First, ChatGPT may struggle with understanding cultural context, figurative language, or rhetorical nuance, which can lead to summaries that are factually correct but semantically shallow. Second, as a black-box model, ChatGPT does not provide transparency regarding its internal decision-making processes, making it difficult to verify or interpret how certain summarization choices are made. Third, since ChatGPT relies on OpenAI’s Moderation API to filter outputs, the moderation standards themselves—being proprietary and subject to change—introduce potential variability in outputs over time. This poses a reproducibility concern for studies or applications dependent on such moderation signals.
These findings highlight both the promise and the constraints of using large language models for automated summarization, especially in high-stakes domains like journalism.
4.1. Comparison Between Summary Sentences by NYT and ChatGPT
In this study, we employed the T5 model developed by [
57] to evaluate the performance of summary generation in comparison with ChatGPT. This involves contrasting the summaries produced by The NYT with those generated by both ChatGPT and T5.
The T5 model, proposed by Google, is a general-purpose natural language processing framework that unifies various language tasks by formulating them as a text-to-text problem. In contrast to ChatGPT, which adopts a decoder-only architecture, T5 is based on a Transformer encoder-decoder structure, enabling it to handle a wide range of tasks—such as translation, summarization, and question answering—within a single, consistent framework.
Studies have demonstrated that the T5 model excels at text transformation and outperforms various other models in generating summaries. It has shown superiority over models such as BART and ProphetNet in abstract summarization tasks, as well as greater efficiency compared to RNNs and LSTMs for news text summarization [
58,
59]. Moreover, T5 surpasses other pre-trained models such as BERT and GPT-2 in general natural language processing tasks [
60].
Studies have demonstrated its superiority over BART and ProphetNet for abstract summaries as well as its efficiency in surpassing RNNs and LSTMs for news text summaries [
58,
59]. Moreover, T5 surpasses pre-trained models such as BERT and GPT-2 in natural language processing [
60].
Through this comparative approach, we aimed to gauge the summary generation performance of the GPT model relative to the alternative models. In addition, we employed BERTScore to calculate the similarity between the NYT summary and both the ChatGPT and T5 summaries. This comparative analysis allowed us to assess the degree of similarity between the summaries produced by the ChatGPT (GPT 3.5) and T5 models and those provided by The New York Times.
Table 2 lists the basic statistics of the BERTScore Precision, Recall, and F1-score results for each summary. Based on the maximum, average, and minimum values of Precision, Recall, and F1-score, ChatGPT demonstrated greater similarity to the NYT summary than T5 across all three indicators. The high similarity between ChatGPT and NYT summaries is evident from their values approaching 1 for all three indicators, indicating a highly congruent summary generation. Furthermore, considering the standard deviation of these indicators, we inferred that ChatGPT consistently provided summaries that were more closely aligned with NYT summaries than those generated by the T5 model.
As shown in
Table 3, the independent two-sample
t-tests conducted to compare BERTScore metrics between ChatGPT and T5 yielded statistically significant results in all three metrics: Precision (
), Recall (
), and F1-score (
). Furthermore, the 95% confidence interval for the mean difference in Precision between ChatGPT and T5 ranged from 0.0202 to 0.0227, indicating that ChatGPT achieved a significantly higher performance of approximately 2.02% to 2.27% relative to T5. These findings robustly demonstrate the quality of the ChatGPT summary compared to T5, emphasizing the statistical reliability and significance of the observed differences.
Moreover, we conducted an in-depth analysis of the case studies that exhibited the highest and lowest F1-score values.
Table 4 and
Table 5 present the best and worst cases and the original article information for both cases. In the best-case scenario, it is apparent that the NYT summaries and those generated by ChatGPT are either aligned closely or are identical. Conversely, in the worst-case scenario, NYT summaries often echo the biases present in the news articles. Notably, the worst-case NYT summary adopted a critical tone, employing terms such as “brazen”. By contrast, summaries generated by ChatGPT tend to extract and synthesize information neutrally from the text. Consequently, when the original news content contains biases, particularly in political contexts, the similarity between human-generated and model-generated summaries may diminish because of inherent human biases and the impartial nature of ChatGPT. Conversely, if the original news content lacks biased elements, the similarity between the human- and model-generated summaries may increase significantly.
The problem of bias in the LLM has existed for a long time [
24,
61,
62]. The task of summarizing news is to extract and summarize a given text. If the news text is already biased, the summary is likely to be biased as well. However, as shown in this
Table 4, the New York Times used the word “militants” and ChatGPT used “Taliban”, indicating that ChatGPT summarizes more factually than the human summarizer. In other words, this study showed that, even with biased news, summaries generated by ChatGPT are less biased than those generated by humans. Consequently, in assessing the summarization process undertaken by ChatGPT, we investigated whether ChatGPT tended to utilize more objective expressions than human summaries. This examination was conducted using the moderation validation test provided by OpenAI.
4.2. Moderation Test for the Summaries by NYT and ChatGPT
Table 6 presents the summaries in cases where both summaries violated moderation and when only the New York Times summary violated moderation. In instances where both summaries infringed moderation, the category of violation was violence, attributed to the simultaneous use of words like “beheaded” and “severed”. Despite this, both the ChatGPT and NYT summaries remained similar, as they encapsulated factual information that was challenging to paraphrase. Conversely, in cases where only the NYT’s summary violated moderation, terms like “con man” and “troublemaker” were employed to criticize a specific individual. However, the ChatGPT summary filtered out direct criticism to deliver a succinct account of the events described in the news text. For example, in the case of “Surgeons Labored to Save the Wounded in El Paso Mass Shooting”, the NYT’s summary conveyed the tense atmosphere without providing specific details, whereas ChatGPT’s summary precisely outlined the events while filtering out violent language.
Consequently, the likelihood of the NYT’s summary violating OpenAI’s moderation is higher than that of the ChatGPT’s summary. This suggests that ChatGPT is more adept at filtering out violent or biased expressions during sentence generation, focusing instead on summarizing objective facts.
We also examined whether the original text of the summary violating moderation also exhibited moderation violations.
Table 7 displays the titles of the articles in which the New York Times summary violated moderation. In one instance, the main body of a news article dated 18 October 2018, received a moderation violence score of 0.3, indicating the absence of violence within the article. However, both the NYT and ChatGPT summaries scored significantly higher at 0.8 and 0.9, respectively, suggesting the inclusion of more violent sentences in the summaries than in the body of the article.
Conversely, in a news article published on 30 July2019, the disgust score was 0.02, signifying an absence of disgust-inducing content. The New York Times summary obtained a disgust score of 0.498, whereas the ChatGPT summary scored 0.001. This discrepancy highlights the higher aversive score in the human-summarized sentence compared to the model-generated sentence. Additionally, in an article from 10 August 2019, with a violence score of 0.5, indicative of moderate violence, the New York Times summary generated a sentence with a violence score of 0.99, whereas ChatGPT produced a nonviolent summary with a violence score of 0.14.
These examples illustrate the two distinct scenarios. Firstly, when words from the news article are verbatim in the summary, as seen in the first case, the violent nature of the sentence may persist if words like “severed” and “beheaded” are directly summarized. Second, when violence in news text is filtered and summarized into new sentences, as demonstrated in the second and third cases, the summaries tend to describe events rather than accusatory language. Consequently, filtering out negative-impact words in the summary reduces the likelihood of misunderstanding or the formation of preconceived notions.
However, the moderation API of OpenAI utilized in this study has a black-box nature in that the parameters and moderation criteria used internally are determined by OpenAI’s internal policies, and this process is not disclosed to the outside world. It is also worth mentioning as a limitation that OpenAI can arbitrarily change the criteria and parameters of the Moderation API at any time, which may cause unexpected bias in future ChatGPT-based summarization systems. Therefore, when applying ChatGPT-based automated summarization systems in practice, it is recommended to recognize the possibility of changing the criteria of the Moderation API and perform periodic checks and additional supplementary evaluations.
5. Discussion and Concluding Remarks
In this study, we utilized ChatGPT to generate news summaries from journalist-provided articles and compared them with original summaries using BERTScore. The analysis yielded an F1-score of 0.87, indicating substantial similarity. Notably, ChatGPT incorporated sentences from periods that were not pretrained, suggesting adaptability for future summaries. In addition, employing OpenAI’s moderation API revealed that journalist-written summaries exhibited more moderation violations, potentially because of their use of violent or hazardous language. By contrast, ChatGPT-generated summaries maintain a focus on events without resorting to language that voilates moderation criteria. This finding suggests that ChatGPT is adept at producing moderation-friendly news summaries.
The main results of this study are twofold.
First, by employing ChatGPT, we conducted a summarization task on news texts utilizing New York Times data up to 2022. Our analysis indicated a performance akin to that of human summarization, as evidenced by the close-to-unity BERTScore between the reference and ChatGPT-generated summaries. Notably, prior studies have often utilized datasets predicting 2021, such as CNN/DM, XSum, and Newsroom [
63,
64,
65], comprising news texts and reference summaries.
Second, in our exploration of ChatGPT-generated news summaries, we observed a tendency for ChatGPT to employ words from the text verbatim, while avoiding the direct usage of violent or emotionally charged language. It is noteworthy that ChatGPT tends to mitigate the biases inherent in news events rather than merely altering wording. For instance, when a politician employs an overly simplistic term to denounce another individual in the news text, the ChatGPT-generated summary omits the derogatory term, focusing solely on the act of criticism by the politician. This finding underscores the potential of ChatGPT-generated summaries to exhibit reduced bias and extremism compared with human-generated summaries, which can vary depending on the author’s perspective and the information being conveyed. Consequently, our study suggests that ChatGPTs may possess the capability to moderate and diminish extreme expressions more effectively in summary generation than their human counterparts.
Finally, when using automated summarization tools such as ChatGPT in news contexts, ethical concerns related to trust, misinformation, and bias can arise. ChatGPT-generated summaries may occasionally produce hallucinations or unintentionally reflect biases present in their training data, potentially affecting the accuracy and objectivity of news reporting. Additionally, unclear accountability for errors or biased outputs may negatively influence audience trust. Therefore, clear accountability guidelines and careful oversight are necessary when integrating automated summarization into journalism.
The implications of these results are as follows:
Our study underscores that news summaries generated by ChatGPT exhibit a high degree of contextual similarity to summaries derived directly from the original news text. This corroborates the findings of prior studies [
24,
27,
66], indicating ChatGPT’s proficiency of ChatGPT in news summarization. Notably, when evaluating the contextual similarity between summaries produced by ChatGPT and those of the New York Times, a prominent international daily, using BERTScore, we observed an F1-score exceeding 0.87, signifying a high level of resemblance. This suggests a substantial advancement in the summarization capabilities of large language models approaching human performance. Furthermore, our study indicates that ChatGPT’s commendable performance in news summarization may be attributed to its pretraining on extensive news data. In addition, the existing literature suggests that the quality of output can vary based on prompt utilization, hinting at the potential for further refining summary generation to align more closely with reference summaries [
19,
25].
Second, leveraging ChatGPT for summarization presents the advantage of mitigating moderation issues. Previous studies demonstrated ChatGPT’s efficacy in simplifying sentences to reduce bias and harmful language [
36]. In the context of news summarization, where objectivity is paramount and summaries shape public perception, the avoidance of biased or inflammatory language is crucial. Words employed in summaries can influence reader perceptions and sentiment analysis outcomes. Our study revealed that the ChatGPT-generated summaries tended to filter out violent or harmful language present in the original text, albeit without consistently using completely neutral language. Nevertheless, existing research highlights persistent biases in language generation based on gender and political orientation, likely stemming from the underlying training data [
37,
38]. Despite these challenges, appropriately formulated prompts offer a potential avenue for reducing bias and extremism in generated summaries [
25].
Our study proposes various potential applications based on these findings, particularly within the journalism industry. Given that ChatGPT-based summaries demonstrate high semantic similarity and reduced bias compared to human-written summaries, they can serve as editorial aids by minimizing unnecessary manual effort in the news summarization process. Moreover, they can function as moderation filters to detect and mitigate subjective emotions or biases that may be unconsciously introduced by human editors. This dual functionality offers substantial benefits in enhancing both the efficiency and objectivity of news production.
Nonetheless, despite these advantages, human oversight remains essential. Especially in media organizations that hold the power to shape public perception and values, it is critical to guard against potential misuse of AI systems. LLMs like GPT are vulnerable to biases embedded in their training data, and since such models are developed and operated by external entities (e.g., OpenAI), the risk of unintended bias persists. Therefore, media organizations should establish and adhere to rigorous ethical standards and implement bias auditing processes when integrating AI-based summarization systems, ensuring responsible and transparent use.
Under these conditions, the automatic summarization system proposed in this study can serve as an effective tool for improving summarization efficiency and enhancing content quality in the journalism industry.
The limitations of this study and avenues for future research are outlined below.
First, as discussed earlier, our study found that ChatGPT-generated summaries tended to reduce the bias present in the original text, as evaluated through the Moderation API. However, bias can still persist depending on the design of the prompts and the characteristics of the training data used for LLMs such as GPT. Such biases, whether implicit or explicit, have the potential to influence the outcomes of summarization tasks. Therefore, future research should not be limited to simple numerical comparisons using moderation APIs, but should develop more sophisticated methods to detect, measure, and mitigate these biases. Moreover, investigations should be expanded to encompass the ethical implications of AI-generated journalism, including how AI-generated content may influence public opinion, reinforce stereotypes, or introduce unintended biases.
Furthermore, our study utilized ChatGPT for news summarization through zero-shot generation. Given the known impact of prompt design on summary quality, future research should explore the influence of prompt design parameters on summarization outcomes.
Second, our analysis focused solely on articles from The New York Times for summary generation and comparisons. Restrictions on news articles necessitate future research exploring summary generation and comparisons across diverse text corpora, including books, research papers, and professional descriptions. Moreover, beyond English-language texts, future studies should also investigate cross-linguistic comparisons to evaluate the generalizability and robustness of ChatGPT-generated summaries across different languages and cultural contexts.
Third, as the application of ChatGPT continues to specialize across various fields, our summarization and evaluation system could similarly be extended by utilizing fine-tuned models tailored to specific domains such as healthcare, education, and others. Furthermore, conducting a comparative analysis of various LLMs such as Claude and Gemini can help elucidate performance differences across models. Integrating explainability tools like LIME and SHAP would also be a significant direction for future research, as they can provide deeper insights into the causes of moderation flags or inconsistencies in similarity scores.
Finally, a potential future research direction involves conducting sentiment analysis on summaries generated by ChatGPT. Comparing the sentiment analysis results between media-provided and ChatGPT-generated summaries can elucidate the summarization capabilities and limitations of ChatGPT. Furthermore, the reliability of ChatGPT can be assessed by scrutinizing the consistency of the sentiment-analysis outcomes between the two sets of summaries. In addition, we propose a study on the hallucinogenic symptoms that occur when ChatGPT generates text. In other words, it is worth considering further study to investigate and analyze the hallucinogenic symptoms that may occur when ChatGPT generates a summary.







{kind=link}
{kind=link}
{kind=link}
{kind=link}