1. Introduction
Human Pose Estimation (HPE) is a critical subfield of Computer Vision (CV) focused on locating and connecting human body joints, i.e., keypoints, in images or video sequences. Accurate pose estimation enables machines to analyze human posture and motion, facilitating a wide range of applications, including video surveillance, human–computer interaction, medical rehabilitation, and autonomous driving [
1]. Despite significant advancements in deep learning (DL) and convolutional neural networks (CNNs) [
2], HPE continues to face several core challenges. These include scale variation, where subjects can appear at vastly different resolutions, the occlusion of keypoints by objects or other individuals, and stringent computational requirements that frequently hinder real-time deployment [
3,
4].
Early approaches relied on hand-crafted features combined with probabilistic models, offering interpretability but limited accuracy in complex scenarios, such as occlusions, varied lighting conditions, and cluttered backgrounds [
5]. The emergence of CNNs significantly improved feature extraction capabilities. For instance, the pioneering work of DeepPose directly regressed keypoint coordinates but struggled with stability in multi-modal distributions [
4]. Subsequently, heatmap-based methods emerged, transforming coordinate regression into spatial heatmap prediction, notably improving robustness and accuracy. Approaches such as Stacked Hourglass Networks [
6] and SimpleBaseline [
7] refined heatmap-based architectures, although at the expense of increased computational overhead due to complex upsampling procedures.
To reduce these computational demands while maintaining accuracy, High-Resolution Networks (HRNets) preserve spatial resolution throughout the network, significantly improving precision, albeit with substantial computational complexity [
8]. Recognizing this trade-off, transformer-based models such as HRFormer [
9], TokenPose [
10], and ViTPose [
11] leveraged global self-attention mechanisms, enabling more accurate keypoint estimation by modeling global contextual relationships. However, these approaches often introduced even greater computational complexity and parameter demands, making practical deployment challenging.
To address these efficiency challenges, coordinate classification approaches have recently emerged, such as SimCC [
12], reformulating keypoint localization as a discrete classification task, significantly reducing the quantization errors inherent in heatmap-based methods. Building on this paradigm, AECA-PRNetCC further enhanced performance by incorporating adaptive channel attention mechanisms, thereby achieving a balance between accuracy and computational efficiency [
13].
Despite these improvements, two major issues persist. Firstly, most advanced methods face a fundamental accuracy–computation trade-off, as higher accuracy typically demands greater computational complexity, complicating real-world deployment. Secondly, existing approaches still suffer from precision limitations in localizing keypoints under occlusion or scale variations, partly due to ineffective local feature refinement and global contextual reasoning capabilities.
In response, we propose AMFACPose (Attentive Multi-scale Features with Adaptive Context PoseResNet), a novel framework designed to address these challenges in 2D HPE. Our model begins with a ResNet structure [
14], which we modified by replacing the standard convolution layers with Coordinate Convolution 2D (CoordConv2d) [
15] to preserve explicit spatial coordinates, as well as by removing the average pooling and fully connected layers. This design retains the model’s feature-extraction capabilities while reducing computational overhead. We also replace the standard 7 × 7 convolution in the initial layer with a series of 3 × 3 CoordConv2d layers, each followed by Batch Normalization (BN) and Mish activation, thereby improving the model’s ability to capture fine-grained features. Furthermore, throughout the four stages of ResBlocks, we employ Depthwise Separable Convolutions (DSCs) [
16] to further reduce computational costs without compromising accuracy, separating spatial and pointwise operations into distinct phases.
A key component of our design is the Adaptive Feature Pyramid Network (AFPN), which replaces computationally expensive deconvolution-based upsampling with an efficient multi-scale feature fusion strategy. By aggregating feature maps at different resolutions, AFPN ensures the robust handling of diverse poses and body sizes without incurring the high overhead of traditional upsampling layers. Building on the AFPN, we introduce Dual-Gate Context Blocks (DGCBs) to refine global contextual information, which is essential for managing occlusions and cluttered backgrounds. To further enhance feature representation, our approach incorporates Squeeze-and-Excitation (SE) blocks and a Spatial–Channel Refinement Module (SCRM). SE adaptively recalibrates channel-wise feature responses, while SCRM simultaneously optimizes spatial and channel dimensions, amplifying critical cues. This collaboration of multi-scale aggregation, global context gating, and attention-based refinement significantly improves the visibility of obscured or overlapping joints, ultimately producing more accurate and efficient pose estimation. We adopt a coordinate classification approach instead of generating dense heatmaps. Specifically, each joint’s feature representation is passed through Multi-Layer Perceptron (MLP) heads that output discrete horizontal and vertical coordinate estimates, alleviating the quantization errors typical of heatmap-based pipelines and removing the memory and computational overhead required for large-scale heatmap generation and post-processing. This design preserves localization precision while reducing both model size and inference latency. Unlike previous coordinate classification approaches such as SimCC and AECA-PRNetCC, our AMFACPose model uniquely combines explicit spatial awareness through CoordConv2d, multi-scale feature fusion via AFPN, and dual-path attention mechanisms, delivering superior accuracy while maintaining low computational cost, making it highly suitable for real-time deployment in resource-constrained environments.
The following three fundamental contributions emerge from this work:
We propose a modified ResNet backbone that replaces the standard convolutions with CoordConv2d and DSC, reducing computational overhead while preserving strong feature extraction capabilities. To further elevate feature quality, the backbone incorporates SE blocks and an SCRM, adaptively enhancing critical regions and channels, which is particularly valuable for partially visible or overlapping keypoints.
To eliminate costly deconvolution-based upsampling, we introduce an AFPN that efficiently aggregates multi-scale feature maps. Building on the AFPN, DGCBs refine global context, ensuring the robust handling of scale variations, cluttered backgrounds, and complex human poses across varying resolutions.
We validate our AMFACPose model on the COCO and CrowdPose datasets, achieving notable improvements in both accuracy and efficiency over the existing methods. Moreover, our model performance on edge devices demonstrates the practicality of these design choices for deployment in diverse, resource-constrained settings.
The remainder of this paper is organized as follows:
Section 2 reviews the key developments in HPE, situating our work within the existing literature.
Section 3 introduces the proposed AMFACPose framework, detailing each of its core components, including the modified ResNet backbone and the AFPN with DGCBs.
Section 4 explains the experimental setup, datasets, and implementation specifics.
Section 5 presents our empirical findings, comparing them against SOTA methods on benchmarks such as COCO and CrowdPose. We also discuss the performance of our model on edge devices in
Section 6 and provide ablation studies in
Section 7 to isolate the contributions of each architectural component. Finally,
Section 8 concludes the paper by summarizing our primary insights and suggesting directions for future research in resource-efficient and high-accuracy 2D HPE.
2. Related Work
DL has substantially transformed 2D HPE by automating feature extraction, leading to improvements in both accuracy and computational efficiency. Early research explored regression-based methods for direct keypoint coordinate prediction. Although these approaches initially faced consistency challenges, the Residual Log-likelihood Estimation (RLE) [
17] achieved good performance comparable to leading heatmap-based techniques. However, these methods continue to face challenges in handling scale variations and occlusions.
A significant development in 2D HPE occurred with the adoption of two-dimensional Gaussian heatmaps for joint localization. Initially transforming the coordinate prediction task into heatmap generation [
18], these methods achieved greater stability. Further progress came from architectures like the Stacked Hourglass Network [
6], which utilized symmetric encoder–decoder structures with repeated pooling and upsampling to capture multi-scale features. However, heatmap-based methods can suffer high computational costs due to the requirement for dense heatmaps, large upsampling layers, and post-processing operations such as non-maximum suppression. To alleviate these burdens, FasterPose [
19] introduced a more streamlined design, while Dense layer and Identity block Parallel Network (IDPNet) [
20] implemented lightweight architectural choices targeted toward resource-constrained deployments.
Despite the accuracy benefits of heatmap-based approaches, quantization errors remain a persistent issue. These errors arise from discretizing joint locations onto the heatmap’s pixel grid, which can reduce precision as resolution declines. Various minimization techniques have been proposed, including Taylor expansion [
21] to refine predictions around the heatmap peak response, and one-dimensional heatmaps [
22], which compress spatial dimensionality without sacrificing localization quality. Furthermore, recent work highlights the role of unbiased data processing in reducing systematic bias [
23]. Attention mechanisms, whether spatial and channel-based, also help address occlusions and cluttered scenes. Examples include spatially oriented channel attention for better joint discernment [
24] and adaptive efficient channel attention for refined feature recalibration [
13].
Given the rising demand for real-time and mobile HPE applications, a critical line of research focuses on designing computationally efficient, accurate architectures. While high-resolution representation learning [
8] preserves spatial detail throughout the network, it often leads to significant memory overhead. For instance, SimCC [
12] reframed HPE to be compatible with both CNN and Transformer architectures, eliminating the need for dense heatmap predictions. Building on this, A. Zakir et al. [
25] proposed an efficient bridge attention integration mechanism that enhances feature representation while maintaining computational efficiency.
An important and emerging direction in HPE focuses on confidence score calibration and keypoint visibility estimation for robust occlusion handling. Jiang et al. [
26] introduced HPCVNet, which jointly calibrates confidence scores and explicitly classifies keypoint visibility, achieving a mAP of 77.6 on COCO. In contrast, our method adopts an implicit occlusion-handling strategy using attention-driven modules such as AFPN and DGCB. Without requiring auxiliary visibility branches, AMFACPose achieves 76.6 mAP on COCO and demonstrates strong performance on occlusion-heavy benchmarks such as CrowdPose. These strategies reflect a distinct approach to handling partial visibility and overlapping joints in 2D pose estimation.
Building on these developments, we propose AMFACPose, a unified and lightweight pose estimation framework. Unlike heatmap-based pipelines, AMFACPose employs a coordinate classification strategy, avoiding deconvolution layers, dense heatmaps, and post-processing stages. This design achieves a practical balance between high localization accuracy and computational efficiency, making it well suited for real-world applications constrained by latency, memory, and power.
3. AMFACPose
In 2D HPE, the task is to determine the spatial configuration of human body joints, i.e., keypoints, within an RGB image or video frame [
27]. Let the pose
be represented by
N keypoints, each defined by a 2D coordinate
. For instance,
in the COCO dataset [
27]. Formally, for each individual in the input, the goal is to estimate:
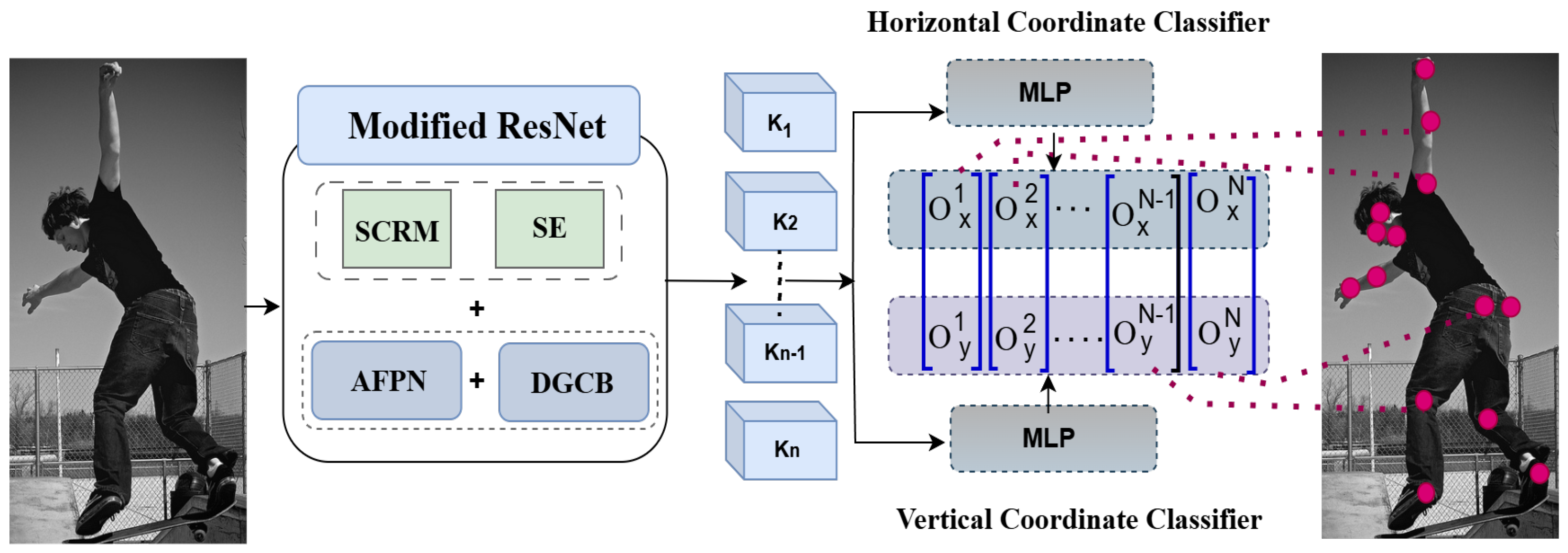
To address the challenges of occlusion, scale variation, and excessive computational overhead, we propose AMFACPose as illustrated in
Figure 1. Our approach uses a ResNet34 backbone [
14] that we modified by integrating CoordConv2d [
15] and DSC [
16], producing an efficient feature extractor that maintains strong spatial representation. Within this backbone, we incorporate attention modules—SE blocks [
28] and an SCRM—to highlight keypoints, relevant channels, and local features, ensuring robust performance under partial occlusions or complex scenes. Next, AFPN fuses multi-scale features extracted from the backbone, retaining both global context and fine-grained details. We then refine these fused features using DGCBs, which selectively enhance relevant contextual information while suppressing background noise. Finally, instead of the commonly used heatmap-based and regression-based approachs, AMFACPose utilizes coordinate classification, thereby avoiding the computationally intensive generation of dense heatmaps and simplifying the inference pipeline. The subsequent sections provide an in-depth exploration of each component, illustrating how AMFACPose successfully balances efficiency with accurate and robust keypoint localization.
3.1. Modified ResNet Backbone
Recent pose estimation frameworks, such as HRNet [
8], Simple Baseline [
7], and Stacked Hourglass Networks [
6], preserve high-resolution feature representations to achieve precise body–joint localization. Although these high-capacity models attain competitive accuracy, they typically demand substantial computational resources, limiting real-time deployment on edge devices. Vision Transformers [
29] likewise exhibit strong performance but often face latency challenges due to expensive self-attention operations.
To balance representational power and computational efficiency, we adopt ResNet34 as our backbone. Compared with deeper variants like ResNet50 or ResNet101, ResNet34 retains the skip connections essential for stable gradient flow [
30] yet lowers parameter counts and FLoating-point OPerations (FLOPs). This design offers fine-grained feature extraction necessary for accurate joint detection without incurring prohibitive overhead.
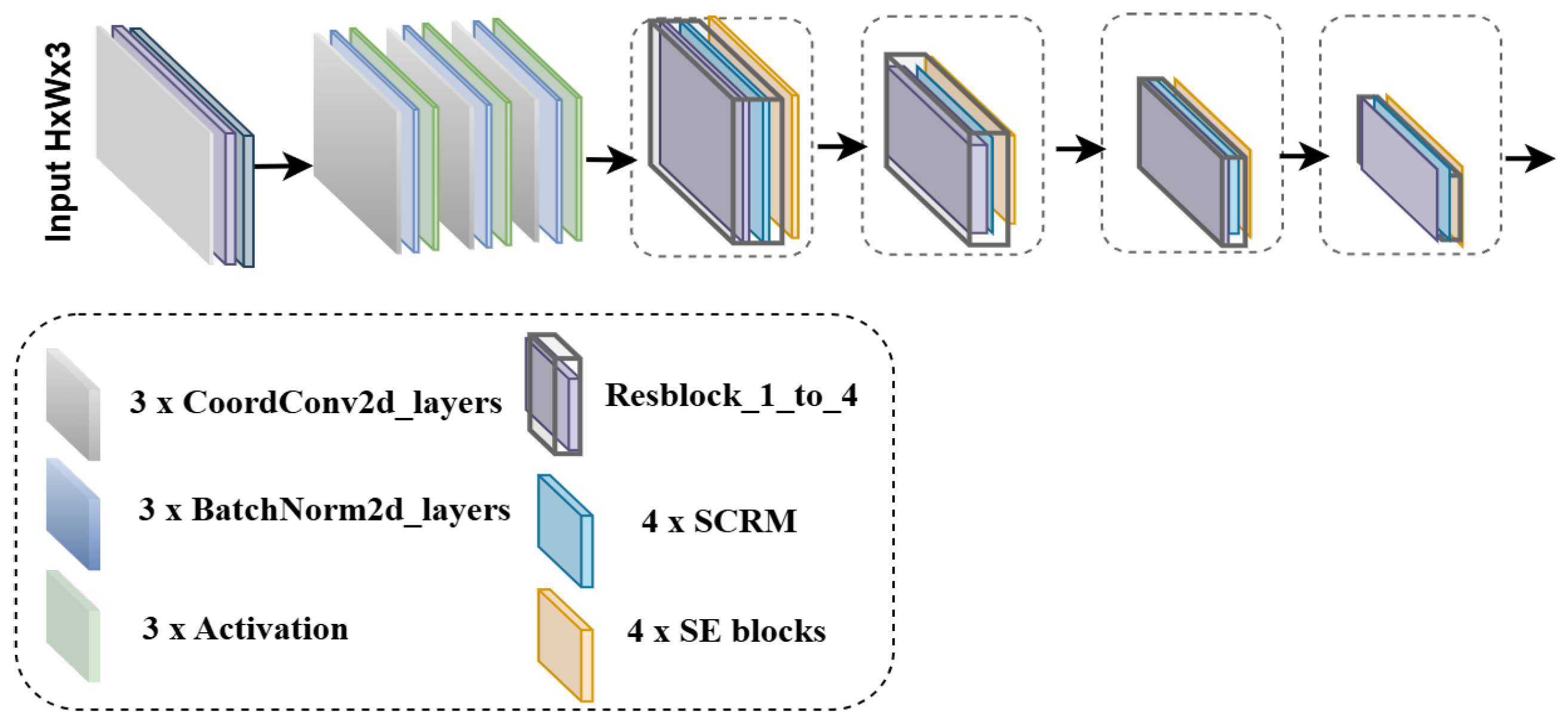
Figure 2 presents an overview of our modified ResNet34 architecture. We remove the final average pooling and fully connected layers, preserving spatial detail in deeper stages and allowing subtle body part cues to remain accessible. Furthermore, the standard
input convolution is replaced by a sequence of
convolutions interleaved with CoordConv2d. Each basic block of the ResNet34 is also enhanced with DSC to reduce computational complexity while maintaining expressive capacity. This modified backbone thus strikes a favorable balance between accuracy and real-time feasibility, serving as the foundation for AMFACPose.
3.1.1. Integration of CoordConv2d for Enhanced Spatial Awareness
The network’s initial stem, as shown in
Figure 2, incorporates CoordConv2d to embed explicit spatial features at the earliest stage. Let
denote the input tensor, where
B is the batch size,
C is the channel count, and
are spatial dimensions. We first construct normalized coordinate grids
, providing a consistent reference frame for each pixel location. Four learnable parameters
then adaptively scale and shift these coordinates, as follows:
After concatenation, a standard convolution processes both the original feature maps and these position-aware channels in tandem.
Algorithm 1 summarizes the key steps of CoordConv2d. By retaining explicit spatial information, the stem ensures improved joint localization even under occlusions or viewpoint shifts. The learnable parameters
and
enable flexible adjustment to variations in scale and perspective.
| Algorithm 1 Coordinate-enhanced convolution layer |
- 1:
Input: Feature tensor - 2:
Output: Enhanced feature maps - 3:
Step 1: Coordinate Grid Initialization Initialize normalized grids . - 4:
Step 2: Learnable Parameters are updated by backpropagation. - 5:
Step 3: Coordinate Transformation , . - 6:
Step 4: Feature Concatenation . - 7:
Step 5: Convolution . - 8:
Step 6: Output return .
|
3.1.2. Depthwise Separable Convolutions for Efficiency
Maintaining spatial detail is crucial for pose estimation, yet computational efficiency is equally important for real-time systems. To address this, each Residual block in ResNet34 replaces the standard 2D convolutions with DSC. In the following equation, a depthwise step applies a unique spatial filter to each input channel:
where the total parameter count and FLOPs are significantly reduced. A subsequent
pointwise convolution integrates cross-channel information, as follows:
Within our Residual blocks, skip connections [
14] preserve gradient flow across these separable layers, retaining the ability to learn rich features. When downsampling is needed, e.g., for stride 2, a lightweight residual path aligns the input and output dimensions without adding substantial overhead. Integrating CoordConv2d-based positional encoding and DSC provides a streamlined expressive backbone, striking a strong balance between accuracy and speed. This backbone then serves as the basis for the subsequent modules in AMFACPose.
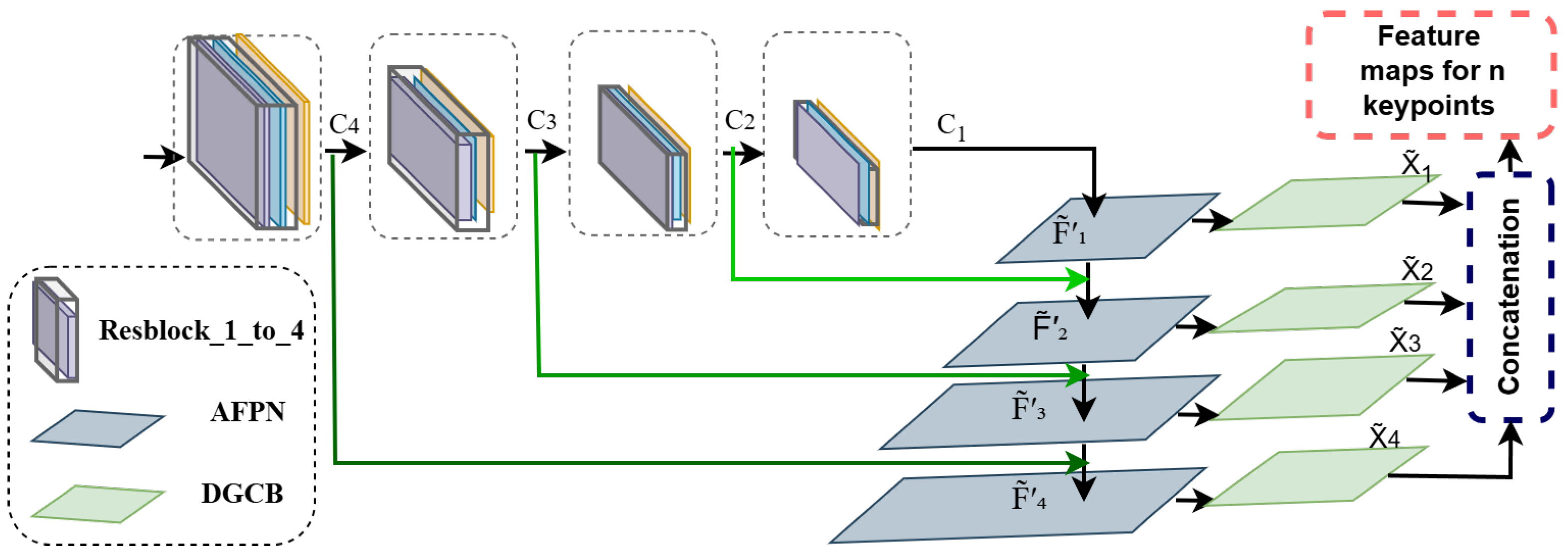
3.2. Adaptive Feature Pyramid Network (AFPN)
Multi-scale feature fusion is central to effective pose estimation, since body parts can appear at various scales and contextual features may span multiple receptive fields. Traditional approaches, including feature pyramid networks with top–down pathways [
31], often rely on deconvolution layers or complex lateral connections, which can amplify computational costs. To address this, we introduce an AFPN that unifies multi-scale representations while preserving critical spatial details, as illustrated in
Figure 3.
Let
be the feature maps produced by the modified ResNet34 backbone at consecutive stages, as shown in
Figure 3, each with a distinct resolution. A
convolution is applied to each
to standardize the channel dimension, as expressed in the following:
For each feature map
, we apply a DGCB (detailed in
Section 3.3) to generate a refined feature representation using two learnable masks—a context mask and a gating mask. Both masks are generated by small convolutional networks with trainable parameters. Formally, the DGCB’s refinement is represented as follows:
where the DGCB internally performs an element-wise multiplication between the input feature map and the context and gating masks, as further explained in
Section 3.3, Equation (11).
Both
and
are subsequently upsampled to match the spatial resolution of
, where the arrow operator
indicates bilinear interpolation, and
represents the height and width of
, as shown in the following:
Each feature map
is then modulated by its corresponding refined representation
, as follows:
where ⊙ denotes the element-wise product. The refined outputs from all scales,
, are concatenated and passed through a
convolution, as follows:
The bilinear upsampling in ensures all features share the same spatial dimensions, enabling their direct combination.
This operation fuses high-level semantics from deeper layers with localized details from shallower ones, producing a consolidated multi-scale feature tensor that captures both global context and fine-grained cues.
The AFPN utilizes bilinear interpolation rather than deconvolution to reduce complexity, and it employs our parameterized DGCB to selectively highlight informative features. This design yields a compact architecture well suited for real-time or resource-limited applications. The resulting multi-scale representation serves as a foundation for subsequent pose estimation modules, enabling more accurate keypoint localization under a broad range of poses and imaging conditions.
The use of bilinear interpolation for upsampling in the AFPN is guided by both theoretical rationale and empirical effectiveness. Bilinear interpolation provides a computationally efficient, parameter-free method for resizing feature maps, making it particularly attractive for real-time or resource-constrained scenarios. In contrast to deconvolution, which increases model complexity and may introduce checkerboard artifacts, bilinear interpolation performs deterministic, smooth upsampling without additional learnable weights.
In our design, the potential limitations of bilinear interpolation, such as information loss or aliasing, are addressed through two mechanisms. First, a
convolution (Equation (
5)) is applied before upsampling, which helps to suppress high-frequency noise and standardize channel dimensions. Second, the upsampled features are modulated by context-aware masks generated from DGCBs (Equation (
8)), which selectively enhance salient regions and suppress irrelevant or noisy activation. This combination preserves critical spatial cues while maintaining efficiency.
Unlike traditional Feature Pyramid Networks that rely on fixed top–down pathways for multi-scale feature fusion, the AFPN introduces several architectural enhancements for more effective scale handling beyond the computational advantages of bilinear interpolation. Conventional FPNs typically apply direct addition or fixed-weight fusion, which may overlook the relative importance of scale-specific features. In contrast, the AFPN integrates Dual-Gate Context Blocks that generate adaptive, context-aware masks to selectively emphasize the most informative features at each scale. Additionally, while traditional FPNs often fuse features sequentially, risking the dilution of fine-grained details from lower levels, the AFPN employs parallel aggregation followed by concatenation and fusion, preserving resolution-specific information. These distinctions collectively enable the AFPN to maintain strong keypoint localization performance across a range of object sizes and challenging visual conditions, while remaining efficient enough for deployment in resource-constrained environments.
3.3. Dual-Gate Context Blocks (DGCBs)
HPE frequently encounters ambiguities stemming from partial occlusions, multiple overlapping individuals, and cluttered scenes. Although previous strategies introduce GCBs or similar modules to incorporate scene-level features [
32,
33], most rely on a single attention mechanism that may not sufficiently separate background noise from body–joint features. In contrast, our proposed DGCB module learns two distinct masks, a context mask and a gating mask, that work together to refine feature representations and enhance joint localization.
Let
be the feature map at a particular scale. A Global Average Pooling (GAP) operation condenses this tensor to
. Two parallel sets of
convolutions with ReLU and sigmoid activations process this pooled descriptor, as follows:
where
and
denote ReLU and sigmoid activations, and
are separate trainable weights, where
c and
g represent the contextual and gated information.
Although both branches appear structurally similar, they learn to serve distinct functional purposes through several mechanisms. First, the weight parameters are initialized independently and updated separately during training, allowing them to evolve toward different feature spaces. Second, the multiplicative interaction in the final output creates complementary specialization between branches; the network benefits when each mask focuses on different aspects of the input features rather than learning redundant information. Through this design, the context branch captures high-level global semantics features, while the gating branch selectively filters these contextual features based on local activation relevance.
Both masks are broadcast to the shape
and applied element-wise to the input, as expressed in the following equation:
where ⊙ denotes element-wise multiplication.
Each scale in the AFPN incorporates a DGCB to refine features prior to the final fusion step. Although DGCBs add only two small 1 × 1 convolutions per scale, they minimally increase computational overhead while substantially boosting keypoint visibility under occlusions or complex backgrounds. Their design segregates global scene information from localized gating cues, fostering more resilient pose estimation in cluttered or overlapping scenarios. A schematic of the DGCB’s internal architecture, illustrating the context mask and gating mask flow, is provided in
Figure 4.
3.4. Attention Mechanisms: Squeeze-and-Excitation and Spatial–Channel Refinement
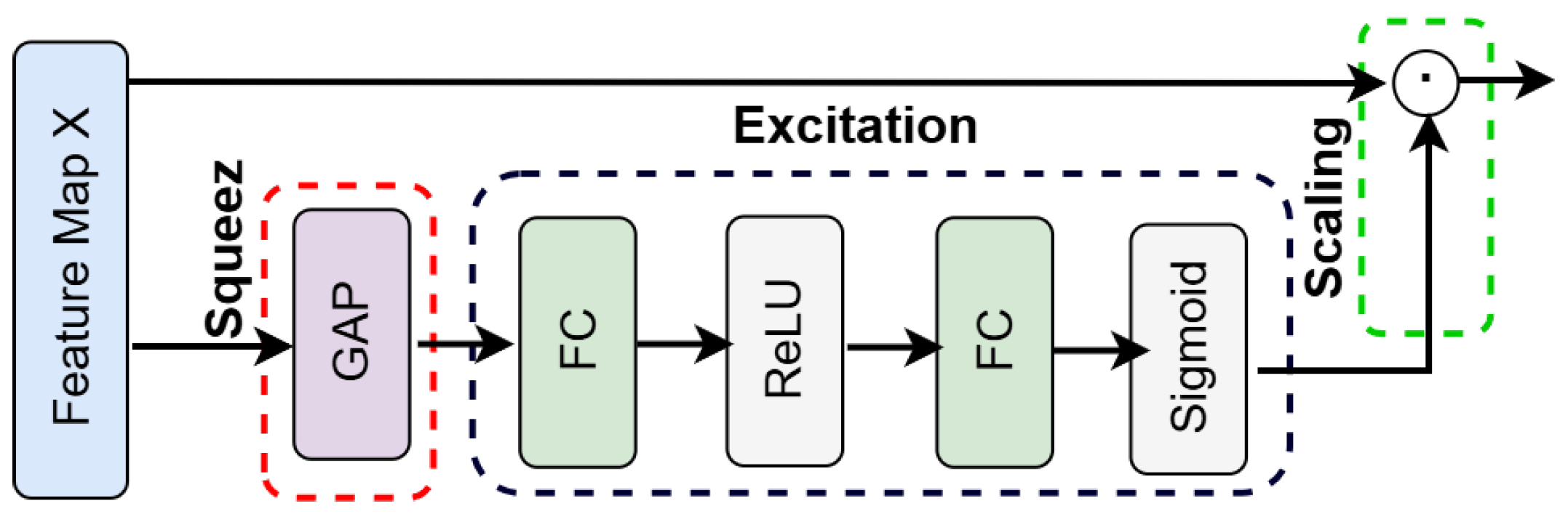
Channel- and spatial-level attention can enhance the discriminative power of convolutional backbones for HPE. The proposed architecture incorporates the following two supportive modules: the classical SE block [
28], which recalibrates feature channels globally, and a novel SCRM, which jointly emphasizes both channel and spatial dimensions. Although both modules utilize channel-wise weighting, their mechanisms differ fundamentally. SE blocks use a fully-connected bottleneck structure to capture global inter-channel dependencies, while the SCRM integrates a lightweight convolutional transformation for channel attention directly fused with spatial attention. These differences result in collaborative behavior during learning and inference.
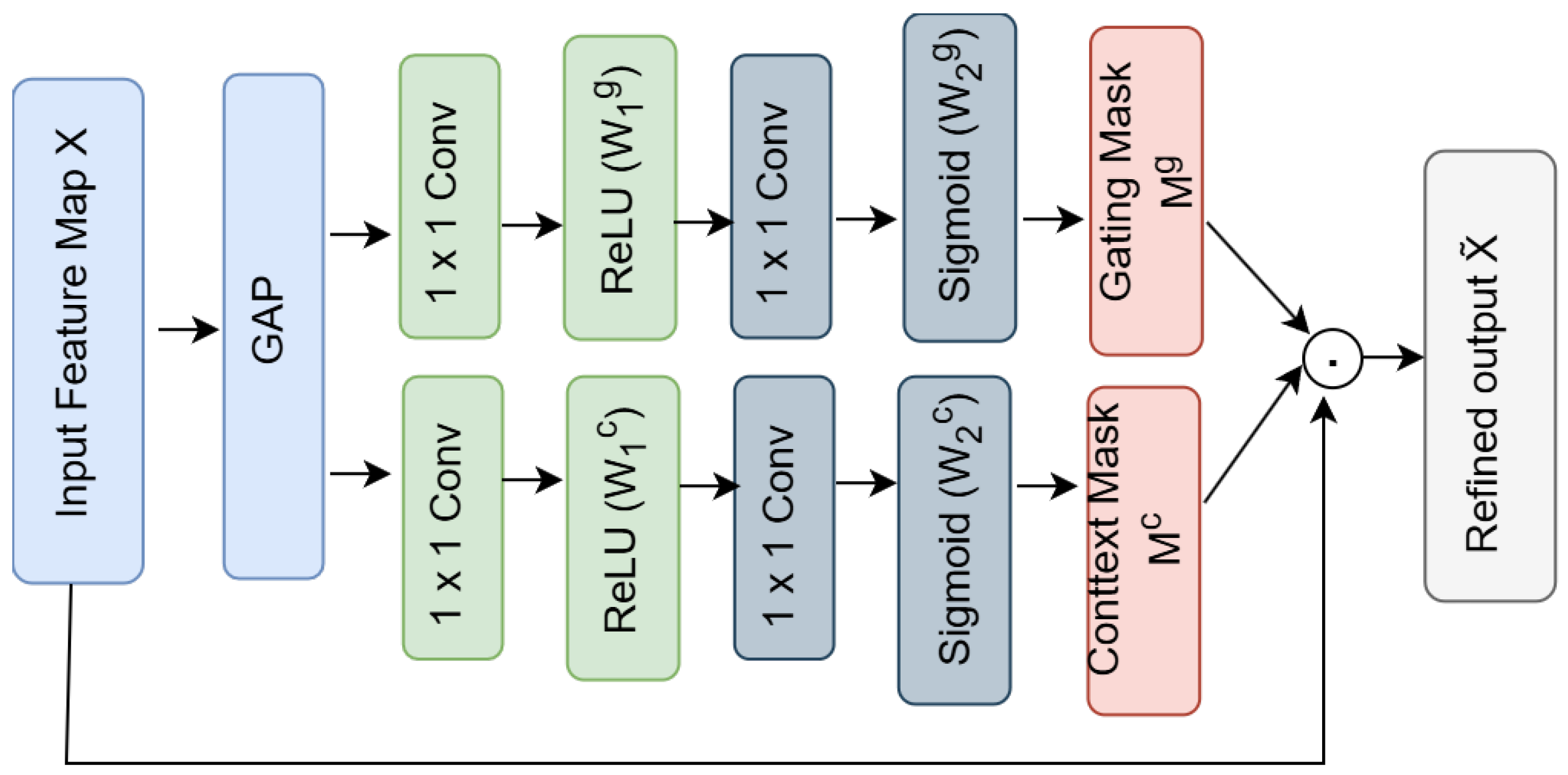
3.4.1. Squeeze-and-Excitation (SE) Blocks
Each SE block adaptively re-weights channels based on a global context vector [
28], effectively amplifying body part features and suppressing less relevant activations. Formally, let
be the incoming feature map. GAP yields
. A small fully connected (FC) network equivalent to
convolutions, equipped with ReLU and sigmoid activations, has parameters
, as expressed in the following:
where
and
denote the ReLU and sigmoid functions, respectively. The resulting channel attention vector
is broadcast and multiplied element-wise with
, as follows:
Integrating an SE block after each of the ResNet34 backbone’s four residual blocks ensures that channel refinements benefit from multi-scale global context.
Figure 5 visually summarizes the main steps of the SE module.
3.4.2. Spatial–Channel Refinement Module (SCRM)
While SE blocks excel at global-channel-level recalibration, local spatial dependencies are crucial for accurately locating body joints, especially under occlusions. Addressing this need, our novel SCRM provides a simultaneous refinement of both the spatial and channel dimensions through a dual-attention mechanism. Let
be the input feature map. An Adaptive Average Pooling (AAP) operation condenses
to
, which is then transformed into a channel attention vector by a 1D convolution, as shown in the following:
where
and
represent the sigmoid and BN functions, respectively. In parallel, a depthwise
convolution with BN and sigmoid activation extracts a spatial attention mask, as follows:
Broadcasting both
and
to
and multiplying them element-wise with
yields the following:
Although channel attention in SCRM is similar to SE, several critical distinctions differentiate their functionalities and effects. First, the channel attention generation differs architecturally. SE uses a bottleneck FC structure, compressing channel dimensions and modeling global inter-channel dependencies in a non-linear transformation, thereby capturing abstract relationships among the channels. In contrast, SCRM maintains the original channel dimensionality via 1D convolution, preserving channel-specific information without dimensionality reduction, thereby modeling simpler yet spatially aware channel relationships.
Second, the most significant distinction lies in the SCRM’s simultaneous integration of spatial attention, which SE blocks lack entirely. By coupling channel emphasis (
) with spatial filtering (
), the SCRM enables the network to focus on which feature channels matter and where within the spatial field they should be emphasized. This dual optimization is particularly beneficial for the accurate localization of joints under challenging conditions such as partial occlusions or complex human poses. Unlike sequential attention methods such as CBAM [
33], which apply spatial and channel attention independently in sequence, the SCRM fuses them in a single step for improved efficiency. Thus, the global channel recalibration of SE blocks and the combined spatial–channel refinement of the SCRM provide attention functionalities and collectively improve the robustness and accuracy of the model.
Figure 6 outlines the SCRM’s structure and highlights its combined spatial–channel approach.
3.5. AMFACPose Head and Coordinate Classification
Most HPE frameworks generate heatmaps for each joint and use peak-finding or regression to extract
coordinates, which can inflate memory usage and computational complexity [
7,
8,
24]. In AMFACPose, we replace heatmaps with a coordinate classification approach that directly predicts discrete
indices for each joint. This methodology reduces the overhead of creating high-resolution heatmaps, enabling efficient inference without compromising accuracy.
3.5.1. Final Feature Reorganization
After passing through the modified ResNet34 backbone, AFPN, and attention modules, i.e., DGCBs, SE, and SCRM, the network outputs a fused feature map
, where
B is the batch size,
C is the number of channels, and
denotes the reduced spatial dimensions. To enable per-joint classification, the channel dimension
C is reshaped into
, where
d represents an embedding size for each joint, as expressed in the following:
This transformation allocates a dedicated d-dimensional embedding for every joint at each spatial location, ensuring that subsequent classifiers can learn rich features specific to each keypoint.
3.5.2. Discrete Coordinate Classification
We discretize the continuous input space
into
and
bins along the horizontal and vertical axes, respectively, as follows:
where
is a scaling factor that controls the granularity of coordinate discretization. Each ground-truth joint coordinate
is mapped to a discrete location in
.
In our implementation, we adopt
, following the design choice proposed by Li et al. [
12]. This value achieves a strong balance between prediction granularity and computational efficiency. Larger values of
k lead to finer bins, which increase memory and computation requirements with limited benefit, while smaller values reduce model cost but introduce quantization artifacts that degrade localization precision.
For each joint
i, the reorganized feature
is fed into two MLPs equipped with Mish activation functions, as follows:
where
and
represent discrete probability distributions over the set of possible
x- and
y-bins. Algorithm 2 outlines this procedure.
| Algorithm 2 AMFACPose: keypoint estimation process |
Require:
RGB image I of size
Ensure: Predicted keypoint coordinates for N keypoints
- 1:
Feature Extraction: - 2:
Process I through the modified ResNet backbone to obtain fused feature map of size - 3:
Feature Reorganization: - 4:
Reshape to of size - 5:
Discretization Setup: - 6:
Let be the scaling factor - 7:
Set and - 8:
for
do - 9:
Horizontal Classification: - 10:
- 11:
Vertical Classification: - 12:
- 13:
end for - 14:
return Keypoint coordinates
|
By framing joint location prediction as a classification problem, AMFACPose streamlines the output space, bypasses large heatmaps, and simplifies post-processing. The MLP-based classifiers with Mish activations can learn complex spatial dependencies, ultimately leading to improved localization precision. This framework also reduce memory usage, making the model more suitable for real-time and resource-constrained scenarios.
3.6. AMFACPose Loss Function: KLDDiscretLoss
Conventional HPE often adopts Mean Squared Error (MSE) [
7] or L1-based losses, which assume continuous error distributions [
34]. However, in our coordinate classification framework, joint positions are discretized into bins along the
x- and
y-axes, rendering such regression-focused objectives less optimal. To address this discrepancy, we propose KLDDiscretLoss, a divergence-based criterion grounded in Kullback–Leibler Divergence (KLD) [
35]. By treating pose estimation as a classification problem, KLDDiscretLoss directly compares predicted probability distributions with discrete ground-truth distributions, thereby capturing the inherent uncertainties of joint positions.
A key advantage of KLDDiscretLoss is that it models probability distributions rather than point estimates. This perspective is particularly beneficial when joint locations are ambiguous due to scale variations, occlusions, or overlapping body parts. In order to refine the network’s confidence calibration, we incorporate two additional mechanisms—label smoothing [
36] and temperature scaling [
37]. Label smoothing allocates a small fraction of the ground-truth probability mass uniformly across all coordinate bins, preventing overfitting and minimizing cases where the network becomes overconfident in a single discrete location.
Temperature scaling, controlled by a parameter
T, modifies the softmax logits by
. When
, the resulting distributions become softer, reflecting higher uncertainty in the model’s predictions; when
, the distributions sharpen, forcing the network to commit more strongly to specific bins. The temperature value plays an important role in situations involving occlusion or pose ambiguity. A moderately sharpened output distribution encourages the model to focus on likely joint locations, improving spatial localization while still expressing uncertainty. In our experiments, we set
, which we found to provide a favorable trade-off between sharpness and calibration. This choice was guided by early empirical validation and is consistent with insights from a previous study on model calibration [
37]. It allows the network to remain confident in its predictions without becoming overly rigid or under-responsive in uncertain contexts, such as occluded joints.
Concretely, let
and
denote the predicted logits for
x- and
y-coordinates of the
i-th joint, and let
and
be the corresponding ground-truth distributions. A joint-specific weight
is assigned to emphasize harder-to-detect keypoints, such as hands or feet. The KLDDiscretLoss for the
i-th joint is given by the following:
where
and
convert the scaled logits into probability distributions. The total KLDiscretLoss is then computed as the mean across all
N joints, as follows:
Compared to regression-based losses such as SmoothL1 or MSE, KLDDiscretLoss offers a principled advantage under occlusion. Regression losses penalize deviations from ground-truth coordinates without accounting for uncertainty, which can result in overconfident and unreliable predictions for occluded or ambiguous joints. In contrast, KLDDiscretLoss allows the network to express uncertainty by distributing probability mass across plausible locations. This soft probabilistic output creates natural error bounds. If a joint is fully occluded, the prediction can approach a uniform distribution, with the error exceeding the expected value by up to half the discretization range. Empirically, this advantage is reflected in our CrowdPose performance, where AMFACPose achieves 65.9 AP in the hard subset, demonstrating robustness in severe occlusion scenarios. Thus, KLDDiscretLoss provides a more reliable and uncertainty-aware mechanism for keypoint localization than point-based regression losses.
Our PyTorch-based implementation [
38] processes the
distributions for each joint independently, facilitating the straightforward integration of label smoothing and temperature scaling in the preprocessing steps. This structure also enables fine-grained control over which joints receive higher weighting, enabling the model to spend more capacity on challenging joints or underrepresented body parts. By guiding the network to produce calibrated probability distributions rather than single-point predictions, KLDiscretLoss enhances robustness against partial visibility, background clutter, and pose variability.
4. Experimental Setup
4.1. Datasets
We conducted comprehensive evaluations of AMFACPose using two established benchmarks in HPE—the MS COCO [
27] and CrowdPose datasets [
39]. These datasets were selected for their complementary characteristics, enabling a thorough assessment of our model across diverse scenarios.
The MS COCO 2017 dataset serves as a primary benchmark for HPE evaluation, containing over 200,000 images with approximately 250,000 annotated person instances. Each instance is labeled with 17 keypoints, encompassing facial features i.e., eyes, ears, nose, and body joints such as shoulders, elbows, wrists, hips, knees, ankles. The dataset is partitioned into 118,000 training images, 5000 validation images, and a separate test set. MS COCO’s strength lies in its diversity, featuring varied poses, scales, and occlusions in natural contexts, thereby providing a robust evaluation framework for model generalization.
On the other hand, the CrowdPose dataset [
39] specifically addresses the challenges of pose estimation in crowded scenarios. Comprising 20,000 images with approximately 80,000 person instances, CrowdPose annotates 14 keypoints per person, focusing on body joints i.e., shoulders, elbows, wrists, hips, knees, ankles, while excluding facial landmarks. The dataset is divided into 10,000 training, 2000 validation, and 8000 testing sets. CrowdPose’s distinctive feature is its emphasis on person-to-person occlusions and high-density scenarios, presenting more challenging conditions than the typical pose estimation datasets. This characteristic makes it particularly valuable for evaluating our model’s performance in real-world crowded environments, where accurate pose estimation is crucial yet technically challenging.
4.2. Evaluation Metrics
Our model’s performance evaluation utilizes the Object Keypoint Similarity (OKS) metric, which provides a rigorous assessment of keypoint localization accuracy. The OKS metric quantifies the similarity between predicted and ground-truth keypoint positions through the following formulation:
where
represents the Euclidean distance between the predicted and ground-truth positions for the
i-th keypoint,
s denotes the person instance scale,
is a keypoint-specific normalization constant, and
indicates keypoint visibility. The indicator function
ensures evaluation focuses exclusively on visible keypoints. We used average precision (AP) as our primary performance metric, calculated across ten OKS thresholds ranging from 0.50 to 0.95 in 0.05 increments. This comprehensive range allows for a detailed performance assessment at various precision levels. We specifically report
and
corresponding to OKS thresholds of 0.50 and 0.75, providing insights into the model’s performance at different precision requirements. Scale-specific metrics
and
evaluate performance on medium- and large-sized instances, respectively. Additionally, we compute average recall (AR) following similar protocols to AP, offering complementary insights into the model’s detection capabilities.
For the CrowdPose dataset evaluation, we maintain consistency with MS COCO by utilizing the same fundamental OKS metric while incorporating additional crowd-specific measures. These include AP metrics stratified by scene complexity, , , and . Scene complexity classification is determined by the crowding level, computed as the average Intersection over Union of the ground-truth bounding boxes within each image. This stratified evaluation framework enables a detailed assessment of our model’s performance across varying levels of scene complexity and person-to-person occlusion. Through this comprehensive evaluation framework, combining standard OKS-based metrics with crowd-specific measures, we ensure a thorough assessment of our model’s keypoint localization capabilities across diverse scenarios. This approach validates the model’s reliability in both general and crowded environments, providing a complete understanding of its real-world applicability.
4.3. Implementation Details
Our implementation strategy emphasizes training stability, efficient resource utilization, and strong generalization for real-world pose estimation. We implemented comprehensive data augmentation techniques including random horizontal flips, rotational variations from −30° to +30°, and scale adjustments from 0.7 to 1.3 [
40]. These augmentations were implemented using the PyTorch 1.12.1 framework, ensuring efficient and reliable model training.
Training proceeds for 140 epochs, with a batch size of 32 to maintain a balance between gradient stability and computational throughput. Six parallel data-processing workers further accelerate input pipelines. The initial learning rate is set to
, enabling gradual convergence while preventing overshooting of local minima. We used the Mish activation function [
41] in the ResNet, a smooth and non-monotonic alternative to ReLU that has demonstrated effectiveness in minimizing vanishing gradients [
42] and improving feature extraction in deeper models.
To refine parameter updates and manage regularization, we adopt the AdamW optimizer [
43], which decouples weight decay from the main optimization steps. This separation grants more precise control over the magnitude of regularization and often produces better generalization performance [
44]. Empirical studies [
45] show that AdamW outperforms classical optimizers in complex tasks by maintaining stable gradients and resisting overfitting, making it particularly suitable for the challenges posed by dense keypoint localization.
The full AMFACPose model—which includes the AFPN, DGCBs, and other attention modules—requires approximately 78 h to converge, while the baseline ResNet34 model converges in approximately 42 h under the same training schedule. Despite the modest increase in training time, the additional modules yield significant accuracy gains, justifying their computational cost.
5. Results and Discussion
This section presents a comprehensive quantitative and qualitative evaluation of the proposed AMFACPose framework. We first detail its performance on the MS COCO dataset, highlighting both accuracy and scalability. Subsequently, we examine resource–efficiency trade-offs and analyze the model’s behavior under congested scenarios using the CrowdPose dataset. Finally, we provide qualitative examples of the model predictions, illustrating AMFACPose’s versatility across diverse real-world conditions.
5.1. Performance on COCO Dataset
Table 1 compares AMFACPose with several SOTA 2D HPE models on the MS COCO dataset, including multiple recent approaches. Utilizing a ResNet34 backbone with an input resolution of 384 × 288, AMFACPose achieves an AP of 76.6, surpassing coordinate-based methods such as AECA-PRNetCC, with an AP of 76.0, and SimCC, with an AP of 73.4. Additionally, AMFACPose marginally outperforms the strong heatmap-based baseline HRNet-W48, which achieves an AP of 76.3. The method also demonstrates superior performance compared to recently introduced techniques, such as BR-Pose with an AP of 75.3, various PCDPose models exhibiting AP scores ranging from 73.5 to 74.3, SDPose variants achieving AP scores between 73.5 and 73.7, and the CSDNet-m/12 model with an AP of 75.0. Many of these methods rely on the robust HRNet backbone, emphasizing the competitive advantage of AMFACPose’s coordinate classification pipeline, which achieves comparable or superior accuracy without incurring significant computational overhead from heatmap generation and post-processing.
A detailed analysis of the threshold-specific metrics reveals strong performances at both moderate and stricter accuracy levels. Specifically, AMFACPose achieves an of 92.6 and an of 83.7. Additionally, the method demonstrates balanced effectiveness across different object scales, achieving an of 73.9 and an of 81.2. These results show the effectiveness of the Adaptive Feature Pyramid Network and the attention modules in managing subjects of varying sizes and enhancing global and local contextual understanding, even under challenging conditions such as partial occlusions or diverse poses. To further investigate the trade-offs between resource efficiency and accuracy, evaluations with smaller input resolutions, such as 256 × 256, and lighter backbones, such as ResNet18, were conducted. These configurations consistently maintain AP scores above 72.0, demonstrating AMFACPose’s adaptability to varying computational constraints. Notably, the most compact configuration with ResNet18 at a resolution of 256 × 256 still achieves an AP of 72.1, competitively close to several recent, larger-architecture methods. This adaptability highlight the practical applicability of AMFACPose, particularly for deployment in real-world scenarios involving edge devices with limited computational resources.
5.2. Model Complexity and Resource Efficiency
Table 2 presents a comparative summary of AMFACPose alongside recent 2D HPE models, emphasizing accuracy and computational efficiency. With a ResNet34 backbone at 384 × 288 input, AMFACPose achieves an AP of 76.6 using only 3.8 M parameters and 5.2 GFLOPs. This reflects a substantial improvement over HRNet-W48, which reports a slightly lower AP of 76.3 but requires 63.6 M parameters and 32.9 GFLOPs. Compared to AECA-PRNetCC, which achieves an AP of 76.0 with 29.0 M parameters and 8.3 GFLOPs, AMFACPose delivers similar accuracy at a fraction of the computational cost.
Recent models further highlight AMFACPose’s efficiency. BR-Pose reaches 75.3 AP with 31.3 M parameters and 9.0 GFLOPs. PCDPose variants yield AP scores from 73.5 to 74.3, with 7.7–13.8 M parameters and 4.5–6.7 GFLOPs. SDPose methods achieve 73.5–73.7 AP with 6.2–13.2 M parameters and 4.7–5.2 GFLOPs, while CSDNet-m/12 reaches 75.0 AP with 17.4 M parameters and 6.9 GFLOPs. In all cases, AMFACPose offers better accuracy with significantly lower resource requirements, supporting its deployment in constrained environments.
Further reductions are achieved using ResNet18. At 256 × 256 input, AMFACPose maintains 72.1 AP with only 2.4 M parameters and 1.9 GFLOPs, showing its adaptability to low-power applications without severe performance loss.
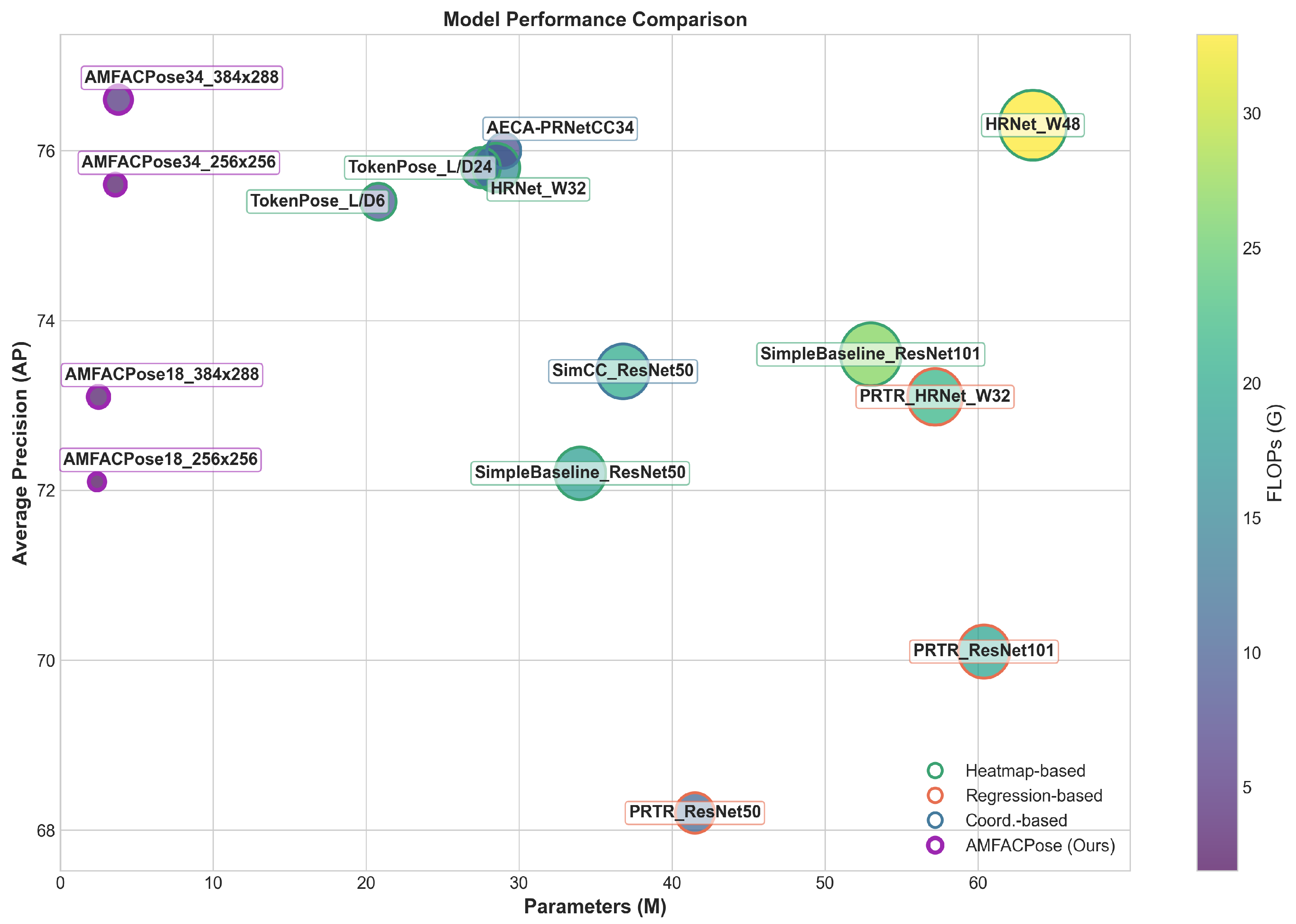
We also visualize these trade-offs in
Figure 7, which plots the AP on the vertical axis versus model parameters on the horizontal axis. The size and color of each bubble correspond to FLOPs, and the outline color denotes the underlying methodology, which are heatmap-based, regression-based, and coordinate-based. As shown, AMFACPose configurations appear near the lower-parameter, lower-FLOP regions while achieving competitive accuracy. In contrast, HRNet-W48 occupies a higher-parameter area with significantly higher computational cost for a similar AP score. These findings point to the efficacy of AMFACPose’s coordinate classification pipeline and lightweight design components, making it well suited for resource-constrained scenarios.
While demonstrating significant improvements in computational efficiency, AMFACPose also introduces several practical trade-offs. The use of DSC and the AFPN substantially reduces computation to 5.2 GFLOPs, compared to 32.9 GFLOPs in HRNet-W48, while maintaining competitive AP scores. This design enables real-time performance even on edge devices such as Jetson platforms, as discussed in
Section 6. However, the coordinate classification strategy, while efficient, involves discretizing the coordinate space, which may introduce localization limitations for small joints (e.g., wrists or ankles) when high precision is required. In such cases, high-resolution heatmap regression may provide better granularity. Moreover, while our approach handles moderate occlusions effectively using attention modules such as DGCBs and the SCRM, it does not incorporate explicit visibility classification. Competing works such as HPCVNet [
26], which achieves 77.6 mAP on COCO, model keypoint visibility directly, offering added robustness in scenarios with extreme occlusion or dense overlapping subjects. These trade-offs reflect the broader goal of balancing accuracy, interpretability, and deployment feasibility in real-world pose estimation systems.
5.3. Performance on CrowdPose Dataset
We further evaluated AMFACPose on the CrowdPose dataset [
39], known for emphasizing challenging scenarios involving person-to-person occlusions and complex group interactions. As detailed in
Table 3, AMFACPose utilizing a ResNet34 backbone achieves a leading AP score of 75.3, along with
and
values of 93.4 and 81.0, respectively. This performance surpasses established frameworks such as PRTR with an AP of 71.6, HRFormer with 72.6, and ED-Pose with Swin-L, which achieves 73.1. Furthermore, AMFACPose demonstrates higher accuracy than recent methods, including GroupPose with an AP of 74.1, MAQT with 74.3, and CCAM-Person with 74.4.
Across varying levels of difficulty, AMFACPose maintains strong performance, reporting an of 82.1 and of 76.4. This highlights its capability to accurately estimate poses under moderate occlusions. Although the model yields a slightly lower of 65.9 compared to CCAM-Person at 66.9 and MAQT at 66.7, it remains highly competitive. These results emphasize the contribution of adaptive multi-scale feature fusion and dual-gate context blocks in resolving complex occlusions and effectively separating overlapping human joints.
Our strong performance on CrowdPose’s challenging occlusion scenarios validates AMFACPose’s approach to occlusion handling through feature enhancement rather than explicit visibility classification as in HPCVNet [
26]. While HPCVNet achieves slightly higher mAP on COCO (77.6 vs. 76.6), its performance on occlusion-heavy datasets like CrowdPose has not been established. The combination of multi-scale feature fusion via the AFPN and contextual refinement through DGCBs in our approach proves particularly effective for distinguishing overlapping subjects in real-world scenarios.
Altogether, AMFACPose combines high accuracy with low parameter complexity and reliable performance in crowded visual scenes. The integration of attention-guided multi-scale processing and a coordinate classification framework makes it particularly well suited for real-time applications and deployment in embedded environments, where both precision and efficiency are essential.
5.4. Qualitative Analysis
Figure 8 depicts representative AMFACPose outputs on the COCO dataset, demonstrating the framework’s adaptability to diverse poses, occlusions, and environmental conditions. In high-action sports scenarios such as tennis, the model accurately tracks rapid limb movements without sacrificing fine-grained joint precision. Outdoor settings, ranging from skateboarding parks to beach environments, highlight the system’s resilience to shifting backgrounds, lighting variations, and dynamic body configurations. Even in multi-person scenes where individuals overlap, AMFACPose reliably distinguishes each subject’s joints, showing the effectiveness of its multi-scale fusion and gating modules. These qualitative observations align with the quantitative metrics reported earlier, suggesting AMFACPose’s potential for real-world deployment in applications demanding both accuracy and computational efficiency.
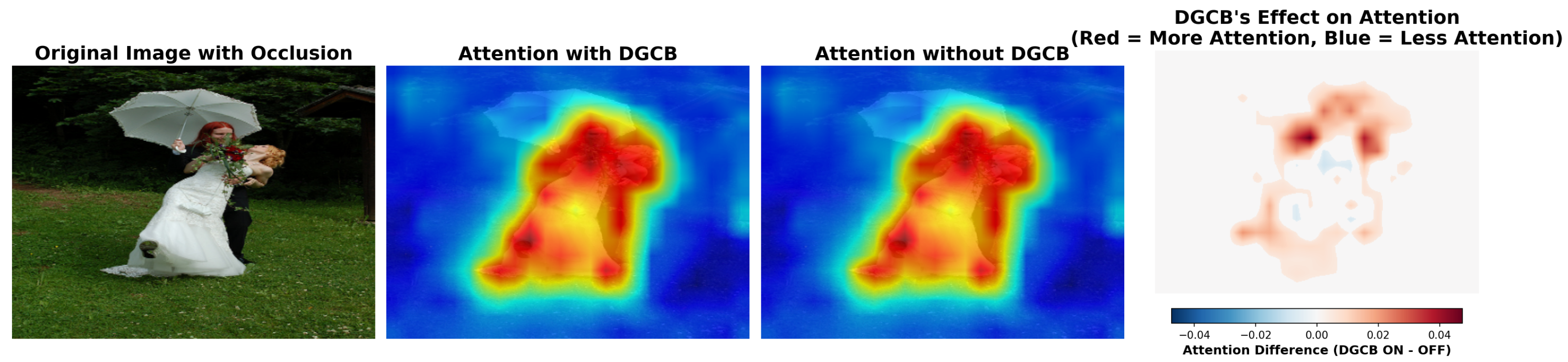
To further investigate the effectiveness of our proposed DGCB module in handling occlusion, we visualize attention maps with and without the DGCB enabled. As shown in
Figure 9, we evaluate a sample image where a subject’s hands and shoulders are partially occluded by flowers. The attention maps indicate that when the DGCB is active, the model maintains more focused attention on the occluded joints. The difference map (rightmost panel) highlights the regions where attention increases (red) or decreases (blue), showing that the DGCB effectively enhances attention near occluded keypoints.
Figure 10 provides a detailed view of the occluded region. Zoomed attention maps clearly show that the DGCB helps maintain activation on partially hidden body parts. The additional focus around occluded limbs demonstrates how the DGCB leverages global context to refine local attention, improving keypoint localization under challenging visibility conditions.
These qualitative results reinforce our quantitative findings on the CrowdPose benchmark and provide visual evidence that DGCBs significantly enhance occlusion robustness in AMFACPose.
6. Performance and Efficiency Analysis
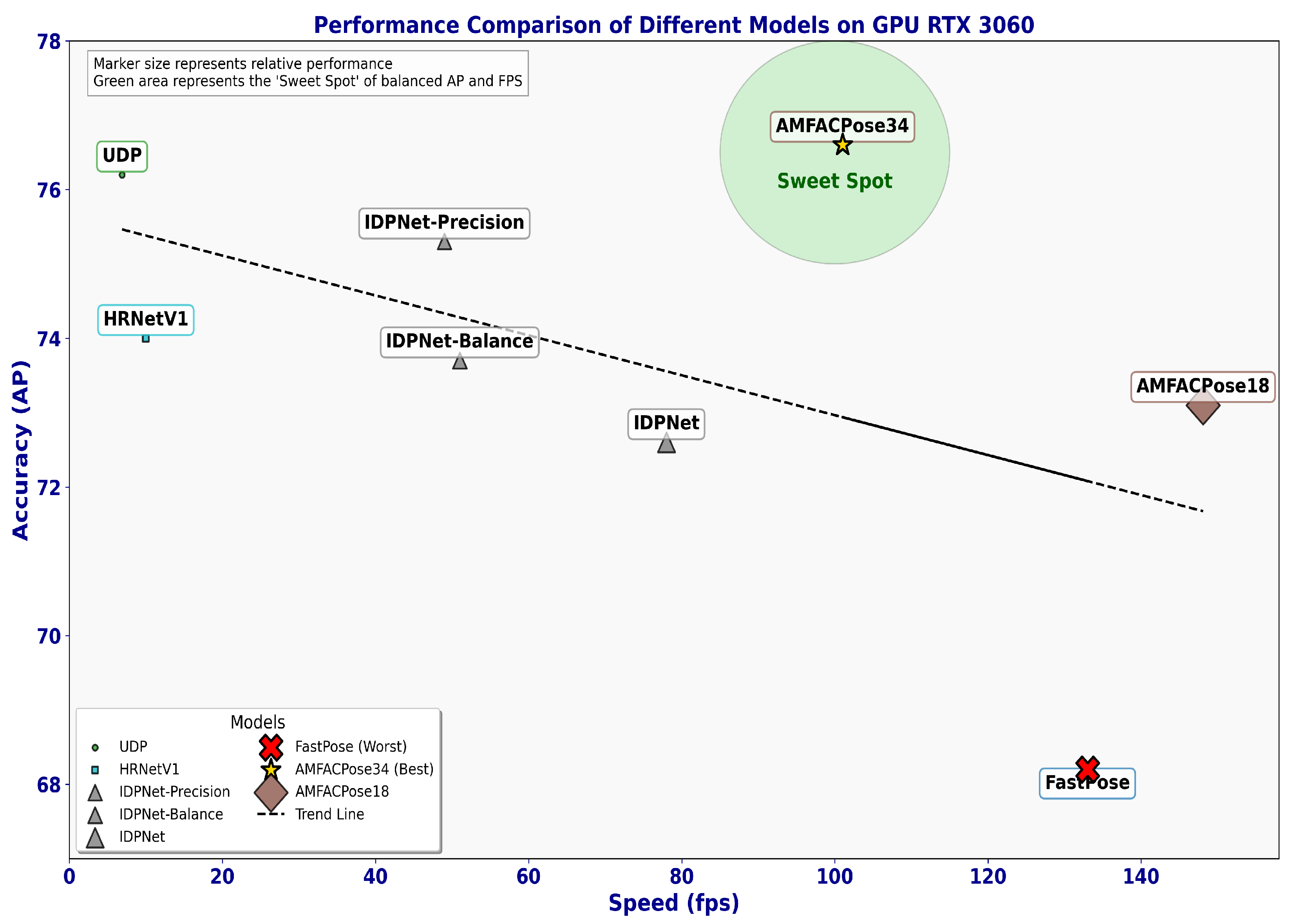
Figure 11 offers a visual overview of the speed–accuracy trade-offs for 2D HPE models, highlighting how AP correlates with inference speed on an RTX 3060 GPU. Each marker’s size denotes the model’s overall performance, while the green-shaded area represents the “sweet spot”, where a favorable balance of high AP and real-time throughput emerges. AMFACPose, with a ResNet34 backbone, resides within this region, emphasizing its ability to maintain robust accuracy while achieving competitive frame rates. In comparison, alternative approaches often sacrifice accuracy for speed, or vice versa, reinforcing AMFACPose’s balanced design.
Table 4 summarizes AMFACPose’s performance across multiple hardware platforms, including the Jetson Orin Nano-8 at 15 W, Orin NX-8 at 20 W, Orin NX-16 at 25 W, and two desktop GPUs, which are RTX 4090 and RTX 3060. Using a ResNet34 backbone with a 384 × 288 input on the Orin Nano-8, this configuration processes each frame in 67.82 ms, corresponding to 14.74 fps. The more powerful Orin NX-16 reduces inference time to 45.97 ms and yields 21.75 fps. High-end GPUs offer even higher throughput, where the same setup runs at 6.74 ms per frame, i.e., 148.45 fps, on the RTX 4090 and 9.90 ms, i.e., 101.04 fps, on the RTX 3060. Reducing the input resolution to 256 × 256 substantially increases speed, especially on lower-wattage devices. For instance, the ResNet34 variant at 256 × 256 runs at 23.59 fps on the Orin Nano-8, scaling to over 30 fps on the Orin NX-8 and exceeding 100 fps on the RTX 3060.
Switching to a ResNet18 backbone trades off some precision for even greater efficiency. At a 384 × 288 input, this lighter configuration processes frames in 43.15 ms with 23.18 fps on the Orin Nano-8. This improves to 29.64 ms with 33.74 fps on the Orin NX-16, and further reduces to under 5 ms per frame with 201.10 fps on the RTX 4090. The 256 × 256 variant pushes the fps further across all devices; it reaches 36.02 fps on the Orin Nano-8 and scales to 50.45 fps on the Orin NX-16, while desktop GPUs offer well over 150 fps with modest sacrifices in accuracy relative to the ResNet34 backbone. These observations confirm that AMFACPose can flexibly adapt to various computational budgets, ranging from highly constrained edge platforms to powerful desktop workstations, while retaining a competitive balance between speed and precision.
Table 5 places AMFACPose alongside prominent 2D HPE methods on an RTX 3060. Even with the ResNet34 backbone, the model obtains 101.0 fps, surpassing the speed of most competing solutions and matching or outperforming many in accuracy. The ResNet18 setup, although slightly lower in AP at 73.1, pushes throughput to 148.1 fps. Models like UDP with ResNet152 reach comparable precision but operate at only 6.9 fps, highlighting AMFACPose’s efficiency advantages. The results of
Table 5 are visualized in
Figure 11. Across diverse settings and hardware, these results demonstrate that our architecture consistently maintains a favorable trade-off between accuracy and real-time usability, making it a versatile choice for applications that demand both precision and scalability.
7. Ablation Study
A systematic ablation study was conducted to evaluate the contribution of each core component in AMFACPose.
Table 6 reports the results on the MS COCO dataset using a ResNet34 backbone with an input resolution of 384 × 288. Starting from the baseline, we incrementally added the AFPN, DGCBs, SCRM, SE blocks, and CoordConv2d layers, enabling a detailed assessment of both the accuracy and computational cost associated with each module.
The baseline configuration achieves an AP of 72.4 with 3.3 M parameters and 4.70 GFLOPs, serving as the initial reference. Adding the AFPN increases AP to 73.2 while slightly increasing the model size to 3.5 M parameters and 5.0 GFLOPs, demonstrating the benefit of efficient multi-scale feature aggregation. Introducing DGCBs further improves AP to 73.4, with parameters at 3.6 M and FLOPs at 5.0, highlighting better contextual encoding with minimal cost.
A more substantial performance gain comes from integrating the SCRM module, which increases AP to 75.4 while maintaining 3.6 M parameters and 5.2 GFLOPs. This shows the effectiveness of joint spatial and channel refinement. The inclusion of SE blocks lifts AP to 76.3, with a modest increase to 3.8 M parameters and no additional GFLOP cost, due to lightweight global re-weighting.
Finally, adding CoordConv2d brings the model to its full configuration, achieving an AP of 76.6, along with , , , and . The model remains compact with 3.8 M parameters and 5.2 GFLOPs.
Importantly, this analysis directly addresses concerns about the integration of multiple attention mechanisms. Across the entire architecture, AMFACPose improves AP by 4.2 while increasing parameter count by just 0.5 M and computation by 0.5 GFLOPs. These results confirm that the proposed modules—the AFPN, DGCBs, SCRM, and SE blocks—work collaboratively and efficiently, making the full model highly suitable for real-time and resource-constrained environments.
8. Conclusions and Future Work
This paper presents AMFACPose, an efficient architecture for 2D HPE that addresses key challenges in scale variation and occlusion while maintaining minimal computational requirements. Through the integration of specialized components—the AFPN, DGCBs, SE blocks, and SCRM—our coordinate-based classification approach achieves high localization accuracy without the computational overhead typical of heatmap-based methods. Extensive evaluations on the COCO and CrowdPose datasets demonstrate AMFACPose’s effectiveness, outperforming state-of-the-art approaches while maintaining significantly lower parameter counts and faster inference speeds across various hardware platforms. The architecture’s adaptability is particularly evident in its consistent performance across resource-constrained edge devices and high-performance GPUs.
Despite its advantages, AMFACPose—like most vision models—may experience performance degradation under extreme conditions such as low-light environments or severe motion blur. Addressing these limitations requires future extensions that integrate spatiotemporal information or leverage cross-modality learning. We also acknowledge the ethical implications of pose estimation technologies, particularly in surveillance contexts, where privacy concerns are critical. Responsible deployment must be guided by transparent governance, informed consent, and equitable data representation to avoid bias and ensure fairness across demographic groups.
Future research directions include extending AMFACPose to 3D pose estimation and multi-view configurations, integrating temporal information for dynamic motion analysis, and developing domain adaptation techniques for limited-data scenarios. Additional focus will be placed on power-optimization strategies for embedded and mobile deployments, further enhancing the model’s practical utility in resource-constrained environments.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}