
Enhanced Graph Diffusion Learning with Transformable Patching via Curriculum Contrastive Learning for Session Recommendation


Abstract
1. Introduction
- (1)
- Several research works [2,6,8] explore information transformation patterns between sessions to further improve recommendation performance through graph neural network techniques. Although these approaches have achieved very good performance, there may be isolated nodes or redundant structures in the graph structure that construct the inter-session global item transformation patterns [9]. As a result, it is difficult for convolutional operations based on graph structures to accurately capture the true item transition relationships between sessions [10]. Several studies have introduced the idea of diffusion [11] into the learning process of graph structures [12]. However, in the diffusion modeling process based on graph structure, due to the influence of noise and other factors, it may lead to a deviation between the graph structure diffusion learning representation and the real value, which cannot accurately characterize the real item transition pattern between sessions.
- (2)
- The dynamic change characteristics based on time evolution between sequences of items in a session lack in-depth mining. In recent years, some researchers have proposed different temporal encoding functions [13,14] to learn specific temporal change patterns between items. Although these approaches have achieved some success, they essentially default to sessions consisting of items that users interact with based on their temporal ordering properties, ignoring the effect of asynchronous timestamps and future timestamp in the sequential data on the pattern of inter-session item transformations, and lacking in-depth mining of temporal influence patterns [15].
- 1.
- The EGDLTP-CCL model employs an energy-constrained graph diffusion technique to learn inter-session item transition patterns. The energy-constraint function guides the global graph diffusion process and alleviates the bias between the graph structure diffusion learning representation and the actual value.
- 2.
- The EGDLTP-CCL model employs a patch-enhanced gated graph neural network to learn intra-session item transition patterns. In particular, the model emphasizes the potential of the patch strategy to capture temporally varying properties of intra-session item transition patterns, enhancing the local semantic features of temporal items and capturing the full semantics through a time-step-based aggregation operation.
- 3.
- The EGDLTP-CCL model employs a contrastive learning framework based on curriculum learning, in which the proposed novel negative sampling method based on curriculum learning enhances the model’s performance and generalization capability.
- 4.
- The performance of the EGDLTP-CCL model is tested on three real-world datasets, and the experimental results show the significant superiority of the proposed model when compared to the state-of-the-art works.
2. Related Work
2.1. Deep Learning Based Session Recommendation
2.2. Application of Contrastive Learning in Recommendation
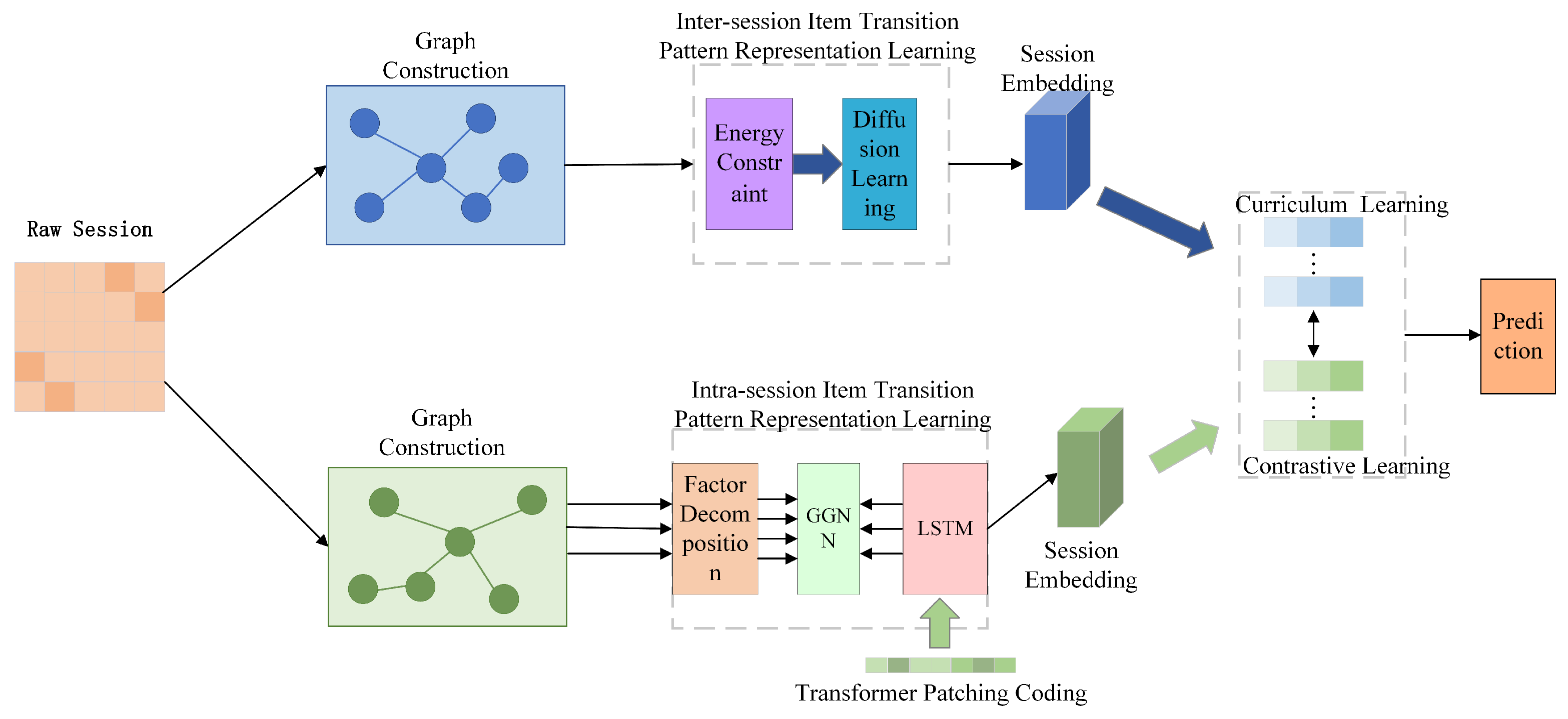
3. EGDLTP-CCL Model
3.1. Formulation
3.2. Inter-Session Item Transition Pattern Representation Learning
3.3. Intra-Session Item Transition Pattern Representation Learning
3.4. Curriculum Contrastive Representation Learning
3.4.1. Sampling of Curriculum Learning
3.4.2. The Loss of Contrastive Learning Framework
3.5. Prediction and Optimization Based on Fusion Representation of Multi-Task Strategies
3.5.1. Prediction
3.5.2. Optimization
| Algorithm 1 The learning algorithm for the EGDLTP-CCL model |
| Input: Item data V, session data S. |
| Output: Recommendation list. |
| for each epoch do: |
| for the Inter-session item transition pattern representation learning each epoch do: |
| Calculate the adjacency matrix by Equations (1)–(3). |
| Calculate the diffusion rate by Equations (4)–(6). |
| Perform diffusion map data embedding and updating by Equations (7) and (8). |
| end |
| for the intra-session item transition pattern representation learning each epoch do: |
| Fine-grained item feature representation by Equation (9). |
| Learning complex transitions between different item embeddings based on a gated graph neural network by Equations (10) and (11). |
| Capturing time behavior of item transition patterns based on patch-enhanced LSTM network by Equations (12)–(17). |
| end |
| for each session do: |
| Sampling and training based on curriculum learning by Equations (18)–(20). |
| Calculation of the contrastive learning loss for both inter-session and intra-session representations by Equations (21) and (22). |
| Predicting the probability of the next item by Equations (23) and (24). |
| Obtain the next predicted loss by Equation (25). |
| end |
| Joint optimization of the overall objective in Equation (26). |
| end |
3.5.3. Time Complexity
4. Experiment
4.1. Datasets
- The Yoochoose dataset is from the 2015 RecSys Challenge and contains data on user clicks to e-commerce websites.
- The RetailRocket dataset is user activity data recorded by a personalized e-commerce company over a six-month period.
- Tmall dataset containing anonymized behavioral logs of Tmall users over a six-month period, which is published in the IJCAI 2015 competition.
- Diginetica dataset is from the CIKM Cup 2016, containing over 6 months of click-through data about users.
4.2. Metric
- is the percentage of real items in the top items that generate recommendations, which measures the accuracy of the model’s predictions:where denotes the number of sessions and is the number of ground-truth items in the generated recommendation list.
- (Mean Reciprocal Rank) represents the inverse of the rank of the items in the generated recommendation list, which measures the positional relationship between the items. The larger value indicates that the real items are ranked more important, which also means that the model performs better, as shown below:where is the sorted position of the ground-truth in the list predicted by the i-th session.
4.3. Experimental Setup
- GRU4REC [18] is an RNN-based session recommendation that aims to capture sequential dependency patterns between items in a session.
- NARM [19] is a recommendation model that integrates an attention mechanism on an RNN-based approach to enhance the sequence representation capability of RNN models.
- STAMP [20] is a recommendation model that integrates attention mechanisms in MLP to fuse users’ long and short-term interests.
- SR-GNN [21] is a GNN-based session recommendation method and effectively combines users’ general interests and short-term preferences.
- TAGNN [22] proposed a target-aware attention network to model the dynamic process of user interest with different target items in order to generate recommendations for users.
- DHCN [2] is a hypergraph-based approach to capture higher-order information between items, and it also introduces contrastive learning to integrate information between different sessions.
- Disen-GNN [32] is a session recommendation method for disentangled GNNs, where the aim of disentanglement learning is to model factor-level features of items.
- HIDE [36] introduces hypergraphs into session recommendations that comprehensively capture user preferences from different perspectives.
- MSGAT [37] brings two-channel sparse attention networks into session recommendation to mitigate in-session noise, which models user preferences based on two parallel channels integrating intra- and inter-session information.
4.4. Analysis of Experimental Results
4.4.1. Overall Comparison
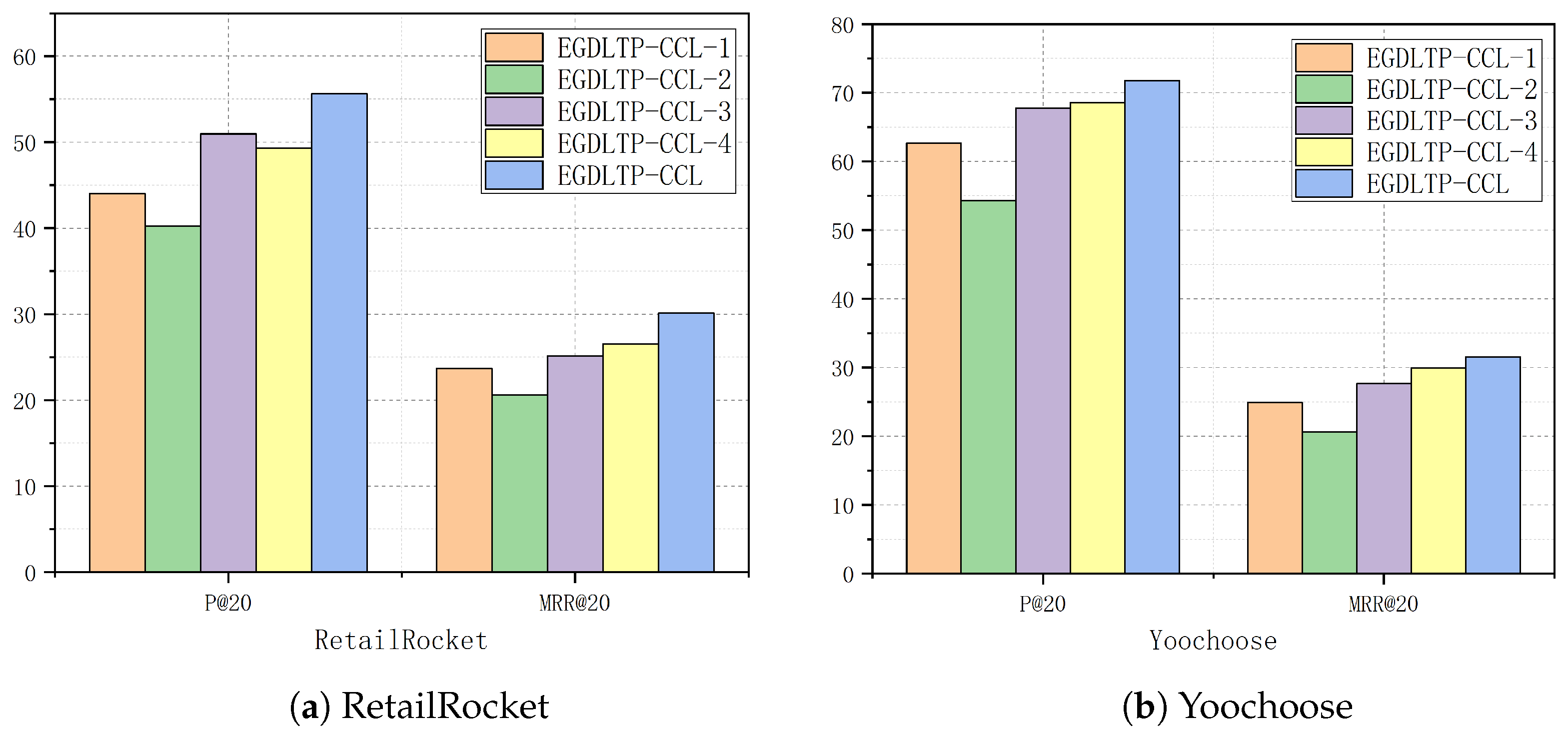
4.4.2. Ablation Analysis
- 1.
- EGDLTP-CCL-2 has the worst performance. When the patch-enhanced gated network module is removed, a large amount of important item information is hidden within the session, and contextual temporal information is ignored. Meanwhile, it is shown that accurately obtaining the impact of time-varying correlations in the transition patterns between items within a session is also important for session recommendation performance enhancement.
- 2.
- EGDLTP-CCL-1 ranks fourth among the five models. When the energy-constrained graph diffusion learning module is removed and the intra-session item switching patterns are learned only by patch augmented gated neural networks, it is not able to fit the inter-session item transition patterns adequately, resulting in a degradation of the overall performance of EGDLTP-CCL.
- 3.
- EGDLTP-CCL-3 is the third among the five models, which justifies the fact that the curriculum contrastive learning task integrates the learned intents into the session based on the curriculum learning recommendation model to further improve the performance and robustness.
- 4.
- EGDLTP-CCL-4 is the second among the five models, which shows that the negative sample selection strategy based on curriculum learning can further improve the performance of the contrastive learning task.
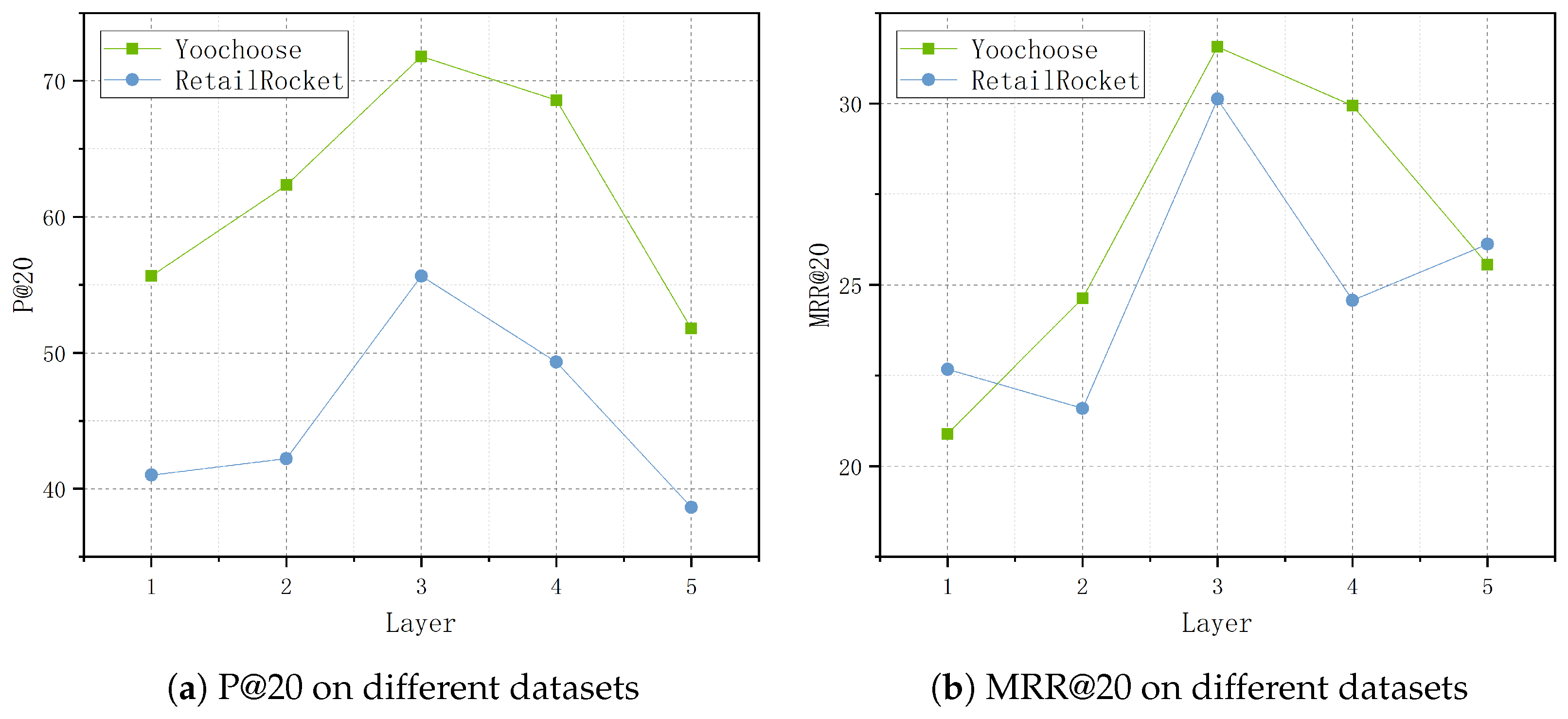
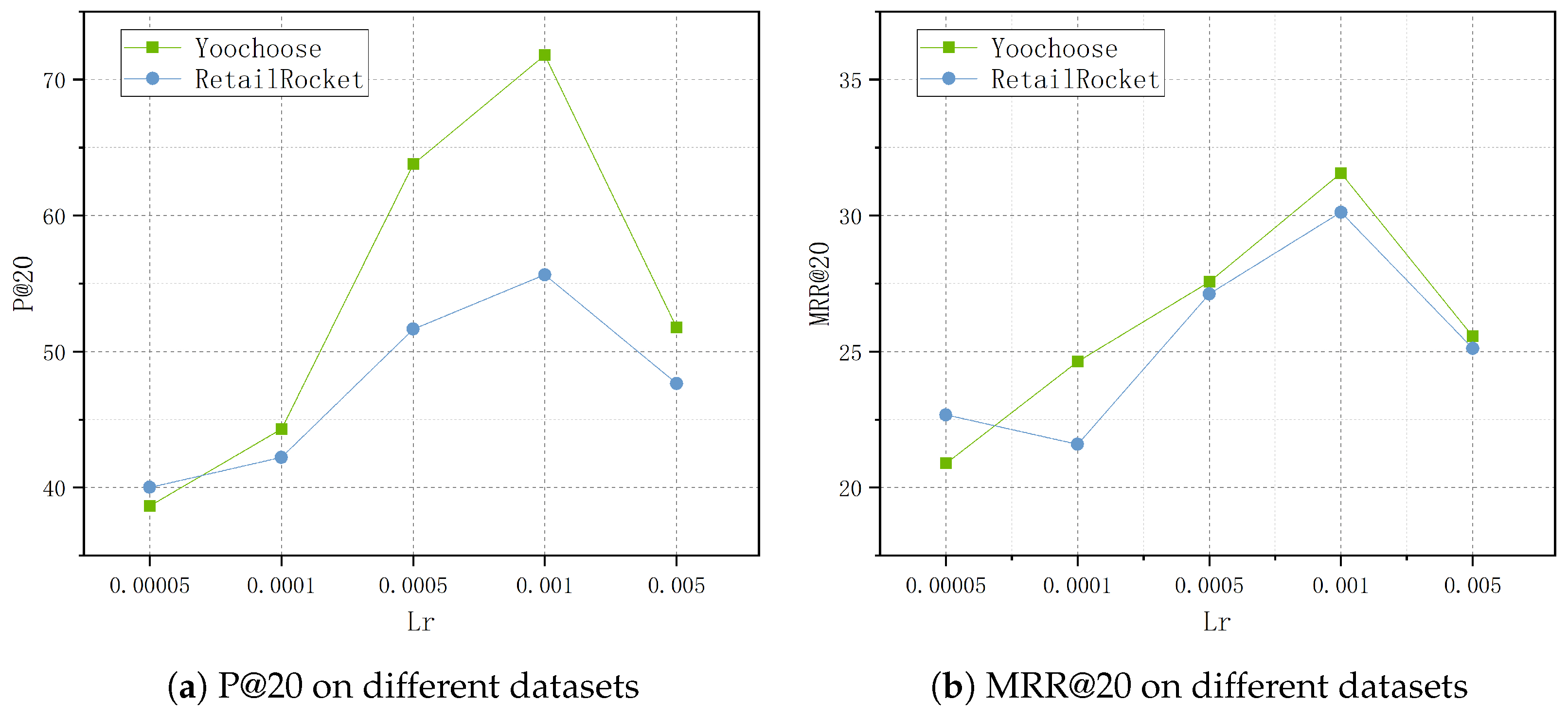
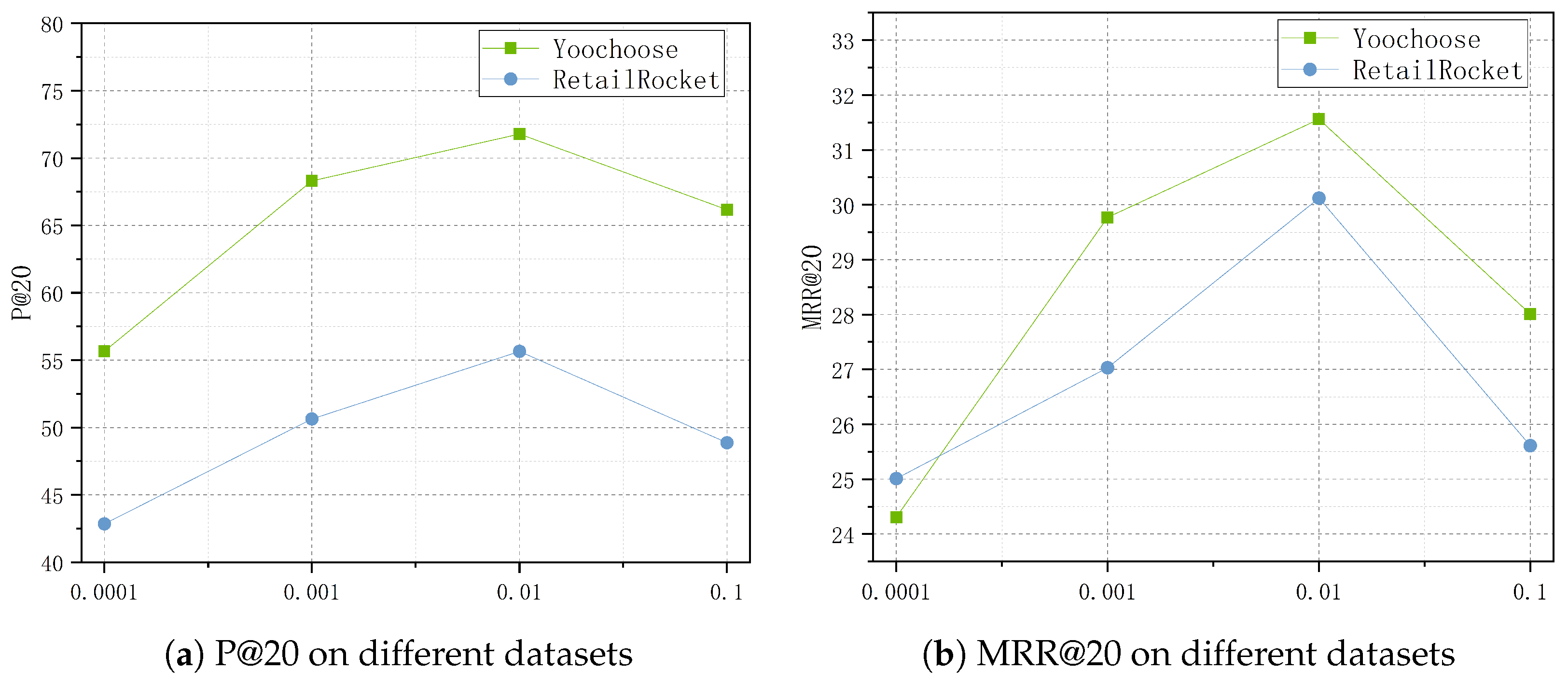
4.4.3. Parameter Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, L.; Yin, H.; Wang, Q.; Chen, T.; Zhou, A.; Quoc Viet Hung, N. Streaming session-based recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1569–1577. [Google Scholar]
- Xia, X.; Yin, H.; Yu, J.; Wang, Q.; Cui, L.; Zhang, X. Self-supervised hypergraph convolutional networks for session-based recommendation. AAAI Conf. Artif. Intell. 2021, 35, 4503–4511. [Google Scholar] [CrossRef]
- Deng, Z.H.; Wang, C.D.; Huang, L.; Lai, J.H.; Yu, P.S. G 3 SR: Global graph guided session-based recommendation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9671–9684. [Google Scholar] [CrossRef] [PubMed]
- Hidasi, B.; Karatzoglou, A. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 843–852. [Google Scholar]
- Li, Z.; Yang, C.; Chen, Y.; Wang, X.; Chen, H.; Xu, G.; Yao, L.; Sheng, M. Graph and sequential neural networks in session-based recommendation: A survey. ACM Comput. Surv. 2024, 57, 1–37. [Google Scholar] [CrossRef]
- Wang, Z.; Wei, W.; Cong, G.; Li, X.L.; Mao, X.L.; Qiu, M. Global context enhanced graph neural networks for session-based recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 169–178. [Google Scholar]
- Chen, Y.H.; Huang, L.; Wang, C.D.; Lai, J.H. Hybrid-order gated graph neural network for session-based recommendation. IEEE Trans. Ind. Inform. 2021, 18, 1458–1467. [Google Scholar] [CrossRef]
- Xia, X.; Yin, H.; Yu, J.; Shao, Y.; Cui, L. Self-supervised graph co-training for session-based recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 2180–2190. [Google Scholar]
- Wu, L.; Sun, P.; Fu, Y.; Hong, R.; Wang, X.; Wang, M. A neural influence diffusion model for social recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 235–244. [Google Scholar]
- Li, Z.; Sun, A.; Li, C. Diffurec: A diffusion model for sequential recommendation. ACM Trans. Inf. Syst. 2023, 42, 1–28. [Google Scholar] [CrossRef]
- Wu, L.; Li, J.; Sun, P.; Hong, R.; Ge, Y.; Wang, M. Diffnet++: A neural influence and interest diffusion network for social recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 4753–4766. [Google Scholar] [CrossRef]
- Qin, Y.; Wu, H.; Ju, W.; Luo, X.; Zhang, M. A diffusion model for POI recommendation. ACM Trans. Inf. Syst. (TOIS) 2023, 42, 1–27. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; McAuley, J. Time interval aware self-attention for sequential recommendation. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 322–330. [Google Scholar]
- Ye, W.; Wang, S.; Chen, X.; Wang, X.; Qin, Z.; Yin, D. Time matters: Sequential recommendation with complex temporal information. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 1459–1468. [Google Scholar]
- Fan, Z.; Liu, Z.; Zhang, J.; Xiong, Y.; Zheng, L.; Yu, P.S. Continuous-time sequential recommendation with temporal graph collaborative transformer. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 433–442. [Google Scholar]
- Wu, Z.; Wang, X.; Chen, H.; Li, K.; Han, Y.; Sun, L.; Zhu, W. Diff4rec: Sequential recommendation with curriculum-scheduled diffusion augmentation. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 9329–9335. [Google Scholar]
- Yang, Y.; Zhang, C.; Zhou, T.; Wen, Q.; Sun, L. Dcdetector: Dual attention contrastive representation learning for time series anomaly detection. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 3033–3045. [Google Scholar]
- Quadrana, M.; Karatzoglou, A.; Hidasi, B.; Cremonesi, P. Personalizing session-based recommendations with hierarchical recurrent neural networks. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 130–137. [Google Scholar]
- Li, J.; Ren, P.; Chen, Z.; Ren, Z.; Lian, T.; Ma, J. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1419–1428. [Google Scholar]
- Liu, Q.; Zeng, Y.; Mokhosi, R.; Zhang, H. STAMP: Short-term attention/memory priority model for session-based recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1831–1839. [Google Scholar]
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-based recommendation with graph neural networks. AAAI Conf. Artif. Intell. 2019, 33, 346–353. [Google Scholar] [CrossRef]
- Yu, F.; Zhu, Y.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. TAGNN: Target attentive graph neural networks for session-based recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 1921–1924. [Google Scholar]
- Qiu, R.; Li, J.; Huang, Z.; Yin, H. Rethinking the item order in session-based recommendation with graph neural networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 579–588. [Google Scholar]
- Wang, J.; Ding, K.; Zhu, Z.; Caverlee, J. Session-based recommendation with hypergraph attention networks. In Proceedings of the 2021 SIAM International Conference on Data Mining (SDM), Virtual, 29 April–1 May 2021; pp. 82–90. [Google Scholar]
- Chen, J.; Zhu, G.; Hou, H.; Yuan, C.; Huang, Y. AutoGSR: Neural architecture search for graph-based session recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1694–1704. [Google Scholar]
- Zhuo, X.; Qian, S.; Hu, J.; Dai, F.; Lin, K.; Wu, G. Multi-hop multi-view memory transformer for session-based recommendation. ACM Trans. Inf. Syst. 2024, 42, 1–28. [Google Scholar] [CrossRef]
- Xu, M.; Wang, H.; Ni, B.; Guo, H.; Tang, J. Self-supervised graph-level representation learning with local and global structure. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 11548–11558. [Google Scholar]
- Zhang, J.; Gao, M.; Yu, J.; Guo, L.; Li, J.; Yin, H. Double-scale self-supervised hypergraph learning for group recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 2557–2567. [Google Scholar]
- Wei, C.; Liang, J.; Liu, D.; Wang, F. Contrastive graph structure learning via information bottleneck for recommendation. Adv. Neural Inf. Process. Syst. 2022, 35, 20407–20420. [Google Scholar]
- Zhao, W.; Tang, D.; Chen, X.; Lv, D.; Ou, D.; Li, B.; Jiang, P.; Gai, K. Disentangled causal embedding with contrastive learning for recommender system. In Proceedings of the Companion Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 406–410. [Google Scholar]
- Yang, K.; Han, H.; Jin, W.; Liu, H. Spectral-Aware Augmentation for Enhanced Graph Representation Learning. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA, 21–25 October 2024; pp. 2837–2847. [Google Scholar]
- Li, A.; Cheng, Z.; Liu, F.; Gao, Z.; Guan, W.; Peng, Y. Disentangled graph neural networks for session-based recommendation. IEEE Trans. Knowl. Data Eng. 2022, 35, 7870–7882. [Google Scholar] [CrossRef]
- Cao, Z.; Li, J.; Wang, Z.; Li, J. Diffusione: Reasoning on knowledge graphs via diffusion-based graph neural networks. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 222–230. [Google Scholar]
- Dang, Y.; Yang, E.; Guo, G.; Jiang, L.; Wang, X.; Xu, X.; Sun, Q.; Liu, H. Uniform sequence better: Time interval aware data augmentation for sequential recommendation. AAAI Conf. Artif. Intell. 2023, 37, 4225–4232. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Li, Y.; Gao, C.; Luo, H.; Jin, D.; Li, Y. Enhancing hypergraph neural networks with intent disentanglement for session-based recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1997–2002. [Google Scholar]
- Qiao, S.; Zhou, W.; Wen, J.; Zhang, H.; Gao, M. Bi-channel multiple sparse graph attention networks for session-based recommendation. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; pp. 2075–2084. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | # Number of Items | # Number of Hits | # Number of Training Sessions | # Number of Test Sessions | Average Length |
|---|---|---|---|---|---|
| Yoochoose | 16,766 | 557,248 | 369,859 | 55,898 | 6.16 |
| Retailrocket | 36,968 | 710,586 | 433,648 | 15,132 | 5.43 |
| Diginetica | 43,097 | 982,961 | 719,470 | 60,858 | 5.12 |
| Tmall | 40,728 | 818,479 | 351,268 | 25,898 | 6.69 |
| Methods | Tmall | Diginetica | Yoochoose | RetailRocket | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P@20 | MRR@20 | P@20 | MRR@20 | P@20 | MRR@20 | P@20 | MRR@20 | ||||||
| GRU4REC | 10.98 | 5.92 | 29.98 | 8.92 | 60.64 | 22.89 | 44.01 | 23.67 | |||||
| NARM | 23.35 | 10.68 | 44.35 | 15.68 | 68.32 | 28.63 | 50.22 | 24.59 | |||||
| STAMP | 26.44 | 13.35 | 45.44 | 14.32 | 68.74 | 29.67 | 50.96 | 25.17 | |||||
| SR-GNN | 27.65 | 13.76 | 50.26 | 17.26 | 70.57 | 30.94 | 50.32 | 26.57 | |||||
| TAGNN | 29.26 | 13.56 | 51.33 | 17.90 | 71.02 | 31.12 | 52.06 | 18.22 | |||||
| DHCN | 31.51 | 15.08 | 53.18 | 18.44 | 70.39 | 29.92 | 53.66 | 27.30 | |||||
| Disen-GNN | 31.56 | 15.31 | 53.79 | 18.99 | 71.46 | 31.36 | 47.44 | 29.32 | |||||
| HIDE | 37.12 | 18.69 | 53.68 | 18.36 | 70.33 | 30.66 | 51.33 | 28.89 | |||||
| MSGAT | 40.14 | 23.35 | 55.68 | 19.22 | 71.66 | 31.46 | 53.88 | 29.76 | |||||
| EGDLTP-CCL | 43.27 | 26.10 | 56.27 | 19.89 | 71.78 | 31.56 | 55.65 | 30.12 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Gao, R.; Yan, L.; Yao, Q.; Peng, X.; Hu, J. Enhanced Graph Diffusion Learning with Transformable Patching via Curriculum Contrastive Learning for Session Recommendation. Electronics 2025, 14, 2089. https://doi.org/10.3390/electronics14102089
Li J, Gao R, Yan L, Yao Q, Peng X, Hu J. Enhanced Graph Diffusion Learning with Transformable Patching via Curriculum Contrastive Learning for Session Recommendation. Electronics. 2025; 14(10):2089. https://doi.org/10.3390/electronics14102089
Chicago/Turabian StyleLi, Jin, Rong Gao, Lingyu Yan, Quanfeng Yao, Xianjun Peng, and Jiwei Hu. 2025. "Enhanced Graph Diffusion Learning with Transformable Patching via Curriculum Contrastive Learning for Session Recommendation" Electronics 14, no. 10: 2089. https://doi.org/10.3390/electronics14102089
APA StyleLi, J., Gao, R., Yan, L., Yao, Q., Peng, X., & Hu, J. (2025). Enhanced Graph Diffusion Learning with Transformable Patching via Curriculum Contrastive Learning for Session Recommendation. Electronics, 14(10), 2089. https://doi.org/10.3390/electronics14102089