
VL-PAW: A Vision–Language Dataset for Pear, Apple and Weed

 , , , , ,
, , , , ,
Abstract
1. Introduction
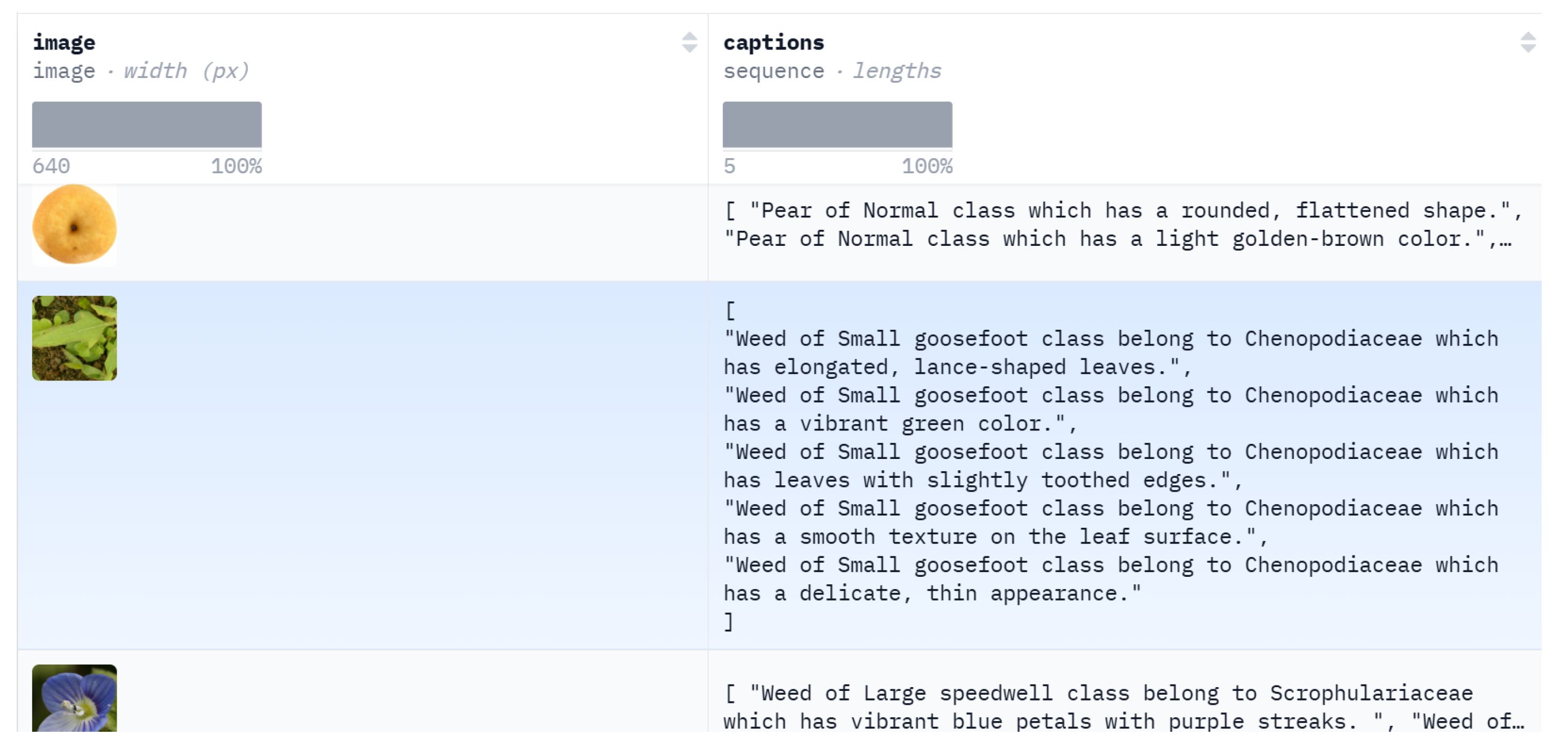
- VL-PAW dataset: A vision–language dataset for agriculture, consisting of 3.9 K image–caption pairs. It was collected through seminal research and annotated by field experts and OpenAI ChatGPT [10] (Section 3.1).
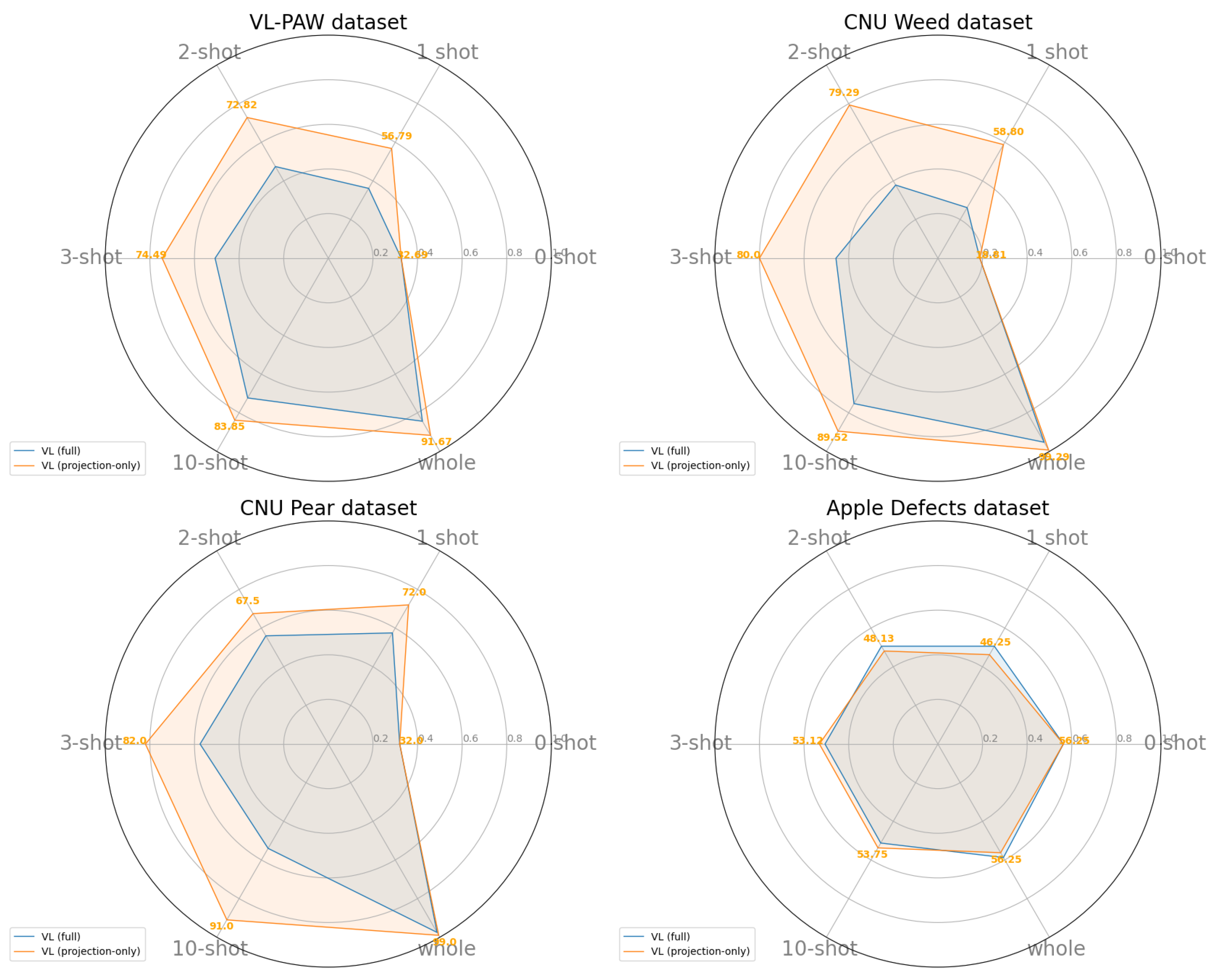
- VLM fine-tuning: Fine-tuning only the projection head of a CLIP model on VL-PAW yields the best performance in few-shot and full-dataset settings, and achieves results on par with fully trained ViT (Section 4.3).
- Benefit of descriptive captions: Using detailed captions enhances performance, particularly for fine-grained tasks like fruit inspection (Section 4.5).
2. Related Work
3. Materials and Methods
3.1. VL-PAW (Vision–Language Dataset for Pear, Apple, and Weed)
- CNU Pear Disease dataset: This dataset addresses disease classification in pears and includes 1000 images divided into four classes. It covers normal samples (400 images) and three disease categories: black spot (200 samples), moth disease (178 samples), and pear cicada disease (222 samples). The dataset emphasizes the challenge of distinguishing between healthy and diseased pears and among different diseases with overlapping visual features.
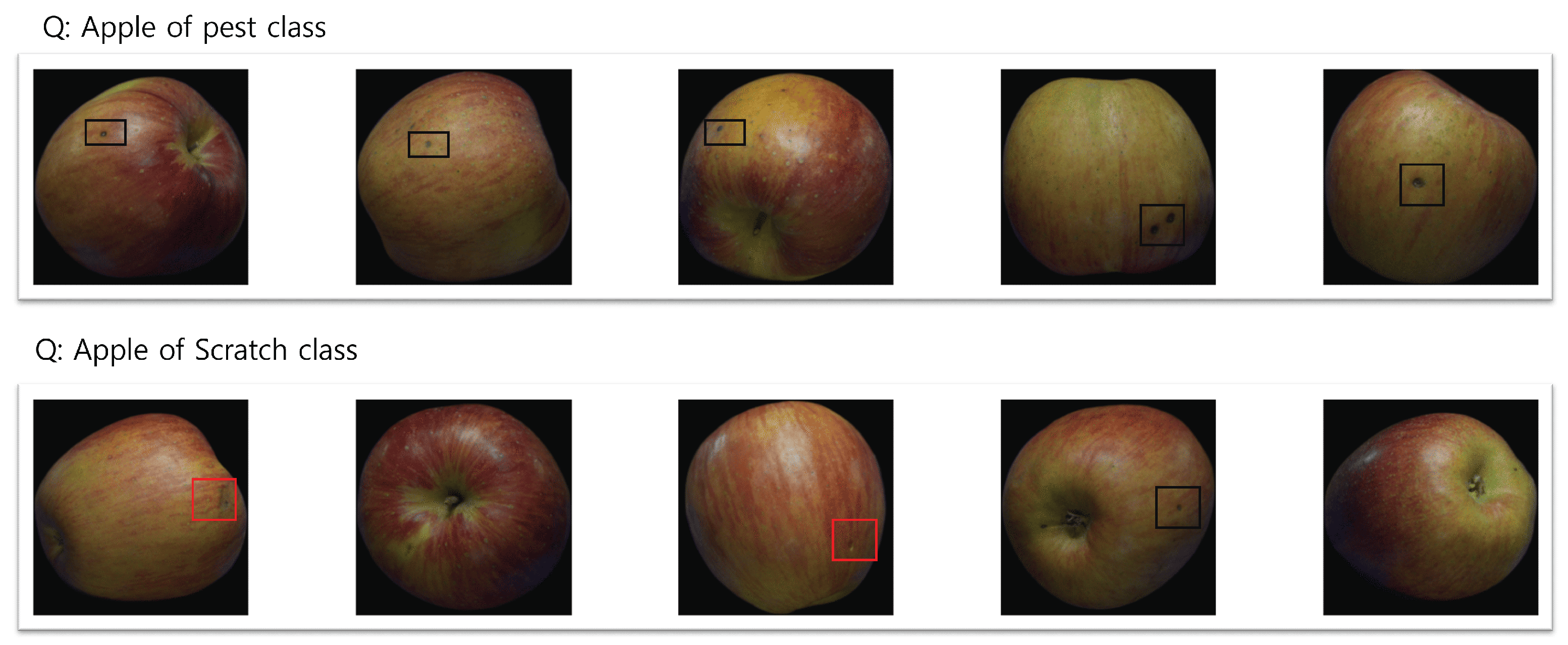
- Surface Subtle Apple Defects dataset: This subset is designed for detecting surface defects on Fuji apples. It contains 800 images distributed across two defect types: pest damage (393 samples) and scratches (407 samples). The dataset captures high-resolution apple surface images, reflecting real-world challenges in identifying small and fine-grained defects that are critical for industrial quality control.
- CNU Weeds dataset: This subset focuses on weed classification, consisting of images annotated at both family and class levels. It includes five families with 21 weed species, each represented by 100 samples, totaling 2100 images. The dataset features subtle inter-class variations, such as those within the Amaranthaceae family (e.g., common pigweed, slender amaranth, smooth pigweed), making it ideal for fine-grained classification tasks. Additionally, it includes diverse families such as Scrophulariaceae, Chenopodiaceae, Convolvulaceae and Asteraceae, ensuring a broad coverage of weed species.
“No response other information, only response 5 different sentences describing the physical properties of the object: color, size, shape, surface, appearance, texture, etc. Each sentence must follow this format: ‘object of cls class which has [context]’. [context] should be described details of the image. Each sentence separated by a new line.”
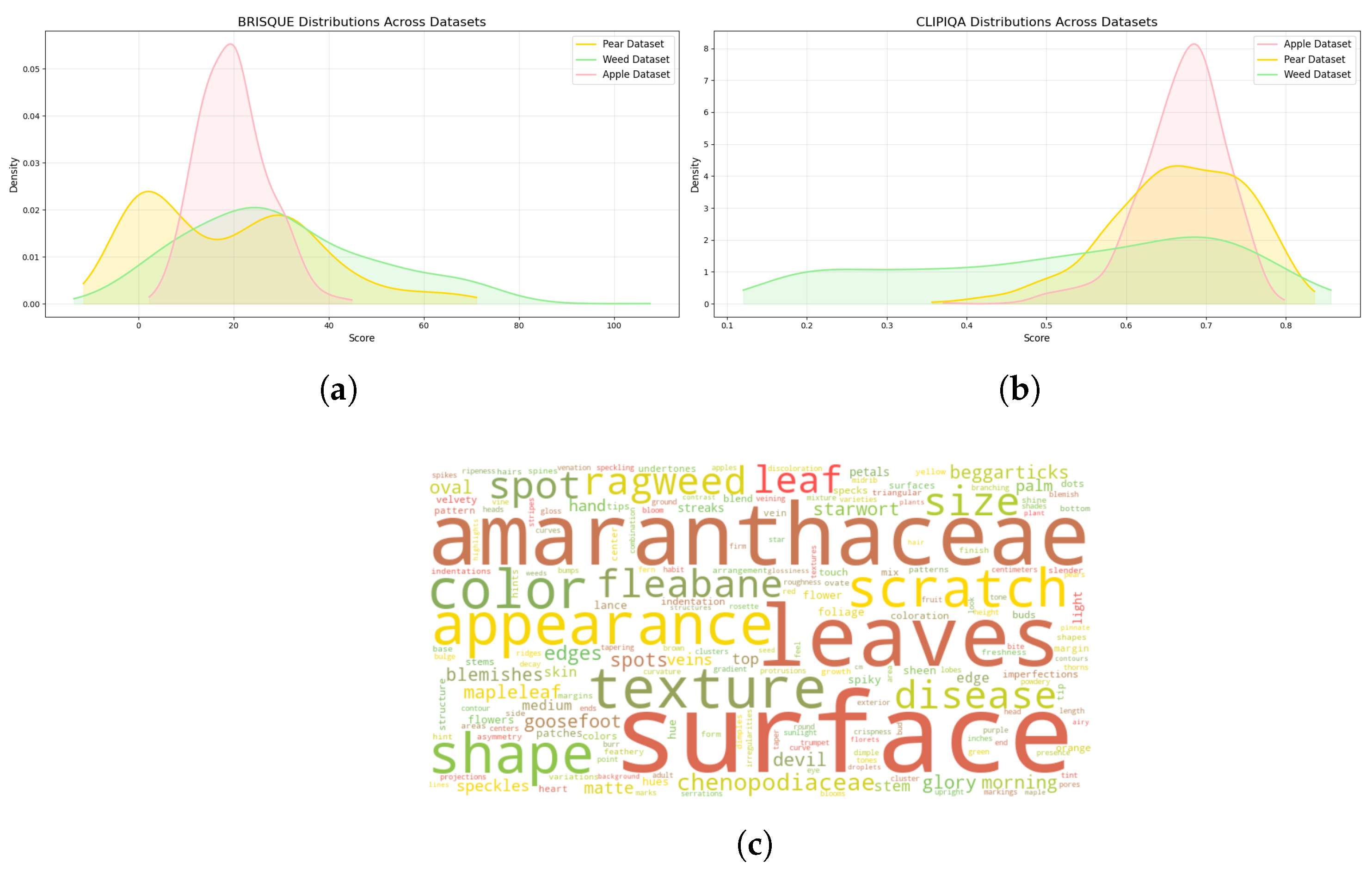
3.2. Dataset Assessment
3.3. Modeling
3.3.1. Architecture of CLIP
- Image Encoder: The image encoder is typically a Convolutional Neural Network (CNN) or Vision Transformer (ViT). It maps images I into an image embedding , where d is the dimensionality of the embedding.
- Text Encoder: The text encoder is based on a Transformer architecture. It encodes textual descriptions T into a textual embedding , sharing the same dimensionality as the image embeddings.
3.3.2. Training Objective
- Embedding Space Alignment: Given a batch of N image–text pairs , the image encoder produces embeddings , and the text encoder produces embeddings . These embeddings are normalized to unit vectors:
- Similarity score: The similarity between the ith image and the jth text embedding is measured using the cosine similarity:
- Contrastive loss: The model optimizes a symmetric cross-entropy loss across the image-to-text and text-to-image directions. The loss for a batch is given aswhere is a temperature parameter that controls the sharpness of the similarity distribution.
3.3.3. Text-Based Image Retrieval
4. Results
4.1. Settings
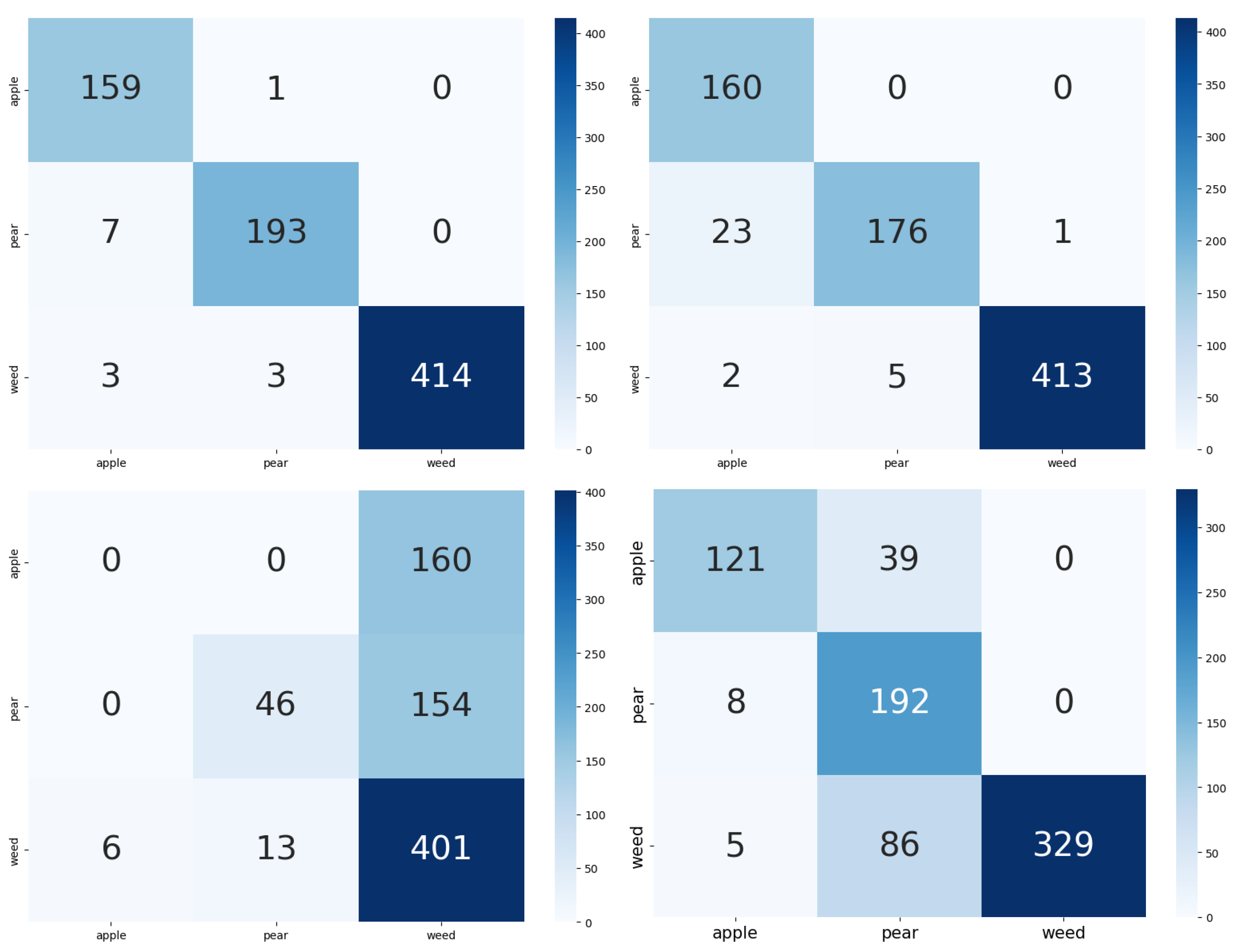
4.2. Zero-Shot Prediction
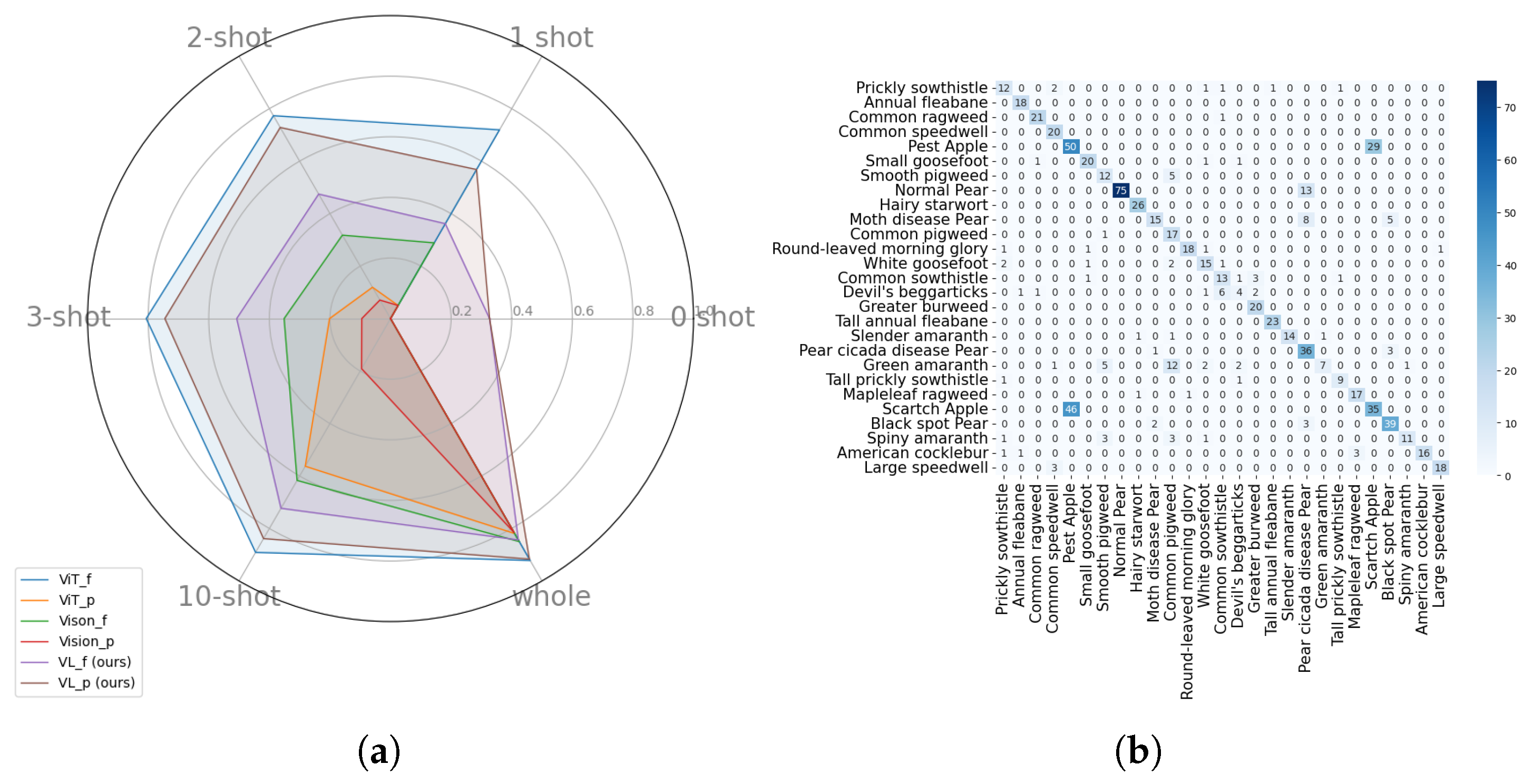
4.3. Few-Shot and Full Fine-Tuning
4.4. Effects of Descriptive Captions
4.5. Text-Based Image Retrieval
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Huang, J.; Jin, S.; Lu, S. Vision-language models for vision tasks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5625–5644. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, L.; Li, J.; Chen, D.; Pu, L.; Yao, H.; Huang, Y. VLLFL: A Vision-Language Model Based Lightweight Federated Learning Framework for Smart Agriculture. arXiv 2025, arXiv:2504.13365. [Google Scholar]
- Yu, P.; Lin, B. A Framework for Agricultural Intelligent Analysis Based on a Visual Language Large Model. Appl. Sci. 2024, 14, 8350. [Google Scholar] [CrossRef]
- Arshad, M.A.; Jubery, T.Z.; Roy, T.; Nassiri, R.; Singh, A.K.; Singh, A.; Hegde, C.; Ganapathysubramanian, B.; Balu, A.; Krishnamurthy, A.; et al. Leveraging Vision Language Models for Specialized Agricultural Tasks. In Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, AZ, USA, 26 February–6 March 2025; IEEE: New York, NY, USA, 2025; pp. 6320–6329. [Google Scholar]
- Nawaz, U.; Awais, M.; Gani, H.; Naseer, M.; Khan, F.; Khan, S.; Anwer, R.M. AgriCLIP: Adapting CLIP for Agriculture and Livestock via Domain-Specialized Cross-Model Alignment. arXiv 2024, arXiv:2410.01407. [Google Scholar]
- Gauba, A.; Pi, I.; Man, Y.; Pang, Z.; Adve, V.S.; Wang, Y.X. AgMMU: A Comprehensive Agricultural Multimodal Understanding and Reasoning Benchmark. arXiv 2025, arXiv:2504.10568. [Google Scholar]
- Awais, M.; Alharthi, A.H.S.A.; Kumar, A.; Cholakkal, H.; Anwer, R.M. AgroGPT: Efficient Agricultural Vision-Language Model with Expert Tuning. arXiv 2024, arXiv:2410.08405. [Google Scholar]
- Yang, X.; Gao, J.; Xue, W.; Alexandersson, E. Pllama: An open-source large language model for plant science. arXiv 2024, arXiv:2401.01600. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. GPT-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Girdhar, R.; El-Nouby, A.; Liu, Z.; Singh, M.; Alwala, K.V.; Joulin, A.; Misra, I. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15180–15190. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2021; pp. 8748–8763. [Google Scholar]
- Schuhmann, C.; Vencu, R.; Beaumont, R.; Kaczmarczyk, R.; Mullis, C.; Katta, A.; Coombes, T.; Jitsev, J.; Komatsuzaki, A. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv 2021, arXiv:2111.02114. [Google Scholar]
- Arshad, M.A.; Jubery, T.Z.; Roy, T.; Nassiri, R.; Singh, A.K.; Singh, A.; Hegde, C.; Ganapathysubramanian, B.; Balu, A.; Krishnamurthy, A.; et al. AgEval: A Benchmark for Zero-Shot and Few-Shot Plant Stress Phenotyping with Multimodal LLMs. arXiv 2024, arXiv:2407.19617. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners. Adv. Neural Inf. Process. Syst. 2022, 35, 22199–22213. [Google Scholar]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2021; pp. 4904–4916. [Google Scholar]
- Lee, J.H.; Vo, H.T.; Kwon, G.J.; Kim, H.G.; Kim, J.Y. Multi-Camera-Based Sorting System for Surface Defects of Apples. Sensors 2023, 23, 3968. [Google Scholar] [CrossRef]
- Yu, J.; Wang, Z.; Vasudevan, V.; Yeung, L.; Seyedhosseini, M.; Wu, Y. Coca: Contrastive captioners are image-text foundation models. arXiv 2022, arXiv:2205.01917. [Google Scholar]
- Zhai, X.; Mustafa, B.; Kolesnikov, A.; Beyer, L. Sigmoid loss for language image pre-training. In Proceedings of the CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 11941–11952. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2022; pp. 12888–12900. [Google Scholar]
- Sun, Q.; Fang, Y.; Wu, L.; Wang, X.; Cao, Y. Eva-clip: Improved training techniques for clip at scale. arXiv 2023, arXiv:2303.15389. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Dai, W.; Li, J.; Li, D.; Tiong, A.M.H.; Zhao, J.; Wang, W.; Li, B.; Fung, P.; Hoi, S. Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv 2023, arXiv:2305.06500. [Google Scholar]
- Bai, J.; Bai, S.; Yang, S.; Wang, S.; Tan, S.; Wang, P.; Lin, J.; Zhou, C.; Zhou, J. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv 2023, arXiv:2308.12966. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. Adv. Neural Inf. Process. Syst. 2023, 36, 34892–34916. [Google Scholar]
- Liu, H.; Li, C.; Li, Y.; Lee, Y.J. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26296–26306. [Google Scholar]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2556–2565. [Google Scholar]
- Chen, X.; Fang, H.; Lin, T.Y.; Vedantam, R.; Gupta, S.; Dollár, P.; Zitnick, C.L. Microsoft coco captions: Data collection and evaluation server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Schuhmann, C.; Beaumont, R.; Vencu, R.; Gordon, C.; Wightman, R.; Cherti, M.; Coombes, T.; Katta, A.; Mullis, C.; Wortsman, M.; et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Adv. Neural Inf. Process. Syst. 2022, 35, 25278–25294. [Google Scholar]
- Dai, D.; Li, Y.; Liu, Y.; Jia, M.; YuanHui, Z.; Wang, G. 15m multimodal facial image-text dataset. arXiv 2024, arXiv:2407.08515. [Google Scholar]
- Zhang, S.; Xu, Y.; Usuyama, N.; Xu, H.; Bagga, J.; Tinn, R.; Preston, S.; Rao, R.; Wei, M.; Valluri, N.; et al. BiomedCLIP: A multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs. arXiv 2023, arXiv:2303.00915. [Google Scholar]
- Zhang, K.; Ma, L.; Cui, B.; Li, X.; Zhang, B.; Xie, N. Visual large language model for wheat disease diagnosis in the wild. Comput. Electron. Agric. 2024, 227, 109587. [Google Scholar] [CrossRef]
- Trong, V.H.; Gwang-hyun, Y.; Vu, D.T.; Jin-young, K. Late fusion of multimodal deep neural networks for weeds classification. Comput. Electron. Agric. 2020, 175, 105506. [Google Scholar] [CrossRef]
- Han, N.B.N.; Lee, J.H.; Vu, D.T.; Murtza, I.; Kim, H.G.; Kim, J.Y. HAFREE: A Heatmap-Based Anchor-Free Detector for Apple Defect Detection. IEEE Access 2024, 12, 182799–182813. [Google Scholar]
- Tonmoy, S.; Zaman, S.; Jain, V.; Rani, A.; Rawte, V.; Chadha, A.; Das, A. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv 2024, arXiv:2401.01313. [Google Scholar]
- Peng, B.; Chen, K.; Li, M.; Feng, P.; Bi, Z.; Liu, J.; Niu, Q. Securing large language models: Addressing bias, misinformation, and prompt attacks. arXiv 2024, arXiv:2409.08087. [Google Scholar]
- Tan, Z.; Li, D.; Wang, S.; Beigi, A.; Jiang, B.; Bhattacharjee, A.; Karami, M.; Li, J.; Cheng, L.; Liu, H. Large language models for data annotation and synthesis: A survey. arXiv 2024, arXiv:2402.13446. [Google Scholar]
- Dong, H.; Li, J.; Wu, B.; Wang, J.; Zhang, Y.; Guo, H. Benchmarking and improving detail image caption. arXiv 2024, arXiv:2405.19092. [Google Scholar]
- Yin, H.; Hsu, T.Y.; Min, J.; Kim, S.; Rossi, R.A.; Yu, T.; Jung, H.; Huang, T.H. Understanding How Paper Writers Use AI-Generated Captions in Figure Caption Writing. arXiv 2025, arXiv:2501.06317. [Google Scholar]
- Huang, Y.; Arora, C.; Houng, W.C.; Kanij, T.; Madulgalla, A.; Grundy, J. Ethical Concerns of Generative AI and Mitigation Strategies: A Systematic Mapping Study. arXiv 2025, arXiv:2502.00015. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Wang, J.; Chan, K.C.; Loy, C.C. Exploring clip for assessing the look and feel of images. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2555–2563. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2020; pp. 1597–1607. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Güldenring, R.; Nalpantidis, L. Self-supervised contrastive learning on agricultural images. Comput. Electron. Agric. 2021, 191, 106510. [Google Scholar] [CrossRef]
- Shen, Z.; Liu, Z.; Qin, J.; Savvides, M.; Cheng, K.T. Partial is better than all: Revisiting fine-tuning strategy for few-shot learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 9594–9602. [Google Scholar]
- Fahes, M.; Vu, T.H.; Bursuc, A.; Pérez, P.; de Charette, R. Fine-Tuning CLIP’s Last Visual Projector: A Few-Shot Cornucopia. arXiv 2024, arXiv:2410.05270. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Family | Class | Samples |
|---|---|---|---|
| CNU Pear Disease | Normal | Normal | 400 |
| Disease | Black spot | 200 | |
| Moth disease | 178 | ||
| Pear Cicada disease | 222 | ||
| Surface Subtle Apple Defects | Fuji apple | Pest | 393 |
| Scratch | 407 | ||
| CNU Weeds | Amaranthaceae | Common pigweed | 100 |
| Slender amaranth | 100 | ||
| Smooth pigweed | 100 | ||
| Green amaranth | 100 | ||
| Spiny amaranth | 100 | ||
| Scrophulariaceae | Large speedwell | 100 | |
| Common speedwell | 100 | ||
| Chenopodiaceae | White goosefoot | 100 | |
| Small goosefoot | 100 | ||
| Convolvulaceae | Round-leaved morning glory | 100 | |
| Asteraceae | Common ragweed | 100 | |
| Mapleleaf ragweed | 100 | ||
| American cocklebur | 100 | ||
| Annual fleabane | 100 | ||
| Hairy starwort | 100 | ||
| Common sowthistle | 100 | ||
| Tall prickly sowthistle | 100 | ||
| Tall annual fleabane | 100 | ||
| Prickly sowthistle | 100 | ||
| Greater burweed | 100 | ||
| Devil’s beggarticks | 100 | ||
| Total | 8 | 27 | 3900 |
| Dataset | Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Apple Defects | CLIP | 56.25 | 56.83 | 56.04 | 54.87 |
| ALIGN | 51.88 | 53.48 | 51.39 | 43.04 | |
| BLIP | 52.50 | 75.80 | 51.90 | 37.69 | |
| CoCa | 57.50 | 60.46 | 57.15 | 53.67 | |
| CNU Weed | CLIP | 18.81 | 13.90 | 17.85 | 14.13 |
| ALIGN | 9.29 | 14.93 | 7.78 | 7.60 | |
| BLIP | 7.14 | 3.66 | 7.43 | 3.32 | |
| CoCa | 10.71 | 12.32 | 10.53 | 7.95 | |
| CNU Weed (5 families) | CLIP | 46.19 | 36.10 | 48.19 | 36.08 |
| ALIGN | 10.24 | 28.47 | 21.25 | 9.57 | |
| BLIP | 23.57 | 11.75 | 19.09 | 8.86 | |
| CoCa | 25.95 | 35.19 | 26.02 | 25.95 | |
| CNU Pear Disease | CLIP | 43.00 | 25.63 | 25.93 | 19.40 |
| ALIGN | 31.50 | 24.08 | 38.30 | 25.87 | |
| BLIP | 9.50 | 9.48 | 10.11 | 8.41 | |
| CoCa | 52.00 | 38.41 | 36.36 | 31.93 | |
| VL-PAW class | CLIP | 35.38 | 20.95 | 24.43 | 20.49 |
| ALIGN | 28.46 | 23.17 | 16.67 | 14.51 | |
| BLIP | 6.54 | 3.55 | 6.34 | 2.74 | |
| CoCa | 30.13 | 22.88 | 17.13 | 14.80 | |
| VL-PAW type | CLIP | 98.21 | 97.35 | 98.15 | 97.72 |
| ALIGN | 82.31 | 83.62 | 83.32 | 81.48 | |
| BLIP | 77.31 | 49.89 | 63.92 | 55.18 | |
| CoCa | 96.03 | 94.49 | 95.44 | 94.73 |
| Model | 0-Shot | 1-Shot | 2-Shot | 3-Shot | 10-Shot | Whole |
|---|---|---|---|---|---|---|
| ViTf [2] | - | 71.92 | 77.31 | 80.64 | 89.10 | 92.18 |
| ViTp | - | 5.00 | 11.92 | 20.13 | 56.28 | 81.92 |
| Vf [48] | - | 28.85 | 31.79 | 35.13 | 61.67 | 85.00 |
| Vp | - | 5.00 | 7.05 | 9.49 | 19.10 | 81.54 |
| VLf (ours) | 35.38 | 36.15 | 47.44 | 50.77 | 72.31 | 84.36 |
| VLp (ours) | 35.38 | 56.79 | 72.82 | 74.49 | 83.85 | 91.67 |
| Dataset | Caption | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Pear | Brief | 72.00 | 71.24 | 59.12 | 58.47 |
| Descriptive | 80.00 | 79.33 | 74.17 | 74.70 | |
| Apple | Brief | 46.25 | 45.42 | 46.02 | 44.29 |
| Descriptive | 54.37 | 56.03 | 54.67 | 51.80 | |
| Weed | Brief | 58.81 | 64.60 | 60.27 | 56.08 |
| Descriptive | 59.29 | 58.39 | 58.23 | 56.37 | |
| VL-PAW | Brief | 56.79 | 65.05 | 56.00 | 53.06 |
| Descriptive | 59.74 | 57.82 | 59.68 | 56.26 |
| Shot | Top@1 | Top@3 | Top@5 |
|---|---|---|---|
| 0-shot | 22.22 | 48.14 | 55.55 |
| 1-shot | 81.48 | 88.88 | 92.59 |
| 2-shot | 85.18 | 92.59 | 96.29 |
| 3-shot | 88.88 | 92.59 | 96.29 |
| 10-shot | 96.29 | 96.29 | 96.29 |
| whole | 96.29 | 96.29 | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, G.-H.; Anh, L.H.; Vu, D.T.; Lee, J.; Rahman, Z.U.; Lee, H.-Z.; Jo, J.-A.; Kim, J.-Y. VL-PAW: A Vision–Language Dataset for Pear, Apple and Weed. Electronics 2025, 14, 2087. https://doi.org/10.3390/electronics14102087
Yu G-H, Anh LH, Vu DT, Lee J, Rahman ZU, Lee H-Z, Jo J-A, Kim J-Y. VL-PAW: A Vision–Language Dataset for Pear, Apple and Weed. Electronics. 2025; 14(10):2087. https://doi.org/10.3390/electronics14102087
Chicago/Turabian StyleYu, Gwang-Hyun, Le Hoang Anh, Dang Thanh Vu, Jin Lee, Zahid Ur Rahman, Heon-Zoo Lee, Jung-An Jo, and Jin-Young Kim. 2025. "VL-PAW: A Vision–Language Dataset for Pear, Apple and Weed" Electronics 14, no. 10: 2087. https://doi.org/10.3390/electronics14102087
APA StyleYu, G.-H., Anh, L. H., Vu, D. T., Lee, J., Rahman, Z. U., Lee, H.-Z., Jo, J.-A., & Kim, J.-Y. (2025). VL-PAW: A Vision–Language Dataset for Pear, Apple and Weed. Electronics, 14(10), 2087. https://doi.org/10.3390/electronics14102087