1. Introduction
The latest World Tourism Barometer from UN Tourism reported that international tourism experienced a significant resurgence in 2024, with an estimated 1.4 billion tourists traveling abroad. This figure represents a near-complete recovery of pre-pandemic levels, achieving 99% of the 2019 benchmark. The increase of 11% over 2023, or an additional 140 million international tourist arrivals, was primarily driven by robust post-pandemic demand, strong performance from major source markets, and the continued recovery of destinations in Asia and the Pacific [
1]. While online travel blogs, tourism-focused Q&A platforms, and search engines provide scattered Points of Interest (POIs), these suggestions often fail to align with individual preferences [
2,
3]. Various model-based approaches, such as next-location, top-k location, and travel region recommendations, have been proposed to enhance travel recommendations [
4,
5,
6,
7]. Next-location recommendation techniques predict subsequent POIs based on users’ prior trajectories, while top-k location recommendations present a selection of appealing POIs. Although these approaches accurately predict user preferences for individual POIs, they struggle to generate complete itineraries that accommodate personalized constraints, such as designated start/end locations and travel time limitations [
8,
9,
10].
To incorporate multiple constraints, itinerary planning has been formulated as variants of the orienteering problem (OP) or traveling salesman problem (TSP), employing optimization techniques to generate recommended itineraries [
11,
12]. For example, reference [
3] formulated tour recommendation as an orienteering problem, addressing time limits and fixed-POI constraints via PERSTOUR, prioritizing POI popularity and user preferences derived from trajectories. Reference [
13] extended classical orienteering by introducing OPFP, where node scores depend on route context and inter-node relationships. Reference [
2] proposed DCC-PersIRE, combining unsupervised deep learning for POI embeddings with ILS-based optimization to balance user interest and POI popularity within time budgets. These methods aim to arrange POIs into itineraries that maximize tourist satisfaction while adhering to temporal and spatial constraints. However, accurately capturing user interests remains challenging.
Despite advancements in model-based and optimization-based methods, model-based methods need to find the best parameter set to achieve high prediction accuracy [
14,
15], while optimization approaches must set up many constraints and might generate unreasonable answers [
2,
16]. Unlike the two methods, sequential pattern mining, which is based on the users’ previous visiting experience, can generate personalized itineraries and avoid the problems caused by the two methods. For instance, Reference [
17] proposed a touring path suggestion system that utilizes previous popular visiting trajectories and a time-interval sequential pattern mining algorithm to generate personalized tours. Reference [
18] introduced the Location-Item-Time (LIT) sequence to describe spatial and temporal behavior in theme parks, developing the LIT PrefixSpan algorithm to discover frequent LIT patterns. They also proposed a route suggestion procedure to retrieve suitable patterns based on visitor preferences, such as time constraints and favorite items. Reference [
19] proposed a novel approach to integrating diverse website tourism data, creating a comprehensive POI knowledge base and structured POI visit sequences. A POI-Visit sequential pattern mining algorithm is developed to generate fine-grained candidate POI routes, incorporating various tourism contexts. The system then retrieves and ranks these routes based on the querying tourist’s specific contexts, such as travel duration, companion type, visit season, and preferred POI types.
Although sequential pattern mining is increasingly used for personalized itinerary recommendations, the current approaches still face three challenges that hinder their practical effectiveness. First, they often rely on a single social media dataset and ignore key variations in users’ time and category preferences. For example, older people like to travel in the early morning, while young people prefer to travel in the afternoon. In addition, family tourists prefer theme parks, while single tourists prefer museums. Ignoring the difference between the users’ time and category preferences makes the generated candidate sequence unsuitable for the target user. Second, most systems evaluate itinerary quality solely based on POI preferences, overlooking crucial factors such as optimal visiting times and travel distance, significantly affecting a tour’s feasibility and comfort [
2,
3,
14]. For example, suppose the best visiting time for A is 10:00, and that for B is 12:00. In that case, the sequence A–B should be a better choice than the sequence B–A if the start visiting time is 10:00. Third, previous studies generate sequence suggestions based on their tailored sequential pattern mining methods. Although these methods can effectively create a set of sequence suggestions, most are feasible but not near-optimal solutions [
20]. For example, if A–D–B, B–E–C, and A–B–C are sequences generated from sequential-pattern-mining-based methods, previous studies might suggest one of them if one’s support value is the largest. However, it should be worthwhile to try sequences of A–D–B–C and A–B–E–C to see if they can satisfy the constraints provided by the user. Exploring the possible sequences from the generated sequences should be worthwhile to obtain a better suggestion result. Addressing these challenges is critical for enhancing the accuracy of recommendations and improving tourists’ satisfaction, optimizing time use, and encouraging deeper engagement with destination experiences.
To address these limitations, we propose a novel personalized itinerary recommendation system. First, to address the issue that users on the social media platform are different, the user preference, which contains time and category preferences, is generated for all users. Users with similar preferences are clustered into the same group. Then, the sequential pattern mining algorithm is adopted to create frequent sequential patterns for each group. Second, to evaluate the suitability of an itinerary, we define the itinerary score according to the following three considerations: POI preference score, time-matching score, and travel distance score. The POI preference score evaluates how the user likes the POIs in the itinerary, which is determined by the POI popularity and the POI attractiveness of the itinerary. The time-matching score evaluates whether the expected arrival time to visit POIs in the itinerary is suitable. The travel distance score considers how the itinerary’s travel distance affects the user’s choice. Third, the Sequential-Pattern-Mining-based Itinerary Recommendation (SPM-IR) algorithm is developed to obtain a better suggestion. The SPM-IR algorithm checks whether the tentative itineraries generated from the sequential pattern mining process meet users’ needs. Then, the sequence extension function is proposed to extend every frequent sequential pattern as long as possible under the user-specified constraints using the frequent sequences generated by the users. Finally, the top-N candidate sequences ranked by the proposed itinerary score are returned to the target user as the itinerary recommendation.
The primary contributions of this research can be summarized as follows. First, this study introduces a novel clustering approach that segments users based on both time and category preferences, enabling the sequential pattern mining process to generate more relevant and tailored itineraries for different traveler types (e.g., families, solo travelers, seniors, and youth). Second, we introduce a comprehensive itinerary scoring mechanism that evaluates recommended routes through three essential dimensions: POI preference score, time-matching score, and travel distance score. This holistic evaluation significantly improves upon existing approaches that predominantly rely on POI preferences alone. By incorporating optimal visiting times and travel efficiency, our system generates recommendations that not only include attractions of interest but also present them in optimal sequence and timing. Third, we develop a novel SPM-IR algorithm that extends beyond traditional sequential pattern mining approaches to identify near-optimal solutions rather than merely feasible ones. The algorithm checks whether tentative itineraries meet user constraints and then systematically extends promising sequential patterns to create more comprehensive itineraries. Fourth, unlike conventional model-based and optimization-based methods, this approach minimizes the need for extensive parameter tuning or rigid constraints and provides a flexible, data-driven alternative by leveraging real-world sequential travel behavior patterns.
The remainder of this paper is organized as follows.
Section 2 reviews and discusses the literature and research related to this study.
Section 3 describes the proposed personalized itinerary recommendation system in detail.
Section 4 provides an implementation case to demonstrate the feasibility of the proposed system.
Section 5 summarizes the conclusions and future research directions.
3. Research Methodology
This study aims to develop a personalized itinerary recommendation system that improves tourists’ satisfaction and matches user constraints. The framework of the proposed personalized itinerary recommendation system is visually illustrated in
Figure 1. First, user travel itineraries, derived from geotagged social media photo records, form the data source for the following itinerary planning, which will be detailed in
Section 3.1. Second, the user preference vectors, which contain time and category preferences of a user, are derived for all users in
Section 3.2. Third, users with similar preferences are clustered into the same group to increase the accuracy of the recommendation. Then, the sequential pattern mining algorithm is adopted to generate the frequent sequential patterns for each group, which will be introduced in
Section 3.3. Finally, in
Section 3.4, when a target user requests an itinerary recommendation, the user group most similar to the target user is identified. Then, the group’s frequent sequential patterns are fed to the proposed Sequential-Pattern-Mining-based Itinerary Recommendation (SPM-IR) algorithm. If the pattern meets the user’s constraints, the pattern will be extended and generate a set of candidate sequences. Finally, the top-N candidate sequences ranked by the itinerary score are returned to the target user as the itinerary recommendation. To facilitate discussion, the main acronyms and notations used in this paper are listed in
Table 1.
3.1. User Itinerary Generation
With the rapid usage of smartphones, numerous photos tagged with GPS coordinates, timestamps, and hashtags have been uploaded to social media. Based on this spatial and temporal information, we can learn about tourist behavior in terms of travel sequence, staying time, and visiting areas in more detail. Let be the set of users. A photo record collected from photo-sharing social media can be represented as , where , is the timestamp of the photo taken, and and are the latitude and longitude of the photo, respectively.
Geographic coordinates in photo records are too inconvenient to be used in practice. Therefore, geographic coordinates in each photo record will be assigned to one of the closest known Points of Interest (POIs). Let the set of POIs be denoted as where is affiliated with latitude and longitude and category information , where are the set of categories. After the Haversine distance between a photo record and all is derived, the POI with the closest distance to will be considered the attraction the photo belongs to. After completing the process above, a photo record can be represented as , where . Note that a POI can belong to more than one category to indicate its multiple attributes. For example, a mall might belong to food, shopping, and entertainment categories.
During traveling, a tourist may take multiple photos at the same POI. In this case, the user’s consecutive photo records at the same POI will be aggregated as one visiting record. The earliest timestamp of the consecutive photo records is considered the arrival time for the POI. In contrast, the last timestamp of the consecutive photo records is regarded as the departure time for the POI. Thus, a visiting record can be represented as where , , , is the arrival time at , and is the departure time at . Finally, the travel itinerary of user is represented as where is the ith visiting record.
3.2. User Preference Generation
In practice, tourists have different time preferences when visiting. For example, older people like to travel in the early morning, while young people prefer to travel in the afternoon. In addition, tourists might favor different types of POIs. Family tourists, for instance, prefer theme parks, while single tourists prefer museums. Therefore, a user’s preference should consider time preference and category preference.
3.2.1. Time Preference
To know the user’s time preference, we can observe whether a user’s itinerary falls in a specific time slot. Let the set of time boundaries be
. Based on
, we have time slots
,
, …,
. For example, if a day is divided into 4 time slots and
T = {07:00, 13:00, 18:00, 22:00}, we will have
= (07:00, 13:00],
= (13:00, 18:00],
= (18:00, 22:00],
= (22:00, 07:00]. As defined in
Section 3.1, the travel itinerary of user
is
and
, where
is the arrival time at
, and
is the departure time at
. Based on the definition, the preference in the time slot
for user
can be derived as follows:
3.2.2. Category Preference
In this study, category preference comprises category popularity and attractiveness. The popularity of category
can be derived as follows:
where
is the number of
that visit POIs with category
. Note that min–max normalization is applied to
to avoid the scaling problem.
The attractiveness of category
for user
can be defined as the average visit time of the POIs with category
for user
. The longer a user stays in the POIs with the category, the more attractive the POI category is to the user. The average visit time for user
to the POIs with category
can be derived as follows:
where
and
are the arrival and departure time in the visiting record
, respectively, and
,
represents the number of
that visit POIs with category
. Then, the attractiveness of POI category
to user
is formulated as follows:
By integrating Equations (2) and (4), the category preference that user
likes POI category
is formulated as follows:
where
is the important weight for
.
3.2.3. User Preference Vector
Based on time preference in Equation (1) and category preference in Equation (5), a user preference vector can be represented as follows:
The dimension of the user preference vector is .
3.3. User Clustering and Frequent Sequential Pattern Mining
To reduce the computational time and increase the accuracy of the recommendation, we cluster users with similar user preferences into the same group according to the K-means algorithm. Then, the sequential pattern mining algorithm is adopted to generate the frequent sequential patterns for each group.
3.3.1. User Grouping by the K-Means Algorithm
After all users are represented as vectors using Equation (6), the K-Means algorithm [
32] is used to cluster users into groups. The K-Means algorithm is a popular clustering algorithm because of its computational efficiency. First, the number of groups is determined. Then, the centroid of each group is randomly chosen from the users. Third, the distance between each user and all centroids is calculated, and users are assigned to the closest cluster centroid. Finally, the above steps are repeated until all groups’ centroids are no longer changed. To reduce the likelihood of POI misclassification, we used threshold-based Haversine distance matching and filtered out ambiguous or borderline assignments. Consecutive visits at the same POI were aggregated to enhance robustness further.
With the clustering process, users with similar preferences will be grouped together. Let be the set of groups clustered by the K-means algorithm and is the set of itineraries contributed by the users in group .
3.3.2. Sequential Pattern Mining for Each Group
This study applies a sequential pattern mining algorithm for each group to find frequent sequences. Sequential pattern mining is an effective method to find statistically relevant sequential patterns, where a sequential pattern is a frequent subsequence in the set of sequences. Given a set of sequences, sequential pattern mining can find all frequent subsequences that meet the user-specified minimum support. If the occurrence frequency of the subsequences in the sequence set is not lower than the minimum support threshold, it is the frequent subsequence [
18,
33,
34].
This research uses the PrefixSpan algorithm, one of the most popular sequential pattern mining algorithms [
29]. The input to the PrefixSpan algorithm includes the set of itineraries
D, and the minimum support value,
min_
sup. The output of the sequential pattern mining algorithm is the set of frequent sequential patterns (i.e., frequent sequential pattern sets) with different lengths
where
represents the sequential patterns with length
, and
is the
th sequential pattern with length
. In addition,
is the
-th sequential pattern with length
where
represents the
th POI in the sequential pattern
. The pseudocode of the PrefixSpan algorithm is shown in Algorithm 1.
| Algorithm 1 The PrefixSpan algorithm |
PrefixSpan(, S, min_sup)
// D: the set of itineraries, : a sequence (initially empty < >), : minimum support value
1 Scan D to find the support of each sequence starting with S that has one more item
2 foreach sequence R such that sup(R)
3 Output R
4 Create the projected database of R by doing a projection with D
5 Call PrefixSpan(, R, min_sup) |
For example,
is the set of users in group 1 clustered by the K-means algorithm.
contains users
and
, whose itineraries are
,
,
,
,
,
,
,
. Therefore,
, where the details of each itinerary are shown in
Table 2. If the input to the PrefixSpan algorithm is
and
, we have the output
=
where
(
,
(
), and
(
.
Table 3 shows the detailed support value for each frequent pattern.
3.4. Framework of the SPM-IR Algorithm
The proposed SPM-IR algorithm aims to find Top-N sequences that meet all the constraints users input and are ranked by the proposed itinerary score.
3.4.1. Frequent Sequential Patterns Retrieval
When a target user requests an itinerary recommendation, we need to know which group the target user should belong to. This research uses cosine similarity to measure the similarity between the target user and the centroid of a group since cosine similarity pays more attention to the difference in the direction of the two vectors. The similarity between the target user
and the centroid of group
can be formulated as follows:
where
and
represent the preference vectors of target user
and the centroid of group
, respectively. If the cosine similarity between the target user and the group’s centroid is the highest, the frequent sequential patterns in the group are input into the proposed SPM-IR algorithm for further processing.
3.4.2. Itinerary Score Calculation
To evaluate the suitability of an itinerary generated by the proposed SPM-IR algorithm, we define the itinerary score according to the following three considerations. First, the POI preference score evaluates how the user likes the POIs in the itinerary, which is determined by the POI popularity and POI attractiveness of the itinerary. Second, the time-matching score evaluates whether the expected arrival time to visit POIs in the itinerary is suitable. Third, the travel distance score considers how the itinerary’s travel distance affects the user’s choice.
The POI preference score evaluates how the user likes the POIs in the itinerary. In this study, the POI preference can be determined by the POI popularity and POI attractiveness. The popularity of POI
can be evaluated as follows:
where
is the number of users
that visit POI
. Note that min–max normalization is applied to
to avoid the scaling problem. In addition, the average visit time for user
to POI
can be defined as follows:
where
and
are the arrival and departure time in the visiting record
, respectively, and
,
represents the total number of
that visit POI
. Then, the attractiveness of POI
to user
is formulated as follows:
By integrating the POI popularity and POI attractiveness, the preference that user
likes POI
is as follows:
where
is the important weight for
. Finally, since an itinerary consists of a set of POIs, the POI preference score of itinerary
for user
can be derived by:
People tend to visit POIs at the time they feel best. In this study, the visiting frequency of a POI for all users in each time slot is used to evaluate whether the time slot is suitable for visiting. If the visiting number of a POI in a time slot is high, the time slot should be ideal for visiting. In this study, the suitability of POI
being visited in time slot
can be defined as follows:
where
is the number of POI
visits during the time slot
. Note that the definition of the time slot can be referred to in
Section 3.2.1. Based on Equation (13), the time-matching score that someone visits POI
at time
can be formulated as follows:
Since the sequential pattern
does not include time information, the arrival time of each POI should be estimated. The arrival time of POI
,
can be derived as follows:
where
is the start time of the itinerary provided by the user,
is the average visiting time of all users in POI
, and
is the transportation time, while
is the traveling speed. Therefore, the time-matching score for itinerary
is as follows:
The travel distance of an itinerary is also an important factor affecting whether a user likes it since most people do not want to spend too much time on transportation. It is common that the longer the travel distance of an itinerary, the less likely a user is to like it. Therefore, the itinerary distance score can be derived by the total travel distance of the itinerary
:
where
indicates the distance between
and
.
Finally, the itinerary score that indicates how user
likes itinerary
can be formulated as follows:
where
is the normalized POI preference score defined in Equation (12),
is the normalized time-matching score defined in Equation (16),
is the normalized itinerary distance score of
defined in Equation (17), respectively, and
,
and
are the weights of each factor.
3.4.3. The SPM-IR Algorithm
The input to the proposed SPM-IR algorithm includes the minimum time length of the candidate itinerary
, the starting POI of the candidate itinerary
, the ending POI of the candidate itinerary
, the set of frequent sequential patterns with length 1 to length
n , and the number of recommended itineraries
. The output is the
itineraries ranked with the itinerary scores. Note that
, where
represents the sequential patterns with length
. In addition,
is the
-th sequential pattern with length
where
is the
-th POI in the sequential pattern. Lines 3 to 8 show that the algorithm starts from the sequential patterns with the longest length
, and checks each pattern
whether its traveling time is no greater than
Tl (i.e.,
) and whether its starting POI and the ending POI meet the user-specified constraints or not. If it is true, the algorithm will call the sequence extension function
and return a set of candidates
that meet the user-specified minimum time length
. Lines 9 to 12 show that the algorithm evaluates the score of each sequence in the candidate list
and return the top-N itineraries according to their itinerary score as the final recommendation. The pseudocode of the proposed SPM-IR algorithm is shown in Algorithm 2.
| Algorithm 2 The SPM-IR algorithm |
INPUT:
// the minimum time length of the candidate itinerary
// the starting POI of the candidate itinerary
// the ending POI of the candidate itinerary
// the set of frequent sequential patterns with length 1 to length n
// the number of recommended itineraries
OUTPUT:
// N itineraries ranked with the itinerary scores
1 begin
2
3 for do //
4 for = do //
5 foreach in do
6 if
7 // see Algorithm 3 for details
8 =
9 foreach in do
10 calculate the itinerary score using Eq (18)
11 = the set of top N itineraries ranked with the itinerary score
12 return |
The input to the sequence extension function includes the frequent sequential pattern to be extended , the set of frequent sequential patterns with length 1 to length n and the minimum time length of the candidate itinerary , while the output is the set of sequences after applying the extension function to , . The function is a recursive function that tries to find all possible sequences that can be extended from . In lines 4 to 8, the function checks every sequence from . If the traveling time of exceeds the user-specified minimum time length (), will not be put into . Otherwise, it will recursively call function , which finds any possible sequence extended from and puts them into . In lines 9 to 12, when all possible extensions do not satisfy the time constraints, will be the candidate sequence. Otherwise, the function will return a set of candidates that extend from to back into the proposed algorithm.
In the sequence extension function,
tries to find a sequence
which meets two constraints. First, the starting POI and ending POI of
must be two consecutive POIs in
. Second, every POI in
must not be duplicated with the POIs in
. Line 17 shows that the function extends the sequence between every two consecutive POIs in
. Line 18 ensures that
is long enough to extend
. Line 21 checks if the starting POI and ending POI of the sequence
meet the first constraint or not, while line 23 checks if
conforms to the second. If
meets both constraints, the function will extend
between position
and
using
in line 24. Therefore, the extended sequence
will be appended to the candidate sequence
. Finally,
will return
which contains every possible extension result of the input sequence
into
. The pseudocode for the sequence extension function is shown in Algorithm 3.
| Algorithm 3 The sequence extension function |
INPUT:
// the frequent sequential pattern to be extended
// the set of frequent sequential patterns with length 1 to length n
// the minimum time length of the candidate itinerary
OUTPUT:
// The set of sequences after applying the extension function to ls.
1 begin
2
3
4 foreach in do
5 if )
6
7 else
8
9 if
10 return
11 else
12 return
13 end
:
14 begin
15
16
17 for do
18 for do //
19 for = do //
20
21 if )
22
23 if every in do
24 =
25 = +
28 return
29 end |
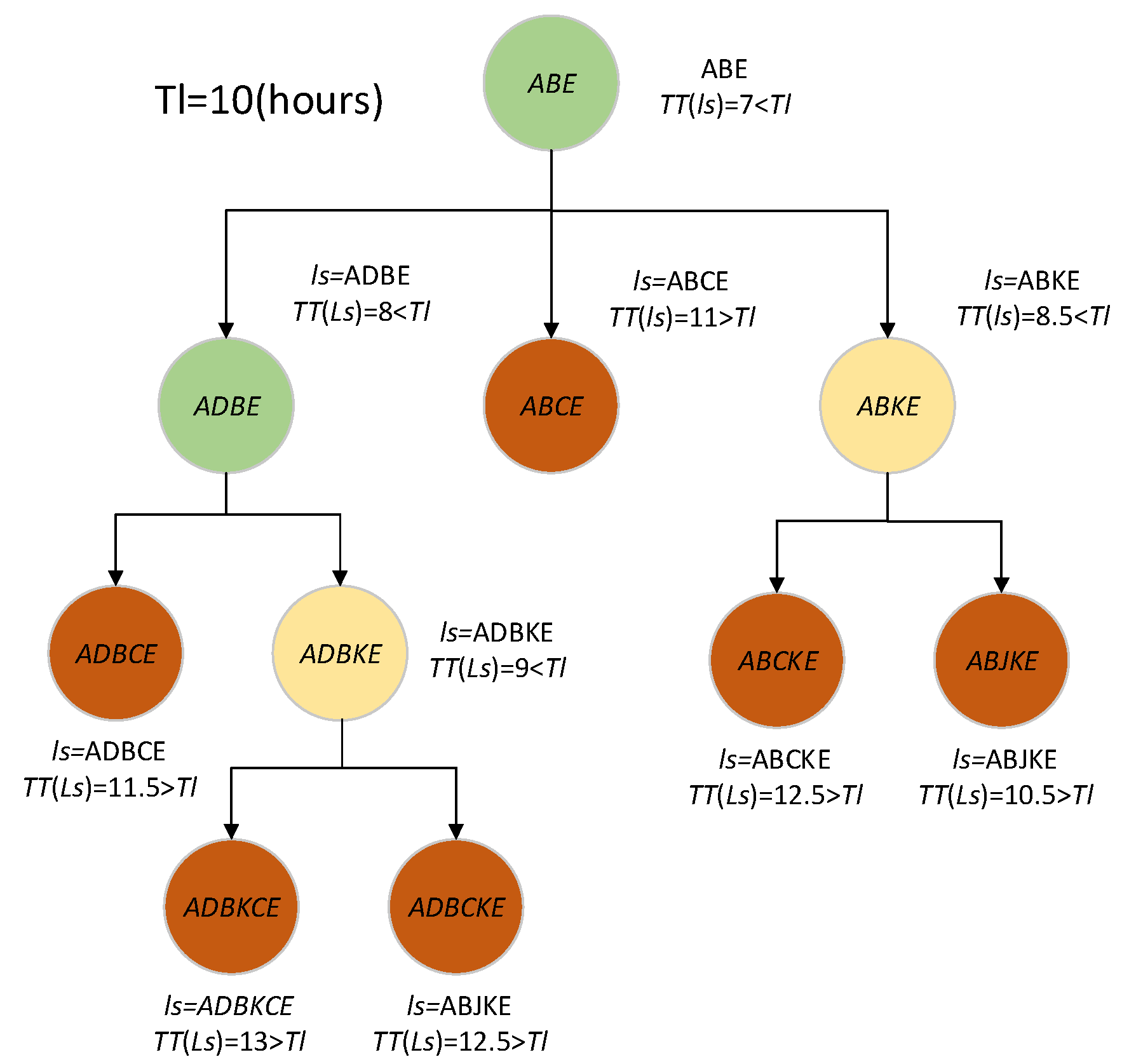
Figure 2 illustrates the process of the sequence extension function
. Assume
,
h. If
h,
will be extended since
. Assume the sequence extension function
returns
and
,
, and
, respectively. Since
,
will not be extended anymore. The candidate sequences returned by
are
. Since
, sequence <ADBCE> will return
. However,
,
will return
. If both
and
are greater than 10, the sequence
will return itself as the candidate sequence to its parent <ADBE>. Since <ADBE> receives non-empty children’s return, which is <ADBKE>, <ADBE> will return <ADBKE> as a candidate sequence to <ABE>. A similar process will be conducted for <ABKE>. Since the traveling times of candidate sequences returned by
,
, are all greater than 10,
will return itself as the candidate sequence. Finally, the candidate sequence
will be obtained. Note that both green and yellow nodes perform the extension process. The green node represents a better solution that can be found in its children, but the yellow node represents no better solution found in its children. The red node represents that the extension process is unnecessary since the itinerary’s traveling time exceeds the time limitation.
4. Implementation
4.1. Dataset Collection
The dataset utilized in this study was obtained through the online Flickr API. The API was used to collect the metadata information from photos taken between 1 January 2013 and 31 December 2022, within a 16 km radius of the center of San Francisco, California. The dataset includes 1,666,957 photo records contributed by 21,418 unique users. As shown in
Table 4, each record includes the photo ID, owner ID, photo taken time, latitude, and longitude of the photo. After eliminating duplicated and incomplete records, 1,027,774 records contributed by 21,418 unique users are studied in the following implementation.
4.2. The Implementation Example
Forty-five popular attractions in San Francisco were selected from Wikipedia, Planetware, Tripadvisor, and Yelp as the set of POIs. This enables the modeling of high-frequency tourist behavior, though we acknowledge that expanding the POI set in future studies could further improve itinerary granularity and diversity. In addition, eight categories, including Active Life, Education, Food, Public Service & Government, Shopping, Arts & Entertainment, Event Planning & Service, and Others, are used to describe the characteristics of POIs.
The POI assignment process was carried out by calculating the Haversine distance between the coordinates of each check-in record and all 45 POIs. After the POI assignment, the dataset was reduced to 494,474 photo records contributed by 5945 unique users. Next, a user’s consecutive photo records at the same POI are aggregated as one visiting record. Through aggregation, the final dataset consists of 110,219 itineraries contributed by 3469 users from 156,134 visiting records. Among them, the number of itineraries with length 1 is 86,583, those with length 2 to 5 is 50,462, those with length 6 to 10 is 14,940, and those with length 10 or above is 4149. The example itineraries in the dataset are shown in
Table 5.
In this implementation, one day is divided into four time slots, which are = (07:00, 13:00], = (13:00, 18:00], = (18:00, 22:00], = (22:00, 07:00]. Based on Equation (1), the time preference of all users in each time slot can be derived. Similarly, the category preference of all users can be obtained using Equation (5). Finally, by combining the time and category preferences, the user preference vector for 3469 users can be obtained. For example, the preference vector for user 100061618@N03 will be <0.388889, 0.555556, 0.555556, 0.000000, 0.00980, 0.000000, …, 0.06331>, where the dimension of the vector is 12 (=4 + 8).
Next, the K-Means algorithm is conducted based on users’ preference vectors. We used threshold-based Haversine distance matching to reduce the likelihood of POI misclassification and filtered out ambiguous or borderline assignments. Consecutive visits to the same POI were aggregated to enhance robustness further.
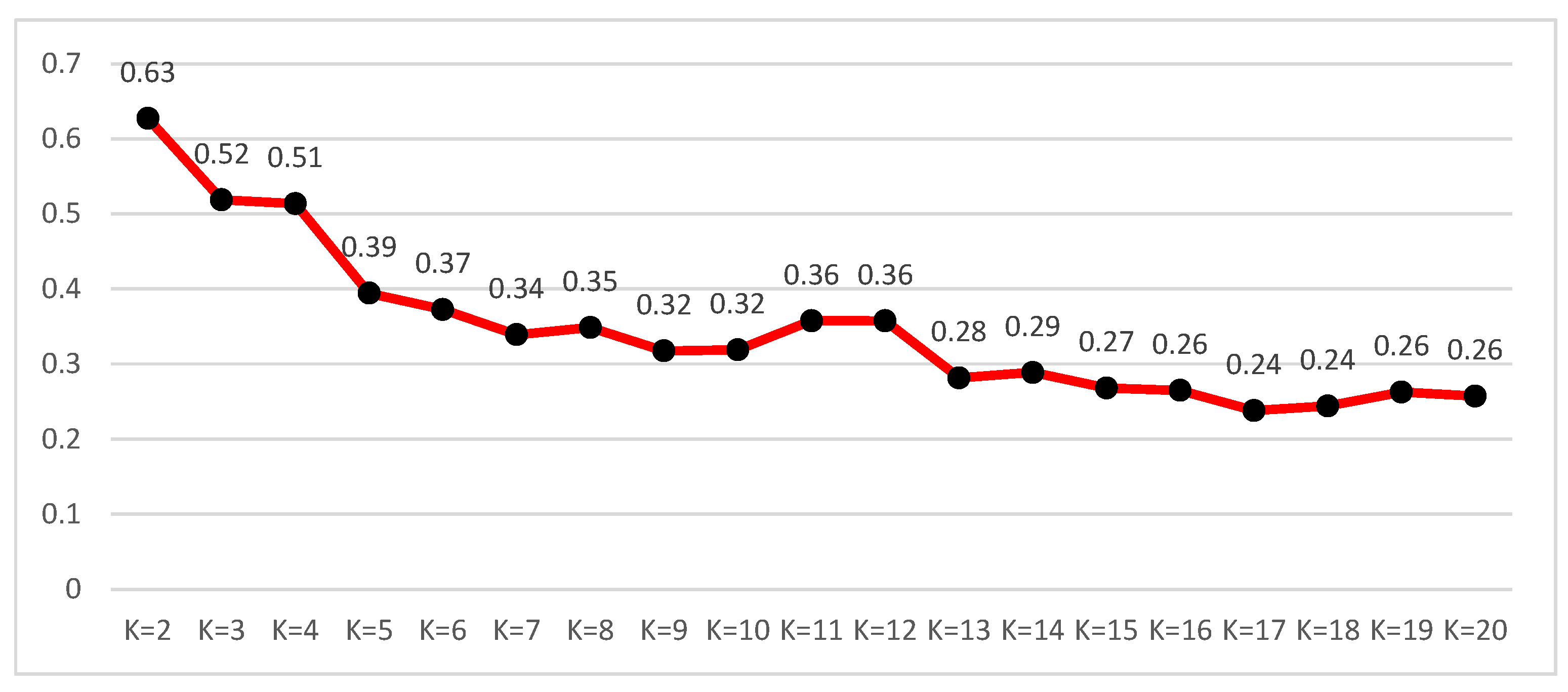
Figure 3 shows the silhouette values, which measure the cohesion and separation of data points within clusters when the K value is changed from 2 to 20. Based on the figure, K = 2 is selected for the following study since the silhouette value is the highest. When K = 2, the number of users in Group 1 is 1167 and that in Group 2 is 2302. In addition, 1167 users contributed 34,234 itineraries in Group 1, while 2302 users contributed 75,985 in Group 2.
Then, the sequential pattern mining algorithm is adopted to generate the frequent sequential patterns for each group. For Group 2, when the minimum support value is 5, 12,353 frequent sequential patterns are generated. Among 12,353 sequences, 45 are length 1, 1622 are length 2, 7488 are length 3, 2812 are length 4, and 386 are lengths greater than or equal to 5. The example frequent sequences are presented in
Table 6, where
to
are the set of lengths 1 to 6 frequent sequences in Group 2.
For a better explanation, let us take user “37996593020@N01”, whose real-life itinerary is [30, 41, 2, 17, 10, 9] with a travel time of 8 h 28 min, as the target user. First, the group to which the target user belongs is identified. Since the similarity between the target user and the centroid of Group 1 is 0.8674 and the similarity between the target user and the centroid of Group 2 is 0.9391, the target user will belong to Group 2. Next, the input to the SPM-IR algorithm is as follows: the starting POI as POI 30, the ending POI as POI 9, the minimum time length of the candidate sequence as 8 h 28 min, the number of recommended itineraries as 5, and the set of frequent sequential patterns from Group 2. With the inputs, the SPM-IR algorithm generated 26,625 candidate sequences and returned the Top 5 recommendations, which are shown in
Table 7.
4.3. Comparisons
Similar to the case in
Section 4.2, itineraries with at least five lengths in Group 2 are used as the dataset for comparison. Therefore, 500 itineraries that generate 2190 frequent sequential patterns by the sequential pattern mining algorithm are used as the real-life test dataset.
4.3.1. Evaluation Metrics
For each real-life itinerary in the testing set, we can derive its starting POI, ending POI, and itinerary time and input to the SPM-IR algorithm to generate a set of candidate sequences . The score of the real-life itinerary (i.e., ) and the score of a candidate sequence (i.e., )) can be evaluated using Equation (18). To assess the performance of different methods, the following metric is employed in this study:
Outperformance Rate (OR): OR counts the number of candidate sequences whose itinerary score exceeds the real-life itinerary’s score, divided by the total number of candidate sequences. A higher value indicates that the method produces superior itineraries than the real-life one. The definition of OR is as follows:
where
if the condition is true; otherwise,
.
Let us take the real-life itinerary [30, 41, 2, 17, 10, 9] described in
Section 4.2 as an example. As shown in
Table 8, the itinerary score of the real-life itinerary is 0.32542 and is ranked 25,246 among 26,625 candidate sequences generated by the SPM-IR algorithm. Therefore, the percentage that generated candidate sequences are better than itinerary l is OR = 25,246/26,625 = 94.82%. That is, 94.82% of the generated candidate sequences are better than [30, 41, 2, 17, 10, 9] regarding the itinerary score.
4.3.2. Ablation Study for User Preference
User preference is important to a personalized sequence recommendation system. This is especially true in our system since user preferences are used to identify similar user groups for later recommendations. This research integrates time preference (TP) and category preference (CP) as the final user preference. In this section, we conducted an ablation study to verify the validity of the two components in the final recommendation. The ablation experiments consist of three parts:
- ▪
-TP: to verify the performance of the category preference, we removed the time preference.
- ▪
-CP: to verify the performance of the time preference, we removed the category preference.
- ▪
Full: consider both TP and CP in this study.
Figure 4 shows the results of the ablation experiment. The experimental results indicate that the best OR metric (46.181%) occurred when TP and CP were considered (e.g., Full). The improvement was 5.9% compared to CP only and 8.23% in OR compared to TP only. In addition, adopting category preference (-TP) achieves a better OR metric (43.609%) than adopting time preference only (-CP) (42.364%).
4.3.3. Ablation Study for Itinerary Score
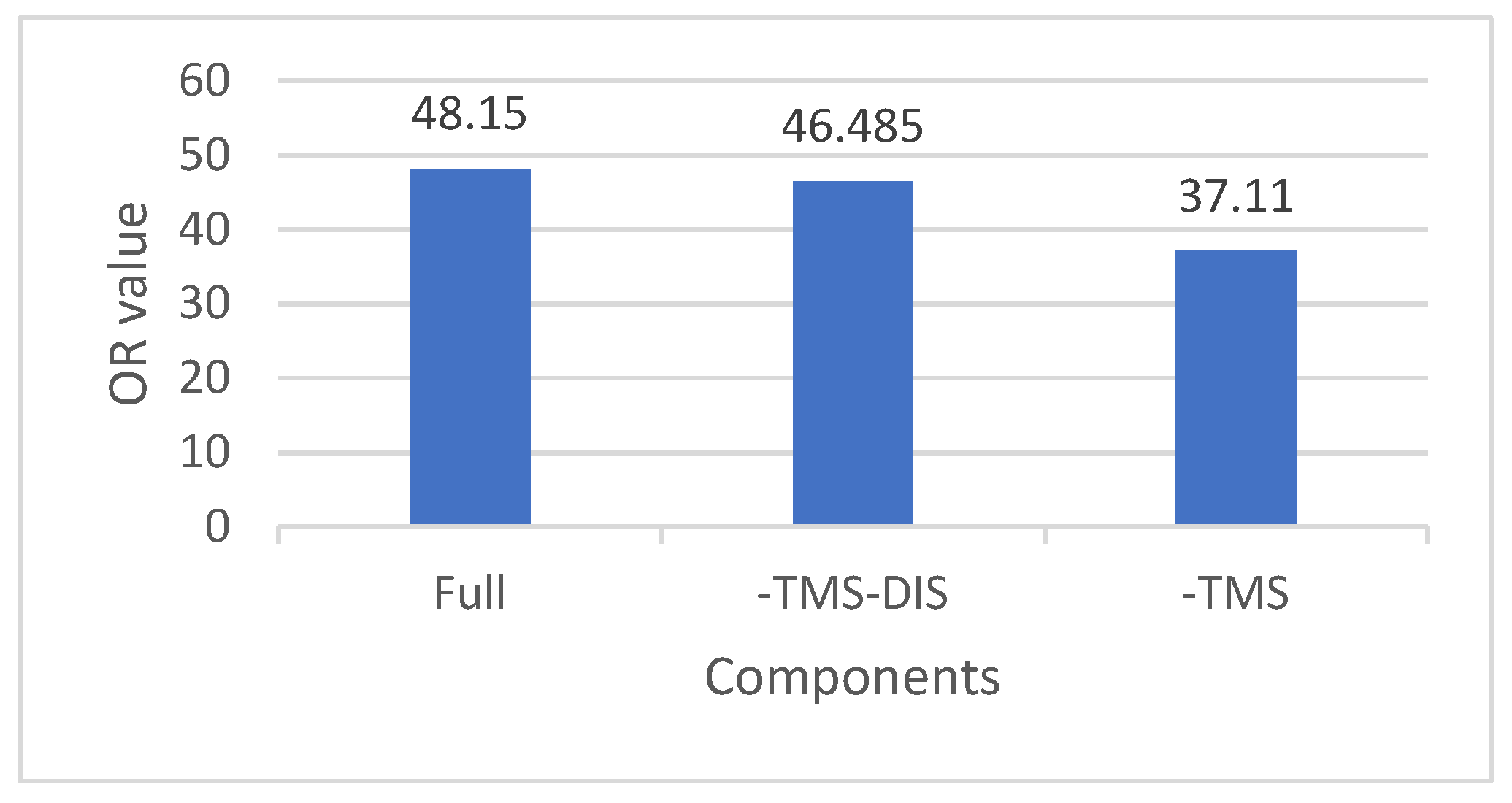
The itinerary score is important to evaluate the suitability of an itinerary in our system. This research integrates the POI preference score (PPS), time-matching score (TMS), and itinerary distance score (DIS) as the itinerary score to make a better itinerary evaluation. We conducted the following ablation experiment to verify the validity of the three components in the final recommendation. The ablation experiment consists of three parts:
- ▪
-TMS: to verify the performance of PPS and DIS, we removed TMS.
- ▪
-TMS-DIS: to verify the performance of PPS, we removed TMS and DIS.
- ▪
Full: considers PPS, TMS, and DIS simultaneously.
Figure 5 shows the results of the ablation experiment. The experimental results indicate that the best OR metric (48.150%) occurred when PPS, TMS, and DIS are considered in the itinerary score (e.g., Full). Removing TMS gives the most significant deduction (11.04%) in the OR metric. This shows that TMS is the most important component in the itinerary score design.
5. Conclusions
In this paper, we presented a novel personalized itinerary recommendation system that addresses key limitations in the existing approaches. Our system first clusters users with similar temporal and categorical preferences, enabling more targeted sequential pattern mining for each group. We then introduced a comprehensive itinerary evaluation incorporating three critical dimensions: POI preference score, time-matching score, and travel distance score. This approach ensures that the recommendation results align with user interests, optimizing visit timing and travel efficiency. Finally, our Sequential-Pattern-Mining-based Itinerary Recommendation (SPM-IR) algorithm extends beyond feasible solutions to near-optimal ones by systematically checking and extending frequent sequential patterns within user-specified constraints. The system returns top-N ranked itineraries that balance personal preferences with practical travel considerations, providing a more holistic approach to personalized travel planning.
A real-life dataset from geotagged social media is implemented to demonstrate the benefits of the proposed personalized itinerary recommendation system. Using a real-world dataset of over 494,000 POI-tagged photos and 110,219 itineraries from 3469 users, the system successfully clustered users and generated 12,353 frequent sequence patterns. For the evaluated target itinerary, 94.82% of the generated candidate sequences achieved a higher itinerary score than the real-life sequence. Moreover, ablation studies showed that incorporating both time and category preferences improved performance by up to 8.23% and that the time-matching score was the most critical component, contributing an 11.04% boost in itinerary quality. These results validate the effectiveness of the proposed multidimensional user profiling and itinerary-scoring approach.
Despite the promising results of the proposed SPM-IR system, several limitations should be acknowledged. First, while the Flickr dataset offers rich spatiotemporal travel records, we acknowledge that its users may not fully represent the general tourist population. Therefore, findings should be interpreted cautiously, and future work should validate the model with more diverse datasets. Second, we used threshold-based Haversine distance matching to reduce the likelihood of POI misclassification and filtered out ambiguous or borderline assignments. Consecutive visits to the same POI were aggregated to enhance robustness further. Future improvements could incorporate semantic or image-based verification of visited sites. Third, while the proposed itinerary score incorporates POI preference, time matching, and travel distance, other influential factors such as transportation mode, weather conditions, or budget constraints were not considered. Fourth, the sequence extension process is based on existing frequent patterns, which may limit its ability to generate highly novel routes for users with unique interests. These limitations allow future research to incorporate more contextual variables, expand data sources beyond social media, and enhance adaptability for niche user groups. Nonetheless, this study provides important implications for designing intelligent travel recommendation systems, emphasizing the value of integrating user segmentation, multi-criteria evaluation, and flexible sequence expansion to deliver more personalized and practical travel itineraries.
Several possible extensions and improvements can be considered for future research. First, the dataset used in this study is based on the Flickr dataset of San Francisco, California. However, the selection method of specific POIs can impact the performance of the proposed method. Further investigation can explore methods to determine the optimal number of POIs and refine the selection process. Second, sequential pattern mining heavily relies on the user experience and may encounter data sparsity issues with insufficient visiting records. Collecting more user data can significantly improve the performance of the proposed method. Third, it would be beneficial to conduct comparative studies with other existing methods using the pairwise comparisons method [
35] to understand the system’s effectiveness and performance better. Finally, due to data limitations, the current model does not incorporate contextual factors such as weather, local events, or travel group size. Future research could enhance the model’s realism and precision by integrating such variables from complementary data sources (e.g., event APIs, weather data, or survey input).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}