
Cache-Based Design of Spaceborne Solid-State Storage Systems


Abstract
1. Introduction
2. Methodology
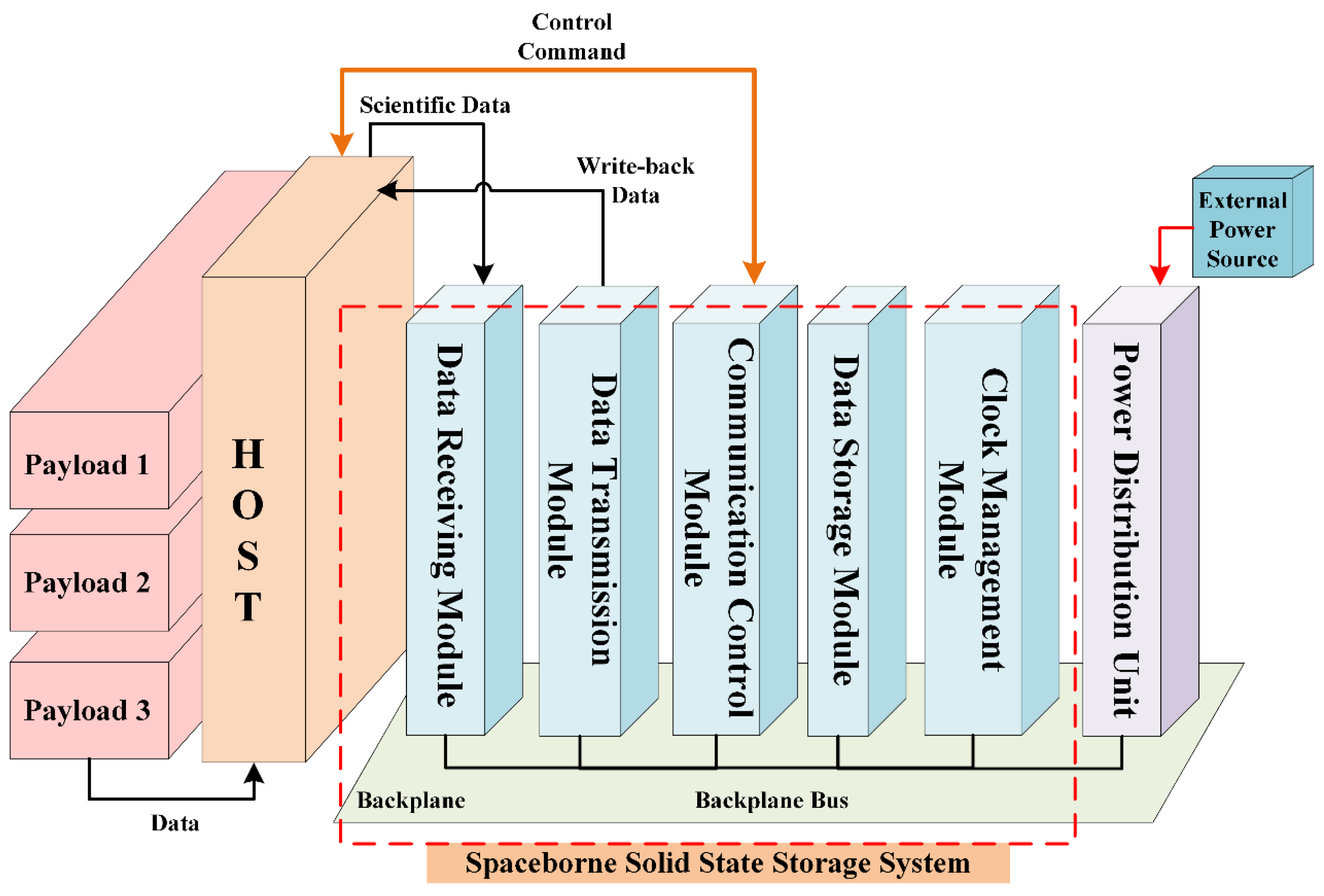
2.1. Overall Architecture
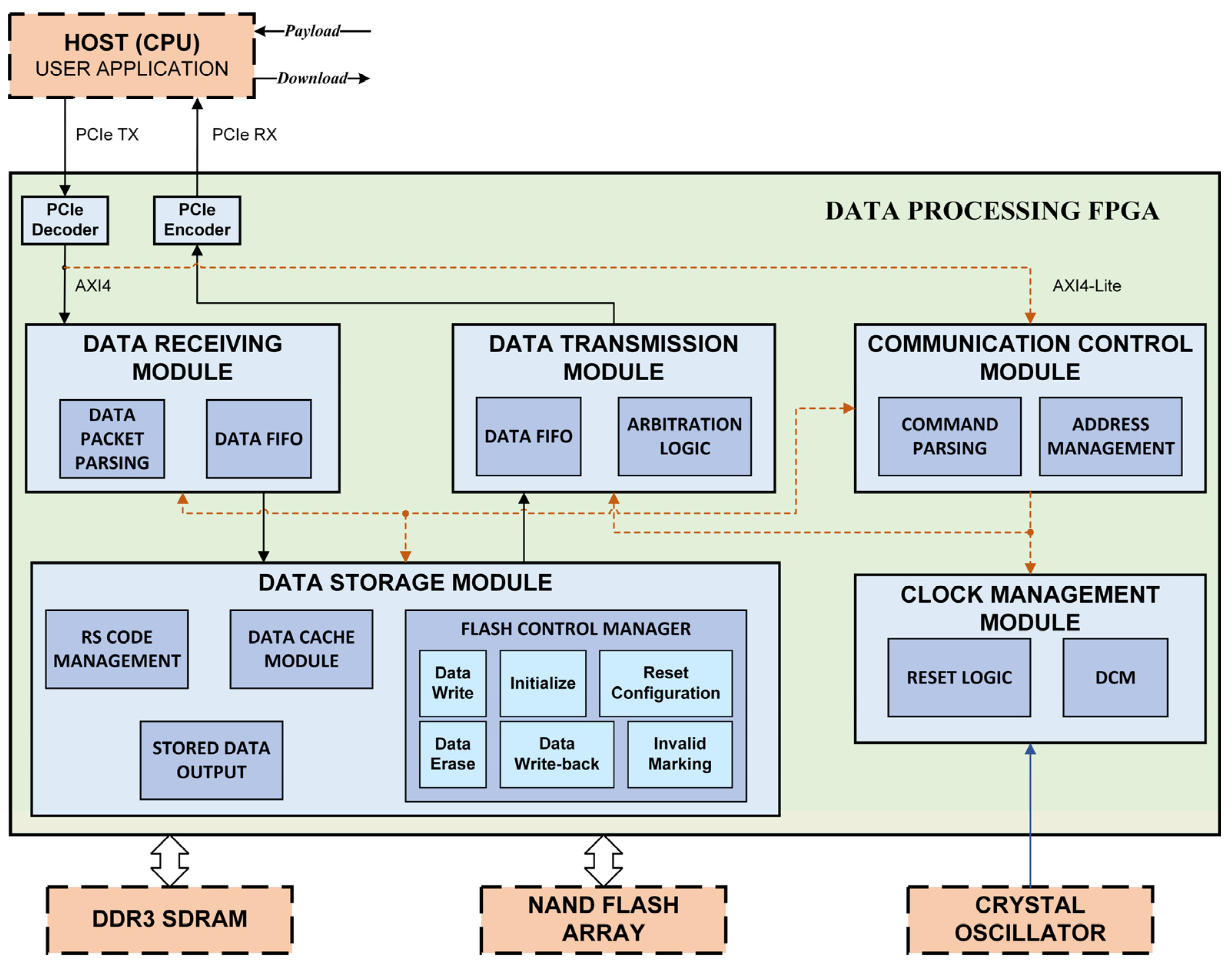
2.2. Storage System Functional Module Design
3. Results and Discussion
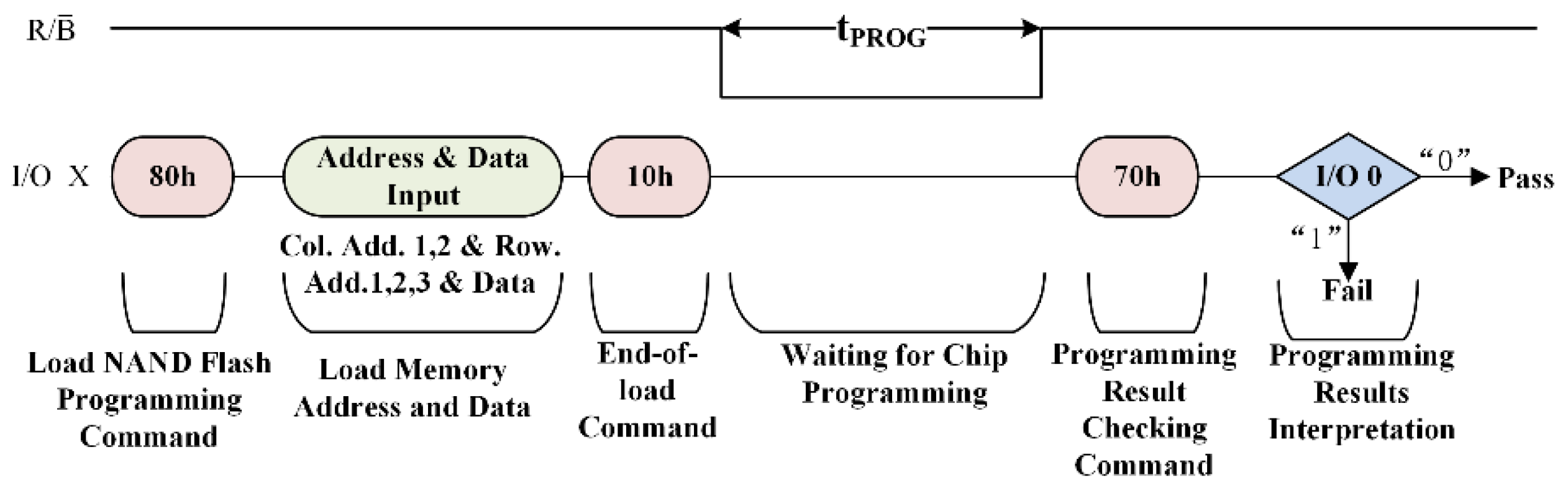
3.1. Analysis of Storage System Throughput Rate Constraints
3.2. Methods to Improve System Throughput
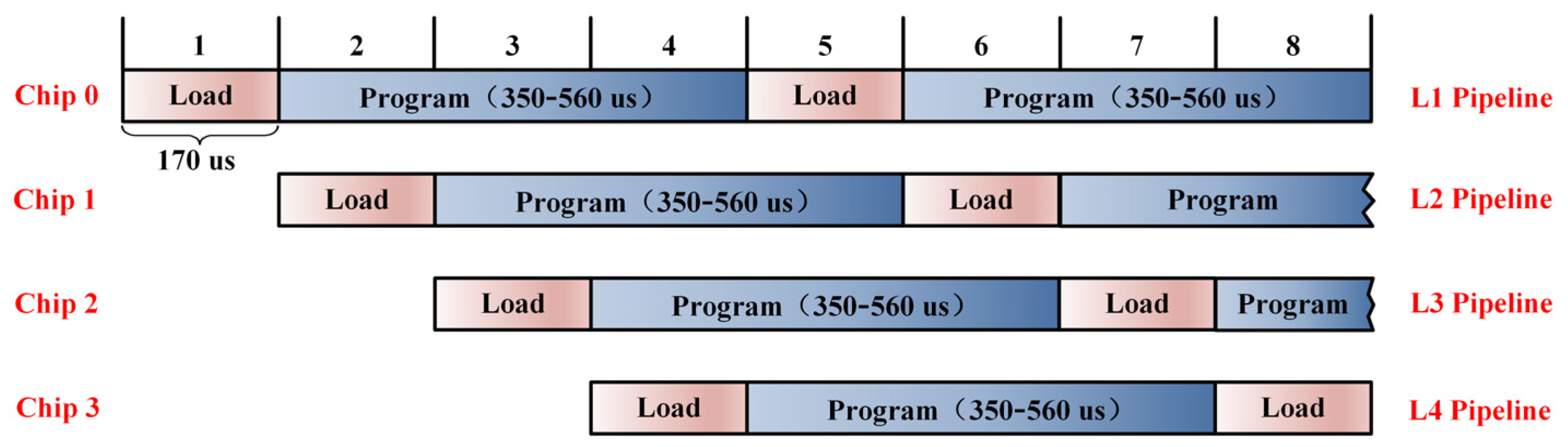
3.2.1. Pipeline Operation
3.2.2. Bus Parallel Expansion Technology
3.2.3. Caching Scheme Design
3.2.4. Channel Cache Scheduling and Storage Algorithm
| Algorithm 1: Channel cache scheduling and storage algorithm. |
| Input: ● Cache channel data transfer rates: v1, v2, …, vn. ● Data buffer status for each cache channel: s1, s2, …, sn. ● NAND FLASH working status (WAIT, PROGRAM, WRITE_BACK, ERASE). ● Minimum pipeline threshold K. Output: NAND FLASH data scheduling strategy. |
| 1 Initialize: Create a queue for each cache channel (vi, si). 2 Sort all cache channels by data transfer rates vi in descending order, then assign file numbers fi (i = 1,2,…,n). 3 for i = n downto 1 do // Poll cache channels from largest to smallest file number. 4 if NAND_Flash.state == FREE then 5 if Si ≥ K then 6 Choose cache channel i firstly with the highest data transfer rate. 7 Store file number fi, read data within the channel in FIFO order. 8 Buffer the data to NAND FLASH. 9 return scheduling strategy: PROGRAM scheduling. 10 else if NAND_Flash.state == WRITE_BACK then 11 Perform data playback operation. 12 return scheduling strategy: WRITE_BACK scheduling. 13 14 else if NAND_Flash.state == ERASE then 15 Perform data erase operation. 16 return scheduling strategy: ERASE scheduling. 17 else 18 Monitor NAND_Flash.state until NAND_Flash.state = FREE. 19 return scheduling strategy: WAIT scheduling. 20 end if 21 End |
3.2.5. Algorithm Complexity Analysis
- ▪
- Step 1: Initializing n queues incurs a time complexity of O (n).
- ▪
- Step 2: Sorting cache channels by transmission rates using optimal algorithms (e.g., quicksort/mergesort) requires O (n log n) time.
- ▪
- Step 3: Iterates through all n cache channels, starting from the maximum file number. Each iteration involves: constant-time conditional checks (Steps 4–18): O (1) per operation.
- ▪
- Worst-case: All channels satisfy si < K with persistent FREE NAND status, requiring full traversal: O (n).
- ▪
- Best-case: Immediate satisfaction at the first channel (si ≥ K): O (1).
- ▪
- Step 1: Queue creation per channel: O (n).
- ▪
- Step 2: Sorting auxiliary space (e.g., mergesort): O (n).
- ▪
- All other operations (status evaluation, strategy selection) use constant space: O (1)
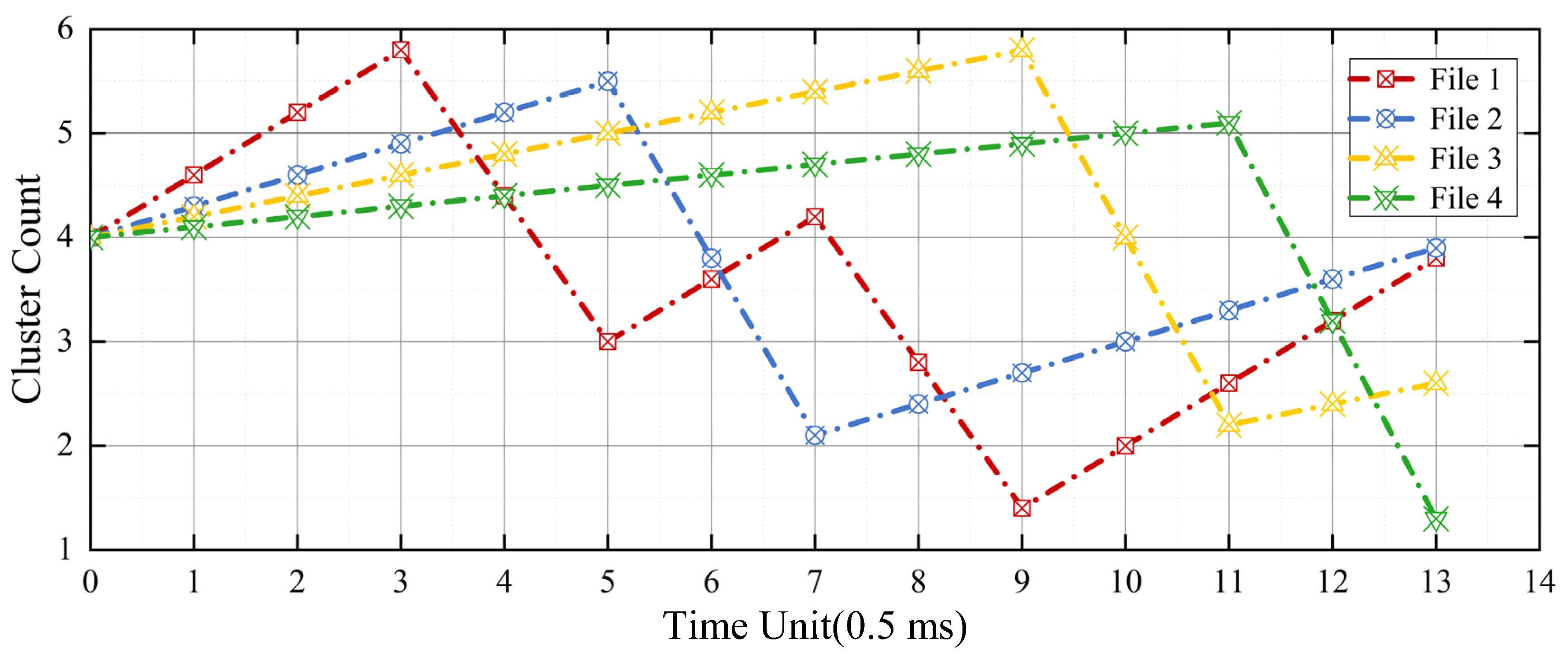
3.3. Simulation Validation
- Four-way load with a data rate of 1.2 Gbps, 600 Mbps, 400 Mbps, and 200 Mbps;
- Setting of file number from 1 to 4;
- Continuous input of load data;
- FLASH erase time of 1.5 ms, and 1 ms pipeline write of 4 data clusters;
- No storage failure.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SDRAM | Synchronous Dynamic Random Access Memory |
| SAR | synthetic aperture radar |
| MSI | multispectral imager |
| HSI | hyperspectral imager |
| DDR | double data rate |
| DMA | direct memory access |
| SPDK | storage performance development kit |
| FPGA | field programmable gate array |
| DCM | digital clock manager |
| FIFO | First in first out |
| RS | Reed–Solomon |
References
- Tu, S.L.; Wang, H.Q.; Huang, Y.; Jin, Z.H. A spaceborne advanced storage system for remote sensing microsatellites. Front. Inf. Technol. Electron. Eng. 2024, 25, 600–615. [Google Scholar] [CrossRef]
- Gong, Y.; Wang, Q.; Su, J. Efficient Management of FLASH Based Satellite Borne Storage. Microcomput. Inf. 2010, 26, 151. [Google Scholar]
- Luo, P.; Zhang, T. Data management of satellite-borne storage based on Flash. Appl. Res. Comput. 2018, 35, 479–482. [Google Scholar]
- Aourra, K.; Zhang, Q.X. An Energy Aware Mass Memory unit for small satellites using Hybrid Architecture. In Proceedings of the 20th IEEE International Conference on Computational Science and Engineering (CSE)/15th IEEE/IFIP International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; pp. 210–213. [Google Scholar]
- Xie, Y.; Xie, Y.Z.; Li, B.Y.; Chen, H. Advancements in Spaceborne Synthetic Aperture Radar Imaging with System-on-Chip Architecture and System Fault-Tolerant Technology. Remote Sens. 2023, 15, 4739. [Google Scholar] [CrossRef]
- Jemmali, M.; Boulila, W.; Cherif, A.; Driss, M. Efficient Storage Approach for Big Data Analytics: An Iterative-Probabilistic Method for Dynamic Resource Allocation of Big Satellite Images. IEEE Access 2023, 11, 91526–91538. [Google Scholar] [CrossRef]
- Wang, C.L.; Yin, L.; Shen, X.H.; Dong, Z.; Ke, L. Design and Implementation of Spaceborne Fast Router Based on SDRAM. In Proceedings of the IEEE 11th International Conference on Communication Software and Networks (ICCSN), Chongqing, China, 12–15 June 2019; pp. 452–457. [Google Scholar]
- Wang, G.Q.; Chen, H.; Xie, Y.Z. An Efficient Dual-Channel Data Storage and Access Method for Spaceborne Synthetic Aperture Radar Real-Time Processing. Electronics 2021, 10, 622. [Google Scholar] [CrossRef]
- Shi, X.J.; Zhang, Y.H.; Dong, X. Evaluation of BAQ on Tiangong-2 Interferometric Imaging Radar Altimeter Data Compression. In Proceedings of the 22nd International Microwave and Radar Conference (MIKON), Poznan, Poland, 14–17 May 2018; pp. 623–624. [Google Scholar]
- Xiao, X.; Li, C.J.; Lei, Y.J. A Lightweight Self-Supervised Representation Learning Algorithm for Scene Classification in Spaceborne SAR and Optical Images. Remote Sens. 2022, 14, 2956. [Google Scholar] [CrossRef]
- Vitolo, P.; Fasolino, A.; Liguori, R.; Di Benedetto, L.; Rubino, A.; Licciardo, G.D. Real-Time On-board Satellite Cloud Cover Detection Hardware Architecture using Spaceborne Remote Sensing Imagery. In Proceedings of the Conference on Real-Time Processing of Image, Depth, and Video Information, Strasbourg, France, 8–9 April 2024. [Google Scholar]
- Wang, S.; Zhang, S.; Huang, X.; Chang, L. Single-chip multi-processing architecture for spaceborne SAR imaging and intelligent processing. J. Northwestern Polytech. Univ. 2021, 39, 510–520. [Google Scholar] [CrossRef]
- Martone, M.; Gollin, N.; Rizzoli, P.; Krieger, G. Performance-Optimized Quantization for SAR and InSAR Applications. IEEE Trans. Geosci. Remote Sens. 2022, 60, 22. [Google Scholar] [CrossRef]
- Gollin, N.; Martone, M.; Villano, M.; Rizzoli, P.; Krieger, G. Predictive Quantization for Onboard Data Reduction in Future SAR Systems. In Proceedings of the 13th European Conference on Synthetic Aperture Radar (EUSAR), Electr Network. 29 March–1 April 2021; pp. 570–575. [Google Scholar]
- Wang, L.; Zhu, Y.; Shen, W.; Liang, Y.; Teng, X.; Zhou, C. Centralized Payload Management System for Dark Matter Particle Explorer Satellite. Chin. J. Space Sci. 2018, 38, 567–574. [Google Scholar] [CrossRef]
- Xu, Y.; Ren, G.; Wu, Q.; Zhang, F. Key technology of invalid block management in NAND flash-based image recorder system. Infrared Laser Eng. 2012, 41, 1101–1106. [Google Scholar]
- Xu, N.; Li, Z.Y.; Wang, Z.Q.; Han, X.D.; An, W.Y.; Wang, X.Y.; Feng, Y.J. Optimization design and realization of GEO satellite onboard computer. Chin. Space Sci. Technol. 2020, 40, 94–100. [Google Scholar] [CrossRef]
- Lv, H.S.; Li, Y.R.; Xie, Y.Z.; Qiao, T.T. An Efficient On-Chip Data Storage and Exchange Engine for Spaceborne SAR System. Remote Sens. 2023, 15, 2885. [Google Scholar] [CrossRef]
- Zhu, J.B.; Wang, L.; Xiao, L.M.; Qin, G.J. uDMA: An Efficient User-Level DMA for NVMe SSDs. Appl. Sci. 2023, 13, 960. [Google Scholar] [CrossRef]
- Ketshabetswe, K.L.; Zungeru, A.M.; Mtengi, B.; Lebekwe, C.K.; Prabaharan, S.R.S. Data Compression Algorithms for Wireless Sensor Networks: A Review and Comparison. IEEE Access 2021, 9, 136872–136891. [Google Scholar] [CrossRef]
- Zhao, Y.; Chi, C.; Zhou, M.; Zheng, Y.; Sun, L.; Wang, X.; Zhang, J. A High Performance Solid State Storage Technology for Massive Data with High Transmission Bandwidth. Spacecr. Eng. 2020, 29, 162–168. [Google Scholar]
- Sun, Y.; Jiang, G.; Li, Y.; Yang, Y.; Dai, H.; He, J.; Ye, Q.; Cao, Q.; Dong, C.; Zhao, S.; et al. GF-5 Satellite: Overview and Application Prospects. Spacecr. Recovery Remote Sens. 2018, 39, 1–13. [Google Scholar]
- Chen, L.F.; Letu, H.; Fan, M.; Shang, H.Z.; Tao, J.H.; Wu, L.X.; Zhang, Y.; Yu, C.; Gu, J.B.; Zhang, N.; et al. An Introduction to the Chinese High-Resolution Earth Observation System: Gaofen-1∼7 Civilian Satellites. Remote Sens. 2022, 2022, 14. [Google Scholar] [CrossRef]
- Micron Technology, Inc. MT29F256G08AUCAB: 256Gb, 3V, 8-Bit, NAND Flash Memory Data Sheet. Available online: https://www.micron.com (accessed on 3 February 2025).
- GJB/Z 35-93; Derating Criteria for Electronic Components. Commission of Science, Technology and Industry for National Defense: Beijing, China, 1993.
- Earth Observation Satellite Missions and Sensors. Available online: https://directory.eoportal.org/ (accessed on 6 May 2025).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Argument | Instructions | Time |
|---|---|---|
| Command loading time | ||
| Address loading time | ||
| Address to data load interval | ||
| Data loading time | ||
| Programming latency | 350–560 μs | |
| Programming results check time |
| Misson | Storage Medium | Capacity | Storage Rate |
|---|---|---|---|
| Sentinel-2 | NAND FLASH | 2400 Gb | 2 × 540 Mbps |
| CSG | SDRAM | 1530 Gb | 2400 Mbps |
| SJ-10 | NAND FLASH | 256 Gb | 512 Mbps |
| ASO-S | NAND FLASH | 4 Tb | 800 Mbps |
| CAS Earth | NAND FLASH | 8 Tb | 2.6 Gbps |
| This Work | NAND FLASH | 8 Tb | 4 Gbps |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; An, J.; Yan, Q.; Dong, Z. Cache-Based Design of Spaceborne Solid-State Storage Systems. Electronics 2025, 14, 2041. https://doi.org/10.3390/electronics14102041
Liu C, An J, Yan Q, Dong Z. Cache-Based Design of Spaceborne Solid-State Storage Systems. Electronics. 2025; 14(10):2041. https://doi.org/10.3390/electronics14102041
Chicago/Turabian StyleLiu, Chang, Junshe An, Qiang Yan, and Zhenxing Dong. 2025. "Cache-Based Design of Spaceborne Solid-State Storage Systems" Electronics 14, no. 10: 2041. https://doi.org/10.3390/electronics14102041
APA StyleLiu, C., An, J., Yan, Q., & Dong, Z. (2025). Cache-Based Design of Spaceborne Solid-State Storage Systems. Electronics, 14(10), 2041. https://doi.org/10.3390/electronics14102041