3.1. Contextual Pooling
Pooling is an important technique in signal processing and data analysis, widely used in fields such as computer vision, speech recognition, and natural language processing [
43,
44,
45,
46]. In image processing, pooling typically refers to reducing the spatial resolution of an image, thereby lowering the dimensionality of the data while preserving the key information in the image. The goal of pooling is to reduce the data size while retaining important feature information.
However, traditional pooling methods, such as max pooling and average pooling, may fail to fully exploit the fine-grained information within the input feature map in certain cases [
47,
48]. The most common pooling operations are generally max pooling and average pooling. Max pooling only focuses on extreme values within local regions, neglecting non-extreme values that may also be important features. Average pooling, on the other hand, may lead to excessive smoothing of significant features, resulting in the loss of important spatial information. These limitations restrict the performance of traditional pooling methods in complex tasks.
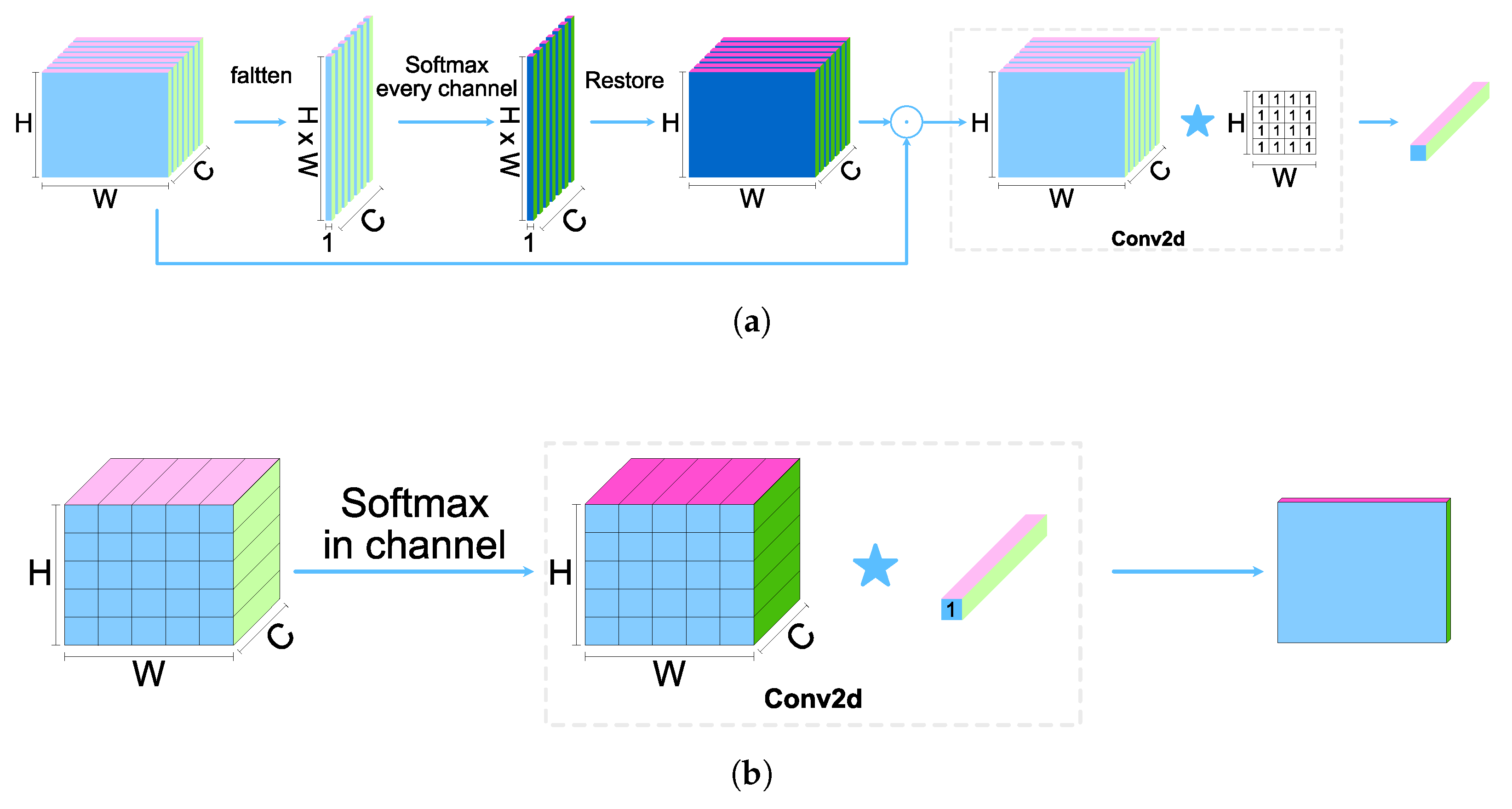
To address these issues, this paper proposes a context-aware pooling method: Contextual Pooling. Unlike traditional pooling methods, contextual pooling dynamically adjusts the weight of each region during the sampling process, allowing each region in the feature map to be adaptively weighted based on its importance. This method not only considers the features of the local regions but also incorporates the contextual relationships between regions, thus better preserving key feature information during pooling. By doing so, contextual pooling overcomes the limitations of traditional pooling methods in handling complex structures and details, enhancing the accuracy of feature extraction and the robustness of the model.
The specific implementation steps are as follows: Given the input feature , the absolute value is first taken at each spatial position , resulting in . This operation addresses the potential weight distribution bias issue in the traditional Softmax function when dealing with features that contain negative values. Negative values, after being processed by the exponential function, experience a sharp decay in magnitude, which results in them being assigned extremely low weights during pooling, thus affecting the accurate representation of features. By introducing an absolute value preprocessing mechanism, this bias is corrected, allowing high-magnitude negative activations to participate in the weight distribution on equal terms with positive activations. This helps more accurately reflect the relative importance of feature magnitudes, further enhancing the adaptivity and accuracy of the pooling process.
In Contextual Pooling, by introducing context-aware weight distribution, the feature of each spatial position dynamically adjusts its weight based on its relative importance. This allows important regions to be assigned higher weights during the pooling operation, which helps retain crucial information more effectively. Particularly when dealing with complex images or multi-scale data, this method can significantly enhance the robustness and expressive power of the model. Contextual pooling not only addresses the limitations of traditional pooling methods but also enhances the spatial correlation of the features, thereby improving the performance of downstream tasks.
A 2D Softmax calculation is performed on the preprocessed features to generate the weight matrix
, for each channel, as shown in Equation (
10), where
represents the context-aware weights:
where
represents the local coordinates in the feature map. This step uses the Softmax function to map the local feature magnitudes to a probability distribution, ensuring that regions with stronger responses receive higher weights. The features of each spatial location are dynamically weighted according to their contextual information, thus adjusting the pooling process based on the importance of different regions. Through the Softmax function, the local feature magnitudes are transformed into a probability distribution, ensuring that regions with stronger responses are assigned higher weights during pooling, thereby enhancing their influence on the final feature representation. Next, the generated weight matrix
is multiplied element-wise by the original input features
, enabling adaptive weighting of the features. This ensures that key information is preserved while reducing the influence of less important areas. This mechanism ensures that the pooling operation not only relies on local extrema but also takes into account the relative importance of spatial positions, further enhancing the accuracy of feature representation and the model’s expressive capacity.
Finally, the weighted window undergoes pooling. This pooling operation is implemented through convolution, as shown in Equation (
12). The feature map, which has been weighted by contextual pooling, has already been adaptively adjusted through the weights, ensuring that the features of each spatial location are weighted according to their importance in the overall image. Next, to further reduce the size of the feature map while retaining the key information from the weighted features, a convolution operation is applied to process the weighted feature map.
Here, the size of the convolution kernel
and the convolution stride are both equal to the pooling factor, with all convolution kernel weights set to 1. By fixing the convolution kernel weights to 1, the summation operation ensures that no additional trainable parameters are introduced, maintaining the parameter-free nature of classical pooling layers. This convolution process is not merely a simple pooling operation but is performed on a weighted basis that takes into account both local features and contextual relationships. This effectively avoids the issues in traditional pooling operations, such as over-smoothing significant features or neglecting important information. The schematic diagrams of the contextual pooling operation are shown in
Figure 1.
3.2. HRDS
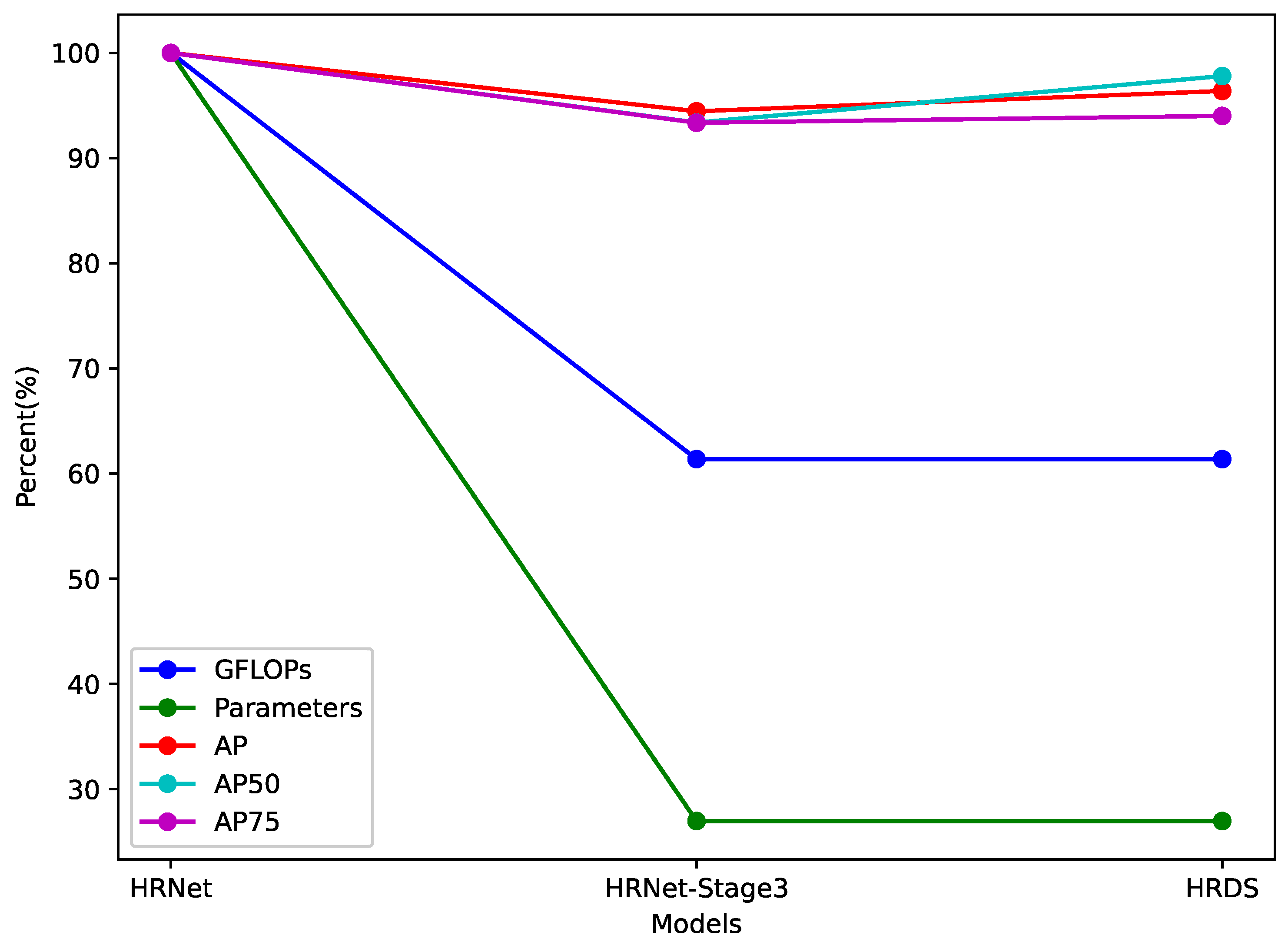
HRNet is a deep learning network architecture used for computer vision tasks (such as pose estimation, semantic segmentation, etc.). Its core idea is to maintain high-resolution feature representations throughout the network, rather than gradually reducing the resolution through pooling and then recovering it as in traditional methods. HRNet achieves this by connecting multiple subnetworks of different resolutions (from high to low) in parallel and performing multi-scale feature fusion through cross-resolution information exchange, resulting in outstanding performance on tasks. In HRNet Stage4, the network further extracts features by stacking multiple repeated modules (such as Bottleneck or Basic Block). However, this design may lead to parameter redundancy issues [
49], which will also be verified in subsequent experimental sections. To address this issue, we propose a lightweight HRNet architecture called HRDS. HRDS retains the advantage of multi-scale feature fusion in HRNet while effectively reducing the model parameter size and improving computational efficiency and inference speed by introducing an attention mechanism module.
Networks based on attention mechanisms have advantages distinct from convolutional neural networks: they possess stronger global modeling capabilities. However, they have a drawback: Transformer structures involve a large number of parameters, significantly increasing computational cost and the number of parameters. During the process of model lightweighting, using low-parameter or even parameter-free attention is especially important.
Figure 2 shows the structure of HRDS. In optimizing the HRNet model structure, we first remove the original HRNet Stage4. The motivation behind this is that Stage4 contains a large number of redundant parameters that do not significantly improve model performance in practical applications. After removing Stage4, the existing branches need to be merged in advance to maintain the overall network structure’s coherence. Stage3-final represents the final iteration of Stage3, for which the three branches need to be merged in advance. To counterbalance the loss of accuracy caused by reducing the model’s parameters, an attention mechanism DS module is used for image feature extraction, strengthening the features in high-dimensional channels and high-dimensional spaces.
Given the input feature
, after passing through the first three stages of HRNet, multi-scale features are merged in advance for output. Then, the Dim-Channel-Aware Attention
and Space Gate Attention
are calculated. The specific calculation process is as follows:
where ⊗ denotes element-wise matrix multiplication,
represents the features after Dim-Channel-Aware Attention, and
represents the features after Space Gate Attention.
3.2.1. Dim-Channel-Aware Attention (DCAA)
For feature maps obtained from traditional convolutional networks, the number of channels is usually large, especially in deeper networks, leading to high-dimensional data. These high-dimensional features not only increase the computational complexity but may also contain redundant information, posing challenges to the model’s learning and generalization. To address this issue, the spatial dimensions of the feature map (height H and width W) are first compressed through the contextual pooling operation to reduce the computation and remove unimportant spatial information, while retaining more discriminative high-dimensional features. Then, the features after contextual pooling are passed into the KAN.
The KAN network, with its powerful expressive capability, is able to approximate any continuous function, thereby demonstrating stronger ability in feature learning and representation, especially in capturing fine-grained relationships and complex interactions in high-dimensional features. Ultimately, the features obtained through the KAN network enhance the model’s performance and generalization ability in high-dimensional data, allowing more precise extraction of subtle relationships and interaction features between different channels.
3.2.2. Space Gate Attention (SCA)
Spatial attention focuses on capturing the regions with the most significant information in the spatial domain, which is crucial for accurately locating the positional relationships in keypoint detection tasks. First, the spatial dimensions of the feature map are compressed through the contextual pooling operation, focusing on the most representative spatial information and reducing redundancy. Then, the downsampled features are passed into the KAN convolution operation to generate Space Gate Attention features, further enhancing the expressiveness of spatial features.
In keypoint detection, spatial features are inherently high-dimensional. Each spatial location not only contains its coordinate information but may also include other important attributes or semantic information, such as pixel values at different positions in the image, color channels, etc. These pieces of information intertwine in the spatial domain, forming complex high-dimensional representations. In keypoint detection tasks, accurately capturing the relationships between each spatial location is crucial, as the positions of the keypoints and their spatial relationships determine the performance of the model.
Spatial features typically contain multi-scale information, ranging from low-level pixel information to high-level semantic information. Features from different levels are extracted and fused in the spatial domain, forming richer and more complex high-dimensional representations. The spatial attention mechanism, by focusing on the most crucial parts of the space, can effectively enhance the feature information at important locations, thus improving the precision of keypoint localization and recognition. In this process, spatial attention helps the model capture fine-grained spatial variations, leading to stronger accuracy and robustness in keypoint detection.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}