1. Introduction
Object detection, a pivotal area in deep learning research, underpins numerous applications and drives interdisciplinary advancements. This computer vision task merges classification, which determines the existence of objects, with regression, which estimates their spatial positions, to recognize and pinpoint objects within images or video streams. Recent advancements in static image object detection [
1,
2,
3,
4,
5,
6] have significantly improved both accuracy and inference speed. Despite these advancements, the closely related field of video object detection remains comparatively underexplored, yet it holds critical importance for real-world applications. Video object detection extends the principles of static image object detection to time-based data, incorporating temporal information that captures object motion, appearance changes, and interactions over time. The temporal dimension in video data is crucial for applications such as UAV navigation, target tracking, encircling, and autonomous driving, where object detection relies on processing dynamic, sequential data [
7,
8,
9,
10].
Leveraging temporal information in video data can significantly improve the performance of object detection algorithms. However, video-based object detection also introduces unique challenges, including motion blur, strict real-time processing requirements, and variability in frame rates. Addressing these challenges is essential for developing robust and efficient video object detection systems capable of performing reliably across diverse real-world scenarios [
11].
Video object detection builds upon static image object detection. Modern deep learning-based frame-wise object detection models predominantly rely on convolutional neural network (CNN) architectures. These models can be broadly classified into two types: two-stage and single-stage detectors. Two-stage detectors, predominantly the R-CNN family [
3,
12,
13,
14,
15], function by initially producing region proposals, which are then categorized into distinct object classes. Due to their two-stage nature, these methods often involve complex loss functions and non-differentiable components, which complicate end-to-end training. In contrast, single-stage detectors, such as the You Only Look Once (YOLO) series [
1,
16,
17] and the Single-Shot Multibox Detector (SSD) [
2], employ a unified pipeline to directly predict object locations and categories in a single forward pass. This streamlined approach enables all computations to be performed in one step, making these detectors significantly faster and more efficient than their two-stage counterparts. Furthermore, because single-stage detectors operate as a unified framework, they facilitate end-to-end training, simplifying the overall training process. Nowadays, many applications still rely on static object detection algorithms for video-based data. While this approach can achieve real-time processing in certain scenarios, it overlooks the temporal context inherent in video data. This omission can lead to challenges when detecting objects across consecutive frames, particularly for moving objects, where temporal coherence is critical.
Various approaches have been proposed to utilize the additional temporal information from video data. One of the earliest methods involves post-processing the results obtained from single-image object detection [
18,
19]. And there are ways of using a tracking model to optimize the detection results [
20]. Additionally, feature filtering techniques have been developed to extract representative features from a frame, prioritizing key regions for detection and guiding the selection of relevant features in subsequent frames [
7,
21]. Another category of methods directly incorporates motion and temporal information into the network architecture. For instance, optical flow has been widely used to capture pixel-wise motion between consecutive frames, enhancing the extraction of temporal context [
22]. However, this approach is limited to pairwise frame analysis and cannot fully exploit the temporal dimension across longer sequences. Zhou et al. [
23] and He et al. [
24] proposed to use Spatial–Temporal transformers to achieve object detection. Cui et al. [
25] proposed to fuse temporal feature from adjacent frames to produce stronger features for detection tasks. Xu et al. [
26] proposed to aggregate spatial–temporal information to enhance video object detection. Alternatively, recurrent neural network (RNN)-based architectures, such as Convolutional LSTM and Convolutional GRU, have been employed to model temporal dependencies more effectively [
27,
28,
29]. These networks can learn spatiotemporal features over a sequence of frames, generating richer representations that integrate both spatial and temporal information for the detection task. In this work, we adopt an RNN-like architecture to perform video object detection.
RNNs are commonly employed to process temporal features in video data, for the overall process resembles a dynamical system; in this work, we sometimes use the word “dynamics” to describe the hidden state of a temporal process. There exists two predominant approaches to model the dynamics of video data. Both methods utilize recurrent units to store and extract temporal information, but they differ in their input representations. The first approach is the box-level methods [
27,
30,
31]. In this method, sequential input frames are initially processed using a standard static image detection model, such as YOLO or SSD. The resulting bounding boxes are then fed into a recurrent unit, which aggregates temporal information across frames based on these bounding box predictions. The recurrent unit refines the bounding box information to produce the final detection results, including object classes and locations. The second approach is the feature-based method [
28,
29,
32]. Here, a feature extractor is used to generate feature maps from the input frames, then these feature maps are sequentially passed into a recurrent unit, which captures temporal dependencies across the video sequence. Finally, the features contain both spatial and temporal information are forwarded to a detection head, which outputs the predictions for object classes and locations.
From previous works, it has been demonstrated that fusing temporal and spatial features using recurrent units can enhance model performance [
28,
29,
30]. However, whether such methods fully capture the environmental context remains an open question. For example, when using traditional recurrent methods to process temporal features from video data, the input typically consists of discrete frames sampled from a continuous time-based process. This introduces problems, such as non-uniform frame intervals, which are often assumed to be uniform in an RNN architecture. Additionally, the model does not inherently recognize that it is processing a continuous-time process, as it operates on discrete inputs. These limitations raise concerns about whether the design architecture of recurrent units is well suited for real-world video data.
Building on the aforementioned challenges, in this work, we propose a NODE-ConvGRU hybrid model for video object detection, using the Recurrent Multi-frame Single Shot Detector (RMf-SSD) [
28] as a baseline. Our approach introduces several key contributions. First, we use Neural ODE to define the hidden states between observations, making our model better align with real-world time-based processes. And this modification allows the model to explicitly account for the time intervals between consecutive observations, addressing one of the limitations of traditional recurrent architectures. Second, we propose a FPN-Up (Feature Fusion Network–Up) feature fusion module to effectively leverage hierarchical features extracted by CNNs. The enhancement facilitates multi-scale feature extraction, enhancing the model’s capacity to accurately detect objects across diverse sizes. Finally, we integrate the Convolutional Block Attention Module (CBAM) [
33] into the model’s detection head to enhance feature representation, boosting overall performance by emphasizing critical spatial and channel-wise features.
2. Related Work
2.1. Static Image Object Detection
Due to their superior feature extraction and adaptive learning capabilities compared to traditional approaches like hand-crafted features [
34], modern object detection predominantly relies on CNN-based methods. These detectors can be broadly categorized into two groups: two-stage detectors and one-stage detectors.
Two-stage detectors [
3,
12,
13,
14,
15] operate by first generating region proposals, which are then classified using CNNs. In contrast, single-stage detectors [
1,
16,
17] make predictions in a single forward pass, achieving faster inference speeds ideal for real-time applications. Due to their architecture, a two-stage approach is generally slower and more complex compared to single-stage detectors.
Here, we introduce SqueezeDet [
4], a single-stage, fully convolutional detector built on SqueezeNet [
35]. Engineered to significantly reduce the parameter count while retaining accuracy comparable to AlexNet, the SqueezeNet architecture empowers SqueezeDet to deliver exceptional computational efficiency without sacrificing detection performance. This makes it particularly well suited for video object detection tasks, where efficiency is of utmost importance.
SqueezeNet minimizes the number of parameters in convolutional layers by utilizing a structure called the Fire module. As depicted in
Figure 1, the Fire module consists of two sequential components: a squeeze layer and an expand layer. The squeeze layer exclusively employs 1 × 1 convolutional filters, functioning as a bottleneck to diminish the dimensionality of the input prior to the application of computationally intensive 3 × 3 convolutions, which can significantly reduce the number of parameters while still being able to preserve the essential information. The expand layer, on the other hand, incorporates both 1 × 1 and 3 × 3 convolutional filters, enabling the capture of low-level features through the former and higher-level spatial features through the latter. And by ensuring that the number of 1 × 1 filters in the squeeze layer is smaller than the total number of filters in the expand layer, the architecture effectively limits the number of input channels to the 3 × 3 filters, thereby further reducing the overall model parameters.
SqueezeNet primarily consists of eight sequential Fire modules, interspersed with max-pooling layers to reduce spatial dimensions. This architecture can serve as an efficient and effective fully convolutional backbone for feature extraction.
For the detection pipeline, inspired by YOLO [
1], SqueezeDet employs a fully convolutional detector called ConvDet. After receiving the feature maps from the backbone, ConvDet generates bounding box coordinates and class probabilities across spatial locations. Subsequently, non-maximum suppression (NMS) eliminates overlapping predictions to yield the final detection results.
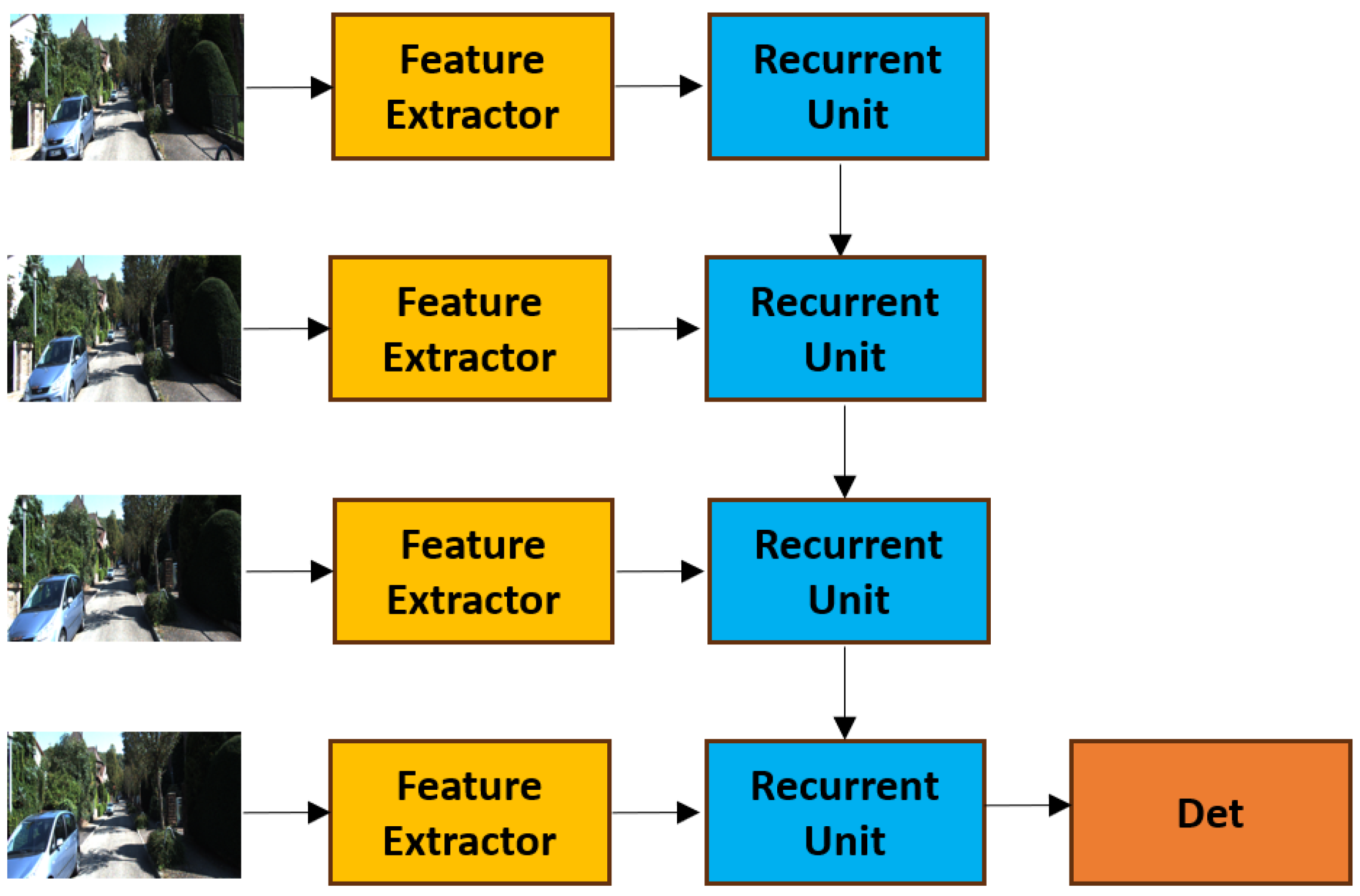
2.2. Feature-Based Video Object Detection
When using RNN-like networks to fuse information from video frames, two primary methods exist: box-level methods [
27,
30,
31] and feature-based methods [
28,
29,
32]. The key distinction lies in their input representations. Box-level methods typically apply RNNs to process bounding boxes generated by single-frame detectors, whereas feature-based methods utilize RNNs to operate on feature maps extracted from multiple frames. In this work, we adopt the feature-based approach to capture both temporal and spatial information.
Several feature-based methods have been proposed for video object detection [
28,
29,
32]. Among these, due to its simplicity, effectiveness, and generalizable architecture, we select RMf-SSD [
28] as our baseline model. The overall detection pipeline of RMf-SSD is illustrated in
Figure 2.
RMf-SSD primarily consists of three components: a feature extractor, a recurrent unit serving as the data fusion layer, and a detection head. The key modification they introduced to the single-frame detection framework is the inclusion of a data fusion layer, which integrates temporal information from multiple frames. In their original research, various data fusion techniques were explored, including addition, max, and concatenation. However, both empirical results and theoretical analysis demonstrate that using a recurrent unit as the fusion mechanism outperforms other methods.
The design of RMf-SSD is based on SqueezeDet, which in turn builds upon the SqueezeNet architecture. SqueezeNet is renowned for its highly efficient design, enabling RMf-SSD to achieve real-time detection despite the additional computational demands of processing video frames. In their experiments, alternative feature extractors such as VGG-16 and ResNet-50 were also tested. While these architectures demonstrated improved performance, their significantly larger number of parameters compared to SqueezeNet posed challenges in terms of memory requirements. To address these constraints, modifications were necessary, but these adjustments limited the extent of performance gains, making SqueezeNet a more practical choice overall.
For the feature fusion unit of the RMf-SSD framework, ConvGRU [
36], a convolutional adaptation of the Gated Recurrent Unit (GRU), is utilized. ConvGRU primarily functions by substituting the dot-product operations inherent in conventional recurrent units with convolutional operations. Such a modification allows the model to exploit localized spatial information derived from convolutional processes, in contrast to the traditional GRU, which is limited to capturing global information. By employing ConvGRU to integrate features extracted from sequential frames, the approach generates a feature map that effectively encapsulates both spatial and temporal dimensions.
After integrating features across multiple frames via ConvGRU, the processed feature representations are subsequently input into the detection head to produce detection outputs. By synthesizing temporal context extracted from the video sequence with spatial details preserved from individual frames, RMf-SSD significantly outperforms its single-frame counterpart, achieving a substantial improvement in detection accuracy while maintaining real-time processing capabilities.
2.3. Neural ODE
Over the past few years, due to the way they process information, it has been recognized that traditional neural networks can be viewed as discrete approximations of Neural Ordinary Differential Equations (ODEs) [
37]. This perspective has led to the development of various differential equation-based networks, which have demonstrated superior performance compared to their discretized counterparts in various tasks [
38,
39,
40]. A seminal work in this field is Neural ODE [
37], the formulation of which is defined as follows:
where
is an arbitrary-dimensional tensor representing the initial condition for the time series data, and
denotes the learned parameters of the neural network
.
In Neural ODE, the hidden state
can be interpreted as the solution to an initial-value problem for an ordinary differential equation (ODE). This solution is obtained using an ODE solver:
From this equation, we can see that unlike traditional discrete-time models, which update the hidden state only at observation points, Neural ODEs define how the hidden state evolves continuously over time.
Neural ODEs are naturally suited for modeling continuous-time-based processes. However, a fundamental limitation of Neural ODEs lies in their dependence on initial conditions: the final solution is entirely determined by the initial condition . This characteristic prevents the ODE solution from being adjusted using subsequent observations, making it unsuitable for online prediction. And this limitation is particularly problematic for real-time applications, such as our work, where immediate predictions based on incoming data are essential.
Several approaches have been proposed to address this limitation. For instance, Kidger et al. [
39] introduced Neural Controlled Differential Equations (Neural CDEs), which use a control path
X to guide the evaluation of
. This allows the model to incorporate both initial and intermediate data points, enhancing its ability to handle continuous-time processes. Building on this, Morrill et al. [
41] demonstrated that constructing specific control signals for Neural CDEs can enable them to perform online prediction tasks effectively. Furthermore, Morrill et al. [
42] extended Neural CDEs by leveraging rough differential equations, enabling the model to handle long time-series data more robustly. Another notable approach is ODE-RNN, proposed by Rubanova et al. [
40]. This model extends traditional RNNs by allowing their hidden states to evolve continuously between observations, making them more suitable for real-world time-based data. In this work, we aim to leverage similar ideas from ODE-RNN to enhance the overall performance of our detection model.
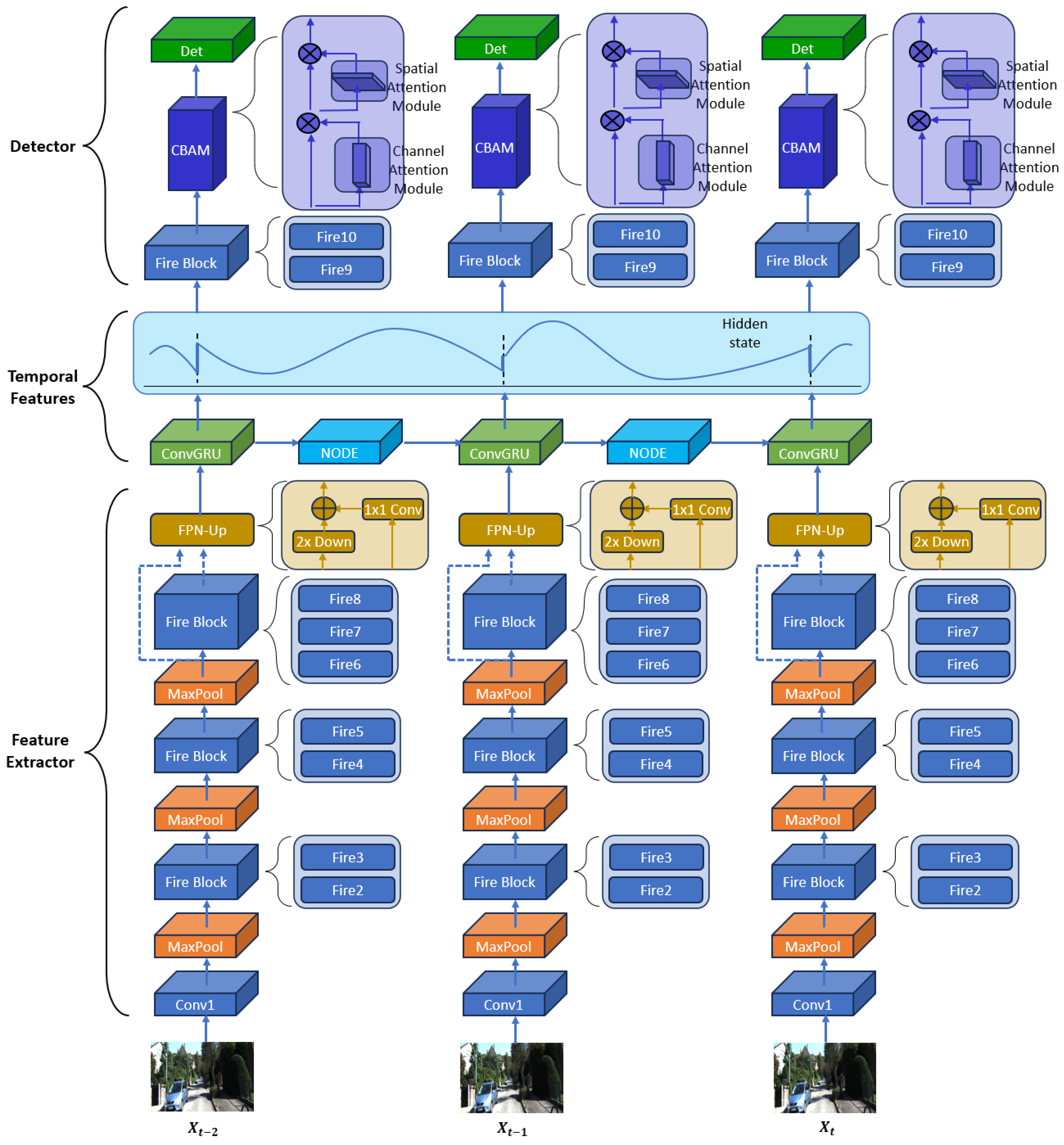
3. Proposed Method
The pipeline of the proposed NODE-ConvGRU hybrid model for video object detection is illustrated in
Figure 3, which mainly includes following modules:
- (1)
A novel pipeline for processing temporal features is introduced in the temporal features block to characterize the hidden states. In contrast to traditional recurrent neural networks (RNNs), which interpret input data as a discrete sequence, our approach utilizes a Neural ODE to model the hidden states between data observations; upon the arrival of new data, the ConvGRU updates the hidden state accordingly, thereby representing the hidden state as a continuous dynamical system throughout the overall framework.
- (2)
An efficient and effective SqueezeNet-based feature extractor is employed to extract spatial features from input frames. Integrated with a feature fusion module, a bottom–up hierarchical structure fuses high-level semantic features with detailed spatial information to enhance the model’s representational capacity.
- (3)
A fully convolutional detector augmented with CBAM is designed to harness attention mechanisms, allowing the model to emphasize critical features in both channel and spatial domains, thereby enhancing feature representation and detection precision.
3.1. NODE-ConvGRU Hybrid for Continuous Dynamics
Prior approaches [
28,
43,
44] leverage temporal features from video data using a ConvGRU [
36] architecture, defined as follows:
where ∗ denotes the convolutional operator, and ⊙ indicates the element-wise product. The terms
,
,
,
, and
represent the update gate, reset gate, candidate activation, and output and input feature maps, respectively.
While ConvGRU adeptly handles discrete frame inputs, it struggles to represent the continuous temporal dynamics of real-world video data and relies on an assumption of uniform time intervals, which does not always hold. To overcome these limitation, we introduce the NODE-ConvGRU architecture, integrating Neural ODEs with ConvGRU. This architecture enables continuous modeling of the network’s hidden states, and it can naturally accommodate variable time intervals. The architecture can be formulated as follows:
where
represents a frame from the video data and
represents the feature representation extracted at time
, with spatial dimensions
and
channels.
The process proceeds as follows: the ODE Solver computes the hidden state before the next observation by integrating the neural network , which governs the evolution of the hidden state through the differential equation , with the initial hidden state set to zero by default. Given an input frame , the feature extractor backbone E generates initial hidden states for the image, represented as feature tensor. Then this feature tensor, along with the hidden state , is passed to the ConvGRU, which computes the updated hidden state as .
The architecture we choose can leverage the strengths of both ConvGRU and Neural ODEs. When observation data from a time-based process are received, the model updates the hidden state using a ConvGRU. However, the input hidden state at this step is not identical to the previously obtained hidden state from ConvGRU. Instead, it utilizes , a hidden state derived and optimized through a Neural ODE network featuring continuous dynamics, so unlike fixed-state approaches, Neural ODEs can adaptively model the hidden state between observations, offering an efficient means to integrate continuous temporal dynamics into our framework. This design allows the model to naturally treat the entire process as a continuous online process, making it better suited for real-world time-based data.
Additionally, standard RNNs perform optimally when the time-series data have uniform intervals. However, the data we are working with may lack this property, especially in a real-world scenario. Our architecture can address this limitation by incorporating timestamps to explicitly capture the timing information, eliminating the need to preprocess or modify the data to fit the requirement. This approach preserves the integrity of the original data, avoiding potential information loss that could arise from such modifications [
45].
3.2. Feature Pyramid Network-Up
To utilize a different scale of features from the backbone, we propose the use of an FPN-Up module to fuse multi-scale features from different layers of the backbone. Such an approach enables our model to better leverage the distinct contributions of features extracted at various levels of the backbone network. The meta architecture of FPN-Up is illustrated in
Figure 4.
The overall process can be defined as follows:
where
i = L, M, H.
Drawing inspiration from traditional FPNs, our approach leverages lateral connections to facilitate feature fusion across different scales. Specifically, we first apply a 1 × 1 convolution to transform the feature layers to a uniform target dimension D, yielding transient features . Next, higher-resolution feature maps are downsampled via max pooling to achieve spatial alignment with deeper-layer features. Subsequently, an element-wise addition is performed to integrate these features, followed by a convolutional operation to refine and fuse the resulting representations. We use the fused feature map as the input to the next layer.
In conventional backbone architectures, deeper layers generally extract high-level, abstract semantic information, while shallower layers preserve detailed spatial features, often associated with smaller-scale objects. However, in the original RMf-SSD implementation, object detection relies exclusively on the final feature layer. This design choice introduces notable limitations, particularly in scenarios involving small-sized targets such as pedestrians or distant objects, where precise localization is paramount. However, it is important to note that SqueezeNet, the backbone architecture employed in this context, prioritizes parameter efficiency and exhibits a comparatively shallow structure relative to architectures such as ResNet-50 or VGG-16. As a result, integrating a full Feature Pyramid Network (FPN) [
46] or BiFPN [
47] for multi-scale feature extraction may not yield commensurate benefits for this specific backbone. Our simplified process emphasizes the enrichment of high-level semantic features with additional spatial context, enhancing the model’s capacity for precise object localization and improving prediction accuracy while still preserving model efficiency.
3.3. Convolutional Block Attention Module (CBAM)
Attention mechanisms form a fundamental component of contemporary deep learning, allowing models to prioritize the most salient aspects of input data and thus enhance overall performance. In this work, we integrate the CBAM module [
33] into our detector to leverage its attention capabilities. Introduced by Woo et al., CBAM is a compact and efficient plug-in module delivering a robust attention mechanism. It improves CNN feature representation by enabling the model to emphasize key regions across channel and spatial dimensions. The architecture of CBAM is illustrated in
Figure 5. The working process of CBAM is as follows: Given an input feature map
F, the module first generates a channel-wise attention map
. This map is then applied to
F to produce a channel-refined feature map
. Subsequently, a spatial-wise attention map
is generated from
and then been applied to
to refine
further, resulting in the final refined feature map
. This dual-attention approach enables the model to enhance features across both channels and spatial regions within the feature maps. The process can be mathematically defined as follows:
In the CBAM architecture, the channel attention module [
33] emphasizes the most informative channels by learning to assign weights based on their relevance to the task. First, it will apply global average pooling and global max pooling across the spatial dimensions of the input to generate channel-wise descriptors. These descriptors are processed by a shared multi-layer perceptron (MLP) to generate outputs from two branches, which are subsequently summed and passed through a sigmoid activation function to yield the final channel attention weights. These weights are then used to scale the original feature maps, enhancing the important channels while suppressing less relevant ones. The process can be mathematically described as follows:
On the other hand, the spatial attention module [
33] focuses on identifying the most relevant spatial locations within the feature maps. It operates by first generating a spatial-wise feature descriptor through average pooling and max pooling across the channel dimension. The pooled features are combined into a feature descriptor, which is then processed by a 7 × 7 convolutional layer followed by a sigmoid activation function to generate the final spatial attention map. This map is subsequently used to enhance feature maps by highlighting key spatial areas. The process can be mathematically described as follows:
4. Experiment Results
4.1. Experimental Setup and Dataset Preparation
The experiments were conducted on an NVIDIA GeForce RTX 4000 GPU (20 GB VRAM) using Ubuntu 22.04, PyTorch 2.4.1, and Torchvision 0.19.1, with CUDA 11.8 for GPU acceleration. ODEs were solved using torchdiffeq (v0.2.4) within PyTorch.
We evaluate the performance of our proposed model on the KITTI object detection dataset [
48], a widely used benchmark for video object detection in the context of autonomous driving and computer vision. The dataset consists of roughly six hours of driving data gathered from urban, rural, and highway settings. Most images feature multiple objects across various classes, often including numerous small objects exhibiting diverse levels of occlusion, saturation, shadows, and truncation. This composition offers a faithful depiction of real-world conditions. The dataset is annotated for three classes: cars, pedestrians, and cyclists.
In the KITTI object detection dataset, objects are divided into three difficulty levels—Easy, Moderate, and Hard—based on criteria such as size, occlusion, and truncation, with harder difficulty levels encompassing objects from easier ones due to less restrictive criteria; for instance, “Easy” objects have a minimum height of 40 pixels, whereas “Moderate” reduces this threshold to 25 pixels. The 2D object detection subset includes 7481 training images and 7518 testing images, all captured with a resolution of 1242 × 375. In the static image object detection task, each image in the KITTI 2D object detection dataset is annotated with bounding boxes and class labels for detection targets. For video object detection, the dataset provides three preceding frames for each detection frame, all captured at a rate of 10 Hz. Although these preceding frames are not labeled, their features can be extracted using the same feature extractor, making them suitable for feature-based video object detection tasks. For approximately 30 detection frames in the dataset where not all three preceding frames are available, we pad the missing frames with the nearest available frames in time to maintain consistency during training. For this experiment, we randomly split the training data into two equal parts to create training and validation sets. All models are trained on the same train/val split to ensure a fair comparison.
4.2. Experimental Parameters and Evaluation Metrics
Concerning the training parameters, the input images were resized to a resolution of 1248 × 384. To prevent overfitting, we employed several data augmentation techniques, such as scaling, rotation, image normalization. We initialized the backbone using the official SqueezeNet pre-trained weights on the ImageNet dataset. For the training process, first, we constructed an RMf-SSD model and trained it for 300 epochs on the KITTI dataset. Subsequently, we utilized the trained weights obtained from RMf-SSD as initialization for our proposed detection pipeline to explore its potential. We used Stochastic Gradient Descent with momentum to optimize the loss function. We set the epochs to 300, initial learning rate to 0.01, learning rate decay factor to 0.5, and decay step to 60. We utilized the KITTI development kit to evaluate the performance of our models.
To evaluate the performance of our model, we employ precision, recall, and mean Average Precision (mAP) as key metrics, while Frames Per Second (FPS) is utilized to assess the model’s real-time processing capabilities. Precision and recall are defined as follows:
where True Positives (
TP) represents the number of targets correctly detected, False Positives (
FP) denotes the number of incorrect detections, and False Negatives (
FN) indicates the number of labeled targets missed by the detector. Precision quantifies the proportion of true detections among all detections made by the model, reflecting its accuracy, while recall measures the proportion of ground-truth targets successfully identified, indicating the model’s completeness. By plotting precision against recall, we can construct the precision–recall (
PR) curve, a critical tool for calculating the Average Precision (
AP). As for the
mAP, it is computed by first determining the
AP for each class, which involves integrating the
PR curve, and then averaging these values across all classes. This can be mathematically expressed as follows:
4.3. Experiment Result
To validate the performance of the proposed model, we conducted experiments on both the RMf-SSD and proposed model. The detection accuracy, measured by mAP, is presented in
Table 1. Our proposed model achieves the highest mAP across all classes.
As illustrated in
Table 1, the proposed NODE-ConvGRU hybrid model achieves a 2.8% improvement in detection accuracy across all classes and difficulty levels compared to the RMf-SSD model. For benchmarking purposes, we also evaluated the performance of a vanilla SqueezeDet model. The results presented in
Table 1 demonstrate that incorporating multi-frame feature extraction to capture temporal dependencies significantly enhances model performance. However, our proposed model further refines this approach by more effectively leveraging temporal and spatial information, resulting in superior accuracy. A comprehensive breakdown of the accuracy metrics is provided in
Table 2.
In terms of real-time performance, our proposed hybrid model delivers detection at 58 frames per second (FPS) during inference, indicating comparable speeds across all three models. This similarity in inference speed can be primarily attributed to the architectural design of the proposed model, which processes video frames sequentially during the inference stage. Consequently, video frames can be processed by the network in real time as they are acquired. Although our model incorporates additional computational components to better leverage real-world time-series data, these enhancements do not compromise its ability to operate in real time. Instead, they contribute to a significant improvement in performance while maintaining real-time capabilities.
Figure 6 presents the PR curve to illustrate our model’s performance. The KITTI development kit streamlines AP calculations by setting precision to 0 beyond the maximum achievable recall. The PR curves showcase our model’s consistent superiority over the baseline RMf-SSD across all object classes and difficulty levels. For instance, consider the Moderate difficulty category for cyclists as a specific example. Here, our model achieves a higher maximum recall, which means it is capable of detecting a greater number of objects compared to the baseline. Additionally, at equivalent recall levels, our model sustains higher precision, indicating that it delivers more accurate detections by correctly identifying true positives while reducing false positives. This combination of enhanced recall and precision underscores the overall effectiveness of our proposed model in object detection tasks.
To provide a more intuitive comparison between the proposed model and RMf-SSD,
Figure 7 presents detection results from some complex real-world scenarios. Upon analyzing the visualization results, we can conclude that our proposed model exhibits superior performance in detecting pedestrians at greater distances and in densely clustered regions with overlapping objects. These findings underscore the effectiveness of our approach in addressing challenging detection tasks.
4.4. Ablation Study
We conducted an ablation study on our proposed model to evaluate the contribution of each modification to the overall performance improvement. We use Floating-Point Operations per Second (FLOPs) and number of parameters as metrics to assess the computational cost of each model. FLOPs mainly measures the computational complexity of the model, while the number of parameters indicates the model’s memory footprint. The results of this analysis are presented in
Table 3.
From
Table 3, it is evident that incorporating a Neural ODE into our model to enable continuous dynamics can significantly improve detection performance, with a computational cost of 72.96 GFLOPs and an additional 2.94 M parameters. Specifically, our proposed architecture enhances detection performance by 1.7 mAP compared to RMf-SSD, and while RMf-SSD achieves a 3.6 mAP improvement over SqueezeDet, our model can deliver a total gain of 5.3 mAP relative to the original SqueezeDet framework. This result underscores the importance of reflecting continuous dynamics in the model, as it leads to a notable enhancement in detection accuracy. Subsequently, the addition of our feature fusion layer further boosts performance by 0.7 mAP with a computational cost of 83.26 GFLOPs and an additional 2.75 M parameters. This improvement is particularly pronounced for detecting pedestrians and cyclists, highlighting the benefits of integrating high-level semantic features with low-level spatial information. Furthermore, the incorporation of the CBAM enables the model to focus on the most relevant regions of the input data, yielding an additional performance gain of 0.5 mAP with a computational cost of 72.97 GFLOPs and 17.09 M parameters. As demonstrated in the results, this attention mechanism provides substantial improvements, underscoring its effectiveness in enhancing feature representation and detection accuracy. Finally, the comprehensive utilization of all the components proposed in our model yields an overall performance improvement of 2.8%, with a total computational cost of 83.27 GFLOPs and 19.84M parameters, while still performing in real time, demonstrating the efficacy and utility of our proposed approach.
5. Conclusions
In this study, we introduced a novel NODE-ConvGRU hybrid model that can leverage continuous hidden states for video object detection tasks. Unlike previous methods that rely on discrete updates, our model’s use of continuous dynamics enables a more natural alignment with real-world time-based processes. Additionally, we incorporated a feature fusion layer to effectively combine high-level semantic features with low-level spatial details, thereby enhancing the utilization of multi-layer features. Moreover, a CBAM was embedded within the detection head to prioritize the most salient regions of the feature maps. Experimental results indicate that these methodological innovations substantially improve performance in video object detection tasks while still performing in real time. While utilizing a standard ODE formulation to capture the continuous dynamics of video data can significantly improve the detection results, considering the substantial body of ODE research, we plan to explore alternative ODE-driven designs in future work, possibly more suited to video data, to further elevate performance. Additionally, in our experiment, for computational resource and temporal constraint reasons, we only assessed the efficacy of our proposed model using the KITTI object detection dataset; in the future, we plan to further evaluate the robustness of our model by applying it to additional datasets and implementing it in a real-world scenario for intelligent inspection purposes.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}