
Improvement of Mask R-CNN Algorithm for Ore Segmentation


Abstract
1. Introduction
- To address the challenge of low segmentation accuracy of ores in complex environments, we propose an improved segmentation algorithm based on Mask R-CNN. Experimental results demonstrate that the proposed algorithm outperforms existing methods in terms of accuracy and adaptability, providing effective support for ore detection and offering significant practical value.
- We introduced the RefConv in the residual network, which optimizes the extraction of fine-grained details through group convolutions. This module enhances the capability of extracting local features when processing complex ore morphologies and mitigates the issue of detail loss caused by insufficient feature fusion in traditional convolution operations.
- To improve the network’s performance in handling multi-scale objects, we incorporate the Efficient Channel Attention into the FPN layer. By dynamically adjusting the weights of each channel in the feature map, the network is guided to focus more effectively on critical features.
2. Methods
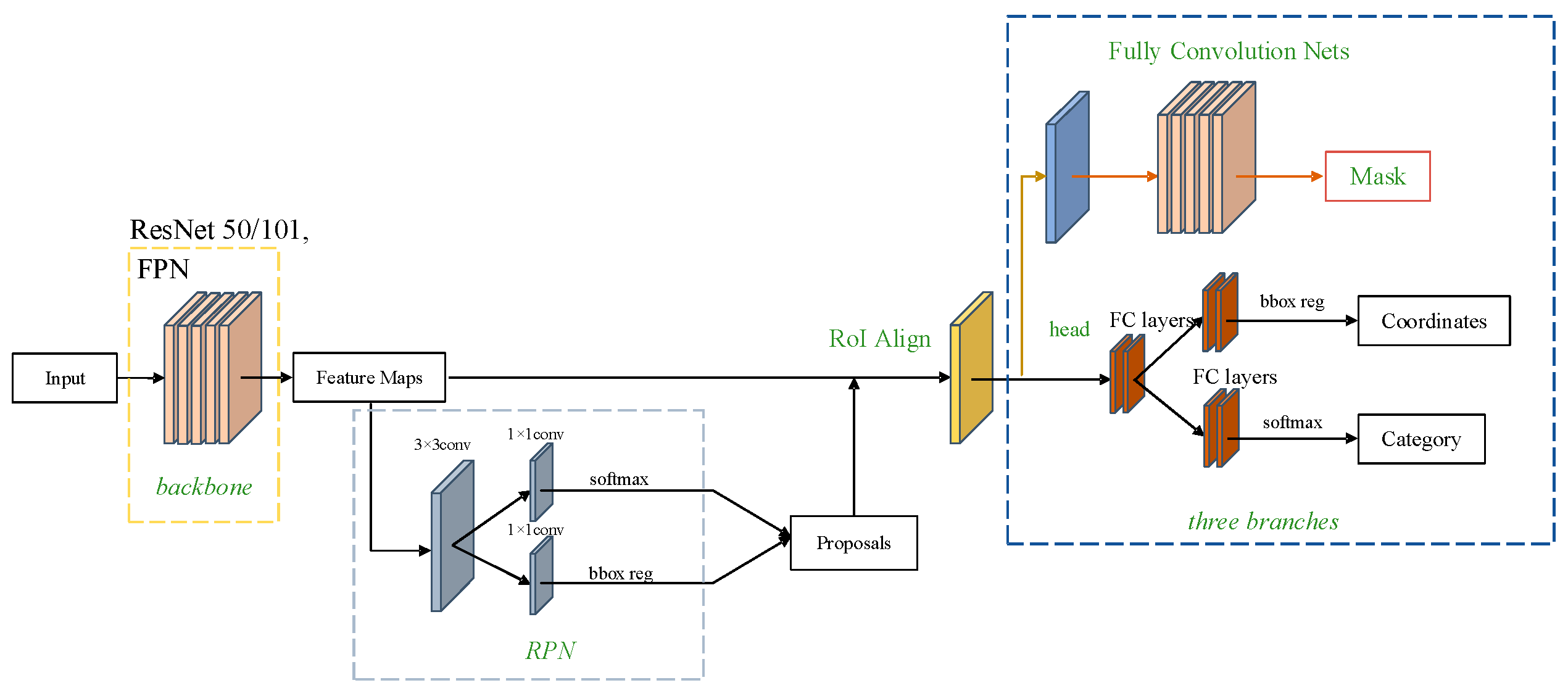
2.1. Mask R-CNN Network Model
2.2. Improved Mask R-CNN Network Model
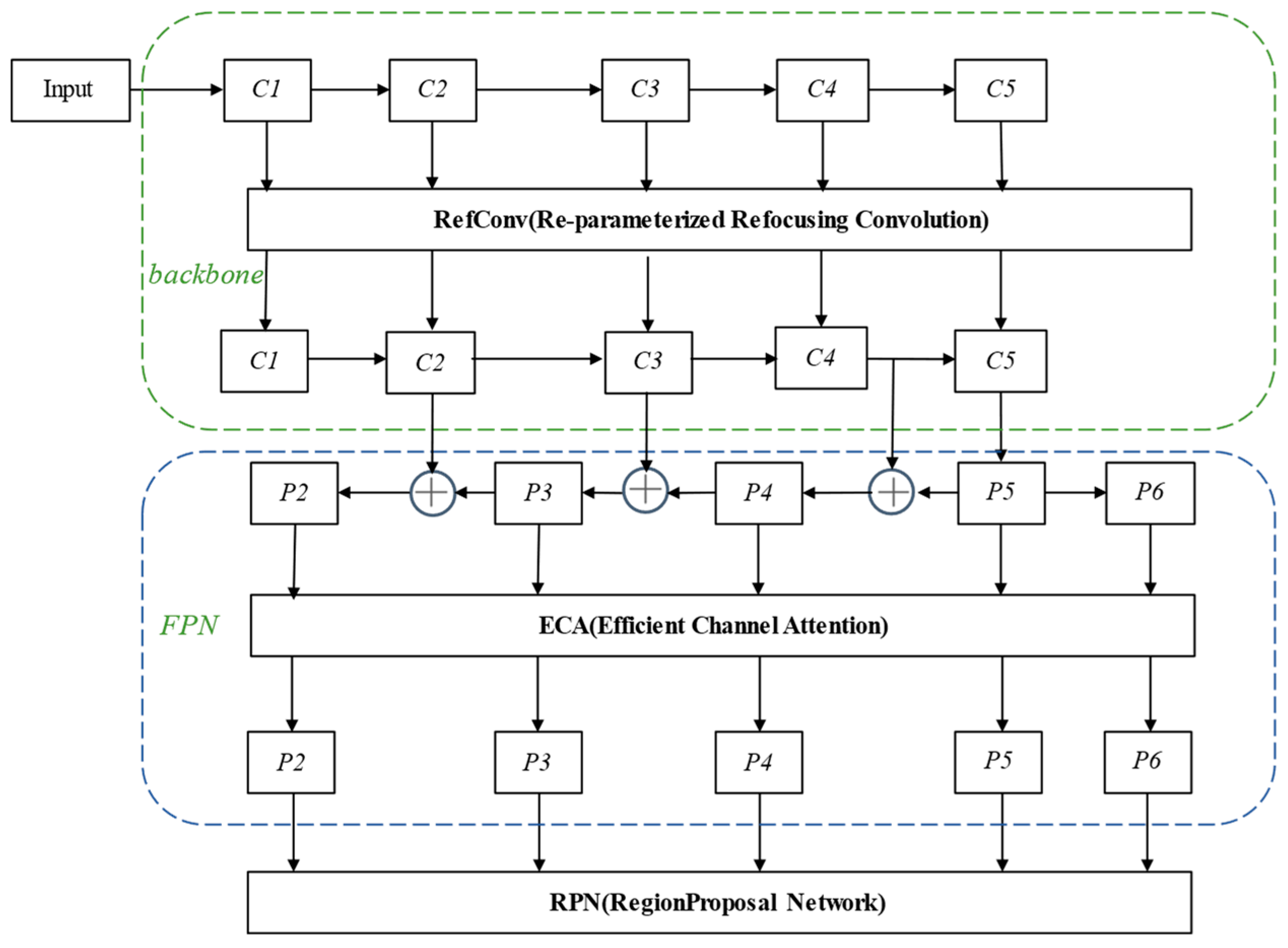
2.2.1. Improved Network Model Architecture
2.2.2. Re-Parameterized Refocus Convolution
2.2.3. Efficient Channel Attention
2.3. Loss Function
3. Experimental Results and Analysis
3.1. Dataset Creation
3.2. Training Platform Setup and Parameter Settings
3.3. Evaluation Metrics
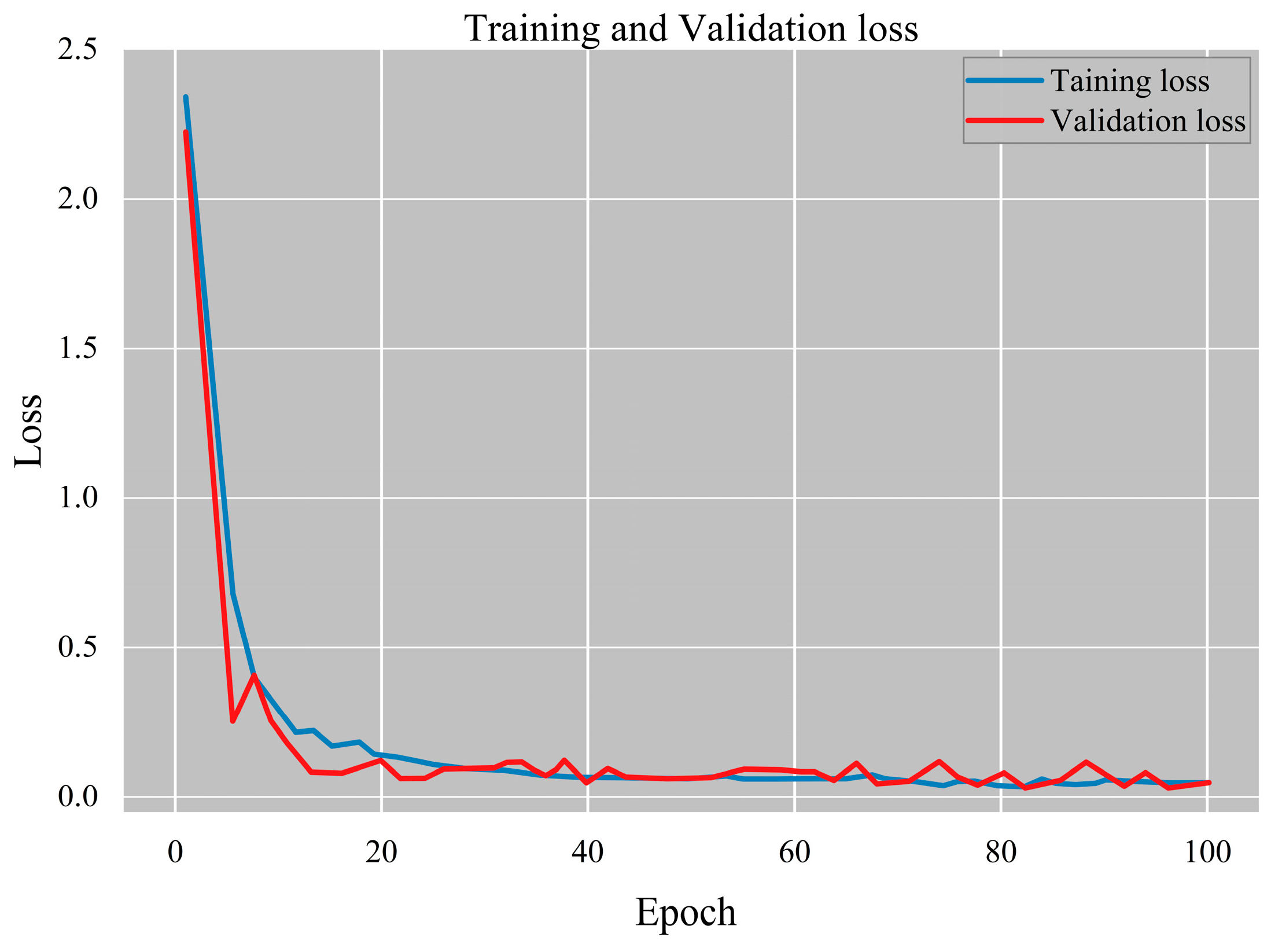
3.4. Experimental Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abubakar, J.; Zhang, Z.; Cheng, Z.; Yao, F.; Bouko, A.-A.B.S.D. Advancing Skarn Iron Ore Detection through Multispectral Image Fusion and 3D Convolutional Neural Networks (3D-CNNs). Remote. Sens. 2024, 16, 3250. [Google Scholar] [CrossRef]
- Wang, W.; Li, Q.; Zhang, D.; Fu, J. Image segmentation of adhesive ores based on MSBA-Unet and convex-hull defect detection. Eng. Appl. Artif. Intell. 2023, 123, 106185. [Google Scholar] [CrossRef]
- Liu, R.; Jiang, Z.; Yang, S.; Fan, X. Twin Adversarial Contrastive Learning for Underwater Image Enhancement and Beyond. IEEE Trans. Image Process. 2022, 31, 4922–4936. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.; Zhao, L.; Zhong, T. Unsupervised Low-Light Image Enhancement Based on Generative Adversarial Network. Entropy 2023, 25, 932. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Computer Science. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Tan, L.; Huangfu, T.; Wu, L.; Chen, W. Comparison of RetinaNet, SSD, and YOLO v3 for real-time pill identification. BMC Med. Inform. Decis. Mak. 2021, 21, 324. [Google Scholar] [CrossRef]
- Murugan, V.; Nidhila, A. Vehicle Logo Recognition using RCNN for Intelligent Transportation Systems. In Proceedings of the 4th IEEE International Conference on Wireless Communications Signal Processing and Networking (WiSPNET), Chennai, India, 21–23 March 2019. [Google Scholar]
- Chen, K.-B.; Xuan, Y.; Lin, A.-J.; Guo, S.-H. Esophageal cancer detection based on classification of gastrointestinal CT images using improved Faster RCNN. Comput. Methods Programs Biomed. 2021, 207, 106172. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Fang, S.; Zhang, B.; Hu, J. Improved Mask R-CNN Multi-Target Detection and Segmentation for Autonomous Driving in Complex Scenes. Sensors 2023, 23, 3853. [Google Scholar] [CrossRef]
- Sahin, M.E.; Ulutas, H.; Yuce, E.; Erkoc, M.F. Detection and classification of COVID-19 by using faster R-CNN and mask R-CNN on CT images. Neural Comput. Appl. 2023, 35, 13597–13611. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Brahimi, S.; Ben Aoun, N.; Ben Amar, C. Boosted Convolutional Neural Network for object recognition at large scale. Neurocomputing 2019, 330, 337–354. [Google Scholar] [CrossRef]
- Shafiq, M.; Gu, Z. Deep Residual Learning for Image Recognition: A Survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- Kim, S.-W.; Kook, H.-K.; Sun, J.-Y.; Kang, M.-C.; Ko, S.-J. Parallel Feature Pyramid Network for Object Detection. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Jiang, S.; Xu, T.; Li, J.; Huang, B.; Guo, J.; Bian, Z. IdentifyNet for Non-Maximum Suppression. IEEE Access 2019, 7, 148245–148253. [Google Scholar] [CrossRef]
- Bi, X.; Hu, J.; Xiao, B.; Li, W.; Gao, X. IEMask R-CNN: Information-Enhanced Mask R-CNN. IEEE Trans. Big Data 2022, 9, 688–700. [Google Scholar] [CrossRef]
- Cai, Z.; Ding, X.; Shen, Q.; Cao, X. Refconv: Re-parameterized refocusing convolution for powerful convnets. arXiv 2023, arXiv:2310.10563. [Google Scholar] [CrossRef] [PubMed]
- Cohen, T.; Welling, M. Group equivariant convolutional networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, Y.; Zhang, Z.; Liu, X.; Wang, L.; Xia, X. Efficient image segmentation based on deep learning for mineral image classification. Adv. Powder Technol. 2021, 32, 3885–3903. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Parameter Configuration |
|---|---|
| Initial Learning Rate | 0.001 |
| Momentum Factor | 0.9 |
| Image Size | 748 × 1024 |
| RPN_ANCHOR_SCALES | (32, 64, 128, 256, 512) |
| Training Epochs | 100 |
| Batch Size | 8 |
| λ | 1.0 |
| γ | 2.0 |
| Network Model | MIoU | |||
|---|---|---|---|---|
| Original Mask RCNN | 0.8531 | 0.8579 | 0.8656 | 0.8588 |
| U-Net | 0.8257 | 0.8311 | 0.8379 | 0.8315 |
| DeepLab v3+ | 0.8074 | 0.8185 | 0.8223 | 0.8160 |
| Improved Mask RCNN | 0.9184 | 0.9228 | 0.9394 | 0.9268 |
| Network Model | mAP | |||
|---|---|---|---|---|
| Original Mask RCNN | 0.9476 | 0.9241 | 0.8913 | 0.9210 |
| U-Net | 0.9168 | 0.9032 | 0.8818 | 0.9006 |
| DeepLab v3+ | 0.9152 | 0.8828 | 0.8732 | 0.8904 |
| Improved Mask RCNN | 0.9866 | 0.9721 | 0.9583 | 0.9723 |
| Method | Average Prediction Time |
|---|---|
| Original Mask R-CNN | 0.208 s |
| Improved Mask RCNN | 0.237 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, K.; Pei, Y.; Wang, X.; Qu, L. Improvement of Mask R-CNN Algorithm for Ore Segmentation. Electronics 2025, 14, 2025. https://doi.org/10.3390/electronics14102025
Tang K, Pei Y, Wang X, Qu L. Improvement of Mask R-CNN Algorithm for Ore Segmentation. Electronics. 2025; 14(10):2025. https://doi.org/10.3390/electronics14102025
Chicago/Turabian StyleTang, Kai, Yuguo Pei, Xiaobo Wang, and Leilei Qu. 2025. "Improvement of Mask R-CNN Algorithm for Ore Segmentation" Electronics 14, no. 10: 2025. https://doi.org/10.3390/electronics14102025
APA StyleTang, K., Pei, Y., Wang, X., & Qu, L. (2025). Improvement of Mask R-CNN Algorithm for Ore Segmentation. Electronics, 14(10), 2025. https://doi.org/10.3390/electronics14102025