

Power Profiling of Smart Grid Users Using Dynamic Time Warping †




Abstract
1. Introduction
- •
- Extracting power consumption patterns by measuring the DTW similarity between a consumer’s load data time series.
- •
- Power profiling based on the signal warping invariability property of the DTW algorithm. Thus time-disordered load data can be used for detecting consumption patterns and load type clustering.
- •
- Enhancing user power profiling by including daily load factor analysis and monitoring user’s consumption behavior, device’s power usage patterns, and the context.
2. Related Work
3. Research Methodology
3.1. Research Approach
- •
- Data collection and preprocessing: extracting appliance-level power consumption data from AMPds2.
- •
- Feature extraction and profiling: using DTW to analyze consumption patterns and generate behavioral profiles.
- •
- Evaluation and comparison: assessing the effectiveness of the model.
3.2. Tools and Techniques
- •
- Dataset: AMPds2 dataset (detailed in Section 5.1).
- •
- Algorithm: DTW for sequence comparison.
- •
- Implementation: Python programming with DTW library.
- •
- Computational Environment: The implementation was conducted using Python 3.11 64-bit in a standard computing environment, with details provided in Section 5.2.
4. Preliminaries and Background
4.1. Time-Series Classification
4.1.1. Euclidean Distance (ED)
4.1.2. k-Nearest Neighbor (KNN)
4.1.3. Dynamic Time Warping (DTW)
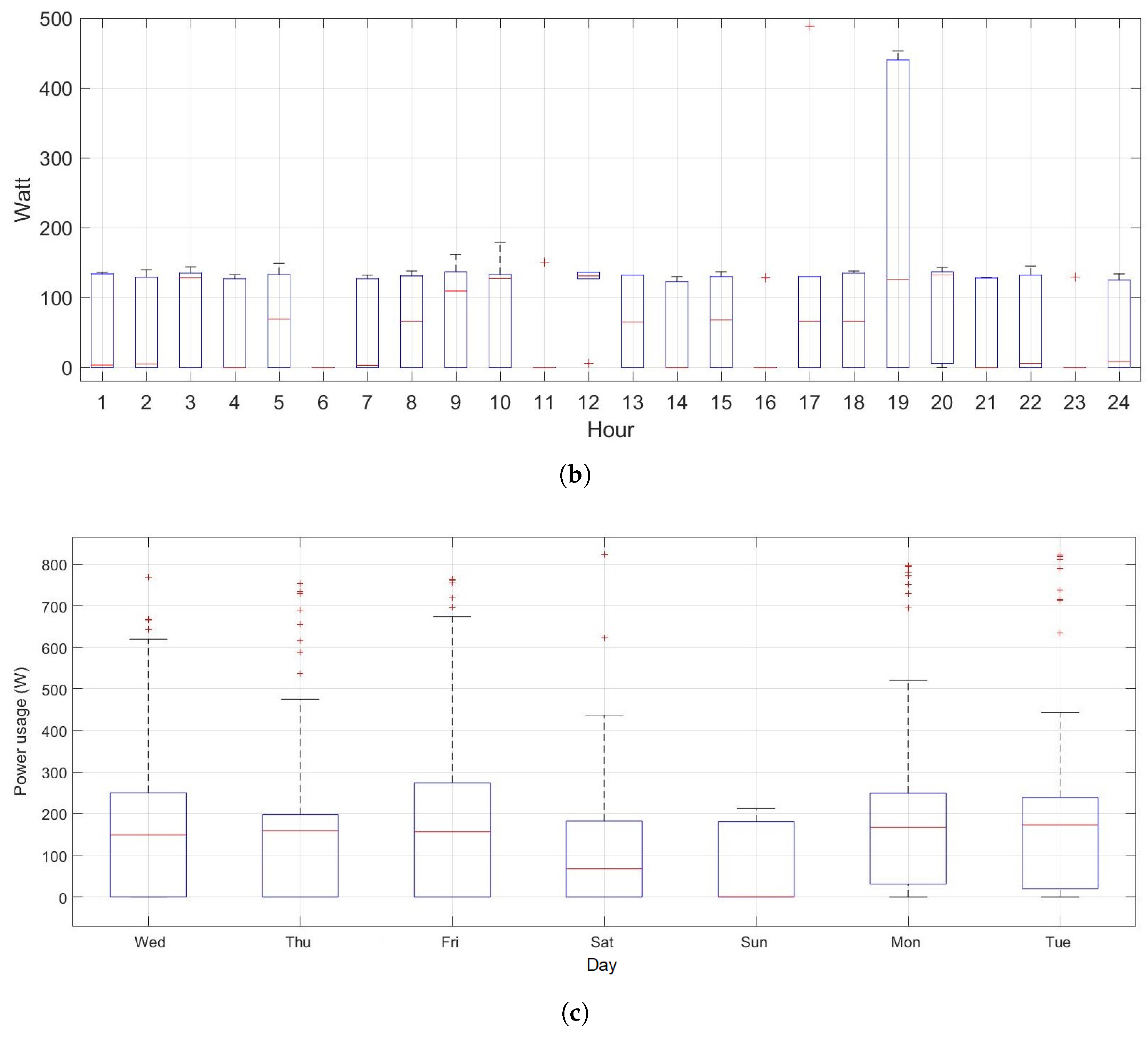
4.2. Daily Load Factor
4.3. Performance Metrics
- •
- Accuracy indicates the proportion of correct predictions, reflecting the true positive rate:
- •
- Precision shows the positive predictive value:
- •
- Sensitivity, or recall, shows the true positive rate, indicating the rate of correctly labeling objects of a certain class. For a good classifier, it should ideally be 1 (high) and is calculated as follows:
- •
- Specificity, or the true negative rate, indicates the rate at which negative objects are correctly labeled. For a good classifier, it should ideally be 1 (high) and is calculated as follows:
- •
- The is a way to measure a classification model’s accuracy and is the harmonic mean of recall and precision, as follows:In classification, the higher the , the more accurate the model is. The highest value of the is , which indicates perfect precision and recall. The lowest possible value is 0, which occurs if either precision or recall is zero.
4.4. Power Profiling
5. Power Profiling Model
5.1. Data Extraction
5.2. Load Data Analysis
- •
- Symmetric Point-to-Point (P2P) matching, ensuring temporal consistency between aligned pairs [68].
- •
- A local continuity constraint, which allows for flexible time warping while preserving signal integrity [67].
- •
- Empirical clustering thresholds, determined through experimentation to optimize classification accuracy and robustness against outliers.
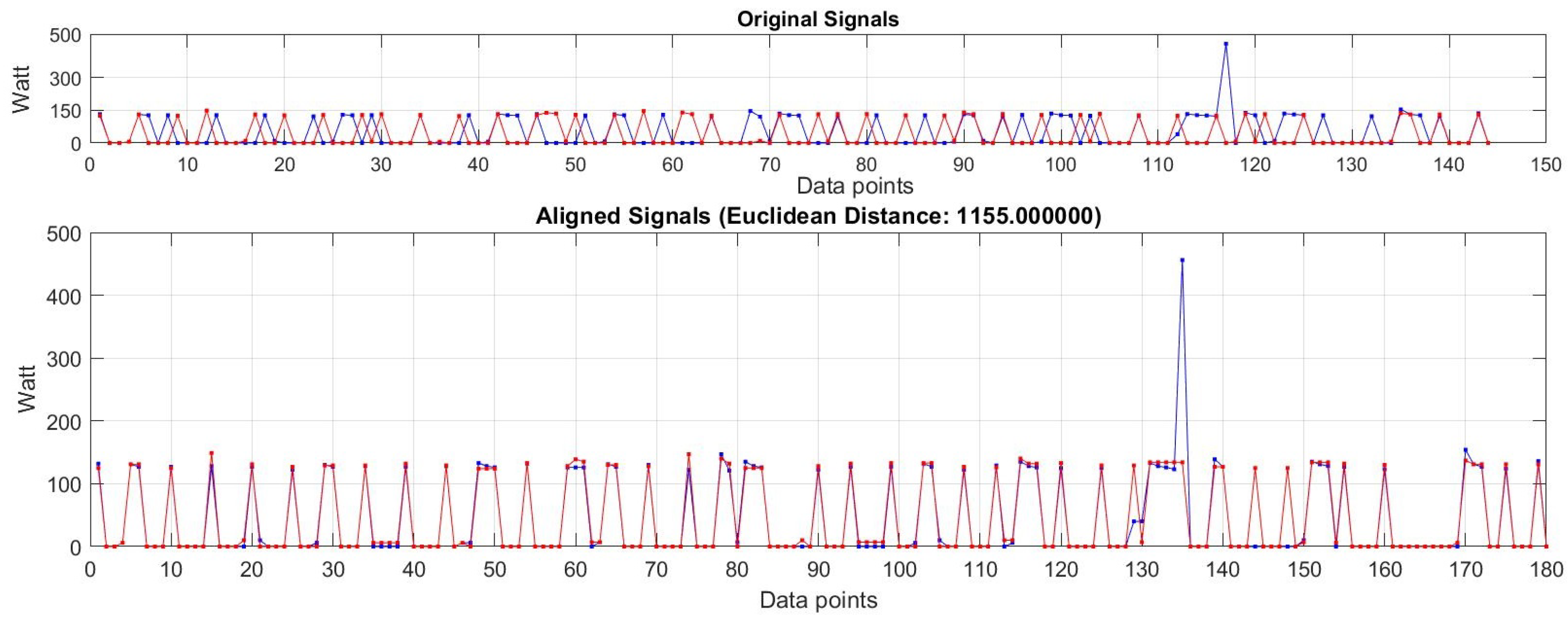
5.3. Load Data Clustering
5.4. Power Profile Assignment
5.5. Analysis
6. Potential Privacy Issues with Power Profiling
6.1. Behavioral Insights and Privacy Risks
6.2. Socioeconomic Inferences and Profiling Risks
6.3. Risks of Malicious Exploitation
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Seo, J.; Jin, J.; Kim, J.; Lee, J. Automated Residential Demand Response Based on Advanced Metering Infrastructure Network. Int. J. Distrib. Sens. Netw. 2016, 12, 4234806. [Google Scholar] [CrossRef]
- Iqteit, N.; Arsoy, A.; Çakır, B. The random varying loads and their impacts on the performance of smart grids. Electr. Power Syst. Res. 2022, 209, 107960. [Google Scholar] [CrossRef]
- NETL Modern Grid Strategy. Advanced Metering Infrastructure; US Department of Energy Office of Electricity and Energy Reliability: Washington, DC, USA, 2008. [Google Scholar]
- Firoozjaei, M.; Lashkari, A.; Ghorbani, A. Memory forensics tools: A comparative analysis. J. Cyber Secur. Technol. 2022, 6, 149–173. [Google Scholar] [CrossRef]
- Ma, X.; Du, Z.; Liu, J. Program power profiling based on phase behaviors. Sustain. Comput. Inform. Syst. 2018, 19, 341–350. [Google Scholar] [CrossRef]
- Toffanin, D. Generation of Customer Load Profiles Based on Smart-Metering Time Series, Building-Level Data and Aggregated Measurements. Master’s Thesis, Technical University of Denmark, Kongens Lyngby, Denmark, 2016. [Google Scholar]
- Meliani, M.; Barkany, A.; Abbassi, I.; Darcherif, A.; Mahmoudi, M. Energy management in the smart grid: State-of-the-art and future trends. Int. J. Eng. Bus. Manag. 2021, 13, 18479790211032920. [Google Scholar] [CrossRef]
- Elahe, M.; Jin, M.; Zeng, P. Review of load data analytics using deep learning in smart grids: Open load datasets, methodologies, and application challenges. Int. J. Energy Res. 2021, 45, 14274–14305. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Kang, C.; Zhang, M.; Wang, K.; Zhao, Y. Load profiling and its application to demand response: A review. Tsinghua Sci. Technol. 2015, 20, 117–129. [Google Scholar] [CrossRef]
- Firoozjaei, M.D.; Kim, M.; Alhadidi, D. Time-series load data analysis for user power profiling. In Proceedings of the 2023 25th International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Republic of Korea, 19–22 February 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 382–387. [Google Scholar]
- Chuan, L.; Ukil, A. Modeling and validation of electrical load profiling in residential buildings in Singapore. IEEE Trans. Power Syst. 2014, 30, 2800–2809. [Google Scholar] [CrossRef]
- Issi, F.; Kaplan, O. The determination of load profiles and power consumptions of home appliances. Energies 2018, 11, 607. [Google Scholar] [CrossRef]
- Firoozjaei, M.; Lu, R.; Ghorbani, A. An evaluation framework for privacy-preserving solutions applicable for blockchain-based internet-of-things platforms. Secur. Priv. 2020, 3, e131. [Google Scholar] [CrossRef]
- Kisielewicz, T.; Stanek, S.; Zytniewski, M. A Multi-Agent Adaptive Architecture for Smart-Grid-Intrusion Detection and Prevention. Energies 2022, 15, 4726. [Google Scholar] [CrossRef]
- Gong, Y.; Cai, Y.; Guo, Y.; Fang, Y. A privacy-preserving scheme for incentive-based demand response in the smart grid. IEEE Trans. Smart Grid 2015, 7, 1304–1313. [Google Scholar] [CrossRef]
- Ghosh, S.; Chatterjee, U.; Chatterjee, D.; Masburah, R.; Mukhopadhyay, D.; Dey, S. Demand Manipulation Attack Resilient Privacy Aware Smart Grid Using PUFs and Blockchain. In Proceedings of the International Conference on Applied Cryptography and Network Security, Kamakura, Japan, 21–24 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 252–275. [Google Scholar]
- Muller, M. Dynamic TimeWarping. In Information Retrieval for Music and Motion; Springer: Berlin/Heidelberg, Germany, 2007; pp. 69–84. [Google Scholar] [CrossRef]
- Makonin, S.; Ellert, B.; Bajić, I.; Popowich, F. Electricity, water, and natural gas consumption of a residential house in Canada from 2012 to 2014. Sci. Data 2016, 3, 160037. [Google Scholar] [CrossRef]
- McLoughlin, F.; Duffy, A.; Conlon, M. Characterising domestic electricity consumption patterns by dwelling and occupant socio-economic variables: An Irish case study. Energy Build. 2012, 48, 240–248. [Google Scholar] [CrossRef]
- Aung, K.H.H.; Kok, C.L.; Koh, Y.Y.; Teo, T.H. An Embedded Machine Learning Fault Detection System for Electric Fan Drive. Electronics 2024, 13, 493. [Google Scholar] [CrossRef]
- Biswal, B.; Deb, S.; Datta, S.; Ustun, T.S.; Cali, U. Review on smart grid load forecasting for smart energy management using machine learning and deep learning techniques. Energy Rep. 2024, 12, 3654–3670. [Google Scholar] [CrossRef]
- Dey, B.; Roy, B.; Datta, S.; Ustun, T.S. Forecasting ethanol demand in India to meet future blending targets: A comparison of ARIMA and various regression models. Energy Rep. 2023, 9, 411–418. [Google Scholar] [CrossRef]
- Li, C. Designing a short-term load forecasting model in the urban smart grid system. Appl. Energy 2020, 266, 114850. [Google Scholar] [CrossRef]
- Son, H.g.; Kim, Y.; Kim, S. Time series clustering of electricity demand for industrial areas on smart grid. Energies 2020, 13, 2377. [Google Scholar] [CrossRef]
- Maurya, A.; Akyurek, A.S.; Aksanli, B.; Rosing, T.S. Time-series clustering for data analysis in smart grid. In Proceedings of the 2016 IEEE International Conference on Smart Grid Communications (SmartGridComm), Sydney, Australia, 6–9 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 606–611. [Google Scholar]
- Tornai, K.; Kovács, L.; Oláh, A.; Drenyovszki, R.; Pintér, I.; Tisza, D.; Levendovszky, J. Classification for consumption data in smart grid based on forecasting time series. Electr. Power Syst. Res. 2016, 141, 191–201. [Google Scholar] [CrossRef]
- Tao, J.; Michailidis, G. A statistical framework for detecting electricity theft activities in smart grid distribution networks. IEEE J. Sel. Areas Commun. 2019, 38, 205–216. [Google Scholar] [CrossRef]
- Ahir, R.K.; Chakraborty, B. Pattern-based and context-aware electricity theft detection in smart grid. Sustain. Energy Grids Netw. 2022, 32, 100833. [Google Scholar] [CrossRef]
- Villar-Rodriguez, E.; Del Ser, J.; Oregi, I.; Bilbao, M.N.; Gil-Lopez, S. Detection of non-technical losses in smart meter data based on load curve profiling and time series analysis. Energy 2017, 137, 118–128. [Google Scholar] [CrossRef]
- Hasan, M.N.; Toma, R.N.; Nahid, A.A.; Islam, M.M.; Kim, J.M. Electricity theft detection in smart grid systems: A CNN-LSTM based approach. Energies 2019, 12, 3310. [Google Scholar] [CrossRef]
- Jiang, M.; Ding, K.; Chen, X.; Cui, L.; Zhang, J.; Yang, Z.; Cang, Y.; Cao, S. Research on time-series based and similarity search based methods for PV power prediction. Energy Convers. Manag. 2024, 308, 118391. [Google Scholar] [CrossRef]
- Salvador, S.; Chan, P. FastDTW: Toward accurate dynamic time warping in linear time and space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar] [CrossRef]
- Çakmak, R. Design and implementation of a low-cost power logger device for specific demand profile analysis in demand-side management studies for smart grids. Expert Syst. Appl. 2024, 238, 121888. [Google Scholar] [CrossRef]
- Cheung, C.M.; Kuppannagari, S.R.; Kannan, R.; Prasanna, V.K. Load demand user profiling in smart grids with distributed solar generation. In Proceedings of the 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 17–20 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Jindal, A.; Schaeffer-Filho, A.; Marnerides, A.K.; Smith, P.; Mauthe, A.; Granville, L. Tackling energy theft in smart grids through data-driven analysis. In Proceedings of the 2020 International Conference on Computing, Networking and Communications (ICNC), Big Island, HI, USA, 17–20 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 410–414. [Google Scholar]
- Liu, C.; Chai, K.K.; Lau, E.T.; Wang, Y.; Chen, Y. Optimised electric vehicles charging scheme with uncertain user-behaviours in smart grids. In Proceedings of the 2017 IEEE 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), Montreal, QC, Canada, 8–13 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Chalmers, C.; Hurst, W.; Mackay, M.; Fergus, P. Smart meter profiling for health applications. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–7. [Google Scholar]
- Nanopoulos, A.; Alcock, R.; Manolopoulos, Y. Feature-based classification of time-series data. Int. J. Comput. Res. 2001, 10, 49–61. [Google Scholar]
- Lin, J.; Keogh, E.; Wei, L.; Lonardi, S. Experiencing SAX: A Novel Symbolic Representation of Time Series. Data Min. Knowl. Discov. 2007, 15, 107–144. [Google Scholar] [CrossRef]
- Faloutsos, C.; Ranganathan, M.; Manolopoulos, Y. Fast subsequence matching in time-series databases. Acm Sigmod Rec. 1994, 23, 419–429. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S. k-Nearest Neighbour Classifiers. arXiv 2020, arXiv:2004.04523. [Google Scholar]
- Berndt, D.; Clifford, J. Using dynamic time warping to find patterns in time series. In Proceedings of the KDD Workshop, Seattle, WA, USA, 31 July–1 August 1994; Volume 10, pp. 359–370. [Google Scholar]
- Kate, R. Using Dynamic Time Warping Distances as Features for Improved Time Series Classification. Data Min. Knowl. Discov. 2016, 30, 283–312. [Google Scholar] [CrossRef]
- Iglesias, F.; Kastner, W. Analysis of Similarity Measures in Times Series Clustering for the Discovery of Building Energy Patterns. Energies 2013, 6, 579–597. [Google Scholar] [CrossRef]
- Ratanamahatana, C.; Keogh, E. Making Time-series Classification More Accurate Using Learned Constraints. In Proceedings of the 2004 SIAM International Conference on Data Mining, Lake Buena Vista, FL, USA, 22–24 April 2004; pp. 11–22. [Google Scholar]
- Peterson, L. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Sutton, O. Introduction to k Nearest Neighbour Classification and Condensed Nearest Neighbour Data Reduction; University lectures; University of Leicester: Leicester, UK, 2012; Volume 1. [Google Scholar]
- Gou, J.; Ma, H.; Ou, W.; Zeng, S.; Rao, Y.; Yang, H. A generalized mean distance-based k-nearest neighbor classifier. Expert Syst. Appl. 2019, 115, 356–372. [Google Scholar] [CrossRef]
- Firoozjaei, M.D.; Kim, M.; Song, J.; Kim, H. O2TR: Offline OTR messaging system under network disruption. Comput. Secur. 2019, 82, 227–240. [Google Scholar] [CrossRef]
- Tran, H.; Ha, C. High precision weighted optimum K-nearest neighbors algorithm for indoor visible light positioning applications. IEEE Access 2020, 8, 114597–114607. [Google Scholar] [CrossRef]
- Cassisi, C.; Montalto, P.; Aliotta, M.; Cannata, A.; Pulvirenti, A. Similarity Measures and Dimensionality Reduction Techniques for Time Series Data Mining. In Advances in Data Mining Knowledge Discovery and Applications; InTech: Rijeka, Croatia, 2012; pp. 71–96. [Google Scholar]
- Cai, X.; Xu, T.; Yi, J.; Huang, J.; Rajasekaran, S. DTWNet: A dynamic time warping network. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Zhang, Z.; Tavenard, R.; Bailly, A.; Tang, X.; Tang, P.; Corpetti, T. Dynamic time warping under limited warping path length. Inf. Sci. 2017, 393, 91–107. [Google Scholar] [CrossRef]
- Cerna, F.; Pourakbari-Kasmaei, M.; Pinheiro, L.; Naderi, E.; Lehtonen, M.; Contreras, J. Intelligent energy management in a prosumer community considering the load factor enhancement. Energies 2021, 14, 3624. [Google Scholar] [CrossRef]
- Morais, H.; Sousa, T.; Vale, Z.; Faria, P. Evaluation of the electric vehicle impact in the power demand curve in a smart grid environment. Energy Convers. Manag. 2014, 82, 268–282. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Awujoola, O.J.; Ogwueleka, F.N.; Odion, P.O.; Awujoola, A.E.; Adelegan, O.R. Genomic data science systems of Prediction and prevention of pneumonia from chest X-ray images using a two-channel dual-stream convolutional neural network. In Data Science for Genomics; Elsevier: Amsterdam, The Netherlands, 2023; pp. 217–228. [Google Scholar]
- Deng, X.; Liu, Q.; Deng, Y.; Mahadevan, S. An improved method to construct basic probability assignment based on the confusion matrix for classification problem. Inf. Sci. 2016, 340, 250–261. [Google Scholar] [CrossRef]
- Demir, F. Deep autoencoder-based automated brain tumor detection from MRI data. In Artificial Intelligence-Based Brain-Computer Interface; Elsevier: Amsterdam, The Netherlands, 2022; pp. 317–351. [Google Scholar]
- Zhang, Y.; Huang, T.; Bompard, E. Big data analytics in smart grids: A review. Energy Informatics 2018, 1, 8. [Google Scholar] [CrossRef]
- Zhao, Q.; Li, H.; Wang, X.; Pu, T.; Wang, J. Analysis of users’ electricity consumption behavior based on ensemble clustering. Glob. Energy Interconnect. 2019, 2, 479–488. [Google Scholar] [CrossRef]
- Sauhats, A.; Varfolomejeva, R.; Lmkevics, O.; Petrecenko, R.; Kunickis, M.; Balodis, M. Analysis and prediction of electricity consumption using smart meter data. In Proceedings of the 2015 IEEE 5th International Conference on Power Engineering, Energy and Electrical Drives (POWERENG), Riga, Latvia, 11–13 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 17–22. [Google Scholar]
- Firoozjaei, M.; Park, J.; Kim, H. Detecting False Emergency Requests Using Callers’ Reporting Behaviors and Locations. In Proceedings of the 2016 30th International Conference on Advanced Information Networking and Applications Workshops (WAINA), Crans-Montana, Switzerland, 23–25 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 243–247. [Google Scholar]
- Lisovich, M.; Mulligan, D.; Wicker, S. Inferring personal information from demand-response systems. IEEE Secur. Priv. 2010, 8, 11–20. [Google Scholar] [CrossRef]
- Firoozjaei, M.; Yu, J.; Kim, H. Privacy Preserving Nearest Neighbor Search Based on Topologies in Cellular Networks. In Proceedings of the 2015 IEEE 29th International Conference on Advanced Information Networking and Applications Workshops, Gwangiu, Republic of Korea, 24–27 March 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 146–149. [Google Scholar]
- DENT Intstruments. PowerScout Series, NETWORKED POWER METERS. 2010. Available online: https://www.pc-s.com/pdf/dent-powerscout-powermeters-submeters-series.pdf (accessed on 10 July 2023).
- Giorgino, T. Computing and visualizing dynamic time warping alignments in R: The dtw package. J. Stat. Softw. 2009, 31, 1–24. [Google Scholar] [CrossRef]
- Zhao, J.; Itti, L. shapedtw: Shape dynamic time warping. Pattern Recognit. 2018, 74, 171–184. [Google Scholar] [CrossRef]
- Folgado, D.; Barandas, M.; Matias, R.; Martins, R.; Carvalho, M.; Gamboa, H. Time alignment measurement for time series. Pattern Recognit. 2018, 81, 268–279. [Google Scholar] [CrossRef]
- Belman-Flores, J.; Pardo-Cely, D.; Gómez-Martínez, M.; Hernández-Pérez, I.; Rodríguez-Valderrama, D.; Heredia-Aricapa, Y. Thermal and energy evaluation of a domestic refrigerator under the influence of the thermal load. Energies 2019, 12, 400. [Google Scholar] [CrossRef]
- Jia, M.; Wang, Y.; Shen, C.; Hug, G. Privacy-preserving distributed clustering for electrical load profiling. IEEE Trans. Smart Grid 2020, 12, 1429–1444. [Google Scholar] [CrossRef]
- Guo, X.; Bai, L.; Zhang, H.; AiZaizi, G.; Liu, Z. Design and implementation of power user profiling system based on big data. In Proceedings of the 2023 2nd International Conference on Artificial Intelligence and Intelligent Information Processing (AIIIP), Hangzhou, China, 27–29 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 251–256. [Google Scholar]
- Ali, W.; Din, I.U.; Almogren, A.; Kim, B.S. A novel privacy preserving scheme for smart grid-based home area networks. Sensors 2022, 22, 2269. [Google Scholar] [CrossRef]
- Proedrou, E. A comprehensive review of residential electricity load profile models. IEEE Access 2021, 9, 12114–12133. [Google Scholar] [CrossRef]
- Saleem, M.U.; Shakir, M.; Usman, M.R.; Bajwa, M.H.T.; Shabbir, N.; Shams Ghahfarokhi, P.; Daniel, K. Integrating smart energy management system with internet of things and cloud computing for efficient demand side management in smart grids. Energies 2023, 16, 4835. [Google Scholar] [CrossRef]
- Hassan, M.U.; Rehmani, M.H.; Chen, J. Differential privacy techniques for cyber physical systems: A survey. IEEE Commun. Surv. Tutor. 2019, 22, 746–789. [Google Scholar] [CrossRef]
- Lindell, Y. Secure multiparty computation. Commun. ACM 2020, 64, 86–96. [Google Scholar] [CrossRef]
- Fahim, M.; Sillitti, A. Analyzing load profiles of energy consumption to infer household characteristics using smart meters. Energies 2019, 12, 773. [Google Scholar] [CrossRef]
- Ahmad, T.; Chen, H.; Wang, J.; Guo, Y. Review of various modeling techniques for the detection of electricity theft in smart grid environment. Renew. Sustain. Energy Rev. 2018, 82, 2916–2933. [Google Scholar] [CrossRef]
- Firoozjaei, M.; Mahmoudyar, N.; Baseri, Y.; Ghorbani, A. An evaluation framework for industrial control system cyber incidents. Int. J. Crit. Infrastruct. Prot. 2022, 36, 100487. [Google Scholar] [CrossRef]
- Yip, S.C.; Tan, W.N.; Tan, C.; Gan, M.T.; Wong, K. An anomaly detection framework for identifying energy theft and defective meters in smart grids. Int. J. Electr. Power Energy Syst. 2018, 101, 189–203. [Google Scholar] [CrossRef]
- Le Ray, G.; Pinson, P. The ethical smart grid: Enabling a fruitful and long-lasting relationship between utilities and customers. Energy Policy 2020, 140, 111258. [Google Scholar] [CrossRef]
- De, S.J.; Le Métayer, D. Privacy harm analysis: A case study on smart grids. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 58–65. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Confusion Matrix | Assigned Class | ||
|---|---|---|---|
| Positive | Negative | ||
| Actual Class | Positive | ||
| Negative | |||
| Characteristics | Power Load Patterns | ||
|---|---|---|---|
| Workday Load (WoLP) | Weekend/Holiday Load (WeLP) | ||
| DTW clustering | DTW distance | ||
| St. deviation | |||
| Power usage | Peak (W) | 484 | |
| Mean (W) | |||
| Daily load factor () | |||
| Performance Measures | Power Profiles | |
|---|---|---|
| Workday Profile (WoLP) | Weekend Profile (WeLP) | |
| Sensitivity/Recall (%) | ||
| Precision (%) | ||
| F-Score | ||
| Accuracy (%) | ||
| Performance Measures | Power Profiles | |
|---|---|---|
| Workday Profile (WoLP) | Weekend Profile (WeLP) | |
| Sensitivity/Recall (%) | ||
| Precision (%) | ||
| F-Score | ||
| Accuracy (%) | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Firoozjaei, M.D.; Kim, H.; El-Hajj, M. Power Profiling of Smart Grid Users Using Dynamic Time Warping. Electronics 2025, 14, 2015. https://doi.org/10.3390/electronics14102015
Kim M, Firoozjaei MD, Kim H, El-Hajj M. Power Profiling of Smart Grid Users Using Dynamic Time Warping. Electronics. 2025; 14(10):2015. https://doi.org/10.3390/electronics14102015
Chicago/Turabian StyleKim, Minchang, Mahdi Daghmehchi Firoozjaei, Hyoungshick Kim, and Mohamad El-Hajj. 2025. "Power Profiling of Smart Grid Users Using Dynamic Time Warping" Electronics 14, no. 10: 2015. https://doi.org/10.3390/electronics14102015
APA StyleKim, M., Firoozjaei, M. D., Kim, H., & El-Hajj, M. (2025). Power Profiling of Smart Grid Users Using Dynamic Time Warping. Electronics, 14(10), 2015. https://doi.org/10.3390/electronics14102015