1. Introduction
General large language models (LLMs) are advanced artificial intelligence (AI) systems trained on vast amounts of text data to understand and generate human-like language. These models, exemplified by systems like GPT-4 [
1], Claude [
2], and LLaMA [
3,
4], represent a significant evolution beyond traditional language models [
5,
6,
7] through their scale and capabilities. The key advantage of LLMs lies in their versatility and adaptability. Through prompt engineering, users can define specific roles, contexts, or constraints that guide the model’s responses without requiring technical modifications to the underlying architecture [
1].
Despite their impressive capabilities, LLMs face some significant challenges when applied to specialized domains such as healthcare and law. These domains are characterized by highly specialized and continuously evolving bodies of knowledge. Legal systems frequently introduce new regulations and case rulings [
8], and the medical field rapidly produces new research findings and treatment guidelines [
9]. Unfortunately, LLMs are typically trained on large, general-purpose datasets that may lack coverage of the most current or domain-specific information. As a result, their knowledge often lags behind real-world developments, which can lead to inaccurate or outdated answers in high-stakes scenarios.
Furthermore, both medical and legal texts are filled with complex terminologies and nuanced expressions that require deep contextual understanding. For human practitioners, years of training are required to master this language. LLMs, in contrast, frequently struggle with accurately interpreting such content, leading to misinterpretations and potential misinformation.
Another critical drawback is that LLMs cannot efficiently update knowledge dynamically. Since their knowledge is fixed at the time of training, they cannot incorporate new knowledge, such as recent legal rulings or medical advancements, without being retrained. However, retraining is costly in both computation and resources, making frequent updates impractical [
10]. As a result, LLMs often provide outdated or incomplete responses, especially in fast-evolving fields, limiting their effectiveness in real-time specialized domains.
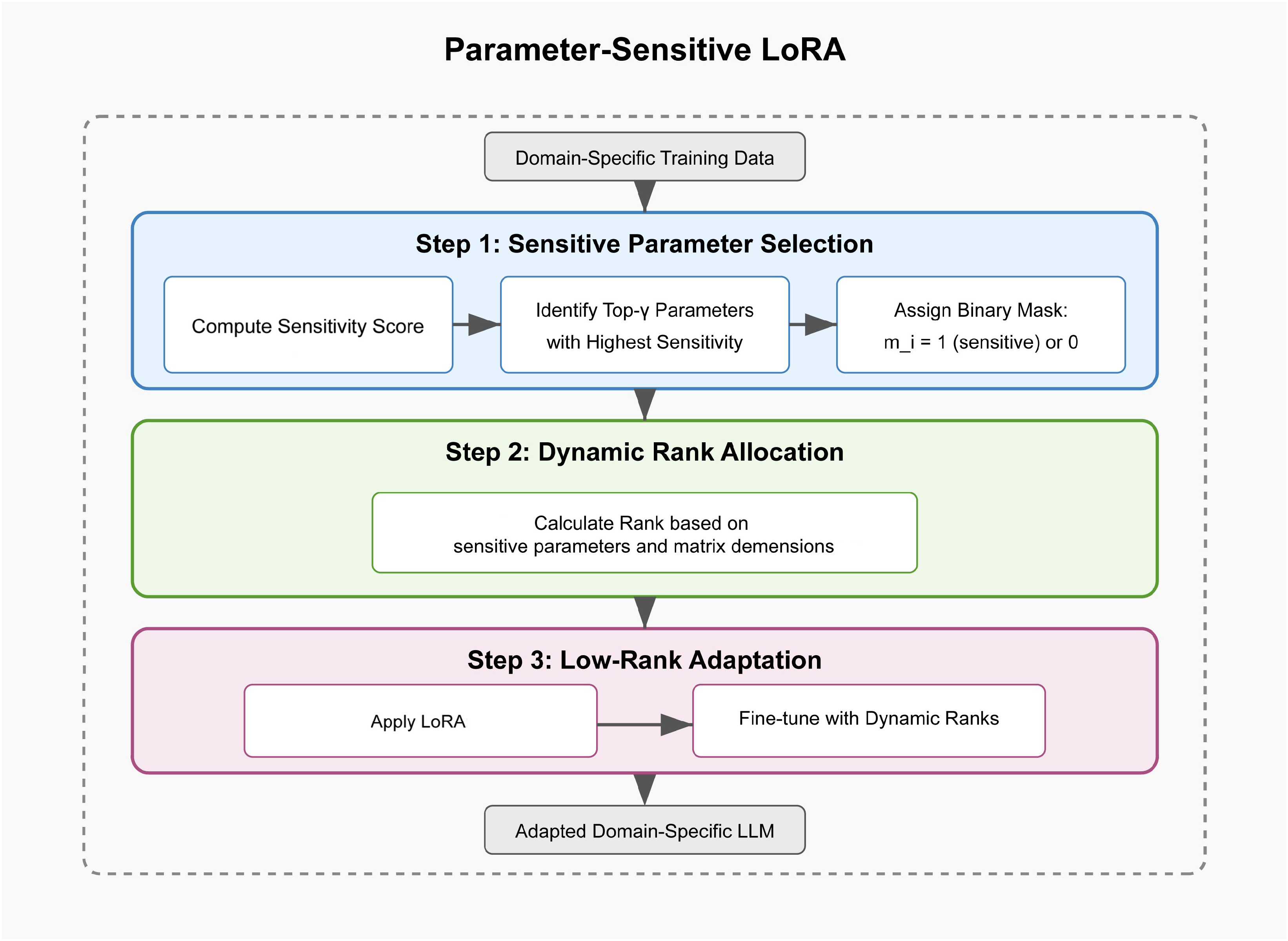
To address the limitations of general large language models in specialized domains, we propose SensiLoRA-RAG, a novel two-stage framework that enhances model performance with minimal domain-specific data and computational cost. Firstly, considering that it is difficult to construct a large number of standard training datasets in a specific domain, in the first stage, we design a novel parameter sensitivity low-rank adaptation (parameter sensitivity LoRA) to improve the domain adaptation of general LLMs. Its advantage is that it enables the general LLM to quickly absorb and understand specific domain knowledge, so as to enhance the performance of understanding the retrieval content in the second stage. Specifically, unlike standard LoRA, which assigns a fixed rank to all weight matrices, our method can dynamically adjust ranks based on parameter sensitivity. This allows the model to efficiently learn domain-specific knowledge with only a small amount of data, enabling rapid adaptation without the need for extensive retraining.
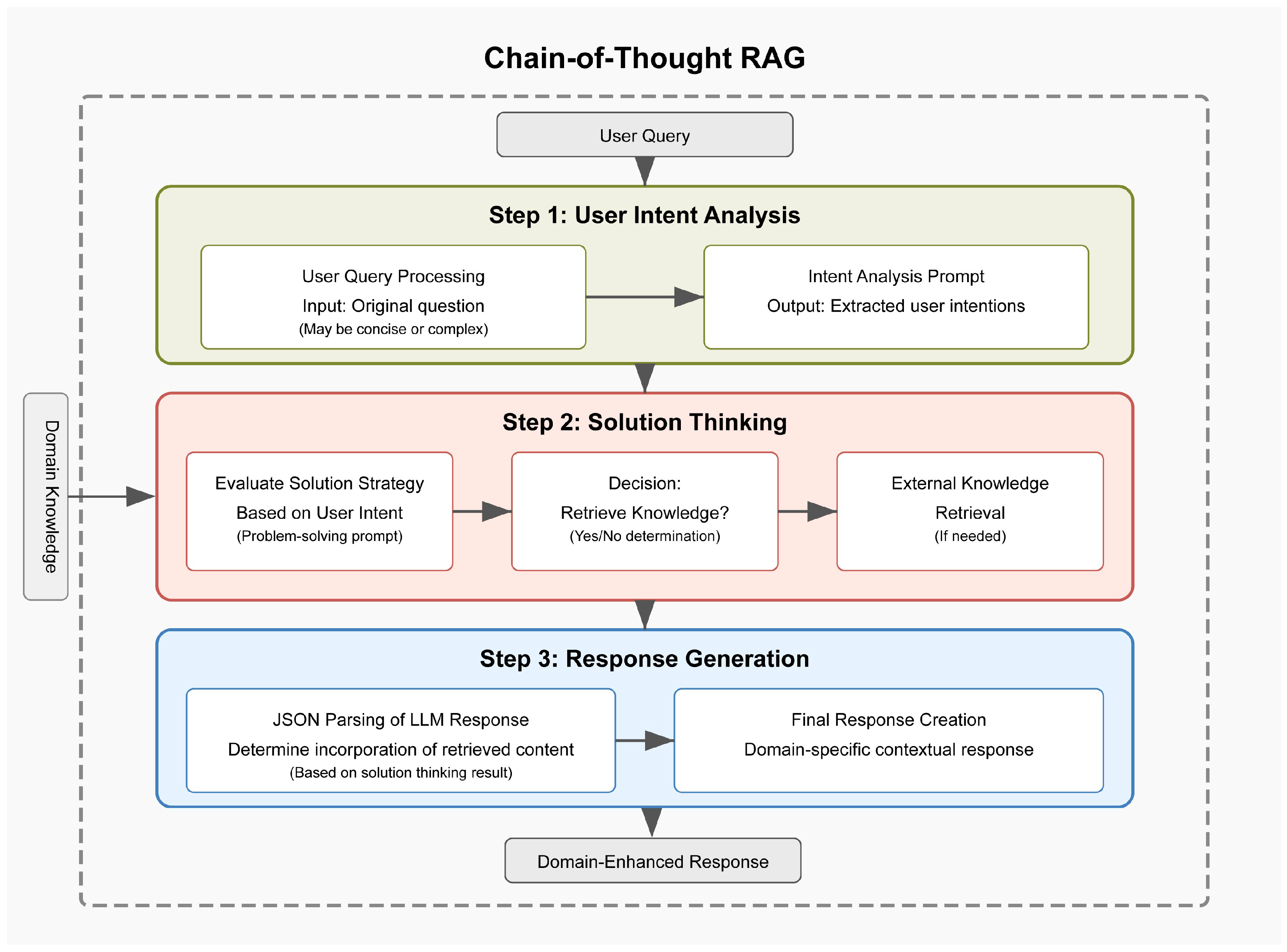
Secondly, to further address the challenge of real-time knowledge updating, inspired by the chain of thought of DeepSeek [
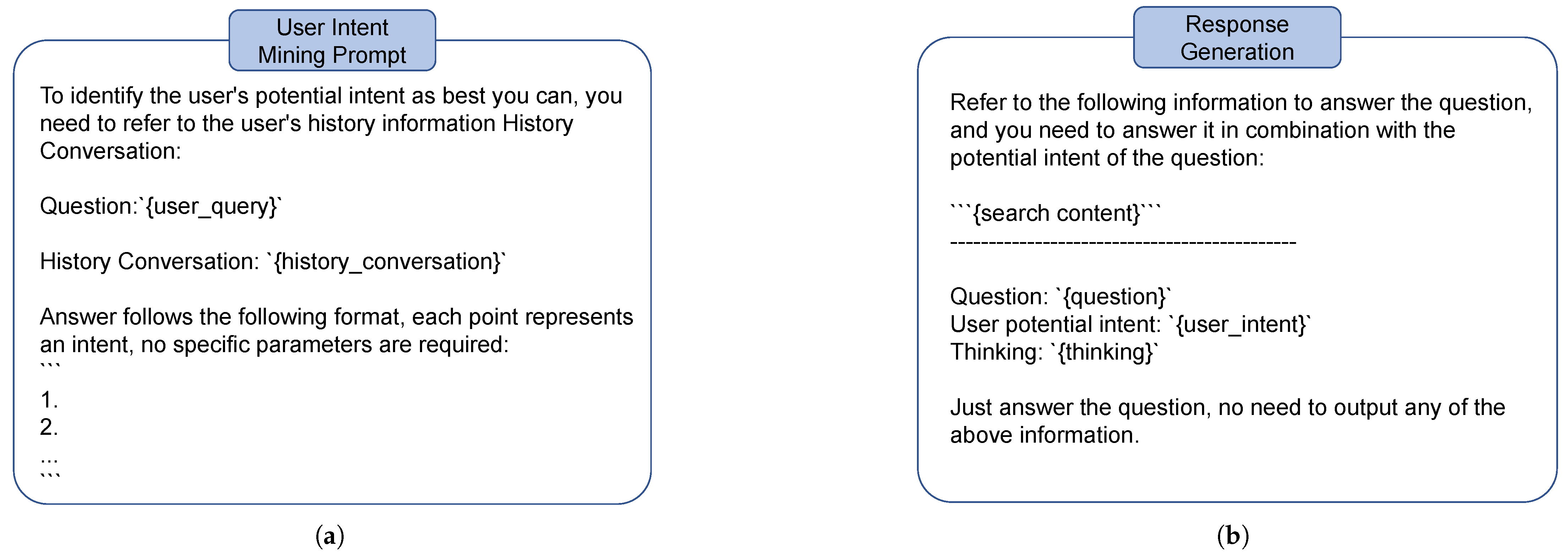
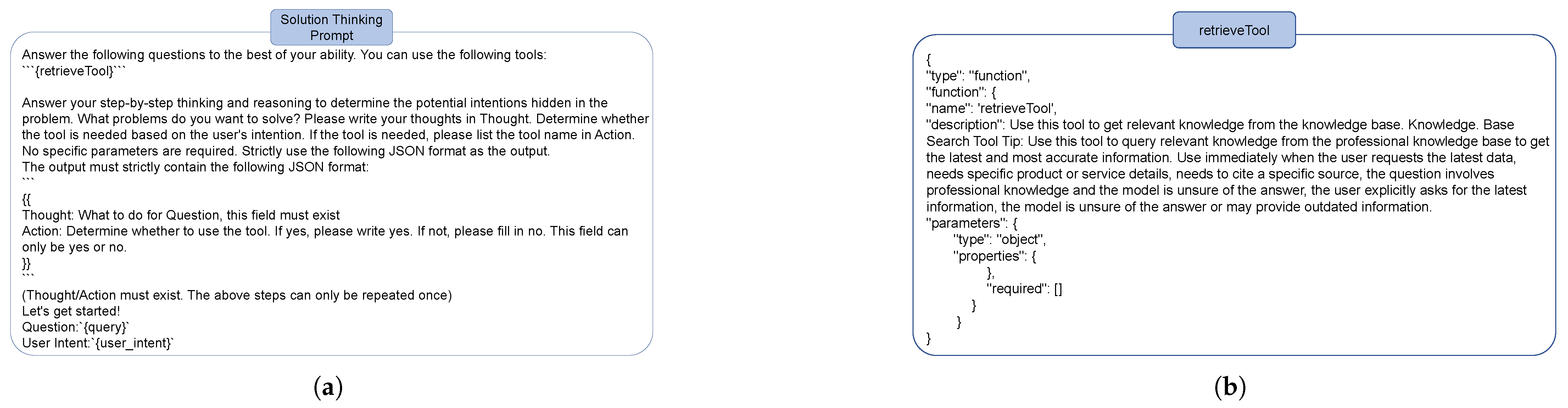
11], we propose a novel retrieval-augmented generation (RAG) approach based on a long-thought chain. Specifically, instead of relying solely on static training data, the model can intelligently retrieve and integrate up-to-date external information before generating responses. The reasoning chain consists of three steps: (1) user intent analysis, where the model analyzes the core intent behind a query; (2) solution thinking, where it evaluates possible response strategies and thinks about whether to use external knowledge; and (3) response generation, where LLM generates the response based on external knowledge or not. By combining adaptive fine-tuning with dynamic retrieval, SensiLoRA-RAG enables LLMs to adapt efficiently in specialized domains while staying updated with the latest knowledge, making it well-suited for real-world specialized domains.
In a nutshell, we summarize our main contributions as follows:
We propose SensiLoRA-RAG, a novel two-stage framework designed to enhance the performance of general LLMs in specialized domains. By combining adaptive fine-tuning with real-time retrieval, our approach enables efficient domain adaptation while maintaining access to the latest knowledge. This framework significantly reduces the need for extensive retraining, making it cost-effective.
We introduce a parameter-sensitive LoRA fine-tuning algorithm, which dynamically adjusts rank allocation based on parameter sensitivity, improving fine-tuning efficiency and effectiveness with minimal domain-specific data. Additionally, we propose a chain-of-thought RAG retrieval strategy, which enhances knowledge integration by guiding retrieval through a structured reasoning process.
We conducted comprehensive experiments on two specialized domains, i.e., law and healthcare, demonstrating that our method significantly improves the performance of general LLMs in domain-specific tasks.
5. Experiments
5.1. Experimental Settings
Datasets. Following LAW-GPT, we evaluate our method of parameter sensitivity LoRA on two datasets, including legal knowledge question-answering and medical knowledge question-answering tasks. For the legal knowledge question-answering dataset, we used crimekgassistant-52k; a multi-category legal consultation question-answering dataset was reconstructed using ChatGPT based on crimekgassistant’s original QA pairs, featuring regenerated responses with enhanced detail and improved linguistic standardization across thirteen case types, including marriage and family, labor disputes, traffic accidents, credit and debts, criminal defense, contract disputes, real estate disputes, infringement, company law, medical disputes, relocation and resettlement, administrative litigation, and construction projects. This dataset served as pretraining data for Xiezhi, a Chinese legal large language model. Huatuo-65k: Huatuo-26M, currently the largest traditional Chinese medicine (TCM) question-answering dataset, comprises over 26 million high-quality medical QA pairs. These pairs encompass comprehensive topics including diseases, symptoms, treatment methods, pharmaceutical information, and TCM theory. The creation of this dataset provides invaluable resources for research in natural language processing (NLP), information extraction, and question-answering systems within the TCM domain. To align the scale with legal QA datasets, we randomly sampled 60,000 entries for the training set and 5000 entries for the test set from this collection.
Evaluation Metrics. To evaluate the performance of the proposed method, we select BLEU, ROUGE, Bert-sim, and edit distance as evaluation metrics [
5,
58,
59,
60]. These metrics are widely recognized standards for assessing text generation quality, particularly in tasks involving open-ended or semi-structured outputs. BLEU measures the n-gram precision between the generated and reference texts, offering a quantitative assessment of content overlap. ROUGE focuses on recall-oriented measures, capturing the degree to which the generated text covers the reference information. Bert-sim measures the vector similarity of two sentences in the semantic space, while edit distance measures the minimum number of operations required to transform one string into another, including insertion, deletion, and substitution of characters.
Implementation Details. Following LAW-GPT, we employ the Lion optimizer to fine-tune the model for 10 epochs. All experiments were conducted on an NVIDIA A6000 GPU.
5.2. Discussion of Results
Question-Answering Task. We evaluated LoRA, AdaLoRA, DyLoRA, and our SensiLoRA on the crimekgassistant-52k and Huatuo-65k datasets. The results are listed in
Table 1 and
Table 2. As can be seen from the results, our SensiLoRA outperforms the baseline in multiple metrics, including BLEU, ROUGE-1, ROUGE-2, and ROUGE-L, fully demonstrating that the answers generated after fine-tuning with our method have better linguistic fluency. Furthermore, our method also shows improvements in two similarity metrics, proving that the answers generated after fine-tuning with our method are closer to the reference answers. Specifically, (1) our method achieved an improvement of approximately 12∼37.5% in BLEU and ROUGE metrics in the legal question-answering task compared to LoRA. (2) Our method achieved a significant improvement in BLEU in the medical question-answering task.
5.3. Ablation Study
How do hyperparameters impact our method’s performance? To investigate this, in
Table 3, we analyze the influence of hyperparameter variations on the medical QA dataset. We tested hyperparameter values ranging from 1100 to 1300 while using LoRA as the baseline. The results show that while performance fluctuates slightly with different hyperparameter values, our method consistently surpasses LoRA. This confirms that hyperparameter settings do not compromise the robustness of our approach.
Is our dynamic rank method effective? To answer this question, in
Table 4, we conducted experiments on the medical QA dataset to validate the efficacy of the dynamic rank approach. Specifically, we compared SensiLoRA against LoRA baselines with fixed ranks of 8, 16, and 32. The results demonstrate that SensiLoRA consistently outperforms LoRA across all tested ranks, proving the effectiveness of our dynamic rank strategy.
Can our CoT-RAG method improve response quality? We visualized a reply case in
Table 5 and
Table 6. Fine-tuning refers to training the model with parameter sensitivity LoRA, while RAG denotes a retrieval-augmented generation method that lacks user intent analysis and solution thinking. As shown in the table, our method accurately provides the correct answer, whereas the RAG method fails to do so. We speculate that the model may not really understand the intention of the user’s question, resulting in the model still giving an incorrect reply even if the context information is given. This demonstrates that guided reasoning enables the model to better grasp the user’s true intent, leading to more accurate responses and improved overall reply quality, thereby validating the effectiveness of our method.
6. Conclusions
In this work, we introduced SensiLoRA-RAG, a novel two-stage framework designed to address the challenges faced by general large language models (LLMs) in specialized domains. By integrating parameter-sensitive LoRA fine-tuning with a structured chain-of-thought-based retrieval-augmented generation (RAG) approach, our framework significantly enhances both domain adaptation and real-time knowledge integration. Extensive experiments conducted on domain-specific tasks in legal and healthcare settings validate the effectiveness of our approach. The results demonstrate that SensiLoRA-RAG significantly outperforms baseline models in both knowledge retention and real-time adaptability, reinforcing its potential for practical applications in specialized domains. In future work, we will (1) explore the scalability of SensiLoRA-RAG to a wider range of specialized domains beyond healthcare and law, such as finance, engineering, and education; (2) develop mechanisms to ensure the trustworthiness and explainability of retrieved information, particularly for high-stakes domains where transparency is critical and (3) examine the potential for continuous learning mechanisms that would allow the model to efficiently update its domain knowledge without extensive retraining. These directions represent promising opportunities to further enhance the capabilities of LLMs in specialized domains while addressing the challenge of domain adaptation.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}