1. Introduction
In the rapidly evolving landscape of e-commerce, efficient and accurate product discovery is essential to enhancing customer experience and driving sales. As online retail platforms expand their product offerings, categorizing and tagging products with precise product-specific attributes—such as color, size, material, brand, and style—is becoming increasingly critical for ensuring accurate search, filtering, and recommendation functions [
1,
2,
3]. This need is particularly pressing for large e-commerce platforms, where hundreds or thousands of products are added or updated frequently. However, the task of maintaining accurate product attributes is often left to individual sellers, leading to inconsistencies, missing data, and errors. These data gaps and inaccuracies can negatively impact the user experience by hindering product discoverability and filtering accuracy. Addressing these issues requires an automated, scalable solution capable of accurately identifying and extracting product attributes across a diverse catalog [
4,
5].
Named Entity Recognition (NER) has been a significant advancement in natural language processing (NLP), facilitating the extraction of specific entities or attributes from text. Traditional NER approaches have shown promise in extracting product features, yet they fall short in the context of large e-commerce platforms [
6]. Platforms like Trendyol (
http://trendyol.com.tr, accessed on 5 May 2025) face unique challenges due to the high variability in product descriptions and the vast array of product categories. Simple rule-based or template-based approaches are inadequate for handling this diversity. Recent advancements in deep learning (DL) and large language models (LLMs) present an opportunity to enhance attribute extraction capabilities. These models are capable of contextual understanding and can adapt to different categories and descriptions, making them well-suited for the e-commerce domain. By leveraging DL and LLM approaches, there is potential to create a system that autonomously extracts relevant product attributes, thus improving product searchability, filter accuracy, and ultimately, customer satisfaction [
7,
8].
This study proposes the development of a robust and scalable attribute extraction system. The Trendyol platform—one of Türkiye’s leading e-commerce environments—serves as the primary application domain, owing to its extensive and heterogeneous product assortment encompassing fashion, electronics, cosmetics, household goods, and groceries. The central research question addressed is: How can LLMs and DL techniques be leveraged to accurately and efficiently extract product attributes from unstructured Turkish-language text at scale? To this end, the study evaluates the performance of an LLM-based model, based on the Mistral architecture, in comparison with a transformer-based DL model, with a particular focus on their ability to extract both explicit and implicit attributes across diverse product categories. The research is structured around four core methodological stages to systematically achieve this objective:
Data Collection and Preparation: Compile and preprocess a comprehensive dataset of product titles, descriptions, and categories that reflect real-world usage patterns on the Trendyol platform.
Model Development: Implement and train two attribute extraction models—a fine-tuned DL-based model and an LLM-based model—each tested on their ability to classify attributes, categories, level 1 hierarchies, and combinations thereof.
Model Integration: Deploy both models into Trendyol’s production environment to enable real-time attribute suggestions during product listing and bulk attribute extraction for catalog-wide updates.
Performance Evaluation: Rigorously compare the models using quantitative metrics (precision, recall, F1-score) and qualitative analysis to assess accuracy, contextual understanding, and scalability.
This study contributes to the growing field of NLP in e-commerce through the following innovations:
Dual-Model Approach: By comparing a lightweight DL model with a context-aware LLM, the study provides empirical insights into trade-offs between interpretability, scalability, and performance. This dual perspective highlights when simpler models suffice and when advanced models are necessary, especially for extracting nuanced or implicit attributes.
Adaptation to Turkish Language: Most existing studies focus on English, leaving a gap in tools for morphologically rich, underrepresented languages like Turkish. This study fills that gap by training on a large-scale Turkish-language dataset, addressing linguistic challenges such as agglutination, flexible word order, and informal product descriptions.
Real-Time and Bulk Processing Capability: The system architecture supports both instantaneous attribute suggestions for sellers and high-throughput batch processing for catalog maintenance. This dual-mode design ensures that the solution is both responsive and scalable in a high-traffic environment.
Transferability to Other Platforms: Although the system is developed for Trendyol, the underlying methodology can be generalized to other multilingual and domain-specific e-commerce settings. It lays the groundwork for future applications like intelligent tagging, automated product listing assistants, or cross-lingual attribute normalization.
The rest of this work is organized as follows:
Section 2 provides a review of related work, focusing on NER and LLMs for attribute extraction in e-commerce, along with a comparative analysis of these approaches.
Section 3 outlines the methodology, detailing data collection, model development, and evaluation procedures. In
Section 4, the implementation and system architecture are discussed, including backend infrastructure, model deployment pipeline, and integration with Trendyol’s platform.
Section 5 presents the results and discussion, performing a comparative analysis of the DL-based and LLM-based models.
Section 6 concludes the work, summarizing key contributions, proposing future research directions, and offering final remarks on the impact of this attribute extraction system.
2. Related Work
In the realm of e-commerce, accurate product attribute extraction is essential for improving searchability, enhancing the shopping experience, and boosting sales. The task of identifying and categorizing product features like color, material, size, and style has been approached using various techniques, including NER and, more recently, LLMs. This section explores the relevant literature on NER and LLMs for attribute extraction.
2.1. Named Entity Recognition (NER) for Attribute Extraction
NER is a foundational technique in NLP, primarily used for extracting specific entities—such as names, locations, and dates—from text. In the context of e-commerce, researchers have adapted NER models to extract product-specific attributes by treating each attribute as an entity to be recognized and classified [
9].
Traditional NER approaches often rely on hand-crafted features and rule-based systems using regular expressions or heuristics to locate and label known attribute patterns. While such systems can be effective in constrained environments, they exhibit significant limitations when applied to large-scale e-commerce platforms with heterogeneous product catalogs [
10]. These rule-based methods struggle to generalize across different brands, sellers, or product lines because they rely on static patterns that do not adapt well to linguistic variability.
In practical terms, rule-based systems often fail when handling multi-attribute product descriptions—for instance, identifying “Red Cotton T-Shirt” as containing both a color and material attribute. Rule-based systems may incorrectly group multiple attributes into a single label or miss attributes entirely if they appear in an unexpected order or with novel phrasing. Moreover, when attributes are implicit or implied rather than explicitly stated (e.g., “sleek metallic finish” instead of “Material: Metal”), rule-based methods lack the contextual understanding needed to infer the correct attribute. These limitations can result in incomplete or erroneous product tagging, reducing the accuracy of search filters and recommendation engines, and ultimately degrading the customer experience. To overcome these issues, DL-based NER models have emerged as a more adaptable solution. These models leverage word embeddings and neural architectures—such as Recurrent Neural Networks (RNNs) and transformers—to learn semantic and syntactic relationships within product text.
Li et al. [
11] demonstrated that DL-based NER models outperform traditional approaches by better handling contextual nuances, leading to substantial improvements in attribute extraction accuracy. These models, trained on large annotated datasets, exhibit strong generalization across diverse linguistic patterns and product descriptions.
Loughnane et al. [
12] introduced a transformer-based NER model designed to extract attribute values directly from search queries. By incorporating weak labels derived from customer interactions, their approach significantly enhanced semantic product retrieval and ranking in real-time e-commerce applications. Similarly, Chen et al. [
13] explored the scalability of NER-based approaches in comparison to question-answering (QA) models for attribute–value extraction. Their study revealed that BERT-based NER models can match the accuracy of QA models while offering faster inference, demonstrating NER’s potential for large-scale attribute extraction.
Nonetheless, even DL-based NER models face challenges in dynamic, multilingual marketplaces like Trendyol. Product listings often vary widely in format, style, and granularity, and models trained on English-language datasets may not transfer well to Turkish, a morphologically rich and less-resourced language. Furthermore, conventional NER approaches may still misclassify polysemous terms (e.g., “bark” as a texture vs. sound) or fail to separate attributes correctly in densely packed descriptions. These challenges have led to increased interest in LLMs, which offer more robust contextual understanding and better scalability for complex attribute extraction tasks in e-commerce.
2.2. Large Language Models in Attribute Extraction
LLMs, such as BERT, GPT-3, and Mistral, have redefined the capabilities of NLP systems by leveraging vast amounts of data and sophisticated architectures to capture deep semantic and contextual understanding [
14,
15,
16]. Unlike traditional NER models, which require explicit rules or structured training data, LLMs are pre-trained on extensive corpora and can be fine-tuned for specific tasks, making them highly versatile and powerful for tasks involving language comprehension. In attribute extraction for e-commerce, LLMs have shown potential due to their ability to understand context, handle ambiguous phrases, and adapt to various product categories without extensive retraining [
3,
17].
LLMs operate through a transformer-based architecture, which uses self-attention mechanisms to process and understand long-range dependencies within text. This ability allows LLMs to excel at identifying attributes within complex product descriptions, even when these attributes are implied or appear in varied linguistic forms [
18]. For example, in the phrase “soft cotton feel”, the word “cotton” is not explicitly presented as a material attribute but as part of a descriptive phrase. A rule-based model would likely overlook this, but an LLM can draw on its pre-training to recognize “cotton” as a common material and infer its relevance in context. This inference is enabled by the model’s internal representations of co-occurrence patterns and contextual embeddings, which help it associate descriptive cues (e.g., “soft feel”) with specific attribute categories (e.g., material).
Moreover, LLMs can resolve ambiguities by considering the broader textual context. For instance, the word “light” in “light jacket for spring” can be understood as a weight-related attribute rather than color or brightness, thanks to the model’s ability to weigh surrounding tokens and construct a holistic semantic interpretation. This contrasts sharply with traditional NER models, which often rely on narrow token windows and may misclassify ambiguous terms.
In addition, the transfer learning capability of LLMs enables them to be fine-tuned on domain-specific datasets with minimal additional data, which is particularly useful for e-commerce applications involving unique or niche vocabulary. Fine-tuning allows the model to retain general language understanding while specializing in recognizing e-commerce-specific patterns, such as naming conventions, product templates, and common seller phrasing.
Several studies have highlighted the advantages of LLMs in e-commerce attribute extraction. For instance, Blume et al. [
19] demonstrated that LLMs could accurately identify product attributes in multilingual contexts by leveraging their pre-trained multilingual embeddings. These multilingual embeddings capture semantically aligned representations across languages, enabling the model to recognize attribute equivalence (e.g., ‘pamuk’—the Turkish word for ‘cotton’—and ‘cotton’ in English) even if the fine-tuning data are limited in one language. In a similar study, Shinzato et al. [
20] showed that LLMs outperformed traditional NER models in extracting attributes from noisy, unstructured text typical of user-generated content in e-commerce. In another study, Fang et al. [
21] proposed an ensemble method combining outputs from multiple LLMs, achieving superior performance in attribute value extraction tasks. Additionally, Zou et al. [
22] introduced a multimodal LLM framework that efficiently extracts implicit attribute values by integrating textual and visual data, further enhancing the robustness of attribute extraction systems.
Despite their advantages, LLMs also come with challenges. Their large size and complexity require significant computational resources, particularly during fine-tuning and real-time inference, making them difficult to deploy at scale. Moreover, LLMs trained on general corpora may sometimes fail to capture domain-specific knowledge without extensive fine-tuning, necessitating targeted training data to achieve optimal results in attribute extraction tasks.
2.3. Comparative Analysis of Approaches
The comparative strengths and limitations of traditional DL-based NER models and LLM-based approaches reveal fundamental trade-offs that influence their suitability for various e-commerce applications. While DL-based NER models offer computational efficiency with relatively low resource requirements for both training and inference, they lack the flexibility needed to handle diverse and nuanced product descriptions. These models perform well when applied to structured and predictable datasets, making them a viable choice for e-commerce applications with stable taxonomies and clearly defined attribute sets. For instance, DL models are well-suited to product catalogs that use template-based descriptions or have a limited number of attributes per item, such as standardized electronics specifications (e.g., screen size, resolution, brand) or tightly regulated product categories like pharmaceuticals. In such cases, their faster inference times and lower deployment costs make them a pragmatic choice, especially for small to mid-scale platforms [
23].
However, their reliance on manually labeled training data and rule-based heuristics limits their adaptability to complex and evolving product descriptions, particularly in large-scale, multilingual marketplaces like Trendyol [
24,
25].
Conversely, LLMs bring a substantial improvement in contextual understanding and generalizability. By leveraging deep contextual embeddings, they excel at recognizing implicit and context-dependent attributes in noisy or unstructured text. Unlike traditional NER models, which depend on predefined rules or manually annotated data, LLMs demonstrate superior adaptability across different product categories and languages. This flexibility is particularly valuable in e-commerce, where product descriptions often contain informal, ambiguous, or colloquial expressions that conventional models struggle to interpret accurately [
26,
27]. LLMs are especially appropriate in scenarios where product content varies widely, such as fashion, home décor, or user-generated listings, where descriptions may contain subjective phrases (“elegant fit”, “cozy material”) or marketing language rather than explicit attributes. They are also advantageous in multilingual settings where attribute vocabularies and expression patterns differ across languages, making it difficult for DL models to generalize without extensive retraining [
28].
However, despite their superior accuracy, LLMs introduce additional challenges related to scalability and computational cost. Deploying LLMs in real-time production environments requires significant resources, and their black box nature can pose interpretability challenges, making quality control and error analysis more complex [
29,
30].
In this study, we propose an LLM for attribute extraction in Turkish-language e-commerce and compare its performance against a DL-based NER model. Our approach evaluates the LLM’s ability to capture implicit and nuanced product attributes, a challenge that conventional NER models often fail to address. Unlike previous studies, which primarily focus on English-language datasets or structured attribute extraction, our work introduces a large-scale, Turkish-language e-commerce dataset containing over 700 product categories and attributes. Furthermore, our study differs from existing research by providing a direct, domain-specific comparison of LLMs and deep learning-based NER models under identical conditions, ensuring a fair and comprehensive evaluation.
3. Methodology
To develop a robust attribute extraction system for Trendyol’s e-commerce platform, a structured methodology was employed. This methodology comprises three main phases: data collection and preparation, model development, and model evaluation and comparison. The following subsections describe the specific processes involved in each phase.
3.1. Data Collection and Preparation
Effective attribute extraction relies on a high-quality dataset that represents the full range of product categories and attribute diversity found on the Trendyol platform. The data collection and preparation phase involved gathering, cleaning, and processing a large volume of product information to create a comprehensive and representative dataset. This dataset was essential for training, validating, and testing both DL and LLM-based approaches.
Two primary datasets were constructed to support model development and evaluation, with data collection rounds completed in March 2023 and September 2023. The March 2023 dataset, denoted as Dataset 1, consisted of approximately 3 million records and was compiled from Trendyol’s live product catalog using internal data pipelines connected to the production PostgreSQL database. The raw data were extracted automatically via SQL queries directly from internal database tables containing product listings and associated attribute–value pairs, without any manual collection. For Dataset 1, the sampling followed a structured approach in which approximately 1000 product records were randomly selected from each of Trendyol’s ~3000 leaf-level product categories, including categories such as apparel, footwear, cosmetics, electronics, and home goods. This method ensured balanced representation across the catalog.
Each record in Dataset 1 primarily included product titles and attribute metadata, consisting of attribute names (e.g., color, size, material) drawn from a standardized attribute name pool and attribute values (e.g., red, cotton, x-small) provided by sellers. This cross-categorical sampling strategy was designed to avoid overrepresentation of any specific product type and to provide a representative training foundation that captures frequently occurring and structurally consistent attributes relevant for general-purpose attribute extraction.
In contrast, Dataset 2, compiled in September 2023, employed a more targeted and business-driven sampling strategy. This second dataset included approximately 867,000 product records and focused on category–attribute pairs identified as high-priority through internal analytics dashboards and expert feedback. Specifically, stratified sampling was used to select ~20,000 high-priority leaf category–attribute pairs, based on business-critical KPIs such as sales performance, product click-through rates, search-to-click ratios, and return rates. As with Dataset 1, the raw data were extracted automatically via SQL from the same backend product tables, but this time included an extended set of features—product titles, descriptions, leaf category identifiers, attribute names, and seller-provided attribute values. Accordingly, Dataset 2 emphasized products with strong commercial relevance where high-precision attribute extraction was most impactful.
The two datasets were compiled independently; however, since they were sampled from overlapping source tables but using different criteria and timeframes, a deduplication step was implemented during preprocessing to ensure that duplicate records between Dataset 1 and Dataset 2 were removed in the final merged corpus.
Both datasets were drawn from real-time product listings and underwent a structured multi-phase cleaning process. The raw datasets contained significant variability and noise, including spelling errors, inconsistent terminology, and irrelevant information. Consequently, a rigorous data cleaning and preprocessing pipeline was implemented to standardize and enhance the quality of the input data. This pipeline involved several steps:
- ○
Text Standardization: Product titles and descriptions were normalized by converting all text to lowercase, removing special characters, and standardizing common terms to ensure consistency across records.
- ○
Stopword Removal: Irrelevant words and phrases that did not contribute to attribute identification, such as “new”, “high quality”, and brand names, were removed to focus the model on attribute-related content.
- ○
Tokenization: Product descriptions were tokenized, breaking down each description into individual words or tokens. This step was essential for both the DL and LLM models, which require tokenized input to understand the structure and relationships within the text.
- ○
Labeling and Annotation: Each product’s attributes were labeled according to specific tags for various features, such as color, material, and style. This labeling followed a Beginning, Inside, Outside (BIO) scheme to help the models learn to recognize attribute boundaries within text.
- ○
Data Augmentation: To improve the model’s generalizability, data augmentation techniques were applied to introduce minor variations in phrasing while preserving the core meaning. This process created additional training examples and improved the models’ ability to handle linguistic diversity in product descriptions.
The dataset was labeled using a regex-based annotation approach, which enabled the rapid and consistent generation of high-quality ground truth data across large-scale product listings. Regular expressions were used to automatically identify and tag attribute values—such as color, material, and size—within product titles and descriptions by matching them against a predefined pool of standardized attribute names and seller-provided values. For the DL model, when an attribute value appeared in the product title, it was labeled using the BIO (Beginning–Inside–Outside) tagging format. For example, if the attribute was “Color: Red Pattern” and the product title was “Cotton t-shirt red pattern”, the annotated sequence would be “O-O-B-I”. This automated annotation process allowed for efficient training data preparation across millions of records without requiring manual intervention, ensuring consistency across product categories and accelerating model development.
Beyond scalability, regex-based annotation contributed to a high degree of alignment between model inputs and Trendyol’s internal product taxonomy. The method ensured that attribute annotations directly reflected the structured attribute–value data sellers provided during product onboarding, creating a strong link between textual descriptions and the platform’s backend data systems. The use of standardized regex patterns also facilitated easy adaptation to new attribute types or product categories, allowing for rapid expansion of the annotation scope as business needs evolved. Overall, regex-based annotation served as a reliable and production-ready foundation for supervised training, supporting both the DL and LLM models in learning attribute extraction across a wide variety of product types and linguistic patterns.
For the LLM, a similar regex-based annotation was applied, but with a different labeling strategy. Attribute values from seller inputs and product titles were standardized, and if a relevant attribute value was present in the title, it was retained in the ground truth annotation. If the attribute was absent, it was labeled as “None”. For example, given attributes “Color: Red Pattern” and “Material: Polyester” with the product title “Cotton t-shirt red pattern”, the ground truth annotation was recorded as {“Color”: “Red Pattern”, “Material”: “None”}. These annotations were fully automated through rule-based preprocessing to ensure consistency and scalability in dataset labeling.
The dataset was structured to reflect real-world scenarios on the platform, capturing the linguistic variability in product descriptions. The labeled data within these datasets facilitated supervised learning, allowing the models to learn associations between product descriptions and corresponding attributes. These datasets also accounted for challenging cases, such as multi-attribute products and ambiguous phrases, which are common in e-commerce text and require sophisticated handling by the models.
Figure 1 illustrates the process of attribute extraction from product information within the dataset. It starts with the model input, which includes the product title and product description provided by the seller. The model input could be something like:
Product Title: “Floral Midi Dress with Straps, Casual Daily Wear”.
Product Description: “This stylish midi dress features a beautiful floral pattern and a fitted design. Made from woven fabric, it comes in a vibrant orange color with a casual style perfect for daily wear. It also includes a fashionable slit for added style”.
Figure 1.
Attribute extraction process from product descriptions.
Figure 1.
Attribute extraction process from product descriptions.
This information is then processed by the model, and the extracted attributes are displayed in the model output. In the output, the model identifies and categorizes specific product attributes, such as Sleeve Type (identified as “Strapped”), Pattern (“Floral”), Length (“Midi”), Color (“Orange”), Fabric Type (“Woven”), Fit (“Fitted”), Occasion (“Casual/Daily”), and Additional Feature (“Slit”). This example demonstrates how the model transforms the provided title and description into a structured format, making each product characteristic easily accessible and searchable on e-commerce platforms.
3.2. Model Development
An LLM was developed as the proposed approach for product attribute extraction, leveraging its advanced contextual understanding and adaptability. To enable a comparison, a DL-based model was also built, allowing for a comprehensive evaluation of both methods.
The DL model utilized a transformer architecture, specifically a fine-tuned RoBERTa model trained on Trendyol’s product data. This model was chosen for its ability to capture contextual relationships within text and handle complex language patterns. In training, the model received tokenized input from product titles and descriptions, enabling it to learn associations between certain words and their corresponding attributes.
The DL model was trained using supervised learning with labeled data that defined attribute boundaries based on the BIO tagging scheme, and its training parameters—including a batch size of 128, seven epochs, and a learning rate of 5 × 10−5—were determined through a structured hyperparameter optimization process. A grid search was conducted over a predefined range of values for key parameters such as batch size (32, 64, 128), learning rate (1 × 10−5 to 5 × 10−4), and number of epochs (3–10). Each configuration was evaluated on a stratified validation set using precision, recall, and F1-score, with macro-averaged F1 serving as the primary metric for model selection. The chosen parameters offered the best balance between training stability, generalization performance, and computational efficiency, ensuring reliable performance across diverse product categories in the attribute extraction task.
However, while effective for attribute extraction within predefined categories, this approach has inherent scalability limitations.
Figure 2 illustrates the transition from a restricted, category-specific NER model to a more adaptable and scalable OpenTag model for e-commerce attribute extraction. The Single Category Transformer NER Model (old approach) operates by selecting a specific category, extracting attribute–value pairs using regex, and fine-tuning a transformer model tailored to that category. This method restricts its generalization across diverse product types. In contrast, the scaled-up OpenTag model, used in this study, is designed to process hundreds of attributes and categories simultaneously. This approach begins with regex-based attribute–value generation, followed by creating labeled (BIO) data for different categories and generating positive and negative examples to enhance model training. As a result, it enables efficient, large-scale attribute extraction across multiple product categories, effectively overcoming the limitations of category-specific NER models.
To further enhance the attribute extraction process and address the limitations of traditional NER models, a more advanced neural network architecture was designed. This architecture integrates multiple DL components to improve contextual understanding and classification accuracy. In
Figure 3, a layered neural network architecture for attribute extraction is depicted, aligning with the study’s goal to develop a robust system for automated attribute extraction in e-commerce. The architecture begins with a Word Representation Layer using BERT, which generates context-aware embeddings for tokens within product titles and attributes, capturing essential linguistic nuances. These embeddings feed into a Contextual Embedding Layer consisting of bi-directional LSTM units, which refine the contextual representation by considering sequential dependencies in both forward and backward directions. An Attention Layer then highlights the most relevant parts of each sequence, enabling the model to focus on crucial tokens for accurate attribute identification. Finally, a Conditional Random Field (CRF) Output Layer classifies each token into beginning (B), inside (I), or outside (O) of an attribute, enhancing prediction consistency by enforcing label dependencies. This architecture combines DL and attention mechanisms to improve the extraction accuracy of complex, context-dependent product attributes, thus fulfilling the paper’s objective of advancing attribute extraction capabilities for Trendyol’s e-commerce platform.
The proposed LLM-based approach, built upon the Mistral architecture, offers advanced capabilities for attribute extraction due to its large-scale pre-training on diverse textual corpora. Mistral, optimized for natural language processing tasks, was fine-tuned on Trendyol-specific data to adapt to the e-commerce domain and the Turkish language.
Unlike the DL model, the LLM used a more complex decoding process to generate responses that identify and contextualize product attributes. This model utilized a sliding-window technique to handle longer product descriptions without sacrificing context, as well as prompt-based fine-tuning to improve accuracy in attribute extraction. During fine-tuning, Mistral was trained to predict up to seven attributes per product title and description, balancing efficiency with accuracy in extracting multiple features simultaneously.
The fine-tuning process was conducted using Low-Rank Adaptation (LoRA), a parameter-efficient tuning method that allows for task-specific adaptation without modifying the full set of model parameters. The configuration included a LoRA rank of 64 and a scaling factor (alpha) of 128. Fine-tuning was selectively applied to critical projection components within the Mistral model: query projection (q_proj), key projection (k_proj), value projection (v_proj), output projection (o_proj), gate projection (gate_proj), and both up and down projections (up_proj, down_proj) in the feedforward layers. These layers were unfrozen and made trainable, while the rest of the model parameters remained fixed. This selective adaptation allowed for precise tuning of the model’s attention and representation mechanisms without the computational burden of full backpropagation through all parameters. A dropout rate of 0.1 was used during training to prevent overfitting and promote generalization across product categories.
Model input was structured to include both product titles and descriptions, formatted via templated prompts to encourage the model to focus on attribute-relevant content. These prompts enabled the model to associate loosely structured or implicit phrases—such as “lightweight for travel” or “soft and breathable”—with target attributes like weight and material.
The design of the LLM allowed it to handle ambiguous and nuanced expressions with greater flexibility compared to traditional NER models. By jointly analyzing product titles and descriptions in a contextualized fashion, the model achieved robust performance in recognizing complex, multi-attribute product information, particularly in informal or marketing-oriented language. Its ability to generalize across unseen categories and attribute combinations without additional manual annotation marked a significant advancement over the limitations of DL-based approaches.
3.3. Target Variables and Performance Evaluation
In this study, we aim to evaluate the predictive capabilities of our LLM in extracting structured product attributes and compare its performance against a DL model. The target variables include multiple levels of classification, reflecting the hierarchical structure of product attributes in e-commerce. Specifically, we focus on predicting the following:
Category Prediction—Assigning products to the correct high-level category (e.g., “Clothing”, “Electronics”, “Home and Furniture”).
Attribute Prediction—Identifying the key product attributes (e.g., “Material”, “Fit”, “Color”, “Processor Type”).
Category + Attribute Prediction—Predicting both category and attribute simultaneously, ensuring that extracted attributes align with the correct category (e.g., “Clothing” + “Fabric Type”).
Category + Level 1 Category Prediction—Hierarchical classification where products are assigned both a broad category and a level 1 subcategory (e.g., “Electronics” → “Laptops”).
Category + Attribute + Level 1 Category Prediction—The most complex prediction task, where the model must assign the correct level 1 category, subcategory, and relevant product attributes (e.g., “Electronics” → “Laptops” + “Processor Model”).
The dataset used in this study consists of over 700 unique categories and attributes. Due to space constraints, it is not feasible to report results for every individual category and attribute. To demonstrate the superiority of our proposed LLM, we employ a two-step evaluation methodology:
Focused Comparative Analysis—We identify the 30 categories and attributes where the DL models achieve the highest F1-scores (excluding cases where F1 = 1, as they already represent optimal performance and cannot be improved further). These cases serve as a benchmark for direct comparison with our LLM, allowing us to highlight performance improvements in challenging classification scenarios.
Overall Performance Evaluation—After analyzing the selected categories and attributes, we report the average performance metrics (precision, recall, and F1-score) across all categories and attributes in the dataset. This provides insight into the general superiority of our LLM over a broader range of classification tasks.
To determine the effectiveness of each model, a comprehensive evaluation and comparison were conducted. The models were evaluated using standard performance metrics for classification tasks: precision, recall, and F1-score. The equations of these metrics are given in Equations (1)–(3):
where
tp (i.e., true positives) represents correctly predicted instances,
fp (i.e., false positives) refers to instances incorrectly classified as positive, and
(i.e., false negatives) denotes actual positive instances that were misclassified.
Precision quantifies the proportion of correct positive predictions among all predicted positives, whereas recall measures the proportion of actual positives correctly identified. The F1-score serves as a harmonic mean of precision and recall, balancing both metrics to provide a holistic measure of classification accuracy.
To evaluate the comparative performance of the LLM and DL models, a classification scheme based on F1-score differences was applied. If the difference between the two models fell within ±3%, their performance was considered statistically similar, and these cases were excluded from the results table, as no clear advantage could be determined. If the LLM’s F1-score exceeded that of the DL model by at least 3%, it was classified as superior; similarly, if the DL model outperformed the LLM by the same margin, it was deemed superior.
A threshold of ±3% was selected based on preliminary experimentation and practical considerations. This margin was found to provide a balanced trade-off between sensitivity to real performance gains and robustness against noise. In large-scale NLP tasks, F1-score differences smaller than 3% were frequently observed to result from random variation in training dynamics or data sampling rather than true model superiority. By applying this threshold, minor fluctuations were filtered out, and only meaningful, consistent improvements were highlighted in the comparative evaluation.
4. Implementation and System Architecture
The methodological framework outlined in the previous section establishes the foundation for attribute extraction using both LLM and DL models. However, deploying such models in a high-traffic e-commerce environment like Trendyol requires a robust and scalable system architecture. Given the platform’s extensive product catalog and frequent updates, the infrastructure must support real-time processing while efficiently handling large datasets. The following section details the backend infrastructure, model deployment pipeline, and integration strategies that enable seamless operation. By leveraging optimized inference techniques and scalable cloud-based solutions, we ensure that our system meets the demands of both bulk attribute extraction and real-time product listing enhancements.
4.1. Backend Infrastructure and Deployment
The backend infrastructure was designed to support the computational demands of training and deploying both the LLM-based and DL-based attribute extraction models. Given the large-scale nature of the datasets and the complexity of the models, careful consideration was given to selecting hardware and software resources that could efficiently handle model training, deployment, and integration with Trendyol’s platform.
The choice of hardware and software was guided by the need for high computational power, storage, and flexibility in handling model updates. Training and deploying the models required access to powerful GPUs, particularly for the LLM, which is computationally intensive. For model training, the infrastructure included custom instances on Google Cloud equipped with 48 vCPUs (Intel Skylake E5-2682v4) and 150 GiB of RAM, along with four NVIDIA A100 GPUs. These high-performance instances enabled efficient parallel processing and reduced training time for both models. For model deployment in a live environment, Trendyol’s internal Kubernetes cluster was employed, providing scalability and fault tolerance necessary for handling large volumes of requests.
The primary software stack consisted of PyTorch (Version 2.0.1) for DL model development, Huggingface’s Transformers library for handling the LLM, and Nvidia Triton Inference Server for serving models in production. Docker and Kubernetes were used to containerize and orchestrate model services, ensuring flexibility in deployment and scaling. Additionally, FastAPI was used to build a RESTful API interface, enabling seamless integration with Trendyol’s backend. Monitoring tools like Grafana, New Relic, and Kibana were employed to track model performance, system health, and log data, ensuring smooth operation and proactive issue resolution in production.
The backend system has been developed using Python (Version 3.9.0) and FastAPI, and follows a Domain-Driven Design (DDD) architecture that cleanly separates concerns into domain, application, and infrastructure layers. Each business capability is encapsulated within its own bounded context, allowing for modular development and independent scalability. The system incorporates internal preprocessing and postprocessing pipelines, enabling dynamic handling of input normalization, validation, enrichment, and output formatting within business logic flows.
The model deployment pipeline was structured to facilitate continuous integration and continuous deployment (CI/CD), enabling rapid updates and ensuring that the latest model versions could be deployed with minimal downtime. The pipeline began with model training and evaluation in a development environment, where both the DL and LLMs were trained and tested. After satisfactory performance was confirmed, the models were exported and packaged into Docker containers, making them portable and easy to deploy.
The deployment process followed a multi-step procedure: first, trained models were serialized into ONNX or PyTorch formats depending on their type (DL or LLM); second, model artifacts were validated through automated tests to ensure compatibility with the Triton Inference Server environment; third, models were versioned and uploaded to an internal model registry. A deployment trigger in the CI/CD pipeline—managed via GitLab—initiated container builds, applied infrastructure-as-code (IaC) templates, and deployed the model as a microservice on Trendyol’s Kubernetes clusters. Canary releases were used to validate performance in production on a limited set of traffic before full rollout.
Challenges during deployment included handling model size constraints, especially for the LLM, which required careful GPU memory allocation and batching strategies to avoid OOM (out-of-memory) errors. Additionally, optimizing model loading time and inference latency required integrating asynchronous request handling and batching support within Triton. Integration with Trendyol’s internal monitoring tools also demanded the implementation of custom logging and error tracing endpoints to support real-time diagnostics.
To ensure stability under high traffic, the service is deployed in a multi-cluster environment with robust health check mechanisms at both application and container orchestration levels. These health checks actively monitor the availability and responsiveness of individual services, enabling automated restarts and traffic rerouting in case of anomalies. The application also supports asynchronous request processing and leverages lightweight concurrency features of FastAPI to handle large volumes of parallel requests efficiently. In addition to extensive unit and integration testing, the system has undergone performance and load testing under simulated high-traffic scenarios. These tests verify throughput limits, response time behavior, and bottleneck identification, ensuring that the platform can reliably meet service-level expectations under pressure. Together, these architectural and operational choices contribute to a backend that is robust, scalable, and resilient, even as business complexity and traffic volume increase.
In production, Nvidia Triton Inference Server handled model inference requests, which allowed for efficient GPU utilization and reduced latency. The deployment pipeline was managed through GitLab CI/CD, which automated testing, containerization, and deployment to Trendyol’s Kubernetes cluster. This approach enabled the backend infrastructure to dynamically allocate resources based on demand, ensuring that the attribute extraction models could handle high volumes of concurrent requests during peak usage times. With this deployment pipeline, Trendyol’s system could accommodate both bulk attribute extraction tasks and real-time processing, providing a flexible and resilient architecture.
4.2. Integration with Trendyol Platform
To maximize the utility of the attribute extraction models, they were integrated directly into Trendyol’s existing e-commerce infrastructure. The integration focused on two primary use cases: bulk processing for updating attributes across Trendyol’s catalog and real-time attribute suggestions for sellers during the product listing process. These implementations were designed to enhance data accuracy, improve customer search experiences, and streamline the product upload process for sellers.
The bulk processing functionality was designed to enable large-scale attribute extraction across Trendyol’s existing product catalog. A dedicated API endpoint was developed to handle bulk requests, allowing Trendyol’s backend to submit batches of products for attribute extraction. This API, built using FastAPI, could process thousands of product records in each request, significantly reducing the time and effort required for catalog-wide attribute updates.
In a typical bulk processing operation, Trendyol’s backend system sends product titles, descriptions, and categories to the API, which then routes the data to the appropriate attribute extraction model (either the LLM- or DL-based model, depending on the task requirements). The model returns a set of predicted attributes for each product, which are then written back to Trendyol’s database. This process allows Trendyol to maintain up-to-date attribute data across its entire catalog, addressing issues related to missing or inaccurate product attributes and enhancing the quality of search and filtering options for customers. Bulk processing can be scheduled during off-peak hours to minimize impact on system performance, while periodic re-runs of the process ensure that the product catalog remains consistent and comprehensive over time.
The real-time attribute suggestion feature was developed to assist sellers in accurately describing their products during the listing process. When a seller enters a product title and description, the system sends this information to the attribute extraction API in real-time, which then returns a set of suggested attributes that the seller can accept, modify, or override. This real-time interaction enables sellers to provide complete and accurate product data, which enhances the overall consistency of Trendyol’s catalog.
The attribute suggestions are generated by the LLM, which is optimized for understanding and predicting attribute values from free-text descriptions. Due to its contextual understanding, the LLM can offer accurate suggestions even when the seller’s input is incomplete or ambiguously worded. This model’s sliding-window mechanism allows it to process long product descriptions efficiently, ensuring low-latency responses suitable for real-time applications. This feature helps sellers by reducing the cognitive load of manually specifying each attribute and minimizes errors that may arise from misinterpretation or oversight. Moreover, by encouraging accurate and standardized attribute entry at the point of product listing, this real-time solution reduces the need for post-listing corrections and enhances the search and discovery experience for Trendyol’s customers.
Beyond its immediate business impact, this system integration contributes to the research community by demonstrating how state-of-the-art language models can be operationalized at scale in a production-grade e-commerce setting. The architectural patterns, model selection logic, and API-level decisioning introduced in this study offer a replicable framework for deploying attribute extraction systems that balance batch and real-time demands. Moreover, the approach highlights how pre-trained models, when domain-adapted and supported by robust backend engineering, can bridge the gap between academic NLP advancements and real-world data infrastructure. As such, the work extends the field of applied NLP by contributing an end-to-end blueprint for integrating transformer-based models into dynamic, high-traffic digital commerce environments.
5. Results and Discussion
This section presents a comprehensive evaluation of the proposed LLM for structured attribute extraction in e-commerce and its comparison with DL models. The results are analyzed across multiple levels, beginning with category-based and attribute-based evaluations, followed by an assessment of category + attribute-based performance. Further, hierarchical category-level and hierarchical category + attribute-level analyses provide insights into the model’s ability to handle complex classification structures. The overall performance evaluation summarizes key findings and highlights the trade-offs between accuracy and computational efficiency. Finally, the obtained results are contextualized with existing literature, comparing our findings with previous studies on attribute extraction and classification tasks in related domains.
5.1. Category-Based Evaluation
Table 1 presents the performance evaluation of LLM and DL models in product category extraction. As mentioned previously, for comparison, only the 30 best-performing categories—those with the highest F1-scores obtained by the DL model—are included, serving as a benchmark for direct comparison with the proposed LLM.
Figure 4 shows the percentage increases in F1-scores of LLMs compared to DL models for category extraction.
The evaluation of the LLM for category extraction in product descriptions demonstrates a highly effective system that significantly improves accuracy over the DL model. Key performance metrics—including precision, recall, and F1-score—highlight the strengths of the LLM, while also identifying areas for further refinement. This comparison does not merely reflect improved numbers but illustrates how pre-trained language models, when fine-tuned with domain-specific data, can generalize across a diverse taxonomy with minimal manual rule engineering—an important contribution to the application of LLMs in structured prediction tasks.
The LLM consistently demonstrates high precision across a majority of categories, with 20 out of 30 instances reaching a perfect precision of 1.00, indicating minimal false positives and highly reliable attribute extraction. In categories such as Christmas Tree, Steam Cleaner, Ball Bag, Gold Pendant, Party Sets, Tie Rod, Gold Bar, Shopping Cart and Bag, and Dog Training Product, the LLM achieves perfect scores across all metrics (precision, recall, and F1-score), substantially outperforming the DL model, which suffers from lower recall and precision in several of these cases. Additionally, in more technically complex or niche domains such as Nut Tightening Machine, Glucosamine, and Car Cover, the LLM again delivers flawless performance (1.00 across all metrics), while the DL model shows considerable drops in precision (ranging from 0.71 to 0.73). These results underscore the LLM’s ability to generalize across both standardized and variable product descriptions, ensuring both completeness and correctness in attribute extraction, a critical capability for scalable, high-fidelity catalog automation in e-commerce environments.
While the LLM exhibits robust overall performance, some categories experience lower recall, meaning that although the extracted attributes are accurate, certain relevant attributes were missed. For instance, in the case of Turnip Juice, the recall drops to 0.50 compared to the DL model’s 1.00, suggesting that the model struggles with retrieving all relevant attributes. Similarly, the Pilates Ball category shows a recall of 0.67, indicating a slight decline in retrieving all necessary attributes, though the precision remains strong at 0.86. Likewise, for Cutting Board, the recall stands at 0.69, slightly lower than the DL model’s 0.81, implying that some attributes remain undetected. These performance discrepancies offer valuable insight into the limitations of LLM-based extraction in handling categories with ambiguous or less frequent attribute phrasing. Such gaps underscore the importance of semantic context and suggest that further improvements may be achieved by incorporating richer contextual signals, such as multimodal data or reinforcement-based feedback loops.
The lower recall in these categories may be attributed to ambiguous product descriptions, variations in terminology, or implicit attributes that require deeper contextual understanding. Despite this, the high precision in these cases ensures that extracted attributes remain highly accurate, even if some relevant ones are missed.
When compared to the DL model, the LLM demonstrates substantial improvements in precision, recall, and F1-score across most categories. In structured product types where attributes are well-defined, such as Gold Pendant, Party Sets, and Ball Bag, the LLM achieves perfect classification, whereas the DL model struggled with recall issues (e.g., Christmas Tree: DL recall 0.83 vs. LLM recall 1.00). This outcome provides empirical support for the LLM’s strength in tasks requiring nuanced interpretation of language, particularly where attribute boundaries are implicit or span multiple tokens, areas where traditional token-level NER approaches often fall short.
Even in categories where the LLM does not achieve perfect recall, its precision remains consistently higher, ensuring that extracted attributes are more reliable and accurate than those of the DL model.
5.2. Attribute-Based Evaluation
Table 2 provides a detailed evaluation of attribute extraction performance using the LLM and DL models.
Figure 5 shows the percentage increases in F1-scores of LLMs compared to DL models for attribute extraction.
Similar to category extraction, the evaluation of the LLM for attribute extraction achieves perfect precision (1.00) across numerous attributes—such as Format, Chain Adjustment, Page Type, Set, Guitar Type, Frame Shape, and Exam Type—indicating a near-complete elimination of false positives. This high precision ensures that the attributes extracted are not only accurate but contextually appropriate, significantly enhancing the trustworthiness of the system. Additionally, recall remains strong across most attributes, frequently reaching or exceeding 0.90, as seen in Gold Setting, Compatible Systems, and Insole Material. This demonstrates the model’s ability to retrieve the vast majority of relevant attributes from diverse product descriptions. Even in moderately challenging attributes such as Processor Model or Ball Size, the LLM maintains competitive recall while preserving high precision. The resulting F1-scores, many of which approach or reach 1.00, confirm that the model achieves a well-balanced optimization of both recall and precision, thereby delivering robust and reliable attribute extraction suitable for scalable deployment in real-world e-commerce applications.
Despite the model’s overall strong performance, a few attributes exhibit lower recall values, meaning that while extracted attributes are accurate, some relevant attributes may have been overlooked. This is particularly evident in Processor Model, Upper Cut, and Step Count, where recall falls below 1.00, indicating that some attributes were missed. The recall drop suggests that the model may struggle with implicit or less explicitly stated attributes, which require deeper contextual understanding or more diverse training data. Such patterns highlight a potential research direction for augmenting LLMs with attribute salience estimation or semi-supervised reinforcement learning to improve recall for less overt attribute types.
One of the more challenging cases is File Type, which has an F1-score of 0.67, due to both precision and recall being significantly below 1.00. This suggests that the model may have difficulty distinguishing between different file types or recognizing variations in how file types are mentioned in product descriptions. Similarly, Display Technology exhibits a lower F1-score, indicating that the model’s ability to recognize all variations of this attribute still requires refinement.
The results, in general, confirm that the LLM outperforms the DL system, particularly in attributes with structured terminology and well-defined characteristics. The improvements in precision ensure that extracted attributes are highly reliable, minimizing false positives and improving classification accuracy. By offering empirical evidence on performance across a wide attribute spectrum, this evaluation also contributes to the field by clarifying where LLMs excel and where complementary techniques may still be needed. However, for attributes where recall remains lower, further fine-tuning is necessary to ensure comprehensive extraction of all relevant information. With continued refinement, the model’s effectiveness in extracting attributes across diverse product categories will continue to improve.
5.3. Category and Attribute-Based Performance
Table 3 provides an analysis of category and attribute-level performance in LLM and DL models.
Figure 6 shows the percentage increases in F1-scores of LLMs compared to DL models for category and attribute extraction.
The evaluation of the LLM for category- and attribute-based extraction yields perfect precision, recall, and F1-scores (1.00) in several category–attribute pairs, including Basketball Shoes (Sport Branch), Softshell and Polar (Closure Type), Gold Necklace (Adjustment), Xbox Consoles (Hard Disk), Diamond Necklace (Adjustment), and Steam Cleaner (Feature). In each of these cases, the LLM not only achieves flawless results but also outperforms the DL model, which exhibits reduced recall values ranging from 0.89 to 0.93. Likewise, categories such as Second-Hand Mobile Phones (Color) and Casual Shoes (Upper Material) further demonstrate the LLM’s robustness, maintaining top-tier performance even in contexts involving consumer-generated content or material-specific features. These consistent outcomes highlight the LLM’s capacity to generalize across both highly structured and semi-structured product descriptions. Importantly, the results validate theoretical assumptions in recent literature: LLMs exhibit strong resilience to lexical variability and domain heterogeneity, enabling their application in scalable, high-fidelity attribute extraction pipelines for digital commerce platforms.
Beyond categories achieving perfect scores, the LLM consistently maintains F1-scores above 0.90 across several complex attribute extractions, reaffirming its robust contextual understanding and adaptability to varied product descriptions. For example, Fit (Large Size Shorts and Bermuda) yields an F1-score of 0.93, Processor Model (Gaming Laptop) scores 0.90, and Lower Silhouette (Fantasy Boxer) reaches 0.95. Furthermore, Upper Material (Casual Shoes) and Color (Maternity Sweatpants) achieve 0.97 and 0.94, respectively, highlighting the model’s competence in handling both standardized and semantically rich attributes. In contrast, the DL model, while achieving high precision, exhibits noticeable recall variability—ranging from 0.89 to 0.99—indicating inconsistent retrieval of relevant attributes. For instance, although it reaches a high recall of 0.99 for Processor Model, it records only 0.89 recall for Upper Material and Color, revealing limitations in generalizing across diverse linguistic patterns. This contrast suggests that while the DL model performs well on clearly stated attributes, it lacks the LLM’s superior capacity for contextual inference and generalization, particularly in cases involving nuanced or compound attribute semantics. These findings underscore the advantages of LLM-based architectures over traditional DL approaches in supporting domain-agnostic, scalable attribute extraction pipelines for heterogeneous e-commerce catalogs.
Despite its strong overall performance, the LLM exhibits minor recall limitations in a few category–attribute pairs, while maintaining superior precision compared to the DL model. For instance, Large Size Kimono and Kaftan (Collection) attains an F1-score of 0.80 due to a recall of 0.67, indicating that the model extracts highly accurate attributes but occasionally misses relevant ones. Similarly, Espadrille (Environment) and Maternity Sweatpants (Color) register recall scores of 0.80 and 0.89, respectively, despite achieving perfect precision (1.00), suggesting that the model’s extractions are correct but not fully comprehensive. In contrast, the DL model reaches perfect recall (1.00) in these same cases but at the expense of reduced precision—e.g., 0.92 for Large Size Kimono and Kaftan and 0.89 for Maternity Sweatpants—resulting in more frequent misclassifications. This trade-off underscores a key differentiation: the LLM prioritizes extraction accuracy over quantity, making it preferable in applications where attribute correctness is critical, while the DL model favors recall, which can introduce more noise in downstream systems.
A closer analysis of processor-related attributes, such as Gaming Laptop (Processor Model), reveals that the LLM attains an F1-score of 0.90, while the DL model achieves a higher score of 0.97. This discrepancy is primarily driven by the DL model’s superior precision and recall (0.95 and 0.99, respectively), indicating its strong capability to extract well-defined technical specifications when these are explicitly stated. In contrast, while the LLM performs reasonably well, its comparatively lower precision and recall (both 0.90) suggest a potential limitation in handling highly structured, domain-specific information. This result contrasts with the broader trend observed in this study: although LLMs demonstrate significant advantages in inferring implicit attributes and managing linguistic variability, traditional DL models may retain a performance edge in contexts involving standardized and template-driven attribute mentions. Therefore, this finding highlights the importance of aligning model selection with the structural characteristics of domain content in vertical-specific NLP applications.
The LLM demonstrates strong performance across most category–attribute combinations, particularly excelling in categories with well-structured and standardized product descriptions. While the DL model outperforms the LLM in select cases—such as ‘Warranty Type’ (0.98 vs. 0.87 F1-score) and ‘Processor Model’ (0.97 vs. 0.90)—the LLM achieves perfect F1-scores (1.00) in a broad range of categories, including ‘Maternity Dress—Collection’, ‘Softshell and Polar—Closure Type’, and ‘Xbox Consoles—Hard Disk’. In categories where both models perform similarly well, such as ‘Fantasy Boxer—Lower Silhouette’ and ‘Casual Shoes—Upper Material’, the LLM offers slightly higher precision or recall, indicating more consistent extraction accuracy. Importantly, the LLM maintains uniformly high precision (often 1.00), even when recall is slightly lower, as seen in ‘Pillow and Pillow Cover—Type’ and ‘Large Size Kimono and Kaftan—Collection’. These results underscore the LLM’s reliability in producing fewer false positives, making it especially valuable for real-world e-commerce deployments. From a practical perspective, the LLM-based pipeline offers a scalable, high-precision solution for automated catalog enrichment, while from a methodological standpoint, it establishes a replicable benchmark for evaluating hierarchical, category-specific attribute extraction models across diverse domains.
Additionally, the LLM demonstrates exceptionally high precision, achieving a perfect precision score of 1.00 in 80% of the evaluated category–attribute pairs. This substantially reduces false positives compared to the DL model and ensures that extracted attributes accurately reflect the underlying product descriptions, thereby enhancing classification reliability and improving search and filtering functionalities on e-commerce platforms.
5.4. Hierarchical Category-Level Analysis
Table 4 presents a detailed evaluation of the LLM for attribute extraction across various product categories and level 1 categories.
Figure 7 shows the percentage increases in F1-scores of LLMs compared to DL models for level 1 category + category.
The results highlight the superior performance of the LLM over the DL-based extraction system, particularly in structured product categories where attribute descriptions follow consistent patterns. The LLM achieves perfect precision, recall, and F1-scores (1.00) in 26 out of 30 categories, demonstrating its ability to accurately classify and extract attributes without errors. In contrast, the DL model struggles with lower precision across multiple categories, indicating a higher tendency for misclassification or the inclusion of irrelevant attributes. This strong hierarchical performance provides empirical validation that LLMs can generalize across nested category taxonomies, a key advancement for vertical NLP applications where product hierarchies are common but underexplored in literature.
The LLM consistently delivers perfect scores in categories such as Perfume (Cosmetics and Personal Care), Diabetic Socks (Clothing), Image Glasses (Accessories), and Nintendo Consoles (Electronics), confirming its effectiveness in handling well-defined product attributes. The DL model, while maintaining high recall in many cases, suffers from precision losses, as seen in categories like Perfume (Cosmetics and Personal Care), where its precision is 0.92, leading to a lower F1-score of 0.96, compared to LLM’s 1.00. Similar discrepancies appear in Nintendo Consoles (Electronics), where the DL model achieves an F1-score of 0.92, significantly lower than the LLM’s 1.00 due to precision limitations. These results suggest that the LLM’s improved linguistic modeling capabilities can translate directly into more reliable attribute classification, especially in categories with clear lexical boundaries, thus contributing methodologically to scalable taxonomy-aware extraction strategies.
Despite its dominant performance, the LLM exhibits slightly lower recall in a few categories, which may indicate challenges in extracting implicit or context-dependent attributes. For example, in Car Mats (Automotive), the recall is 0.92, leading to an F1-score of 0.96, suggesting that while precision is perfect, some attributes may not have been fully captured. Similarly, in Ladders (Home and Furniture), precision drops to 0.89, though recall remains 1.00, resulting in an F1-score of 0.94, implying occasional misclassifications. From a scientific standpoint, this highlights a meaningful frontier for future research: how LLMs can be further fine-tuned to better capture attributes that are less explicitly stated or rely on cross-sentence dependencies.
A notable exception is the Perfume Set (Cosmetics and Personal Care) category, where the LLM has a recall of 1.00 but a significantly lower precision of 0.75, leading to an F1-score of 0.86. This suggests that while the model captures all relevant attributes, it also introduces some irrelevant ones, reducing overall precision. In contrast, the DL model achieves higher precision (1.00) but at the cost of recall (0.83), leading to an F1-score of 0.91. This indicates a trade-off between precision and recall, with the LLM being more comprehensive but less selective, whereas the DL model is more precise but prone to missing attributes. Such comparative observations contribute to the growing discussion on model selection for real-world information extraction tasks, offering practitioners a quantifiable basis to choose between coverage-focused and precision-focused strategies depending on business needs.
5.5. Hierarchical Category- and Attribute-Level Analysis
Table 5 presents a comparative analysis of the LLM and DL models in extracting attributes across various level 1 categories and subcategories.
Figure 8 shows the percentage increases in F1-scores of LLMs compared to DL models for level 1 category + category + attribute.
The results demonstrate that the LLM consistently outperforms the DL-based extraction system, particularly in categories where product attributes are clearly defined and structured. The LLM achieves perfect precision, recall, and F1-scores of 1.00 in 26 out of 30 categories, whereas the DL model struggles to reach similar levels of accuracy across most categories. This suggests that the LLM excels in extracting attributes from structured product descriptions where attribute names and values follow consistent naming conventions. This finding is significant because it empirically supports the LLM’s ability to maintain semantic fidelity across multi-level taxonomies, a key capability for scalable and automated ontology-based classification in real-world e-commerce systems.
By contrast, the DL model often exhibits lower precision, indicating a tendency to misclassify attributes or introduce irrelevant extractions. For example, in the Perfume category within Cosmetics and Personal Care, the LLM achieves perfect performance with a precision and recall of 1.00, while the DL model, despite having perfect recall, has a lower precision of 0.92, resulting in an F1-score of 0.96. This pattern is also observed in categories such as Nintendo Consoles (Electronics), where the DL model achieves a precision of 0.86 and a recall of 0.92, leading to an F1-score of 0.92, while the LLM maintains a perfect score. These discrepancies indicate that while the DL model may retrieve relevant attributes, it is more prone to misclassification errors than the LLM. Such comparative insights demonstrate the LLM’s advantage not only in linguistic modeling but also in its capacity to handle multi-dimensional classification tasks more reliably. These observations extend the current understanding of model generalization in NLP literature, especially in domain-specific attribute tagging.
Despite its strong overall performance, the LLM exhibits minor recall limitations in a few categories where implicit attributes or contextual nuances play a greater role. For instance, in the Car Mats (Automotive) category, the LLM achieves perfect precision but slightly lower recall at 0.92, resulting in an F1-score of 0.96, suggesting that some relevant attributes may have been overlooked. Similarly, in the Ladders (Home and Furniture) category, the LLM achieves full recall but a slightly reduced precision of 0.89, yielding an F1-score of 0.94. This implies that while the model captures all relevant attributes, occasional misclassifications or attribute variations affect precision. These outlier cases provide opportunities for further refinement and raise meaningful questions about how LLMs interpret implicit or context-dependent attributes, a topic not yet fully addressed in the existing body of attribute extraction research.
The Perfume Set (Cosmetics and Personal Care) category presents an interesting case where the LLM achieves a recall of 1.00 but a notably lower precision of 0.75, leading to an F1-score of 0.86. This suggests that the model extracts all relevant attributes but also includes some non-relevant ones. In contrast, the DL model achieves a higher precision of 1.00 but a recall of only 0.83, resulting in an F1-score of 0.91. This difference highlights a trade-off between precision and recall, with the LLM favoring comprehensive extractions while the DL model is more selective but at the cost of missing relevant attributes. This trade-off reflects a broader theoretical discussion in information retrieval and extraction research—namely, the tension between coverage and accuracy. The presented findings contribute concrete evidence to this discourse by quantifying the performance dynamics of two distinct model classes in a high-dimensional, real-world setting.
5.6. Overall Performance Evaluation
The overall performance evaluation, measured in terms of average F1-score, offers a detailed assessment of the effectiveness of LLM and DL models in attribute extraction across diverse prediction tasks in e-commerce (over 700 different categories and attributes). The results in
Table 6 indicate a clear advantage of the proposed LLM approach, which consistently outperforms the DL model in all evaluated categories. The average F1-scores highlight the LLM’s superior accuracy in predicting product attributes, categories, and hierarchical classifications.
Across all prediction types, the LLM demonstrates a substantial improvement over the DL approach. In category-based classification, the LLM achieves an average F1-score of 0.77 compared to 0.53 for the DL model, reflecting a 45.28% increase in accuracy. This suggests that the LLM has a far greater ability to recognize and classify products correctly, reducing misclassification errors and ensuring a more structured product taxonomy. Similarly, in attribute-based classification, the LLM achieves an average F1-score of 0.75, outperforming the DL model’s 0.54 with a 38.88% improvement. This indicates that the LLM is significantly better at extracting product-specific attributes, even in cases where they are implied or ambiguously stated within product descriptions. These gains provide empirical validation for the LLM’s capacity to handle both explicitly stated and contextually implied attribute data, addressing a key challenge in automatic metadata generation for digital commerce.
A particularly notable finding emerges in the combined category and attribute-based predictions, where the LLM achieves an average F1-score of 0.81 compared to the DL model’s 0.58, marking a 39.65% improvement. This suggests that the LLM excels in understanding the relationships between product categories and their associated attributes, ensuring more accurate classifications and reducing errors in filtering and search functionalities. The improvement is even more pronounced in hierarchical classification tasks. For category and level 1 predictions, the LLM achieves an average F1-score of 0.86, significantly surpassing the DL model’s 0.58 with a remarkable 48.27% increase. This demonstrates the LLM’s ability to recognize multi-level category structures, a crucial factor in ensuring a well-organized e-commerce product catalog. The highest average F1-score is obtained in the combined category, attribute, and level 1 classification task, where the LLM achieves 0.90, outperforming the DL model’s 0.72 with a 25.00% improvement. These results go beyond mere performance benchmarks; they advance the academic conversation on the practical deployment of LLMs in domain-specific classification tasks by showcasing their ability to operationalize semantic hierarchies, which is rarely explored with this level of granularity in the existing literature.
The results confirm that LLM-based attribute extraction offers a significant advancement over traditional DL methods. The ability of LLMs to process both explicit and implicit attributes, their superior contextual understanding, and their adaptability across hierarchical classification tasks make them a highly effective solution for large-scale e-commerce platforms. By significantly improving classification accuracy, LLMs contribute to better product discoverability, more efficient filtering mechanisms, and a more structured and scalable approach to catalog management. From a scientific standpoint, this study contributes methodologically by integrating prompt-based learning and sliding window decoding into hierarchical taxonomy resolution, and practically by validating these mechanisms through large-scale deployment. While the improvements are substantial, further research could explore optimization techniques such as model distillation to enhance efficiency and reduce computational costs, as well as multilingual adaptations to expand the applicability of the system beyond Turkish-language datasets.
5.7. Comparing Results with Literature
This section compares our findings with existing research, highlighting methodological differences and the LLM’s strengths in implicit attribute extraction and hierarchical classification.
5.7.1. Overview of Existing Research on Attribute Extraction
Product attribute extraction is a well-studied problem in the field of NLP and e-commerce. Over the past decade, various approaches have been proposed, ranging from rule-based systems to machine learning models, DL architectures, and, more recently, LLMs. The evolution of these methods has significantly improved the accuracy and efficiency of attribute extraction tasks. However, the comparability of results remains limited due to differences in datasets, task definitions, and evaluation methodologies.
Several notable studies have focused on leveraging DL and LLMs for extracting attributes from e-commerce product descriptions. Brinkmann et al. [
17] analyzed the performance of GPT-4 in attribute extraction, achieving an average F1-score of 85% by utilizing detailed attribute descriptions and example demonstrations. This work demonstrated the potential of generative LLMs for attribute extraction but also highlighted limitations in handling ambiguous and implicit attributes.
Similarly, in a further study, Brinkmann et al. [
31] found that LLMs outperformed traditional DL-based models by approximately 10% in F1-score, with their best-performing model reaching an F1-score of 91%. However, this study focused primarily on English-language datasets, limiting its applicability to non-English languages such as Turkish.
Another study, Fang et al. [
21] proposed an ensemble learning approach that combined outputs from multiple LLMs, including GPT-4 and LLaMA-2. The ensemble method demonstrated superior performance over individual models, leading to increased accuracy in business applications such as product categorization and improved search functionalities. The findings of this study suggest that integrating multiple LLM architectures may provide robust solutions for attribute extraction tasks. Our work builds upon this foundation by applying an LLM-based attribute extraction model to a Turkish-language e-commerce corpus spanning over 700 distinct categories and attributes. This represents a substantial extension to the current literature, not only due to the language shift—which introduces challenges such as agglutination, free word order, and rich morphological variation—but also because of the expanded label space and hierarchical prediction structure involved. By addressing these dimensions, our study advances the field’s understanding of LLM performance in linguistically and structurally complex real-world scenarios.
5.7.2. Methodological Differences in Studies
While the aforementioned studies provide valuable insights, direct comparison with our work is challenging due to several key methodological differences.
One major distinction lies in dataset size and language. Our study utilizes a dataset containing over 700 product categories and attributes in Turkish, whereas most existing research is conducted on English-language datasets with fewer categories. The linguistic structure of Turkish presents additional challenges, such as agglutination and morphosyntactic variations, which are not present in English datasets. These differences impact the complexity of attribute extraction and classification, making direct comparisons less straightforward.
Evaluation metrics also differ across studies. Related works often report precision, recall, and F1-scores but does not specify whether hierarchical relationships between attributes and categories are considered. In contrast, our evaluation framework includes hierarchical classification tasks, such as Category + Attribute + Level 1 Category, introducing an additional layer of complexity beyond simple attribute matching.
Another key distinction is the choice of comparative baselines. Most existing research benchmarks LLMs against conventional DL models, such as BERT, RoBERTa, or CNN-LSTM architectures. Our study, however, directly compares an LLM with a domain-specific DL model trained on the same dataset, ensuring a fair performance evaluation that accounts for domain-specific nuances.
Finally, while several prior studies report performance gains in the 85–91% F1-score range, few explicitly assess the model’s proficiency in handling implicit, contextually derived attributes, a core strength of our approach. Our LLM’s ability to infer attributes that are not overtly stated but implied through linguistic context represents a key advancement. These attributes are especially prevalent in low-resource product types and user-generated descriptions, where standard terminology is inconsistently applied. By systematically outperforming the DL baseline in both explicit and implicit attribute extraction under linguistically complex conditions, our study offers novel evidence for the contextual robustness and semantic generalization capacity of LLMs in multilingual e-commerce environments.
5.7.3. Performance Comparison and Findings
Given the methodological differences, a direct numerical comparison between our results and those of previous studies is not possible. However, some qualitative insights can be drawn to assess the relative performance of our proposed LLM.
One key advantage of our model is its superiority in implicit attribute extraction. Prior studies highlight the limitations of DL models in extracting attributes that are not explicitly mentioned in product descriptions. Our results indicate that the LLM significantly outperforms the DL model in this aspect, demonstrating a higher capability to infer attributes from contextual cues. This improvement is particularly relevant for e-commerce applications, where product descriptions often lack standardized attribute mentions.
Another area where our study contributes to the literature is the handling of hierarchical relationships in classification. While existing research does not explicitly focus on hierarchical attribute extraction, our study evaluates models across multiple classification levels, including Category, Attribute, and Level 1 Category. The LLM achieves an average F1-score of 90.00% for the most complex task (Level 1 Category + Category + Attribute), demonstrating its ability to manage multi-level classification tasks with high accuracy. This performance underscores the potential of LLMs to enhance structured data extraction in large-scale e-commerce taxonomies.
Scalability and computational efficiency also play a critical role in model evaluation. Research by Fang et al. [
21] discusses the trade-off between accuracy and computational efficiency when deploying LLM ensembles. Our study observes similar trade-offs, as LLM inference requires significantly more computational resources compared to the DL model. However, the increased resource demand is offset by the LLM’s higher accuracy, particularly in complex classification tasks and implicit attribute extraction. These findings emphasize the need for optimizing LLM-based attribute extraction models for real-time and large-scale deployment.
Our study aligns with existing research in demonstrating the effectiveness of LLMs for attribute extraction while addressing unique challenges associated with Turkish-language datasets and hierarchical classification. Although direct numerical comparison is infeasible due to dataset differences, qualitative findings suggest that our LLM performs competitively with state-of-the-art approaches. By refining benchmarking methodologies and expanding multilingual capabilities, future research can further advance attribute extraction for global e-commerce applications.
6. Conclusions and Future Work
This section concludes the evaluation of the proposed LLM, comparing its performance with a DL benchmark. Future work will focus on improving interpretability and addressing identified limitations.
6.1. Conclusions
This study introduced an LLM-based approach for attribute extraction in e-commerce and provided a comparative evaluation against a DL-based NER model. Conducted on Trendyol’s Turkish-language product catalog, the research addressed critical challenges in automated attribute classification, including linguistic variability, inconsistencies in product descriptions, and the need for a scalable, high-accuracy solution. By leveraging the contextual understanding capabilities of LLMs, the proposed system significantly outperformed traditional DL-based approaches in both precision and recall, demonstrating its ability to extract explicit and implicit product attributes with greater accuracy.
A key contribution of this study is the multi-faceted prediction framework, where the model was designed to predict not only individual attributes but also entire hierarchical classifications, including product categories, level 1 categories, and category–attribute combinations. The LLM demonstrated substantial improvements in all classification levels, achieving an F1-score increase of up to 48.27% in hierarchical classification tasks compared to the DL model. This capability ensures that products are categorized more accurately across multiple dimensions, enhancing searchability, filtering, and structured data management in large-scale e-commerce platforms. Unlike conventional NER models, which typically focus on extracting isolated attributes, the LLM exhibited a deeper contextual awareness, allowing it to predict category–attribute associations, hierarchical product classifications, and implicit attributes with greater precision.
Beyond classification accuracy, this study demonstrated the feasibility of integrating LLM-based attribute extraction into a real-time e-commerce infrastructure. The developed system was seamlessly deployed within Trendyol’s backend, utilizing Kubernetes and Nvidia Triton Inference Server to enable both bulk attribute extraction across millions of products and real-time attribute suggestions during product listing. This implementation significantly streamlined the product categorization process, reduced manual errors, and improved the consistency of the platform’s product catalog. The scalability of the system ensures that as the volume and diversity of product listings expand, the attribute extraction model remains robust and adaptable to evolving marketplace demands.
Despite its strong performance, some challenges remain, particularly in cases where product descriptions contained highly implicit or ambiguous attributes. Although precision remained consistently high, recall exhibited minor variability in certain categories, suggesting that additional fine-tuning and domain-specific training could further enhance the model’s ability to extract less explicitly stated attributes. Future research should explore multimodal attribute extraction approaches, incorporating both textual and visual cues from product images to improve recognition in ambiguous cases. Additionally, optimizing computational efficiency remains a crucial consideration for scaling LLM-based attribute extraction, particularly in high-traffic e-commerce environments where real-time inference speed is critical.
The findings of this study contribute to the broader field of NLP in e-commerce, demonstrating how LLMs can transform product classification and attribute extraction through context-aware, scalable, and high-accuracy models. As e-commerce continues to evolve, leveraging advanced language models for automated multi-level attribute extraction will play a pivotal role in enhancing search functionality, product discoverability, and the overall user experience. Future work should focus on multilingual adaptations, self-supervised learning techniques, and efficient model distillation methods to further refine LLM-driven attribute extraction systems for global marketplaces.
6.2. Potential Future Directions
While the current models and infrastructure represent a significant advancement in attribute extraction, several areas of future research and development could further enhance the system’s capabilities and efficiency. One promising direction is to explore model distillation techniques, which involve creating smaller, more efficient versions of large language models. Model distillation could reduce computational costs and latency, enabling the LLM-based approach to be deployed more feasibly in real-time applications, especially during peak traffic periods. This optimization would be particularly beneficial in reducing the infrastructure demands associated with LLM inference, potentially making it more cost-effective for large-scale e-commerce platforms like Trendyol.
Another future direction involves improving the interpretability of the LLM. Currently, the “black box” nature of large language models poses challenges for understanding how the model arrives at specific attribute predictions. Integrating attention visualization or saliency mapping techniques could provide insights into the model’s decision-making process, enabling Trendyol’s development team to refine and debug the model more effectively. Enhanced interpretability would not only facilitate better quality control but also enable more targeted adjustments to the model for handling specific attribute extraction challenges.
Additionally, exploring a hybrid model approach that combines the strengths of both the DL and LLM models could yield a more versatile and resource-efficient solution. For example, a tiered system could use the DL model for extracting simple, explicitly stated attributes while relying on the LLM for more complex or ambiguous cases. This hybrid approach would allow for the efficient allocation of computational resources, enabling faster processing of straightforward cases while preserving high accuracy for challenging ones.
Another valuable avenue for future work is to extend the attribute extraction system to support multilingual processing. As Trendyol continues to expand its customer base, enabling the attribute extraction models to handle multiple languages could significantly enhance the platform’s adaptability and usability across regions. Incorporating multilingual capabilities would involve training the models on additional language-specific datasets, allowing them to accurately process product descriptions in various languages and meet the needs of a broader, more diverse user base.
Lastly, conducting longitudinal evaluations of model performance could offer insights into the system’s effectiveness over time and under changing conditions. As product descriptions evolve and new attributes emerge, periodically retraining and evaluating the models would ensure that the attribute extraction system remains robust, accurate, and responsive to shifts in language usage and product trends. This continuous improvement process could include incorporating user feedback and monitoring the model’s performance in live settings, allowing for timely adjustments and refinements to maintain high levels of accuracy and relevance.
6.3. Final Remarks
The proposed LLM-based attribute extraction system marks a significant advancement in automating and optimizing product data management for e-commerce. By leveraging the strengths of LLMs, this study effectively addressed challenges arising from diverse product descriptions and complex linguistic patterns. The DL model served as a reference point, allowing for a comparative evaluation that demonstrated the superiority of the LLM approach in handling implicit attributes and hierarchical classifications. Additionally, the system’s scalable backend infrastructure and seamless integration with Trendyol’s platform ensure efficient and accurate attribute extraction, ultimately enhancing both the seller’s product listing experience and the customer’s search and discovery process.
The contributions of this study extend beyond Trendyol, as the methods and findings can serve as a reference for other e-commerce platforms aiming to enhance product data management through advanced NLP techniques. However, the work also highlighted challenges, particularly regarding the computational demands of large language models, and offered insights into potential solutions through model optimization and hybrid approaches.
As e-commerce continues to grow and diversify, the ability to accurately capture and utilize product attributes will become increasingly crucial. The advancements achieved through this project lay the groundwork for further innovations in attribute extraction, with the potential to expand into new languages, markets, and application areas. By continuing to refine and enhance these models, Trendyol can stay at the forefront of e-commerce technology, delivering a superior experience for both sellers and customers.




 ,
, 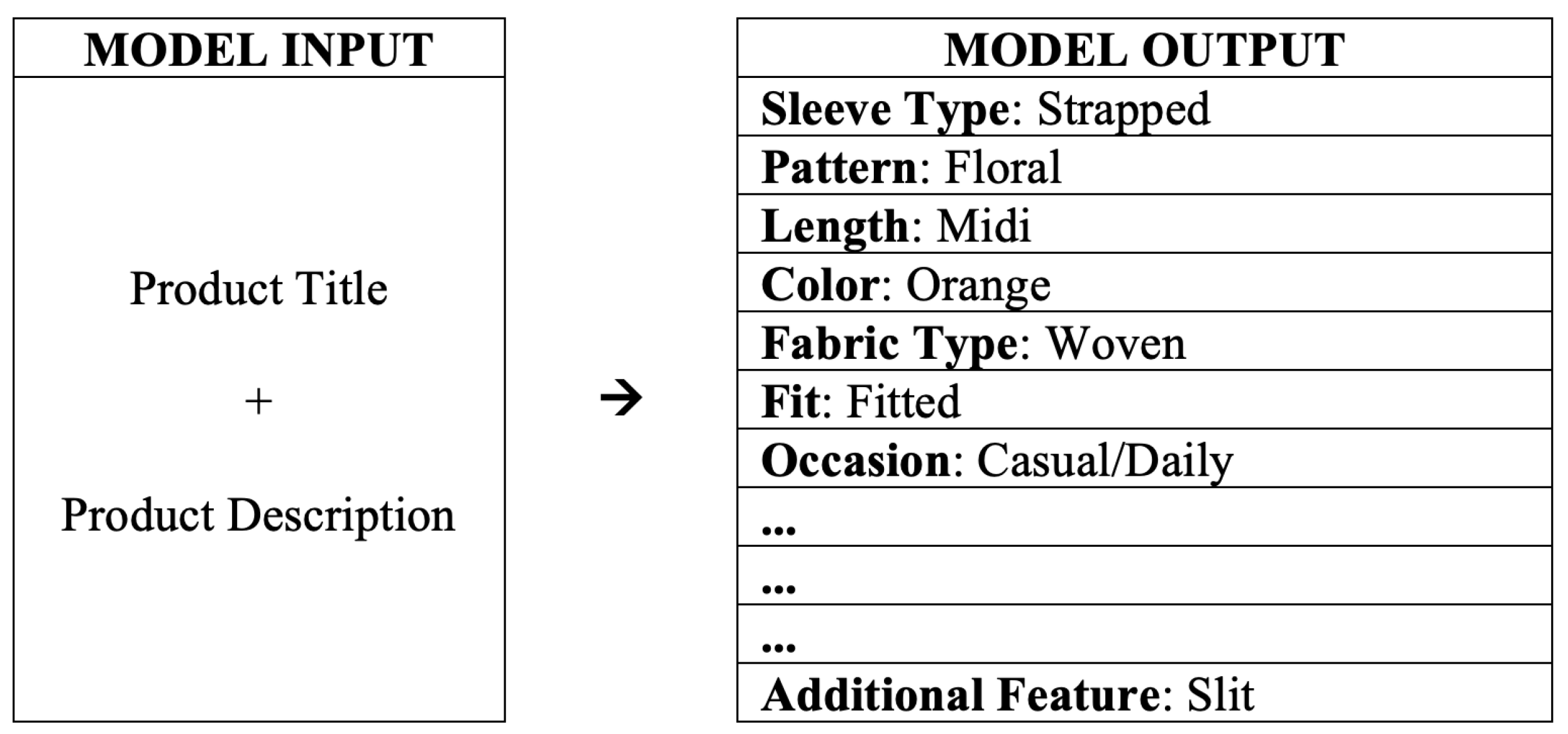
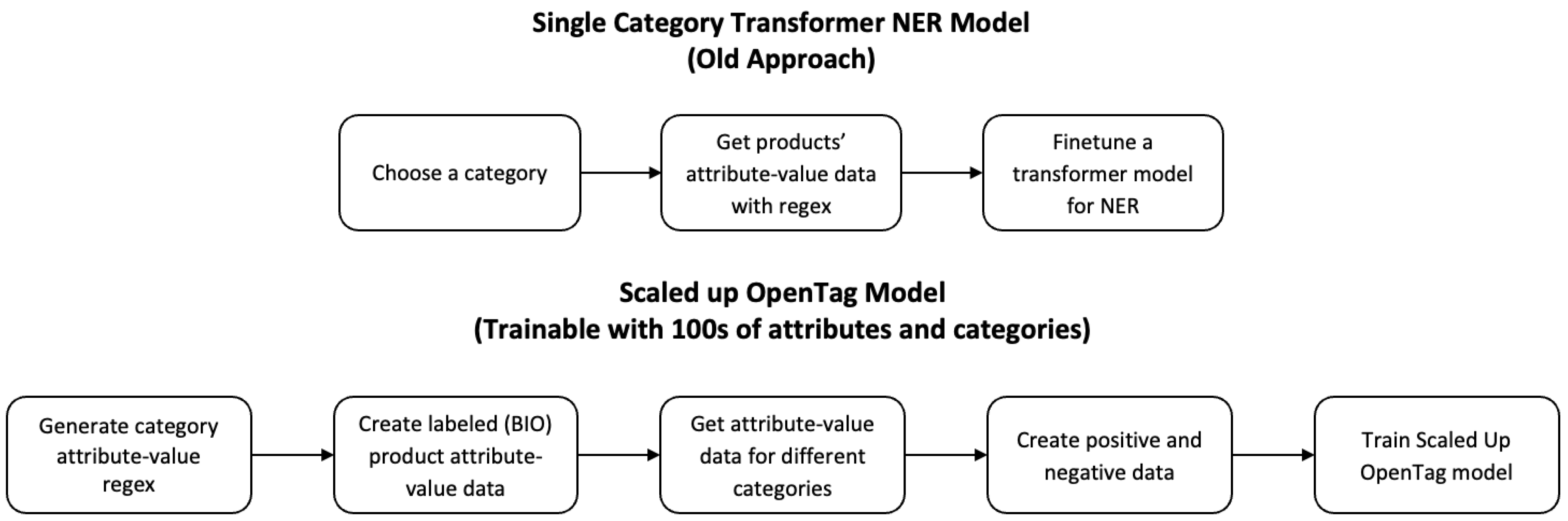

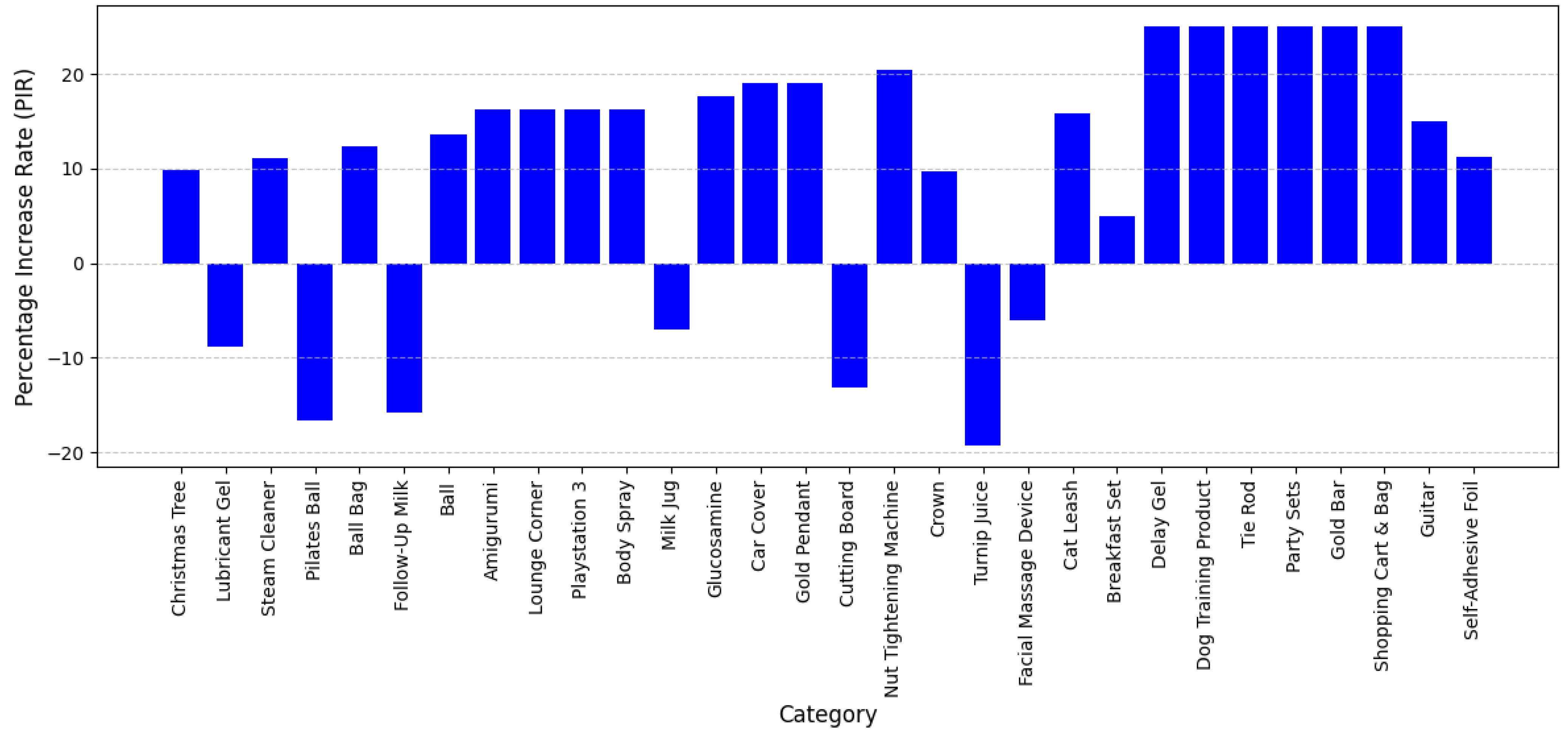

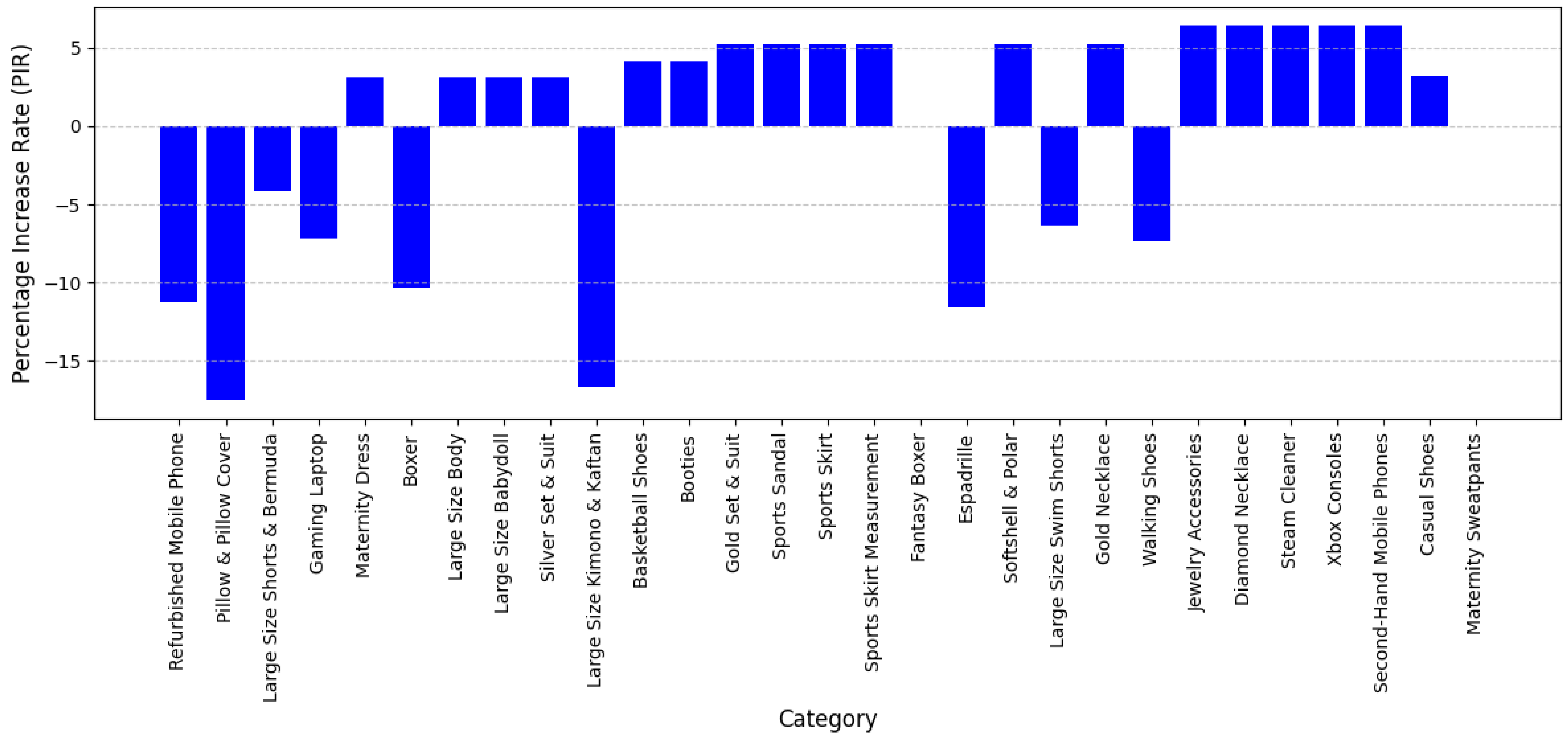

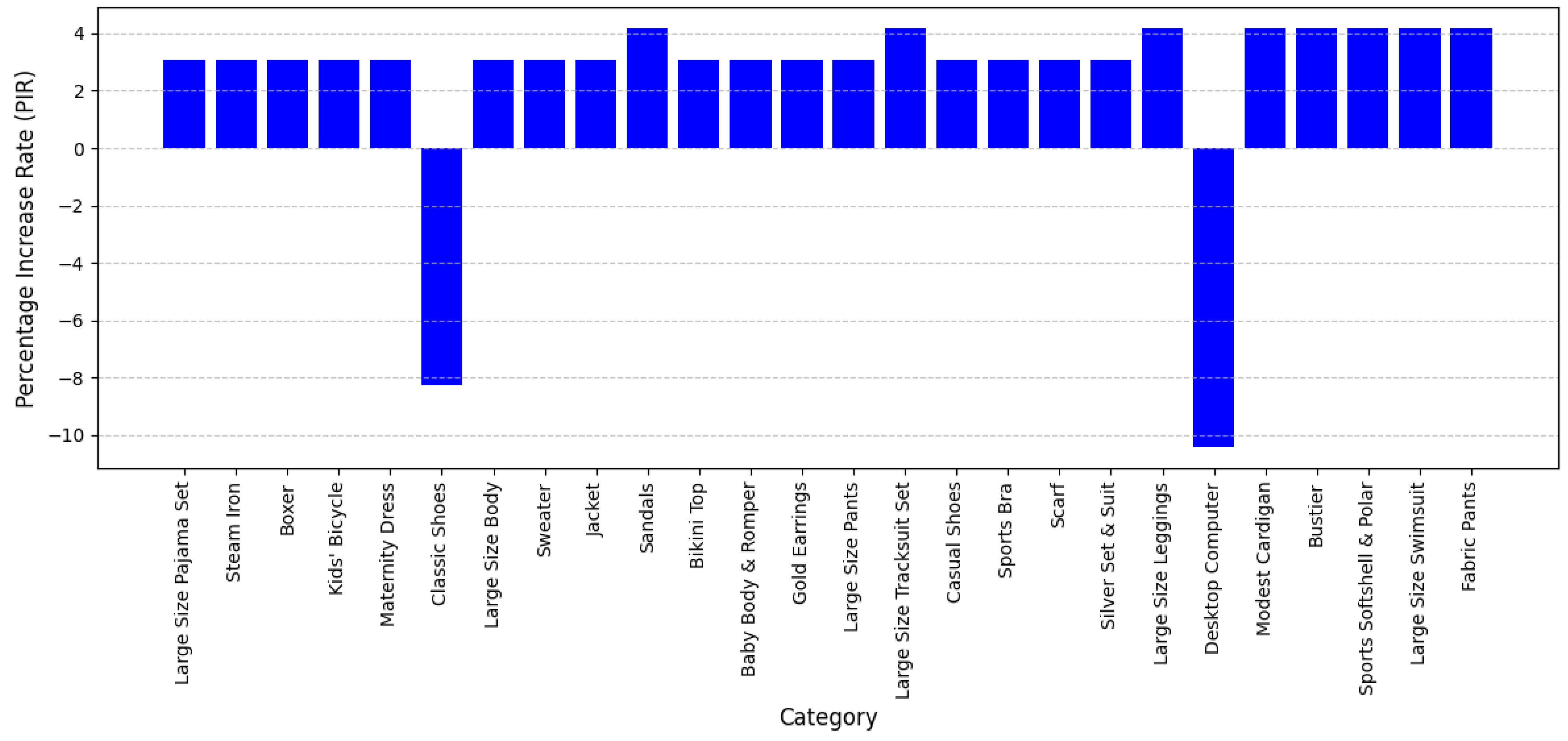

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}