3.1. Model Prior Distributions
The initialization step is to model the prior distribution of latent variables. According to the definition of
in (
3), the prior distribution of the system state, i.e., predicted pdf, can be derived as follows:
where
and
represent the conditional state and conditional model identity at time
k conditioned on the run length
, respectively. Meanwhile,
and
denote the predicted mean and the corresponding covariance matrix of the conditional state for model
at time
k, respectively. The notation
signifies a predicted value.
Subsequently, based on the state transition function in (
1), we can obtain
where
and
denote the estimated mean and the corresponding covariance matrix of the conditional state at time
, respectively. The notation
signifies an estimated value.
is the process noise covariance for model
.
The prior
of the run length
at time
k is presented as follows:
where
denotes the transition probability of the run length. Since the probability mass of
is non-zero only in two distinct scenarios—either the absence of a change point, resulting in the continuation of the run length
, or the occurrence of a change point, truncating
to 1—the transition probability of the run length can be mathematically formulated as follows:
where
represents a penalty function, as defined in (
11).
In this paper, can be formulated as a discrete exponential (or geometric) distribution with a time scale . Given the memoryless nature of this process, the penalty function can be simplified to , where represents the maneuvering period.
By substituting (
10) into (
9), the prior
is finally obtained:
As
follows a categorical distribution, the prior of the conditional model identity
at time
k is assumed to be,
where
represents the parameter set of the conditional model identity
.
In the case where
, it indicates a target undergoing stationary motion. However, for
, this situation indicates the occurrence of a change point. Thus, the prior parameter
is defined as:
where
represents the hyperparameter of
when a change point occurs.
There are several different choices
for
. In this paper, we compute the likelihood of the target state under each choice in (
17), where the run length is 1, and select the one that maximizes the likelihood as the initial model weight:
Subsequently, the parameter will be updated through the variational posterior, and its number will linearly increase with growth in the run length.
3.2. Update Approximate Posterior Distributions
Utilizing Bayes’ theorem, the posterior distribution
can be computed as
with
Conditioned on the run length
, the joint distribution
is
Using the measurement function from (
2) and the prior distributions from (
6) and (
13), the three terms on the right-hand side of (
18) are given as follows:
In the following, we will derive the posterior distributions for each latent variable related to run length, system state, and the motion model separately.
By incorporating (
19) through (
21) into (
17), the likelihood previously presented in (
17) is expressed in a compact form as
where
denotes the expectation operator, and the term
is denoted as
Due to
and
, it follows that:
Consequently, by substituting (
12), and (
22) into (
16), we can obtain the posterior pdf
of the run length.
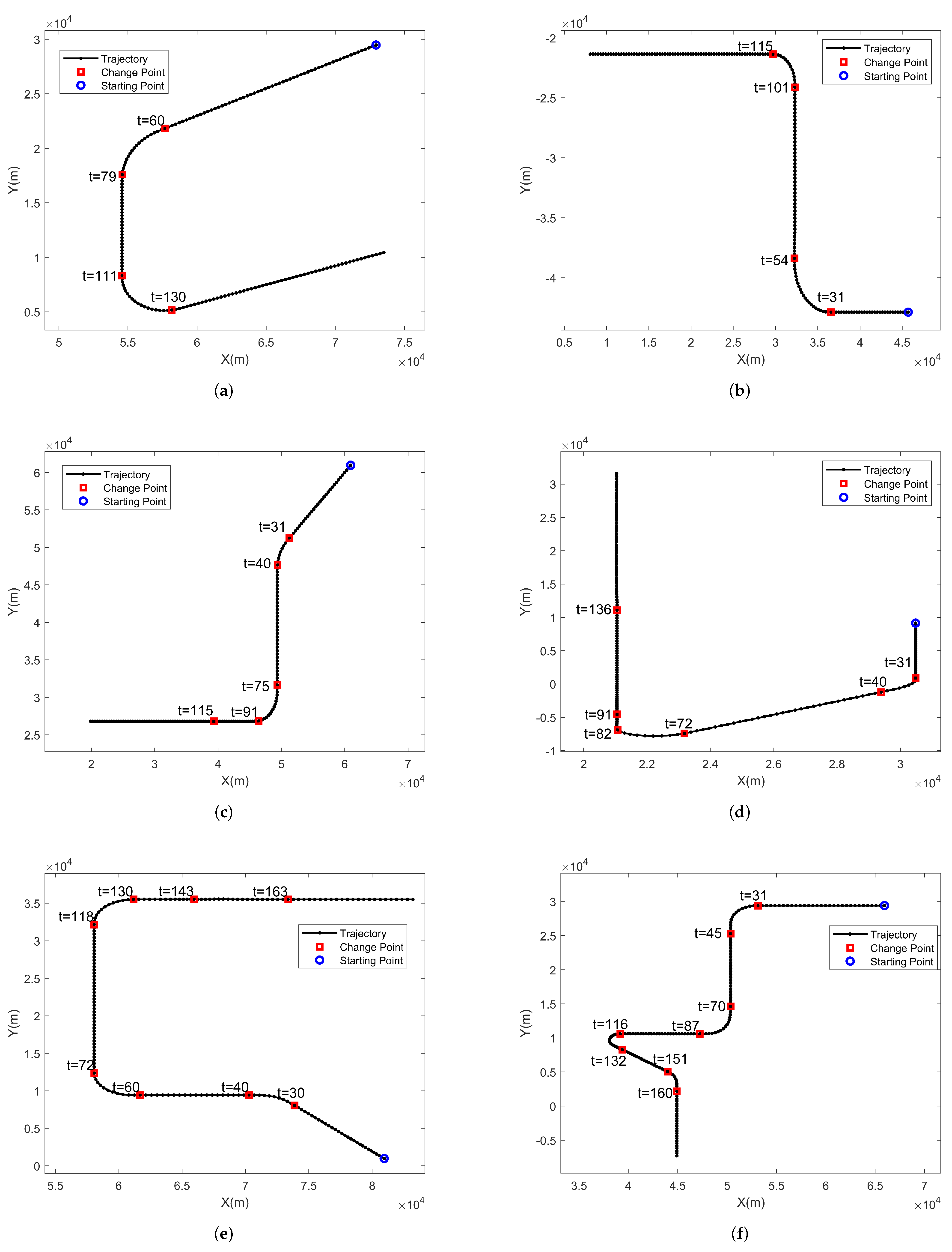
A change point is formally identified when the absolute difference between successive run length estimates
exceeds a preset detection threshold
, mathematically expressed as:
To estimate the latent variables
, we employ a mean-field variational family that assumes mutual independence among the latent variables. Specifically, each latent variable is governed by a distinct factor within the variational density. Consequently, the variational distribution,
, serves as an approximation to the true posterior distribution
through a free-form factorization, which can be formulated as:
Remark 1. The mean-field variational family assumes that the latent variables are mutually independent. In highly dynamic or nonlinear systems, this assumption may seem restrictive at first glance. In such systems, the latent variables are likely to be highly correlated. Despite this, mean-field factorization can still be useful. It provides a computationally efficient way to approximate the variational posterior. In some cases, even if the variables are correlated, the mean-field approximation can capture the main characteristics of the distribution. As shown in the reference paper [17], the mean-field approximation can capture any marginal density of the latent variables, which can be sufficient for certain types of analysis. Relevant literature can be found where run-length modeling is also employed to capture maneuvering behavior in highly dynamic scenarios, and mean-field factorization is adopted to perform approximate variational inference in nonlinear systems [27,30]. However, the limitations of the mean-field approximation are also noteworthy. Specifically, it fails to capture dependencies between latent variables, which can be helpful for accurate modeling in highly dynamic or nonlinear systems [17]. To address this issue, structured variational approximations can be considered. As noted in [31], hierarchical variational models (HVMs) and copula variational inference (copula VI) are two approaches that aim to preserve such dependencies. HVMs introduce a prior over the variational parameters and marginalize them out to model latent dependencies, while copula VI leverages a copula distribution to explicitly restore the correlations among latent variables. With the variational parameter denoted as
, the ELBO according to the standard variational method is given by:
The optimal variational parameters
can be obtained by maximizing the ELBO
as follows:
By taking the logarithm of both sides of (
18) and subsequently incorporating (
19)–(
21) into (
18), the logarithmic joint distribution
can be decomposed as follows:
The expression of the state’s expected parameters is as follows:
Rewriting the ELBO
as the function of the state’s expected parameters
, and omitting the rest terms that are independent of
, denoted by
for brevity,
Extending the express and omitting the constant term,
can be further simplified to
with
By setting the derivative with respect to the expected parameter equal to 0, we have
Analogous to the derivation process of
, we reformulate the ELBO
as the function of the expected parameters of the model identity,
, and omit the rest terms that are independent of
, denoted by
for brevity,
Upon further calculation and ignoring the constant term,
can be written as:
By equating the derivative of (
40) with respect to
to zero, we arrive at:
where the expression for
is presented as follows:
with
The expected expressions involved in (
43) and (
44) are given as follows:
Based on the preceding derivations, we derive the posterior distribution of the run length
, denoted as
via Bayes’ theorem. Subsequently, by applying variational Bayesian methods, we obtain the conditional posterior distributions of
and
, expressed as
and
, respectively. Following the definition of the mixed posterior distribution, we have:
To proceed, we utilize conjugate computations and the information filtering method outlined in [
32] to derive the update formulas for the posterior distribution parameters of
and
, i.e.,
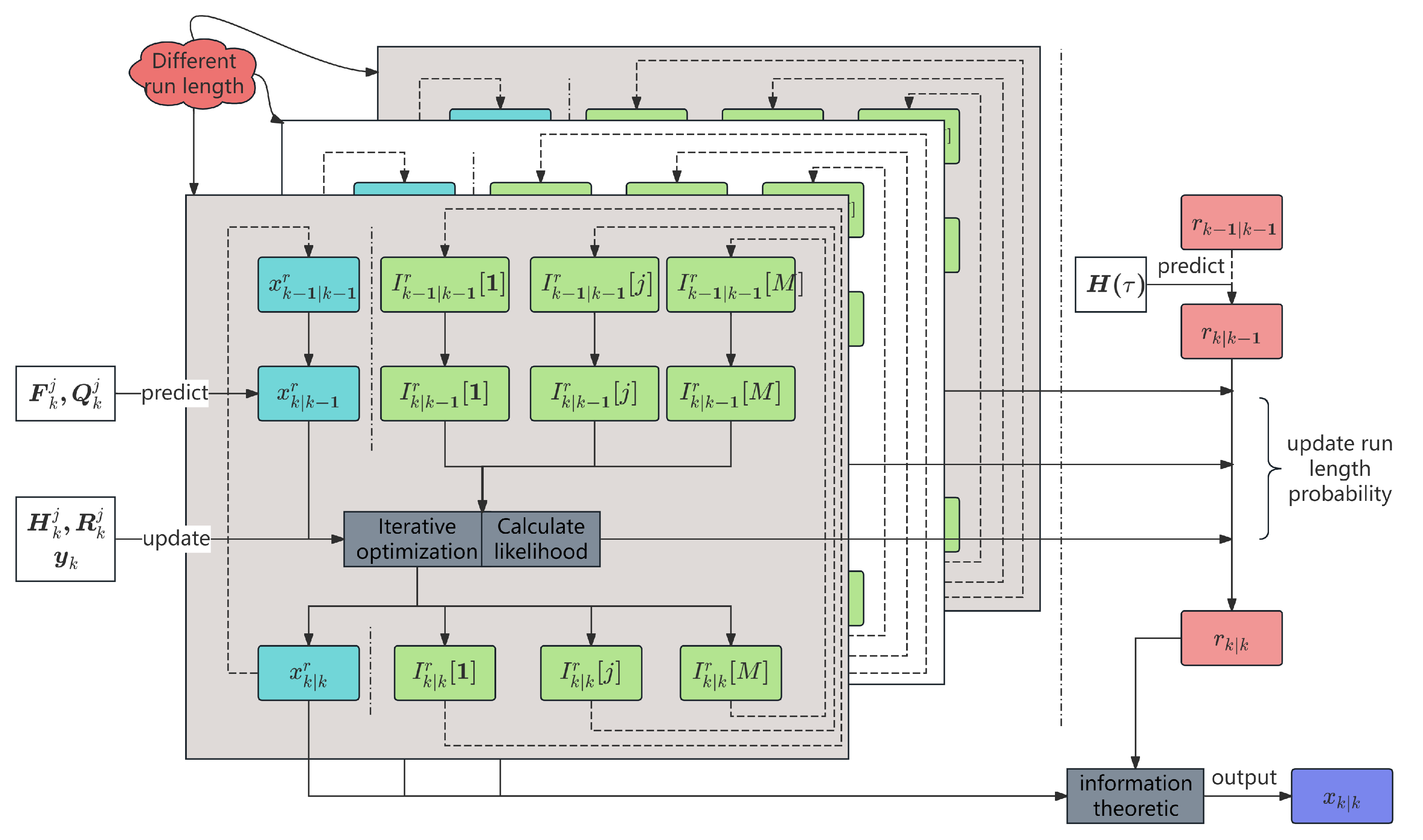
The proposed VBOCPDMS algorithm can be summarized in Algorithm 1.
| Algorithm 1 VBOCPDMS: variational Bayesian online change-point detection with model selection. |
- Require:
Measurement , approximated posterior pdfs , , at last time, iterations , model domain , detection threshold , penalty function ; - Ensure:
Approximated posterior pdfs , , , and at current time; - 1:
Time prediction: - 2:
Calculate prior pdf via ( 6) - 3:
Calculate prior pdf via ( 13) - 4:
Calculate prior pdf via ( 12) - 5:
Measurement update: - 6:
update run length parameters via ( 16) - 7:
Initialization: - 8:
, ;
- 9:
for alldo - 10:
update posterior : update variational parameters via ( 37) and ( 38) - 11:
update posterior : update variational parameters via ( 41) - 12:
end for - 13:
Hybrid estimation: - 14:
Calculate state estimation and corresponding covariance via ( 49) and ( 50); - 15:
New run length initialization: - 16:
Calculate the likelihood and select the via ( 15) - 17:
Change point detection: - 18:
Calculate the MAP estimate of via ( 27)
|
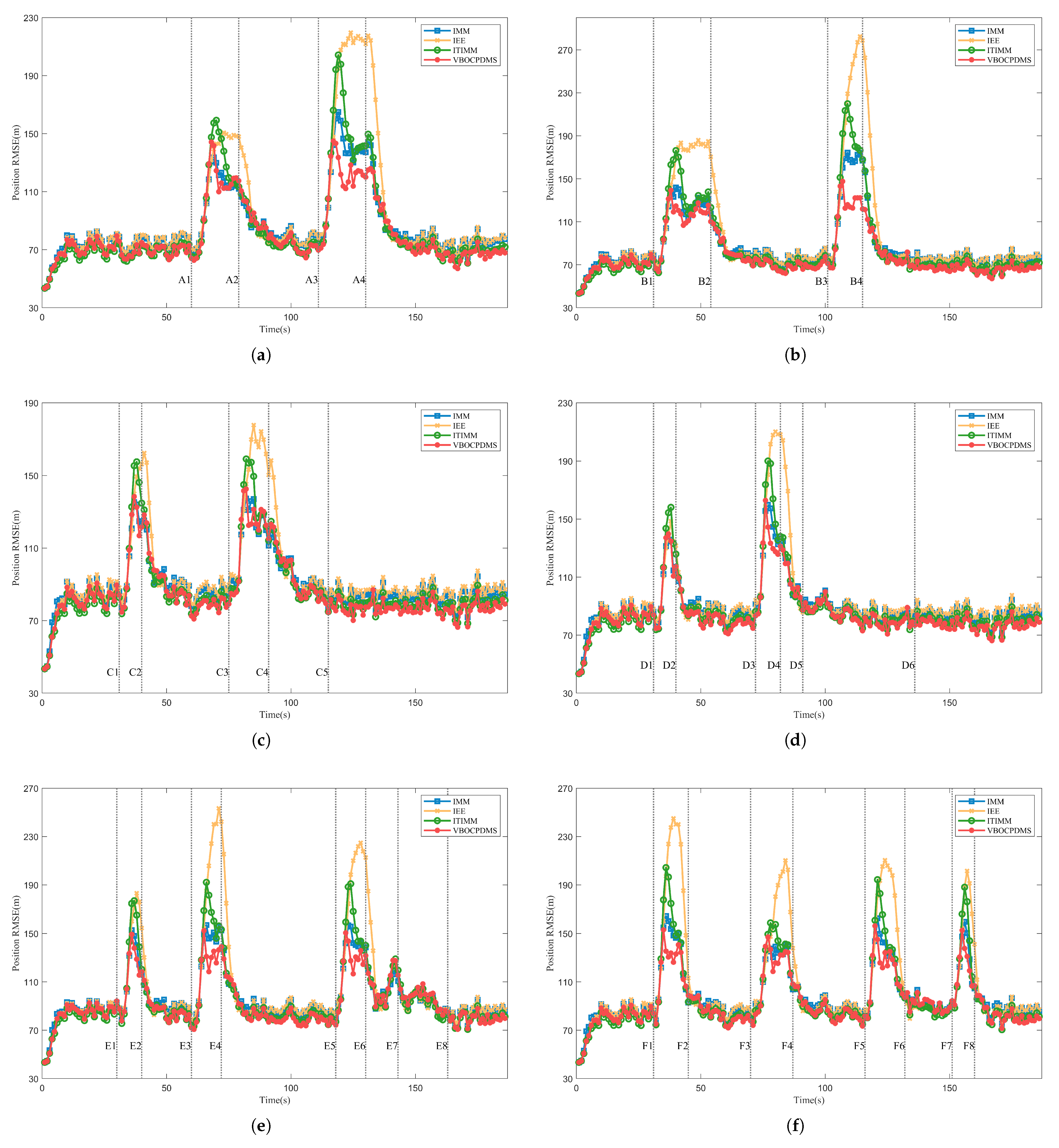
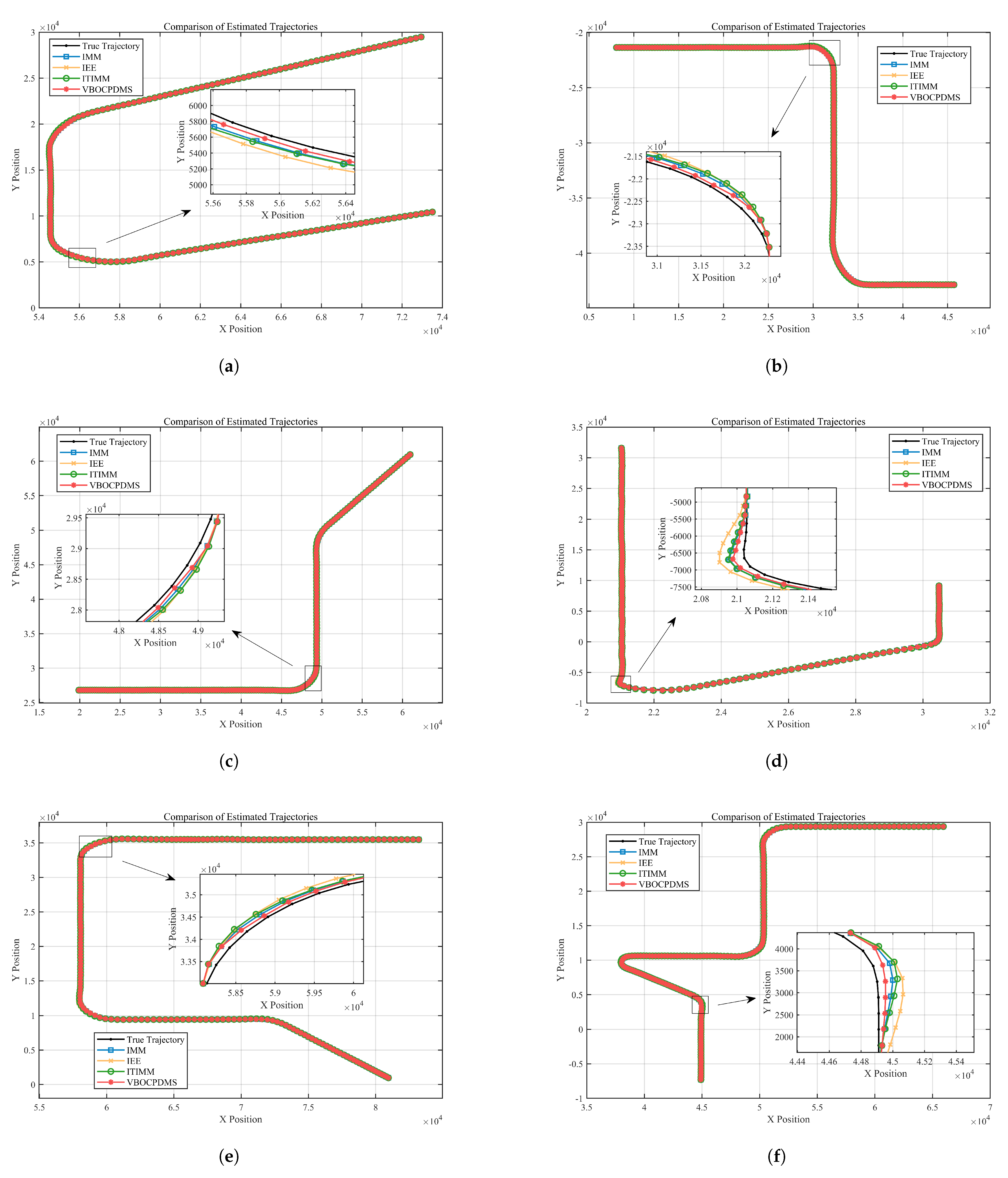
Remark 2. The computational complexity of the proposed algorithm primarily arises from two factors: (1) the increasing number of run-lengths over time, and (2) the iterative optimization required for variational inference. To address the first issue, we adopted the pruning strategy proposed in [29], which effectively controls the growth of the run-lengths. In theory, pruning the number of run-lengths may lead to a decrease in algorithm performance. However, it is important to note that the performance improvement gained from increasing the number of run-lengths is also limited. Experimental analysis shows that when the number of run-lengths is kept around 15, the algorithm strikes a good balance between computational load and filtering accuracy. To address the second issue, we propose two parameter settings to reduce the number of iterations. The first is the most intuitive approach—setting the maximum iteration . Since the average number of iterations in the experiments is around 5, reducing naturally reduces the computational load, and even with , the algorithm still outperforms the comparison algorithms in terms of accuracy. Alternatively, we can set the value in the reinitialization model weights to be close to 1. This approach brings the initial weights closer to the true weights during maneuvers, resulting in an average iteration count of around 2, with minimal loss in filtering accuracy. Therefore, this is the most recommended method for reducing computational burden in engineering applications.
These conclusions are supported by the experiments in Section 4.1.5. Additionally, since the state filtering computations for different run-lengths are independent, parallel computing can be employed to further reduce runtime when hardware resources are sufficient. 


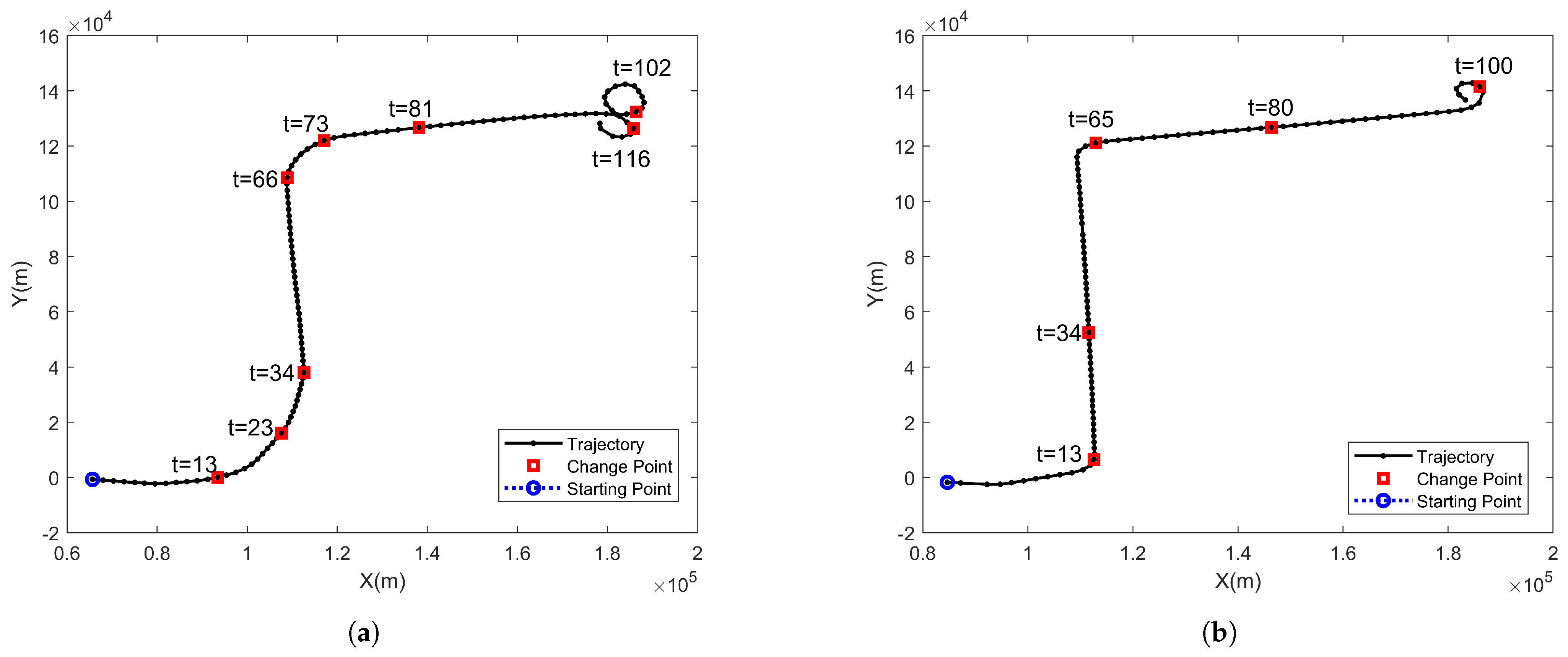
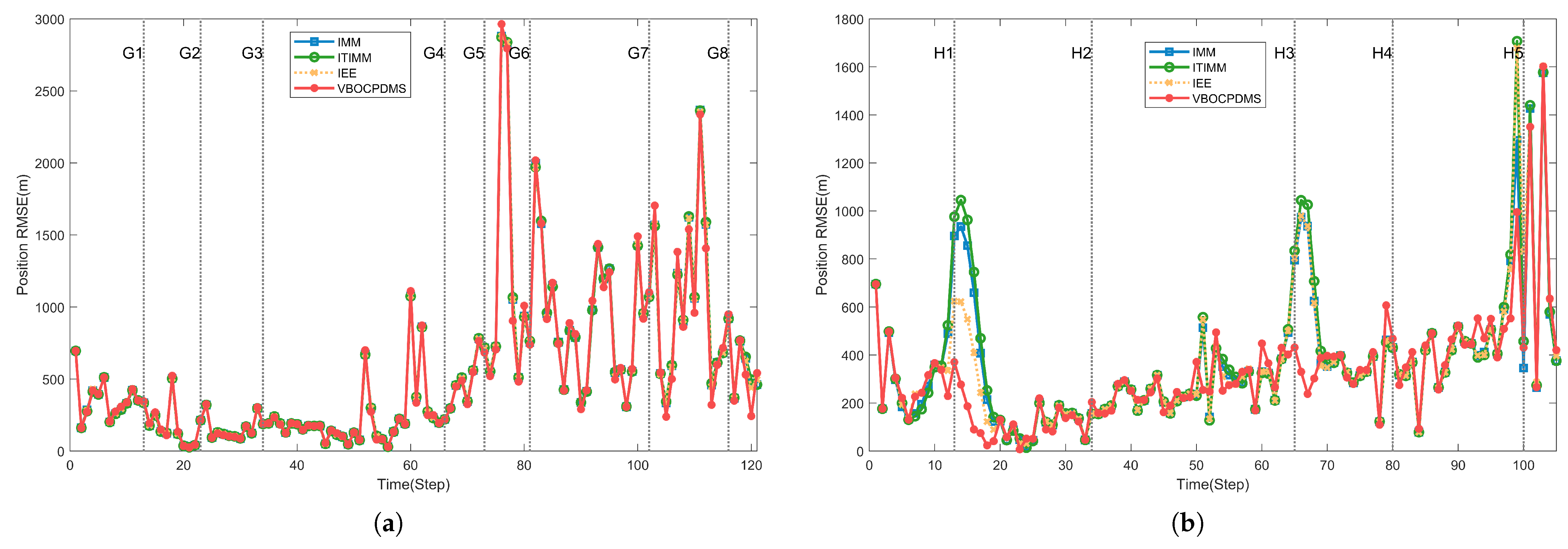

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}