
Design of Multimodal Obstacle Avoidance Algorithm Based on Deep Reinforcement Learning


Abstract
1. Introduction
2. Related Work
3. Algorithm Implementation
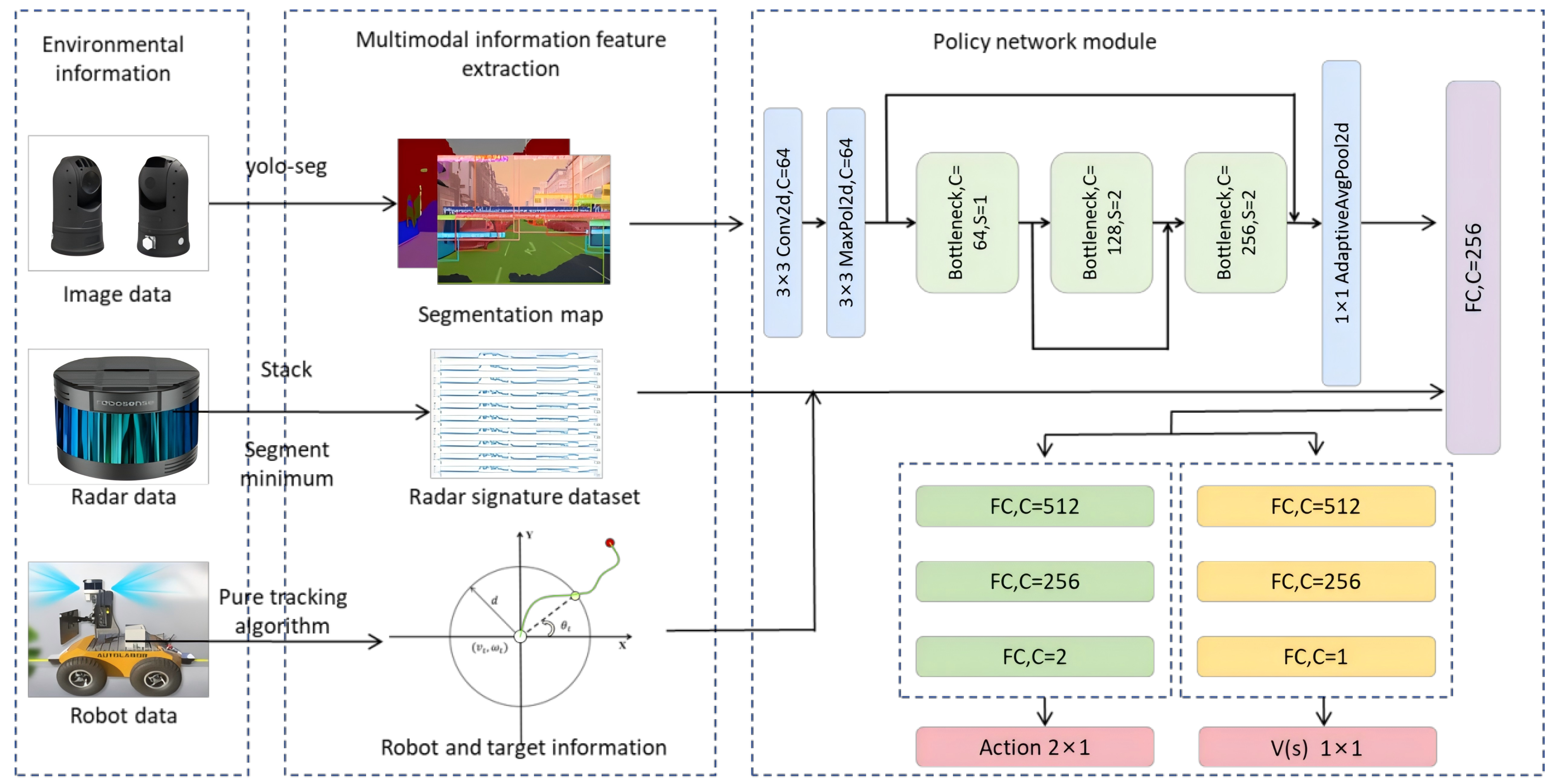
3.1. MMSEG-PPO Design of Local Obstacle Avoidance Algorithms
3.2. Reinforcement Learning
3.3. Multimodal Feature Extraction Module
3.3.1. Robot’s Self-State Information Processing
3.3.2. Visual Image Perception Information Processing
3.3.3. LiDAR Perception Data Processing
3.4. Multimodal Feature Extraction Module
3.5. Curriculum Learning
4. Experiment and Analysis
4.1. Simulation Experiment and Analysis of Multimodal Deep Reinforcement Learning for Local Obstacle Avoidance
4.1.1. Training Environment and Parameter Configuration
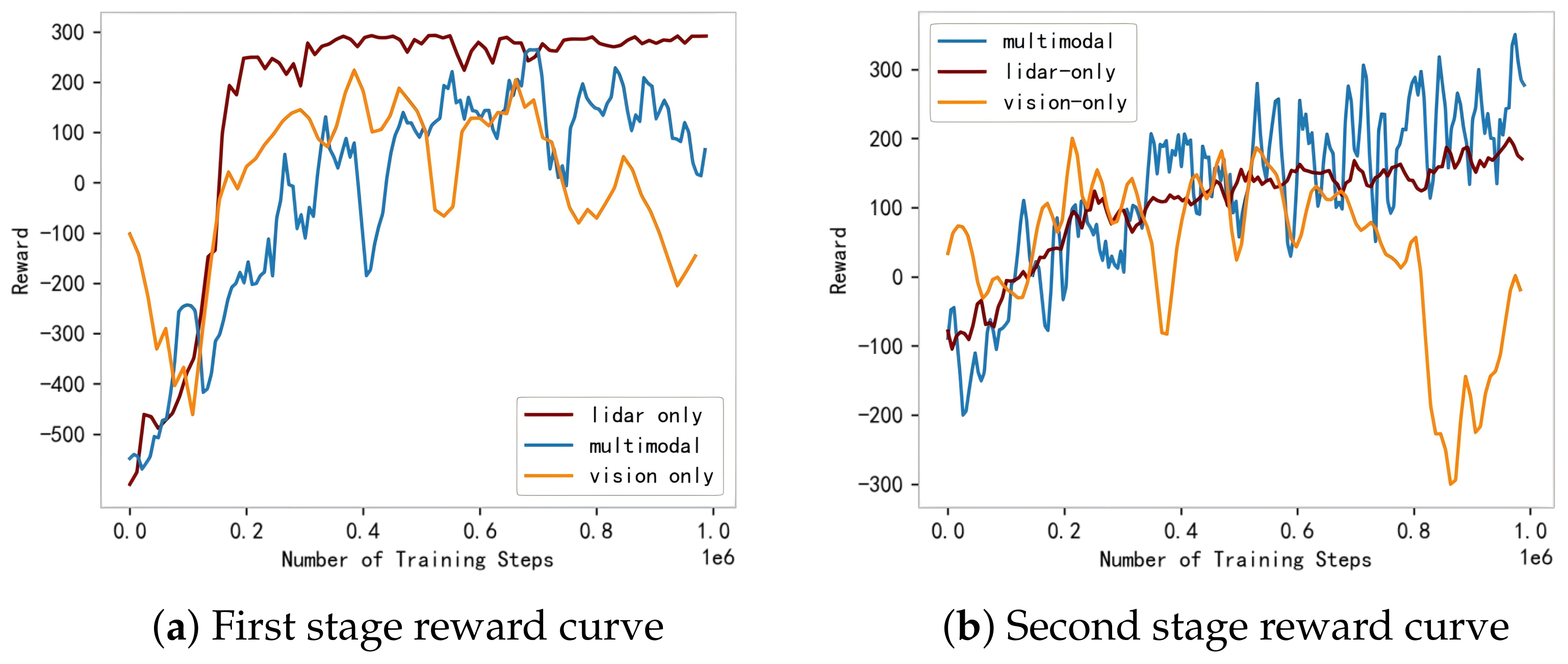
4.1.2. Algorithm Training Experiment and Analysis
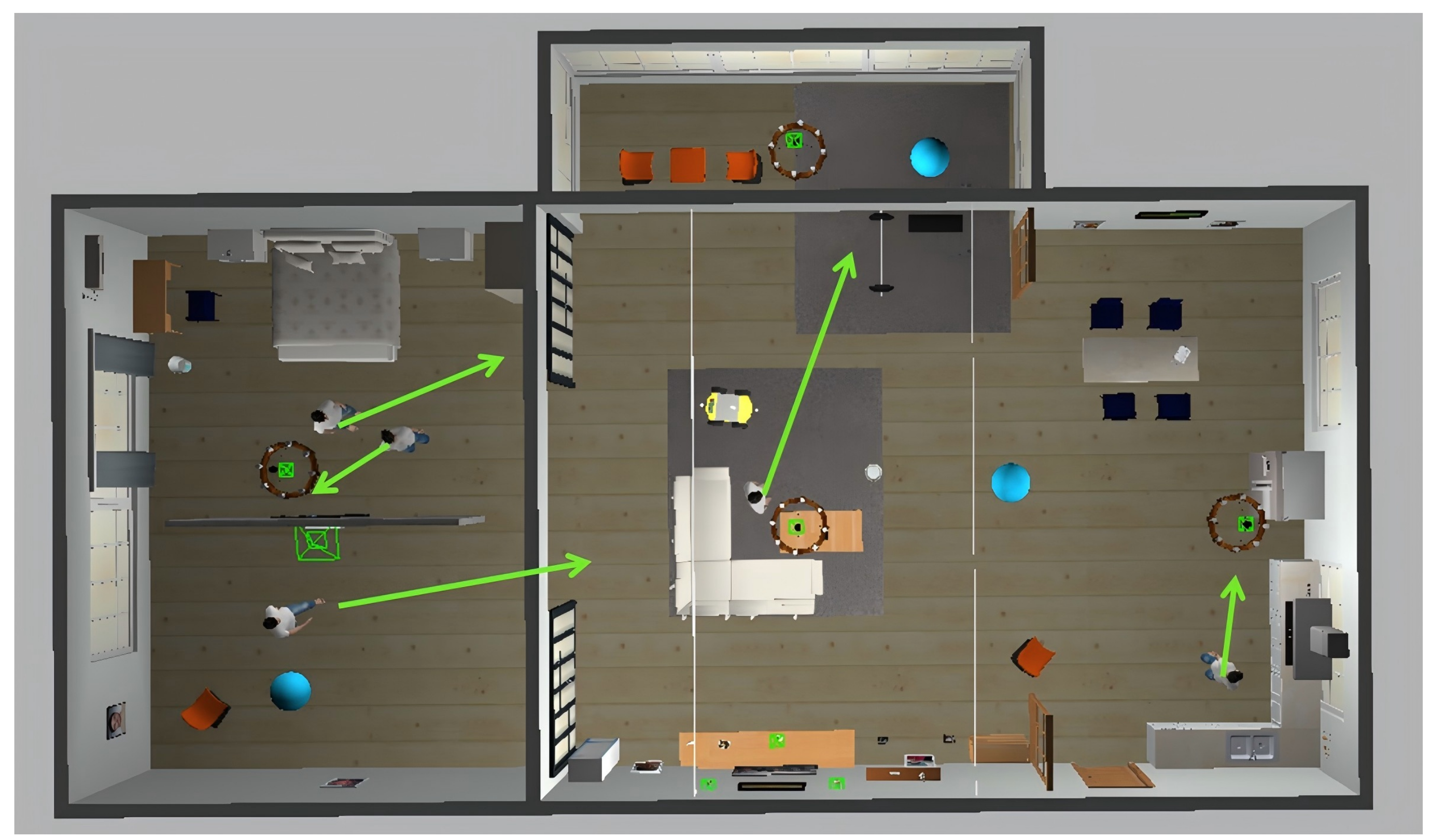
4.1.3. Testing and Analysis of the Algorithm’s Obstacle Avoidance Effectiveness
4.2. Multimodal Deep Reinforcement Learning for Local Obstacle Avoidance: Real Vehicle Experiment and Analysis
4.2.1. Model Deployment Process
4.2.2. Real World Effectiveness Testing and Analysis
4.3. Summary of This Section
5. Results
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Farazi, N.P.; Zou, B.; Ahamed, T.; Barua, L. Deep reinforcement learning in transportation research: A review. Transp. Res. Interdiscip. Perspect. 2021, 11, 100425. [Google Scholar]
- Ma, J.; Chen, G.; Jiang, P.; Zhang, Z.; Cao, J.; Zhang, J. Distributed multi-robot obstacle avoidance via logarithmic map-based deep reinforcement learning. In Proceedings of the Third International Conference on Artificial Intelligence and Computer Engineering (ICAICE 2022), Wuhan, China, 11–13 November 2022; SPIE: St Bellingham, WA, USA, 2023; Volume 12610, pp. 65–72. [Google Scholar]
- Ding, J.; Gao, L.; Liu, W.; Piao, H.; Pan, J.; Du, Z.; Yang, X.; Yin, B. Monocular camera-based complex obstacle avoidance via efficient deep reinforcement learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 756–770. [Google Scholar] [CrossRef]
- Huang, X.; Chen, W.; Zhang, W.; Song, R.; Cheng, J.; Li, Y. Autonomous multi-view navigation via deep reinforcement learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: New York, NY, USA, 2021; pp. 13798–13804. [Google Scholar]
- Barron, T.; Whitehead, M.; Yeung, A. Deep reinforcement learning in a 3-d blockworld environment. In Proceedings of the IJCAI 2016 Workshop: Deep Reinforcement Learning: Frontiers and Challenges, New York, NY, USA, 11 July 2016; Volume 2016, p. 16. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: New York, NY, USA, 2017; pp. 31–36. [Google Scholar]
- Wang, Y.; Sun, J.; He, H.; Sun, C. Deterministic policy gradient with integral compensator for robust quadrotor control. IEEE Trans. Syst. Man Cybern. Syst. 2019, 50, 3713–3725. [Google Scholar] [CrossRef]
- Srouji, M.; Thomas, H.; Tsai, Y.H.H.; Farhadi, A.; Zhang, J. Safer: Safe collision avoidance using focused and efficient trajectory search with reinforcement learning. In Proceedings of the 2023 IEEE 19th International Conference on Automation Science and Engineering (CASE), Auckland, New Zealand, 26–30 August 2023; IEEE: New York, NY, USA, 2023; pp. 1–8. [Google Scholar]
- Tan, J. A Method to Plan the Path of a Robot Utilizing Deep Reinforcement Learning and Multi-Sensory Information Fusion. Appl. Artif. Intell. 2023, 37, 2224996. [Google Scholar] [CrossRef]
- Huang, X.; Deng, H.; Zhang, W.; Song, R.; Li, Y. Towards multi-modal perception-based navigation: A deep reinforcement learning method. IEEE Robot. Autom. Lett. 2021, 6, 4986–4993. [Google Scholar] [CrossRef]
- Khalil, Y.H.; Mouftah, H.T. Exploiting multi-modal fusion for urban autonomous driving using latent deep reinforcement learning. IEEE Trans. Veh. Technol. 2022, 72, 2921–2935. [Google Scholar] [CrossRef]
- Zhou, B.; Yi, J.; Zhang, X. Learning to navigate on the rough terrain: A multi-modal deep reinforcement learning approach. In Proceedings of the 2022 IEEE 4th International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 29–31 July 2022; IEEE: New York, NY, USA, 2022; pp. 189–194. [Google Scholar]
- Chen, K.; Lee, Y.; Soh, H. Multi-modal mutual information (mummi) training for robust self-supervised deep reinforcement learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: New York, NY, USA, 2021; pp. 4274–4280. [Google Scholar]
- Li, L.; Zhao, W.; Wang, C. POMDP motion planning algorithm based on multi-modal driving intention. IEEE Trans. Intell. Veh. 2022, 8, 1777–1786. [Google Scholar] [CrossRef]
- Li, K.; Xu, Y.; Wang, J.; Meng, M.Q.-H. SARL: Deep Reinforcement Learning based Human-Aware Navigation for Mobile Robot in Indoor Environments. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 688–694. [Google Scholar]
- Mackay, A.K.; Riazuelo, L.; Montano, L. RL-DOVS: Reinforcement Learning for Autonomous Robot Navigation in Dynamic Environments. Sensors 2022, 22, 3847. [Google Scholar] [CrossRef] [PubMed]
- Cimurs, R.; Suh, I.H.; Lee, J.H. Goal-driven autonomous exploration through deep reinforcement learning. IEEE Robot. Autom. Lett. 2021, 7, 730–737. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Parameter Size | Meaning |
|---|---|---|
| max_steps | 3,000,000 | Maximum Number of Steps in the Training Process |
| max_ep_steps | 2000 | Maximum Number of Steps Per Episode During Training |
| update_timestep | 10,000 | Update Interval for Policy Parameters |
| K_epochs | 80 | Number of Episodes Per Policy Update |
| batch_size | 64 | Data Volume Per Parameter Update |
| gamma | 0.99 | Discount Factor for Future Rewards |
| eps_clip | 0.2 | Clipping Boundary in PPO Algorithm |
| lr_actor | 0.0003 | Learning Rate of the Actor Network |
| lr_critic | 0.001 | Learning Rate of the Critic Network |
| expl_noise | 0.1 | Exploration Noise Variance |
| Environment | Environment Size | Number of Static Obstacles | Dynamic Number of Pedestrians |
|---|---|---|---|
| indoor room environment | 9 m × 12 m | 3–4 | 3–4 |
| indoor hall environment | 25 m × 30 m | 5–6 | 10–20 |
| Scene | Algorithm | Number of Successes | Number of Treks | Number of Collisions |
|---|---|---|---|---|
| indoor room environment (static) | GD-RL | 78 | 8 | 14 |
| MCB-DRL | 87 | 5 | 8 | |
| LiDAR-only | 85 | 5 | 10 | |
| Vision-only | 80 | 5 | 15 | |
| Ours | 91 | 0 | 9 | |
| indoor room environment (dynamic) | GD-RL | 70 | 8 | 22 |
| MCB-DRL | 81 | 6 | 13 | |
| LiDAR-only | 78 | 4 | 18 | |
| Vision-only | 77 | 5 | 18 | |
| Ours | 86 | 2 | 12 | |
| indoor hall environment (static) | GD-RL | 83 | 5 | 12 |
| MCB-DRL | 82 | 3 | 15 | |
| LiDAR-only | 79 | 3 | 18 | |
| Vision-only | 83 | 2 | 15 | |
| Ours | 88 | 1 | 11 | |
| indoor hall environment (dynamic) | GD-RL | 78 | 2 | 20 |
| MCB-DRL | 75 | 5 | 20 | |
| LiDAR-only | 70 | 4 | 26 | |
| Vision-only | 78 | 3 | 19 | |
| Ours | 83 | 3 | 14 |
| Scene | Algorithm | Obstacle Avoidance Success Rate |
|---|---|---|
| Laboratory indoor environment (static) | GD-RL | 66% |
| MCB-DRL | 72% | |
| LiDAR-only | 68% | |
| Vision-only | 63% | |
| Ours | 79% | |
| Laboratory indoor environment (dynamic) | GD-RL | 62% |
| MCB-DRL | 61% | |
| LiDAR-only | 55% | |
| Vision-only | 46% | |
| Ours | 76% | |
| Corridor environment in the building (static) | GD-RL | 65% |
| MCB-DRL | 75% | |
| LiDAR-only | 70% | |
| Vision-only | 68% | |
| Ours | 82% | |
| Corridor environment in the building (dynamic) | GD-RL | 57% |
| MCB-DRL | 65% | |
| LiDAR-only | 53% | |
| Vision-only | 46% | |
| Ours | 78% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, W.; Gao, X.; Wu, H.; Chen, J.; Zhou, X.; Zhou, Z. Design of Multimodal Obstacle Avoidance Algorithm Based on Deep Reinforcement Learning. Electronics 2025, 14, 78. https://doi.org/10.3390/electronics14010078
Zhu W, Gao X, Wu H, Chen J, Zhou X, Zhou Z. Design of Multimodal Obstacle Avoidance Algorithm Based on Deep Reinforcement Learning. Electronics. 2025; 14(1):78. https://doi.org/10.3390/electronics14010078
Chicago/Turabian StyleZhu, Wenming, Xuan Gao, Haibin Wu, Jiawei Chen, Xuehua Zhou, and Zhiguo Zhou. 2025. "Design of Multimodal Obstacle Avoidance Algorithm Based on Deep Reinforcement Learning" Electronics 14, no. 1: 78. https://doi.org/10.3390/electronics14010078
APA StyleZhu, W., Gao, X., Wu, H., Chen, J., Zhou, X., & Zhou, Z. (2025). Design of Multimodal Obstacle Avoidance Algorithm Based on Deep Reinforcement Learning. Electronics, 14(1), 78. https://doi.org/10.3390/electronics14010078