
NRDPA: Review-Aware Neural Recommendation with Dynamic Personalized Attention


Abstract
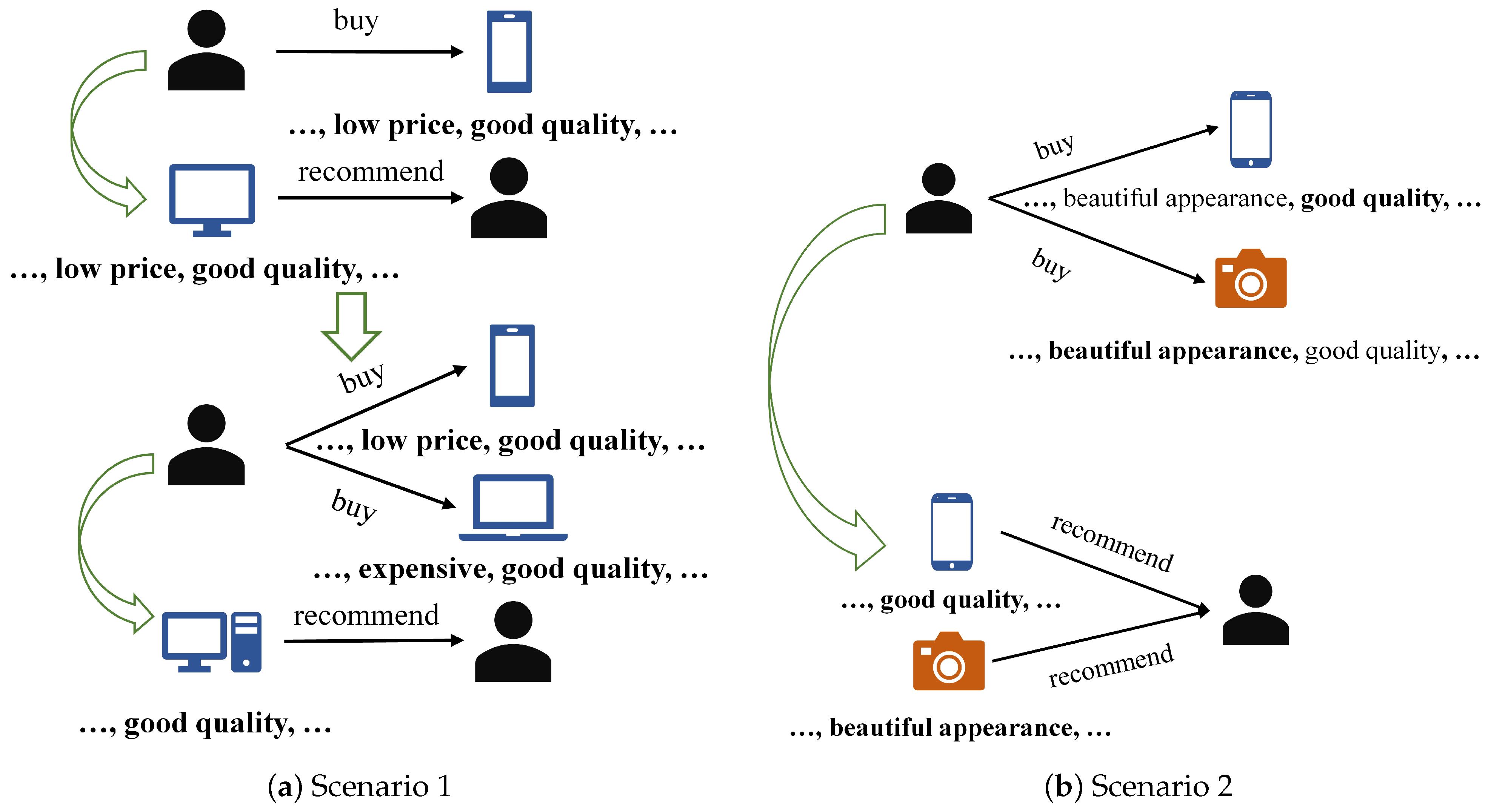
1. Introduction
- We propose a review-based recommendation framework called NRDPA to solve the dynamic personalization problem. The proposed framework integrates multiple attention mechanisms to dynamically mine the personalized features of users and items in reviews.
- We propose a dynamic personalized word-level and review-level attention mechanism that can perceive the changes in the personalized features of users and items, capturing the current user personality and item attributes through the user’s historical rating behavior to dynamically construct users and items.
- We propose a personalized interactive attention mechanism that can adjust the features of both sides of the current interaction and dynamically obtain more accurate personalized features of users and items by perceiving the different preferences of users for items.
- Our experiments on five public datasets from Amazon demonstrate that the rating prediction accuracy of our model outperforms the baseline model. Ablation experiments and interpretability analysis further validate the superiority of the proposed NRDPA.
2. Related Work
2.1. Feature Extraction-Based Recommendation
2.2. Aspect Mining-Based Recommendation
2.3. Graph Construction-Based Recommendation
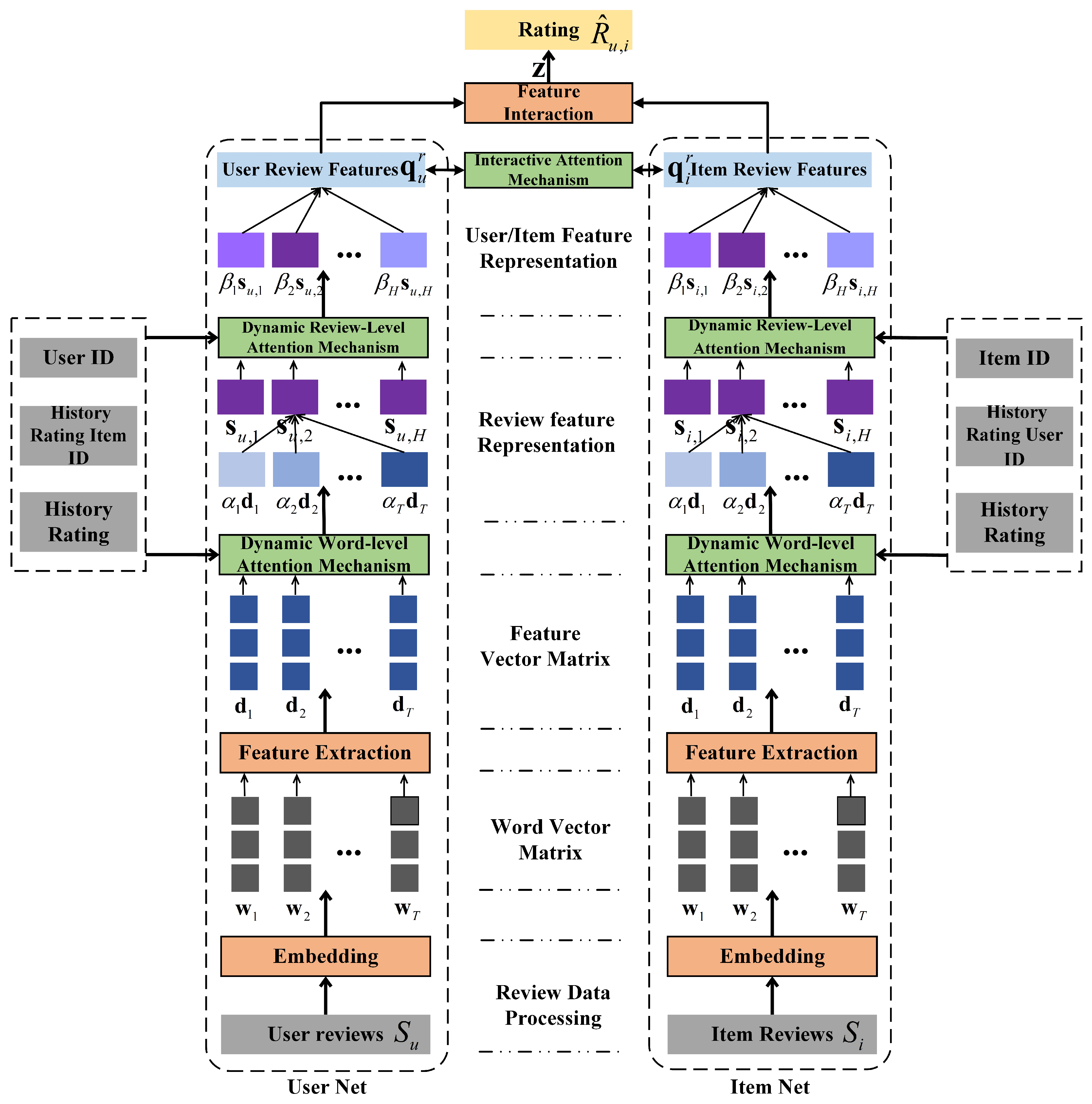
3. Method
3.1. Review Encoder
3.2. User and Item Encoder
3.3. Rating Prediction
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Baselines
- DeepCoNN [24]: Uses simple user and item networks to respectively extract user and item features from reviews. This is a classic deep learning-based model for review recommendation.
- DAML [32]: Focuses on word meaning relevance in reviews both locally and globally during feature extraction, and combines rating and review features. This model explores word-level attention mechanisms in depth.
- NRPA [33]: Implements dual personalized attention mechanisms at the word and review levels, emphasizing static personalization of user interests and item attributes. This model combines word-level and review-level attention.
- NRCMA [34]: Implements cross-modal mutual attention, focusing on the information interaction between users and items during feature modeling at both the word and review levels. This model introduces information interaction into the modeling process.
- ARPCNN [35]: Focuses on the sparsity of static personalized review data and establishes an auxiliary network by defining trust relationships, representing a relatively new approach in this field.
- ERUR [47]: A novel user representation model for learning social graph recommendations based on enhanced reviews, which effectively integrates user reviews and social relationships. This research branch has gained significant attention recently.
4.4. Experimental Configuration and Parameter Settings
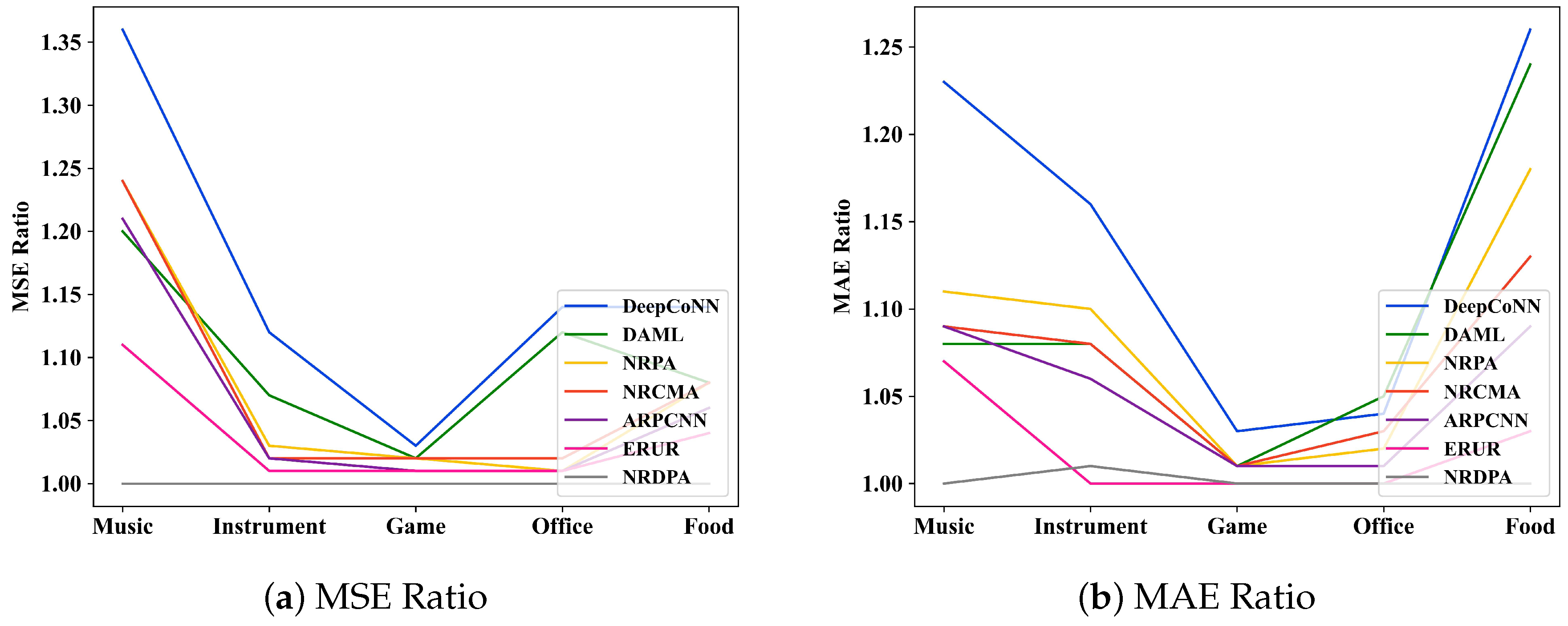
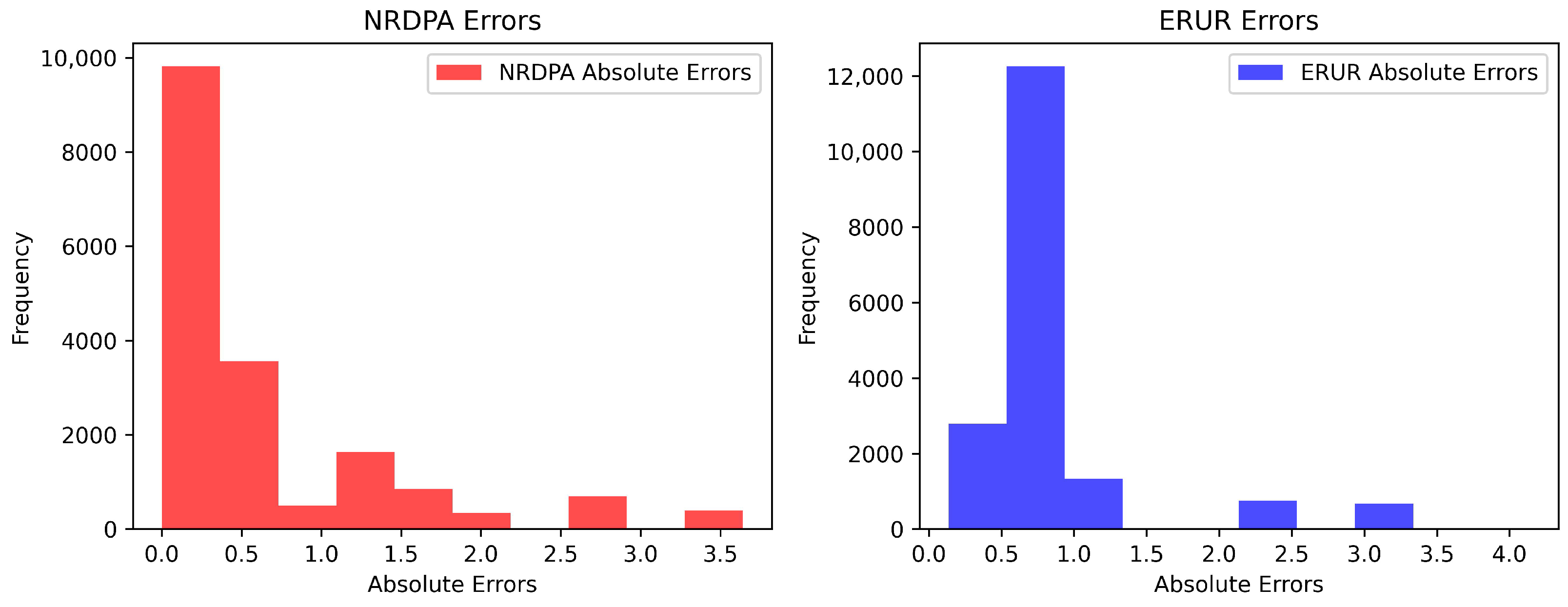
4.5. Performance Comparison
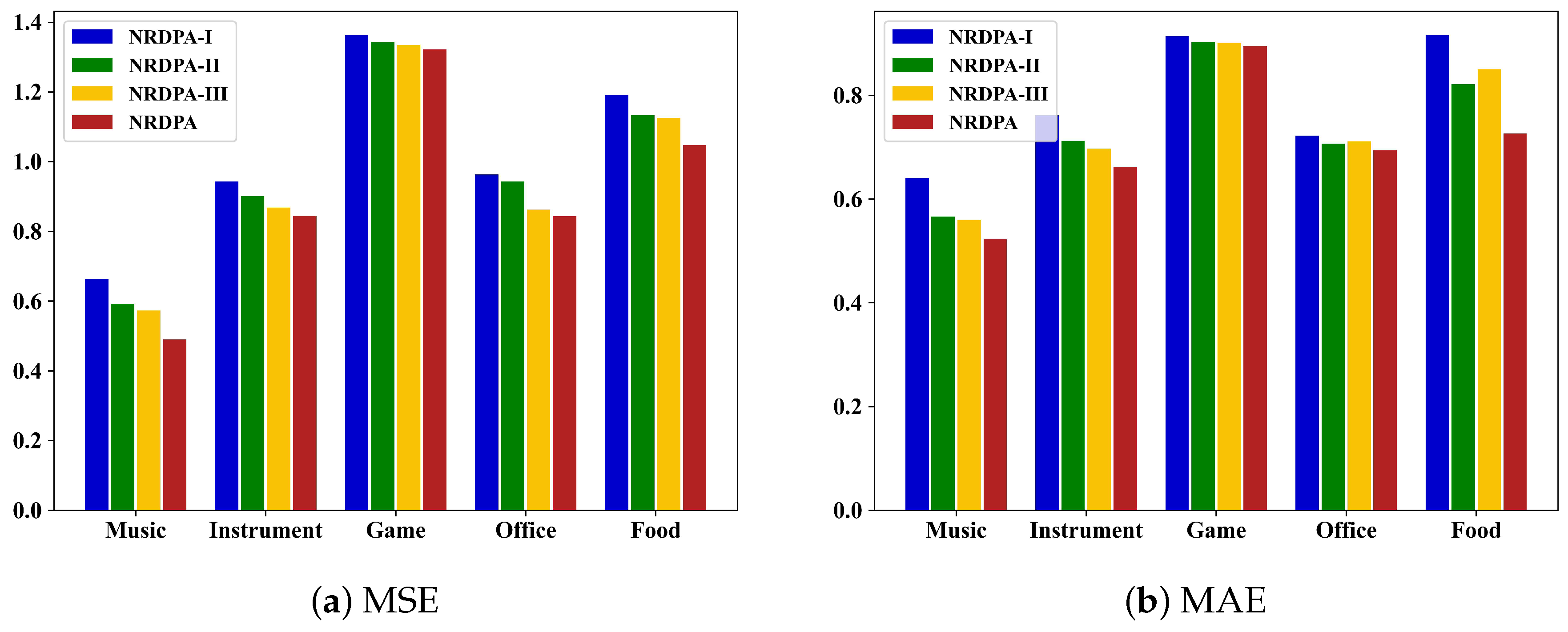
4.6. Ablation Study
- NRDPA-I: Extracts features of reviews using a basic network that is not personalized.
- NRDPA-II: Adds a dynamic personalized word-level attention mechanism to NRDPA-I.
- NRDPA-III: Adds a dynamic personalized review-level attention mechanism to NRDPA-II.
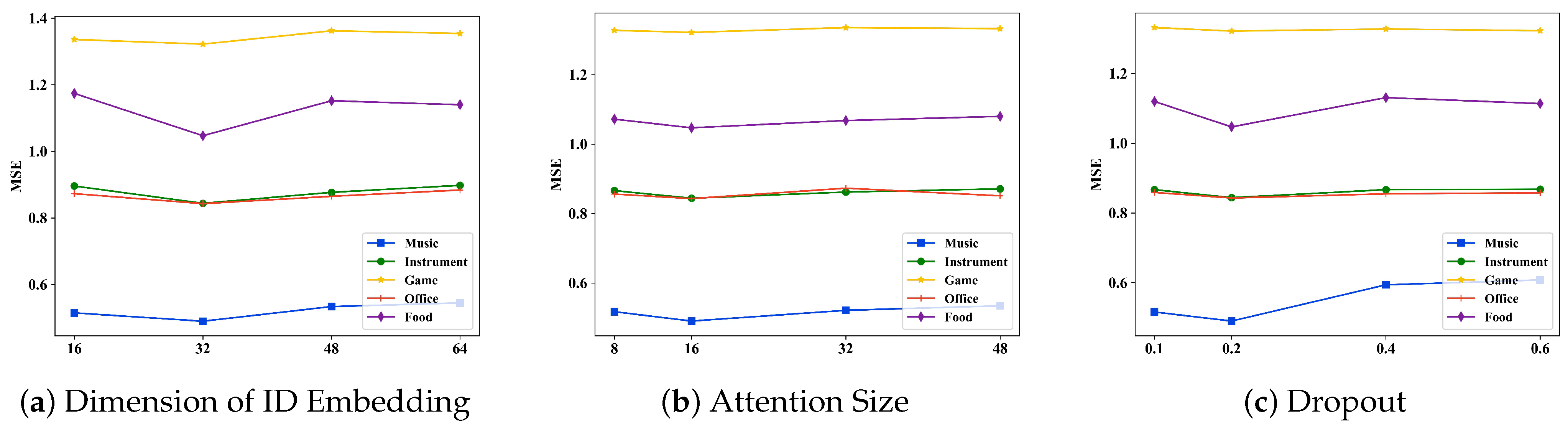
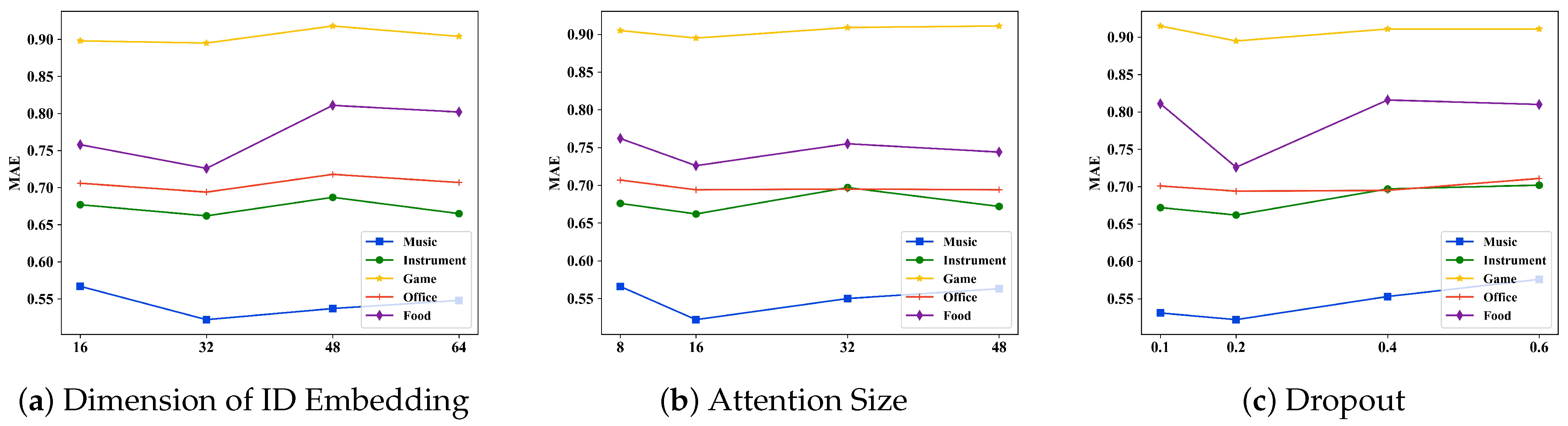
4.7. Parameter Sensitivity Analysis
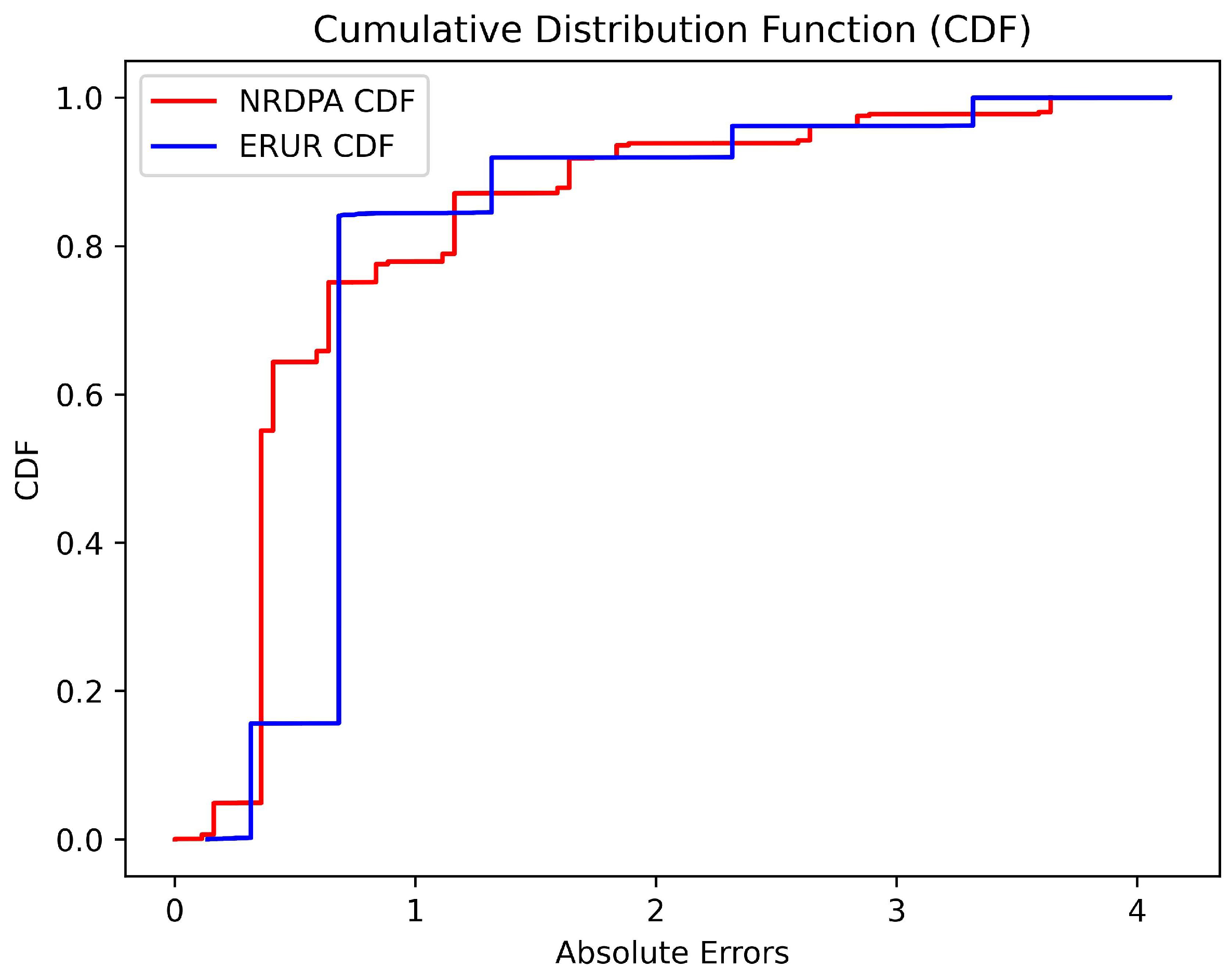
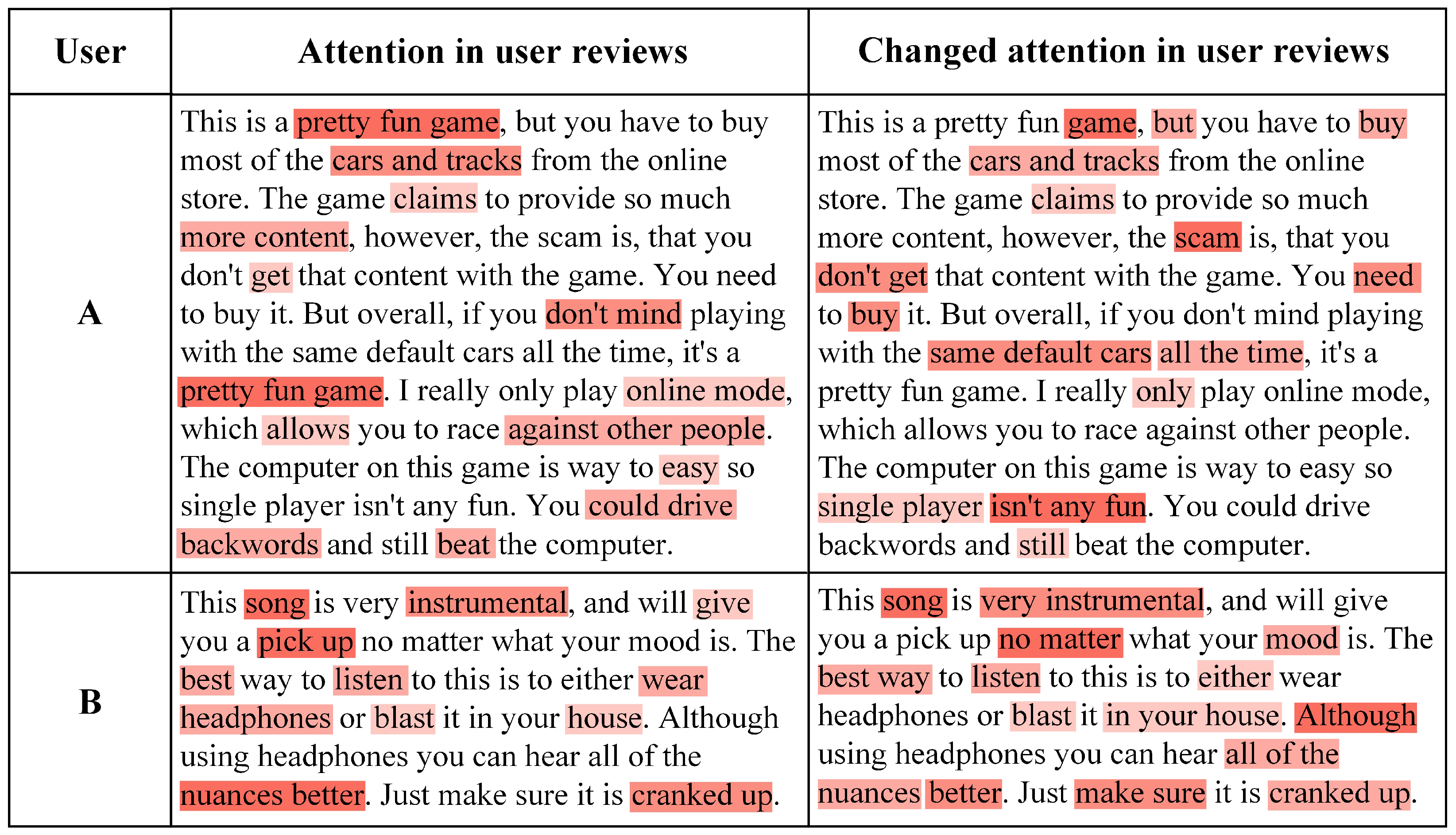
4.8. Interpretability Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Burke, R. Hybrid recommender systems: Survey and experiments. User Model. User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Roy, D.; Dutta, M. A systematic review and research perspective on recommender systems. J. Big Data 2022, 9, 59. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 1–19. [Google Scholar] [CrossRef]
- Cacheda, F.; Carneiro, V.; Fernández, D.; Formoso, V. Comparison of collaborative filtering algorithms: Limitations of current techniques and proposals for scalable, high-performance recommender systems. ACM Trans. Web 2011, 5, 1–33. [Google Scholar] [CrossRef]
- Rendle, S.; Krichene, W.; Zhang, L.; Anderson, J. Neural collaborative filtering vs. matrix factorization revisited. In Proceedings of the 14th ACM Conference on Recommender Systems, Virtual Event, Brazil, 22–26 September 2020; pp. 240–248. [Google Scholar]
- Chen, H.; Shi, S.; Li, Y.; Zhang, Y. Neural collaborative reasoning. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 1516–1527. [Google Scholar]
- Chen, L.; Chen, G.; Wang, F. Recommender systems based on user reviews: The state of the art. User Model. User-Adapt. Interact. 2015, 25, 99–154. [Google Scholar] [CrossRef]
- Wu, L.; He, X.; Wang, X.; Zhang, K.; Wang, M. A survey on neural recommendation: From collaborative filtering to content and context enriched recommendation. arXiv 2021, arXiv:2104.13030. [Google Scholar]
- Sachdeva, N.; McAuley, J. How useful are reviews for recommendation? A critical review and potential improvements. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 1845–1848. [Google Scholar]
- McAuley, J.; Leskovec, J. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 165–172. [Google Scholar]
- Zhou, J.P.; Cheng, Z.; Pérez, F.; Volkovs, M. TAFA: Two-headed attention fused autoencoder for context-aware recommendations. In Proceedings of the 14th ACM Conference on Recommender Systems, Virtual Event, Brazil, 22–26 September 2020; pp. 338–347. [Google Scholar]
- Chuang, Y.N.; Chen, C.M.; Wang, C.J.; Tsai, M.F.; Fang, Y.; Lim, E.P. TPR: Text-aware preference ranking for recommender systems. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, Ireland, 19–23 October 2020; pp. 215–224. [Google Scholar]
- Li, X.; Yu, J.; Wang, Y.; Chen, J.Y.; Chang, P.X.; Li, Z. DAHP: Deep attention-guided hashing with pairwise labels. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 933–946. [Google Scholar] [CrossRef]
- Li, X.; Yu, J.; Jiang, S.; Lu, H.; Li, Z. Msvit: Training multiscale vision transformers for image retrieval. IEEE Trans. Multimed. 2024, 26, 2809–2823. [Google Scholar] [CrossRef]
- Li, X.; Yu, J.; Lu, H.; Jiang, S.; Li, Z.; Yao, P. MAFH: Multilabel aware framework for bit-scalable cross-modal hashing. Knowl. Based Syst. 2023, 279, 110922. [Google Scholar] [CrossRef]
- Lu, W.; Altenbek, G. A recommendation algorithm based on fine-grained feature analysis. Expert Syst. Appl. 2021, 163, 113759. [Google Scholar] [CrossRef]
- Wang, X.; Ounis, I.; Macdonald, C. Leveraging review properties for effective recommendation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2209–2219. [Google Scholar]
- Xiong, K.; Ye, W.; Chen, X.; Zhang, Y.; Zhao, W.X.; Hu, B.; Zhang, Z.; Zhou, J. Counterfactual review-based recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, Queensland, Australia, 1–5 November 2021; pp. 2231–2240. [Google Scholar]
- Tran, N.T.; Lauw, H.W. Aligning dual disentangled user representations from ratings and textual content. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 1798–1806. [Google Scholar]
- Liu, W.; Zheng, X.; Hu, M.; Chen, C. Collaborative filtering with attribution alignment for review-based non-overlapped cross domain recommendation. In Proceedings of the ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; pp. 1181–1190. [Google Scholar]
- Pan, S.; Li, D.; Gu, H.; Lu, T.; Luo, X.; Gu, N. Accurate and explainable recommendation via review rationalization. In Proceedings of the ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; pp. 3092–3101. [Google Scholar]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint deep modeling of users and items using reviews for recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar]
- Catherine, R.; Cohen, W. Transnets: Learning to transform for recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 288–296. [Google Scholar]
- Libing, W.; Cong, Q.; Chenliang, L.; Donghong, J. PARL: Let strangers speak out what you like. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 22–26. [Google Scholar]
- Seo, S.; Huang, J.; Yang, H.; Liu, Y. Interpretable convolutional neural networks with dual local and global attention for review rating prediction. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–30 August 2017; pp. 297–305. [Google Scholar]
- Chen, C.; Zhang, M.; Liu, Y.; Ma, S. Neural attentional rating regression with review-level explanations. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1583–1592. [Google Scholar]
- Lu, Y.; Dong, R.; Smyth, B. Coevolutionary recommendation model: Mutual learning between ratings and reviews. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 773–782. [Google Scholar]
- Tay, Y.; Luu, A.T.; Hui, S.C. Multi-pointer co-attention networks for recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2309–2318. [Google Scholar]
- Wu, L.; Quan, C.; Li, C.; Wang, Q.; Zheng, B.; Luo, X. A context-aware user-item representation learning for item recommendation. ACM Trans. Inf. Syst. 2019, 37, 1–29. [Google Scholar] [CrossRef]
- Liu, D.; Li, J.; Du, B.; Chang, J.; Gao, R. Daml: Dual attention mutual learning between ratings and reviews for item recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 344–352. [Google Scholar]
- Liu, H.; Wu, F.; Wang, W.; Wang, X.; Jiao, P.; Wu, C.; Xie, X. NRPA: Neural recommendation with personalized attention. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 1233–1236. [Google Scholar]
- Luo, S.; Lu, X.; Wu, J.; Yuan, J. Review-Aware neural recommendation with cross-modality mutual attention. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Queensland, Australia, 1–5 November 2021; pp. 3293–3297. [Google Scholar]
- Li, Z.; Chen, H.; Ni, Z.; Deng, X.; Liu, B.; Liu, W. ARPCNN: Auxiliary review-based personalized attentional CNN for trustworthy recommendation. IEEE Trans. Ind. Inform. 2023, 19, 1018–1029. [Google Scholar] [CrossRef]
- Chin, J.Y.; Zhao, K.; Joty, S.; Cong, G. ANR: Aspect-based neural recommender. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 147–156. [Google Scholar]
- Cheng, Z.; Ding, Y.; He, X.; Zhu, L.; Song, X.; Kankanhalli, M.S. A3NCF: An Adaptive Aspect Attention Model for Rating Prediction. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3748–3754. [Google Scholar]
- Li, C.; Quan, C.; Peng, L.; Qi, Y.; Deng, Y.; Wu, L. A Capsule Network for Recommendation and Explaining What You Like and Dislike. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR’19, New York, NY, USA, 21–25 July 2019; pp. 275–284. [Google Scholar]
- Guan, X.; Cheng, Z.; He, X.; Zhang, Y.; Zhu, Z.; Peng, Q.; Chua, T.S. Attentive aspect modeling for review-aware recommendation. ACM Trans. Inf. Syst. 2019, 37, 1–27. [Google Scholar] [CrossRef]
- Da’u, A.; Salim, N.; Rabiu, I.; Osman, A. Weighted aspect-based opinion mining using deep learning for recommender system. Expert Syst. Appl. 2020, 140, 112871. [Google Scholar]
- Ding, H.; Liu, Q.; Hu, G. TDTMF: A recommendation model based on user temporal interest drift and latent review topic evolution with regularization factor. Inf. Process. Manag. 2022, 59, 103037. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Qi, T.; Ge, S.; Huang, Y.; Xie, X. Reviews meet graphs: Enhancing user and item representations for recommendation with hierarchical attentive graph neural network. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4884–4893. [Google Scholar]
- Gao, J.; Lin, Y.; Wang, Y.; Wang, X.; Yang, Z.; He, Y.; Chu, X. Set-sequence-graph: A multi-view approach towards exploiting reviews for recommendation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, Ireland, 19–23 October 2020; pp. 395–404. [Google Scholar]
- Cai, Y.; Wang, Y.; Wang, W.; Chen, W. RI-GCN: Review-aware interactive graph convolutional network for review-based item recommendation. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 475–484. [Google Scholar]
- Shuai, J.; Zhang, K.; Wu, L.; Sun, P.; Hong, R.; Wang, M.; Li, Y. A review-aware graph contrastive learning framework for recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1283–1293. [Google Scholar]
- Liu, Y.; Yang, S.; Zhang, Y.; Miao, C.; Nie, Z.; Zhang, J. Learning hierarchical review graph representations for recommendation. IEEE Trans. Knowl. Data Eng. 2021, 35, 658–671. [Google Scholar] [CrossRef]
- Liu, H.; Chen, Y.; Li, P.; Zhao, P.; Wu, X. Enhancing review-based user representation on learned social graph for recommendation. Knowl.-Based Syst. 2023, 266, 110438. [Google Scholar] [CrossRef]
- Hassani, H.; Silva, E.S. A Kolmogorov-Smirnov based test for comparing the predictive accuracy of two sets of forecasts. Econometrics 2015, 3, 590–609. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Users | #Items | #Ratings | Density |
|---|---|---|---|---|
| Music | 1909 | 742 | 12,099 | 0.854% |
| Instrument | 3113 | 1002 | 23,711 | 0.760% |
| Game | 5080 | 2071 | 45,422 | 0.432% |
| Office | 8361 | 3056 | 75,046 | 0.294% |
| Food | 16,813 | 6386 | 178,206 | 0.166% |
| Methods | Deep Learning | Review Text | Word-Level Attention | Review-Level Attention | Interactive Attention | Rating Matrix | Auxiliary Feature |
|---|---|---|---|---|---|---|---|
| DeepCoNN | ✓ | ✓ | × | × | × | × | × |
| DAML | ✓ | ✓ | ✓ | × | × | ✓ | × |
| NRPA | ✓ | ✓ | ✓ | ✓ | × | × | × |
| NRCMA | ✓ | ✓ | ✓ | ✓ | × | × | × |
| ARPCNN | ✓ | ✓ | ✓ | ✓ | × | × | ✓ |
| ERUR | ✓ | ✓ | × | × | × | × | ✓ |
| NRDPA | ✓ | ✓ | ✓ | ✓ | ✓ | × | × |
| Resource | Configuration |
|---|---|
| OS | Ubuntu 20.04.6 LTS |
| Nvidia Driver | 550.90.07 |
| CPU | Intel i7-13700KF |
| GPU | GeForce RTX 3090 |
| RAM | 94 GB |
| CUDA | 12.4 |
| CuDNN | 11.3 |
| Python | 3.7.16 |
| Pytorch | 1.12.0 |
| Optimizer | Adam |
| Methods | Music | Instrument | Game | Office | Food | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | |
| DeepCoNN | 0.664 | 0.641 | 0.943 | 0.761 | 1.363 | 0.914 | 0.963 | 0.722 | 1.190 | 0.916 |
| DAML | 0.592 | 0.566 | 0.901 | 0.712 | 1.355 | 0.902 | 0.943 | 0.729 | 1.133 | 0.897 |
| NRPA | 0.610 | 0.578 | 0.868 | 0.725 | 1.344 | 0.904 | 0.854 | 0.707 | 1.128 | 0.860 |
| NRCMA | 0.606 | 0.569 | 0.860 | 0.711 | 1.342 | 0.901 | 0.862 | 0.711 | 1.125 | 0.821 |
| ARPCNN | 0.595 | 0.567 | 0.857 | 0.697 | 1.335 | 0.898 | 0.852 | 0.698 | 1.105 | 0.791 |
| ERUR | 0.545 | 0.557 | 0.852 | 0.657 | 1.330 | 0.891 | 0.851 | 0.693 | 1.086 | 0.751 |
| NRDPA | 0.490 | 0.522 | 0.844 | 0.662 | 1.322 | 0.895 | 0.843 | 0.694 | 1.047 | 0.726 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Q.; Li, Z.; Yu, J.; Li, X.; Wang, X. NRDPA: Review-Aware Neural Recommendation with Dynamic Personalized Attention. Electronics 2025, 14, 33. https://doi.org/10.3390/electronics14010033
Sun Q, Li Z, Yu J, Li X, Wang X. NRDPA: Review-Aware Neural Recommendation with Dynamic Personalized Attention. Electronics. 2025; 14(1):33. https://doi.org/10.3390/electronics14010033
Chicago/Turabian StyleSun, Qinghao, Ziyang Li, Jiong Yu, Xue Li, and Xin Wang. 2025. "NRDPA: Review-Aware Neural Recommendation with Dynamic Personalized Attention" Electronics 14, no. 1: 33. https://doi.org/10.3390/electronics14010033
APA StyleSun, Q., Li, Z., Yu, J., Li, X., & Wang, X. (2025). NRDPA: Review-Aware Neural Recommendation with Dynamic Personalized Attention. Electronics, 14(1), 33. https://doi.org/10.3390/electronics14010033