
Sentiment Dimensions and Intentions in Scientific Analysis: Multilevel Classification in Text and Citations

 ,
,  ,
,  and
and 
Abstract
1. Introduction
“Gregori et al. [19] introduced an innovative algorithm for sentiment analysis, leveraging a revolutionary methodology that enables the identification of nuanced emotional nuances within textual data. This state-of-the-art approach provides an adaptable, user-defined, and context-independent framework for sentiment analysis, thereby enhancing accuracy and efficiency in natural language processing tasks”.
2. Research Methodology
- Defining the research questions.
- Searching for literature in reliable repositories.
- Setting criteria for rejecting certain papers.
- Removal of duplicate documents.
2.1. Research Questions
- RQ1. What algorithms and models have been developed for Sentiment Analysis in texts and how do they compare with traditional methods?
- RQ2. What preprocessing methods and classification accuracy metrics are applied in Sentiment Analysis?
- RQ3. In which cases do Machine Learning models perform better compared to Deep Learning models?
- RQ4. Which types of learning are most often used in classification problems in Sentiment Analysis?
- RQ5. How can Sentiment Analysis improve the understanding and evaluation of scientific communication?
- RQ6. What are the challenges in Sentiment Analysis in scientific texts?
- RQ7. What classifications are generally applied in the analysis of reporting frameworks?
- RQ8. Are there datasets available for Sentiment Analysis in citation contexts?
- RQ9. What is the role of emotions in communicating scientific results and how do they affect the acceptance of information?
2.2. Search Strategy and Selection Criteria
- Be Conference Papers or Journal Articles.
- Apply NLP and Machine Learning methods.
- Apply Sentiment Analysis methods in citation contexts.
- Be Research Papers.
- The full text is available.
- Be published in reputable Journals or Conferences that show high-quality research.
- Rejection due to contradictions. If there are contradictions in the data or results presented, the article may not be credible.
- Rejection based on content. If the screening process finds that the content of the article is not relevant to the topic of our study, we reject it.
3. Literature Review
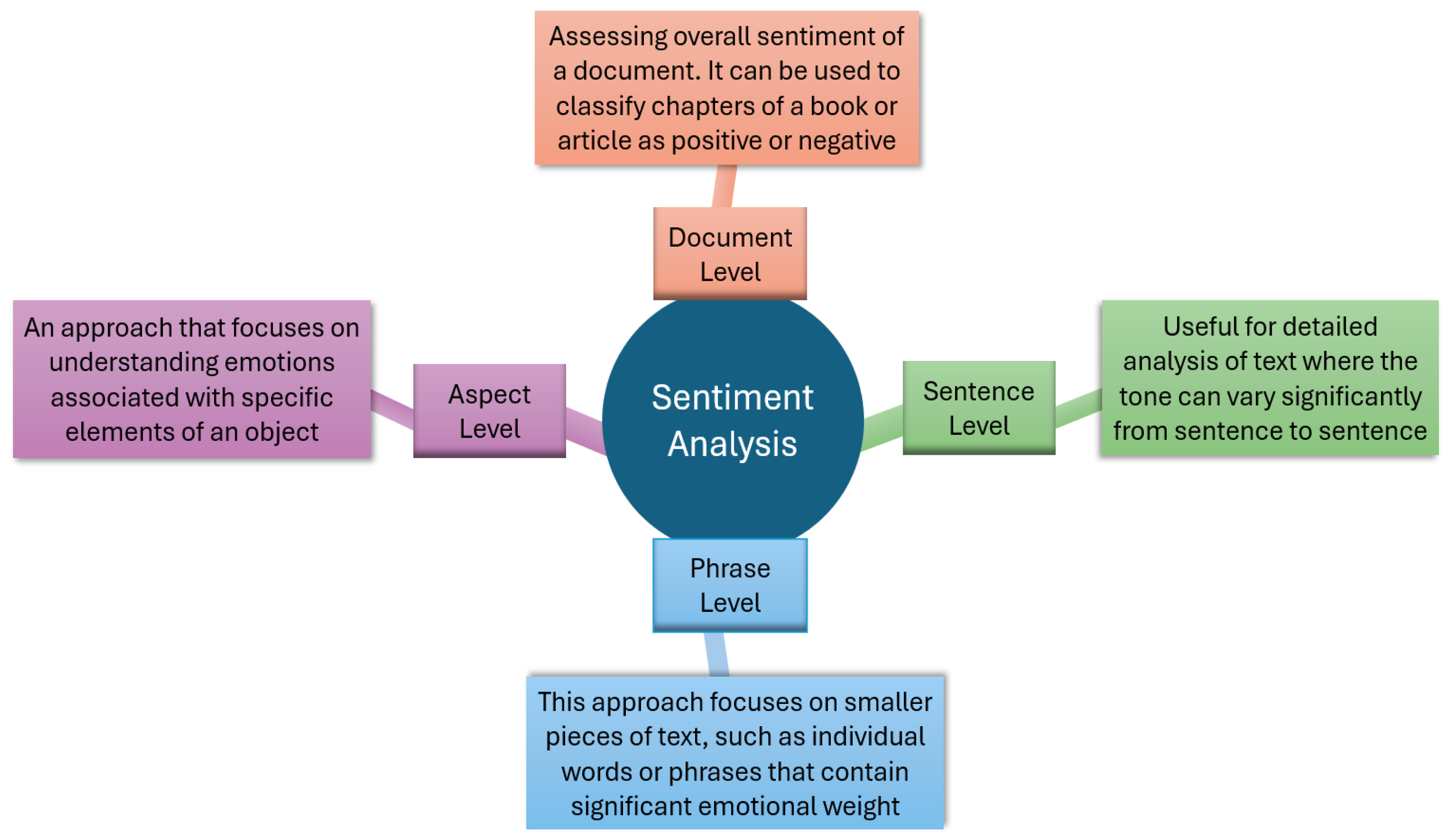
3.1. Sentiment Analysis
3.2. Scientometrics
3.3. Scientific Citation Analysis (SCA)
3.3.1. Citation Contribution
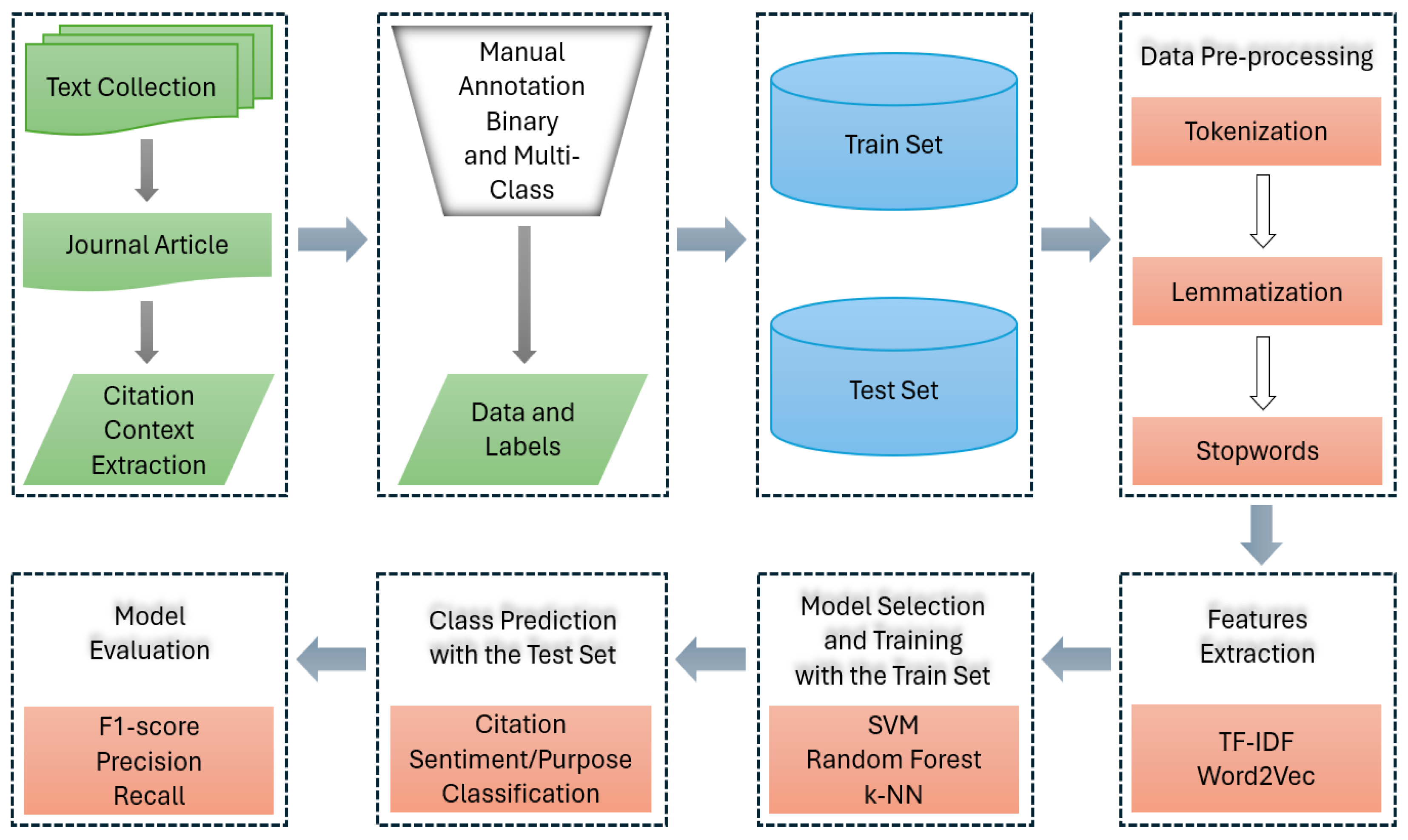
3.3.2. Text and Citation Preprocessing
3.3.3. Citation Context Retrieval Methods and Classification
- Unigram. Unigram refers to a model of language analysis where the key element is the individual word. In this framework, each word in a sentence is considered an independent element or feature. In NLP, Unigrams are used to analyze and understand texts based on the individual words that make up the texts [37].
- Bigram. Bigram is a linguistic unit consisting of two consecutive words. In NLP, Bigrams are used to understand the relationships and structures created between two consecutive words in a sentence. This helps in analyzing the language flow and word combinations that are frequent in each text [37].
- Proper Nouns. These are nouns that describe the names of people, places, and organisms. These features are of great importance in the detection of referential sentences, as it is known that such sentences tend to focus on different institutions, specific scientists, and the systems they have developed [37].
- Previous and Next Sentence. This is information about neighboring sentences. For example, if a sentence follows a sentence with a citation, it may continue the discussion of the same topic, so it is less likely to include an additional citation [37].
- Position. The position attribute provides information about the part of the document in which a sentence appears. These attributes are important, as sentences appearing in certain sections have different probabilities of containing a citation. For example, sentences in the middle or at the end of a research article are more likely to discuss authors’ works, evaluations, or experiment results, so they are considered less likely to be areas with citation compared to the beginning of the article, where authors often discuss and acknowledge previous work [37].
- Orthographic. This group of features looks at various morphological elements in sentences, including the specific orthographic forms used. Sentences that include numbers or single capital letters tend to be more suggestive of citation sentences, as they may indicate comparative figures or the initial letters of the name of the authors of the papers being referenced [37].
- All. Includes all the above features.
3.3.4. Citation Recommendation
4. Challenges in Sentiment Analysis
- Syntax errors. Natural language is complex, and people often make syntactic errors which can make it difficult to process language automatically.
- Multiple meaning. Words can have multiple meanings depending on the context in which they are used, which can create confusion and misinterpretation. The use of complex vocabulary usually makes it difficult to understand the information. For example, in a text containing the phrase “It was terribly good”, the word “terrible” usually has a negative connotation; however, in this phrase it is used to reinforce a positive adjective, “good”, which can confuse automated sentiment analysis systems.
- Variety and style. Texts in general can include various types of written expression, such as literature, essay, narrative, journalism, and many others, each with its own style and mode of expression.
- Complexity. Natural language in general is complex and multidimensional, with sarcasm, allegory, hyperbole, and other elements adding considerable complexity to the analysis of emotions [47]. Irony and innuendo often escape analysis by automatic systems, which can lead to misunderstandings and misinterpretations of emotional tones in research.
- Subjectivity. As the understanding of emotions is subjective, different people may interpret the same texts differently [47].
- Ambiguity. Dealing with vague or contradictory statements in texts is a very important challenge.
- Cultural differences. Cultural and dialectal differences can affect the way emotions are expressed, making analysis difficult for systems not trained in different languages or cultures [47]. For example, in some cultures, the expression of anger may be less direct or intense compared to others. This may affect the accuracy of emotion analysis models that have not been trained to recognize such variations.
- Spam detection. The content present in messages can be complex, which makes it difficult to identify as spam. Moreover, the amount of data to be analyzed is huge, making spam detection resource intensive [47].
- Language evolution. Natural language is dynamic and constantly evolving, requiring a corresponding evolution of methods and systems for emotion analysis.
- Complexity and complex vocabulary. Scientific citations often include specialized vocabulary and technical terms that may not express emotions in the traditional way.
- Abstraction. The use of language is often more abstract and less direct, resulting in a lack of strong feelings towards the reported research [2].
- Multilingualism. Citations can be written in multiple languages, increasing the complexity of sentiment analysis due to differences in grammar, syntax, and affective expressions that are specific to each language [2].
- Context and social environment. Understanding the context and social environment in which a scientific article was written is essential for accurate analysis of emotions.
- NLP methods. The development of algorithms that can recognize and interpret polarity in scientific texts requires advanced NLP techniques.
- Lack of datasets. There are not many datasets available that are labeled either for purpose or for citation polarity [2]. The creation of a database that is enriched with citation contexts to serve later in the training of a model capable of recognizing citations in scientific texts (while, at the same time, distinguishing their polarity) emerges as a significant challenge.
- Stop words. As mentioned, these are a category of words that are usually removed from the data in NLP applications. These words often include prepositions, links, and other common words that do not add significant meaning to the essence of a document. However, in scientific texts, the absence of some of these words can negatively affect classification performance [2].
- Exporting a citation context. Identifying the right context is an important issue. The contexts derived are varied. Some researchers focus on extracting a single sentence, while others extract entire paragraphs. This diversity makes accurate extraction an important and complex process [2].
- Citation label. How a class is assigned to a citation sentence is of great importance. In many cases this process is undertaken manually, making it difficult to label large datasets. Therefore, the process of automatic tagging in such texts is a very important challenge [2].
- Words of denial. The role of negation words is crucial in determining the emotional direction of a citation context. Identifying and handling negation is a difficult process and continues to be a significant challenge, as it can result in reverse polarity [2].
5. Discussion
- RQ1. Machine Learning based techniques, such as SVM, Naive Bayes, and Decision Tree, and advanced Machine Learning models, such as LSTM, BERT, RoBERTa, and BioBERT, have provided significant improvements in the accuracy of detection and the analysis of emotions. Deep Learning models have shown wonderful progress because they can identify semantic patterns in the data. However, Deep Learning requires significant computational resources and expertise, while traditional methods are often simpler and more accessible.
- RQ2. In our review, the researchers used several preprocessing methods, such as removing unimportant words (stopwords) from the text and converting words to vectors using TF-IDF and Word2Vec techniques. Additionally, precision, recall, and accuracy were used as evaluation metrics.
- RQ3. Machine Learning models, such as SVM, Naive Bayes, Decision Tree, etc., may perform better in applications where data is limited or where parameters need to be slightly modified. In contrast, Deep Learning models, such as CNN, LSTM, BERT, etc., are more suitable in cases of large and complex datasets. This is confirmed in [15], where a small dataset was used and the SVM achieved excellent classification accuracy, coming very close to the BERT model.
- RQ4. In Sentiment Analysis, and classification tasks in general, the two main types of learning used are Supervised Learning and Unsupervised Learning. Supervised Learning is particularly popular because of its ability to provide accurate predictions based on labelled data, which is critical in Sentiment Analysis. Unsupervised Learning is a type of Machine Learning where models are trained on previously unlabeled data. Its goal is to discover hidden patterns in the data. In our review, we observed the implementation of Supervised Learning.
- RQ5. Sentiment Analysis allows for the identification of both positive and negative emotions in scientific citations, increasing the ability to critique and understand the motivations behind scientific findings. By understanding the emotion conveyed through scientific texts, researchers can improve communication and collaboration among themselves. Recognizing the emotional cues in texts can help avoid misinterpretations and create more constructive communication.
- RQ6. Challenges include dealing with complex scientific terminology, multilingualism, and the abstract nature of discussions that require specialized language processing techniques.
- RQ7. In addition to polarity detection, many researchers, as we observed in our review, apply classification based on the purpose of the citation. For example, a frame of reference can be supportive (supportive type) and reinforce an idea or viewpoint presented in the text, critique another research (critique type), be used to compare research results of papers (comparison type), document important previous studies that support or influence the current research (documentation type), or even refer to a paper that forms the theoretical background of the current study (base type).
- RQ8. The availability of public datasets is still limited. Although there are some sources that offer access to scientific articles and their references, datasets that include labeled citation contexts are rare. One reason for this relates to the copyright that protects scientific documents. Moreover, in the case of Supervised Learning it is necessary to label citations manually, which makes it a complex process.
- RQ9. Emotions play a crucial role in communicating scientific results, as they influence the acceptance of information by the scientific community and the wider public. Emotions can strengthen or weaken the persuasiveness of arguments, and they can also encourage confidence in findings or, conversely, cause doubt. For example, a scientific article that receives more positive citations may stimulate more interest and active acceptance, while an article that receives negative citations may potentially raise reservations among other researchers.
6. Future Research
- Increase data. By increasing the amount of data, models become more accurate and achieve higher generalization. In addition, the ability to collect data from different platforms offers a more comprehensive approach to analyzing emotions.
- Combination of different types of data. Merging information, such as text, image, audio, and video, can improve the accuracy and completeness of sentiment analysis.
- Pre-process methods. Data processing prior to model training can have a major impact on the final performance. The choice of the most appropriate pre-processing method depends on the nature of the data and the goal of each application.
- Model selection. The process of selecting the appropriate model for solving a Machine Learning problem is also a very important process. Any model trained on specific data will perform well on such new data.
- Architecture. The use of more complex Neural Network architectures (number of layers and neurons) clearly affects the performance of the models.
- Analysis of implicit and explicit citations. Extensive studying of the distinction and interpretation of implicit and explicit citations within scientific texts for a better understanding of purpose and polarity.
- Citation context retrieval methods. Focus on developing and improving methods for retrieving, processing, and analyzing the citation context, including more advanced approaches to reveal its deeper meaning.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wankhade, M.; Rao, A.C.S.; Kulkarni, C. A Survey on Sentiment Analysis Methods, Applications, and Challenges. Artif. Intell. Rev. 2022, 55, 5731–5780. [Google Scholar] [CrossRef]
- Yousif, A.; Niu, Z.; Tarus, J.K.; Ahmad, A. A Survey on Sentiment Analysis of Scientific Citations. Artif. Intell. Rev. 2019, 52, 1805–1838. [Google Scholar] [CrossRef]
- Hernández, M.; Gómez, J.M. Survey in Sentiment, Polarity and Function Analysis of Citation. In Proceedings of the First Workshop on Argumentation Mining, Baltimore, MD, USA, 26 June 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 102–103. [Google Scholar]
- Bonzi, S. Characteristics of a Literature as Predictors of Relatedness Between Cited and Citing Works. J. Am. Soc. Inf. Sci. 1982, 33, 208–216. [Google Scholar] [CrossRef]
- Aljuaid, H.; Iftikhar, R.; Ahmad, S.; Asif, M.; Tanvir Afzal, M. Important Citation Identification Using Sentiment Analysis of In-Text Citations. Telemat. Inform. 2021, 56, 101492. [Google Scholar] [CrossRef]
- Small, H. Interpreting Maps of Science Using Citation Context Sentiments: A Preliminary Investigation. Scientometrics 2011, 87, 373–388. [Google Scholar] [CrossRef]
- Athar, A.; Teufel, S. Detection of Implicit Citations for Sentiment Detection. In Proceedings of the Workshop on Detecting Structure in Scholarly Discourse, Jeju, Republic of Korea, 25 May 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 18–26. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. J. Clin. Epidemiol. 2021, 134, 178–189. [Google Scholar] [CrossRef] [PubMed]
- Tsakalidis, A.; Papadopoulos, S.; Kompatsiaris, I. An Ensemble Model for Cross-Domain Polarity Classification on Twitter. In Proceedings of the Web Information Systems Engineering–WISE 2014: 15th International Conference, Thessaloniki, Greece, 12–14 October 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; Volume 8787, pp. 168–177. [Google Scholar]
- Ekman, P. An Argument for Basic Emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Kalamatianos, G.; Mallis, D.; Symeonidis, S.; Arampatzis, A. Sentiment Analysis of Greek Tweets and Hashtags Using a Sentiment Lexicon. In Proceedings of the PCI ’15: Proceedings of the 19th Panhellenic Conference on Informatics, Athens, Greece, 1–3 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 63–68. [Google Scholar]
- Petasis, G.; Spiliotopoulos, D.; Tsirakis, N.; Tsantilas, P. Sentiment Analysis for Reputation Management: Mining the Greek Web. In Proceedings of the Artificial Intelligence: Methods and Applications: 8th Hellenic Conference on AI, SETN 2014, Ioannina, Greece, 15–17 May 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; Volume 8445 LNCS, pp. 327–340. [Google Scholar]
- Avgeros Nikos Skroutz Sentiment Analysis. Available online: https://www.kaggle.com/code/nikosavgeros/skroutz-sentiment-analysis (accessed on 7 February 2024).
- Fragkis Nikos Skroutz Sentiment Analysis with BERT (Greek). Available online: https://www.kaggle.com/code/nikosfragkis/skroutz-sentiment-analysis-with-bert-greek (accessed on 7 February 2024).
- Bilianos, D. Experiments in Text Classification: Analyzing the Sentiment of Electronic Product Reviews in Greek. J. Quant. Linguist. 2022, 29, 374–386. [Google Scholar] [CrossRef]
- Giatsoglou, M.; Vozalis, M.G.; Diamantaras, K.; Vakali, A.; Sarigiannidis, G.; Chatzisavvas, K.C. Sentiment Analysis Leveraging Emotions and Word Embeddings. Expert. Syst. Appl. 2017, 69, 214–224. [Google Scholar] [CrossRef]
- Cui, H.; Mittal, V.; Datar, M. Comparative Experiments on Sentiment Classification for Online Product Reviews. In Proceedings of the 21st National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 June 2006; Association for the Advancement of Artificial Intelligence (AAAI): Washington, DC, USA, 2006; pp. 1–6. [Google Scholar]
- Acosta, J.; Lamaute, N.; Luo, M.; Finkelstein, E.; Cotoranu, A. Sentiment Analysis of Twitter Messages Using Word2Vec. In Proceedings of the Student-Faculty Research Day, Pleasantville, NY, USA, 5 May 2017; CSIS, Pace University: White Plains, NY, USA, 2017; pp. 1–7. [Google Scholar]
- Muhammad, P.F.; Kusumaningrum, R.; Wibowo, A. Sentiment Analysis Using Word2vec and Long Short-Term Memory (LSTM) for Indonesian Hotel Reviews. Procedia Comput. Sci. 2021, 179, 728–735. [Google Scholar] [CrossRef]
- Alexandridis, G.; Varlamis, I.; Korovesis, K.; Caridakis, G.; Tsantilas, P. A Survey on Sentiment Analysis and Opinion Mining in Greek Social Media. Information 2021, 12, 331. [Google Scholar] [CrossRef]
- Jha, R.; Jbara, A.A.; Qazvinian, V.; Radev, D.R. NLP-Driven Citation Analysis for Scientometrics. Nat. Lang. Eng. 2017, 23, 93–130. [Google Scholar] [CrossRef]
- Mercer, R.E.; Di Marco, C. The Importance of Fine-Grained Cue Phrases in Scientific Citations. In Proceedings of the Conference of the Canadian Society for Computational Studies of Intelligence, Canadian AI 2003, Advances in Artificial Intelligence, Halifax, NS, Canada, 11–13 June 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 550–556. [Google Scholar]
- González-Alcaide, G.; Salinas, A.; Ramos, J.M. Scientometrics Analysis of Research Activity and Collaboration Patterns in Chagas Cardiomyopathy. PLoS Negl. Trop. Dis. 2018, 12, e0006602. [Google Scholar] [CrossRef]
- Mosallaie, S.; Rad, M.; Schiffaeurova, A.; Ebadi, A. Discovering the Evolution of Artificial Intelligence in Cancer Research Using Dynamic Topic Modeling. COLLNET J. Scientometr. Inf. Manag. 2021, 15, 225–240. [Google Scholar] [CrossRef]
- Wahid, N.; Warraich, F.; Tahira, M. Group Level Scientometric Analysis of Pakistani Authors. COLLNET J. Scientometr. Inf. Manag. 2021, 15, 287–304. [Google Scholar] [CrossRef]
- Daradkeh, M.; Abualigah, L.; Atalla, S.; Mansoor, W. Scientometric Analysis and Classification of Research Using Convolutional Neural Networks: A Case Study in Data Science and Analytics. Electronics 2022, 11, 2066. [Google Scholar] [CrossRef]
- Smith, L.C. Citation Analysis. Libr. Trends 1981, 30, 83–106. [Google Scholar]
- Budi, I.; Yaniasih, Y. Understanding the Meanings of Citations Using Sentiment, Role, and Citation Function Classifications. Scientometrics 2022, 128, 735–759. [Google Scholar] [CrossRef]
- Catalini, C.; Lacetera, N.; Oettl, A. The Incidence and Role of Negative Citations in Science. Proc. Natl. Acad. Sci. USA 2015, 112, 13823–13826. [Google Scholar] [CrossRef]
- Athar, A. Sentiment Analysis of Citations Using Sentence Structure-Based Features. In Proceedings of the ACL 2011 Student Session, Portland, OR, USA, 19 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 81–87. [Google Scholar]
- Radev, D.R.; Joseph, M.T.; Gibson, B.; Muthukrishnan, P. A Bibliometric and Network Analysis of the Field of Computational Linguistics. J. Assoc. Inf. Sci. Technol. 2016, 67, 683–706. [Google Scholar] [CrossRef]
- ACL Welcome to the ACL Anthology. Available online: https://aclanthology.org/ (accessed on 9 February 2024).
- Councill, I.G.; Giles, C.L.; Kan, M.-Y. ParsCit: An Open-Source CRF Reference String Parsing Package. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’ 08), Marrakech, Morocco, 26 May–1 June 2008; European Language Resources Association (ELRA): Paris, France, 2008; pp. 661–667. [Google Scholar]
- Peng, F.; Mccallum, A. Accurate Information Extraction from Research Papers Using Conditional Random Fields. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics: HLT-NAACL, Boston, MA, USA, 2 May 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 329–336. [Google Scholar]
- Seymore, K.; Mccallum, A.; Rosenfeld, R. Learning Hidden Markov Model Structure for Information Extraction. In Proceedings of the Workshop Paper, AAAI ’99 Workshop on Machine Learning for Information Extraction, Pittsburgh, PA, USA, 31–36 July 1999; pp. 37–42. [Google Scholar]
- Abu-Jbara, A.; Ezra, J.; Radev, D. Purpose, and Polarity of Citation: Towards NLP-Based Bibliometrics. In Proceedings of the Proceedings of the North American Association for Computational Linguistics (NAACL-HLT), Atlanta, GA, USA, 9–14 June 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 596–606. [Google Scholar]
- Sugiyama, K.; Kumar, T.; Kan, M.-Y.; Tripathi, R.C. Identifying Citing Sentences in Research Papers Supervised Learning. In Proceedings of the International Conference on Information Retrieval & Knowledge Management (CAMP), Shah Alam, Malaysia, 17 March 2010; IEEE: New York, NY, USA, 2010; pp. 67–72. [Google Scholar]
- Bird, S.; Dale, R.; Dorr, B.J.; Gibson, B.; Joseph, M.T.; Kan, M.-Y.; Lee, D.; Powley, B.; Radev, D.R.; Fan Tan, Y. The ACL Anthology Reference Corpus: A Reference Dataset for Bibliographic Research in Computational Linguistics. In Proceedings of the 6th International Conference on Language Resources and Evaluation, LREC 2008, Marrakech, Morocco, 26 May–1 June 2008; European Language Resources Association (ELRA): Paris, France, 2008; pp. 1755–1759. [Google Scholar]
- Munkhdalai, T.; Lalor, J.; Yu, H. Citation Analysis with Neural Attention Models. In Proceedings of the Seventh International Workshop on Health Text Mining and Information Analysis, Austin, TX, USA, 5 November 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 69–77. [Google Scholar]
- Yu, D.; Hua, B. Sentiment Classification of Scientific Citation Based on Modified BERT Attention by Sentiment Dictionary. In Proceedings of the Joint Workshop of the 4th Extraction and Evaluation of Knowledge Entities from Scientific Documents and the 3rd AI + Informetrics (EEKEAII 2023), Santa Fe, NM, USA, 26 June 2023; CEUR Workshop Proceedings: Aachen, Germany, 2023; pp. 59–64. [Google Scholar]
- Cohan, A.; Ammar, W.; Van Zuylen, M.; Cady, F. Structural Scaffolds for Citation Intent Classification in Scientific Publications. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3586–3596. [Google Scholar]
- Yang, N.; Zhang, Z.; Huang, F. A Study of BERT-Based Methods for Formal Citation Identification of Scientific Data. Scientometrics 2023, 128, 5865–5881. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- He, Q.; Pei, J.; Kifer, D.; Mitra, P.; Giles, L. Context-Aware Citation Recommendation. In Proceedings of the 19th International Conference on World Wide Web, WWW ’10, Raleigh, NC, USA, 26 April 2010; Association for Computing Machinery (ACM): New York, NY, USA, 2010; pp. 421–430. [Google Scholar]
- Caragea, C.; Silvescu, A.; Mitra, P.; Giles, L. Can’t See the Forest for the Trees? A Citation Recommendation System. In Proceedings of the 13th ACM/IEEE-CS joint conference on Digital libraries (JCDL ’13), Indianapolis, IN, USA, 22 July 2013; Association for Computing Machinery (ACM): New York, NY, USA, 2013; pp. 111–114. [Google Scholar]
- CiteSeerX About CiteSeerX. Available online: https://csxstatic.ist.psu.edu/home (accessed on 24 February 2024).
- Devi, V.; Sharma, A. Sentiment Analysis Approaches, Types, Challenges, and Applications: An Exploratory Analysis. In Proceedings of the PDGC 2022—2022 7th International Conference on Parallel, Distributed and Grid Computing, Solan, Himachal Pradesh, India, 25 November 2022; IEEE: New York, NY, USA, 2022; pp. 34–38. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Digital Repositories/Databases | Number of Query | Query |
|---|---|---|
| Springer | 1 | with the exact phrase: Sentiment Analysis Challenges. with at least one of the words: sentiment analysis challenges methods [Filters] year: 2021–2022 |
| 2 | with at least one of the words: Scientometrics Citation. where the title contains: “Citation Context” OR “Citation Function Classification” | |
| 3 | with at least one of the words: Polarity Classification. where the title contains: “Polarity Classification” AND “Twitter” | |
| 4 | with all the words: Automatic Content Extraction. with the exact phrase: Named-entity Recognition. with at least one of the words: Sentiment Analysis Polarity Detection. where the title contains: “Sentiment Analysis” AND “Mining” [Filters] year: 2014–2019 | |
| 5 | with at least one of the words: Scientific Citation Sentiment Function BERT. where the title contains: “Scientific Citations” OR “BERT” AND “Formal Citation” | |
| Google Scholar | 1 | (“sentiment analysis” AND “emotions”) AND (“Word2Vec”) AND “lexicon” AND (“word embeddings”) AND “NLP” AND “machine learning” AND “online user reviews” |
| 2 | (“Text Classification” AND “Product Reviews”) AND (“Sentiment Analysis” OR (“Support Vector Machines” AND “TF-IDF” AND “Naive Bayes” AND “BERT”) | |
| 3 | “sentiment classification” AND “comparative experiments” AND “product reviews” OR “text reviews” | |
| 4 | “Patterns” AND “Scientometrics” AND “Scientometrics Analysis” AND “Citation Analysis” | |
| 5 | “Sentiment Analysis” AND “Natural Language Toolkit” AND (“Twitter Messages” OR “tweets”) AND “Word2Vec” AND (“CBOW” AND “Skip-Gram”) | |
| 6 | “Sentiment Analysis” OR “Scientometric Analysis” AND “Convolutional Neural Networks” AND “CNN” AND “KNN” AND “Explicit Features” | |
| 7 | “Scientometrics” AND “citation function” AND “citation role” | |
| 8 | “Role” AND “Negative Citations” AND “natural language processing” AND “objective citations” | |
| 9 | Bibliometric AND “Analysis Methods” AND PageRank AND “Author citation” | |
| 10 | “Conditional random fields” AND “Extracting citation metadata” AND “citation indexing” AND “CiteSeer” AND “Extracting Citation Contexts” | |
| 11 | “BERT” AND “Attention Layer” AND “Sentiment Classification” AND “Attention” AND “Classification” AND “Citation” AND “Dictionary” | |
| Semantic Scholar | 1 | “Basic Emotions” AND “Detection of Implicit Citations” [Filters] Fields of Study: Psychology, Computer Science Date Range: 1990–2012, Has PDF = ON |
| 2 | “Characteristics” AND “Citing Paper” AND “Cited and Citing” [Filters] Fields of Study: Computer Science Date Range: 1980–2007, Has PDF = ON | |
| 3 | “citation identification” AND “text citations” AND “Citation sentiment analysis” AND “Analysis Using Word2vec” AND “CBOW” OR “Skip-Gram” [Filters] Fields of Study: Computer Science, Has PDF = ON | |
| Science Direct | 1 | (“Sentiment Analysis” AND “word embeddings” AND “Machine Learning”) AND (“Sentiment lexicon” OR emotions OR “lexicon-based”) AND “Supervised Machine Learning” |
| 2 | (“Sentiment Analysis” AND “Reviews”) AND (“LSTM” OR “Word2vec” AND (“RNN” OR “CNN”) AND (“CBOW” OR “Skip-gram”) | |
| Association for Computing Machinery (ACM) | 1 | [[[Full Text: tweets] AND [Full Text: hashtags]] OR [[Full Text: “hashtag sentiment”] AND [Full Text: “sentiment lexicon”]]] AND [Title: tweets hashtags] AND [[Title: sentiment] OR [Title: lexicon]] |
| 2 | [All: “citation recommendation system”] AND [All: “citation recommendation”] | |
| MDPI | 1 | (Title: Sentiment Analysis) AND (Title: Social Media) OR (Title: Scientometric Analysis) AND (Title: Convolutional Neural Networks) AND (Full Text: CNN) OR (Full Text: NER) [Filters] year: 2021–2022, Journals: Electronics and Information, Article Types: Article |
| ACL Anthology | 1 | “Sentiment Detection” AND “Polarity” AND “Citation” AND “Implicit Citations” OR “Survey in Sentiment” |
| 2 | “HMM” AND “Hidden Markov Models” AND “CRF” AND “Conditional Random Fields” AND “Information Extraction” | |
| 3 | Dataset Bibliographic Research | |
| 4 | Citation Analysis AND Neural networks | |
| 5 | “Conditional Random Fields” OR “CRF” AND “Function” AND “Analysis” AND “Citation” | |
| 6 | “Sentiment Analysis” AND “Citations” AND “Polarity Features” AND “Sentence Splitting” | |
| 7 | “scientific papers” AND “citation intent classification” AND “sentence extractions” OR “citation intent classification” | |
| IEEE Xplore | 1 | (“Document Title”: Citing Sentences) AND (“Document Title”: Research Papers) OR (“Full Text Only”: Citation Analysis) AND (“Document Title”: Challenges) OR (“Document Title”: Applications) AND (“Document Title”: Sentiment Analysis) [Filters] year: 2010–2022 |
| Digital Repositories/Databases | Number of Query | Papers Found | Papers Saved |
|---|---|---|---|
| Springer | 1 | 16 | 16 |
| 2 | 43 | 43 | |
| 3 | 17 | 17 | |
| 4 | 15 | 15 | |
| 5 | 10 | 10 | |
| Google Scholar | 1 | 53 | 10 |
| 2 | 768 | 10 | |
| 3 | 651 | 10 | |
| 4 | 508 | 10 | |
| 5 | 305 | 10 | |
| 6 | 51 | 10 | |
| 7 | 17 | 17 | |
| 8 | 6 | 6 | |
| 9 | 62 | 10 | |
| 10 | 10 | 10 | |
| 11 | 246 | 10 | |
| Semantic Scholar | 1 | 783 | 10 |
| 2 | 62 | 10 | |
| 3 | 12 | 12 | |
| Science Direct | 1 | 205 | 25 |
| 2 | 353 | 25 | |
| ACM | 1 | 36 | 36 |
| 2 | 21 | 21 | |
| MDPI | 1 | 30 | 30 |
| ACL Anthology | 1 | 6 | 6 |
| 2 | 585 | 10 | |
| 3 | 782 | 10 | |
| 4 | 67 | 10 | |
| 5 | 702 | 10 | |
| 6 | 4 | 4 | |
| 7 | 51 | 10 | |
| IEEE Xplore | 1 | 324 | 25 |
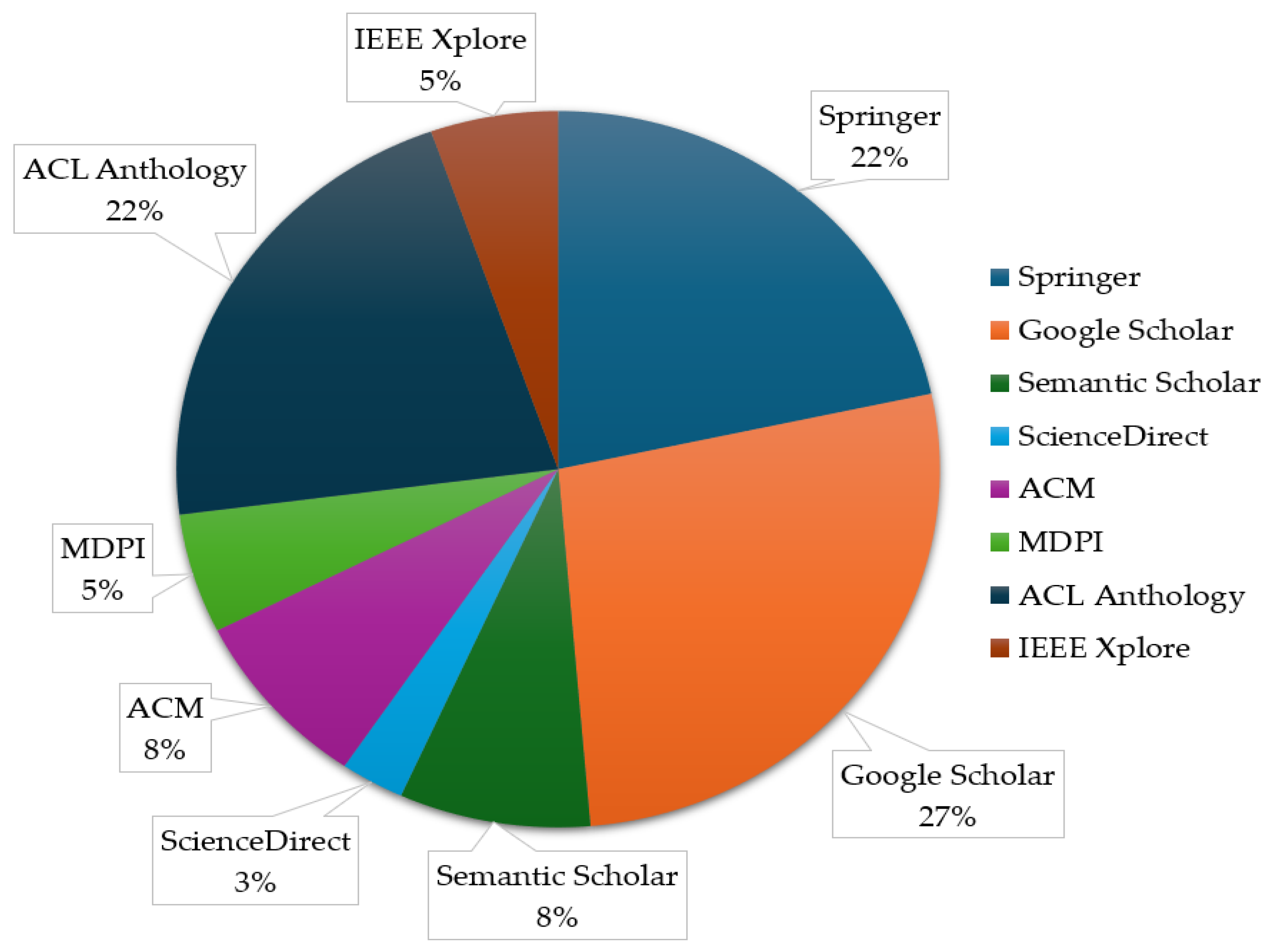
| Digital Repositories/Databases | Papers Found | Papers Saved | Papers Included |
|---|---|---|---|
| Springer | 101 | 101 | 8 |
| Google Scholar | 2677 | 113 | 10 |
| Semantic Scholar | 857 | 32 | 3 |
| ScienceDirect | 558 | 50 | 1 |
| ACM | 57 | 57 | 3 |
| MDPI | 30 | 30 | 2 |
| ACL Anthology | 2197 | 60 | 8 |
| IEEE Xplore | 324 | 25 | 2 |
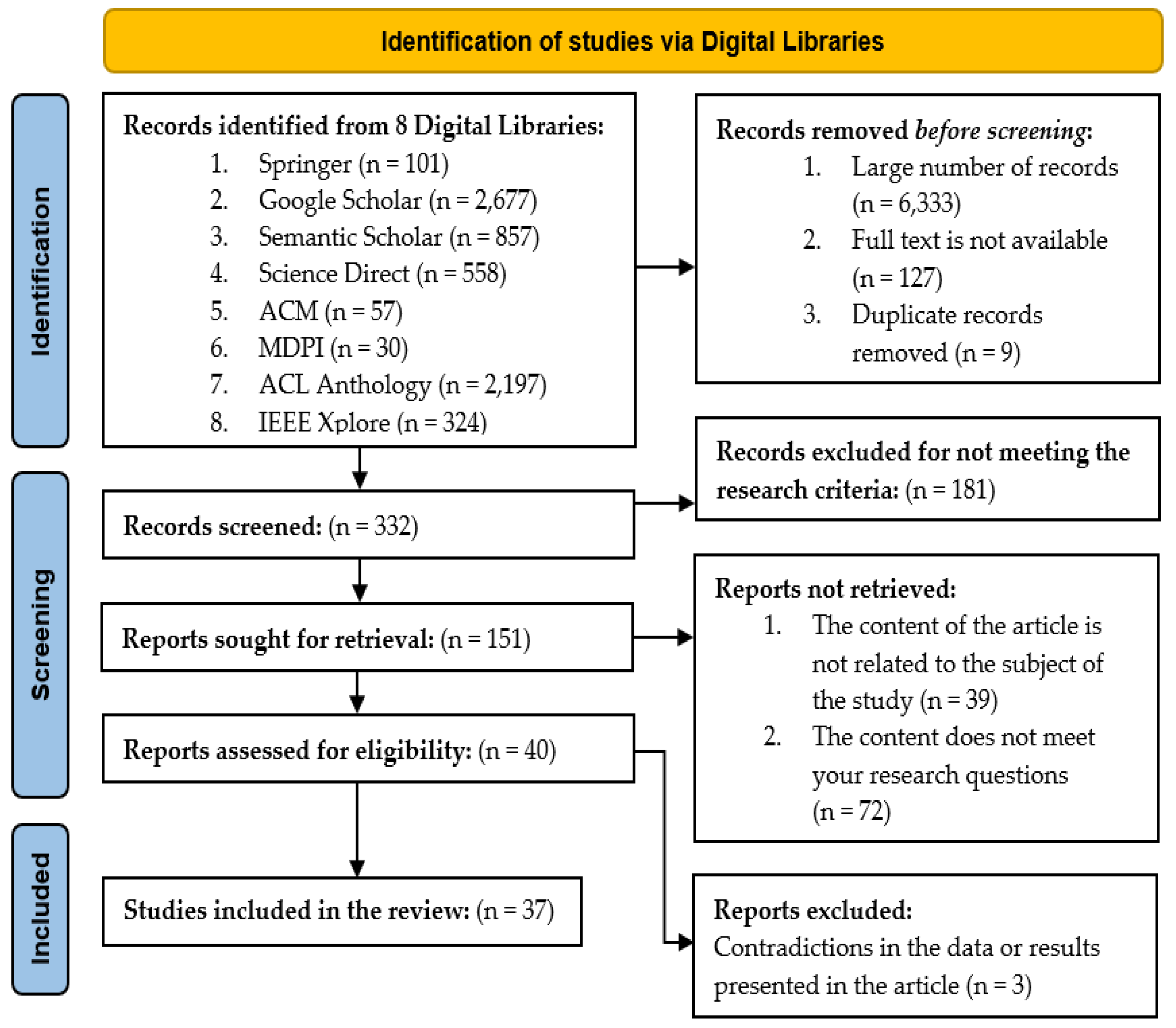
| Total | 6801 | 468 | 37 |
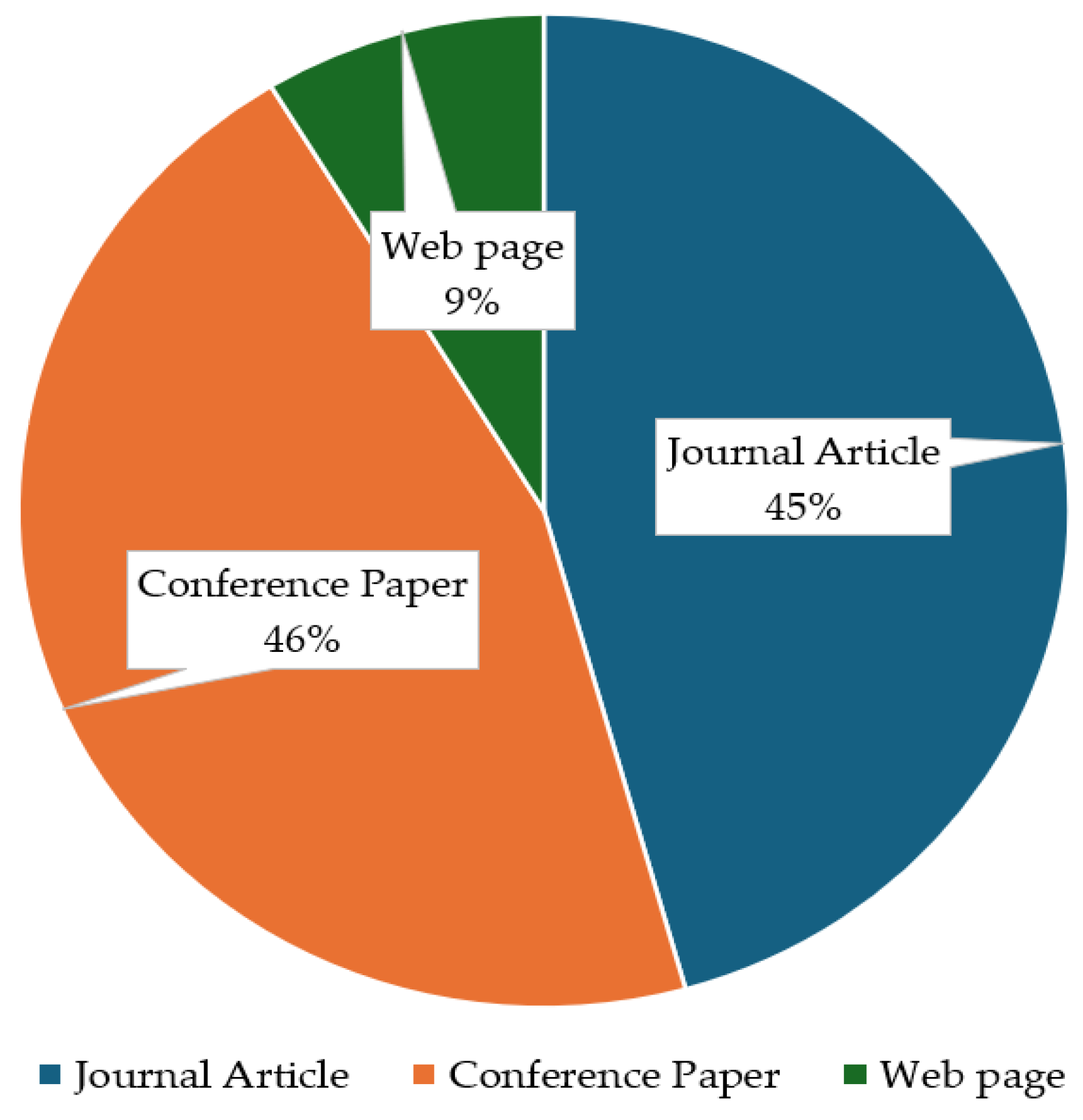
| Publication Type | Number of Papers |
|---|---|
| Journal Article | 21 1 |
| Conference Paper | 21 1 |
| Website | 4 |
| Total | 46 |
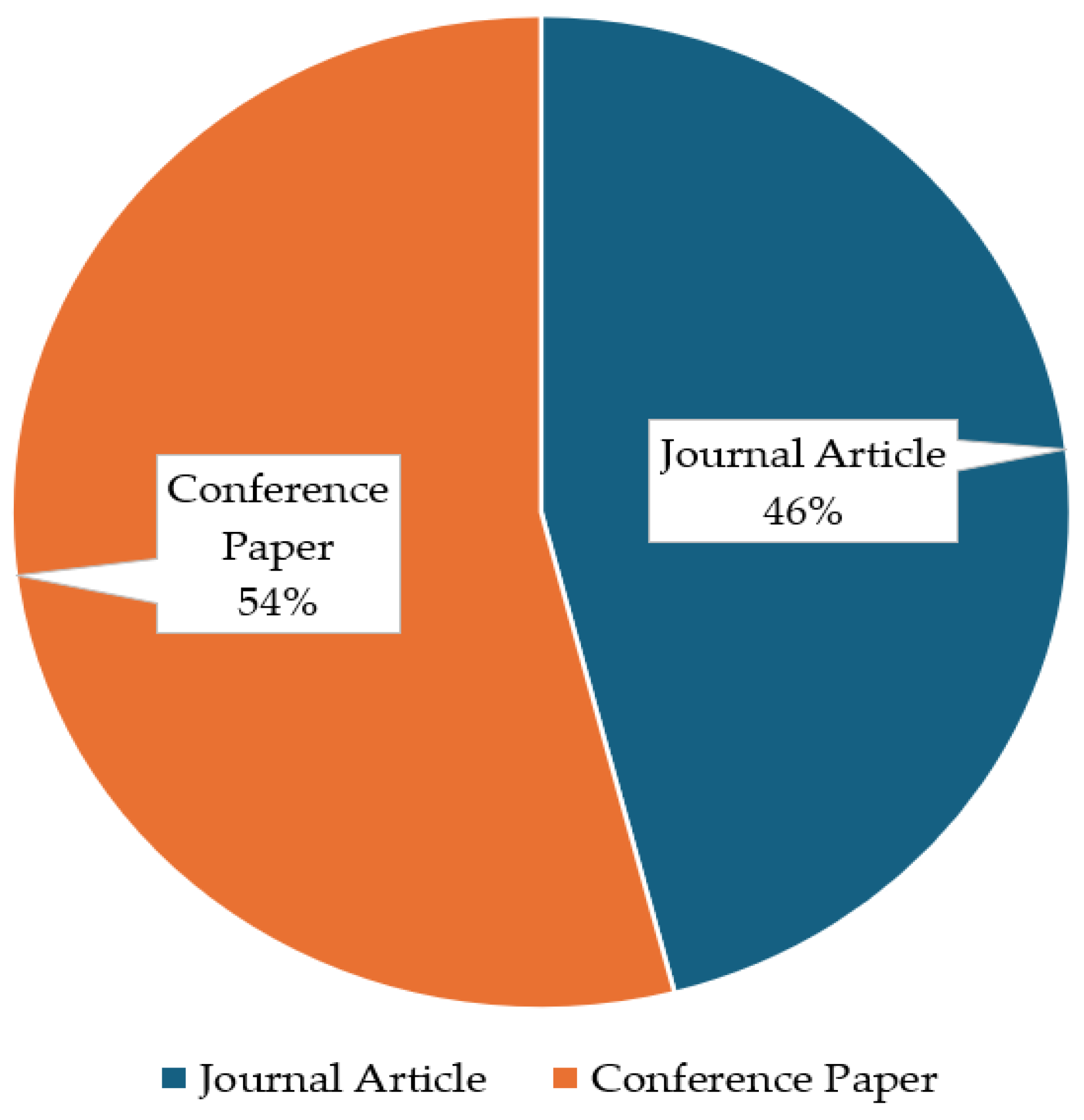
| Publication Type | Number of Papers |
|---|---|
| Journal Article | 17 |
| Conference Paper | 20 |
| Total | 37 |
| BERT | SCIBERT | |||
|---|---|---|---|---|
| Models | Accuracy | Macro-F1 | Accuracy | Macro-F1 |
| FNN | 93.05 | 80 | 95.14 | 86 |
| LSTM | 93.11 | 80 | 94.63 | 84 |
| TextCNN | 83.20 | 52 | 94.57 | 86 |
| Self-ATTENTION | 93.30 | 80 | 94.44 | 84 |
| DictSentiBERT | 93.49 1 | 81 | 95.20 1 | 86 |
| METRICS | |||
|---|---|---|---|
| Models | Precision | Recall | F1-Score |
| Random Forest | 82.80 | 71.60 | 75.20 |
| Decision Tree | 75 | 75.40 | 75.20 |
| TextCNN | 86.40 | 75.60 | 79.40 |
| TextRCNN | 84.20 | 76.50 | 79.50 |
| BERT | 86.90 | 82.70 | 84.60 |
| SCIBERT | 86.70 | 84.10 | 85.30 |
| BioBERT | 85.70 | 84.90 1 | 85.30 |
| Authors, Year | Challenges | Models, Techniques | Datasets, Data Sources | Experimental Results |
|---|---|---|---|---|
| H. Cui et al., 2006 [17] | Sentiment Analysis in Product Reviews | Passive-Aggressive (PA) Language Modeling (LM) | Froogle | Accuracy: 90% |
| I. G. Councill et al., 2008 [33] | References Extraction, ParsCit vs. Peng CRF Comparison | ParsCit, Peng | CORA Dataset | ParsCit micro-F1: 95% Peng CRF macro-F1: 91% |
| K. Sugiyama et al., 2010 [37] | Citation Recognition, Binary Classification | Max Entropy (ME), Support Vector Machine (SVM) | ACL Anthology | Min Accuracy (Bigram Feature) ME: 82.70% SVM: 85.10%, Max Accuracy (Proper Noun and Previous and Next Sentence) ME and SVM: 88.20% |
| A. Athar, 2011 [30] | Polarity Analysis in Explicit Citations | SVM, WEKA | ACL Anthology and Resources 1 | macro-F1: 76.40% micro-F1: 89.80% |
| A. A. Jbara et al., 2013 [36] | Citation Context Analysis, Citation Purpose Classification, Citation Polarity Classification | SVM, Logistic Regression (LR), Naïve Bayes (NB) | ACL Anthology | SVM only Purpose Class. Accuracy: 70.50% macro-F1: 58%, Polarity Class. Explicit Accuracy: 74.20% macro-F1: 62.10%, Polarity Class. Wide Content Accuracy: 84.20% macro-F1: 74.20% |
| A. Tsakalidis et al., 2014 [9] | Tweets Extraction, Polarity Analysis, Feature Extraction | TBR, FBR, LBR, CR, Twitter API, Ensemble Algorithm | Resources 2 | Accuracy: 81.81% |
| P. Tsantilas et al., 2014 [12] | Sentiment Analysis, Named Entity Recognition | PaloPro 3 OpinionBuster 4 | Real News 5 Kathimerini 6 Facebook, Twitter | Accuracy: 64% |
| S. Symeonidis et al., 2015 [11] | Greek tweets Extraction, Sentiment Analysis | Maximum, CombMNZ, Arithmetic Mean, Quadratic Mean, Twitter Streaming API | Dataset with Greek tweets | Pearson Correlation 0.26 Kendall Correlation 0.22 |
| T. Munkhdalai et al., 2016 [39] | Citation Function Classification, Citation Sentiment Classification | Compositional Attention Network (CAN) | PubMed Central (PMC) and Resources 7,8 | Citation Function F1-score Bi-LSTMs + CAN Majority Voting: 60.67% and Three Label Matching: 75.57%, Citation Sentiment F1-score LSTM + CAN Maj. Vot.: 76.04% and T. L. Matching: 78.10% |
| M. Giatsoglou et al., 2017 [16] | Sentiment Analysis | Word2Vec, Lexicon Based | Mobile—PAR | Accuracy: 83.60% |
| J. Acosta et al., 2017 [18] | Sentiment Analysis of Twitter Messages | LR, Gaussian Naïve Bayes (GNB), Bernoulli Naïve Bayes (BNB), SVM, CBOW, Skip-Gram, Word2Vec | Twitter, Kaggle 9 | Accuracy CBOW + SVM: 70% Skip-Gram + SVM: 72% Skip-Gram + LR: 72% |
| P. Muhammad et al., 2021 [19] | Sentiment Analysis | Word2Vec, LSTM, Selenium, Scrapy | Traveloka Travel Platform 10 | Accuracy: 85.96% |
| G. Alexandridis et al., 2021 [20] | Polarity Analysis in Greek Social Media | Transformers, GreekBERT, PaloBERT, RoBERTa, GreekSocialBERT, GPT | Greek Social Media | Binary Classification GPT Accuracy: 99% Multi Classification GreekSocialBERT Accuracy: 80% |
| N. Avgeros, 2022 [13] | Sentiment Analysis | Neural Networks | Database from Skroutz | Accuracy: 92% |
| N. Fragkis, 2022 [14] | Sentiment Analysis | BERT Model | Database from Skroutz | Accuracy: 96% |
| D. Bilianos, 2022 [15] | Sentiment Analysis | SVM, NB, TF-IDF, BERT | Resources 11 | NB + Bigrams + Stopwords Accuracy: 89%, SVM + TF-IDF Accuracy: 92%, BERT Accuracy: 97% |
| M. Daradkeh et al., 2022 [26] | Scientometrics | CNNs Models | Unknown | Accuracy: 81% |
| D. Yu et al., 2023 [40] | Sentiment Classification of Scientific Citation | BERT, SCIBERT, DictSentiBERT, LSTM, FNN, TextCNN, Self-Attention | Resources 12,13 | DictSentiBERT (BERT) Accuracy: 93.49%, DictSentiBERT (SCIBERT) Accuracy: 95.20% |
| N. Yang et al., 2023 [42] | Entity Citation Recognition, Binary Classification | Random Forest, Decision Tree, TextCNN, TextRCNN, BERT, SCIBERT, BIOBERT | PubMed Central (PMC) | SCIBERT and BIOBERT F1-score: 85.30% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kampatzis, A.; Sidiropoulos, A.; Diamantaras, K.; Ougiaroglou, S. Sentiment Dimensions and Intentions in Scientific Analysis: Multilevel Classification in Text and Citations. Electronics 2024, 13, 1753. https://doi.org/10.3390/electronics13091753
Kampatzis A, Sidiropoulos A, Diamantaras K, Ougiaroglou S. Sentiment Dimensions and Intentions in Scientific Analysis: Multilevel Classification in Text and Citations. Electronics. 2024; 13(9):1753. https://doi.org/10.3390/electronics13091753
Chicago/Turabian StyleKampatzis, Aristotelis, Antonis Sidiropoulos, Konstantinos Diamantaras, and Stefanos Ougiaroglou. 2024. "Sentiment Dimensions and Intentions in Scientific Analysis: Multilevel Classification in Text and Citations" Electronics 13, no. 9: 1753. https://doi.org/10.3390/electronics13091753
APA StyleKampatzis, A., Sidiropoulos, A., Diamantaras, K., & Ougiaroglou, S. (2024). Sentiment Dimensions and Intentions in Scientific Analysis: Multilevel Classification in Text and Citations. Electronics, 13(9), 1753. https://doi.org/10.3390/electronics13091753