
Performance Improvements via Peephole Optimization in Dynamic Binary Translation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We apply the peephole optimization to DBT, and propose several optimizations to offset the overhead of consecutive memory access and improve the quality of the generated code.
- We introduce data flow analysis based on live analysis and successfully address redundant consecutive memory-access write-backs and unused condition bit status flag memory storage.
- We utilize instruction fusion techniques based on pattern-matching and apply ISA-specific instruction sequences to address significant gaps between guest-to-host ISA.
- We conduct several experiments to evaluate our optimization. The results show a maximum performance speedup of 1.52× on SPEC CINT2006, alongside a reduction in code size of up to 13.98%.
2. Preliminaries
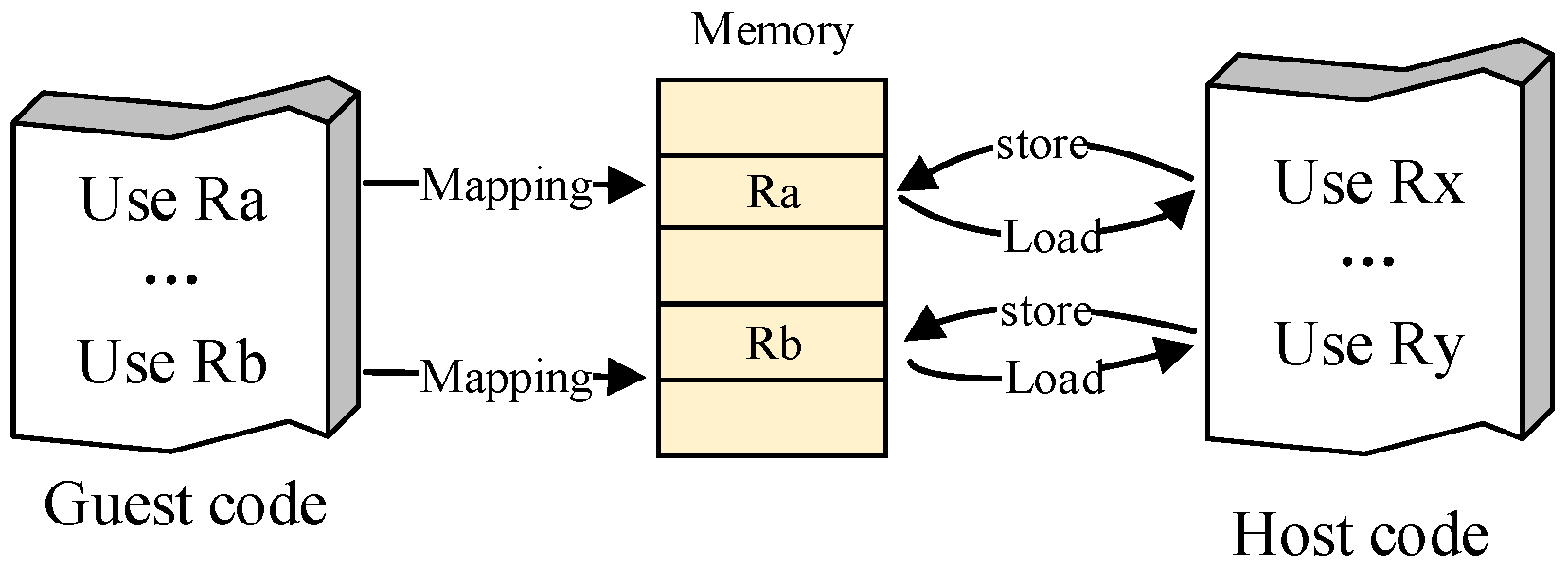
2.1. Program State Virtualization
2.2. Instruction Translation
2.2.1. Instruction Emulation
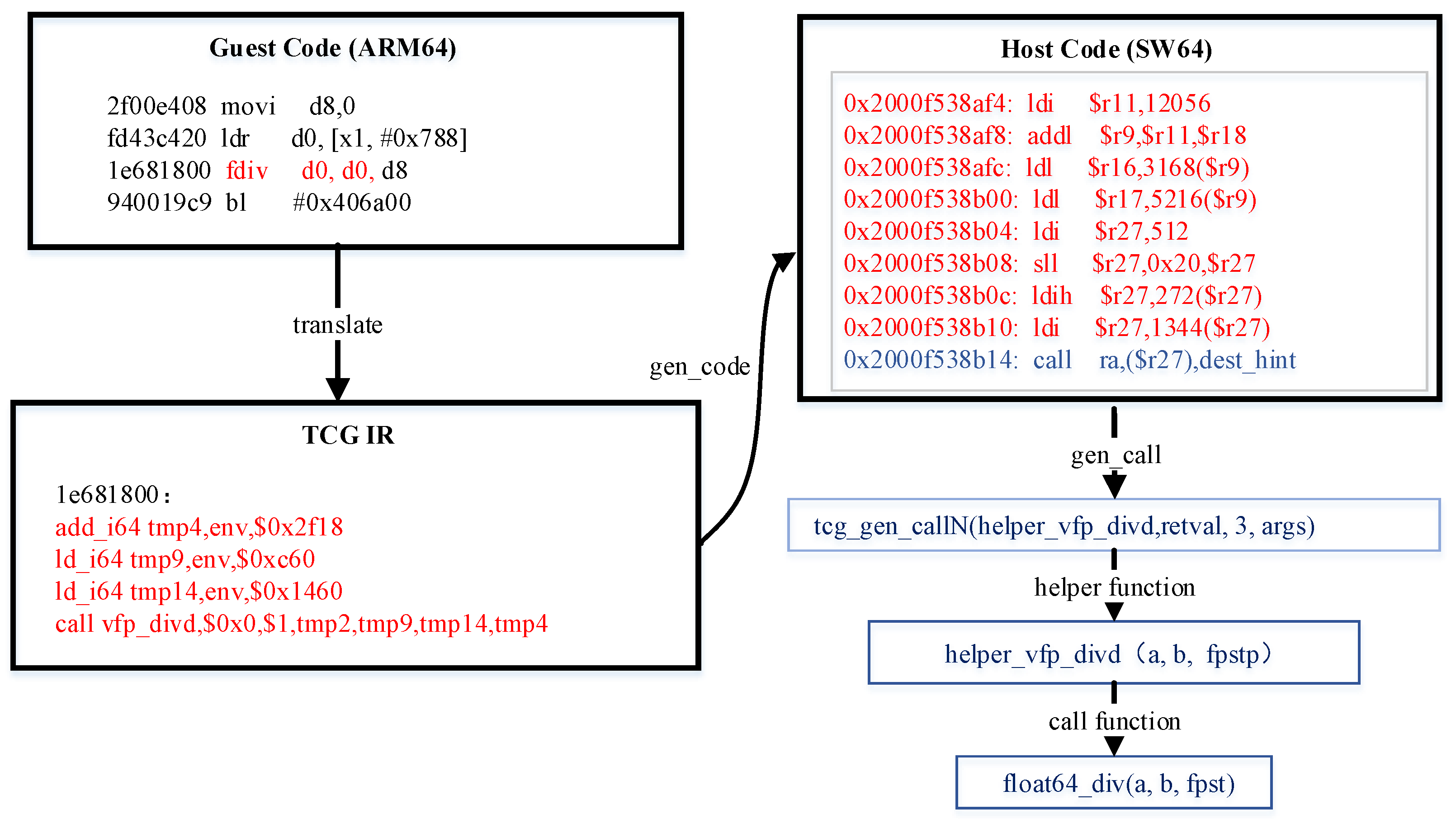
2.2.2. Handling Helper Function
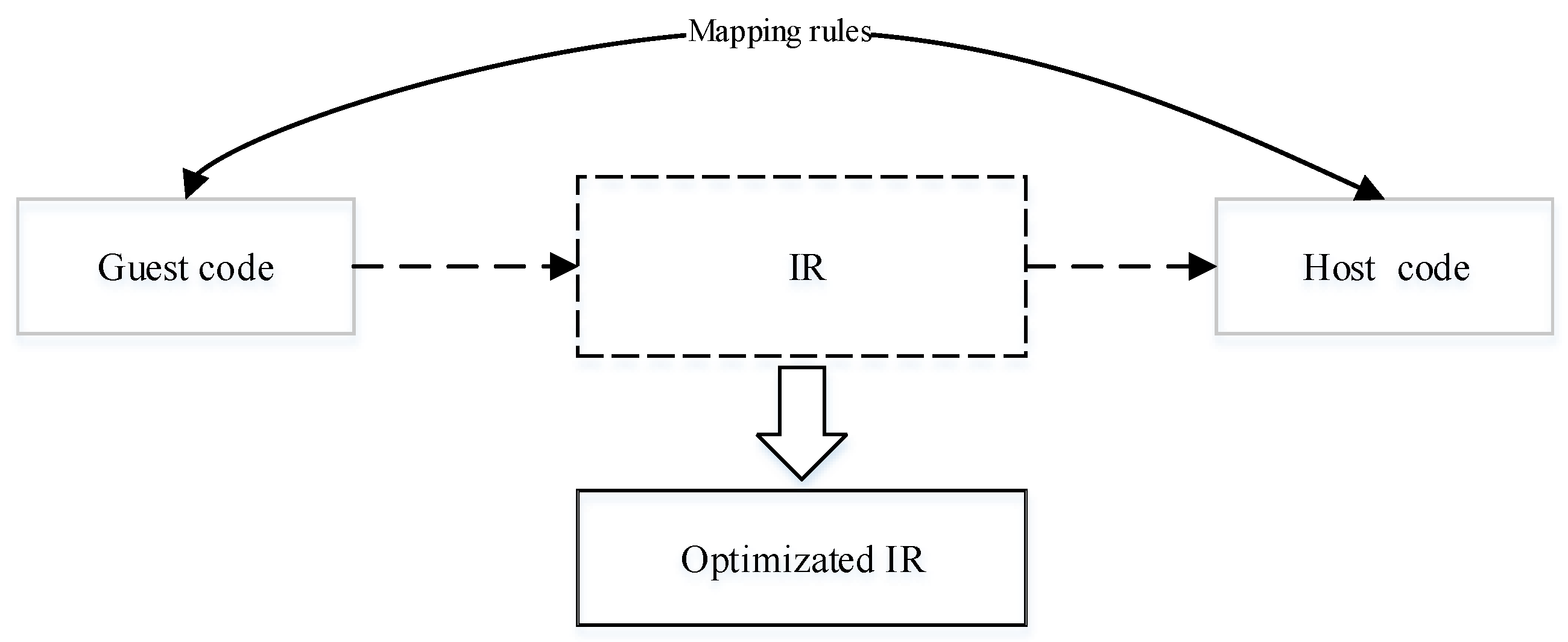
2.3. Optimization of QEMU
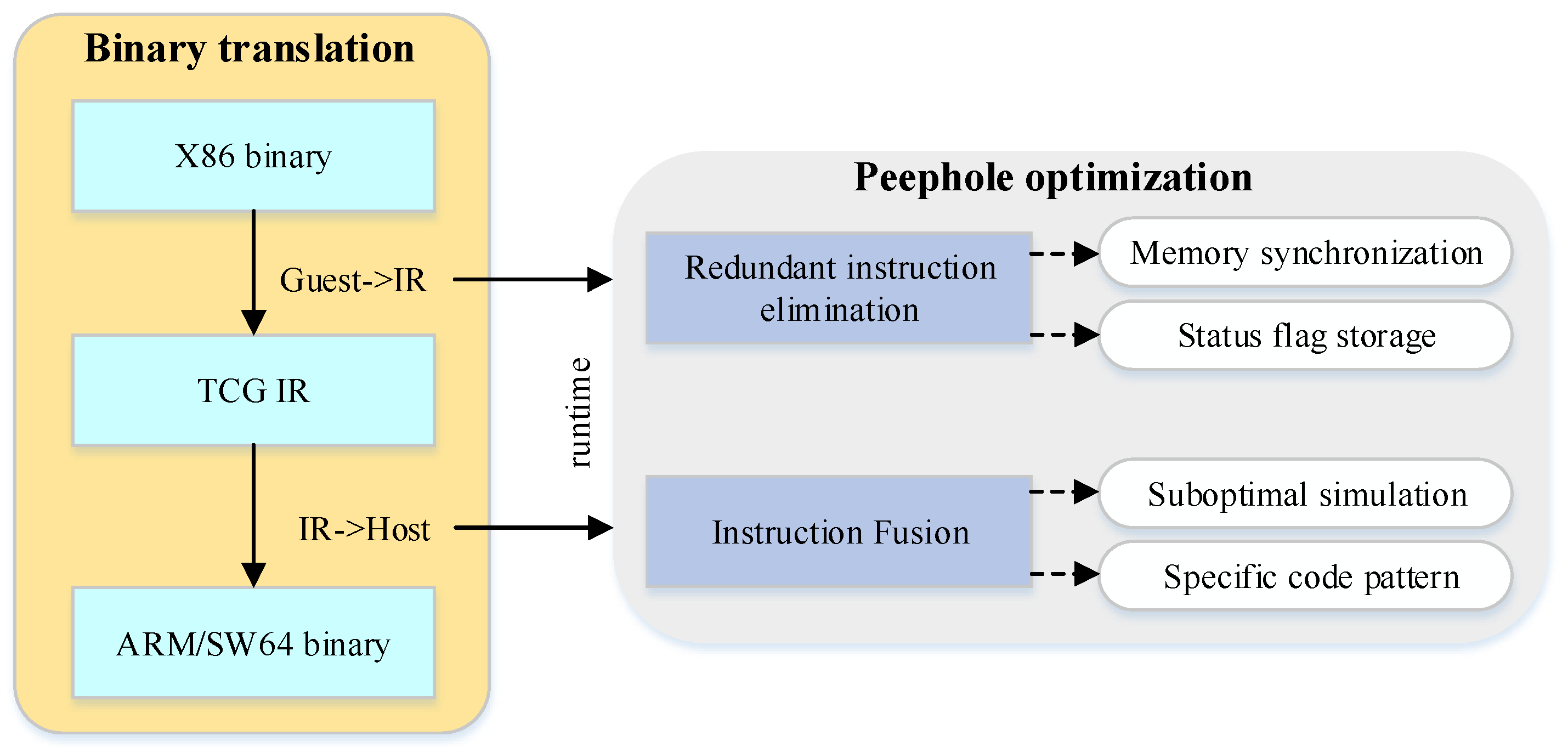
2.4. Peephole Optimization
3. Motivation
3.1. Eliminating Redundant Instructions
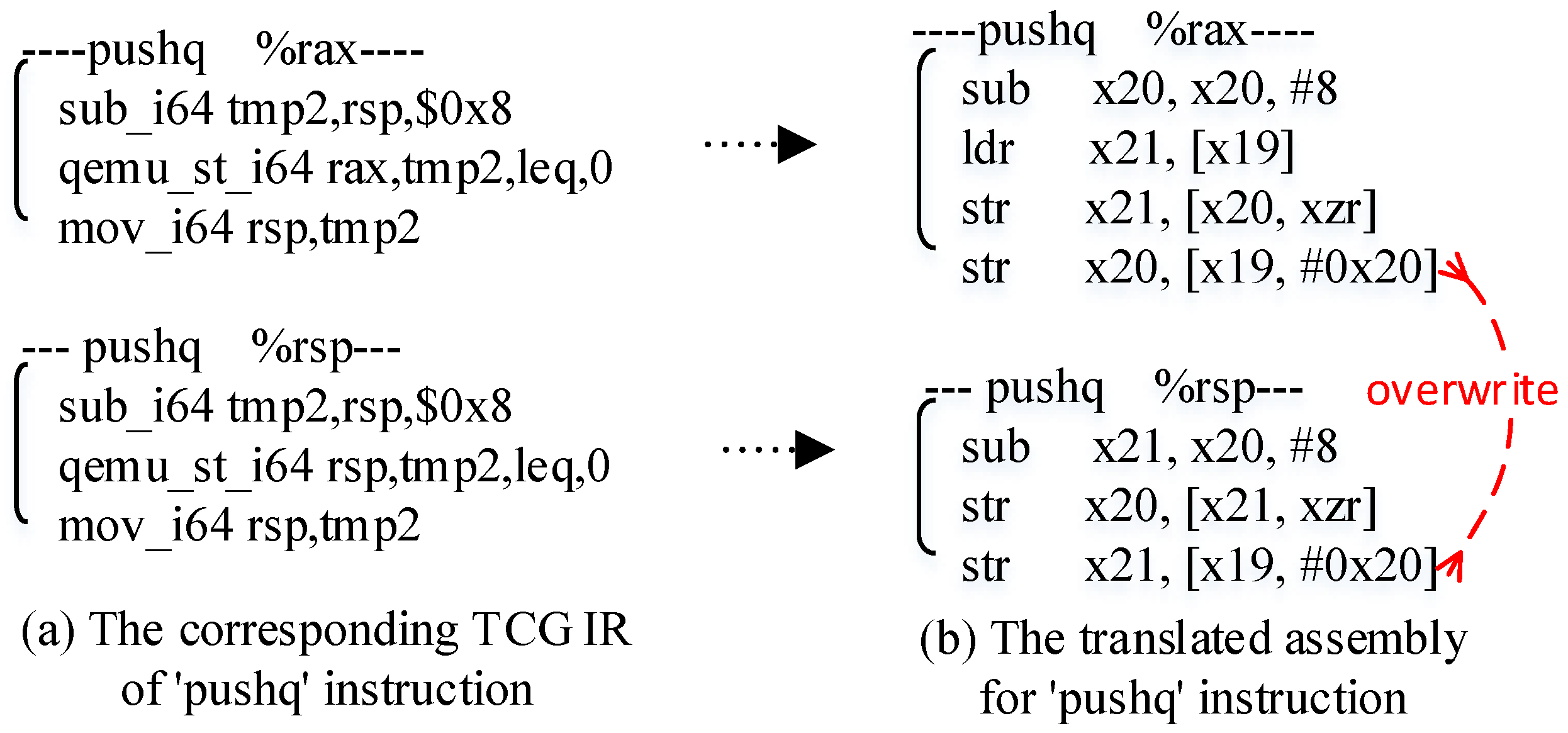
3.1.1. Redundant Memory Access
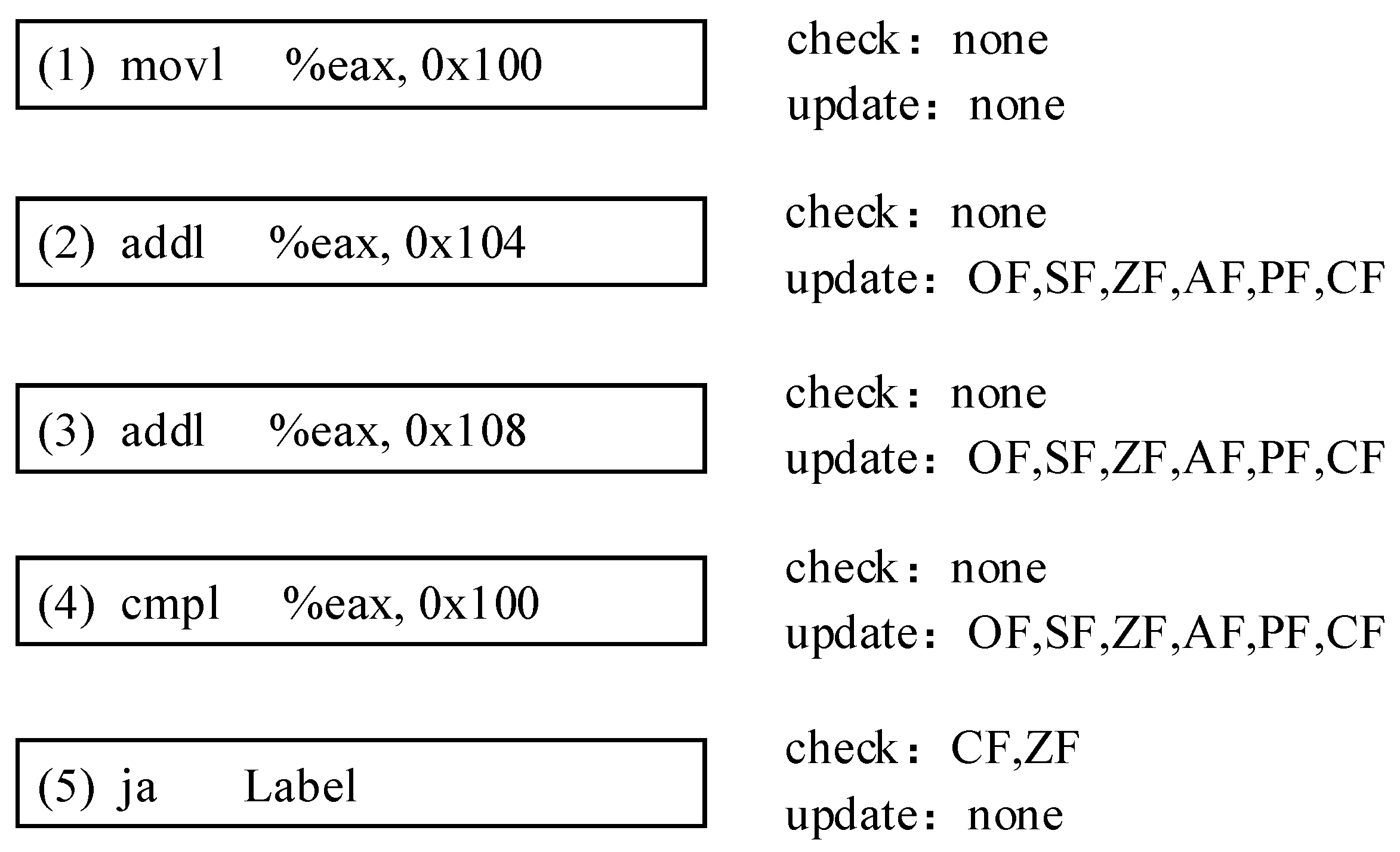
3.1.2. Unused Status Flag Storage
- (1)
- movl %eax, 0x100
- (2)
- addl %eax, 0x104
- (3)
- addl %eax, 0x108
- (4)
- cmpl %eax, 0x100
- (5)
- ja Label
3.2. Simplifying Suboptimal Instruction Sequence
3.2.1. Suboptimal Instruction Simplification
3.2.2. Specific Code Replacement
4. Performance Optimization via Peephole Optimization
4.1. Methodology Overview
4.2. Optimization for Consecutive Memory Access
4.2.1. Formalizing Consecutive Memory Access
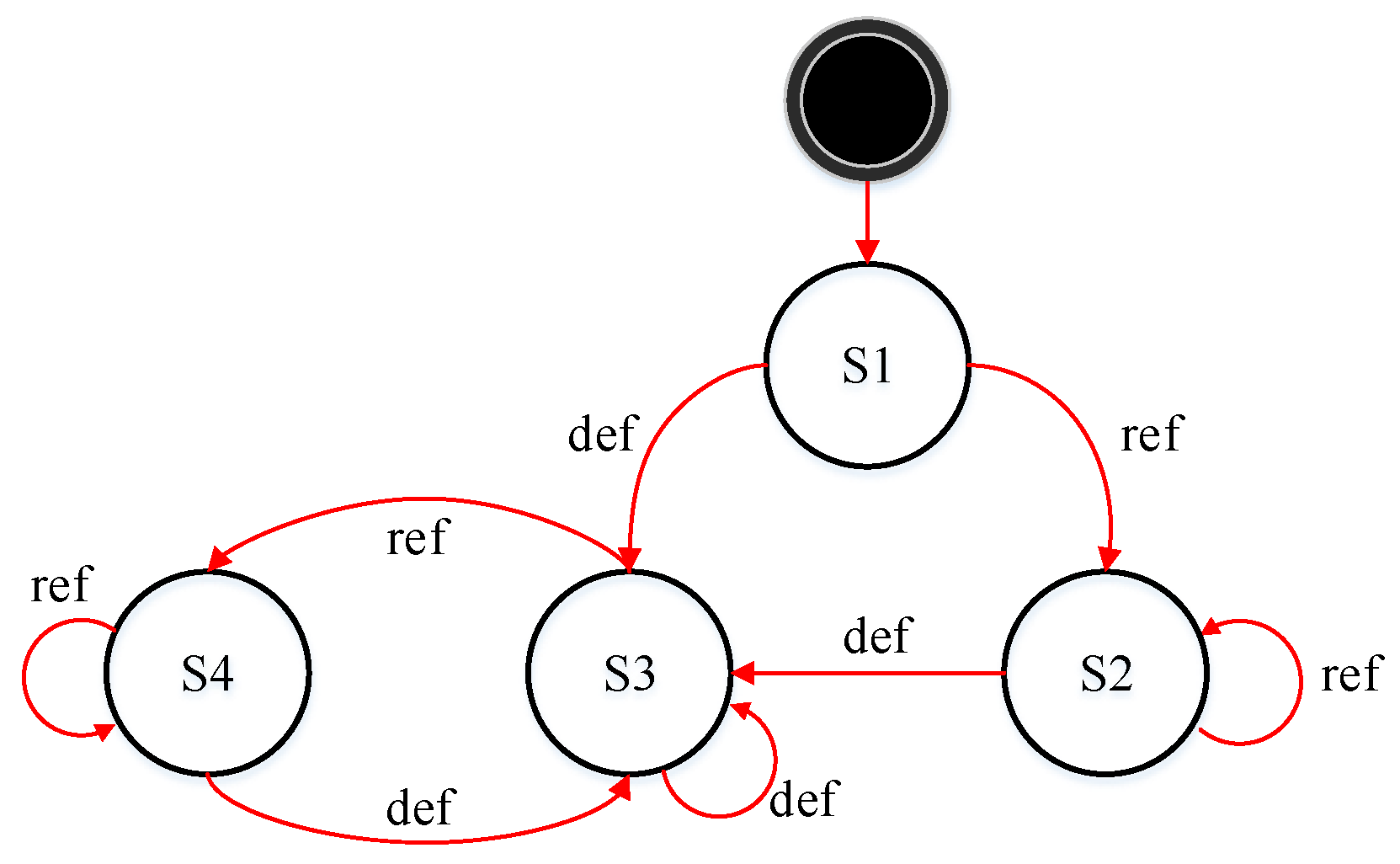
4.2.2. Live Variable Analysis in DBT
4.2.3. Eliminating Redundant Memory Access Based on LVA
| Algorithm 1 RIE-LVA algorithm. |
 |
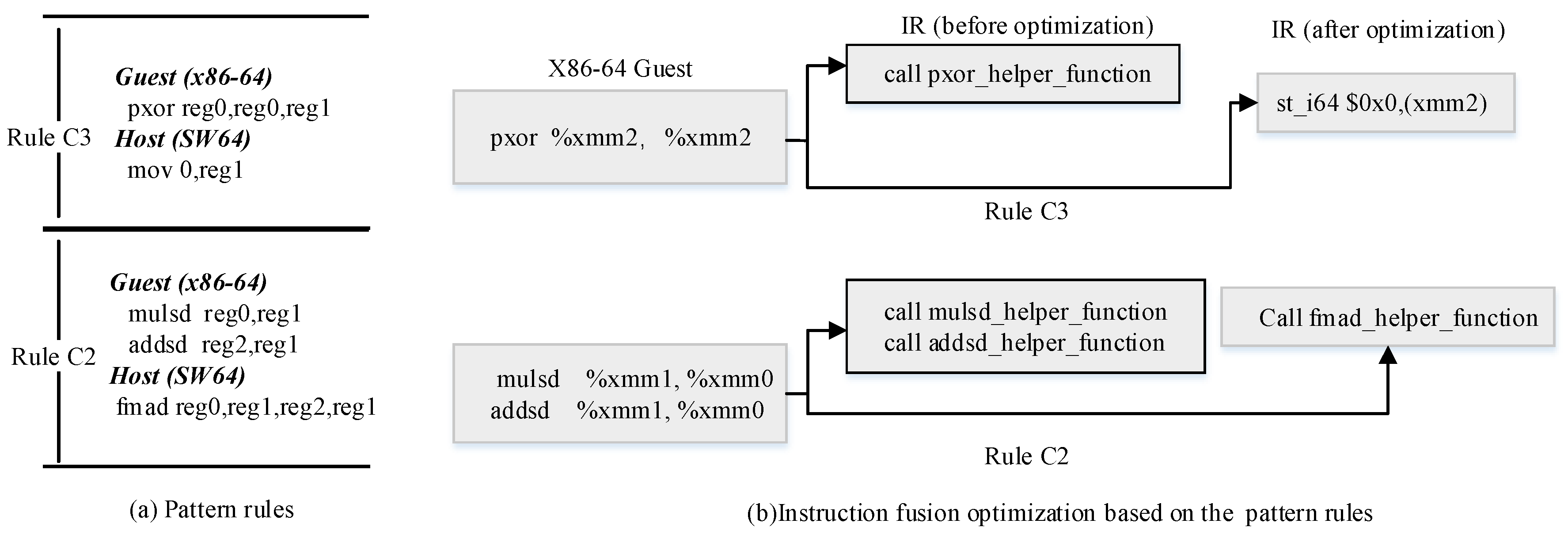
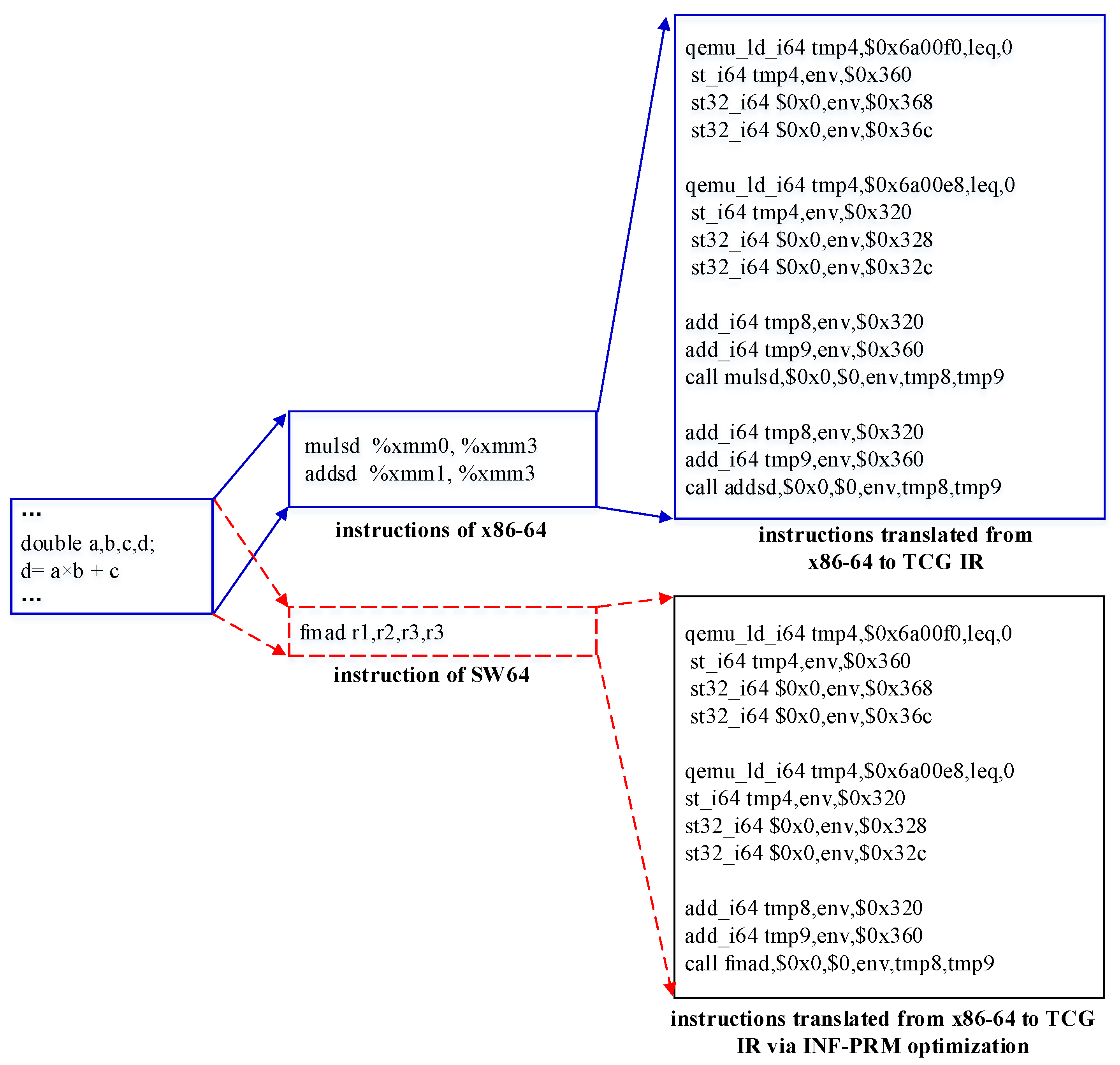
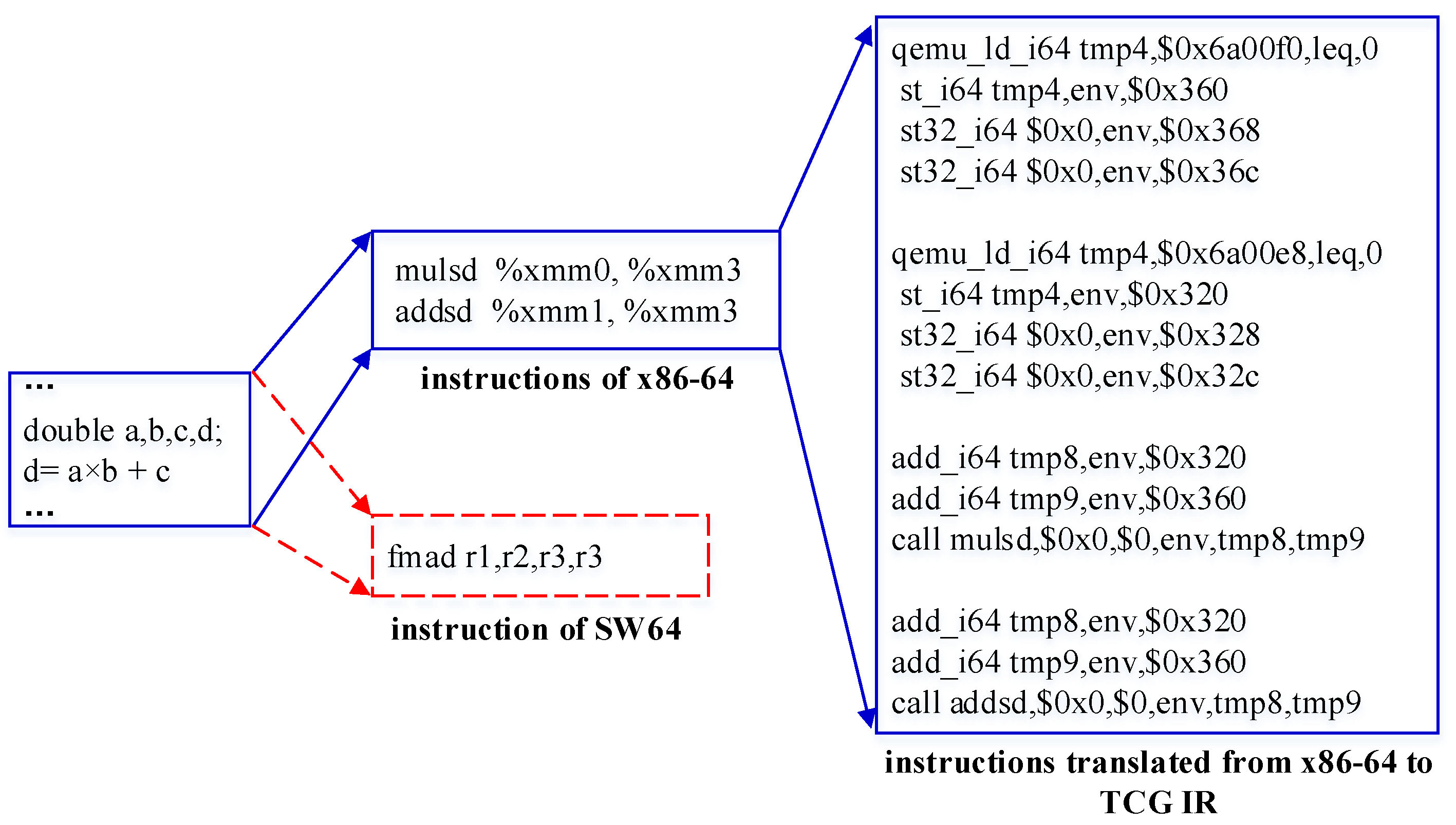
4.3. Instruction Fusion Optimization
4.3.1. Instruction Semantic-Level Transformation Model
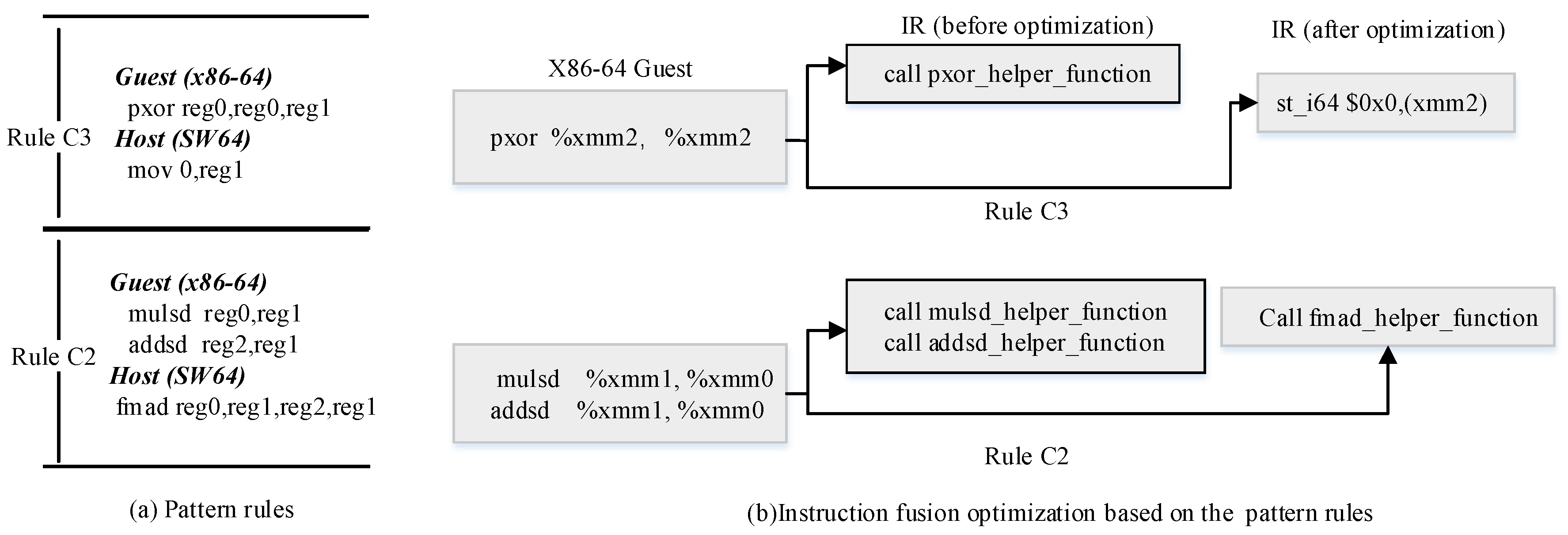
- Case 1: and . Both the guest ISA and host ISA encompass the functionality of instruction I.
- Case 2: and . The guest ISA set encompasses the functionality of instruction I, but the host does not.
- Case 3: and . The host ISA set encompasses the functionality of instruction I, but the guest does not.
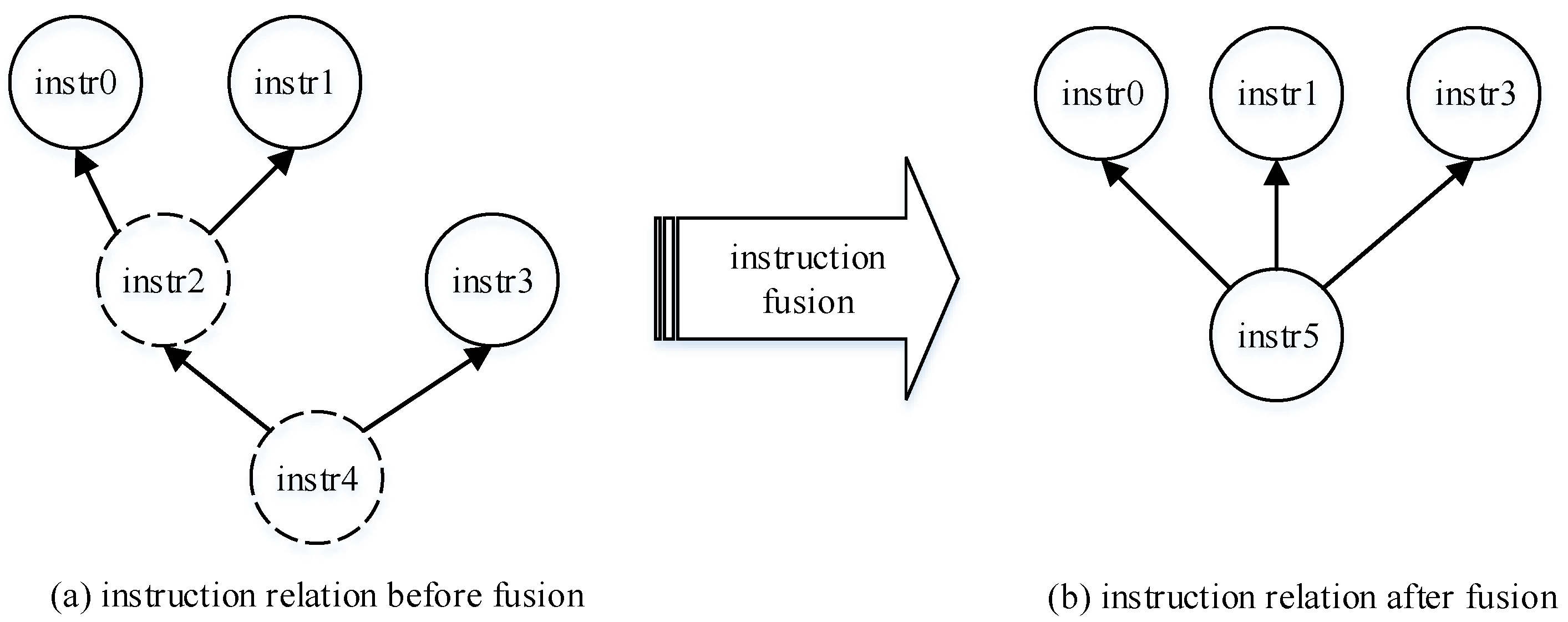
4.3.2. Analyzing Data Dependency
4.3.3. Instruction Fusion Optimization Based on Pattern-Matching
5. Experimental Results
5.1. Experimental Setup
- SW64 host: The host machine has 2.40 GHZ and SW3231 processors for a total of 32 cores. The machine is equipped with 512 GB of RAM, 32 KB of L1 cache, 512 KB of L2 cache, and 64 MB of shared L3 cache and runs UOS V20 with Linux kernel v4.19.0.
- ARM64 host: The host machine has 2.1 GHZ and Phytium S2500 processors for a total of 64 cores. The machine is equipped with 2 MB of L2 cache and 64 MB of shared L3 cache and runs Kylin Linux kernel v4.19.0.
- QEMU base version: Compiles the QEMU v6.0 using GCC on both ARM64 and SW64 platforms, employing the default configuration settings.
- ARM64-opt version: Combines ARM64 with the QEMU base version, incorporating RIE-LVA and INF-PRM optimizations.
- SW64-opt version: Combines SW64 with the QEMU base version, incorporating RIE-LVA and INF-PRM optimizations.
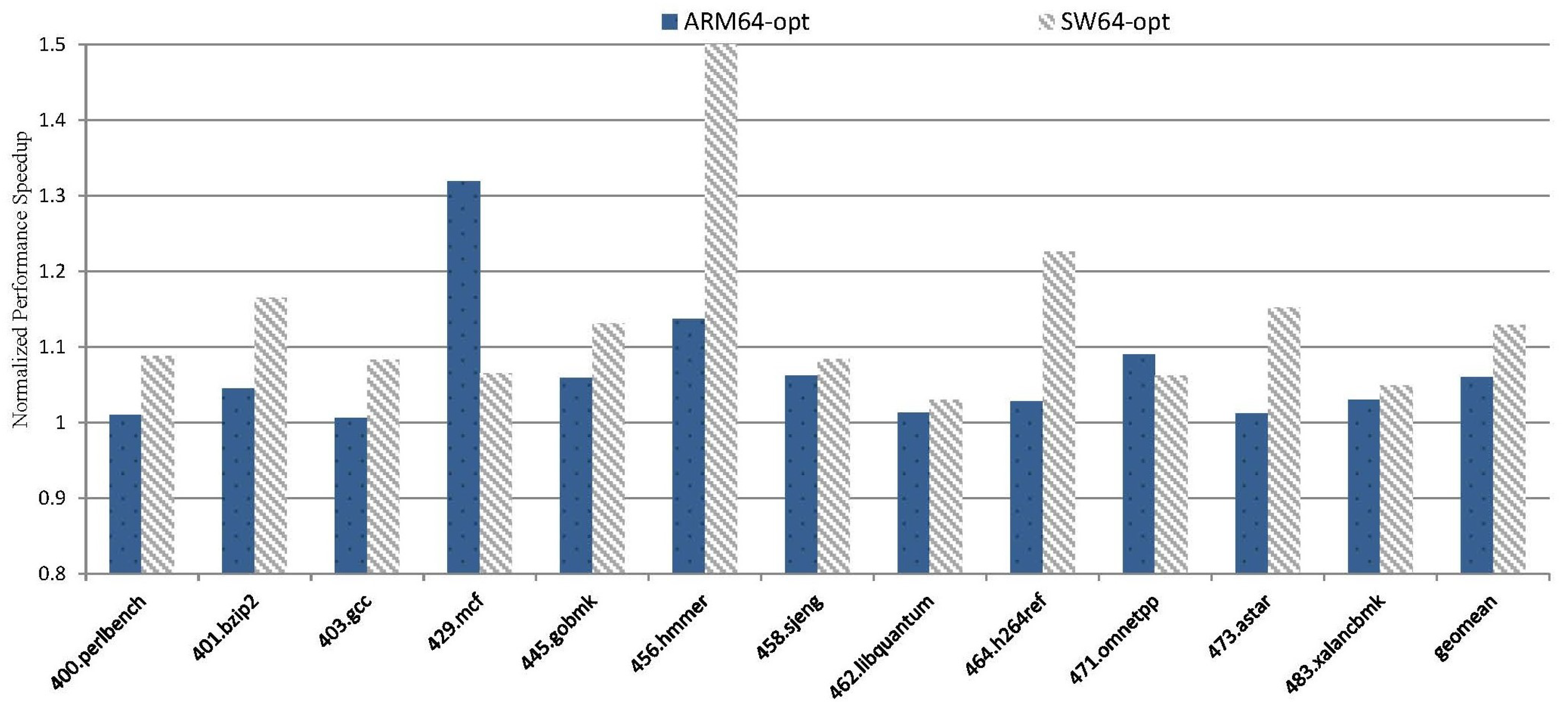
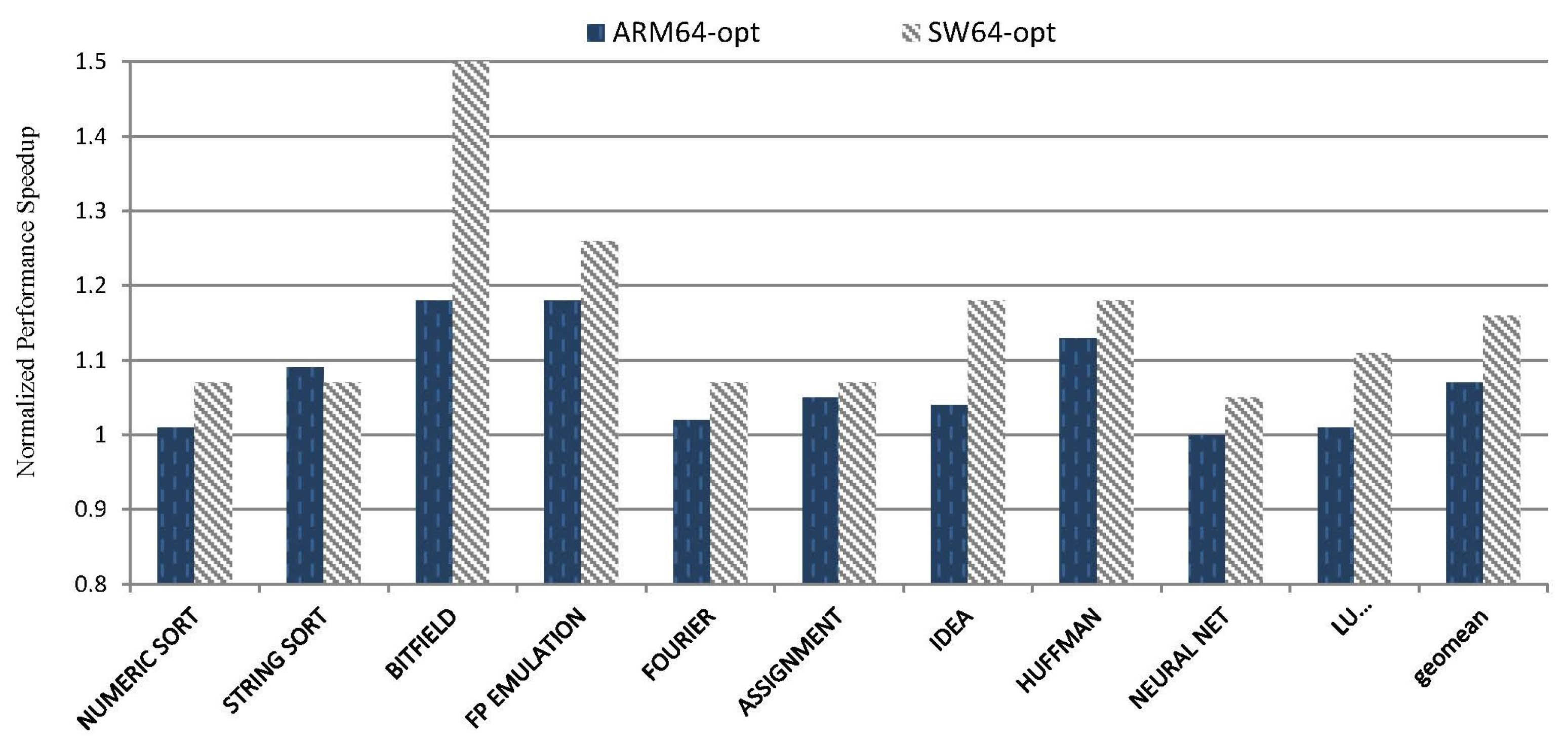
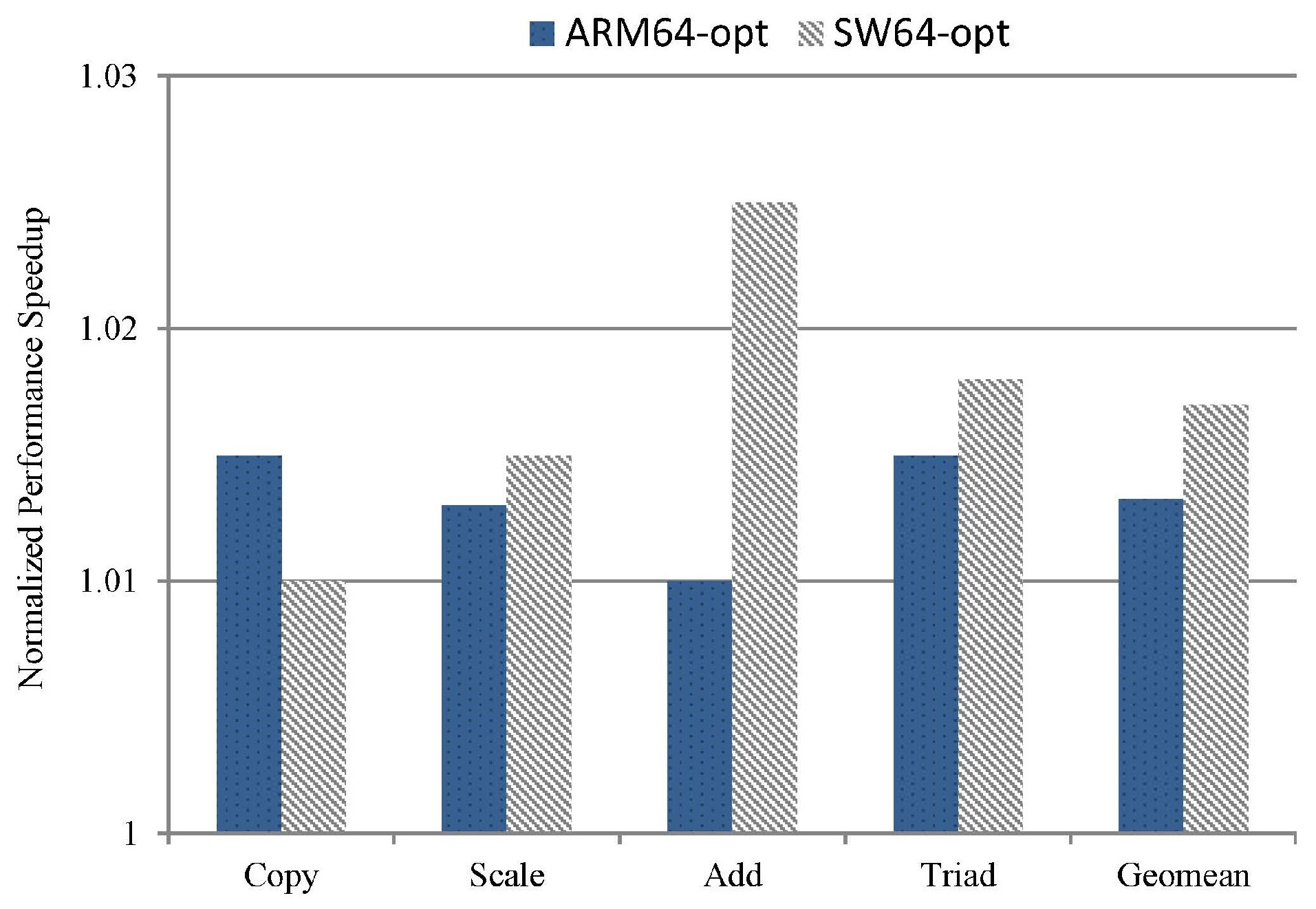
5.2. Overall Impact on Performance
5.2.1. RIE-LVA Performance
5.2.2. INF-PRM Performance
5.2.3. Multi-Thread Suite Performance
5.2.4. Translation Overhead Impact
5.3. Overall Impact on Code Size
5.4. Discussion and Limitations
5.4.1. Limitations
5.4.2. Benefiting Other Applications
6. Related Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Waterman, A.; Asanovic, K. The RISC-V Instruction Set Manual, Volume I: User-Level ISA; Document Version 20191213. 2019. Available online: https://riscv.org/wp-content/uploads/2019/12/riscv-spec-20191213.pdf (accessed on 5 January 2024).
- Hu, W.; Wang, W.; Wu, R.; Wang, H.; Zeng, L.; Xu, C.; Gao, X.; Zhang, F. Loongson Instruction Set Architecture Technology. J. Comput. Res. Dev. 2023, 60, 2–16. [Google Scholar]
- Chengdu Sunway Technologies CO., L. Swcpu. 2017. Available online: http://www.swcpu.cn/uploadfile/2018/0709/20180709033115724.pdf (accessed on 5 January 2024).
- Arm Developer. ARMv8-M Architecture Technical Overview. 2023. Available online: https://developer.arm.com (accessed on 5 January 2024).
- Apple. Porting Your macOS Apps to Apple Silicon. 2022. Available online: https://developer.apple.com/documentation/apple-silicon/porting-your-macos-apps-to-apple-silicon (accessed on 5 January 2024).
- Yarza, I.; Azkarate-askatsua, M.; Onaindia, P.; Grüttner, K.; Ittershagen, P.; Nebel, W. Legacy software migration based on timing contract aware real-time execution environments. J. Syst. Softw. 2021, 172, 110849. [Google Scholar] [CrossRef]
- Hong, D.Y.; Hsu, C.C.; Yew, P.C.; Wu, J.J.; Hsu, W.C.; Liu, P.; Wang, C.M.; Chung, Y.C. HQEMU: A multi-threaded and retargetable dynamic binary translator on multicores. In Proceedings of the Tenth International Symposium on Code Generation and Optimization, CGO ’12, San Jose, CA, USA, 31 March–4 April 2012; pp. 104–113. [Google Scholar]
- Cota, E.G.; Carloni, L.P. Cross-ISA machine instrumentation using fast and scalable dynamic binary translation. In Proceedings of the 15th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, New York, NY, USA, 14 April 2019; Association for Computing Machinery: Providence, RI, USA, 2019; pp. 74–87. [Google Scholar]
- Spink, T.; Wagstaff, H.; Franke, B. A Retargetable System-level DBT Hypervisor. ACM Trans. Comput. Syst 2020, 36, 14. [Google Scholar] [CrossRef]
- Fu, S.Y.; Hong, D.Y.; Liu, Y.P.; Wu, J.J.; Hsu, W.C. Efficient and retargetable SIMD translation in a dynamic binary translator. Softw.-Pract. Exp. 2018, 48, 1312–1330. [Google Scholar] [CrossRef]
- Clark, M.; Hoult, B. rv8: A high performance RISC-V to x86 binary translator. In Proceedings of the First Workshop on Computer Architecture Research with RISC-V, Boston, MA, USA, 14 October 2017; pp. 1–7. [Google Scholar]
- Wang, J.; Pang, J.; Liu, X.; Yue, F.; Tan, J.; Fu, L. Dynamic Translation Optimization Method Based on Static Pre-Translation. IEEE Access 2019, 7, 21491–21501. [Google Scholar] [CrossRef]
- Huang, J.S.; Yang, W.; You, Y.P. Profile-guided optimisation for indirect branches in a binary translator. Connect. Sci. 2022, 34, 749–765. [Google Scholar] [CrossRef]
- Bellard, F. QEMU, a fast and portable dynamic translator. In Proceedings of the 2005 USENIX Annual Technical Conference, Anaheim, CA, USA, 10–15 April 2005. [Google Scholar]
- Intel. EFLAGS Cross-Reference and Condition Codes. 2023. Available online: https://www.cs.utexas.edu/~byoung/cs429/condition-codes.pdf (accessed on 8 January 2024).
- Li, C.; Liu, Z.; Shang, Y.; He, L.; Yan, X. A Hardware Non-Invasive Mapping Method for Condition Bits in Binary Translation. Electronics 2023, 12, 3014. [Google Scholar] [CrossRef]
- Ottoni, G.; Hartin, T.; Weaver, C.; Brandt, J.; Kuttanna, B.; Wang, H. Harmonia: A transparent, efficient, and harmonious dynamic binary translator targeting the Intel® architecture. In Proceedings of the 8th ACM International Conference on Computing Frontiers, Ischia, Italy, 3–5 May 2011; Association for Computing Machinery: Ischia, Italy, 2011; pp. 1–10. [Google Scholar]
- Tanenbaum, A.S.; Van Staveren, H.; Stevenson, J.W. Using Peephole Optimization on Intermediate Code. ACM Trans. Program. Lang. Syst. 1982, 4, 21–36. [Google Scholar] [CrossRef]
- Chakraborty, P. Fifty years of peephole optimization. Curr. Sci. 2015, 108, 2186–2190. [Google Scholar]
- Standard Performance Evaluation Corporation. 2006. Available online: https://www.spec.org/cpu2006 (accessed on 24 January 2024).
- Bansal, S.; Aiken, A. Binary translation using peephole superoptimizers. In Proceedings of the 8th USENIX Conference on Operating Systems Design and Implementation, San Diego, CA, USA, 8–10 December 2008; USENIX Association: San Diego, CA, USA, 2008; pp. 177–192. [Google Scholar]
- Grisenthwaite, R. ARMv8 Technology Preview. 2011. Available online: http://classweb.ece.umd.edu/enee447/ARMv8-Documentation/ARMv8_Arch_slides.pdf (accessed on 12 January 2024).
- AMD64 Technology. 2022. Available online: https://kib.kiev.ua/x86docs/AMD/AMD64 (accessed on 12 January 2024).
- Wikipedia. NBench. 2017. Available online: https://en.wikipedia.org/wiki/NBench (accessed on 12 January 2024).
- Stream Benchmark. 2023. Available online: https://www.cs.virginia.edu/stream/ref.html (accessed on 12 January 2024).
- Tan, J.; Pang, J.; Shan, Z.; Yue, F.; Lu, S.; Dai, T. Redundant Instruction Optimization Algorithm in Binary Translation. J. Comput. Res. Dev. 2017, 54, 1931–1944. [Google Scholar]
- Sun, L.; Wu, Y.; Li, L.; Zhang, C.; Tang, J. A Dynamic and Static Binary Translation Method Based on Branch Prediction. Electronics 2023, 12, 3025. [Google Scholar] [CrossRef]
- Rocha, R.C.O.; Sprokholt, D.; Fink, M.; Gouicem, R.; Spink, T.; Chakraborty, S.; Bhatotia, P. Lasagne: A static binary translator for weak memory model architectures. In Proceedings of the 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation, San Diego, CA, USA, 13–17 June 2022; Association for Computing Machinery: San Diego, CA, USA, 2022; pp. 888–902. [Google Scholar]
- Lopes, N.P.; Menendez, D.; Nagarakatte, S.; Regehr, J. Provably correct peephole optimizations with alive. In Proceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation, Portland, OR, USA, 15–17 June 2015; Association for Computing Machinery: Portland, OR, USA, 2015; pp. 22–32. [Google Scholar]
- Hu, S.; Smith, J.E. Using dynamic binary translation to fuse dependent instructions. In Proceedings of the International Symposium on Code Generation and Optimization, CGO 2004, San Jose, CA, USA, 20–24 March 2004. [Google Scholar]
- Hu, H.; Li, S.; Zhou, Q.; Gong, L. Node Fusion Optimization Method Based on LLVM Compiler. Comput. Sci. 2020, 47, 561–566. [Google Scholar]
- Celio, C.; Dabbelt, P.; Patterson, D.A.; Asanović, K. The Renewed Case for the Reduced Instruction Set Computer: Avoiding ISA Bloat with Macro-Op Fusion for RISC-V. arXiv 2016, arXiv:1607.02318. [Google Scholar]
- Perais, A.; Jimborean, A.; Ros, A. Exploring Instruction Fusion Opportunities in General Purpose Processors. In Proceedings of the 2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), Chicago, IL, USA, 1–5 October 2022. [Google Scholar]
- Lupon, M.; Gibert, E.; Magklis, G.; Samudrala, S.; Martínez, R.; Stavrou, K.; Ditzel, D.R. Speculative hardware/software co-designed floating-point multiply-add fusion. In Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems, Salt Lake City, UT, USA, 1–5 March 2014; Association for Computing Machinery: Salt Lake City, UT, USA, 2014; pp. 623–638. [Google Scholar]
- Jinhu, J.; Dong, R.; Zhou, Z.; Song, C.; Wang, W.; Yew, P.C.; Zhang, W. More with Less – Deriving More Translation Rules with Less Training Data for DBTs Using Parameterization. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020. [Google Scholar]
- Wenwen, W.; Wu, C.; Bai, T.; Wang, Z.; Yuan, X.; Cui, H. A Pattern Translation Method for Flags in Binary Translation. J. Comput. Res. Dev. 2014, 51, 2336–2347. [Google Scholar]
- Salgado, F.; Gomes, T.; Pinto, S.; Cabral, J.; Tavares, A. Condition Codes Evaluation on Dynamic Binary Translation for Embedded Platforms. IEEE Embed. Syst. Lett. 2017, 9, 89–92. [Google Scholar] [CrossRef]
- Wu, J.; Dong, J.; Fang, R.; Zhang, W.; Wang, W.; Zuo, D. WDBT: Wear Characterization, Reduction, and Leveling of DBT Systems for Non-Volatile Memory. In Proceedings of the International Symposium on Memory Systems, Washington, DC, USA, 3–6 October 2022; Association for Computing Machinery: Washington, DC, USA, 2022; pp. 1–13. [Google Scholar]
- Tan, J.; Pang, J.M.; Lu, S.B. Using Local Library Function in Binary Translation. Curr. Trends Comput. Sci. Mech. Autom. 2018, 1, 123–132. [Google Scholar]
- Badaroux, M.; Pétrot, F. Arbitrary and Variable Precision Floating-Point Arithmetic Support in Dynamic Binary Translation. In Proceedings of the 26th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 18–21 January 2021; Association for Computing Machinery: Tokyo, Japan, 2021; pp. 325–330. [Google Scholar]
- Fu, S.Y.; Hong, D.Y.; Wu, J.J.; Liu, P.; Hsu, W.C. SIMD Code Translation in an Enhanced HQEMU. In Proceedings of the 2015 IEEE 21st International Conference on Parallel and Distributed Systems (ICPADS), Melbourne, Australia, 14–17 December 2015. [Google Scholar]
- Wu, J.; Dong, J.; Fang, R.; Zhao, Z.; Gong, X.; Wang, W.; Zuo, D. Effective exploitation of SIMD resources in cross-ISA virtualization. In Proceedings of the 17th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, Virtual Event, 16 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 84–97. [Google Scholar]
- Jiang, J.; Liang, C.; Dong, R.; Yang, Z.; Zhou, Z.; Wang, W.; Yew, P.-C.; Zhang, W. A System-Level Dynamic Binary Translator Using Automatically-Learned Translation Rules. In Proceedings of the 2024 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Edinburgh, UK, 2–6 March 2024. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, W.; Luo, Q.; Tian, X.; Huang, J.; Qi, F. Performance Improvements via Peephole Optimization in Dynamic Binary Translation. Electronics 2024, 13, 1608. https://doi.org/10.3390/electronics13091608
Xie W, Luo Q, Tian X, Huang J, Qi F. Performance Improvements via Peephole Optimization in Dynamic Binary Translation. Electronics. 2024; 13(9):1608. https://doi.org/10.3390/electronics13091608
Chicago/Turabian StyleXie, Wenbing, Qiaoling Luo, Xue Tian, Junyi Huang, and Fengbin Qi. 2024. "Performance Improvements via Peephole Optimization in Dynamic Binary Translation" Electronics 13, no. 9: 1608. https://doi.org/10.3390/electronics13091608
APA StyleXie, W., Luo, Q., Tian, X., Huang, J., & Qi, F. (2024). Performance Improvements via Peephole Optimization in Dynamic Binary Translation. Electronics, 13(9), 1608. https://doi.org/10.3390/electronics13091608